1. Introduction
Programming online judges (POJs) are e-learning platforms which have been widely accepted in the last few years for programming practices in computer science education and for training in competitive programming scenarios [
1,
2]. Basically, they are composed of a collection of programming exercises to be completed by the users. As an important feature, these platforms automate the evaluation of the proposed solution by doing an instantaneous verdict regarding its correctness. Key examples of POJs are the University of Valladolid Online Judge with more than 210,000 users and 1700 problems, and the Peking University Online Judge with more than 600,000 users and 3000 problems.
The typical interaction sequence between the user and the POJ is as follows:
The user selects a problem to solve from the online judge (
Figure 1).
The code for solving such a problem is written.
This source code is uploaded to the online judge (
Figure 2).
The judge automatically indicates whether the solution is correct or not. If not, classifies the failure mainly in Wrong Answer, Time limited exceeded or Runtime Error, allowing new solution attempts to the same problem.
One of the most important advantages of POJs is that they allow users to select and try to solve the problems they consider suitable for improving their knowledge acquisition at their personalized pace. According to the amount of problems finally solved by each user, the POJ also publishes a ranking (
Figure 3). The reaching of a top position in this ranking is an extra motivation for the users, being then this gamification environment a very good scenario for boosting the users’ programming abilities and knowledge [
3].
The wide acceptance of POJs and the increasing number of users that are currently solving a very high percentage of all the available problems, have implied an increment of such available problems. Therefore, it is currently difficult for several users to find out the appropriate problem for trying to solve, according to their current experience and learning needs. This is a typical information overloading scenario, in which users can experiment a high discouragement and frustration when the actual difficult level of the problems they are trying to solve does not match with their current knowledge profile and therefore it is difficult to develop a successful solution.
Nowadays, the classical solution to face these information overload problems is the development of a recommender system focused on the corresponding scenario. Recommender Systems goal is to provide users the items that best fit their preferences and needs in an overload search space [
4,
5,
6]. They have been successfully used in scenarios such as tourism [
7], e-commerce, e-learning, or social networks [
8]. In the specific case of e-learning, there are also specific application scenarios such as the recommendation in learning objects repositories [
9], in learning management systems [
10], or in the students’ course recommendation [
11]. However, in contrast to its wide use in other e-learning context, there have been few research efforts focused on the development of recommendation tools for POJs [
12,
13].
Regarding the e-learning systems research area, it is important to remark that the problem we are facing in the current research is different from the task related to users’ guiding through the learning context, which is usually handled with very traditional approaches such as Intelligent Tutoring Systems or ontologies-supported approaches [
14,
15]. Generally, such approaches require as input an important amount of structured information characterizing e-learning content and user activity associated to the corresponding e-learning scenario, for guaranteeing an appropriate user characterization. At this moment such information is not available for typical POJs scenarios, making very difficult the use of traditional approaches such as the previous ones. Therefore, recommender systems will be used in this context as an appropriate solution for reducing information overload in these scenarios. Specifically, we will focus on collaborative filtering recommendation [
16], which is a popular paradigm that does not depend on the availability of structured information.
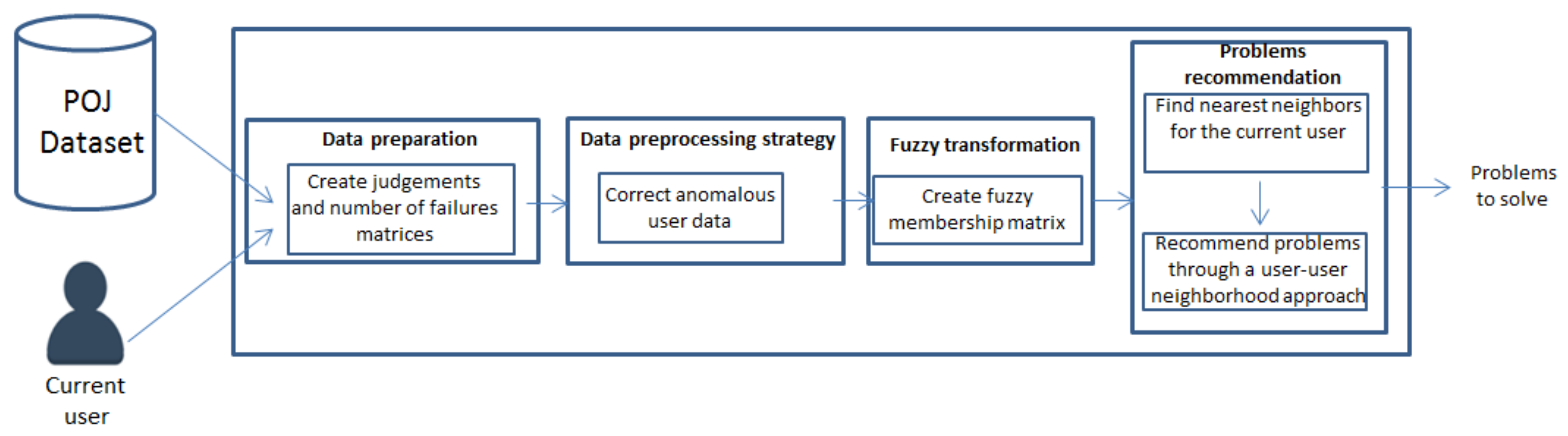
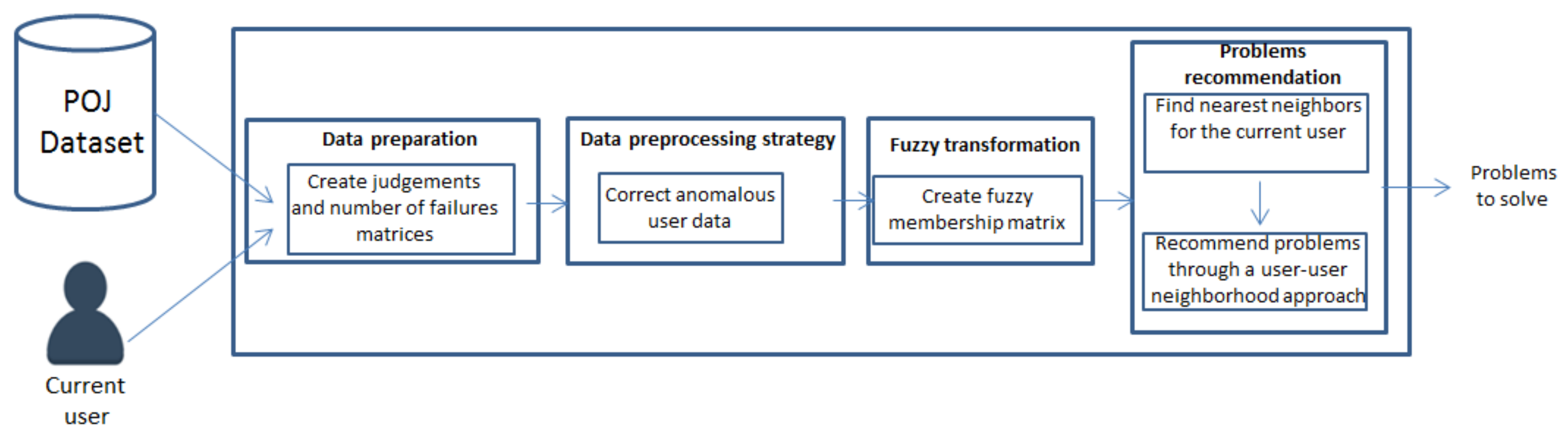
This paper is then focused on the development of an uncertainty-aware framework for recommending problems to be solved in POJs, supporting and guiding the users in the search of problems they should be able to solve during their knowledge acquisition, and avoiding in this way failures and frustration. The management of the uncertainty associated to the user’s behavior in the current scenario, would improve the recommendation generation process in relation to previous proposals that perform a crisp management of the user profile.
The main contributions of the paper are:
A fuzzy based uncertainty-aware approach for recommending problems to solve in POJs.
A data preprocessing strategy to be used on the user profile to remove anomalous behaviors that could affect the later recommendation generation.
This paper is structured as follows.
Section 2 shows the needed background for the proposal presentation, including programming online judges, fuzzy tools in recommender systems, and recommender systems approaches for POJs.
Section 3 presents the new uncertainty-aware proposal for problems recommendation in POJs, which also includes a novel data preprocessing approach to be used in this scenario.
Section 4 presents the evaluation of the proposal, including comparison against previous related works.
Section 5 concludes the current research, pointing out future works.
4. Experimental Study
The evaluation of the current proposal is done through a dataset obtained from the Caribbean Online Judge, composed of 1910 users, 584 problems, and around 148,000 user attempts. This dataset has been already used in previous research works presented in the background section [
13].
Considering this dataset, the training and test sets were created according to a typical splitting procedure for this kind of recommender systems scenarios [
36]. Specifically, it is based on a popular hold out scheme where all the solved problems for each user are randomly splitted in two sets which are respectively appended to the training set and the test set. As a feature of the hold out protocol, this splitting procedure was developed 10 times, composing 10 pairs of training-test sets. The recommendation accuracy of each set is calculated independently, and the average of the accuracy values are then showed in the results presented in the current section.
The F1 measure will be used for evaluating the generated recommendations, being a popular evaluation criteria for the top-n recommendation generation task [
36]. F1 (Equation (
18)) is defined in terms of Precision and Recall measures (Equations (
19) and (
20)), that in addition, as it is presented in
Table 2, depend on the amount of recommended problems that were solved (precision) and the amount of solved problems that were recommended (recall).
Specifically, the evaluation protocol is performed by obtaining a list of recommended problems for each user, considering training set data. Such list, as well as the solved problems at the test set, are used for calculating F1 for each user. Finally, the global F1 value is calculated by averaging the F1 values obtained for each user.
The current proposal depends on three main parameters:
The amount of k nearest neighbors: It will be used , considering it is a value previously used in related works presented in the background section. As future works, it will be explored the behavior of the proposal for other values of k.
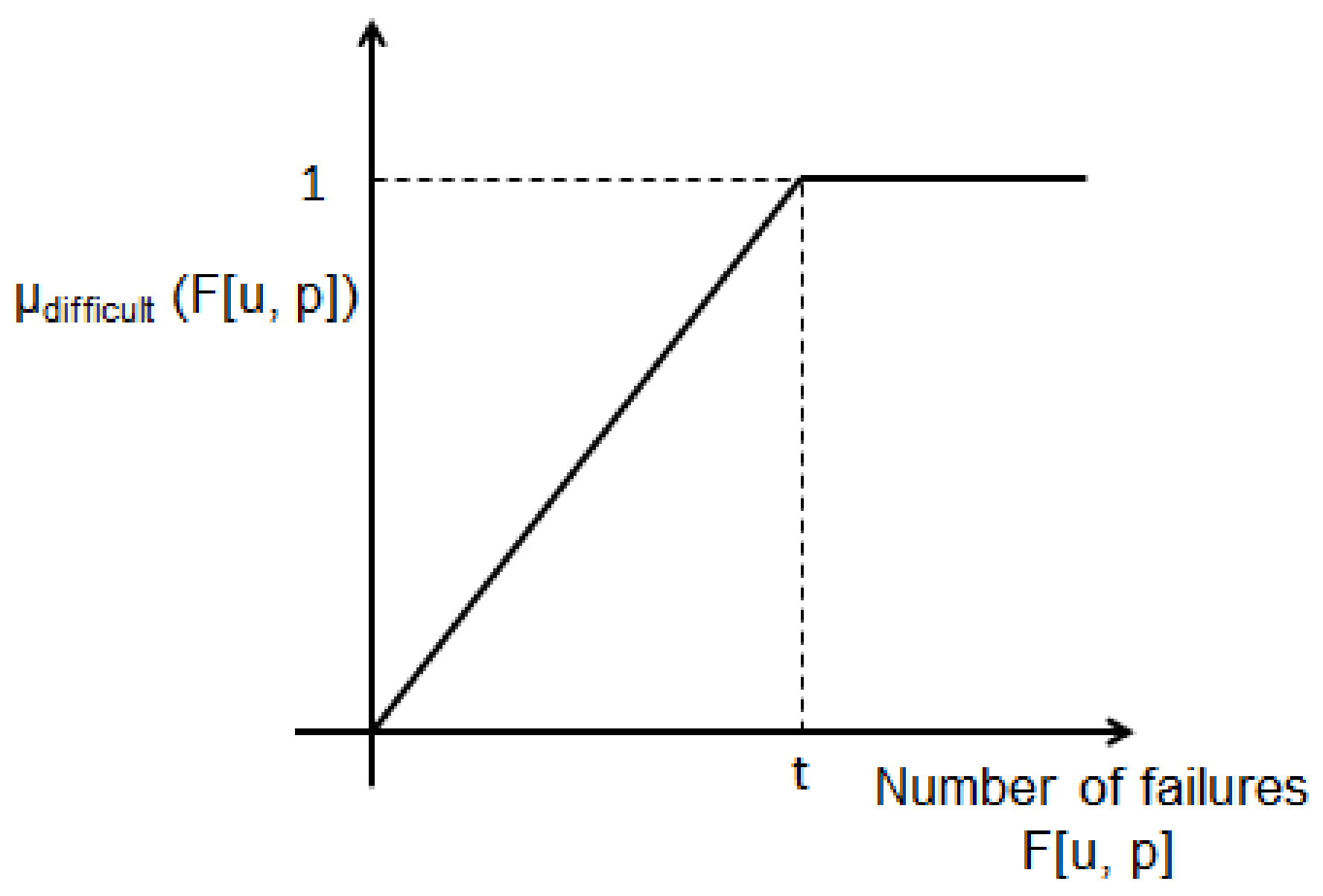
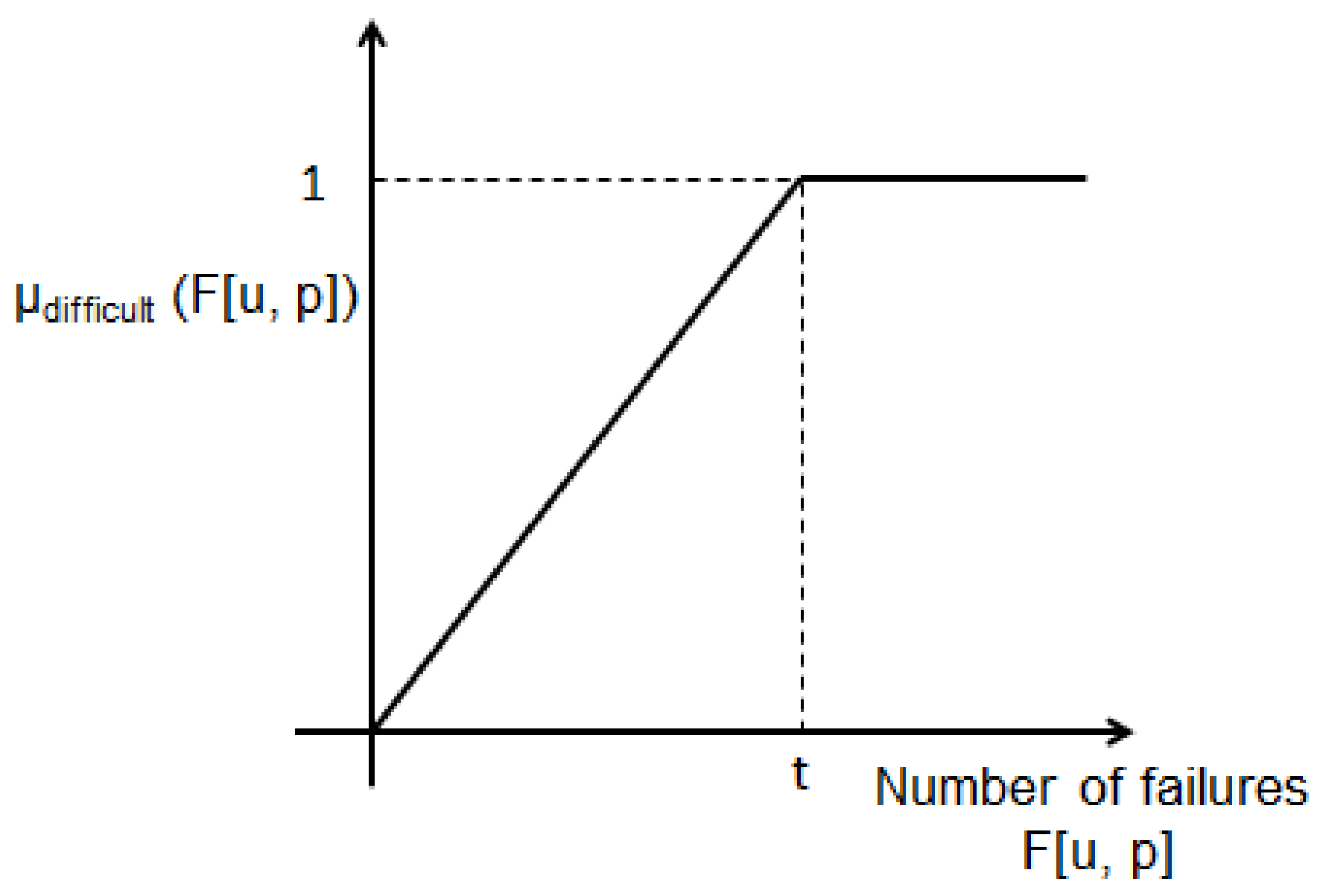
The value of
t, in the fuzzy membership function presented in
Figure 5. This value is connected to the number of attempts where the difficulty of the problems can be considered as maximum (see
Section 3.3). Therefore, it could be linked with the global average of
, being
the average number of attempts for user u (see
Table 1). Regarding that the average of
for the current data was 1.18 with a mean deviation of 1.17, here it will be considered
. Specifically, it will be reported the results for
,
, and
. Further experiments were developed considering other values (e.g.,
), but their performances were under the associated to the mentioned ones.
The value of in the data preprocessing strategy. To verify whether the flexibility in the definition of the interval for the outliers characterization leads to positive results, it will be considered (no flexibility), and (a small flexibility, considering correct values to some small amounts of attempts treated as outliers by ).
The current experiments have two main objectives. In both cases it will be considered two scenarios regarding the size of the recommendation list:
At first it will be considered recommendation lists with large sizes, varying such size n in the range [5, 25] with step 10, and
At second it will be considered smaller recommendation lists, varying n in the range [1, 5] with step 1.
Objective 1: Determine whether the fuzzy recommendation approach outperforms previous approaches that do not consider the management of the uncertainty associated to POJ data.
In order to accomplish this objective, we compare the accuracy (F1) of the current proposal (without the data preprocessing step), in relation to the proposals presented by Yera and Caballero [
12] (
UCF-OJ in the results tables), and Yera and Martínez [
13], in the last case also without considering the data preprocessing step (
UCF-OJ++ in the tables). It is also included a comparison against a successful approach presented at [
35], specifically the problem-based approach using as similarity the weight of the relation between two problems, regarding the social network analysis-related strategies presented in the mentioned [
35] (
PCF-OJ in the tables). Other approaches in [
35] perform worse in this scenario and then were not included here. As it was explained before, the current proposal considers
,
, and
as possible values of the parameter
t, being identified as
Fuzzy-UCF-OJ in the mentioned tables.
Table 3 and
Table 4 show the results of this comparison for larger and smaller recommendation lists, respectively. As it was expected the performance associated to the new proposal is similar or better than the related to the previous approaches. Specifically, the more notable improvements were obtained for
in larger recommendation lists, and for all cases in smaller recommendation lists. However, for larger values of
n the improvement becomes modest in relation to Yera and Martínez [
13]. Furthermore, the best results of the proposal were obtained for
and
, leaving for
a lower accuracy value.
It is also remarkable the poor performance associated to the work [
35]. In this case, this approach was originally evaluated in a different dataset in relation to the used in the current proposal. Therefore, we think that its positive performance previously reported by [
35], could be closely related to the nature of data where it is used. Furthermore, this mentioned work disregards the number of previous attempts as a valuable information for recommendation generation, being proved later in [
13] that this information could be important in such task. We think that this fact could justify this unexpected behavior, although a future analysis should be developed to support these assumptions and to fully exploit the results exposed by [
35].
Table 5 presents the statistical comparison using Wilcoxon test [
36], between the previous work that performs best in the state-of-art [
13], and the three evaluated proposals (with
,
, and
). For all cases, our proposals statistically outperform the previous work (
p < 0.05).
Objective 2: Determine the effect of the proposed data preprocessing strategy, in contrast to previous approaches that also consider data preprocessing in POJ scenarios.
To accomplish this objective it will be considered the use of the data preprocessing strategy previously presented in this work, to clean the original data and therefore improve the recommendation accuracy. With this aim in mind, it will be considered the values of
t and
previously mentioned in this section, together with the three data preprocessing schemes explained in the previous section (global, evaluation-based, and failed-evaluation-based). In the failed-evaluation-based strategy, it was only considered
because other values obtained poor results and therefore they were not reported. We also consider a comparison against a previous related work that also considers data preprocessing [
13], which is identified as
UCF-OJ++ + preproc in the tables. Our current proposal in this case is identified as
Fuzzy-UCF-OJ + preproc.
The analysis of the presented results for large recommendation lists (
Table 6), at first concludes that for smaller sizes of such list the proposal introduces an improvement in the recommendation accuracy (e.g., for
, the best F1 value for the proposal was 0.3674, while for the previous work was 0.3615). However, for larger sizes the improvements become more modest.
Additionally, it is worthy to note that although for higher values of
n the best performance was obtained for the global strategy for
and
; for smaller values in such
Table 6 (where the improvement is more relevant), it is not a specific execution scenario that leads to the achievement of the best F1 values. Here, the best performance was obtained for the failed-evaluation-based strategy with
and
(in
), and for the evaluation-based strategy also with
and
(in
).
Globally, as an unexpected finding in large recommendation lists, it was detected that the most sophisticated data preprocessing strategy (the evaluation-based), does not necessarily lead to the reaching of a better recommendation accuracy.
In contrast to the results obtained for large recommendation lists, in the case of smaller recommendation lists with sizes lying in the range [1, 5] (
Table 7), for all cases it was obtained that the more sophisticated data preprocessing strategies lead to the reaching of the best results (i.e., evaluation-based and failed-evaluation-based).
Table 8 presents the statistical comparison using Wilcoxon test [
36], between the previous work that performs best in the state-of-art [
13], and four evaluated proposals which have positive performance across all the parameter settings. For all cases, our proposals statistically outperforms the previous work (
p < 0.05).
Overall, these last results suggest that the use of techniques for preprocessing the data in the current POJ scenario can improve the recommendation accuracy, in a similar way to other preprocessing approaches for recommendation scenarios [
37,
38].
Beyond the two main objectives of the current evaluation, mentioned at the beginning of this section and focused on the accuracy of the proposal, we also focus briefly on analyzing the amount of data modified by the data preprocessing strategies.
Table 9 presents the percentage of data modified in the data preprocessing step. In the case of the global and the failed-eval-based strategies the values were always under 17%, which guarantee a low intrusiveness level and match with values previously obtained in similar works according to this criteria [
39]. For the eval-based strategy, the intrusion degree was higher.
Summarizing, the globally-obtained results suggest that the current proposal can be associated to a POJ for generating effective problems’ recommendations. Furthermore, it is important to point out that such proposal could be coupled with other very popular e-learning frameworks, being Massive Open Online Courses (MOOCs) a key example of such platforms. MOOCs and POJs have as common features, the fact that both contain e-learning content where users have to access at their personalized pace. However, while current POJs are mainly focused on programming practices, the users at MOOCs are usually learning and practising simultaneously inside the platform. Therefore, it is expected larger levels of participation in MOOCs, in relation to POJs. This increasing number of users leads to a sparser user preference dataset, which could make necessary the transformation of the current proposal, to be used in this new scenario. In fact, recent works have faced the recommendation in MOOCs through different innovative approaches such as the reciprocal recommendation [
40], or the use of information from external sources [
41]. Our future work will then explore these approaches to extend the current proposal to guarantee a successful tentative integration with MOOC-like frameworks. Furthermore, with the same aim in mind, it will be developed user studies for a better understanding of their motivations and needs.
In other direction, future works will also consider an adaptive modification of the size
n of the top
n recommendation list, varying it according to past user behavior. This approach has been successfully used in previous works such as [
42].






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}