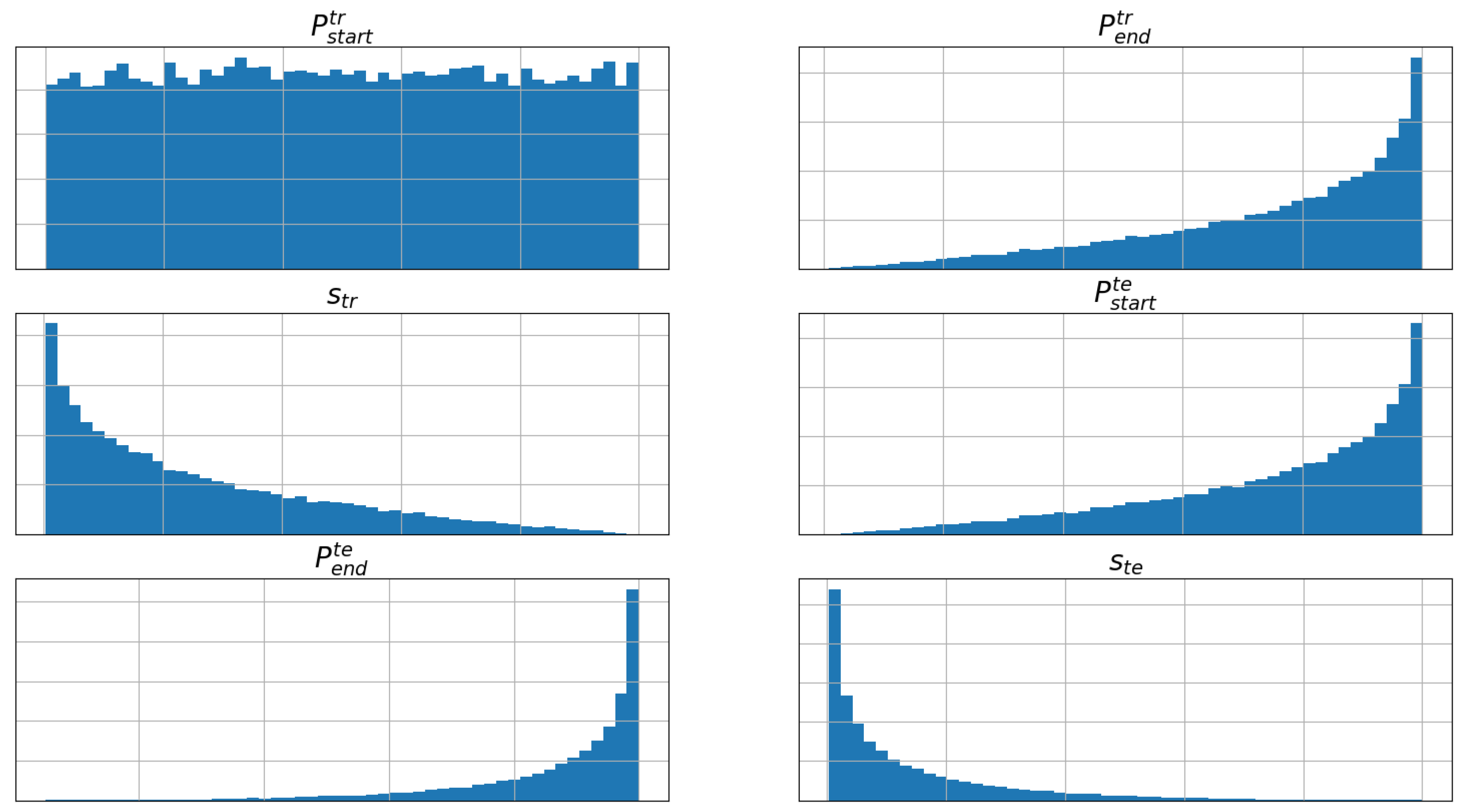
The sampling algorithm results for the four datasets are shown in
Table 5. Per the definition of the sampling algorithm for Unbiased Evaluation and the selected total number of models, the total number of models equals the number of data points. However, for EAF1, EAF2, and LRF, the algorithm produced several training and test data intervals with the same length and start positions. Since these samples are identical, they were removed.
It is evident that the fraction of models that are removed by the stability filter is significantly larger for the EAF datasets. This agrees well with the known behavior of the EAF that is consequently reflected in the data. Frequent changes in charged scrap in the EAF, which also affect the EE consumption, make it challenging to consistently produce stable models since the frequent changes will be interpreted as noise. The number of models passing the stability filter for EAF2 is low compared to the other processes. While 95 models can be used to draw conclusions, the empirical evidence of these conclusions will not be as strong as for the other datasets, which have between 1048 and 33,888 models passing the stability filter. The following graphs (
Figure 5,
Figure 6 and
Figure 7) were created using the results from the experiments that were filtered using
. Each graph contains a line representing a 200-value moving average over the
x-axis. Furthermore, each graph also has a corresponding Pearson correlation test calculated using the variables represented by the
x-axis and
y-axis.
4.1. Research Question 1
It is possible to determine the number of training data points that are needed to create an ML model with near-upper-bound predictive performance on test data by observing the highest -value. However, the highest -value may reside in a region of where has large variance indicating that could be lower than the near-upper-bound predictive performance for a similar number of training data points. Thus, a relatively low variance of at the highest -values will also be an indicator when answering this RQ. In addition, the maximum of the 200-value moving average curve shows what the -value is expected to be by taking into account all -values for every 200-value segment of .
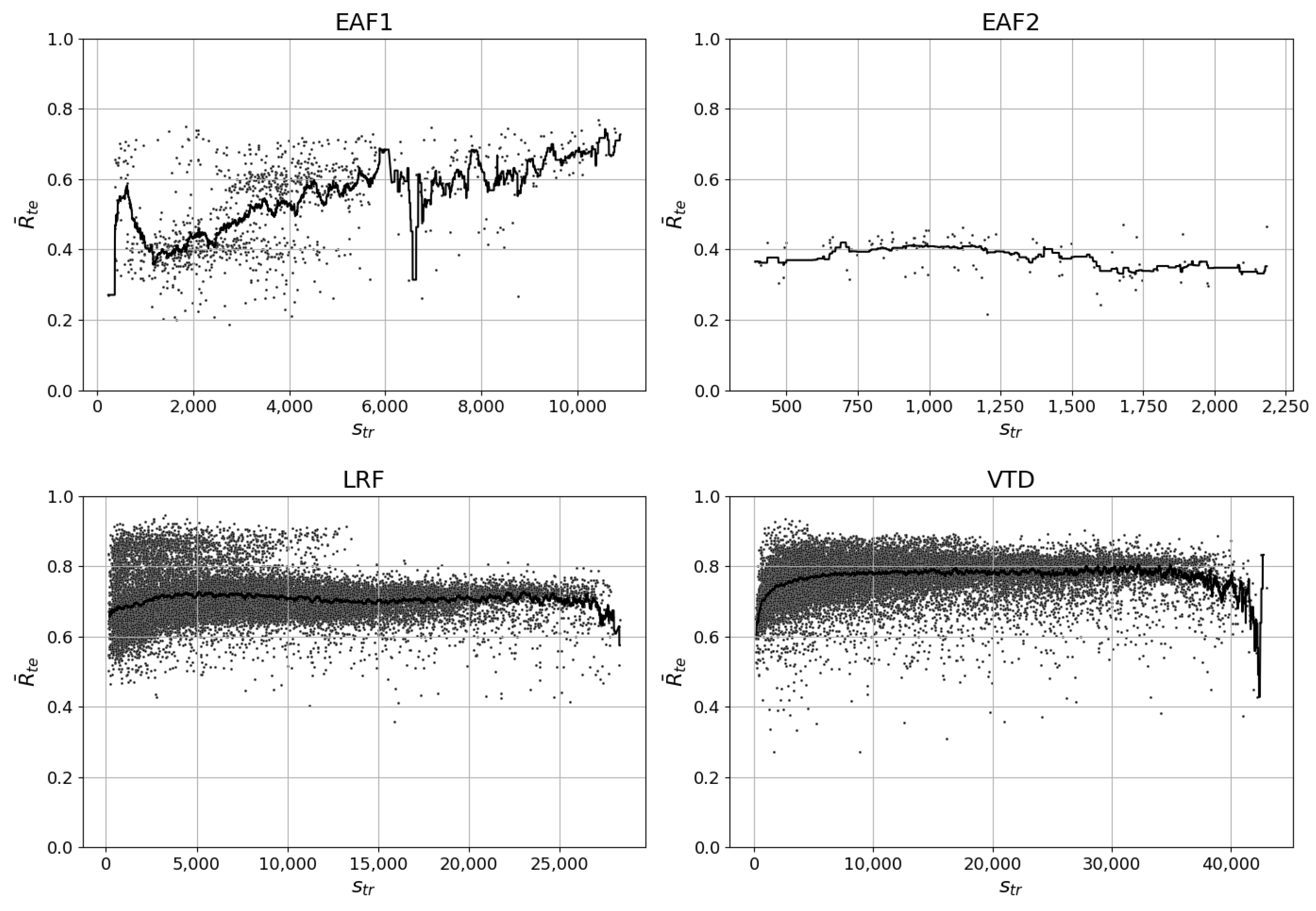
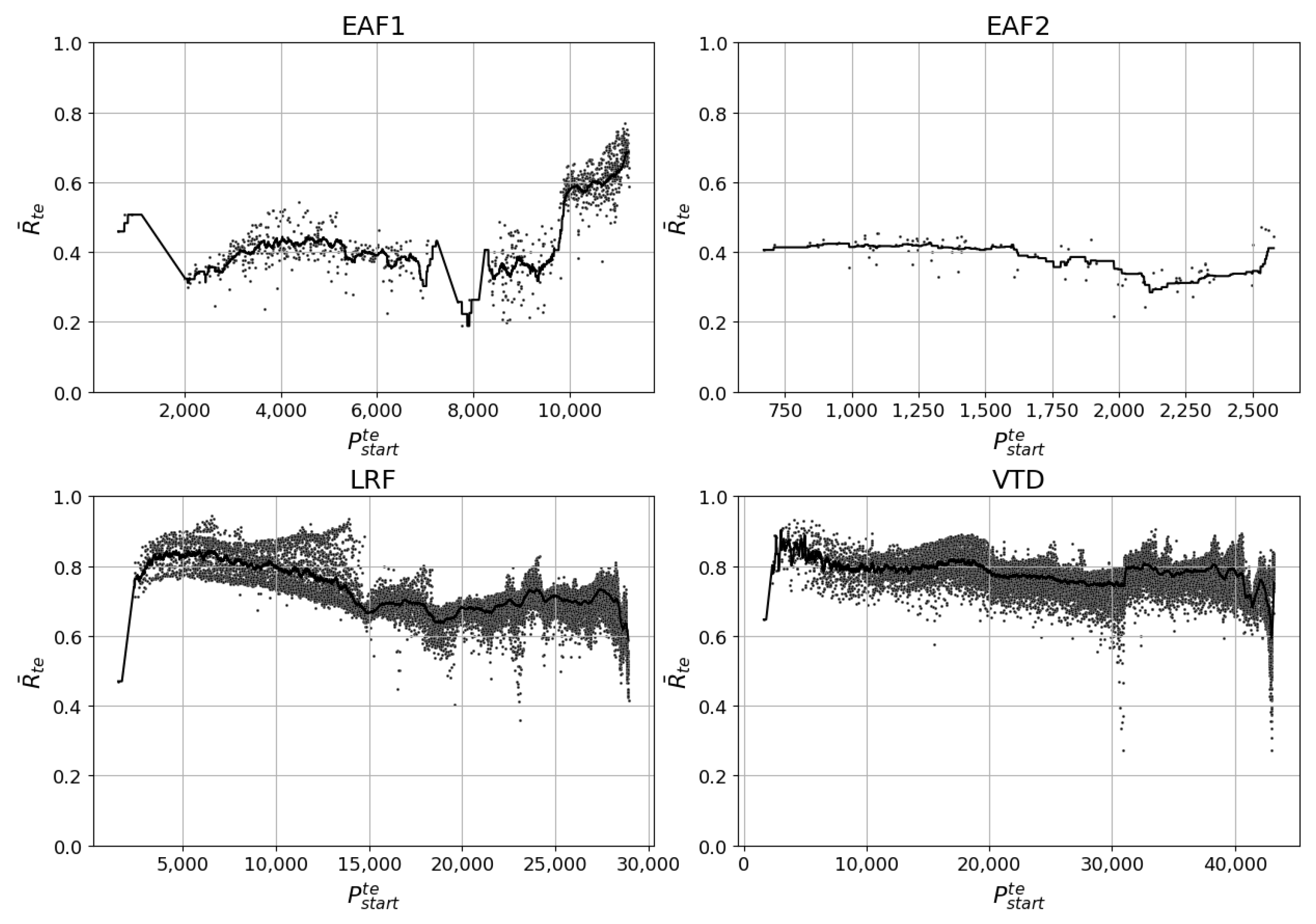
For the EAF1 dataset, as observed in
Figure 5, the highest
occurs at around 10,500 training samples where it varies between 0.67 and 0.78.
is almost as high around 2000 training samples but the variance is considerably larger since
varies between 0.23 and 0.76. The Pearson correlation value of 0.51 and the 200-value moving average curve provide further evidence that the highest
is expected to occur when
is around its maximum value. Since the Pearson correlation value is positive,
increases linearly with increasing
. The 200-value moving average curve is also steadily increasing, albeit irregularly, and peaks at around 10,500 training samples.
For the EAF2 dataset, the highest occurs when is around 1700 and 2200 where the variance is slightly higher in the former segment. The Pearson correlation value is −0.29, which indicates that will decrease with higher . The 200-value moving average line adds additional empirical evidence that decreases with higher .
Two distinct regions can be observed for produced by the models on the LRF dataset. The first region exists when is between 100 and 13,800 where between 0.40 and 0.93. Simultaneously, the second region extends from 13,800 to the maximum number of possible where varies between 0.37 and 0.81. One possible explanation for the high variance of for the LRF dataset is that the LRF production pattern changed due to changes in steel types produced, which in turn is due to changes in demand during the past 14 years. The Pearson correlation value is 0.03, which indicates that a higher barely increases the of the created models. However, the 200-value moving average line peaks at an -value of 4500 and decreases significantly after a -value of 27,000. Again, this indicates a difference between the global and local relationship between and .
Figure 5.
The mean R-squared on the test data () plotted against the number of data points in the training set () for all randomized samples whose model types satisfy . Pearson correlation tests (statistic, p-value). - EAF1: (0.51, 0.0) - EAF2: (−0.29, 0.004) - LRF: (0.03, 0.0) - VTD: (0.22, 0.0).
Figure 5.
The mean R-squared on the test data () plotted against the number of data points in the training set () for all randomized samples whose model types satisfy . Pearson correlation tests (statistic, p-value). - EAF1: (0.51, 0.0) - EAF2: (−0.29, 0.004) - LRF: (0.03, 0.0) - VTD: (0.22, 0.0).
A similar reasoning can be conducted for the VTD results as for the LRF results. However, the VTD has only one main region but the variance of is even larger, i.e., between 0.28 and 0.93. Furthermore, the Pearson correlation value is 0.22 while the peak of the 200-value moving average line occurs when is around 30,000. However, the value of the 200-value moving average line does not increase significantly after the -value exceeds 10,000. The most prominent change in the average line occurs when the -value is between 100 and 10,000. Lastly, the moving average decrease at the end is more prominent than the corresponding curve for LRF. The reason why the curve jumps back from the decrease at the end of the curve is because the last point is the only point available in the 200-value segment used to calculate that specific 200-value moving average value.
The decrease in the moving average curve for the LRF and VTD means that almost all available training data used by the models makes the models perform worse on the test data compared to when the models are trained on other segments of training data. If a model is trained on almost all available training data then it will also be tested on a subset, or the full set, of remaining data points according to the sampling algorithm described in
Section 3.3.2. Since the predictive performance decreases for this segment of test data points, the distribution change reflected in this segment makes the test dataset different from the training dataset to such an extent that it warrants a significant decrease in
. Significant changes in the process layout were performed in steel plant C during the year 2021. The datasets from both LRF and VTD represent production from 2008 until the middle of 2022. Hence, the aforementioned change is a reasonable explanation for this decrease in
.
The challenge in answering this RQ is illuminated by the fact that the three indicators used, i.e., the highest -values, a relatively low variance of at the highest -values, and the maximum of the 200-value moving average curve, do not always coincide in the graphs. Consequently, it is here where where the utility of the proposed method shows itself since it facilitates the analysis of the models to enable stakeholders to deduce the number of training data points required to create a model with near-upper-bound predictive predictive performance on test data.
4.2. Research Question 2
Determining the near-upper-bound predictive performance on test data could be performed by analyzing the same figure that was used to answer RQ1, i.e.,
Figure 5. However, this figure does not provide information on which segment of test data produces the near-upper-bound predictive performance. On the other hand,
Figure 6 shows the relationship between
and
.
For EAF1, the model with the highest -value, i.e., 0.77, is located where is above 11,000, which is almost at the end of the complete dataset. In addition, the Pearson correlation value is 0.73 and the trend of the 200-value moving average curve is positive when is above 11,000. However, some caution should be exercised on these results since it is not possible to know if this trend in predictive performance will continue in subsequent produced heats. After all, the -values when is below 9700 varies between 0.2 and 0.55. It is only after the abrupt jump, which occurs when is around 9800, that the -values concentrate between 0.55 and 0.77. In addition, the reason behind this sudden improvement in is not known.
Figure 6.
The mean R-squared on the test data () plotted against the start of test set () for all randomized samples whose model types satisfies . Pearson correlation tests (statistic, p-value). EAF1: (0.73, 0.0) - EAF2: (−0.52, 0.60) - LRF: (−0.46, 0.0) - VTD: (−0.27, 0.0).
Figure 6.
The mean R-squared on the test data () plotted against the start of test set () for all randomized samples whose model types satisfies . Pearson correlation tests (statistic, p-value). EAF1: (0.73, 0.0) - EAF2: (−0.52, 0.60) - LRF: (−0.46, 0.0) - VTD: (−0.27, 0.0).
Like EAF1, -values for EAF2 are highest when is at the end of the dataset, i.e., when is above 2500. The 200-value moving average curve indicates that recovers from its lows, occurring at a -value of 2120, and ends at its highest when is between 2500 and 2678. Hence, the near-upper-bound predictive performance on test data for EAF2 is a -value 0.44.
The results of the LRF dataset show a steady decrease in for test data from earlier segments to the last segment of the dataset. This is shown by both the 200-value moving average curve and the Pearson correlation value of −0.46. While the near-upper-bound predictive performance is a -value of 0.93, it is not expected to reoccur soon considering that the long-term effects of the previously mentioned production overhaul performed in steel plant C has not yet been established. Furthermore, both the negative Pearson correlation value and the negative trend of the 200-value moving average curve illuminate a continuing decrease in predictive performance. Since the LRF and VTD processes are located in the same steel plant, similar reasoning can be used for the results from the VTD process. Here, the 200-value moving average also trends downward in the last segment of the dataset and the Pearson correlation value is −0.27. The near-upper-bound predictive performance for the VTD is a -value of 0.92.
It should be noted that there are very few stable models when
occurs at the earliest segment of the dataset for all four processes. The corresponding graph, i.e.,
Figure A1 in the
Appendix A, contains the
-values for all models and illuminates the minimum number of training data points needed to create stable models. If
occurs early in the dataset, then
will also be low per the definition of the sampling algorithm.
4.3. Research Question 3
By observing
Figure 7, it is possible to understand how long a model can be used before its predictive performance starts to decrease. Here, the start point of a decrease in the 200-value moving average curve will be determined as the
-value that indicates how long the model can be used.
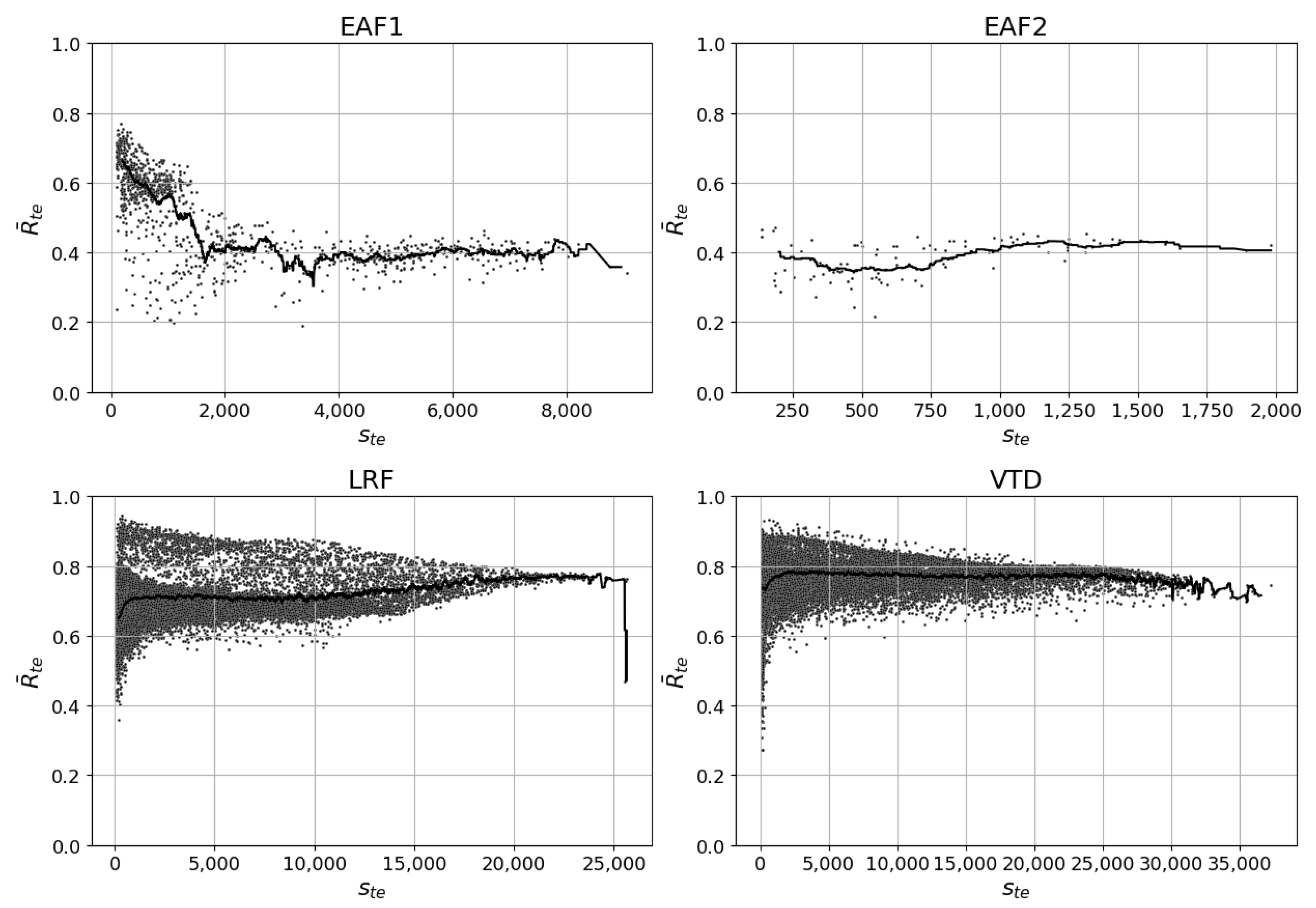
For EAF1, decreases significantly immediately following the start of the 200-value moving average curve, i.e., when is 200. This means that models predicting the EE of the EAF1 should be retrained after predicting on 200 test data points.
Figure 7.
The mean R-squared on the test data () plotted against the number of data points in the test set () for all randomized samples whose model types satisfy Pearson correlation tests (statistic, p-value). - EAF1: (−0.64, 0.0) - EAF2: (0.45, 0.0) - LRF: (0.19, 0.0) - VTD: (0.05, 0.0).
Figure 7.
The mean R-squared on the test data () plotted against the number of data points in the test set () for all randomized samples whose model types satisfy Pearson correlation tests (statistic, p-value). - EAF1: (−0.64, 0.0) - EAF2: (0.45, 0.0) - LRF: (0.19, 0.0) - VTD: (0.05, 0.0).
For EAF2, the models with the highest -values are the ones that have -values below 200. However, the 200-value moving average curve indicates that a higher -values leads to a slightly higher -value. This increase in , albeit low, is contradictory to established ML knowledge since a decrease in is expected if the model has been applied on more test data points, i.e., when the -value is higher. Data points that are chronologically adjacent are more similar than data points that are chronologically far apart, which is partly explained by changes in the steel process under study. The Pearson correlation value of 0.45 provides further evidence that increases when increases.
For LRF, the models with the highest -values are the ones that have -values in the lower region. However, this region also produces models that have the largest range of possible -values. The range of -values are between 0.35 and 0.93. The range decreases significantly when approaches 15,000 and even more so beyond 20,000. However, the similarity between test datasets that approaches the maximum number of possible test data points is large, per definition of the sampling algorithm. Therefore, it is expected that the variance of decreases when approaches its maximum value. Contrary to expectations and similarly to EAF2, both the 200-value moving average curve and the Pearson correlation value of 0.19 illustrate that the increases when increases. Hence, the LRF model can be used for 24,000 heats before its predictive performance starts to deteriorate. The severe sudden decrease in the moving average curve at its end is because only one stable model with a relatively low -value exists in the last 200-value interval.
The results from the VTD models are similar to those for the LRF models, reflecting the fact that these two processes have similar process characteristics and reside in the same steel plant. The Pearson correlation value is 0.05 and the 200-value moving average curve increases. However, the moving average curve only increases when the -value is between 100 and 2000. Beyond an -value of 2000, the moving average curve slowly decreases from 0.79 to 0.72.
Table 6 summarizes the answers to the three RQs as discussed in this section.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}