
A Data-Centric Approach to Design and Analysis of a Surface-Inspection System Based on Deep Learning in the Plastic Injection Molding Industry



Abstract
:1. Introduction
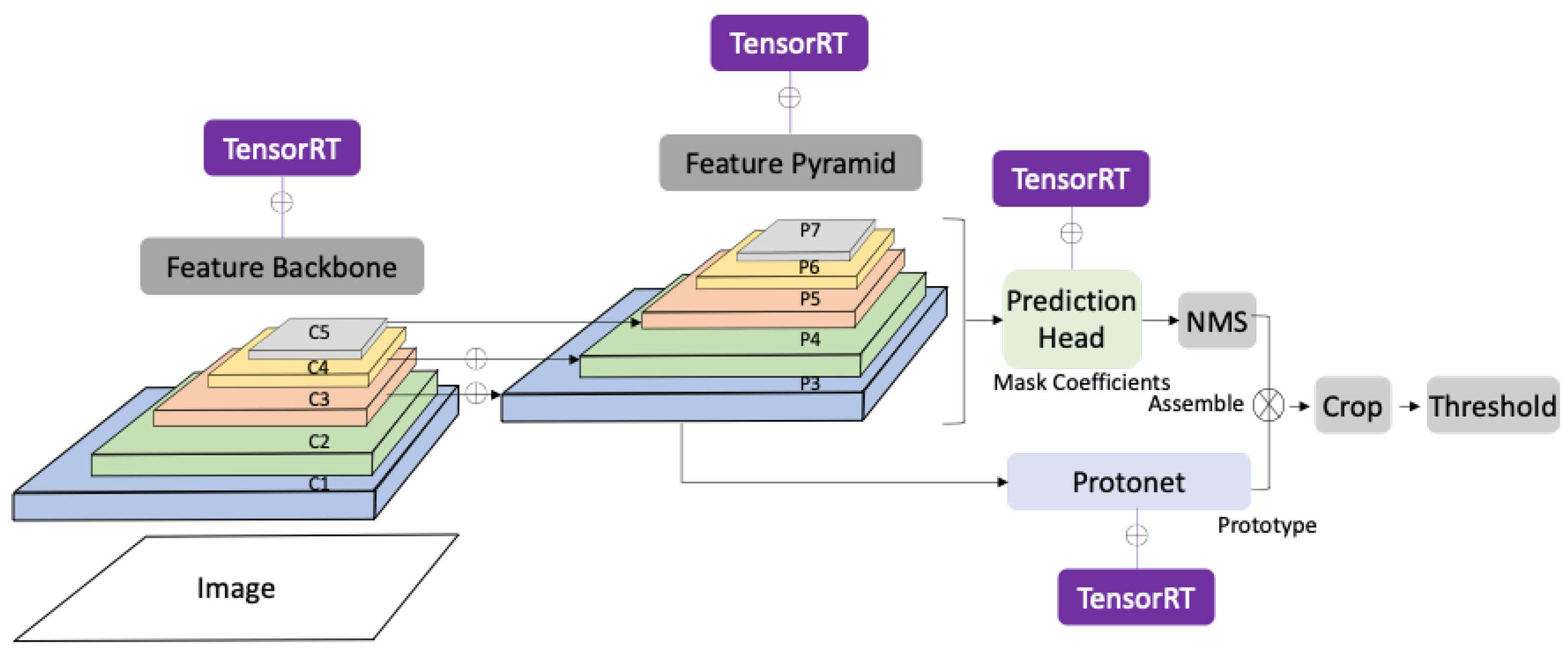
- We propose a DL-based inspection system for moving applicators. Our inspection system uses the structural characteristics of the applicator, allowing it to roll during the inspection interval, which is critical for data acquisition. For defect inspection, we have tested the state-of-the-art object-detection and instance-segmentation models, You Only Look Once version 4 (YOLOv4) and You Only Look At CoefficienTs (YOLACT), respectively. We describe the system configuration, including hardware, network, software specifications, and inspection mechanisms.
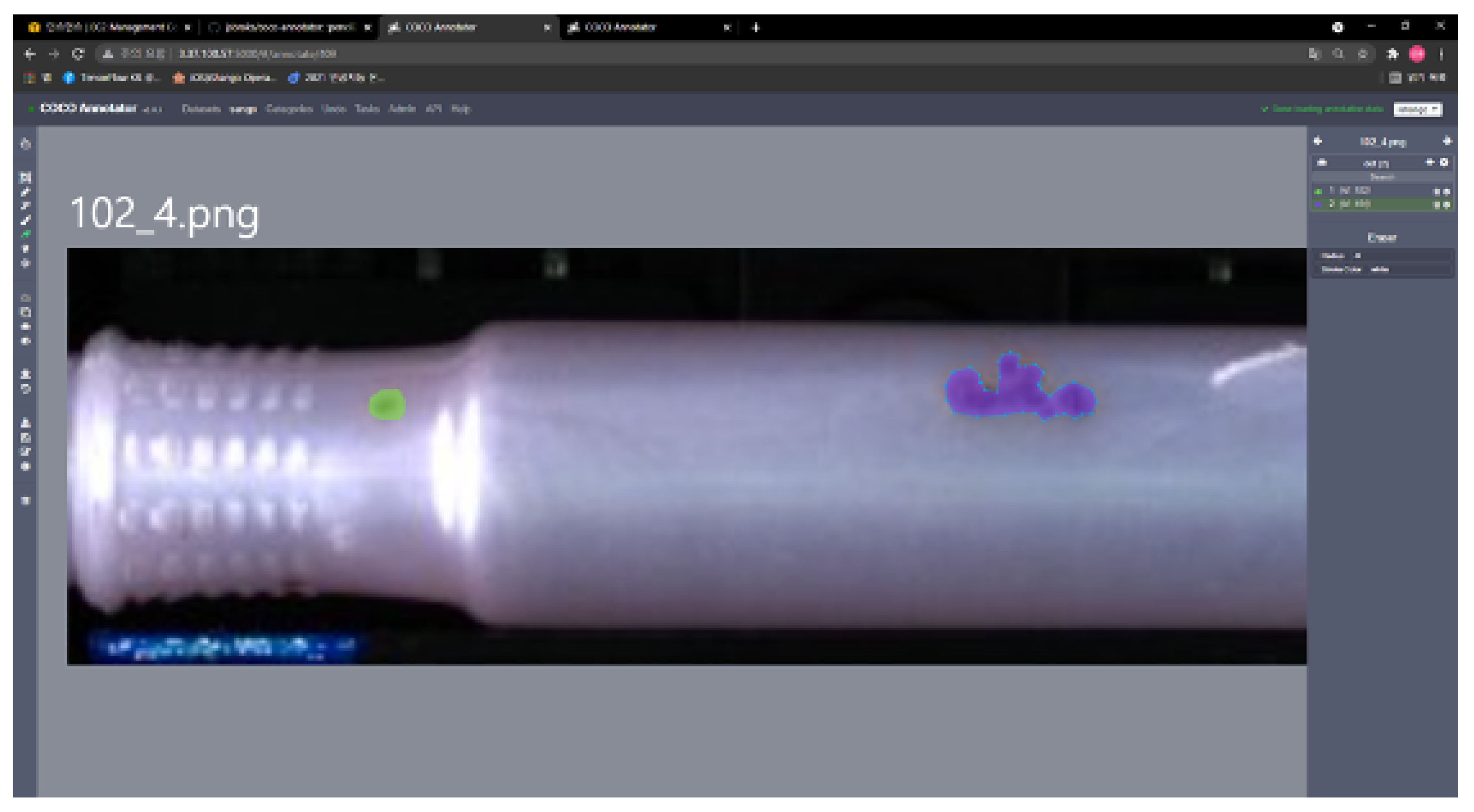
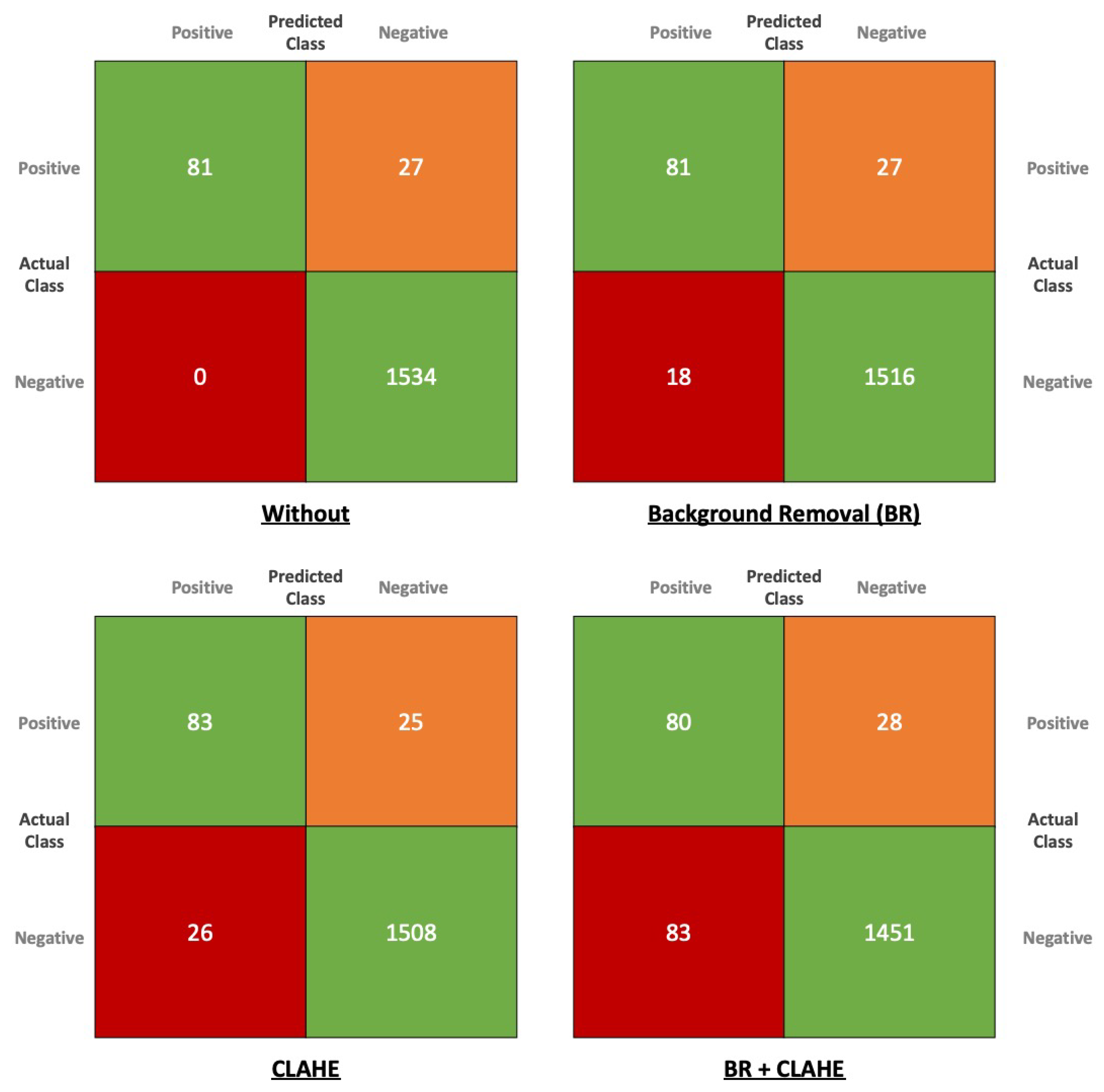
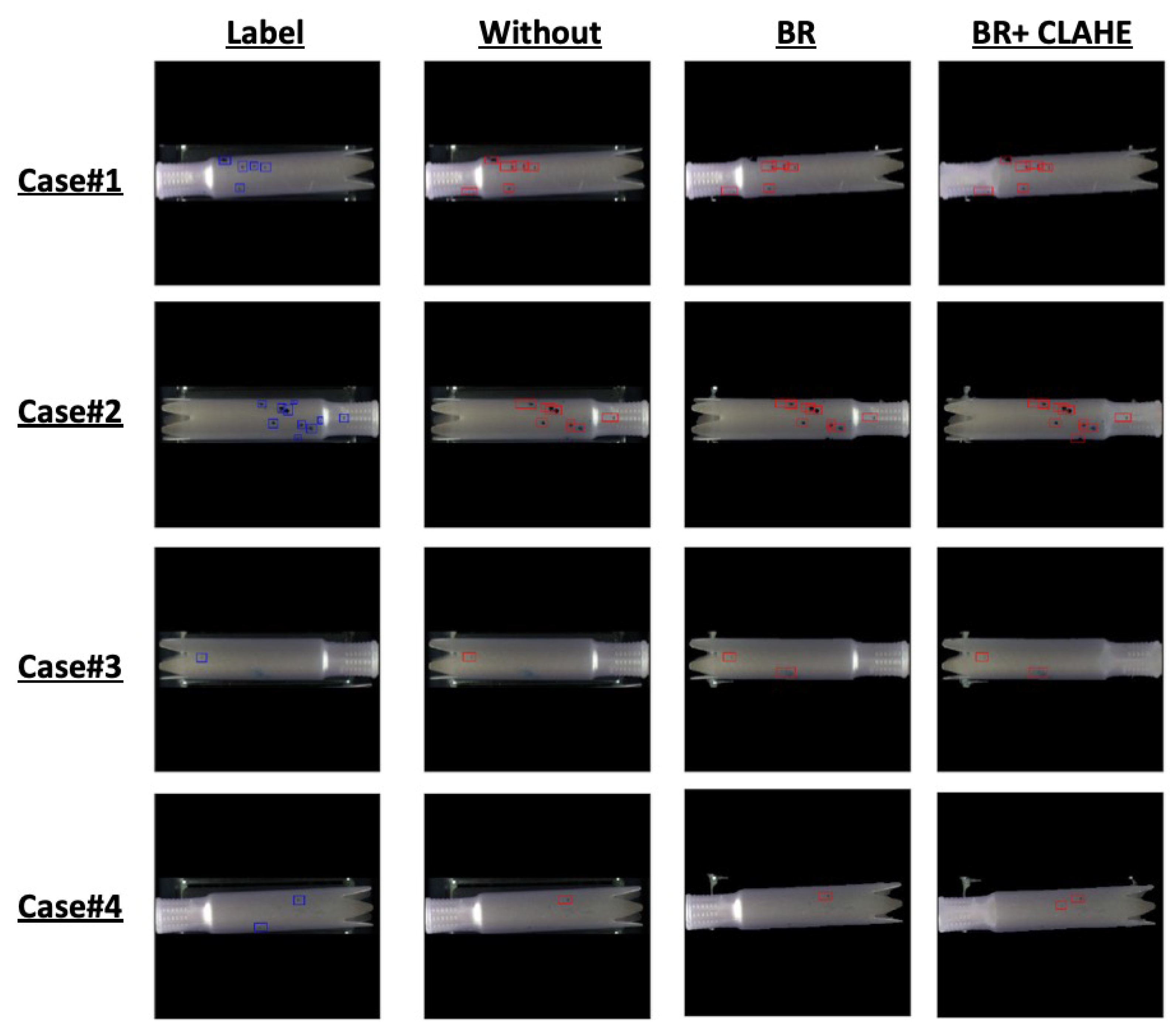
- By applying the object-detection model (YOLOv4) on site, we have experienced some malfunctions that detected the conveyor and light as defects. We used a data-centric approach to solve the problem. Instead of the micro-adjusting the model, we have applied different data pre-processing techniques to overcome the malfunction. To validate the performance of the data pre-processing methods, we have conducted an experiment that compares the different combinations of data pre-processing techniques based on the validation metrics such as Accuracy, F1-score, Precision, Recall, and Average Precision. We generated a dataset of 1534 normal and 908 NG (No Good) images for the experiment, labeled with skilled inspectors’ help.
2. Related Work
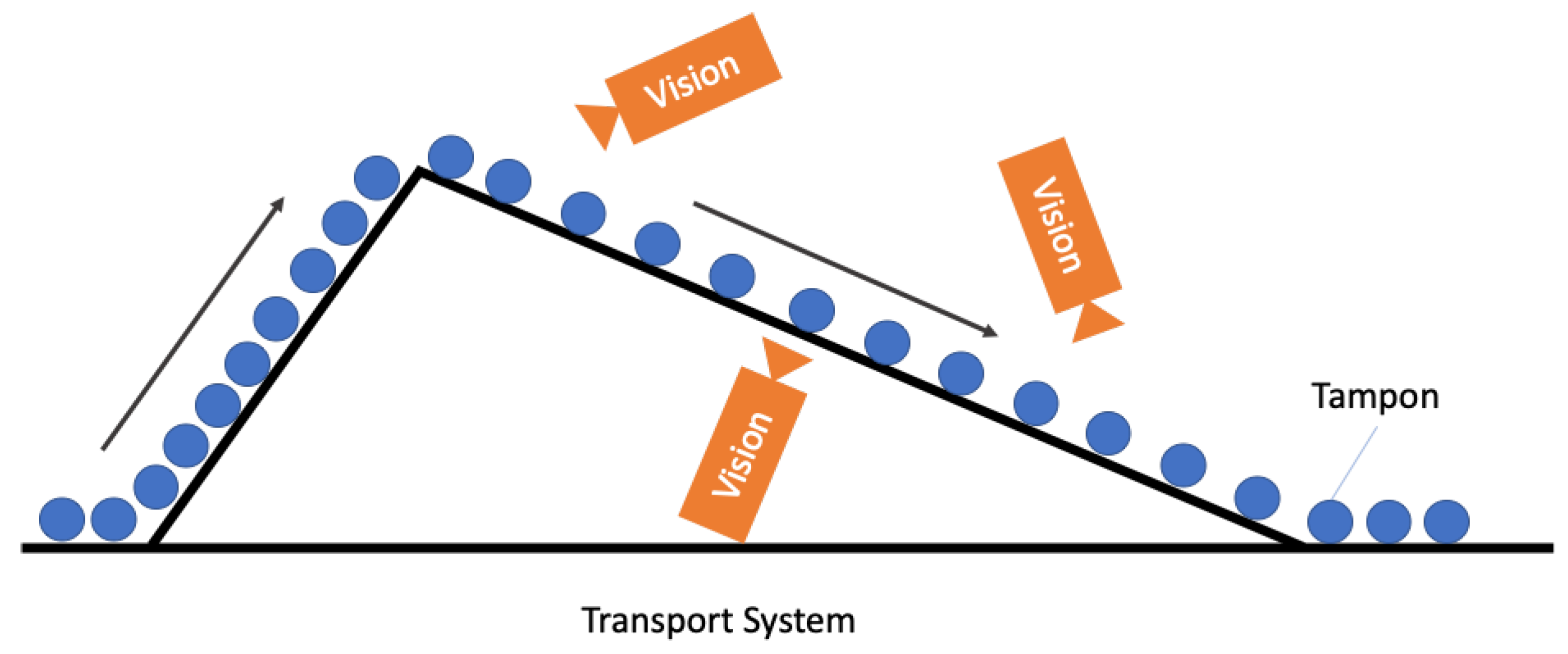
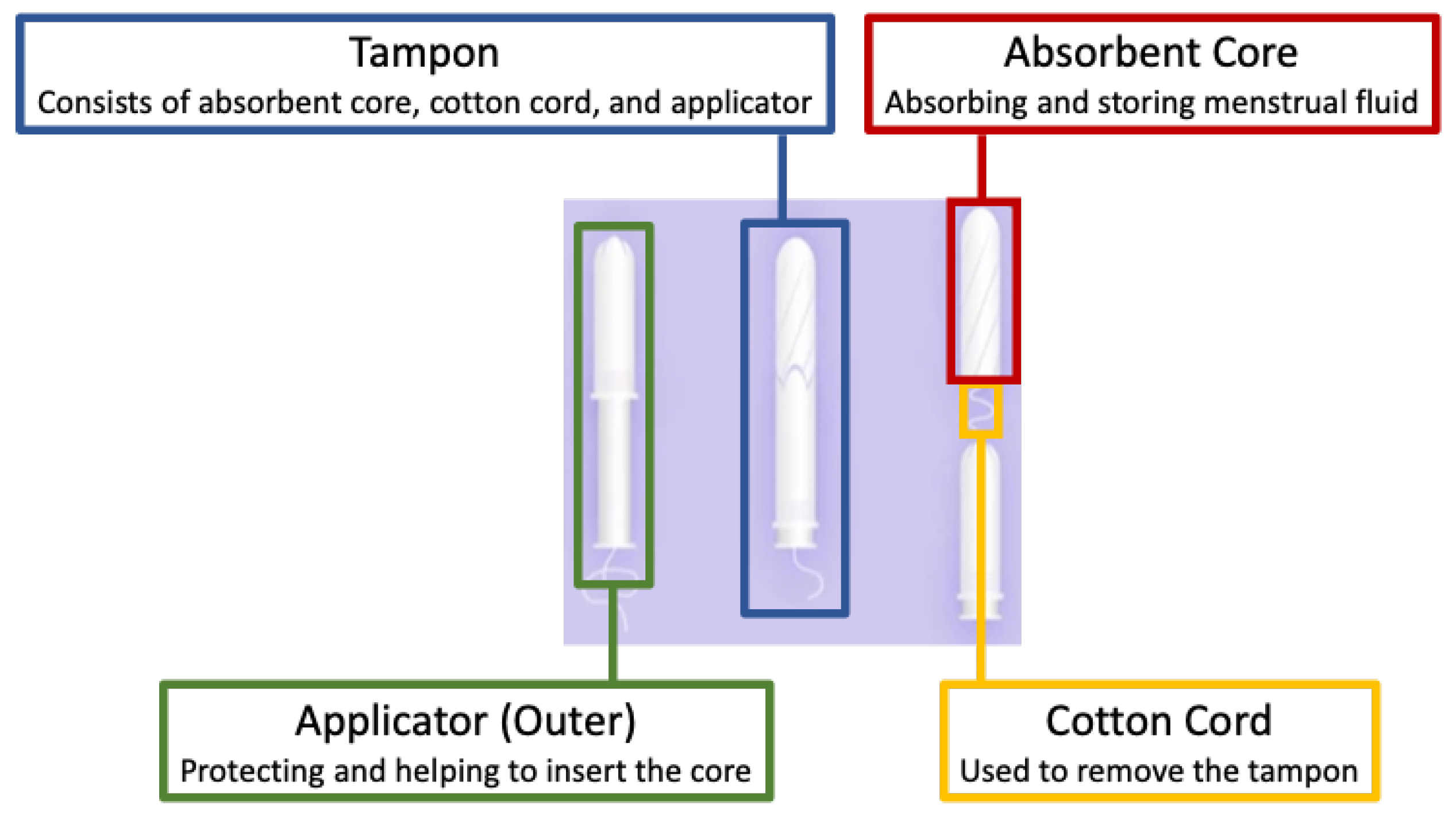
2.1. Tampon Inspection Unit
2.2. AI Technologies Applied for Industrial Applications
3. A Surface-Inspection System Based on Deep Learning
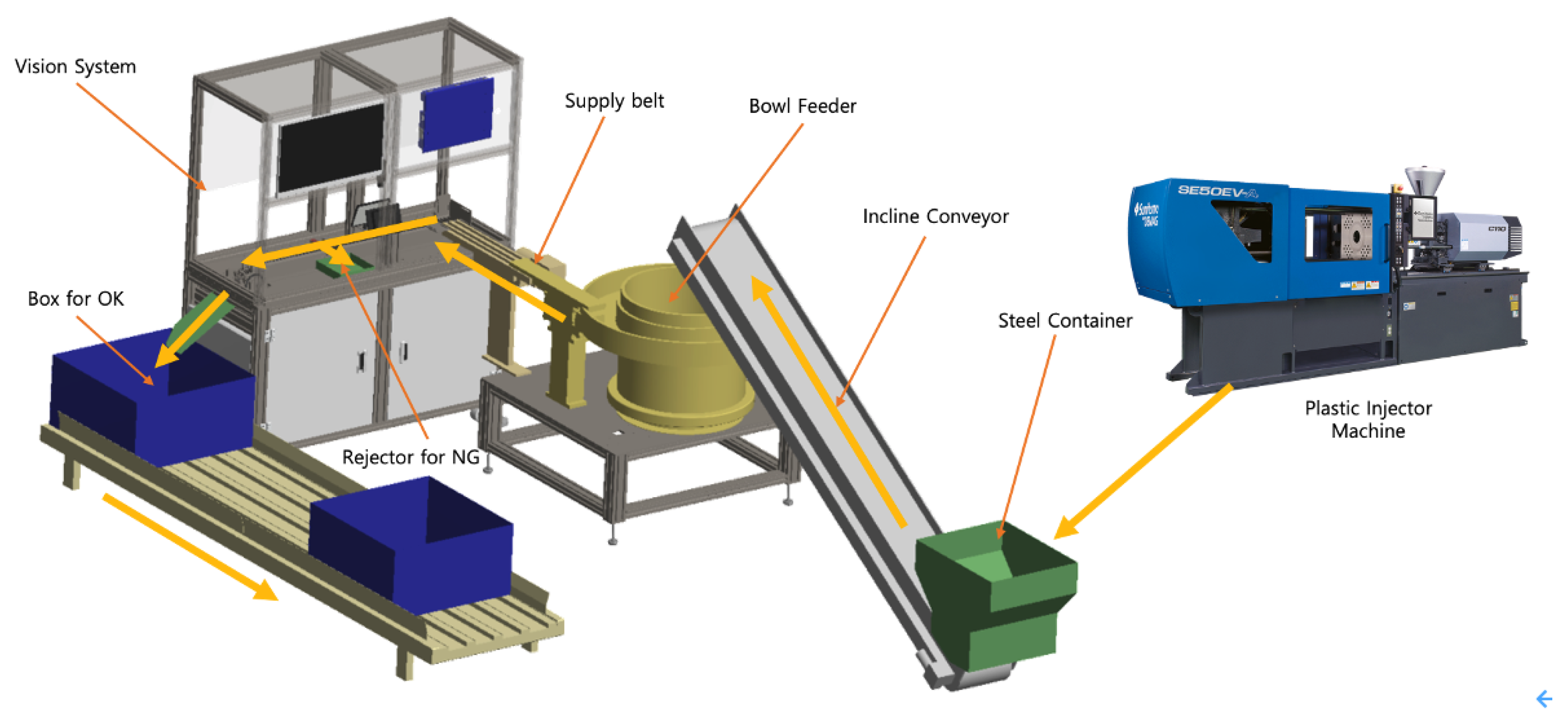
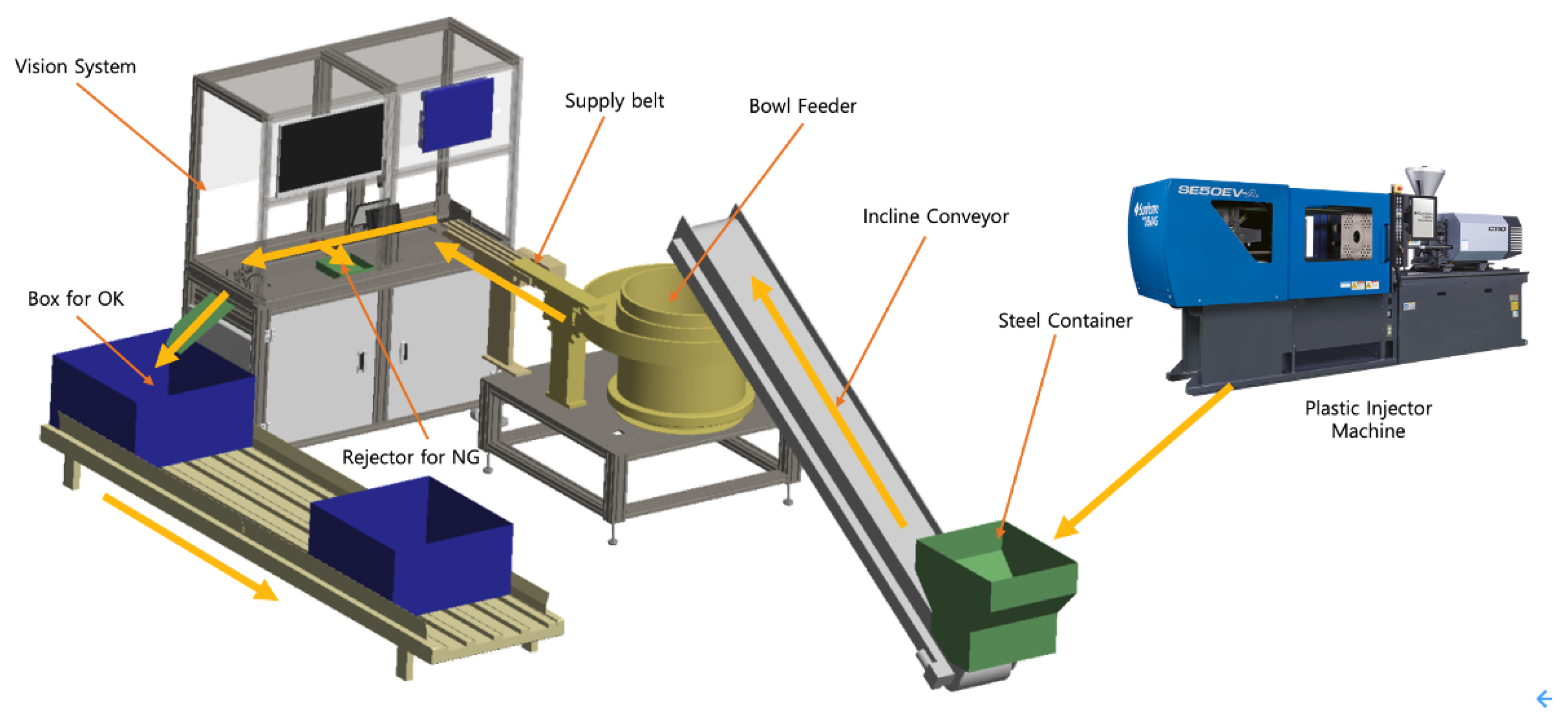
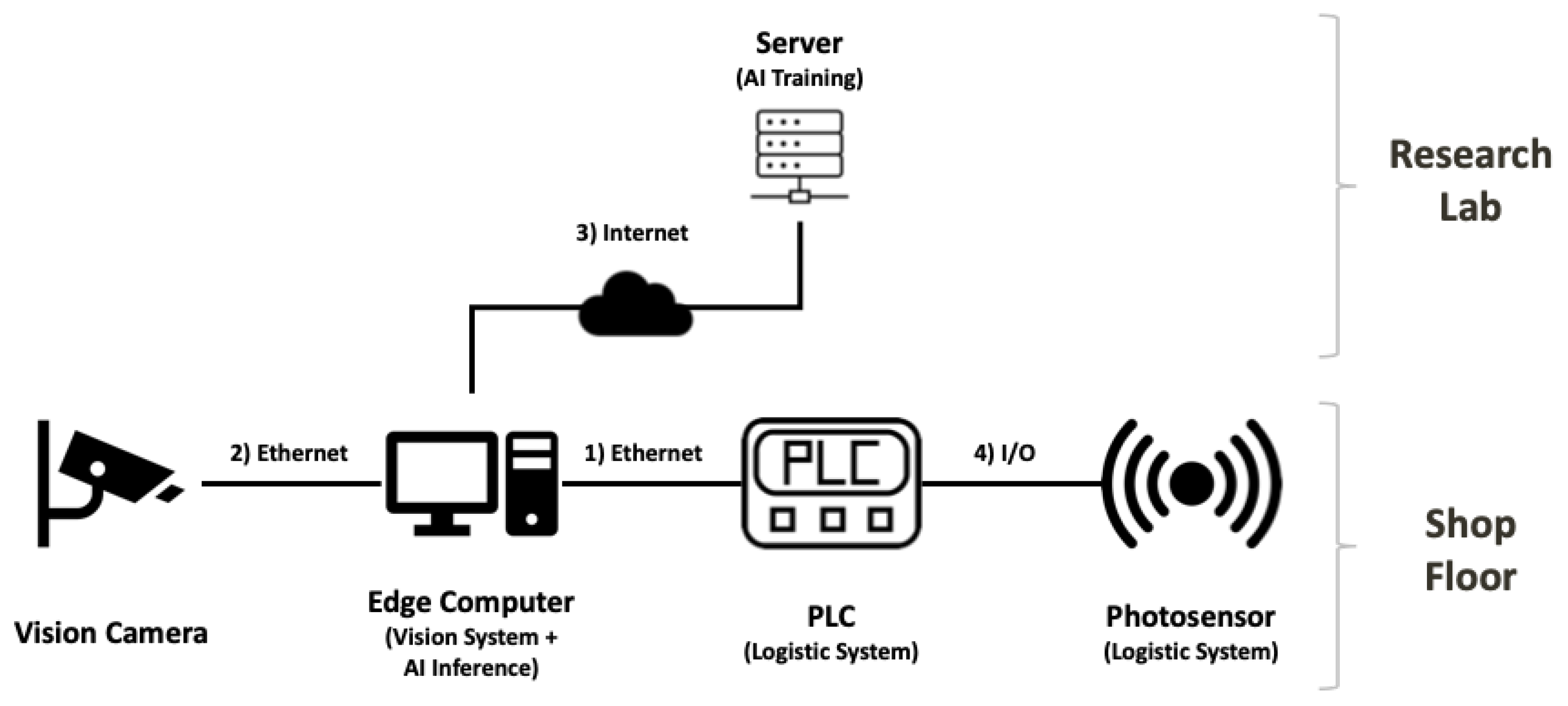
3.1. System Architecture
- Drop of the applicators from the plastic injection molding machine to the steel container.
- Transport of the applicators from the steel container to the bowl feeder with the incline conveyor.
- Transport of the products from the bowl feeder to the supply belt.
- The supply belt shoots each applicator to the inspection conveyor.
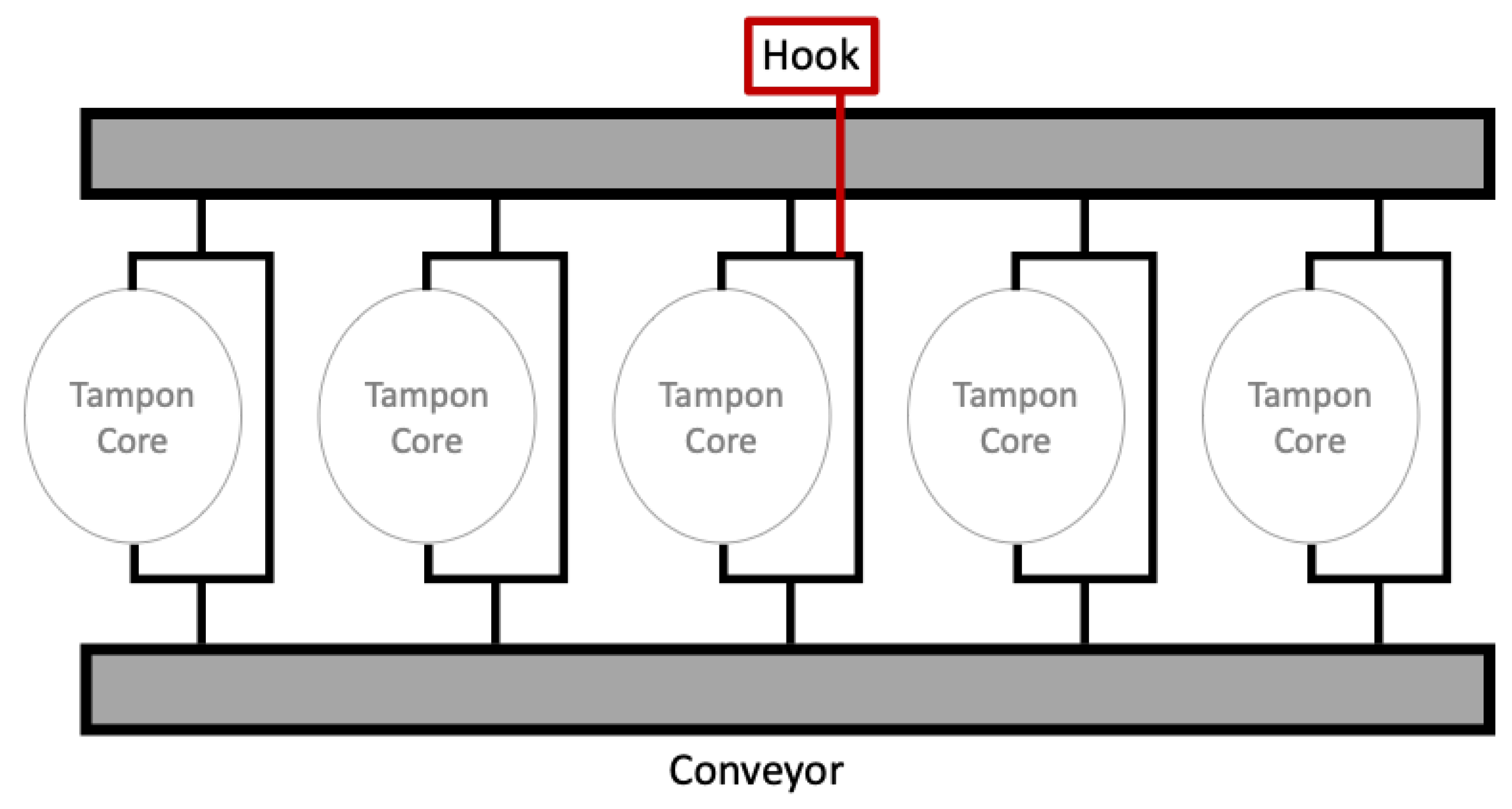
- The tray-based conveyor transports the applicators to the inspection station.
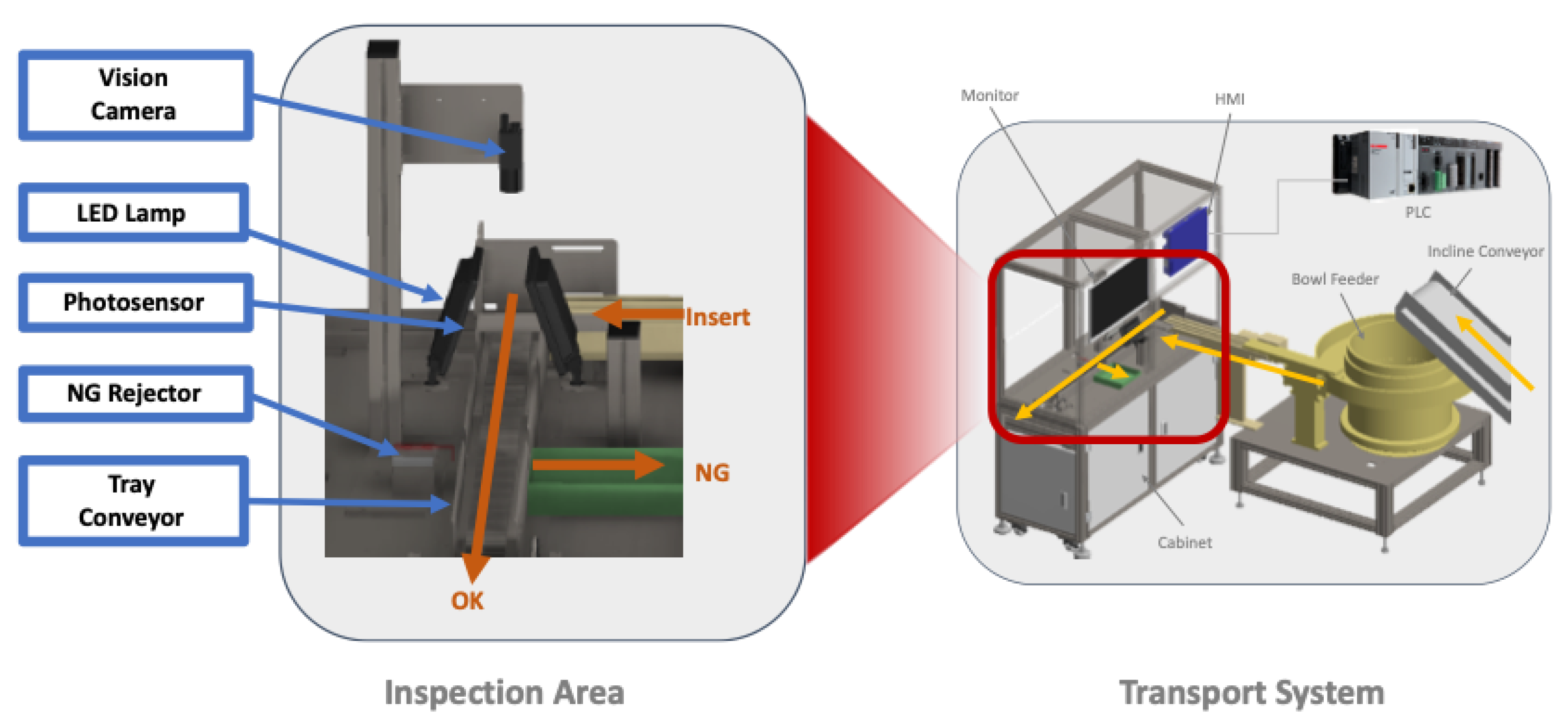
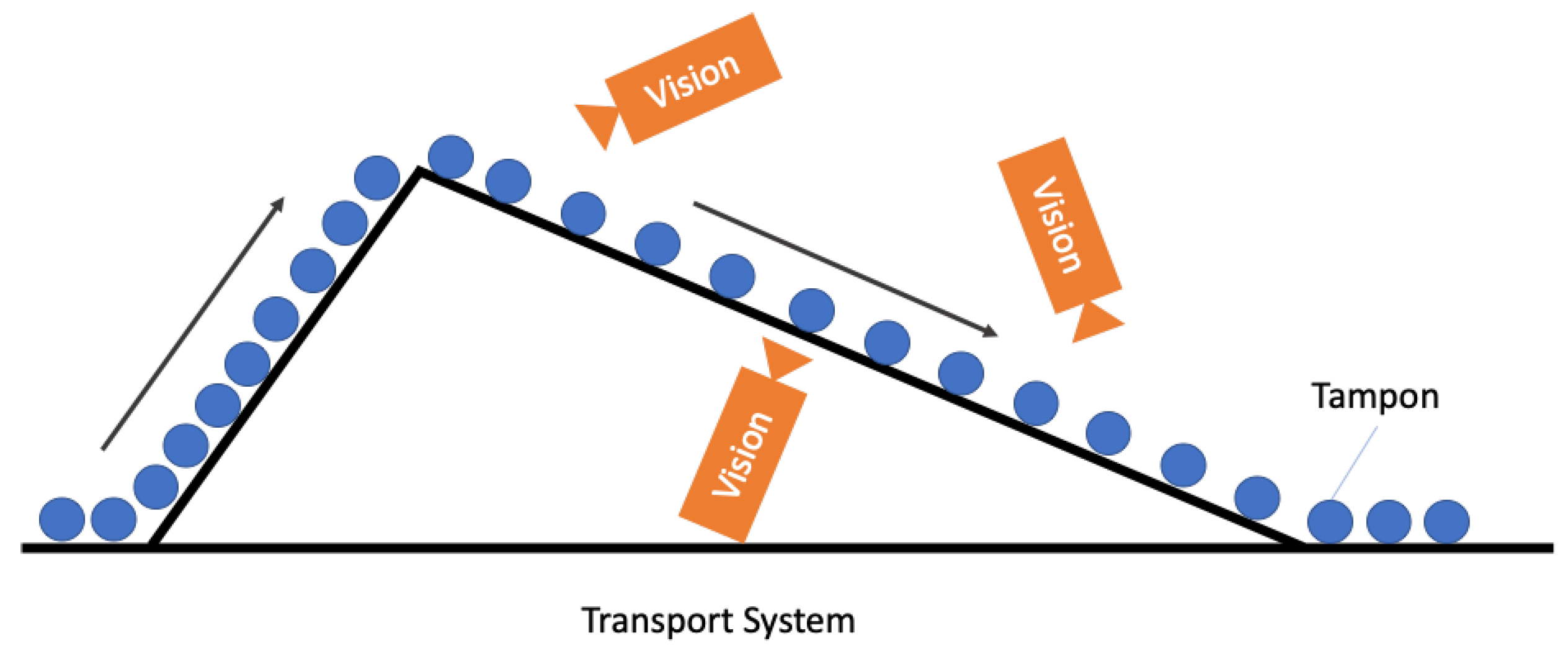
- Data acquisition of the rolling applicators by the vision camera.
- Data transfer from the vision camera to the ECD for AI inference.
- Data pre-processing and defect inspection by AI.
- Position values of the trays captured by the photosensors are sent to the PLC.
- Discharge of the defective products by the NG rejector.
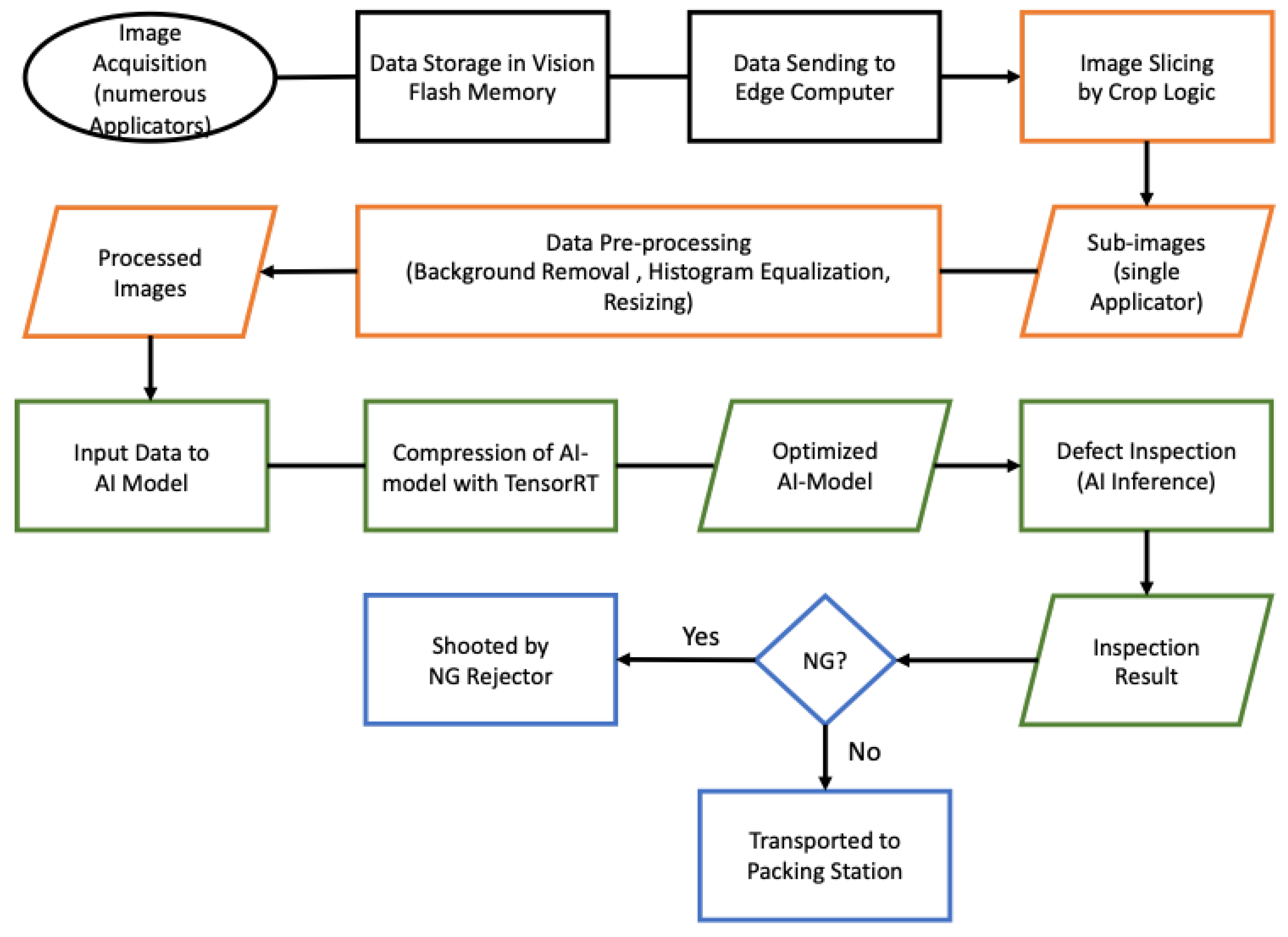
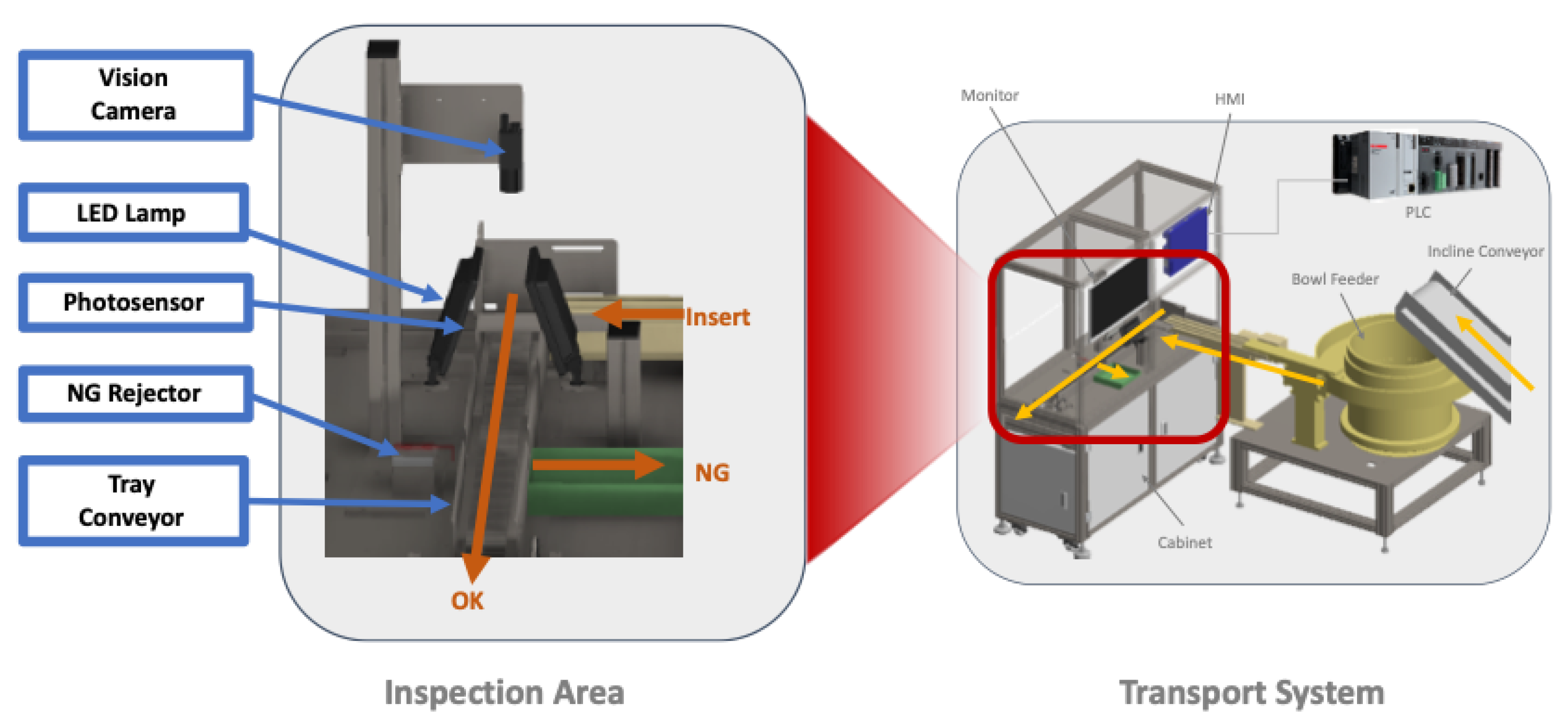
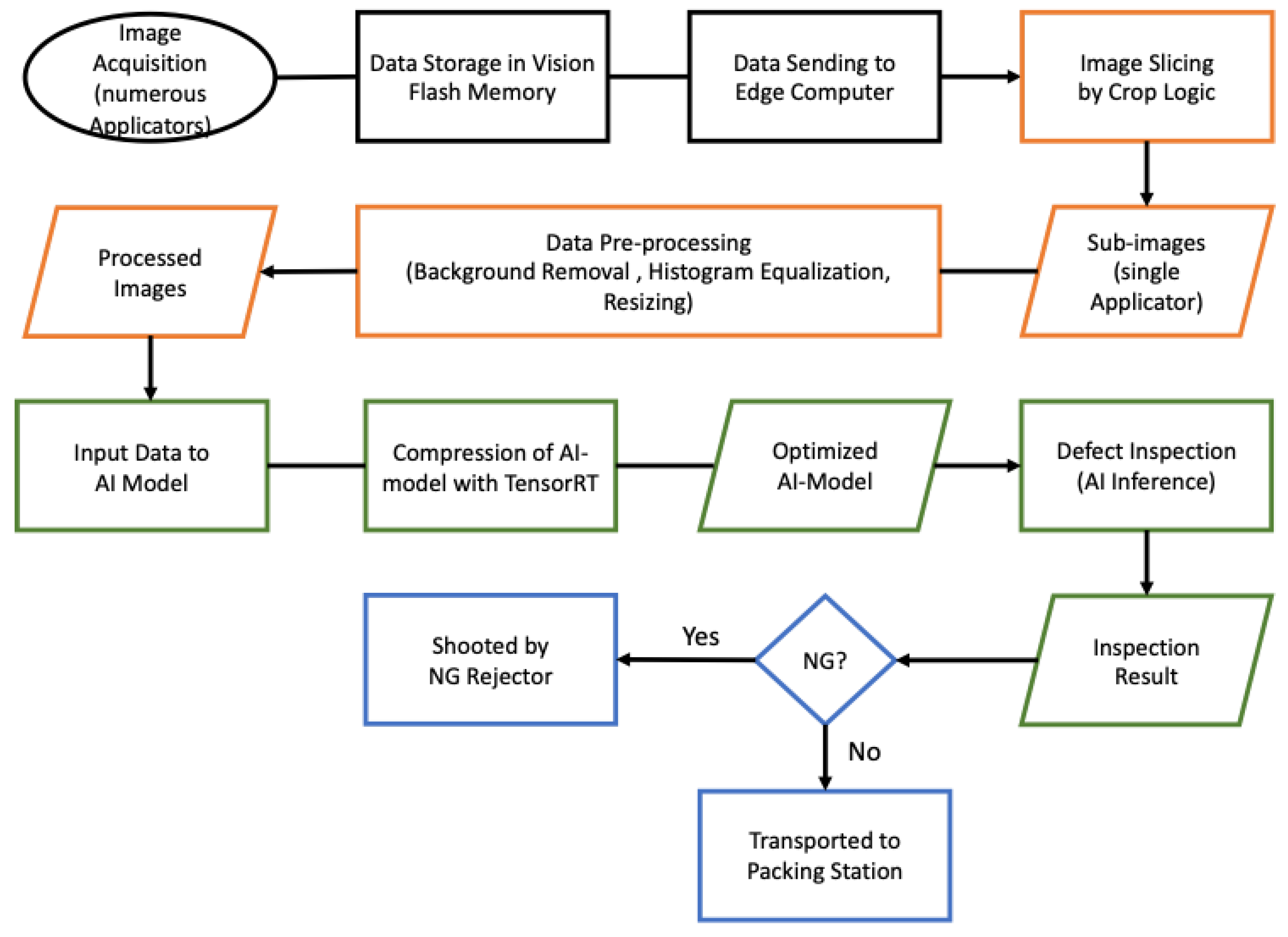
3.2. Inspection Mechanism
- Data Acquisition (in black)
- Data Pre-Processing (orange)
- Model Optimization and Inference (green)
- Machine Control (blue)
| Algorithm 1: CLAHE. |
| Input: Original Image I; |
| 1. Resizing I to M x M; Decompose I→ (n) tiles; (n) ←; |
| 2. ← histogram(n); // histogram of a m x m tile; |
| 3. Clip limit: ← x ; // ←; // → number of gray levels in the tile; // , → number of pixels in the x, y dimensions of a tile; // ← 0.002 // normalized contrast limit; |
| 4. Clipping of using ; // For gray levels greater than ; let pixels are clipped; |
| 5. → pixels → distribution over the remaining pixels; // contrast limited histogram of each tile after pixel distribution; |
| 6. CLAHE(n) ← Equalization of contrast limited tile histogram using (1); |
| 7. ← bilinear interpolation of CLAHE processed n tiles; // combining neighborhood tiles |
| return CLAHE processed Image ; |
4. Experimental Setup
4.1. Metrics and Hypotheses
4.2. Dataset and Parameters
4.3. Results
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Villalba-Diez, J.; Wellbrock, W.; Schmidt, D.; Gevers, R.; Ordieres-Meré, J.; Buchwitz, M. Deep learning for industrial computer vision quality control in the printing industry 4.0. Sensors 2019, 19, 3987. [Google Scholar] [CrossRef] [Green Version]
- Weimer, D.; Scholz-Reiter, B.; Shpitalni, M. Design of deep convolutional neural network architectures for automated feature extraction in industrial inspection. Manuf. Technol. 2016, 65, 417–420. [Google Scholar] [CrossRef]
- Liau, Y.; Ryu, K. Framework of Automated Inspection System for Real-time Injection Molding. In Proceedings of the 2017 Journal of Academic Conference of the Korean Society of Business Administration and Sciences, Yeosu, Korea, 26–29 April 2017. [Google Scholar]
- Liu, B.; Wu, S.; Zou, S. Automatic detection technology of surface defects on plastic products based on machine vision. In Proceedings of the 2010 International Conference on Mechanic Automation and Control Engineering (MACE2010), Wuhan, China, 26–28 June 2010. [Google Scholar]
- Czimmermann, T.; Ciuti, G.; Milazzo, M.; Chiurazzi, M.; Roccella, S.; Oddo, C.M. Visual-Based Defect Detection and Classification Approaches for Industrial Applications—A Survey. Sensors 2020, 20, 1459. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Scholz-Reiter, B.; Weimer, D.; Thamer, H. Automated surface inspection of cold-formed micro-parts. Cirp Ann.-Manuf. Technol. 2012, 61, 531–534. [Google Scholar] [CrossRef]
- Kumar, A. Computer-Vision-Based Fabric Defect Detection: A Survey. IEEE Trans. Ind. Electron. 2008, 55, 348–363. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef]
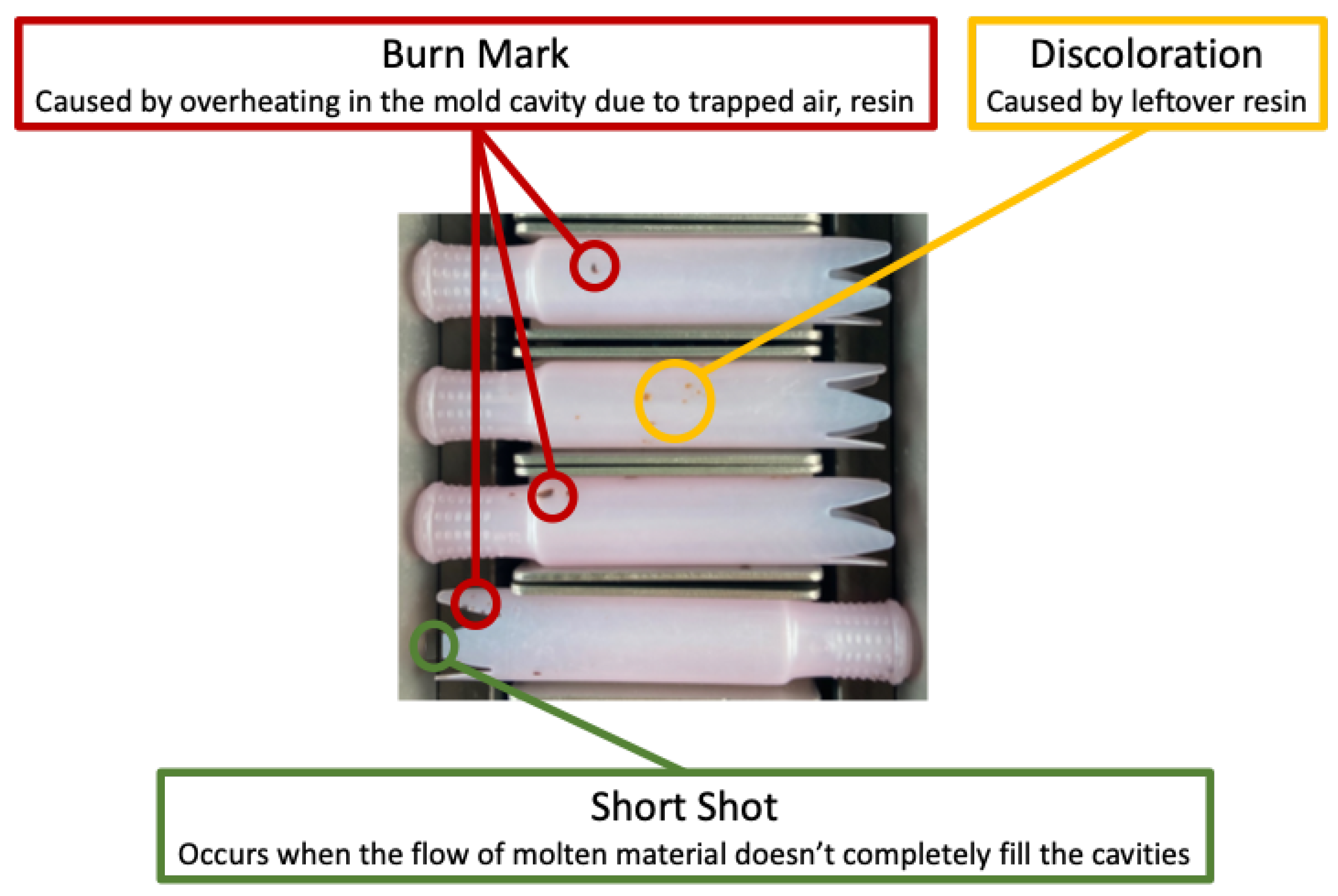
- 11 Injection Molding Defects and How to Prevent Them. Available online: https://www.intouch-quality.com/blog/injection-molding-defects-and-how-to-prevent (accessed on 22 August 2021).
- Tatzer, P.; Wögerer, C.; Panner, T.; Nittmann, G. Tampon Inspection Unit—Automation and Image Processing Application in an Industrial Production Process. IFAC Proc. 2004, 37, 395–400. [Google Scholar] [CrossRef]
- Xie, X. A review of recent advances in surface defect detection using texture analysis techniques. Electron. Lett. Comput. Vis. Image Anal 2008, 7, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Wen, G.; Gao, Z.; Cai, Q.; Wang, Y.; Mei, S. A Novel Method Based on Deep Convolutional Neural Networks for Wafer Semiconductor Surface Defect Inspection. IEEE Trans. Instrum. Meas. 2020, 69, 9668–9680. [Google Scholar] [CrossRef]
- Scharcanski, J. Stochastic Texture Analysis for Measuring Sheet Formation Variability in the Industry. IEEE Trans. Instrum. Meas. 2006, 55, 1778–1785. [Google Scholar] [CrossRef]
- Schneider, D.; Merhof, D. Blind weave detection for woven fabrics. Pattern Anal. Appl. 2015, 18, 725–737. [Google Scholar] [CrossRef]
- Basile, T.M.A.; Caponetti, L.; Castellano, G.; Sforza, G. A texture-based image processing approach for the description of human oocyte cytoplasm. IEEE Trans. Instrum. Meas. 2010, 59, 2591–2601. [Google Scholar] [CrossRef]
- Lecun, Y.; Boxer, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yang, J.; Fu, G.; Zhu, W.; Cao, Y.; Yang, M.Y. A Deep Learning-Based Surface Defect Inspection System Using Multiscale and Channel-Compressed Features. IEEE Trans. Instrum. Meas. 2020, 69, 8032–8042. [Google Scholar]
- Zhong, J.; Liu, Z.; Han, Z.; Han, Y.; Zhang, W. A CNN-Based Defect Inspection Method for Catenary Split Pins in High-Speed Railway. IEEE Trans. Instrum. Meas. 2019, 68, 2849–2860. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Liyun, X.; Boyu, L.; Hong, M.; Xingzhong, L. Improved Faster R-CNN algorithm for defect detection in powertrain assembly line. Procedia CIRP 2020, 93, 479–484. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, M.; Zheng, P.; Yang, H.; Zou, J. A smart surface inspection system using faster R-CNN in cloud-edge computing environment. Adv. Eng. Inform. 2020, 43, 101037. [Google Scholar] [CrossRef]
- Oh, S.; Jung, M.; Lim, C.; Shin, S. Automatic Detection of Welding Defects Using Faster R-CNN. Appl. Sci. 2020, 10, 8629. [Google Scholar] [CrossRef]
- Attard, L.; Debono, C.J.; Valentino, G.; Di Castro, M.; Masi, A.; Scibile, L. Automatic Crack Detection using Mask R-CNN. In Proceedings of the 11th International Symposium on Image and Signal Processing and Analysis (ISPA), Dubrovnik, Croatia, 23–25 September 2019; pp. 152–157. [Google Scholar]
- Zhao, G.; Hu, J.; Xiao, W.; Zou, J. A mask R-CNN based method for inspecting cable brackets in aircraft. Chin. J. Aeronaut. 2020. [Google Scholar] [CrossRef]
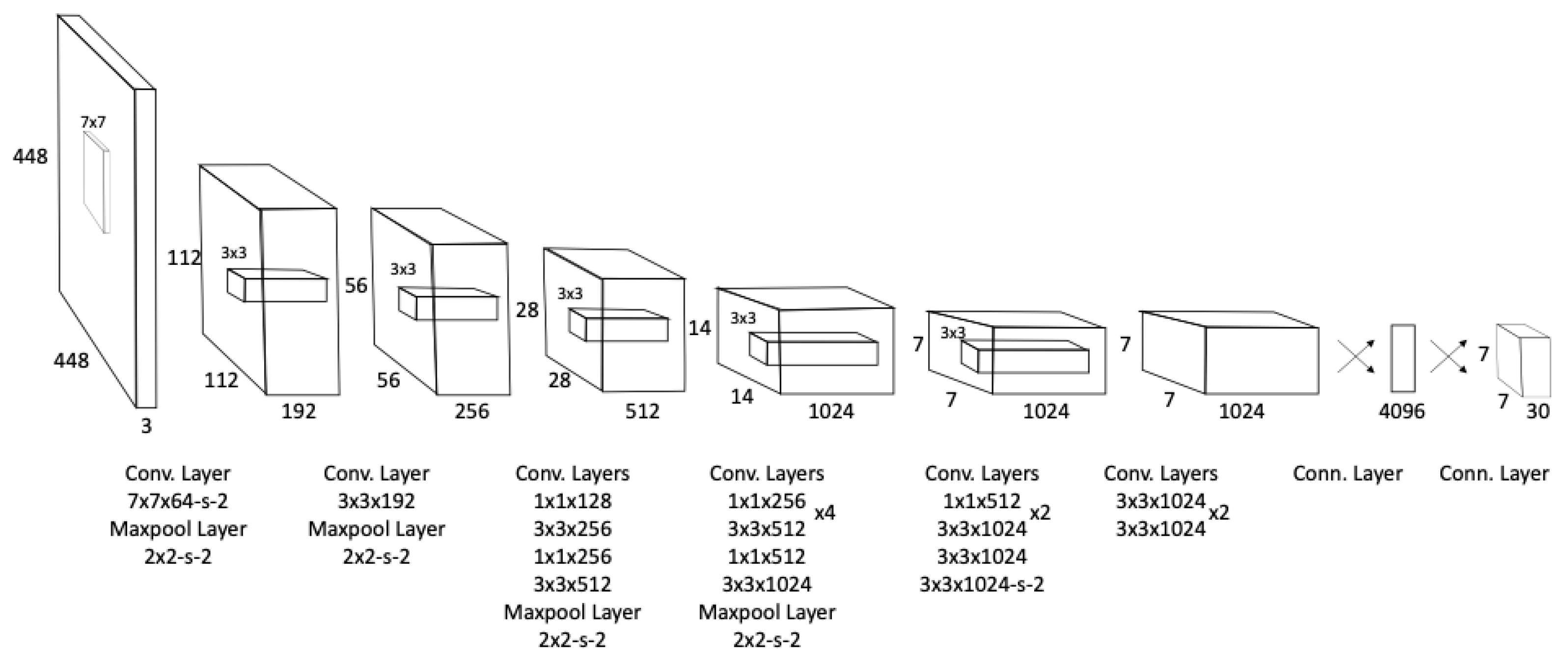
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, CA, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Qiu, Z.; Wang, S.; Zeng, Z.; Yu, D. Automatic visual defects inspection of wind turbine blades via YOLO-based small object detection approach. J. Electron. Imaging 2019, 28, 043023. [Google Scholar] [CrossRef]
- Adibhatla, V.A.; Chih, H.; Hsu, C.; Cheng, J.; Abbod, M.F.; Shieh, J. Defect Detection in Printed Circuit Boards Using You-Only-Look-Once Convolutional Neural Networks. Electronics 2020, 9, 1547. [Google Scholar] [CrossRef]
- Wu, W.; Li, Q. Machine Vision Inspection of Electrical Connectors Based on Improved Yolo v3. IEEE Access 2020, 8, 166184–166196. [Google Scholar] [CrossRef]
- Shi, Q.; Li, C.; Guo, B.; Wang, Y.; Tian, H.; Wen, H.; Meng, F.; Duan, X. Manipulator-based autonomous inspections at road checkpoints: Application of faster YOLO for detecting large objects. Def. Technol. 2020, in press. [Google Scholar] [CrossRef]
- Hsieh, C.; Lin, Y.; Tsai, L.; Huang, W.; Hsieh, S.; Hung, W. Offline Deep-learning-based Defective Track Fastener Detection and Inspection System. Sens. Mater. 2020, 32, 3429–3442. [Google Scholar] [CrossRef]
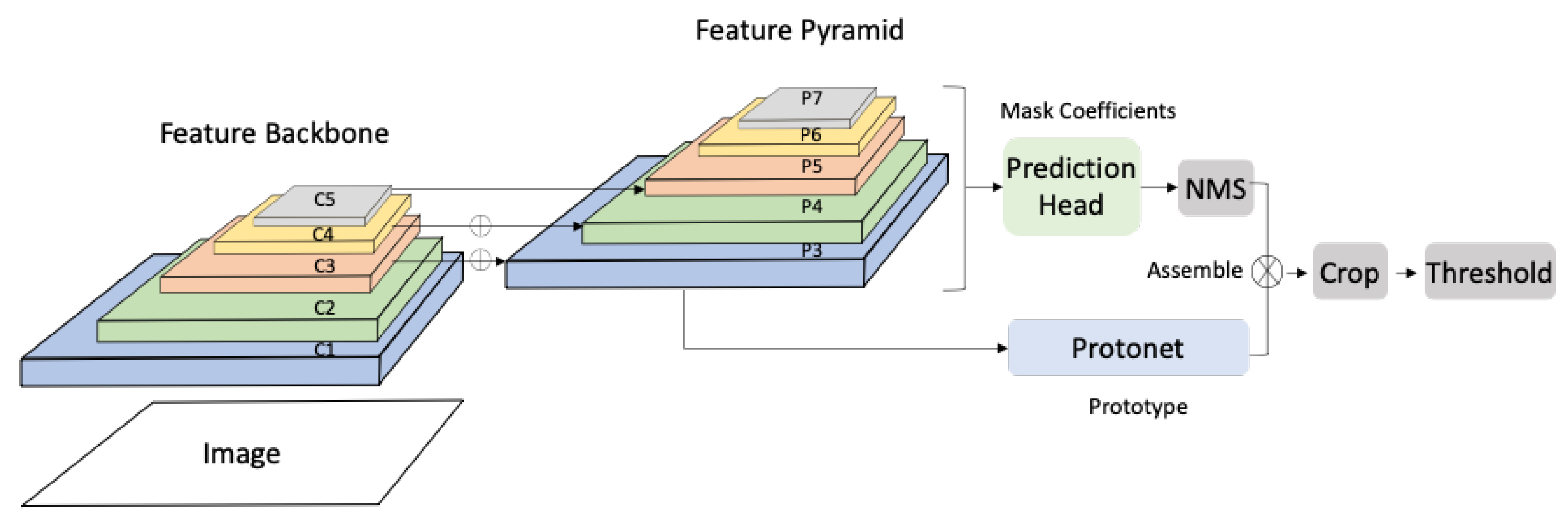
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-time instance segmentation. In Proceedings of the 2019 IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9156–9165. [Google Scholar]
- Guo, F.; Qian, Y.; Wu, Y.; Leng, Z.; Yu, H. Automatic railroad track components inspection using real-time instance segmentation. Comput.-Aided Civ. Infrastruct. Eng. 2021, 36, 362–377. [Google Scholar] [CrossRef]
- Pan, Z.; Yang, J.; Wang, X.; Wang, F.; Azim, I.; Wang, C. Image-based surface scratch detection on architectural glass panels using deep learning approach. Constr. Build. Mater. 2021, 282, 122717. [Google Scholar] [CrossRef]
- Sambasivan, N.; Kapania, S.; Highfill, H.; Akrong, D.; Kumar, P.P.; Aroyo, L.M. “Everyone wants to do the model work, not the data work”: Data Cascades in High-Stakes AI. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar]
- Andrew Ng Launches A Campaign For Data-Centric, AI. Available online: https://www.forbes.com/sites/gilpress/2021/06/16/andrew-ng-launches-a-campaign-for-data-centric-ai/ (accessed on 22 August 2021).
- Tang, Z.; Tian, E.; Wang, Y.; Wang, L.; Yang, T. Nondestructive Defect Detection in Castings by Using Spatial Attention Bilinear Convolutional Neural Network. IEEE Trans. Ind. Inform. 2021, 17, 82–89. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Y.; Zhu, Q.; Mao, J.; Xiao, C.; Lu, X.; Zhang, H. A Surface Defect Detection Framework for Glass Bottle Bottom Using Visual Attention Model and Wavelet Transform. IEEE Trans. Ind. Inform. 2020, 16, 2189–2201. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Edge Computing Device | Server | |
|---|---|---|
| H/W | Intel® Core™ i9-10900 @ 2.80 GHz | Intel® Core™ i9-10900X @ 3.70 GHz |
| 32 GB RAM | 128 GB RAM | |
| 1/Nvidia Geforce RTX2080(Ti) GPU | 4/Nvidia Geforce RTX2080(Ti) GPU | |
| S/W | Ubuntu LTS 18.04.1 | Ubuntu LTS 18.04.1 |
| Python 3.6.9 | Python 3.6.9 | |
| Tensorflow 2.3.1 | Tensorflow 2.3.1 | |
| Docker 19.03.12 | Docker 19.03.12 |
| Normal | Defect | Total | |
|---|---|---|---|
| Total Data | 1534 (62.8%) | 908 (37.2%) | 2442 (100%) |
| Training Data | 0 (0%) | 800 (100%) | 800 (100%) |
| Test Data | 1534 (93.5%) | 108 (6.5%) | 1642 (100%) |
| Backbone | Batch | Input | Optimizer | Learning Rate | Beta1 | Beta2 |
|---|---|---|---|---|---|---|
| CSPDarknet53 | 8 | 320 × 320 | Adam | 0.001 | 0.9 | 0.999 |
| Data Pre-Processing | Precision | Recall | F1-Score | Accuracy |
|---|---|---|---|---|
| Without | 1 | 0.75 | 0.86 | 0.98 |
| BR | 0.82 | 0.75 | 0.78 | 0.97 |
| CLAHE | 0.76 | 0.76 | 0.76 | 0.97 |
| BR + CLAHE | 0.49 | 0.74 | 0.59 | 0.93 |
| Data Pre-Processing | Precision | Recall | AP50 |
|---|---|---|---|
| Without | 0.49 | 0.56 | 40.39 |
| BR | 0.55 | 0.53 | 38.75 |
| CLAHE | 0.53 | 0.50 | 36.16 |
| BR + CLAHE | 0.53 | 0.52 | 37.43 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Im, D.; Lee, S.; Lee, H.; Yoon, B.; So, F.; Jeong, J. A Data-Centric Approach to Design and Analysis of a Surface-Inspection System Based on Deep Learning in the Plastic Injection Molding Industry. Processes 2021, 9, 1895. https://doi.org/10.3390/pr9111895
Im D, Lee S, Lee H, Yoon B, So F, Jeong J. A Data-Centric Approach to Design and Analysis of a Surface-Inspection System Based on Deep Learning in the Plastic Injection Molding Industry. Processes. 2021; 9(11):1895. https://doi.org/10.3390/pr9111895
Chicago/Turabian StyleIm, Donggyun, Sangkyu Lee, Homin Lee, Byungguan Yoon, Fayoung So, and Jongpil Jeong. 2021. "A Data-Centric Approach to Design and Analysis of a Surface-Inspection System Based on Deep Learning in the Plastic Injection Molding Industry" Processes 9, no. 11: 1895. https://doi.org/10.3390/pr9111895
APA StyleIm, D., Lee, S., Lee, H., Yoon, B., So, F., & Jeong, J. (2021). A Data-Centric Approach to Design and Analysis of a Surface-Inspection System Based on Deep Learning in the Plastic Injection Molding Industry. Processes, 9(11), 1895. https://doi.org/10.3390/pr9111895