
Searching Deterministic Chaotic Properties in System-Wide Vulnerability Datasets





Abstract
:1. Introduction
1.1. Motivation and Contribution
1.2. Paper Structure
2. Literature Review
- It must be sensitive to the initial conditions
- It must be topologically transitive
- It must have dense periodic orbits.
3. Problem Description
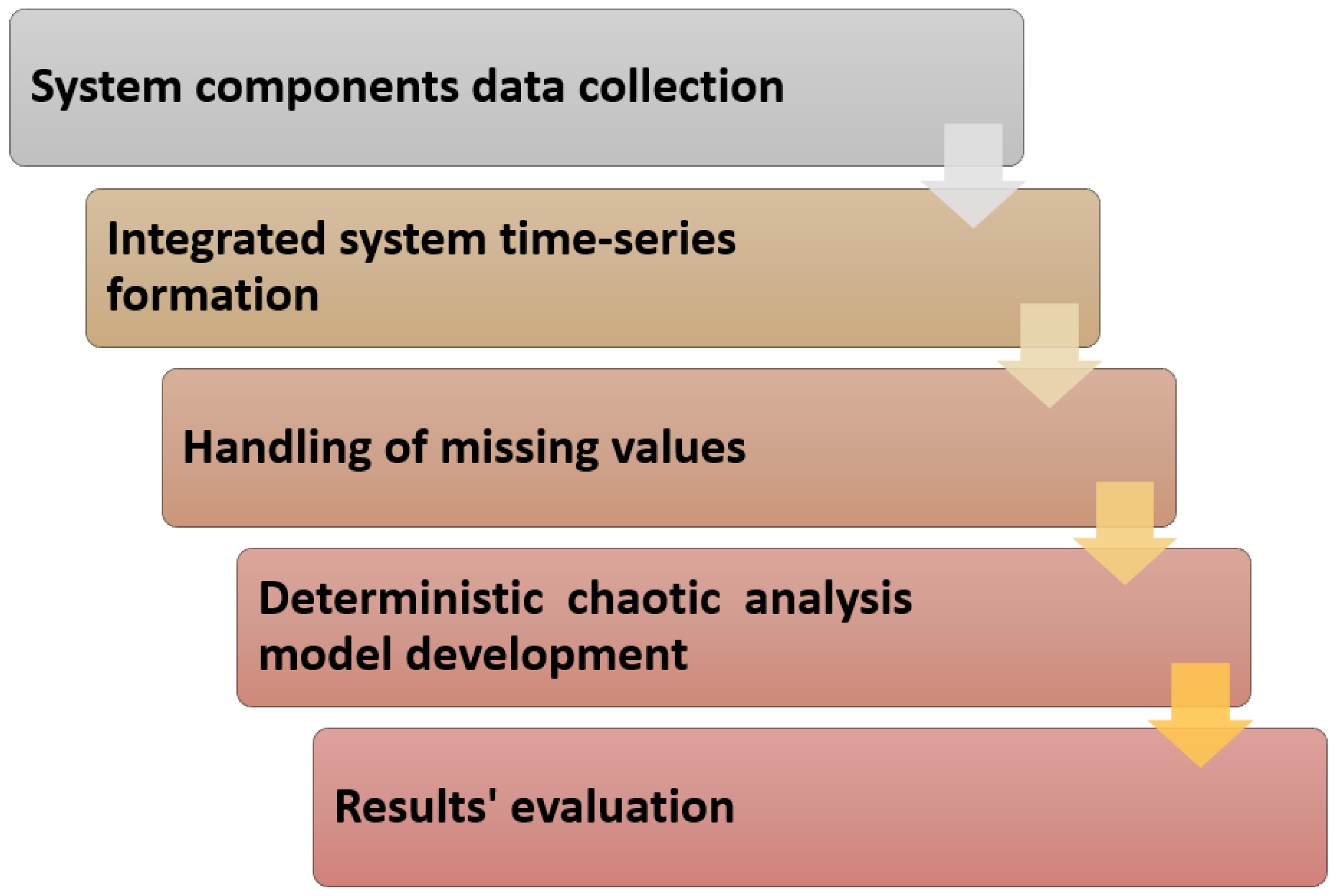
4. Methodology
4.1. Data Collection
4.1.1. Software System Definition
- CVE ID
- Published datetime
- Vulnerability Score
- Vulnerability software list.
4.1.2. NVD Processing
- Create 8 synthetic base models (open/closed source) of real-life systems from the services extracted from NVD database and perform the above calculations.
- Create 1000 synthetic systems as models of open/closed source systems, from randomly selected services extracted from the NVD database and perform the above calculations.
4.2. Deterministic Chaos Analysis Methods
- The calculation of the Largest Lyapunov exponent (LLE).
- The calculation of the Hurst exponent (HE) and of the Fractal dimension (FD).
- The calculation of the Shannon entropy (SE).
4.2.1. Largest Lyapunov Exponent (LLE)
4.2.2. Fractal Analysis: Hurst Exponent (HE) and Fractal Dimension (FD)
4.2.3. Shannon Entropy (SE)
5. Empirical Analysis and Discussion
5.1. Systems Time Series Construction and Pre-Processing
- In the Extreme approach, we use the maximum value of each day/week/month interval to fill the weekly score column.
- In the Average approach, we use the average of each day/week/month values to fill the weekly score column.
- Finally, in the Relaxed approach, we use the minimum value in each day/week/month interval to fill the weekly score column.
5.2. Application of Non Linear Deterministic Chaotic Analysis Methods to the Defined Systems Time Series
5.2.1. LLE Estimation
5.2.2. HE Estimation
5.2.3. SE Estimation
5.3. Computational Overhead
6. Discussion of the Results
- : 6, 7 and 8.
- : 5 and 7.
- : 3, 4 and 5.
- : 1 and 2.
Limitations
7. Conclusions and Future Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schultz, E.E., Jr.; Brown, D.S.; Longstaff, T.A. Responding to Computer Security Incidents: Guidelines for Incident Handling; Technical Report; No. UCRL-ID-104689; Lawrence Livermore National Lab: Livermore, CA, USA, 1990. [Google Scholar]
- Alhazmi, O.H.; Malaiya, Y.K.; Ray, I. Measuring, analyzing and predicting security vulnerabilities in software systems. Comput. Secur. 2007, 26, 219–228. [Google Scholar] [CrossRef]
- Hassan, S.G.; Iqbal, S.; Garg, H.; Hassan, M.; Shuangyin, L.; Kieuvan, T.T. Designing Intuitionistic Fuzzy Forecasting Model Combined With Information Granules and Weighted Association Reasoning. IEEE Access 2020, 8, 141090–141103. [Google Scholar] [CrossRef]
- Kakimoto, M.; Endoh, Y.; Shin, H.; Ikeda, R.; Kusaka, H. Probabilistic solar irradiance forecasting by conditioning joint probability method and its application to electric power trading. IEEE Trans. Sustain. Energy 2018, 10, 983–993. [Google Scholar] [CrossRef]
- Alhazmi, O.H.; Malaiya, Y.K. Application of vulnerability discovery models to major operating systems. IEEE Trans. Reliab. 2008, 57, 14–22. [Google Scholar] [CrossRef]
- Alhazmi, O.H.; Malaiya, Y.K. Prediction capabilities of vulnerability discovery models. In Proceedings of the Reliability and Maintainability Symposium, RAMS’06, Newport Beach, CA, USA, 23–26 January 2006; pp. 86–91. [Google Scholar]
- Roumani, Y.; Nwankpa, J.K.; Roumani, Y.F. Time series modeling of vulnerabilities. Comput. Secur. 2015, 51, 32–40. [Google Scholar] [CrossRef]
- Johnson, P.; Gorton, D.; Lagerström, R.; Ekstedt, M. Time between vulnerability disclosures: A measure of software product vulnerability. Comput. Secur. 2016, 62, 278–295. [Google Scholar] [CrossRef]
- Zhang, S.; Caragea, D.; Ou, X. An empirical study on using the national vulnerability database to predict software vulnerabilities. In International Conference on Database and Expert Systems Applications; Springer: Berlin/Heidelberg, Germany, 2011; pp. 217–231. [Google Scholar]
- Nguyen, V.H.; Massacci, F. A Systematically Empirical Evaluation Of Vulnerability Discovery Models: A Study On Browsers’ Vulnerabilities. arXiv 2013, arXiv:1306.2476. [Google Scholar]
- Tang, M.; Alazab, M.; Luo, Y.; Donlon, M. Disclosure of cyber security vulnerabilities: Time series modelling. Int. J. Electron. Secur. Digit. Forensics 2018, 10, 255–275. [Google Scholar] [CrossRef]
- Shrivastava, A.K.; Sharma, R. Modeling Vulnerability Discovery and Patching with Fixing Lag; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Williams, M.A.; Dey, S.; Barranco, R.C.; Naim, S.M.; Hossain, M.S.; Akbar, M. Analyzing Evolving Trends of Vulnerabilities in National Vulnerability Database. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3011–3020. [Google Scholar]
- Sharma, R.; Singh, R.K. Vulnerability Discovery in Open- and Closed-Source Software: A New Paradigm. In Software Engineering; Springer: Singapore, 2019; pp. 533–539. [Google Scholar]
- Johnston, R.; Sarkani, S.; Mazzuchi, T.; Holzer, T.; Eveleigh, T. Bayesian-model averaging using MCMCBayes for web-browser vulnerability discovery. Reliab. Eng. Syst. Saf. 2019, 183, 341–359. [Google Scholar] [CrossRef]
- Johnson, P.; Lagerstrom, R.; Ekstedt, M.; Franke, U. Can the common vulnerability scoring system be trusted? A Bayesian analysis. IEEE Trans. Dependable Secur. Comput. 2018, 15, 1002–1015. [Google Scholar] [CrossRef]
- Biswas, B.; Mukhopadhyay, A. G-RAM framework for software risk assessment and mitigation strategies in organisations. J. Enterp. Inf. Manag. 2018, 31, 276–299. [Google Scholar] [CrossRef]
- Jimenez, M.; Papadakis, M.; Traon, Y.L. Vulnerability Prediction Models: A Case Study on the Linux Kernel. In Proceedings of the 2016 IEEE 16th International Working Conference on Source Code Analysis and Manipulation, Raleigh, NC, USA, 2–3 October 2016; pp. 1–10. [Google Scholar]
- Sahin, S.E.; Tosun, A. A Conceptual Replication on Predicting the Severity of Software Vulnerabilities. In Proceedings of the Evaluation and Assessment on Software Engineering, Copenhagen, Denmark, 15–17 April 2019; pp. 244–250. [Google Scholar]
- Spanos, G.; Angelis, L. A multi-target approach to estimate software vulnerability characteristics and severity scores. J. Syst. Softw. 2018, 146, 152–166. [Google Scholar] [CrossRef]
- Zhu, X.; Cao, C.; Zhang, J. Vulnerability severity prediction and risk metric modeling for software. Appl. Intell. 2017, 47, 828–836. [Google Scholar] [CrossRef]
- Geng, J.; Ye, D.; Luo, P. Predicting Severity of Software Vulnerability Based on Grey System Theory. In International Conference on Algorithms and Architectures for Parallel Processing; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Geng, J.; Ye, D.; Luo, P. Forecasting Severity of Software Vulnerability Using Grey Model GM(1,1). In Proceedings of the 2015 IEEE Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 19–20 December 2015; pp. 344–348. [Google Scholar]
- Ozment, A. Improving Vulnerability Discovery Models: Problems with Definitions and Assumptions. In Proceedings of the 2007 ACM Workshop on Quality of Protection, Lexandria, VA, USA, 29 October 2007; pp. 6–11. [Google Scholar]
- Shamal, P.K.; Rahamathulla, K.; Akbar, A. A Study on Software Vulnerability Prediction Model. In Proceedings of the 2017 International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 22–24 April 2017; pp. 703–706. [Google Scholar]
- Wu, W.; Zhang, W.; Yang, Y.; Wang, Q. Time series analysis for bug number prediction. In Proceedings of the 2nd International Conference on Software Engineering and Data Mining, Chengdu, China, 23–25 June 2010; pp. 589–596. [Google Scholar]
- Morrison, P.; Herzig, K.; Murphy, B.; Williams, L. Challenges with Applying Vulnerability Prediction Models. In Proceedings of the 2015 Symposium and Bootcamp on the Science of Security, Urbana, IL, USA, 21–22 April 2015; pp. 1–9. [Google Scholar]
- Gencer, K.; Başçiftçi, F. Time series forecast modeling of vulnerabilities in the android operating system using ARIMA and deep learning methods. Sustain. Comput. Inform. Syst. 2021, 30. [Google Scholar] [CrossRef]
- Last, D. Using historical software vulnerability data to forecast future vulnerabilities. In Proceedings of the Resilience Week (RWS), Philadelphia, PA, USA, 18–20 August 2015; pp. 1–7. [Google Scholar]
- Shrivastava, A.K.; Sharma, R.; Kapur, P.K. Vulnerability Discovery Model for a Software System Using Stochastic Differential Equation. In Proceedings of the 2015 International Conference on Futuristic Trends on Computational Analysis and Knowledge Management (ABLAZE), Greater Noida, India, 26–27 February 2015; pp. 199–205. [Google Scholar]
- Tang, M.; Alazab, M.; Luo, Y. Exploiting Vulnerability Disclosures: Statistical Framework and Case Study. In Proceedings of the Cybersecurity and Cyberforensics Conference (CCC), Amman, Jordan, 2–4 August 2016; pp. 117–122. [Google Scholar]
- Chatzipoulidis, A.; Michalopoulos, D.; Mavridis, I. Information infrastructure risk prediction through platform vulnerability analysis. J. Syst. Softw. 2015, 106, 28–41. [Google Scholar] [CrossRef]
- Woo, S.W.; Joh, H.; Alhazmi, O.H.; Malaiya, Y.K. Modeling vulnerability discovery process in Apache and IIS HTTP servers. Comput. Secur. 2011, 30, 50–62. [Google Scholar] [CrossRef]
- Wang, X.; Ma, R.; Li, B.; Tian, D.; Wang, X. E-WBM: An Effort-Based Vulnerability Discovery Model. IEEE Access 2019, 7, 44276–44292. [Google Scholar] [CrossRef]
- Kudjo, P.K.; Chen, J.; Mensah, S.; Amankwah, R. Predicting Vulnerable Software Components via Bellwethers. In Chinese Conference on Trusted Computing and Information Security; Springer: Singapore, 2018; pp. 389–407. [Google Scholar]
- Li, Z.; Shao, Y. A Survey of Feature Selection for Vulnerability Prediction Using Feature-Based Machine Learning. In Proceedings of the 2019 11th International Conference on Machine Learning and Computing, Zhuhai, China, 22–24 February 2019; Volume Part F1481, pp. 36–42. [Google Scholar]
- Wei, S.; Zhong, H.; Shan, C.; Ye, L.; Du, X.; Guizani, M. Vulnerability Prediction Based on Weighted Software Network for Secure Software Building. In Proceedings of the 2018 IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018. [Google Scholar]
- Nguyen, T.K.; Ly, V.D.; Hwang, S.O. An efficient neural network model for time series forecasting of malware. J. Intell. Fuzzy Syst. 2018, 35, 6089–6100. [Google Scholar] [CrossRef]
- Catal, C.; Akbulut, A.; Ekenoglu, E.; Alemdaroglu, M. Development of a Software Vulnerability Prediction Web Service Based on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Alves, H.; Fonseca, B.; Antunes, N. Experimenting Machine Learning Techniques to Predict Vulnerabilities. In Proceedings of the 2016 Seventh Latin-American Symposium on Dependable Computing (LADC), Cali, Colombia, 19–21 October 2016; pp. 151–156. [Google Scholar]
- Last, D. Forecasting Zero-Day Vulnerabilities. In Proceedings of the 11th Annual Cyber and Information Security Research Conference, Oak Ridge, TN, USA, 5–7 April 2016; p. 13. [Google Scholar]
- Pang, Y.; Xue, X.; Wang, H. Predicting Vulnerable Software Components through Deep Neural Network. In Proceedings of the 2017 International Conference on Deep Learning Technologies, Chengdu, China, 2–4 June 2017; Volume Part F1285, pp. 6–10. [Google Scholar]
- Walden, J.; Stuckman, J.; Scandariato, R. Predicting Vulnerable Components: Software Metrics vs. Text Mining. In Proceedings of the 2014 IEEE 25th International Symposium on Software Reliability Engineering, Naples, Italy, 3–6 November 2014; pp. 23–33. [Google Scholar]
- Scandariato, R.; Walden, J.; Hovsepyan, A.; Joosen, W. Predicting vulnerable software components via text mining. IEEE Trans. Softw. Eng. 2014, 40, 993–1006. [Google Scholar] [CrossRef]
- Wei, S.; Du, X.; Hu, C.; Shan, C. Predicting Vulnerable Software Components Using Software Network Graph; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Kansal, Y.; Kapur, P.K.; Kumar, U.; Kumar, D. Prioritising vulnerabilities using ANP and evaluating their optimal discovery and patch release time. Int. J. Math. Oper. Res. 2019, 14, 236–267. [Google Scholar] [CrossRef]
- Zhang, M.; De Carne De Carnavalet, X.; Wang, L.; Ragab, A. Large-scale empirical study of important features indicative of discovered vulnerabilities to assess application security. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2315–2330. [Google Scholar] [CrossRef]
- Jimenez, M.; Papadakis, M.; Traon, Y.L. An Empirical Analysis of Vulnerabilities in OpenSSL and the Linux Kernel. In Proceedings of the 2016 23rd Asia-Pacific Software Engineering Conference (APSEC), Hamilton, New Zealand, 6–9 December 2016; pp. 105–112. [Google Scholar]
- Siavvas, M.; Kehagias, D.; Tzovaras, D. A Preliminary Study on the Relationship among Software Metrics and Specific Vulnerability Types. In Proceedings of the 2017 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2017; pp. 916–921. [Google Scholar]
- Wai, F.K.; Yong, L.W.; Divakaran, D.M.; Thing, V.L.L. Predicting Vulnerability Discovery Rate Using Past Versions of a Software. In Proceedings of the 2018 IEEE International Conference on Service Operations and Logistics, and Informatics (SOLI), Singapore, 31 July–2 August 2018; pp. 220–225. [Google Scholar]
- Rahimi, S.; Zargham, M. Vulnerability scrying method for software vulnerability discovery prediction without a vulnerability database. IEEE Trans. Reliab. 2013, 62, 395–407. [Google Scholar] [CrossRef]
- Munaiah, N. Assisted Discovery of Software Vulnerabilities. In Proceedings of the 40th International Conference on Software Engineering: Companion Proceeedings, New York, NY, USA, 30 May–1 June 2018; pp. 464–467. [Google Scholar]
- Javed, Y.; Alenezi, M.; Akour, M.; Alzyod, A. Discovering the relationship between software complexity and software vulnerabilities. J. Theor. Appl. Inf. Technol. 2018, 96, 4690–4699. [Google Scholar]
- Last, D. Consensus Forecasting of Zero-Day Vulnerabilities for Network Security. In Proceedings of the 2016 IEEE International Carnahan Conference on Security Technology (ICCST), Orlando, FL, USA, 24–27 October 2016. [Google Scholar]
- Han, Z.; Li, X.; Xing, Z.; Liu, H.; Feng, Z. Learning to Predict Severity of Software Vulnerability Using Only Vulnerability Description. In Proceedings of the 2017 IEEE International Conference on Software Maintenance and Evolution (ICSME), Shanghai, China, 17–22 September 2017; pp. 125–136. [Google Scholar]
- Heltberg, M.L.; Krishna, S.; Kadanoff, L.P.; Jensen, M.H. A tale of two rhythms: Locked clocks and chaos in biology. Cell Syst. 2021, 12, 291–303. [Google Scholar] [CrossRef]
- Jiang, K.; Qiao, J.; Lan, Y. Chaotic renormalization flow in the Potts model induced by long-range competition. Phys. Rev. E 2021, 103. [Google Scholar] [CrossRef] [PubMed]
- Lahmiri, S.; Bekiros, S. Cryptocurrency forecasting with deep learning chaotic neural networks. Chaos Solitons Fractals 2019, 118, 35–40. [Google Scholar] [CrossRef]
- Yan, B.; Chan, P.W.; Li, Q.; He, Y.; Shu, Z. Dynamic analysis of meteorological time series in Hong Kong: A nonlinear perspective. Int. J. Climatol. 2021, 41, 4920–4932. [Google Scholar] [CrossRef]
- Picano, B.; Chiti, F.; Fantacci, R.; Han, Z. Passengers Demand Forecasting Based on Chaos Theory. In Proceedings of the ICC 2019—2019 IEEE International Conference on Communications (ICC), Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Kawauchi, S.; Sugihara, H.; Sasaki, H. Development of very-short-term load forecasting based on chaos theory. Electr. Eng. Jpn. 2004, 148, 55–63. [Google Scholar] [CrossRef]
- Liu, X.; Fang, X.; Qin, Z.; Ye, C.; Xie, M. A Short-term forecasting algorithm for network traffic based on chaos theory and SVM. J. Netw. Syst. Manag. 2011, 19, 427–447. [Google Scholar] [CrossRef]
- Fouladi, R.F.; Ermiş, O.; Anarim, E. A DDoS attack detection and defense scheme using time-series analysis for SDN. J. Inf. Secur. Appl. 2020, 54. [Google Scholar] [CrossRef]
- Procopiou, A.; Komninos, N.; Douligeris, C. ForChaos: Real Time Application DDoS Detection Using Forecasting and Chaos Theory in Smart Home IoT Network. Wirel. Commun. Mob. Comput. 2019, 2019, 8469410. [Google Scholar] [CrossRef]
- Devaney, R.L. An Introduction to Chaotic Dynamical Systems; Chapman and Hall/CRC: Boca Raton, FL, USA, 1989. [Google Scholar]
- Lahmiri, S.; Bekiros, S. Chaos, randomness and multi-fractality in Bitcoin market. Chaos Solitons Fractals 2018, 106, 28–34. [Google Scholar] [CrossRef]
- Gunay, S.; Kaşkaloğlu, K. Seeking a Chaotic Order in the Cryptocurrency Market. Math. Comput. Appl. 2019, 24, 36. [Google Scholar] [CrossRef] [Green Version]
- da Silva Filho, A.C.; Maganini, N.D.; de Almeida, E.F. Multifractal analysis of Bitcoin market. Phys. A Stat. Mech. Its Appl. 2018, 512, 954–967. [Google Scholar] [CrossRef]
- Rosenstein, M.T.; Collins, J.J.; De Luca, C.J. A practical method for calculating largest Lyapunov exponents from small data sets. Phys. D Nonlinear Phenom. 1993, 65, 117–134. [Google Scholar] [CrossRef]
- Hurst, H.E. The problem of long-term storage in reservoirs. Hydrol. Sci. J. 1956, 1, 13–27. [Google Scholar] [CrossRef] [Green Version]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef] [Green Version]
- Fix, E.; Hodges, J.L. Discriminatory analysis. Nonparametric discrimination: Consistency properties. Int. Stat. Rev. Int. De Stat. 1989, 57, 238–247. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Batista, G.E.; Monard, M.C. A study of K-nearest neighbour as an imputation method. His 2002, 87, 48. [Google Scholar]
- Schölzel, C. NOnLinear Measures for Dynamical Systems (Nolds). Available online: https://github.com/CSchoel/nolds (accessed on 6 September 2021).
- Tarnopolski, M. Correlation between the Hurst exponent and the maximal Lyapunov exponent: Examining some low-dimensional conservative maps. Phys. A Stat. Mech. Its Appl. 2018, 490, 834–844. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
| General Server Type | Used Services | |
|---|---|---|
| Open Source Code | Linux Openstack Control Server | Ubuntu, Linux kernel, IPtables, Fail2ban, RabbitMQ, MySQL, NTP, MongoDB, memcached, apache2, Openstack keystone, Openstack glance, Openstack neutron, Openstack horizon, Openstack nova, Openstack ceilometer |
| Linux Openstack Compute Server | Ubuntu, Linux kernel, IPtables, Fail2ban, NTP, Openstack neutron, Openstack nova, Openstack ceilometer | |
| Linux Mail Server | Ubuntu, Linux kernel, IPtables, Fail2ban, Zimbra, clamAV, SpamAssassin, ufw, Ltab | |
| Linux Java Application Server | Ubuntu, Linux kernel, IPtables, Fail2ban, clamAV, ufw, Ltab, JBoss (or TomCat), Java | |
| Linux Database Server | Ubuntu, Linux kernel, IPtables, Fail2ban, clamAV, ufw, Ltab, MySQL (or PostgreSQL) | |
| Proprietary Source Code | Microsoft Mail Server | Microsoft Windows Server, Microsoft Exchange, Spam Assassin, McAfee, Active Directory |
| Microsoft Dot Net Application Server | Microsoft Windows Server, Dot Net Framework, McAfee, Active Directory, IIS | |
| Microsoft Database Server | Microsoft Windows Server, Microsoft SQL Server, McAfee, Active Directory |
| emb_dim | 3 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 7 | 7 | 4 | 4 | 7 | 7 | 4 | 4 | 7 | 7 | 4 | 4 | 8 | 7 | 4 | 4 |
| <0 | 1 | 1 | 4 | 4 | 1 | 1 | 4 | 4 | 1 | 1 | 4 | 4 | 0 | 1 | 4 | 4 |
| emb_dim | 5 | |||||||||||||||
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 8 | 8 | 7 | 3 | 8 | 8 | 6 | 3 | 8 | 8 | 7 | 3 | 8 | 8 | 6 | 3 |
| <0 | 0 | 0 | 1 | 5 | 0 | 0 | 2 | 5 | 0 | 0 | 1 | 5 | 0 | 0 | 2 | 5 |
| emb_dim | 7 | |||||||||||||||
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 8 | 8 | 4 | 5 | 8 | 8 | 4 | 5 | 8 | 8 | 4 | 4 | 8 | 8 | 4 | 5 |
| <0 | 0 | 0 | 4 | 3 | 0 | 0 | 4 | 3 | 0 | 0 | 4 | 4 | 0 | 0 | 4 | 3 |
| emb_dim | 3 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 2 | 5 | 3 | 6 | 2 | 5 | 3 | 5 | 2 | 5 | 3 | 6 | 2 | 5 | 3 | 5 |
| <0 | 6 | 3 | 5 | 2 | 6 | 3 | 5 | 3 | 6 | 3 | 5 | 2 | 6 | 3 | 5 | 3 |
| emb_dim | 5 | |||||||||||||||
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 8 | 6 | 6 | 3 | 8 | 8 | 6 | 4 | 8 | 7 | 6 | 3 | 8 | 7 | 6 | 4 |
| <0 | 0 | 2 | 2 | 5 | 0 | 0 | 2 | 4 | 0 | 1 | 2 | 5 | 0 | 1 | 2 | 4 |
| emb_dim | 7 | |||||||||||||||
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 8 | 7 | 5 | 4 | 8 | 6 | 5 | 5 | 8 | 7 | 5 | 4 | 8 | 8 | 5 | 4 |
| <0 | 0 | 1 | 3 | 4 | 0 | 2 | 3 | 3 | 0 | 1 | 3 | 4 | 0 | 0 | 3 | 4 |
| emb_dim | 3 | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 3 | 4 | 6 | 5 | 3 | 4 | 6 | 6 | 3 | 4 | 6 | 3 | 3 | 4 | 6 | 4 |
| <0 | 5 | 4 | 2 | 3 | 5 | 4 | 2 | 2 | 5 | 4 | 2 | 5 | 5 | 4 | 2 | 4 |
| emb_dim | 5 | |||||||||||||||
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 8 | 7 | 1 | 5 | 8 | 8 | 1 | 5 | 8 | 7 | 1 | 5 | 8 | 8 | 2 | 4 |
| <0 | 0 | 1 | 7 | 3 | 0 | 0 | 7 | 3 | 0 | 1 | 7 | 3 | 0 | 0 | 6 | 4 |
| emb_dim | 7 | |||||||||||||||
| min_neighbors | 2 | 3 | 4 | 5 | ||||||||||||
| lag | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 | 1 | 2 | 3 | 4 |
| >0 | 8 | 8 | 1 | 6 | 8 | 8 | 1 | 7 | 8 | 8 | 1 | 6 | 8 | 8 | 1 | 7 |
| <0 | 0 | 0 | 7 | 2 | 0 | 0 | 7 | 1 | 0 | 0 | 7 | 2 | 0 | 0 | 7 | 1 |
| Closed source (500) | Total number of tests all variations of Rosenstein method parameters | 72,000 |
| Number of tests witd positive LLEs | 44,733 | |
| Percentage (%) | 62 | |
| Open source (500) | Total number of tests all variations of Rosenstein method parameters | 72,000 |
| Number of tests with positive LLEs | 51,913 | |
| Percentage (%) | 72 |
| trajectory_len | emb_dim | min_neighbors | lag | Total Systems with Non-Zero LLE |
|---|---|---|---|---|
| 7 | 5 | 4 | 1 | 500 |
| 7 | 7 | 2 | 1 | 500 |
| 6 | 5 | 5 | 1 | 500 |
| 6 | 7 | 3 | 1 | 500 |
| 6 | 5 | 4 | 1 | 500 |
| 6 | 7 | 4 | 1 | 500 |
| 6 | 5 | 3 | 1 | 500 |
| 6 | 7 | 5 | 1 | 500 |
| 7 | 5 | 2 | 1 | 500 |
| 6 | 5 | 2 | 1 | 500 |
| 6 | 7 | 2 | 1 | 500 |
| 7 | 5 | 5 | 1 | 500 |
| 7 | 5 | 3 | 1 | 500 |
| 7 | 7 | 3 | 1 | 500 |
| 7 | 7 | 5 | 1 | 500 |
| 8 | 5 | 2 | 1 | 500 |
| 8 | 7 | 5 | 1 | 500 |
| 8 | 5 | 3 | 1 | 500 |
| 8 | 5 | 4 | 1 | 500 |
| 8 | 5 | 5 | 1 | 500 |
| 7 | 7 | 4 | 1 | 500 |
| 8 | 7 | 4 | 1 | 500 |
| 8 | 7 | 2 | 1 | 500 |
| 8 | 7 | 3 | 1 | 500 |
| 6 | 3 | 2 | 1 | 495 |
| 6 | 3 | 5 | 1 | 494 |
| 6 | 3 | 3 | 1 | 493 |
| 6 | 3 | 4 | 1 | 492 |
| 7 | 3 | 5 | 1 | 206 |
| 7 | 3 | 3 | 1 | 204 |
| 7 | 3 | 2 | 1 | 203 |
| 7 | 3 | 4 | 1 | 203 |
| 8 | 3 | 4 | 1 | 191 |
| 8 | 3 | 3 | 1 | 190 |
| 8 | 3 | 2 | 1 | 190 |
| 8 | 3 | 5 | 1 | 189 |
| trajectory_len | emb_dim | min_neighbors | lag | Total Systems with Non-Zero LLE |
|---|---|---|---|---|
| 6 | 5 | 4 | 2 | 499 |
| 6 | 5 | 5 | 2 | 499 |
| 6 | 5 | 2 | 2 | 498 |
| 6 | 5 | 3 | 2 | 496 |
| 6 | 7 | 4 | 2 | 495 |
| 6 | 7 | 2 | 2 | 495 |
| 6 | 7 | 5 | 2 | 494 |
| 6 | 7 | 3 | 2 | 493 |
| 8 | 7 | 4 | 2 | 490 |
| 8 | 7 | 3 | 2 | 486 |
| 8 | 7 | 5 | 2 | 485 |
| 8 | 7 | 2 | 2 | 483 |
| 7 | 5 | 3 | 2 | 460 |
| 7 | 5 | 5 | 2 | 459 |
| 7 | 5 | 4 | 2 | 456 |
| 8 | 5 | 3 | 2 | 456 |
| 8 | 5 | 4 | 2 | 452 |
| 8 | 5 | 2 | 2 | 451 |
| 7 | 5 | 2 | 2 | 450 |
| 8 | 5 | 5 | 2 | 449 |
| 7 | 7 | 5 | 2 | 435 |
| 7 | 7 | 3 | 2 | 433 |
| 7 | 7 | 2 | 2 | 430 |
| 7 | 7 | 4 | 2 | 420 |
| 6 | 3 | 4 | 2 | 391 |
| 6 | 3 | 3 | 2 | 380 |
| 6 | 3 | 5 | 2 | 380 |
| 6 | 3 | 2 | 2 | 378 |
| 7 | 3 | 5 | 2 | 226 |
| 7 | 3 | 3 | 2 | 226 |
| 7 | 3 | 2 | 2 | 226 |
| 7 | 3 | 4 | 2 | 225 |
| 8 | 3 | 5 | 2 | 192 |
| 8 | 3 | 4 | 2 | 191 |
| 8 | 3 | 3 | 2 | 190 |
| 8 | 3 | 2 | 2 | 188 |
| trajectory_len | emb_dim | min_neighbors | lag | Total Systems with Non-Zero LLE |
|---|---|---|---|---|
| 7 | 5 | 4 | 1 | 500 |
| 6 | 5 | 5 | 1 | 500 |
| 6 | 7 | 5 | 1 | 500 |
| 6 | 5 | 4 | 1 | 500 |
| 6 | 7 | 4 | 1 | 500 |
| 7 | 5 | 2 | 1 | 500 |
| 6 | 5 | 3 | 1 | 500 |
| 7 | 5 | 3 | 1 | 500 |
| 7 | 5 | 5 | 1 | 500 |
| 6 | 7 | 3 | 1 | 500 |
| 6 | 5 | 2 | 1 | 500 |
| 7 | 7 | 2 | 1 | 500 |
| 7 | 7 | 3 | 1 | 500 |
| 7 | 7 | 4 | 1 | 500 |
| 7 | 7 | 5 | 1 | 500 |
| 8 | 5 | 2 | 1 | 500 |
| 8 | 5 | 3 | 1 | 500 |
| 6 | 7 | 2 | 1 | 500 |
| 8 | 5 | 4 | 1 | 500 |
| 8 | 5 | 5 | 1 | 500 |
| 8 | 7 | 2 | 1 | 500 |
| 8 | 7 | 3 | 1 | 500 |
| 8 | 7 | 4 | 1 | 500 |
| 8 | 7 | 5 | 1 | 500 |
| 6 | 3 | 5 | 1 | 498 |
| 6 | 3 | 4 | 1 | 498 |
| 6 | 3 | 2 | 1 | 495 |
| 6 | 3 | 3 | 1 | 495 |
| 7 | 3 | 4 | 1 | 266 |
| 7 | 3 | 5 | 1 | 266 |
| 7 | 3 | 3 | 1 | 266 |
| 7 | 3 | 2 | 1 | 265 |
| 8 | 3 | 3 | 1 | 226 |
| 8 | 3 | 2 | 1 | 225 |
| 8 | 3 | 4 | 1 | 223 |
| 8 | 3 | 5 | 1 | 222 |
| trajectory_len | emb_dim | min_neighbors | lag | Total Systems with Non-Zero LLE |
|---|---|---|---|---|
| 6 | 5 | 3 | 2 | 500 |
| 6 | 7 | 4 | 2 | 500 |
| 6 | 7 | 3 | 2 | 499 |
| 6 | 5 | 4 | 2 | 499 |
| 6 | 5 | 2 | 2 | 498 |
| 6 | 7 | 2 | 2 | 498 |
| 6 | 5 | 5 | 2 | 497 |
| 6 | 7 | 5 | 2 | 496 |
| 8 | 7 | 4 | 2 | 490 |
| 8 | 7 | 3 | 2 | 489 |
| 8 | 5 | 5 | 2 | 489 |
| 8 | 7 | 5 | 2 | 486 |
| 8 | 5 | 3 | 2 | 485 |
| 8 | 7 | 2 | 2 | 485 |
| 8 | 5 | 4 | 2 | 483 |
| 8 | 5 | 2 | 2 | 481 |
| 7 | 5 | 4 | 2 | 475 |
| 7 | 5 | 2 | 2 | 474 |
| 7 | 5 | 5 | 2 | 468 |
| 6 | 3 | 3 | 2 | 465 |
| 6 | 3 | 4 | 2 | 464 |
| 6 | 3 | 2 | 2 | 464 |
| 7 | 5 | 3 | 2 | 463 |
| 6 | 3 | 5 | 2 | 463 |
| 7 | 7 | 5 | 2 | 447 |
| 7 | 7 | 3 | 2 | 439 |
| 7 | 7 | 2 | 2 | 430 |
| 7 | 7 | 4 | 2 | 427 |
| 7 | 3 | 3 | 2 | 382 |
| 7 | 3 | 4 | 2 | 382 |
| 8 | 3 | 5 | 2 | 382 |
| 7 | 3 | 5 | 2 | 382 |
| 8 | 3 | 2 | 2 | 378 |
| 7 | 3 | 2 | 2 | 378 |
| 8 | 3 | 4 | 2 | 374 |
| 8 | 3 | 3 | 2 | 372 |
| System Type | HE Ranges | Counts |
|---|---|---|
| Closed source | 0.0–0.4 | 154 |
| 0.4–0.49 | 304 | |
| 0.49–0.509 | 23 | |
| 0.51–0.6 | 17 | |
| 0.6–1.0 | 2 | |
| Open source | 0.0–0.4 | 0 |
| 0.4–0.49 | 78 | |
| 0.49–0.509 | 35 | |
| 0.51–0.6 | 349 | |
| 0.6–1.0 | 38 |
| System Type | Entropy | HE Values | |
|---|---|---|---|
| Microsoft Dot Net Application Server | 2.187 | 8.707 | 0.380 |
| Microsoft Database Server | 2.222 | 8.707 | 0.363 |
| Microsoft Mail Server | 2.045 | 7.714 | 0.487 |
| Linux Openstack Controler Server | 2.272 | 8.508 | 0.587 |
| Linux Openstack Compute Server | 2.093 | 7.700 | 0.556 |
| Linux Mail Server | 2.35 | 9.878 | 0.560 |
| Linux Java Application Server | 2.311 | 9.878 | 0.566 |
| Linux Database Server | 2.209 | 9.709 | 0.465 |
| Closed Source Systems | ||||
|---|---|---|---|---|
| Range | Mean Entropy | Mean Entropy Variance Variance | Mean | Systems Tested |
| 1–2 | 1.967 | 0.0007 | 8.2937 | 53 |
| >2 | 2.0851 | 0.0020 | 8.8460 | 447 |
| Open Source Systems | ||||
|---|---|---|---|---|
| Range | Mean Entropy | Mean Entropy Variance Variance | Mean | Systems Tested |
| 1–2 | 1.9901 | 0.0001 | 8.8805 | 10 |
| >2 | 2.2711 | 0.0111 | 9.4739 | 490 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsantilis, I.; Dasaklis, T.K.; Douligeris, C.; Patsakis, C. Searching Deterministic Chaotic Properties in System-Wide Vulnerability Datasets. Informatics 2021, 8, 86. https://doi.org/10.3390/informatics8040086
Tsantilis I, Dasaklis TK, Douligeris C, Patsakis C. Searching Deterministic Chaotic Properties in System-Wide Vulnerability Datasets. Informatics. 2021; 8(4):86. https://doi.org/10.3390/informatics8040086
Chicago/Turabian StyleTsantilis, Ioannis, Thomas K. Dasaklis, Christos Douligeris, and Constantinos Patsakis. 2021. "Searching Deterministic Chaotic Properties in System-Wide Vulnerability Datasets" Informatics 8, no. 4: 86. https://doi.org/10.3390/informatics8040086
APA StyleTsantilis, I., Dasaklis, T. K., Douligeris, C., & Patsakis, C. (2021). Searching Deterministic Chaotic Properties in System-Wide Vulnerability Datasets. Informatics, 8(4), 86. https://doi.org/10.3390/informatics8040086