
Research on Beef Marbling Grading Algorithm Based on Improved YOLOv8x



Abstract
1. Introduction
2. Materials and Methods
2.1. Dataset and Preprocessing
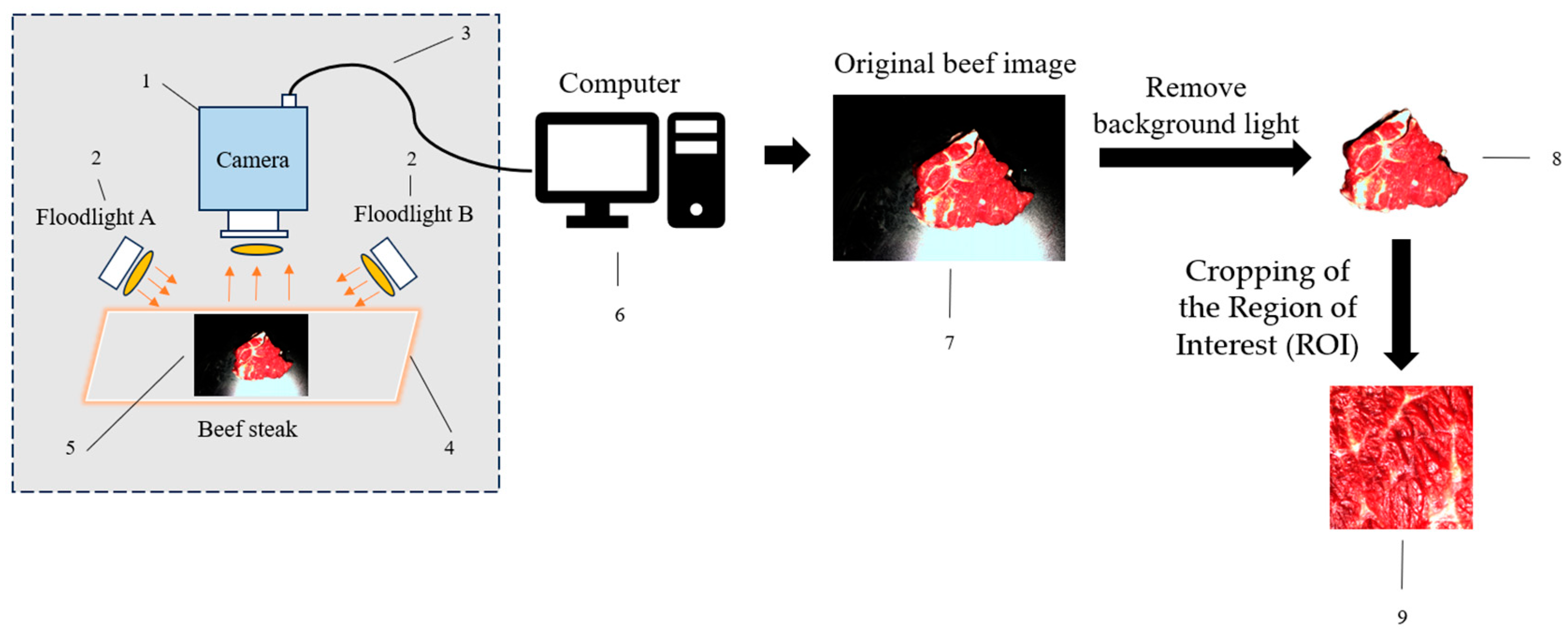
2.1.1. Image Acquisition
2.1.2. Test Materials
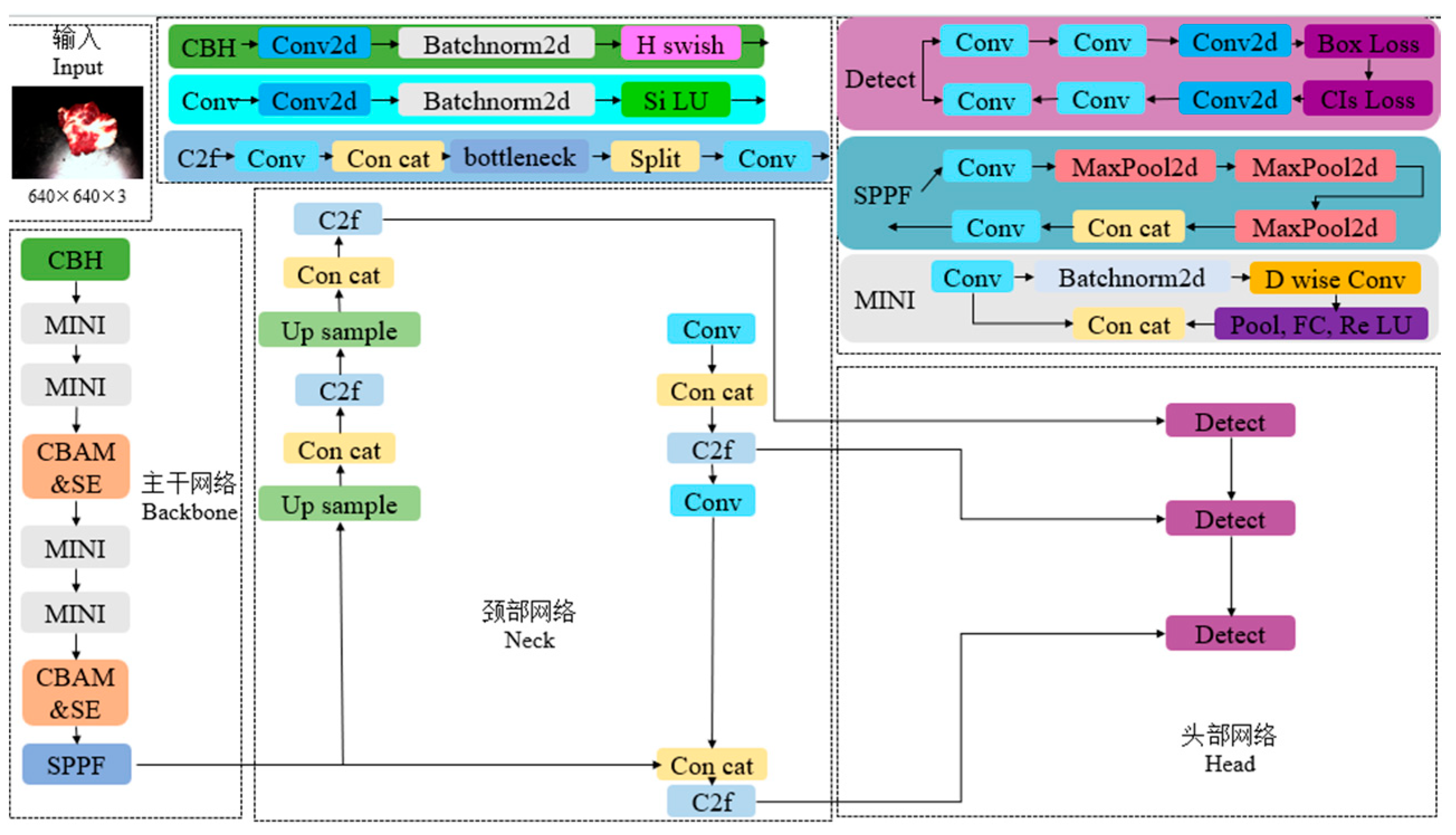
2.2. YOLOv8x Network Model Improvement
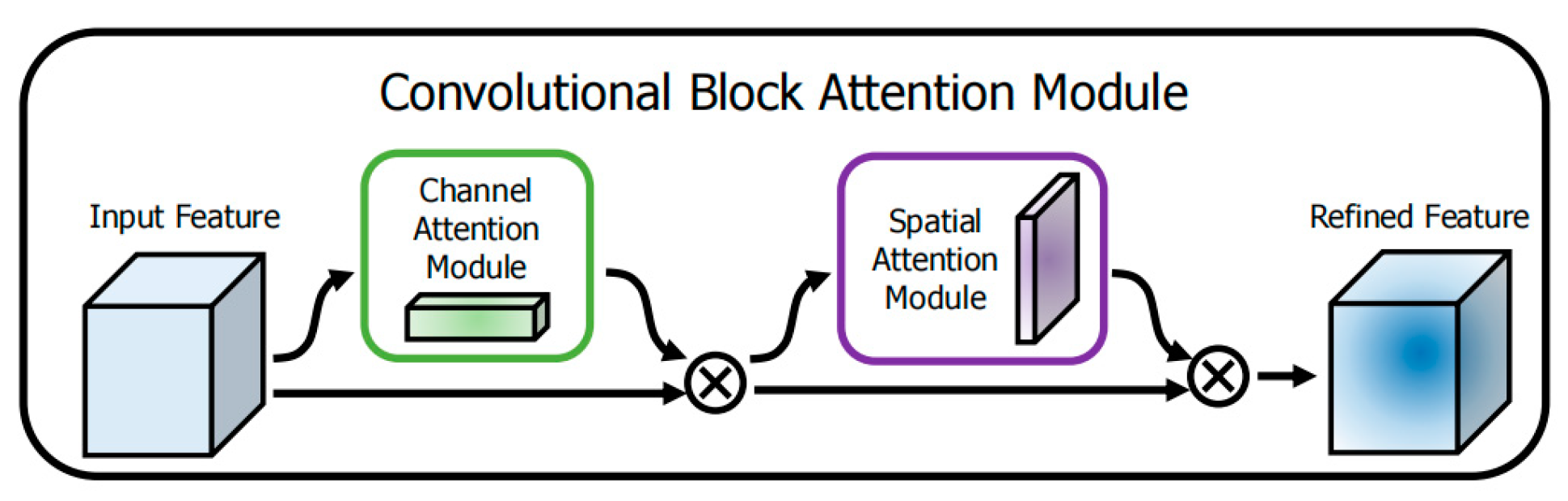
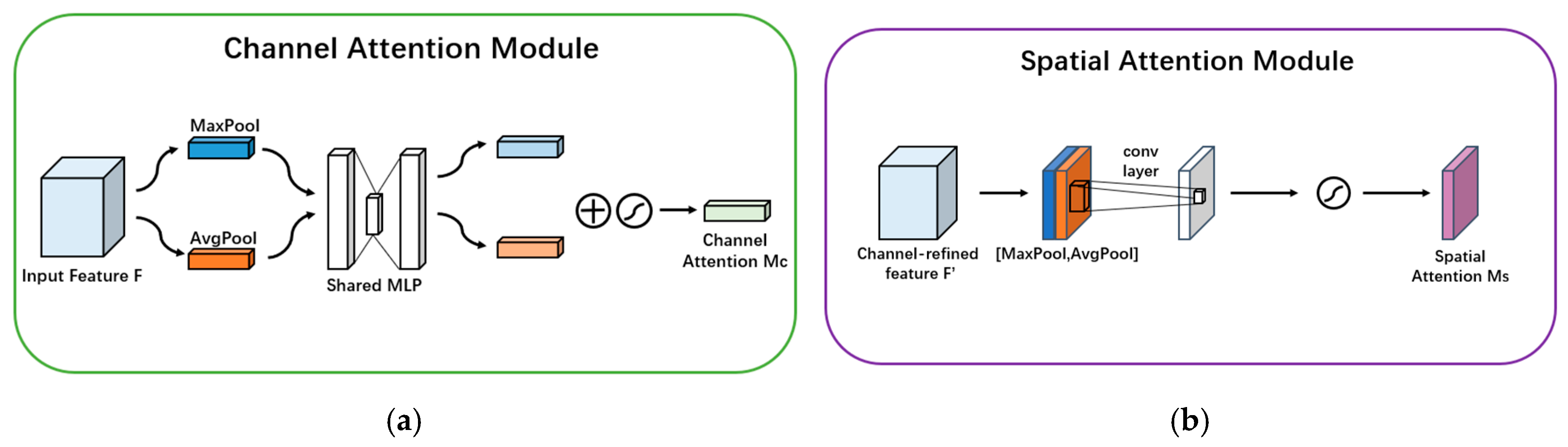
2.2.1. Embedding of CBAM Attention Mechanism Module
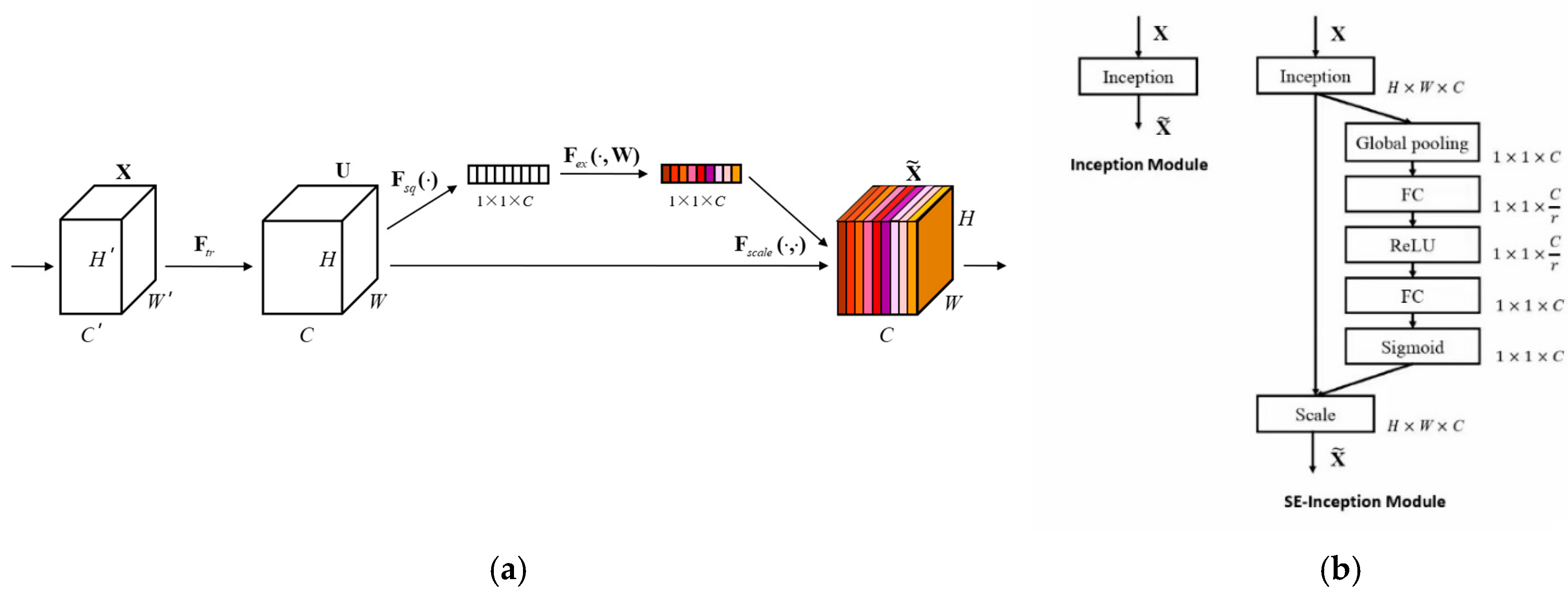
2.2.2. Embedding of SE Attention Mechanism Module
2.2.3. CIoU Loss Function Design
2.2.4. Improved YOLOv8x Network Model
2.2.5. Evaluation Metrics
3. Results and Discussion
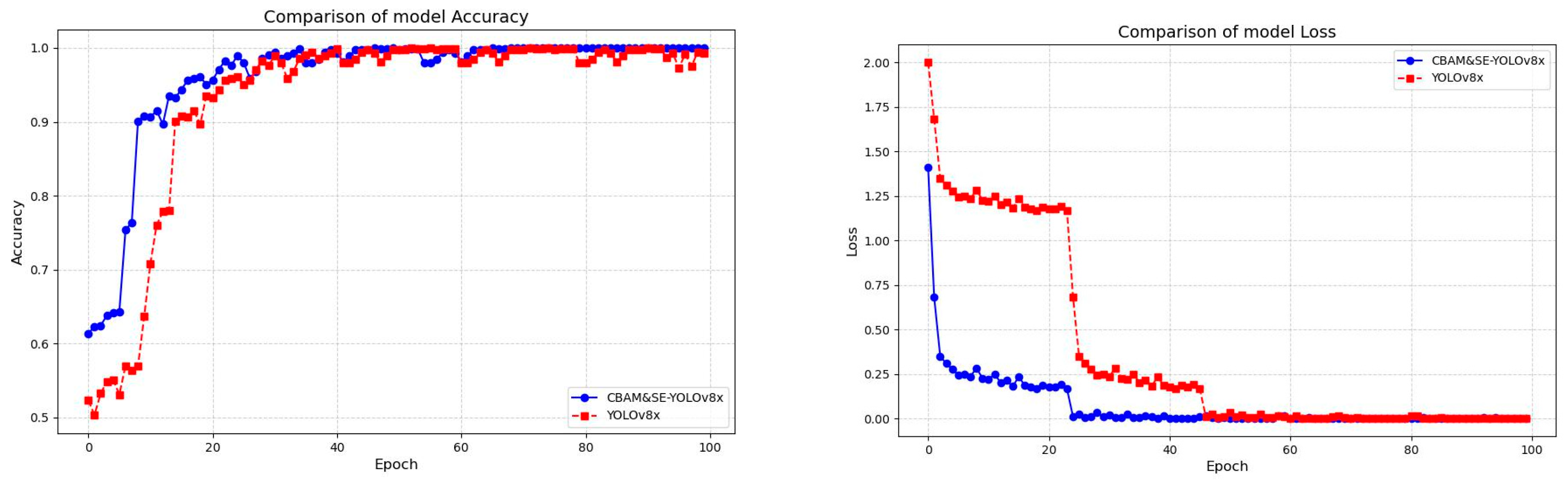
3.1. Experimental Platform and Model Training Results
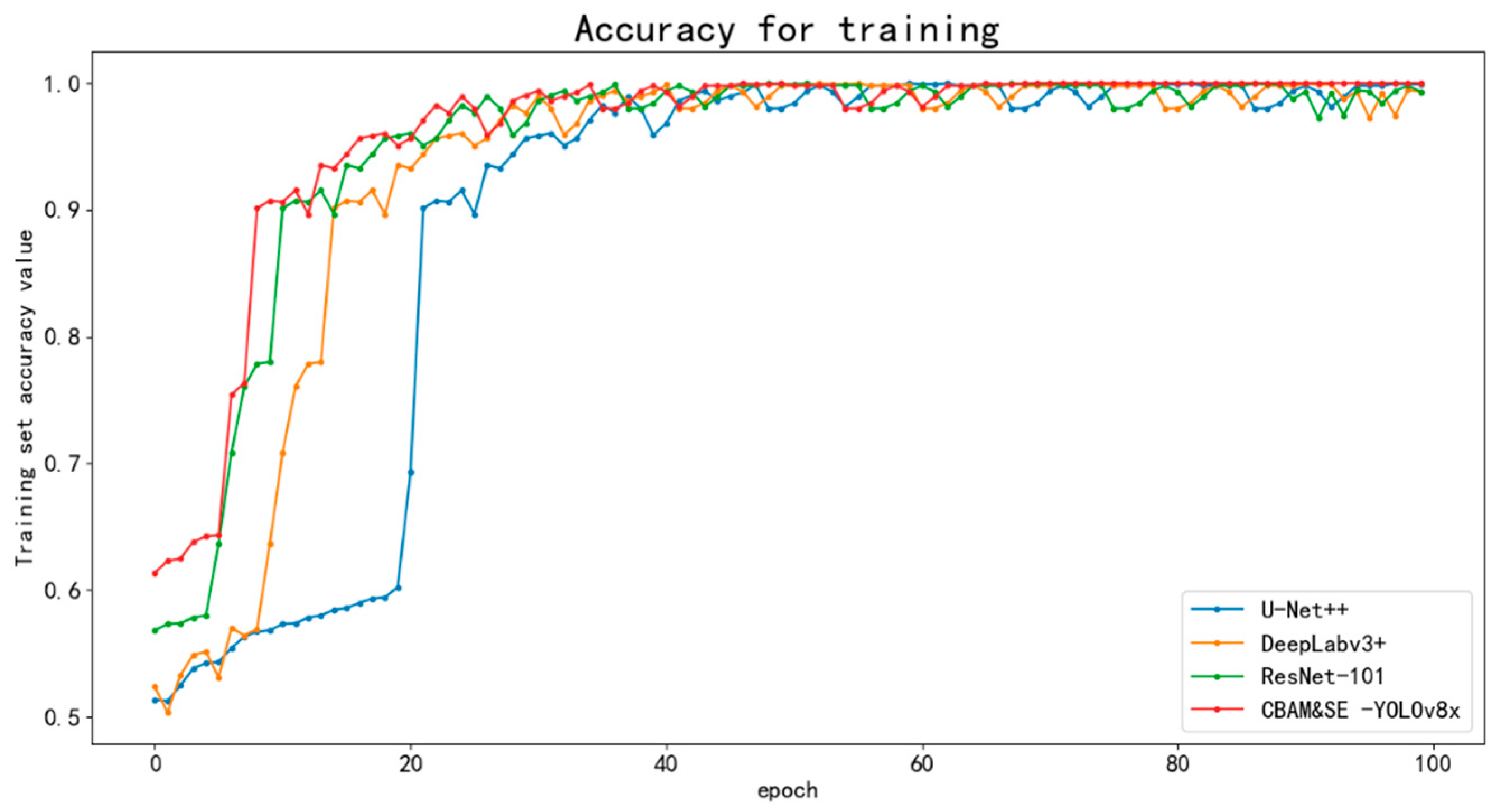
3.2. Comparative Experiments of Different Deep Learning Models
3.3. YOLOv8x Model Ablation Test
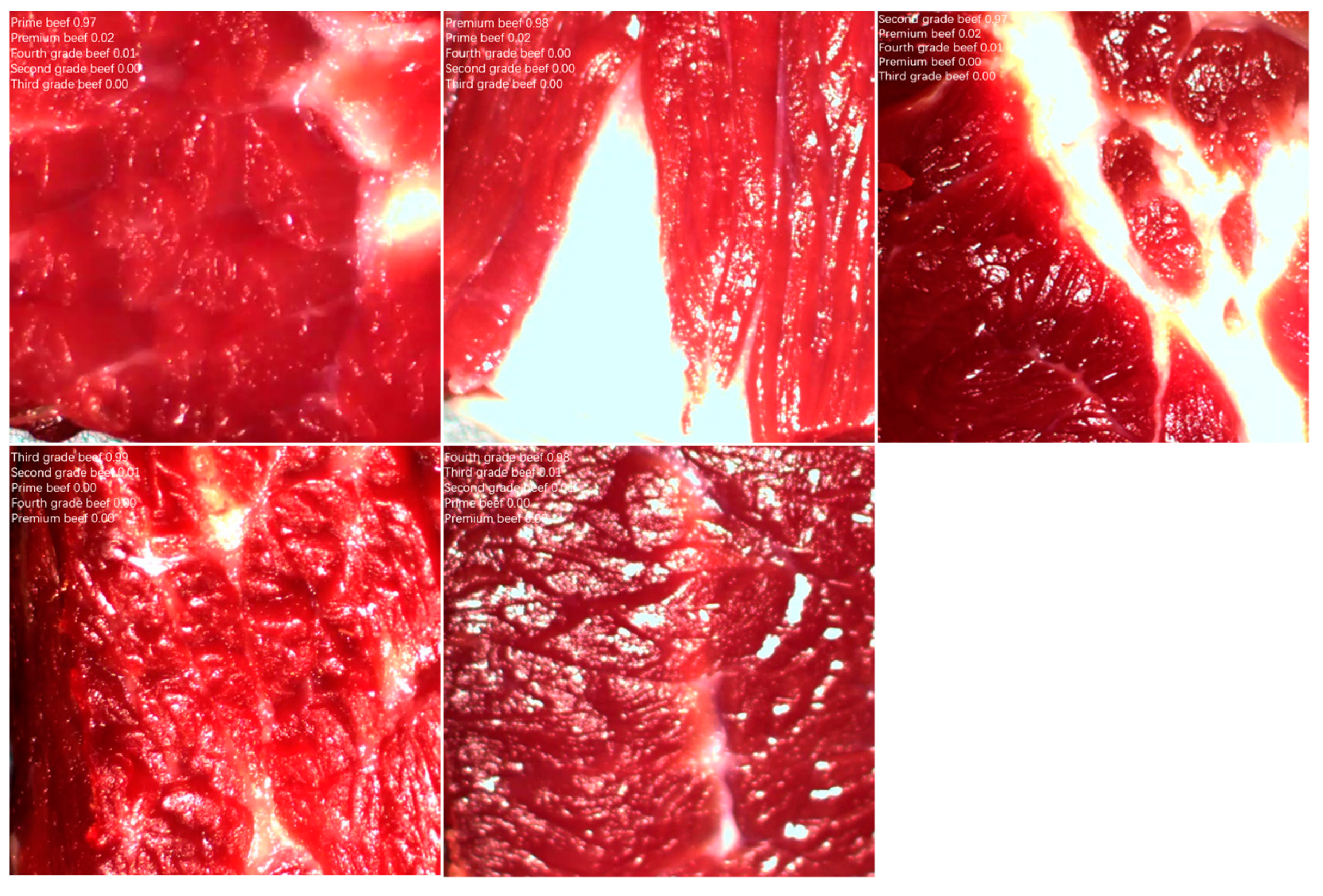
3.4. Comparison of Image Acquisition Methods
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Smith, S.B.; Gotoh, T.; Greenwood, P.L. Current Situation and Future Prospects for Global Beef Production: Overview of Special Issue. Asian-Australas. J. Anim. Sci. 2018, 31, 927–932. [Google Scholar] [CrossRef] [PubMed]
- Li, X.Z.; Yan, C.G.; Zan, L.S. Current Situation and Future Prospects for Beef Production in China—A Review. Asian-Australas. J. Anim. Sci. 2018, 31, 984–991. [Google Scholar] [CrossRef]
- Cheng, W.; Cheng, J.; Sun, D.; Pu, H. Marbling Analysis for Evaluating Meat Quality: Methods and Techniques. Comp. Rev. Food Sci. Food Safe 2015, 14, 523–535. [Google Scholar] [CrossRef]
- Clinquart, A.; Ellies-Oury, M.P.; Hocquette, J.F.; Guillier, L.; Santé-Lhoutellier, V.; Prache, S. Review: On-Farm and Processing Factors Affecting Bovine Carcass and Meat Quality. Animal 2022, 16, 100426. [Google Scholar] [CrossRef]
- Huerta-Leidenz, N. Progress on Nutrient Composition, Meat Standardization, Grading, Processing, and Safety for Different Types of Meat Sources. Foods 2021, 10, 2128. [Google Scholar] [CrossRef]
- Pannier, L.; Van De Weijer, T.M.; Van Der Steen, F.T.H.J.; Kranenbarg, R.; Gardner, G.E. Adding Value to Beef Portion Steaks through Measuring Individual Marbling. Meat Sci. 2023, 204, 109279. [Google Scholar] [CrossRef] [PubMed]
- Stewart, S.M.; Gardner, G.E.; Williams, A.; Pethick, D.W.; McGilchrist, P.; Kuchida, K. Association between Visual Marbling Score and Chemical Intramuscular Fat with Camera Marbling Percentage in Australian Beef Carcasses. Meat Sci. 2021, 181, 108369. [Google Scholar] [CrossRef] [PubMed]
- Cai, J.; Lu, Y.; Olaniyi, E.; Wang, S.; Dahlgren, C.; Devost-Burnett, D.; Dinh, T. Beef Marbling Assessment by Structured-Illumination Reflectance Imaging with Deep Learning. J. Food Eng. 2024, 369, 111936. [Google Scholar] [CrossRef]
- Muñoz, I.; Gou, P.; Fulladosa, E. Computer Image Analysis for Intramuscular Fat Segmentation in Dry-Cured Ham Slices Using Convolutional Neural Networks. Food Control 2019, 106, 106693. [Google Scholar] [CrossRef]
- Gorji, H.T.; Shahabi, S.M.; Sharma, A.; Tande, L.Q.; Husarik, K.; Qin, J.; Chan, D.E.; Baek, I.; Kim, M.S.; MacKinnon, N.; et al. Combining Deep Learning and Fluorescence Imaging to Automatically Identify Fecal Contamination on Meat Carcasses. Sci. Rep. 2022, 12, 2392. [Google Scholar] [CrossRef]
- Cengel, T.A.; Gencturk, B.; Yasin, E.T.; Yildiz, M.B.; Cinar, I.; Koklu, M. Automating Egg Damage Detection for Improved Quality Control in the Food Industry Using Deep Learning. J. Food Sci. 2025, 90, e17553. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the Rise of YOLO and Its Complementary Nature toward Digital Manufacturing and Industrial Defect Detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Ye, S.; Zhang, S.; Meng, Q.; Wang, H.; Zhu, J. Disease Detection Module for SBCE Images Using Modified YOLOv8. In Proceedings of the 2024 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Sarawak, Malaysia, 6–10 October 2024; IEEE: Kuching, Malaysia; pp. 5175–5182. [Google Scholar]
- Hussain, M. YOLOv1 to v8: Unveiling Each Variant–A Comprehensive Review of YOLO. IEEE Access 2024, 12, 42816–42833. [Google Scholar] [CrossRef]
- Badgujar, C.M.; Poulose, A.; Gan, H. Agricultural Object Detection with You Look Only Once (YOLO) Algorithm: A Bibliometric and Systematic Literature Review. Comput. Electron. Agric. 2024, 223, 109090. [Google Scholar] [CrossRef]
- Wu, X.; Tang, R.; Mu, J.; Niu, Y.; Xu, Z.; Chen, Z. A Lightweight Grape Detection Model in Natural Environments Based on an Enhanced YOLOv8 Framework. Front. Plant Sci. 2024, 15, 1407839. [Google Scholar] [CrossRef]
- Farahmand, S.; Fernandez, A.I.; Ahmed, F.S.; Rimm, D.L.; Chuang, J.H.; Reisenbichler, E.; Zarringhalam, K. Deep Learning Trained on Hematoxylin and Eosin Tumor Region of Interest Predicts HER2 Status and Trastuzumab Treatment Response in HER2+ Breast Cancer. Mod. Pathol. 2022, 35, 44–51. [Google Scholar] [CrossRef] [PubMed]
- Oyelade, O.N.; Ezugwu, A.E.; Almutairi, M.S.; Saha, A.K.; Abualigah, L.; Chiroma, H. A Generative Adversarial Network for Synthetization of Regions of Interest Based on Digital Mammograms. Sci. Rep. 2022, 12, 6166. [Google Scholar] [CrossRef]
- Dang, M.; Wang, H.; Li, Y.; Nguyen, T.-H.; Tightiz, L.; Xuan-Mung, N.; Nguyen, T.N. Computer Vision for Plant Disease Recognition: A Comprehensive Review. Bot. Rev. 2024, 90, 251–311. [Google Scholar] [CrossRef]
- Shi, Y.; Wang, X.; Borhan, M.S.; Young, J.; Newman, D.; Berg, E.; Sun, X. A Review on Meat Quality Evaluation Methods Based on Non-Destructive Computer Vision and Artificial Intelligence Technologies. Food Sci. Anim. Resour. 2021, 41, 563–588. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, D.; Su, Y.; Zheng, X.; Li, S.; Chen, L. Research on the Authenticity of Mutton Based on Machine Vision Technology. Foods 2022, 11, 3732. [Google Scholar] [CrossRef]
- Gao, Q.; Liu, H.; Wang, Z.; Lan, X.; An, J.; Shen, W.; Wan, F. Recent Advances in Feed and Nutrition of Beef Cattle in China—A Review. Anim. Biosci. 2023, 36, 529–539. [Google Scholar] [CrossRef]
- Zakariah, M.; Alnuaim, A. Recognizing Human Activities with the Use of Convolutional Block Attention Module. Egypt. Inform. J. 2024, 27, 100536. [Google Scholar] [CrossRef]
- Wang, S.; Huang, L.; Jiang, D.; Sun, Y.; Jiang, G.; Li, J.; Zou, C.; Fan, H.; Xie, Y.; Xiong, H.; et al. Improved Multi-Stream Convolutional Block Attention Module for sEMG-Based Gesture Recognition. Front. Bioeng. Biotechnol. 2022, 10, 909023. [Google Scholar] [CrossRef]
- Qin, X.; Li, M.; Liu, Y.; Zheng, H.; Chen, J.; Zhang, M. An Efficient Coding-based Grayscale Image Automatic Colorization Method Combined with Attention Mechanism. IET Image Process. 2022, 16, 1765–1777. [Google Scholar] [CrossRef]
- Zhou, T.; Ye, X.; Lu, H.; Zheng, X.; Qiu, S.; Liu, Y. Dense Convolutional Network and Its Application in Medical Image Analysis. BioMed Res. Int. 2022, 2022, 2384830. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Sun, W.; Zhu, Q.; Shi, P. Face Mask-Wearing Detection Model Based on Loss Function and Attention Mechanism. Comput. Intell. Neurosci. 2022, 2022, 2452291. [Google Scholar] [CrossRef]
- Goceri, E. GAN Based Augmentation Using a Hybrid Loss Function for Dermoscopy Images. Artif. Intell. Rev. 2024, 57, 234. [Google Scholar] [CrossRef]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Gao, J.; Chen, Y.; Wei, Y.; Li, J. Detection of Specific Building in Remote Sensing Images Using a Novel YOLO-S-CIOU Model. Case: Gas Station Identification. Sensors 2021, 21, 1375. [Google Scholar] [CrossRef]
- Hicks, S.A.; Strümke, I.; Thambawita, V.; Hammou, M.; Riegler, M.A.; Halvorsen, P.; Parasa, S. On Evaluation Metrics for Medical Applications of Artificial Intelligence. Sci. Rep. 2022, 12, 5979. [Google Scholar] [CrossRef] [PubMed]
- Vujovic, Ž.Ð. Classification Model Evaluation Metrics. IJACSA 2021, 12, 599–606. [Google Scholar] [CrossRef]
- Zhou, J.; Gandomi, A.H.; Chen, F.; Holzinger, A. Evaluating the Quality of Machine Learning Explanations: A Survey on Methods and Metrics. Electronics 2021, 10, 593. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Bartz-Beielstein, T. PyTorch Hyperparameter Tuning—A Tutorial for spotPython 2023. arXiv 2023, arXiv:2305.11930. [Google Scholar]
- Wisaeng, K. U-Net++DSM: Improved U-Net++ for Brain Tumor Segmentation With Deep Supervision Mechanism. IEEE Access 2023, 11, 132268–132285. [Google Scholar] [CrossRef]
- Chang, Z.; Li, H.; Chen, D.; Liu, Y.; Zou, C.; Chen, J.; Han, W.; Liu, S.; Zhang, N. Crop Type Identification Using High-Resolution Remote Sensing Images Based on an Improved DeepLabV3+ Network. Remote Sens. 2023, 15, 5088. [Google Scholar] [CrossRef]
- Mahapatra, S.K.; Pattanayak, B.K.; Pati, B. Attendance Monitoring of Masked Faces Using ResNext-101. JSMS 2023, 26, 117–131. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy (%) | mAP (%) | Recall (%) | F1(%) | Rate (ms/sheet) |
|---|---|---|---|---|---|
| U-Net++ | 99.48 | 99.36 | 93.26 | 85.96 | 35.4 |
| DeepLabv3+ | 96.8 | 96.53 | 96.32 | 86.72 | 37.5 |
| ResNet-101 | 97.62 | 97.53 | 95.78 | 88.72 | 28.2 |
| CBAM&SE-YOLOv8x | 99.99 | 99.99 | 99.49 | 99.53 | 5.3 |
| CBAM | SE-Attention | CIoU | mAP (%) | Params (M) | Weights (MB) |
|---|---|---|---|---|---|
| - | - | - | 92.7 | 61.98 | 232.82 |
| √ | - | - | 93.6 | 12.52 | 44.56 |
| √ | √ | - | 95.4 | 12.48 | 41.28 |
| √ | √ | √ | 99.9 | 12.48 | 41.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wang, L.; Xu, H.; Pi, J.; Wang, D. Research on Beef Marbling Grading Algorithm Based on Improved YOLOv8x. Foods 2025, 14, 1664. https://doi.org/10.3390/foods14101664
Liu J, Wang L, Xu H, Pi J, Wang D. Research on Beef Marbling Grading Algorithm Based on Improved YOLOv8x. Foods. 2025; 14(10):1664. https://doi.org/10.3390/foods14101664
Chicago/Turabian StyleLiu, Jun, Lian Wang, Huafu Xu, Jie Pi, and Daoying Wang. 2025. "Research on Beef Marbling Grading Algorithm Based on Improved YOLOv8x" Foods 14, no. 10: 1664. https://doi.org/10.3390/foods14101664
APA StyleLiu, J., Wang, L., Xu, H., Pi, J., & Wang, D. (2025). Research on Beef Marbling Grading Algorithm Based on Improved YOLOv8x. Foods, 14(10), 1664. https://doi.org/10.3390/foods14101664