
A Scientometric Study of the Stylometric Research Field


Abstract
:1. Introduction
- RQ1: What is the current trend and evolution of publications and citations in stylometry research?
- RQ2: Which are the productive and influential sources and countries that are relevant to the research field of stylometry?
- RQ3: Which are the papers that have a significant impact on stylometry research?
- RQ4: What is the conceptual structure and topics related to stylometry?
- RQ5: What is the intellectual structure of the science of stylometry?
- RQ6: What is the country collaboration structure in stylometry research?
2. Materials and Methods
2.1. Data Collection and Preparation
2.2. Data Analysis
3. Performance Results
3.1. Descriptive Statistics of Data Collection
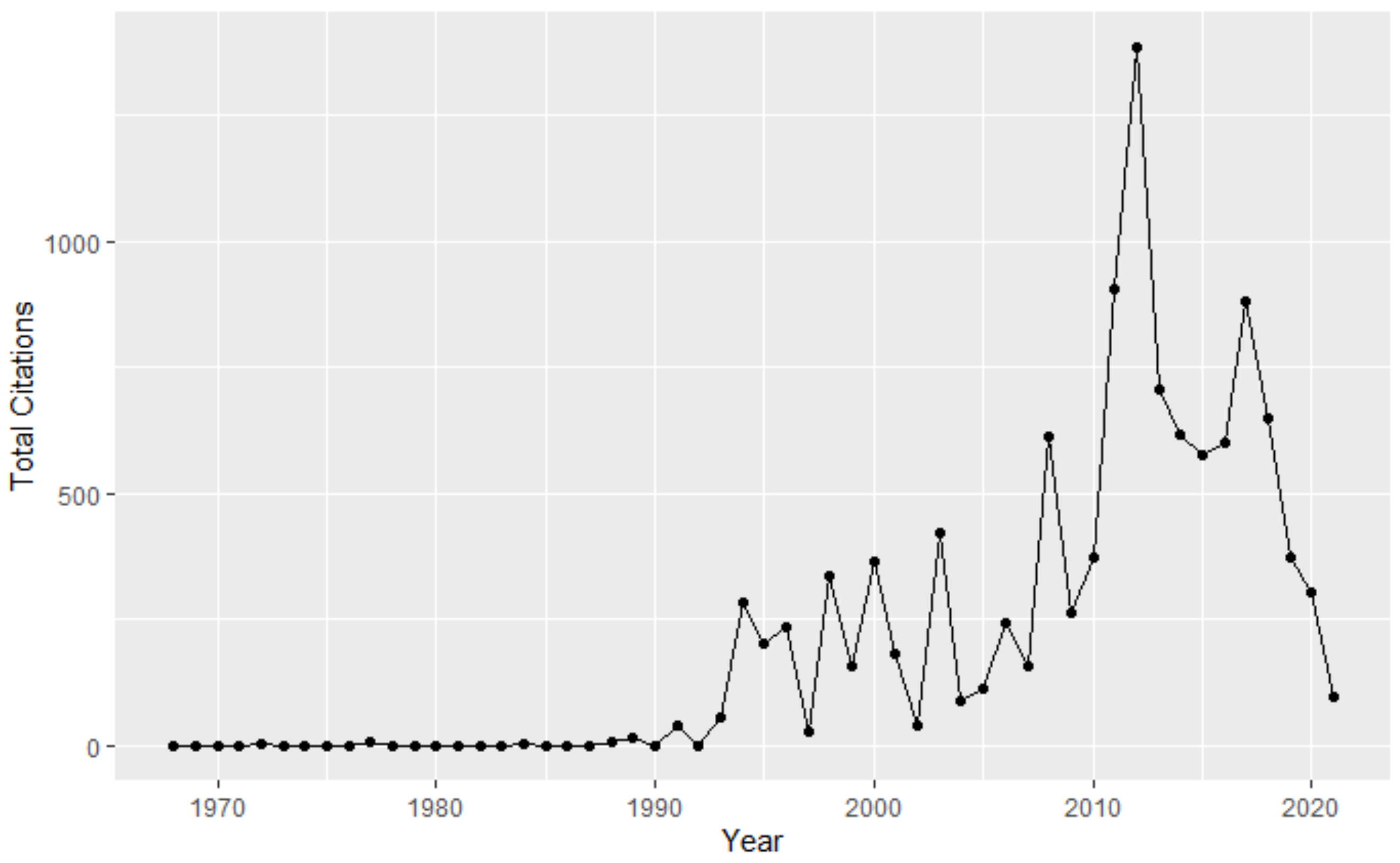
3.2. Publication and Citation Trends
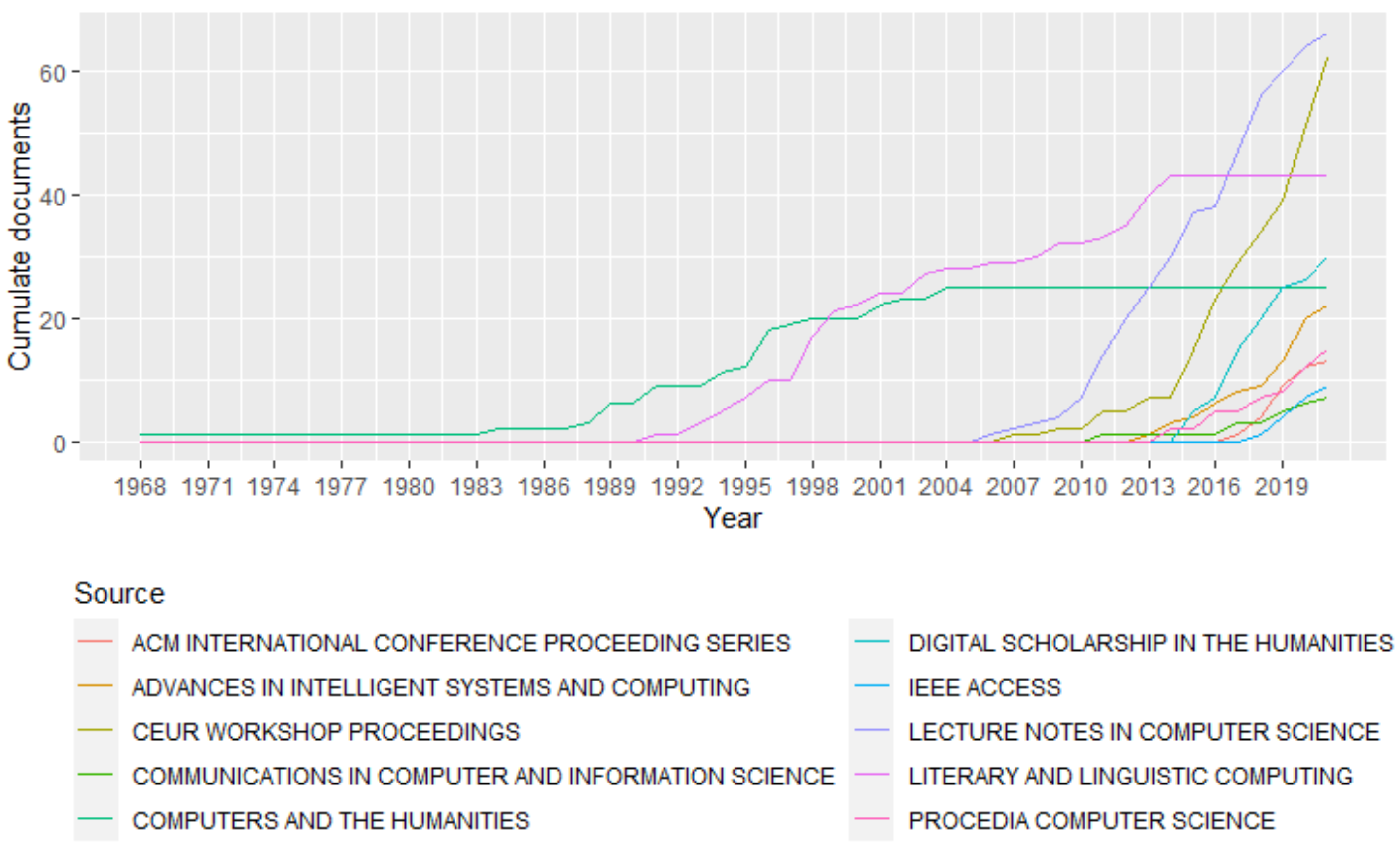
3.3. Most Productive and Influential Sources
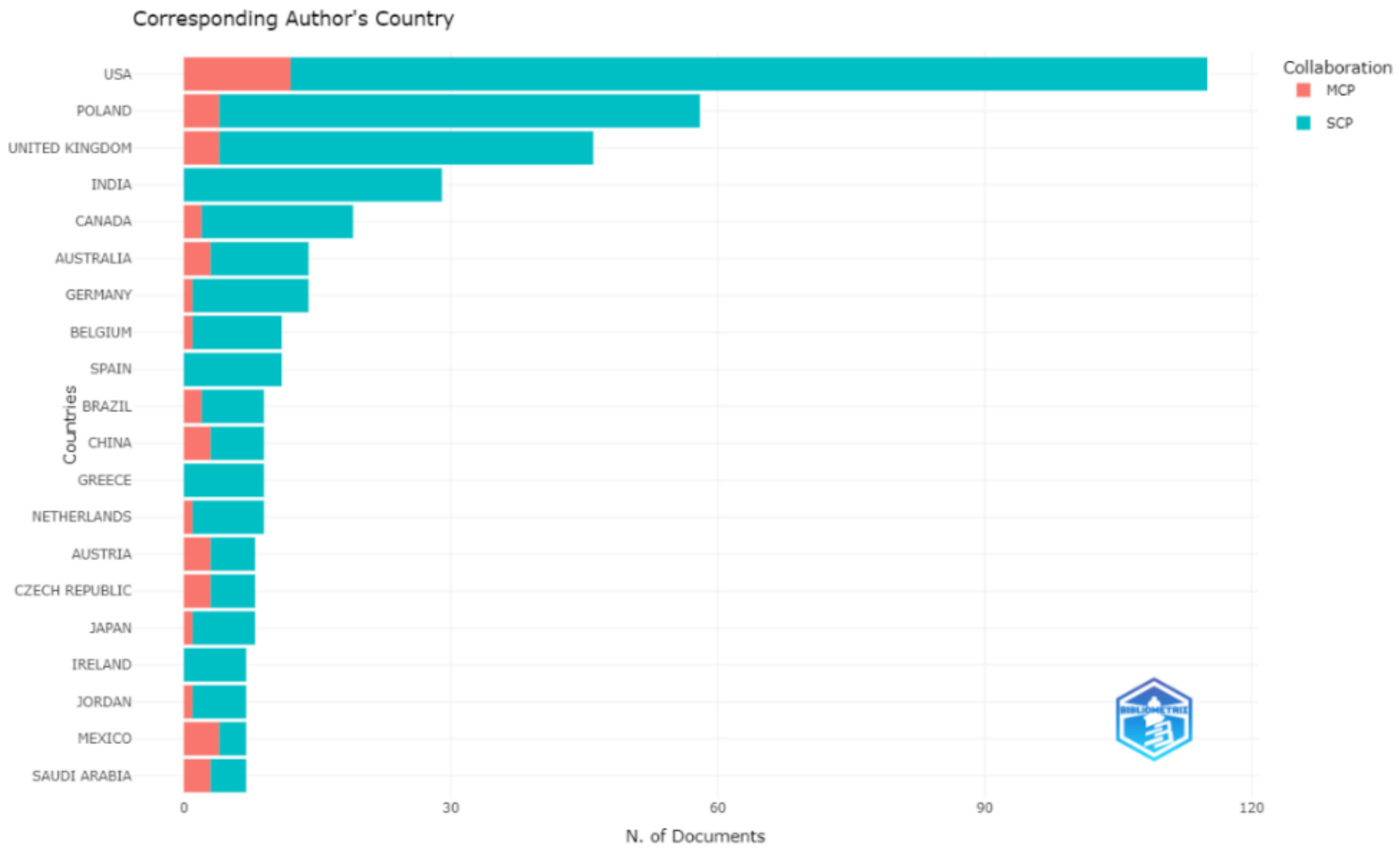
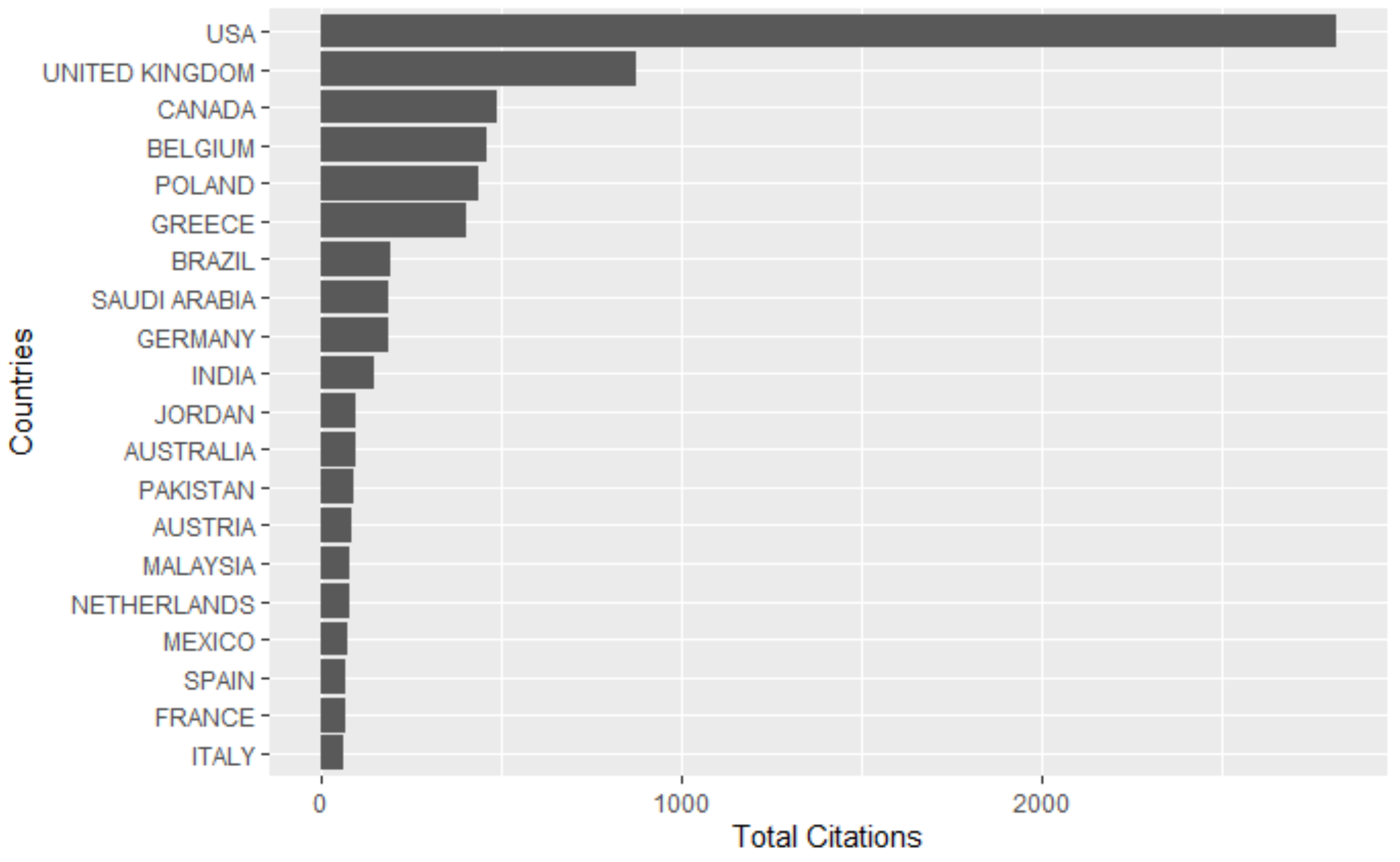
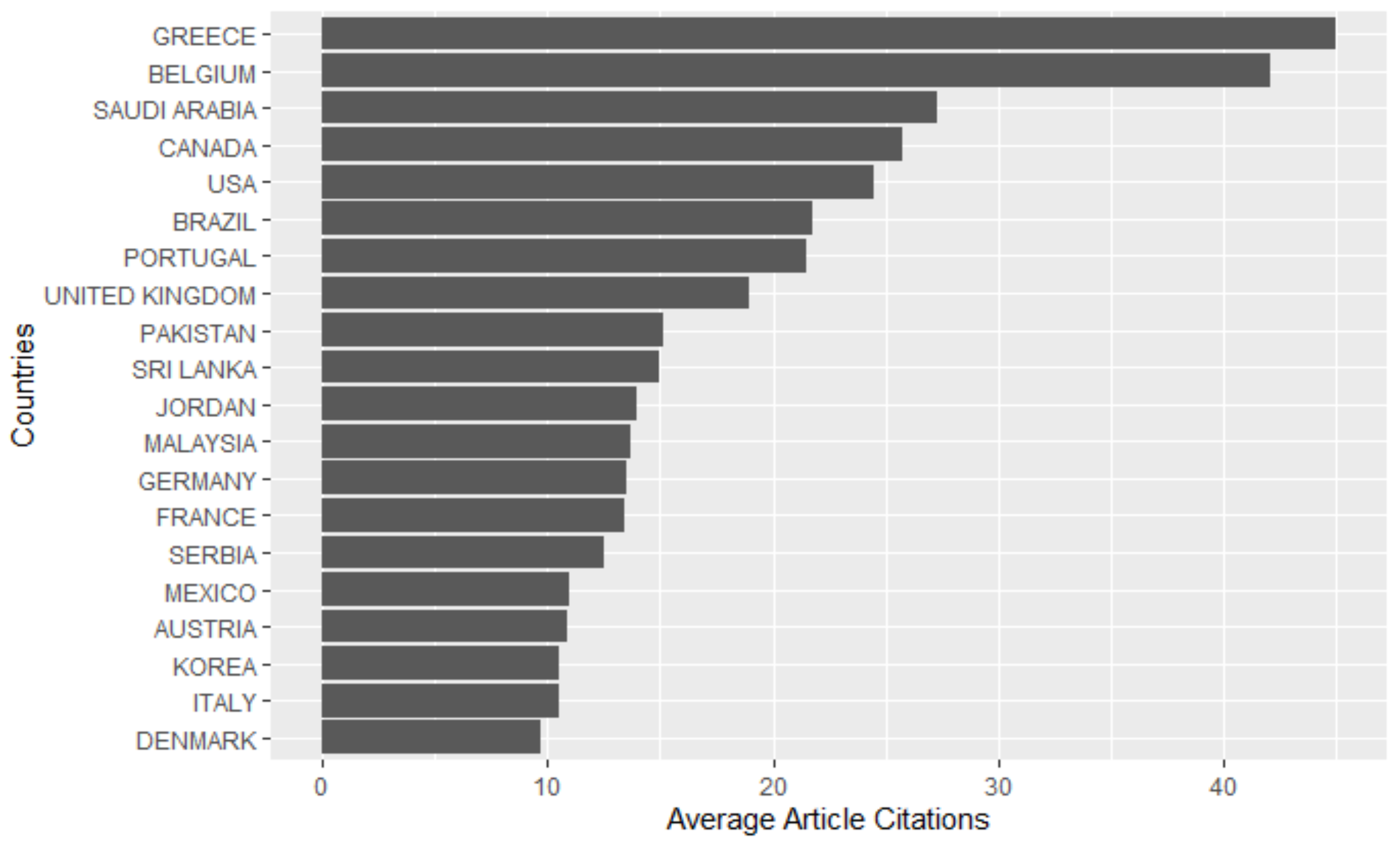
3.4. Most Productive and Influential Countries
3.5. Most Cited Papers
4. Science Mapping Results
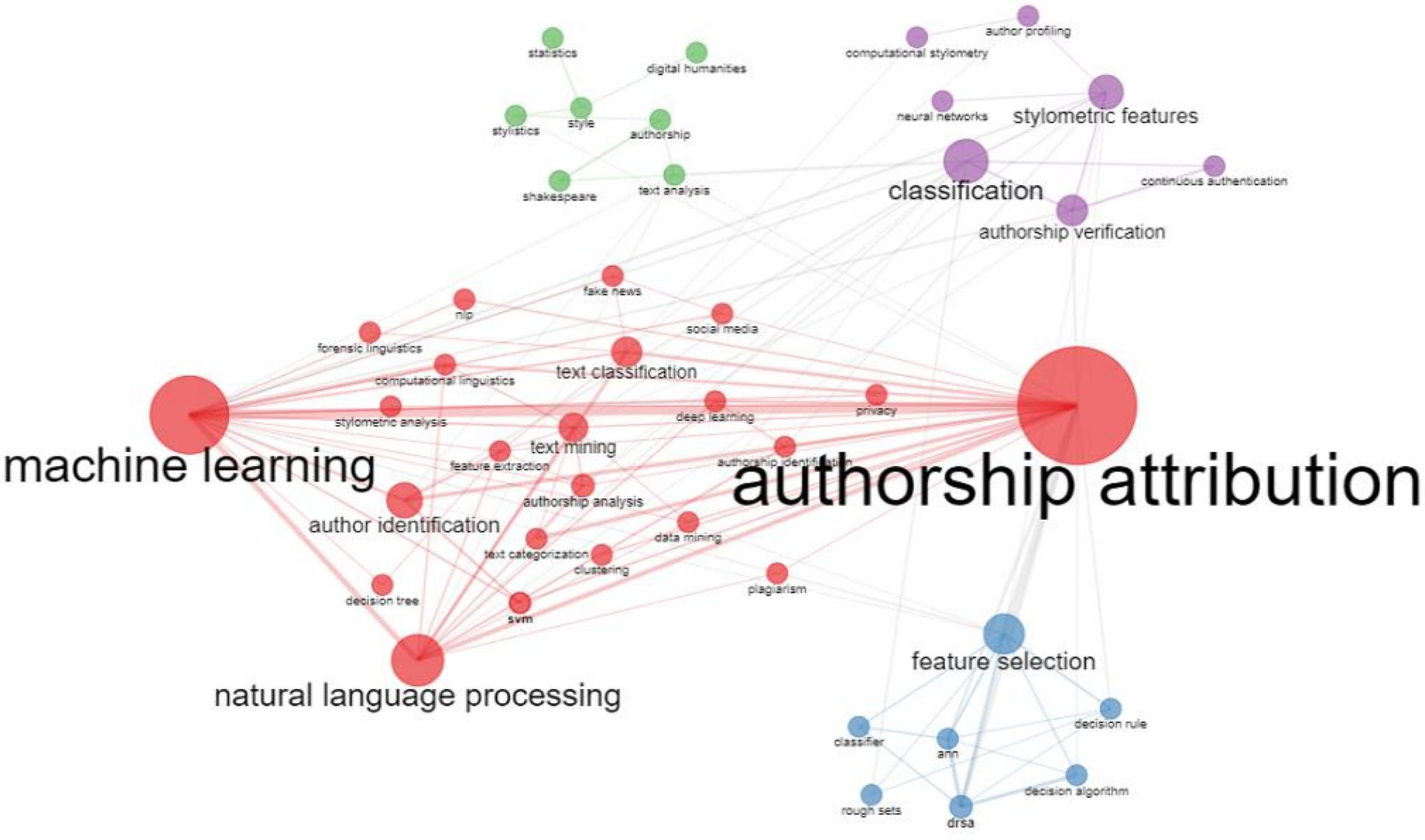
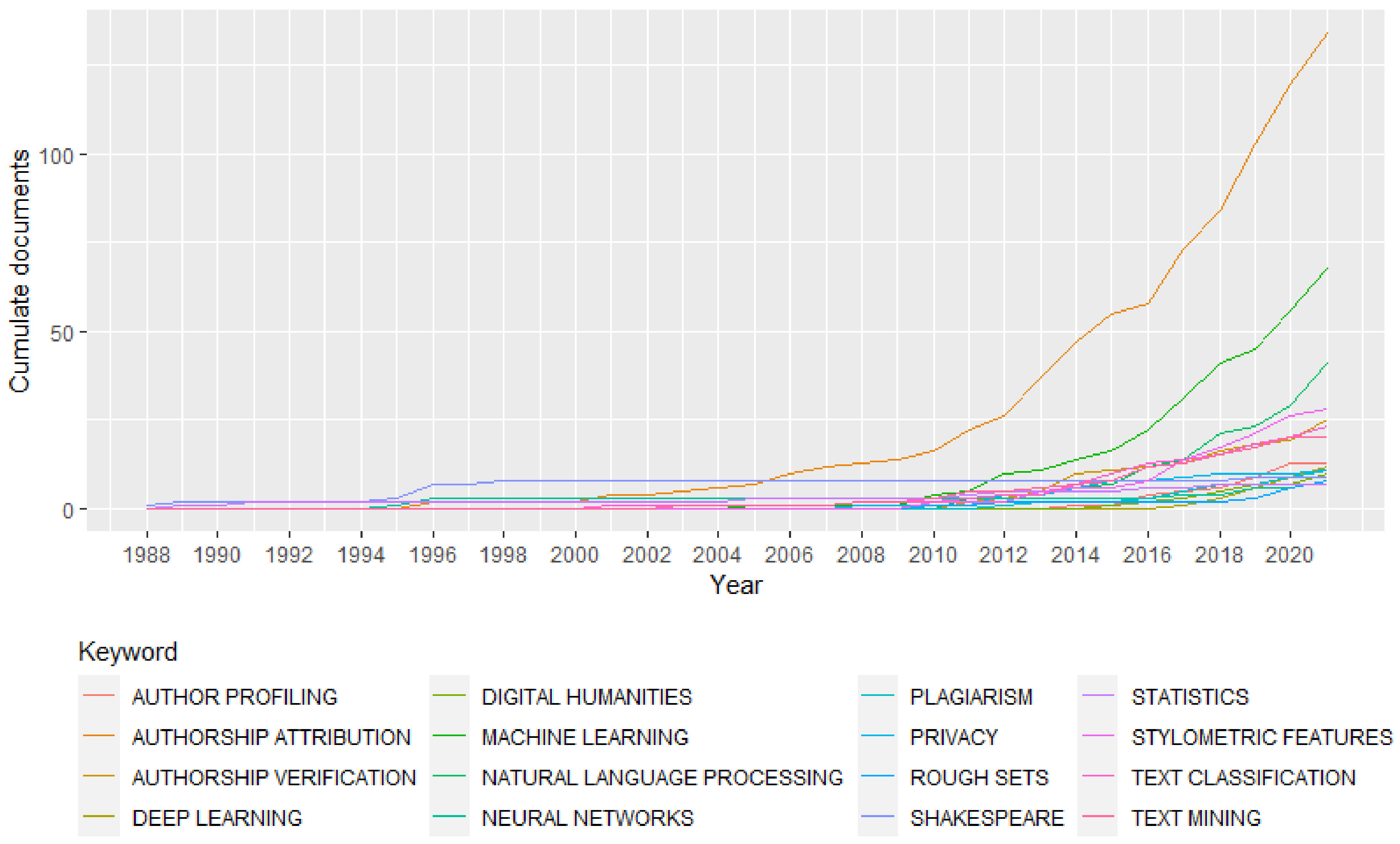
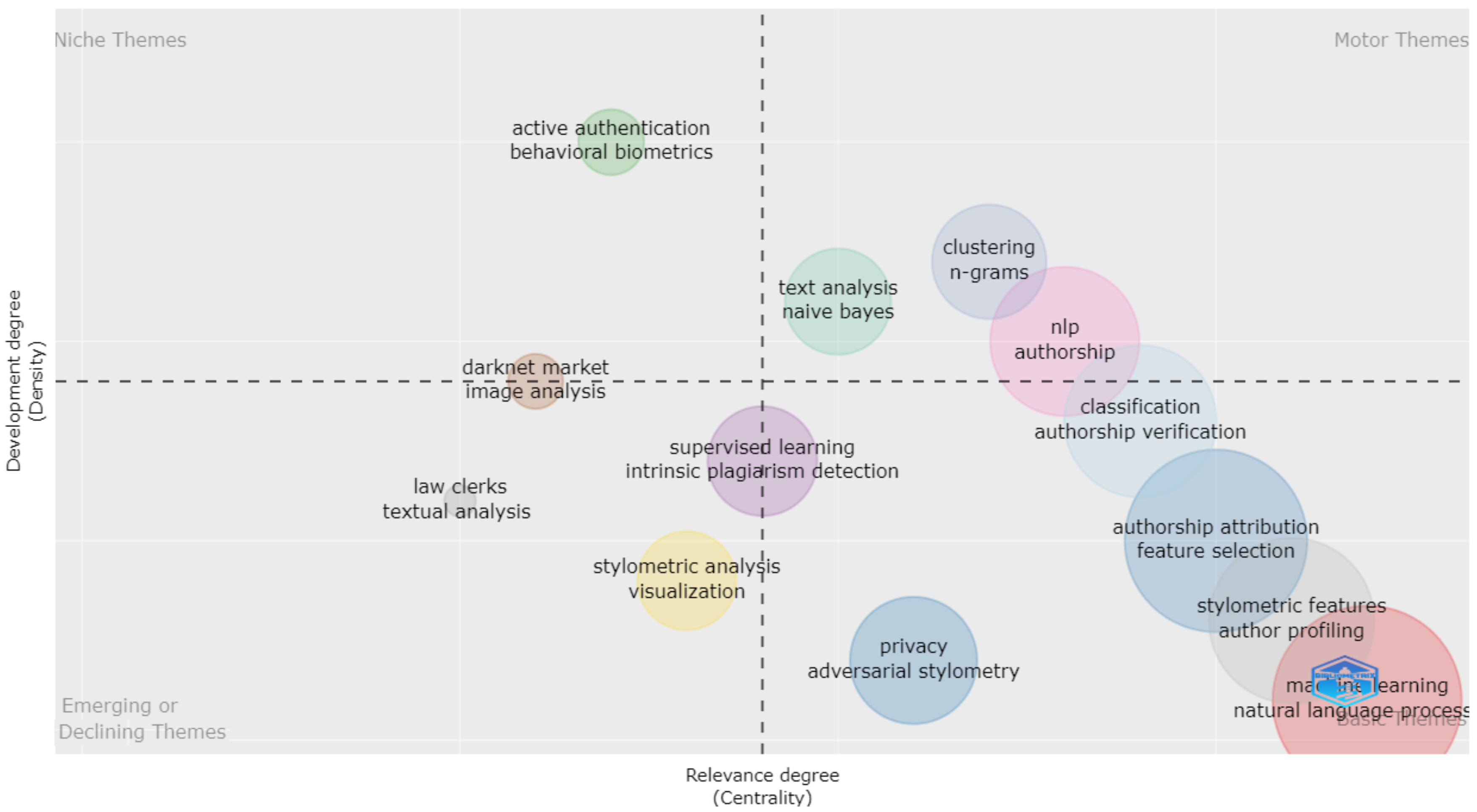
4.1. Topic and Keywords Trends
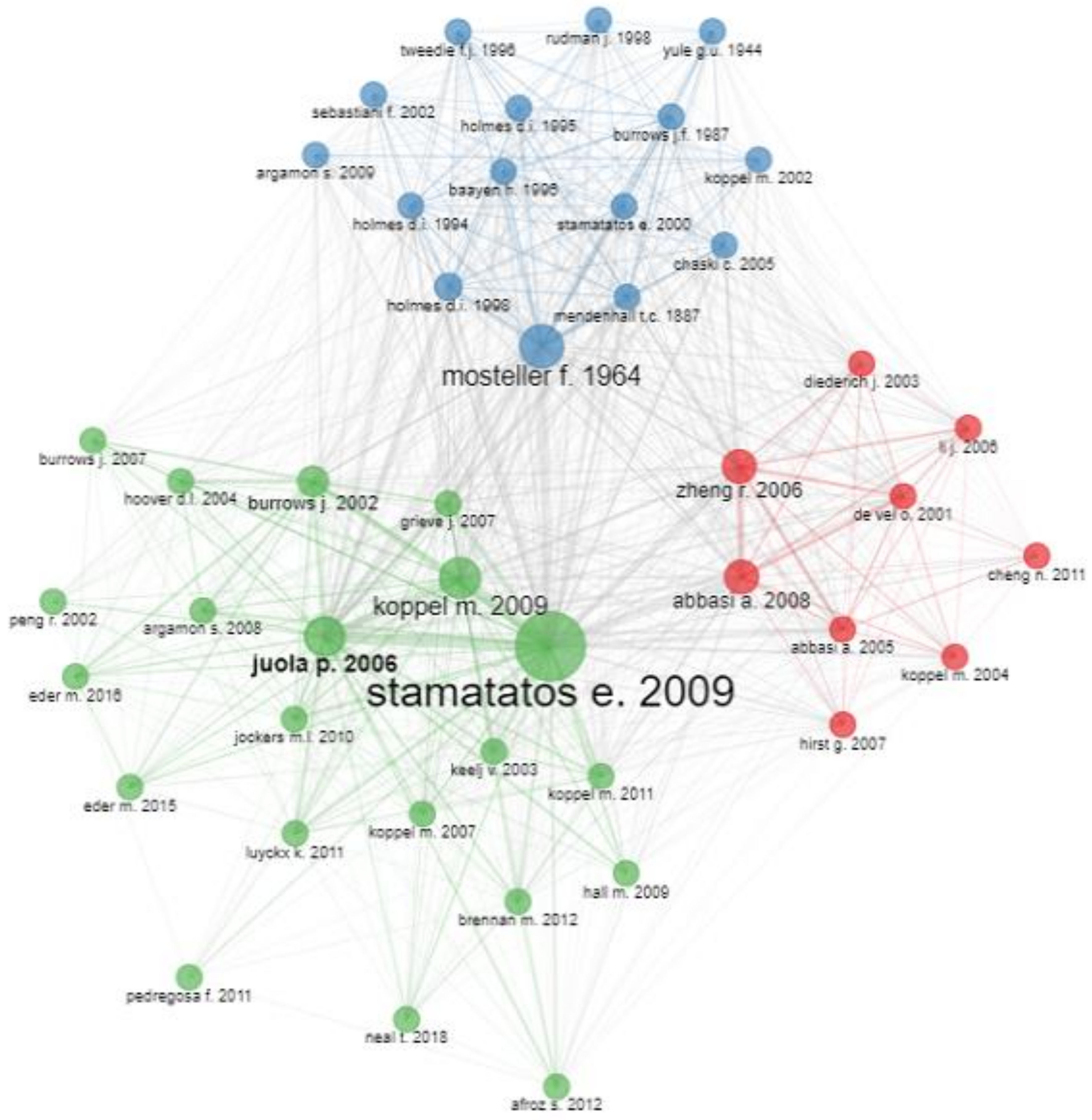
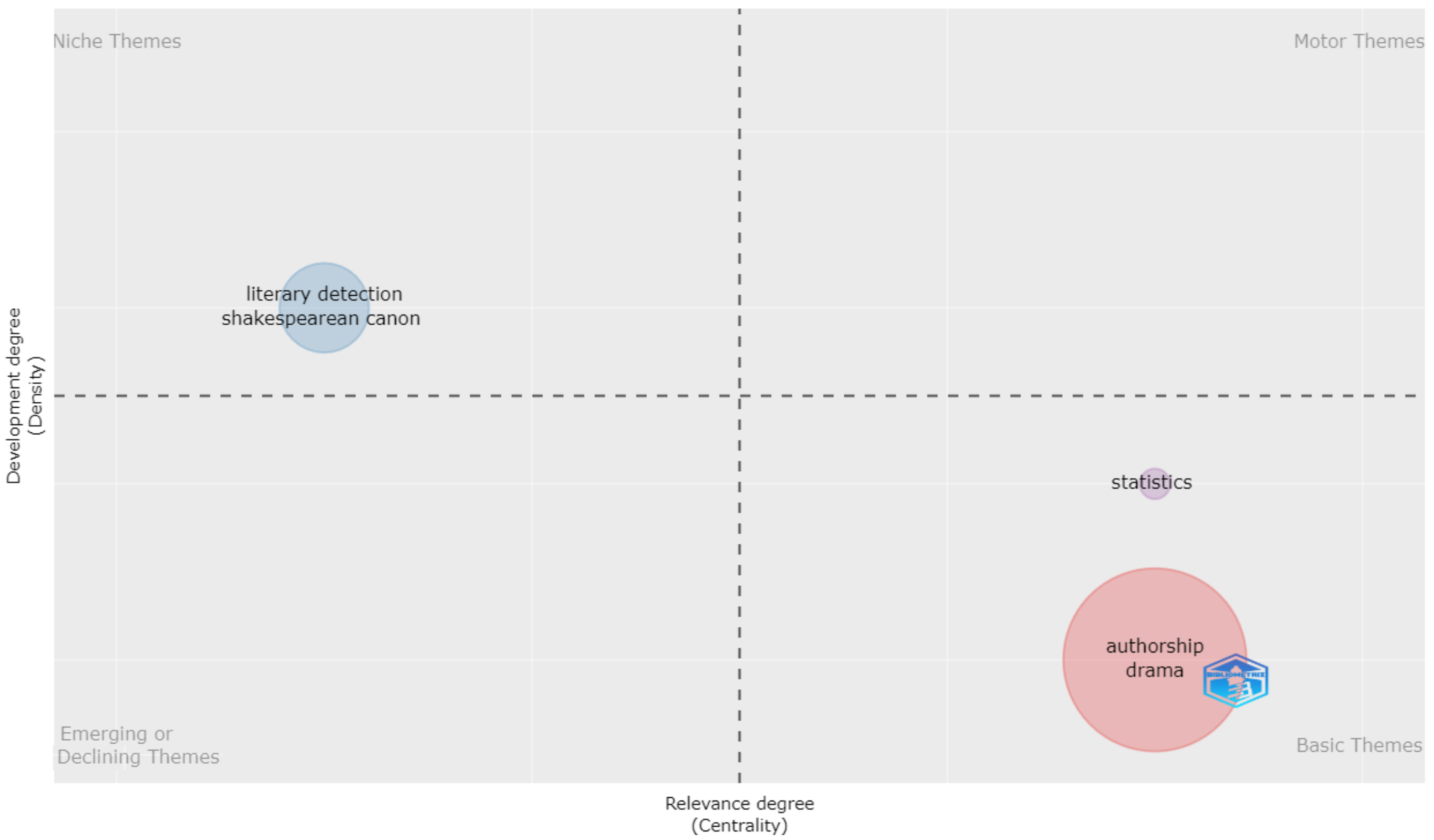
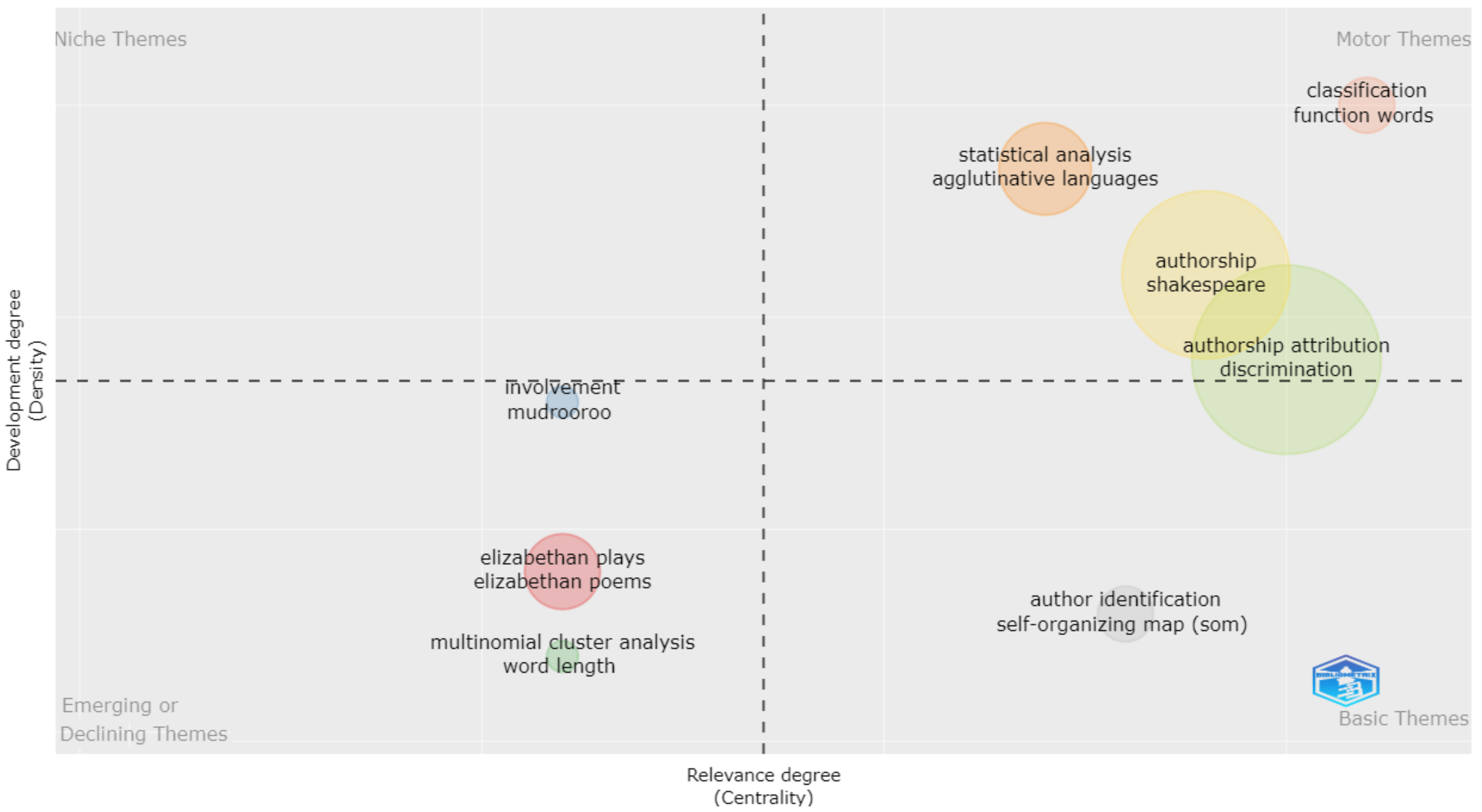
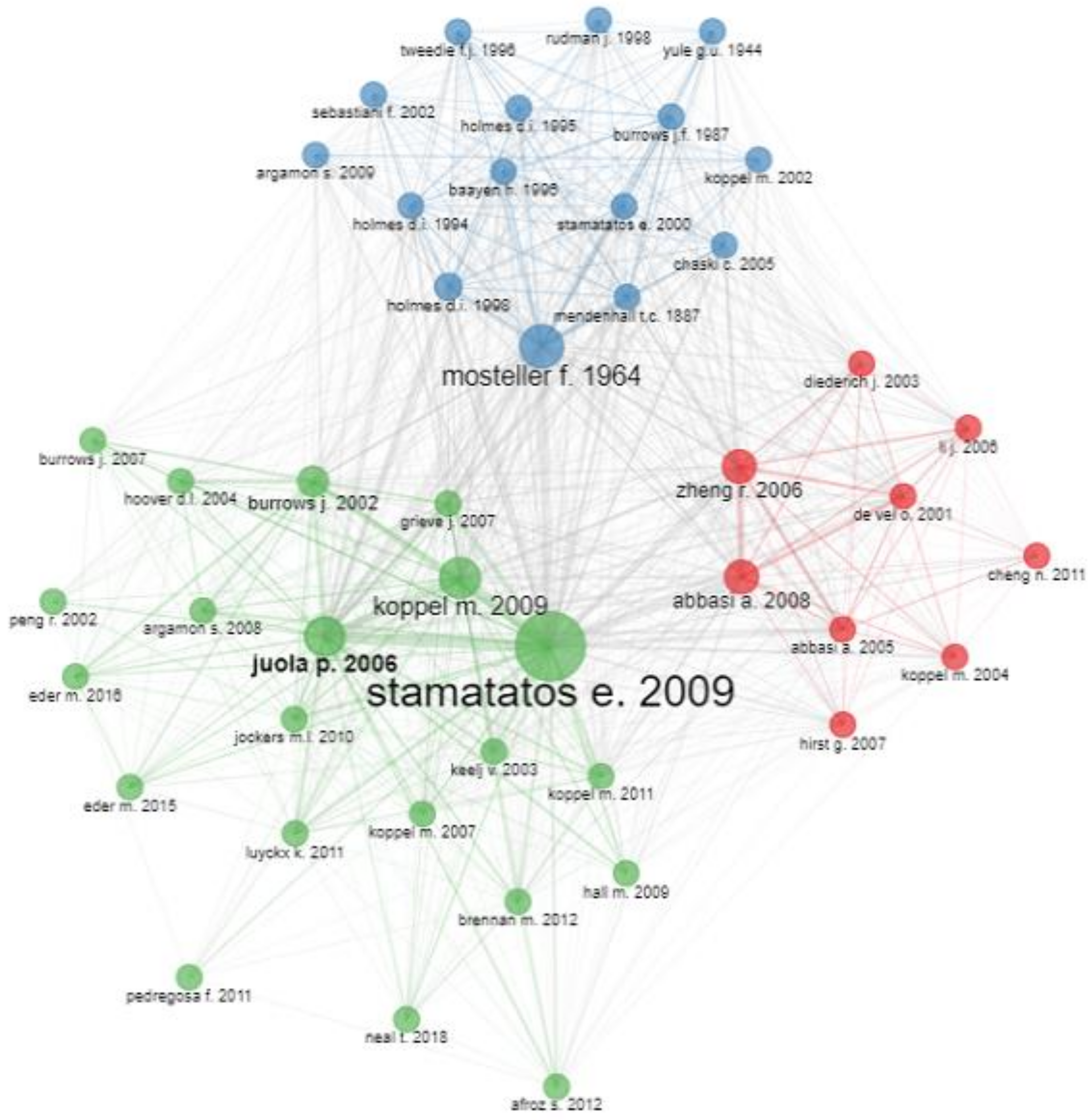
4.2. Analysis of Co-Citation
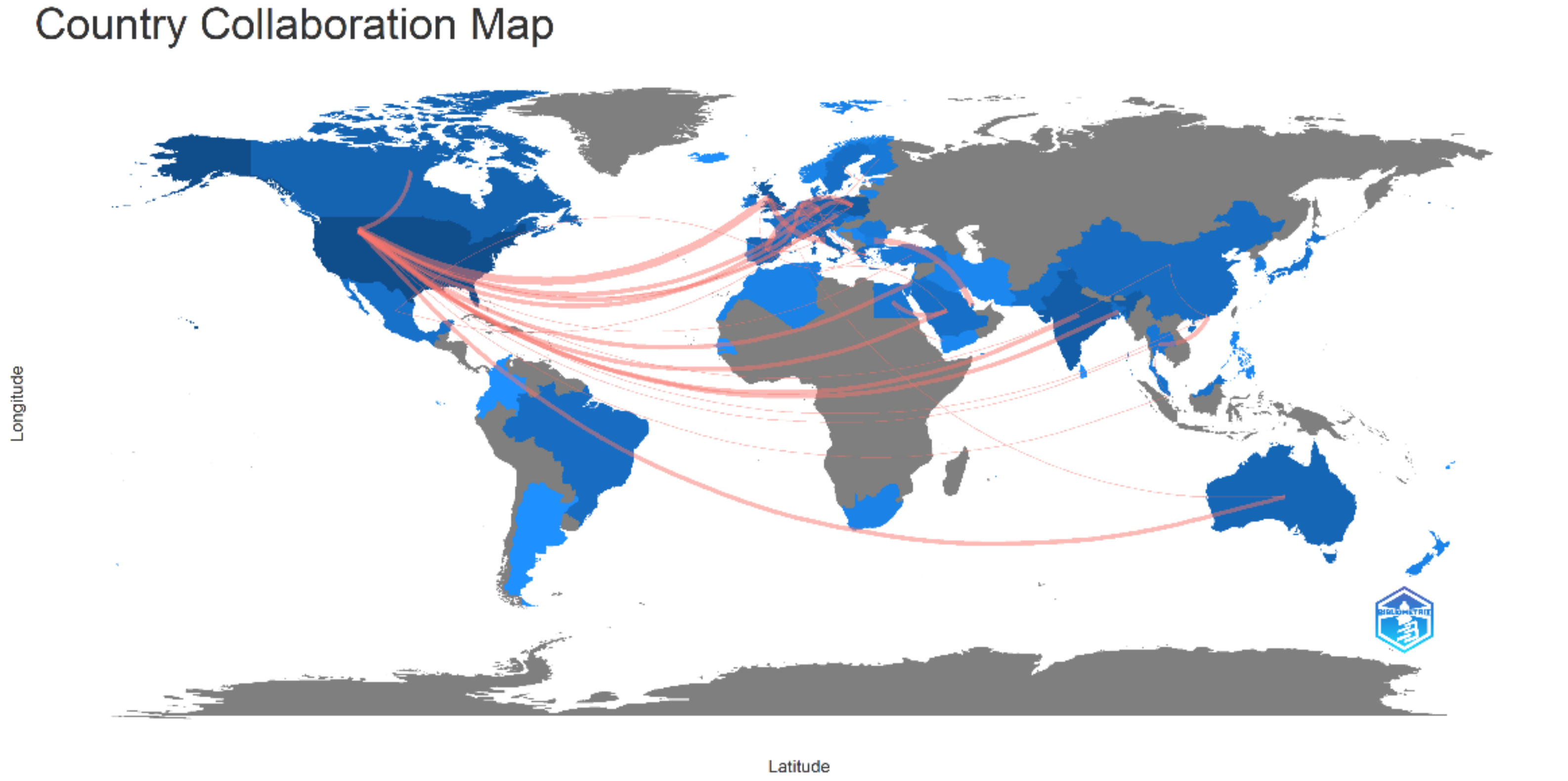
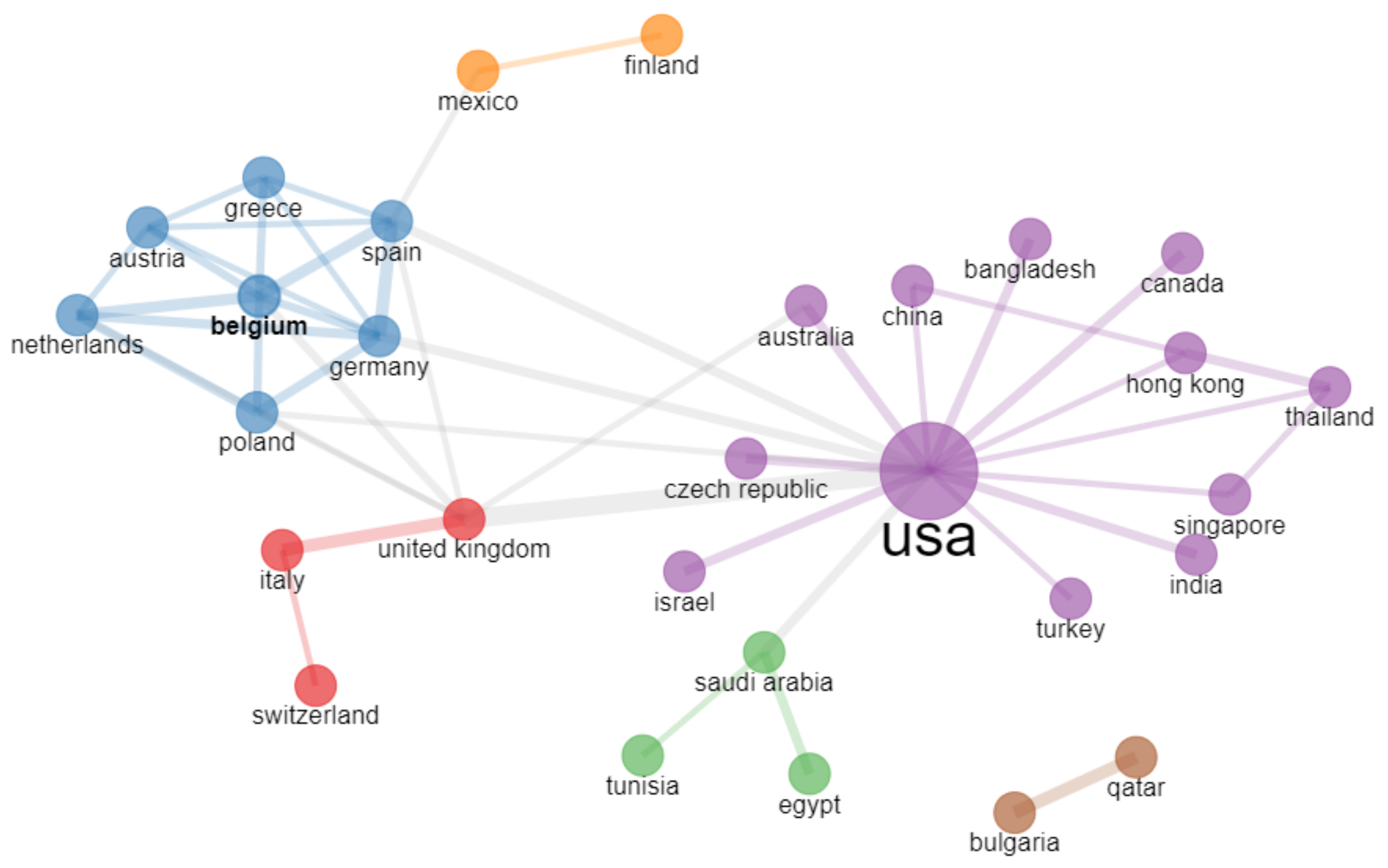
4.3. Analysis of Country Collaboration
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Neal, T.; Sundararajan, K.; Fatima, A.; Yan, Y.; Xiang, Y.; Woodard, D. Surveying stylometry techniques and applications. ACM Comput. Surv. 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Donthu, N.; Kumar, S.; Mukherjee, D.; Pandey, N.; Lim, W.M. How to conduct a bibliometric analysis: An overview and guidelines. J. Bus. Res. 2021, 133, 285–296. [Google Scholar] [CrossRef]
- Zupic, I.; Cater, T. Bibliometric methods in management and organization. Organ. Res. Methods 2015, 18, 429–472. [Google Scholar] [CrossRef]
- Moral-Muñoz, J.A.; Herrera-Viedma, E.; Santisteban-Espejo, A.; Cobo, M.J. Software tools for conducting bibliometric analysis in science: An up-to-date review. Prof. Inf. 2020, 29, e290103. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C. Bibliometrix: An R-tool for comprehensive science mapping analysis. J. Informetr. 2017, 11, 959–975. [Google Scholar] [CrossRef]
- Argamon, S.; Koppel, M.; Fine, J.; Shimoni, A.R. Gender, genre, and writing style in formal written texts. Text Talk 2003, 23, 321–346. [Google Scholar] [CrossRef]
- Feng, S.; Banerjee, R.; Choi, Y. Syntactic stylometry for deception detection. In Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics, Jeju Island, Korea, 8–14 July 2012; pp. 171–175. [Google Scholar]
- Holmes, D.I. The evolution of stylometry in humanities scholarship. Lit. Linguist. Comput. 1998, 13, 111–117. [Google Scholar] [CrossRef]
- Abbasi, A.; Chen, H. Writeprints: A stylometric approach to identity-level identification and similarity detection in cyberspace. ACM Trans. Inf. Syst. 2008, 26, 1–29. [Google Scholar] [CrossRef]
- Stamatatos, E.; Fakotakis, N.; Kokkinakis, G. Automatic text categorization in terms of genre and author. Comput. Linguist. 2000, 26, 471–495. [Google Scholar] [CrossRef]
- Holmes, D.I. Authorship attribution. Comput. Humanit. 1994, 28, 87–106. [Google Scholar] [CrossRef]
- Narayanan, A.; Paskov, H.; Zhenqiang Gong, N.; Bethencourt, J.; Stefanov, E.; Chul Richard Shin, E.; Song, D. On the feasibility of Internet-scale author identification. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 300–314. [Google Scholar] [CrossRef]
- Peersman, C.; Daelemans, W.; Vaerenbergh, L. Predicting age and gender in online social networks. In Proceedings of the 3rd International Workshop on Search and Mining User-Generated Contents, Glasgow, Scotland, UK, 28 October 2011; pp. 37–44. [Google Scholar] [CrossRef]
- Cheng, N.; Chandramouli, R.; Subbalakshmi, K.P. Author gender identification from text. Digit. Investig. 2011, 8, 78–88. [Google Scholar] [CrossRef]
- Alzahrani, S.M.; Salim, N.; Abraham, A. Understanding plagiarism linguistic patterns, textual features, and detection methods. IEEE Trans. Syst. Man Cybern. 2012, 42, 133–149. [Google Scholar] [CrossRef]
- Afroz, S.; Brennan, M.; Greenstadt, R. Detecting hoaxes, frauds, and deception in writing style online. In Proceedings of the IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 461–475. [Google Scholar] [CrossRef]
- Holmes, D.I.; Forsyth, R.S. The federalist revisited: New directions in authorship attribution. Lit. Linguist. Comput. 1995, 10, 111–127. [Google Scholar] [CrossRef]
- Potthast, M.; Kiesel, J.; Reinartz, K.; Bevendorff, J.; Stein, B. A stylometric inquiry into hyperpartisan and fake news. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 231–240. [Google Scholar] [CrossRef]
- Eder, E.; Rybicki, J.; Kestemont, M. Stylometry with R: A package for computational text analysis. R J. 2016, 8, 107–121. [Google Scholar] [CrossRef]
- Caliskan-Islam, A.; Harang, R.; Liu, A.; Narayanan, A.; Voss, C.; Yamaguchi, F.; Greenstadt, R. De-anonymizing programmers via code stylometry. In Proceedings of the 24th USENIX Security Symposium, Washington, DC, USA, 12–14 August 2015; pp. 255–270. [Google Scholar]
- Lyckx, K.; Daelemans, W. Authorship attribution and verification with many authors and limited data. In Proceedings of the Coling 2008—22nd International Conference on Computational Linguistics, Manchester, UK, 18–22 August 2008; pp. 513–520. [Google Scholar]
- Rocha, A.; Scheirer, W.J.; Forstall, C.W.; Cavalcante, T.; Theophilo, A.; Shen, B.; Carvalho, A.R.; Stamatatos, E. Authorship attribution for social media forensics. IEEE Trans. Inf. Forensics Secur. 2017, 12, 5–33. [Google Scholar] [CrossRef]
- Brennan, M.; Afroz, S.; Greenstadt, R. Adversarial stylometry: Circumventing authorship recognition to preserve privacy and anonymity. ACM Trans. Inf. Syst. Secur. 2012, 15, 1–22. [Google Scholar] [CrossRef]
- Fridman, L.; Weber, S.; Greenstadt, R.; Kam, M. Active authentication on mobile devices via stylometry, application usage, web browsing, and GPS location. IEEE Syst. J. 2017, 11, 513–521. [Google Scholar] [CrossRef]
- Iqbal, F.; Binsalleeh, H.; Fung, B.C.M.; Debbabi, M. Mining writeprints from anonymous e-mails for forensic investigation. Digit. Investig. 2010, 7, 56–64. [Google Scholar] [CrossRef]
- Cobo, M.J.; López-Herrera, A.G.; Herrera-Viedma, E.; Herrera, F. An approach for detecting, quantifying, and visualizing the evolution of a research field: A practical application to the fuzzy sets theory field. J. Informetrics. 2011, 5, 146–166. [Google Scholar] [CrossRef]
- Stamatatos, E. A survey of modern authorship attribution methods. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 538–556. [Google Scholar] [CrossRef]
- Juola, P. Authorship Attribution. Found. Trends Inf. Retr. 2006, 1, 233–334. [Google Scholar] [CrossRef]
- Koppel, M.; Schler, J.; Argamon, S. Computational methods in authorship attribution. J. Am. Soc. Inf. Sci. Technol. 2009, 60, 9–26. [Google Scholar] [CrossRef]
- Mosteller, F.; Wallace, D.L. Inference and Disputed Authorship: The Federalist; Addison-Wesley: Boston, MA, USA, 1964. [Google Scholar]
- Mendenhall, T.C. The characteristic curves of composition. Science 1887, 11, 237–249. [Google Scholar] [CrossRef] [PubMed]
- Zheng, R.; Li, J.; Chen, H.; Huang, Z. A framework for authorship identification of online messages: Writing-style features and classification techniques. J. Am. Soc. Inf. Sci. Technol. 2006, 57, 378–393. [Google Scholar] [CrossRef]
- Abbasi, A.; Chen, H. Applying authorship analysis to extremist-group Web forum messages. IEEE Intell. Syst. 2005, 20, 67–75. [Google Scholar] [CrossRef]
- Scopus Database. Available online: https://www.scopus.com/ (accessed on 23 April 2022).















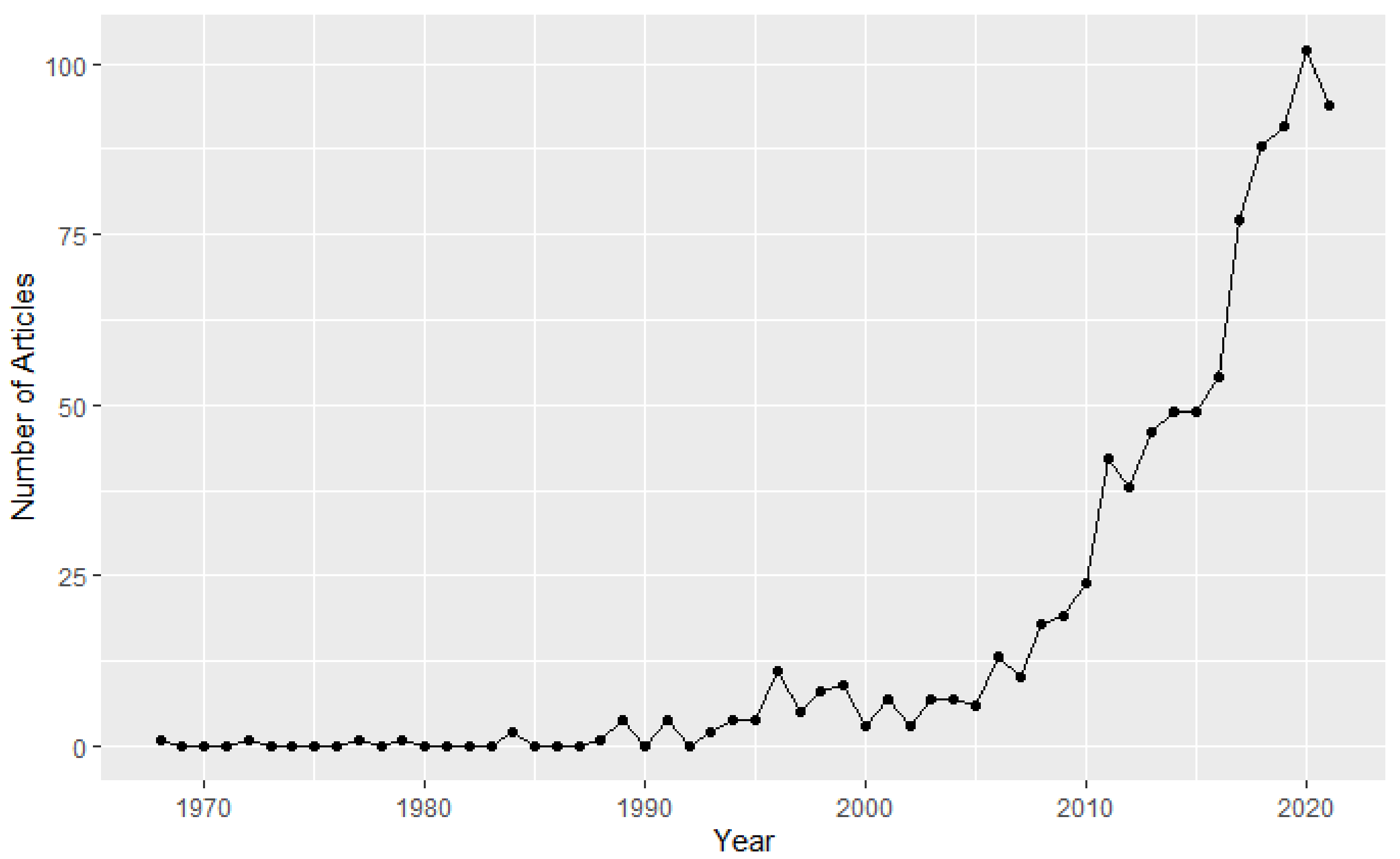{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Description | Results |
|---|---|
| Timespan | 1968–2021 |
| Documents | 905 |
| Sources (Journals, Books, etc.) | 477 |
| Authors | 1687 |
| Author Appearances | 2526 |
| Single-authored documents | 221 |
| Authors per document | 1.86 |
| Co-authors per documents | 2.79 |
| Collaboration index | 2.24 |
| Sources | Documents |
|---|---|
| Lecture Notes in Computer Science | 66 |
| CEUR Workshop Proceedings | 62 |
| Literary and Linguistic Computing | 43 |
| Digital Scholarship in the Humanities | 30 |
| Computers and the Humanities | 25 |
| Advances in Intelligent Systems and Computing | 22 |
| Procedia Computer Science | 15 |
| ACM International Conference Proceedings Series | 13 |
| IEEE Access | 9 |
| Communications in Computer and Information Science | 7 |
| Proceedings of SPIE | 7 |
| Glottometrics | 6 |
| Journal of Quantitative Linguistics | 6 |
| International Joint Conference on Neural Networks | 6 |
| Style | 6 |
| Digital Humanities Quarterly | 5 |
| Expert Systems with Applications | 5 |
| IFIP Advances in Information and Communication Technology | 5 |
| Journal of Applied Statistics | 5 |
| Sources | h-Index | g-Index | m-Index | Total Citations |
|---|---|---|---|---|
| Literary and Linguistic Computing | 17 | 32 | 0.53 | 1106 |
| Computers and the Humanities | 11 | 23 | 0.28 | 675 |
| Lecture Notes in Computer Science | 12 | 21 | 0.71 | 591 |
| Proceedings-IEEE Symposium on Security and Privacy | 3 | 3 | 0.27 | 392 |
| Text | 1 | 1 | 0.05 | 304 |
| 50th Annual Meeting of The Association for Computational Linguistics | 1 | 1 | 0.09 | 303 |
| Computational Linguistics | 2 | 2 | 0.09 | 286 |
| Digital Investigation | 3 | 3 | 0.23 | 278 |
| ACM Transactions on Information Systems | 1 | 1 | 0.07 | 274 |
| Digital Scholarship in the Humanities | 7 | 13 | 0.88 | 202 |
| International Conference on Information and Knowledge Management | 3 | 3 | 0.20 | 191 |
| CEUR Workshop Proceedings | 7 | 10 | 0.44 | 183 |
| Proceedings of the National Academy of Sciences of the USA | 3 | 3 | 0.23 | 174 |
| IEEE Transactions on Systems, Man and Cybernetics Part C | 2 | 2 | 0.12 | 162 |
| 56th Annual Meeting of the Association for Computational Linguistics | 1 | 1 | 0.20 | 141 |
| Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining | 2 | 2 | 0.10 | 122 |
| ACM Transactions on Information and System Security | 2 | 2 | 0.18 | 118 |
| R Journal | 1 | 1 | 0.14 | 115 |
| Proceedings of the 24th Usenix Security Symposium | 1 | 1 | 0.13 | 108 |
| Coling 2008—22nd International Conf. on Computational Linguistics | 1 | 1 | 0.07 | 107 |
| Article | Total Citations | Total Citations per Year | Ref. |
|---|---|---|---|
| S. Argamon, M. Koppel, J. Fine and A.R. Shimoni (2003), Gender, genre, and writing style in formal written texts, Text & Talk, 23(3), 321–346. | 304 | 15.2 | [6] |
| S. Feng, R. Banerjee and Y. Choi (2012), Syntactic stylometry for deception detection, Proc. Of the 50th Annual Meeting of the Association for Computational Linguistics, 171–175. | 303 | 27.55 | [7] |
| D.I. Holmes (1998), The Evolution of Stylometry in Humanities Scholarship, Literary and Linguistic Computing, 13(3), 111–117. | 276 | 11.04 | [8] |
| A.Abbasi and H. Chen (2008), Writeprints: A stylometric approach to identity-level identification and similarity detection in cyberspace, ACM Transactions on Information Systems, 26(2), 1–29. | 274 | 18.26 | [9] |
| E. Stamatatos, N. Fakotakis and G. Kokkinakis (2000), Automatic Text Categorization in Terms of Genre and Author, Computational Linguistics, 26(4), 471–495. | 273 | 11.87 | [10] |
| D.I. Holmes (1994), Authorship attribution, Computers and the Humanities, 28, 87–106. | 228 | 7.86 | [11] |
| A Narayanan et al. (2012), On the Feasibility of Internet-Scale Author Identification, IEEE Symposium on Security and Privacy, 300–314. | 176 | 16 | [12] |
| C. Peersman, W. Daelemans and L. Vaerenbergh (2011), Predicting age and gender in online social networks, Proc. Of the 3rd International Workshop on Search and mining user-generated contents, 37–44. | 175 | 14.59 | [13] |
| N. Cheng, R. Chandramouli and K.P. Subbalakshmi (2011), Author gender identification from text, Digital Investigation, 8(1), 78–88. | 156 | 13 | [14] |
| S.M. Alzahrani, N. Salim and A. Abraham (2012), Understanding Plagiarism Linguistic Patterns, Textual Features, and Detection Methods, IEEE Transactions on Systems, Man, and Cybernetics, Part C, 42(2), 133–149 | 154 | 14 | [15] |
| S. Afroz, M. Brennan and R. Greenstadt (2012), Detecting Hoaxes, Frauds, and Deception in Writing Style Online, IEEE Symposium on Security and Privacy, 461–475 | 149 | 13.55 | [16] |
| D.I. Holmes and R.S. Forsyth (1995), The Federalist Revisited: New Directions in Authorship Attribution, Literary and Linguistic Computing, 10(2), 111–127. | 147 | 5.25 | [17] |
| M. Potthast, J. Kiesel, K. Reinartz, J. Bevendorff and B. Stein (2018), A Stylometric Inquiry into Hyperpartisan and Fake News, Proc. Of the 56th Annual Meeting of the Association for Computational Linguistics, 231–240 | 141 | 28.2 | [18] |
| M. Eder, J. Rybicki and M. Kestemont (2016), Stylometry with R: A Package for Computational Text Analysis, The R Journal, 8(1), 107–121. | 115 | 16.43 | [19] |
| Caliskan-Islam et al. (2015), De-anonymizing Programmersvia Code Stylometry, Proc. Of the 24th USENIX Security Symposium, 255–270 | 108 | 13.5 | [20] |
| K. Lyckx and W. Daelemans (2008), Authorship attribution and verification with many authors and limited data, Proc. Of the Coling 2008–22nd International Conference on Computational Linguistics, 513–520. | 107 | 7.13 | [21] |
| A. Rocha et al. (2017), Authorship Attribution for Social Media Forensics, IEEE Transactions on Information Forensics and Security, 12(1), 5–33. | 102 | 17 | [22] |
| M. Brennan, S. Afroz and R. Greenstadt (2012), Adversarial stylometry: Circumventing authorship recognition to preserve privacy and anonymity, ACM Transactions on Information and System Security, 15(3), 1–22. | 102 | 9.27 | [23] |
| L. Fridman, S. Weber, R. Greenstadt and M. Kam (2017), Active Authentication on Mobile Devices via Stylometry, Application Usage, Web Browsing, and GPS Location, IEEE Systems Journal, 11(2), 513–521. | 97 | 16.17 | [24] |
| F. Iqbal, H. Binsalleeh, B.C.M.Fung and M. Debbabi (2010), Mining writeprints from anonymous e-mails for forensic investigation, Digital Investigation, 7(1–2), 56–64. | 95 | 7.30 | [25] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Michailidis, P.D. A Scientometric Study of the Stylometric Research Field. Informatics 2022, 9, 60. https://doi.org/10.3390/informatics9030060
Michailidis PD. A Scientometric Study of the Stylometric Research Field. Informatics. 2022; 9(3):60. https://doi.org/10.3390/informatics9030060
Chicago/Turabian StyleMichailidis, Panagiotis D. 2022. "A Scientometric Study of the Stylometric Research Field" Informatics 9, no. 3: 60. https://doi.org/10.3390/informatics9030060
APA StyleMichailidis, P. D. (2022). A Scientometric Study of the Stylometric Research Field. Informatics, 9(3), 60. https://doi.org/10.3390/informatics9030060