The Role of Auxiliary Stages in Gaussian Quantum Metrology


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Distributed-Parameter Quantum-Enhanced Estimation
3. Typicality of Quantum Enhanced Sensitivity
3.1. The Role of the Generator
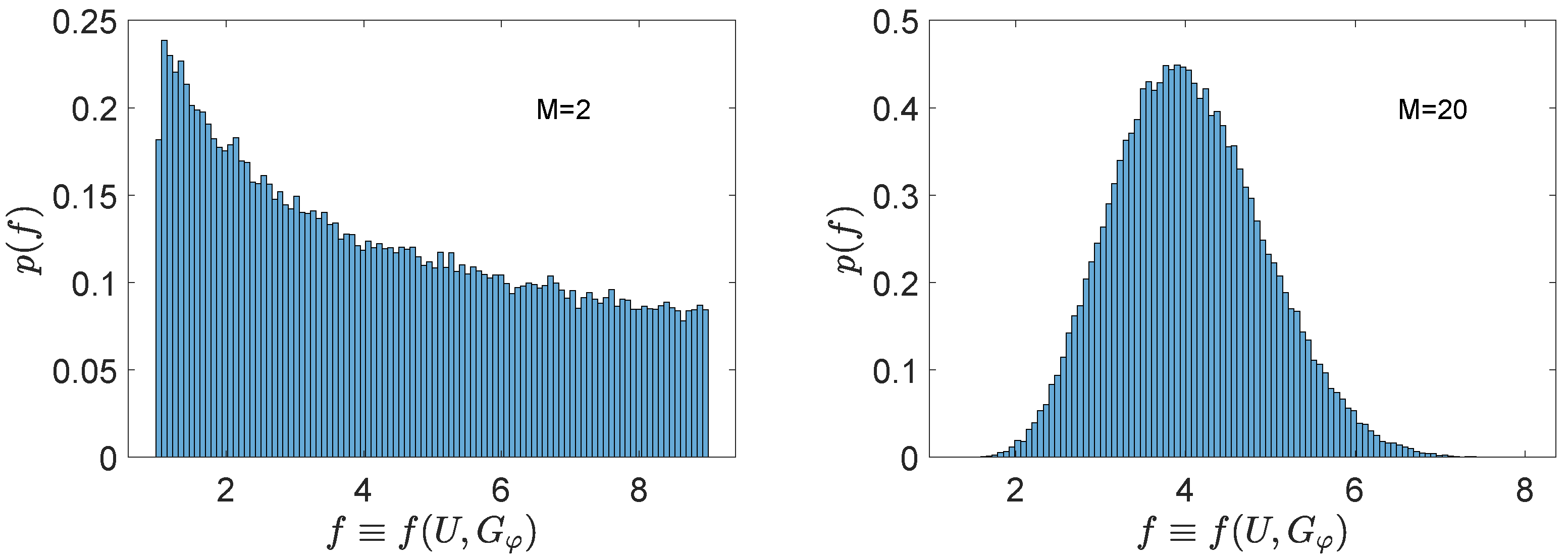
3.2. Typical Behaviour of the Pre-Factor in the Heisenberg Scaling
4. Estimation of Functions of Parameters
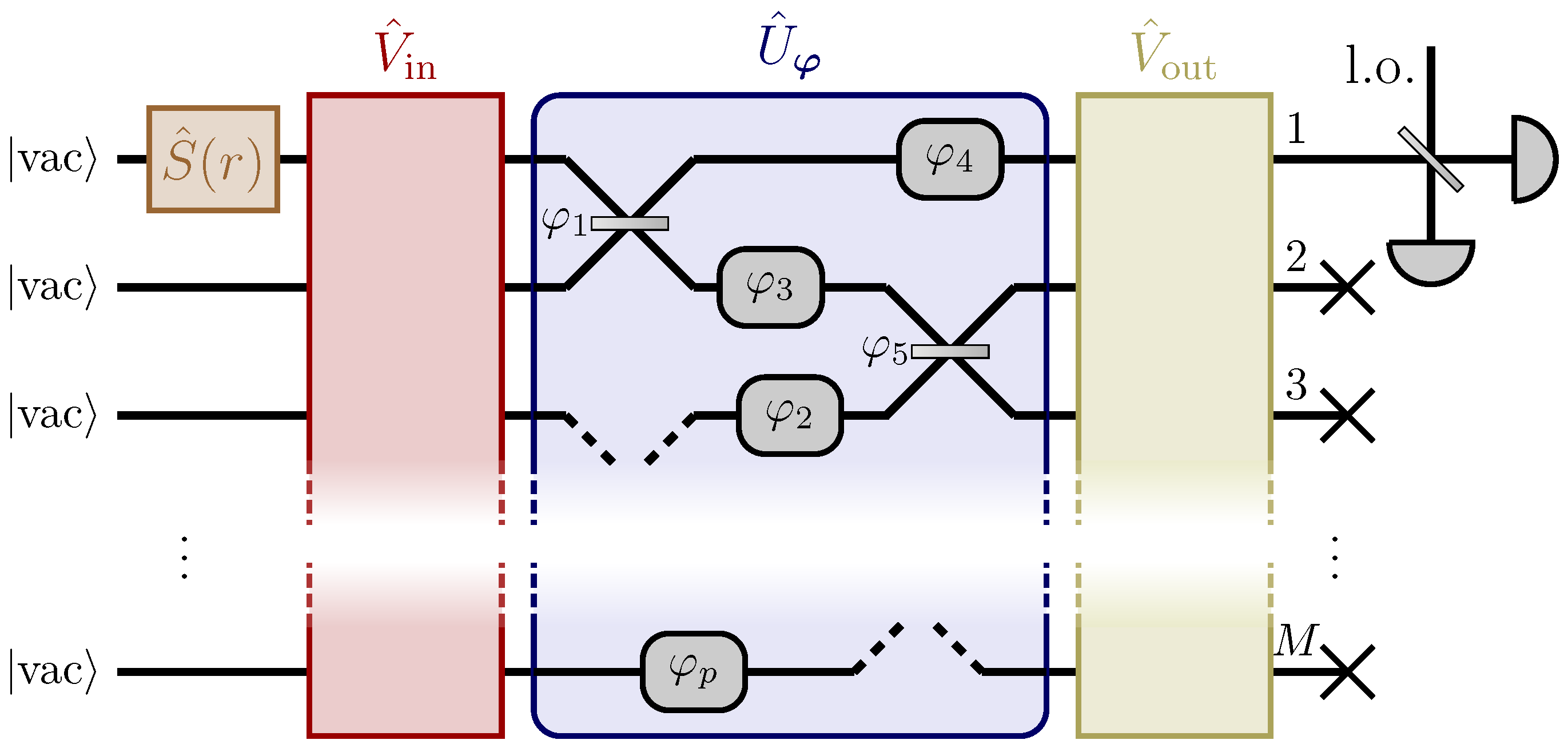
4.1. Setup
4.2. Heisenberg Scaling
4.3. On the Conditions for the Heisenberg Scaling
4.4. Examples of Quantum-Enhanced Estimation of Functions
4.4.1. Non-Linear Functions
4.4.2. Linear Combinations of Arbitrary Parameters
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Typicality of Gaussian Metrology
Appendix A.1. Derivation of the Average of the Pre-Factor
Appendix A.2. Derivation of the Typicality Results
Appendix B. Probability Distributions from Homodyne Measurements
Appendix C. Asymptotic Analysis of Gaussian Metrology
Appendix D. Maximum-Likelihood Estimators for Gaussian Distributions
Appendix E. Derivation of the Cramér-Rao Bound for Singular Fisher Information Matrix
Appendix F. Analysis of the Transition Amplitude
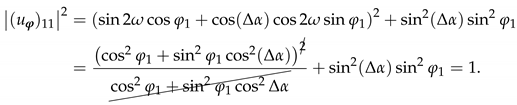
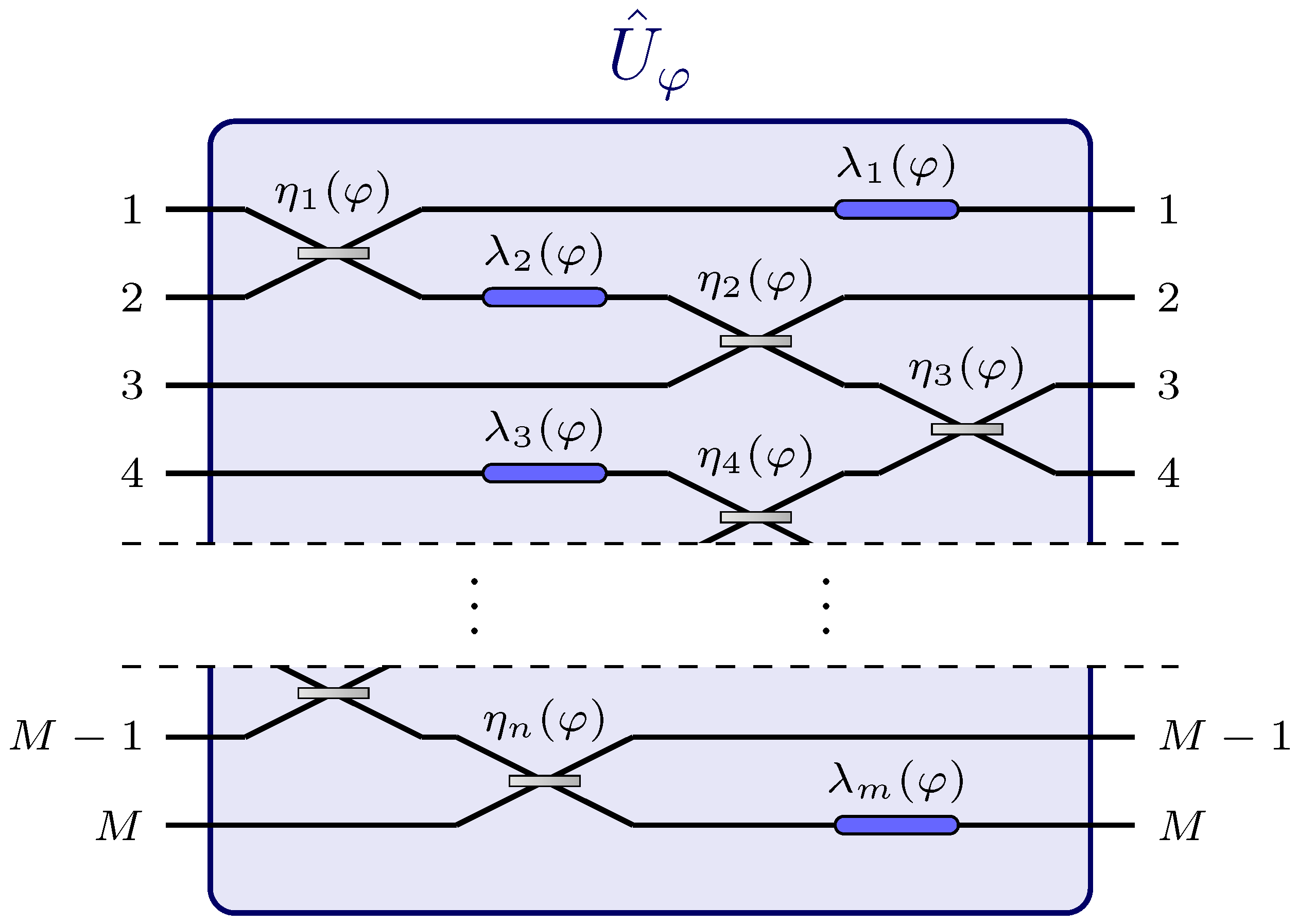
Appendix G. Generalized Setup
References
- McConnell, R.; Low, G.H.; Yoder, T.J.; Bruzewicz, C.D.; Chuang, I.L.; Chiaverini, J.; Sage, J.M. Heisenberg scaling of imaging resolution by coherent enhancement. Phys. Rev. A 2017, 96, 051801. [Google Scholar] [CrossRef] [Green Version]
- Unternährer, M.; Bessire, B.; Gasparini, L.; Perenzoni, M.; Stefanov, A. Super-resolution quantum imaging at the Heisenberg limit. Optica 2018, 5, 1150–1154. [Google Scholar] [CrossRef] [Green Version]
- De Pasquale, A.; Stace, T.M. Quantum Thermometry. In Thermodynamics in the Quantum Regime; Springer: Cham, Switzerland, 2018; Volume 195, pp. 503–527. [Google Scholar] [CrossRef] [Green Version]
- Seah, S.; Nimmrichter, S.; Grimmer, D.; Santos, J.P.; Scarani, V.; Landi, G.T. Collisional Quantum Thermometry. Phys. Rev. Lett. 2019, 123, 180602. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Razzoli, L.; Ghirardi, L.; Siloi, I.; Bordone, P.; Paris, M.G.A. Lattice quantum magnetometry. Phys. Rev. A 2019, 99, 062330. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharjee, S.; Bhattacharya, U.; Niedenzu, W.; Mukherjee, V.; Dutta, A. Quantum magnetometry using two-stroke thermal machines. New J. Phys. 2020, 22, 013024. [Google Scholar] [CrossRef]
- Aasi, J.; Abadie, J.; Abbott, B.P.; Abbott, R.; Abbott, T.D.; Abernathy, M.R.; Adams, C.; Adams, T.; Addesso, P.; Adhikari, R.X.; et al. Enhanced sensitivity of the LIGO gravitational wave detector by using squeezed states of light. Nat. Photonics 2013, 7, 613–619. [Google Scholar] [CrossRef]
- Caves, C.M. Quantum-mechanical noise in an interferometer. Phys. Rev. D 1981, 23, 1693–1708. [Google Scholar] [CrossRef]
- Bondurant, R.S.; Shapiro, J.H. Squeezed states in phase-sensing interferometers. Phys. Rev. D 1984, 30, 2548–2556. [Google Scholar] [CrossRef]
- Wineland, D.J.; Bollinger, J.J.; Itano, W.M.; Moore, F.L.; Heinzen, D.J. Spin squeezing and reduced quantum noise in spectroscopy. Phys. Rev. A 1992, 46, R6797–R6800. [Google Scholar] [CrossRef]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Quantum-Enhanced Measurements: Beating the Standard Quantum Limit. Science 2004, 306, 1330–1336. [Google Scholar] [CrossRef] [Green Version]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Quantum Metrology. Phys. Rev. Lett. 2006, 96, 010401. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dowling, J.P. Quantum optical metrology—The lowdown on high-N00N states. Contemp. Phys. 2008, 49, 125–143. [Google Scholar] [CrossRef]
- Paris, M.G. Quantum estimation for quantum technology. Int. J. Quantum Inf. 2009, 7, 125–137. [Google Scholar] [CrossRef]
- Giovannetti, V.; Lloyd, S.; Maccone, L. Advances in quantum metrology. Nat. Photonics 2011, 5, 222–229. [Google Scholar] [CrossRef]
- Lang, M.D.; Caves, C.M. Optimal Quantum-Enhanced Interferometry Using a Laser Power Source. Phys. Rev. Lett. 2013, 111, 173601. [Google Scholar] [CrossRef] [Green Version]
- Tóth, G.; Apellaniz, I. Quantum metrology from a quantum information science perspective. J. Phys. A Math. Theor. 2014, 47, 424006. [Google Scholar] [CrossRef] [Green Version]
- Erol, V.; Ozaydin, F.; Altintas, A.A. Analysis of Entanglement Measures and LOCC Maximized Quantum Fisher Information of General Two Qubit Systems. Sci. Rep. 2014, 4, 5422. [Google Scholar] [CrossRef] [Green Version]
- Dowling, J.P.; Seshadreesan, K.P. Quantum Optical Technologies for Metrology, Sensing, and Imaging. J. Light. Technol. 2015, 33, 2359–2370. [Google Scholar] [CrossRef] [Green Version]
- Czekaj, L.; Przysiężna, A.; Horodecki, M.; Horodecki, P. Quantum metrology: Heisenberg limit with bound entanglement. Phys. Rev. A 2015, 92, 062303. [Google Scholar] [CrossRef] [Green Version]
- Ozaydin, F.; Altintas, A.A. Quantum Metrology: Surpassing the shot-noise limit with Dzyaloshinskii-Moriya interaction. Sci. Rep. 2015, 5, 16360. [Google Scholar] [CrossRef] [Green Version]
- Szczykulska, M.; Baumgratz, T.; Datta, A. Multi-parameter quantum metrology. Adv. Phys. X 2016, 1, 621–639. [Google Scholar] [CrossRef]
- Schnabel, R. Squeezed states of light and their applications in laser interferometers. Phys. Rep. 2017, 684, 1–51. [Google Scholar] [CrossRef] [Green Version]
- Braun, D.; Adesso, G.; Benatti, F.; Floreanini, R.; Marzolino, U.; Mitchell, M.W.; Pirandola, S. Quantum-enhanced measurements without entanglement. Rev. Mod. Phys. 2018, 90, 035006. [Google Scholar] [CrossRef] [Green Version]
- Pirandola, S.; Bardhan, B.R.; Gehring, T.; Weedbrook, C.; Lloyd, S. Advances in photonic quantum sensing. Nat. Photonics 2018, 12, 724–733. [Google Scholar] [CrossRef]
- Tóth, G.; Vértesi, T. Quantum States with a Positive Partial Transpose are Useful for Metrology. Phys. Rev. Lett. 2018, 120, 020506. [Google Scholar] [CrossRef] [Green Version]
- Polino, E.; Valeri, M.; Spagnolo, N.; Sciarrino, F. Photonic quantum metrology. AVS Quantum Sci. 2020, 2, 024703. [Google Scholar] [CrossRef]
- Pál, K.F.; Tóth, G.; Bene, E.; Vértesi, T. Bound entangled singlet-like states for quantum metrology. Phys. Rev. Res. 2021, 3, 023101. [Google Scholar] [CrossRef]
- Schleich, W. Quantum Optics in Phase Space; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Weedbrook, C.; Pirandola, S.; García-Patrón, R.; Cerf, N.J.; Ralph, T.C.; Shapiro, J.H.; Lloyd, S. Gaussian quantum information. Rev. Mod. Phys. 2012, 84, 621–669. [Google Scholar] [CrossRef]
- Adesso, G.; Ragy, S.; Lee, A.R. Continuous Variable Quantum Information: Gaussian States and Beyond. Open Syst. Inf. Dyn. 2014, 21, 1440001. [Google Scholar] [CrossRef] [Green Version]
- Lvovsky, A.I. Squeezed Light. In Photonics; John Wiley and Sons, Ltd.: Hoboken, NJ, USA, 2015; Chapter 5; pp. 121–163. [Google Scholar] [CrossRef]
- Maccone, L.; Riccardi, A. Squeezing metrology: A unified framework. Quantum 2020, 4, 292. [Google Scholar] [CrossRef]
- Gatto, D.; Facchi, P.; Narducci, F.A.; Tamma, V. Distributed quantum metrology with a single squeezed-vacuum source. Phys. Rev. Res. 2019, 1, 032024. [Google Scholar] [CrossRef] [Green Version]
- Gramegna, G.; Triggiani, D.; Facchi, P.; Narducci, F.A.; Tamma, V. Heisenberg scaling precision in multi-mode distributed quantum metrology. New J. Phys. 2021, 23, 053002. [Google Scholar] [CrossRef]
- Gramegna, G.; Triggiani, D.; Facchi, P.; Narducci, F.A.; Tamma, V. Typicality of Heisenberg scaling precision in multimode quantum metrology. Phys. Rev. Res. 2021, 3, 013152. [Google Scholar] [CrossRef]
- Triggiani, D.; Facchi, P.; Tamma, V. Heisenberg scaling precision in the estimation of functions of parameters in linear optical networks. Phys. Rev. A 2021, 104, 062603. [Google Scholar] [CrossRef]
- Triggiani, D.; Facchi, P.; Tamma, V. Non-adaptive Heisenberg-limited metrology with multi-channel homodyne measurements. Eur. Phys. J. Plus 2022, 137, 125. [Google Scholar] [CrossRef]
- Triggiani, D.; Tamma, V. Estimation with Heisenberg-Scaling Sensitivity of a Single Parameter Distributed in an Arbitrary Linear Optical Network. Sensors 2022, 22, 2657. [Google Scholar] [CrossRef]
- Gatto, D.; Facchi, P.; Tamma, V. Heisenberg-limited estimation robust to photon losses in a Mach-Zehnder network with squeezed light. Phys. Rev. A 2022, 105, 012607. [Google Scholar] [CrossRef]
- Triggiani, D.; Tamma, V. Estimation of the average of arbitrary unknown phase delays with Heisenberg-scaling precision. In Proceedings of the Optical and Quantum Sensing and Precision Metrology II; Scheuer, J., Shahriar, S.M., Eds.; International Society for Optics and Photonics, SPIE: San Francisco, CA, USA, 2022; Volume 12016, pp. 97–101. [Google Scholar] [CrossRef]
- Proctor, T.J.; Knott, P.A.; Dunningham, J.A. Multiparameter Estimation in Networked Quantum Sensors. Phys. Rev. Lett. 2018, 120, 080501. [Google Scholar] [CrossRef] [Green Version]
- Zhuang, Q.; Zhang, Z.; Shapiro, J.H. Distributed quantum sensing using continuous-variable multipartite entanglement. Phys. Rev. A 2018, 97, 032329. [Google Scholar] [CrossRef] [Green Version]
- Matsubara, T.; Facchi, P.; Giovannetti, V.; Yuasa, K. Optimal Gaussian metrology for generic multimode interferometric circuit. New J. Phys. 2019, 21, 033014. [Google Scholar] [CrossRef] [Green Version]
- Qian, K.; Eldredge, Z.; Ge, W.; Pagano, G.; Monroe, C.; Porto, J.V.; Gorshkov, A.V. Heisenberg-scaling measurement protocol for analytic functions with quantum sensor networks. Phys. Rev. A 2019, 100, 042304. [Google Scholar] [CrossRef] [Green Version]
- Guo, X.; Breum, C.R.; Borregaard, J.; Izumi, S.; Larsen, M.V.; Gehring, T.; Christandl, M.; Neergaard-Nielsen, J.S.; Andersen, U.L. Distributed quantum sensing in a continuous-variable entangled network. Nat. Phys. 2020, 16, 281–284. [Google Scholar] [CrossRef] [Green Version]
- Oh, C.; Lee, C.; Lie, S.H.; Jeong, H. Optimal distributed quantum sensing using Gaussian states. Phys. Rev. Res. 2020, 2, 023030. [Google Scholar] [CrossRef] [Green Version]
- Grace, M.R.; Gagatsos, C.N.; Guha, S. Entanglement-enhanced estimation of a parameter embedded in multiple phases. Phys. Rev. Res. 2021, 3, 033114. [Google Scholar] [CrossRef]
- Armen, M.A.; Au, J.K.; Stockton, J.K.; Doherty, A.C.; Mabuchi, H. Adaptive Homodyne Measurement of Optical Phase. Phys. Rev. Lett. 2002, 89, 133602. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Monras, A. Optimal phase measurements with pure Gaussian states. Phys. Rev. A 2006, 73, 033821. [Google Scholar] [CrossRef] [Green Version]
- Aspachs, M.; Calsamiglia, J.; Muñoz Tapia, R.; Bagan, E. Phase estimation for thermal Gaussian states. Phys. Rev. A 2009, 79, 033834. [Google Scholar] [CrossRef] [Green Version]
- Berni, A.A.; Gehring, T.; Nielsen, B.M.; Händchen, V.; Paris, M.G.A.; Andersen, U.L. Ab initio quantum-enhanced optical phase estimation using real-time feedback control. Nat. Photonics 2015, 9, 577–581. [Google Scholar] [CrossRef]
- Grace, M.R.; Gagatsos, C.N.; Zhuang, Q.; Guha, S. Quantum-Enhanced Fiber-Optic Gyroscopes Using Quadrature Squeezing and Continuous-Variable Entanglement. Phys. Rev. Appl. 2020, 14, 034065. [Google Scholar] [CrossRef]
- Cramér, H. Mathematical Methods of Statistics (PMS-9); Princeton University Press: Princeton, NJ, USA, 1946. [Google Scholar] [CrossRef]
- Rohatgi, V.K.; Saleh, A.M.E. An Introduction to Probability and Statistics; John Wiley and Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Haar, A. Der Massbegriff in der Theorie der Kontinuierlichen Gruppen. Ann. Math. 1933, 34, 147–169. [Google Scholar] [CrossRef]
- Nichols, R.; Liuzzo-Scorpo, P.; Knott, P.A.; Adesso, G. Multiparameter Gaussian quantum metrology. Phys. Rev. A 2018, 98, 012114. [Google Scholar] [CrossRef] [Green Version]
- Demkowicz-Dobrzanski, R.; Górecki, W.; Guţă, M. Multi-parameter estimation beyond quantum Fisher information. J. Phys. A Math. Theor. 2020, 53, 363001. [Google Scholar] [CrossRef]
- Stoica, P.; Marzetta, T.L. Parameter estimation problems with singular information matrices. IEEE Trans. Signal Process. 2001, 49, 87–90. [Google Scholar] [CrossRef]
- Gross, J.A.; Caves, C.M. One from Many: Estimating a Function of Many Parameters. J. Phys. A Math. Theor. 2021, 54, 014001. [Google Scholar] [CrossRef]
- Hiai, F.; Petz, D. The Semicircle Law, Free Random Variables and Entropy; Number 77; American Mathematical Soc.: Providence, RI, USA, 2000. [Google Scholar] [CrossRef]
- Puchała, Z.; Miszczak, J.A. Symbolic integration with respect to the Haar measure on the unitary groups. Bull. Pol. Acad. Sci. Tech. Sci. 2017, 65, 21–27. [Google Scholar] [CrossRef] [Green Version]
- Facchi, P.; Garnero, G. Quantum thermodynamics and canonical typicality. Int. J. Geom. Methods Mod. Phys. 2017, 14, 1740001. [Google Scholar] [CrossRef] [Green Version]
- Popescu, S.; Short, A.J.; Winter, A. Entanglement and the foundations of statistical mechanics. Nat. Phys. 2006, 2, 754. [Google Scholar] [CrossRef] [Green Version]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Triggiani, D.; Facchi, P.; Tamma, V. The Role of Auxiliary Stages in Gaussian Quantum Metrology. Photonics 2022, 9, 345. https://doi.org/10.3390/photonics9050345
Triggiani D, Facchi P, Tamma V. The Role of Auxiliary Stages in Gaussian Quantum Metrology. Photonics. 2022; 9(5):345. https://doi.org/10.3390/photonics9050345
Chicago/Turabian StyleTriggiani, Danilo, Paolo Facchi, and Vincenzo Tamma. 2022. "The Role of Auxiliary Stages in Gaussian Quantum Metrology" Photonics 9, no. 5: 345. https://doi.org/10.3390/photonics9050345
APA StyleTriggiani, D., Facchi, P., & Tamma, V. (2022). The Role of Auxiliary Stages in Gaussian Quantum Metrology. Photonics, 9(5), 345. https://doi.org/10.3390/photonics9050345