1. Introduction
The large volumes of data generated in online social networks (SNs), such as Facebook [
1] and Twitter [
2], used by millions of people every day, have created information overload for the application users, necessitating the use of personalization techniques, to limit, as well as prioritize the information presented to them, according to its perceived value. Researchers seek methods to exploit these data for personalization purposes [
3,
4,
5]; these data are deemed of high value in the context of personalization, because of the importance and the intrinsic relationship with people’s everyday lives. However, due to the high volume of SN-generated data, identifying the data relevant to each individual user, which are highly useful to support personalized queries, still remains a challenge. A considerable part of personalized information is delivered in the form of recommendations, including suggestions of pages to view, items to buy, people to connect to, and so forth.
For the creation of these recommendations, SNs employ techniques and algorithms from the field of recommender systems (RSs). As far as RSs are concerned, research has shown that the collaborative filtering (CF)-based recommendation approach is the most successful and widely used approach for implementing RSs [
6]. CF formulates personalized recommendations on the basis of ratings expressed by people having similar tastes to the user for whom the recommendation is generated; taste similarity is computed by examining the resemblance of already entered ratings [
6]. CF works on the assumption that if users have similar tastes regarding choosing an item in the past then they are likely to have similar interests in the future too. Typically, for each user, a set of “nearest neighbor” users is found, i.e., those users that display the strongest correlation to the target user. Scores for unseen items are predicted based on a combination of the scores given from the nearest neighbors [
7]. The biggest advantage of CF is that explicit content description is not required (as in content-based systems): instead, traditional CF relies only on opinions expressed by users on items either explicitly (e.g., a user enters a rating for the item) or implicitly (e.g., a user purchases an item, which indicates a positive assessment).
Although traditional RSs assume that users are independent and do not take into account important social aspects that denote interaction among users, current research [
4,
8,
9] enhances recommendation quality, by incorporating SN information such as tie strength [
3,
10], that quantifies the projected influence of one user to another, along with static data from the user profile, such as location, age or gender, during the recommendation process. However, within the recommendation process, most typical RSs, as well as SN RSs, assume that the rating time is not relevant and ignore how old each user-item rating is. Rating age can be exploited to substantially enhance recommendation quality, due to phenomena such as shift of interest [
11,
12] and concept drift [
13]. Concept drift occurs when the concept about which data is being collected shifts from time to time after a minimum stability period [
14]. Such changes are reflected in incoming instances and deteriorate the accuracy of classifiers learned from past training tuples. Examples of real life concept drifts include spam categorization, weather predictions, monitoring systems, financial fraud detection, and evolving customer preferences [
15].
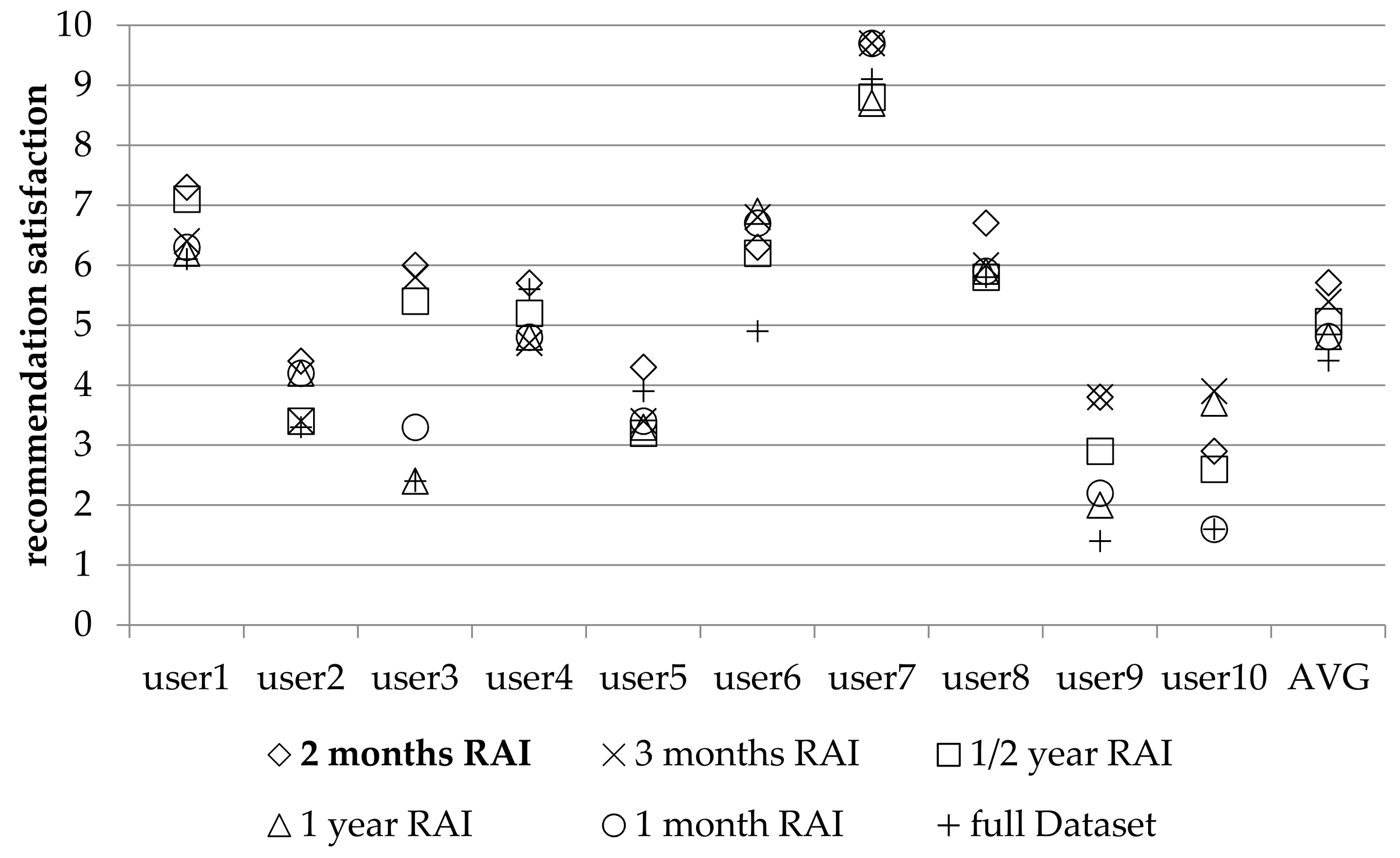
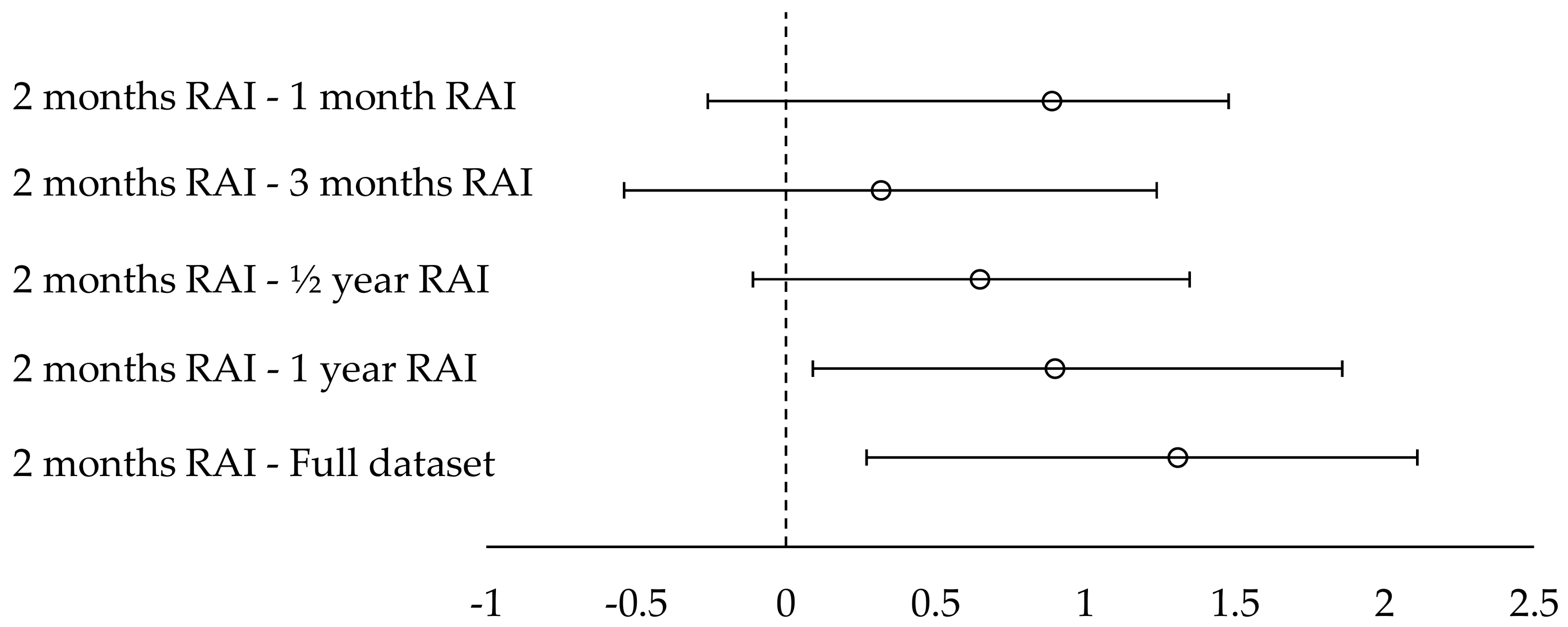
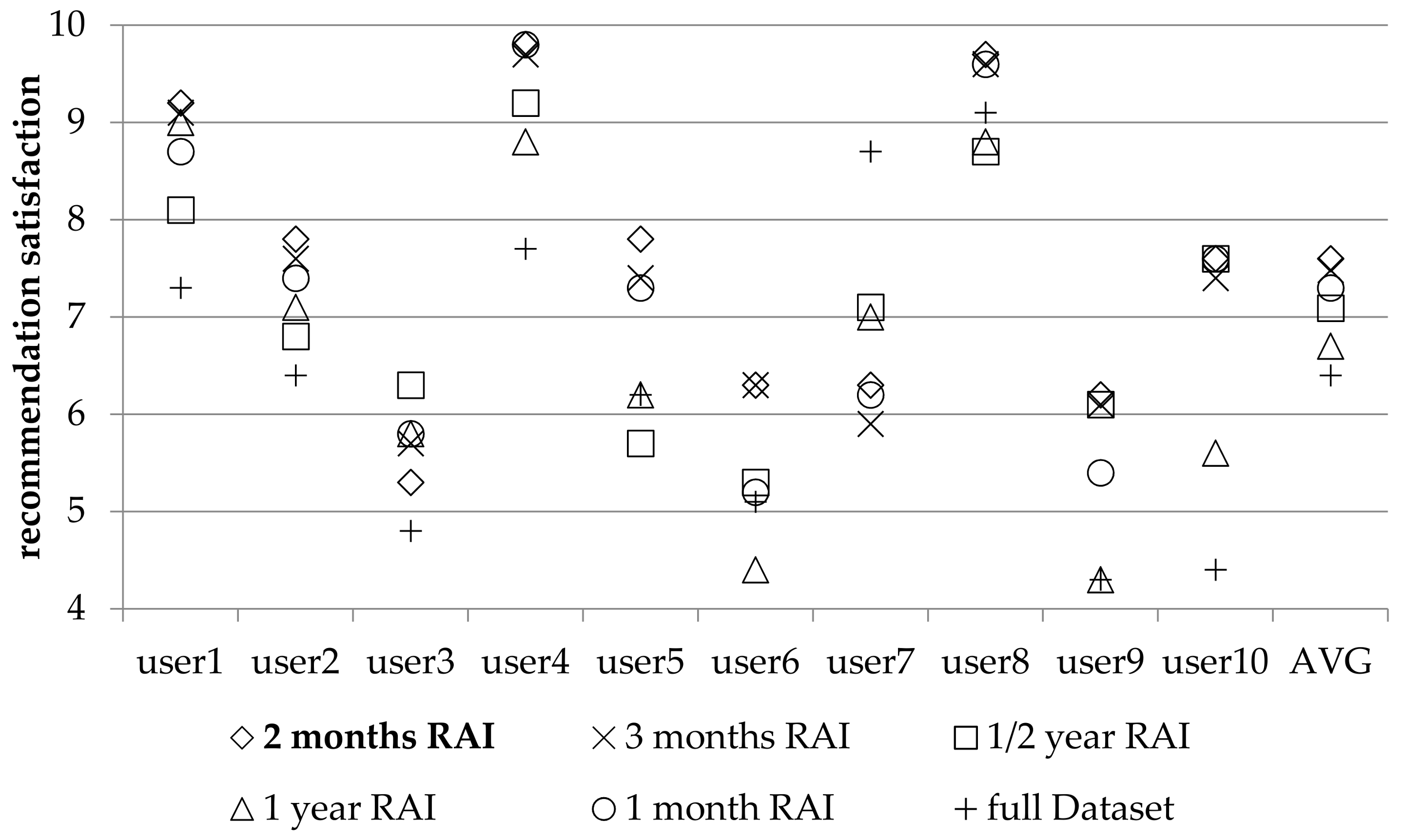
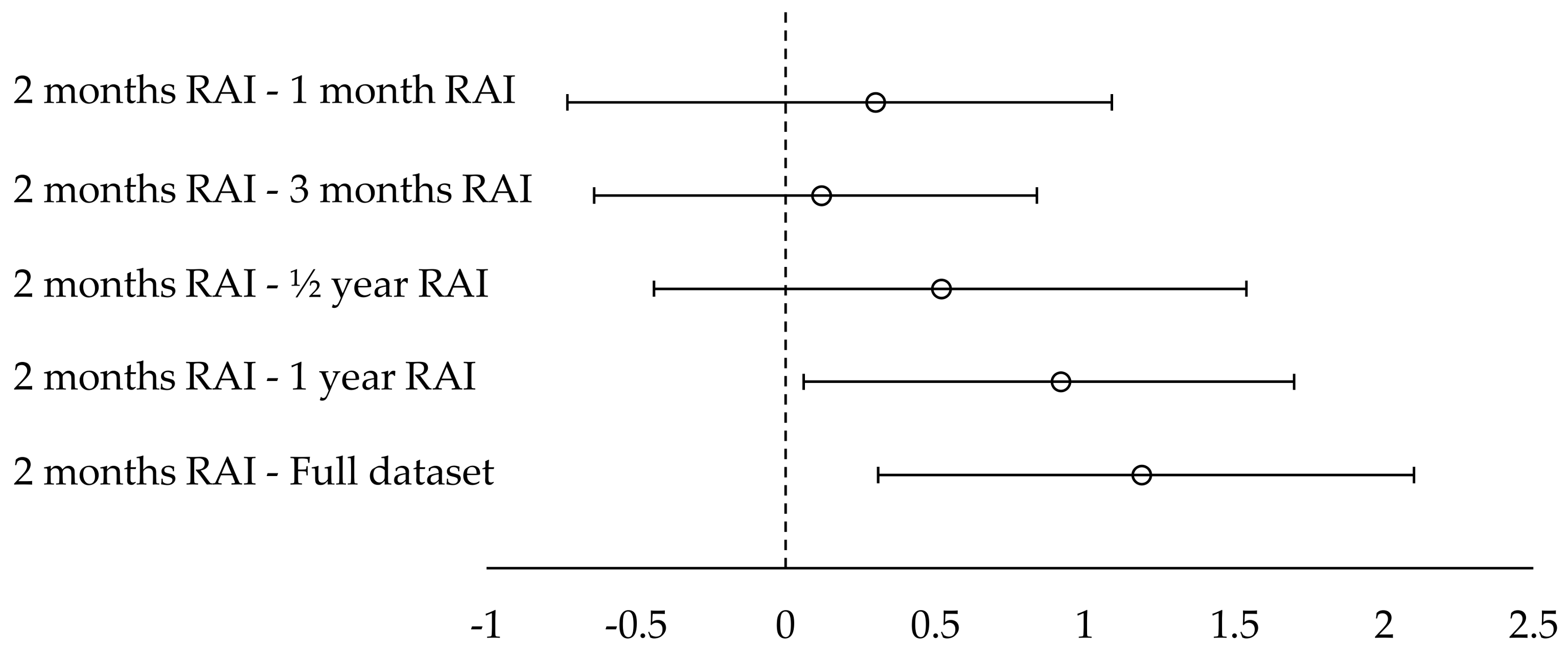
In this paper, we contribute to the state-of-the-art of SN RSs by: (1) establishing that when a user abstains from submitting ratings for a long time, it is a strong indication that concept drift has occurred and (2) presenting a technique, that exploits the abstention interval concept, to drop ratings from the database, under the rationale that these ratings correspond to user preferences and likings that are not valid anymore, due to the concept drift and shift of interest phenomena. By dropping these ratings, database consistency is promoted and prediction quality is improved. The proposed technique (1) can be exploited in the context of SNs, to offer more accurate and successful recommendations to SN users and (2) is evaluated in both real SN users’ satisfaction, as well as against widely used RSs’ datasets with diverse characteristics, and in both SN metrics and traditional RSs metrics. Furthermore, the proposed technique can operate without any extra information concerning the items’ to be recommended characteristics (e.g., categories that they belong to or attributes’ values, e.g., price, availability, etc.), can be used in all rating databases that include a timestamp, as a preprocessing step, and has been shown to be effective in any size and type of users-items database. However, where item categories are available, the algorithm can take them into account to further improve recommendation quality.
The rest of the paper is structured as follows:
Section 2 overviews related work, while
Section 3 presents the proposed technique.
Section 4 evaluates the proposed technique, both in terms of user satisfaction and by evaluating it against real RSs’ datasets, and discusses its results, and finally,
Section 5 concludes the paper and outlines future work.
2. Literature Review
Bakshy et al. [
16] examine the role of SNs in the recommendation process within a field experiment that randomizes exposure to signals about friends’ information and the relative role of strong and weak ties. In [
3], Bakshy et al. demonstrate the substantial consequences of including minimal social cues in advertising and measure the positive relationship between a consumer’s response and the strength of his connection with an affiliated peer. Moreover, ref. [
3] provides an influence metric between two SN users in an interest category C; this metric is termed influence level and is denoted as IL(C). Both these works establish that recommendation algorithms are valuable tools in SN, and examine social cues and other methods to increase the probability that a recommendation is adopted. Oechslein and Hess [
17] also assert that a strong tie relationship has positive influence on the value of a recommendation.
In [
9], Margaris et al. present an algorithm for ordering query results when SN users execute queries, taking into account the behavior of users in the past, as well as the influencing factors between SN users. Furthermore, Margaris et al. [
9] assert that for each SN user, only his/her 30 strongest influencers need to be computed in order to produce reliable and successful recommendations. Margaris et al. [
8] present an algorithm for fostering information diffusion in SNs through the generation of appropriate recommendations. The method proposed therein takes into account two perspectives for identifying items that are more likely to be of interest to each particular user: (a) qualitative aspects of the recommended items, such as price and reliability, which are matched against the buying and viewing habits of each user within the relevant product category and (b) the actions and likings of the user’s social neighborhood, as well as the influence level of each one of the user’s social neighbors on the particular user. When an item is deemed interesting by a user’s social neighborhood, but its qualitative aspects significantly differ from the user’s preferences within the particular item category, semantic similarity is employed to identify items that are similar to the original item and at the same time close to the user’s preferences on qualitative aspects. Furthermore, Margaris et al. [
8] show that more reliable and successful recommendations can be produced when utilizing distinct sets of influencers per interest category, instead of using a single set of influencers for every recommendation to be made. The same conclusion is reached by Margaris et al. [
4]: in this work, a novel algorithm for making accurate knowledge-based leisure time recommendations to social media users is presented. The proposed algorithm considers qualitative attributes of the places (e.g., price, service, atmosphere), the profile and habits of the user for whom the recommendation is generated, place similarity, the physical distance of locations within which places are located, and the opinions of the user’s influencers. Regarding the number of influencers within a category that need to be considered for formulating recommendations, Margaris et al. [
8] establish that for each SN user, only his/her eight strongest influencers per category need to be used.
Trust-based RSs take an alternative approach for considering the ties between users of SNs: under this approach, the trust level between users is computed and exploited, instead of the influence level. In this context, Gulcin and Polat [
18] present a comparative review of RSs, trust/reputation systems, and their combined usage. Then, a sample trust based agent oriented RS is proposed and its effectiveness is justified with the help of some experiments. Fotia et al. [
19] demonstrate, by an extended set of experiments on datasets extracted from real communities, that trust measures can effectively replace profile matching in order to optimize group’s cohesion and that it is also possible to replace the global trust measure with a local measure of trust, called local reputation, which is not highly sensitive to the size of the network, thus allowing to perform computations which are limited on the size of the ego-network of the single node. Martinez-Cruz et al. [
20] develop an ontology to characterize the trust between users using the fuzzy linguistic modeling, so that in the recommendation generation process they do not take into account users with similar ratings history, but users in which each user can trust. They present their ontology and provide a method to aggregate the trust information captured in the trust-ontology and to update the user profiles based on the feedback. Walter et al. [
21] present a model of a trust-based RS on a SN, where agents use their SN to reach information and their trust relationships to filter it. They investigate how the dynamics of trust among agents affect the performance of the system by comparing it to a frequency-based RS. Furthermore, they identify the impact of network density, preference heterogeneity among agents, and knowledge sparseness to be crucial factors for the performance of the system. Finally, O’Donovan and Smyth [
22] suggest that the traditional emphasis on user similarity may be overstated and they argue that additional factors have an important role to play in guiding recommendation. Specifically they propose that the trustworthiness of users must be an important consideration. Furthermore, they present two computational models of trust and show how they can be readily incorporated into standard CF frameworks in a variety of ways. They also show how these trust models can lead to improved predictive accuracy during recommendation.
Bedi et al. [
23] accommodate trust into a more comprehensive semantic structure, proposing the design of a RS that uses knowledge stored in the form of ontologies. The interactions amongst the peer agents for generating recommendations are based on the trust network that exists between them. Recommendations about a product given by peer agents are in the form of Intuitionistic Fuzzy Sets specified using degree of membership, non-membership and uncertainty. The presented design uses ontologies, a knowledge representation technique for creating annotated content for Semantic Web. The presented RS uses temporal ontologies that absorb the effect of changes in the ontologies due to the dynamic nature of domains, in addition to the benefits of ontologies. Semantic information is also utilized by Rosaci [
24]; this work focuses on the importance of taking into account semantic information, and proposes an approach for finding semantic associations which would not emerge without considering the structure of the data groups. His approach is based on the introduction of a new metadata model, which is an extension of the direct, labeled graph allowing the possibility to have nodes with a hierarchical structure. Semantics are also used by Rivera et al. [
25], who propose a method capable to use the users’ preferences, like points of interests (POIs) and activities that users want to realize during their vacations. Moreover, some weighted features such as the max distance that users want to walk between POIs, and opinions of other users, coming from the web 2.0 by means of social media are taken into account.
Besides semantics and SN dynamics, some works on RSs consider the overall context of the recommendation, in order to formulate the set of items that will be proposed to the user. Adomavicius and Tuzhilin [
26] examine how context can be defined and used in RSs in order to create more intelligent and useful recommendations. Furthermore, they present how to defining context in RSs and discuss different paradigms of incorporating it into the recommendation process. Additionally, Liu and Aberer [
27] present SoCo, a novel context-aware RS incorporating elaborately processed SN information. It handles contextual information by applying random decision trees to partition the original user-item-rating matrix, such that the ratings with similar contexts are grouped. Matrix factorization is then employed to predict missing preference of a user for an item using the partitioned matrix. In order to incorporate SN information, they introduce an additional social regularization term to the matrix factorization objective function to infer a user’s preference for an item by learning opinions from his/her friends who are expected to share similar tastes. Furthermore, a context-aware version of the Pearson Correlation Coefficient is proposed to measure user similarity.
In the domain of RSs, Tsymbal [
28] recognizes two kinds of concept drift that may occur in the real world, sudden (also known as abrupt or instantaneous), and gradual concept drift. For example, someone graduating from college might suddenly have completely different monetary concerns, whereas a slowly wearing piece of factory equipment might cause a gradual change in the quality of output parts. Stanley [
29] further divides gradual drift into moderate and slow drifts, depending on the rate of the changes, while Gama et al. [
13] extend the patterns of changes over time by adding incremental concept drift (consisting of many intermediate concepts in between, e.g., a person becomes increasingly interested in history documentaries, losing interest in science fiction movies) and reoccuring concepts (when new concepts that were not seen before, or previously seen concepts may reoccur after some time).
The issue of dealing with concept drifts has lately received considerable research attention. Brzezinski and Stefanowski [
30] focus on the topic of adaptive ensembles which generate component classifiers sequentially from fixed size blocks of training examples called data chunks and propose a new data stream classifier, called the Accuracy Updated Ensemble (AUE2), which aims at reacting equally well to different types of drift. AUE2 combines accuracy-based weighting mechanisms known from block-based ensembles (in such ensembles, when a new block arrives, existing component classifiers are evaluated and their combination weights are updated) with the incremental nature of Hoeffding Trees. Ning et al. [
31] present a novel method for detecting concept drift in a case-based reasoning system. They introduce a new competence model that detects differences through changes in competence. Their competence-based concept detection method requires no prior knowledge of case distribution and provides statistical guarantees on the reliability of the changes detected, as well as meaningful descriptions and quantification of these changes. Liu et al. [
32] propose a novel concept drift detection method, which is called Anomaly Analysis Drift Detection (AADD), to improve the performance of machine learning algorithms under non-stationary environment. The proposed AADD method is based on an anomaly analysis of learner’s accuracy associated with the similarity between learners’ training domain and test data. Shao et al. [
33] propose a prototype-based learning method to mine evolving data streams.
To dynamically identify prototypical examples, error-driven representativeness learning is used to compute the representativeness of examples over time. Noisy examples with low representativeness are discarded, and representative examples can be further summarized by a smaller set of prototypes using synchronization-inspired constrained clustering. Margaris and Vassilakis [
34] explore the use of a pruning algorithm, maintaining the last N ratings of each user, for achieving better prediction accuracy, while Margaris and Vassilakis [
35] present an algorithm, namely k
early-N%, for pruning user histories in rating prediction systems, which increases the rating database (ratings DB) consistency and consequently prediction quality, since it achieves to prune old “noisy” ratings. Both of these works show that pruning can achieve improved prediction accuracy, while achieving considerable database size gains and decrease prediction computation time. However, none of the above mentioned works exploits users’ rating abstention interval in both RSs’ datasets, as well as SN RSs, as a trigger in order to recognize and deal with occurrences of concept drift.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
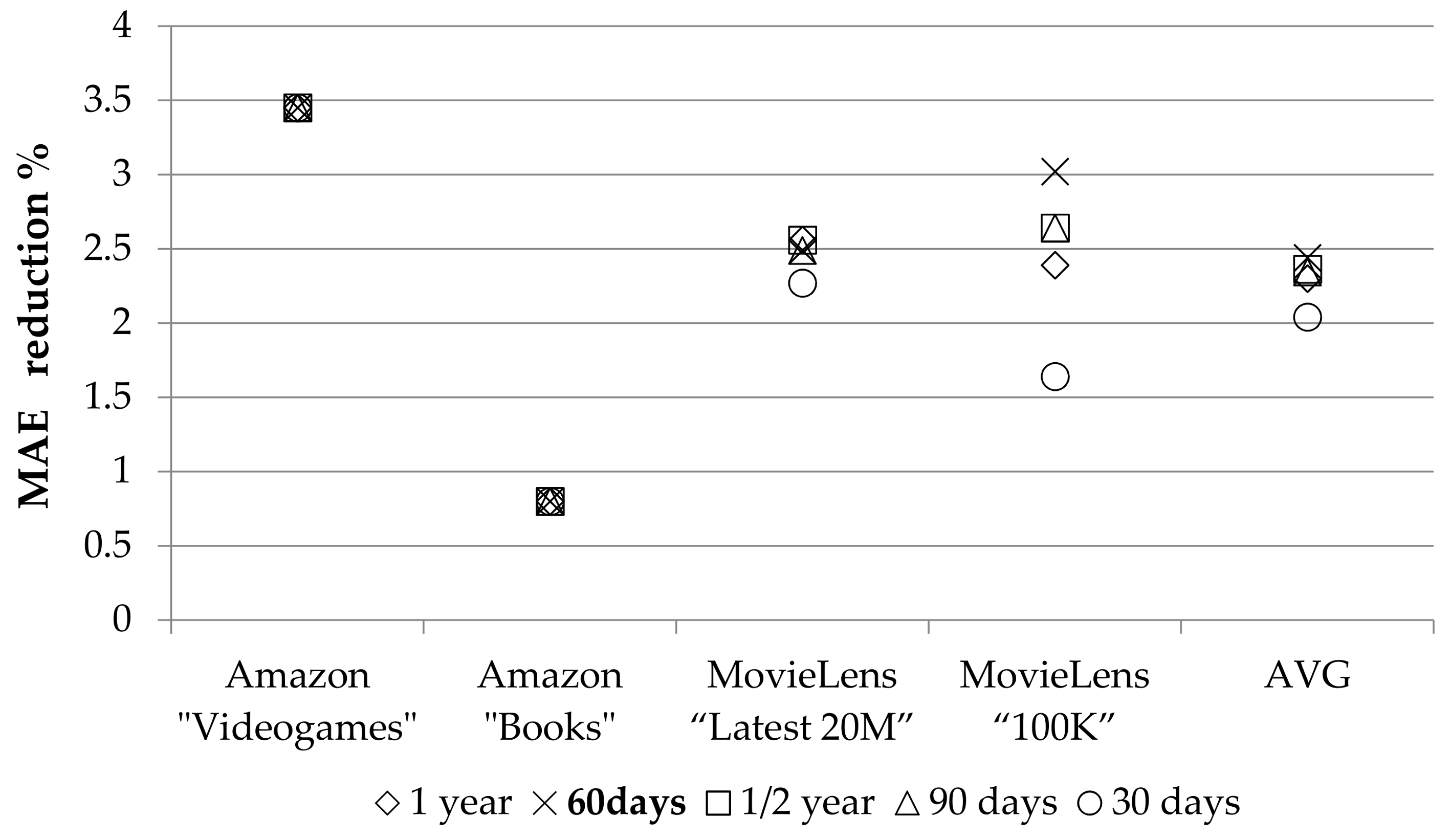{kind=link}