Improving the Translation Environment for Professional Translators

 , , , , , , , , ,
, , , , , , , , ,  , , ,
, , , 
 , , , and add
Show full author list
, , , and add
Show full author list
Abstract
1. Introduction
2. Translation Technologies
2.1. Improved Fuzzy Matching
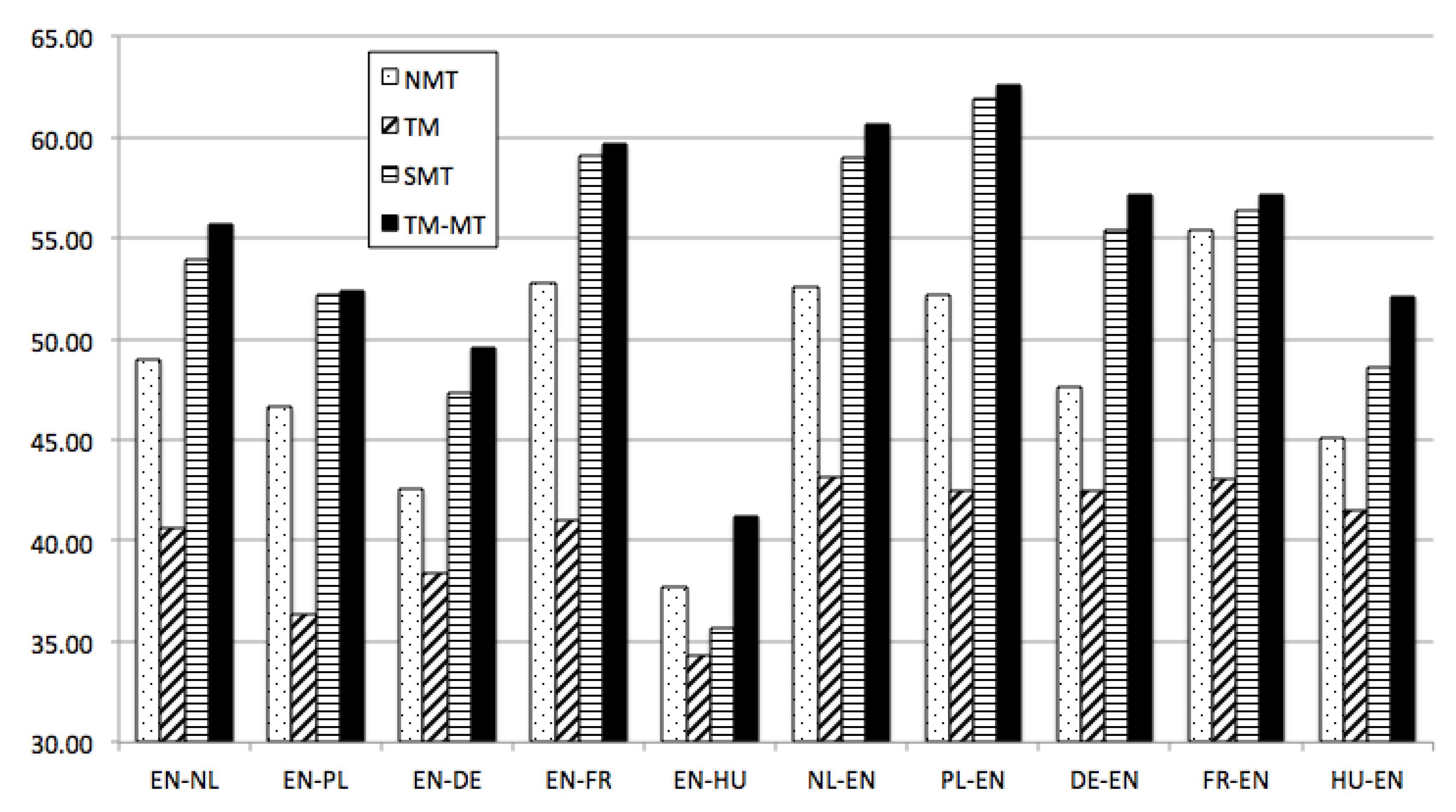
2.2. Integration of Translation Memory with Machine Translation
2.3. Building Resources for Syntax-Based Translation
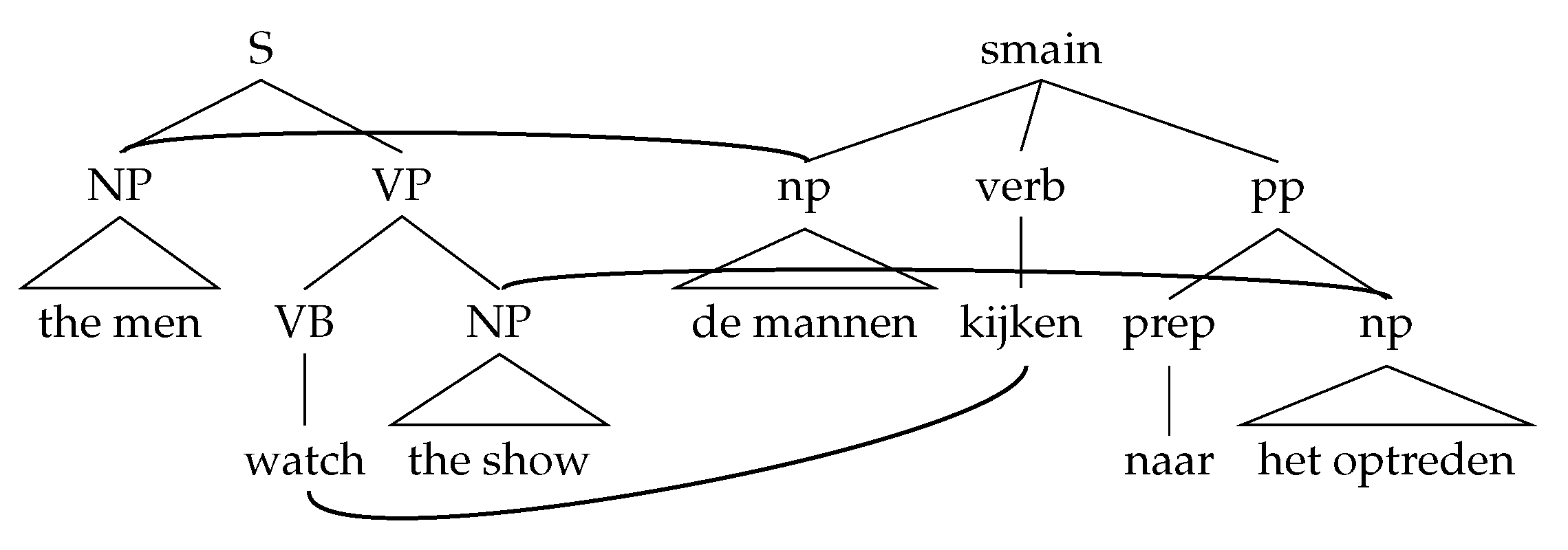
2.3.1. Sub-Sentential Alignment
2.3.2. Machine Translation Rules
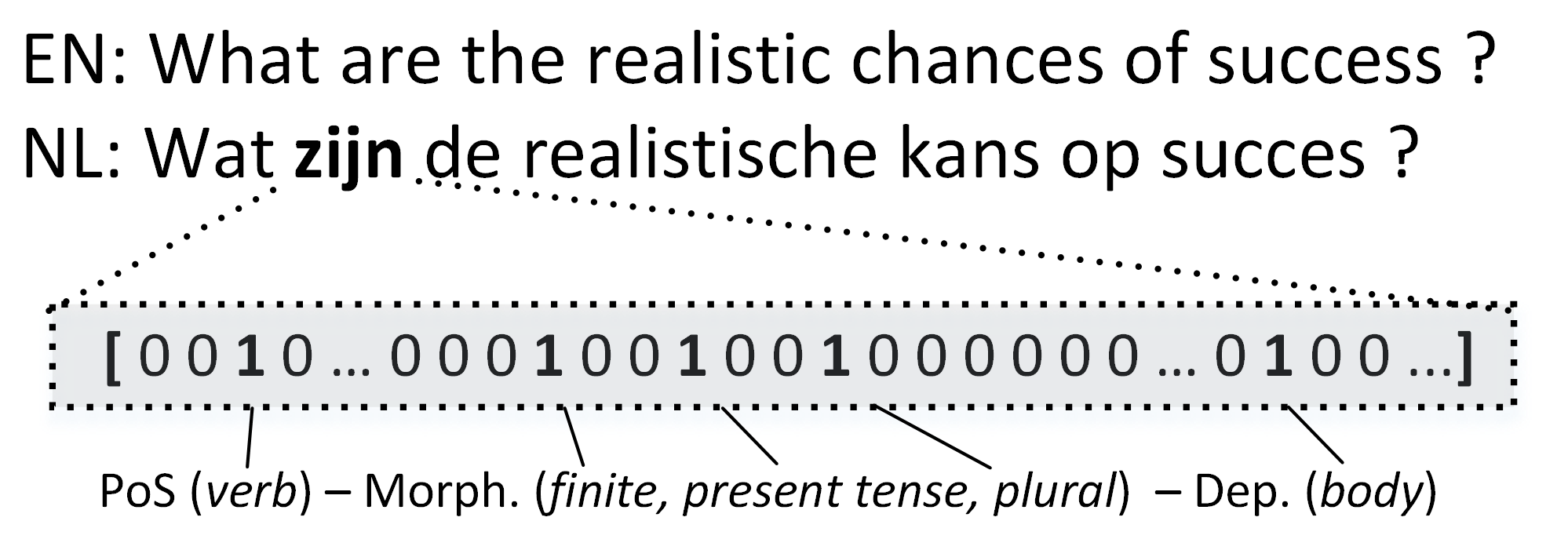
2.3.3. Semantic Information
2.3.4. Searching Parallel Treebanks
3. Quality Estimation of Computer-Aided Translation
3.1. Taxonomy and Annotated Data Set of Machine Translation Errors
3.2. Quality Estimation
3.2.1. The Predictive Power of MT Errors on Temporal Post-Editing Effort
3.2.2. Automatic Error Detection
3.2.3. Informative Quality Estimation
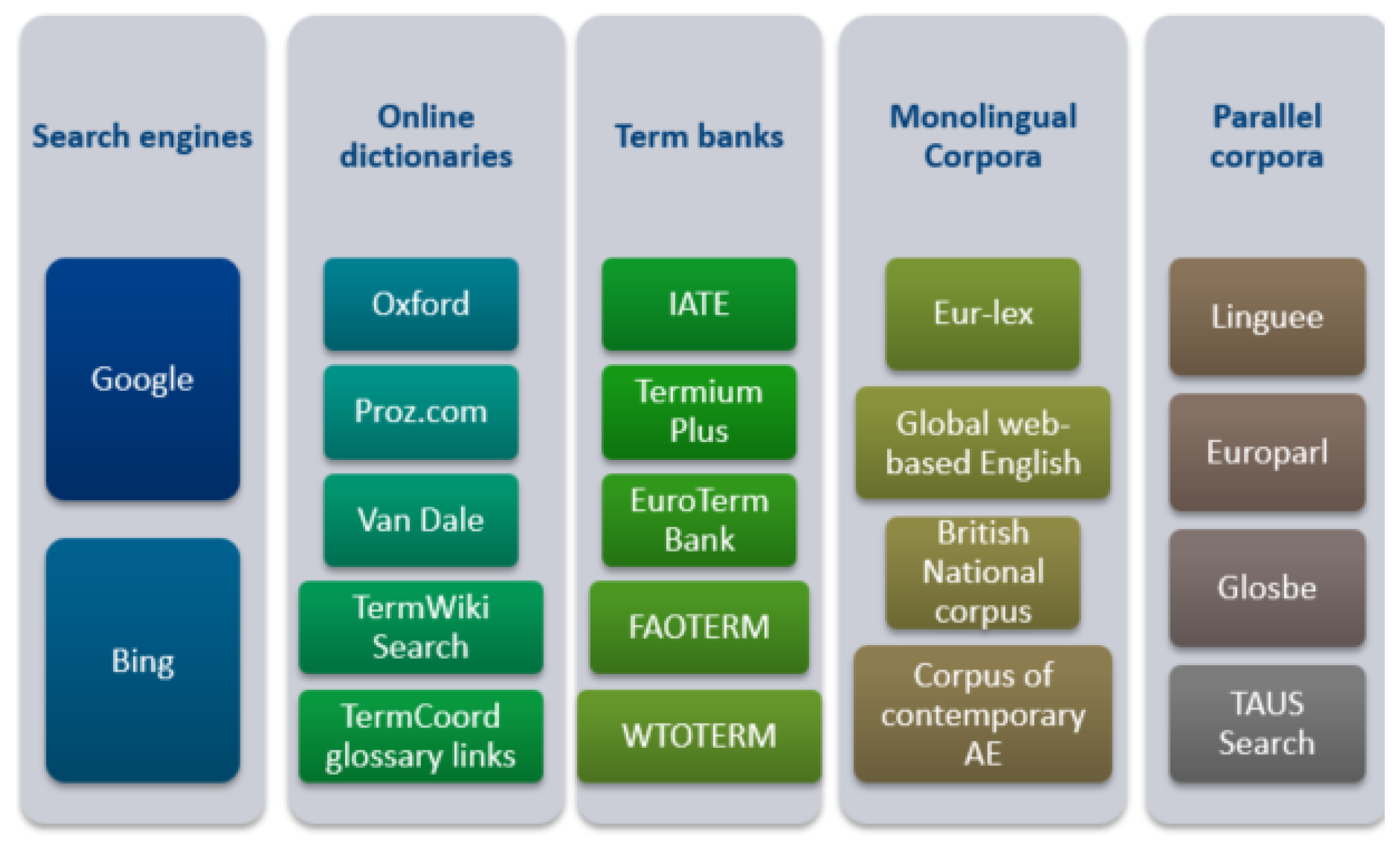
4. Terminology Extraction
4.1. Studying Translator’s Methods of Acquiring Domain-Specific Terminology
- (1)
- Related to specialised terminology: the translator does not know the meaning of the source term; the translator does understand the source term but does not know how to translate it in the target language; the translator does not know which target language equivalent to select from several translation alternatives coming from a large database.
- (2)
- Related to general language.
- (3)
- Related to the translation of named entities, acronyms, ambiguity, low quality of the source text and punctuation.
4.2. Terminology Extraction from Comparable Text
4.2.1. Comparison of Weakly-Supervised Word-Level BLI Models
4.2.2. Combining Word-Level and Character-Level Representations
4.2.3. Datasets and Gold Standards for Future Research
5. Speech Recognition
5.1. Adaptation of the Speech Recognition Language Model by Machine Translation
5.2. Automatic Domain Adaptation
5.3. Translation of Spoken Data
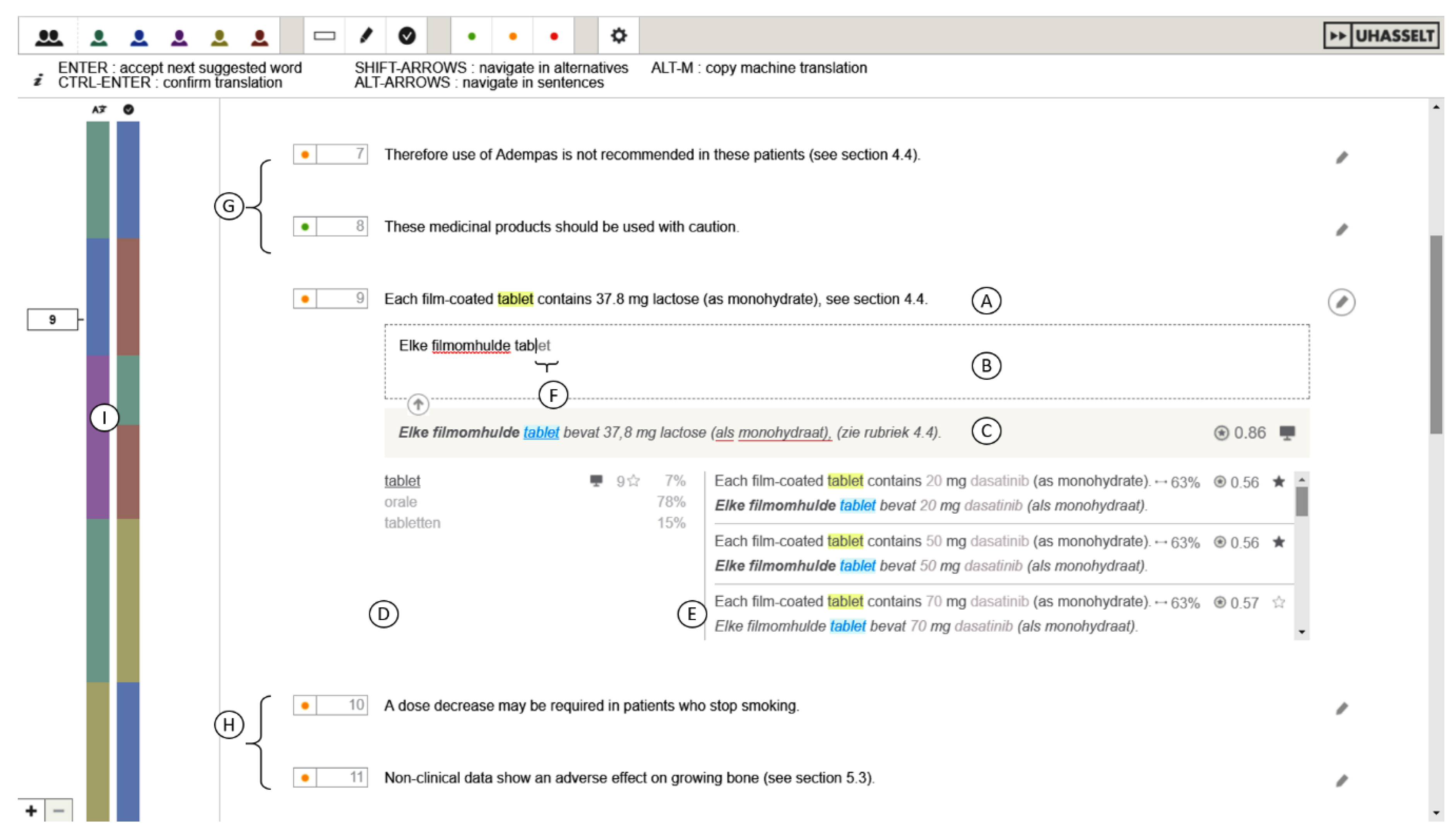
6. The SCATE Interface
6.1. Related Work
6.2. Intelligible Translation Suggestions
6.3. Evaluation
6.3.1. Influence of Visualisation on Experience and Preference
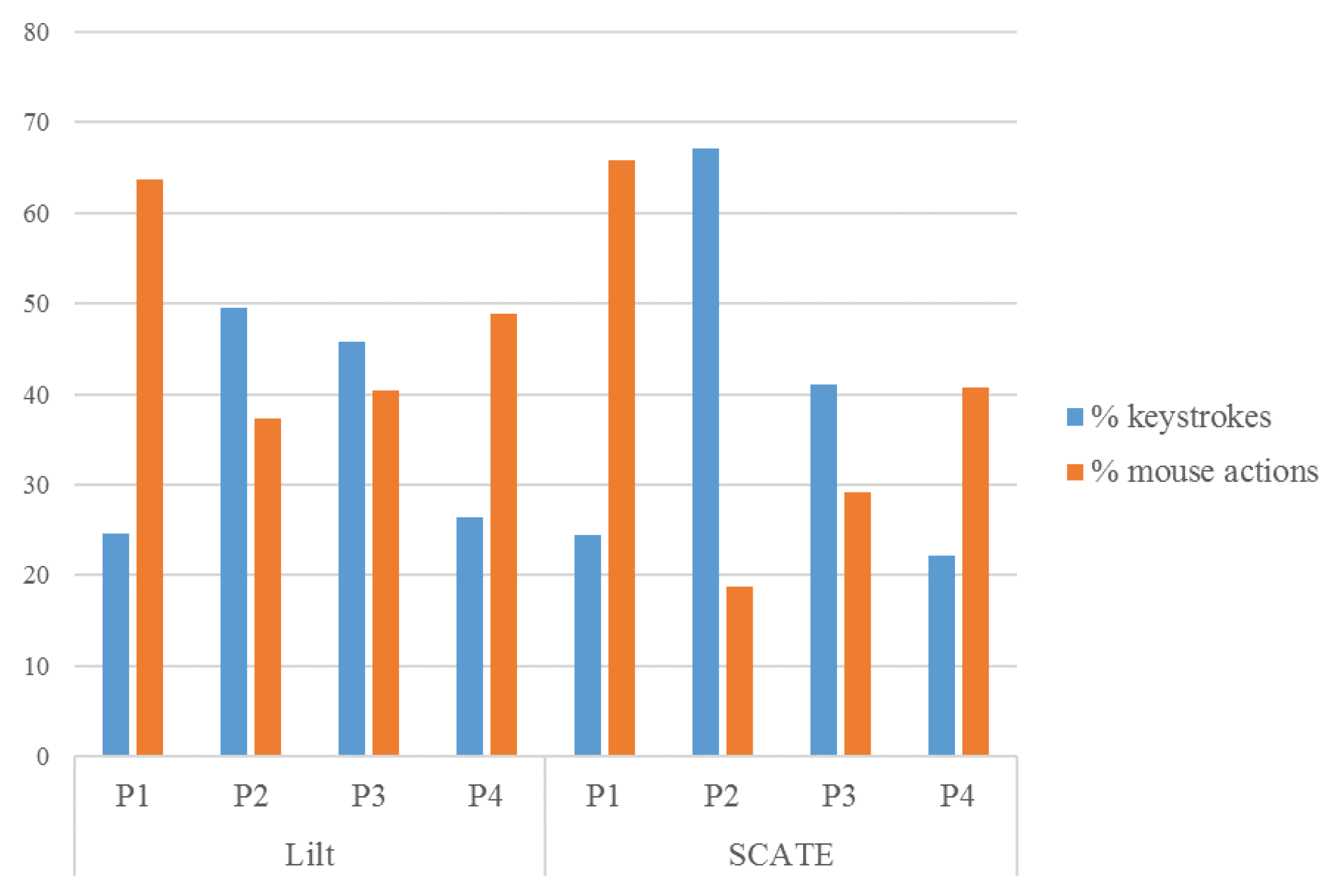
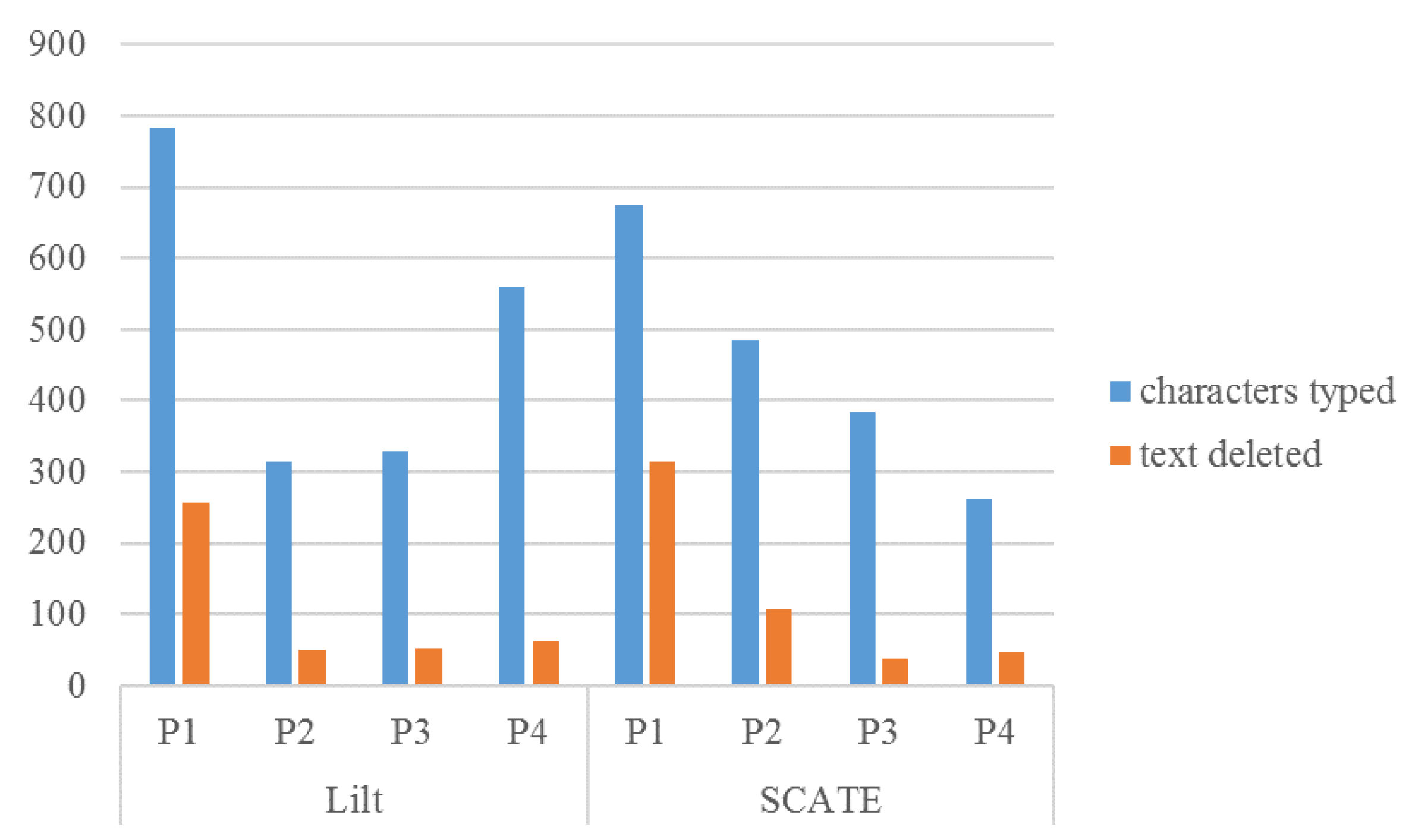
6.3.2. Comparison with Lilt
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application programming interface |
| ASR | Automated Speech Recognition |
| BiLDA | Bilingual Latent Dirichlet Allocation |
| BLEU | BiLingual Evaluation Understudy |
| BLI | Bilingiual Lexicon Induction |
| BWESG | Bilingual Word Embedding Skip Grams |
| CAT | Computer-aided Translation |
| C-BiLDA | Comparable Bilingual Latent Dirichlet Allocation |
| CBOW | Continuous Bag-of-Words |
| CLARIN | Comman Language Resources Research Infrastructure |
| DGT | Directorate General for Translation |
| DNT | Do-Not-Iranslate |
| EN | English |
| GrETEL | Greedy Extraction of Trees for Empirical Linguistics |
| GRU | Gated Recurrent Unit |
| HTER | Human-targeted Translation Edit Rate |
| IAA | Inter-Annotator Agreement |
| ITP | Interactive Translation Prediction |
| LENG | Lexical Equivalent Node Grouping |
| LM | Language Model |
| LSA | Latens Semantic Analysis |
| LSTM | Long Short-term Memory |
| METEOR | Metric for Evaluation of Translation with Explicit ORdering |
| ML | Machine Learning |
| MT | Machine Translation |
| NL | Dutch |
| NMT | Neural Machine Translation |
| OOV | Out-of-Vocabulary |
| PET | Post-Editing Time |
| PoS | Part-of-Speech |
| QE | Quality Estimation |
| RBMT | Rule-based Machine Translation |
| RNN | Recurrent Neural Network |
| SCATE | Smart Computer-Aided Translation Environment |
| SMT | Statistical Machine Translation |
| TAP | Think Aloud Protocol |
| TB | Term-Base |
| TBX | Term-Base eXchange |
| TEnT | Translation Environment |
| TER | Translation Edit Rate |
| TM | Translation Memory |
| UI | User Interface |
| VRT | Vlaamse Radio en Televisie |
| WMT | Workshop on Machine Translation |
References
- Levenshtein, V.I. Binary codes capable of correcting deletions, insertions, and reversals. Sov. Phys. Dokl. 1966, 10, 707–710. [Google Scholar]
- Snover, M.; Madnani, N.; Dorr, B.; Schwartz, R. TER-Plus: Paraphrase, semantic, and alignment enhancements to Translation Edit Rate. Mach. Transl. 2009, 23, 117–127. [Google Scholar] [CrossRef]
- Bloodgood, M.; Strauss, B. Translation Memory Retrieval Methods. In Proceedings of the 14th Conference of the European Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; pp. 202–210. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.J. BLEU: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, Philadelphia, PA, USA, 7–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Lavie, A.; Agarwal, A. Meteor: An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments. In Proceedings of the Second Workshop on Statistical Machine Translation StatMT ’07, Prague, Czech Republic, 23 June 2007; Association for Computational Linguistics: Stroudsburg, PA, USA, 2007; pp. 228–231. [Google Scholar]
- Prüfer, H. Neuer Beweis eines Satzes über Permutationen. Arch. Math. Phys. 1918, 27, 742–744. [Google Scholar]
- Vanallemeersch, T.; Vandeghinste, V. Assessing linguistically aware fuzzy matching in Translation Memories. In Proceedings of the 18th Annual Conference of the European Association for Machine Translation, Antalya, Turkey, 11–13 May 2015; pp. 153–160. [Google Scholar]
- Koehn, P.; Senellart, J. Convergence of translation memory and statistical machine translation. In Proceedings of the AMTA Workshop on MT Research and the Translation Industry, Denver, CO, USA, 4 November 2010; pp. 21–31. [Google Scholar]
- Steinberger, R.; Eisele, A.; Klocek, S.; Pilos, S.; Schlüter, P. DGT-TM: A freely available Translation Memory in 22 languages. arXiv, 2013; arXiv:1309.5226. [Google Scholar]
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R.; et al. Moses: Open Source Toolkit for Statistical Machine Translation. In Proceedings of the 45th Annual Meeting of the ACL Interactive Poster and Demonstration Sessions, Prague, Czech Republic, 25–27 June 2007; Association for Computational Linguistics: Prague, Czech Republic, 2007; pp. 177–180. [Google Scholar]
- Klein, G.; Kim, Y.; Deng, Y.; Senellart, J.; Rush, A.M. OpenNMT: Open-Source Toolkit for Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the ACL, Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar] [CrossRef]
- Bulté, B.; Vanallemeersch, T.; Vandeghinste, V. M3TRA: integrating TM and MT for professional translators. In Proceedings of the 21st Annual Conference of the European Association for Machine Translation, Alacant/Alicante, Spain, 28–30 May 2018. [Google Scholar]
- Kotzé, G.; Vandeghinste, V.; Martens, S.; Tiedemann, J. Large Aligned Treebanks for Syntax-based Machine Translation. Lang. Resour. Eval. 2016, 51, 249–282. [Google Scholar] [CrossRef]
- Koehn, P. Neural Machine Translation. arXiv, 2017; arXiv:1709.07809. [Google Scholar]
- Vandeghinste, V.; Martens, S.; Kotzé, G.; Tiedemann, J.; Van den Bogaert, J.; De Smet, K.; Van Eynde, F.; van Noord, G. Parse and Corpus-based Machine Translation. In Essential Speech and Language Technology for Dutch: Results by the STEVIN Programme; Spyns, P., Odijk, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 305–319. [Google Scholar]
- Williams, P.; Sennrich, R.; Post, M.; Koehn, P. Syntax-Based Statistical Machine Translation; Synthesis Lectures on Human Language Technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2016. [Google Scholar]
- Li, J.; Xiong, D.; Tu, Z.; Zhu, M.; Zhang, M.; Zhou, G. Modeling Source Syntax for Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 688–697. [Google Scholar]
- Eriguchi, A.; Tsuruoka, Y.; Cho, K. Learning to Parse and Translate Improves Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 2, pp. 72–78. [Google Scholar]
- Aharoni, R.; Goldberg, Y. Towards String-To-Tree Neural Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 132–140. [Google Scholar] [CrossRef]
- Nadejde, M.; Reddy, S.; Sennrich, R.; Dwojak, T.; Junczys-Dowmunt, M.; Koehn, P.; Birch, A. Predicting Target Language CCG Supertags Improves Neural Machine Translation. In Proceedings of the Second Conference on Machine Translation, Copenhagen, Denmark, 7–8 September 2017; Association for Computational Linguistics: Stroudsburg, PA, USA, 2017; pp. 68–79. [Google Scholar] [CrossRef]
- Chen, X.; Liu, C.; Song, D. Tree-to-tree Neural Networks for Program Translation, 2018. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Och, F.; Ney, H. A Systematic Comparison of Various Statistical Alignment Models. Comput. Linguist. 2003, 29, 19–51. [Google Scholar] [CrossRef]
- Macken, L. Analysis of Translational Correspondence in view of Sub-sentential Alignment. In Proceedings of the METIS-II Workshop on New Approaches to Machine Translation, Leuven, Belgium, 11 January 2007; pp. 97–105. [Google Scholar]
- Kotzé, G. Complementary Approaches to Tree Alignment: Combining Statistical and Rule-Based Methods. Ph.D. Thesis, University of Groningen, Groningen, The Netherlands, 2013. [Google Scholar]
- Tiedemann, J. Lingua-Align: An Experimental Toolbox for Automatic Tree-to-Tree Alignment. In Proceedings of the Seventh International Conference on Language Resources and Evaluation LREC, Miyazaki, Japan, 7–12 May 2010. [Google Scholar]
- Zhechev, V.; van Genabith, J. Maximising TM Performance through Sub-Tree Alignment and SMT. In Proceedings of the Ninth conference of the Association for Machine Translation in the Americas, Denver, CO, USA, 31 October–5 November 2010. [Google Scholar]
- Vanallemeersch, T. Data-driven Machine Translation using Semantic Tree Alignment. Ph.D. Thesis, KU Leuven, Leuven, Belgium, 2017. [Google Scholar]
- Augustinus, L.; Vandeghinste, V.; Vanallemeersch, T. Poly-GrETEL: Cross-Lingual Example-based Querying of Syntactic Constructions. In Proceedings of the 10th Language Resources and Evaluation Conference (LREC), Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Augustinus, L.; Vandeghinste, V.; Schuurman, I.; Van Eynde, F. GrETEL. A Tool for Example-Based Treebank Mining. In CLARIN in the Low Countries; Odijk, J., van Hessen, A., Eds.; Ubiquity Press: London, UK, 2017; Chapter 22; pp. 269–280. [Google Scholar]
- Vandeghinste, V.; Augustinus, L. Making Large Treebanks Searchable. The SoNaR case. In Challenges in the Management of Large Corpora (CMLC-2) Workshop Programme; LREC: Reykjavík, Iceland, 2014. [Google Scholar]
- Vanroy, B.; Vandeghinste, V.; Augustinus, L. Querying Large Treebanks: Benchmarking GrETEL Indexing. Comput. Linguist. Neth. J. 2017, 7, 145–166. [Google Scholar]
- Bojar, O.; Chatterjee, R.; Federmann, C.; Graham, Y.; Haddow, B.; Huck, M.; Jimeno Yepes, A.; Koehn, P.; Logacheva, V.; Monz, C.; et al. Findings of the 2016 Conference on Machine Translation. In Proceedings of the First Conference on Machine Translation (Volume 2, Shared Task Papers), Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 131–198. [Google Scholar] [CrossRef]
- Bojar, O.; Chatterjee, R.; Federmann, C.; Graham, Y.; Haddow, B.; Huang, S.; Huck, M.; Koehn, P.; Liu, Q.; Logacheva, V.; et al. Findings of the 2017 Conference on Machine Translation (WMT17). In Proceedings of the Second Conference on Machine Translation (Volume 2: Shared Task Papers), Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 169–214. [Google Scholar]
- Specia, L.; Blain, F.; Logacheva, V.; Astudillo, R.; Martins, A. Findings of the WMT 2018 Shared Task on Quality Estimation. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Brussels, Belgium, 31 October–1 November 2018; pp. 689–709. [Google Scholar]
- Tezcan, A.; Hoste, V.; Macken, L. SCATE Taxonomy and Corpus of Machine Translation Errors. In Trends in E-tools and Resources for Translators and Interpreters; Approaches to Translation Studies; Pastor, G.C., Durán-Muñoz, I., Eds.; Brill | Rodopi: Leiden, The Netherlands, 2017; Volome 45, pp. 219–244. [Google Scholar]
- Macken, L.; De Clercq, O.; Paulussen, H. Dutch Parallel Corpus: A Balanced Copyright-Cleared Parallel Corpus. Meta J. Trad./Meta Transl. J. 2011, 56, 274–390. [Google Scholar] [CrossRef]
- Tezcan, A.; Hoste, V.; Macken, L. Estimating Post-Editing Time Using a Gold-Standard Set of Machine Translation Errors. Comput. Speech Lang. 2018, 55, 120–144. [Google Scholar] [CrossRef]
- Van Noord, G. At Last Parsing is Now Operational, TALN06. Verbum Ex Machina. Actes de la 13e Conference sur le Traitement Automatique des Langues Naturelles; Leuven University Press: Leuven, Belgium, 2006; pp. 20–42. [Google Scholar]
- Martins, A.F.; Astudillo, R.F.; Hokamp, C.; Kepler, F. Unbabel’s Participation in the WMT16 Word-Level Translation Quality Estimation Shared Task. In Proceedings of the First Conference on Machine Translation, Berlin, Germany, 11–12 August 2016; Association for Computational Linguistics: Berlin, Germany, 2016; pp. 806–811. [Google Scholar]
- Tezcan, A.; Hoste, V.; Macken, L. Detecting Grammatical Errors in Machine Translation Output Using Dependency Parsing and Treebank Querying. Balt. J. Mod. Comput. 2016, 4, 203–217. [Google Scholar]
- Tezcan, A. Informative Quality Estimation of Machine Translation Output. Ph.D. Thesis, Ghent University, Ghent, Belgium, 2018. [Google Scholar]
- Chollampatt, S.; Ng, H.T. Neural Quality Estimation of Grammatical Error Correction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Specia, L.; Paetzold, G.; Scarton, C. Multi-level translation quality prediction with quest++. In Proceedings of the ACL-IJCNLP 2015 System Demonstrations, Beijing, China, 26–31 July 2015; pp. 115–120. [Google Scholar]
- Beyer, H.; Holtzblatt, K. Contextual Design: Defining Customer-Centered Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1997. [Google Scholar]
- Lewis, C. Using the “Thinking Aloud” Method in Cognitive Interface Design; Research Report; IBM TJ Watson Research Center: Cambridge, MA, USA, 1982. [Google Scholar]
- Van den Bergh, J.; Geurts, E.; Degraen, D.; Haesen, M.; van der Lek-Ciudin, I.; Coninx, K. Recommendations for Translation Environments to Improve Translators’ Workflows; Translating and the Computer 37; AsLing: London, UK, 2015. [Google Scholar]
- Steurs, F.; van der Lek-Ciudin, I. Report on Human Terminology Extraction. Deliverable D3.1; Technical Report; KU Leuven: Leuven, Belgium, 2016. [Google Scholar]
- Bowker, L. Productivity vs. Quality? A Pilot Study on the Impact of Translation Memory Systems. Localis. Focus 2005, 4, 13–20. [Google Scholar]
- LeBlanc, M. Translators on translation memory (TM). Results of an ethnographic study in three translation services and agencies. Transl. Interpret. 2013, 5, 1–13. [Google Scholar] [CrossRef]
- Delpech, E.M. Leveraging Comparable Corpora for Computer-assisted Translation. In Comparable Corpora and Computer-Assisted Translation; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2014. [Google Scholar]
- Bernardini, S.; Castagnoli, S. Corpora for translator education and translation practice. In Topics in Language Resources for Translation and Localisation; John Benjamins: Amsterdam, The Netherlands, 2008; pp. 39–55. [Google Scholar]
- Blancafort, H.; Ulrich, A.X.; Heid, U.; Tatiana, S.C.; Gornostay, T.; Claude, K.A.L.; Méchoulam, C.; Daille, B.; Sharoff, S. User-centred Views on Terminology Extraction Tools: Usage Scenarios and Integration into MT and CAT Tools. In Translation Careers and Technologies: Convergence Points for the Future (TRALOGY); INIST: Vandoeuvre-les-Nancy, France, 2011. [Google Scholar]
- De Smet, W.; Moens, M.F. Cross-Language Linking of News Stories on the Web using Interlingual Topic Modeling. In Proceedings of the CIKM 2009 Workshop on Social Web Search and Mining (SWSM@CIKM), Hong Kong, China, 2 November 2009; pp. 57–64. [Google Scholar]
- Heyman, G.; Vulić, I.; Moens, M.F. C-BiLDA Extracting Cross-lingual Topics from Non-Parallel Texts by Distinguishing Shared from Unshared Content. Data Min. Knowl. Discov. 2016, 30, 1299–1323. [Google Scholar] [CrossRef]
- Vulić, I.; Moens, M.F. Bilingual Word Embeddings from Non-Parallel Document-Aligned Data Applied to Bilingual Lexicon Induction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 2: Short Papers), Beijing, China, 26–31 July 2015; Association for Computational Linguistics: Stroudsburg, PA, USA, 2015; pp. 719–725. [Google Scholar] [CrossRef]
- Vulić, I.; De Smet, W.; Moens, M.F. Identifying Word Translations from Comparable Corpora Using Latent Topic Models. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (ACL-HLT), Portland, OR, USA, 19–24 June 2011; pp. 479–484. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Heyman, G.; Vulić, I.; Moens, M.F. Bilingual Lexicon Induction by Learning to Combine Word-Level and Character-Level Representations. In Proceedings of the EACL, Valencia, Spain, 3–7 April 2017; pp. 1085–1095. [Google Scholar]
- Heyman, G.; Vulić, I.; Moens, M.F. A Deep Learning Approach to Bilingual Lexicon Induction in the Biomedical Domain. BMC Bioinform. 2018, 19, 259. [Google Scholar] [CrossRef]
- Rigouts Terryn, A.; Hoste, V.; Lefever, E. A Gold Standard for Multilingual Automatic Term Extraction from Comparable Corpora: Term Structure and Translation Equivalents. In Proceedings of the 11th Language Resources and Evaluation Conference (LREC), Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Rodríguez, L.; Reddy, A.M.; Ros, R.C. Efficient Integration of Translation and Speech Models in Dictation Based Machine Aided Human Translation. In Proceedings of the ICASSP, Kyoto, Japan, 25–30 March 2012; pp. 4949–4952. [Google Scholar]
- Pelemans, J.; Vanallemeersch, T.; Demuynck, K.; Van hamme, H.; Wambacq, P. Efficient Language Model Adaptation for Automatic Speech Recognition of Spoken Translations. In Proceedings of the INTERSPEECH 2015, 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 2262–2266. [Google Scholar]
- Pelemans, J.; Vanallemeersch, T.; Demuynck, K.; Verwimp, L.; Van hamme, H.; Wambacq, P. Language Model Adaptation for ASR of Spoken Translations Using Phrase-based Translation Models and Named Entity Models. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2016, Shanghai, China, 20–25 March 2016; pp. 5985–5989. [Google Scholar] [CrossRef]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Pelemans, J.; Verwimp, L.; Demuynck, K.; Van hamme, H.; Wambacq, P. SCALE: A Scalable Language Engineering Toolkit. In Proceedings of the Tenth International Conference on Language Resources and Evaluation LREC 2016, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Verwimp, L.; Pelemans, J.; Van hamme, H.; Wambacq, P. Character-Word LSTM Language Models. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Volume 1: Long Papers, EACL 2017, Valencia, Spain, 3–7 April 2017; pp. 417–427. [Google Scholar]
- Verwimp, L.; Van hamme, H.; Wambacq, P. TF-LM: TensorFlow-based Language Modeling Toolkit. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, LREC 2018, Miyazaki, Japan, 7–12 May 2018. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Boes, W.; Van Rompaey, R.; Verwimp, L.; Van hamme, H.; Wambacq, P. Domain Adaptation for LSTM Language Models; Computational Linguistics in the Netherlands: Leuven, Belgium, 2017. [Google Scholar]
- Grave, E.; Joulin, A.; Usunier, N. Improving Neural Language Models with a Continuous Cache. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Kuhn, R.; Mori, R.D. A Cache-Based Natural Language Model for Speech Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 570–583. [Google Scholar] [CrossRef]
- Verwimp, L.; Pelemans, J.; Van hamme, H.; Wambacq, P. Information-Weighted Neural Cache Language Models for ASR. In Proceedings of the IEEE Workshop on Spoken Language Technology (SLT), Athens, Greece, 18–21 December 2018. [Google Scholar]
- Matusov, E.; Mauser, A.; Ney, H. Automatic Sentence Segmentation and Punctuation Prediction for Spoken Language Translation. In Proceedings of the 2006 International Workshop on Spoken Language Translation, IWSLT 2006, Keihanna Science City, Kyoto, Japan, 27–28 November 2006; pp. 158–165. [Google Scholar]
- Peitz, S.; Freitag, M.; Mauser, A.; Ney, H. Modeling Punctuation Prediction as Machine Translation. In Proceedings of the IWSLT, San Francisco, CA, USA, 8–9 December 2011; pp. 238–245. [Google Scholar]
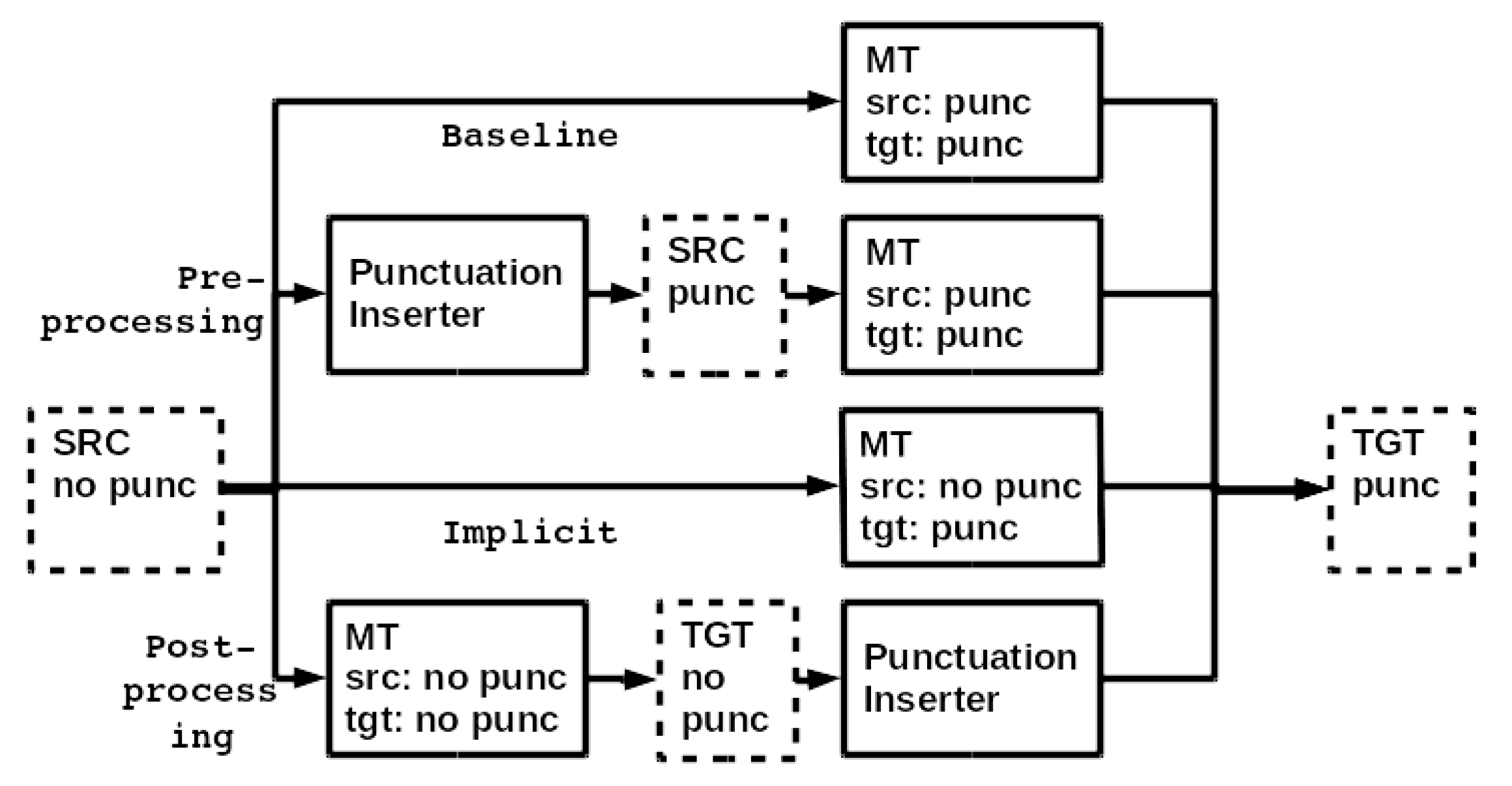
- Vandeghinste, V.; Verwimp, L.; Pelemans, J.; Wambacq, P. A Comparison of Different Punctuation Prediction Approaches in a Translation Context. In Proceedings of the Annual Conference of the European Association for Machine Translation EAMT, Alicante, Spain, 28–30 May 2018. [Google Scholar]
- Lagoudaki, E. Translation Memories Survey 2006. User’s perceptions around TM use. In Translation and the Computer; ASLIB: London, UK, 2006; Volume 28, pp. 1–29. [Google Scholar]
- O’Brien, S.; O’Hagan, M.; Flanagan, M. Keeping an eye on the UI design of Translation Memory: How do translators use the “Concordance” feature ? In Proceedings of the 28th Annual Conference of the European Association of Cognitive Ergonomics, Delft, The Netherlands, 25–27 August 2010; pp. 187–190. [Google Scholar]
- Moorkens, J.; O’Brien, S. Assessing User Interface Needs of Post-Editors of Machine Translation. Hum. Issues Transl. Technol. 2017, 109–130. [Google Scholar]
- Teixeira, C.S.C.; Moorkens, J.; Turner, D.; Vreeke, J.; Way, A. Creating a Multimodal Translation Tool and Testing Machine Translation Integration Using Touch and Voice. Informatics 2019, 6, 13. [Google Scholar] [CrossRef]
- Pal, S.; Naskar, S.K.; Zampieri, M.; Nayak, T.; van Genabith, J. CATaLog Online: A Web-based CAT Tool for Distributed Translation with Data Capture for APE and Translation Process Research. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: System Demonstrations, Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 98–102. [Google Scholar]
- Herbig, N.; Pal, S.; van Genabith, J.; Krüger, A. Multi-Modal Approaches for Post-Editing Machine Translation. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems CHI’19, Glasgow, UK, 4–9 May 2019; ACM: New York, NY, USA, 2019; pp. 231:1–231:11. [Google Scholar] [CrossRef]
- Nayak, T.; Pal, S.; Naskar, S.K.; Bandyopadhyay, S.; van Genabith, J. Beyond Translation Memories: Generating Translation Suggestions based on Parsing and POS Tagging. In Proceedings of the 2nd Workshop on Natural Language Processing for Translation Memories (NLP4TM-2016), Portoroz, Slovenia, 28 May 2016. [Google Scholar]
- Orasan, C.; Parra, C.; Barbu, E.; Federico, M. (Eds.) 2nd Workshop on Natural Language Processing for Translation Memories (NLP4TM 2016); ELRA: Portoroz, Slovenia, 2016. [Google Scholar]
- Koehn, P.; Haddow, B. Interactive Assistance to Human Translators using Statistical Machine Translation methods. In Proceedings of the MT Summit XII, Ottawa, ON, Canada, 26–30 August 2009; pp. 1–8. [Google Scholar]
- Sanchis-Trilles, G.; Alabau, V.; Buck, C.; Carl, M.; Casacuberta, F.; García-Martínez, M.; Germann, U.; González-Rubio, J.; Hill, R.L.; Koehn, P.; et al. Interactive translation prediction versus conventional post-editing in practice: A study with the CasMaCat workbench. Mach. Transl. 2014, 217–235. [Google Scholar] [CrossRef]
- Torregrosa Rivero, D.; Pérez-Ortiz, J.A.; Forcada, M.L. Comparative Human and Automatic Evaluation of Glass-Box and Black-Box Approaches to Interactive Translation Prediction. Prague Bull. Math. Linguist. 2017, 108, 97–108. [Google Scholar] [CrossRef][Green Version]
- Green, S.; Wang, S.I.; Chuang, J.; Heer, J.; Schuster, S.; Manning, C.D. Human Effort and Machine Learnability in Computer Aided Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Doha, Qatar, 2014; pp. 1225–1236. [Google Scholar] [CrossRef]
- Zaretskaya, A. The Use of Machine Translation among Professional Translators. In Proceedings of the EXPERT Scientific and Technological Workshop, Malaga, Spain, 26–17 June 2015; pp. 1–12. [Google Scholar]
- Teixeira, C. The Impact of Metadata on Translator Performance: How Translators Work With Translation Memories and Machine Translation. Ph.D. Thesis, Universitat Rovira i Virgili and Katholieke Universiteit Leuven, Leuven, Belgium, 2014. [Google Scholar]
- Vieira, L.N.; Specia, L. A Review of Translation Tools from a Post-Editing Perspective. In Proceedings of the 3rd Joint EM+/CNGL Workshop Bringing MT to the User: Research Meets Translators (JEC), Luxembourg, 14 October 2011; pp. 33–42. [Google Scholar]
- Coppers, S.; Van den Bergh, J.; Luyten, K.; Coninx, K.; van der Lek-Ciudin, I.; Vanallemeersch, T.; Vandeghinste, V. Intellingo: An Intelligible Translation Environment. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; ACM: New York, NY, USA, 2018. CHI ’18. pp. 524:1–524:3. [Google Scholar] [CrossRef]
- Green, S.; Heer, J.; Manning, C.D. The Efficacy of Human Post-Editing for Language Translation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; ACM: New York, NY, USA, 2013; pp. 439–448. [Google Scholar]
- Sinha, R.; Swearingen, K. The Role of Transparency in Recommender Systems. In Proceedings of the Extended Abstracts on Human Factors in Computing Systems CHI EA ’02, Minneapolis, MN, USA, 20–25 April 2002; ACM: New York, NY, USA, 2002; pp. 830–831. [Google Scholar] [CrossRef]
- Bellotti, V.; Edwards, K. Intelligibility and Accountability: Human Considerations in Context-Aware Systems. Hum.-Comput. Interact. 2001, 16, 193–212. [Google Scholar] [CrossRef]
- Green, S.; Chuang, J.; Heer, J.; Manning, C.D. Predictive Translation Memory: A Mixed-Initiative System for Human Language Translation. In Proceedings of the 27th annual ACM symposium on User Interface Software and Technology, Honolulu, HI, USA, 5–8 October 2014; ACM: New York, NY, USA, 2014; pp. 177–187. [Google Scholar]
- Tiedemann, J. News from OPUS—A Collection of Multilingual Parallel Corpora with Tools and Interfaces. In Recent Advances in Natural Language Processing; Nicolov, N., Bontcheva, K., Angelova, G., Mitkov, R., Eds.; John Benjamins: Amsterdam, The Netherlands, 2009; Volume V, pp. 237–248. [Google Scholar]
- Leijten, M.; Van Waes, L. Keystroke Logging in Writing Research: Using Inputlog to Analyze and Visualize Writing Processes. Writ. Commun. 2013, 30, 358–392. [Google Scholar] [CrossRef]
- Asadi, P.; Séguinot, C. Shortcuts, Strategies and General Patterns in a Process Study of Nine Professionals. Meta 2005, 50, 522–547. [Google Scholar] [CrossRef]
- Koehn, P. A process study of computer-aided translation. Mach. Transl. 2009, 23, 241–264. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System | Precision | Recall | F-Score |
|---|---|---|---|
| SubTree Aligner [26] | 69.30 | 71.55 | 70.40 |
| Lingua-Align [25] | 79.29 | 88.78 | 83.77 |
| LENG | 83.48 | 89.96 | 86.60 |
| Participant | Environment | Text | Total Time | |
|---|---|---|---|---|
| P1 | Exp1 | Lilt | Text1 | 23 |
| Exp2 | SCATE | Text2 | 19 | |
| P2 | Exp1 | Lilt | Text2 | 17 |
| Exp2 | SCATE | Text1 | 14 | |
| P3 | Exp1 | SCATE | Text1 | 19 |
| Exp2 | Lilt | Text2 | 15 | |
| P4 | Exp1 | SCATE | Text2 | 19 |
| Exp2 | Lilt | Text1 | 27 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vandeghinste, V.; Vanallemeersch, T.; Augustinus, L.; Bulté, B.; Van Eynde, F.; Pelemans, J.; Verwimp, L.; Wambacq, P.; Heyman, G.; Moens, M.-F.; et al. Improving the Translation Environment for Professional Translators. Informatics 2019, 6, 24. https://doi.org/10.3390/informatics6020024
Vandeghinste V, Vanallemeersch T, Augustinus L, Bulté B, Van Eynde F, Pelemans J, Verwimp L, Wambacq P, Heyman G, Moens M-F, et al. Improving the Translation Environment for Professional Translators. Informatics. 2019; 6(2):24. https://doi.org/10.3390/informatics6020024
Chicago/Turabian StyleVandeghinste, Vincent, Tom Vanallemeersch, Liesbeth Augustinus, Bram Bulté, Frank Van Eynde, Joris Pelemans, Lyan Verwimp, Patrick Wambacq, Geert Heyman, Marie-Francine Moens, and et al. 2019. "Improving the Translation Environment for Professional Translators" Informatics 6, no. 2: 24. https://doi.org/10.3390/informatics6020024
APA StyleVandeghinste, V., Vanallemeersch, T., Augustinus, L., Bulté, B., Van Eynde, F., Pelemans, J., Verwimp, L., Wambacq, P., Heyman, G., Moens, M.-F., van der Lek-Ciudin, I., Steurs, F., Rigouts Terryn, A., Lefever, E., Tezcan, A., Macken, L., Hoste, V., Daems, J., Buysschaert, J., ... Luyten, K. (2019). Improving the Translation Environment for Professional Translators. Informatics, 6(2), 24. https://doi.org/10.3390/informatics6020024