1. Introduction
Statistical process monitoring is one of the most intensely-studied problems for the modern process industry. With the rising need for sustainable operation, it has been attracting extensive research effort in the last few decades [
1,
2]. The key step of statistical process monitoring is to define normal operating regions by applying statistical techniques to data samples obtained from the process system. Typical examples of such techniques include principal component analysis (PCA) [
3,
4,
5,
6], partial least squares [
7,
8,
9], independent component analysis [
10,
11], and support vector machine [
12,
13]. Any data sample that does not lie in the normal operating region is then classified as a fault, and its root cause needs to be identified through fault diagnosis.
Recently, deep learning and neural networks have been widely used for the purpose of statistical process monitoring, where both supervised and unsupervised learning algorithms have been implemented. In designing process monitoring systems in a supervised manner, various types of neural networks have been used, such as feedforward neural networks [
14], deep belief networks [
15], convolutional neural networks [
16], and recurrent neural networks [
17]. In the case of unsupervised learning, the autoassociative neural network (also known as an autoencoder), which has been proposed as a nonlinear generalization of PCA [
18], is typically used [
19,
20,
21]. While the traditional statistical approaches typically rely only on the normal operating data to develop the process monitoring systems, most of the deep learning-based process monitoring studies have adopted supervised learning approaches. However, in the real industrial processes, it is difficult to obtain a large number of data samples for different fault types, which can be used for the training of deep neural networks. Thus, it is important to examine rigorously the potential of autoassociative neural networks as a basis for the design of process monitoring systems.
In the process systems area, the Tennessee Eastman (TE) process, a benchmark chemical process introduced by Downs and Vogel [
22], has been a popular test bed for process monitoring techniques. There already exist a few studies where the process monitoring systems for this process are designed on the basis of autoassociative neural networks [
23,
24,
25]. However, considering the complexity of the neural network training, these studies have two limitations. First, a rigorous case study has not been performed to evaluate the effects of different neural network settings, such as neural network hyperparameters and training objective functions, which can have great impact on the performance of the process monitoring systems. Furthermore, a few thousand normal training samples were used to train neural networks with much more parameters, ranging from a hundred thousand to a million parameters. A larger dataset is required to investigate the effectiveness of unsupervised deep learning for the statistical process monitoring. In addition to the above limitations, there is another issue that is directly related to the structure of autoassociative neural networks. It has been reported that there is a high chance for the principal components, which are extracted using autoassociative neural networks, to be redundant due to the co-adaptation in the early phase of neural network training [
18]. The objective of this work is to address these limitations.
The rest of the article is organized as follows. First, the concept of linear PCA is briefly explained, and how it can be used for the statistical process monitoring is discussed. Then, the information on autoassociative neural networks is provided, and the parallel autoassociative neural network architecture, which was proposed in our previous work [
26] to alleviate the co-adaptation issue mentioned above, is described. This is followed by the description of the statistical process monitoring procedure using autoassociative neural networks. Finally, a comprehensive case study is designed and performed to evaluate the effects of different neural network settings on the process monitoring performance. The dataset used in this study has 250,000 normal training samples, which is much larger than the ones considered in the previous studies.
4. Process Monitoring of the Tennessee Eastman Process
Let us now evaluate the performance of the NLPCA-based statistical process monitoring with the Tennessee Eastman (TE) process as an illustrative example. The TE process is a benchmark chemical process [
22], which involves five major process units (reactor, condenser, compressor, separator, and stripper) and eight chemical compounds (from A–H). A data sample from this process is a vector of 52 variables, and there are 21 programmed fault types. In this work, Faults 3, 9, and 15 are not considered since they are known to be difficult to detect due to no observable change in the data statistics [
41]. The large dataset provided by Rieth et al. [
42] is used in this study, and the data structure is summarized in
Table 1. Note that Fault 21 is not included in this dataset, and thus not considered in this study. This dataset includes data samples from 500 simulation runs as the training data of each operating mode (normal and 20 fault types) and from another 500 simulation runs as the test data of each operating mode. From each simulation run, 500 data samples were obtained for training, while 960 data samples were recorded for testing. Different types of faults were introduced to the process after Sample Numbers 20 and 160 for the fault training and fault testing, respectively.
All the neural networks were trained for 1000 training epochs with the learning rate of 0.001. The rectified linear unit (ReLU) was used as the nonlinear activation function, which is defined as max(0,x). The ADAM optimizer [
43] and the Xavier initialization [
44] were used for the network training. The results reported here are the average values of 10 simulation runs.
In what follows, we first check the validity of the upper control limits estimated using the data only. Then, the performance of the process monitoring using NLPCA is evaluated by analyzing the effects of various neural network settings. Finally, the performance of the NLPCA-based process monitoring is compared with the linear-PCA-based process monitoring.
4.1. Upper Control Limit Estimation
Let us first compare the upper control limits calculated from the
F- and
χ2-distributions and from the data distribution. The objective of this analysis is to show that the dataset used in this study is large enough so that the upper control limits can be well approximated from the data. Another dataset, which contains only 500 normal training samples, is also used for illustration purposes and was obtained from
http://web.mit.edu/braatzgroup/links.html. This dataset and the large dataset from Rieth et al. [
42] will be denoted as the S (small) dataset and L (large) dataset, respectively.
Equations (9) and (10) were used to calculate the upper control limits for the L dataset on the basis of the
F- and
χ2-distributions, while those for the S dataset were computed using Equations (6)–(8). Linear PCA was used to calculate the upper control limits in the principal component space and the residual space with
α = 0.99, and the results are tabulated in
Table 2. Note that, for the L dataset, the control limits obtained directly from the data had almost the same values as the ones from the
F- and
χ2-distributions, while large deviations were observed for the S dataset. Thus, in the subsequent analyses, the control limits obtained directly from the data will be used for both linear PCA and nonlinear PCA.
4.2. Neural Network Hyperparameters
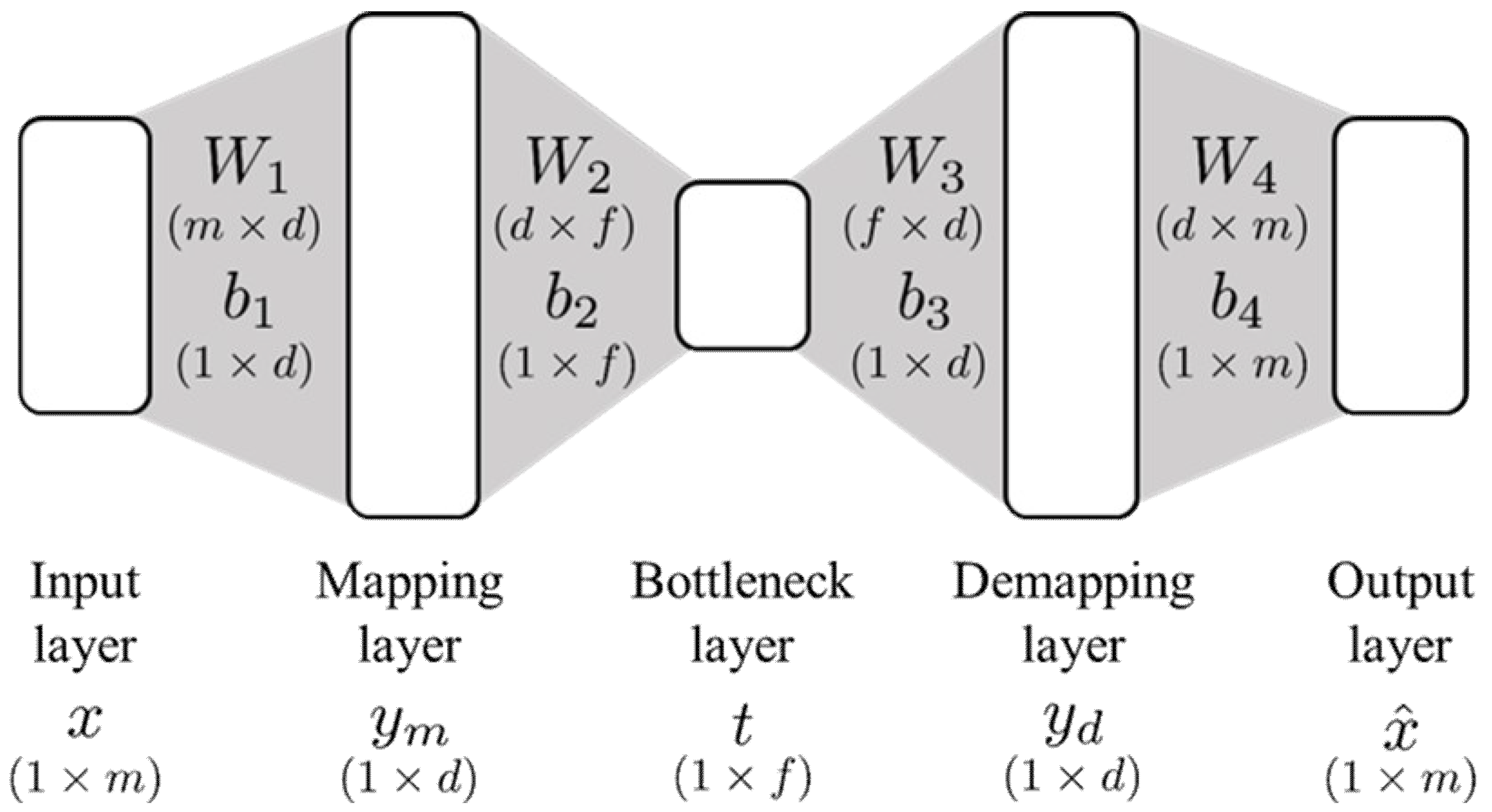
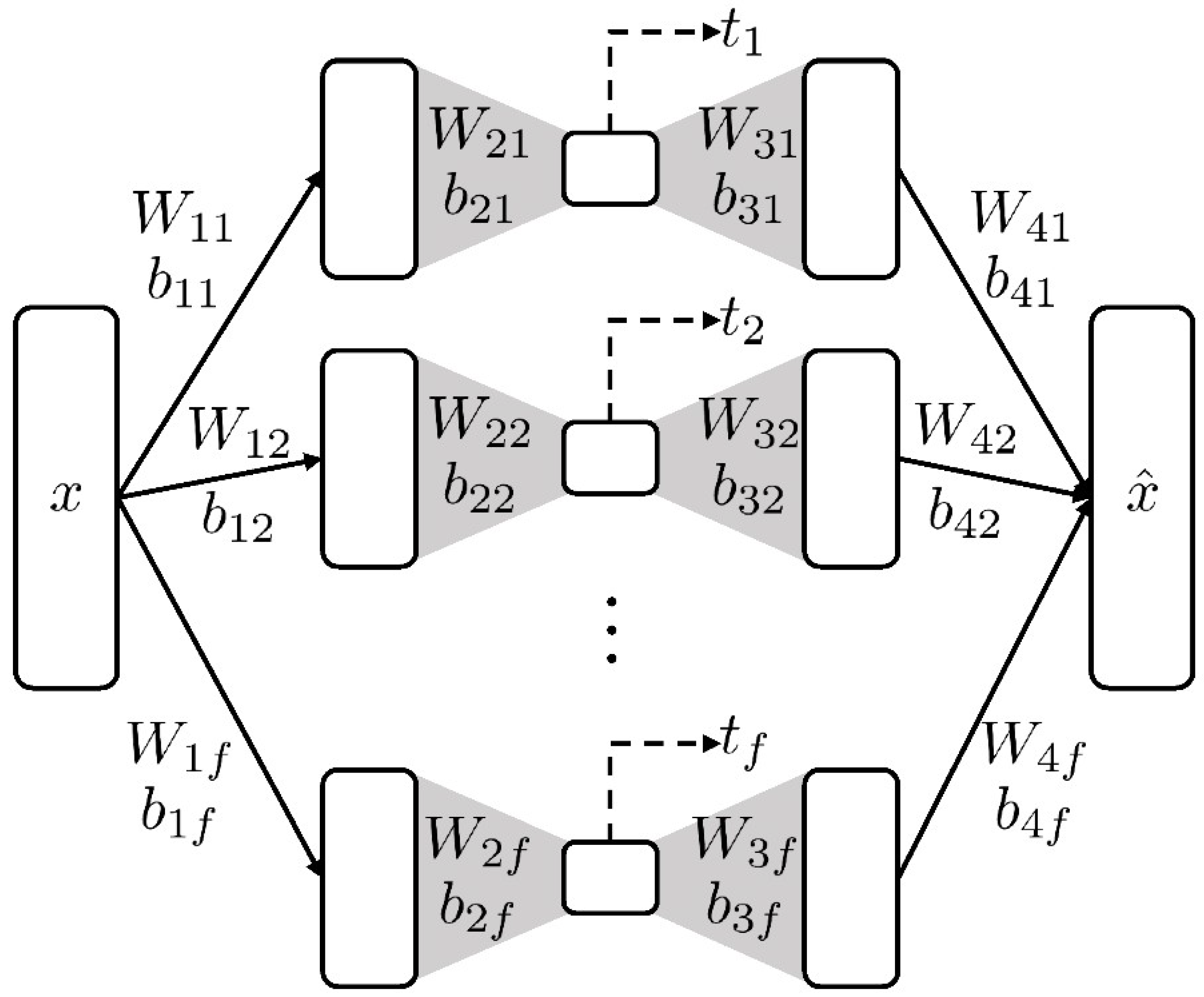
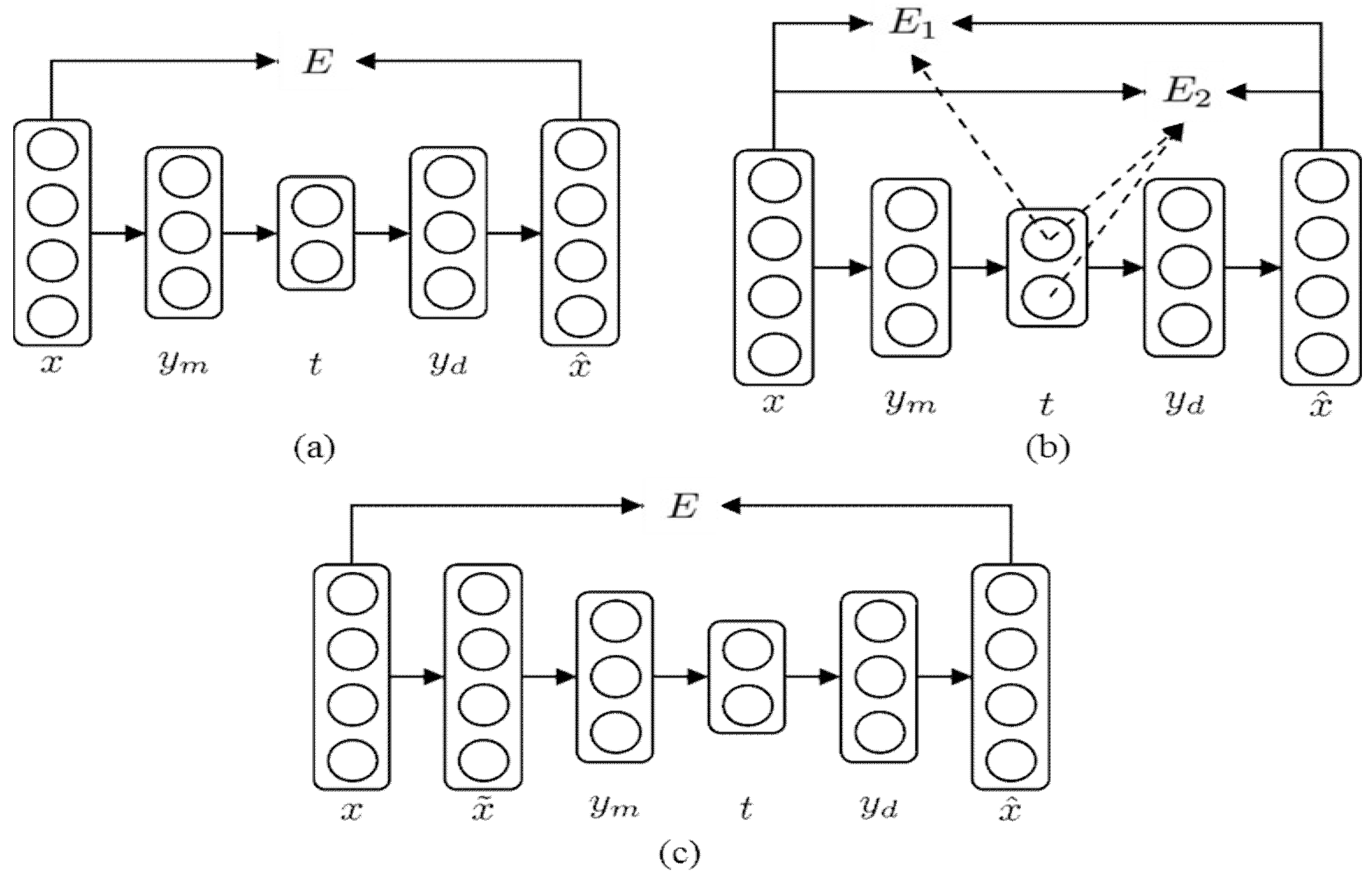
In this work, two neural network architectures were used to evaluate the NLPCA-based process monitoring. The NLPCA methods utilizing the networks shown in
Figure 1 and
Figure 2 will be referred to as sm-NLPCA (simultaneous NLPCA) and p-NLPCA (parallel NLPCA), respectively. The performance of the process monitoring was evaluated by two indices, fault detection rate (FDR) and false alarm rate (FAR). The effects of the following hyperparameters were analyzed:
We designed four different types of neural networks to evaluate the effects of the hyperparameters listed above. Types 1 and 2 had five layers (three hidden layers), while seven layers (five hidden layers) were used for Types 3 and 4. In Types 1 and 3, the numbers of mapping/demapping nodes were fixed at specific values, while they were proportional to the number of principal components to be extracted for Types 2 and 4. The number of parameters for different network types are summarized in
Table 3. The numbers for the network structures represent the number of nodes in each layer starting from the input layer. Note that, for the same network type, p-NLPCA always had fewer parameters compared to sm-NLPCA due to the network decoupling.
Table 4 and
Table 5 show the process monitoring results for Types 1 and 2 and Types 3 and 4, respectively. Note that, in this analysis, only the average value of FDR (over all the fault types) is reported for brevity.
The main trends to note are:
The FDR in the residual space always showed a higher value than that in the principal component space, which matches the results reported in the literature where different techniques were utilized [
45,
46].
In all network types, the FDR in the principal component space was improved with diminishing rates as the number of principal components increased.
On the other hand, the number of principal components, which resulted in the best FDR value in the residual space, was different for different types of neural networks. As the size of the network became larger, the FAR in the residual space increased significantly, and sm-NLPCA completely failed when Network Type 4 was used, classifying the majority of the normal test data as faults. The main reason for this observation was the overfitting of the neural networks. Despite the network overfitting, the FDR in the principal component space was increased by adding more nodes in the mapping/demapping layers, while the FAR in the principal component space was not affected by such addition.
Regarding the last point, in the case of the demapping functions, the input had a lower dimension than the output, which made the problem of approximating demapping functions ill-posed. Thus, it can be speculated that the network overfitting mainly occurred during the reconstruction of the data (i.e., demapping functions were overfitted), leaving the results in the principal component space unaffected by the network overfitting. In addition to this, it was observed that, by including more nodes in the mapping/demapping layers, the average standard deviation of the principal components was increased by a factor of 2~8. This implies that, in Network Types 2 and 4, the normal operating region in the principal component space was more “loosely” defined (i.e., the normal data cluster had a larger volume) compared to Network Types 1 and 3, which can make the problem of approximating the demapping functions more ill-posed. It can also be a reason why the FAR in the principal component space was consistently low regardless of the network size and the degree of network overfitting.
Table 6 shows the FDR values obtained by adjusting the upper control limits such that the FAR became 0.01 for the normal test data. The following can be clearly seen:
By comparing the results from Network Types 1 and 3, adding additional hidden layers was shown to improve the FDR in the principal component space for sm-NLPCA and the FDR in the residual space for p-NLPCA. However, the effects of such addition cannot be evaluated clearly for Network Types 2 and 4. Thus, in what follows, we apply the neural network regularization techniques to Network Types 2 and 4 and evaluate the effects of such techniques on the performance of NLPCA-based process monitoring.
4.3. Neural Network Regularization
In this analysis, we consider three different types of neural network regularization: dropout and
L1 and
L2 regularizations. Dropout is a neural network regularization technique, where randomly-selected nodes and their connections are dropped during the network training to prevent co-adaptation [
47].
L1 and
L2 regularizations prevent network overfitting by putting constraints on the
L1 norm and
L2 norm of the weight matrices, respectively.
The process monitoring results for Network Types 2 and 4 are tabulated in
Table 7 and
Table 8, respectively. In the case of Network Type 2, dropout did not address the problem of overfitting for p-NLPCA, and therefore, the results obtained using dropout are not presented here.
In most cases, neural network regularization degraded the process monitoring performance in the principal component space with p-NLPCA of Network Type 4 regularized by dropout being the only exception.
On the other hand, it dramatically reduced the FAR values in the residual space for sm-NLPCA, while such reduction was not significant for p-NLPCA (the FAR in the residual space even increased for Network Type 2). This indicates that overfitting was a problem for the residual space detection using sm-NLPCA.
Table 9 shows the process monitoring results obtained by adjusting the upper control limits as mentioned in the previous analysis. Overall, p-NLPCA performed better than sm-NLPCA, while sm-NLPCA was better than p-NLPCA in the principal component space when Network Type 4 was used. By comparing the results provided in
Table 6 and
Table 9, it can be seen that having more nodes in the mapping/demapping layers is only beneficial to the process monitoring in the principal component space. Putting more nodes implies the increased complexity of the functions approximated by neural networks. Thus, it makes the problem of approximating demapping functions more ill-posed and has the potential to be detrimental to the performance of process monitoring in the residual space. Although neural network regularization techniques can reduce the stiffness and complexity of the functions approximated by neural networks [
48], they seem to be unable to define better boundaries for one-class classifiers.
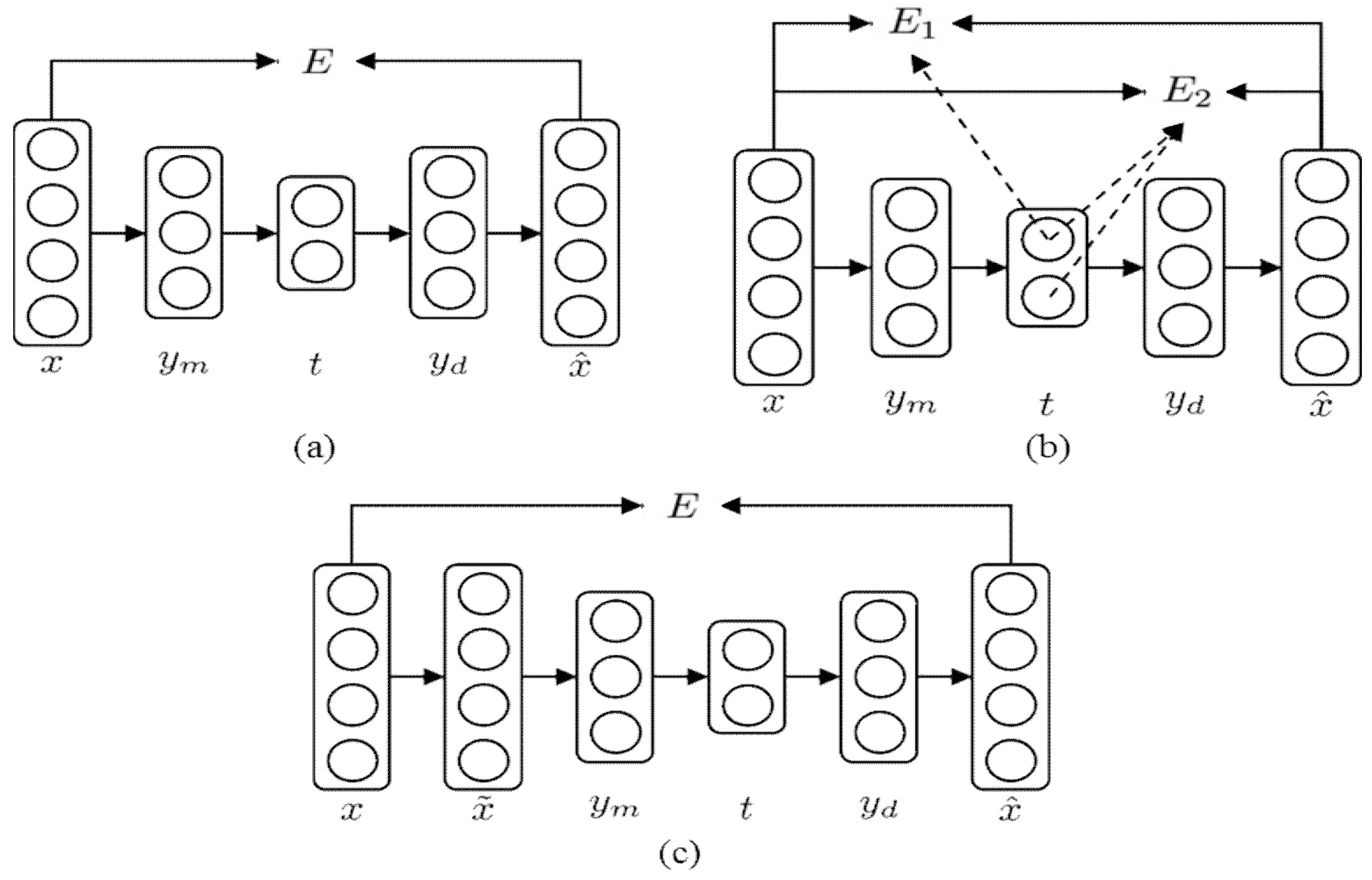
4.4. Network Training Objective Function
Let us now evaluate the effects of different objective functions on the process monitoring performance. For illustration purposes, only Network Type 4 was considered in this analysis. All the values of
αk were set to one for the hierarchical error, and the corrupted input was generated by using a Gaussian noise of zero mean and 0.1 standard deviation for the denoising criterion.
L2 regularization and
L1 regularization were used to prevent overfitting for sm-NLPCA and p-NLPCA, respectively.
Table 10 and
Table 11 summarize the process monitoring results obtained by using the autoassociative neural networks trained with different objective functions.
The following are the major trends to note:
The monitoring performance of sm-NLPCA in the principal component space became more robust by using the hierarchical error, showing similar FDR values regardless of the number of principal components.
However, the FDR value in the principal component space scaled better with the reconstruction error objective function. On the other hand, the monitoring performance of p-NLPCA in the principal component space became more sensitive to the number of principal components with the hierarchical error as the objective function. As a result, the FDR value in the principal component space was improved when the number of principal components was 20.
While the hierarchical error provided a slight improvement to the monitoring performance in the residual space for sm-NLPCA, it degraded the performance of p-NLPCA in the residual space.
The denoising criterion was beneficial to both NLPCA methods in the residual space, improving the FDR values when the upper control limits were adjusted. The monitoring performance of p-NLPCA in the principal component space was not affected by using the denoising criterion, while that of sm-NLPCA deteriorated.
4.5. Neural Network Training Epochs
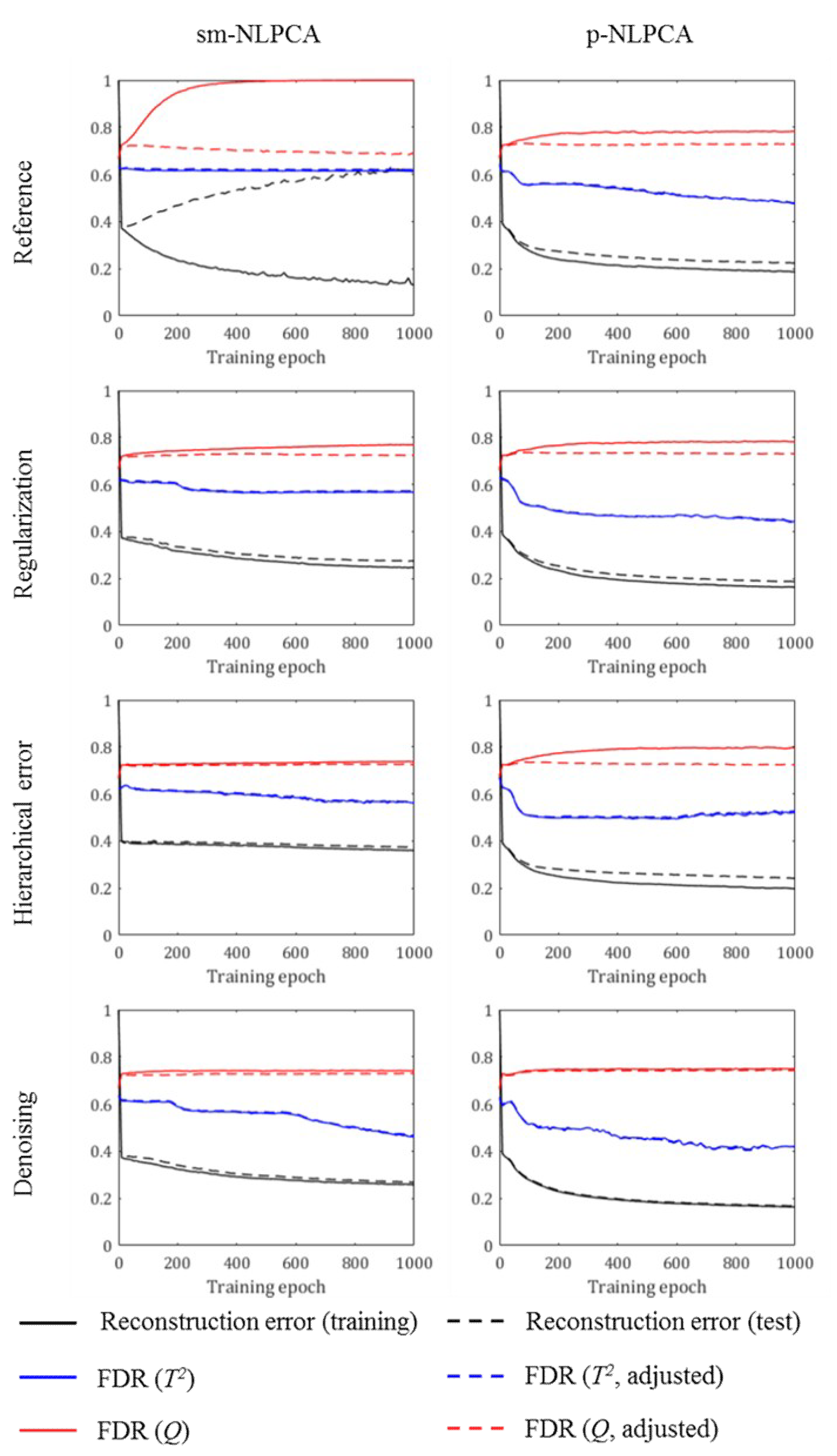
In this analysis, the effects of neural network training epochs are analyzed. To this end, Network Type 4 with 15 principal components was trained, and the neural network parameters were saved at every 10 epochs.
Figure 4 shows how different values evolve as the neural networks are trained. For the reference case, the neural networks were trained without any regularization and with the reconstruction error as the objective function. It can be clearly seen that the network overfitting (which is captured by the difference between the solid and dashed black lines) resulted in high FAR values in the residual space (which is captured by the difference between the solid and dashed red lines), while it did not affect the FAR values in the principal component space (which is captured by the difference between the solid and dashed blue lines).
Note the following:
Despite the decrease in the reconstruction error over a wide range of training epochs, the adjusted FDR value in the residual space increased during only the first few training epochs and was kept almost constant in the rest of the training.
In some cases, there was even a tendency that the adjusted FDR value in the principal component space decreased as the network was trained more.
Thus, during the network training, it was required to monitor both reconstruction error and process monitoring performance indices, and early stopping needed to be applied as necessary to ensure high monitoring performances. Nonetheless, from the above observations, it can be concluded that the objective functions available in the literature, which focus on the reconstruction ability of the autoassociative neural networks, may not be most suitable for the design of one-class classifiers. This necessitates the development of alternative training algorithms of autoassociative neural networks to improve the performance of neural-network-based one-class classifiers.
4.6. Comparison with Linear-PCA-Based Process Monitoring
Let us finally compare the NLPCA-based process monitoring with the linear-PCA-based one. For the linear-PCA-based process monitoring, based on the parallel analysis [
35], the number of principal components to be retained was selected as 15. The same number of principal components was used in the NLPCA-based process monitoring. For sm-NLPCA, the following setting was used: Network Type 2, no regularization, reconstruction error as the objective function. For p-NLPCA, the following setting was used: Network Type 3, no regularization, reconstruction error as the objective function.
Table 12 tabulates the process monitoring results obtained using three different PCA methods. Note that the upper control limits were adjusted to have FAR values of 0.01. The main trends observed were:
Compared to the linear PCA, the process monitoring results in both spaces were improved slightly by using sm-NLPCA. The most significant improvements were obtained for Faults 4 and 10 in the principal component space and Faults 5 and 10 in the residual space.
On the other hand, p-NLPCA showed a lower performance than linear PCA in the principal component space, while the performance in the residual space was significantly improved. The adjusted FDR value in the residual space from p-NLPCA was higher than that from the linear PCA for all the fault types, with Faults 5, 10, and 16 being the most significant ones.
Let us consider two cases that illustrate the advantages of p-NLPCA over the linear PCA as the basis for the process monitoring system design.
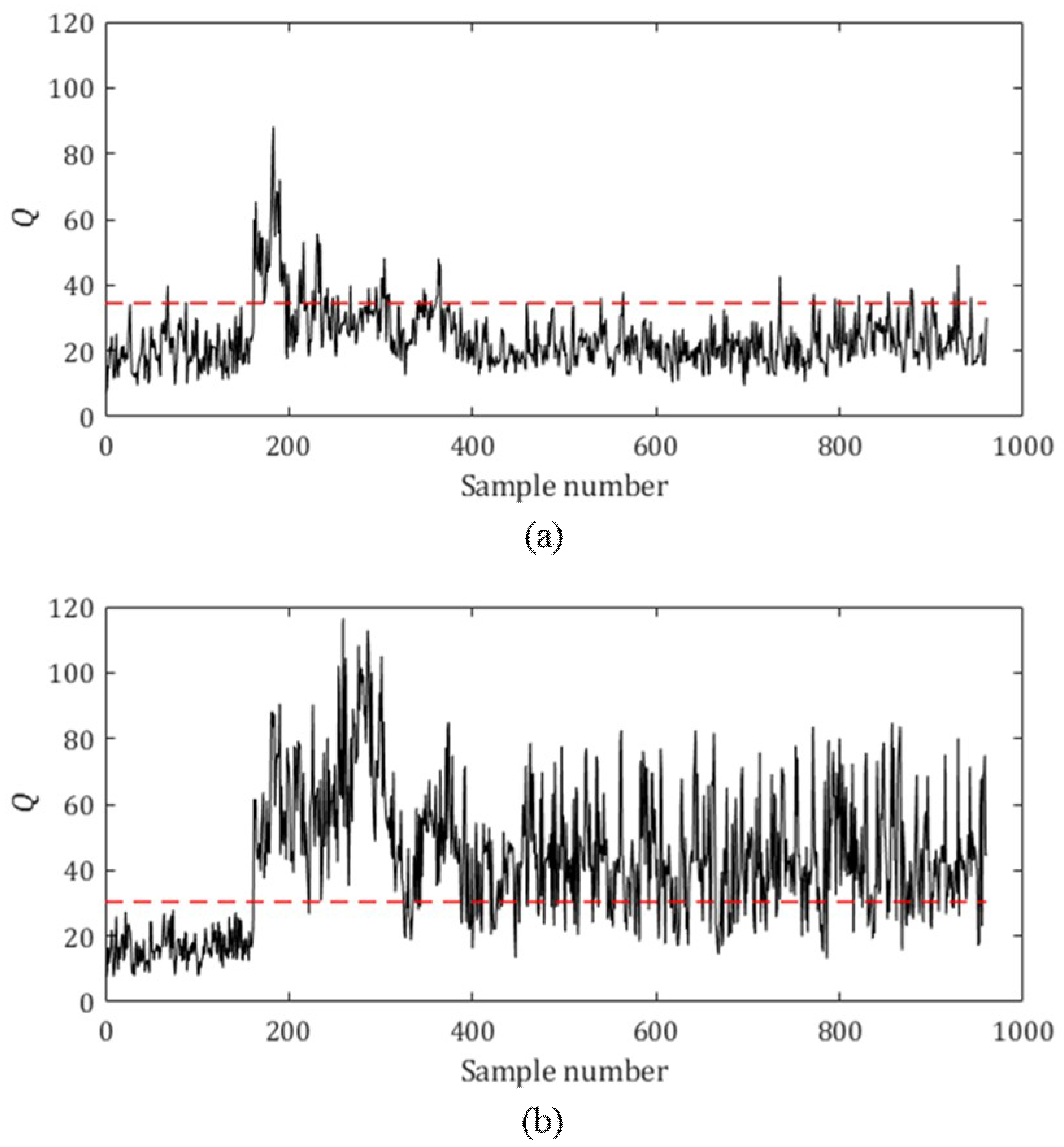
Figure 5 shows the
Q statistic values (black solid line) for one complete simulation run with Fault 5, along with the upper control limit (dashed red line). Although both linear PCA and p-NLPCA detected the fault very quickly (fault introduced after Sample Number 160 and detected at Sample Number 162), in the case of the linear PCA, the
Q statistic value dropped below the upper control limit after around Sample Number 400. The
Q statistic value calculated from p-NLPCA did not decrease much, indicating that the fault was not yet removed from the system.
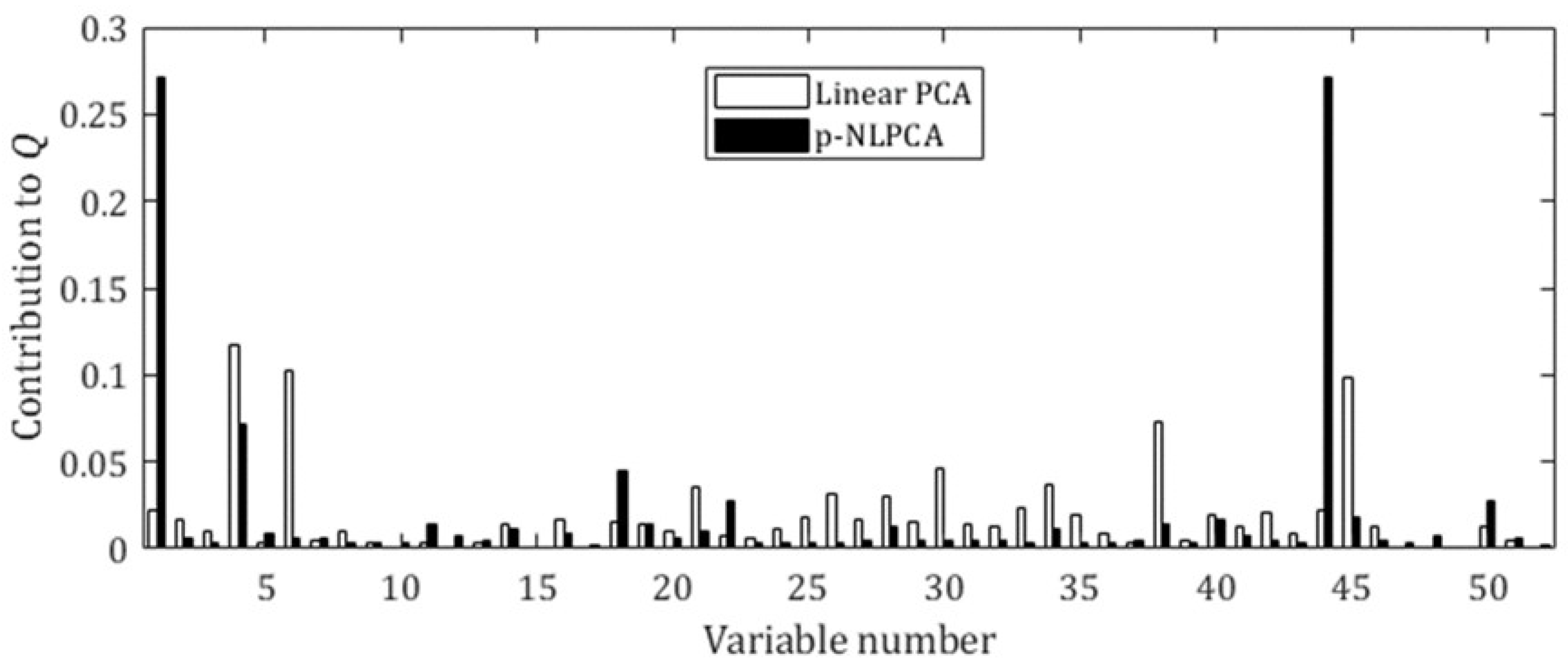
The contribution plots of
Q statistic for Fault 1, which involves a step change in the flowrate of the A feed stream, are provided in
Figure 6. In the case of the linear PCA, the variables with the highest contribution to the
Q statistic were Variables 4 and 6, which are the flowrates of Stream 4 (which contains both A and C) and the reactor feed rate, respectively. Note that although these variables were also highly affected by the fault, they were not the root cause of the fault. On the other hand, in the case of p-NLPCA, the variables with the highest contribution to the
Q statistic were Variables 1 and 44, which both represent the flowrate of the A feed stream, the root cause of the fault. Thus, it can be concluded that the process monitoring using p-NLPCA showed some potential to perform better at identifying the root cause of the fault introduced to the system.
5. Conclusions
The statistical process monitoring problem of the Tennessee Eastman process was considered in this study using autoassociative neural networks to define normal operating regions. Using the large dataset allowed us to estimate the upper control limits for the process monitoring directly from the data distribution and to train relatively large neural networks without overfitting. It was shown that the process monitoring performance was very sensitive to the neural network settings such as neural network size and neural network regularization. p-NLPCA was shown to be more effective for the process monitoring than the linear PCA and sm-NLPCA in the residual space, while its performance was worse than the others in the principal component space. p-NLPCA also showed the potential of better fault diagnosis capability than the linear PCA, locating the root cause more correctly for some fault types.
There still exist several issues that need to be addressed to make autoassociative neural networks more attractive as a tool for statistical process monitoring. First, a systematic procedure needs to be developed to provide a guideline for the design of optimal autoassociative neural networks to be used for the statistical process monitoring. Furthermore, a new neural network training algorithm may be required to extract principal components that are more relevant to the process monitoring tasks. Finally, the compatibility of different techniques to define the upper control limits, other than the T2 and Q statistics, needs to be extensively evaluated.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}