Optimization-Based Scheduling for the Process Industries: From Theory to Real-Life Industrial Applications



Abstract
1. Introduction
- A large number of time periods is required to capture all significant events and extract a high quality solution—this usually results to extremely large models;
- Operations in which the processing time is dependent on the batch size are difficult to be modelled;
- The modelling of continuous and semi-continuous operations must be approximately modelled.
2. Theoretical Aspects of Optimization-Based Process Scheduling
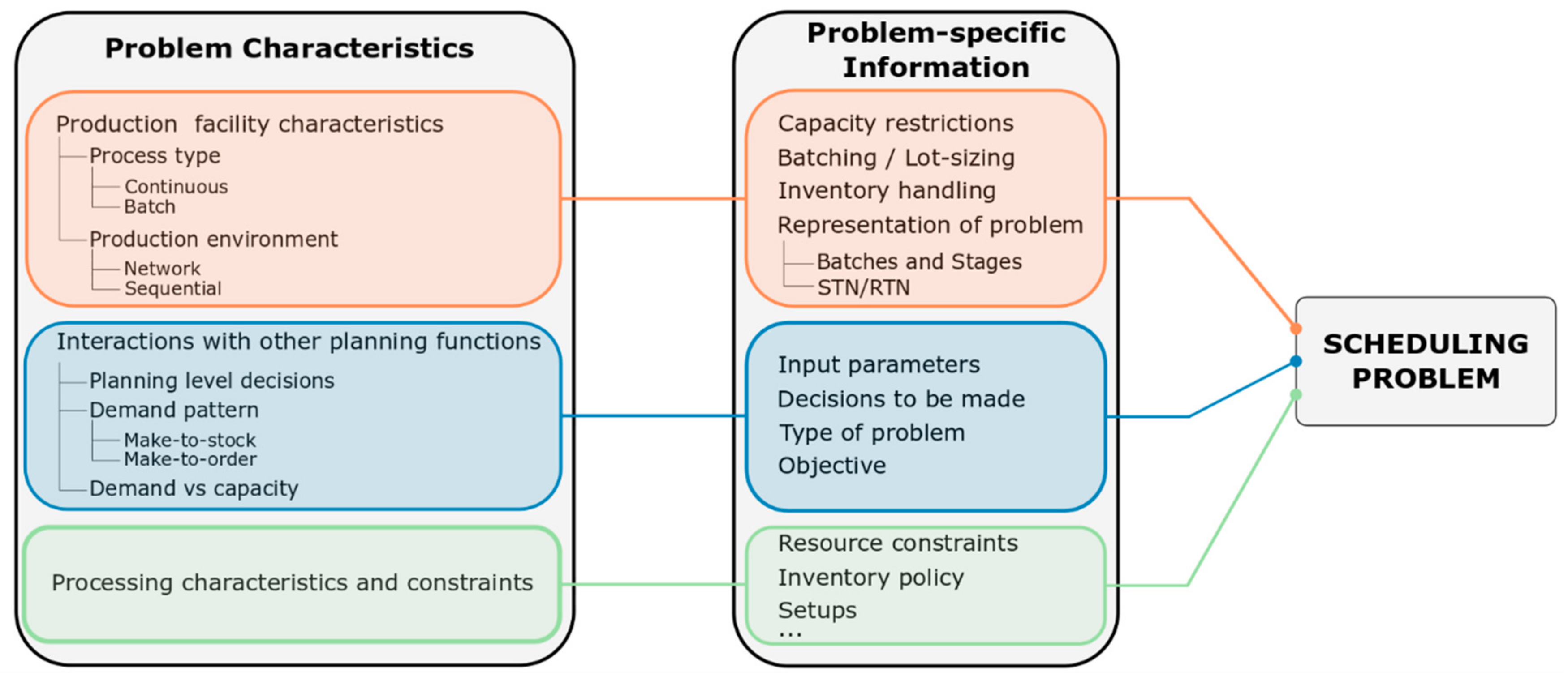
2.1. Classification of Scheduling Problems
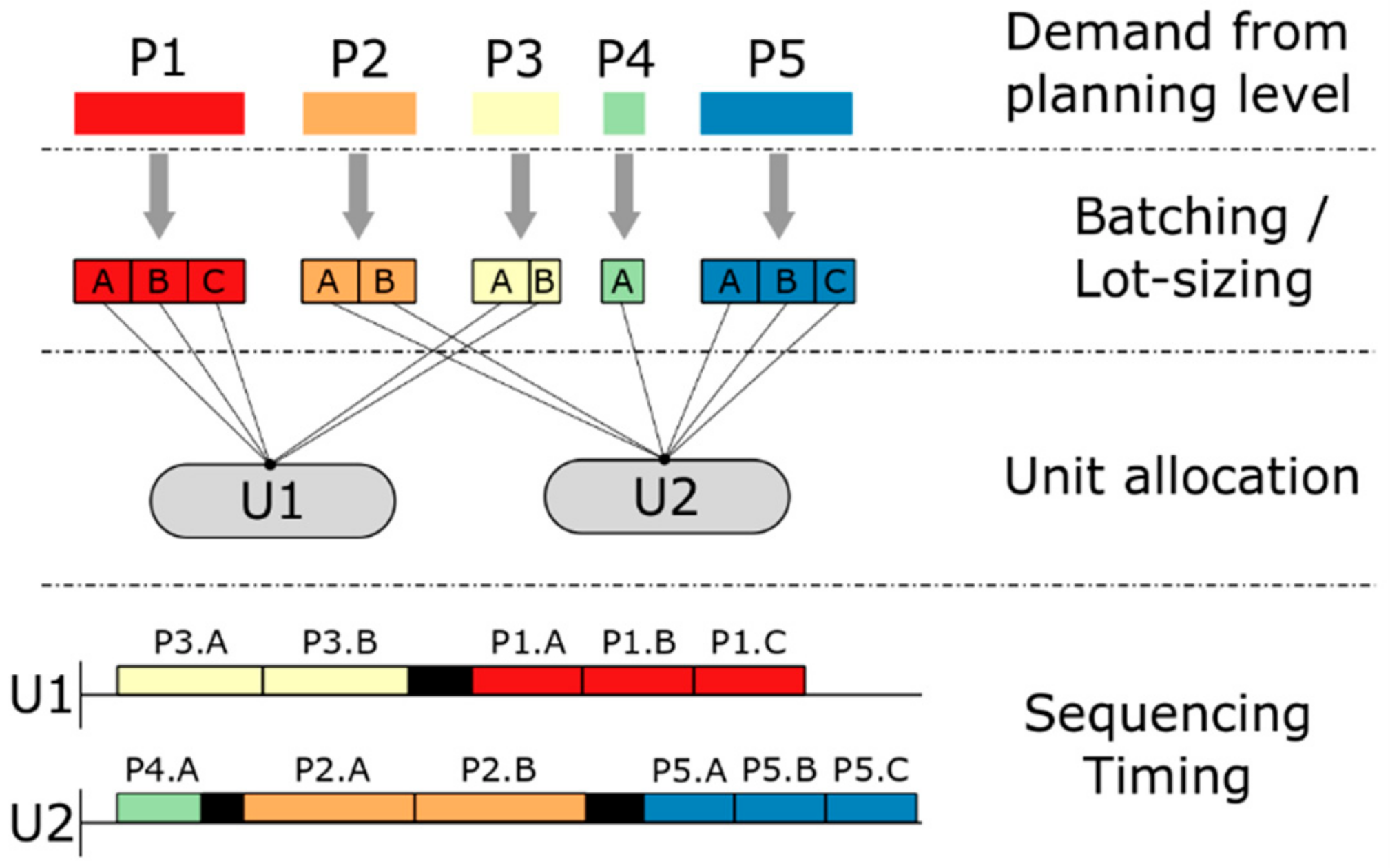
- What tasks must be executed to satisfy the given demand (batching/lot-sizing)?
- How should the given resources be utilized (task-resource assignment)?
- In what order are batches/lots processed (sequencing and/or timing)?
- Facility data; e.g., processing stages and units, storage vessels, processing rates, unit to task compatibility.
- Production targets that need to be satisfied.
- Availability of raw materials and resource limitations; e.g., maintenance of units, availability of utilities.
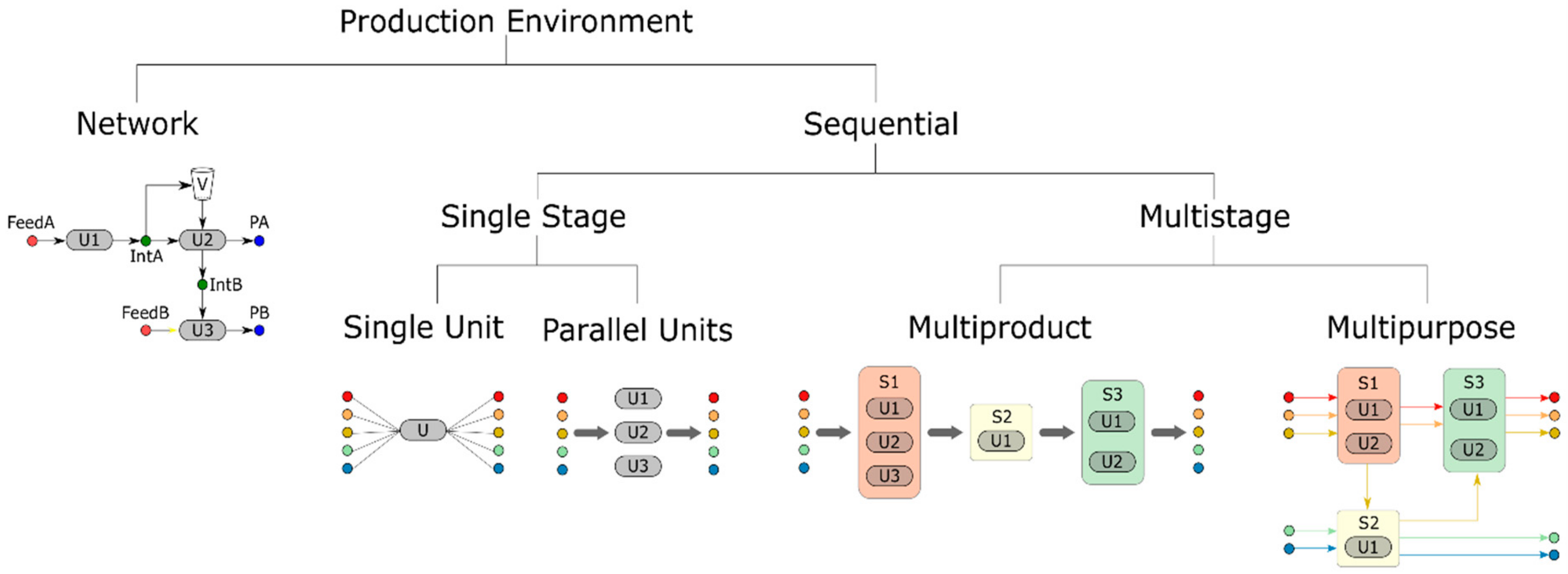
2.1.1. The Production Facility
Process Type
Production Environment
- Single stage: Production facility that consists of just one processing stage, which may consist of a single unit or multiple parallel units. The product to unit compatibility may be fixed (batch can be processed in a single unit) or flexible (batch can be processed in multiple units), but in all cases each batch must be processed in a single unit.
- Multistage: Each batch must be processed in more than one processing stages, each consisting of a single unit or multiple parallel units. The multistage environment can be further categorized into multiproduct and multipurpose, depending on the imposed routing restrictions. Multiproduct facilities are equivalent to flowshop environments in discrete manufacturing, where all products go through the same sequence of processing stages. In contrast, a facility is characterized as multipurpose when the routings are product-specific, or when a processing unit belongs to different processing stages depending on the product, thus being equivalent to jobshop environments in discrete manufacturing.
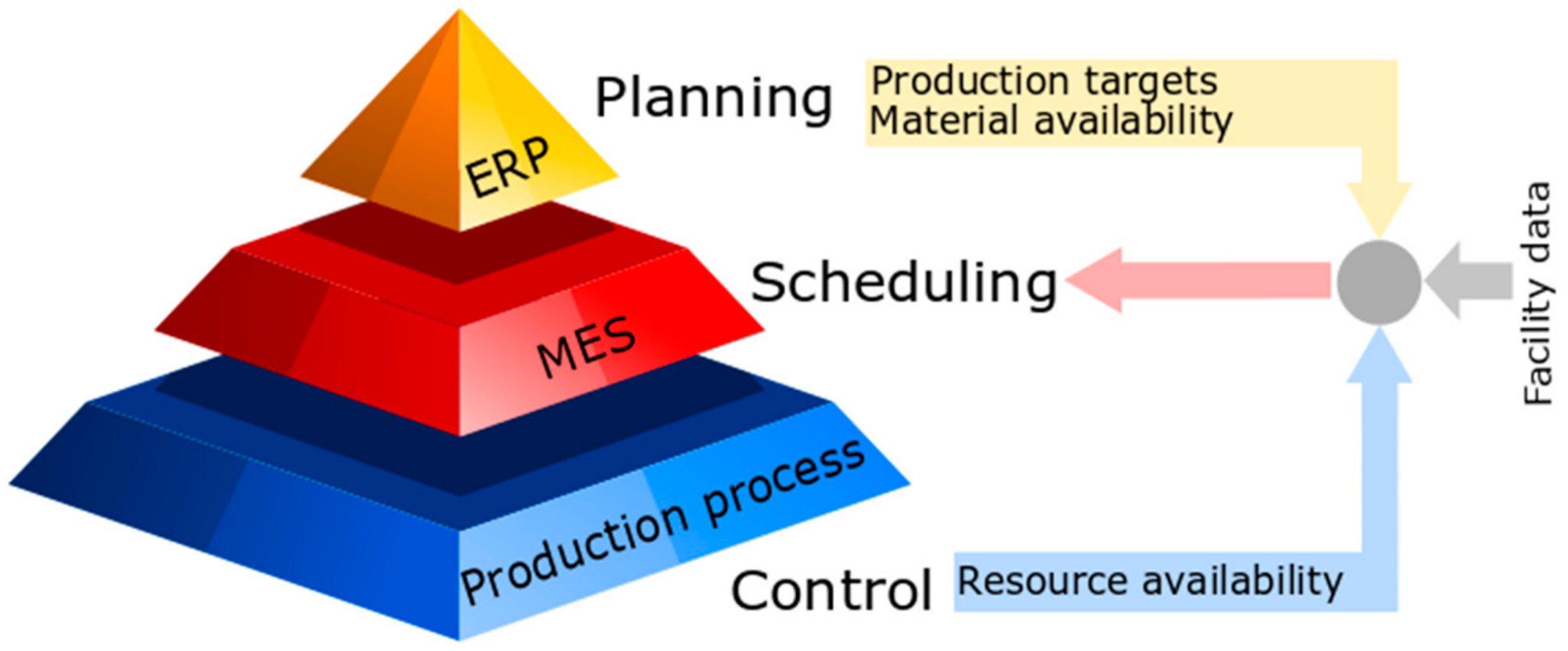
2.1.2. Interaction with Other Planning Functions
2.1.3. Processing Characteristics and Constraints
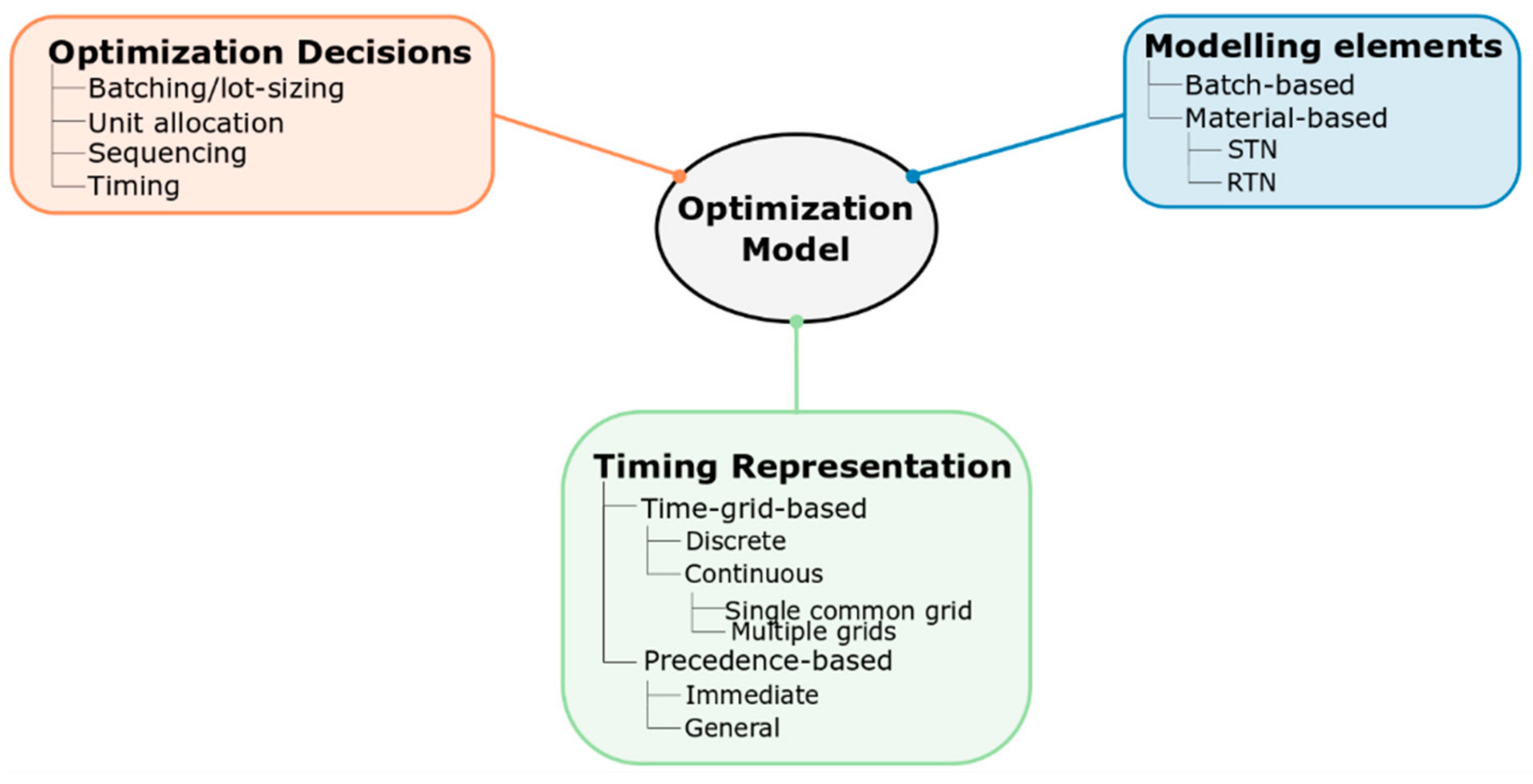
2.2. Classification of Modelling Approaches
2.2.1. Optimization Decisions
2.2.2. Modelling Elements
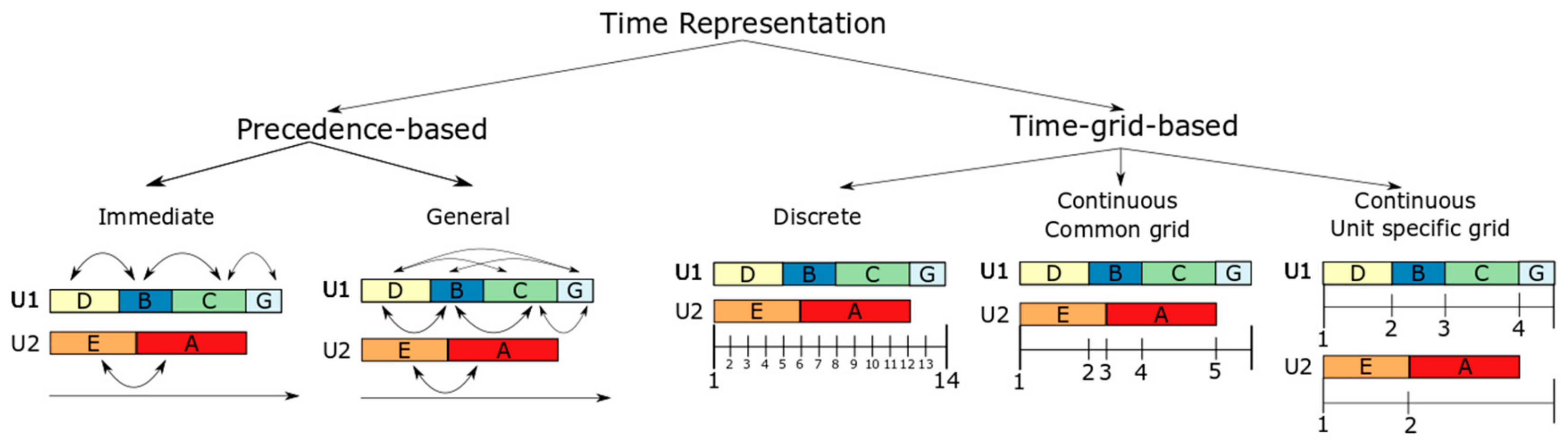
2.2.3. Time Representations
2.3. Alternative MILP Models for Process Scheduling
2.3.1. Models for Network Production Environments
2.3.2. Models for Sequential Production Environments
3. Real-Life Process Systems Industrial Applications
3.1. Chemical Industries
3.2. Pharmaceutical Industries
3.3. Petrochemical Industries
3.4. Food Industries
3.5. Consumer Goods Industries
3.6. Steel Plants
3.7. Paper Industries
4. Industrial Applications of Optimization-Based Scheduling—Challenges
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Nomenclature
| processing tasks | |
| orders to be processed | |
| units | |
| time events | |
| processing stages | |
| resources | |
| states | |
| storage tasks | |
| tasks requiring resource r | |
| tasks that can be executed in unit j | |
| storage tasks for state s | |
| tasks that produce state s | |
| tasks that consume state s | |
| resources corresponding to unit j | |
| resources corresponding to storage that can be used for task i | |
| units that can perform task i | |
| units that can execute both order i and order i’ at stage l | |
| units that can execute order i at stage l | |
| stage required for the production of order o and o’ |
| constant term for the processing time of task i | |
| proportional term for the processing time of task i | |
| time horizon | |
| minimum batch size of task i | |
| maximum batch size of task i | |
| minimum available resource r | |
| maximum available resource r | |
| fixed term for the production of resource r at the end of task i | |
| fixed term for the consumption of resource r at the beginning of task i | |
| variable term for the production of resource r at the end of task i | |
| variable term for the consumption of resource r at the beginning of task i | |
| proportion of state s consumed/produced by task i | |
| processing time of order o in unit j | |
| setup time for order o in unit j | |
| changeover time between orders o and o’ processed in unit j |
| exact time of event point t | |
| defines a task I that starts at event point t and ends at time point t’ | |
| amount of material processed by task I, that starts at t and ends at t’ | |
| amount of resource r consumed at event point t | |
| denotes that a task i starts at event point t | |
| denotes that a task i ends at event point t | |
| denotes that a task i is active at event point t | |
| batch size of the task i in unit j started at event point t | |
| batch size of the task i in unit j being processed at event point t | |
| batch size of the task i in unit j finished at event point t | |
| batch size of storage task ist at event point t | |
| time at which the execution of task i by unit j at event point t starts | |
| time at which the execution of task i by unit j at event point t ends | |
| binary variable denoting that order o is allocated to unit j | |
| completion time of order o in unit j | |
| binary variable that is activated when order o is processed before order o′ at stage l |
References
- Kondili, E.; Pantelides, C.C.; Sargent, R.W.H. A General Algorithm for Short-term Scheduling of Batch Operations-I. MILP Formulation. Comput. Chem. Eng. 1993, 17, 211–227. [Google Scholar] [CrossRef]
- Bixby, R.; Rothberg, E. Progress in Computational Mixed Integer Programming—A Look Back from the Other Side of the Tipping Point. Ann. Oper. Res. 2007, 149, 37–41. [Google Scholar] [CrossRef]
- Shah, N.; Pantelides, C.C.; Sargent, R.W.H. A General Algorithm for Short-Term Scheduling of Batch-Operations 2. Computational Issues. Comput. Chem. Eng. 1993, 17, 229–244. [Google Scholar] [CrossRef]
- Kondili, E.; Pantelides, C.C.; Sargent, R.W.H. A General Algorithm for Scheduling of Batch Operations. In Proceedings of the Third International Symposium on Process Systems Engineering (PSE’88), Sydney, Australia, 28 August–2 September 1998; pp. 62–75. [Google Scholar]
- Shah, N.; Pantelides, C.C.; Sargent, R.W.H. Optimal Periodic Scheduling of Multipurpose Batch Plants. Ann. Oper. Res. 1993, 42, 193–228. [Google Scholar] [CrossRef]
- Papageorgiou, L.G.; Pantelides, C.C. Optimal Campaign Planning/Scheduling of Multipurpose Batch/Semicontinuous Plants. 1. Mathematical Formulation. Ind. Eng. Chem. Res. 1996, 35, 488–509. [Google Scholar] [CrossRef]
- Papageorgiou, L.G.; Pantelides, C.C. Optimal Campaign Planning/Scheduling of Multipurpose Batch/Semicontinuous Plants. 2. A Mathematical Decomposition Approach. Ind. Eng. Chem. Res. 1996, 35, 510–529. [Google Scholar] [CrossRef]
- Yee, K.L.; Shah, N. Scheduling of Multistage Fast-Moving Consumer Goods Plants. J. Oper. Res. Soc. 1997, 48, 1201–1214. [Google Scholar] [CrossRef]
- Yee, K.L.; Shah, N. Improving the Efficiency of Discrete Time Scheduling Formulation. Comput. Chem. Eng. 1998, 22, S403–S410. [Google Scholar] [CrossRef]
- Pantelides, C.C.; Realff, M.J.; Shah, N. Short-term Scheduling of Pipeless Batch Plants. Chem. Eng. Res. Des. 1997, 75, S156–S169. [Google Scholar] [CrossRef]
- Pantelides, C.C. Unified Frameworks for Optimal Process Planning and Scheduling. In Proceedings of the Second International Conference on Foundations of Computer-Aided Process Operations, Crested Butte, CO, USA, 18–23 July 1993; pp. 253–274. [Google Scholar]
- Schilling, G.H. Algorithms for Short-Term and Periodic Process Scheduling and Rescheduling. Ph.D. Thesis, University of London, London, UK, 1997. [Google Scholar]
- Tahmassebi, T. Industrial Experience with a Mathematical-programming Based System for Factory Systems Planning/Scheduling. Comput. Chem. Eng. 1996, 20, S1565–S1570. [Google Scholar] [CrossRef]
- Dimitriadis, A.D.; Shah, N.; Pantelides, C.C. RTN-based Rolling Horizon Algorithms for Medium Term Scheduling of Multipurpose Plants. Comput. Chem. Eng. 1997, 21, S1061–S1066. [Google Scholar] [CrossRef]
- Wilkinson, S.J. Aggregate Formulations for Large-Scale Process Scheduling. Ph.D. Thesis, University of London, London, UK, 1996. [Google Scholar]
- Shah, N. Process Industry Supply Chains: Advances and Challenges. Comput. Chem. Eng. 2005, 29, 1225–1235. [Google Scholar] [CrossRef]
- Castro, P.M.; Barbosa-Póvoa, A.P.; Matos, H. An Improved RTN Continuous-Time Formulation for the Short-term Scheduling of Multipurpose Batch Plants. Ind. Eng. Chem. Res. 2001, 40, 2059–2068. [Google Scholar] [CrossRef]
- Ierapetritou, M.G.; Floudas, C.A. Effective Continuous-Time Formulation for Short-Term Scheduling. 1. Multipurpose Batch Processes. Ind. Eng. Chem. Res. 1998, 37, 4341–4359. [Google Scholar] [CrossRef]
- Méndez, C.A.; Henning, G.P.; Cerdá, J. An MILP Continuous-Time Approach to Short-Term Scheduling of Resource-Constrained Multistage Flowshop Batch Facilities. Comput. Chem. Eng. 2001, 25, 701–711. [Google Scholar] [CrossRef]
- Gabow, H.N. On the Design and Analysis of Efficient Algorithms for Deterministic Scheduling. In Proceedings of the 2nd International Conference Foundations of Computer-Aided Process Design, Snowmass, CO, USA, 19–24 June 1983; pp. 473–528. [Google Scholar]
- Pinedo, M.L. Scheduling: Theory, Algorithms and Systems, 5th ed.; Springer: Berlin, Germany, 2016. [Google Scholar]
- Maravelias, C.T. General Framework and Modeling Approach Classification for Chemical Production Scheduling. AIChE J. 2012, 58, 1812–1828. [Google Scholar] [CrossRef]
- Harjunkoski, I.; Maravelias, C.T.; Bongers, P.; Castro, P.M.; Engell, S.; Grossmann, I.E.; Hooker, J.; Méndez, C.; Sand, G.; Wassick, J. Scope for Industrial Applications of Production Scheduling Models and Solution Methods. Comput. Chem. Eng. 2014, 62, 161–193. [Google Scholar] [CrossRef]
- Baumann, P.; Trautmann, N.A. Continuous-Time MILP Model for Short-Term Scheduling of Make-and-Pack Production Processes. Int. J. Prod. Res. 2013, 51, 1707–1727. [Google Scholar] [CrossRef]
- Georgiadis, G.P.; Ziogou, C.; Kopanos, G.M.; Pampin, B.M.; Cabo, D.; Lopez, M.; Georgiadis, M.C. On the Optimization of Production Scheduling in Industrial Food Processing Facilities. In Proceedings of the 29th European Symposium on Computer Aided Process Engineering, Eindhoven, The Netherlands, 16–19 June 2019. Accepted manuscript. [Google Scholar]
- Egli, U.M.; Rippin, D.W.T. Short-term Scheduling for Multiproduct Batch Chemical Plants. Comput. Chem. Eng. 1986, 10, 303–325. [Google Scholar] [CrossRef]
- Vaselenak, J.A.; Grossmann, I.E.; Westerberg, A.W. An Embedding Formulation for the Optimal Scheduling and Design of Multipurpose Batch Plants. Ind. Eng. Chem. Res. 1987, 26, 139–148. [Google Scholar] [CrossRef]
- Grossmann, I. Enterprise-wide Optimization: A New Frontier in Process Systems Engineering. AIChE J. 2005, 51, 1846–1857. [Google Scholar] [CrossRef]
- Kopanos, G.M.; Puigjaner, L.; Maravelias, C.T. Production Planning and Scheduling of Parallel Continuous Processes with Product Families. Ind. Eng. Chem. Res. 2011, 50, 1369–1378. [Google Scholar] [CrossRef]
- Li, Z.; Ierapetritou, M.G. Rolling Horizon Based Planning and Scheduling Integration with Production Capacity Consideration. Chem. Eng. Sci. 2010, 65, 5887–5900. [Google Scholar] [CrossRef]
- Sel, C.; Bilgen, B.; Bloemhof-Ruwaard, J.M.; van der Vorst, J.G.A.J. Multi-bucket Optimization for Integrated Planning and Scheduling in the Perishable Dairy Supply Chain. Comput. Chem. Eng. 2015, 77, 59–73. [Google Scholar] [CrossRef]
- Du, J.; Park, J.; Harjunkoski, I.; Baldea, M. A Time Scale-bridging Approach for Integrating Production Scheduling and Process Control. Comput. Chem. Eng. 2015, 79, 59–69. [Google Scholar] [CrossRef]
- Charitopoulos, V.M.; Dua, V.; Papageorgiou, L.G. Traveling salesman Problem-based Integration of Planning, Scheduling, and Optimal Control for Continuous Processes. Ind. Eng. Chem. Res. 2017, 56, 11186–11205. [Google Scholar] [CrossRef]
- Méndez, C.A.; Cerdá, J.; Grossmann, I.E.; Harjunkoski, I.; Fahl, M. State-of-the-art Review of Optimization Methods for Short-term Scheduling of Batch Processess. Comput. Chem. Eng. 2006, 30, 913–946. [Google Scholar] [CrossRef]
- Malapert, A.; Guéret, C.; Rousseau, L.M. A Constraint Programming Approach for a Batch Processing Problem with Non-identical Job Sizes. Eur. J. Oper. Res. 2012, 221, 533–545. [Google Scholar] [CrossRef]
- Zeballos, L.J.; Novas, J.M.; Henning, G.P. A CP Formulation for Scheduling Multiproduct Multistage Batch Plants. Comput. Chem. Eng. 2011, 35, 2973–2989. [Google Scholar] [CrossRef]
- Bassett, M.H.; Pekny, J.F.; Reklaitis, G.V. Decomposition Techniques for the Solution of Large-Scale Scheduling Problems. AIChE J. 1996, 42, 3373–3387. [Google Scholar] [CrossRef]
- Panek, S.; Engell, S.; Subbiah, S.; Stursberg, O. Scheduling of Multi-Product Batch Plants Based Upon Timed Automata models. Comput. Chem. Eng. 2008, 32, 275–291. [Google Scholar] [CrossRef]
- Kopanos, G.M.; Méndez, C.A.; Puigjaner, L. MIP-Based Decomposition Strategies for Large-Scale Scheduling Problems in Multiproduct Multistage Batch Plants: A Benchmark Scheduling Problem of the Pharmaceutical Industry. Eur. J. Oper. Res. 2010, 207, 644–655. [Google Scholar] [CrossRef]
- Prasad, P.; Maravelias, C.T. Batch Selection, Assignment and Sequencing in Multi-Stage Multi-Product Processes. Comput. Chem. Eng. 2008, 32, 1106–1119. [Google Scholar] [CrossRef]
- Sundaramoorthy, A.; Maravelias, C.T. Simultaneous Batching and Scheduling in Multistage Multiproduct Processes. Ind. Eng. Chem. Res. 2008, 47, 1546–1555. [Google Scholar] [CrossRef]
- Lee, H.; Maravelias, C.T. Mixed-integer Programming Models for Simultaneous Batching and Scheduling in Multipurpose Batch Plants. Comput. Chem. Eng. 2017, 106, 621–644. [Google Scholar] [CrossRef]
- Castro, P.M.; Grossmann, I.E.; Novais, A.Q. Two New Continuous-Time Models for the Scheduling of Multistage Batch Plants with Sequence Dependent Changeovers. Ind. Eng. Chem. Res. 2006, 45, 6210–6226. [Google Scholar] [CrossRef]
- Velez, S.; Maravelias, C.T. Mixed-Integer Programming Model and Tightening Methods for Scheduling in General Chemical Production environments. Ind. Eng. Chem. Res. 2013, 52, 3407–3423. [Google Scholar] [CrossRef]
- Pinto, J.M.; Grossmann, I.E. Assignment and Sequencing Models of the Scheduling of Process Systems. Ann. Oper. Res. 1998, 1621, 36–43. [Google Scholar] [CrossRef]
- Kopanos, G.M.; Puigjaner, L.; Georgiadis, M.C. Optimal Production Scheduling and Lot-Sizing in Dairy Plants: The Yogurt Production Line. Ind. Eng. Chem. Res. 2009, 49, 701–718. [Google Scholar] [CrossRef]
- Velez, S.; Maravelias, C.T. Multiple and Nonuniform Time Grids in Discrete-Time MIP Models for Chemical Production Scheduling. Comput. Chem. Eng. 2013, 53, 70–85. [Google Scholar] [CrossRef]
- Maravelias, C.T.; Sung, C. Integration of Production Planning and Scheduling: Overview, Challenges and Opportunities. Comput. Chem. Eng. 2009, 33, 1919–1930. [Google Scholar] [CrossRef]
- Sundaramoorthy, A.; Maravelias, C.T. Computational Study of Network-Based Mixed-Integer Programming Approaches for Chemical Production Scheduling. Ind. Eng. Chem. Res. 2011, 50, 5023–5040. [Google Scholar] [CrossRef]
- Lee, H.; Maravelias, C.T. Combining the Advantages of Discrete- and Continuous-Time Scheduling Models: Part 1. Framework and Mathematical Formulations. Comput. Chem. Eng. 2018, 116, 176–190. [Google Scholar] [CrossRef]
- Reklaitis, G.V.; Mockus, L. Mathematical Programming Formulation for Scheduling of Batch Operations based on Non-uniform Time Discretization. Acta Chim. Slov. 1995, 42, 81–86. [Google Scholar]
- Xueja, Z.; Sargent, R.W.H. The Optimal Operation of Mixed Production Facilities—A General Formulation and some Approaches for the Solution. In Proceedings of the 5th International Symposium Process Systems Engineering, Kyongju, Korea, 30 May–3 June 1994; pp. 171–178. [Google Scholar]
- Zhang, X.; Sargent, R.W.H. The Optimal Operation of Mixed Production Facilities—Extensions and Improvements. Comput. Chem. Eng. 1996, 20, S1287–S1293. [Google Scholar] [CrossRef]
- Schilling, G.; Pantelides, C.C. A Simple Continuous-Time Process Scheduling Formulation and a Novel Solution Algorithm. Comput. Chem. Eng. 1996, 20, 1221–1226. [Google Scholar] [CrossRef]
- Castro, P.M.; Barbosa-Póvoa, A.P.; Matos, H.A.; Novais, A.Q. Simple Continuous-Time Formulation for Short-Term Scheduling of Batch and Continuous Processes. Ind. Eng. Chem. Res. 2004, 43, 105–118. [Google Scholar] [CrossRef]
- Giannelos, N.F.; Georgiadis, M.C. A Simple New Continuous-Time Formulation for Short-Term Scheduling of Multipurpose Batch Processes. Ind. Eng. Chem. Res. 2002, 41, 2178–2184. [Google Scholar] [CrossRef]
- Maravelias, C.T.; Grossmann, I.E. New General Continuous-Time State−Task Network Formulation for Short-Term Scheduling of Multipurpose Batch Plants. Ind. Eng. Chem. Res. 2003, 42, 3056–3074. [Google Scholar] [CrossRef]
- Sundaramoorthy, A.; Karimi, I.A. A Simpler Better Slot-Based Continuous-Time Formulation for Short-Term Scheduling in Multipurpose Batch Plants. Chem. Eng. Sci. 2005, 60, 2679–2702. [Google Scholar] [CrossRef]
- Vin, J.P.; Ierapetritou, M.G. A New Approach for Efficient Rescheduling of Multiproduct Batch Plants. Ind. Eng. Chem. Res. 2000, 39, 4228–4238. [Google Scholar] [CrossRef]
- Janak, S.L.; Lin, X.; Floudas, C.A. Enhanced Continuous-Time Unit-Specific Event-Based Formulation for Short-Term Scheduling of Multipurpose Batch Processes: Resource Constraints and Mixed Storage Policies. Ind. Eng. Chem. Res. 2004, 43, 2516–2533. [Google Scholar] [CrossRef]
- Shaik, M.A.; Floudas, C.A. Novel Unified Modeling Approach for Short-Term Scheduling. Ind. Eng. Chem. Res. 2009, 48, 2947–2964. [Google Scholar] [CrossRef]
- Velez, S.; Maravelias, C.T. Theoretical Framework for Formulating MIP Scheduling Models with Multiple and Non-Uniform Discrete-Time Grids. Comput. Chem. Eng. 2015, 72, 233–254. [Google Scholar] [CrossRef]
- Pinto, J.M.; Grossmann, I.E. A Continuous Time Mixed Integer Linear Programming Model for Short Term Scheduling of Multistage Batch Plants. Ind. Eng. Chem. Res. 1995, 34, 3037–3051. [Google Scholar] [CrossRef]
- Castro, P.M.; Grossmann, I. New Continuous-Time MILP Model for the Short-Temr Scheduling of Multistage Batch Plants. Ind. Eng. Chem. Res. 2005, 44, 9175–9190. [Google Scholar] [CrossRef]
- Sundaramoorthy, A.; Maravelias, C.T.; Prasad, P. Scheduling of Multistage Batch Processes under Utility Constraints. Ind. Eng. Chem. Res. 2009, 48, 6050–6058. [Google Scholar] [CrossRef]
- Merchan, A.F.; Lee, H.; Maravelias, C.T. Discrete-time Mixed-integer Programming Models and Solution Methods for Production Scheduling in Multistage Facilities. Comput. Chem. Eng. 2016, 94, 387–410. [Google Scholar] [CrossRef]
- Lee, H.; Maravelias, C.T. Discrete-time mixed-integer programming models for short-term scheduling in multipurpose environments. Comput. Chem. Eng. 2017, 107, 171–183. [Google Scholar] [CrossRef]
- Gupta, S.; Karimi, I.A. An Improved MILP Formulation for Scheduling Multiproduct, Multistage Batch Plants. Ind. Eng. Chem. Res. 2003, 42, 2365–2380. [Google Scholar] [CrossRef]
- Kopanos, G.M.; Laınez, M.; Puigjaner, L. An Efficient Mixed-Integer Linear Programming Scheduling Framework for Addressing Sequence-Dependent Setup Issues in Batch Plants. Ind. Eng. Chem. Res. 2009, 48, 6346–6357. [Google Scholar] [CrossRef]
- Harjunkoski, I.; Grossmann, I. Decomposition Techniques for Multistage Scheduing Problems Using Mixed-Integer and Constraint Programming Methods. Comput. Chem. Eng. 2002, 26, 1533–1552. [Google Scholar] [CrossRef]
- Cerda, J.; Henning, G.P.; Grossmann, I.E. A Mixed-Integer Linear Programming Model for Short-Term Scheduling of Single-Stage Multiproduct Batch Plants with Parallel Lines. Ind. Eng. Chem. Res. 1997, 36, 1695–1707. [Google Scholar] [CrossRef]
- Méndez, C.A.; Henning, G.P.; Cerdá, J. Optimal Scheduling of Batch Plants Satisfying Multiple Product Orders with Different Due-Dates. Comput. Chem. Eng. 2000, 24, 2223–2245. [Google Scholar] [CrossRef]
- Mendez, C.A.; Cerdá, J. An MILP Framework for Batch Reactive Scheduling with Limited Discrete Resources. Comput. Chem. Eng. 2004, 28, 1059–1068. [Google Scholar] [CrossRef]
- Castro, P.M.; Erdirik-Dogan, M.; Grossmann, I.E. Simultaneous Batching and Scheduling ofSingle Stage Batch Plants with Parallel Units. AIChE J. 2007, 54, 183–193. [Google Scholar] [CrossRef]
- Lin, X.; Floudas, C.A. Continuous-Time Optimization Approach for Medium-Range Production Scheduling of a Multiproduct Batch Plant. Ind. Eng. Chem. Res. 2002, 41, 3884–3906. [Google Scholar] [CrossRef]
- Janak, S.L.; Floudas, C.A.; Kallrath, J.; Vormbrock, N. Production Scheduling of a Large-Scale Industrial Batch Plant. I. Short-Term and Medium-Term Scheduling. Ind. Eng. Chem. Res. 2006, 45, 8234–8252. [Google Scholar] [CrossRef]
- Westerlund, J.; Hästbacka, M.; Forssell, S.; Westerlund, T. Mixed-Time Mixed-Integer Linear Programming Scheduling Model. Ind. Eng. Chem. Res. 2007, 46, 2781–2796. [Google Scholar] [CrossRef]
- Velez, S.; Merchan, A.F.; Maravelias, C.T. On the Solution of Large-Scale Mixed Integer Programming Scheduling Models. Chem. Eng. Sci. 2015, 136. [Google Scholar] [CrossRef]
- Kallrath, J. Planning and Scheduling in the Process Industry. OR Spectrum 2002, 24, 219–250. [Google Scholar] [CrossRef]
- Nie, Y.; Biegler, L.T.; Wassick, J.M.; Villa, C.M. Extended Discrete-Time Resource Task Network Formulation for the Reactive Scheduling of a Mixed Batch/Continuous Process. Ind. Eng. Chem. Res. 2014, 53, 17112–17123. [Google Scholar] [CrossRef]
- Moniz, S.; Barbosa-Póvoa, A.P.; de Sousa, J.P.; Duarte, P. Solution Methodology for Scheduling Problems in Batch Plants. Ind. Eng. Chem. Res. 2014, 53, 19265–19281. [Google Scholar] [CrossRef]
- Stefansson, H.; Sigmarsdottir, S.; Pall, J.; Shah, N. Discrete and Continuous Time Representations and Mathematical Models for Large Production Scheduling Problems: A Case Study from the Pharmaceutical Industry. Eur. J. Oper. Res. 2011, 215, 383–392. [Google Scholar] [CrossRef]
- Castro, P.M.; Harjunkoski, I.; Grossmann, I.E. Optimal Short-Term Scheduling of Large-Scale Multistage Batch Plants. Ind. Eng. Chem. Res. 2009, 48, 11002–11016. [Google Scholar] [CrossRef]
- Kabra, S.; Shaik, M.A.; Rathore, A.S. Multi-period scheduling of a multi-stage multi-product bio-pharmaceutical process. Comp. Chem. Eng. 2013, 57, 95–103. [Google Scholar] [CrossRef]
- Liu, S.; Yahia, A.; Papageorgiou, L. Optimal Production and Maintenance Planning of biopharmaceutical Manufacturing under Performance Decay. Ind. Eng. Chem. Res. 2014, 53, 17075–17091. [Google Scholar] [CrossRef]
- Shah, N.K.; Sahay, N.; Ierapetritou, M.G. Efficient Decomposition Approach for Large-Scale Refinery Scheduling. Ind. Eng. Chem. Res. 2015, 54, 9964–9991. [Google Scholar] [CrossRef]
- Zhang, B.J.; Hua, B. Effective MILP Model for Oil Refinery-wide Production Planning and Better Energy Utilization. J. Clean. Prod. 2007, 15, 439–448. [Google Scholar] [CrossRef]
- Iyer, R.; Grossmann, I.E.; Vasantharajan, S.; Cullick, A. Optimal Planning and Scheduling of Offshore Oil Field Infrastructure Investment and Operations. Ind. Eng. Chem. Res. 1998, 37, 1380–1397. [Google Scholar] [CrossRef]
- Assis, L.; Camponogara, E.; Zimberg, B.; Ferreira, E.; Grossmann, I.E. A piecewise McCormick relaxation-based strategy for scheduling operations in a crude oil terminal. Comp. Chem. Eng. 2017, 106, 309–321. [Google Scholar] [CrossRef]
- Castro, P.M.; Mostafaei, H. Batch-centric Scheduling Formulation for Treelike Pipeline Systems with Forbidden Product Sequences. Comput. Chem. Eng. 2018, 122, 2–18. [Google Scholar] [CrossRef]
- Castro, P.M. Optimal Scheduling of Multiproduct Pipelines in Networks with Reversible Flow. Ind. Eng. Chem. Res. 2017, 56, 9638–9656. [Google Scholar] [CrossRef]
- Cafaro, D.C.; Cerdá, J. Efficient Tool for the Scheduling of Multiproduct Pipelines and Terminal Operations. Ind. Eng. Chem. Res. 2008, 47, 9941–9956. [Google Scholar] [CrossRef]
- Cafaro, V.G.; Cafaro, D.C.; Mendez, C.A.; Cerdá, J. Detailed Scheduling of Single-Source Pipelines with Simultaneous Deliveries to Multiple Offtake Stations. Ind. Eng. Chem. Res. 2012, 51, 6145–6165. [Google Scholar] [CrossRef]
- Rejowski, R.; Pinto, J. Scheduling of a multiproduct pipeline system. Comp. Chem. Res. 2003, 27, 1229–1246. [Google Scholar] [CrossRef]
- Boschetto, S.; Magatão, L.; Brondani, W.; Neves-Jr, F.; Arruda, L.; Barbosa-Povoa, A.; Relvas, S. An Operational Scheduling Model to Product Distribution through a Pipeline Network. Ind. Eng. Chem. Res. 2010, 49, 5661–5682. [Google Scholar] [CrossRef]
- Baldo, T.A.; Santos, M.O.; Almada-Lobo, B.; Morabito, R. An Optimization Approach for the Lot Sizing and Scheduling Problem in the Brewery Industry. Comput. Ind. Eng. 2014, 72, 58–71. [Google Scholar] [CrossRef]
- Simpson, R.; Abakarov, A. Optimal Scheduling of Canned Food Plants Including Simultaneous Sterilization. J. Food Eng. 2009, 90, 53–59. [Google Scholar] [CrossRef]
- Georgiadis, G.P.; Ziogou, C.; Kopanos, G.M.; Garcia, M.; Cabo, D.; Lopez, M.; Georgiadis, M.C. Production Scheduling of Multi-Stage, Multi-product Food Process Industries. In Proceedings of the 28th European Symposium on Computer Aided Process Engineering, Graz, Austria, 10–13 June 2018; pp. 1075–1080. [Google Scholar]
- Liu, S.; Pinto, J.M.; Papageorgiou, L.G. Single-Stage Scheduling of Multiproduct Batch Plants: An Edible-Oil Deodorizer Case Study. Ind. Eng. Chem. Res. 2010, 49, 8657–8669. [Google Scholar] [CrossRef]
- Polon, P.E.; Alves, A.F.; Olivo, J.E.; Paraíso, P.R.; Andrade, C.M.G. Production Optimization in Sausage Industry Based on the Demand of the Products. J. Food Process. Eng. 2018, 41. [Google Scholar] [CrossRef]
- Doganis, P.; Sarimveis, H. Optimal Scheduling in a Yogurt Production Line Based on Mixed Integer Linear Programming. J. Food Eng. 2007, 80, 445–453. [Google Scholar] [CrossRef]
- Sel, C.; Bilgen, B.; Bloemhof-Ruwaard, J. Planning and Scheduling of the Make-and-Pack Dairy Production under Lifetime Uncertainty. Appl. Math. Model. 2017, 51, 129–144. [Google Scholar] [CrossRef]
- Touil, A.; Echechatbi, A.; Charkaoui, A. An MILP Model for Scheduling Multistage, Multiproducts Milk Processing. In Proceedings of the IFAC-PapersOnLine, Troyes, France, 28–30 June 2016; pp. 869–874. [Google Scholar]
- Kopanos, G.M.; Puigjaner, L.; Georgiadis, M.C. Resource-constrained production planning in semicontinuous food industries. Comput. Chem. Eng. 2011, 35, 2929–2944. [Google Scholar] [CrossRef]
- Georgiadis, G.P.; Kopanos, G.M.; Karkaris, A.; Ksafopoulos, H.; Georgiadis, M.C. Optimal Production Scheduling in the Dairy Industries. Ind. Eng. Chem. Res. 2019, 58, 6537–6550. [Google Scholar] [CrossRef]
- van Elzakker, M.A.H.; Zondervan, E.; Raikar, N.B.; Grossmann, I.E.; Bongers, P.M.M. Scheduling in the FMCG Industry: An Industrial Case Study. Ind. Eng. Chem. Res. 2012, 51, 7800–7815. [Google Scholar] [CrossRef]
- Kopanos, G.M.; Puigjaner, L.; Georgiadis, M.C. Efficient mathematical frameworks for detailed production scheduling in food processing industries. Comput. Chem. Eng. 2012, 42, 206–216. [Google Scholar] [CrossRef]
- Giannelos, N.F.; Georgiadis, M.C. Efficient scheduling of consumer goods manufacturing processes in the continuous time domain. Comput. Oper. Res. 2003, 30, 1367–1381. [Google Scholar] [CrossRef]
- Méndez, C.A.; Cerdá, J. An MILP-based approach to the short-term scheduling of make-and-pack continuous production plants. OR Spectr. 2002, 24, 403–429. [Google Scholar] [CrossRef]
- Baumann, P.; Trautmann, N. A Hybrid Method for Large-Scale Short-Term Scheduling of Make-and-Pack Production Processes. Eur. J. Oper. Res. 2014, 236, 718–735. [Google Scholar] [CrossRef][Green Version]
- Honkomp, S.J.; Lombardo, S.; Rosen, O.; Pekny, J.F. The curse of reality—Why process scheduling optimization problems are difficult in practice. Comput. Chem. Eng. 2000, 24, 323–328. [Google Scholar] [CrossRef]
- Elekidis, A.; Corominas, F.; Georgiadis, M.C. Optimal short-term Scheduling of Industrial Packing Facilities. In Proceedings of the 29th European Symposium on Computer Aided Process Engineering, Eindhoven, The Netherlands, 16–19 June 2019. Accepted manuscript. [Google Scholar]
- Georgiadis, M.C.; Levis, A.A.; Tsiakis, P.; Sanidiotis, I.; Pantelides, C.C.; Papageorgiou, L.G. Optimisation-based scheduling: A discrete manufacturing case study. Comput. Ind. Eng. 2005, 49, 118–145. [Google Scholar] [CrossRef]
- Biondi, M.; Saliba, S.; Harjunkoski, I. Production Optimization and Scheduling in a Steel Plant: Hot Rolling Mill. In Proceedings of the IFAC, Milano, Italy, 28 August–2 September 2011; pp. 11750–11754. [Google Scholar]
- Yang, J.; Cai, J.; Sun, W.; Liu, J. Optimization and Scheduling of Byproduct Gas System in Steel Plant. J. Iron Steel Res. Int. 2015, 22, 408–413. [Google Scholar] [CrossRef]
- Li, J.; Xiao, X.; Tang, Q.; Floudas, C.A. Production Scheduling of a Large-Scale Steelmaking Continuous Casting Process via Unit-Specific Event-Based Continuous-Time Models: Short-Term and Medium-Term Scheduling. Ind. Eng. Chem. Res. 2012, 51, 7300–7319. [Google Scholar] [CrossRef]
- Gajic, D.; Hadera, H.; Onofri, L.; Harjunkoski, I.; Di Gennaro, S. Implementation of an integrated production and electricity optimization system in melt shop. J. Clean. Prod. 2017, 155, 39–46. [Google Scholar] [CrossRef]
- Hadera, H.; Harjunkoski, I.; Sand, G.; Grossmann, I.E.; Engell, S. Optimization of steel production scheduling with complex time-sensitive electricity cost. Comput. Chem. Eng. 2015, 76, 117–139. [Google Scholar] [CrossRef]
- Castro, P.M.; Harjunkoski, I.; Grossmann, I.E. Optimal scheduling of continuous plants with energy constraints. Comput. Chem. Eng. 2011, 35, 372–387. [Google Scholar] [CrossRef]
- Castro, P.M.; Harjunkoski, I.; Grossmann, I.E. New Continuous-Time Scheduling Formulation for Continuous Plants under Variable Electricity Cost. Ind. Eng. Chem. Res. 2009, 48, 6701–6714. [Google Scholar] [CrossRef]
- Kong, H.; Qi, E.; He, S.; Gang, L. MILP Model for Plant-Wide Optimal By-Product Gas Scheduling in Iron and Steel Industry. J. Iron Steel Res. Int. 2010, 17, 34–37. [Google Scholar] [CrossRef]
- Wang, S.; Liu, M.; Chu, F.; Chu, C. Bi-objective optimization of a single machine batch scheduling problem with energy cost consideration. J. Clean. Prod. 2016, 137, 1205–1215. [Google Scholar] [CrossRef]
- Westerlund, J.; Isaksson, J.; Harjunkoski, I. Solving a two-dimensional trim-loss problem with MILP. Eur. J. Oper. Res. 1998, 104, 572–581. [Google Scholar] [CrossRef]
- Roslöf, J.; Harjunkoski, I.; Westerlund, J.; Isaksson, J. A Short-Term Scheduling Problem in the Paper-Converting Industry. Comput. Chem. Eng. 1999, 23, S871–S874. [Google Scholar] [CrossRef]
- Roslöf, J.; Harjunkoski, I.; Björkqvist, J.; Karlsson, S.; Westerlund, J. An MILP-based reordering algorithm for complex industrial scheduling and rescheduling. Comput. Chem. Eng. 2001, 25, 821–828. [Google Scholar] [CrossRef]
- Giannelos, N.F.; Georgiadis, M.C. Scheduling of Cutting-Stock Processes on Multiple Parallel Machines. Chem. Eng. Res. Des. 2001, 79, 747–753. [Google Scholar] [CrossRef]
- Castro, P.M.; Barbosa-Póvoa, A.P.; Matos, H.A. Optimal Periodic Scheduling of Batch Plants Using RTN-Based Discrete and Continuous-Time Formulations: A Case Study Approach. Ind. Eng. Chem. Res. 2003, 42, 3346–3360. [Google Scholar] [CrossRef]
- Castro, P.M.; Westerlund, J.; Forssell, S. Scheduling of a continuous plant with recycling of byproducts: A case study from a tissue paper mill. Comput. Chem. Eng. 2009, 33, 347–358. [Google Scholar] [CrossRef]
- Janak, S.L.; Floudas, C.A.; Kallrath, J.; Vormbrock, N. Production scheduling of a large-scale industrial batch plant. II. Reactive scheduling. Ind. Eng. Chem. Res. 2006, 45, 8253–8269. [Google Scholar] [CrossRef]
- Harjunkoski, I. Deploying scheduling solutions in an industrial environment. Comput. Chem. Eng. 2016, 91, 127–135. [Google Scholar] [CrossRef]
- Grossmann, I.E.; Harjunkoski, I. Process systems Engineering: Academic and industrial perspectives. Comput. Chem. Eng. 2019, 126, 474–484. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Industrial Sector | Main Research Features |
|---|---|---|
| Lin and Floudas [75] | Chemical industry | • Continuous time event-based mixed-integer linear programming (MILP) • Decomposition methodology |
| Janak et al. [129] | Chemical industry | • Graphical user interface development • Rolling horizon approach |
| Westerlund et al. [77] | Chemical industry | • Planning tool connected with the plant’s ERP system |
| Velez, Merchan and Maravelias [78] | Chemical industry | • Multiple discrete-time grids • A real case study from Dow company |
| Moniz et al. [81] | Pharmaceutical industry | • A Visio-based decision-making tool development |
| Stefansson et al. [82] | Pharmaceutical industry | • Discrete and continuous time representations • Stage decomposition |
| Castro, Harjunkoski and Grossmann [83] | Pharmaceutical industry | • Decomposition-based algorithm |
| Kopanos, Méndez and Puigjaner [39] | Pharmaceutical industry | • Precedence-based MILP models • Decomposition-based solution strategy |
| Liu et al. [84] | Pharmaceutical industry | • Maintenance planning • 1 h CPU time |
| Kabra et al. [85] | Pharmaceutical industry | • State-task network (STN) representation • Computational time in the range of 1–2 min. |
| Shah, Sahay and Ierapetritou [86] | Oil refineries | • Six-step MILP based heuristic algorithm • A case study provided by Honeywell Process Solutions (HPS). |
| Zhang and Hua [87] | Oil refineries | • Integration of the plant processes and the utility system |
| Iyer et al. [88] | Oil refineries | • Decomposition algorithm • Feasible solutions within 6600 s are obtained |
| Assis et al. [89] | Oil refineries | • Scheduling of a crude oil terminal • A case study by the national refinery of Uruguay |
| Casrto and Mostafei [90] | Pipeline systems | • A case study from the Iranian Oil Pipelines and Telecommunication Company • 6.2% capacity increase |
| Cafaro et al. [93] | Pipeline systems | • Simultaneous product deliveries are allowed • A case study, related to REPLAN refinery |
| Rejowski and Pinto [94] | Pipeline systems | • Integrality gap of 5.8% in 10,000 CPU s • A case study, related to REPLAN refinery |
| Boschetto et al. [95] | Pipeline systems | • Heuristic rules • Computational times within 3–5 min. |
| Baldo et al. [96] | Food industries | • A novel MILP-based relax and fix heuristic algorithm • A case study from a brewery industry |
| Kopanos, Puigjaner and Maravelias [29] | Food industries | • An immediate precedence-based MILP formulation • A case study from a brewery industry |
| Abakarov andSimpson [97] | Food industries | • A food cannery case study • Scheduling of the sterilization stage |
| Georgiadis et al. [98] | Food industries | • A case study from a large-scale canned fish industry case study • MILP based decomposition algorithm |
| Liu, Pinto and Papageorgiou [99] | Food industries | • An edible-oil deodorized industry case study • Mixed discrete and continuous MILP mathematical |
| Polon et al. [100] | Food industries | • A case study from a sausage production industry • Scheduling of the production stage |
| Doganis and Sarimveis [101] | Dairy industry | • A single yoghurt production line |
| Sel, Bilgen and Bloenhof-Ruwaard [102] | Dairy industry | • Integrated planning and scheduling of a yoghurt facility |
| Touil, Echchatbi and Charkaoui [103] | Dairy industry | • A case study from a milk industry |
| Kopanos, Puigjaner and Georgiadis [104] | Dairy industry | • A case study from a yoghurt industry • Novel resource constraints |
| Georgiadis et al. [105] | Dairy industry | • An integrated software tool connects the plant’s ERP system with the proposed MILP model • A total cost decrease of 20% is achieved |
| Giannelos and Georgiadis [108] | Consumer goods industry | • STN continuous time formulation • Medium-size industrial consumer goods manufacturing process |
| Baumann and Trautmann [110] | Consumer goods industry | • General precedence MILP hybrid method • 10 large-scale problem instances provided by The Procter and Gamble Company |
| Elzakker et al. [106] | Fast-moving consumer goods (FMCG) industry | • A unit-specific, continuous time interval-based algorithm • Ice cream production process of Unilever |
| Kopanos, Puigjaner and Georgiadis [107] | Fast-moving consumer goods (FMCG) industry | • Ice cream production process |
| Elekidis, Corominas and Georgiadis [112] | Consumer goods industry | • An immediate-general precedence-based decomposition algorithm |
| Georgiadis et al. [113] | Manufacturing industries | • Resource task network (RTN) and STN based models • A comparison with a PSE scheduling tool and an MILP model • Development of a middleware interface for data transfer |
| Biondi, Saliba and Harjunkoski [114] | Steel industry | • Slot-based MILP formulation • communication with ERP and DCS |
| Li et al. [116] | Steel industry | • A unit-specific event-based continuous-time MILP model |
| Gajic et al. [117] | Steel industry | • Integrated scheduling and electricity optimization problem • A melt shop case study • 3% electricity cost reduction |
| Hadera et al. [118] | Steel industry | • A melt shop case study • Integrated scheduling and electricity optimization problem • A general precedence MILP scheduling model |
| Castro, Harjunkoski and Grossmann [120] | Steel industry | • Integrated scheduling and energy optimization problem • RTN-based MILP model • 20% electricity cost reduction |
| Wang et al. [122] | glass company | • Bi-objective optimization problem • Makespan and the total energy cost minimization |
| Westerlund, Isaksson and Harjunkoski [123] | Paper Industry | • Trim-loss problem of a paper converting mill |
| Roslöf et al. [124] | Paper Industry | • MILP based decomposition algorithm |
| Giannelos and Georgiadis [126] | Paper Industry | • A slot-based MILP model • A paper mill company case study |
| Castro, Barbosa-Povoa and Matos [127] | Paper Industry | • Continuous and discrete time RTN representation • A case study from a pulp mill plant |
| Castro, Westerlund and Forssell [128] | Paper Industry | • RTN-based formulation • Novel recycling policies |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Georgiadis, G.P.; Elekidis, A.P.; Georgiadis, M.C. Optimization-Based Scheduling for the Process Industries: From Theory to Real-Life Industrial Applications. Processes 2019, 7, 438. https://doi.org/10.3390/pr7070438
Georgiadis GP, Elekidis AP, Georgiadis MC. Optimization-Based Scheduling for the Process Industries: From Theory to Real-Life Industrial Applications. Processes. 2019; 7(7):438. https://doi.org/10.3390/pr7070438
Chicago/Turabian StyleGeorgiadis, Georgios P., Apostolos P. Elekidis, and Michael C. Georgiadis. 2019. "Optimization-Based Scheduling for the Process Industries: From Theory to Real-Life Industrial Applications" Processes 7, no. 7: 438. https://doi.org/10.3390/pr7070438
APA StyleGeorgiadis, G. P., Elekidis, A. P., & Georgiadis, M. C. (2019). Optimization-Based Scheduling for the Process Industries: From Theory to Real-Life Industrial Applications. Processes, 7(7), 438. https://doi.org/10.3390/pr7070438