
A Dual-Technology Approach: Handheld NIR Spectrometer and CNN for Fritillaria spp. Quality Control


Abstract

1. Introduction
2. Experimental Materials and Methods
2.1. Sample Preparation
2.2. Near-Infrared Spectra
2.3. Algorithms
2.3.1. Data Preprocessing
2.3.2. Machine Learning Algorithms
2.3.3. Convolutional Neural Network
2.3.4. Data Segmentation
2.4. Model Effect Evaluation
3. Results and Analysis
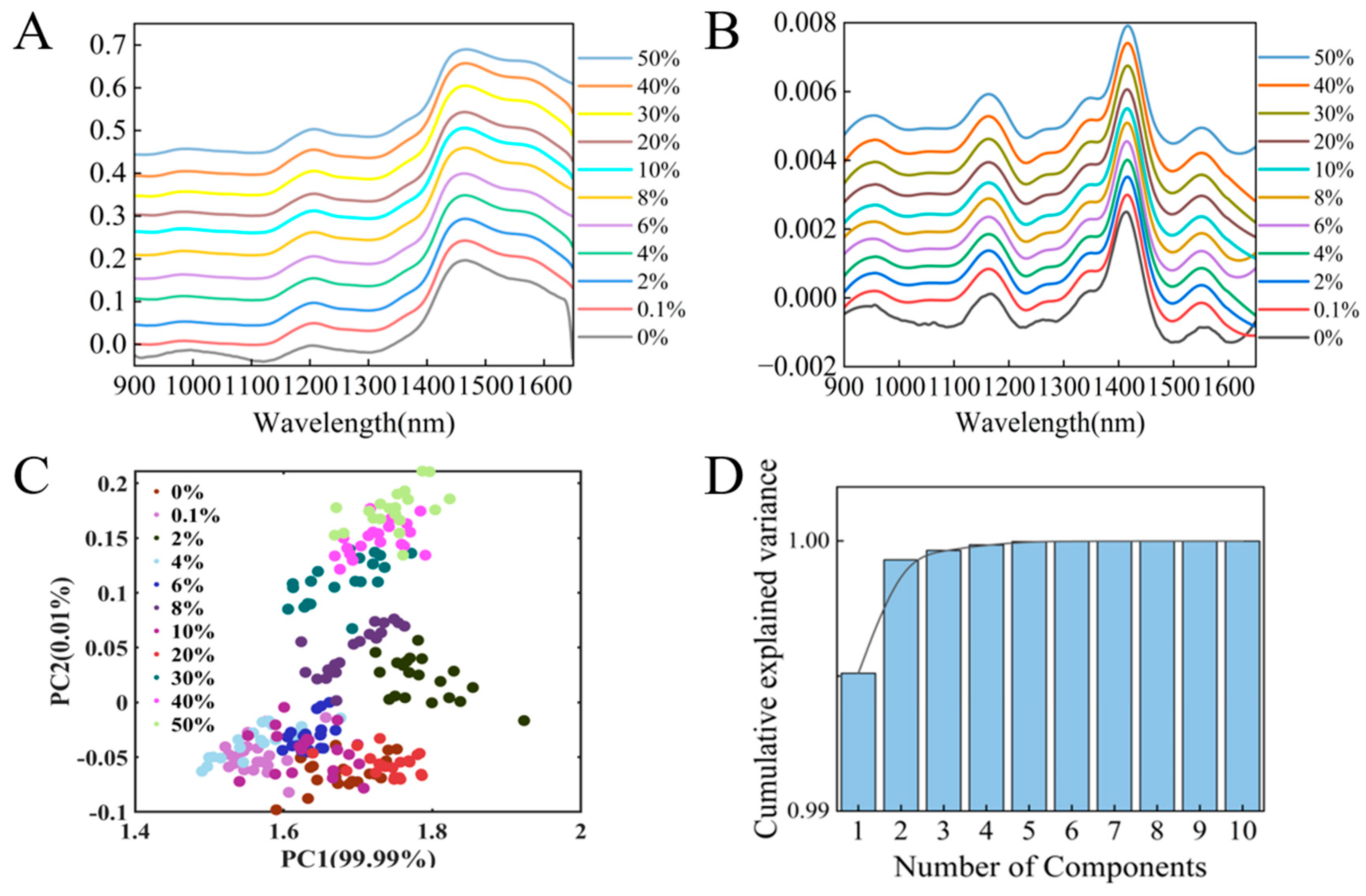
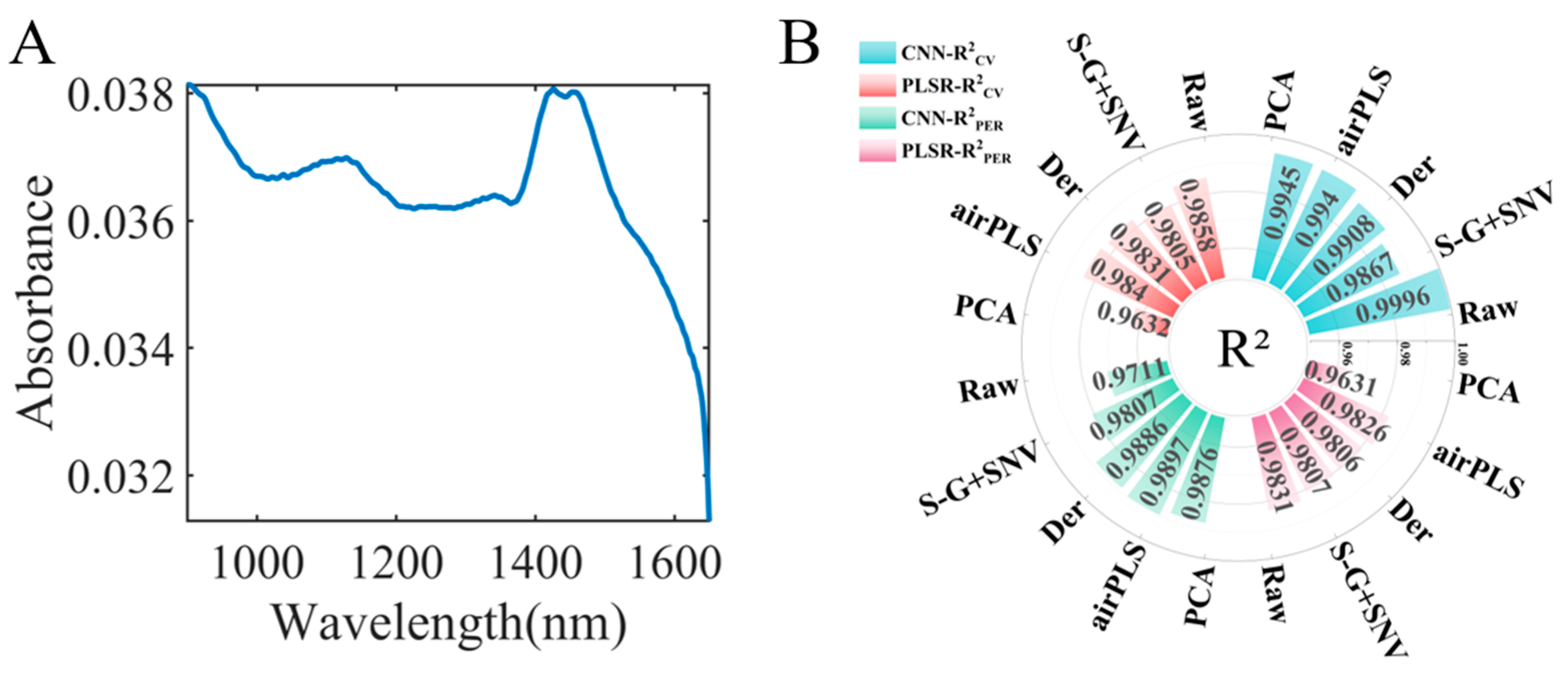
3.1. Near-Infrared Spectroscopy and Data Preprocessing
3.2. Principal Component Analysis
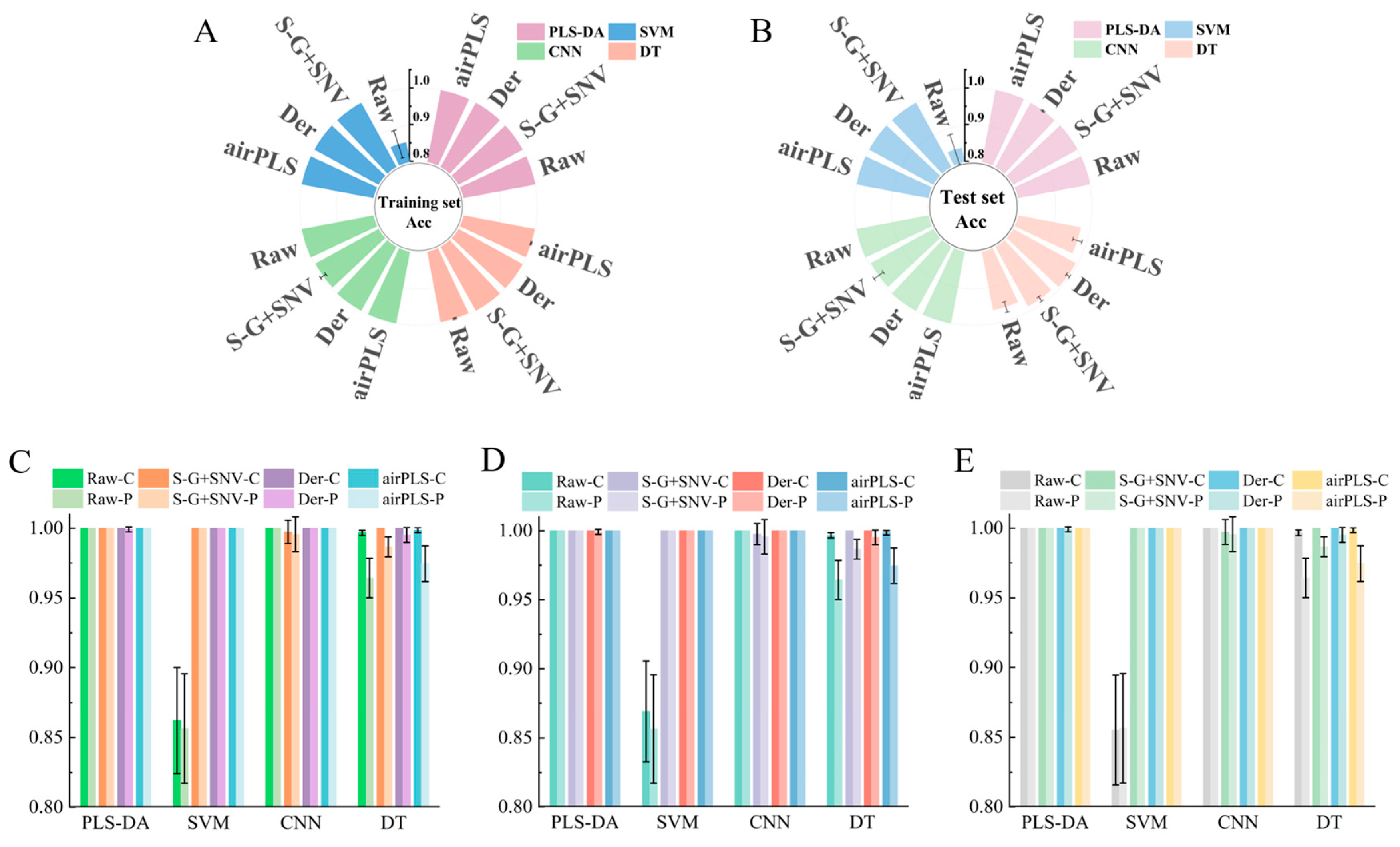
3.3. The Identification Model of Fritillaria spp. Origin
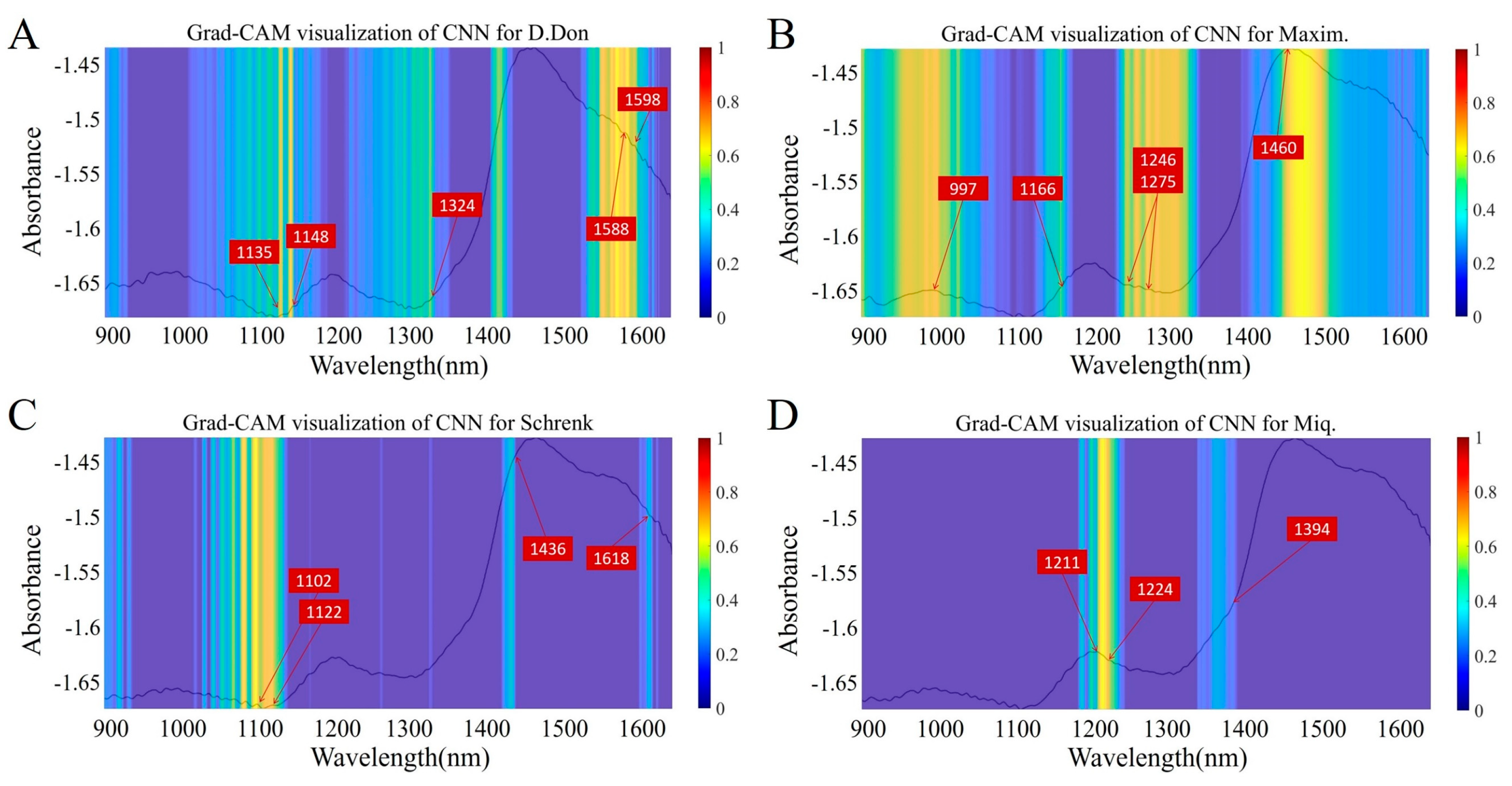
3.4. Feature Visualization Analysis
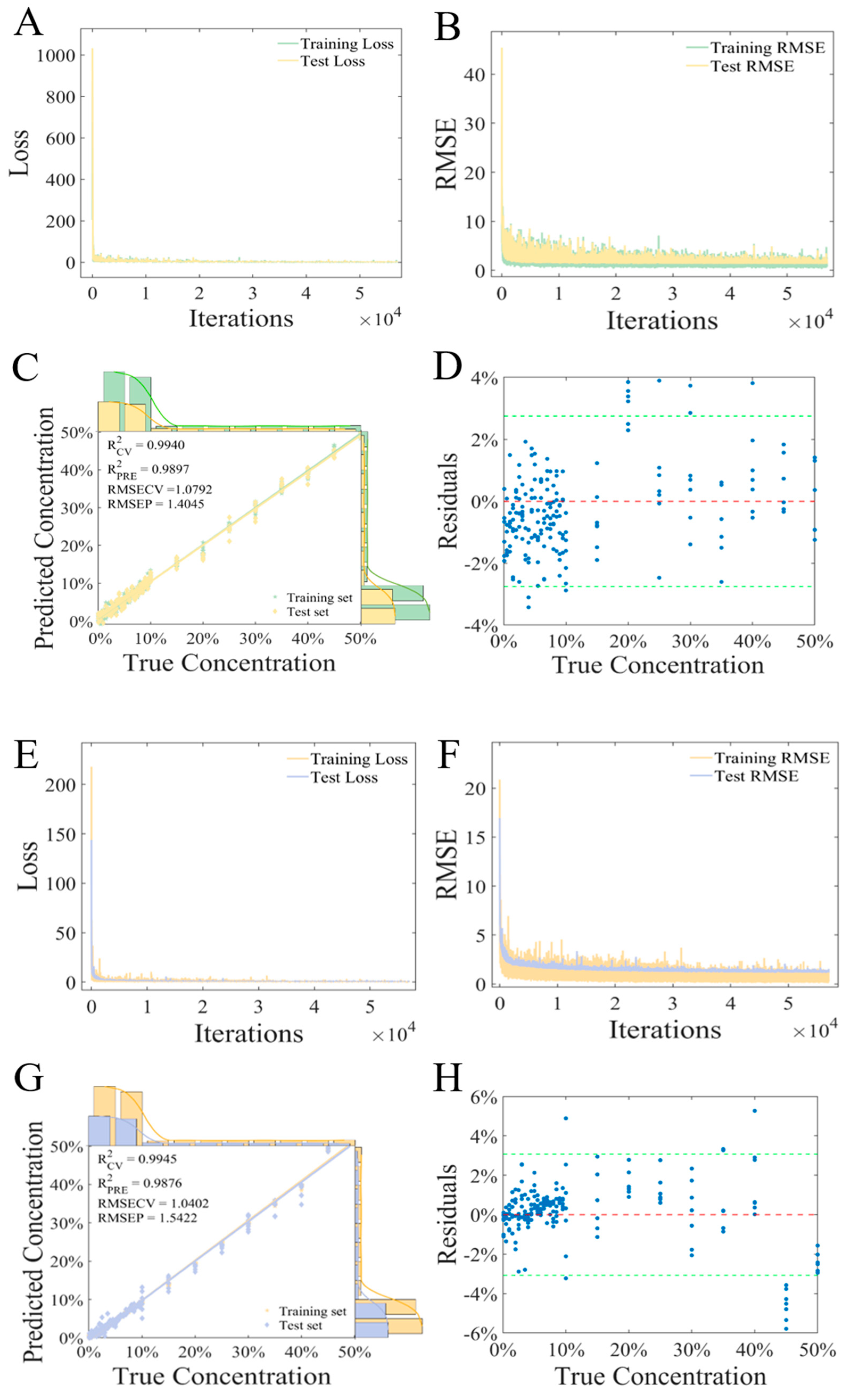
3.5. Adulteration Prediction Model of Fritillaria cirrhosa D. Don
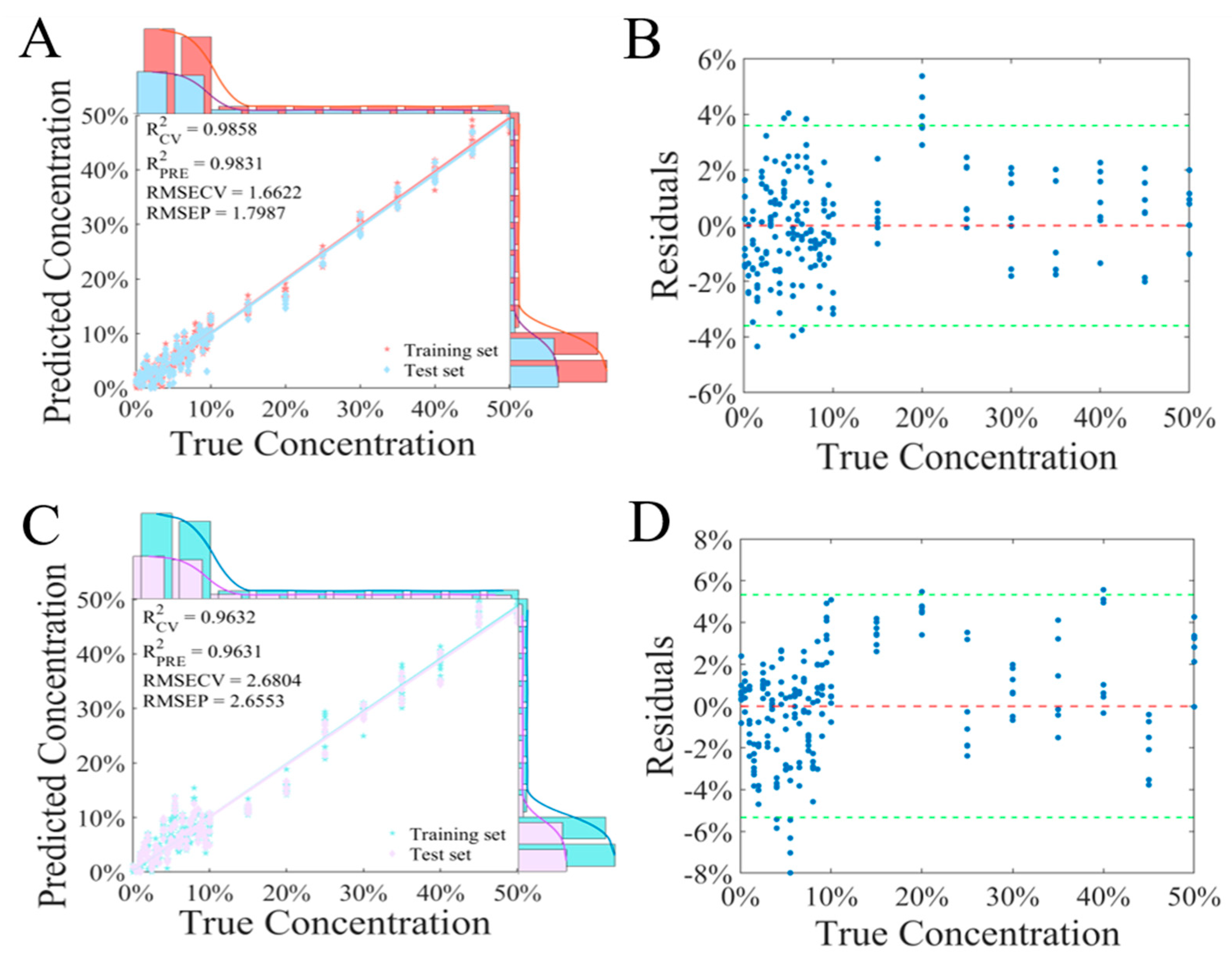
3.5.1. PLSR Regression Model
3.5.2. CNN Regression Model
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pharmacopoeia of the People’s Republic of China, 2020 ed.; China Medical Science and Technology Press: Beijing, China, 2020; pp. 36, 97, 141, 292. ISBN 978-750-670-077-8.
- Liang, Y.; Zhang, J.; Wang, X.; Gao, T.; Li, H.; Zhang, D. Applying DNA barcoding to identify the cultivated provenance of Fritillaria taipaiensis PY Li and its related species. J. Appl. Res. Med. Aromat. Plants 2024, 39, 100530. [Google Scholar] [CrossRef]
- Liu, Z.; Pei, Y.; Chen, T.; Yang, Z.; Jiang, W.; Feng, X.; Li, X. Molecular quantification of fritillariae cirrhosae bulbus and its adulterants. Chin. Med. 2024, 19, 628–632. [Google Scholar] [CrossRef]
- Dai, Y.; Liu, S.; Yang, L.; He, Y.; Guo, X.; Ma, Y.; Li, S.; Huang, D. Explorative study for the rapid detection of Fritillaria using gas chromatography-ion mobility spectrometry. Front. Nutr. 2024, 11, 1361668. [Google Scholar] [CrossRef]
- Liu, C.; Liu, S.; Tse, W.M.; Tse, K.W.G.; Erbu, A.; Xiong, H.; Lanzi, G.; Liu, Y.; Ye, B. A distinction between Fritillaria Cirrhosa Bulbus and Fritillaria Pallidiflora Bulbus via LC–MS/MS in conjunction with principal component analysis and hierarchical cluster analysis. Sci. Rep. 2023, 13, 2735. [Google Scholar] [CrossRef]
- Zhu, X.; Zhou, T.; Wang, S.; Ye, B.; Singla, R.K.; Tewari, D.; Atanasov, A.G.; Wang, D.; Liu, S. LC–MS/MS Coupled with Chemometric Analysis as an Approach for the Differentiation of Fritillariae cirrhosae Bulbus and Fritillariae pallidiflorae Bulbus. Separations 2023, 10, 75. [Google Scholar] [CrossRef]
- Xin, L.; Ren, W.; Zhao, D.; Wang, S.; Li, Y. Application of Fourier Transform Near Infrared Spectroscopy in Origin Tracing of Ginseng. J. Jilin Agric. Univ. 2023, 45, 36–41. [Google Scholar] [CrossRef]
- Liu, K.; Hu, Z.; Long, W.; Lei, G.; Wang, X.; He, J.; Yang, X.; Yang, J.; Fu, H. Geographical Origin Traceability of Eucommiae Cortex Based on Near and Mid Infrared Spectroscopy. Chem. Reag. 2022, 44, 952–959. [Google Scholar] [CrossRef]
- Jiang, Y.; Lin, M.; He, S.; Ding, Y.; Guo, L.; Shi, J.; Chen, J. Identification of Panax notoginseng from Different Producing Area Based on Infrared Spectroscopy Combined with SIMCA Mode. Acta Chin. Med. Pharmacol. 2019, 47, 54–57. [Google Scholar] [CrossRef]
- Li, G.Y.; Li, J.Q.; Liu, H.G.; Wang, Y. Rapid and accurate identification of Gastrodia elata Blume species based on FTIR and NIR spectroscopy combined with chemometric methods. Talanta 2025, 281, 126910. [Google Scholar] [CrossRef]
- Li, G.Y.; Li, J.Q.; Liu, H.G.; Wang, Y. Geographic traceability of Gastrodia elata Blum based on combination of NIRS and Chemometrics. Food Chem. 2024, 464, 141529. [Google Scholar] [CrossRef]
- Coqueiro, J.S.; de Lima, A.B.S.; de Jesus, J.C.; Silva, R.R.; Ferrão, S.P.B.; Santos, L.S. Ensuring authenticity of cinnamon powder: Detection of adulteration with coffee husk and corn meal using NIR, MIR spectroscopy and chemometrics. Food Control 2024, 166, 110681. [Google Scholar] [CrossRef]
- Amirvaresi, A.; Nikounezhad, N.; Amirahmadi, M.; Daraei, B.; Parastar, H. Comparison of near-infrared (NIR) and mid-infrared (MIR) spectroscopy based on chemometrics for saffron authentication and adulteration detection. Food Chem. 2021, 344, 128647. [Google Scholar] [CrossRef]
- Tian, M.; Han, Y.; Ma, X.; Liang, W.; Meng, Z.; Cao, G.; Luo, Y.; Zang, H. Quality study of animal-derived traditional Chinese medicinal materials based on spectral technology: Calculus bovis as a case. Phytochem. Anal. 2024, 35, 1278–1285. [Google Scholar] [CrossRef] [PubMed]
- Peng, C.; Zhang, M.; Kong, M.; Zhang, S.; Li, C.; Feng, T.; Tian, W.; Nie, L.; Zang, H. Integrating deep learning and near-infrared spectroscopy for quality control of traditional Chinese medicine extracts. Microchem. J. 2024, 205, 111310. [Google Scholar] [CrossRef]
- An, Y.-L.; Li, Y.; Wei, W.-L.; Li, Z.-W.; Zhang, J.-Q.; Yao, C.-L.; Li, J.-Y.; Bi, Q.-R.; Qu, H.; Pan, H. Species discrimination of multiple botanical origins of Fritillaria species based on infrared spectroscopy, thin layer chromatography-image analysis and untargeted metabolomics. Phytomedicine 2024, 123, 155228. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Fu, S.; Xie, H.; Ye, L.; Wang, S.; Ye, B. Identification and validation of bulbs of Fritillariae species using Near-infrared spectroscopy data. West. China J. Pharm. Sci. 2021, 36, 193–197. [Google Scholar] [CrossRef]
- Wei, K.; Teng, G.; Wang, Q.; Xu, X.; Zhao, Z.; Liu, H.; Bao, M.; Zheng, Y.; Luo, T.; Lu, B. Rapid Test for Adulteration of Fritillaria Thunbergii in Fritillaria Cirrhosa by Laser-Induced Breakdown Spectroscopy. Foods 2023, 12, 1710. [Google Scholar] [CrossRef] [PubMed]
- Kabir, M.H. Quality Detection of Fritillaria Thubergii Using Spectroscopic Techniques and Machine Learning. Ph.D. Thesis, Zhejiang University, Hangzhou, China, 2023. [Google Scholar] [CrossRef]
- Zhao, Y.; Du, W.; Wang, S.; Cong, X.; Cai, B.; Ge, W. Rapid Detection of Peimine and Peininine in Bulbus FritillariaeThunbergii by Near Infrared Spectroscopy. Chin. Arch. Tradit. Chin. Med. 2013, 31, 756–758. [Google Scholar] [CrossRef]
- Di, W. Study on the Selection of Spectral Preprocessing Methods. Spectrosc. Spectr. Anal. 2019, 39, 2800–2806. [Google Scholar]
- Savitzky, A.; Golay, M.J.E. Smoothing and Differentiation of Data by Simplified Least Squares Procedures. Anal. Chem. 1964, 36, 1627–1639. [Google Scholar] [CrossRef]
- Barnes, R.J.; Dhanoa, M.S.; Lister, S.J. Standard Normal Variate Transformation and De-trending of Near-Infrared Diffuse Reflectance Spectra. Appl. Spectrosc. 1989, 43, 772–777. Available online: https://opg.optica.org/as/abstract.cfm?uri=as-43-5-772 (accessed on 27 March 2025). [CrossRef]
- Zhang, Z.-M.; Chen, S.; Liang, Y.-Z. Baseline correction using adaptive iteratively reweighted penalized least squares. Analyst 2010, 135, 1138–1146. [Google Scholar] [CrossRef] [PubMed]
- Anowar, F.; Sadaoui, S.; Selim, B. Conceptual and empirical comparison of dimensionality reduction algorithms (PCA, KPCA, LDA, MDS, SVD, LLE, ISOMAP, LE, ICA, t-SNE). Comput. Sci. Rev. 2021, 40, 100378. [Google Scholar] [CrossRef]
- Zontov, Y.V.; Rodionova, O.Y.; Kucheryavskiy, S.V.; Pomerantsev, A.L. PLS-DA—A MATLAB GUI tool for hard and soft approaches to partial least squares discriminant analysis. Chemom. Intell. Lab. Syst. 2020, 203, 104064. [Google Scholar] [CrossRef]
- Moore, G.; Bergeron, C.; Bennett, K.P. Model selection for primal SVM. Mach. Learn. 2011, 85, 175–208. [Google Scholar] [CrossRef]
- Weinberg, A.I.; Last, M. Selecting a representative decision tree from an ensemble of decision-tree models for fast big data classification. J. Big Data 2019, 6, 23. [Google Scholar] [CrossRef]
- Acquarelli, J.; van Laarhoven, T.; Gerretzen, J.; Tran, T.N.; Buydens, L.M.C.; Marchiori, E. Convolutional neural networks for vibrational spectroscopic data analysis. Anal. Chim. Acta 2017, 954, 22–31. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 128, pp. 618–626. [Google Scholar] [CrossRef]
- Zhu, T.; Yan, F.; Lv, X.; Zhao, H.; Wang, Z.; Dong, K.; Fu, Z.; Jia, R.; Lv, C. A Deep Learning Model for Accurate Maize Disease Detection Based on State-Space Attention and Feature Fusion. Plants 2024, 13, 3151. [Google Scholar] [CrossRef]
- Chen, H.; Zhang, S.; Huang, Y.; Li, S.; Chen, J.; Ao, H. Comparative study on the content determination and the anti-tussive and anti-inflammatory effects of the total alkaloids of Pingbeimu and Chuanbeimu. Sci. Technol. Food Ind. 2017, 38, 63–67. [Google Scholar] [CrossRef]
- Wang, X.; Qiao, Y.; Wen, J.; Li, Y. Correlation between alkaloid and polysaccharide content of Fritillariae Ussuriensis Bulbus from different origins and ecological factors and in vitro antioxidant activity. Nat. Prod. Res. Dev. 2025, 37, 293–303. [Google Scholar] [CrossRef]
- Bai, Y.; Zhang, S.; Zhang, H. Analysis of Chemical Constituents and Pharmacological Activities of Alkaloids in Fritillaria. Chem. Eng. Des. Commun. 2023, 49, 197–199. [Google Scholar] [CrossRef]
- Fan, L.; He, L.; Tan, C.; Tian, Y.; Zhang, C.; Wu, C.; Huang, Y. Rapid Detection of Adulteration of Fritillariae Cirrhosae Bulbus Based on Portable Near Infrared Spectroscopy. Chin. J. Exp. Tradit. Med. Formulae 2022, 28, 131–138. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, X.; Zhao, W.-J.; Liu, F.-J.; Yang, L.-L.; Li, P.; Li, H.-J. Integration of untargeted and pseudotargeted metabolomics reveals specific markers for authentication and adulteration detection of Fritillariae Bulbus using tandem mass spectrometry and chemometrics. J. Pharm. Biomed. Anal. 2024, 242, 116013. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Yang, M.; Zhang, M.; Jia, M. Inkjet-printed colorimetric sensor array for the rapid identification of adulterated Fritillariae cirrhosae bulbus. Sens. Actuators B Chem. 2022, 368, 132210. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Pretreatments | Training | Test | ||
|---|---|---|---|---|---|
| R2 | RMSECV (%) | R2 | RMSEP (%) | ||
| CNN | Raw spectra | 0.9996 | 0.2915 | 0.9711 | 2.3524 |
| PCA | 0.9945 | 1.0402 | 0.9876 | 1.5422 | |
| S–G + SNV | 0.9867 | 0.6118 | 0.9807 | 1.9201 | |
| Der | 0.9908 | 1.3412 | 0.9886 | 1.4789 | |
| airPLS | 0.9940 | 1.0792 | 0.9897 | 1.4045 | |
| PLSR | Raw spectra | 0.9858 | 1.6622 | 0.9831 | 1.7987 |
| PCA | 0.9632 | 2.6804 | 0.9631 | 2.6553 | |
| S–G + SNV | 0.9805 | 1.9525 | 0.9807 | 1.9206 | |
| Der | 0.9831 | 1.8173 | 0.9806 | 1.9280 | |
| airPLS | 0.9840 | 1.7667 | 0.9826 | 1.8226 | |
| Method | Models | Categories of Adulteration | R2 | Minimum Adulteration Concentration | References |
|---|---|---|---|---|---|
| NIR | PLSR | D. Don–Miq. | 0.8402 | 5% | [35] |
| D. Don–Maxim. | 0.9612 | ||||
| D. Don–Schrenk | 0.7657 | ||||
| D. Don–FHB | 0.9025 | ||||
| D. Don–BT | 0.9574 | ||||
| D. Don–flour | 0.9761 | ||||
| LIBS | PLSR-SVR | D. Don–Miq. | 0.9983 | 5% | [18] |
| UHPLC–QQQ-MS | PLSR | Maxim.–UNI | 0.9949 | 10% | [36] |
| Miq.–UNI | 0.9721 | ||||
| WAL–DEL | 0.9895 | ||||
| CSA | PLSR | D. Don–Maxim. | 0.9570 | 25% | [37] |
| D. Don–Miq. | 0.9050 | ||||
| D. Don–CS | 0.9560 | ||||
| D. Don–WF | 0.8730 | ||||
| D. Don–BT | 0.9230 | ||||
| D. Don–MGST | 0.9060 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, F.; Lei, W.; Li, J.; Wang, X.; Su, J.; Sahati, T.; Aierkenjiang, X.; Tian, R.; Zhou, W.; Zhang, J.; et al. A Dual-Technology Approach: Handheld NIR Spectrometer and CNN for Fritillaria spp. Quality Control. Foods 2025, 14, 1907. https://doi.org/10.3390/foods14111907
Li F, Lei W, Li J, Wang X, Su J, Sahati T, Aierkenjiang X, Tian R, Zhou W, Zhang J, et al. A Dual-Technology Approach: Handheld NIR Spectrometer and CNN for Fritillaria spp. Quality Control. Foods. 2025; 14(11):1907. https://doi.org/10.3390/foods14111907
Chicago/Turabian StyleLi, Fengling, Wen Lei, Juan Li, Xiaoting Wang, Jingyu Su, Tangnuer Sahati, Xiahenazi Aierkenjiang, Ruyi Tian, Weihong Zhou, Jixiong Zhang, and et al. 2025. "A Dual-Technology Approach: Handheld NIR Spectrometer and CNN for Fritillaria spp. Quality Control" Foods 14, no. 11: 1907. https://doi.org/10.3390/foods14111907
APA StyleLi, F., Lei, W., Li, J., Wang, X., Su, J., Sahati, T., Aierkenjiang, X., Tian, R., Zhou, W., Zhang, J., & Xia, J. (2025). A Dual-Technology Approach: Handheld NIR Spectrometer and CNN for Fritillaria spp. Quality Control. Foods, 14(11), 1907. https://doi.org/10.3390/foods14111907