
The Application of Near-Infrared Spectroscopy Combined with Chemometrics in the Determination of the Nutrient Composition in Chinese Cyperus esculentus L.


Abstract

1. Introduction
2. Materials and Methods
2.1. Sample Preparation and Near-Infrared Spectrum Collection
2.2. The Analyses of Crude Oil, Crude Protein, and Total Starch
2.3. Algorithms
2.4. Software and Datasets
2.5. Evaluation Metrics
3. Results
3.1. Sample Composition Content
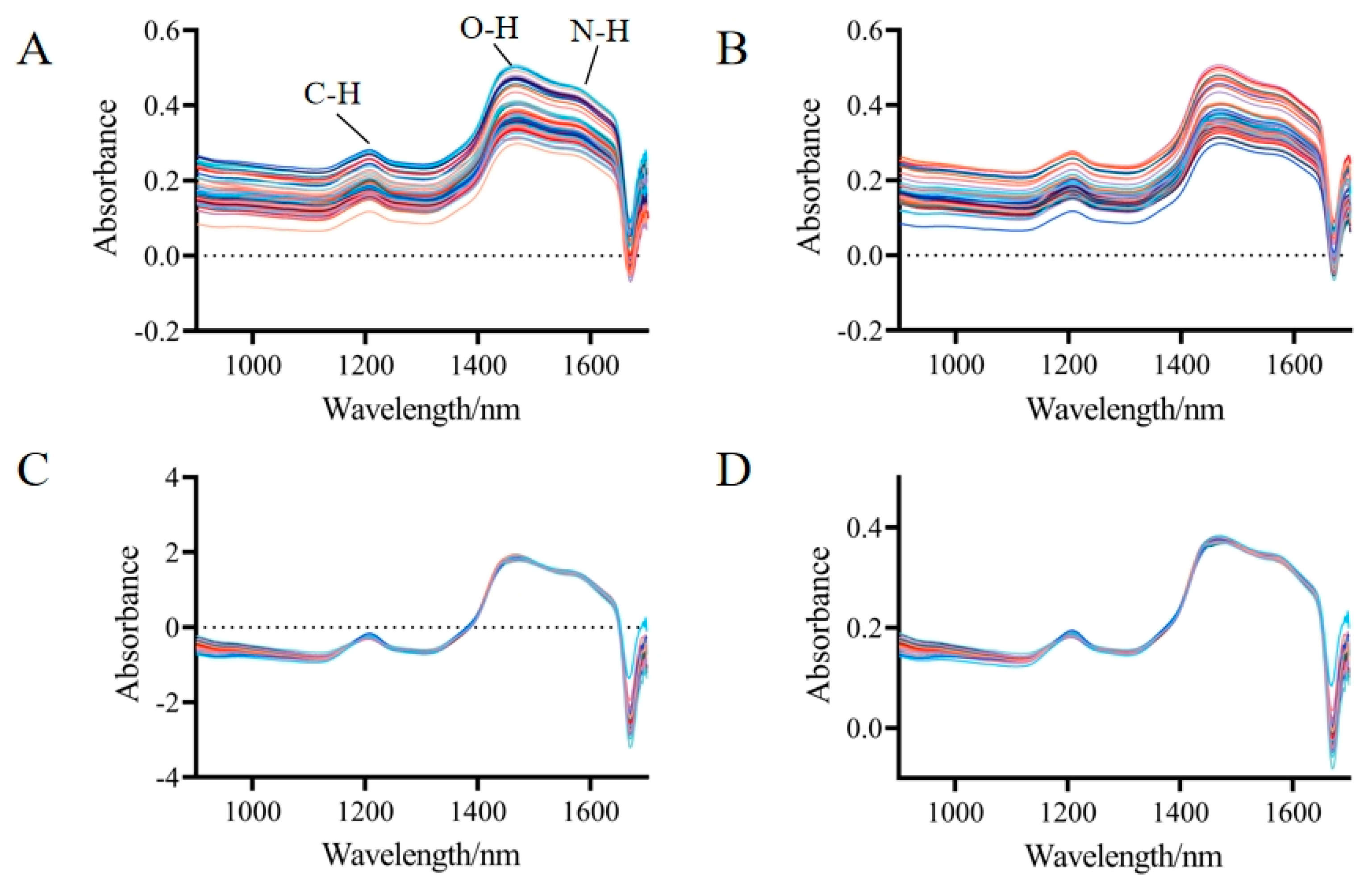
3.2. Near-Infrared Spectroscopy and Preprocessing
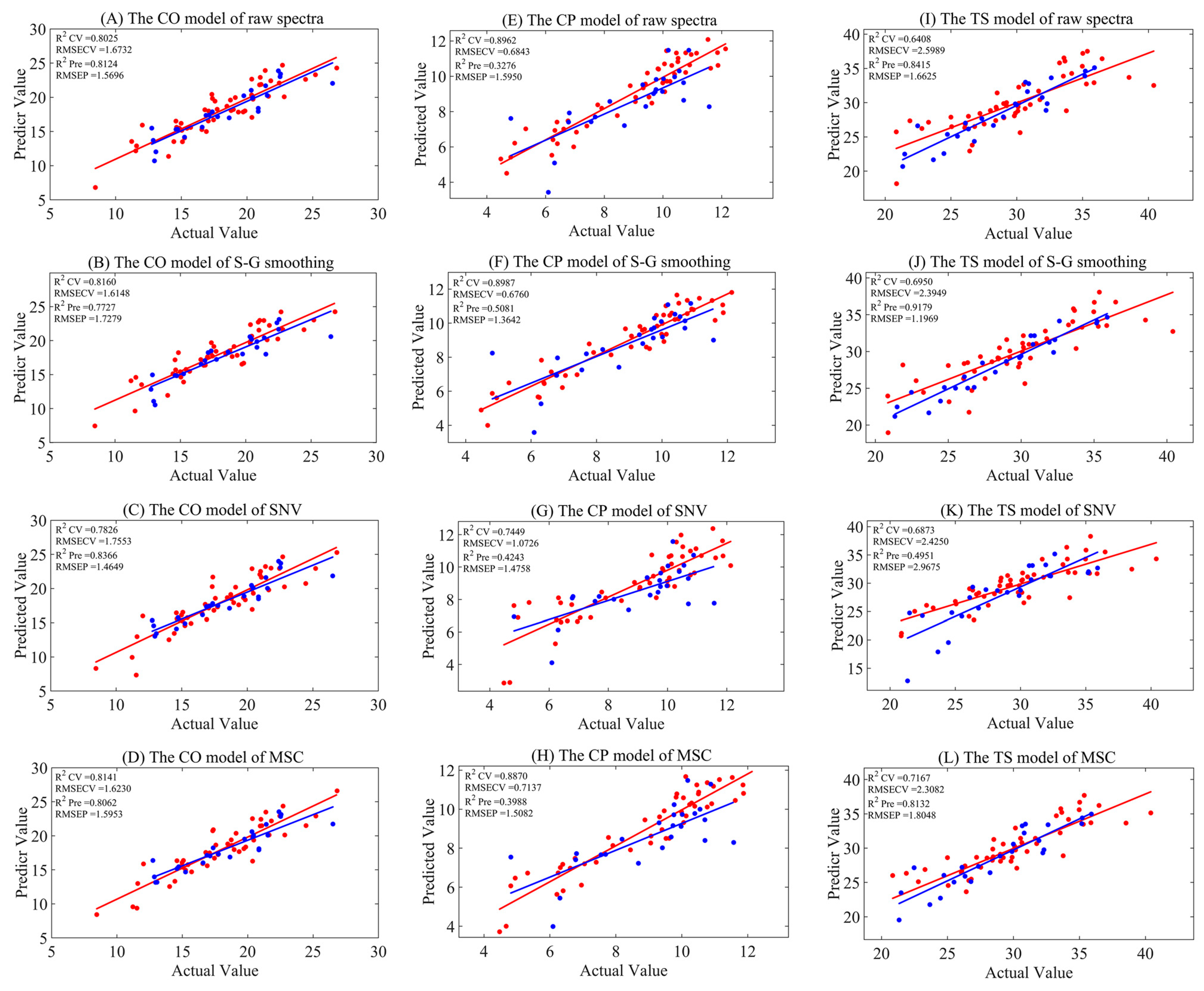
3.3. Full-Spectrum Model
3.4. Variable Selection Algorithm Model
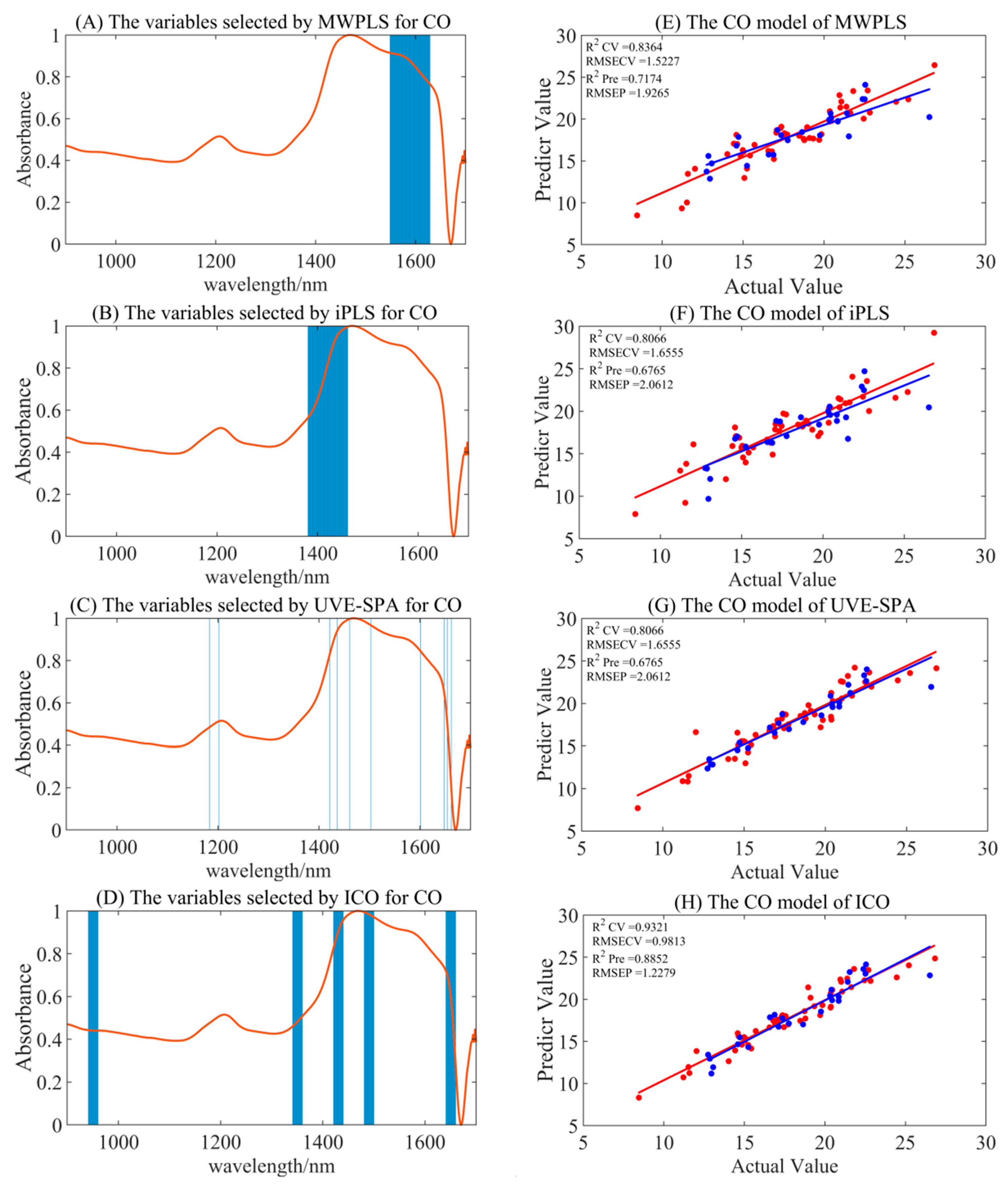
3.4.1. Variable Selection Model for CO
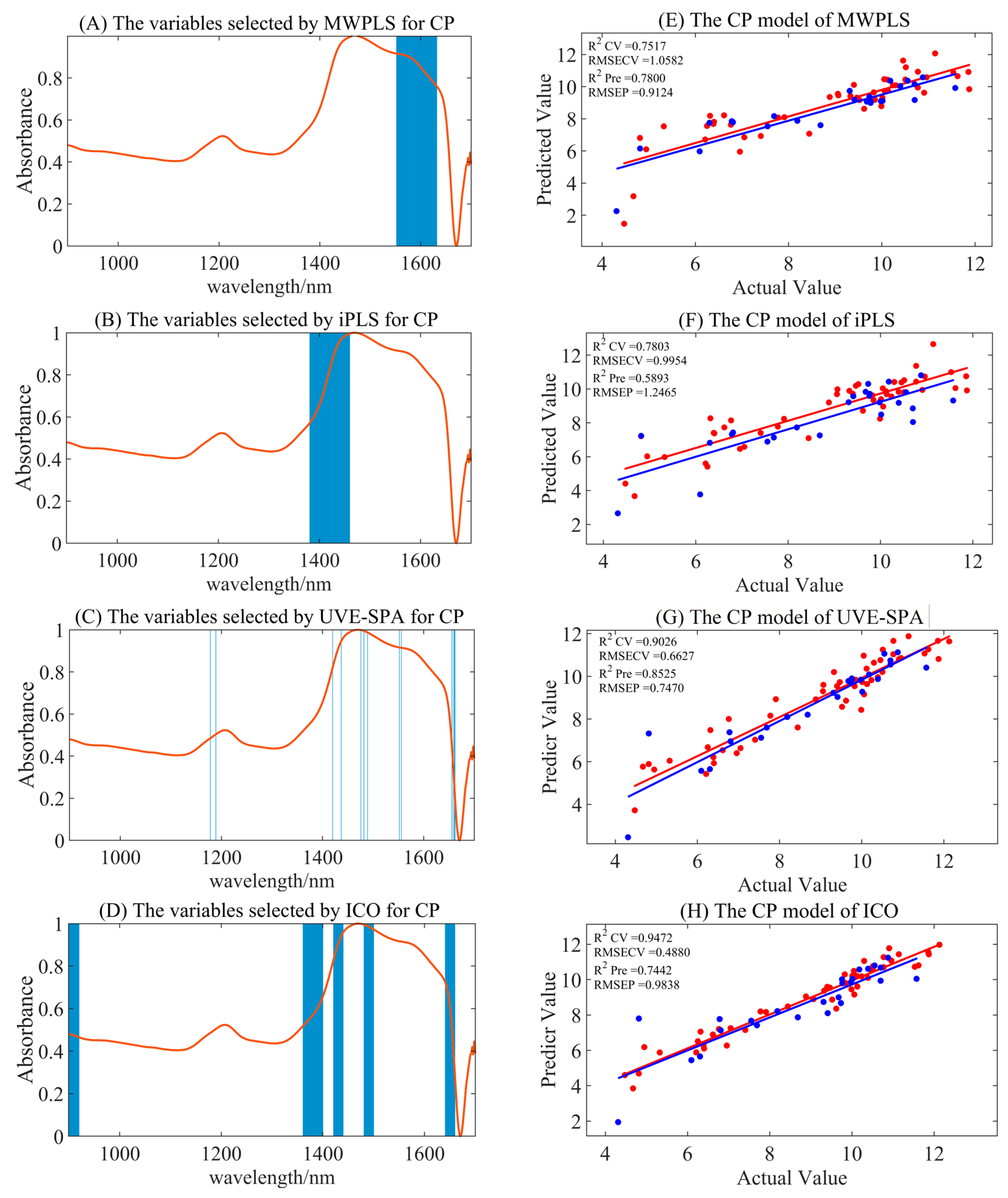
3.4.2. Variable Selection Model for CP
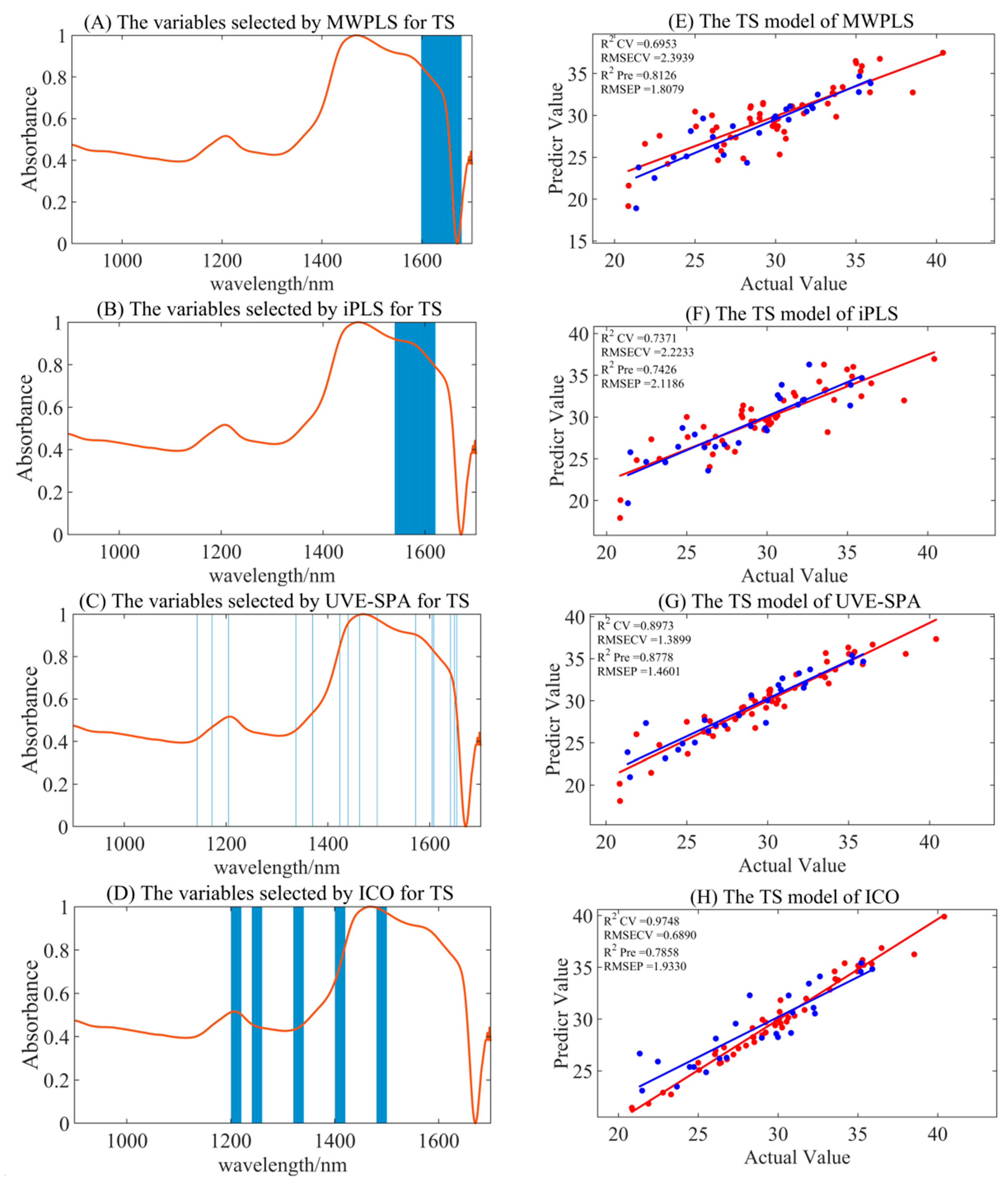
3.4.3. Variable Selection Model of TS
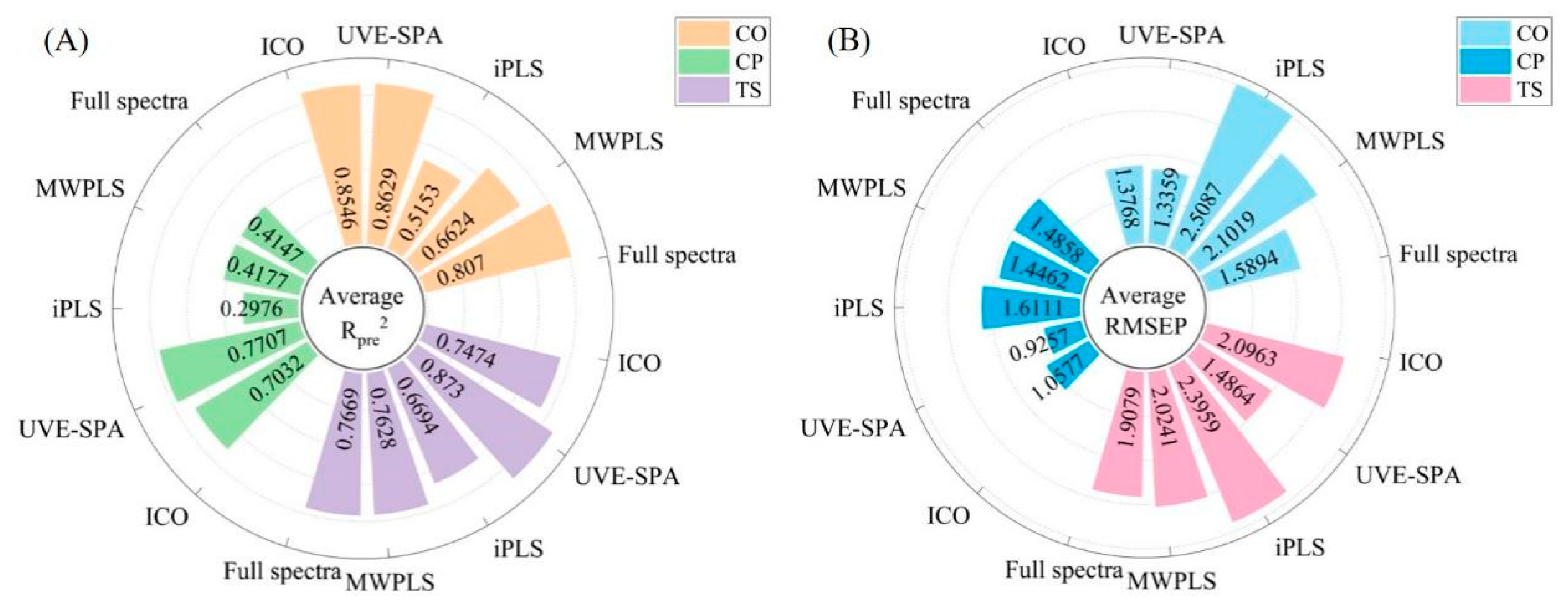
3.5. Comparison of Variable Selection and Full-Spectrum Modeling
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rebezov, M.; Khan, M.U.; Bouyahya, A.; Imran, M.; Tufail, T.; Loretts, O.; Neverova, O.; Artyukhova, S.; Kuznetsova, E.; Ermolaev, V.; et al. Nutritional and technical aspect of Tiger Nut and its micro-constituents: An overview. Food Rev. Int. 2021, 39, 3262–3282. [Google Scholar] [CrossRef]
- Sánchez-Zapata, E.; Fernández-López, J.; Pérez-Alvarez, J.A. Tiger Nut (Cyperus esculentus) Commercialization: Health Aspects, Composition, Properties, and Food Applications. Compr. Rev. Food Sci. Food Saf. 2012, 11, 366–377. [Google Scholar] [CrossRef]
- Zhang, R.-Y.; Liu, C.; Chen, P.-X.; Jiang, M.-M.; Zhu, W.-X.; Liu, H.-M. Sequential extraction of oligosaccharide and polysaccharides from defatted tiger nut (Cyperus esculentus) meal for its comprehensive utilization. J. Food Meas. Charact. 2023, 17, 4357–4370. [Google Scholar] [CrossRef]
- Yu, Y.; Jiang, X.; Lu, X.; Zhang, T.; Cai, R.; Zheng, H.; Gao, F. Nutritional, structural and functional properties of protein fractions from tiger nut (Cyperus esculentus L.) seed meal. J. Food Meas. Charact. 2024, 18, 9867–9878. [Google Scholar] [CrossRef]
- Ijarotimi, O.S.; Yinusa, M.A.; Adegbembo, P.A.; Adeniyi, M.D. Chemical compositions, functional properties, antioxidative activities, and glycaemic indices of raw and fermented tigernut tubers (Cyperus esculentus Lativum) flour. J. Food Biochem. 2018, 42, e12591. [Google Scholar] [CrossRef]
- Du, Y.; Zhang, Y.; Chai, X.; Li, X.; Ullah, A.; Islam, W.; Zhang, Z.; Zeng, F. Effects of different tillage systems and mowing time on nutrient accumulation and forage nutritive value of Cyperus esculentus. Front. Plant Sci. 2023, 14, 1162572. [Google Scholar] [CrossRef]
- Zou, Z.; Zheng, Y.; Zhang, Z.; Xiao, Y.; Xie, Z.; Chang, L.; Zhang, L.; Zhao, Y. Molecular characterization of oleosin genes in Cyperus esculentus, a Cyperaceae plant producing oil in underground tubers. Plant Cell Rep. 2023, 42, 1791–1808. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Wang, Y.; Wei, Z.; Zhang, X.; Jiao, B.; Tian, Y.; Yan, F.; Li, J.; Liu, Y.; Yang, X.; et al. Analysis of oil synthesis pathway in Cyperus esculentus tuber and identification of oleosin and caleosin genes. J. Plant Physiol. 2023, 284, 153961. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Jiang, Y.; Tong, Y.; Leng, J.; Zhou, T.; Gao, Z.; Liu, H.; Zhu, C.; Zhang, W.; Yang, R. An Innovative Strategy of Comprehensive Utilization of Tiger Nuts (Cyperus esculentus L.): Simultaneous Extraction of Oil and Glucose Syrup by Amylolysis-Assisted Aqueous Extraction Process. Food Bioprocess Technol. 2025, 18, 1283–1295. [Google Scholar] [CrossRef]
- Jiang, W.; Goncalves, J.; Kostakos, V. Mobile near-infrared sensing—A systematic review on devices, data, modeling, and applications. J. ACM Comput. Surv. 2024, 56, 1–36. [Google Scholar] [CrossRef]
- Duan, J.; Huang, Y.; Li, Z.; Zheng, B.; Li, Q.; Xiong, Y.; Wu, L.; Min, S. Determination of 27 chemical constituents in Chinese southwest tobacco by FT-NIR spectroscopy. Ind. Crops Prod. 2012, 40, 21–26. [Google Scholar] [CrossRef]
- Ritota, M.; Manzi, P. Melamine Detection in Milk and Dairy Products: Traditional Analytical Methods and Recent Developments. Food Anal. Methods 2018, 11, 128–147. [Google Scholar] [CrossRef]
- Zontov, Y.V.; Balyklova, K.S.; Titova, A.V.; Rodionova, O.Y.; Pomerantsev, A.L. Chemometric aided NIR portable instrument for rapid assessment of medicine quality. J. Pharm. Biomed. Anal. 2016, 131, 87–93. [Google Scholar] [CrossRef] [PubMed]
- Syunyaev, R.Z.; Balabin, R.M.; Akhatov, I.S.; Safieva, J.O. Adsorption of Petroleum Asphaltenes onto Reservoir Rock Sands Studied by Near-Infrared (NIR) Spectroscopy. Energy Fuels 2009, 23, 1230–1236. [Google Scholar] [CrossRef]
- Chao, T.; Xin, Q.; Li, M. An ensemble method based on a self-organizing map for near-infrared spectral calibration of complex beverage samples. Anal. Bioanal. Chem. 2008, 392, 515–521. [Google Scholar]
- Fodor, M.; Matkovits, A.; Benes, E.L.; Jókai, Z. The role of near-infrared spectroscopy in food quality assurance: A review of the past two decades. Foods 2024, 13, 3501. [Google Scholar] [CrossRef]
- Singh, T.; Garg, N.M.; Iyengar, S.R.S.; Singh, V. Near-infrared hyperspectral imaging for determination of protein content in barley samples using convolutional neural network. J. Food Meas. Charact. 2023, 17, 3548–3560. [Google Scholar] [CrossRef]
- Cataltas, O.; Tutuncu, K. Detection of protein, starch, oil, and moisture content of corn kernels using one-dimensional convolutional autoencoder and near-infrared spectroscopy. PeerJ Comput. Sci. 2023, 9, e1266. [Google Scholar] [CrossRef]
- Díaz, E.O.; Iino, H.; Koyama, K.; Kawamura, S.; Koseki, S.; Lyu, S. Non-destructive quality classification of rice taste properties based on near-infrared spectroscopy and machine learning algorithms. Food Chem. 2023, 429, 136907. [Google Scholar] [CrossRef]
- Zhang, G.; Li, P.; Zhang, W.; Zhao, J. Analysis of multiple soybean phytonutrients by near-infrared reflectance spectroscopy. Anal. Bioanal. Chem. 2017, 409, 3515–3525. [Google Scholar] [CrossRef]
- Mourya, V.; Kumar, V.; Rani, A.; Jain, M.; Husain, S.M. Near-Infrared Reflectance Spectroscopy for Protein Content in Soybean Flour and Screening of Germplasm Across Different Countries. Agric. Res. 2016, 5, 29–34. [Google Scholar] [CrossRef]
- Yakubu, A.B.; Shaibu, A.S.; Mohammed, S.G.; Ibrahim, H.; Mohammed, I.B. NIR-Based Prediction for Protein, Oil, and Fatty Acids in Soybean (Glycine max (L.) Merrill) Seeds. Food Anal. Methods 2024, 17, 1592–1600. [Google Scholar]
- Höskuldsson, A. PLS regression methods. J. Chemom. 1988, 2, 211–228. [Google Scholar] [CrossRef]
- Mevik, B.H.; Cederkvist, H.R. Mean squared error of prediction (MSEP) estimates for principal component regression (PCR) and partial least squares regression (PLSR). J. Chemom. 2004, 18, 422–429. [Google Scholar] [CrossRef]
- Zhang, X.; Li, W.; Yin, B.; Chen, W.; Kelly, D.P.; Wang, X.; Zheng, K.; Du, Y. Improvement of near infrared spectroscopic (NIR) analysis of caffeine in roasted Arabica coffee by variable selection method of stability competitive adaptive reweighted sampling (SCARS). Spectrochim. Acta. A Mol. Biomol. Spectrosc. 2013, 114, 350–356. [Google Scholar] [CrossRef]
- Pereira, A.F.C.; Pontes, M.J.C.; Neto, F.F.G.; Santos, S.R.B.; Galvão, R.K.H.; Araújo, M.C.U. NIR spectrometric determination of quality parameters in vegetable oils using iPLS and variable selection. Food Res. Int. 2008, 41, 341–348. [Google Scholar] [CrossRef]
- Leardi, R.; Nørgaard, L. Sequential application of backward interval partial least squares and genetic algorithms for the selection of relevant spectral regions. J. Chemom. 2004, 18, 486–497. [Google Scholar] [CrossRef]
- Fu, H.-Y.; Huan, S.-Y.; Xu, L.; Tang, L.-J.; Jiang, J.-H.; Wu, H.-L.; Shen, G.-L.; Yu, R.-Q. Moving Window Partial Least-Squares Discriminant Analysis for Identification of Different Kinds of Bezoar Samples by near Infrared Spectroscopy and Comparison of Different Pattern Recognition Methods. J. Infrared Spectrosc. 2007, 15, 291–297. [Google Scholar] [CrossRef]
- Ye, S.; Wang, D.; Min, S. Successive projections algorithm combined with uninformative variable elimination for spectral variable selection. Chemom. Intell. Lab. Syst. 2008, 91, 194–199. [Google Scholar] [CrossRef]
- Araújo, M.C.U.; Saldanha, T.C.B.; Galvão, R.K.H.; Yoneyama, T.; Chame, H.C.; Visani, V. The successive projections algorithm for variable selection in spectroscopic multicomponent analysis. Chemom. Intell. Lab. Syst. 2001, 57, 65–73. [Google Scholar] [CrossRef]
- Song, X.; Huang, Y.; Yan, H.; Xiong, Y.; Min, S. A novel algorithm for spectral interval combination optimization. Anal. Chim. Acta 2016, 948, 19–29. [Google Scholar] [CrossRef]
- Li, Q.; Huang, Y.; Song, X.; Zhang, J.; Min, S. Spectral interval combination optimization (ICO) on rapid quality assessment of Solanaceae plant: A validation study. J. Food Sci. Technol. 2019, 56, 2158–2166. [Google Scholar] [CrossRef] [PubMed]
- Iino, H.; Kawamura, S.; Díaz, E.O.; Ishizu, H.; Nagata, T.; Koseki, S. Non-destructive measurement of rice amylose content using near-infrared spectroscopy for application at grain elevators and milling plants. J. Food Meas. Charact. 2024, 18, 8275–8288. [Google Scholar] [CrossRef]
- Gullifa, G.; Barone, L.; Papa, E.; Giuffrida, A.; Materazzi, S.; Risoluti, R. Portable NIR spectroscopy: The route to green analytical chemistry. Front. Chem. 2023, 11, 1214825. [Google Scholar] [CrossRef]
- Morris, D.L. Quantitative determination of carbohydrates with Dreywood’s anthrone reagent. Science 1948, 107, 254–255. [Google Scholar] [CrossRef] [PubMed]
- Luo, J.W.; Ying, K.; Bai, J. Savitzky-Golay smoothing and differentiation filter for even number data. Signal Process. 2005, 85, 1429–1434. [Google Scholar] [CrossRef]
- Bi, Y.; Yuan, K.; Xiao, W.; Wu, J.; Shi, C.; Xia, J.; Chu, G.; Zhang, G.; Zhou, G. A local pre-processing method for near-infrared spectra, combined with spectral segmentation and standard normal variate transformation. Anal. Chim. Acta 2016, 909, 30–40. [Google Scholar] [CrossRef] [PubMed]
- Thennadil, S.N.; Martens, H.; Kohler, A. Physics-based multiplicative scatter correction approaches for improving the performance of calibration models. Appl. Spectrosc. 2006, 60, 315–321. [Google Scholar] [CrossRef]
- Jiang, W.; Lu, C.; Zhang, Y.; Ju, W.; Wang, J.; Hong, F.; Wang, T.; Ou, C. Moving-window-improved Monte Carlo uninformative variable elimination combining successive projections algorithm for near-infrared spectroscopy (NIRS). J. Spectrosc. 2020, 3590301. [Google Scholar] [CrossRef]
- Hu, R.; Zhang, L.; Yu, Z.; Zhai, Z.; Zhang, R. Optimization of soluble solids content prediction models in “Hami” melons by means of Vis-NIR spectroscopy and chemometric tools. Infrared Phys. Technol. 2019, 102, 102999. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, W.; Zhou, L.; Cheng, H.; Ye, X.; He, Y. Developing deep learning based regression approaches for determination of chemical compositions in dry black goji berries (Lycium ruthenicum Murr.) using near-infrared hyperspectral imaging. Food Chem. 2020, 319, 126536. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | Datasets | Numbers | Max Value | Min Value | Mean Value |
|---|---|---|---|---|---|
| CO | Calibration set | 50 | 26.83 | 8.45 | 17.95 |
| Validation set | 25 | 26.51 | 12.75 | 18.40 | |
| CP | Calibration set | 50 | 12.13 | 4.31 | 8.90 |
| Validation set | 25 | 11.57 | 4.47 | 8.79 | |
| TS | Calibration set | 50 | 40.40 | 20.85 | 29.82 |
| Validation set | 25 | 35.90 | 21.33 | 28.60 |
| Preprocessing Methods | Indicators | nLV | Rcv2 | RMSECV | Rpre2 | RMSEP |
|---|---|---|---|---|---|---|
| Raw spectra | CO | 10 | 0.8025 | 1.6732 | 0.8124 | 1.5696 |
| CP | 10 | 0.8962 | 0.6843 | 0.3276 | 1.5950 | |
| TS | 10 | 0.6408 | 2.5989 | 0.8415 | 1.6625 | |
| S–G smoothing | CO | 7 | 0.8160 | 1.6148 | 0.7727 | 1.7279 |
| CP | 10 | 0.8987 | 0.6760 | 0.5081 | 1.3642 | |
| TS | 10 | 0.6950 | 2.3949 | 0.9179 | 1.1969 | |
| SNV | CO | 10 | 0.7826 | 1.7553 | 0.8366 | 1.4649 |
| CP | 7 | 0.7449 | 1.0726 | 0.4243 | 1.4758 | |
| TS | 3 | 0.6873 | 2.4250 | 0.4951 | 2.9675 | |
| MSC | CO | 10 | 0.8141 | 1.6230 | 0.8062 | 1.5953 |
| CP | 10 | 0.8870 | 0.7137 | 0.3988 | 1.5082 | |
| TS | 10 | 0.7167 | 2.3082 | 0.8132 | 1.8048 |
| Preprocessing Methods | Variable Selection Algorithms | nLV | Rcv2 | RMSECV | Rpre2 | RMSEP |
|---|---|---|---|---|---|---|
| Raw spectra | MWPLS | 5 | 0.7716 | 1.7991 | 0.6275 | 2.2117 |
| iPLS | 3 | 0.6885 | 2.1013 | 0.5088 | 2.5399 | |
| UVE-SPA | 9 | 0.8700 | 1.3575 | 0.8677 | 1.3182 | |
| ICO | 10 | 0.9383 | 0.9355 | 0.8682 | 1.3157 | |
| S–G smoothing | MWPLS | 5 | 0.7747 | 1.7870 | 0.6220 | 2.2279 |
| iPLS | 5 | 0.7160 | 2.0062 | 0.4534 | 2.6792 | |
| UVE-SPA | 10 | 0.8718 | 1.3478 | 0.8946 | 1.1764 | |
| ICO | 10 | 0.9321 | 0.9813 | 0.8852 | 1.2279 | |
| SNV | MWPLS | 4 | 0.7778 | 1.7746 | 0.6826 | 2.0416 |
| iPLS | 3 | 0.6466 | 2.2380 | 0.4223 | 2.7544 | |
| UVE-SPA | 10 | 0.8716 | 1.3491 | 0.8674 | 1.3194 | |
| ICO | 10 | 0.9540 | 0.8077 | 0.8177 | 1.5471 | |
| MSC | MWPLS | 4 | 0.8364 | 1.5227 | 0.7174 | 1.9265 |
| iPLS | 5 | 0.8066 | 1.6555 | 0.6765 | 2.0612 | |
| UVE-SPA | 10 | 0.8938 | 1.2268 | 0.8218 | 1.5297 | |
| ICO | 10 | 0.9594 | 0.7589 | 0.8473 | 1.4163 |
| Pretreatment Methods | Variable Selection Techniques | nLV | Rcv2 | RMSECV | Rpre2 | RMSEP |
|---|---|---|---|---|---|---|
| Raw spectra | MWPLS | 3 | 0.7313 | 1.1008 | 0.1980 | 1.7419 |
| iPLS | 4 | 0.7058 | 1.1518 | 0.0365 | 1.9092 | |
| UVE-SPA | 10 | 0.9313 | 0.5566 | 0.7454 | 0.9815 | |
| ICO | 10 | 0.9607 | 0.4208 | 0.6575 | 1.1383 | |
| S–G smoothing | MWPLS | 3 | 0.7341 | 1.0951 | 0.2228 | 1.7148 |
| iPLS | 3 | 0.7112 | 1.1412 | 0.1885 | 1.7522 | |
| UVE-SPA | 9 | 0.9026 | 0.6627 | 0.8525 | 0.7470 | |
| ICO | 10 | 0.9532 | 0.4594 | 0.6775 | 1.1045 | |
| SNV | MWPLS | 5 | 0.6796 | 1.2020 | 0.4701 | 1.4159 |
| iPLS | 2 | 0.7059 | 1.1517 | 0.3759 | 1.5366 | |
| UVE-SPA | 9 | 0.9260 | 0.5776 | 0.7418 | 0.9884 | |
| ICO | 10 | 0.9472 | 0.4880 | 0.7442 | 0.9838 | |
| MSC | MWPLS | 4 | 0.7517 | 1.0582 | 0.7800 | 0.9124 |
| iPLS | 5 | 0.7803 | 0.9954 | 0.5893 | 1.2465 | |
| UVE-SPA | 10 | 0.9446 | 0.5000 | 0.7432 | 0.9857 | |
| ICO | 10 | 0.9487 | 0.4810 | 0.7336 | 1.0040 |
| Pretreatment Methods | Variable Selection Techniques | nLV | Rcv2 | RMSECV | Rpre2 | RMSEP |
|---|---|---|---|---|---|---|
| Raw spectra | MWPLS | 5 | 0.6927 | 2.4039 | 0.7977 | 1.8784 |
| iPLS | 3 | 0.6561 | 2.5431 | 0.6473 | 2.4801 | |
| UVE-SPA | 10 | 0.7901 | 1.9870 | 0.8906 | 1.3813 | |
| ICO | 7 | 0.9523 | 0.9470 | 0.7139 | 2.2340 | |
| S–G smoothing | MWPLS | 5 | 0.6953 | 2.3939 | 0.8126 | 1.8079 |
| iPLS | 3 | 0.6600 | 2.5285 | 0.6479 | 2.4783 | |
| UVE-SPA | 10 | 0.7972 | 1.9528 | 0.8621 | 1.5508 | |
| ICO | 7 | 0.9513 | 0.9566 | 0.7345 | 2.1519 | |
| SNV | MWPLS | 4 | 0.7902 | 1.9864 | 0.6922 | 2.3168 |
| iPLS | 4 | 0.6161 | 2.6869 | 0.6398 | 2.5064 | |
| UVE-SPA | 7 | 0.9079 | 1.3160 | 0.8616 | 1.5535 | |
| ICO | 7 | 0.9648 | 0.8134 | 0.7553 | 2.0661 | |
| MSC | MWPLS | 4 | 0.7675 | 2.0909 | 0.7488 | 2.0932 |
| iPLS | 4 | 0.7371 | 2.2233 | 0.7426 | 2.1186 | |
| UVE-SPA | 7 | 0.8973 | 1.3899 | 0.8778 | 1.4601 | |
| ICO | 7 | 0.9748 | 0.6890 | 0.7858 | 1.9330 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, X.; Guo, D.; Zhang, X.; Su, Y.; Ma, R.; Chen, L.; Tian, K.; Su, J.; Sahati, T.; Aierkenjiang, X.; et al. The Application of Near-Infrared Spectroscopy Combined with Chemometrics in the Determination of the Nutrient Composition in Chinese Cyperus esculentus L. Foods 2025, 14, 366. https://doi.org/10.3390/foods14030366
Jiao X, Guo D, Zhang X, Su Y, Ma R, Chen L, Tian K, Su J, Sahati T, Aierkenjiang X, et al. The Application of Near-Infrared Spectroscopy Combined with Chemometrics in the Determination of the Nutrient Composition in Chinese Cyperus esculentus L. Foods. 2025; 14(3):366. https://doi.org/10.3390/foods14030366
Chicago/Turabian StyleJiao, Xiaobo, Dongliang Guo, Xinjun Zhang, Yunpeng Su, Rong Ma, Lewen Chen, Kun Tian, Jingyu Su, Tangnuer Sahati, Xiahenazi Aierkenjiang, and et al. 2025. "The Application of Near-Infrared Spectroscopy Combined with Chemometrics in the Determination of the Nutrient Composition in Chinese Cyperus esculentus L." Foods 14, no. 3: 366. https://doi.org/10.3390/foods14030366
APA StyleJiao, X., Guo, D., Zhang, X., Su, Y., Ma, R., Chen, L., Tian, K., Su, J., Sahati, T., Aierkenjiang, X., Xia, J., & Xie, L. (2025). The Application of Near-Infrared Spectroscopy Combined with Chemometrics in the Determination of the Nutrient Composition in Chinese Cyperus esculentus L. Foods, 14(3), 366. https://doi.org/10.3390/foods14030366