1. Introduction
Visible light communication (VLC) [
1,
2,
3] refers to a method of data transmission that uses light waves within the visible spectrum, ranging from 380 nm to 750 nm. A key feature of this communication method is its ability to transfer data unobtrusively, without affecting the perceived illumination of the environment. VLC stands out from other wireless communication methods for several reasons. First, the growing demand for mobile data over the past two decades has revealed the limitations of relying solely on radio frequency (RF) communication, as the RF spectrum has become increasingly scarce. In contrast, the visible light spectrum offers hundreds of terahertz of license-free bandwidth, which remains largely untapped for communication purposes. VLC can complement RF-based systems, contributing to the creation of high-capacity mobile data networks. Secondly, the high frequency of visible light prevents it from penetrating most objects and walls, allowing for interference-free small cells of LED transmitters. This feature not only boosts wireless channel capacity but also enhances the security of communications. Finally, VLC’s ability to leverage existing lighting infrastructure makes system deployment easy and cost-effective. There are various applications of VLC in the context of 6G and beyond, having versatility across different environments. For indoor communication, VLC supports applications such as screen–camera communication (SCC), indoor localization, and human–computer interaction, enabling hands-free control of devices or systems. In outdoor scenarios, key applications include vehicular and underwater communication. Additionally, emerging technologies such as the Internet of Things (IoT) [
4] and simultaneous lightwave information and power transfer (SLIPT) [
5] are crucial for 6G networks. VLC, when integrated with IoT, provides reliable uplink and high-speed downlink communication using energy-efficient methods, even in low-light conditions. This makes it ideal for operating zero-energy devices without the need for battery replacements. SLIPT further enhances VLC by combining data transmission with energy harvesting, enabling simultaneous power and information transfer in indoor, underwater, and aerial environments. This makes it highly applicable to IoT devices, smart cities, and vehicular communication systems. In this study, we will review a particularly promising application and research area of VLC, namely, SCC.
SCC is a specialized application of VLC, where an LCD/LED screen and a camera sensor facilitate device-to-device (D2D) communication. SCC represents an innovative intersection of optical communication and digital technology, leveraging the widespread presence of screens and cameras in modern devices to enable a novel form of data transmission. The global proliferation of mobile devices, including smartphones, tablets, and sensors, has surged in recent years, making these devices an integral part of daily life. Their increasing capabilities are driven by the growing demand for constant connectivity and uninterrupted sensing abilities. SCC involves transmitting information from a digital screen (such as those on smartphones, tablets, televisions, and computer monitors) to a camera-equipped device (like smartphones, tablets, and wearables) using visual codes or modulations.
In the 1970s, barcodes were introduced to encode information that could be scanned and decoded using optical readers. Displaying a barcode on a screen allowed it to be captured by a camera-based scanner, enabling data transfer from screen to camera. QR codes, a more versatile form of two-dimensional barcodes, were invented in the 1990s and gained widespread popularity after the 2010s. By displaying a QR code on a screen and capturing it with a camera-equipped device [
6], users could access URLs, store contact information, and perform various interactive tasks. However, dedicated communication channels for data transfer between devices face limitations, such as the need for additional hardware and interference with user experience. Additionally, QR codes can only transfer limited amounts of data and often create visual obstructions that detract from the aesthetic appeal (cf.,
Figure 1). Unlike barcodes and QR codes, which are static information retrieval systems, SCC has evolved into a dynamic communication system that enables real-time data exchange between devices.
The advent of smartphones and their integrated cameras marked a major turning point in the development of SCC. As smartphones became ubiquitous, the ability to capture and process visual information expanded. Researchers and developers have since explored various techniques to enhance SCC, including the use of specific color patterns, specialized markers, and computer vision algorithms to improve the accuracy and reliability of data transfer between displays and cameras [
7,
8]. Moreover, recent trends in increasing screen resolution and camera quality, combined with advances in digital signal processing and computer vision algorithms, have enabled more sophisticated and unobtrusive methods of data transmission. These include the use of imperceptible modulations in displayed images or videos, which cameras can seamlessly decode. One pivotal advancement in SCC development was recognizing that it could facilitate a wide range of applications beyond simple information retrieval from static codes, such as interactive advertising, secure authentication, augmented reality (AR), and smart device connectivity.
In this review, we provide a comprehensive overview of SCC research, highlighting key challenges that warrant further investigation. Our analysis specifically covers the following:
A detailed examination of SCC system components, including the characteristics of transmitters and receivers.
An exploration of the physical layer, including display-to-camera (D2C) channel models, signal propagation, and modulation with coding strategies.
An in-depth survey on display field communication (DFC), a spectral-domain-based SCC scheme.
DFC system architecture and signal processing aspects.
Comparisons of various SCC and DFC schemes.
State of the art in DFC, challenges, and future direction.
Although significant progress has been made in SCC over the past few decades, no comprehensive surveys on SCC currently exist to the best of our knowledge. A major portion of this manuscript focuses on DFC [
9], an innovative hidden SCC method proposed by our lab that enables unobtrusive data transfer between electronic displays and cameras. Leveraging concepts from two-dimensional orthogonal frequency division multiplexing (2D-OFDM) [
10], we describe different versions of DFC and compare achievable data rates (ADRs). Additionally, we present a practical implementation of DFC, incorporating machine learning (ML) concepts.
The structure of this paper is as follows.
Section 2 describes the fundamentals of the human vision system (HVS) and its similarities to a camera. Since SCC is a type of optical camera communication (OCC), we also cover the basics of camera image capturing.
Section 3 outlines the SCC system architecture, including the transmitter, receiver, and applications.
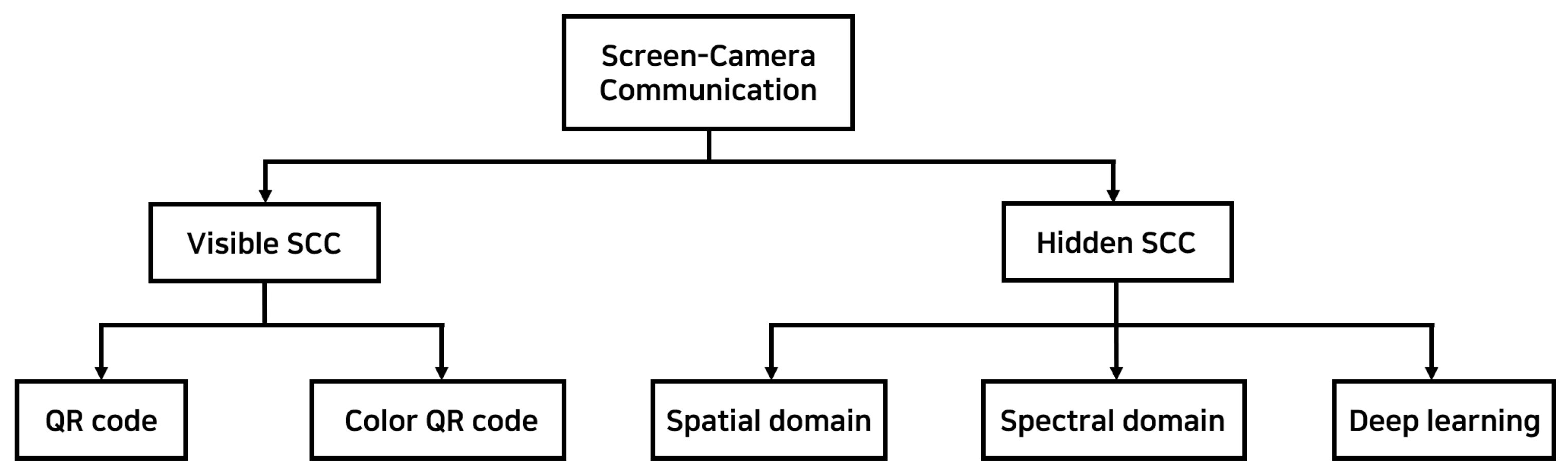
Section 4 broadly classifies SCC into visible and hidden types and explains fundamental theories with references to related works. In
Section 5, we delve into the specific topic of DFC, detailing its design and operation. We explain the system model, the various DFC variants, and the coding and decoding processes, including ML and channel coding parts.
Section 6 presents the signal processing aspects of DFC, especially at the physical layer. This includes frequency conversion, modulation, data embedding, channel coding, and data decoding strategies.
Section 7 compares the performances of multiple DFC forms within a common framework of ADR, including experimental DFC results.
Section 8 and
Section 9 conclude the paper, discussing recent trends, challenges, and future directions.
2. Human Vision System (HVS)
Before diving into the survey of SCC and signal processing aspects, it is important to understand the working of the HVS and the capabilities of modern displays and cameras. The HVS is responsible for capturing information about object shapes, colors, depth, and motion. Vision serves as the primary mechanism through which humans acquire information. The HVS is both sophisticated and complex [
11,
12]. At the core of the HVS are the eyes, which respond to light. As shown in
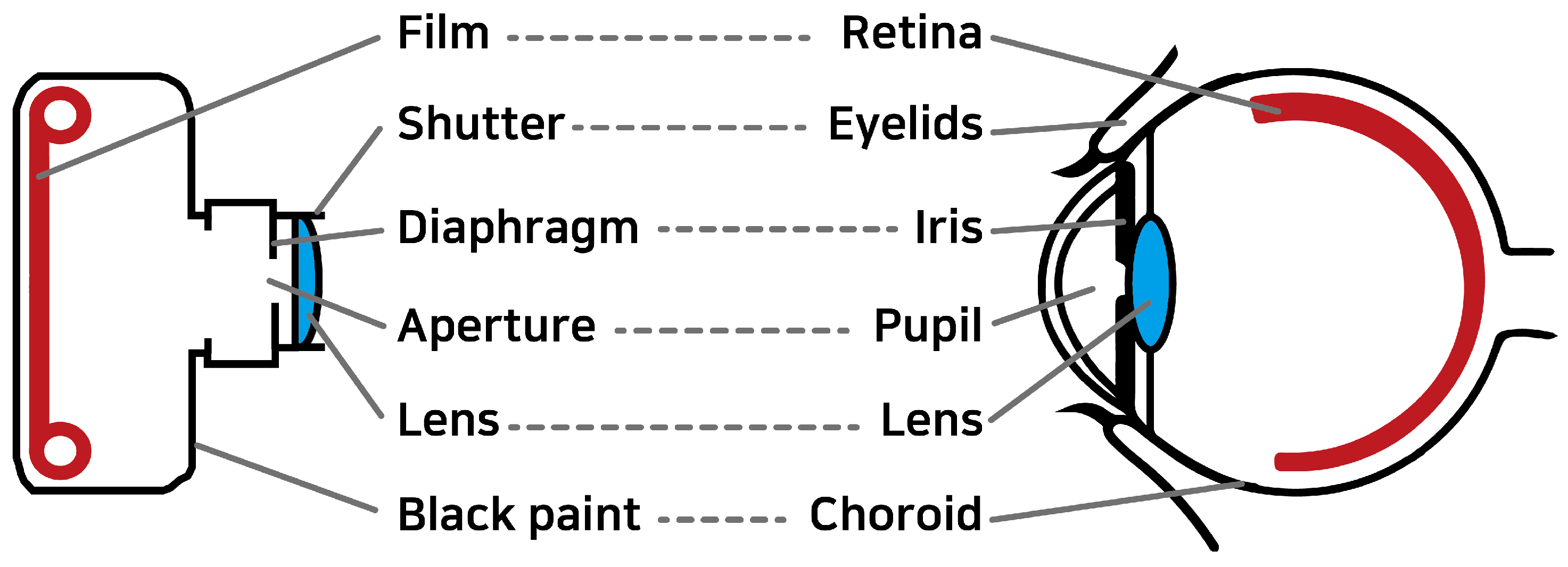
Figure 2, the structure of a camera bears a resemblance to that of the eye [
13], featuring a lens (the crystalline lens) and a sensor surface (the retina). The density of receptor cells on the retina is higher in the center and gradually decreases toward the edges, giving rise to central (or foveal) vision and peripheral vision. Central vision is crucial for detailed visual processing, while peripheral vision, rich in light-sensitive rod cells, excels in motion detection and performs better under low-light conditions.
While the eyes provide a wealth of information about the physical environment, they also have inherent limitations in both spatial and temporal resolution. The human eye’s ability to discern fine details is limited by the spacing between adjacent receptor cells on the retina. Typically, the finest spatial resolution achievable by the human eyes is 0.07°, which equates to 1.2 mm at a distance of 1 m [
14]. This resolution varies with spatial contrast, and the eye’s receptive field responds differently at its center compared to its periphery, depending on the spatial frequency. Our spatial perception exhibits bandpass (or near-low-pass) characteristics, with the highest frequency around 2–4 cycles per visual angle. As a result, exceedingly small details may blend into an average appearance. This effect is evident during vision tests, where details beyond the eye’s resolution appear as vague shapes. Light intensity variations become indiscernible when they exceed a certain threshold, known as the critical flicker frequency (CFF) [
15]. Beyond this frequency, the human eye perceives only an average luminance, similar to the response of a linear low-pass filter to high frequencies. For instance, a rapidly rotating car wheel may appear semi-transparent. The CFF is influenced by various factors such as color contrast and luminance waveforms, typically ranging from 40 to 50 Hz [
16,
17]. This explains why flicker from a 60 Hz monitor is generally not noticeable.
A notable distinction between the human eye and a camera is the absence of a shutter in the eye, meaning that there is no exposure process or perception of images in discrete frames. In contrast, cameras capture discrete snapshots, allowing for detailed inspection of each frame. While the HVS excels in many respects, camera technology has already surpassed it in certain aspects, particularly in spatial and temporal resolution. The unique characteristics of the HVS, combined with the expanding gap in capabilities due to rapid advancements in camera technology, present significant opportunities for innovative design. Since the HVS has remained relatively unchanged over time while camera technologies have evolved rapidly, this gap—and the innovation potential—will only continue to grow in the future.
Modern displays, especially high-refresh-rate monitors, are becoming increasingly popular. Most standard monitors have a refresh rate of 60
, which means they can display up to 60 frames per second. However, monitors with higher refresh rates, such as 144
, 240
, or even 360
, are now commercially available. Additionally, many smartphones are equipped with advanced cameras capable of high-frame-rate video capturing. These devices typically support video resolutions up to 8K and can capture footage at various frame rates, such as 4 K at 60 fps, 1080 p at 240 fps, and even super slow-motion video at 720 p up to 960 fps. These features make them highly versatile for SCC. When transmitting data-embedded frames at a refresh rate of at least 60 Hz, the human eye perceives only the average values due to the low-pass filtering effect. However, as we will see later, DFC can embed data in frames with minimal visual disparity from the original, making the changes imperceptible to the human eye, even at low frame rates [
9].
3. SCC System Architecture
A typical SCC system is designed to facilitate data transmission through visual channels, with a screen serving as the transmitter and a camera-equipped device as the receiver. In this section, we provide an overview of the SCC system and its modes of communication. While SCC can involve different types of communications, this survey focuses primarily on SCC systems where an LCD/LED screen functions as the transmitter, transmitting data through visual image frames.
3.1. SCC Transmitter
The transmitter in an SCC system is any device capable of displaying visual information, such as smartphones, tablets, digital signage, and LEDs or LCDs. A digital display is a complex unit consisting of multiple pixels that can be individually controlled to present images, videos, or specific patterns. These pixels, composed of red (R), green (G), and blue (B) sub-pixels, enable precise control of color and brightness across the display surface. In the SCC transmitter, the pixel matrix of the display is used to encode and transmit data by modulating visual patterns or light intensity, which can be captured by a camera-equipped receiver. This modulation can involve altering the brightness, color, or pattern of the pixels to encode the data. The adaptation of existing display technology for SCC purposes has led to innovative techniques that ensure efficient data transmission without affecting display performance. For example, CDMA-like modulation techniques [
11,
12] can encode data within the normal operation of the display, taking advantage of the high resolution and rapid refresh rates of modern screens to transmit data within the displayed content.
3.2. SCC Receiver
There are two primary types of receivers used in SCC systems to capture and decode signals transmitted via display screens:
A standard camera in mobile devices serves as the core component of an SCC receiver. These cameras, equipped with advanced image sensors, can capture high-resolution images and videos, enabling them to detect and decode the modulated data embedded in the screen’s visual output. Modern mobile device cameras can sample visual signals at varying frame rates, making them readily available for SCC reception. Advanced imaging sensors or high-speed cameras provide enhanced capabilities, offering significantly higher frame rates. These sensors are designed to capture rapid temporal variations in visual signals, enabling more complex or high-speed SCC applications. Although less common than mobile device cameras, these specialized sensors can achieve higher data rates and more precise signal detection.
One of the primary challenges for SCC receivers, particularly standard cameras, is balancing high-resolution capture with fast signal processing. The spatial resolution of the camera sensor, determined by the number of photodetectors (pixels), directly affects its ability to resolve fine details in the transmitted signal. However, higher resolutions often come at the cost of lower maximum frame rates due to the increased data volume per frame, which can limit the speed of data reception. To mitigate this, techniques such as temporal and spatial modulation decoding have been developed. These techniques allow efficient data extraction from captured images or video frames by leveraging the camera’s ability to detect subtle variations in light intensity, color, and pattern. For example, color shift keying (CSK) in SCC enables the encoding of data through color changes that can be easily detected by the camera’s sensor [
18]. Additionally, recent advancements in computational photography and image processing algorithms have significantly improved SCC receiver’s capabilities. These innovations allow for more reliable data extraction from video streams, even at lower frame rates, enhancing the robustness of SCC systems in diverse lighting conditions and over varying distances.
3.3. SCC Modes of Communication
In SCC, communication between the screen and camera occurs in a D2D mode. Consider an indoor setting such as a retail store or a museum, where digital signage or interactive displays are common. In this scenario, these displays can transmit information or interactive content directly to users’ smartphones or tablets within the vicinity. Displays can be synchronized or individually programmed to minimize interference and enhance the user experience by delivering targeted content to different users. Users can simply capture an image of the display to access additional information related to the content. Beyond indoor environments, SCC extends to outdoor and public spaces, where information kiosks or advertising screens are frequently used. These can provide information or interactive experiences to pedestrians and passersby, enriching the urban environment with digital interactivity.
In the context of near-field D2D communication, SCC enables a wide range of applications, including secure peer-to-peer data exchanges, multiplayer gaming, and collaborative work in close proximity. An interesting variant of D2D SCC is its application in in-vehicle communication. For example, displays within a vehicle can transmit navigational information, alerts, or entertainment directly to passengers’ devices. Similarly, information screens at bus stops or train stations can communicate timetables or service updates when users capture them with their devices. Augmented reality (AR) is a natural extension of SCC, and its applications are inherent to the technology.
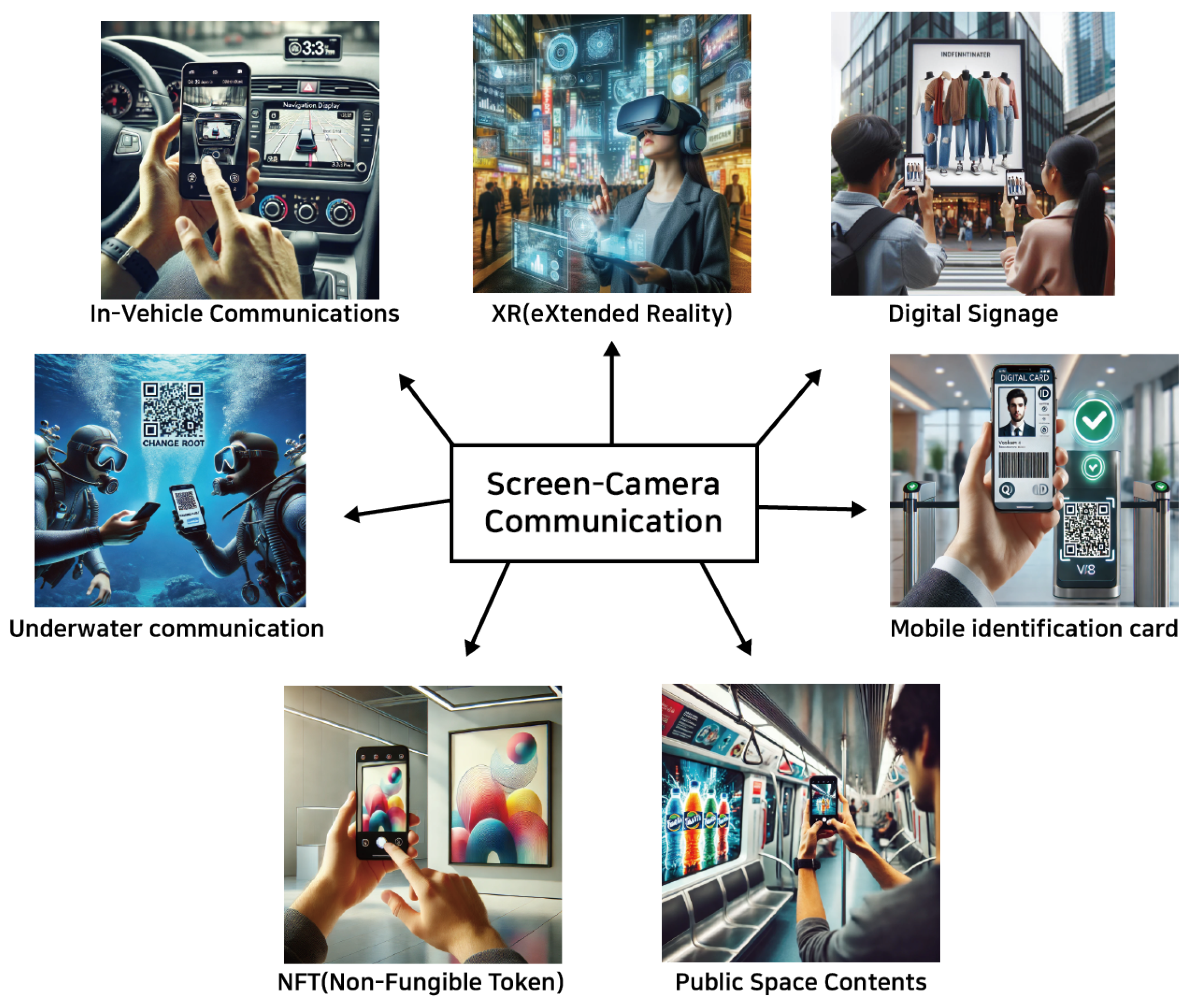
Figure 3 illustrates various SCC applications, including eXtended reality (XR) and digital signage, among others. An exciting potential application of SCC lies in the NFT space, where it could be used to verify ownership or display digital art. Users could scan a screen displaying an NFT with their mobile device to confirm its authenticity or interact with it in various ways. Another interesting application could be in art museums, where additional information about any digital art could be embedded within the artwork itself, which can be accessed by interested persons by scanning the painting.
Apart from typical environments, SCC also has the potential to operate in harsh settings, such as underwater environments, where turbulent effects are prevalent [
19,
20,
21]. In underwater environments, radio waves attenuate rapidly, and acoustic communication suffers from issues like low bandwidth, significant delays, and high susceptibility to noise and multipath effects. In contrast, SCC systems rely on light-based communication, which is less affected by these turbulent effects. Underwater turbulence, caused by water currents, temperature variations, or particulate matter, can scatter acoustic signals, but optical communication using light offers a more stable medium over short distances. While water clarity (turbidity) can impact light-based communication, advanced modulation techniques such as CSK or OFDM can enhance robustness by dynamically adapting to changing environmental conditions. Moreover, SCC can achieve significantly higher speeds and enable real-time data transmission and environmental monitoring, offering lower latency and greater efficiency compared to traditional communication.
Figure 3.
SCC applications: images generated using ChatGPT [
22] based on SCC applications in 6G and beyond.
Figure 3.
SCC applications: images generated using ChatGPT [
22] based on SCC applications in 6G and beyond.
7. Performance Evaluation
In this section, we present a performance comparison of multiple DFC variants. The results are divided based on the input type: first, when the input is a still image frame on the display, and second, when the input is a continuous video. Additionally, the ADR is used as the performance metric, defined as follows [
41]:
with
where
is the theoretical maximum data rate,
is the display’s refresh rate,
is the number of data bits per channel,
N is the total number of frames per packet, and
is the receiver parameter [
41]. From these equations, we observe that the refresh rate directly impacts the number of frames transmitted per second. As
increases, the number of frames transmitted within a given time also increases, leading to an improved data rate. This highlights the inverse relationship between
and
, where higher refresh rates contribute to higher data rates.
7.1. When Input Is a Still Image Frame
When capturing the display screen, the camera also captures the background, introducing noise into the image. Additionally, this study assumes perfect alignment between the screen and the camera. With perfect alignment, all the light from the screen is focused onto the camera, ensuring no data signal energy is lost. For the simulations, we used grayscale and color Lena image frames of
pixels, with BPSK modulation (cf.
Figure 9). The number of embedded data symbols was set to 20 horizontal pixels. For 2D DFC, we embedded up to 30 vertical and horizontal data pixels. A standard 30
off-the-shelf camera was used to capture the image frames.
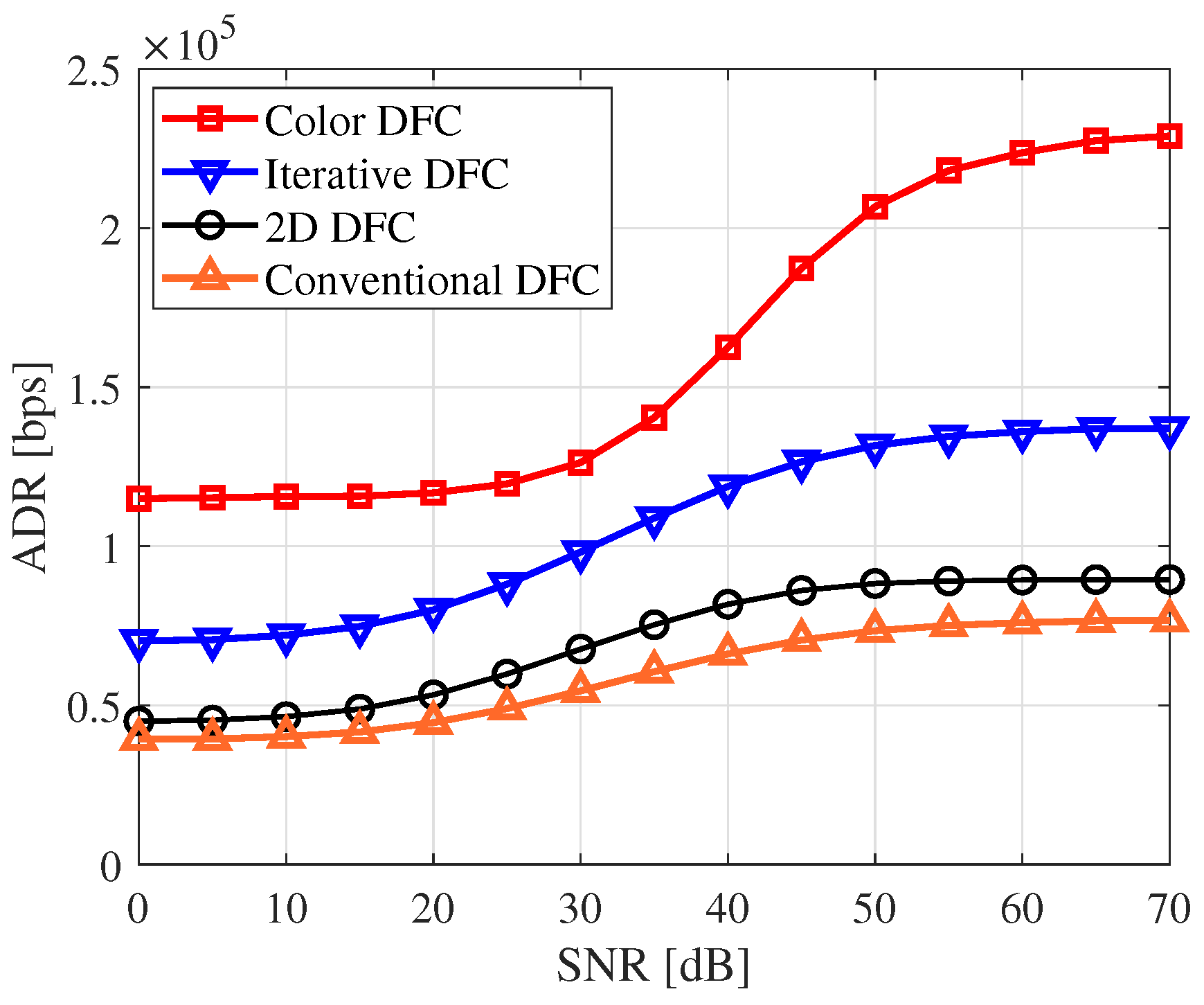
Figure 10 compares four DFC variants in terms of ADR. The results show that conventional DFC performs the worst, while color DFC delivers the best performance. This is because conventional DFC transmits one reference frame per data-embedded frame, resulting in the lowest data rate. In contrast, 2D DFC performs slightly better, indicating that more data can be transmitted using the 2D DFC approach. Iterative DFC achieves even higher data rates as it eliminates the need for reference frames. For implementing iterative DFC, we used
of the total data-embedded pixels as pilots [
44], which were uniformly distributed within the sub-bands. Lastly, the results highlight that color DFC delivers the best overall performance. This is because all R, G, and B channels carry data, unlike the other variants, where only a single grayscale channel is used.
7.2. When Input Is a Continuous Video
In this section, we consider the scenario where a continuous data-embedded video is displayed on the screen. The experiments were conducted in real-world environments. In such experiments, misalignment between the screen and camera may occur, leading to data signal loss or noise during the capture process. To account for these realistic conditions, we used a
p color video [
67] with BPSK modulation and turbo coding. The encoded data size was set to 200 bits per frame. The data-embedded video was displayed on a 60 Hz Samsung monitor and captured using a 120
iPhone 15 Pro camera.
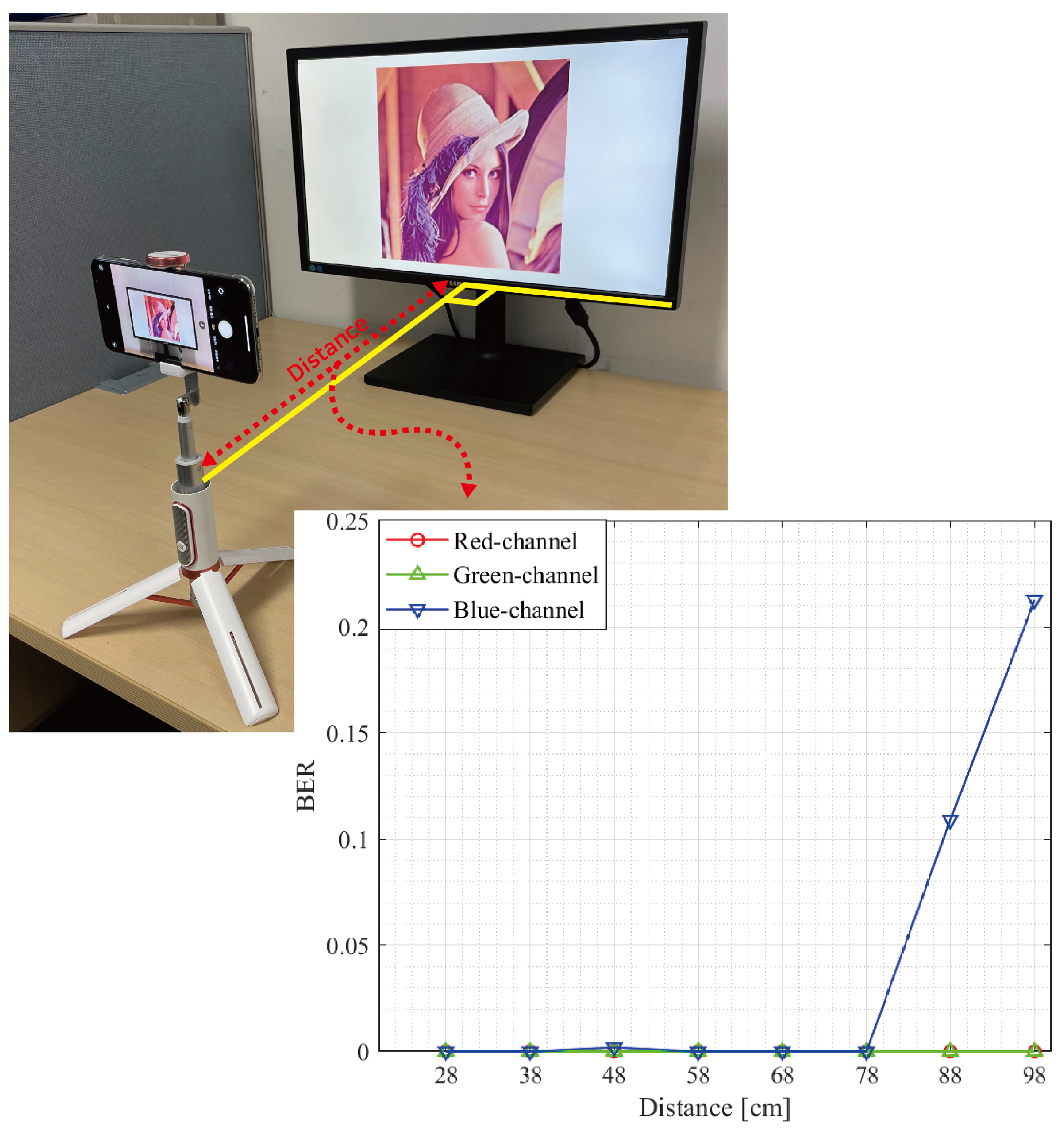
The experimental setup is presented in
Figure 11. We also present the BER result for experimental DFC conducted in a controlled laboratory environment in
Figure 11. The results indicate error-free DFC communication up to a distance of approximately 1
for both the R and G channels. This demonstrates the feasibility of DFC in real-life applications, suggesting it could potentially replace QR codes. Note that since the BER is zero at most distances, the exact values are provided in
Table 8.
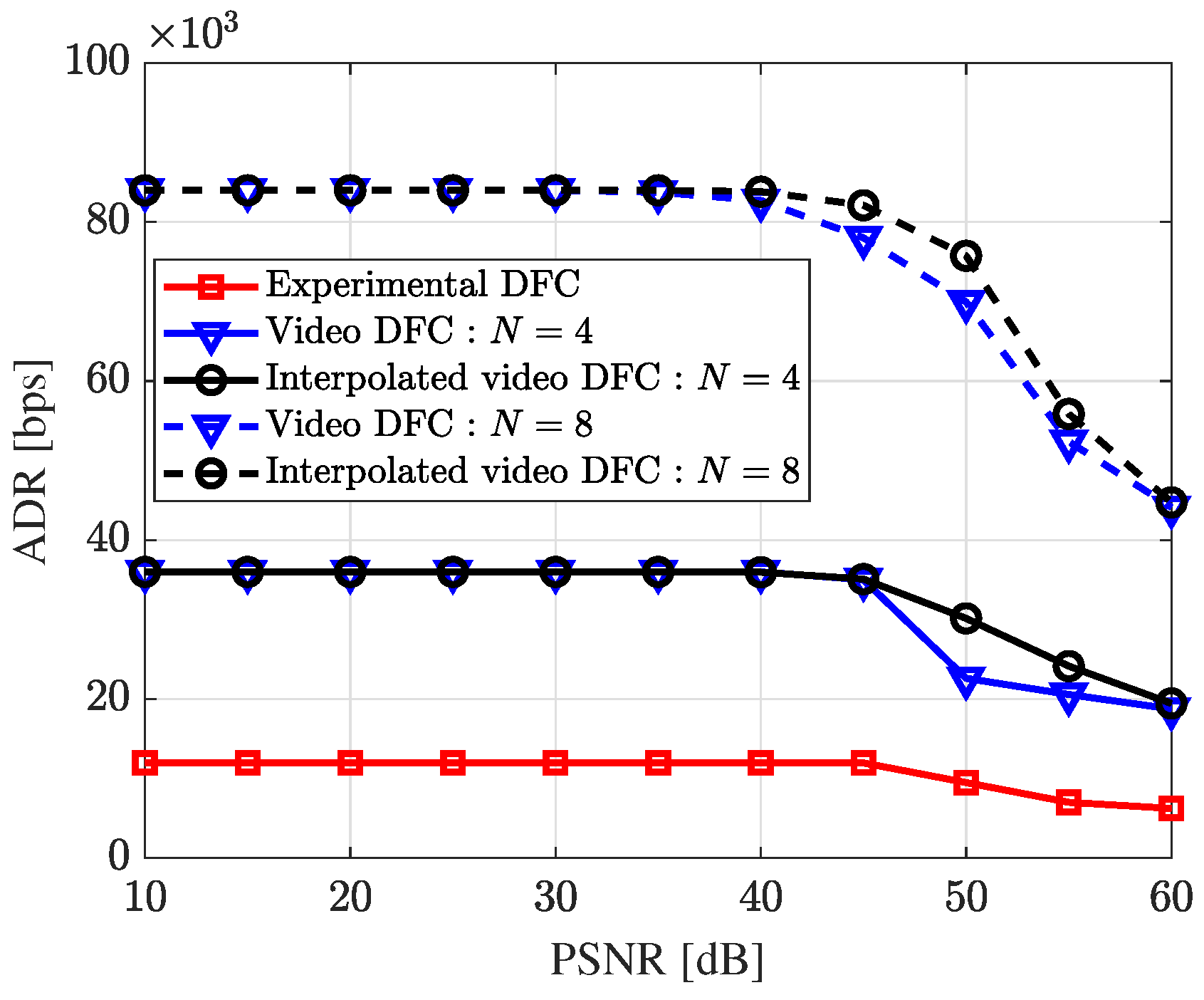
Figure 12 compares the data rate of five real-world DFC variants across different PSNR levels. Up to around 40 dB, all variants maintained a consistent data rate without errors. Video DFC achieved a higher data rate than experimental DFC, as it embeds data in every frame. For both video [
47] and interpolated video DFC [
48],
N represents the total number of frames per packet. Notably, when
N is 8, the data rate is higher than that when
N is 4. Interpolated video DFC demonstrated higher data rates compared to video DFC. This improvement occurs because, rather than transmitting a single reference image frame, interpolated video DFC generates a new estimated reference frame at the receiver through interpolation for each data-embedded image, allowing all frames to carry data.
7.3. ADR Comparison
Table 9 presents the experimental parameters and a comparison of data rates for various DFC schemes. Both video DFC [
47] and interpolated video DFC [
48] used video as the input media, except for experimental DFC [
46]. By setting the number of frames per packet,
N, to 8, video DFC and interpolated video DFC transmitted approximately 7 times more data than the experimental DFC. Interpolated video DFC achieved the highest performance, reaching 76 kbps, particularly when the input had a PSNR of 50 dB.
8. Recent Trends, Challenges, and Future Directions
Though DFC is still in its early stages, the technology has the potential to revolutionize how we interact with devices and the environment. As research and development progress, several challenges remain to be addressed. While we focus on DFC here, many of these challenges also apply to SCC in general, and DFC in particular.
8.1. Machine Learning in DFC
The ML algorithms enable intelligent processing of visual data captured by cameras, improving data rates, error correction, and robustness to variations in channel conditions. Deep learning techniques, particularly convolutional neural networks (CNNs), have significantly enhanced the accuracy and efficiency of tasks such as object detection, image segmentation, and pose estimation.
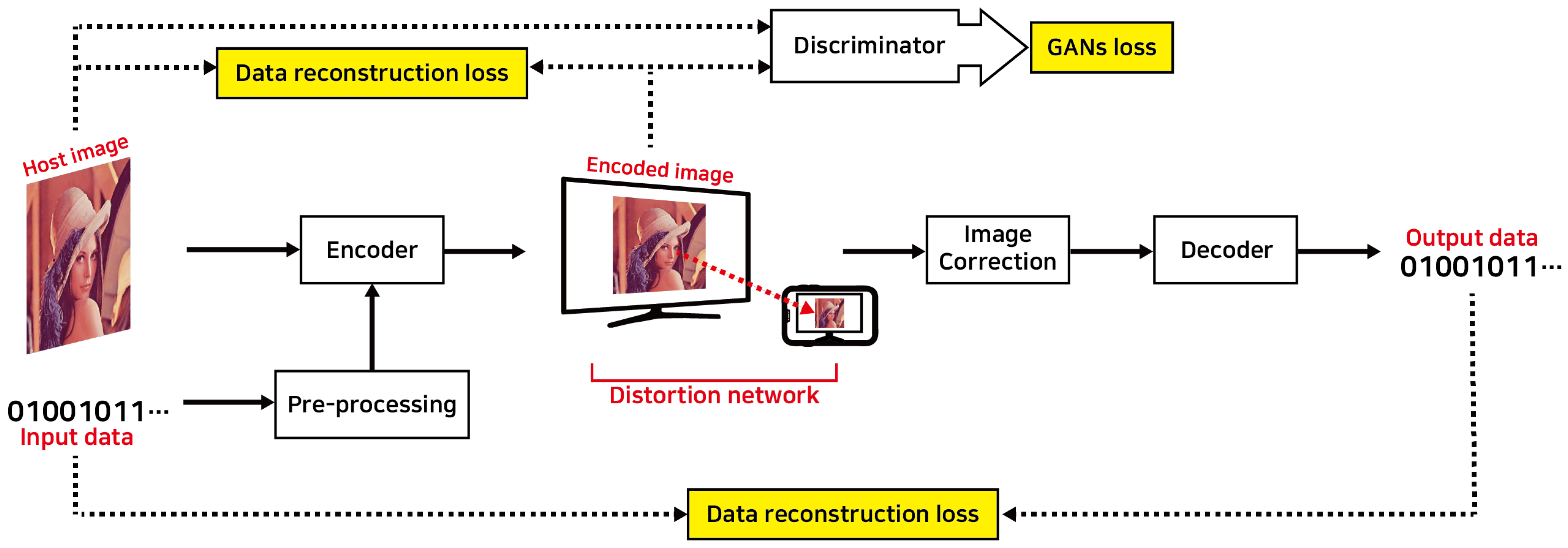
Figure 13 shows a typical ML-based DFC architecture. The structure is divided into two primary components: the encoder network, which embeds data, and the decoder network, which extracts the embedded data. The input image, along with pre-processed data, is fed into the encoder network, where it passes through multiple CNN layers, producing an encoded image containing the embedded data. The encoder seamlessly embeds the secret data into the image. To account for potential distortions in the SCC channel, a distortion network simulates noise and distortions found in real-world conditions, ensuring the system remains robust under challenging D2C environments. Afterward, the image undergoes a correction process to adjust for regional distortions before being input into the decoder network, where the hidden data are extracted. The entire process is managed through end-to-end learning, where the loss generated during training is minimized using back propagation. The network parameters are continuously adjusted to reduce the loss, and through iterative learning, the model’s performance improves. This approach offers strong data security and concealment, making it applicable to a wide range of use cases.
Let us look at the detailed ML-based DFC architectures recently proposed by our lab. In Deep D2C-Net [
53], we introduced a DCNN for embedding and extracting data from image frames. It leverages a CNN to learn the relationship between the displayed image and the camera-captured image, improving the data decoding performance. It features fully end-to-end encoding and decoding networks, which generate high-quality data-embedded images and enable robust data recovery, even in challenging screen–camera channels. The encoding process includes hybrid layers, where the feature maps of both the data and the cover images are combined in a feed-forward manner. For decoding, a simple CNN is employed.
Figure 14 illustrates the deep D2C-Net architecture [
53], including the encoding and decoding networks. In
Figure 14a, the encoder takes upsampled binary data and a cover image to generate a data-embedded image for display. Both the cover image and the data pass through 2D convolutional layers to extract intermediate features, which are then merged into the hybrid layers. These layers concatenate feature maps from both inputs, embedding data into the image. After six hybrid layers, the output is processed by additional convolutional layers to produce the final image. Skip connections between the original image and later layers help preserve key features and prevent degradation, enhancing both PSNR and BER performance by minimizing training losses. On the receiver side, the camera captures the data-embedded image, which may be distorted due to the optical wireless transmission. To correct this, a perspective transformation is applied to adjust the image and extract a corrected version. This corrected image is then fed into the decoder for data extraction. The decoder uses a DCNN to recover the embedded data, learning the complex relationship between the received and transmitted data through deep learning techniques. Unlike conventional receivers that rely on predefined modulation and coding schemes, the deep D2C-Net decoder adapts to varying channel conditions, enabling robust data recovery. It includes multiple convolutional layers for feature extraction, followed by a fully connected (FC) layer that uses binary classifiers to reconstruct the data bit stream, with each classifier recovering a single bit. An upgraded version of deep D2C-Net called dense D2C-Net [
56], supports real-time data encoding and decoding. In our other work on experimental DFC [
46], the YOLO ML algorithm was employed to detect the display region in the captured image.
However, many applications require real-time data transmission and processing, which demands highly efficient algorithms. This presents a challenge due to the computational complexity of deep learning models. Developing end-to-end systems where both encoding at the transmitter and decoding at the receiver are governed by ML models allows for a fully optimized SCC communication pipeline.
8.2. DFC Channel Model
In both SCC and DFC, channel modeling is crucial. Accurate channel models are essential for designing robust SCC systems that can handle the various distortions and noise inherent in this form of communication. However, developing a comprehensive D2C channel model remains a challenge. In addition to conventional channel characteristics including path loss, blooming, background noise, and geometric distortions, the wireless D2C channel introduces several other non-linear distortions, including defocus blur, occlusion, incomplete screen capture, and display size mismatch with the camera’s FoV, among others. In controlled laboratory experiments, many of these distortions can be neglected since they can be corrected in real time. However, in real-life SCC, these issues must be properly modeled. In contrast, ML techniques, particularly deep learning models, are increasingly being used to estimate and model channel characteristics in SCC [
68,
69]. These models can learn complex channel behaviors from data, including non-linear distortions, and adapt dynamically to changing conditions. Furthermore, much of the existing DFC work assumes perfect synchronization between the screen and camera. However, in real-life scenarios, synchronization errors may occur during the camera capture process. For example, when the input is a video, the camera capture rate must be at least twice the screen refresh rate to satisfy the Nyquist criteria [
47]. Additionally, challenges arise from the rolling shutter effect [
47]. Further research is needed to develop a comprehensive SCC channel model that accounts for all these effects. Further investigations may also explore the impact of display and camera type, size, and resolution on SCC.
8.3. Boosting the Data Rate
Although we have eliminated the use of reference frames and nearly doubled the data rate using iterative DFC, it remains limited. While data rates can be directly improved by using larger, high-resolution displays, smarter screens, and higher-quality cameras, more research is needed on the technical aspects. For example, determining how data can be embedded across a large area of an image without introducing visible artifacts on the screen. Another simple way to improve data rates is by using advanced receivers, as DFC infrastructure is not power-limited [
42]. Nevertheless, addressing challenges of the D2C channel is crucial for boosting the data rate of SCC systems. For instance, the camera must capture the light emitted from the display with high accuracy to decode the data. This can be difficult in environments with bright ambient light or when the display is not adequately illuminated. Additionally, external light sources such as sunlight or artificial lighting can interfere with the light emitted by the display, making data decoding challenging.
8.4. Real-World Deployment
Designing any communication method involves a trade-off between data rate and robustness. While several methods can achieve high data rates, they often perform only in controlled laboratory settings. In contrast, communication methods applied in consumer settings must operate reliably in uncontrolled, real-world environments, often at the expense of data rate. DFC must work effectively in challenging scenarios, such as when the display is significantly smaller or larger than the camera’s FoV, or in situations involving occlusion, camera rotation, or defocus blur. The system must also perform despite slight screen obstructions caused by external interference. Therefore, future research on DFC (or SCC) should focus on addressing the practical challenges of real-world deployments. Developing robust designs and testbeds will help facilitate the wider adoption of SCC technologies.
Additionally, research could explore integration of SCC with augmented/virtual reality (AR/VR), ML, and IoT systems, opening new applications and expanding the capabilities of these technologies. Moreover, DFC not only provides users with additional detailed information but also excels in terms of security by embedding data on the screen without compromising image quality [
70]. This makes it ideal to use a watermark to prevent information leakage. However, one of the key challenges will be ensuring the interoperability of DFC, specifically how to multiplex video and data frames on any display (TV, monitor, and smartphone screen, among others). Additionally, hardware compatibility and standardization issues will need to be addressed.
9. Conclusions
SCC is a form of VLC that uses screens as transmitters and cameras as receivers, with applications across various domains such as digital signage and underwater communication. This paper surveys key advancements and state-of-the-art technologies in SCC, covering both visible and hidden SCC methods. Several SCC schemes are presented, discussed, and compared, including color QR codes, spatial- and spectral-domain SCC, as well as deep-learning-based approaches. This paper primarily focuses on an innovative hidden SCC scheme based on the spectral domain, known as DFC, where data are embedded within the spectral domain of an image frame. By leveraging the frequency-domain properties of image frames, DFC enables unobtrusive data transmission, even at low frame rates. Multiple variants of DFC are explored, including experimental DFC and ML-enhanced DFC. Our experimental results demonstrate that under still image transmission, DFC can achieve theoretical data rates of up to 225 kbps using the colored version. In contrast, under real-world conditions with video, DFC achieves data rates of 85 kbps within a PSNR range of 10–40 dB. Additionally, we show that error-free data transmission is feasible within a transmitter–receiver distance of up to 78 cm under controlled laboratory settings. As DFC technology continues to evolve, ongoing research is focused on improving data rates, enhancing robustness in diverse environmental conditions, and expanding compatibility for real-world applications. With its potential for seamless integration into existing infrastructure, SCC has the potential to transform display interactions and enable innovative forms of communication across various fields.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
