Discrimination of Chinese Liquors Based on Electronic Nose and Fuzzy Discriminant Principal Component Analysis



Abstract
1. Introduction
2. Materials and Methods
2.1. Chinese Liquor Samples
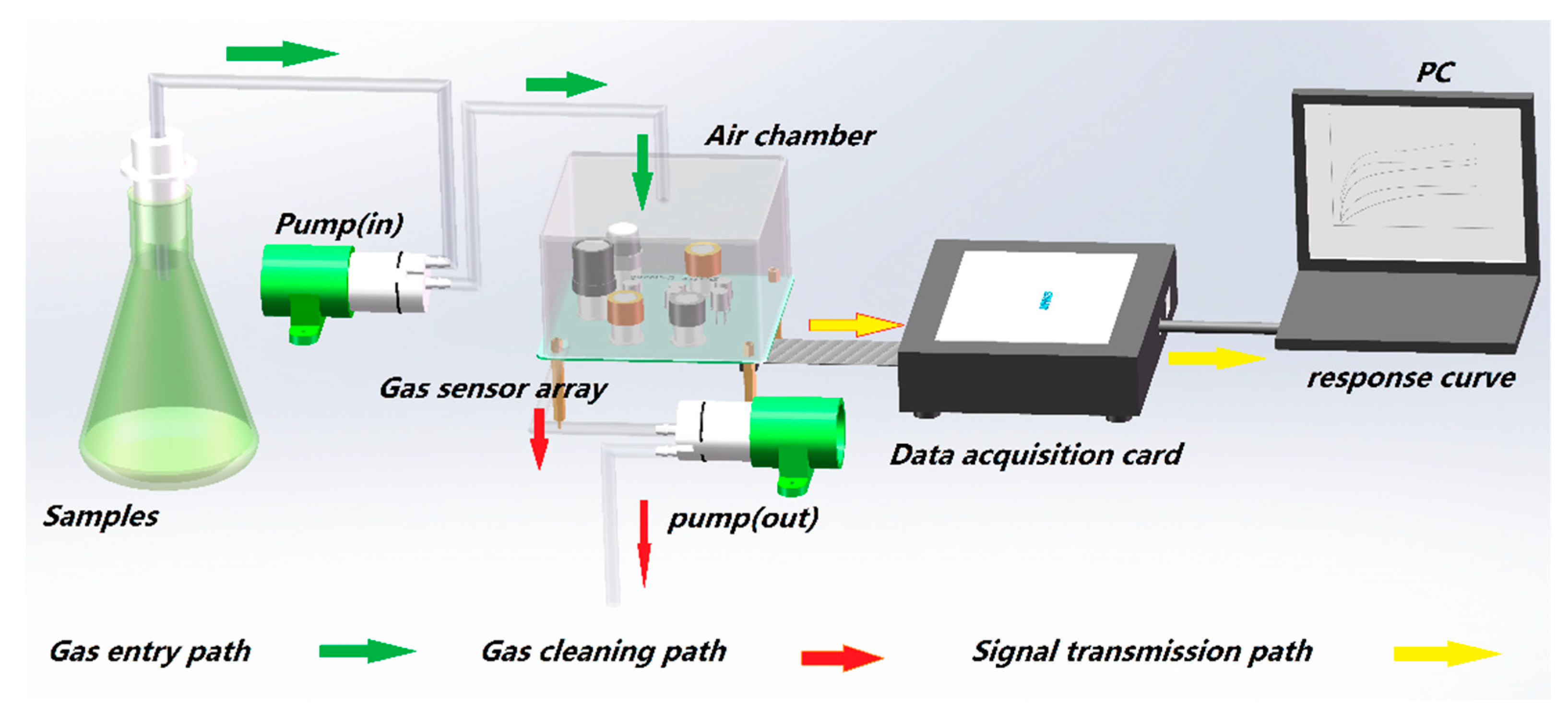
2.2. Electronic-Nose System
2.3. Experimental Steps and Data Processing
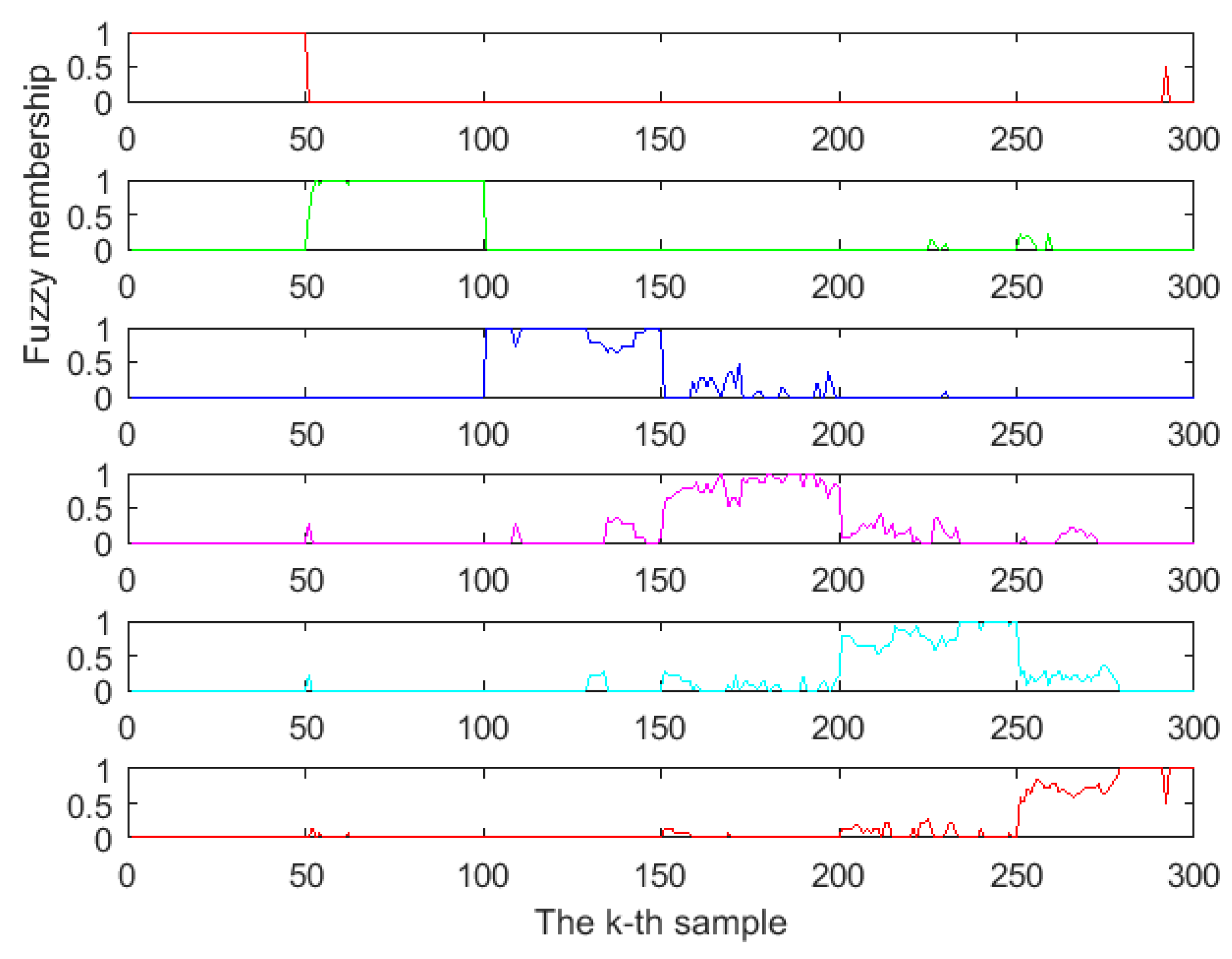
2.4. Discriminant Principal Component Analysis and Fuzzy Discriminant Principal Component Analysis
- c is the number of class; n is the number of training samples;
- the mean of training samples;
- T represents the transpose of the matrix.
- is the inverse of the fuzzy total class scatter matrix;
- Ψ and λ are the eigenvector and the corresponding eigenvalue, respectively. After obtaining the maximum eigenvalue λ1 and the corresponding eigenvector Ψ1, suppose that Ψ1 is the first vector of the fuzzy optimal discriminant vectors.
- Ψr+1 is the r+1th eigenvector;
- β is the corresponding eigenvalue;
- I is the identity matrix;
- Ψ1, Ψ2,…, Ψr is a set of fuzzy optimal discriminant vectors.
3. Results and Discussion
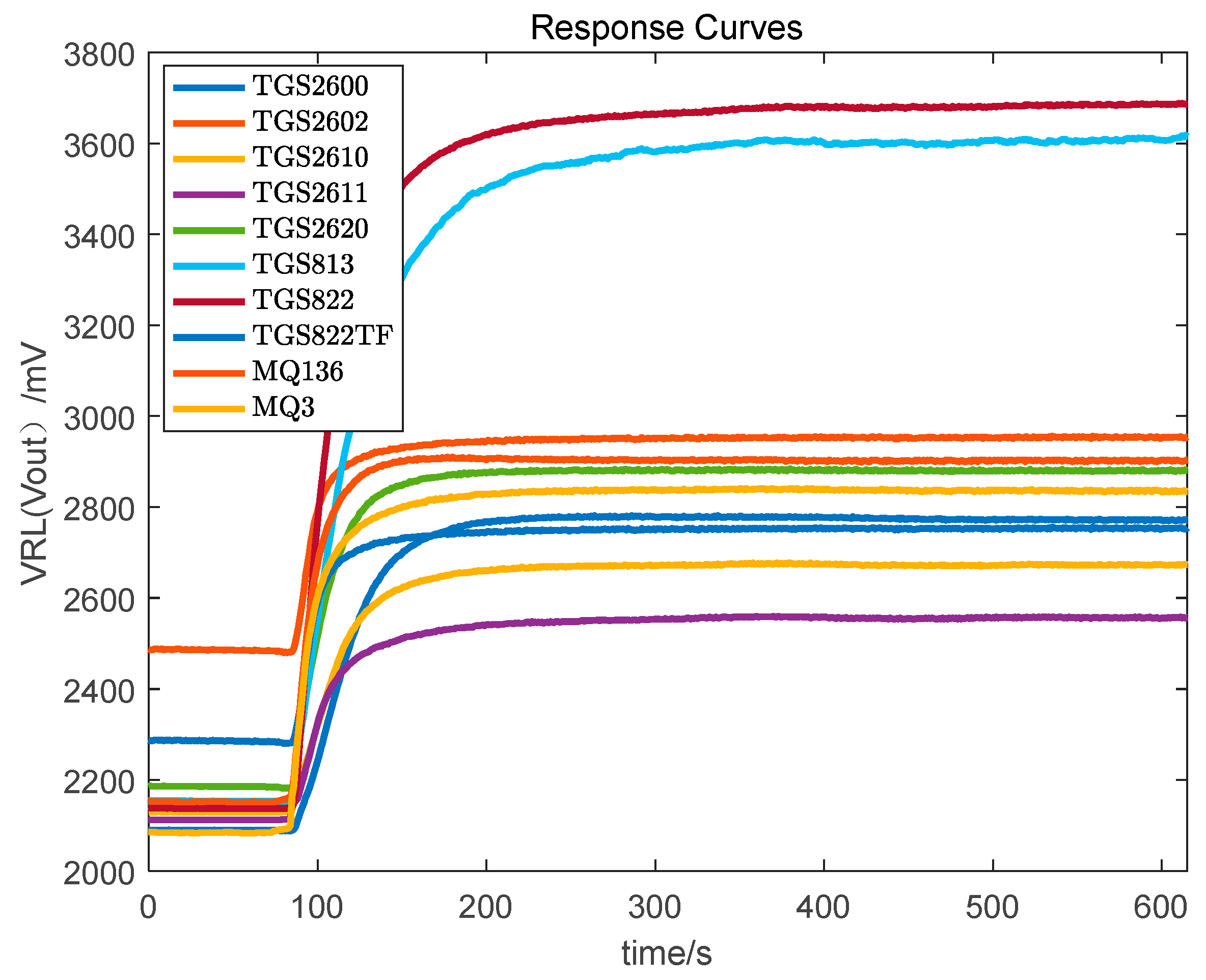
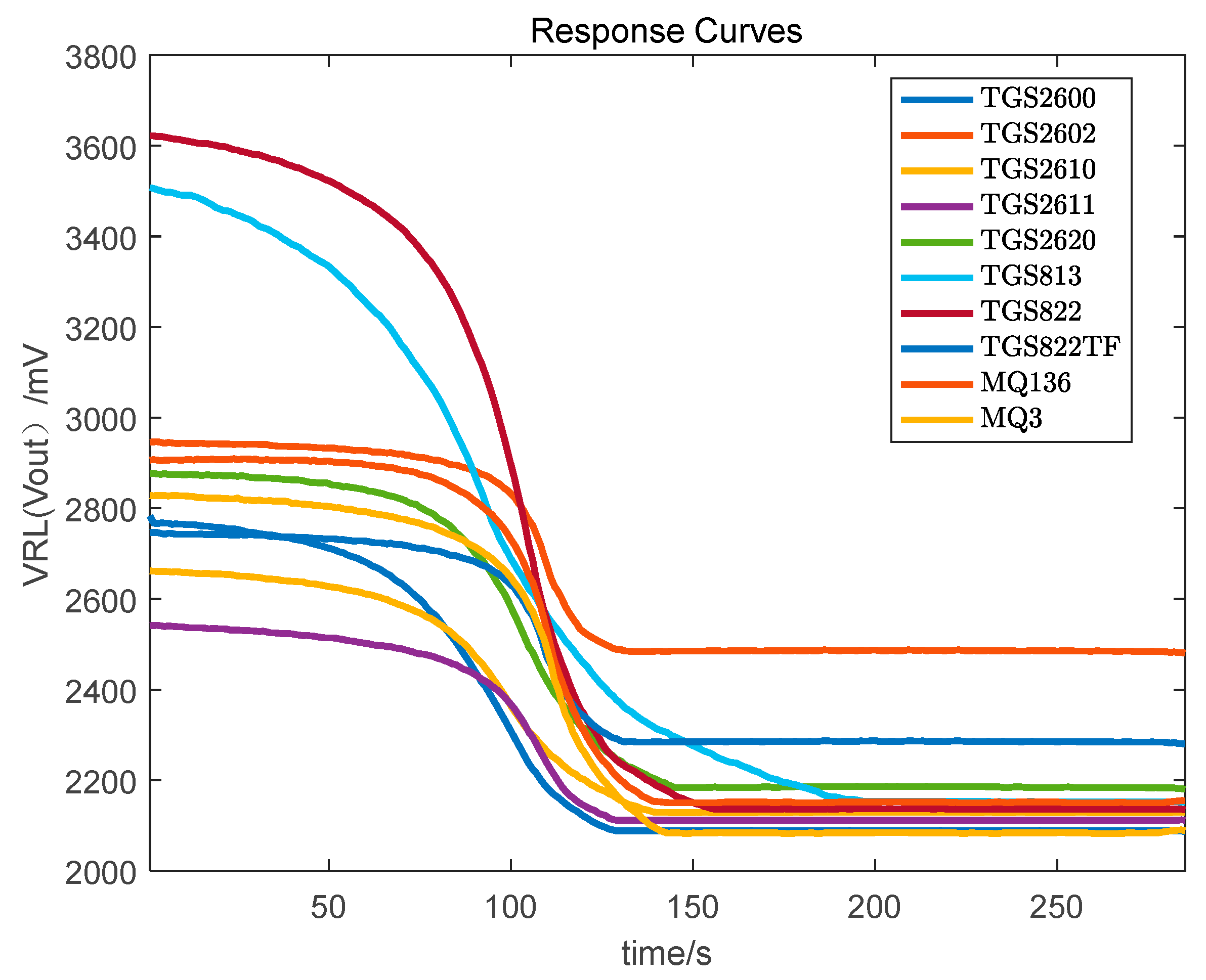
3.1. Data Preprocessing
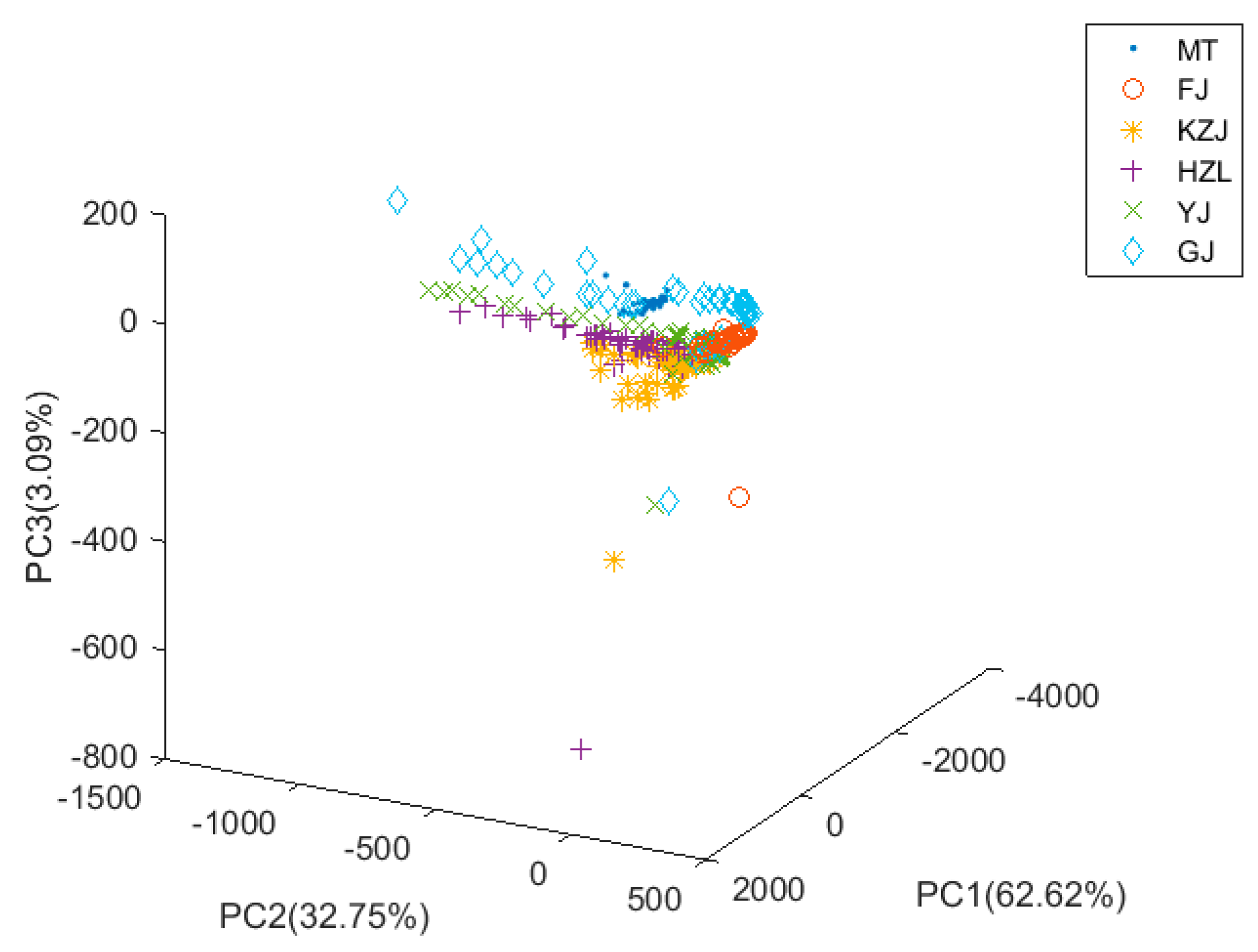
3.2. PCA Analysis
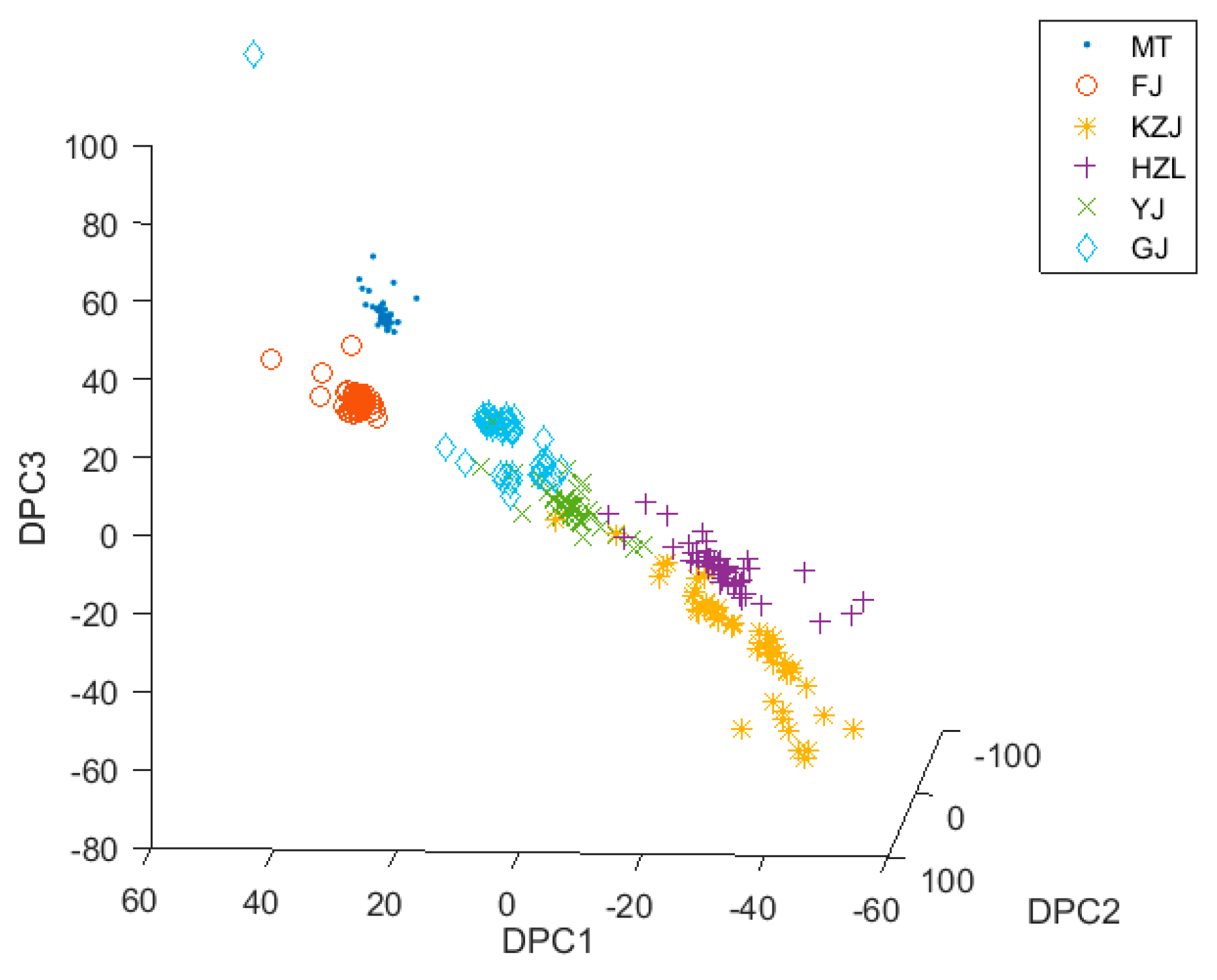
3.3. Classification with DPCA
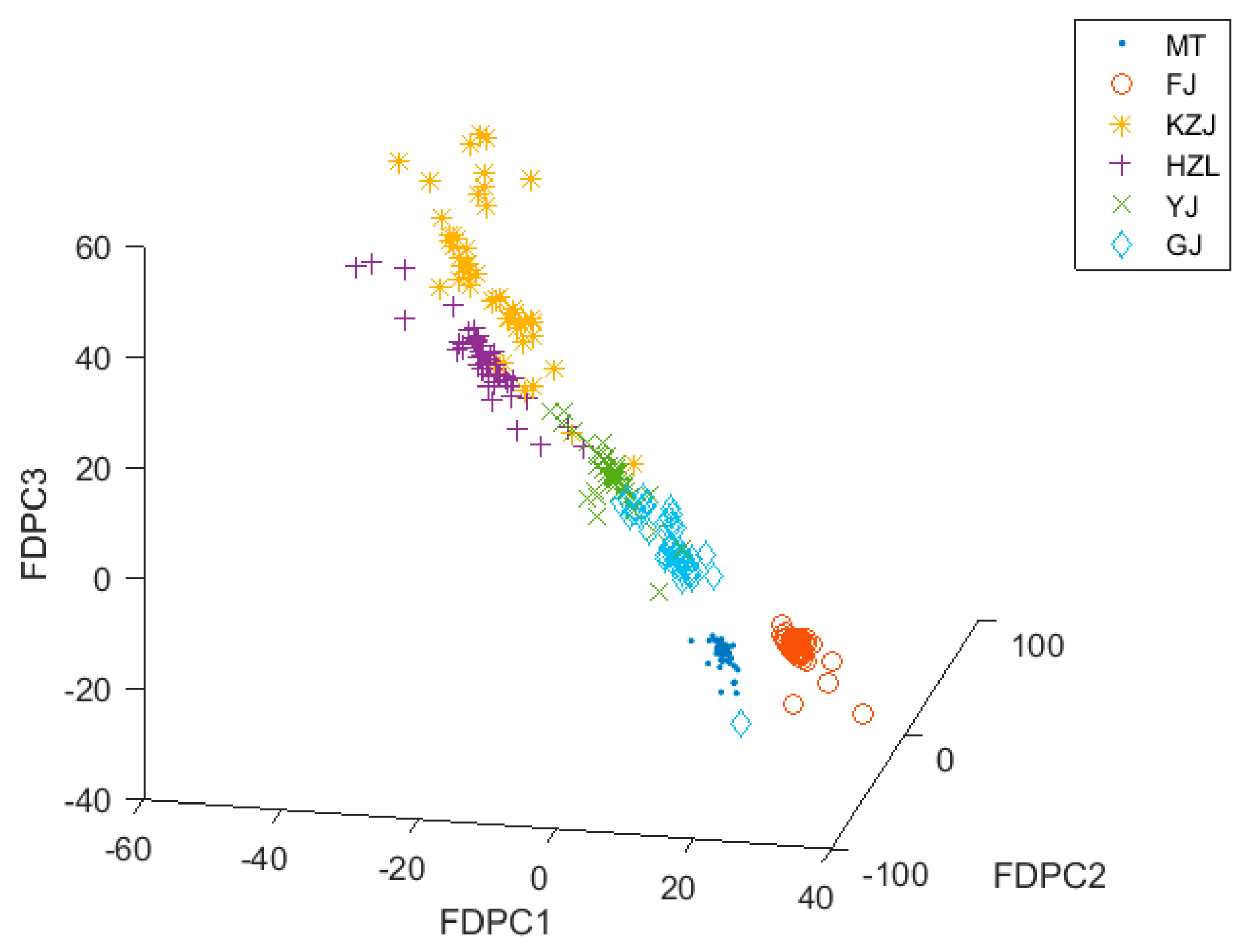
3.4. Classification with PCA and FDPCA
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wu, J.F.; Xu, Y. Comparison of pyrazine compounds in seven Chinese liquors using headspace solid-phase micro-extraction and GC-nitrogen phosphourus detection. Food Sci. Biotechnol. 2013, 22, 1–6. [Google Scholar] [CrossRef]
- Ding, X.F.; Wu, C.D.; Huang, J.; Zhou, R.Q. Changes in volatile compounds of Chinese Luzhou-flavor liquor during the fermentation and distillation process. J. Food Sci. 2015, 80, 2373–2381. [Google Scholar] [CrossRef] [PubMed]
- Du, H.; Fan, W.; Xu, Y. Characterization of geosmin as source of earthy odor in different aroma type Chinese liquors. J. Agric. Food Chem. 2011, 59, 8331–8337. [Google Scholar] [CrossRef] [PubMed]
- Yao, F.; Yi, B.; Shen, C.H.; Tao, F.; Liu, Y.M.; Lin, Z.X.; Xu, P. Chemical analysis of the Chinese liquor Luzhoulaojiao by comprehensive two-dimensional gas chromatography/time-of-flight mass spectrometry. Sci. Rep. 2015, 5, 9553. [Google Scholar] [CrossRef] [PubMed]
- Zhu, X.D.; Cai, Y.; Yang, H. The creation and application of the anti-counterfeit packing of alcoholic drinks in China. J. Jiamusi Univ. 2007, 25, 182–184. [Google Scholar]
- Wilson, A.D. Diverse applications of electronic-nose technologies in agriculture and forestry. Sensors 2013, 13, 2295–2348. [Google Scholar] [CrossRef] [PubMed]
- Baietto, M.; Wilson, A.D. Electronic-nose applications for fruit identification, ripeness and quality grading. Sensors 2015, 15, 899–931. [Google Scholar] [CrossRef] [PubMed]
- Heidarbeigi, K.; Mohtasebi, S.S.; Foroughirad, A.; Ghasemi-varnamkhasti, M.; Rafiee, S.; Rezaei, K. Detection of adulteration in saffron samples using electronic nose. Int. J. Food Prop. 2014, 18, 1391–1401. [Google Scholar] [CrossRef]
- Cevoli, C.; Cerretani, L.; Gori, A.; Caboni, M.F.; Toschi, T.G.; Fabbri, A. Classification of Pecorino cheeses using electronic nose combined with artificial neural network and comparison with GC-MS analysis of volatile compounds. Food Chem. 2011, 129, 1315–1319. [Google Scholar] [CrossRef]
- Peng, Q.; Tian, R.; Chen, F.; Li, B.; Gao, H. Discrimination of producing area of Chinese Tongshan kaoliang spirit using electronic nose sensing characteristics combined with the chemometrics methods. Food Chem. 2015, 178, 301–305. [Google Scholar] [CrossRef]
- Wu, T.X.; Zheng, Y.; Tang, Q.L. Study on gas chromatography fingerprint map of Maotai-flavor liquor. Liquor Mak. Sci. Technol. 2008, 10, 30–36. [Google Scholar]
- Xiao, Z.B.; Yu, D.; Niu, Y.W.; Chen, F.; Song, S.Q.; Zhu, J.C.; Zhu, G.Y. Characterization of aroma compounds of Chinese famous liquors by gas chromatography-mass spectrometry and flash GC electronic-nose. J. Chromatogr. B. 2014, 945, 92–100. [Google Scholar] [CrossRef] [PubMed]
- Gardner, J.W.; Bartlett, P.N. A brief history of electronic noses. Sens. Actuat. B Chem. 1994, 18, 210–211. [Google Scholar] [CrossRef]
- Gutiérrez, J.; Horrillo, M.C. Advances in artificial olfaction: Sensors and applications. Talanta 2014, 124, 95–105. [Google Scholar] [CrossRef] [PubMed]
- Axel, R.; Buck, L. A novel multigene family may encode odorant receptors: A molecular basis for odor recognition. Cell 1991, 65, 175–187. [Google Scholar]
- Xu, X.T.; Tian, F.C.; Yan, J.; Ma, J.W.; Liu, T. Rapid detection of wound pathogen by enose with a gas condensation unit. Chin. J. Sens. Actuat. 2009, 22, 303–306. [Google Scholar]
- Hassan, M.; Bermak, A. Robust Bayesian inference for gas identification in electronic nose applications by using random matrix theory. IEEE Sens. J. 2016, 16, 2036–2045. [Google Scholar] [CrossRef]
- Zhang, L.; Tian, F.C.; Nie, H.; Dang, L.J.; Li, G.R.; Ye, Q.; Kadria, C. Classification of multiple indoor air contaminants by an electronic nose and a hybrid support vector machine. Sensor. Actuat. B Chem. 2012, 174, 114–125. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Y.; Deng, P. Odor recognition in multiple E-nose systems with cross-domain discriminative subspace learning. IEEE Trans. Instrum. Meas. 2017, 66, 1679–1692. [Google Scholar] [CrossRef]
- Haddi, Z.; Barbri, N.E.; Tahri, K.; Bougrini, M.; Bari, N.E.; Llobet, E.; Bouchikhi, B. Instrumental assessment of red meat origins and their storage time using electronic sensing systems. Anal. Methods 2015, 7, 5193–5203. [Google Scholar] [CrossRef]
- Capone, S.; Distante, S.; Francioso, C.; Presicce, L.; Taurino, D.; Siciliano, A.M.; Zuppa, P. The electronic nose applied to food analysis. Anales Des La Asociacion Quimica Argentina 2005, 93, 123–135. [Google Scholar]
- Loutfi, A.; Coradeschi, S.; Mani, G.K.; Shankar, P.; Rayappan, J.B.B. Electronic noses for food quality: A review. J. Food Eng. 2015, 144, 103–111. [Google Scholar] [CrossRef]
- Turner, A.P.F.; Magan, N. Electronic noses and disease diagnostics. Nat. Rev. Microbiol. 2004, 2, 161–166. [Google Scholar] [CrossRef] [PubMed]
- Wilson, A.D. Review of electronic-nose technologies and algorithms to detect hazardous chemicals in the environment. Procedia Technol. 2012, 1, 453–463. [Google Scholar] [CrossRef]
- Romain, A.C.; Nicolas, J. Long term stability of metal oxide-based gas sensors for e-nose environmental applications: An overview. Sens. Actuat. B Chem. 2010, 146, 502–506. [Google Scholar] [CrossRef]
- Yang, S.; Xie, S.; Xu, M.; Zhang, C.; Wu, M.; Yang, J.; Zhang, L.; Zhang, D.Y.; Jiang, Y.; Wu, C.J. A novel method for rapid discrimination of bulbus of Fritillaria by using electronic nose and electronic tongue technology. Anal. Methods 2015, 7, 943–952. [Google Scholar] [CrossRef]
- Han, F.K.; Huang, X.; Teye, E.; Gu, F.; Gu, H. Nondestructive detection of fish freshness during its preservation by combining electronic nose and electronic tongue techniques in conjunction with chemometric analysis. Anal. Methods 2014, 6, 529–536. [Google Scholar] [CrossRef]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Jia, X.M.; Meng, Q.H.; Jing, Y.Q.; Qi, P.Y.; Zeng, M.; Ma, S.G. A new method combining KECA-LDA with ELM for classification of Chinese liquors using electronic nose. IEEE Sens. J. 2016, 16, 8010–8017. [Google Scholar] [CrossRef]
- Qi, P.F.; Meng, Q.H.; Jing, Y.Q.; Liu, Y.J.; Zeng, M. A bio-inspired breathing sampling electronic nose for rapid detection of Chinese liquors. IEEE Sens. J. 2017, 17, 4689–4698. [Google Scholar] [CrossRef]
- Liu, M.; Wang, M.J.; Wang, J.; Li, D. Comparison of random forest, support vector machine and back propagation neural network for electronic tongue data classification: Application to the recognition of orange beverage and Chinese vinegar. Sens. Actuat. B Chem. 2013, 177, 970–980. [Google Scholar] [CrossRef]
- Qiu, S.; Wang, J.; Tang, C.; Du, D. Comparison of ELM, RF, and SVM on e-nose and e-tongue to trace the quality status of mandarin (Citrus unshiu Marc.). J. Food Eng. 2015, 166, 193–203. [Google Scholar] [CrossRef]
- Han, J.W.; Breckon, T.P.; Randell, D.A.; Landini, G. The application of support vector machine classification to detect cell nuclei for automated microscopy. Mach. Vis. Appl. 2012, 23, 15–24. [Google Scholar] [CrossRef]
- Li, Q.; Gu, Y.; Wang, N.F. Application of random forest classifier by means of a QCM-based e-nose in the identification of Chinese liquor flavors. IEEE Sens. J. 2017, 17, 1788–1794. [Google Scholar] [CrossRef]
- Qin, H.; Huo, D.Q.; Zhang, L.; Yang, L.M.; Zhang, S.Y.; Yang, M.; Shen, C.H.; Hou, C.J. Colorimetric artificial nose for identification of Chinese liquor with different geographic origins. Food Res. Int. 2012, 45, 45–51. [Google Scholar] [CrossRef]
- Liu, M.; Han, X.M.; Tu, K.; Pan, L.Q.; Tu, J.; Tang, L.; Liu, P.; Zhan, G.; Zhong, Q.D.; Xiong, Z.H. Application of electronic nose in Chinese spirits quality control and flavor assessment. Food Control 2012, 26, 564–570. [Google Scholar] [CrossRef]
- Verma, P.; Yadava, R.D.S. Polymer selection for SAW sensor array based electronic noses by fuzzy c-means clustering of partition coefficients: Model studies on detection of freshness and spoilage of milk and fish. Sens. Actuat. B Chem. 2015, 209, 751–769. [Google Scholar] [CrossRef]
- Duchene, J.; Leclercq, S. An optimal transformation for discriminant and principal component analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1988, 10, 978–983. [Google Scholar] [CrossRef]
- Lee, M.M.S.; Keerthi, S.S.; Chong, J.O.; Decoste, D. An efficient method for computing leave-one-out error in support vector machines with Gaussian kernels. IEEE Trans. Neural Netw. 2004, 15, 750–757. [Google Scholar] [CrossRef] [PubMed]
- Martinelli, E.; Santonico, M.; Pennazza, G.; Paolesse, R.; D’Amico, A.; Di Natale, C. Short time gas delivery pattern improves long-term sensor reproducibility. Sens. Actuat. B Chem 2011, 156, 753–759. [Google Scholar] [CrossRef]
- Keller, J.M.; Gray, M.R.; Givens, J.A. A fuzzy k-nearest neighbor algorithm. IEEE Trans. Syst. Man Cybern. 1985, 4, 580–585. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chinese Liquors | Proof | Raw Material | Place of Origin |
|---|---|---|---|
| Maotai (MT) | 53%vol | Sorghum, wheat, water | Zunyi City, Guizhou Province |
| Gujinggongjiu (GJ) | 53%vol | Water, sorghum, rice, wheat, glutinous rice, corn | Haozhou City, Anhui Province |
| Yingjiagongjiu (YJ) | 52%vol | Water, sorghum, rice, corn, wheat | Mianzhu City, Sichuan Province |
| Haizhilan (HZL) | 42%vol | Water, sorghum, rice, corn, wheat, barley, peas | Suqian City, Jiangsu Province |
| Fenjiu (FJ) | 53%vol | Water, sorghum, barley, peas | Fenyang City, Shaanxi Province |
| Kouzijiao (KZJ) | 46%vol | Water, sorghum, corn, rice, wheat, barley, peas | Huaibei City, Anhui Province |
| Sensor | Target Gas | Standard Test Conditions | |
|---|---|---|---|
| Circuit Conditions | Preheat Time | ||
| TGS2600 | Air pollution (hydrogen, alcohol, etc.) | VC = 5.0 +/− 0.01 V DC VH = 5.0 +/− 0.05 V DC | 7 days or more |
| TGS2602 | Air pollution (VOC, ammonia, hydrogen sulfide, etc.) | VC = 5.0 +/− 0.01 V DC VH = 5.0 +/− 0.05 V DC | 7 days or more |
| TGS2610 | Butane, LP gas | VC = 5.0 +/− 0.01 V DC VH = 5.0 +/− 0.05 V DC | 7 days or more |
| TGS2620 | Ethanol, organic solvents | VC = 5.0 +/− 0.01 V DC VH = 5.0 +/− 0.05 V DC | 7 days or more |
| TGS2611 | Methane, natural gas | VC = 5.0 +/− 0.01 V DC VH = 5.0 +/− 0.05 V DC | 7 days or more |
| TGS813 | Methane, propane, butane | VC = 10.0 +/− 0.1 DC/AC VH = 5.0 +/− 0.05 DC/AC RL = 4.0 kΩ +/− 1% | 7 days or more |
| TGS822 | Alcohol, organic solvents | VC = 10.0 +/− 0.1 V DC/AC VH = 5.0 +/− 0.05 V DC/AC RL = 10.0 kΩ +/− 1% | 7 days or more |
| TGS822TF | Coal gas, which includes H2 and CO | VC = 10.0 +/− 0.1 V DC/AC VH = 5.0 +/− 0.05 V DC/AC | 7 days or more |
| MQ136 | Hydrogen sulfide benzene vapor | VC = 5.0 +/− 0.1 V DC VH = 5.0 +/− 0.05 V DC/AC | More than 48 h |
| MQ3 | Alcohol gas (volatile alcohol) | VC = 5.0 +/− 0.1 V DC/AC VH = 5.0 +/− 0.05 V DC/AC | More than 48 h |
| Types of Models | Feature Number | k (-Nearest Neighbor Algorithm) | LOO Cross- Validation Accuracy | 5-Fold Cross-Validation Accuracy | 10-Fold Cross-Validation Accuracy | 20-Fold Cross-Validation Accuracy | 25-Fold Cross-Validation Accuracy | Average Validation Accuracy |
|---|---|---|---|---|---|---|---|---|
| PCA | 5 | 7 | 88.6% | 90.44% | 90.78% | 89.78% | 90.28% | 89.98% |
| DPCA | 5 | 7 | 96% | 94.44% | 95.56% | 95.33% | 96.38% | 95.54% |
| FDPCA | 5 | 7 | 98.33% | 98.67% | 98.56% | 98.89% | 99.44% | 98.78% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Zhu, J.; Wu, B.; Zhao, C.; Sun, J.; Dai, C. Discrimination of Chinese Liquors Based on Electronic Nose and Fuzzy Discriminant Principal Component Analysis. Foods 2019, 8, 38. https://doi.org/10.3390/foods8010038
Wu X, Zhu J, Wu B, Zhao C, Sun J, Dai C. Discrimination of Chinese Liquors Based on Electronic Nose and Fuzzy Discriminant Principal Component Analysis. Foods. 2019; 8(1):38. https://doi.org/10.3390/foods8010038
Chicago/Turabian StyleWu, Xiaohong, Jin Zhu, Bin Wu, Chao Zhao, Jun Sun, and Chunxia Dai. 2019. "Discrimination of Chinese Liquors Based on Electronic Nose and Fuzzy Discriminant Principal Component Analysis" Foods 8, no. 1: 38. https://doi.org/10.3390/foods8010038
APA StyleWu, X., Zhu, J., Wu, B., Zhao, C., Sun, J., & Dai, C. (2019). Discrimination of Chinese Liquors Based on Electronic Nose and Fuzzy Discriminant Principal Component Analysis. Foods, 8(1), 38. https://doi.org/10.3390/foods8010038