Fast Quantum State Reconstruction via Accelerated Non-Convex Programming


Abstract
1. Introduction
- (i)
- We prove that the non-convex MiFGD algorithm asymptotically enjoys an accelerated linear convergence rate in terms of the iterate distance, in the noiseless measurement data case and under common assumptions.
- (ii)
- We provide QST results using the real measurement data from IBM’s quantum computers up to 8-qubits, contributing to recent efforts on testing QST algorithms in real quantum data [22]. Our synthetic examples scale up to 12-qubits effortlessly, leaving the space for an efficient and hardware-aware implementation open for future work.
- (iii)
- (iv)
- We further increase the efficiency of MiFGD by extending its implementation to utilize parallel execution over the shared and distributed memory systems. We experimentally showcase the scalability of our approach, which is particularly critical for the estimation of larger quantum system.
- (v)
- We provide the implementation of our approach at https://github.com/gidiko/MiFGD (accessed on 18 January 2023), which is compatible with the open-source software Qiskit [28].
2. Methods
2.1. Problem Setup
2.2. The MiFGD Algorithm
| Algorithm 1 Momentum-Inspired Factored Gradient Descent (MiFGD). |
Input: (sensing map), y (measurement data), r (rank), and (momentum parameter). Set randomly or as in Equation (8). Set . Set as in Equation (9). for
do end for Output:
|
2.3. Theoretical Guarantees of the MiFGD Algorithm
3. Experimental Setup
3.1. Density Matrices and Quantum Circuits
- The (generalized) GHZ state:
- The (generalized) GHZ-minus state:
- The Hadamard state:
- A random state .
3.2. Measuring Quantum States
- (i)
- We sample or Pauli monomials uniformly over with , where represents the percentage of measurements out of full tomography.
- (ii)
- For every monomial, , in the generated set, we identify an experimental setting that corresponds to the monomial. There, qubits, for which their Pauli operator in is the identity operator, are measured, without loss of generality, in the basis. For example, for and , we identify the measurement setting .
- (iii)
- We measure the quantum state in the Pauli basis that corresponds to , and record the outcomes.
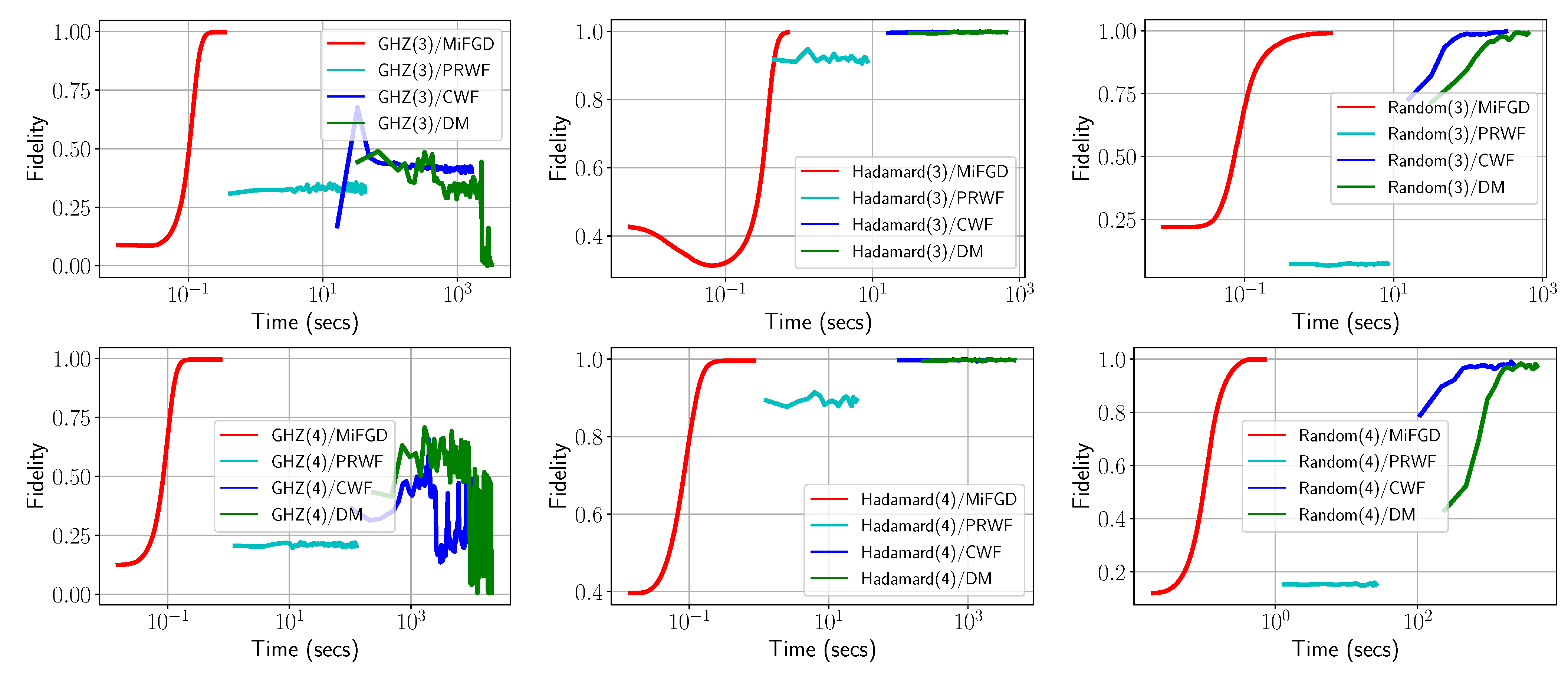
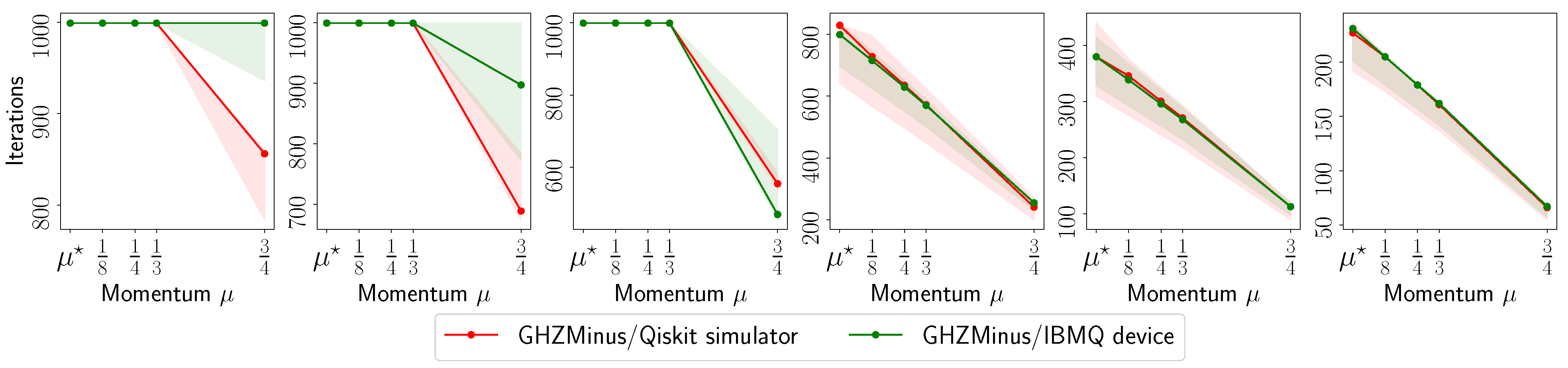
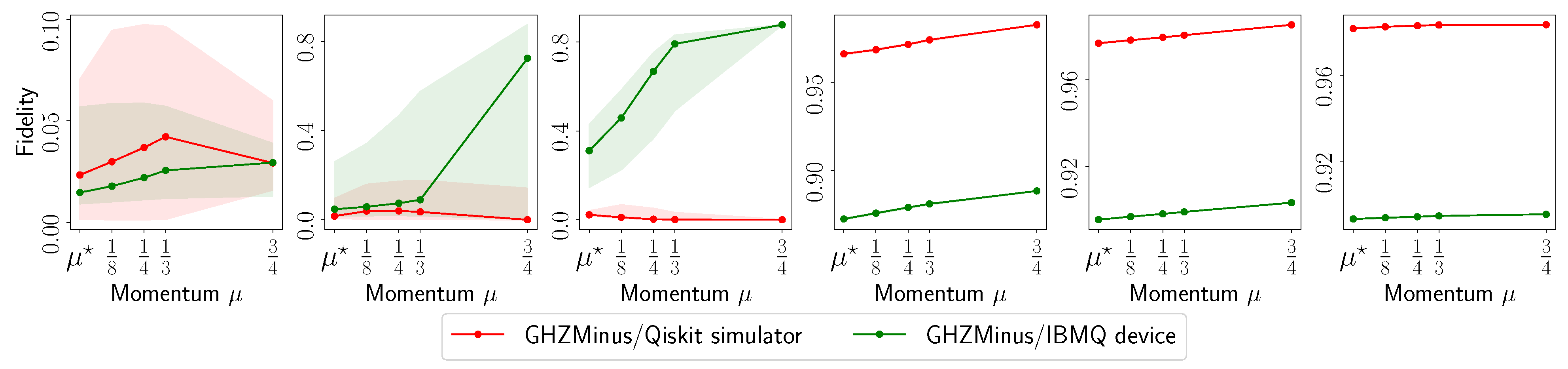
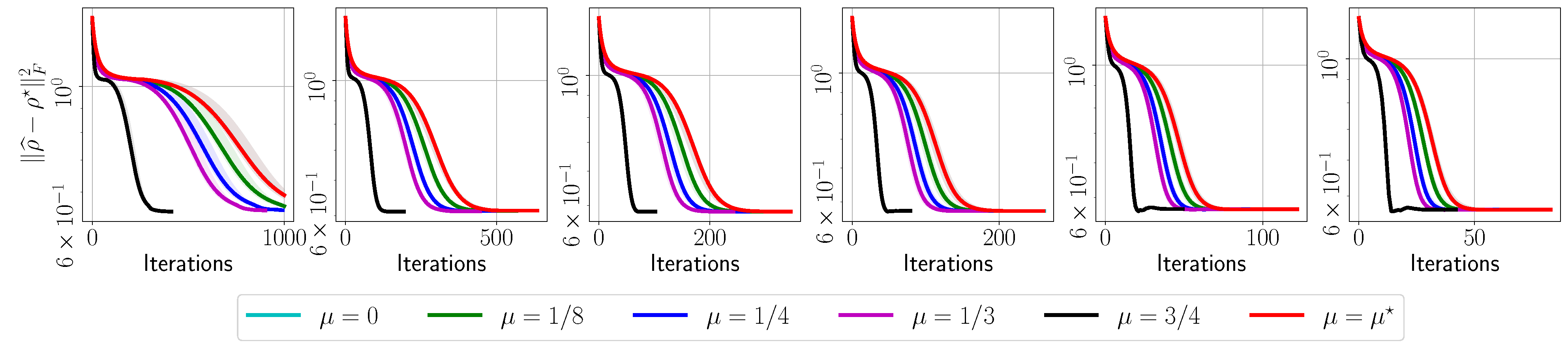
3.3. Algorithmic Setup
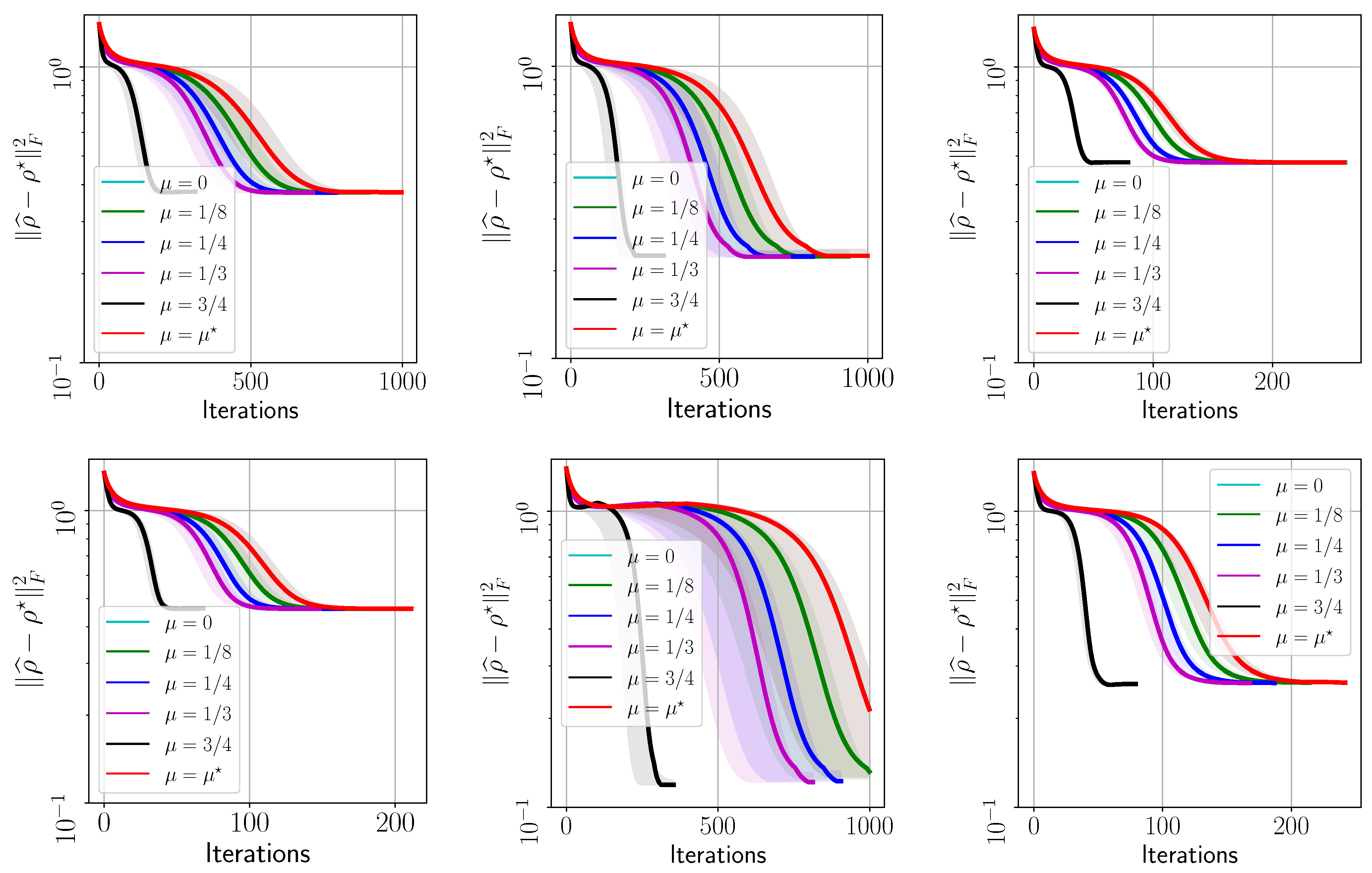
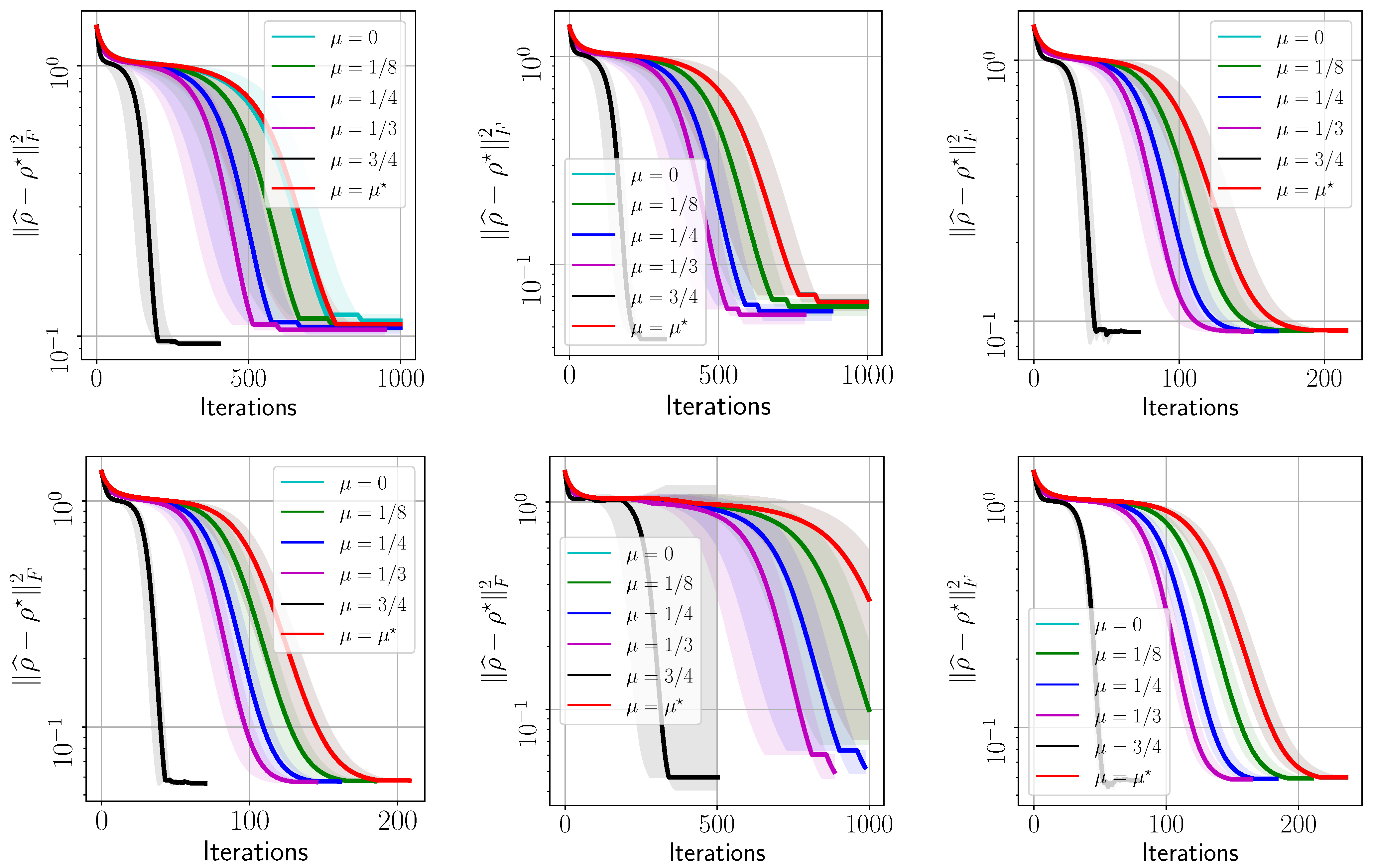
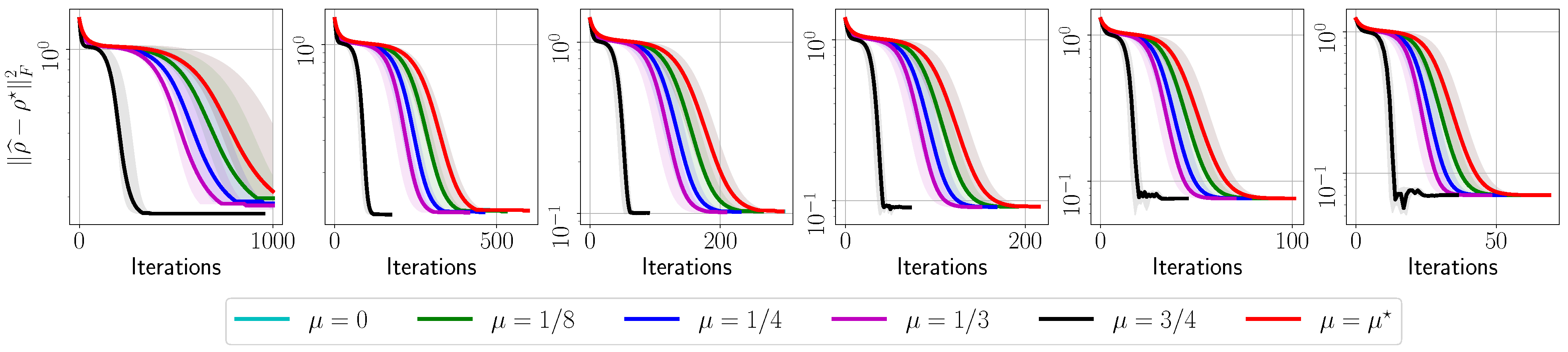
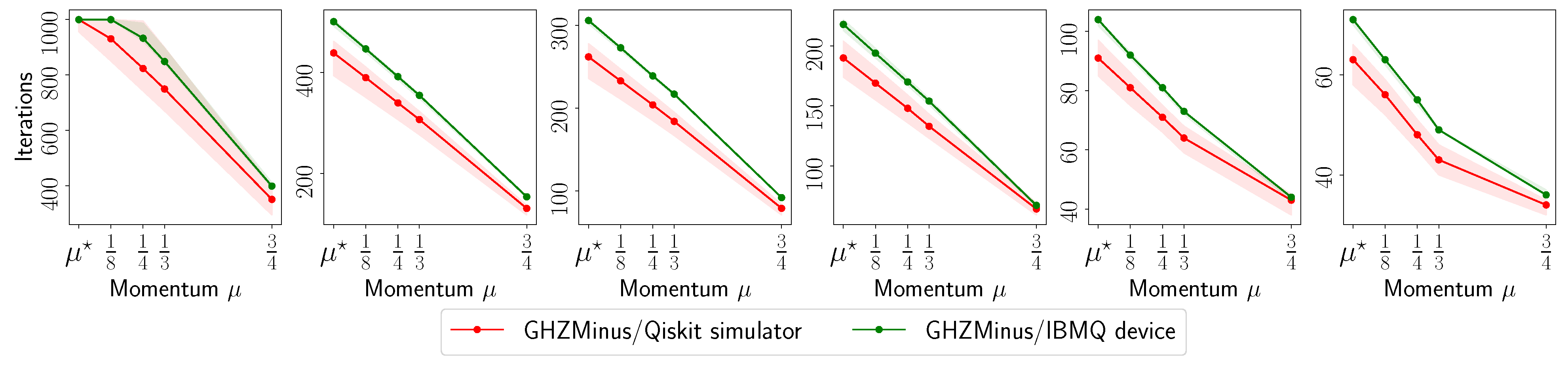
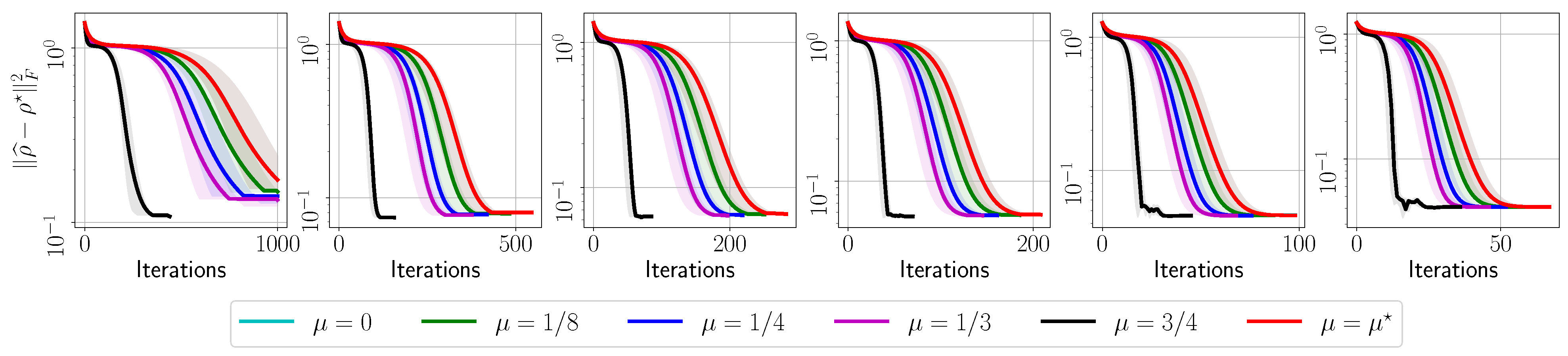
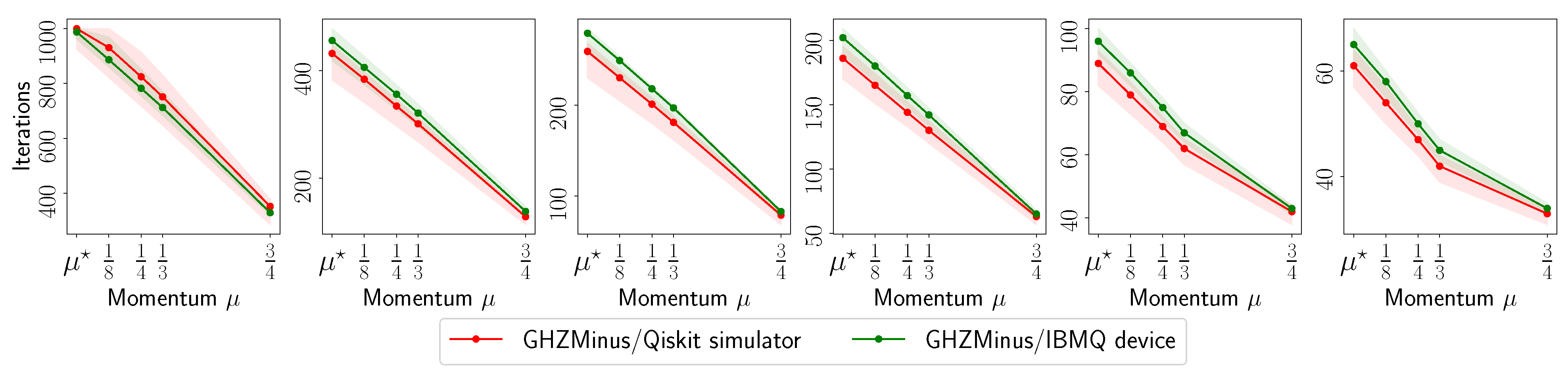
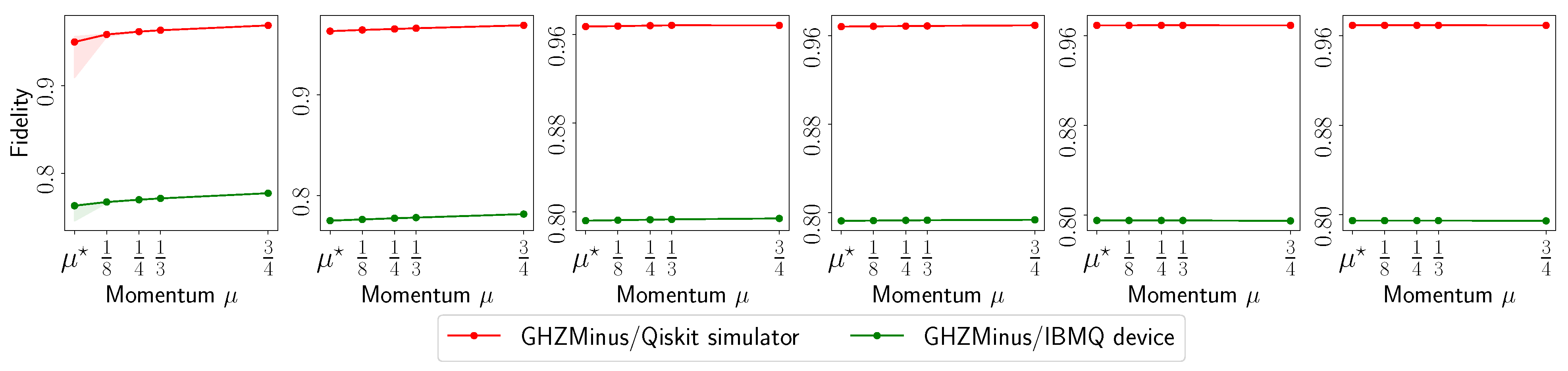
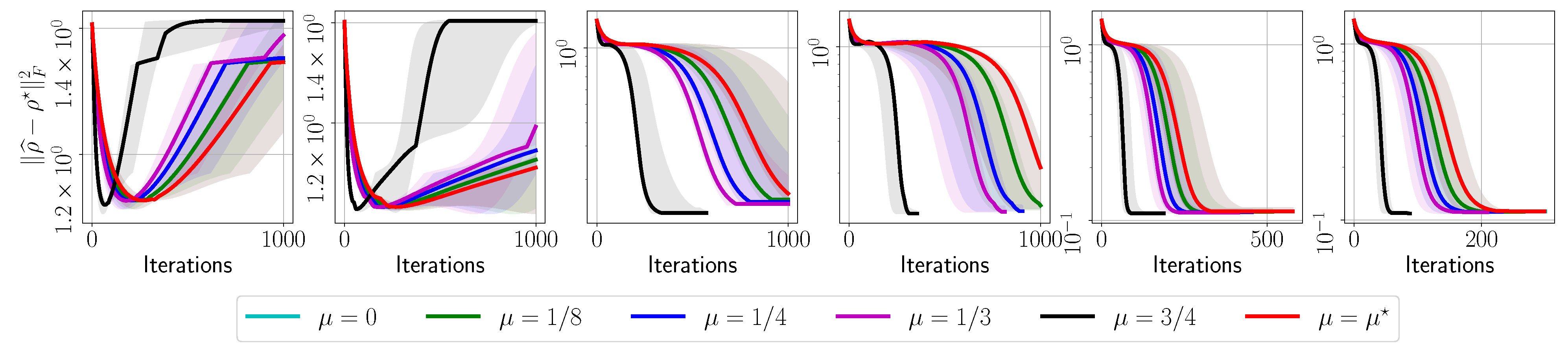
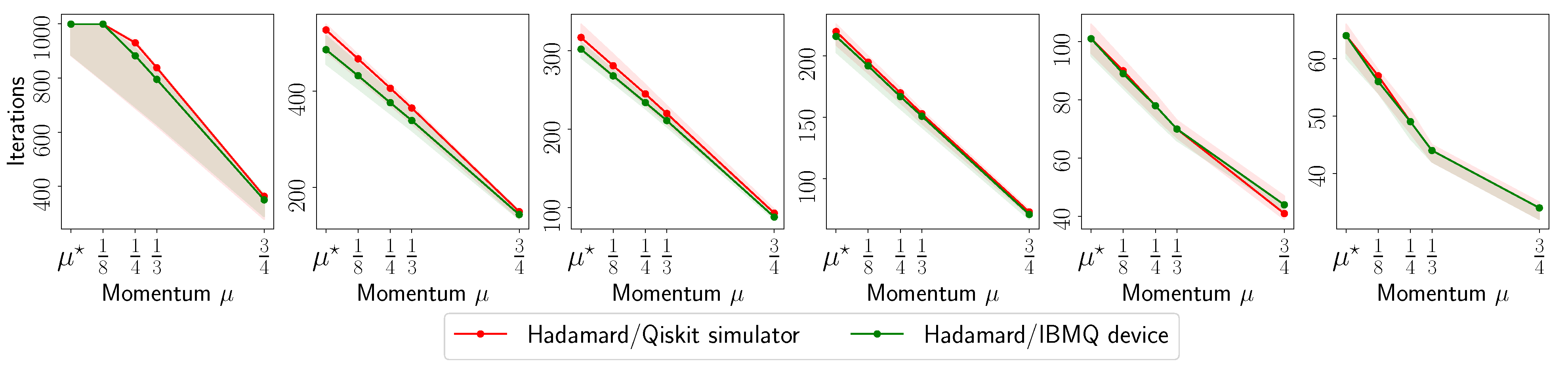
- The evolution with respect to the distance between and : , for various ’s.
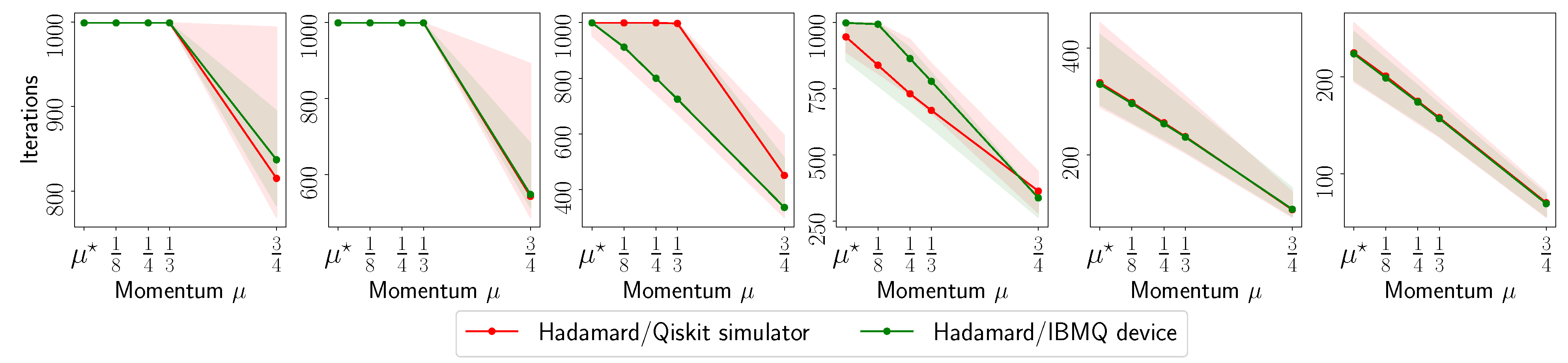
- The number of iterations to reach to for various ’s.
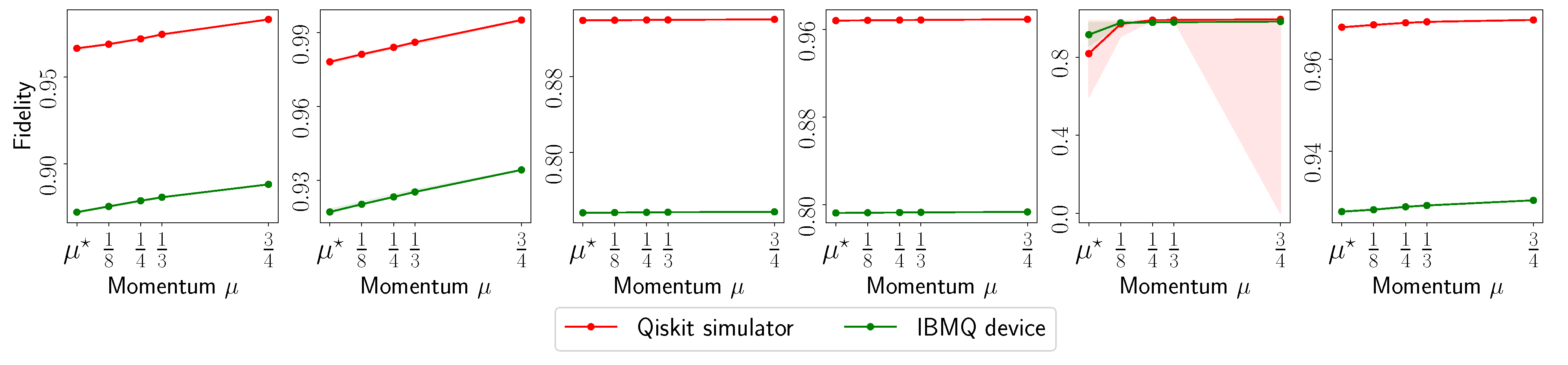
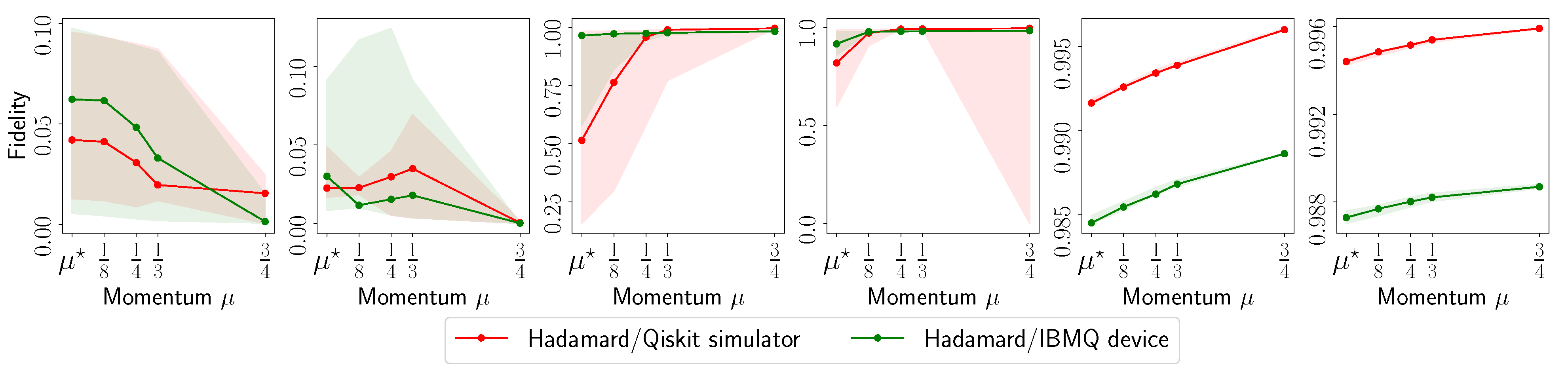
- The fidelity of , defined as (for rank-1 ), as a function of the acceleration parameter in the default set.
3.4. Experimental Setup on Quantum Processing Unit (QPU)
4. Results
4.1. MiFGD on 6- and 8-Qubit Real Quantum Data
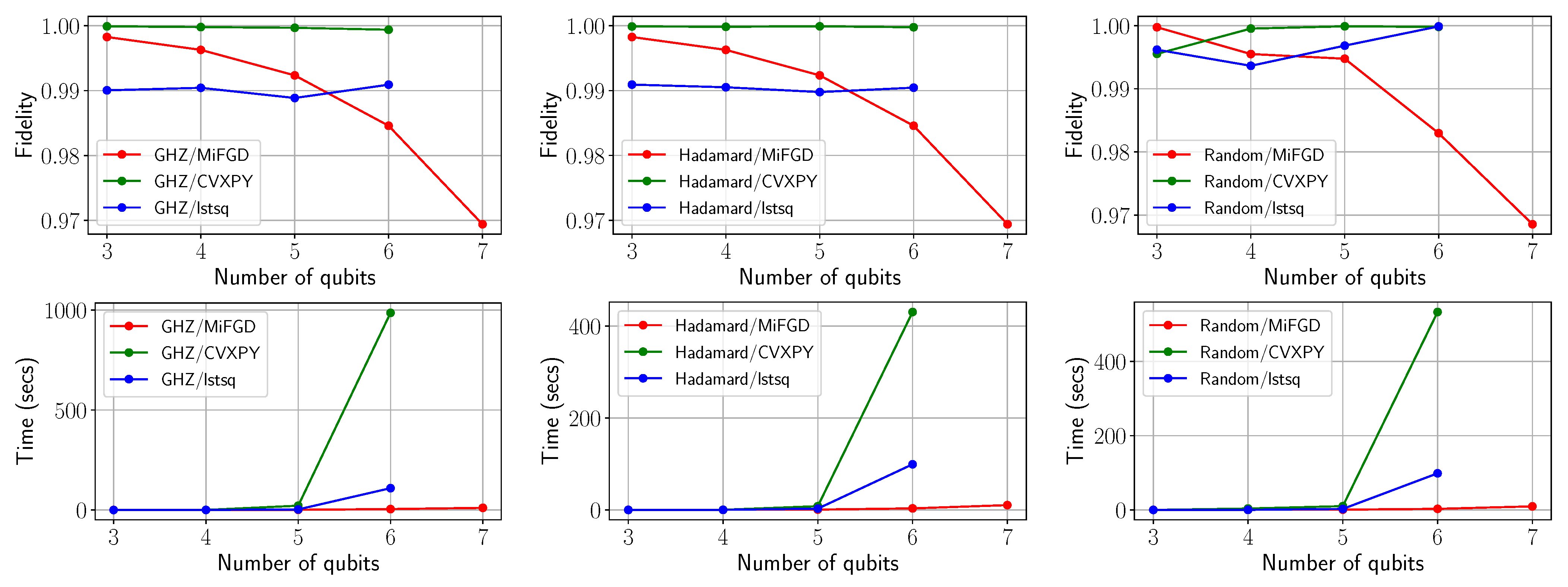
4.2. Performance Comparison with Full Tomography Methods in Qiskit
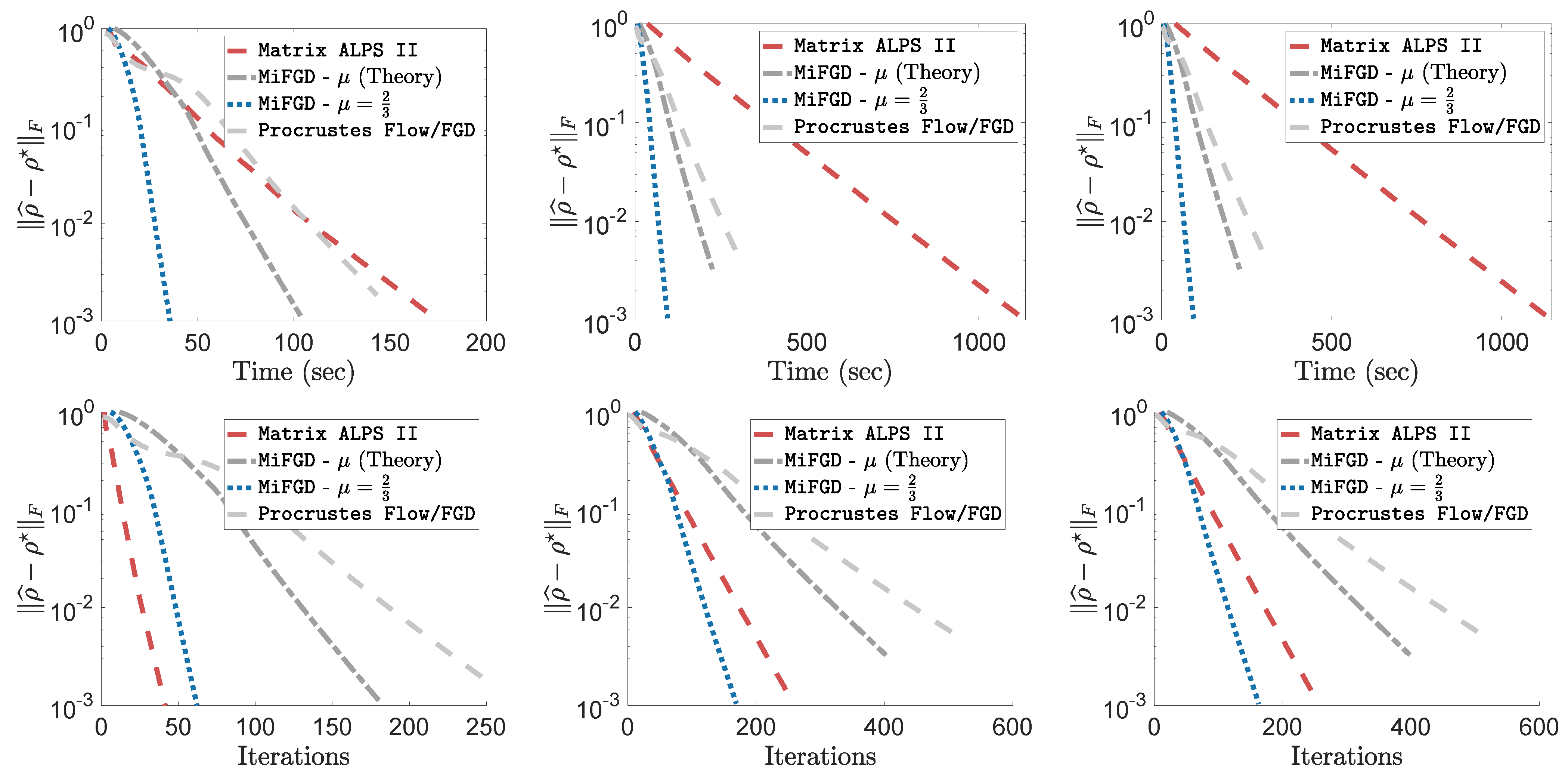
4.3. Performance Comparison of MiFGD with Neural-Network Quantum State Tomography
4.4. The Effect of Parallelization
5. Conclusions and Discussions
Related Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Additional Experiments
Appendix A.1. IBM Quantum System Experiments: GHZ—(6) Circuit, 2048 Shots




Appendix A.2. IBM Quantum System Experiments: GHZ—(8) Circuit, 2048 Shots




Appendix A.3. IBM Quantum System Experiments: GHZ—(8) Circuit, 4096 Shots




Appendix A.4. IBM Quantum System Experiments: Hadamard(6) Circuit, 8192 Shots




Appendix A.5. IBM Quantum System Experiments: Hadamard(8) Circuit, 4096 Shots




Appendix A.6. Synthetic Experiments for n = 12

Appendix A.7. Asymptotic Complexity Comparison of lstsq, CVXPY, and MiFGD
- lstsq is based on the computation of eigenvalues/eigenvector pairs (among other steps) of a matrix of size equal to the density matrix we want to reconstruct. Based on our notation, the density matrices are denoted as with dimensions . Here, n is the number of qubits in the quantum system. Standard libraries for eigenvalue/eigenvector calculations, like LAPACK, reduce a Hermitian matrix to tridiagonal form using the Householder method, which takes overall a computational complexity. The other steps in the lstsq procedure either take constant time, or complexity. Thus, the actual run-time of an implementation depends on the eigensystem solver that is being used.
- CVXPY is distributed with the open source solvers; for the case of SDP instances, CVXPY utilizes the Splitting Conic Solver (SCS) (https://github.com/cvxgrp/scs (accessed on 18 January 2023)), a general numerical optimization package for solving large-scale convex cone problems. SCS applies Douglas-Rachford splitting to a homogeneous embedding of the quadratic cone program. Based on the PSD constraint, this again involves the computation of eigenvalues/eigenvector pairs (among other steps) of a matrix of size equal to the density matrix we want to reconstruct. This takes overall a computational complexity, not including the other steps performed within the SCS solver. This is an iterative algorithm that requires such complexity per iteration. Douglas-Rachford splitting methods enjoy convergence rate in general [53,102,103]. This leads to a rough overall iteration complexity (This is an optimistic complexity bound since we have skipped several details within the Douglas-Rachford implementation of CVXPY).
- For MiFGD, and for sufficiently small momentum value, we require iterations to get close to the optimal value. Per iteration, MiFGD does not involve any expensive eigensystem solvers, but relies only on matrix-matrix and matrix-vector multiplications. In particular, the main computational complexity per iteration origins from the iteration:Here, for all k. Observe that where each element is computed independently. For an index , requires complexity, and thus computing requires complexity, overall. By definition the adjoing operation satisfies: ; thus, the operation is still dominated by complexity. Finally, we perform one more matrix-matrix multiplication with , which results into an additional complexity. The rest of the operations involve adding matrices, which does not dominate the overall complexity. Combining the iteration complexity with the per-iteration computational complexity, MiFGD has a complexity.
Appendix B. Detailed Proof of Theorem 1
Supporting Lemmata
References
- Altepeter, J.B.; James, D.F.; Kwiat, P.G. 4 qubit quantum state tomography. In Quantum State Estimation; Springer: Berlin/Heidelberg, Germany, 2004; pp. 113–145. [Google Scholar]
- Eisert, J.; Hangleiter, D.; Walk, N.; Roth, I.; Markham, D.; Parekh, R.; Chabaud, U.; Kashefi, E. Quantum certification and benchmarking. arXiv 2019, arXiv:1910.06343. [Google Scholar] [CrossRef]
- Mohseni, M.; Rezakhani, A.; Lidar, D. Quantum-process tomography: Resource analysis of different strategies. Phys. Rev. A 2008, 77, 032322. [Google Scholar] [CrossRef]
- Gross, D.; Liu, Y.K.; Flammia, S.; Becker, S.; Eisert, J. Quantum state tomography via compressed sensing. Phys. Rev. Lett. 2010, 105, 150401. [Google Scholar] [CrossRef] [PubMed]
- Vogel, K.; Risken, H. Determination of quasiprobability distributions in terms of probability distributions for the rotated quadrature phase. Phys. Rev. A 1989, 40, 2847. [Google Scholar] [CrossRef]
- Ježek, M.; Fiurášek, J.; Hradil, Z. Quantum inference of states and processes. Phys. Rev. A 2003, 68, 012305. [Google Scholar] [CrossRef]
- Banaszek, K.; Cramer, M.; Gross, D. Focus on quantum tomography. New J. Phys. 2013, 15, 125020. [Google Scholar] [CrossRef]
- Kalev, A.; Kosut, R.; Deutsch, I. Quantum tomography protocols with positivity are compressed sensing protocols. NPJ Quantum Inf. 2015, 1, 15018. [Google Scholar] [CrossRef]
- Torlai, G.; Mazzola, G.; Carrasquilla, J.; Troyer, M.; Melko, R.; Carleo, G. Neural-network quantum state tomography. Nat. Phys. 2018, 14, 447–450. [Google Scholar] [CrossRef]
- Beach, M.J.; De Vlugt, I.; Golubeva, A.; Huembeli, P.; Kulchytskyy, B.; Luo, X.; Melko, R.G.; Merali, E.; Torlai, G. QuCumber: Wavefunction reconstruction with neural networks. SciPost Phys. 2019, 7, 009. [Google Scholar] [CrossRef]
- Torlai, G.; Melko, R. Machine-Learning Quantum States in the NISQ Era. Annu. Rev. Condens. Matter Phys. 2020, 11, 325–344. [Google Scholar] [CrossRef]
- Cramer, M.; Plenio, M.B.; Flammia, S.T.; Somma, R.; Gross, D.; Bartlett, S.D.; Landon-Cardinal, O.; Poulin, D.; Liu, Y.K. Efficient quantum state tomography. Nat. Comm. 2010, 1, 149. [Google Scholar] [CrossRef] [PubMed]
- Lanyon, B.; Maier, C.; Holzäpfel, M.; Baumgratz, T.; Hempel, C.; Jurcevic, P.; Dhand, I.; Buyskikh, A.; Daley, A.; Cramer, M.; et al. Efficient tomography of a quantum many-body system. Nat. Phys. 2017, 13, 1158–1162. [Google Scholar] [CrossRef]
- Gonçalves, D.; Gomes-Ruggiero, M.; Lavor, C. A projected gradient method for optimization over density matrices. Optim. Methods Softw. 2016, 31, 328–341. [Google Scholar] [CrossRef]
- Bolduc, E.; Knee, G.; Gauger, E.; Leach, J. Projected gradient descent algorithms for quantum state tomography. NPJ Quantum Inf. 2017, 3, 44. [Google Scholar] [CrossRef]
- Shang, J.; Zhang, Z.; Ng, H.K. Superfast maximum-likelihood reconstruction for quantum tomography. Phys. Rev. A 2017, 95, 062336. [Google Scholar] [CrossRef]
- Hu, Z.; Li, K.; Cong, S.; Tang, Y. Reconstructing Pure 14-Qubit Quantum States in Three Hours Using Compressive Sensing. IFAC-PapersOnLine 2019, 52, 188–193. [Google Scholar] [CrossRef]
- Hou, Z.; Zhong, H.S.; Tian, Y.; Dong, D.; Qi, B.; Li, L.; Wang, Y.; Nori, F.; Xiang, G.Y.; Li, C.F.; et al. Full reconstruction of a 14-qubit state within four hours. New J. Phys. 2016, 18, 083036. [Google Scholar] [CrossRef]
- Candes, E.; Tao, T. Near-optimal signal recovery from random projections: Universal encoding strategies? IEEE Trans. Inf. Theory 2006, 52, 5406–5425. [Google Scholar] [CrossRef]
- Gross, D. Recovering low-rank matrices from few coefficients in any basis. IEEE Trans. Inf. Theory 2011, 57, 1548–1566. [Google Scholar] [CrossRef]
- Liu, Y.K. Universal low-rank matrix recovery from Pauli measurements. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; pp. 1638–1646. [Google Scholar]
- Riofrío, C.; Gross, D.; Flammia, S.; Monz, T.; Nigg, D.; Blatt, R.; Eisert, J. Experimental quantum compressed sensing for a seven-qubit system. Nat. Commun. 2017, 8, 15305. [Google Scholar] [CrossRef]
- Kliesch, M.; Kueng, R.; Eisert, J.; Gross, D. Guaranteed recovery of quantum processes from few measurements. Quantum 2019, 3, 171. [Google Scholar] [CrossRef]
- Flammia, S.T.; Gross, D.; Liu, Y.K.; Eisert, J. Quantum tomography via compressed sensing: Error bounds, sample complexity and efficient estimators. New J. Phys. 2012, 14, 095022. [Google Scholar] [CrossRef]
- Bhojanapalli, S.; Kyrillidis, A.; Sanghavi, S. Dropping convexity for faster semi-definite optimization. In Proceedings of the Conference on Learning Theory, New York, NY, USA, 23–26 June 2016; pp. 530–582. [Google Scholar]
- Kyrillidis, A.; Kalev, A.; Park, D.; Bhojanapalli, S.; Caramanis, C.; Sanghavi, S. Provable compressed sensing quantum state tomography via non-convex methods. NPJ Quantum Inf. 2018, 4, 36. [Google Scholar] [CrossRef]
- Gao, X.; Duan, L.M. Efficient representation of quantum many-body states with deep neural networks. Nat. Commun. 2017, 8, 1–6. [Google Scholar] [CrossRef]
- tA v, A.; Anis, M.S.; Mitchell, A.; Abraham, H.; AduOffei; Agarwal, R.; Agliardi, G.; Aharoni, M.; Ajith, V.; Akhalwaya, I.Y.; et al. Qiskit: An Open-Source Framework for Quantum Computing. 2021. Available online: https://zenodo.org/record/7591922#.Y9zUYK1BxPY (accessed on 18 January 2023).
- Recht, B.; Fazel, M.; Parrilo, P.A. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Rev. 2010, 52, 471–501. [Google Scholar] [CrossRef]
- Park, D.; Kyrillidis, A.; Caramanis, C.; Sanghavi, S. Finding low-rank solutions to matrix problems, efficiently and provably. arXiv 2016, arXiv:1606.03168. [Google Scholar]
- Park, D.; Kyrillidis, A.; Bhojanapalli, S.; Caramanis, C.; Sanghavi, S. Provable Burer-Monteiro factorization for a class of norm-constrained matrix problems. arXiv 2016, arXiv:1606.01316. [Google Scholar]
- Tu, S.; Boczar, R.; Simchowitz, M.; Soltanolkotabi, M.; Recht, B. Low-rank solutions of linear matrix equations via Procrustes flow. In Proceedings of the 33rd International Conference on International Conference on Machine Learning-Volume 48, New York, NY, USA, 19–24 June 2016; pp. 964–973. [Google Scholar]
- Zhao, T.; Wang, Z.; Liu, H. A nonconvex optimization framework for low rank matrix estimation. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 559–567. [Google Scholar]
- Zheng, Q.; Lafferty, J. A convergent gradient descent algorithm for rank minimization and semidefinite programming from random linear measurements. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 109–117. [Google Scholar]
- Cauchy, A. Méthode générale pour la résolution des systemes d’équations simultanées. Comp. Rend. Sci. Paris 1847, 25, 536–538. [Google Scholar]
- Park, D.; Kyrillidis, A.; Caramanis, C.; Sanghavi, S. Non-square matrix sensing without spurious local minima via the Burer-Monteiro approach. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 20–22 April 2017; pp. 65–74. [Google Scholar]
- Ge, R.; Jin, C.; Zheng, Y. No spurious local minima in nonconvex low rank problems: A unified geometric analysis. arXiv 2017, arXiv:1704.00708. [Google Scholar]
- Hsieh, Y.P.; Kao, Y.C.; Karimi Mahabadi, R.; Alp, Y.; Kyrillidis, A.; Cevher, V. A Non-Euclidean Gradient Descent Framework for Non-Convex Matrix Factorization. IEEE Trans. Signal Process. 2018, 66, 5917–5926. [Google Scholar] [CrossRef]
- Polyak, B. Some methods of speeding up the convergence of iteration methods. USSR Comput. Math. Math. Phys. 1964, 4, 1–17. [Google Scholar] [CrossRef]
- Nesterov, Y. A method of solving a convex programming problem with convergence rate O(1k2). Sov. Math. Dokl. 1983, 27, 372–376. [Google Scholar]
- Bhojanapalli, S.; Neyshabur, B.; Srebro, N. Global optimality of local search for low rank matrix recovery. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3873–3881. [Google Scholar]
- Stöger, D.; Soltanolkotabi, M. Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction. Adv. Neural Inf. Process. Syst. 2021, 34, 23831–23843. [Google Scholar]
- Lanczos, C. An Iteration Method for the Solution of the Eigenvalue Problem of Linear Differential and Integral Operators1. J. Res. Natl. Bur. Stand. 1950, 45. [Google Scholar] [CrossRef]
- Nesterov, Y. Introductory Lectures on Convex Optimization: A Basic Course; Springer Science & Business Media: Berlin, Germany, 2013; Volume 87. [Google Scholar]
- Carmon, Y.; Duchi, J.; Hinder, O.; Sidford, A. Accelerated methods for non-convex optimization. arXiv 2016, arXiv:1611.00756. [Google Scholar]
- Li, Y.; Ma, C.; Chen, Y.; Chi, Y. Nonconvex Matrix Factorization from Rank-One Measurements. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Naha, Japan, 16–18 April 2019. [Google Scholar]
- Khanna, R.; Kyrillidis, A. IHT dies hard: Provable accelerated Iterative Hard Thresholding. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Canary Islands, 9–11 April 2018; pp. 188–198. [Google Scholar]
- Rudelson, M.; Vershynin, R. On sparse reconstruction from Fourier and Gaussian measurements. Commun. Pure Appl. Math. A J. Issued Courant Inst. Math. Sci. 2008, 61, 1025–1045. [Google Scholar] [CrossRef]
- Vandenberghe, L. The CVXOPT Linear and Quadratic Cone Program Solvers. 2010. Available online: https://www.seas.ucla.edu/vandenbe/publications/coneprog.pdf (accessed on 18 January 2023).
- Diamond, S.; Boyd, S. CVXPY: A Python-embedded modeling language for convex optimization. J. Mach. Learn. Res. 2016, 17, 1–5. [Google Scholar]
- Agrawal, A.; Verschueren, R.; Diamond, S.; Boyd, S. A rewriting system for convex optimization problems. J. Control. Decis. 2018, 5, 42–60. [Google Scholar] [CrossRef]
- Smolin, J.A.; Gambetta, J.M.; Smith, G. Efficient method for computing the maximum-likelihood quantum state from measurements with additive gaussian noise. Phys. Rev. Lett. 2012, 108, 070502. [Google Scholar] [CrossRef]
- O’Donoghue, B.; Chu, E.; Parikh, N.; Boyd, S. Conic Optimization via Operator Splitting and Homogeneous Self-Dual Embedding. J. Optim. Theory Appl. 2016, 169, 1042–1068. [Google Scholar] [CrossRef]
- O’Donoghue, B.; Chu, E.; Parikh, N.; Boyd, S. SCS: Splitting Conic Solver, Version 2.1.2. 2019. Available online: https://github.com/cvxgrp/scs (accessed on 18 January 2023).
- Forum, T.M. MPI: A Message Passing Interface. In Proceedings of the 1993 ACM/IEEE Conference on Supercomputing, Portland, OR, USA, 19 November 1993; Association for Computing Machinery: New York, NY, USA, 1993; pp. 878–883. [Google Scholar] [CrossRef]
- Dalcin, L.D.; Paz, R.R.; Kler, P.A.; Cosimo, A. Parallel distributed computing using Python. Adv. Water Resour. 2011, 34, 1124–1139. [Google Scholar] [CrossRef]
- Lee, K.; Bresler, Y. Guaranteed minimum rank approximation from linear observations by nuclear norm minimization with an ellipsoidal constraint. arXiv 2009, arXiv:0903.4742. [Google Scholar]
- Liu, Z.; Vandenberghe, L. Interior-point method for nuclear norm approximation with application to system identification. SIAM J. Matrix Anal. Appl. 2009, 31, 1235–1256. [Google Scholar] [CrossRef]
- Jain, P.; Meka, R.; Dhillon, I.S. Guaranteed rank minimization via singular value projection. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 6–9 December 2010; pp. 937–945. [Google Scholar]
- Lee, K.; Bresler, Y. Admira: Atomic decomposition for minimum rank approximation. IEEE Trans. Inf. Theory 2010, 56, 4402–4416. [Google Scholar] [CrossRef]
- Kyrillidis, A.; Cevher, V. Matrix recipes for hard thresholding methods. J. Math. Imaging Vis. 2014, 48, 235–265. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tieleman, T.; Hinton, G. Lecture 6.5-RMSPro: Divide the gradient by a running average of its recent magnitude. COURSERA Neural Netw. Mach. Learn. 2012, 4, 26–31. [Google Scholar]
- Beck, A.; Teboulle, M. A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM J. Imaging Sci. 2009, 2, 183–202. [Google Scholar] [CrossRef]
- O’Donoghue, B.; Candes, E. Adaptive restart for accelerated gradient schemes. Found. Comput. Math. 2015, 15, 715–732. [Google Scholar] [CrossRef]
- Bubeck, S.; Lee, Y.T.; Singh, M. A geometric alternative to Nesterov’s accelerated gradient descent. arXiv 2015, arXiv:1506.08187. [Google Scholar]
- Goh, G. Why Momentum Really Works. Distill 2017, 2, e6. [Google Scholar] [CrossRef]
- Kyrillidis, A.; Cevher, V. Recipes on hard thresholding methods. In Proceedings of the Computational Advances in Multi-Sensor Adaptive Processing (CAMSAP), San Juan, PR, USA, 13–16 December 2011; pp. 353–356. [Google Scholar]
- Xu, P.; He, B.; De Sa, C.; Mitliagkas, I.; Re, C. Accelerated stochastic power iteration. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Playa Blanca, Lanzarote, Canary Islands, 9–11 April 2018; pp. 58–67. [Google Scholar]
- Ghadimi, S.; Lan, G. Stochastic first-and zeroth-order methods for nonconvex stochastic programming. SIAM J. Optim. 2013, 23, 2341–2368. [Google Scholar] [CrossRef]
- Lee, J.; Simchowitz, M.; Jordan, M.; Recht, B. Gradient descent only converges to minimizers. In Proceedings of the Conference on Learning Theory, New York, NY, USA, 23–26 June 2016; pp. 1246–1257. [Google Scholar]
- Agarwal, N.; Allen-Zhu, Z.; Bullins, B.; Hazan, E.; Ma, T. Finding approximate local minima for nonconvex optimization in linear time. arXiv 2016, arXiv:1611.01146. [Google Scholar]
- Burer, S.; Monteiro, R.D. A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization. Math. Program. 2003, 95, 329–357. [Google Scholar] [CrossRef]
- Jain, P.; Dhillon, I.S. Provable inductive matrix completion. arXiv 2013, arXiv:1306.0626. [Google Scholar]
- Chen, Y.; Wainwright, M.J. Fast low-rank estimation by projected gradient descent: General statistical and algorithmic guarantees. arXiv 2015, arXiv:1509.03025. [Google Scholar]
- Sun, R.; Luo, Z.Q. Guaranteed matrix completion via non-convex factorization. IEEE Trans. Inf. Theory 2016, 62, 6535–6579. [Google Scholar] [CrossRef]
- O’Donnell, R.; Wright, J. Efficient quantum tomography. In Proceedings of the Forty-Eighth Annual ACM Symposium on Theory of Computing, Cambridge, MA, USA, 19–21 June 2016; pp. 899–912. [Google Scholar]
- Hayashi, M.; Matsumoto, K. Quantum universal variable-length source coding. Phys. Rev. A 2002, 66, 022311. [Google Scholar] [CrossRef]
- Christandl, M.; Mitchison, G. The spectra of quantum states and the Kronecker coefficients of the symmetric group. Commun. Math. Phys. 2006, 261, 789–797. [Google Scholar] [CrossRef]
- Alicki, R.; Rudnicki, S.; Sadowski, S. Symmetry properties of product states for the system of N n-level atoms. J. Math. Phys. 1988, 29, 1158–1162. [Google Scholar] [CrossRef]
- Keyl, M.; Werner, R.F. Estimating the spectrum of a density operator. In Asymptotic Theory of Quantum Statistical Inference: Selected Papers; World Scientific: Singapore, 2005; pp. 458–467. [Google Scholar]
- Tóth, G.; Wieczorek, W.; Gross, D.; Krischek, R.; Schwemmer, C.; Weinfurter, H. Permutationally invariant quantum tomography. Phys. Rev. Lett. 2010, 105, 250403. [Google Scholar] [CrossRef] [PubMed]
- Moroder, T.; Hyllus, P.; Tóth, G.; Schwemmer, C.; Niggebaum, A.; Gaile, S.; Gühne, O.; Weinfurter, H. Permutationally invariant state reconstruction. New J. Phys. 2012, 14, 105001. [Google Scholar] [CrossRef]
- Schwemmer, C.; Tóth, G.; Niggebaum, A.; Moroder, T.; Gross, D.; Gühne, O.; Weinfurter, H. Experimental comparison of efficient tomography schemes for a six-qubit state. Phys. Rev. Lett. 2014, 113, 040503. [Google Scholar] [CrossRef] [PubMed]
- Banaszek, K.; D’Ariano, G.M.; Paris, M.G.A.; Sacchi, M.F. Maximum-likelihood estimation of the density matrix. Phys. Rev. A 1999, 61, 010304. [Google Scholar] [CrossRef]
- Paris, M.; D’Ariano, G.; Sacchi, M. Maximum-likelihood method in quantum estimation. In Proceedings of the AIP Conference Proceedings; 2001; Volume 568, pp. 456–467. [Google Scholar]
- Řeháček, J.; Hradil, Z.; Knill, E.; Lvovsky, A.I. Diluted maximum-likelihood algorithm for quantum tomography. Phys. Rev. A 2007, 75, 042108. [Google Scholar] [CrossRef]
- Gonçalves, D.; Gomes-Ruggiero, M.; Lavor, C.; Farias, O.J.; Ribeiro, P. Local solutions of maximum likelihood estimation in quantum state tomography. Quantum Inf. Comput. 2012, 12, 775–790. [Google Scholar] [CrossRef]
- Teo, Y.S.; Řeháček, J.; Hradil, Z. Informationally incomplete quantum tomography. Quantum Meas. Quantum Metrol. 2013, 1, 57–83. [Google Scholar] [CrossRef]
- Sutskever, I.; Hinton, G.E.; Taylor, G.W. The recurrent temporal restricted boltzmann machine. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 1601–1608. [Google Scholar]
- Ahmed, S.; Muñoz, C.S.; Nori, F.; Kockum, A. Quantum state tomography with conditional generative adversarial networks. arXiv 2020, arXiv:2008.03240. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, S.; Muñoz, C.; Nori, F.; Kockum, A. Classification and reconstruction of optical quantum states with deep neural networks. arXiv 2020, arXiv:2012.02185. [Google Scholar] [CrossRef]
- Paini, M.; Kalev, A.; Padilha, D.; Ruck, B. Estimating expectation values using approximate quantum states. Quantum 2021, 5, 413. [Google Scholar] [CrossRef]
- Huang, H.Y.; Kueng, R.; Preskill, J. Predicting Many Properties of a Quantum System from Very Few Measurements. arXiv 2020, arXiv:2002.08953. [Google Scholar] [CrossRef]
- Flammia, S.T.; Liu, Y.K. Direct fidelity estimation from few Pauli measurements. Phys. Rev. Lett. 2011, 106, 230501. [Google Scholar] [CrossRef] [PubMed]
- da Silva, M.P.; Landon-Cardinal, O.; Poulin, D. Practical characterization of quantum devices without tomography. Phys. Rev. Lett. 2011, 107, 210404. [Google Scholar] [CrossRef] [PubMed]
- Kalev, A.; Kyrillidis, A.; Linke, N.M. Validating and certifying stabilizer states. Phys. Rev. A 2019, 99, 042337. [Google Scholar] [CrossRef]
- Aaronson, S. Shadow tomography of quantum states. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing, Los Angeles, CA, USA, 25–29 June 2018; pp. 325–338. [Google Scholar]
- Aaronson, S.; Rothblum, G.N. Gentle measurement of quantum states and differential privacy. In Proceedings of the 51st Annual ACM SIGACT Symposium on Theory of Computing, Phoenix, AZ, USA, 23–26 June 2019; pp. 322–333. [Google Scholar]
- Smith, A.; Gray, J.; Kim, M. Efficient Approximate Quantum State Tomography with Basis Dependent Neural-Networks. arXiv 2020, arXiv:2009.07601. [Google Scholar]
- Waters, A.E.; Sankaranarayanan, A.C.; Baraniuk, R. SpaRCS: Recovering low-rank and sparse matrices from compressive measurements. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–14 December 2011; pp. 1089–1097. [Google Scholar]
- He, B.; Yuan, X. On the convergence rate of Douglas–Rachford operator splitting method. Math. Program. 2015, 153, 715–722. [Google Scholar] [CrossRef]
- O’Donoghue, B. Operator Splitting for a Homogeneous Embedding of the Linear Complementarity Problem. SIAM J. Optim. 2021, 31, 1999–2023. [Google Scholar] [CrossRef]
- Foucart, S. Matrix Norms and Spectral Radii. 2012. Available online: https://www.math.drexel.edu/~foucart/TeachingFiles/F12/M504Lect6.pdf (accessed on 18 January 2023).
- Johnson, S.G. Notes on the Equivalence of Norms. 2012. Available online: https://math.mit.edu/~stevenj/18.335/norm-equivalence.pdf (accessed on 18 January 2023).
- Horn, R.; Johnson, C. Matrix Analysis; Cambridge University Press: Cambridge, UK, 1990. [Google Scholar]
- Mirsky, L. A trace inequality of John von Neumann. Monatshefte Math. 1975, 79, 303–306. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.0072 | 0.0062 | 0.0087 | 0.0077 | 0.0152 | 0.0167 | 0.0133 |
| Circuit | ||||||
|---|---|---|---|---|---|---|
| # shots | 2048 | 8192 | 2048 | 4096 | 8192 | 4096 |
| Circuit | Method | Fidelity | Time (s) |
|---|---|---|---|
| MiFGD | 0.969397 | 10.6709 | |
| MiFGD | 0.969397 | 10.4926 | |
| MiFGD | 0.968553 | 9.59607 | |
| All above | lstsq, CVXPY | Memory limit exceeded | |
| MiFGD | 0.940389 | 35.0666 | |
| MiFGD | 0.940390 | 37.5331 | |
| MiFGD | 0.942815 | 36.3251 | |
| All above | lstsq, CVXPY | Memory limit exceeded | |
| Circuit | Method | |||||
|---|---|---|---|---|---|---|
| MiFGD | FGD | PRWF | CWF | DM | ||
| Fidelity | 0.997922 | 0.997857 | 0.314167 | 0.401737 | 0.005389 | |
| Time (s) | 0.348652 | 1.061421 | 42.27607 | 1649.224 | 3279.118 | |
| Fidelity | 0.997229 | 0.994191 | 0.912268 | 0.997914 | 0.997222 | |
| Time (s) | 0.706872 | 2.399405 | 8.492405 | 325.7040 | 656.6696 | |
| Fidelity | 0.991063 | 0.988746 | 0.074774 | 0.997493 | 0.989754 | |
| Time (s) | 1.447057 | 3.431218 | 8.345135 | 322.4730 | 640.8185 | |
| Fidelity | 0.996029 | 0.996041 | 0.204313 | 0.276491 | 0.138459 | |
| Time (s) | 0.733128 | 2.081035 | 126.2749 | 10756.87 | >3 h | |
| Fidelity | 0.996078 | 0.996083 | 0.894883 | 0.998071 | 0.997389 | |
| Time (s) | 0.852895 | 2.368223 | 25.15520 | 2087.540 | 4613.964 | |
| Fidelity | 0.998850 | 0.998876 | 0.152971 | 0.984164 | 0.972877 | |
| Time (s) | 0.713302 | 2.380326 | 26.18863 | 2185.091 | 4802.495 | |
| Fidelity | 0.992105 | 0.992106 | 0.132725 | 0.274665 | 0.005138 | |
| Time (s) | 0.946350 | 3.287358 | 395.3379 | >3 h | >3 h | |
| Fidelity | 0.992102 | 0.992100 | 0.869603 | 0.998246 | 0.996516 | |
| Time (s) | 1.183290 | 3.895312 | 79.39444 | 9319.140 | >3 h | |
| Fidelity | 0.995126 | 0.995109 | 0.015913 | 0.623273 | 0.086777 | |
| Time (s) | 0.988173 | 3.407487 | 79.22450 | 9275.836 | >3 h | |
| Fidelity | 0.984352 | 0.984340 | 0.089355 | 0.437323 | 0.310067 | |
| Time (s) | 3.829866 | 13.306954 | 1167.985 | >3 h | >3 h | |
| Fidelity | 0.984384 | 0.984377 | 0.842515 | 0.990849 | 0.998077 | |
| Time (s) | 2.500354 | 8.661999 | 246.0011 | >3 h | >3 h | |
| Fidelity | 0.989543 | 0.989536 | 0.143145 | 0.784873 | 0.302534 | |
| Time (s) | 1.991154 | 7.604232 | 237.7037 | >3 h | >3 h | |
| Fidelity | 0.969174 | 0.969168 | 0.058387 | 0.080648 | N/A | |
| Time (s) | 6.174129 | 15.895504 | 3633.082 | >3 h | >3 h | |
| Fidelity | 0.969156 | 0.969156 | 0.818174 | 0.996586 | N/A | |
| Time (s) | 6.324469 | 16.283301 | 713.9404 | >3 h | >3 h | |
| Fidelity | 0.967640 | 0.967619 | 0.141745 | 0.06568 | N/A | |
| Time (s) | 6.802577 | 16.594162 | 746.2630 | >3 h | >3 h | |
| Fidelity | 0.940601 | 0.940600 | 0.0400391 | N/A | N/A | |
| Time (s) | 21.16011 | 36.892739 | >3 h | >3 h | >3 h | |
| Fidelity | 0.940638 | 0.940638 | 0.794892 | N/A | N/A | |
| Time (s) | 22.30246 | 41.472961 | 2344.796 | >3 h | >3 h | |
| Fidelity | 0.939418 | 0.939416 | 0.050521 | N/A | N/A | |
| Time (s) | 22.81059 | 41.193810 | 2196.259 | >3 h | >3 h | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.L.; Kollias, G.; Kalev, A.; Wei, K.X.; Kyrillidis, A. Fast Quantum State Reconstruction via Accelerated Non-Convex Programming. Photonics 2023, 10, 116. https://doi.org/10.3390/photonics10020116
Kim JL, Kollias G, Kalev A, Wei KX, Kyrillidis A. Fast Quantum State Reconstruction via Accelerated Non-Convex Programming. Photonics. 2023; 10(2):116. https://doi.org/10.3390/photonics10020116
Chicago/Turabian StyleKim, Junhyung Lyle, George Kollias, Amir Kalev, Ken X. Wei, and Anastasios Kyrillidis. 2023. "Fast Quantum State Reconstruction via Accelerated Non-Convex Programming" Photonics 10, no. 2: 116. https://doi.org/10.3390/photonics10020116
APA StyleKim, J. L., Kollias, G., Kalev, A., Wei, K. X., & Kyrillidis, A. (2023). Fast Quantum State Reconstruction via Accelerated Non-Convex Programming. Photonics, 10(2), 116. https://doi.org/10.3390/photonics10020116