Recognition of Physical Activities from a Single Arm-Worn Accelerometer: A Multiway Approach

 ,
,
Abstract
:1. Introduction
2. Materials and Methods
2.1. Data
- The first session, consisting of 28 patients, is recorded with a bi-axial accelerometer (Sensewear Pro 3 Armband, Bodymedia Inc., Pittsburgh, PA, USA). The remaining 11 subjects were equipped with the tri-axial Shimmer3 (Shimmer, Dublin, Ireland) since the Sensewear sensor had been discontinued. Two Shimmer axes were selected to correspond to the Sensewear setup. The remaining axis was left out.
- In the second recording, only four out of six selected activities were performed, lieDown and maxReach were not present. Nevertheless, all six activities are included in the study to allow for a wider variability. Table 1 indicates the number of patients that performed the activity in its last column.
2.2. Data Representation
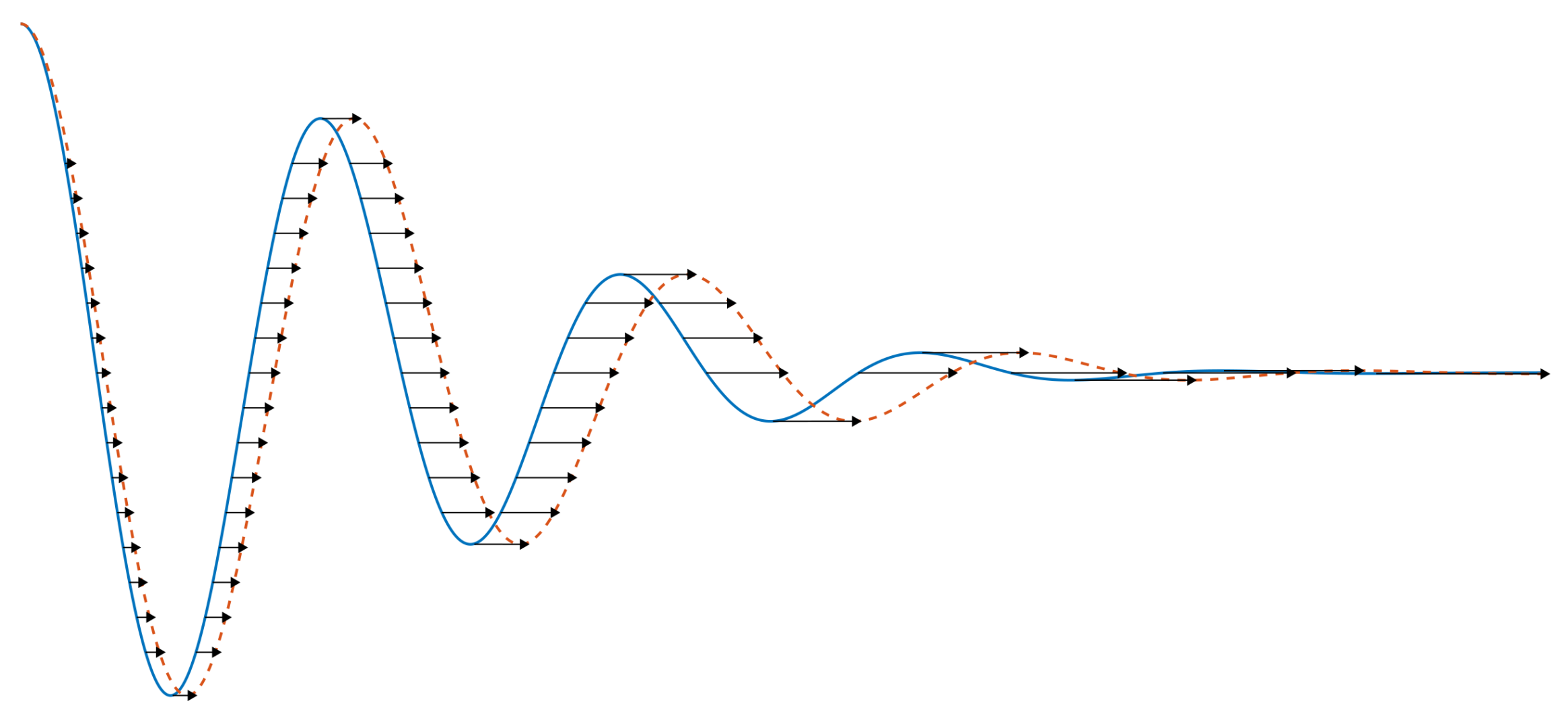
2.2.1. Pattern Definition with Dynamic Time Warping (DTW)
2.2.2. Simple Pattern Features
- Match the segment to an activity pattern using DTW. This is a simple match between the two-channel segment and a two-channel pattern. Its result is a two-channel deformed segment and a distance score.
- Repeat the first step for all activity patterns.
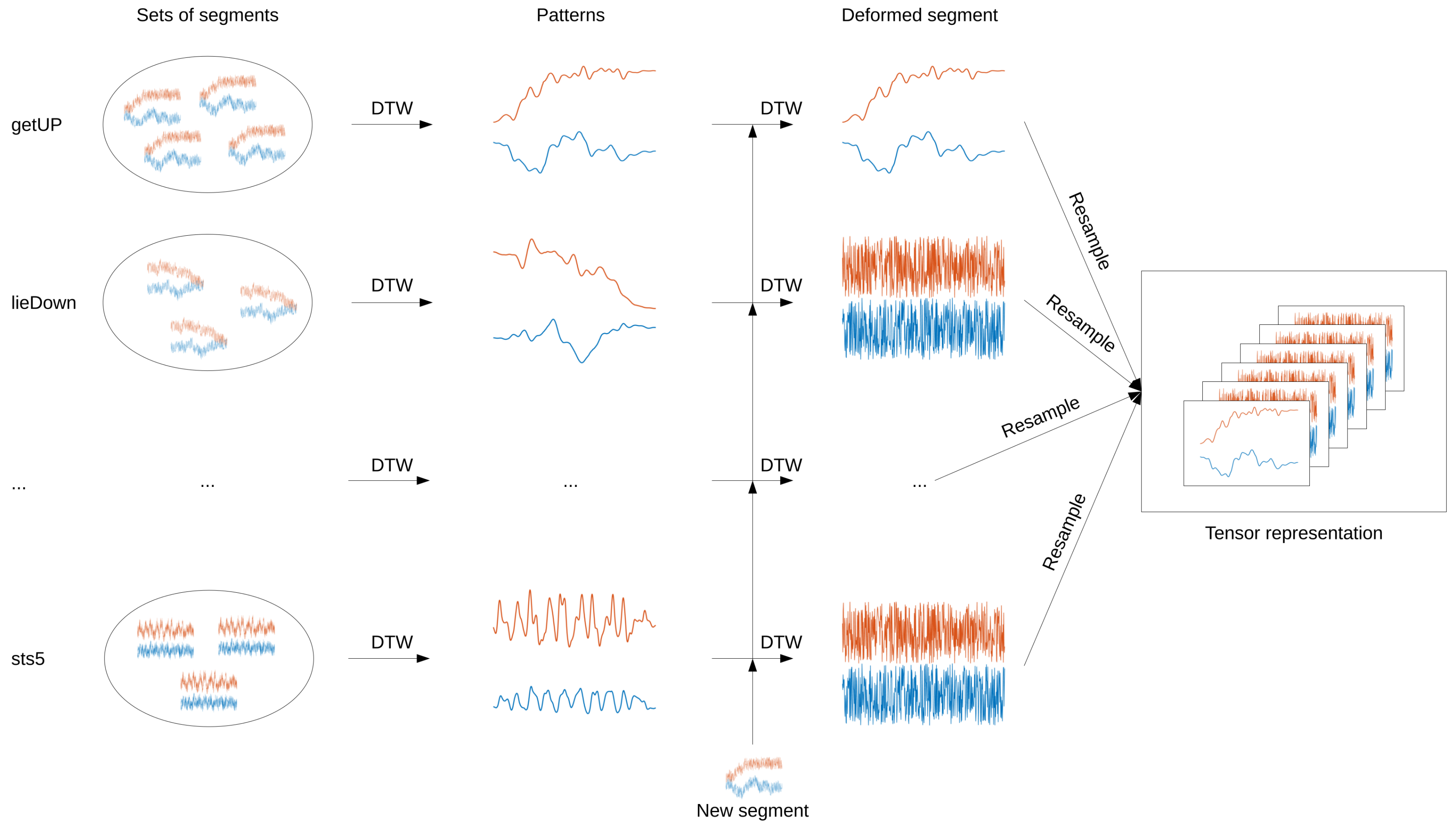
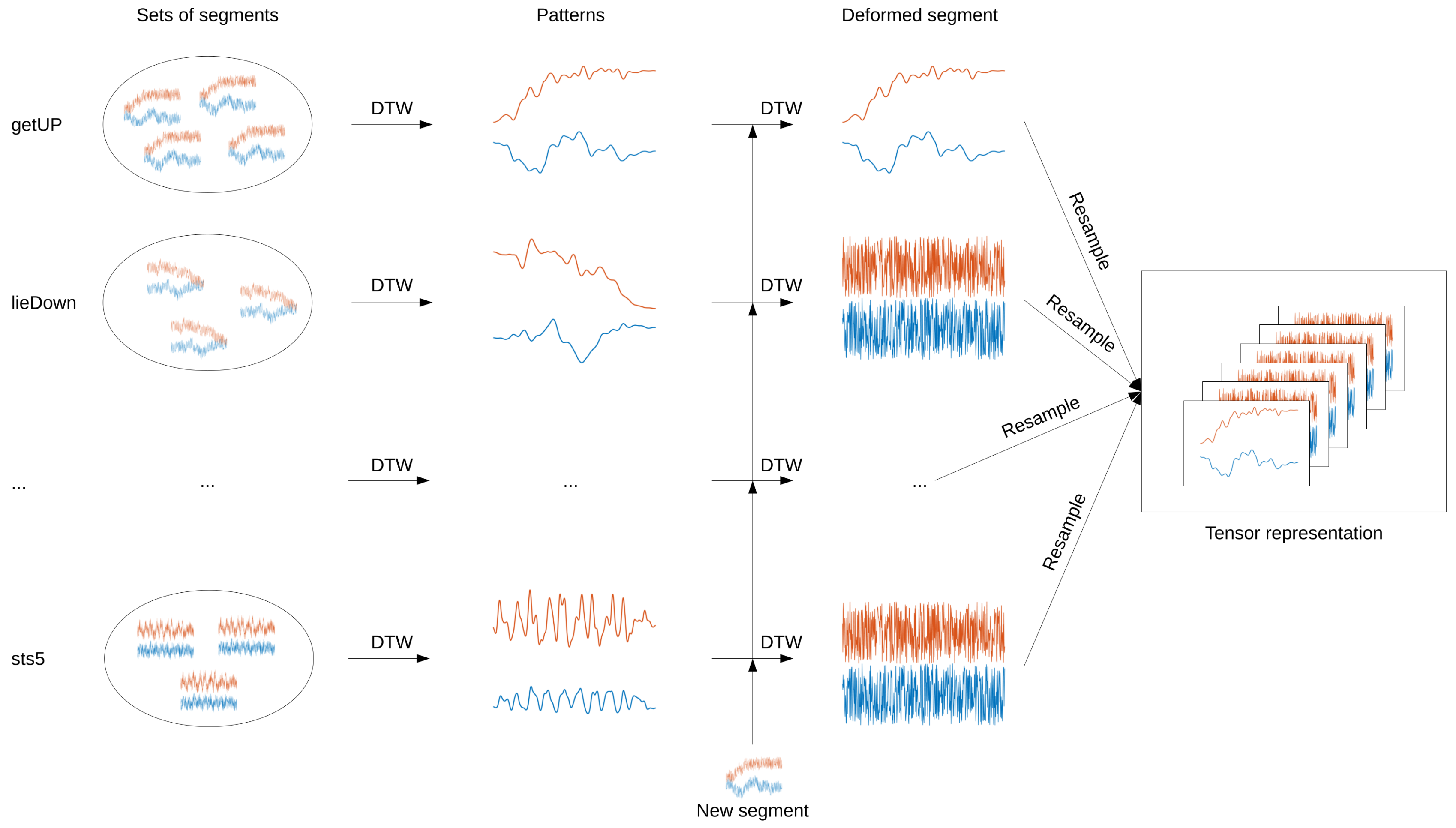
2.2.3. Tensor Construction from Activity Patterns
- Match the segment to an activity pattern using DTW. This is a simple match between the two-channel segment and a two-channel pattern. Its result is a two-channel deformed segment.
- Repeat the first step for all activity patterns.
- Resample all deformed segments to a common length. A length of 150 samples was empirically selected for this study.
- Stack all resampled deformed segments into a time × channel × activity tensor. Here, this yields a tensor.
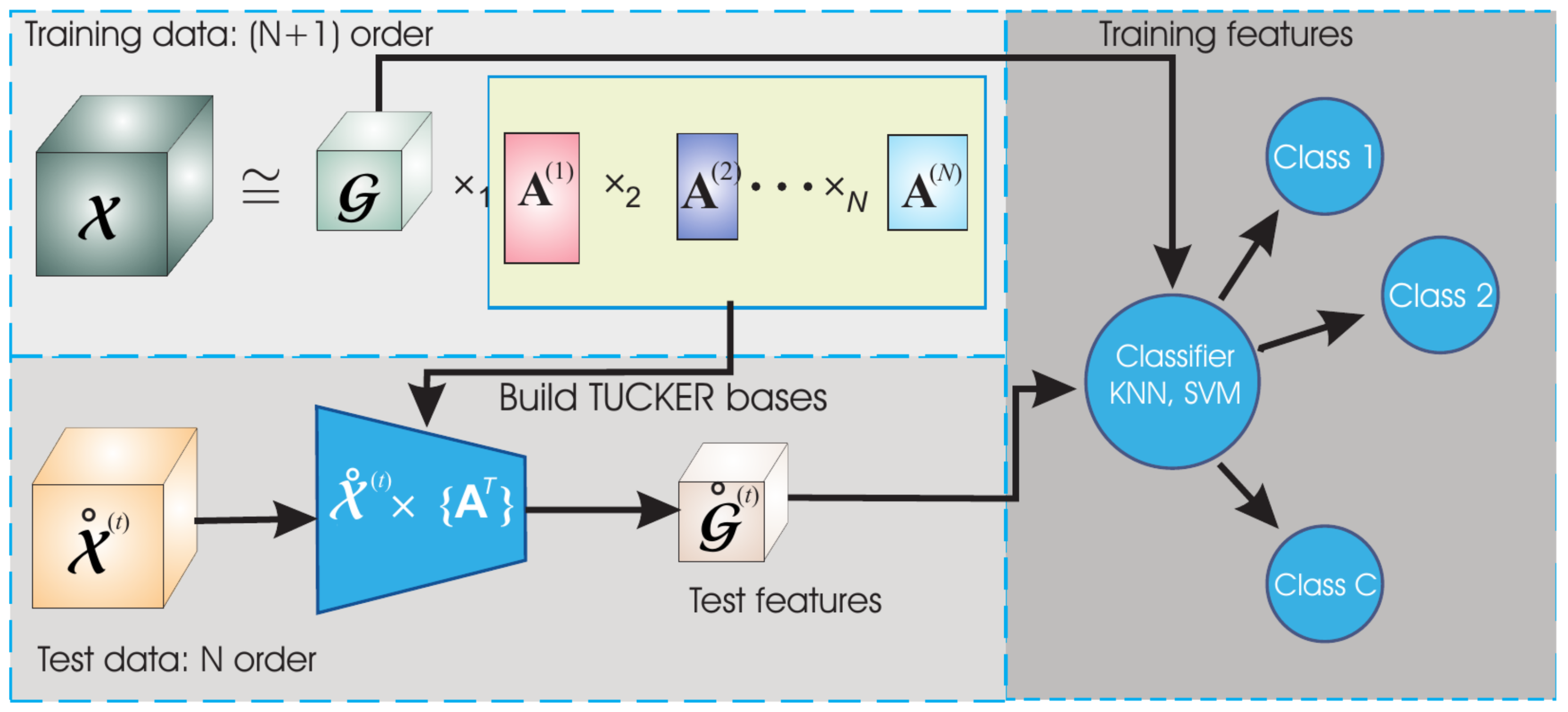
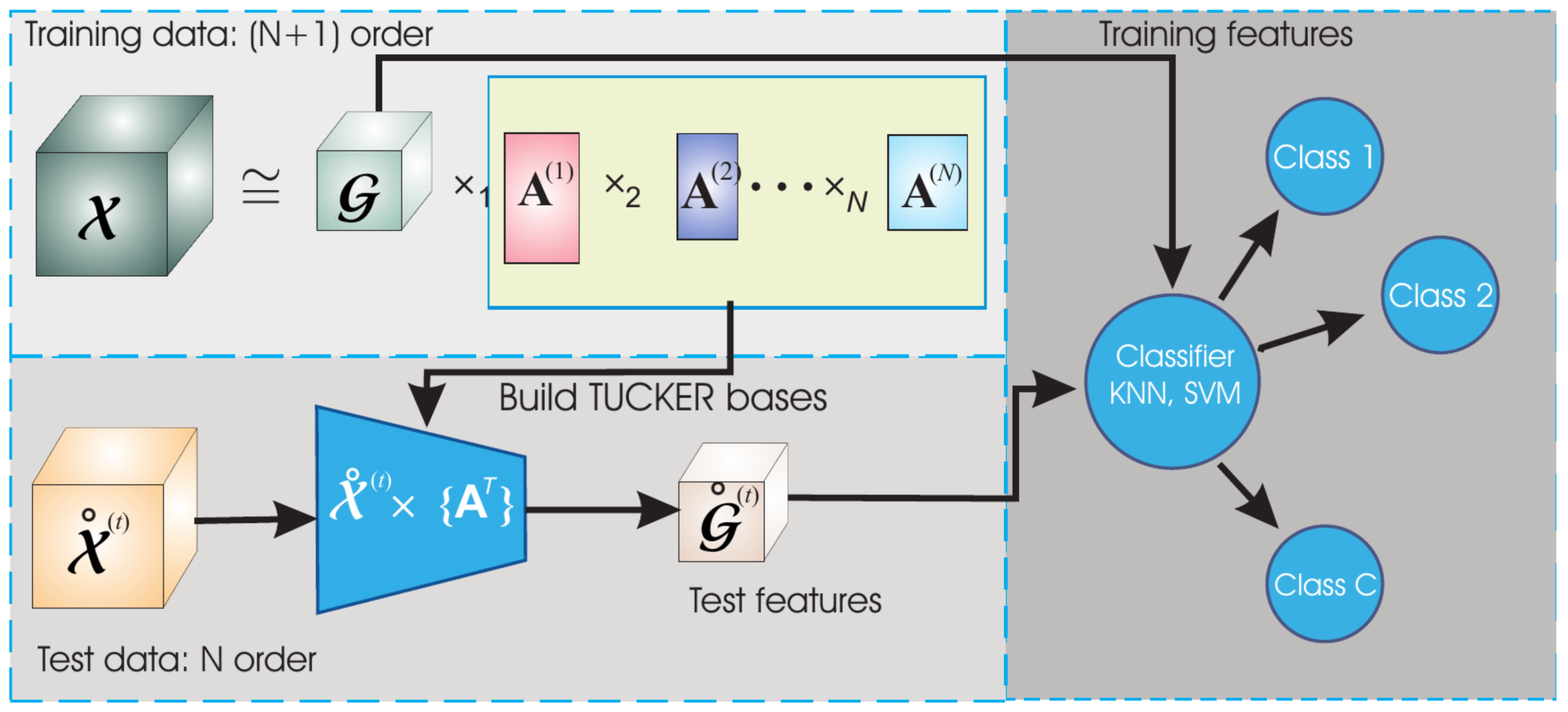
2.3. HODA Features
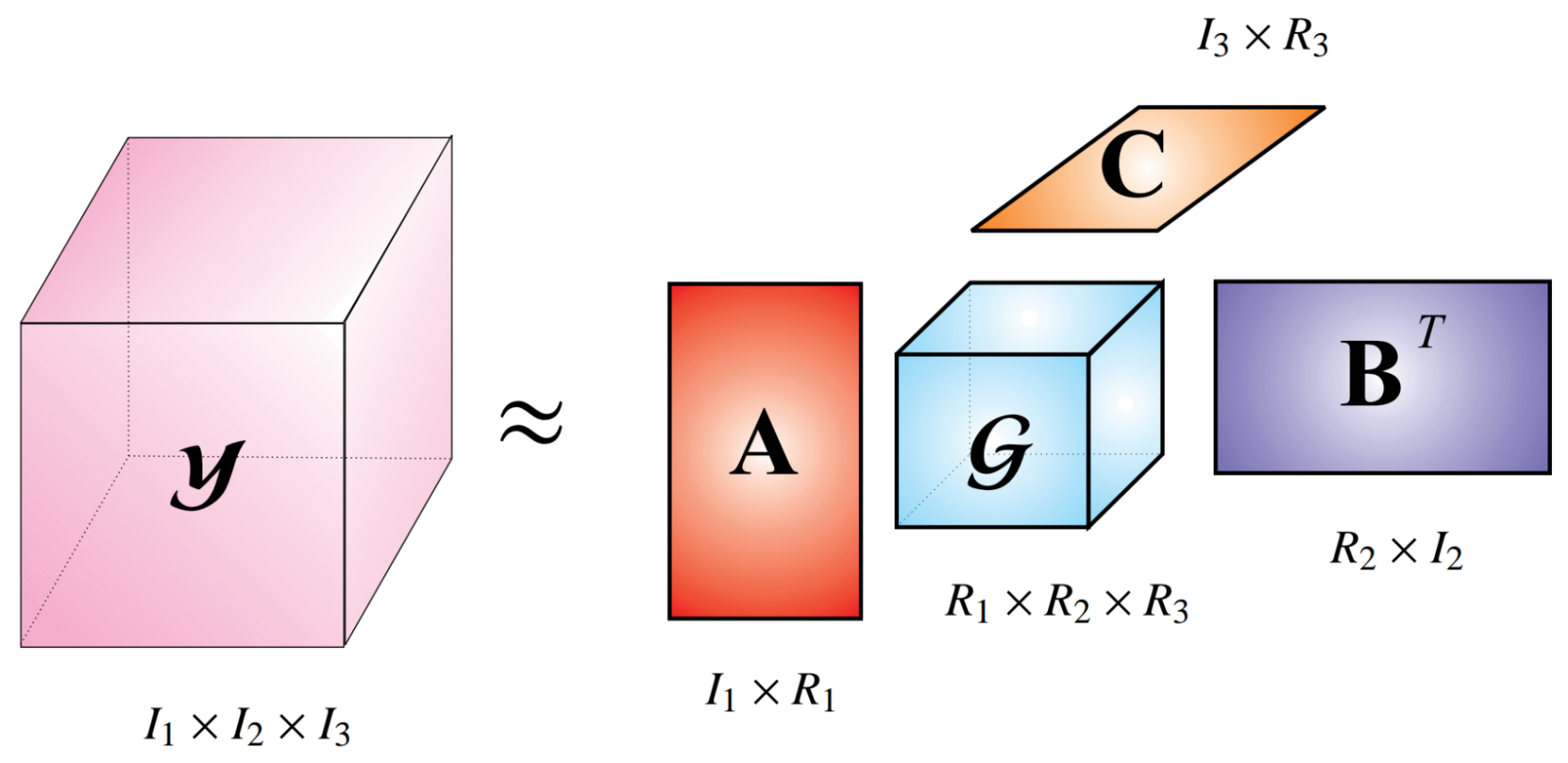
2.3.1. Tucker Decomposition
2.3.2. Higher Order Discriminant Analysis (HODA)
2.4. Detection and Recognition
2.4.1. Segment Identification
- The continuous data is filtered with a low-pass butterworth filter of the fourth order, with a cut-off frequency of 1.6 Hz. This corresponds to 10% of the signal bandwidth. To judge the general movement pattern, low frequencies are the most important ones.
- A rough segmentation splits the signal into windows of two seconds, with 50% overlap. Segments are marked as dynamic based on their standard deviation and range, compared to empirical thresholds obtained from preliminary analysis of the training data.
- Refinement of the dynamic regions is achieved by shrinking or extending the static regions in between dynamic segments based with half a second. The decision is based on the difference in variance between half-second regions and is identical for the start and end of a region, so the discussion will be limited to the start. The initial second of a static region serves as baseline. Extension is accepted if the second starting at half a second before the current start has a variance which is maximally 10% higher than the baseline. This tries to grow the static region without incorporating too much movement. Shrinking is accepted if the variance of the second starting at half a second later than the current start is at least 10% lower. This tries to eliminate movement at the start of the region.
- The above procedure is carried out independently for different channels. The detected dynamic regions are subsequently joined over all channels. Static gaps of less than a second in between dynamic regions are discarded if the means of the regions are similar. As a last step, dynamic regions of less than two seconds are discarded.
2.4.2. Rejection
2.5. Experiments
2.5.1. Recognition
- Class-specific patterns are derived from the training data using DTW.
- Data segments, both training and test, are warped to all training class patterns. This yields deformed segments with the associated distances as simple features.
- The deformed segments are converted to a tensorial representation.
- HODA derives the discriminative subspaces and core tensors based on the training data. As toolbox parameters, the quality of the approximation is set to 98.5 and the subspaces are derived via generalized eigenvalue decomposition.
- The subspaces defined by the factor matrices are used to extract the core tensors for the test data.
- Training and test HODA features are obtained by vectorization of the core tensors.
- Test data is evaluated via a multiclass-trained linear discriminant analysis classifier (LDA) for both types of features [49].
2.5.2. Segmentation
2.5.3. Combination
- The number of false detections FD is the amount of segments classified as belonging to one of the six classes, whereas they should be in the rejection class.
- Detection True Positive Rate (DTPR) is the ratio of the number of segments that have (correctly) been accepted and the number of actual informative segments. It is an alternative for the number of false negatives, that is, missed detections (FN). Whether segments are classified correctly is irrelevant for the DTPR, only the difference between accepted and rejection is assessed.
- The pure accuracy ACC is the classification accuracy when only looking at the accepted segments. This neglects the impact of FD and FN.
- The actual accuracy ACC is the most complete measure of performance. It is the classification accuracy taking into account both FDs and FNs as misclassifications.
3. Results
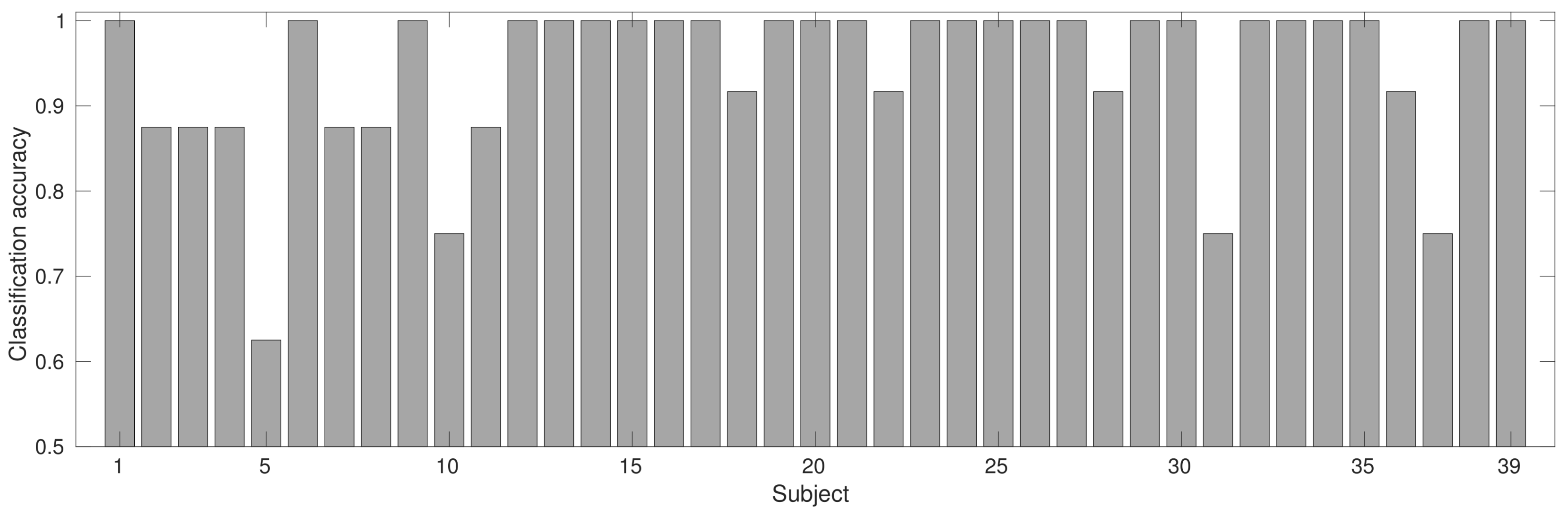
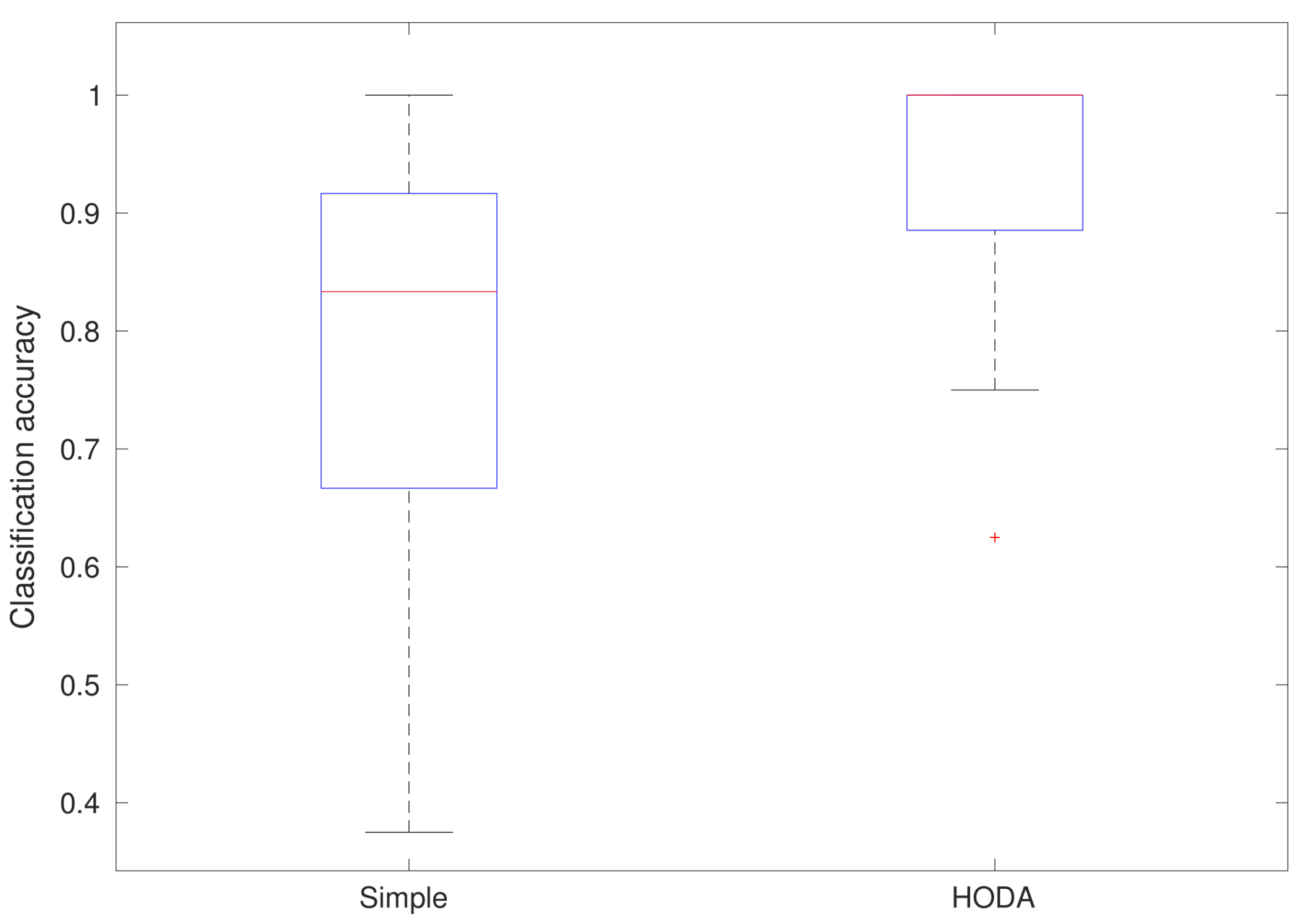
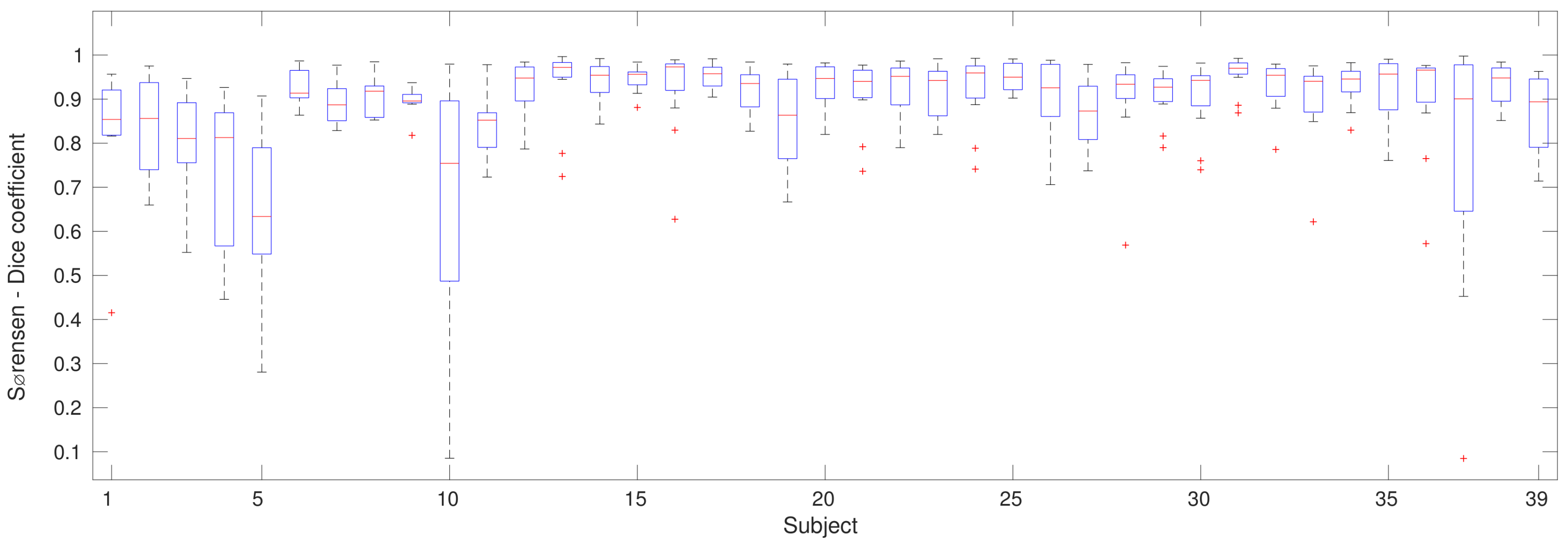
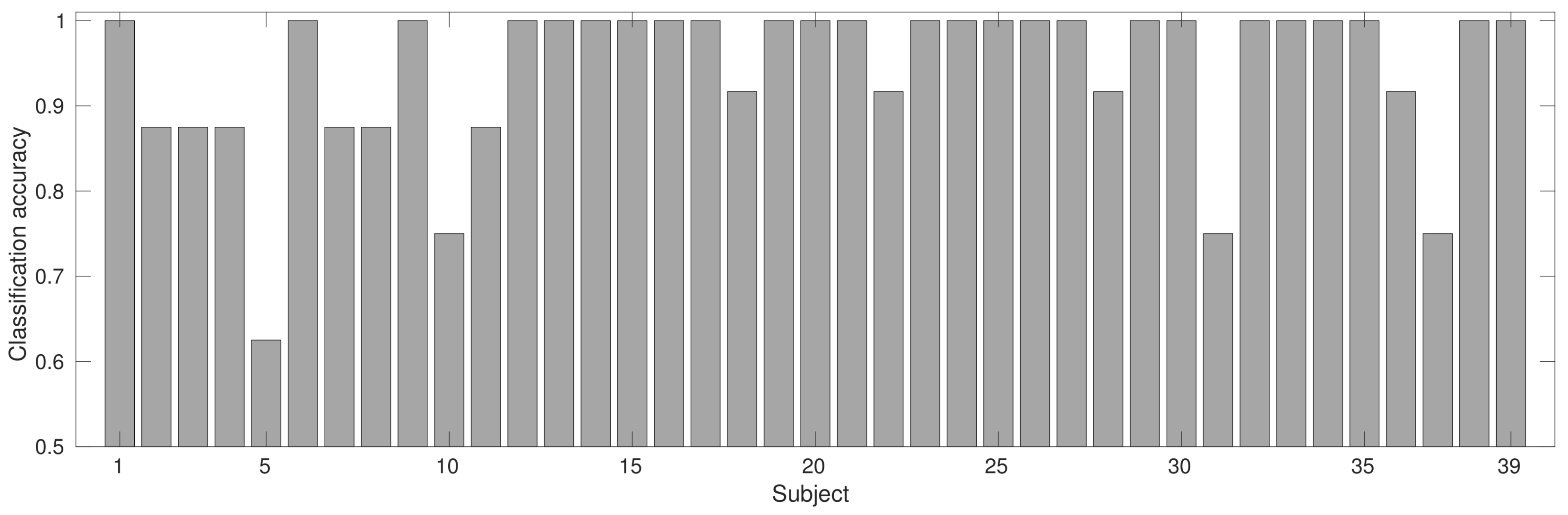
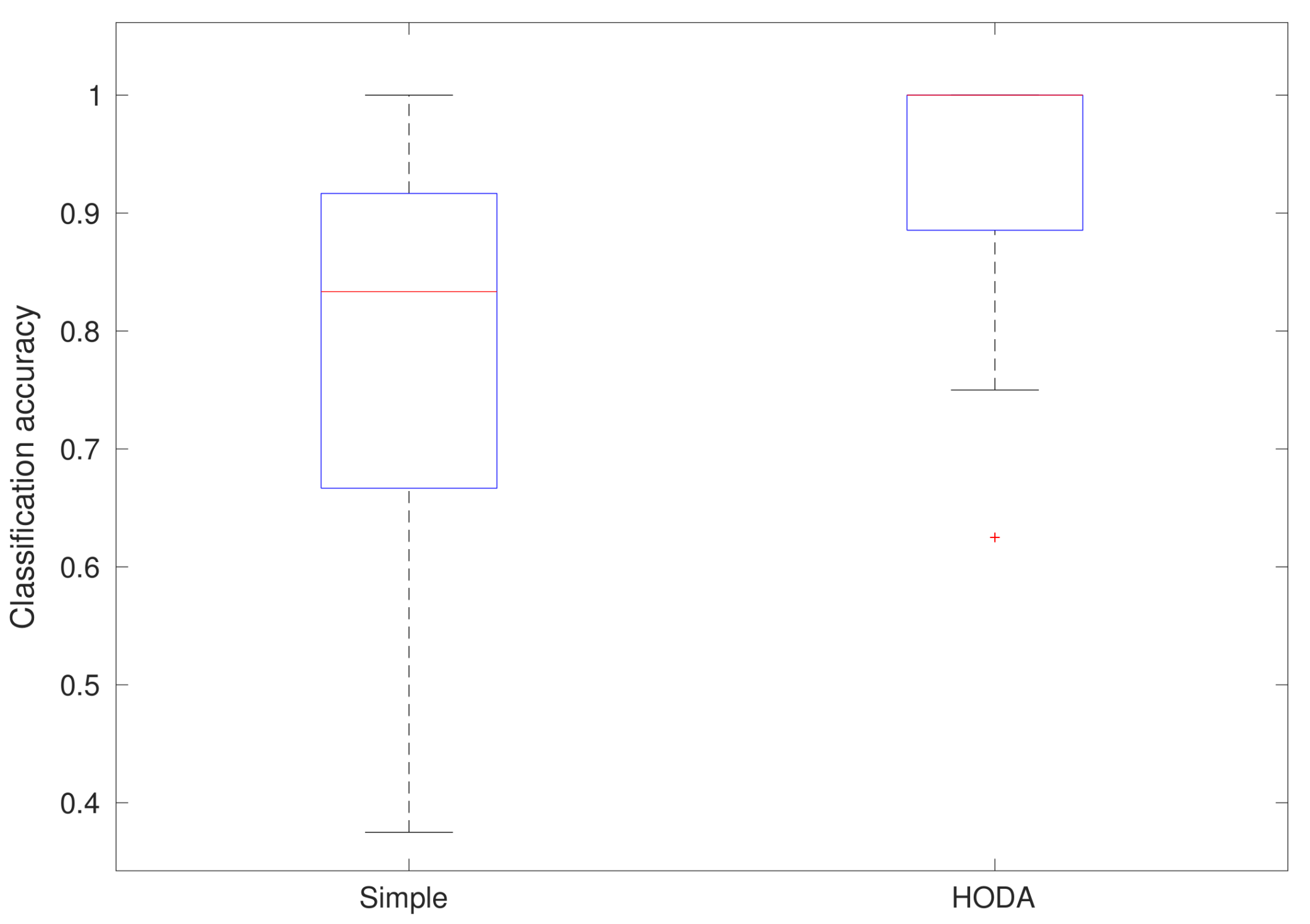
3.1. Recognition Results
3.2. Segmentation Results
3.3. Combination Results
4. Discussion
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- O’Dwyer, T.; O’Shea, F.; Wilson, F. Exercise therapy for spondyloarthritis: A systematic review. Rheumatol. Int. 2014, 34, 887–902. [Google Scholar] [CrossRef] [PubMed]
- Rudwaleit, M.; van der Heijde, D.; Landewé, R.; Listing, J.; Akkoc, N.; Brandt, J.; Braun, J.; Chou, C.T.; Collantes-Estevez, E.; Dougados, M.; et al. The development of Assessment of SpondyloArthritis international Society classification criteria for axial spondyloarthritis (part II): Validation and final selection. Ann. Rheum. Dis. 2009, 68, 777–783. [Google Scholar] [CrossRef] [PubMed]
- Calin, A.; Garrett, S.; Whitelock, H.; Kennedy, L.G.; O’Hea, J.; Mallorie, P.; Jenkinson, T. A new approach to defining functional ability in ankylosing spondylitis: The development of the Bath Ankylosing Spondylitis Functional Index. J. Rheumatol. 1994, 21, 2281–2285. [Google Scholar] [PubMed]
- Weiss, A.; Herman, T.; Plotnik, M.; Brozgol, M.; Maidan, I.; Giladi, N.; Gurevich, T.; Hausdorff, J.M. Can an accelerometer enhance the utility of the Timed Up & Go Test when evaluating patients with Parkinson’s disease? Med. Eng. Phys. 2010, 32, 119–125. [Google Scholar] [CrossRef] [PubMed]
- Swinnen, T.W.; Milosevic, M.; Van Huffel, S.; Dankaerts, W.; Westhovens, R.; de Vlam, K. Instrumented BASFI (iBASFI) Shows Promising Reliability and Validity in the Assessment of Activity Limitations in Axial Spondyloarthritis. J. Rheumatol. 2016, 43, 1532–1540. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, J.; Cai, Q. Human Motion Analysis: A Review. Comput. Vis. Image Underst. 1999, 73, 428–440. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Williamson, J.; Liu, Q.; Lu, F.; Mohrman, W.; Li, K.; Dick, R.; Shang, L. Data sensing and analysis: Challenges for wearables. In Proceedings of the 20th Asia and South Pacific Design Automation Conference, Chiba, Japan, 19–22 January 2015; pp. 136–141. [Google Scholar]
- Roetenberg, D.; Luinge, H.; Slycke, P. Xsens MVN: Full 6DOF Human Motion Tracking Using Miniature Inertial Sensors; Technical Report; Xsens: Enschede, The Netherlands, 2009. [Google Scholar]
- Altini, M.; Penders, J.; Vullers, R.; Amft, O. Estimating Energy Expenditure Using Body-Worn Accelerometers: A Comparison of Methods, Sensors Number and Positioning. IEEE J. Biomed. Health Inform. 2015, 19, 219–226. [Google Scholar] [CrossRef] [PubMed]
- Bouten, C.; Westerterp, K.; Verduin, M.; Janssen, J. Assessment of energy expenditure for physical activity using a triaxial accelerometer. Med. Sci. Sports Exerc. 1994, 23, 21–27. [Google Scholar] [CrossRef]
- Lyden, K.; Kozey, S.L.; Staudenmeyer, J.W.; Freedson, P.S. A comprehensive evaluation of commonly used accelerometer energy expenditure and MET prediction equations. Eur. J. Appl. Physiol. 2011, 111, 187–201. [Google Scholar] [CrossRef] [PubMed]
- Crouter, S.E.; Churilla, J.R.; Bassett, D.R. Estimating energy expenditure using accelerometers. Eur. J. Appl. Physiol. 2006, 98, 601–612. [Google Scholar] [CrossRef] [PubMed]
- Kozey-Keadle, S.; Libertine, A.; Lyden, K.; Staudenmayer, J.; Freedson, P.S. Validation of wearable monitors for assessing sedentary behavior. Med. Sci. Sports Exerc. 2011, 43, 1561–1567. [Google Scholar] [CrossRef] [PubMed]
- Butte, N.F.; Ekelund, U.; Westerterp, K.R. Assessing physical activity using wearable monitors: Measures of physical activity. Med. Sci. Sports Exerc. 2012, 44, S5–S12. [Google Scholar] [CrossRef] [PubMed]
- Maurer, U.; Smailagic, A.; Siewiorek, D.; Deisher, M. Activity recognition and monitoring using multiple sensors on different body positions. In Proceedings of the 2006 BSN International Workshop on Wearable and Implantable Body Sensor Networks, Cambridge, MA, USA, 3–5 April 2006; pp. 113–116. [Google Scholar]
- Preece, S.; Goulermas, J.; Kenney, L.; Howard, D.; Meijer, K.; Crompton, R. Activity identification using body-mounted sensors—A review of classification techniques. Physiol. Meas. 2009, 30, R1–R33. [Google Scholar] [CrossRef] [PubMed]
- Bulling, A.; Blanke, U.; Schiele, B. A Tutorial on Human Activity Recognition Using Body-worn Inertial Sensors. ACM Comput. Surv. 2014, 46, 33:1–33:33. [Google Scholar] [CrossRef]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2013, 15, 1192–1209. [Google Scholar] [CrossRef]
- Chavarriaga, R.; Sagha, H.; Calatroni, A.; Digumarti, S.T.; Tröster, G.; del R. Millán, J.; Roggen, D. The Opportunity challenge: A benchmark database for on-body sensor-based activity recognition. Pattern Recognit. Lett. 2013, 34, 2033–2042. [Google Scholar] [CrossRef]
- Preece, S.; Goulermas, J.; Kenney, L.; Howard, D. A Comparison of Feature Extraction Methods for the Classification of Dynamic Activities From Accelerometer Data. IEEE Trans. Biomed. Eng. 2009, 56, 871–879. [Google Scholar] [CrossRef] [PubMed]
- Avci, A.; Bosch, S.; Marin-Perianu, M.; Marin-Perianu, R.; Havinga, P. Activity recognition using inertial sensing for healthcare, wellbeing and sports applications: A survey. In Proceedings of the 2010 23rd International Conference on Architecture of Computing Systems (ARCS), Hannover, Germany, 22–23 February 2010; pp. 1–10. [Google Scholar]
- Altun, K.; Barshan, B. Human Activity Recognition Using Inertial/Magnetic Sensor Units; Human Behavior Understanding; Salah, A.A., Gevers, T., Sebe, N., Vinciarelli, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 38–51. [Google Scholar]
- Leutheuser, H.; Schuldhaus, D.; Eskofier, B.M. Hierarchical, Multi-Sensor Based Classification of Daily Life Activities: Comparison with State-of-the-Art Algorithms Using a Benchmark Dataset. PLoS ONE 2013, 8, e75196. [Google Scholar] [CrossRef] [PubMed]
- Bao, L.; Intille, S.S. Activity Recognition from User-Annotated Acceleration Data; Pervasive Computing; Ferscha, A., Mattern, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 1–17. [Google Scholar]
- Casale, P.; Pujol, O.; Radeva, P. Human Activity Recognition from Accelerometer Data Using a Wearable Device. In Pattern Recognition and Image Analysis; Vitrià, J., Sanches, J.M., Hernández, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 289–296. [Google Scholar]
- Mannini, A.; Intille, S.S.; Rosenberger, M.; Sabatini, A.M.; Haskell, W. Activity recognition using a single accelerometer placed at the wrist or ankle. Med. Sci. Sports Exerc. 2013, 45, 2193. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window size impact in human activity recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.M.; Lee, Y.K.; Lee, S.Y.; Kim, T.S. A triaxial accelerometer-based physical-activity recognition via augmented-signal features and a hierarchical recognizer. IEEE Trans. Inf. Technol. Biomed. 2010, 14, 1166–1172. [Google Scholar] [CrossRef] [PubMed]
- Ganea, R.; Paraschiv-lonescu, A.; Aminian, K. Detection and Classification of Postural Transitions in Real-World Conditions. IEEE Trans. Neural Syst. Rehabilit. Eng. 2012, 20, 688–696. [Google Scholar] [CrossRef] [PubMed]
- Albert, M.V.; Toledo, S.; Shapiro, M.; Koerding, K. Using mobile phones for activity recognition in Parkinson’s patients. Front. Neurol. 2012, 3, 158. [Google Scholar] [CrossRef] [PubMed]
- Huisinga, J.M.; Mancini, M.; St. George, R.J.; Horak, F.B. Accelerometry Reveals Differences in Gait Variability Between Patients with Multiple Sclerosis and Healthy Controls. Ann. Biomed. Eng. 2012, 41, 1670–1679. [Google Scholar] [CrossRef] [PubMed]
- Muscillo, R.; Conforto, S.; Schmid, M.; Caselli, P.; D’Alessio, T. Classification of Motor Activities through Derivative Dynamic Time Warping applied on Accelerometer Data. In Proceedings of the 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBS), Lyon, France, 23–26 August 2007; pp. 4930–4933. [Google Scholar]
- Margarito, J.; Helaoui, R.; Bianchi, A.M.; Sartor, F.; Bonomi, A.G. User-Independent Recognition of Sports Activities From a Single Wrist-Worn Accelerometer: A Template-Matching-Based Approach. IEEE Trans. Biomed. Eng. 2016, 63, 788–796. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Sawchuk, A.A. Motion Primitive-based Human Activity Recognition Using a Bag-of-features Approach. In Proceedings of the 2nd ACM SIGHIT International Health Informatics Symposium, Miami, FL, USA, 28–30 January 2012; pp. 631–640. [Google Scholar]
- Lee, Y.S.; Cho, S.B. Activity recognition using hierarchical hidden markov models on a smartphone with 3D accelerometer. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Wroclaw, Poland, 23–25 May 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 460–467. [Google Scholar]
- Guenterberg, E.; Ostadabbas, S.; Ghasemzadeh, H.; Jafari, R. An Automatic Segmentation Technique in Body Sensor Networks Based on Signal Energy. In Proceedings of the BodyNets ’09 Fourth International Conference on Body Area Networks, Los Angeles, CA, USA, 1–3 April 2009; ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering): Brussels, Belgium, 2009; pp. 21:1–21:7. [Google Scholar]
- Yang, A.Y.; Iyengar, S.; Kuryloski, P.; Jafari, R. Distributed segmentation and classification of human actions using a wearable motion sensor network. In Proceedings of the 2008 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Phan, A.H.; Cichocki, A. Tensor decompositions for feature extraction and classification of high dimensional datasets. Nonlinear Theory Appl. IEICE 2010, 1, 37–68. [Google Scholar] [CrossRef]
- Sieper, J.; Rudwaleit, M.; Baraliakos, X.; Brandt, J.; Braun, J.; Burgos-Vargas, R.; Dougados, M.; Hermann, K.; Landewe, R.; Maksymowych, W.; et al. The Assessment of SpondyloArthritis international Society (ASAS) handbook: a guide to assess spondyloarthritis. Ann. Rheum. Dis. 2009, 68, ii1–ii44. [Google Scholar] [CrossRef] [PubMed]
- Müller, M. Dynamic Time Warping. In Information Retrieval for Music and Motion; Springer: Berlin/Heidelberg, Germnay, 2007; pp. 69–84. [Google Scholar]
- Keogh, E.J.; Pazzani, M.J. Derivative dynamic time warping. In Proceedings of the 2001 SIAM International Conference on Data Mining, Chicago, IL, USA, 5–7 April 2001; pp. 1–11. [Google Scholar]
- Zhou, F.; De la Torre, F. Generalized time warping for multi-modal alignment of human motion. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 1282–1289. [Google Scholar]
- Cichocki, A.; Mandic, D.; De Lathauwer, L.; Zhou, G.; Zhao, Q.; Caiafa, C.; Phan, H.A. Tensor decompositions for signal processing applications: From two-way to multiway component analysis. IEEE Signal Process. Mag. 2015, 32, 145–163. [Google Scholar] [CrossRef]
- Phan, A.H. NFEA: Tensor Toolbox for Feature Extraction and Applications; Technical Report; Lab for Advanced Brain Signal Processing, Brain Science Institute RIKEN: Hirosawa Wako City, Japan, 2011. [Google Scholar]
- Bader, B.W.; Kolda, T.G.; Sun, J.; Acar, E.; Dunlavy, D.M.; Chi, E.C.; Mayo, J. MATLAB Tensor Toolbox Version 3.0-Dev. 2017. Available online: https://www.tensortoolbox.org (accessed on 11 April 2018).
- Billiet, L.; Swinnen, T.W.; Westhovens, R.; de Vlam, K.; Van Huffel, S. Accelerometry-Based Activity Recognition and Assessment in Rheumatic and Musculoskeletal Diseases. Sensors 2016, 16, 2151. [Google Scholar] [CrossRef] [PubMed]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Izenman, A.J. Linear Discriminant Analysis. In Modern Multivariate Statistical Techniques: Regression, Classification, and Manifold Learning; Springer: New York, NY, USA, 2008; pp. 237–280. [Google Scholar]
- Sørensen, T. A Method of Establishing Groups of Equal Amplitude in Plant Sociology Based on Similarity of Species Content and Its Application to Analyses of the Vegetation on Danish Commons; Biologiske Skrifter//Det Kongelige Danske Videnskabernes Selskab; I kommission Hos E. Munksgaard: København, Danmark, 1948. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Activity | Description | # Patients |
|---|---|---|
| getUp | getting up starting from lying down | 39 |
| lieDown | lying down from stance | 28 |
| maxReach | reaching up as high as possible | 28 |
| pen5 | picking up a pen five times as quickly as possible | 39 |
| reach5 | reaching up five times as quickly as possible | 39 |
| sts5 | sit-to-stand from a chair 5 times as quickly as possible | 39 |
| Predicted Labels | |||||||
|---|---|---|---|---|---|---|---|
| getUp | lieDown | maxReach | pen5 | reach5 | sts5 | ||
| Actual labels | getUp | 76 | 0 | 0 | 0 | 1 | 1 |
| lieDown | 0 | 56 | 0 | 0 | 0 | 0 | |
| maxReach | 0 | 0 | 56 | 0 | 0 | 0 | |
| pen5 | 0 | 0 | 0 | 68 | 5 | 5 | |
| reach5 | 0 | 0 | 0 | 1 | 76 | 1 | |
| sts5 | 2 | 0 | 0 | 3 | 2 | 71 | |
| HODA | Simple | |||||||
|---|---|---|---|---|---|---|---|---|
| Subject | FD | DTPR | ACC (%) | ACC (%) | FD | DTPR | ACC (%) | ACC (%) |
| 1 | 3 | 0.5 | 50 | 18.1818 | 9 | 0.25 | 50 | 5.8824 |
| 2 | 16 | 0.8750 | 71.4286 | 20.8333 | 15 | 0.625 | 60 | 13.0435 |
| 3 | 8 | 0.8750 | 85.7143 | 37.5 | 12 | 0.875 | 100 | 35 |
| 4 | 5 | 0.6250 | 80 | 30.7692 | 7 | 0.625 | 80 | 26.6667 |
| 5 | 6 | 0.7500 | 33.3333 | 14.2857 | 12 | 0.5 | 0 | 0 |
| 6 | 10 | 0.8750 | 85.7143 | 33.3333 | 19 | 0.875 | 71.4286 | 18.5185 |
| 7 | 3 | 1 | 75 | 54.5455 | 8 | 0.75 | 100 | 37.5 |
| 8 | 5 | 0.7500 | 66.6667 | 30.7692 | 6 | 1 | 87.5 | 50 |
| 9 | 5 | 0.7500 | 100 | 46.1538 | 15 | 0.75 | 83.3333 | 21.7391 |
| 10 | 4 | 0.5 | 100 | 33.3333 | 13 | 0.625 | 80 | 19.0476 |
| 11 | 7 | 0.6250 | 80 | 26.6667 | 10 | 1 | 37.5 | 16.6667 |
| 12 | 3 | 0.9167 | 81.8182 | 60 | 10 | 0.75 | 100 | 40.9091 |
| 13 | 0 | 0.5 | 100 | 50 | 7 | 0.9167 | 81.8182 | 47.3684 |
| 14 | 2 | 0.8333 | 90 | 64.2857 | 7 | 0.8333 | 100 | 52.6316 |
| 15 | 2 | 1 | 75 | 64.2857 | 6 | 0.8333 | 100 | 55.5556 |
| 16 | 3 | 0.8333 | 80 | 53.3333 | 5 | 0.8333 | 100 | 58.8235 |
| 17 | 2 | 0.9167 | 90.9091 | 71.4286 | 15 | 0.9167 | 81.8182 | 33.3333 |
| 18 | 0 | 1 | 91.6667 | 91.6667 | 2 | 1 | 83.3333 | 71.4286 |
| 19 | 0 | 1 | 91.6667 | 91.6667 | 6 | 0.8333 | 100 | 55.5556 |
| 20 | 1 | 1 | 100 | 92.3077 | 4 | 0.9167 | 81.8182 | 56.2500 |
| 21 | 0 | 1 | 83.3333 | 83.3333 | 1 | 0.8333 | 100 | 76.9231 |
| 22 | 6 | 0.8333 | 90 | 50 | 21 | 0.6667 | 87.5 | 21.2121 |
| 23 | 2 | 1 | 83.3333 | 71.4286 | 6 | 0.75 | 100 | 50 |
| 24 | 0 | 0.8333 | 100 | 83.3333 | 0 | 0.75 | 100 | 75 |
| 25 | 0 | 0.8333 | 100 | 83.3333 | 4 | 1 | 83.3333 | 62.5 |
| 26 | 2 | 1 | 91.6667 | 78.5714 | 4 | 1 | 75 | 56.25 |
| 27 | 0 | 1 | 100 | 100 | 1 | 1 | 91.6667 | 84.6154 |
| 28 | 1 | 0.9167 | 81.8182 | 69.2308 | 10 | 0.75 | 55.5556 | 22.7273 |
| 29 | 0 | 0.9167 | 100 | 91.6667 | 6 | 0.8333 | 100 | 55.5556 |
| 30 | 0 | 1 | 100 | 100 | 3 | 1 | 91.6667 | 73.3333 |
| 31 | 2 | 0.6667 | 100 | 57.1429 | 6 | 0.7500 | 100 | 50 |
| 32 | 2 | 1 | 91.6667 | 78.5714 | 9 | 0.9167 | 90.9091 | 47.619 |
| 33 | 2 | 0.9167 | 90.9091 | 71.4286 | 7 | 0.8333 | 90 | 47.3684 |
| 34 | 1 | 0.8333 | 100 | 76.9231 | 8 | 1 | 91.6667 | 55 |
| 35 | 2 | 1 | 83.3333 | 71.4286 | 5 | 0.8333 | 70 | 41.1765 |
| 36 | 1 | 0.8333 | 80 | 61.5385 | 8 | 0.9167 | 81.8182 | 45 |
| 37 | 6 | 0.5833 | 85.7143 | 33.3333 | 10 | 0.5833 | 71.4286 | 22.7273 |
| 38 | 0 | 1 | 100 | 100 | 8 | 0.9167 | 90.9091 | 50 |
| 39 | 1 | 1 | 91.6667 | 84.6154 | 3 | 1 | 83.3333 | 66.6667 |
| AVG | 2.8974 | 0.8536 | 86.7272 | 62.3391 | 7.8974 | 0.8216 | 82.9061 | 44.0922 |
| STD | 3.3150 | 0.1576 | 14.2076 | 25.0301 | 4.7395 | 0.1630 | 20.3669 | 20.7116 |
| DTPR | ACC (%) | ACC (%) | |
|---|---|---|---|
| getUp | 0.9103 | 95.7746 | 87.1795 |
| lieDown | 0.875 | 100 | 87.5 |
| maxReach | 1 | 100 | 100 |
| pen5 | 0.8718 | 79.4118 | 69.2308 |
| reach5 | 0.7436 | 93.1034 | 69.2308 |
| sts5 | 0.8333 | 66.1538 | 55.1282 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Billiet, L.; Swinnen, T.; De Vlam, K.; Westhovens, R.; Van Huffel, S. Recognition of Physical Activities from a Single Arm-Worn Accelerometer: A Multiway Approach. Informatics 2018, 5, 20. https://doi.org/10.3390/informatics5020020
Billiet L, Swinnen T, De Vlam K, Westhovens R, Van Huffel S. Recognition of Physical Activities from a Single Arm-Worn Accelerometer: A Multiway Approach. Informatics. 2018; 5(2):20. https://doi.org/10.3390/informatics5020020
Chicago/Turabian StyleBilliet, Lieven, Thijs Swinnen, Kurt De Vlam, Rene Westhovens, and Sabine Van Huffel. 2018. "Recognition of Physical Activities from a Single Arm-Worn Accelerometer: A Multiway Approach" Informatics 5, no. 2: 20. https://doi.org/10.3390/informatics5020020
APA StyleBilliet, L., Swinnen, T., De Vlam, K., Westhovens, R., & Van Huffel, S. (2018). Recognition of Physical Activities from a Single Arm-Worn Accelerometer: A Multiway Approach. Informatics, 5(2), 20. https://doi.org/10.3390/informatics5020020