3.1. Matching Polynomials of Fullerenes
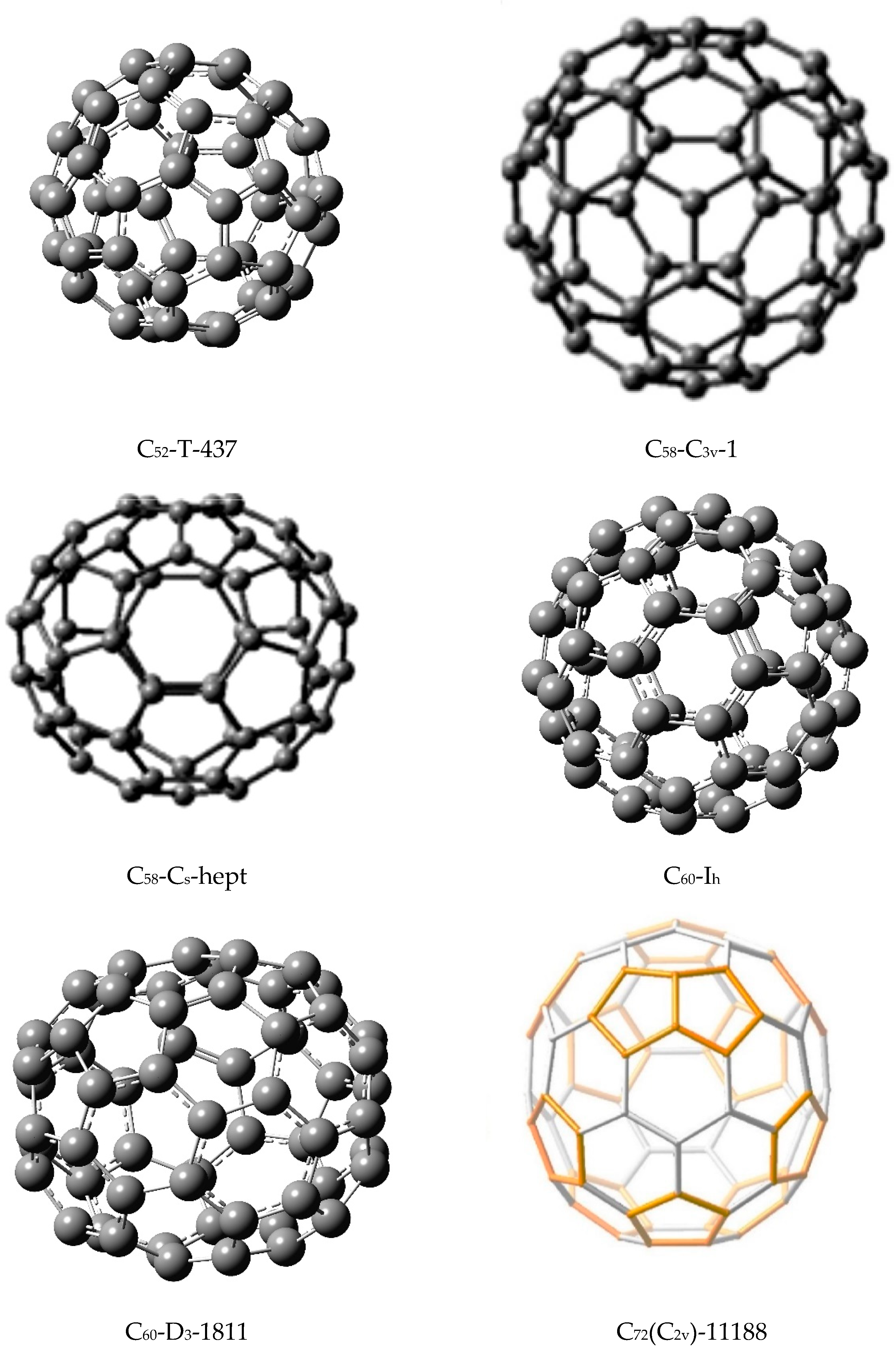
I have chosen a variety of isomers of fullerenes of varied sizes. In order to consider a contrasting case, I also included a relatively stable fullerene isomer of C
58 with C
s symmetry that contains 1 heptagon and 13 pentagons. This isomer, denoted as C
58(C
s)-hept, is although strictly not a fullerene, several workers [
74,
75] have considered this as an energetically viable low-lying isomer compared to the C
58(C
3v)-1 fullerene. Consequently, I have included this isomer also for the derivation of our matching polynomial-based similarity matrices. The fullerene isomers that are included in the present study are shown in
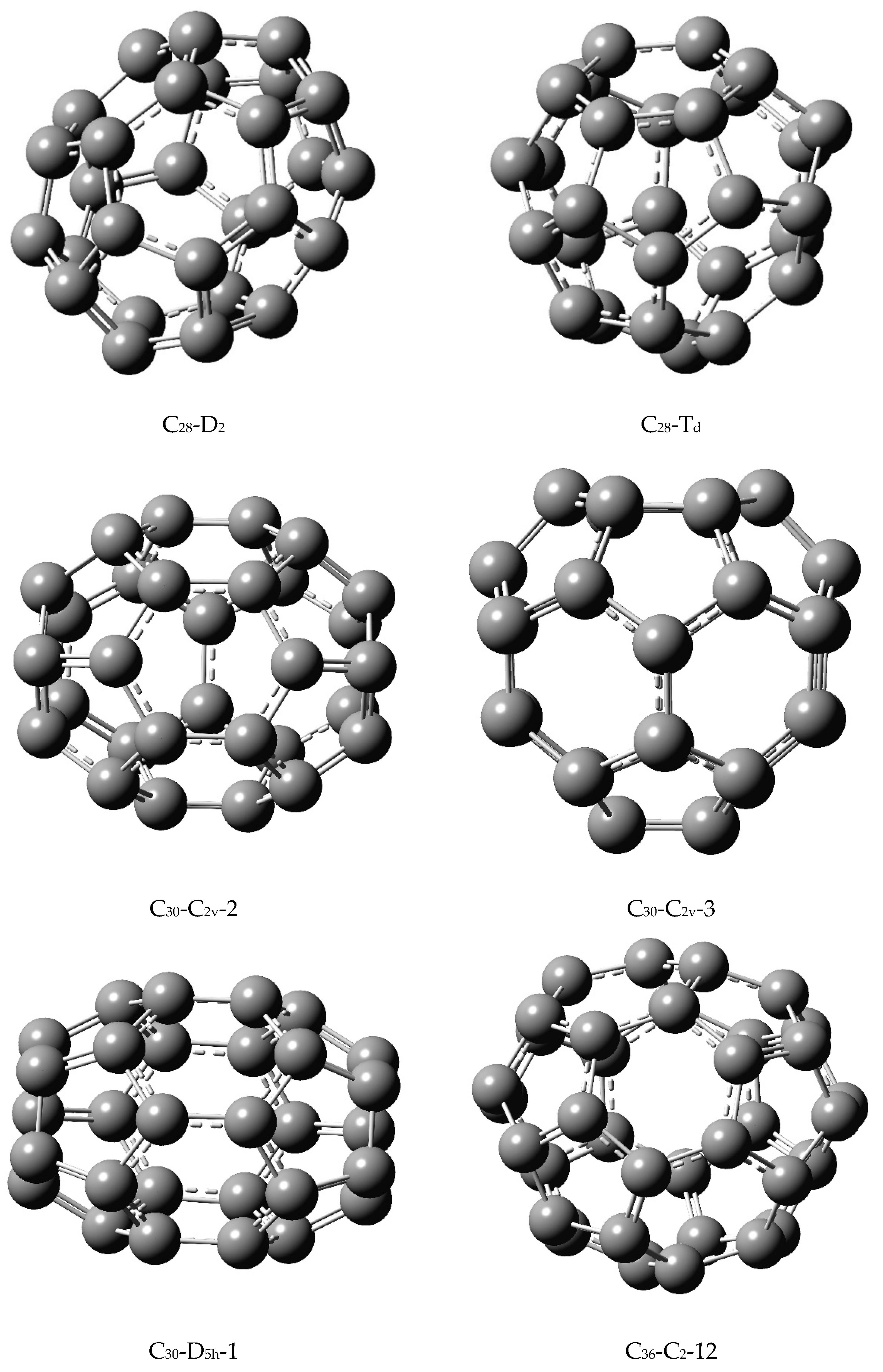
Figure 1. I designate each fullerene by the number of carbon atoms, its symmetry, and a standard label as per fullerene library designations. Although there are several more isomers for each fullerene compared to the ones shown in
Figure 1, I chose the isomers on the basis of their stabilities, differing symmetries, or shapes so that the similarity analysis would be meaningful and provide contrasting comparisons in order to assess the efficacy of the matching-based similarity analysis of these isomers of fullerenes. I have computed the matching polynomials of all of the fullerenes shown in
Figure 1. As mentioned in the previous section, I employed a combination of recursive techniques and a binary database of previously computed and stored polynomials of the common fragments generated during the pruning process.
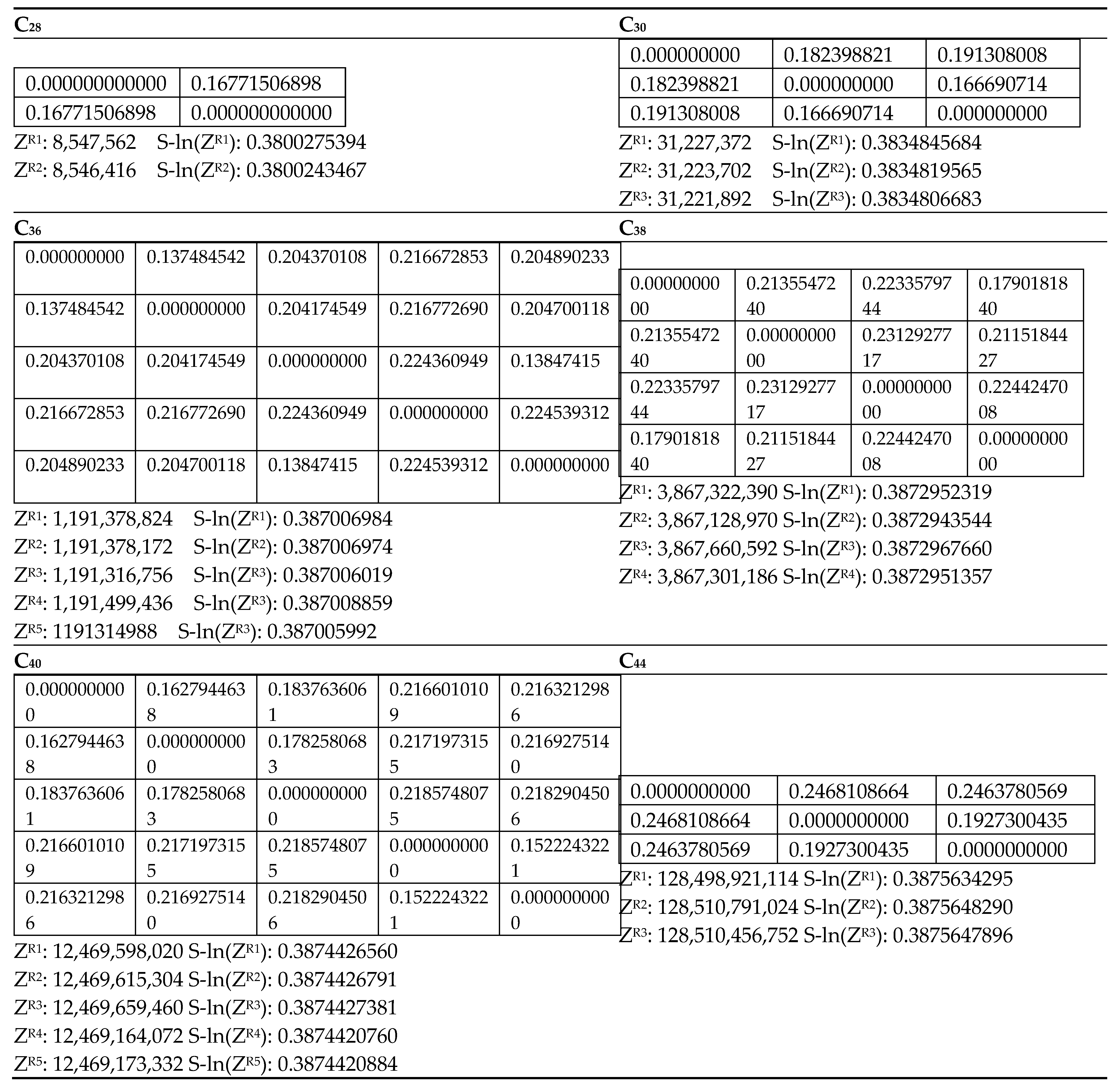
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12 show the matching polynomials of the various isomers of fullerenes organized according to their formula. In each table, the various columns provide the matching polynomials of the isomers of a given constitution. The tables are constructed in the same order as the structures appear in
Figure 1. All the results shown in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12 were computed with quadruple precision accuracy and, hence, every digit in these tables is valid. Consider
Table 1, which shows the matching polynomials of two isomers of C
28, namely C
28(D
2) and C
28(T
d). They have different symmetries but their shapes are somewhat similar (see,
Figure 1). The T
d structure has less strain compared to the D
2 structure. As a result of the close similarity between the T
d and D
2 isomers of C
28, their matching polynomials are also quite similar, as can be seen in
Table 1. The identical nature of the first eight coefficients of the matching polynomials of the isomers of fullerenes has nothing to do with the symmetry of the structure of C
28. This arises from the fact that the first 8 coefficients of all fullerenes, that is, for the cage structures with 12 pentagons and any number of hexagons, do not depend on the structures but only on the number of carbon atoms. I shall discuss this in depth subsequently. However, it is noted that other coefficients for the C
28(D
2) versus C
28(T
d) structures also differ very little, consistent with the similarity of the shapes and other structural features, as seen from
Figure 1.
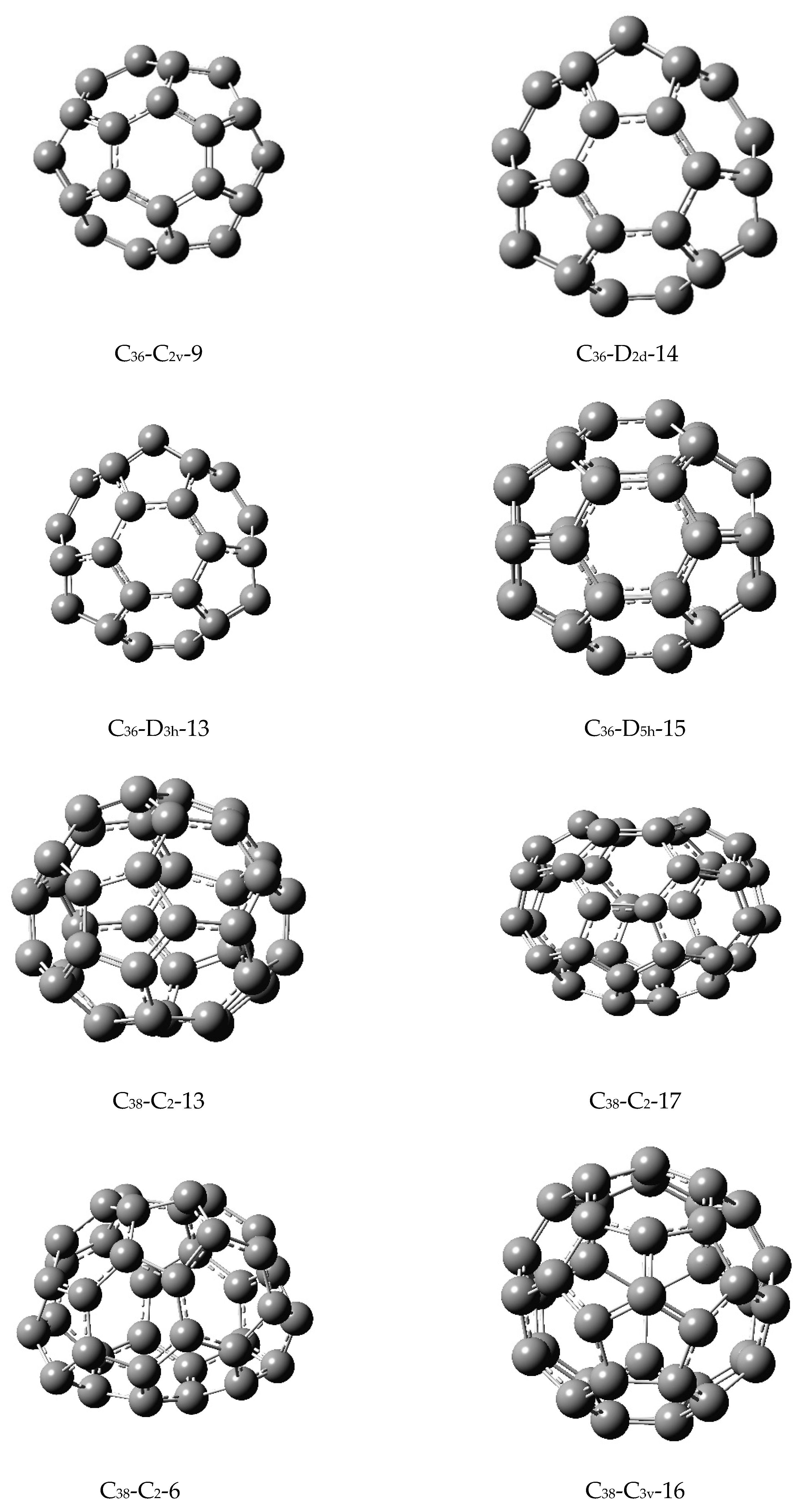
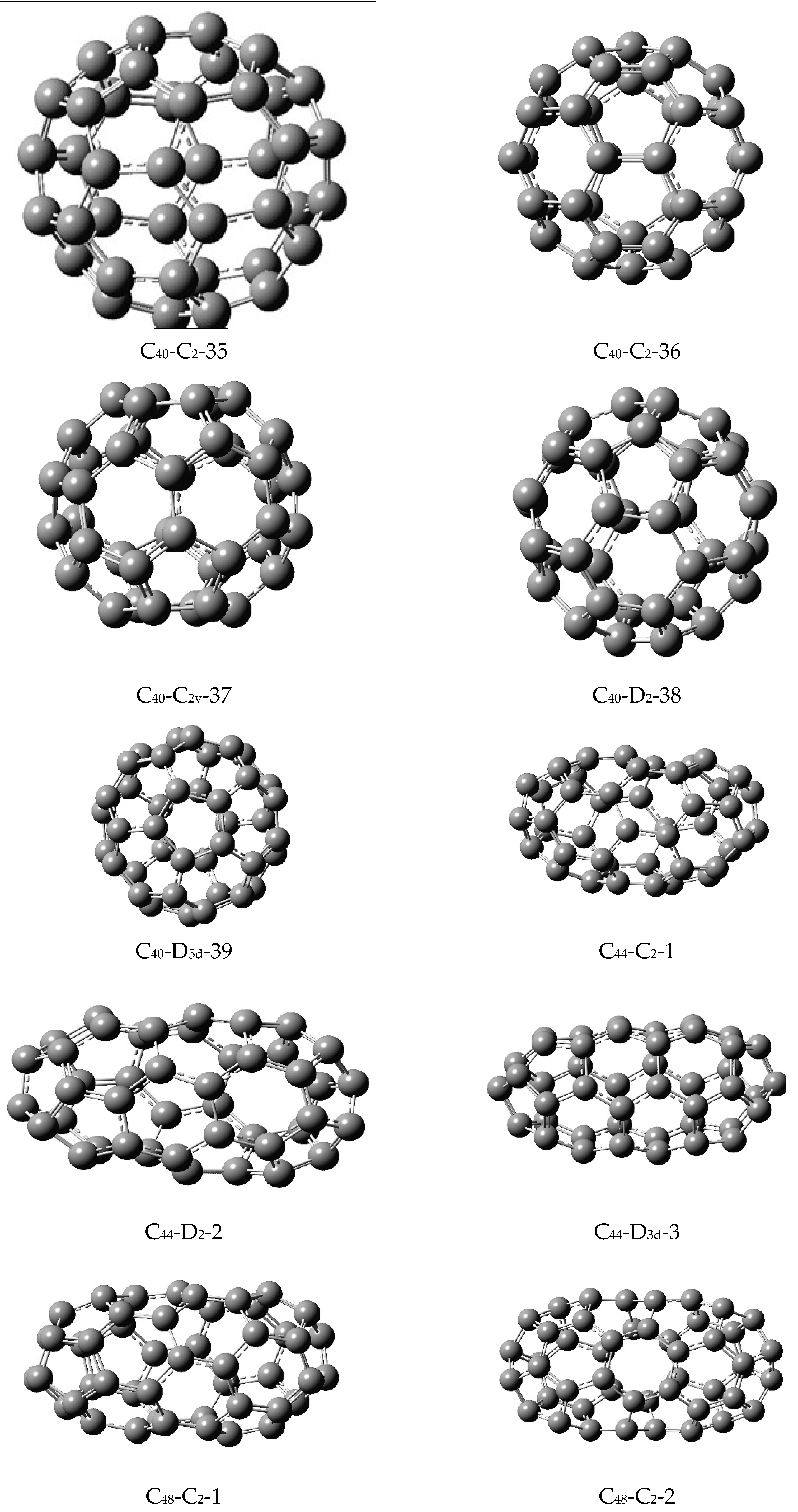
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10 display the computed matching polynomials of a number of isomers of fullerenes, C
30 through C
58. Among these, fullerenes C
36, C
40, and C
50 were considered for five isomers with contrasting symmetries and shapes in
Table 3 and
Table 5, respectively (see
Figure 1 for the corresponding structures of the isomers).
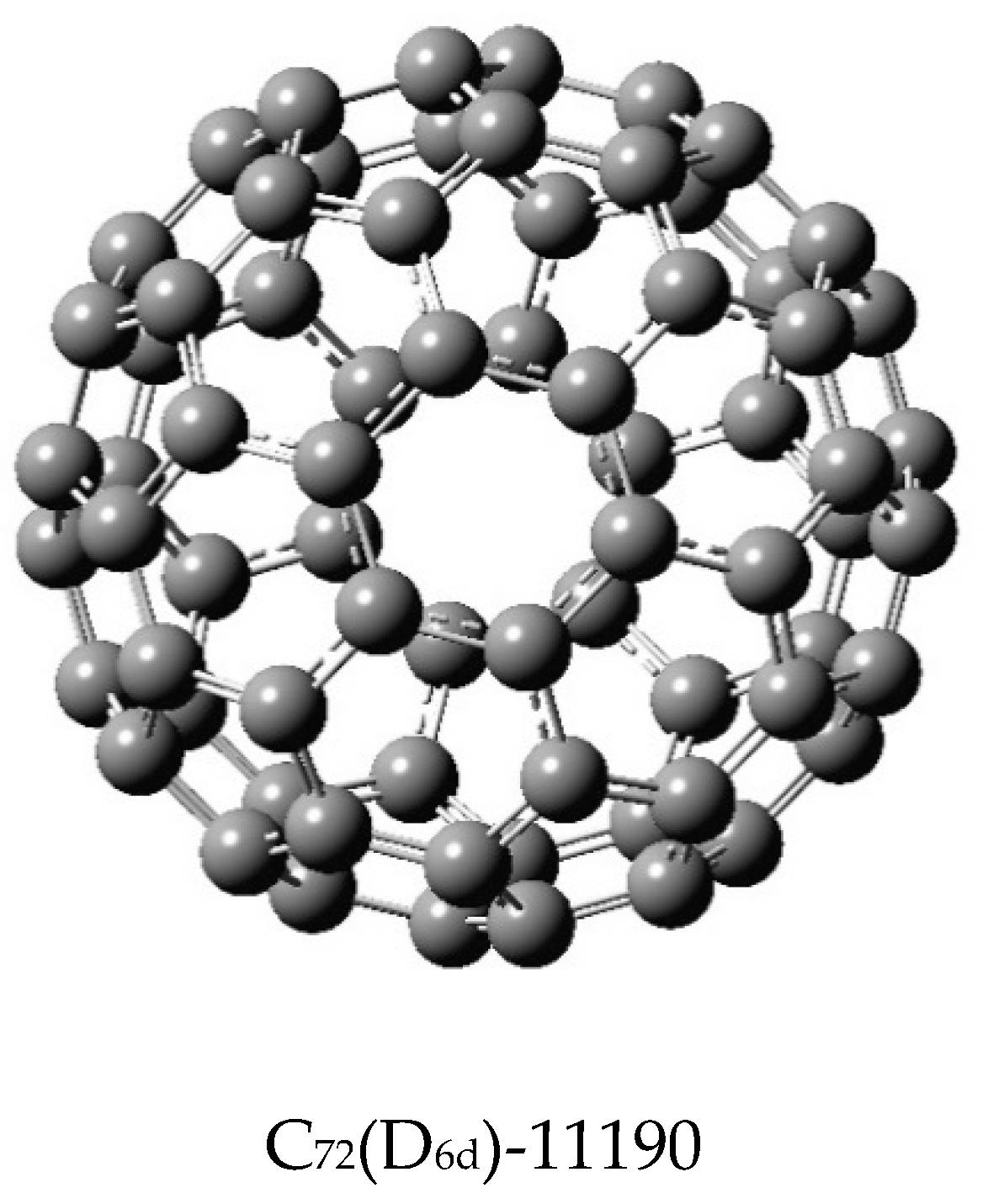
Table 11 and
Table 12 display the matching polynomials of two isomers, C
60 and C
72, where for each case, two isomers of contrasting shapes or symmetries were considered. In the case of C
72, the two isomers as well as C
70 have been considered in quantum chemical studies [
76,
77]. A critical analysis of all matching polynomials displayed in the Tables reveals that for all fullerenes containing only pentagons and hexagons, the first eight coefficients are identical for the isomers in that these coefficients do not exhibit any structural dependence. That is, they vary as polynomials of n. As discussed earlier [
52], the exact analytical expressions for the first few coefficients of fullerene cages can be derived through a combination of Sach’s theorem and the coefficients of the corresponding terms in the characteristic polynomials. The resulting expressions are shown below:
where c
n is the corresponding coefficient in the characteristic polynomial of the fullerene,
is the number of ways of choosing k adjacent
l-membered rings in the fullerene whereas
is the number of ways to choose k disjoint
l-membered rings from the fullerene.
The coefficients of the first 8 terms in the matching polynomials of all cages containing 12 pentagons and varied number of hexagons are the same for the isomers, as can be inferred to be identical from
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12. The only exception to this is the C
58(C
s)-hept structure which is comprised of 13 pentagons and 1 heptagon and, thus, the ring structures are different compared to the C
58(C
3v)-1 fullerene, which contains 12 pentagons and no heptagons. Even then, the first five coefficients of the matching polynomials of the two isomers of C
58 are identical, with the sixth coefficient differing only by unity. Although the results for C
72(D
6d) in
Table 12 were derived from [
50] and hence they lack the accuracy of C
72(C
2v)-11188 computed here, the similarity indices computed subsequently for C
72 do not suffer from the accuracy issue, as the similarity measures are based on a natural logarithmic scale.
The constant coefficients of the matching polynomials yield the number of Kekulé structures of fullerene isomers, although there exists no direct correlation between the stability of the fullerene structure and the number of resonance structures. However, a number of related topological indices have been derived and used from the coefficients of the matching polynomials as well as their spectra. For example, the sum of the absolute values of the coefficients of the matching polynomials is the well-known Hosoya’s topological index [
78] while the sum of the difference in the eigenvalues of the characteristic and matching polynomials yields the topological resonance energy; the latter has been employed as a measure of the relative stabilities of isomers of fullerenes. The isomers that exhibit extremal values of Hosoya’s topological Z-index [
78] are also of interest. It can thus be inferred that if two isomers of fullerenes exhibit Z-indices close to each other, then they can be viewed as candidates for further investigations by a higher level of computations in order to assess further their relative stabilities. Although many such variants have been proposed, up to now, no similarity measures have been developed for comparing the isomers of fullerenes or other structures. As the first eight coefficients are identical, I have proposed the reduced Z-indices for fullerenes which consider only the differing coefficients of the matching polynomials in deriving the Z-indices. I have further introduced natural logarithms and scaling techniques for deriving the indices proposed in the next section for both the comparison and similarity analysis of fullerenes.
3.2. The Similarity Matrices of Fullerenes and Reduced Z-Indices
As can be seen from
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12, the matching polynomials of isomers of fullerenes exhibit similarities and, hence, I develop quantitative similarity measures in terms of the similarity matrices that would have the capability to offer a contrast among isomers as well as across the platform of fullerenes. These matrices are defined using the coefficients of the matching polynomials with a scaling incorporated into them. Hence, I define the similarity matrix based on matching polynomials as follows:
where
is the k
th coefficient of the matching polynomial of fullerene isomer
Gi, while
is the k
th coefficient of the matching polynomial of fullerene isomer
Gj. The absolute differences of the corresponding coefficients are taken and, thus, the difference is always positive so as to maintain this as a true difference without regard for the sign variations of the alternate terms of the matching polynomials. We obtain a matrix element S
ij for any two members (
i, j) among a set of isomers considered for comparison. The diagonal elements of the similarity matrix are set to 0 as the similarity distance between two identical isomers is 0. Consequently, the larger the similarity matrix element, the greater is the dissimilarity between the isomers
i and
j, while a small value would then imply that the two isomers are very similar. I have computed the similarity matrices for all of the isomers of fullerenes considered in this study, and the computed similarity matrices are shown in
Figure 2 for each fullerene considered here.
As the first eight coefficients of the matching polynomials of isomers of fullerenes are identical, I have introduced a scaled, natural logarithmic version of the reduced Z-index, Z
R, as follows:
A primary advantage of the reduced-scaled version is that it facilitates a comparison of isomers of fullerenes across the platform. Hence, I have shown in
Figure 2 both S-ln(Z
R) as well as Z
R for comparing isomers, where Z
R is simply the sum of the absolute coefficients starting with the eighth coefficient of the matching polynomials.
As seen from
Figure 2, the computed similarity measures are in a logarithmic scale and the matrix elements vary between 0.137 and 0.313 where the lowest value corresponding to the most similar structures are for the first two isomers of C
36 (
Figure 1) which are C
36(C
2)-12 and C
36(C
2v)-9. As can be seen from both
Figure 1 and
Table 3, the two isomers are very similar in multiple ways. Their overall shapes and structural similarities are striking. At a quantitative level, an inspection of
Table 3 reveals that the first 10 coefficients in the matching polynomial are identical while the 11th coefficient differs only by unity. Several other subsequent coefficients are also close to each other. This is in turn reflected by the similarity matrix element of 0.137484542 for the two isomers. Likewise, the isomers 5 and 3, which correspond to C
36-D
5h-15 and C
36-D
2d-14, exhibit remarkable similarity both in terms of their shape, structures, and matching polynomials. That is, the arrangements of pentagons and hexagons are such that they provide very similar combinatorial matchings. I note that other structures which exhibit such similarities are the two isomers of C
28 in
Figure 1; the two isomers have a similarity measure of 0.1677151 on the basis of their combinatorial matchings. Likewise, two isomers of C
30 also exhibit comparable similarity measures (see
Figure 2). The first isomers of C
40 (
Figure 1) have comparable similarity measures of 0.1627944 and this is corroborated by the corresponding matching polynomials shown in
Table 5 where I find that the first 12 coefficients of the two isomers are identical, with the 13th coefficient differing by only 12.
Although most of the other isomers of fullerenes exhibit similarity indices close to 0.2, the two isomers of C
58 are important cases to be noted for the dramatic similarity contrast. First, as noted before, their similarity index is the highest among all the isomers considered here with a striking value of 0.312761 given that this is a logarithmic scale. The contrasting similarity measure is fully consistent with the fact that the first isomer of C
58 is a true fullerene containing 12 pentagons and hexagons while the second one designated as C
58(C
s)-hept contains 1 heptagon and 13 pentagons. This contrasting juxtaposition shown in
Figure 1 as well as
Table 10 is truly echoed in their similarity index measure introduced here. This is a direct validation of the similarity matrix measure that I have developed in that the measure faithfully reflects the variations and dissimilarities as well as similarities among the structures. Moreover, with the values shown in
Figure 2, I now have a reference platform to evaluate the similarities among isomers through such quantitative similarity measures.
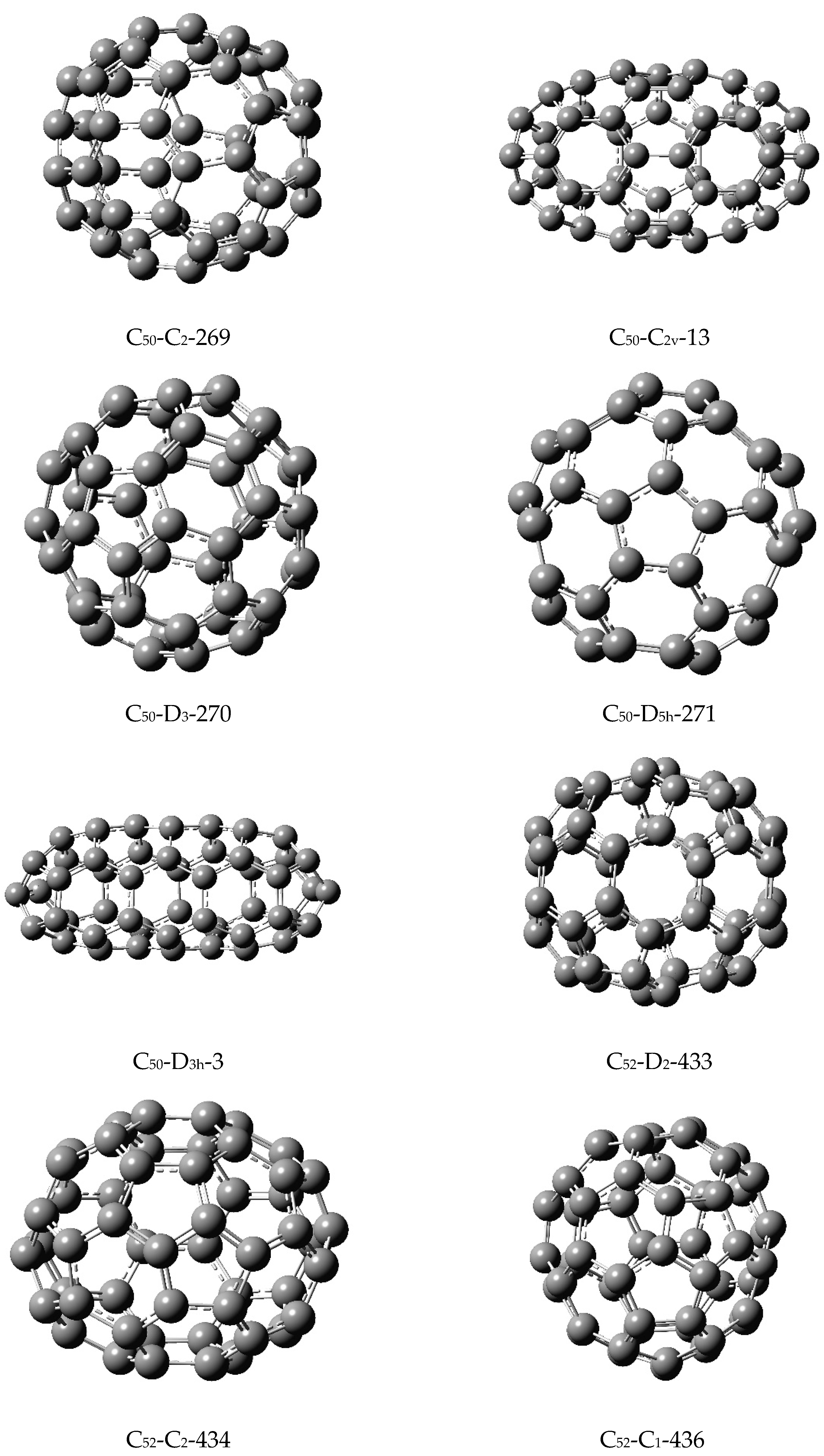
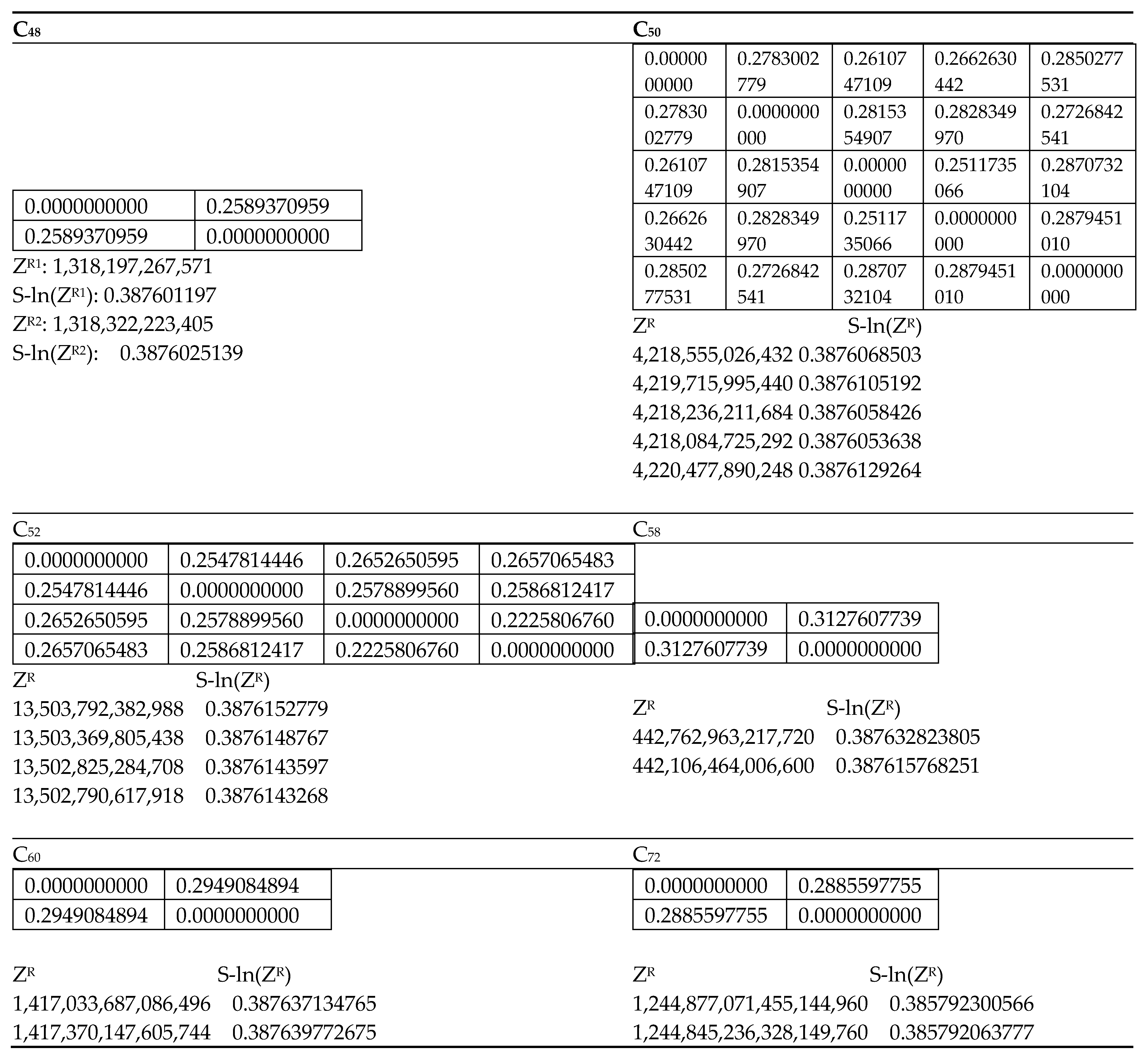
To shed further light into the similarity matrix invariants, let us consider the five isomers of C
50 shown in
Figure 1 with their matching polynomials displayed in
Table 8. Let us consider the computed similarity matrix which is highlighted below for the five isomers of C
50 in the order:
-
C50(C2)-269, C50(C2v)-13, C50(D3)-270, C50(D5h)-271, and C50(D3h)-3.
| | C50(C2)-269 | C50(C2v)-13 | C50(D3)-270 | C50(D5h)-271 | C50(D3h)-3 |
| C50(C2)-269 | 0.0000000000 | 0.2783002779 | 0.2610747109 | 0.2662630442 | 0.2850277531 |
| C50(C2v)-13 | 0.2783002779 | 0.0000000000 | 0.2815354907 | 0.2828349970 | 0.2726842541 |
| C50(D3)-270 | 0.2610747109 | 0.2815354907 | 0.0000000000 | 0.2511735066 | 0.2870732104 |
| C50(D5h)-271 | 0.2662630442 | 0.2828349970 | 0.2511735066 | 0.0000000000 | 0.2879451010 |
| C50(D3h)-3 | 0.2850277531 | 0.2726842541 | 0.2870732104 | 0.2879451010 | 0.0000000000 |
The above array suggests that the smallest matrix element (0.251174) is between the isomers 3 and 4, while the largest matrix element is between the isomers 4 and 5 (0.2879451010). I now refer to
Figure 1, where indeed I find the isomers 3 and 4, C
50(D
3)-270 and C
50(D
5h)-271, which are quite similar in their shapes and overall structural features. On the other hand, the isomers C
50(D
5h)-271 and C
50(D
3h)-3 are extremely dissimilar in that the latter is an oblate spheroid while the former is more spherical. Likewise, as can be seen from the fifth row of the similarity matrix, the oblate spheroidal C
50(D
3h)-3 stands out in having larger matrix elements with the entire array of other isomers of C
50 considered here. This is consistent with the fact that the C
50(D
3h)-3 isomer is conspicuous among the five isomers of C
50 in being an oblate spheroid while the other four isomers are closer to spherical structures (See
Figure 1).
I note from
Figure 2 that although Z
R increases rapidly as a function of the number of atoms in fullerenes, the scaled-logarithmic version can be used to make comparisons. As pointed out by Hosoya [
78], the Z-index by itself does not correlate with the aromaticity or stability of polycyclic aromatics. However, the reduced index Z
R can provide first-order information on the total number of resonance structures and possible full and partial matchings. If I consider the two isomers of C
60, their Z
R values are 1,417,033,687,086,496 and 1,417,370,147,605,744 for the I
h and D
3 isomers, respectively. Although the numbers of the resonance structures of the I
h and D
3 structures are 12,500 and 9622, respectively, their Z
R indices exhibit an opposite trend with the I
h isomer exhibiting an overall lower Z
R index. The lower overall Z
R for the I
h isomer together with the greater number of resonance structures for the I
h structure suggests a considerably enhanced stability for the I
h isomer. This is consistent with the DFT quantum chemical studies on these isomers which reveal that the D
3 isomer of C
60 is higher in energy [
76]. I find a similar correlation for other fullerenes such as C
50 and C
36 with the cautionary note that there is no direct correlation between the relative stability and the Z
R indices as well as the total number of resonance structures.
Finally, there appears to be a correlation between the shapes of fullerene structures and the combinatorial matching-based similarity indices. For example, nearly spherical structures have very close similarity indices while a fullerene isomer with an oblate spheroid structure exhibits a numerically larger value of the similarity index when compared to more spherical structures. Likewise, two oblate spheroid isomers have closer similarity and, thus, a smaller similarity matrix element. The subject matter of quantifying shapes and QShAR has received attention over the years [
79,
80]. Consequently, the present similarity matrices derived from the matchings add yet another novel dimension to the shape similarity problem. The similarity indices derived here based on combinatorial matchings could find applications in water clusters [
81] where the hydrogen bonds between any two water molecules could become matchings. Moreover, dimer covers could also model placing dimers such as transition metal dimers [
82] that avoid being neighbors and, thus, could also serve as models for the chemisorption or substitution of dimeric molecules on fullerene cages and nanotubes.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}