1. Introduction: Literature Review
Translation revision is “an emerging topic in the translation industry, in translator training and in translation research” [
1] due to its strategic role in the private and public sector quality assurance processes—including international organisations (IOs). This is a direct consequence of the significant increase in translation outsourcing [
2]. A decade ago the term
revision was rather more ambiguous, appearing in “
self-revision”, “
other-revision”, “
unilingual revision” and “
post-editing (i.e., revision)” [
3]. In the meantime, standardisation efforts such as ISO 17100 [
4] (and BS 15038 before it) have sought to separate these tasks terminologically, too, assigning them the terms
check, revision, review,
proofread and
post-edit, respectively.
Moreover, following the effort to disambiguate these related, but essentially separate tasks, as with any trainable activity, it is important to clarify several dimensions: what each task consists of, who should be performing it, when it happens in the translation or localisation workflow, how it is performed and which success criteria there are. This article aims to contribute to the how dimension of revision, but we will briefly introduce the other dimensions, too, in order to set the context.
In ISO 17100, the
what dimension of
revision is defined as “bilingual examination of
target language content against source language content for its suitability for the agreed purpose” [
4] (p. 2). The standard also specifies that this source-target comparison should include several aspects, which the translator should have addressed, from “compliance with specific domain and client terminology” through to ensuring that the “target audience and purpose of the target language content” have been considered [
4] (p. 10). Thus,
revision is distinct from
review (“monolingual examination of
target language content for its suitability for the agreed purpose”),
post-edit (“edit and correct
machine translation output”),
check (“examination of
target language content carried out by the
translator”) and
proofread (“examine the revised
target language content and applying
corrections before printing”) [
4] (pp. 2–3).
In terms of who can be a reviser, the ISO 17100 standard specifies that it should be “a person other than the translator”, who has the same competencies and qualifications as the ones listed by the standard for the translator, together with “translation and/or revision experience in the domain under consideration” [
4] (p. 10). Having another (ideally, more knowledgeable) pair of eyes comparing the target text (TT) against the source text (ST) makes intuitive sense and has been shown to be effective even in non-standard settings such as crowdsourcing, where integrating one or occasionally two stages of revision ensured that the final quality of the translated product was within accepted professional standards [
5]. However, in certain IOs, the progression from the role of the Translator to the much-coveted one of Reviser also includes the role of Self-revising translator, which assumes that translators with more experience can always effectively identify their own errors. This is a risky assumption to make, nevertheless, given that all the studies mentioned in [
3], the error analysis performed in [
5], and our own experiment, have highlighted that even experienced linguists miss a number of translation errors during revision.
Although our experiment was not specifically designed to study self-revising translators, but revisers as individuals different from an initial translator, the finding that the revisers in our study did not correct all of the errors present in the initial translation (see
Section 3.1) highlights the need for new methods to improve this situation. Should a third person not be available—as is most often the case due to budget and time constraints—we hypothesised that alternative attention-raising technology such as automatic speech synthesis could be integrated into current CAT/TEnT/Revision tools to enhance the effectiveness of the traditional silent revision process.
As for the when dimension of revision, the Translation Workflow proposed in ISO 17100 suggests that Revision be performed after the stages of Translation and Check and before the optional, client-negotiable stages of Review and Proofreading. Therefore, revision is not an optional component of an effective translation workflow that aims to produce a translation of publishable quality. However, the widespread practice of spot-checking (selective revision) can undermine the claimed effectiveness of the compulsory stage of revision.
Our case study aims to contribute to the
how dimension of
revision. Given the recent development of speech technologies such as speech synthesis (text-to-speech) and speech recognition (speech-to-text), revisers have very slowly started to integrate these tools into their workflows, as well as CAT/TEnT set-ups [
6,
7]. Today, CAT tools are certainly widespread, with only 1% of companies and 13% of language professionals recently surveyed not using them [
8]. Moreover, speech recognition (dictation) now ranks third for companies and professionals in the category of ‘other technologies’ used in the translation process, “but it is clearly more popular with the individuals than with the companies” [
8] (p. 19).
We believe that the investigation of a speech-enabled CAT/TEnT is timely, especially given that, although speech technologies are still not ubiquitous, professional translators already use “reading aloud” to various degrees in the self-revision process: in a 2017 survey of professional translators, 20% of the 55 participants stated that “they regularly read the translated text aloud, 44% never read aloud the translation they are revising, and the remaining 36% read the translation aloud only occasionally or when the sound and rhythm effects are particularly hard to recreate” [
9] (p. 15). Our study aims to complement such self-reported evidence by combining eye-tracking, error annotation and questionnaire data to investigate the impact of hearing the source text on the revision process.
To date, research suggests that monolingual revision involving only the target language is ineffective and even dangerous—which should also send a serious warning message to supporters of post-editing machine translation (PEMT) carried out without knowledge of the source language. For example, Brunette et al. [
10] showed that bilingual revision consistently achieves better results and outperforms monolingual revision in terms of accuracy, readability, appropriateness and linguistic coding. They also reported the use of monolingual revision to be “an irrational practice, even less helpful than no revision” (ibid.).
At the same time, linguists appear to mix and match approaches depending on personal preferences rather than scientific research: an empirical study of revision practices in the Danish translation profession—with particular focus on translation companies—revealed that “the preferred procedure seems to be that the target text is first checked on its own and that a comparison with the source text is only carried out where it is deemed necessary or relevant” [
11] (p. 114). The researchers also found that “some revisers prefer to do it the other way round, i.e., starting with a full comparative revision followed by a unilingual revision” [
11] (p. 114). Moreover, a recent professional translator survey [
9] indicated that, of the 55 respondents, 40% of them start revising by reading the ST beforehand (only 8% read the ST in full) and 52% check the ST against TT line by line. These practices are present in even higher proportion in trainee translators, with an eye-tracking study of 36 participants indicating that 55.6% of students read the ST in the initial planning stages (which will be called the
orientation phase in the current article), 88.9% check the ST against TT in the revision per se, and none of the participants focus solely on the TT at the expense of the ST [
12]. Lack of time seems to be the main factor preventing professional translators from applying these practices to the whole text, while trainees are influenced by their translation proficiency, as well as text type, length and complexity [
12].
In an attempt to describe an “ideal” revision process, a three-step activity is proposed by some researchers [
10], consisting of an initial reading of the ST, followed by a comparative reading of ST and TT (referred to as “bilingual revision”), and finally a correction and re-reading of the TT. Conversely, others advocate for “unilingual revision,” that is, the reviser’s reading of the target text alone, going back to the source text only when the reviser detects a problem and subsequently makes a change [
3]. This unilingual re-reading “may well produce a translation that is not quite as close in meaning to the source as a comparative re-reading will produce. On the other hand, it will often read better because the reviser has been attending more to the flow and logic of the translation” [
3] (p. 116). Another benefit of “reading the draft translation without looking at the source text,” can be that revisers “have the unique opportunity to avoid coming under the spell of source-language structures.” [
13] (p. 13).
Leaving aside the drive to improve target language fluency, currently the hype around monolingual target language revision feeds on the hype around the occasionally surprising quality of neural machine translation (NMT) and the constantly-publicised need for ever-faster translations. However, Robert and Van Waes [
14] found that a bilingual revision does not take significantly more time than the ineffective (especially from the point of view of ensuring the accuracy of the translation) monolingual approach in their study that investigated the correlation between
quality and
revision method (monolingual; bilingual; bilingual followed by monolingual; and monolingual followed by bilingual) among 16 professional translators. Moreover, although some professional linguists still seem to prefer combining a monolingual revision stage with bilingual revision, Robert and Van Waes [
14] found that to be unnecessary. Following the analysis of key-logging, revisions made, and think-aloud protocols, they concluded that contrary to their expectations, for full revision “there is no significant difference between the bilingual revision procedure and the two procedures involving a bilingual revision together with a monolingual revision” (a comparative re-reading followed by a monolingual re-reading, and a monolingual re-reading followed by a comparative re-reading). This led them to state that “re-reading a second time does not seem to be worth the effort”. This is a very important suggestion, especially given the growing productivity expectations of the language services industry [
15].
As more translators are translating and revising using CAT and speech recognition and/or synthesis tools together, the challenge becomes identifying the optimum integration and combination of such tools when carrying out specific tasks such as revision. A piece of technology that is proving helpful in this sense is eye-tracking, a well-established method in psychology that is being increasingly exploited in Translation Studies. More recently, eye-tracking has been used in Translation Process Research (TPR) to investigate viewing habits of different categories of language users (translators, revisers, post-editors, subtitlers, even language learners). In our experiment, eye-tracking is used, first of all, to describe participant behaviour when revising with and without sound. It is also used to investigate whether there is any relationship between the eye measures considered, the quality of the revised output, and the participants’ perception of the speech technology used.
Eye-tracking studies can take into account different types of eye movements—e.g.,
fixations and
saccades. A fixation can be defined as “an instance of gaze that remains for longer than a predefined duration on the same point on the screen” [
16] (p. 35). A saccade, on the other hand, is a “rapid jerk-like movement (…) necessary to direct the gaze to a new location” during which, however, “no meaningful new visual information is gathered” [
17] (p. 2). In this paper we will only report on fixation data. Among these data, some of the most commonly used measures are fixation counts, fixation durations and mean fixation durations (MFD). Generally speaking, fixation counts refer to the number of fixations made on a particular item; fixation durations represent the amount of time spent processing that item (usually calculated in milliseconds—ms); and mean fixation duration (MFD) is a secondary measure calculated by dividing fixation durations on one item by fixation counts. When all fixation durations on a particular item are added together, dwell time is obtained.
Following current interpretations of eye movements in reading research, we work on the assumption that fixation counts and dwell time provide a measure of overall attention and total cognitive effort dedicated to the ST and TT, while MFD provides a measure of depth of processing, which includes ease of access to word meanings and word integration into the sentence being read [
16,
17,
18,
19]. On average, a longer fixation duration is “often associated with a deeper and more effortful cognitive processing” [
20] (p. 381), which is relevant to the present investigation as the aim is to establish whether speech synthesis hinders or facilitates the revision task.
Our case study investigated the impact of adding sound produced by speech synthesis tools to what has been traditionally a silent, text-only process—namely, revision in a CAT tool. We acknowledge working with a small number of revisers—with all the limitations that this approach entails—addressed specifically in
Section 5.
2. Materials and Methods
2.5. Hardware and Software Set-Up
The French ST and the corresponding English TT to be revised were presented in the CAT tool memoQ in the Tahoma typeface, size 14. We chose memoQ (version 8.5) for our study because we designed our experiment to incorporate source sound triggered by voice commands uttered by the reviser, and at the time of the design memoQ was the most speech-friendly CAT tool available on the market, with the highest compatibility level with Dragon NaturallySpeaking (DNS, version 15 Professional), the most popular dictation tool for professional linguists [
6].
However, at the time of the experiment (December, 2018–March, 2019), our experimental hardware running concurrently memoQ 8.5, DNS 15 Professional, Google Chrome and the eye-tracking software EyeLink 1000 Plus (SR Research) with its built-in Screen Recorder software resulted in a lag of approximately 8 seconds between users uttering a “Read Sentence” command in DNS and hearing the ‘spoken’ output of that command.
During a series of successively-tuned pilot studies with volunteers, it became clear that 8 seconds was too long for revisers to wait and, since no alternative software combination met the research criteria, the research team created separate audio files for all individual source text segments using the Microsoft Word built-in Read Aloud French synthetic voice. During the experiment, revisers uttered the command “Read source 1/2/3/n” to listen to that particular recording played without delay by a research team member.
In order to investigate our third research question regarding the impact on viewing behaviour of incorporating sound into the revision process, we used eye-tracking technology. Initially, for ecological validity, we set out to use a mobile eye-tracking approach, which would allow participants to move their heads freely during the tasks. However, during the pilot phase, a series of calibration and tracking issues arose, which impacted the quality and reliability of the recorded data. The chosen alternative option of using a tower mount with a fixed head-and chin-rest ensured a much higher eye-tracking accuracy and eliminated tracking issues caused by the participant moving out of the head-box space (the trackable area when working with remote eye-trackers).
The experiment was run remotely on a display laptop (with an Intel i7 processor, 8 GB of RAM, and running Windows 10) that was connected to an external keyboard, mouse, and 22-inch LCD monitor screen to improve the ergonomic set-up for the participants. The display laptop was also connected to the Host PC, where the calibration process was run by the experimenter. Data were recorded using Screen Recorder, a dedicated piece of software provided by SR Research, which interfaces with the eye-tracker hardware, allowing researchers to simultaneously record eye movements, ambient sound and screen activity, including keyboard typing and mouse clicks. Screen Recorder produces not only the eye-tracking data file (.edf) but also a separate video (.mpeg) and audio (.wav) file for each participant recording.
2.6. Data Preparation for Analysis
Our experiment produced three types of data: revision error analysis data; participant questionnaire data; and participant eye-tracking data.
First, the revised English text T1 was exported as MS Word files out of memoQ for subsequent error analysis. Following industry practices, the error annotation was performed using the TAUS harmonised DQF-MQM error typology [
21], which is well-known in the localisation industry. Two independent assessors worked collaboratively to identify how many of the initial T1 Accuracy, Fluency and Style errors had been corrected by each participant.
Secondly, the post-eye-tracking questionnaire gathered the following information:
Demographic information on the participants’ gender, age, translation, interpreting and revision experience, as well as previous exposure to CAT and speech technologies;
Participants’ perceptions regarding revision quality, productivity and concentration when using speech synthesis in the experiment;
Participants’ preferences regarding future use of speech technologies in the process of translation and revision.
The questionnaire consisted of close-ended questions, following a three-level Likert scale approach, except for the final question, which asked participants to comment on their overall evaluation of speech technologies in the process of revision. The questionnaire was designed in Google Forms and was filled in by participants electronically in the lab. The results were downloaded from Google Forms in MS Excel format for analysis.
Thirdly, the software Data Viewer (SR Research) was used to visualise the eye-tracking and screen activity data, and to produce the fixation data files. In the Data Viewer replay function, the experimenters manually identified which time intervals (called ‘interest periods’ IPs) of each participant’s video recording were spent revising in the CAT tool (labelled ‘memoQ intervals’), and which time intervals were spent consulting external resources (labelled ‘web searches’). The beginning and end of each of these IPs were marked in Data Viewer, so that fixation data can be extracted on these two types of IPs, either individually (a particular memoQ interval or web search) or cumulatively (e.g., aggregation of all or some memoQ intervals). In this study, we extracted data cumulatively, which means that eye movement measures on each memoQ interval were collated in one dataset by Data Viewer, which was then exported for analysis. Importantly, the number and length of the memoQ intervals differs between participants working on the same text because each participant had the freedom to make as many or as few web searches as they deemed necessary. Data were extracted for each memoQ interval on the two areas of interest (AOIs) relevant to the study, namely the source text (ST) and the target text (TT). To ensure our eye-tracking data were genuinely collected only on ST and TT, the AOIs were drawn only around the texts themselves; thus, any looks anywhere else on the computer screen (e.g., at the time, taskbar, segment numbers, or fuzzy match percentages in memoQ) were not counted, preventing artificial inflation of fixation measures.
As already briefly mentioned in
Section 1, fixation count, dwell time and MFD data were collected and analysed in this study. Specifically, we defined
fixation counts as the total number of fixations falling within an AOI. We defined
dwell time as the sum of the durations of all fixations falling in an AOI. In this study, therefore, dwell time refers to the amount of time spent processing the ST or the TT
while being capable of processing visual information, i.e., excluding saccades.
MFD in each memoQ interval was obtained by dividing dwell time on an AOI by fixation counts on that AOI. Alongside these values, for two participants’ full-length revision session screen recordings, we present a
weighted average MFD for both ST and TT in order to acknowledge the relative importance of the separate memoQ interval fixation counts. These two participants’ experiment ids are
s08 and
s09. When extracting data for analysis, fixation counts and dwell times are primary measures calculated by the eye-tracking software, whereas MFD and weighted average MFD are secondary measures calculated from the primary ones.
Finally, given the different word counts between source text and target texts, we have normalised our participants’ fixation counts per 1000 words.
4. Discussion
In answer to our RQ1, the error analysis performed suggests that the presence of source sound was conducive to better revision quality overall. All the TAUS DQF-MQM categories used—i.e., Accuracy, Fluency and Style—registered improvements for G1_2 (
Table 3). The largest improvement was for Accuracy, where G1_2 achieved an average score of 66% compared to 37% for G1_1. Style was the category which benefitted next—G1_2 scored 70% compared to 61% for G1_1, while the scores for Fluency are very close: G1_2 achieved 52% compared to 51% for G1_1. Overall, G1_2 corrected a total of 60% of all errors, while G1_1 only managed 48%.
The open-ended part of our questionnaire helped explain this better performance from G1_2, who had been revising with source sound: “[source sound] helped me to understand the flow of the speech better”; “[it] alerted me to particular kinds of errors (such as spelling errors) that I may have missed from reading the source text”; “[I spotted] different kinds of errors”; “having the source text read to me ensured I was more focused on it”; “speech technology made me focus back on the ST”; “it allowed me to check that all of the info (and the same logic) was to be found in the target text”; “I noticed errors in the translation as a result of hearing the source, it was useful to have these ‘jump out’ at me in this way”; “it was very useful for picking up subtle content errors”; “checking for typos, proof-listening, if you like”; “I concentrated better in this case than if I had only been reading the text”.
We find these improvements in revision quality encouraging given that T1 had an increased level of difficulty based on the majority of readability scores produced by StyleWriter 4, a popular tool used by content editors to assess the difficulty and appropriateness of English content for different target audiences (for details on how StyleWriter 4 calculates the scores, see
Table A1 in
Appendix B).
One of the known features of challenging texts is segment length—in T1, ST segments ranged between 3 and 51 words (average size 27.09), and TT segments ranged between 2 and 43 (average size 24.09). The issue of segment length was also raised by our participants: “I found my concentration drifting with longer segments” and “[revising with sound] would take some getting used to in longer chunks”. Therefore, we suggest that the presence of sound during the revision process will have different impacts depending on the length and complexity of the source and target segments—with the emerging evidence presented here pointing to a higher likelihood that users will find it more comfortable to adapt to this new working mode on shorter segments.
Secondly, in connection with RQ2, as our participants had no consistent experience with speech technologies, their views on their impact on the translation and revision processes only reflect their limited exposure to these technologies during our experiment. Overall, a majority of seven participants said that they would prefer hearing the source sound when revising, while four said that they would prefer not having source sound (SS) during revision. From their comments, it appears that using synthetic sound effectively takes practice. After attempting to carry out visual bilingual text processing concomitantly with aural source processing, some of our participants stated: “I simply couldn’t read the source and target and listen to the source at the same time”, as well as “I am not used to having to think about hearing the source, so it was an additional thing to do and slightly disrupted my usual way of approaching a revision”, and “occasionally I would get distracted while trying to edit the target segment and listen to the source segment at the same time”. At times, though, this disruption was welcomed: “it was slowing me down as I stopped writing to listen; [… it] alerted me to particular kinds of errors that I may have missed”.
We believe that, with specialised training, linguists can learn to progress from “shorter segments, especially segments with figures, [where] I found the dictation quite useful” to longer and more complex segments, especially as most of our participants saw clear benefits in using speech. Nine out of 11 participants expressed an interest in continuing to explore using speech technologies—“it would help to get used to doing actual translation in this way”—and four even thought that they were more productive when using it. Such progress is certainly possible, given that even 1 hour in the lab was considered useful: “I quickly adapted”.
Our questionnaire shows that, when listening to source sound, three translators reported to have been more alert to the corresponding target segment, five to the source segment being read, and the remaining three reported no change. Such alertness was beneficial for identifying more subtle errors: “it was very useful for picking up subtle content errors and I feel that in time, with practice it would be very helpful in improving my productivity”; “[it] allowed me to focus on which words or expressions were difficult for me, which sped up the process”. All those who reported enhanced alertness to the target had interpreting training. On the other hand, other participants reported that source sound was “difficult to process”, and that their listening skills were not always sufficiently developed to enable them to cope with the multimodal processing of information. As all of these skills are part of interpreting training, we believe that they should be included in future translation courses exploring the integration of speech technologies in translation and revision workflows.
Moreover, such training needs to be customised because all four participants who, at the end of the experiment, expressed a preference for revision without sound, in fact had interpreting training and/or experience. An enhanced focus on the very challenging task of bilingual text processing concomitantly with aural input processing will be needed for revisers to perform comfortably in this environment.
Having said that, even without customised training and during a very short experiment such as ours, none of the participants perceived any adverse effect on quality posed by the presence of source sound—see
Table 6. All those who reported SS to have had a positive impact on the quality of their revision also reported SS to have led them to focus more on the source segments. We believe that this increased focus also contributed to Accuracy scores being much higher for the group which heard the source sound than the group who revised T1 in silence.
Except for the Quality category in
Table 6, the reported data on the other two indicators—Concentration and Productivity—is less conclusive. Similarly, we found no correlations between the participants’ profiles as summarised in
Table 4 and
Table 5 and their attitudes and preferences towards using source sound in the revision process.
Finally, the difference of the artificial voice from a human one—“not sound[ing] like a natural human speaker”—was also mentioned by participants: “the robotic voice was difficult to listen to”. As speech technologies continue to evolve and are gradually integrated into CAT/TEnT environments, we hope that this inconvenience will be addressed.
Thirdly, in response to our initial RQ3, we would like to reiterate that the data reported here on s08 and s09 does not allow us to make any generalisations—we chose to report on these two participants because their professional profiles were most similar, but there are no data available indicating they are also representative of their respective groups in terms of reading behaviour. Therefore, our discussion below only highlights interesting comparative elements.
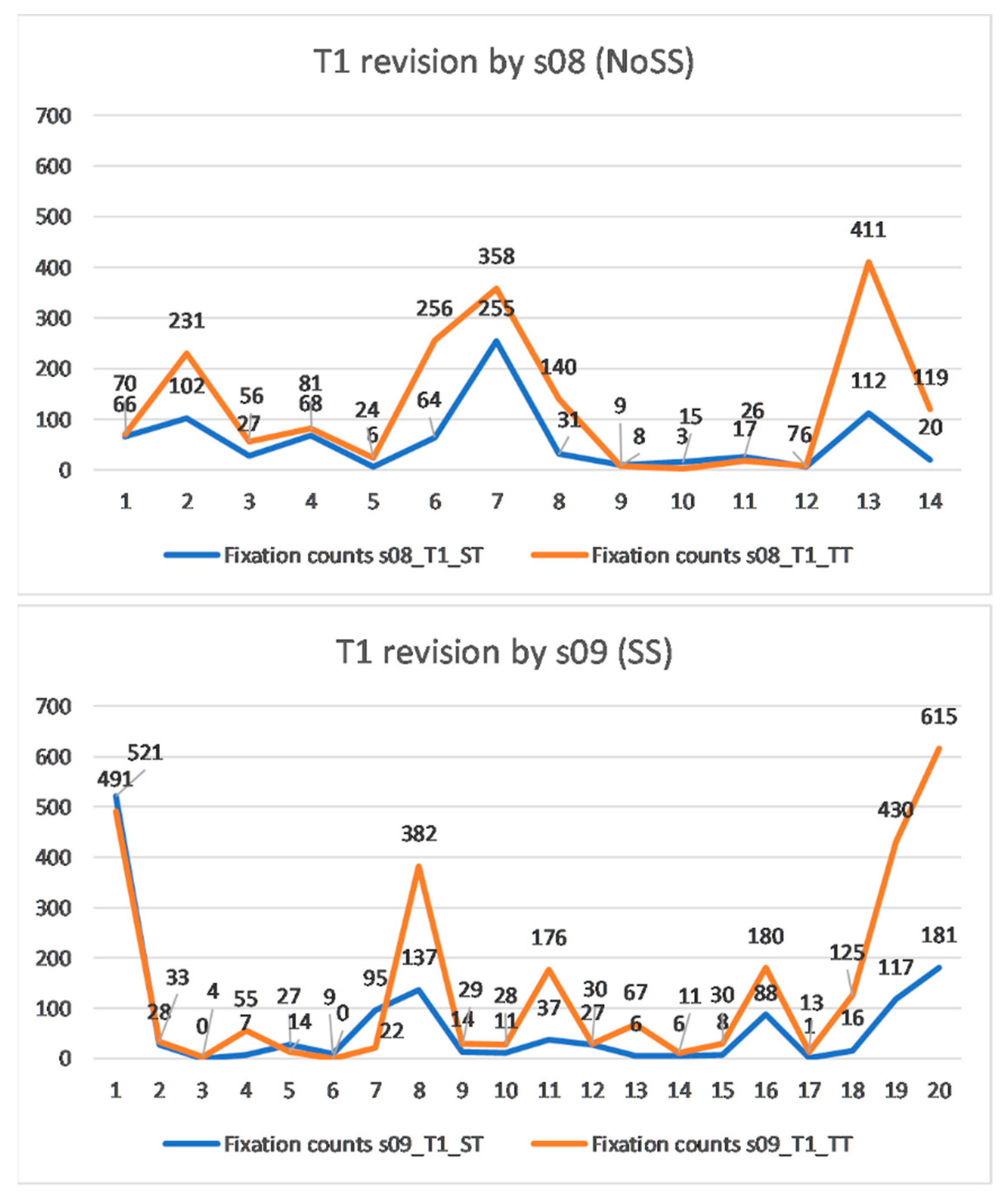
First of all, the fixation counts presented in
Table 7 show that, as expected, both participants focused more on the target text than the source text. s08 made fewer fixations on ST and TT than s09, yet we cannot state whether this was due to the impact of introducing source sound in s09’s condition (G1_2). However, it is interesting to observe, when comparing the normalised fixation counts per 1000 words, that, despite the rather different values between s08 and s09 (2708 versus 4483 for ST and 6720 versus 10,320 for TT), the ratio of TT fixations to ST fixations is quite similar: 2.48 for s08 and 2.30 for s09.
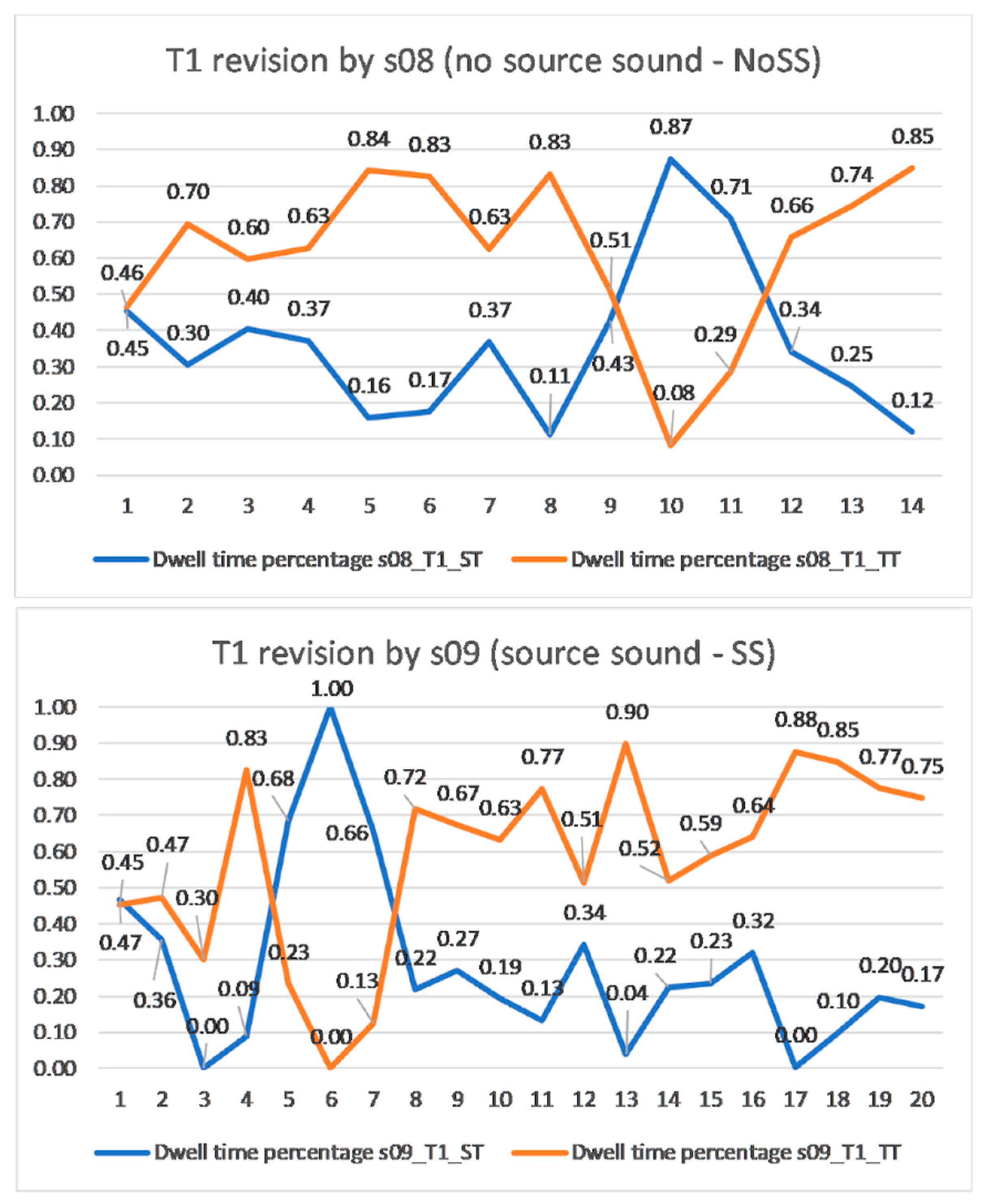
Focusing more closely on s08 and s09,
Figure 1 and
Figure 2 show that s08 had a finalisation phase, while s09 had both an orientation and a finalisation phase. The orientation phase we observed for s09 is similar to the stage discussed in [
22] for translation tasks, which encompasses activities carried out before typing begins, and, in our case, before starting the revision proper with source sound (SS). The presence of the orientation phase for s09 is in line with Scocchera’s [
9] and Huang’s [
12] findings, which show that 40% of professional revisers and 55.6% of student translators prefer to read the ST before revising the TT.
Moreover, our eye-tracking data showed the presence of a finalisation phase, in which both s08 and s09 had a larger number of fixations on the TT while checking once more the TT against the ST segment by segment. The data captured for both participants also confirm the results of previous studies where fewer referrals to the ST are made in the finalisation phase [
12,
23,
24]. The questionnaire results suggest that source sound is perceived by some as actively supporting the finalisation phase: “[speech synthesis was] useful as a kind of final check, as it allowed me to go through the ST more quickly than if I had only been reading the text”.
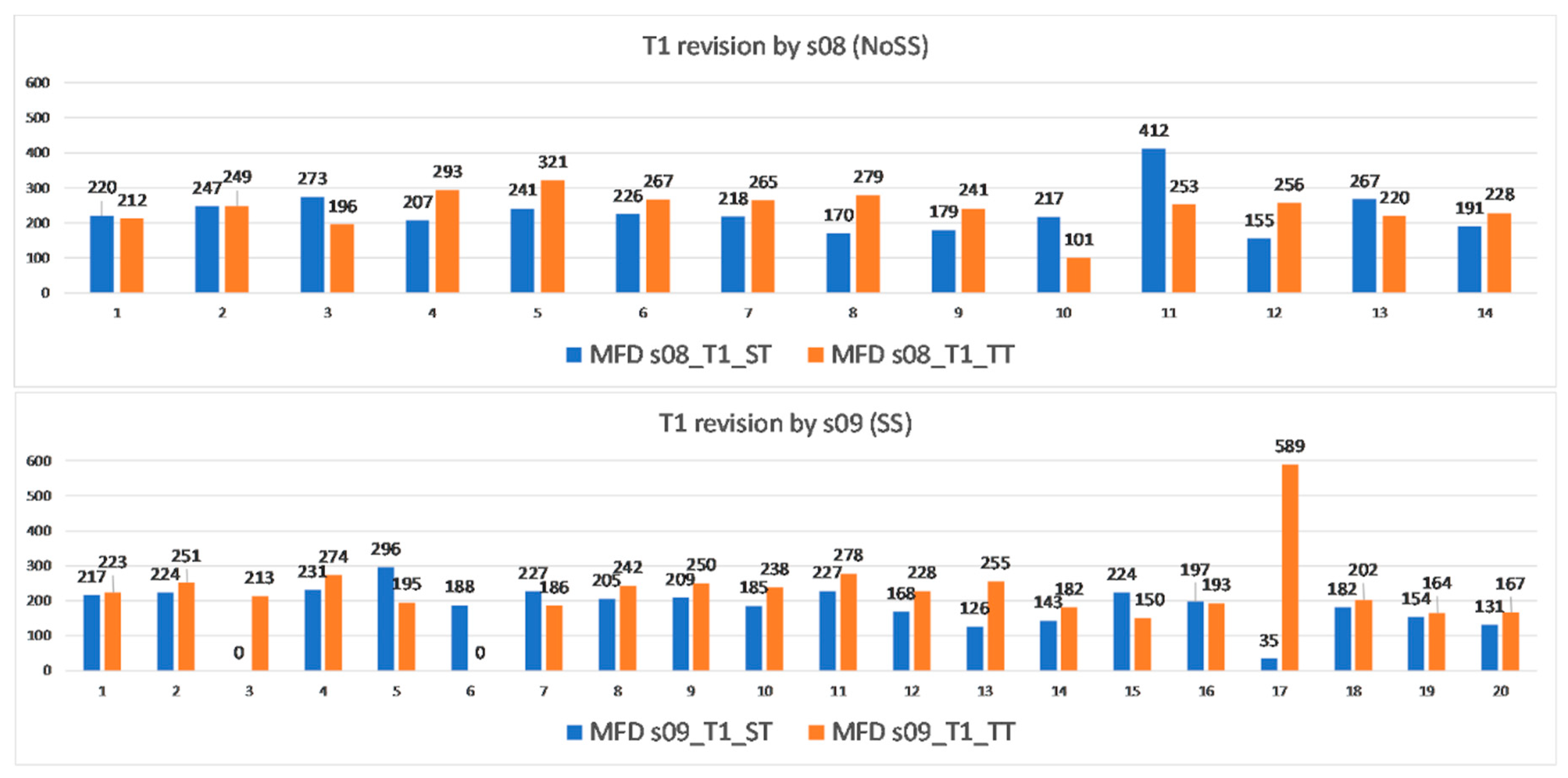
The weighted average MFD values which we calculated in order to mitigate the relative importance of the separate memoQ interval fixation counts were consistently higher for s08 than s09 (233 ms versus 197 ms for ST, and 248 ms versus 207 ms for TT). By comparing only two participants, however, it is not possible to establish whether this is due to the presence of source sound. As expected, from these values, as well as the ones presented in
Figure 3, both participants appear to concentrate more on the target text. Further analysis at group level will enable us to see whether the presence of source sound generally leads to shorter weighted average MDF values or whether s09 is an exception.
Eye-tracking data also showed that s09 had more memoQ intervals than s08, which means that s09 stopped more frequently to perform web searches in websites such as Reverso, Linguee, or in Google. Daems and colleagues [
25] investigated the use of external resources (ER) by trainee translators for translation (T) and post-editing (PE) tasks. Their results showed that, overall, more time was spent by trainees on ER for T than PE, but that the type of ER used and task (T or PE) were not significantly inter-dependent. Moreover, spending a longer time on ER correlated with better quality when translating, but not when post-editing. Once we have analysed all the eye-tracking data from all our participants, it will be interesting to see whether G1_2 as a whole (the group who worked with source sound—SS) made more web searches than G1_1 (the group who worked without sound—NoSS), whether there were any differences in the nature of these web searches and whether spending longer time on ER correlates with revision quality.




{kind=link}
{kind=link}
{kind=link}


