Abstract
This work introduces a two-stage framework, named the Distorted underwater image Restoration Network (DR-Net), to address the complex degradation of underwater images caused by turbulence, water flow fluctuations, and optical properties of water. The first stage employs the Distortion Estimation Network (DE-Net), which leverages a fusion of Transformer and U-Net architectures to estimate distortion information from degraded images and focuses on image distortion recovery. Subsequently, the Image Restoration Generative Adversarial Network (IR-GAN) in the second stage utilizes this estimated distortion information to deblur images and regenerate lost details. Qualitative and quantitative evaluations on both synthetic and real-world image datasets demonstrate that DR-Net outperforms traditional methods and restoration strategies from different perspectives, showcasing its broader applicability and robustness. Our approach enables the restoration of underwater images from a single frame, which facilitates the acquisition of marine resources and enhances seabed exploration capabilities.
1. Introduction
The underwater imaging quality significantly affects the retrieval of marine resources and the exploitation of seabed resources [1]. Despite substantial advancements in optical imaging technology [2] driven by rapid progress in science and technology, underwater imaging differs from aerial imaging, with relatively fewer associated perturbations. The underwater environment is more complex, as water exerts a significant influence on light propagation [3]. Moreover, the presence of numerous suspended particles in water often results in underwater images suffering from quality degradation issues such as blurriness, low contrast, and color distortion. Additionally, the fluidity of water leads to frequent underwater turbulence [4,5] and water fluctuations [6], which further complicate the image degradation process by introducing unpredictable and intricate patterns, thereby increasing the difficulty of image restoration. In summary, three primary factors contribute to the prevalence of underwater image distortion: the optical properties of water, underwater turbulence (thermal perturbations in the water body under extreme conditions), and water fluctuations.
In this paper, we investigate image restoration techniques aimed at improving the clarity of underwater images affected by irregular distortion and complex blurring caused by water fluctuations and underwater turbulence. Traditional approaches involve using long-time image sequences or videos captured in static scenes to calculate mean and median frames from multiple frames [7,8], or adapting the “lucky imaging” method from astronomical imaging [9,10] to identify minimally distorted image patches for fusion, which can potentially yield undistorted images. Image alignment methods [8,11] can then utilize these obtained potentially less distorted images to iteratively align and restore the original image. The work in [12] proposed a model-based tracking approach that utilizes a fluctuation model and attempts to fit the fluctuations in image sequences to obtain an undistorted image; however, it struggles with more intricate distortions [13] and blurring degradation induced by the water environment. Li et al. [14] introduced a deep learning-based restoration method that can enhance distorted images from a single frame, demonstrating better applicability.
Additionally, the vision transformer (ViT) [15] has shown exceptional performance in image processing and restoration. Restormer [16] proposes a multi-Dconv head transposed attention (MDTA) module and a gated-Deconv feedforward network (GDFN), which effectively balance local context modeling and global dependency capture to handle high-resolution restoration tasks such as deraining and deblurring. Histoformer [17] employs histogram self-attention, sorting spatial features into intensity-based bins to capture long-range dependencies among weather-degraded pixels, and excels in unified adverse weather removal and restoration. TransMRSR [18] combines convolutional and Transformer blocks for super-resolution and image restoration, using a two-stage strategy with generative prior and self-distilled truncation. While these methods perform well in their respective domains and general fields, they are not designed to address underwater-specific challenges such as turbulence-induced distortions and optical scattering.
Building upon the aforementioned methodologies, this paper introduces a two-stage deep learning-based framework named DR-Net for restoring underwater distorted images. As illustrated in Figure 1, the framework assigns distinct restoration objectives to its two stages. The first stage, DE-Net (Distortion Estimation Network), primarily focuses on distortion correction: it leverages the global feature extraction capability of the ViT model to estimate a distortion map, which is principally represented as a displacement vector field derived from the input degraded image and subsequently generates a distortion-corrected image based on this computed distortion information. The second stage, IR-GAN (Image Restoration Generative Adversarial Network), addresses image blurring—a common artifact in underwater imagery. Notably, pixel blurring is inevitably introduced during the distortion correction process of the first stage; thus, this stage enhances image clarity through the adversarial generative network while recovering partially lost image details.
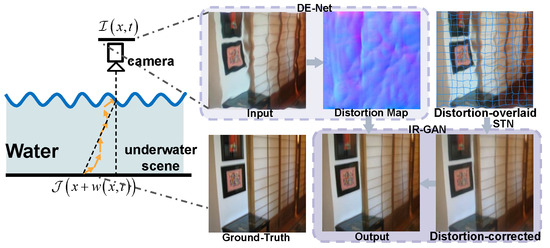
Figure 1.
We propose a two-stage framework for underwater image restoration. Inputting the distorted image, we estimate the distortion information/map and distortion-corrected image in the initial stage, DE-Net. Then, we enhance image detail restoration and regeneration in the subsequent stage, IR-GAN.
Our network was trained and evaluated using the dataset established by Li et al. [14], with additional validation performed on other real-world and synthetic datasets [12,19,20,21]. Comparative experiments against classical methods [8,11,12,14,19,22] and restoration methods [16,17,18] from various perspectives demonstrate that our approach consistently outperforms alternatives in image restoration. A key advantage is its enhanced versatility: unlike traditional methods that rely on multi-frame sequences or extended video inputs from the same scene, our method only requires a single frame for effective underwater image restoration. Furthermore, quantitative evaluations using multiple metrics confirm that our approach achieves state-of-the-art performance across most scenarios.
To summarize, the main contributions of our work are as follows:
- We propose DR-Net, a novel two-stage deep learning framework specifically designed to address underwater image degradation caused by turbulence and water fluctuations, integrating the strengths of Transformer and GAN architectures.
- The staged design of DR-Net enables targeted handling of distinct degradation factors: DE-Net focuses on distortion estimation and correction, while IR-GAN specializes in deblurring and detail recovery, effectively mitigating the cumulative artifacts introduced during sequential processing.
- Our method achieves superior performance on both synthetic and real-world datasets, outperforming classical and state-of-the-art approaches in both qualitative and quantitative evaluations. And DR-Net enhances practical applicability in scenarios by enabling high-quality restoration from a single frame.
2. Related Work
Distorted underwater image restoration. Restoration of distorted underwater images presents a formidable challenge in image processing. Various perspectives have been explored to address the restoration of degraded underwater images:
(1) Early methods, including using the mean or median frame of a static scene image sequence, or calculating water surface refraction concurrently [7] with recording water surface images, have proven effective for recovering simple distortions. (2) In the image combination perspective, the lucky imaging [9,10] method is utilized to select the least distorted patches of an image sequence and fuse them, with selection methods such as k-means clustering [23,24], bicoherence techniques [25], streaming algorithms [10], and bispectral analysis [26] employed.
(3) With regard to the image alignment approach, where multiple frames of a static scene are aligned to a reference image for recovery, techniques like averaging frames [27] or sequential frame-by-frame alignment [28] are commonly used. Researchers like Oreifej et al. [8] proposed a two-stage restoration method incorporating denoising post-alignment, while authors like Halder et al. [11] implement mean-filtered denoising in the second stage, and Yang et al. [29] combine non-rigid alignment and lucky block fusion. (4) The wave model perspective addresses water surface fluctuation-induced distortions, aiming to estimate the fluctuation structure and image distortion by analyzing consecutive image frames to reconstruct the scene image, with researchers like Tian et al. [12] pioneering a fluctuation equation-based modeling approach.
Even recently, (5) developments in pixel point tracking and compressive sensing areas focus on estimating the global pixel displacement vector, tracking multiple feature points in the image sequence, and employing compressed sensing and sparse representation methods [19,30] to dewarp the images. Additionally, sparse or dense optical flow methods [31,32] can be employed for restoration. (6) Furthermore, from a deep learning perspective, Li et al. [14] utilize adversarial generative networks to correct distortions in a single-frame underwater image. Our method integrates global feature extraction to address distortions, blurring, and details, producing high-quality restored images from a single frame.
End-to-end image translation. In image processing tasks, an end-to-end image translation methodology emerges as a straightforward and practical framework, commonly featuring an encoder–decoder architecture tailored for images. The encoder efficiently captures essential image features, while the decoder deciphers and reconstructs the desired image. One of the pioneering architectures is the U-Net [33], initially devised for medical image segmentation and promptly adapted to diverse image processing applications. Over the past decade, the versatile U-Net framework has garnered widespread adoption and demonstrated remarkable outcomes.
The integration of the end-to-end structure with Generative Adversarial Networks [34] for image-to-image translation and synthesis has proven highly successful across various visual tasks, including image denoising, deblurring [35,36,37], style migration [38,39], restoration [40,41], and super-resolution [42,43]. This approach involves training two networks in tandem through adversarial training, where the discriminator and generator engage in a game-like dynamic to enhance the realism of generated images. Isola et al. [22] introduced a comprehensive framework for image translation, using L1 loss and adversarial loss to train end-to-end network for source–target image pairs. In our study, we extend this concept by applying GANs to underwater imaging in our second phase, harnessing their potent generative capabilities to enhance image details effectively.
ViT-based image processing. In deep learning, various robust backbone networks exist, among which Transformer has been widely adopted in computer vision due to its powerful global feature modeling capability [44]. Specifically, Dosovitskiy et al. [15] pioneeringly introduced Transformers to computer vision tasks, demonstrating its significant value in visual domains and enabling its expansion to diverse visual tasks. ViT enhances operational efficiency by segmenting images into sequential patches, embedding them into a Transformer network, and effectively extracting more discriminative feature information to improve performance.
Cong et al. [45] proposed an encoding–decoding framework based on ViT, which employs Transformer modules for feature extraction and is trained with a multi-loss combination. This optimization effectively enhances color fidelity and contrast in underwater images. Similarly, Peng et al. [46] designed a U-shaped Transformer network integrating two modules: the channel-based multi-scale feature fusion Transformer (CMSFFT) and the spatial-based global feature modeling Transformer (SGFMT), strengthening the processing capacity for attentional attenuation in color channels and spatial regions. Xue et al. [47] developed a lightweight cross-gated Transformer algorithm for image restoration, aiming to achieve superior results with fewer parameters and lower computational costs. Additionally, Zheng et al. [48] built a multi-scale modulation module atop a ViT to dynamically select representative features in the feature space of underwater images. More recently, Gao et al. [49] combined a Transformer with a CNN for local feature enhancement, effectively improving image details, while Xu et al. [50] proposed a semi-supervised framework using an Agg Transformer to enhance underwater images.
Transformer-based image restoration. In recent years, there has been a proliferation of Transformer-based image restoration techniques that have excelled in various restoration tasks. For instance, SwinIR [51] utilizes the Swin Transformer as a robust baseline model for image restoration. TransMRSR [18], on the other hand, targets single-image super-resolution reconstruction by introducing a Transformer-based self-distillation generation prior network, which has demonstrated notable performance in relevant domains. Additionally, Restormer [16] and Histoformer [17] have introduced innovative approaches to the realm of image restoration. Restormer enhances the foundational elements of Transformer models, such as multi-head attention and feedforward networks, to facilitate the capture of long-range pixel interactions while maintaining adaptability to large images. Histoformer, on the other hand, centers around a novel histogram self-attention mechanism, which intelligently focuses on spatial features across a dynamic range, allowing for adaptive emphasis on deteriorated features exhibiting similar patterns. Zhu et al. [52] proposed FDNet, a Fourier transform-guided dual-channel underwater image enhancement diffusion network, outperforming existing learning-based methods on multiple underwater datasets. Transformer-based methodologies have been proposed for diverse tasks, including super-resolution, deblurring, and image enhancement.
3. Method: DR-Net
Consider a scenario where a camera is positioned above the water surface, capturing an underwater scene through the air–water medium. The optical properties of water cause light absorption and scattering [53]. Additionally, light refraction occurs at the air–water interface, exacerbated by surface fluctuations, resulting in complex distortions in the final image. Further, fluid dynamics of water and underwater turbulence introduce intricate blurring effects. Let denote the captured distorted underwater image, and represent the ground-truth undistorted image of the underwater scene. Our goal is to estimate a de-distorted image from such that closely approximates .
Mathematically, the de-distortion process can be modeled as a transformation that maps the distorted image to the de-distorted one: . To optimize this transformation, we aim to find the optimal that minimizes the loss between the transformed result and the ground-truth:
where denotes a suitable loss function that quantifies the discrepancy between the estimated de-distorted image and the ground-truth image .
To address this underwater image restoration task, we propose DR-Net, a two-stage framework that decomposes the task into a distortion correction stage (DE-Net) and a detail recovery and deblurring stage (IR-GAN). Figure 2 illustrates the following:
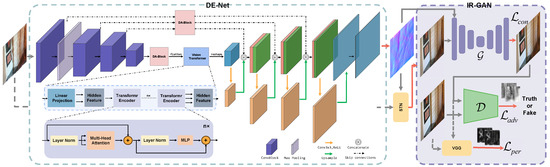
Figure 2.
The two-stage architecture of our DR-Net comprises (1) the Distortion Estimation Network (DE-Net) for extracting distorted information, and (2) the GAN-based Underwater Image Restoration Network (IR-GAN). The Dual-Attention Block (DA-Block) and Spatial Transformer Network (STN, inspired by [54]) are elaborated in Section 3.2. Here, and denote the generator and discriminator of IR-GAN, respectively.
- The degraded captured image is first fed into DE-Net, which integrates a U-Net architecture with a ViT for global feature extraction at high dimensions, supplemented by a dual-channel attention block (DA-Block). Specifically, DE-Net initially employs U-Net to capture multi-scale features, enabling adaptation to diverse distortion factors in the image. For high-dimensional features, the DA-Block is utilized to extract effective features, which are then processed by ViT for global feature modeling. This process ultimately yields valid global distortion information (or a distortion map), which is used to generate a distortion-corrected image.
- Subsequently, the distortion-corrected image, combined with the estimated distortion information as guidance, is input to IR-GAN. Leveraging the powerful generative modeling capability of GANs, IR-GAN further deblurs the image and regenerates lost details, completing the overall restoration process.
3.1. IR-GAN: GAN-Based Restoration
Underwater image degradation arises from multiple factors, including water’s optical properties, particulate matter, surface fluctuations, and turbulence. A straightforward restoration approach involves directly mapping distorted images to clear ones via a single model. Initially, we explored an end-to-end network leveraging nonlinear fitting capabilities to simultaneously address distortion and blurriness. We modeled the intricate distortion in underwater images using a system function H, where
Here, x denotes pixel spatial position and t is the imaging timestamp.
For image-to-image translation, we adopted a GAN framework (building on pix2pix success) given its strong generative modeling capabilities. Our IR-GAN comprises a generator (outputting restored images) and a discriminator (distinguishing restored images from ground-truth undistorted ones). The goal is to optimize such that cannot differentiate its outputs from real undistorted images. As shown in Figure 2, IR-GAN takes distorted underwater images (incorporating distortion information) as input and outputs restored results directly.
To stabilize training and mitigate mode collapse, we employed Least Squares GAN (LSGAN) [55], which uses least squares loss to minimize the divergence between generated and target data. The objective functions are
The generator architecture (Figure 3) includes downsampling layers, residual blocks, and upsampling layers. After initial downsampling (three convolutional modules) for feature extraction, eight residual blocks refine features, followed by three upsampling modules for reconstruction. To preserve details efficiently, we adopted the lightweight dynamic upsampler DySample [56] for upsampling. The discriminator follows a design similar to [57], i.e., all convolutional layers (except the final one) are paired with Batch Normalization and LeakyReLU, while the final layer uses a Sigmoid activation to output discriminative probabilities.
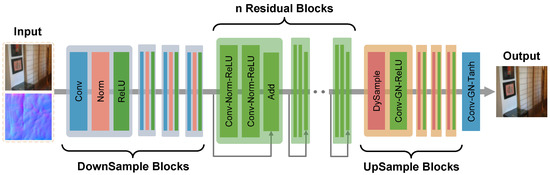
Figure 3.
The network structure of our generator of IR-GAN. It is mainly structured with downsample blocks, residual blocks, and upsample blocks.
3.2. DE-Net: Distortion Information Estimation
The preceding section described IR-GAN’s end-to-end reconstruction, which directly maps distorted images to restored ones via a generator :
However, evaluations of IR-GAN (see Section 4.3) reveal that this direct GAN-based approach, simultaneously handling distortion correction and deblurring, fails to achieve optimal performance. While deblurring results are relatively satisfactory, distortion correction across varying scales remains unstable.
This limitation motivates us to decouple the process, first focusing on accurate distortion estimation to lay a robust foundation for subsequent restoration. We model the underwater distortion phenomenon as
where denotes the distortion vector at spatial position x and time t. For clarity, this formulation isolates distortion (ignoring blurring) to specifically address spatial perturbations in the image.
To precisely capture such distortion characteristics, DE-Net integrates Transformer and U-Net architectures, leveraging their complementary strengths: U-Net extracts local hierarchical features via convolutional layers, while a Transformer encoder enhances global feature modeling. This hybrid design ensures seamless feature mapping between shallow convolutional layers and U-Net’s sampling processes, maximizing the utility of multi-scale features. Further, we incorporate a Dual-Attention Block (DA-Block) [54] into U-Net’s skip connections (Figure 4) to strengthen feature representation and utilization. The DA-Block combines a Position Attention Module (PAM) and Channel Attention Module (CAM), which respectively refine spatial- and channel-wise feature interactions. This dual attention mechanism enhances feature parsing capabilities, facilitating efficient transmission of critical information—enabling DE-Net to accurately estimate fine-grained underwater distortion details. Notably, placing the DA-Block before Transformer input also improves feature embedding quality.
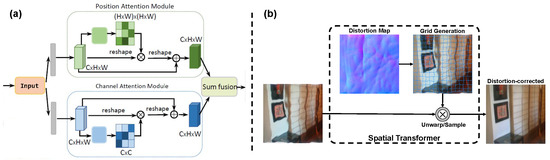
Figure 4.
(a) The DA-Block comprises two modules: a Position Attention Module and a Channel Attention Module. Their outputs are fused to generate the final feature map. (b) The STN primarily functions to unwarp the distorted image using the estimated distortion map/information, yielding a distortion-corrected image through sampling.
In the processing pipeline, DE-Net takes camera-captured distorted images as input, estimates distortion information , and applies a Spatial Transformer Network (STN) to perform distortion correction, yielding a de-distorted intermediate image. Through iterative supervised training against ground-truth images, the model is refined to output precise distortion information, laying the groundwork for subsequent blurring removal.
3.3. Network and Training Object
While DE-Net effectively corrects spatial distortions, relying solely on it introduces issues like smooth blurring and color inconsistencies. Additionally, the spatial transformation process cannot eliminate pre-existing blur in the input image. To address these limitations, we introduce this two-stage cascaded framework: DE-Net first estimates and rectifies distortions, and IR-GAN subsequently refines details and removes blurring, leveraging GAN’s strength in recovering lost information during degradation. Experimental results confirm that this integration yields superior restoration performance. The complete architecture of DR-Net is illustrated in Figure 2.
Training Object. Three key loss functions are employed to train the network: the content loss, the adversarial loss, and the perceptual loss:
- The Content Loss: We use L1 loss to enforce pixel-wise similarity between the restored image and ground-truth:where denotes the ground-truth image, and is the generator output. However, L1 loss alone may result in insufficient high-frequency details, motivating the inclusion of adversarial loss to enhance detail restoration and even recover information lost due to significant distortions.
- The Adversarial Loss: Adopting LSGAN’s loss function stabilizes training and mitigates mode collapse:
- The Perceptual Loss: To reduce artifacts introduced by GANs, we incorporate perceptual loss, which measures feature-level similarity using a pre-trained network. It is defined asHere, represents the output of an intermediate feature layer from a pre-trained network.
The perceptual loss is computed by separately feeding the generated image and the ground-truth image into the pre-trained network, extracting features from corresponding layers, and calculating the L1 or MSE distance between these feature maps. By measuring the content discrepancy between high-level features of the generated and ground-truth images, this loss enhances the generalization of the restoration results. In this study, we utilize the outputs of the conv4_3 layer from a pre-trained VGG16 model for this purpose.
Thus, the total loss function is a weighted combination of the three components:
where and are scaling factors. We initially set empirical weights and adjust them during training based on restoration quality, ultimately adopting and . For standalone DE-Net training, (since adversarial loss is specific to IR-GAN).
4. Experiments
In this section, we present the evaluation of our model DR-Net using both synthetic datasets and real datasets. We conduct comparisons with the classical approach and perform ablation studies on our proposed model.
4.1. Network Training
Data preparation and metrics. For training our proposed underwater image restoration model DR-Net, we use the LiSet obtained from Li et al. [14]. This dataset is a comprehensive collection of underwater images based on the ImageNet dataset [58], where the researchers utilized a Cannon 5D Mark IV, (Beijing, China), camera to capture images by passing ImageNet images through a water tank at a distance exceeding 1.5 m. In total, the dataset comprises 324,452 images from 1000 ImageNet classes, with 5 images retained per class for a validation set totaling 5000 images.
Given the varied sensitivity of individuals to image attributes such as brightness, blur, and distortion, it is imperative to employ appropriate image evaluation metrics to subjectively assess the results of image restoration. Traditional metrics like Peak Signal-to-Noise Ratio (PSNR) [59] and Structural Similarity Index (SSIM) [60,61] are commonly used for assessing image restoration quality and similarity. This study also includes a comparison of these fully referenced evaluation metrics.
Traditional metrics may lack the ability to capture intricate perceptual differences due to their simplistic pixel-based evaluation functions. Recent advancements in deep learning have introduced more effective evaluation metrics such as Learned Perceptual Image Patch Similarity (LPIPS) [62] and Deep Image Structure and Texture Similarity (DISTS) [63], which have demonstrated superior performance in image quality assessment by incorporating perceptual features and complex image information. LPIPS, particularly adept at assessing local details that align with human visual perception, provides consistent evaluations across diverse distortion types. In this work, we utilize the pre-trained LPIPS model as described in [64]. DISTS employs deep neural networks to extract both structure and texture features, enabling a comprehensive analysis of complex image characteristics. Additionally, this paper utilizes reference-free assessment metrics, Blind/Referenceless Image Spatial Quality Evaluator (BRISQUE) [65], which considers contrast, brightness, and texture aspects.
Implementation details. Our model DR-Net is formulated and trained using the PyTorch1.10 framework as a two-stage architecture with three phases involving separate and cascading training. Initially, the Distortion Information Estimation Network (DE-Net) is trained using the Adam optimizer with a learning rate of 0.0002 and a batch size of 16 for both training and testing. A pre-trained vision transformer is utilized during training to accelerate convergence. The subsequent phase involves training the image restoration model, IR-GAN, based on Generative Adversarial Networks (GANs). The distortion information estimated by DE-Net, along with the distorted image corrected through bilinear interpolation or Spatial Transformer Networks (STN), serves as inputs for the IR-GAN model during the second phase of training. Supervision is enforced through the loss function delineated in Section 3.3, leveraging the Adam optimizer with a learning rate of 0.0002. The final phase encompasses fine-tuning the cascaded training of the two networks to enhance the cascade performance, leading to improved restoration outcomes through interactive refinement within the two-stage network structure. Detailed algorithmic training specifications are presented in Algorithm 1.
| Algorithm 1 Training process of our network |
|
4.2. Comparison with the State-of-The-Arts
To provide a more comprehensive evaluation of our model’s restoration performance, we conducted a comparative analysis with established underwater image restoration methods [8,11,12,14,16,17,18,19,22]. Specifically, Tian et al. [12], Oreifej et al. [8], and Halder et al. [11] all employed conventional image restoration approaches. Tian et al. implemented a model-based tracking restoration method using the fluctuation equation, while Oreifej et al. and Halder et al. primarily utilized image alignment for underwater image restoration. In our comparative study, we replace the non-rigid alignment method employed in Halder et al.’s approach with the optical flow method [66] for experimental evaluation. James et al. incorporated a compressed perception technique into the underwater image restoration process to enhance the quality of restoration outcomes.
Moreover, Isola et al. [22], Li et al. [14], TransMRSR [18], Restormer [16], and Histoformer [17] all employed deep learning approaches for image restoration tasks. Isola et al.’s method excels in pixel-to-pixel tasks, demonstrating strong performance in style transfer through the generative model. Li et al. concentrated on underwater image restoration, utilizing a dataset obtained from ImageNet capturing underwater distortions to conduct restoration-related research. TransMRSR is a Transformer-based self-distillation prior network that utilizes pre-trained Generative Adversarial Networks (GANs) to establish a robust prior for enhancing image super-resolution reconstruction. Both Restormer and Histoformer enhance the fundamental components of Transformer models to proficiently address image restoration tasks and yield positive outcomes across multiple image restoration scenarios.
Testing datasets. To conduct a comprehensive evaluation of our model, we perform simultaneous tests and evaluations on Li et al.’s test dataset along with various synthetic and real datasets: (1) LiSet [14], an extensive underwater image dataset curated by Li et al. derived from the ImageNet dataset, comprising 5000 images from 1000 classes for testing; (2) TianSet [12], an authentic dataset consisting of underwater image sequences compiled by Tian and Narasimhan from ground-truth images; (3) JamesSet [19], a diverse dataset akin to Tian’s dataset, featuring 14 image sequence categories encompassing blue lines, bricks, cartoon images, checkerboards, and more; (4) ThapaSet [20], a collection of synthetic images with 20 categories synthesized by Thapa et al.; and (5) NianSet [21], a synthetic dataset comprising images of both animals and plants assembled by Nian et al. Our evaluation of image restoration outcomes encompasses both qualitative and quantitative analyses.
Comparison results. As the approaches of Tian et al., Oreifej et al., Halder et al., and James et al. [8,11,12,19] necessitate an image sequence input, image restoration evaluations could not be conducted on the LiSet. Initially, we compare the image restoration outcomes of Isola’s method, Li’s method, Restormer, TransMRSR, Histoformer, and our model based on the LiSet test dataset. Figure 5 presents a comparison of the image restoration results on the LiSet, with the first column displaying the captured perturbed degraded image as the model input. Subsequently, the seventh and eighth columns depict the results of the image restoration via our method and the actual image, and the second to sixth columns showcase the restoration outcomes utilizing other methods, respectively.

Figure 5.
Visual comparison with the learning-based method [14,16,17,18,22] and our DR-Net on LiSet [14] for underwater distorted image restoration.
As illustrated in Figure 5, our method, DR-Net, demonstrates enhanced recovery performance compared to other methods across various levels of distortion. This is attributed to our model’s comprehensive consideration of both image distortion and detail restoration aspects, as evidenced by superior management of image details, patterns, and deblurring. While Isola and Li’s method, based on adversarial generative networks, shows favorable outcomes in image details and restored contrast, it lacks effectiveness in addressing different scales of distortion restoration. On the other hand, the recent image restoration methods, such as Restormer, TransMRSR, and Histoformer, do not separately account for distortion degradation, thereby impacting their overall image restoration performance to some extent.
Notably, our model demonstrates enhanced robustness against partial occlusions within the image, facilitated by the guidance of the perturbation map estimated in the initial stage and the utilization of the adversarial generative model. Table 1 outlines the quantitative evaluation outcomes on the LiSet, indicating the favorable performance of our methodologies. Moreover, Figure 6 illustrates the model’s outstanding stability and recovery efficacy.

Table 1.
Quantitative comparisons on LiSet for underwater distorted image restoration. Note: The upward arrows (↑) indicate that larger values of the corresponding evaluation metrics are better, while the downward arrows (↓) indicate that smaller values are better, where the same applies hereinafter.
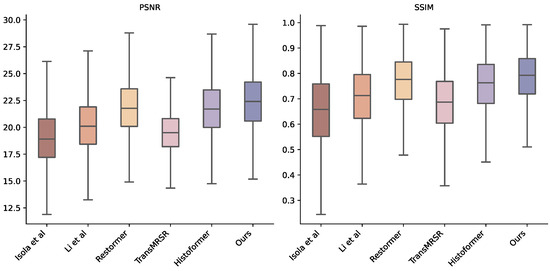
Figure 6.
Box plots of PSNR (left) and SSIM (right) distributions across six methods: Isola et al. [22], Li et al. [14], Restormer [16], TransMRSR [18], Histoformer [17], and our DR-Net. Evaluations use the LiSet test dataset (5000 samples), where box plots illustrate central tendencies, variability, and outliers. Our method shows consistent superiority via tighter distributions.
In addition, Figure 7 displays the test results for the image datasets by Tian, James, Thapha, and Nian. The performance of the methods proposed by Tian et al. [12], Oreifej et al. [8], Halde et al. [11], and James et al. [19] are compared using 11 frames of image input (denoted as Tian-11, Oreifej-11, Halde-11, and James-11).

Figure 7.
Visual comparison with the state-of-the-arts on synthetic and real captured datasets: the TianSet [12], the JamesSet [19], the ThapaSet [20], and th NianSet [21]. Note that Tian-11, Oreifej-11, Halder-11, and James-11 refer to using an 11-frame sequence as input to the methods [8,11,12,19], respectively.
The analysis in Figure 7 reveals that the methods Tian-11, Oreifej-11, Halder-11, and James-11 exhibit distortion to some extent owing to the limited number of frames in the input image sequence. Our approach, regarding visual quality, demonstrates superior performance in distortion correction and image sharpness, yielding the most visually appealing results among the showcased methods. Table 2 presents a comparative evaluation of our method’s quantitative test outcomes against those of other methods across various datasets.
Table 2.
Quantitative comparison of synthetic and real datasets for underwater distorted image restoration. Orange and blue indicate the best and second best performance, respectively. The top 3 results are marked as gray. Note: The upward arrows (↑) indicate that larger values of the corresponding evaluation metrics are better, while the downward arrows (↓) indicate that smaller values are better, where the same applies hereinafter.
4.3. Ablation Studies
In order to evaluate the efficacy of individual components within our two-stage restoration model DR-Net (as shown in Figure 8 and Table 3), for image restoration, we performed ablation experiments to assess the quality of restored images under varying conditions, considering both qualitative and quantitative aspects. The dataset by Li et al. was utilized for both training and testing in these experiments.

Figure 8.
Visual comparison with individual components for ablation study.
Table 3.
Ablation study of our method, DR-Net, to evaluate the efficacy of individual components.
Effect of the distorted information estimation. A comparative analysis of IR-GAN, CNNWarp, and DE-Net reveals that the network estimating distortion information for restoration exhibits advantages in distortion correction, yielding superior outcomes from both quantitative and qualitative standpoints. Moreover, our DE-Net model incorporating a Transformer structure demonstrates enhanced performance. The utilization of global features within the Transformer encoder enables a more effective extraction of distortion details in the degradation process of underwater images, supporting improved results in the subsequent stage. Figure 9 illustrates the distortion information estimated in the initial phase, showcasing the enhanced feature representation and more precise estimation of underwater image perturbations achieved through the self-attention mechanism of the Transformer and the integration of a two-channel attention mechanism in U-Net.

Figure 9.
Visualization of distortion information estimated by DE-Net. From left to right of each group: distortion-free image (ground-truth), DE-Net-estimated distortion information, and the distorted input image (degraded image to be restored). The bottom row displays warped grids overlaid on the distorted images, where grid deformation (inferred from the estimated distortion) visualizes displacement patterns intuitively. This comparison demonstrates DE-Net’s ability to capture distortion characteristics from degraded inputs.
Effect of the GAN-based image restoration model. Analysis of IR-GAN restoration outputs reveals that the dynamic “game process” inherent in GAN facilitates continuous enhancement of the generator’s ability to produce realistic image data. This advancement enables the GAN-based image restoration model to effectively restore image intricacies, enhance color and contrast, and recover potential lost details. A comparative assessment between the restoration outcomes of the model utilizing IR-GAN and the model solely estimating perturbation information demonstrates the enhanced performance of incorporating a GAN-based image restoration model in the second stage. Notably, this integration proves more adept at mitigating image blurring and achieving superior quality outcomes.
Effect of the training strategy. In addition to assessing the efficacy of our model training strategy, we systematically oversee image restoration outcomes across stages. Progressing from the initial deployment of DE-Net, through the subsequent DE-Net+IR-GAN phase, and culminating in the cascade fine-tuning with DR-Net, the quantitative metrics of image restoration consistently exhibit enhancement. Comparative evaluations of image outputs further confirm a continual refinement in both image details and quality. Every component within our two-stage underwater image restoration framework, combined with the model training strategy, proficiently contributes to advancing the quality of image restoration procedures.
5. Conclusions
Our proposed DR-Net is a two-stage network designed for the restoration of underwater images afflicted by distortions caused by water surface fluctuations and turbulence-induced blurring. The initial stage involves leveraging DE-Net, a fusion network combining U-Net and Transformer architectures, to predict perturbation information in underwater images. Subsequently, utilizing the perturbation information in conjunction with the initial restoration results, IR-GAN, an image restoration model employing adversarial generative networks, addresses image blurring and detail restoration. Experimental findings demonstrate the superior effectiveness of our method in restoring degraded underwater images, showcasing promising prospects due to its efficacy as a single-frame image restoration technique.
Practical considerations to guide refinements include the following: the Transformer-GAN integration, while effective for complex patterns, entails higher computational demands (common in accuracy-prioritizing models), posing challenges for resource-constrained real-time deployment; like other data-driven methods, performance is influenced by training data diversity, with minor overfitting risks in rare distortion cases (mitigable via richer datasets); and in extreme conditions beyond the training scope, restoration quality may slightly degrade (though robust in typical scenarios). To address these aspects, our future work will focus on optimizing efficiency via lightweight architectures, enhancing generalization with advanced data augmentation and integrating underwater physical priors to strengthen adaptability—efforts aimed at resolving these limitations and further boosting DR-Net’s real-world utility.
Author Contributions
Conceptualization: C.W. and C.F. (Chang Feng); Methodology: C.W. and J.L.; Software: J.L., C.F. (Chuncheng Feng) and L.L. (Lei Liu); Validation: J.L., W.G., Z.C. and L.L. (Libin Liao); Writing—original draft preparation: J.L.; Writing—review and editing: C.W.; Supervision: C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China under Grant No. 62205342.
Informed Consent Statement
This article does not involve studies with human participants or animals.
Data Availability Statement
The data supporting the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
All authors declare that they have no competing financial interests or personal relationships that could influence the work reported in this paper.
References
- Xue, Q.; Li, H.; Lu, F.; Bai, H. Underwater Hyperspectral Imaging System for Deep-sea Exploration. Front. Phys. 2022, 10, 1058733. [Google Scholar] [CrossRef]
- Chen, W.; Tang, M.; Wang, L. Optical Imaging, Optical Sensing and Devices. Sensors 2023, 23, 2882. [Google Scholar] [CrossRef]
- Zhou, J.; Wei, X.; Shi, J.; Chu, W.; Zhang, W. Underwater Image Enhancement Method with Light Scattering Characteristics. Comput. Electr. Eng. 2022, 100, 107898. [Google Scholar] [CrossRef]
- Alford, M.H.; Gerdt, D.W.; Adkins, C.M. An Ocean Refractometer: Resolving Millimeter-Scale Turbulent Density Fluctuations via the Refractive Index. J. Atmos. Ocean. Technol. 2006, 23, 121–137. [Google Scholar] [CrossRef]
- Wang, M.; Peng, Y.; Liu, Y.; Li, Y.; Li, L. Three-Dimensional Reconstruction and Analysis of Target Laser Point Cloud Data in Simulated Turbulent Water Environment. Opto-Electron. Eng. 2023, 50, 230004-1. [Google Scholar]
- Levin, I.M.; Savchenko, V.V.; Osadchy, V.J. Correction of an Image Distorted by a Wavy Water Surface: Laboratory Experiment. Appl. Opt. 2008, 47, 6650–6655. [Google Scholar] [CrossRef]
- Shefer, R.; Malhi, M.; Shenhar, A. Waves Distortion Correction Using Cross Correlation. Tech. Rep. Isr. Inst. Technol. 2001. Available online: http://visl.technion.ac.il/projects/2000maor (accessed on 17 September 2025).
- Oreifej, O.; Shu, G.; Pace, T.; Shah, M. A Two-Stage Reconstruction Approach for Seeing Through Water. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1153–1160. [Google Scholar]
- Fried, D.L. Probability of Getting a Lucky Short-Exposure Image Through Turbulence. JOSA 1978, 68, 1651–1658. [Google Scholar] [CrossRef]
- Efros, A.; Isler, V.; Shi, J.; Visontai, M. Seeing Through Water. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2004; Volume 17. [Google Scholar]
- Halder, K.K.; Tahtali, M.; Anavatti, S.G. Simple and Efficient Approach for Restoration of Non-Uniformly Warped Images. Appl. Opt. 2014, 53, 5576–5584. [Google Scholar] [CrossRef]
- Tian, Y.; Narasimhan, S.G. Seeing Through Water: Image Restoration Using Model-Based Tracking. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 Sepember–2 October 2009; pp. 2303–2310. [Google Scholar]
- Thapa, S.; Li, N.; Ye, J. Learning to Remove Refractive Distortions from Underwater Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5007–5016. [Google Scholar]
- Li, Z.; Murez, Z.; Kriegman, D.; Ramamoorthi, R.; Chandraker, M. Learning to See Through Turbulent Water. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 512–520. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H. Restormer: Efficient Transformer for High-Resolution Image Restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5728–5739. [Google Scholar]
- Sun, S.; Ren, W.; Gao, X.; Wang, R.; Cao, X. Restoring Images in Adverse Weather Conditions via Histogram Transformer. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2022; Springer: Berlin/Heidelberg, Germany, 2025; pp. 111–129. [Google Scholar]
- Huang, S.; Liu, X.; Tan, T.; Hu, M.; Wei, X.; Chen, T.; Sheng, B. TransMRSR: Transformer-Based Self-Distilled Generative Prior for Brain MRI Super-Resolution. Vis. Comput. 2023, 39, 3647–3659. [Google Scholar] [CrossRef]
- James, J.G.; Agrawal, P.; Rajwade, A. Restoration of Non-Rigidly Distorted Underwater Images Using a Combination of Compressive Sensing and Local Polynomial Image Representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7839–7848. [Google Scholar]
- Thapa, S.; Li, N.; Ye, J. Dynamic Fluid Surface Reconstruction Using Deep Neural Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 21–30. [Google Scholar]
- Li, N.; Thapa, S.; Whyte, C.; Reed, A.W.; Jayasuriya, S.; Ye, J. Unsupervised Non-Rigid Image Distortion Removal via Grid Deformation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2522–2532. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Donate, A.; Dahme, G.; Ribeiro, E. Classification of Textures Distorted by Water Waves. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, 20–24 August 2006; Volume 2, pp. 421–424. [Google Scholar]
- Donate, A.; Ribeiro, E. Improved Reconstruction of Images Distorted by Water Waves. In Proceedings of the Advances in Computer Graphics and Computer Vision: International Conferences VISAPP and GRAPP 2006, Revised Selected Papers, Setúbal, Portugal, 25–28 February 2006; Springer: Berlin/Heidelberg, Germany, 2007; pp. 264–277. [Google Scholar]
- Wen, Z.; Lambert, A.; Fraser, D.; Li, H. Bispectral Analysis and Recovery of Images Distorted by a Moving Water Surface. Appl. Opt. 2010, 49, 6376–6384. [Google Scholar] [CrossRef] [PubMed]
- Wen, Z.; Fraser, D.; Lambert, A.; Li, H. Reconstruction of Underwater Image by Bispectrum. In Proceedings of the 2007 IEEE International Conference on Image Processing, San Antonio, TX, USA, 16–19 September 2007; Volume 3, pp. III–545. [Google Scholar]
- Fraser, D.; Thorpe, G.; Lambert, A. Atmospheric Turbulence Visualization with Wide-Area Motion-Blur Restoration. JOSA A 1999, 16, 1751–1758. [Google Scholar] [CrossRef]
- Tahtali, M.; Lambert, A.J.; Fraser, D. Restoration of Nonuniformly Warped Images Using Accurate Frame by Frame Shiftmap Accumulation. In Proceedings of the Image Reconstruction from Incomplete Data IV, San Diego, CA, USA, 14–15 August 2006; Volume 6316, pp. 24–35. [Google Scholar]
- Yang, B.; Zhang, W.; Xie, Y.; Li, Q. Distorted Image Restoration via Non-Rigid Registration and Lucky-Region Fusion Approach. In Proceedings of the 2013 IEEE Third International Conference on Information Science and Technology (ICIST), Yangzhou, China, 23–25 March 2013; pp. 414–418. [Google Scholar]
- Zhang, Z.; Tang, Y.G.; Yang, K. A Two-Stage Restoration of Distorted Underwater Images Using Compressive Sensing and Image Registration. Adv. Manuf. 2021, 9, 273–285. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Fischer, P.; Ilg, E.; Hausser, P.; Hazirbas, C.; Golkov, V.; Van Der Smagt, P.; Cremers, D.; Brox, T. Flownet: Learning Optical Flow with Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2758–2766. [Google Scholar]
- Muller, P.; Savakis, A. Flowdometry: An Optical Flow and Deep Learning Based Approach to Visual Odometry. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 27–29 March 2017; pp. 624–631. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Part III. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2014; Volume 27. [Google Scholar]
- Chen, J.; Chen, J.; Chao, H.; Yang, M. Image Blind Denoising with Generative Adversarial Network Based Noise Modeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3155–3164. [Google Scholar]
- Wang, F.; Xu, Z.; Ni, W.; Chen, J.; Pan, Z. An Adaptive Learning Image Denoising Algorithm Based on Eigenvalue Extraction and the GAN Model. Comput. Intell. Neurosci. 2022, 2022, 5792767. [Google Scholar] [CrossRef]
- Zhao, C.; Yin, W.; Zhang, T.; Yao, X.; Qiao, S. Neutron Image Denoising and Deblurring Based on Generative Adversarial Networks. Nucl. Instruments Methods Phys. Res. Sect. Accel. Spectrometers, Detect. Assoc. Equip. 2023, 1055, 168505. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Kim, Y.H.; Nam, S.H.; Hong, S.B.; Park, K.R. GRA-GAN: Generative Adversarial Network for Image Style Transfer of Gender, Race, and Age. Expert Syst. Appl. 2022, 198, 116792. [Google Scholar] [CrossRef]
- Zheng, C.; Cham, T.J.; Cai, J. Pluralistic Image Completion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1438–1447. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H.; Guo, B. Aggregated Contextual Transformations for High-Resolution Image Inpainting. IEEE Trans. Vis. Comput. Graph. 2022, 29, 3266–3280. [Google Scholar] [CrossRef] [PubMed]
- de Farias, E.C.; Di Noia, C.; Han, C.; Sala, E.; Castelli, M.; Rundo, L. Impact of GAN-Based Lesion-Focused Medical Image Super-Resolution on the Robustness of Radiomic Features. Sci. Rep. 2021, 11, 21361. [Google Scholar] [CrossRef]
- Wang, H.; Zhong, G.; Sun, J.; Chen, Y.; Zhao, Y.; Li, S.; Wang, D. Simultaneous Restoration and Super-Resolution GAN for Underwater Image Enhancement. Front. Mar. Sci. 2023, 10, 1162295. [Google Scholar] [CrossRef]
- Ma, Q.; Li, X.; Li, B.; Zhu, Z.; Wu, J.; Huang, F.; Hu, H. STAMF: Synergistic Transformer and Mamba Fusion Network for RGB-Polarization Based Underwater Salient Object Detection. Inf. Fusion 2025, 122, 103182. [Google Scholar] [CrossRef]
- Cong, X.; Gui, J.; Zhang, J. Underwater Image Enhancement Network Based on Visual Transformer with Multiple Loss Functions Fusion. Chin. J. Intell. Sci. Technol. 2022, 4, 522–532. [Google Scholar]
- Peng, L.; Zhu, C.; Bian, L. U-Shape Transformer for Underwater Image Enhancement. IEEE Trans. Image Process. 2023, 32, 3066–3079. [Google Scholar] [CrossRef]
- Xue, J.; Wu, Q. Lightweight Cross-Gated Transformer for Image Restoration and Enhancement. J. Front. Comput. Sci. Technol. 2024, 18. [Google Scholar]
- Zheng, S.; Wang, R.; Zheng, S.; Wang, F.; Wang, L.; Liu, Z. A Multi-scale Feature Modulation Network for Efficient Underwater Image Enhancement. J. King Saud Univ.-Comput. Inf. Sci. 2024, 36, 101888. [Google Scholar] [CrossRef]
- Gao, Z.; Yang, J.; Zhang, L.; Jiang, F.; Jiao, X. TEGAN: Transformer Embedded Generative Adversarial Network for Underwater Image Enhancement. Cogn. Comput. 2024, 16, 191–214. [Google Scholar] [CrossRef]
- Xu, S.; Wang, J.; He, N.; Xu, G.; Zhang, G. Optimizing Underwater Image Enhancement: Integrating Semi-Supervised Learning and Multi-Scale Aggregated Attention. Vis. Comput. 2024, 41, 3437–3455. [Google Scholar] [CrossRef]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Zhu, Z.; Li, X.; Ma, Q.; Zhai, J.; Hu, H. FDNet: Fourier Transform Guided Dual-Channel Underwater Image Enhancement Diffusion Network. Sci. China Technol. Sci. 2025, 68, 1100403. [Google Scholar] [CrossRef]
- Alsakar, Y.M.; Sakr, N.A.; El-Sappagh, S.; Abuhmed, T.; Elmogy, M. Underwater Image Restoration and Enhancement: A Comprehensive Review of Recent Trends, Challenges, and Applications. Vis. Comput. 2024, 41, 3735–3783. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial Transformer Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2015; Volume 28. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least Squares Generative Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to Upsample by Learning to Sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 6027–6037. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012; Volume 25. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of Validity of PSNR in Image/Video Quality Assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Sara, U.; Akter, M.; Uddin, M.S. Image Quality Assessment Through FSIM, SSIM, MSE and PSNR—A Comparative Study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Ding, K.; Ma, K.; Wang, S.; Simoncelli, E.P. Image Quality Assessment: Unifying Structure and Texture Similarity. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2567–2581. [Google Scholar] [CrossRef]
- Kastryulin, S.; Zakirov, J.; Prokopenko, D.; Dylov, D.V. PyTorch Image Quality: Metrics for Image Quality Assessment. arXiv 2022, arXiv:2208.14818. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-Reference Image Quality Assessment in the Spatial Domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Farnebäck, G. Two-Frame Motion Estimation Based on Polynomial Expansion. In Proceedings of the Image Analysis: 13th Scandinavian Conference, SCIA 2003, Halmstad, Sweden, 29 June–2 July 2003; Proceedings 13. Springer: Berlin/Heidelberg, Germany, 2003; pp. 363–370. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).