
Past, Present, and Future of Using Neuro-Fuzzy Systems for Hydrological Modeling and Forecasting



Abstract
1. Introduction
2. Neuro-Fuzzy Systems
2.1. Fuzzy Inference System
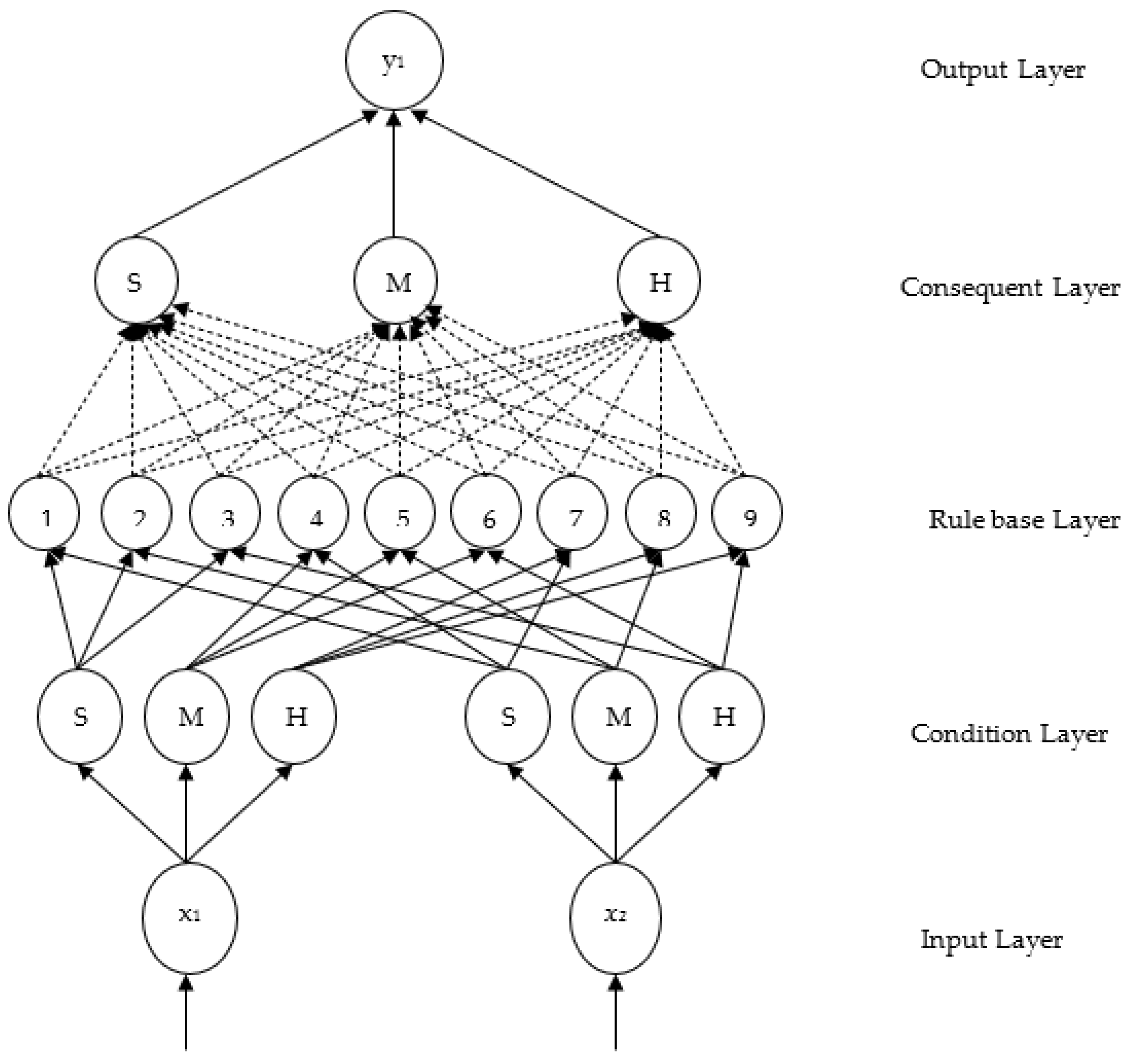
2.2. Types of Neuro-Fuzzy Systems
2.2.1. Cooperative Neuro-Fuzzy Systems
2.2.2. Concurrent Neuro-Fuzzy Systems
2.2.3. Hybrid Neuro-Fuzzy Systems
3. Challenges in Developing NFS-Based Hydrological Models
3.1. Data Pre-Processing
3.2. Input Selection
3.3. Training Data Selection
3.3.1. Continuous Time Series Modeling
3.3.2. Event-Based Modeling
3.4. Adaptability of NFS-Based Hydrological Models
3.5. Interpretability of the NFS Models
3.6. Optimization of Model Parameters
4. Future Directions
5. Conclusions
- (i)
- Data pre-processing is necessary for NFS model development. All conventional methods based on data standardization would work well. Additionally, new advancements in wavelet transform functions and their successful integration into NFS algorithms suggest further study.
- (ii)
- Different input selection methods reported in the literature perform well in developing NFS models. However, further study is needed for cases with multiple sources of inputs (e.g., catchments with multiple rain gauges), as using more inputs may not necessarily enhance model performance.
- (iii)
- The sensitivity of NFS models to training datasets is yet to be explored in detail. The impact of training data size, sequence, etc., on model performance in several NFS algorithms is not explored.
- (iv)
- NFS models with local learning have the potential to develop online models which can be employed for adapting to hydrological changes and real-time modeling. Despite using a few algorithms, such as a DENFIS, SaFIN, and GSETSK, in hydrological modeling and forecasting, limited works have been published in this area.
- (v)
- The interpretability of NFS models is yet to be explored in hydrological modeling. For this, the Mamdani-type NFS with fuzzy rule consequent is advantageous over the Takagi–Sugeno NFS. The extracted linguistic IF–THEN rules could reveal the problem’s physics while helping to formulate the association between inputs and output in a qualitative manner. Further study is necessary to explore interpretability in NFS-based hydrological models
- (vi)
- Efforts to integrate optimization techniques into NFS models have improved the model’s performance. These studies have been mainly focused on ANFISs; however, such improvements have not been significant over the conventional NFS. Anyway, no substantial superiority has been reported in any optimization tool, meaning that using any of them could be reasonably helpful. However, further study on using optimization tools in various NFS algorithms is needed.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Daneshmand, H.; Alaghmand, S.; Camporese, M.; Talei, A.; Daly, E. Water and salt balance modelling of intermittent catchments using a physically-based integrated model. J. Hydrol. 2018, 568, 1017–1030. [Google Scholar] [CrossRef]
- Singh, V.P. Hydrologic Systems. Rainfall-Runoff Modeling, Volume I; Prentice Hall: Englewood Cliffs, NJ, USA, 1988; Volume 1, p. 988. [Google Scholar]
- Halff, A.H.; Halff, H.; Azmoodeh, M. Predicting runoff from rainfall using neural networks. In Proceeding Engineering Hydrology; ASCE: New York, NY, USA, 1993; pp. 760–765. [Google Scholar]
- Nayak, P.C.; Sudheer, K.P.; Rangan, D.M.; Ramasastri, K.S. A neuro-fuzzy computing technique for modeling hydrological time series. J. Hydrol. 2004, 291, 52–66. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation; Prentice Hall: Englewood Cliffs, NJ, USA, 1999. [Google Scholar]
- Govindaraju, R.S. Artificial neural networks in hydrology. II: Hydrologic applications. J. Hydrol. Eng. 2000, 5, 124–137. [Google Scholar]
- Dawson, C.W.; Wilby, R.L. Hydrological modelling using artificial neural networks. Prog. Phys. Geogr. 2001, 25, 80–108. [Google Scholar] [CrossRef]
- Govindaraju, R.S. Artificial neural networks in hydrology. I: Preliminary concepts. J. Hydrol. Eng. 2000, 5, 115–123. [Google Scholar]
- Mamdani, E.H.; Assilian, S. An experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man-Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy Identification of Systems and Its Applications to Modeling and Control. IEEE Trans. Syst. Man Cybern. 1985, 15, 116–132. [Google Scholar] [CrossRef]
- Gautam, D.K.; Holz, K.P. Rainfall-runoff modelling using adaptive neuro-fuzzy systems. J. Hydroinform. 2001, 3, 3–10. [Google Scholar] [CrossRef]
- Gautam, D.K.; Holz, K.P.; Meyer, Z. Real-time forecasting of water levels using adaptive neuro-fuzzy systems. Arch. Hydroeng. Environ. Mech. 2001, 48, 3–21. [Google Scholar]
- Bartoletti, N.; Casagli, F.; Marsili-Libelli, S.; Nardi, A.; Palandri, L. Data-driven rainfall/runoff modelling based on a neuro-fuzzy inference system. Environ. Model. Softw. 2018, 106, 35–47. [Google Scholar] [CrossRef]
- Chen, S.-H.; Lin, Y.-H.; Chang, L.-C.; Chang, F.-J. The strategy of building a flood forecast model by neuro-fuzzy network. Hydrol. Process. 2005, 20, 1525–1540. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J.; Tombul, M. Modeling rainfall-runoff process using soft computing techniques. Comput. Geosci. 2013, 51, 108–117. [Google Scholar] [CrossRef]
- Jeong, C.; Shin, J.-Y.; Kim, T.; Heo, J.-H. Monthly Precipitation Forecasting with a Neuro-Fuzzy Model. Water Resour. Manag. 2012, 26, 4467–4483. [Google Scholar] [CrossRef]
- Mekanik, F.; Alam Imteaz, M.; Talei, A. Seasonal rainfall forecasting by adaptive network-based fuzzy inference system (ANFIS) using large scale climate signals. Clim. Dyn. 2015, 46, 3097–3111. [Google Scholar] [CrossRef]
- Zeynoddin, M.; Bonakdari, H.; Azari, A.; Ebtehaj, I.; Gharabaghi, B.; Madavar, H.R. Novel hybrid linear stochastic with non-linear extreme learning machine methods for forecasting monthly rainfall a tropical climate. J. Environ. Manag. 2018, 222, 190–206. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Trajkovic, S.; Zounemat-Kermani, M.; Li, B.; Kisi, O. Daily streamflow prediction using optimally pruned extreme learning machine. J. Hydrol. 2019, 577, 123981. [Google Scholar] [CrossRef]
- Nayak, P.C.; Sudheer, K.P.; Rangan, D.M.; Ramasastri, K.S. Short-term flood forecasting with a neurofuzzy model. Water Resour. Res. 2005, 41, 1–16. [Google Scholar] [CrossRef]
- Sanikhani, H.; Kisi, O. River Flow Estimation and Forecasting by Using Two Different Adaptive Neuro-Fuzzy Approaches. Water Resour. Manag. 2012, 26, 1715–1729. [Google Scholar] [CrossRef]
- Shiri, J.; Kisi, O. Short-term and long-term streamflow forecasting using a wavelet and neuro-fuzzy conjunction model. J. Hydrol. 2010, 394, 486–493. [Google Scholar] [CrossRef]
- Dixon, B. Applicability of neuro-fuzzy techniques in predicting ground-water vulnerability: A GIS-based sensitivity analysis. J. Hydrol. 2005, 309, 17–38. [Google Scholar] [CrossRef]
- Kholghi, M.; Hosseini, S.M. Comparison of Groundwater Level Estimation Using Neuro-fuzzy and Ordinary Kriging. Environ. Model. Assess. 2009, 14, 729–737. [Google Scholar] [CrossRef]
- Shirmohammadi, B.; Vafakhah, M.; Moosavi, V.; Moghaddamnia, A. Application of Several Data-Driven Techniques for Predicting Groundwater Level. Water Resour. Manag. 2013, 27, 419–432. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Jaafari, A.; Milan, S.G.; Kisi, O.; Heddam, S.; Zounemat-Kermani, M. Hybridized Adaptive Neuro-Fuzzy Inference System with Metaheuristic Algorithms for Modeling Monthly Pan Evaporation. Water 2022, 14, 3549. [Google Scholar] [CrossRef]
- Goyal, M.K.; Bharti, B.; Quilty, J.; Adamowski, J.; Pandey, A. Modeling of daily pan evaporation in sub tropical climates using ANN, LS-SVR, Fuzzy Logic, and ANFIS. Expert Syst. Appl. 2014, 41, 5267–5276. [Google Scholar] [CrossRef]
- Kişi, Ö.; Öztürk, Ö. Adaptive Neurofuzzy Computing Technique for Evapotranspiration Estimation. J. Irrig. Drain. Eng. 2007, 133, 368–379. [Google Scholar] [CrossRef]
- Wang, L.; Kisi, O.; Hu, B.; Bilal, M.; Zounemat-Kermani, M.; Li, H. Evaporation modelling using different machine learning techniques. Int. J. Clim. 2017, 37, 1076–1092. [Google Scholar] [CrossRef]
- Ly, Q.V.; Nguyen, X.C.; Lê, N.C.; Truong, T.-D.; Hoang, T.-H.T.; Park, T.J.; Maqbool, T.; Pyo, J.; Cho, K.H.; Lee, K.-S.; et al. Application of Machine Learning for eutrophication analysis and algal bloom prediction in an urban river: A 10-year study of the Han River, South Korea. Sci. Total Environ. 2021, 797, 149040. [Google Scholar] [CrossRef]
- Parmar, K.S.; Makkhan, S.J.S.; Kaushal, S. Neuro-fuzzy-wavelet hybrid approach to estimate the future trends of river water quality. Neural Comput. Appl. 2019, 31, 8463–8473. [Google Scholar] [CrossRef]
- Yeon, I.S.; Kim, J.H.; Jun, K.W. Application of artificial intelligence models in water quality forecasting. Environ. Technol. 2008, 29, 625–631. [Google Scholar] [CrossRef]
- Ghavidel, S.Z.Z.; Montaseri, M. Application of different data-driven methods for the prediction of total dissolved solids in the Zarinehroud basin. Stoch. Environ. Res. Risk Assess. 2014, 28, 2101–2118. [Google Scholar] [CrossRef]
- Idrees, M.B.; Jehanzaib, M.; Kim, D.; Kim, T.-W. Comprehensive evaluation of machine learning models for suspended sediment load inflow prediction in a reservoir. Stoch. Environ. Res. Risk Assess. 2021, 35, 1805–1823. [Google Scholar] [CrossRef]
- Kisi, O.; Zounemat-Kermani, M. Suspended Sediment Modeling Using Neuro-Fuzzy Embedded Fuzzy c-Means Clustering Technique. Water Resour. Manag. 2016, 30, 3979–3994. [Google Scholar] [CrossRef]
- Rajaee, T.; Mirbagheri, S.A.; Zounemat-Kermani, M.; Nourani, V. Daily suspended sediment concentration simulation using ANN and neuro-fuzzy models. Sci. Total Environ. 2009, 407, 4916–4927. [Google Scholar] [CrossRef]
- Jang, J.-S.R. ANFIS: Adaptive-Network-Based Fuzzy Inference System. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Karray, F.O.; De Silva, C.W. Soft Computing and Intelligent Systems Design: Theory, Tools and Applications; Addison Wesley Longman: White Plains, NY, USA, 2004. [Google Scholar]
- Lin, C.-T.; Lee, C. Neural-network-based fuzzy logic control and decision system. IEEE Trans. Comput. 1991, 40, 1320–1336. [Google Scholar] [CrossRef]
- Nauck, D.; Klawonn, F.; Kruse, R. Foundations of Neuro-Fuzzy Systems; John Wiley & Sons, Inc.: New York, NY, USA, 1997. [Google Scholar]
- Talei, A.; Chua, L.H.C.; Wong, T.S. Evaluation of rainfall and discharge inputs used by Adaptive Network-based Fuzzy Inference Systems (ANFIS) in rainfall–runoff modeling. J. Hydrol. 2010, 391, 248–262. [Google Scholar] [CrossRef]
- Beker, H.; Piper, F. The principles of cryptography, part IV: Stream ciphers, section a: Randomness. Secur. Speech Comm. Acad. Press Chapter 1985, 3, 104–109. [Google Scholar]
- Akrami, S.A.; El-Shafie, A.; Jaafar, O. Improving Rainfall Forecasting Efficiency Using Modified Adaptive Neuro-Fuzzy Inference System (MANFIS). Water Resour. Manag. 2013, 27, 3507–3523. [Google Scholar] [CrossRef]
- Heddam, S.; Bermad, A.; Dechemi, N. ANFIS-based modelling for coagulant dosage in drinking water treatment plant: A case study. Environ. Monit. Assess. 2012, 184, 1953–1971. [Google Scholar] [CrossRef]
- Emamgholizadeh, S.; Moslemi, K.; Karami, G. Prediction the Groundwater Level of Bastam Plain (Iran) by Artificial Neural Network (ANN) and Adaptive Neuro-Fuzzy Inference System (ANFIS). Water Resour. Manag. 2014, 28, 5433–5446. [Google Scholar] [CrossRef]
- Abba, S.; Abdulkadir, R.A.; Gaya, M.; Saleh, M.; Esmaili, P.; Jibril, M.B. Neuro-fuzzy ensemble techniques for the prediction of turbidity in water treatment plant. In Proceedings of the 2019 2nd International Conference of the IEEE Nigeria Computer Chapter, NigeriaComputConf, Zaria, Nigeria, 14–17 October 2019. [Google Scholar]
- Khaki, M.; Yusoff, I.; Islami, N. Simulation of groundwater level through artificial intelligence system. Environ. Earth Sci. 2015, 73, 8357–8367. [Google Scholar] [CrossRef]
- Sönmez, A.Y.; Kale, S.; Ozdemir, R.C.; Kadak, A.E. An adaptive neuro-fuzzy inference system (ANFIS) to predict of cadmium (Cd) concentrations in the filyos river, Turkey. Turk. J. Fish. Aquat. Sci. 2018, 18, 1333–1343. [Google Scholar] [CrossRef]
- Van Ooyen, A.; Nienhuis, B. Improving the convergence of the back-propagation algorithm. Neural Netw. 1992, 5, 465–471. [Google Scholar] [CrossRef]
- Aqil, M.; Kita, I.; Yano, A.; Nishiyama, S. Analysis and prediction of flow from local source in a river basin using a Neuro-fuzzy modeling tool. J. Environ. Manag. 2007, 85, 215–223. [Google Scholar] [CrossRef]
- Moosavi, V.; Vafakhah, M.; Shirmohammadi, B.; Behnia, N. A Wavelet-ANFIS Hybrid Model for Groundwater Level Forecasting for Different Prediction Periods. Water Resour. Manag. 2013, 27, 1301–1321. [Google Scholar] [CrossRef]
- Barzegar, R.; Adamowski, J.; Moghaddam, A.A. Application of wavelet-artificial intelligence hybrid models for water quality prediction: A case study in Aji-Chay River, Iran. Stoch. Environ. Res. Risk Assess. 2016, 30, 1797–1819. [Google Scholar] [CrossRef]
- Fu, Z.; Cheng, J.; Yang, M.; Batista, J. Prediction of industrial wastewater quality parameters based on wavelet de-noised ANFIS model. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference, CCWC, Las Vegas, NV, USA, 8–10 January 2018. [Google Scholar]
- Poul, A.K.; Shourian, M.; Ebrahimi, H. A Comparative Study of MLR, KNN, ANN and ANFIS Models with Wavelet Transform in Monthly Stream Flow Prediction. Water Resour. Manag. 2019, 33, 2907–2923. [Google Scholar] [CrossRef]
- Ahmed, A.N.; Othman, F.B.; Afan, H.A.; Ibrahim, R.K.; Fai, C.M.; Hossain, S.; Ehteram, M.; Elshafie, A. Machine learning methods for better water quality prediction. J. Hydrol. 2019, 578, 124084. [Google Scholar] [CrossRef]
- Shabri, A. A hybrid wavelet analysis and adaptive neuro-fuzzy inference system for drought forecasting. Appl. Mathe-Matical Sci. 2014, 8, 6909–6918. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J. Wavelet and neuro-fuzzy conjunction model for predicting water table depth fluctuations. Hydrol. Res. 2012, 43, 286–300. [Google Scholar] [CrossRef]
- Sehgal, V.; Sahay, R.R.; Chatterjee, C. Effect of Utilization of Discrete Wavelet Components on Flood Forecasting Per-formance of Wavelet Based ANFIS Models. Water Resour. Manag. 2014, 28, 1733–1749. [Google Scholar] [CrossRef]
- Seo, Y.; Kim, S.; Kisi, O.; Singh, V.P. Daily water level forecasting using wavelet decomposition and artificial intelligence techniques. J. Hydrol. 2015, 520, 224–243. [Google Scholar] [CrossRef]
- Nourani, V.; Alami, M.T.; Vousoughi, F.D. Hybrid of SOM-Clustering Method and Wavelet-ANFIS Approach to Model and Infill Missing Groundwater Level Data. J. Hydrol. Eng. 2016, 21, 05016018. [Google Scholar] [CrossRef]
- Nourani, V.; Partoviyan, A. Hybrid denoising-jittering data pre-processing approach to enhance multi-step-ahead rainfall–runoff modeling. Stoch. Environ. Res. Risk Assess. 2017, 32, 545–562. [Google Scholar] [CrossRef]
- Abda, Z.; Chettih, M. Forecasting daily flow rate-based intelligent hybrid models combining wavelet and Hilbert–Huang transforms in the mediterranean basin in northern Algeria. Acta Geophys. 2018, 66, 1131–1150. [Google Scholar] [CrossRef]
- Chang, F.-J.; Chang, Y.-T. Adaptive neuro-fuzzy inference system for prediction of water level in reservoir. Adv. Water Resour. 2006, 29, 1–10. [Google Scholar] [CrossRef]
- Esmaeelzadeh, S.R.; Adib, A.; Alahdin, S. Long-term streamflow forecasts by Adaptive Neuro-Fuzzy Inference System using satellite images and K-fold cross-validation (Case study: Dez, Iran). KSCE J. Civ. Eng. 2014, 19, 2298–2306. [Google Scholar] [CrossRef]
- Ali, M.; Deo, R.C.; Downs, N.J.; Maraseni, T. Multi-stage committee based extreme learning machine model incorporating the influence of climate parameters and seasonality on drought forecasting. Comput. Electron. Agric. 2018, 152, 149–165. [Google Scholar] [CrossRef]
- Lohani, A.; Kumar, R.; Singh, R. Hydrological time series modeling: A comparison between adaptive neuro-fuzzy, neural network and autoregressive techniques. J. Hydrol. 2012, 442–443, 23–35. [Google Scholar] [CrossRef]
- Doǧan, E. Reference evapotranspiration estimation using adaptive neuro-fuzzy inference systems. Irrig. Drain. 2009, 58, 617–628. [Google Scholar] [CrossRef]
- Stefánsson, A.; Končar, N.; Jones, A.J. A note on the gamma test. Neural Comput. Appl. 1997, 5, 131–133. [Google Scholar] [CrossRef]
- Malik, A.; Kumar, A.; Kisi, O. Monthly pan-evaporation estimation in Indian central Himalayas using different heuristic approaches and climate based models. Comput. Electron. Agric. 2017, 143, 302–313. [Google Scholar] [CrossRef]
- Moghaddamnia, A.; Gousheh, M.G.; Piri, J.; Amin, S.; Han, D. Evaporation estimation using artificial neural networks and adaptive neuro-fuzzy inference system techniques. Adv. Water Resour. 2009, 32, 88–97. [Google Scholar] [CrossRef]
- Malik, A.; Kumar, A.; Piri, J. Daily suspended sediment concentration simulation using hydrological data of Pranhita River Basin, India. Comput. Electron. Agric. 2017, 138, 20–28. [Google Scholar] [CrossRef]
- Dodangeh, E.; Ewees, A.A.; Shahid, S.; Yaseen, Z.M. Daily scale river flow simulation: Hybridized fuzzy logic model with metaheuristic algorithms. Hydrol. Sci. J. 2021, 66, 2155–2169. [Google Scholar] [CrossRef]
- Wan, J.; Huang, M.; Ma, Y.; Guo, W.; Wang, Y.; Zhang, H.; Li, W.; Sun, X. Prediction of effluent quality of a paper mill wastewater treatment using an adaptive network-based fuzzy inference system. Appl. Soft Comput. 2011, 11, 3238–3246. [Google Scholar] [CrossRef]
- Civelekoglu, G.; Perendeci, A.; Yigit, N.O.; Kitis, M. Modeling Carbon and Nitrogen Removal in an Industrial Wastewater Treatment Plant Using an Adaptive Network-Based Fuzzy Inference System. CLEAN—Soil Air Water 2007, 35, 617–625. [Google Scholar] [CrossRef]
- Civelekoglu, G.; Yigit, N.O.; Diamadopoulos, E.; Kitis, M. Modelling of COD removal in a biological wastewater treatment plant using adaptive neuro-fuzzy inference system and artificial neural network. Water Sci. Technol. 2009, 60, 1475–1487. [Google Scholar] [CrossRef]
- Parsaie, A.; Haghiabi, A.H. Prediction of discharge coefficient of side weir using adaptive neuro-fuzzy inference system. Sustain. Water Resour. Manag. 2016, 2, 257–264. [Google Scholar] [CrossRef]
- Aqil, M.; Kita, I.; Yano, A.; Nishiyama, S. A comparative study of artificial neural networks and neuro-fuzzy in continuous modeling of the daily and hourly behaviour of runoff. J. Hydrol. 2007, 337, 22–34. [Google Scholar] [CrossRef]
- Nawaz, N.; Harun, S.; Talei, A. Application of adaptive network-based fuzzy inference system (ANFIS) for river stage prediction in a tropical catchment. Appl. Mech. Mater. 2015, 735, 195–199. [Google Scholar] [CrossRef]
- Gong, Y.; Wang, Z.; Xu, G.; Zhang, Z. A Comparative Study of Groundwater Level Forecasting Using Data-Driven Models Based on Ensemble Empirical Mode Decomposition. Water 2018, 10, 730. [Google Scholar] [CrossRef]
- Nguyen, P.K.-T.; Chua, L.H.-C.; Talei, A.; Chai, Q.H. Water level forecasting using neuro-fuzzy models with local learning. Neural Comput. Appl. 2018, 30, 1877–1887. [Google Scholar] [CrossRef]
- Nguyen, P.K.-T.; Chua, L.H.-C.; Son, L.H. Flood forecasting in large rivers with data-driven models. Nat. Hazards 2014, 71, 767–784. [Google Scholar] [CrossRef]
- Sun, Y.; Tang, D.; Sun, Y.; Cui, Q. Comparison of a fuzzy control and the data-driven model for flood forecasting. Nat. Hazards 2016, 82, 827–844. [Google Scholar] [CrossRef]
- Üneş, F.; Kaya, Y.Z.; Mamak, M. Daily reference evapotranspiration prediction based on climatic conditions applying different data mining techniques and empirical equations. Theor. Appl. Clim. 2020, 141, 763–773. [Google Scholar] [CrossRef]
- Lee, M.Z.; Mekanik, F.; Talei, A. Dynamic Neuro-Fuzzy Systems for Forecasting El Niño Southern Oscillation (ENSO) Using Oceanic and Continental Climate Parameters as Inputs. J. Mar. Sci. Eng. 2022, 10, 1161. [Google Scholar] [CrossRef]
- Chang, T.K.; Talei, A.; Alaghmand, S.; Ooi, M.P.L. Choice of rainfall inputs for event-based rainfall-runoff modeling in a catchment with multiple rainfall stations using data-driven techniques. J. Hydrol. 2017, 545, 100–108. [Google Scholar] [CrossRef]
- Talei, A.; Chua, L.H. Influence of lag time on event-based rainfall–runoff modeling using the data driven approach. J. Hydrol. 2012, 438–439, 223–233. [Google Scholar] [CrossRef]
- Firat, M.; Güngör, M. Hydrological time-series modelling using an adaptive neuro-fuzzy inference system. Hydrol. Process. 2008, 22, 2122–2132. [Google Scholar] [CrossRef]
- Singh, S.K.; Bárdossy, A. Calibration of hydrological models on hydrologically unusual events. Adv. Water Resour. 2012, 38, 81–91. [Google Scholar] [CrossRef]
- Firat, M.; Güngör, M. River flow estimation using adaptive neuro fuzzy inference system. Math. Comput. Simul. 2007, 75, 87–96. [Google Scholar] [CrossRef]
- Khosravi, K.; Panahi, M.; Tien Bui, D. Spatial prediction of groundwater spring potential mapping based on an adaptive neuro-fuzzy inference system and metaheuristic optimization. Hydrol. Earth Syst. Sci. 2018, 22, 4771–4792. [Google Scholar] [CrossRef]
- Karimaldini, F.; Teang Shui, L.; Ahmed Mohamed, T.; Abdollahi, M.; Khalili, N. Daily evapotranspiration modeling from limited weather data by using neuro-fuzzy computing tech-nique. J. Irrig. Drain. Eng. 2012, 138, 21–34. [Google Scholar] [CrossRef]
- Shiri, J.; Keshavarzi, A.; Kisi, O.; Karimi, S. Using soil easily measured parameters for estimating soil water capacity: Soft computing approaches. Comput. Electron. Agric. 2017, 141, 327–339. [Google Scholar] [CrossRef]
- Talei, A.; Chua, L.H.C.; Quek, C. A novel application of a neuro-fuzzy computational technique in event-based rain-fall-runoff modeling. Expert Syst. Appl. 2010, 37, 7456–7468. [Google Scholar] [CrossRef]
- Zhang, S.; Lu, L.; Yu, J.; Zhou, H. Short-term water level prediction using different artificial intelligent models. In Proceedings of the 2016 5th International Conference on Agro-Geoinformatics, Agro-Geoinformatics, Tianjin, China, 18–20 July 2016; pp. 1–6. [Google Scholar]
- Hong, Y.-S.T.; White, P.A. Hydrological modeling using a dynamic neuro-fuzzy system with on-line and local learning algorithm. Adv. Water Resour. 2009, 32, 110–119. [Google Scholar] [CrossRef]
- Kasabov, N. Evolving fuzzy neural networks for supervised/unsupervised online knowledge-based learning. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2001, 31, 902–918. [Google Scholar] [CrossRef]
- Kasabov, N.K.; Song, Q. DENFIS: Dynamic evolving neural-fuzzy inference system and its application for time-series prediction. IEEE Trans. Fuzzy Syst. 2002, 10, 144–154. [Google Scholar] [CrossRef]
- Nguyen, N.N.; Zhou, W.J.; Quek, C. GSETSK: A generic self-evolving TSK fuzzy neural network with a novel Hebbi-an-based rule reduction approach. Appl. Soft Comput. J. 2015, 35, 29–42. [Google Scholar] [CrossRef]
- Quah, K.H.; Quek, C. FITSK: Online local learning with generic fuzzy input Takagi-Sugeno-Kang fuzzy framework for nonlinear system estimation. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 2006, 36, 166–178. [Google Scholar] [CrossRef]
- Tung, S.W.; Quek, C.; Guan, C. SaFIN: A Self-Adaptive Fuzzy Inference Network. IEEE Trans. Neural Netw. 2011, 22, 1928–1940. [Google Scholar] [CrossRef]
- Talei, A.; Chua, L.H.C.; Quek, C.; Jansson, P.-E. Runoff forecasting using a Takagi–Sugeno neuro-fuzzy model with online learning. J. Hydrol. 2013, 488, 17–32. [Google Scholar] [CrossRef]
- Heddam, S. Modelling hourly dissolved oxygen concentration (DO) using dynamic evolving neural-fuzzy inference system (DENFIS)-based approach: Case study of Klamath River at Miller Island Boat Ramp, OR, USA. Environ. Sci. Pollut. Res. 2014, 21, 9212–9227. [Google Scholar] [CrossRef]
- Heddam, S.; Dechemi, N. A new approach based on the dynamic evolving neural-fuzzy inference system (DENFIS) for modelling coagulant dosage (Dos): Case study of water treatment plant of Algeria. Desalination Water Treat. 2015, 53, 1045–1053. [Google Scholar] [CrossRef]
- Kwin, C.T.; Talei, A.; Alaghmand, S.; Chua, L.H. Rainfall-runoff Modeling Using Dynamic Evolving Neural Fuzzy Inference System with Online Learning. Procedia Eng. 2016, 154, 1103–1109. [Google Scholar] [CrossRef][Green Version]
- Eray, O.; Mert, C.; Kisi, O. Comparison of multi-gene genetic programming and dynamic evolving neural-fuzzy inference system in modeling pan evaporation. Hydrol. Res. 2018, 49, 1221–1233. [Google Scholar] [CrossRef]
- Esmaeilbeiki, F.; Nikpour, M.R.; Singh, V.K.; Kisi, O.; Sihag, P.; Sanikhani, H. Exploring the application of soft computing techniques for spatial evaluation of groundwater quality variables. J. Clean. Prod. 2020, 276, 124206. [Google Scholar] [CrossRef]
- Ye, L.; Zahra, M.M.A.; Al-Bedyry, N.K.; Yaseen, Z.M. Daily scale evapotranspiration prediction over the coastal region of southwest Bangladesh: New development of artificial intelligence model. Stoch. Environ. Res. Risk Assess. 2022, 36, 451–471. [Google Scholar] [CrossRef]
- Chang, T.K.; Talei, A.; Chua, L.H.C.; Alaghmand, S. The Impact of Training Data Sequence on the Performance of Neuro-Fuzzy Rainfall-Runoff Models with Online Learning. Water 2018, 11, 52. [Google Scholar] [CrossRef]
- Chang, T.K.; Talei, A.; Quek, C.; Pauwels, V.R. Rainfall-runoff modelling using a self-reliant fuzzy inference network with flexible structure. J. Hydrol. 2018, 564, 1179–1193. [Google Scholar] [CrossRef]
- Chang, T.K.; Talei, A.; Quek, C. Rainfall-runoff modelling in a semi-urbanized catchment using self-adaptive Fuzzy In-ference Network. In Proceedings of the 10th International Joint Conference on Computational Intelligence—IJCCI 2018, Seville, Spain, 18–20 September 2018. [Google Scholar]
- Yu, L.; Tan, S.K.; Chua, L.H.C. Online Ensemble Modeling for Real Time Water Level Forecasts. Water Resour. Manag. 2017, 31, 1105–1119. [Google Scholar] [CrossRef]
- Ashrafi, M.; Chua, L.H.C.; Quek, C.; Qin, X. A fully-online Neuro-Fuzzy model for flow forecasting in basins with limited data. J. Hydrol. 2017, 545, 424–435. [Google Scholar] [CrossRef]
- Ashrafi, M.; Chua, L.H.C.; Quek, C. The applicability of Generic Self-Evolving Takagi-Sugeno-Kang neuro-fuzzy model in modeling rainfall–runoff and river routing. Hydrol. Res. 2019, 50, 991–1001. [Google Scholar] [CrossRef]
- Deka, P.; Chandramouli, V. Fuzzy Neural Network Model for Hydrologic Flow Routing. J. Hydrol. Eng. 2005, 10, 302–314. [Google Scholar] [CrossRef]
- Mehta, R.; Jain, S.K. Optimal Operation of a Multi-Purpose Reservoir Using Neuro-Fuzzy Technique. Water Resour. Manag. 2009, 23, 509–529. [Google Scholar] [CrossRef]
- Nayak, P.C. Explaining Internal Behavior in a Fuzzy If-Then Rule-Based Flood-Forecasting Model. J. Hydrol. Eng. 2010, 15, 20–28. [Google Scholar] [CrossRef]
- Talei, A. Rainfall-Runoff Modelling with Neuro-Fuzzy Systems. Ph.D. Thesis, Nanyang Technological University, Singapore, 2013; p. 247. Available online: https://hdl.handle.net/10356/54946 (accessed on 15 November 2022).
- Heddam, S. Modeling hourly dissolved oxygen concentration (DO) using two different adaptive neuro-fuzzy inference systems (ANFIS): A comparative study. Environ. Monit. Assess. 2014, 186, 597–619. [Google Scholar] [CrossRef]
- Chang, F.-J.; Tsai, M.-J. A nonlinear spatio-temporal lumping of radar rainfall for modeling multi-step-ahead inflow forecasts by data-driven techniques. J. Hydrol. 2016, 535, 256–269. [Google Scholar] [CrossRef]
- Muhammad Adnan, R.; Yuan, X.; Kisi, O.; Yuan, Y.; Tayyab, M.; Lei, X. Application of soft computing models in streamflow forecasting. Proc. Inst. Civ. Eng. Water Manag. 2019, 172, 123–134. [Google Scholar] [CrossRef]
- Cobaner, M. Evapotranspiration estimation by two different neuro-fuzzy inference systems. J. Hydrol. 2011, 398, 292–302. [Google Scholar] [CrossRef]
- Montaseri, M.; Ghavidel, S.Z.Z.; Sanikhani, H. Water quality variations in different climates of Iran: Toward modeling total dissolved solid using soft computing techniques. Stoch. Environ. Res. Risk Assess. 2018, 32, 2253–2273. [Google Scholar] [CrossRef]
- Kisi, O.; Yaseen, Z.M. The potential of hybrid evolutionary fuzzy intelligence model for suspended sediment concentration prediction. Catena 2019, 174, 11–23. [Google Scholar] [CrossRef]
- Azad, A.; Karami, H.; Farzin, S.; Saeedian, A.; Kashi, H.; Sayyahi, F. Prediction of water quality parameters using ANFIS optimized by intelligence algorithms (case study: Gor-ganrood river). KSCE J. Civ. Eng. 2018, 22, 2206–2213. [Google Scholar] [CrossRef]
- Azad, A.; Karami, H.; Farzin, S.; Mousavi, S.-F.; Kisi, O. Modeling river water quality parameters using modified adaptive neuro fuzzy inference system. Water Sci. Eng. 2019, 12, 45–54. [Google Scholar] [CrossRef]
- Jahanara, A.-A.; Khodashenas, S.R. Prediction of Ground Water Table Using NF-GMDH Based Evolutionary Algorithms. KSCE J. Civ. Eng. 2019, 23, 5235–5243. [Google Scholar] [CrossRef]
- Maroufpoor, S.; Maroufpoor, E.; Bozorg-Haddad, O.; Shiri, J.; Yaseen, Z.M. Soil moisture simulation using hybrid artificial intelligent model: Hybridization of adaptive neuro fuzzy inference system with grey wolf optimizer algorithm. J. Hydrol. 2019, 575, 544–556. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Catchment (Country) | Type | Area (km2) | Model | CE | R2 | MAE (m3/s) | Reference |
|---|---|---|---|---|---|---|---|
| Sungai Kayu Ara (Malaysia) | Urbanized | 23.22 | SaFIN | 0.851 | 0.868 | 3.021 | Chang, Talei [110] |
| DENFIS | 0.796 | 0.845 | 3.252 | Chang, Talei [104] | |||
| Dandenong (Australia) | Semi-urbanized | 272 | SaFIN | 0.893 | 0.900 | 0.468 | Chang, Talei [110] |
| DENFIS | 0.812 | 0.843 | 0.881 | Unpublished-presented by the authors | |||
| Clarence (Australia) | Rural with minor development | 22,400 | SaFIN | 0.821 | 0.838 | 81.608 | Chang, Talei [109] |
| DENFIS | 0.670 | 0.670 | 106.191 | Chang, Talei [109] | |||
| Heshui (China) | Rural with minor development | 2275 | SaFIN | 0.839 | 0.849 | 6.222 | Chang, Talei [109] |
| DENFIS | 0.821 | 0.823 | 7.400 | Chang, Talei [109] | |||
| Klippan_2 (Sweden) | Rural | 241.33 | SaFIN | 0.918 | 0.919 | 0.536 | Chang, Talei [109] |
| DENFIS | 0.899 | 0.903 | 0.601 | Chang, Talei [109] |
| Rule Number | Input X1 | Input X2 | Output Y (POP-FNN) | Output Y (ANFIS) |
|---|---|---|---|---|
| 1 | L | L | L | Y = 1.213X1 + 0.548X2 − 0.069 |
| 2 | L | H | L | Y = −0.297X1 + 0.172X2 + 0.043 |
| 3 | H | L | H | Y = 1.467X1 − 1.140X2 − 0.026 |
| 4 | H | H | H | Y = −5.228X1 − 0.851X2 + 5.153 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ang, Y.K.; Talei, A.; Zahidi, I.; Rashidi, A. Past, Present, and Future of Using Neuro-Fuzzy Systems for Hydrological Modeling and Forecasting. Hydrology 2023, 10, 36. https://doi.org/10.3390/hydrology10020036
Ang YK, Talei A, Zahidi I, Rashidi A. Past, Present, and Future of Using Neuro-Fuzzy Systems for Hydrological Modeling and Forecasting. Hydrology. 2023; 10(2):36. https://doi.org/10.3390/hydrology10020036
Chicago/Turabian StyleAng, Yik Kang, Amin Talei, Izni Zahidi, and Ali Rashidi. 2023. "Past, Present, and Future of Using Neuro-Fuzzy Systems for Hydrological Modeling and Forecasting" Hydrology 10, no. 2: 36. https://doi.org/10.3390/hydrology10020036
APA StyleAng, Y. K., Talei, A., Zahidi, I., & Rashidi, A. (2023). Past, Present, and Future of Using Neuro-Fuzzy Systems for Hydrological Modeling and Forecasting. Hydrology, 10(2), 36. https://doi.org/10.3390/hydrology10020036