Abstract
Social media platforms have become a widely used medium for individuals to express complex and multifaceted emotions. Traditional single-label emotion classification methods fall short in accurately capturing the simultaneous presence of multiple emotions within these texts. To address this limitation, we propose a classification model that enhances the pre-trained Cardiff NLP transformer by integrating additional self-attention layers. Experimental results show our approach achieves a micro-F1 score of 0.7208, a macro-F1 score of 0.6192, and an average Jaccard index of 0.6066, which is an overall improvement of approximately 3.00% compared to the baseline. We apply this model to a real-world dataset of tweets related to the 2011 Christchurch earthquakes as a case study to demonstrate its ability to capture multi-category emotional expressions and detect co-occurring emotions that single-label approaches would miss. Our analysis revealed distinct emotional patterns aligned with key seismic events, including overlapping positive and negative emotions, and temporal dynamics of emotional response. This work contributes a robust method for fine-grained emotion analysis which can aid disaster response, mental health monitoring and social research.
1. Introduction
Social media platforms enable individuals to freely express a wide range of emotions in real time. These expressions usually carry subtle meanings that reflect the complexity of human emotional experience. Emotion classification plays an important role in areas like disaster response and crisis management, product reviews, customer support, mental health monitoring, and social media analysis. Understanding emotions expressed in natural language text enables organizations to respond with empathy, make more informed decisions, and improve user experiences.
Emotion classification in text is the process of automatically identifying emotions such as joy, anger, sadness, fear, or surprise expressed in a written text. Early research focused on single-label classification, where each text was assigned only one dominant emotion, based on the assumption that emotional expressions are discrete and mutually exclusive. However, this approach fails to capture the complexity of real-world emotional expression. On social media, people often convey multiple, overlapping emotions within a single post. Limiting classification to a single emotion can lead to loss of subtle emotional nuances, lower accuracy, and misunderstandings of user intent. To address these challenges, more flexible and expressive modeling approaches are necessary. Multi-label emotion classification allows a post to be associated with multiple emotions, enabling a richer and more accurate understanding of the complex emotional landscape found in social media data.
For example, during the 2011 Christchurch earthquake, users posted tweets such as “My house is shaking again, I’m terrified this will never stop” (expressing fear and worry) and “So proud of everyone helping out despite the chaos” (expressing gratitude and sympathy). Such posts often contain multiple emotional cues within a single message, illustrating the challenge of distinguishing and interpreting overlapping emotions in real-world communication. These examples highlight the importance of multi-label emotion classification for capturing the depth and nuance of public responses during crisis events.
Transformer models, introduced by Ref. [1], have revolutionized natural language processing by leveraging self-attention mechanisms to capture contextual relationships within text more effectively than previous architectures such as Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs). The self-attention mechanism allows the model to weigh the importance of each word in a sentence relative to all others, enabling it to capture both local and long-range dependencies in parallel. Unlike traditional sequential models, transformers process input tokens in parallel, to enable them to model long-range dependencies and complex linguistic patterns with greater accuracy. Due to their superiority in understanding nuanced context, transformer-based models like Bidirectional Encoder Representations from Transformers (BERTs) [2], A Robustly Optimized BERT Pretraining Approach (RoBERTa) [3], and Generative Pre-trained Transformer (GPT) [4] have been widely used for various text classification tasks, including multi-label classification. In multi-label settings, these models are fine-tuned on datasets where each instance can have multiple associated labels. The transformer’s contextual embeddings serve as rich feature representations, allowing the classifier head to predict multiple emotions or categories simultaneously.
Building on RoBERTa, specialized variants such as BERTweet [5] and Cardiff NLP (TweetNLP) [6] have been developed to better handle social media text and emotion-specific tasks. These models are pre-trained on large-scale Twitter data, enabling them to capture the informal language, slang, and unique linguistic patterns found in social media posts. Rather than building a classifier from scratch, we leveraged a pre-trained transformer model Cardiff NLP (cardiffnlp/twitter-roberta-base-emotion) which combines RoBERTa’s robust architecture with extensive pre-training on Twitter data. We apply this modified model to real-world disaster-related social media data, focusing on tweets related to the 2011 Christchurch earthquake to demonstrate the model’s ability to accurately detect multiple simultaneous emotions expressed in disaster related communication.
Our novel contributions include: (1) the integration of additional self-attention blocks above a Twitter-optimized transformer to refine emotional context in multi-label classification; (2) the application of label-wise threshold tuning for improved precision-recall tradeoff across imbalanced emotion classes; and (3) a real-world case study on historical crisis tweets.
The remainder of this paper is organized as follows: Section 2 reviews related work on emotion classification in social media analysis. Section 3 details the architecture of the modified Cardiff NLP model and the multi-label classification approach. Section 4 presents the experimental setup, evaluation metrics, and results. Section 5 provides a case study demonstrating the application of our model to Christchurch earthquake tweets. Finally, Section 6 discusses the implications of our findings, limitations, and future research directions.
2. Related Work
Emotion identification in text has evolved significantly over the years, transitioning from traditional machine learning approaches to advanced deep learning models. Early systems relied on handcrafted features and classical algorithms such as Naive Bayes, Support Vector Machines (SVMs), and decision trees, to perform single-label classification, where each text instance was assigned only one dominant emotion. While these approaches achieved moderate performance, they were limited in capturing contextual dependencies and overlapping emotions, which are common in social media posts.
2.1. Single-Label Emotion Classification
Early single-label emotion classification techniques included lexicon-based, machine learning, and hybrid approaches. Lexicon-based methods extracted emotion features using predefined word lists [7], whereas hybrid strategies combined lexicon features with classifiers such as SVM or Naïve Bayes [8]. Deep learning architectures, including LSTM, Bi-GRU, and CNN-BiGRU hybrids, improved performance by modeling sequential or local patterns in text [9,10,11,12]. RNN variants, particularly BiLSTMs combined with word embeddings, achieved high prediction accuracy in diverse datasets [11]. More recently, transformer-based models such as IndoBERT was fine-tuned for single-label classification in specific domains, achieving superior F1 scores compared with prior methods [13]. Despite these advances, single-label approaches remain constrained by their inability to capture co-occurring emotions, limiting their applicability to informal social media text or crisis-related communications.
2.2. Multi-Label Emotion Classification
As the complexity and overlap of human emotions became increasingly evident, multi-label emotion classification emerged. Early approaches employed deep learning architectures such as CNNs, RNNs, LSTM, and BiLSTMs to model sequential dependencies and local patterns for multi-label emotion inference [14,15,16]. Additional strategies included probabilistic models, problem transformation, and ensemble techniques to handle multiple labels simultaneously [15,17]. Notable innovations include the Joint Binary Neural Network (JBNN), which performs multiple binary classifications jointly [16], and Seq2Emo, a latent variable chain model that captures emotion co-occurrence dependencies through sequence prediction [17]. Other studies transformed multi-label classification into multiple binary tasks [18] or incorporated content-based features such as word and character n-grams [19]. These approaches demonstrated early promise. However, many relied heavily on curated feature sets and were limited in capturing long-range contextual dependencies, especially in informal social media text.
To address language-specific challenges and data scarcity, researchers developed new datasets and embedding strategies. For instance, ExaAEC, an Arabic-language dataset annotated across ten emotion categories, utilized ELMo embeddings with LSTM classifiers to improve classification performance [20]. Comparative studies evaluating traditional baselines, deep neural networks, and early transformer-based models such as BERT highlighted the advantages of contextual embeddings for multi-label classification [21,22,23]. Other efforts, including extensions to the Multi-label K-Nearest Neighbors (MLkNN) algorithm and hybrid CNN–LSTM models, incorporated contextual information from entire posts, further improving emotional inference [22,23].
2.3. Transformer-Based Approach to Multi-Label Classification
Transformer architectures, including BERT, RoBERTa, GPT, and Transformer-XL, leverage self-attention mechanisms to capture long-range dependencies and contextual nuances, providing significant performance improvements in multi-label emotion classification [24,25,26,27]. Several studies have extended transformers by integrating semantic, topical, and contextual information simultaneously. Examples include BERT fused with LDA topic vectors [24] or topic-enhanced capsule networks [25] as well as Latent Emotion Memory (LEM) networks designed to capture implicit emotional representations [26]. Hybrid and ensemble strategies combining transformers with Bi-LSTMs, CNNs, and lexical knowledge further improved performance on benchmark datasets [28,29]. Generative and semi-supervised strategies, including Text-Label Mutual Attention Networks [30], ChatGPT (GPT-3.5) pseudo-labeling [31], and prompt-tuned GPT-2 [32], demonstrate efficacy in low-resource and cross-lingual settings. Social media-specific variants such as BERTweet [5] and Cardiff NLP (TweetNLP) [6] models, pre-trained on large-scale Twitter corpora, effectively handle informal language, slang, and stylistic nuances. Nevertheless, even these models often require task-specific adaptation to address class imbalance, domain-specific jargon, or complex multi-label dependencies.
2.4. Applications of Emotion Classification
Emotion classification has found critical applications in crisis response and disaster management, where understanding public sentiment can improve situational awareness and decision-making. For instance, annotated social media data have been used to train classifiers to support real-time crisis monitoring tools, as demonstrated by [33]. During events like the Brisbane floods and Christchurch earthquake, emotion analysis helped shape emergency communication strategies. More recent work has leveraged deep learning and transformer-based models to detect emotional trends in disaster-related tweets, such as [34]’s classification of earthquake-related emotions and [35]’s integration of Natural Language Processing (NLP) with geospatial visualization. Similarly, [36] developed a BERT-based model tailored for identifying typhoon-related damage in Chinese social media.
Beyond emergencies, emotion classification has been applied in diverse fields including sports and activism. In sports analytics, CNN-based models were used to interpret public sentiment during major sporting events [37]. Meanwhile, in climate activism, researchers have analyzed emotional content around movements like the Global Youth Climate Protest, capturing sentiment linked to hashtags such as #ClimateJustice and #WeDontHaveTime [38]. These applications illustrate how emotion detection can provide deeper insights into public engagement and discourse.
Commercial and societal applications are also growing. In e-commerce, emotion classification enables a more nuanced understanding of customer feedback beyond simple positive/negative sentiment, as shown by [39]. Models have also been developed for content moderation such as detecting hate speech [40], identifying mental health signals in social media posts [41] and cyberbullying detection [42]. During health crises like the COVID-19 pandemic [43,44] and the monkeypox outbreak [45], emotion analysis of millions of posts has offered valuable insights into public fears and reactions, helping to inform health communication strategies. These varied applications highlight the expanding relevance and adaptability of emotion classification across domains.
Despite the success of transformer-based models, few studies explicitly address social media–specific adaptation, class imbalance, and refined multi-label prediction in crisis contexts [5,6,28,29]. Our approach extends prior work by integrating additional self-attention layers on a Twitter-optimized RoBERTa model and implementing label-wise threshold tuning, validated on real-world disaster tweets. This framework improves multi-label detection in informal, noisy social media text and represents a practical advancement over existing transformer-based methods, particularly in the context of crisis communication.
3. Methods
3.1. Dataset and Preprocessing
In this study, we utilized the SemEval-2018 Task 1: Affect in Tweets (English) dataset, which comprises 11 emotion categories of anger, anticipation, disgust, fear, joy, love, optimism, pessimism, sadness, surprise, and trust. This taxonomy captures a broad spectrum of emotional experiences across positive and negative valences, as well as anticipatory and reflective states. Although SemEval-2018 is relatively small and somewhat dated, it remains one of the few publicly available datasets with high-quality, manually annotated multi-label emotion data, making it suitable for benchmarking transformer-based models. To ensure balanced representation of all emotion classes in both training and validation sets, we applied an iterative stratified train-test split that preserves label distributions across subsets. While this choice limits the generalizability of our findings, the proposed approach can be extended in future work to larger, more recent, or domain-specific datasets to further evaluate model robustness.
Each tweet was tokenized using Hugging Face’s AutoTokenizer in conjunction with the Cardiff NLP model, which is pre-trained on Twitter data and designed to handle informal language, hashtags, emojis, and slang. Minimal preprocessing was performed to preserve the richness of social media expressions, which often carry important emotional and sentimental cues. Specifically, empty tweets were removed, and duplicate whitespace was stripped, while other informal characteristics, such as emojis, repeated characters, punctuation, and hashtags, were retained to enhance the model’s ability to capture nuanced emotions. Token sequences were truncated or zero-padded to a fixed maximum length of 64 tokens to ensure uniform input dimensions. A maximum sequence length of 64 tokens was used, as the typical tweet falls within this length. The 11 emotion labels were then converted into multi-hot encoded vectors, where each dimension indicates the presence (1) or absence (0) of a specific emotion. These preprocessed token sequences and encoded labels were then used as input to fine-tune the transformer-based model for multi-label emotion classification.
3.2. Model Architecture
Our proposed architecture builds upon Cardiff NLP which is a RoBERTa transformer pre-trained on emotional language from social media. It is adapted for multi-label classification as shown in Figure 1. The model was configured for 11 output labels corresponding to the emotion categories.
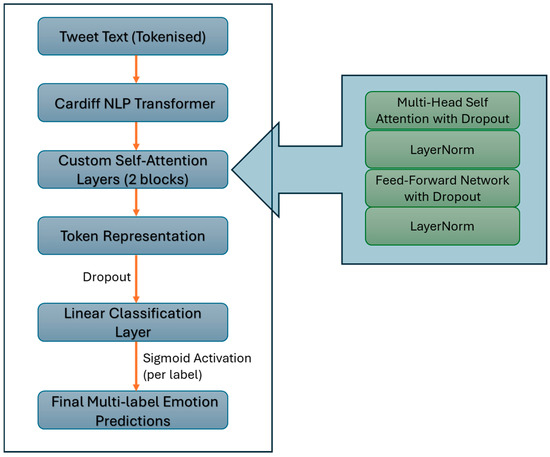
Figure 1.
Model Architecture.
To enhance contextual representations beyond the base outputs of the Cardiff NLP model, we incorporated a stack of two custom self-attention blocks specifically designed to refine token embeddings for the emotion classification task. While Cardiff NLP provides robust contextual embeddings from pretraining on generic Twitter tasks, it may not fully capture patterns most relevant to multi-label emotion detection. Two self-attention layers were chosen Figure, as they are sufficient to model higher-level interactions beyond the base RoBERTa outputs, introducing additional expressiveness without making the model overly deep or difficult to train. This choice was empirically evaluated by comparing models with one and two layers, with two layers showing improved performance. These layers enable the model to selectively focus on input tokens carrying critical emotional information, thereby improving its ability to discern nuanced and overlapping emotional cues. Each block includes:
- Multi-Head Self-Attention: This mechanism allows the model to attend to different positions within the token sequence simultaneously, capturing diverse aspects of the tweet’s context. Eight attention heads are used, providing sufficient capacity to model multiple contextual relationships without introducing excessive computational complexity. Each head projects the input into a subspace to learn specialized attention patterns, enabling the model to focus on words or phrases that are most indicative of specific emotions.
- Layer Normalization: Applied both after the attention output and the subsequent feed-forward layers, layer normalization standardizes activations to stabilize training and improve convergence.
- Feed-Forward Network (FFN): The FFN transforms the token embeddings through a two-layer fully connected network with a Gaussian Error Linear Unit (GELU) activation function between layers. The first linear layer expands the dimensionality of embeddings to four times their original size (hidden size × 4), enabling the network to learn more complex, nonlinear feature transformations. GELU activation is chosen for its smooth, non-monotonic curve that combines properties of Rectified Linear Unit (ReLU) and sigmoid functions, enhancing gradient flow and performance.
- Dropout Layers: Dropout with a rate of 0.2 is applied after both the attention and FFN components to reduce overfitting by randomly disabling neurons during training. This value was determined empirically, balancing regularization with the model’s ability to learn meaningful token-level patterns relevant to emotion classification.
After passing through these stacked attention blocks, the representation of the first token (the [CLS] token) is extracted as a summary embedding of the entire tweet. This embedding undergoes dropout and is then passed to a simple linear classification layer, which outputs raw logits for each of the 11 emotion labels. This linear layer directly maps the refined features to multi-label predictions without further nonlinear transformations, favoring simplicity and potentially better generalization.
3.3. Loss Function and Class Imbalance Handling
To address label imbalance, we employed the Binary Cross-Entropy with Logits Loss (BCEWithLogitsLoss) with per-label positive weights. For each emotion , the weight was calculated as:
where is the total number of training samples and is the number of samples labeled with emotion . This weighting ensures that rarer emotions contribute more to the loss, encouraging the model to remain sensitive to less frequent classes while maintaining balanced learning across all categories. BCE is appropriate for multi-label emotion classification because it treats each label independently, allowing the model to predict co-occurring emotions within a single text.
3.4. Training Procedure and Optimization
The model was trained for up to 15 epochs with a batch size of 8, chosen primarily due to GPU memory constraints when fine-tuning a transformer-based model with self-attention blocks. The learning rate of was empirically determined through preliminary experiments and provided the best balance between stable convergence and effective learning. The 15-epoch limit was selected as a balance between allowing sufficient training time for the model to learn patterns from the data avoiding excessive overfitting or wasting computational resources. Since the training loop incorporates early stopping with a patience of five epochs, the model can halt training earlier if no improvement in micro-F1 is observed, making an upper bound rather than a fixed training duration. Model parameters were optimized using the AdamW optimizer with a weight decay of 0.0005 to regularize training. Training employed automatic mixed precision (AMP) to speed up computations and reduce memory usage on GPUs. AMP uses dynamic loss scaling to maintain numerical stability during backpropagation.
3.5. Evaluation and Threshold Optimization
The raw model outputs (logits) were converted to probabilities using the sigmoid function. Each label required a threshold to decide whether the emotion is present or absent. Instead of a fixed threshold (e.g., 0.5), thresholds were optimized individually per emotion using the precision-recall curve derived from the validation set. The threshold that maximized the F1 score for each label was selected, improving classification performance by balancing precision and recall. Model evaluation metrics included:
- Micro-F1 Score: Aggregates contributions of all labels to compute a global F1 score, sensitive to overall performance.
- Macro-F1 Score: Calculates F1 per label and averages, treating all labels equally.
- Hamming Loss: Fraction of incorrect labels to the total number of labels.
- Jaccard Similarity Index: Measures overlap between predicted and true label sets on a per-sample basis.
3.6. Implementation Details
The model and training pipeline were implemented using PyTorch 2.8.0, leveraging Hugging Face’s Transformers library for the pretrained Cardiff NLP model and tokenizer. Data loading and batching used custom PyTorch Dataset and DataLoader classes tailored for multi-label emotion data. Training progress was visualized using tqdm progress bars. All training and evaluation procedures were conducted on a CUDA-enabled GPU.
4. Results
We evaluated multiple pretrained transformer models for multilabel emotion classification on the SemEval-2018 Task 1 English dataset. The models compared include DeBERTa-v3-base, a general-purpose language model with disentangled attention mechanisms [46]; BERTweet-base, a RoBERTa-based model pretrained on large-scale English tweets [5]; and Cardiff NLP’s Twitter RoBERTa-base, also pretrained on Twitter data for social media NLP tasks [6]. Additionally, we introduce two enhanced variants of the Cardiff NLP model that incorporate custom self-attention blocks for contextual refinement, and experiment with two classifier head designs: a simple linear layer and a deeper feed-forward classifier with GELU activation, batch normalization, and dropout. The performance of all models is summarized in Table 1.

Table 1.
Overall Performance.
Our best performing model, Cardiff NLP with two additional self-attention blocks and a simple linear classifier (Cardiff NLP + SA + simple classifier), achieves the highest micro-F1-score (0.721) and the lowest Hamming loss (0.133), indicating superior multi-label classification capability compared to all baselines. While formal statistical significance testing was not performed, the consistent improvements across multiple evaluation metrics suggest that the enhancements, particularly the additional self-attention blocks contribute meaningfully to improved multi-label emotion classification performance.
Notably, the simple classifier outperformed the deeper feed-forward alternative. The deeper classifier, with its increased number of parameters and complexity, can lead to overfitting given the limited size of the dataset, whereas the RoBERTa model with self-attention blocks already produces rich, expressive embeddings. Adding a more complex classifier on top may be redundant or even detrimental, while a simpler head allows for better generalization and reduces the risk of fitting noise in the data. This performance is comparable to [29] which recorded 74.2% for micro-F1 and 60.3% for macro-F1.
The per-label precision, recall, and F1-score for our best-performing model is summarized in Table 2. The model achieves high precision, recall and F1-score for emotions such as anger, disgust, fear, joy, optimism, and sadness, indicating strong detection capabilities for these categories. Lower scores on anticipation, pessimism, surprise, and trust reflect the challenges in identifying these more nuanced or less frequent emotional states, which may benefit from further data augmentation or specialized modeling strategies.
Table 2.
Per-label Precision, Recall and F1-Score.
Ablation Study
To assess the impact of architectural modifications on model performance, we conducted an ablation study using the Cardiff NLP as the baseline. We examined the effect of adding custom self-attention (SA) blocks and compared two classifier designs: a simple classifier (SC) consisting of a single linear layer, and a deeper classifier (DC) incorporating GELU activation, batch normalization, and dropout.
Adding a single self-attention block with a simple classifier resulted in a modest performance gain over the baseline (Micro-F1: 0.7062 vs. 0.7030), while stacking two self-attention layers led to further improvements (Micro-F1: 0.7208, Macro-F1: 0.6192, Jaccard Index: 0.6066). However, integrating the deeper classifier led to inferior performance across all configurations. For example, with one self-attention layer and the deeper classifier, the Micro-F1 dropped to 0.6922, and the Jaccard Index to 0.5659. This suggests that the added complexity of the deeper classifier may lead to overfitting or optimization difficulties in this task.
Overall, the best performance was achieved by combining two self-attention blocks with a simple classifier, showing consistent improvements across Micro-F1, Macro-F1, Hamming Loss, and Jaccard Index, as shown in Table 3.
Table 3.
Ablation Study Results.
5. Case Study: Christchurch Earthquake
To evaluate the practical applicability of our best-performing emotion classification model, we applied it to a real-world crisis communication scenario. Specifically, we analyzed public emotional responses on Twitter during the 2011 Christchurch earthquakes. This case study demonstrates how transformer-based emotion detection can provide meaningful insights into social media discourse during natural disasters, to support future work in crisis informatics, digital humanitarianism, and psychological monitoring.
We did not fine-tune the model on a labeled earthquake dataset, as no publicly available earthquake-related datasets with emotion annotations currently exist. Existing domain-specific datasets such as CrisisNLP (https://crisisnlp.qcri.org/) and CrisisLex (https://crisislex.org) are labeled for information type and information relevance, respectively, rather than emotional content. Prior work [34] identified six main emotions in earthquake-related tweets as anger, fear, gratitude, humor, sympathy, and worry which can be approximately mapped to the SemEval emotion categories (e.g., anger → anger, fear → fear, grateful → trust/joy, sympathy → sadness/trust, worry → anticipation/pessimism). While humor lacks a direct equivalent, it overlaps with emotions such as joy, surprise, or disgust. This suggests that the SemEval emotion set adequately captures the emotional range found in earthquake events. Fine-tuning on a crisis-specific, emotion-labeled dataset is left for future work.
5.1. Dataset Description
Tweets related to the 2011 Christchurch earthquakes were collected which focuses on two major seismic events: the February 22 and June 13 earthquakes, both of which caused significant disruption and public response in New Zealand. To capture relevant tweets, we employed a keyword-based filtering strategy targeting earthquake-related discourse. Tweets were retrieved using the hashtag #eqnz, which was widely used by the public and media during the crisis. In addition to this hashtag, we included a curated list of keywords and phrases commonly associated with the events, including “Christchurch earthquake”, “chch eqnz”, “nzquake”, “NZ earthquake”, and “quake” [34]. The collection window spanned from the 1 January 2011 to 21 December 2011 to capture both anticipatory and reactive emotional content. This ensured coverage of not only immediate public responses but also the ongoing emotional discourse in the aftermath. There are 55,270 tweets collected.
Importantly, no additional text preprocessing was applied to the tweets. This was a deliberate choice based on the use of the Cardiff NLP RoBERTa-base model, whose tokenizer is specifically designed to handle the informal and varied linguistic features of Twitter data including hashtags, emojis, user mentions, and nonstandard punctuation. This design enables direct and effective processing of raw tweet text, preserving the integrity of the emotional expressions conveyed in the original posts.
5.2. Emotion Distribution
The overall emotion distribution for all tweets collected in 2011 is shown in Figure 2. Among the eleven emotion categories, anticipation was the most frequently detected, appearing over 25,000 tweets. This was followed by sadness, optimism, joy, disgust, and anger. These results suggest a complex blend of emotional responses to events, with both negative (e.g., sadness, disgust) and forward-looking (e.g., anticipation, optimism) emotions being prominently expressed.
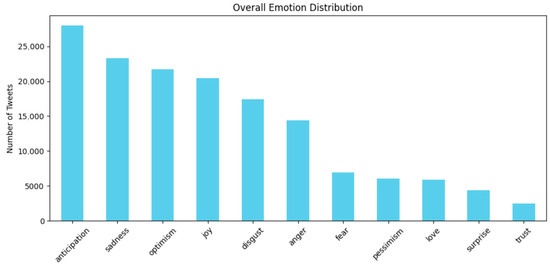
Figure 2.
Overall Emotion Distribution.
Figure 3 illustrates the number of emotion labels assigned per tweet, highlighting the multi-label nature of emotional expression in social media discourse. A significant proportion of tweets were associated with 2 to 4 concurrent emotion labels, reflecting the emotional nuance often conveyed in short-form messages.
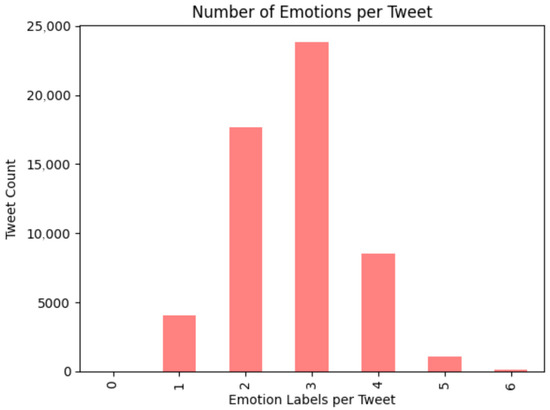
Figure 3.
Number of Emotions per Tweet.
Table 4 present sample tweets along with their corresponding emotional classifications. The tweets presented here are samples selected to illustrate the range of emotional categories identified in the dataset. Each tweet demonstrates different emotional tones that users expressed in response to the event. These examples reflect the diversity of emotional expression captured through social media text classification.
Table 4.
Sample Tweets and Corresponding Multi-Label Emotion Annotations.
The top 10 multi-emotion combinations for the year 2011 are shown in Figure 4. The most frequent combination, anticipation+ joy + optimism, highlights a forward-looking and hopeful sentiment, followed by joy + love + optimism reflecting community support and positive engagement. Negative combinations also appear, with anger + disgust + sadness and anger + disgust indicating concentrated periods of distress. Other notable combinations include pessimism + sadness, joy + optimism and anticipation + sadness, showing that many tweets express nuanced blends of positive and negative emotions simultaneously. Less frequent but still significant combinations, such as anticipation, anger + anticipation + disgust and anticipation + optimism further demonstrate the diversity of emotional expression. Overall, these results reveal that, while negative emotions spike around seismic events, the broader Twitter discourse is dominated by overlapping positive and forward-looking emotions, emphasizing the community’s resilience and hope.
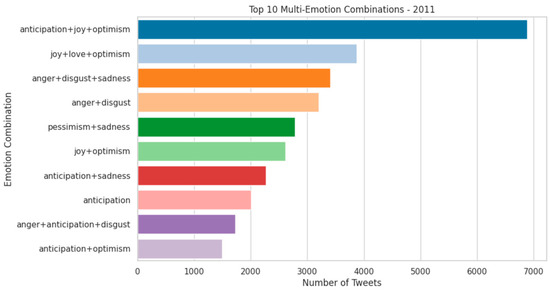
Figure 4.
Top 10 Multi-Emotion Combinations for 2011.
5.3. Emotion Co-Occurrence
Following the 22 February 2011 earthquake, high co-occurrence counts were observed (Figure 5 and Figure 6), with pairs of disgust + sadness (1976), anger + disgust (1859), and joy + optimism (1742) dominating. These patterns indicate that tweets often express multiple negative and positive emotions simultaneously, reflecting both distress and emerging hope or social support. The June 13 earthquake showed similar co-occurrence patterns but at lower intensity (e.g., disgust + anger = 862, joy + optimism = 728, disgust + sadness = 593), suggesting that while the same emotional clusters were present, the overall public reaction was less intense. It can also be observed that fear co-occurs with sadness, disgust, anticipation and anger in both February and June earthquakes. Overall, the comparison demonstrates that the February earthquake triggered more layered and intense emotional responses, whereas the June earthquake elicited a moderate but still mixed emotional reaction, providing insights into the evolving emotional dynamics of the community during crises.
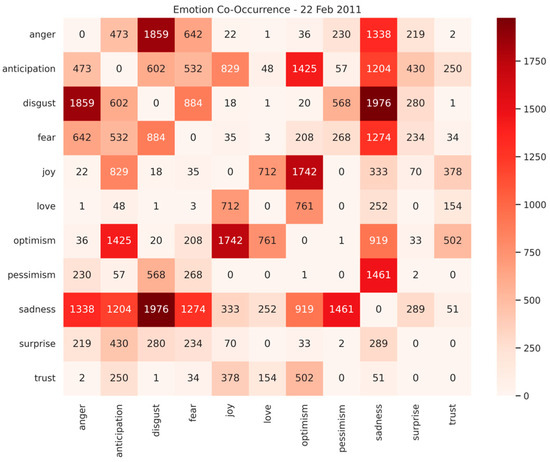
Figure 5.
Emotion Co-Occurrence Matrix for 22 February 2011.
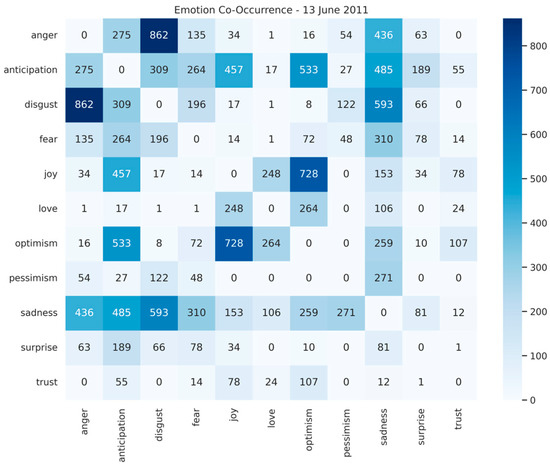
Figure 6.
Emotion Co-Occurrence Matrix for 13 June 2011.
This analysis highlights that fundamental negative emotions (sadness, anger, fear, and disgust) frequently appear together in contexts of trauma and loss, consistent with established emotion theory and Plutchik’s Wheel of Emotions [47]. These emotions also activate overlapping neural networks and behavioral responses, as shown in studies of fear and disgust-conditioned responses [48].
5.4. Temporal Multi-Emotions Dynamics
The temporal analysis of multi-emotion patterns in tweets shown in Figure 7 and Figure 8, provides a detailed view of the collective emotional response to two major seismic events in Christchurch, New Zealand, in 2011. Figure 7, covering January to March, reveals a dramatic and multifaceted emotional spike on 22 February 2011, corresponding to the devastating magnitude 6.3 earthquake. Tweet volume peaked at over 2500, highlighting the scale of the immediate public reaction. The emotional landscape was complex, dominated by anticipation + sadness along with anger+ disgust + sadness and pessimism + sadness. This emotional mix suggests that the collective response was not solely grief, but also included elements of hope, resilience, and a focus on recovery in the face of immense tragedy.
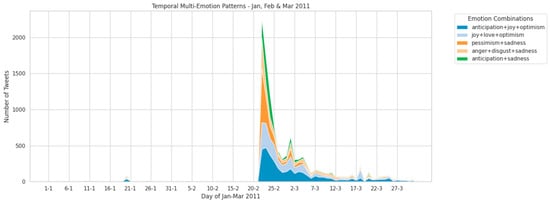
Figure 7.
Temporal Multi-Emotion Patterns for January–March 2011.
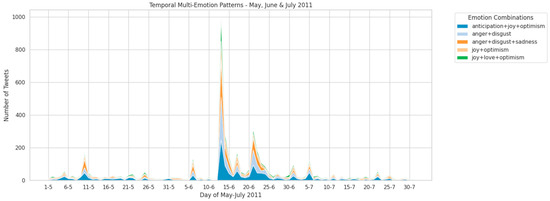
Figure 8.
Temporal Multi-Emotion Patterns for May–July 2011.
A similar but less intense, spike is observed in Figure 8, covering May to July with a clear peak on 13 June 2011. While this earthquake caused further damage and distress, tweet volume was considerably lower, peaking at around 1000 tweets. The emotional patterns largely mirrored those of the initial earthquake, with a mix of both negative and positive emotions. During this time, the dominant mixed emotions were joy + love + optimism, followed by joy + optimism and anger + disgust + sadness. This suggests that while the intensity of the emotional reaction had diminished, the psychological dynamics marked by ongoing distress coupled with resilience and hopefulness remained consistent. The difference in emotional response between the two earthquake events highlights the greater psychological impact of the initial disaster, demonstrating how a community’s evolving emotional dynamics can be both quantitatively and qualitatively mapped over time through social media data.
6. Conclusions and Future Work
This study introduces an enhanced emotion classification model that augments the pre-trained Cardiff NLP transformer with additional self-attention layers. This modification results in a 3.00% overall improvement in multi-label emotion detection performance compared to the baseline.
Applying this model to a real-world dataset of tweets related to the 2011 Christchurch earthquakes, we were able to capture complex emotional expressions across multiple categories simultaneously which is not possible with single-label classification. The analysis revealed distinct patterns of co-occurring emotions, such as disgust + sadness, anger + disgust, and joy + optimism, which aligned closely with the February and June seismic events (as highlighted in Figure 5 and Figure 6). The temporal analysis identifies distinct shifts in public sentiment that closely align with key seismic events, highlighting the evolution of emotional responses. By leveraging multi-label classification, this case study demonstrates the ability to analyze layered emotional responses, overlapping positive and negative sentiments, and their temporal dynamics, providing a richer and more nuanced understanding of public reactions during crises.
Despite these strengths, several limitations should be acknowledged. First, the experiments relied exclusively on the SemEval-2018 Task 1 dataset, which is relatively small, somewhat dated, and limited to English tweets. While effective for benchmarking, this constrains the model’s generalization to more recent, domain-specific, or multilingual contexts. Second, label imbalance was addressed using Binary Cross-Entropy (BCE) loss with positive class weighting, yet rare emotions such as trust, surprise, and pessimism remain challenging to detect. Alternative approaches including focal loss, weak supervision, or data augmentation could improve recognition of these underrepresented categories. Third, although the additional self-attention blocks improved contextual representation, confusion persists between semantically related emotions (e.g., fear and sadness), and the model struggles with sarcasm, irony, and other subtle affective cues. Computational constraints, such as small batch sizes and limited sequence lengths, may further restrict performance. Finally, practical deployment carries potential risks, including the misinterpretation of emotions or amplification of social biases, underscoring the need for careful monitoring and ethical safeguards.
Future research should aim to address these limitations and expand the interdisciplinary scope of this work. Promising directions include fine-tuning on crisis-specific and multilingual emotion-labeled datasets, annotating subsets of crisis tweets for validation, and conducting benchmark comparisons with alternative transformer architectures. Exploring weak supervision techniques to generate proxy labels and experimenting with different imbalance-handling strategies may enhance robustness, particularly for rare emotions.
Beyond model development, integrating psychological and social science perspectives could deepen the understanding of emotional expression and context, while applications in crisis communication and mental health monitoring offer pathways for real-world impact. Ultimately, this line of research advances the potential of transformer-based emotion detection systems as valuable tools for crisis informatics, enabling more informed, empathetic, and data-driven responses during emergencies.
Author Contributions
Conceptualization, P.A. methodology, P.A. and J.Z.; software, P.A.; validation, P.A. and J.Z.; writing—original draft preparation, P.A.; writing—review and editing, P.A. and J.Z.; All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| RNN | Recurrent Neural Networks |
| CNN | Convolutional Neural Networks |
| BERT | Bidirectional Encoder Representations from Transformers |
| RoBERTA | A Robustly Optimized BERT Pretraining Approach |
| GPT | Generative Pre-Trained Transformer |
| SVM | Support Vector Machine |
| LSTM | Long Short-Term Memory |
| GRU | Gated Recurrent Unit |
| BiLSTM | Bidirectional Long Short-Term Memory |
| MME | Multi-label Maximum Entropy |
| JBNN | Joint Binary Neural Network |
| JBCE | Joint Binary Cross-Entropy |
| LVC | Latent Variable Chain |
| ELMo | Embeddings from Language Models |
| MLkNN | Multi-label K-Nearest Neighbors |
| LDA | Latent Dirichlet Allocation |
| LEM | Latent Emotion Memory |
| ALBERT | A Lite BERT |
| TLMAN | Text-Label Mutual Attention Network |
| GCN | Graph Convolutional Networks |
| NLP | Natural Language Processing |
| ERC | Emotion Recognition in Conversation |
| FFN | Feed-Forward Network |
| GELU | Gaussian Error Linear Unit |
| ReLU | Rectified Linear Unit |
| CLS | Classification |
| BCE | Binary Cross-Entropy |
| AMP | Automatic Mixed Precision |
| DeBERTa | Decoding-enhanced BERT with Disentangled Attention |
| SA | Self-Attention |
| SC | Simple Classifier |
| DC | Deeper Classifier |
References
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Tuan Nguyen, A. BERTweet: A pre-trained language model for English Tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 9–14. [Google Scholar]
- Camacho-collados, J.; Rezaee, K.; Riahi, T.; Ushio, A.; Loureiro, D.; Antypas, D.; Boisson, J.; Espinosa Anke, L.; Liu, F.; Martínez Cámara, E. TweetNLP: Cutting-Edge Natural Language Processing for Social Media. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 38–49. [Google Scholar]
- Bandhakavi, A.; Wiratunga, N.; Padmanabhan, D.; Massie, S. Lexicon based feature extraction for emotion text classification. Pattern Recognit. Lett. 2017, 93, 133–142. [Google Scholar] [CrossRef]
- Gimenez, R.; Gaviola, M.; Sabellano, M.J.; Gorro, K. Emotion Classification of Duterte Administration Tweets Using Hybrid Approach. In Proceedings of the 2017 International Conference on Software and e-Business, Hong Kong, 28–30 December 2017. [Google Scholar]
- Aslam, N.; Rustam, F.; Lee, E.; Washington, P.B.; Ashraf, I. Sentiment Analysis and Emotion Detection on Cryptocurrency Related Tweets Using Ensemble LSTM-GRU Model. IEEE Access 2022, 10, 39313–39324. [Google Scholar] [CrossRef]
- Bharti, S.K.; Varadhaganapathy, S.; Gupta, R.K.; Shukla, P.K.; Bouye, M.; Hingaa, S.K.; Mahmoud, A. Text-Based Emotion Recognition Using Deep Learning Approach. Comput. Intell. Neurosci. 2022, 2022, 2645381. [Google Scholar] [CrossRef] [PubMed]
- Glenn, A.; LaCasse, P.M.; Cox, B.A. Emotion classification of Indonesian Tweets using Bidirectional LSTM. Neural Comput. Appl. 2023, 35, 9567–9578. [Google Scholar] [CrossRef]
- Anbazhagan, K.; Kurlekar, S.; Brindha, T.V.; Sudhish Reddy, D. Twitter Based Emotion Recognition Using Bi-LSTM. In Proceedings of the 2024 International Conference on Trends in Quantum Computing and Emerging Business Technologies, Pune, India, 22–23 March 2024; pp. 1–5. [Google Scholar]
- Shaw, C.; LaCasse, P.; Champagne, L. Exploring emotion classification of indonesian tweets using large scale transfer learning via IndoBERT. Soc. Netw. Anal. Min. 2025, 15, 22. [Google Scholar] [CrossRef]
- Li, J.Y.; Rao, Y.; Jin, F.; Chen, H.; Xiang, X. Multi-label maximum entropy model for social emotion classification over short text. Neurocomputing 2016, 210, 247–256. [Google Scholar] [CrossRef]
- Almeida, A.M.G.; Cerri, R.; Paraiso, E.C.; Mantovani, R.G.; Junior, S.B. Applying multi-label techniques in emotion identification of short texts. Neurocomputing 2018, 320, 35–46. [Google Scholar] [CrossRef]
- He, H.; Xia, R. Joint Binary Neural Network for Multi-label Learning with Applications to Emotion Classification. In Proceedings of the Natural Language Processing and Chinese Computing, Hohhot, China, 26–30 August 2018. [Google Scholar]
- Huang, C.; Trabelsi, A.; Qin, X.; Farruque, N.; Zaiane, O.R. Seq2Emo for Multi-label Emotion Classification Based on Latent Variable Chains Transformation. arXiv 2019, arXiv:1911.02147. [Google Scholar]
- Jabreel, M.; Moreno, A. A Deep Learning-Based Approach for Multi-Label Emotion Classification in Tweets. Appl. Sci. 2019, 9, 1123. [Google Scholar] [CrossRef]
- Ameer, I.; Ashraf, N.; Sidorov, G.; Gómez-Adorno, H. Multi-label Emotion Classification using Content-Based Features in Twitter. Comput. Y Sist. 2020, 24. [Google Scholar] [CrossRef]
- Sarbazi-Azad, S.; Akbari, A.; Khazeni, M. ExaAEC: A New Multi-label Emotion Classification Corpus in Arabic Tweets. In Proceedings of the 2021 11th International Conference on Computer Engineering and Knowledge (ICCKE), Mashhad, Iran, 28–29 October 2021; pp. 465–470. [Google Scholar]
- Ashraf, M.; Saeed, M.; Ali, F.; Ahmad, W. Multi-label emotion classification of Urdu tweets using machine learning and deep learning techniques. PeerJ Comput. Sci. 2022, 8, e896. [Google Scholar] [CrossRef]
- Liu, X.; Shi, T.; Zhou, G.; Liu, M.; Yin, Z.; Yin, L.; Zheng, W. Emotion classification for short texts: An improved multi-label method. Humanit. Soc. Sci. Commun. 2023, 10, 306. [Google Scholar] [CrossRef]
- Maragheh, H.K.; Gharehchopogh, F.S.; Majidzadeh, K.; Sangar, A.B. A Hybrid Model Based on Convolutional Neural Network and Long Short-Term Memory for Multi-label Text Classification. Neural Process. Lett. 2024, 56, 42. [Google Scholar] [CrossRef]
- Ding, F.; Kang, X.; Nishide, S.; Guan, Z.; Ren, F. A fusion model for multi-label emotion classification based on BERT and topic clustering. In Proceedings of the International Symposium on Artificial Intelligence and Robotics, Kitakyushu, Japan, 1–10 August 2020; SPIE: Bellingham, DC, USA, 2020; Volume 11574. [Google Scholar]
- Fei, H.; Ji, D.; Zhang, Y.; Ren, Y. Topic-Enhanced Capsule Network for Multi-Label Emotion Classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 1839–1848. [Google Scholar] [CrossRef]
- Fei, H.; Zhang, Y.; Ren, Y.; Ji, D. Latent Emotion Memory for Multi-Label Emotion Classification. Proc. AAAI Conf. Artif. Intell. 2020, 34, 7692–7699. [Google Scholar] [CrossRef]
- Acheampong, F.A.; Nunoo-Mensah, H.; Chen, W. Transformer models for text-based emotion detection: A review of BERT-based approaches. Artif. Intell. Rev. 2021, 54, 5789–5829. [Google Scholar] [CrossRef]
- Ahanin, Z.; Ismail, M.A.; Singh, N.S.S.; AL-Ashmori, A. Hybrid Feature Extraction for Multi-Label Emotion Classification in English Text Messages. Sustainability 2023, 15, 12539. [Google Scholar] [CrossRef]
- Ameer, I.; Bölücü, N.; Siddiqui, M.H.F.; Can, B.; Sidorov, G.; Gelbukh, A. Multi-label emotion classification in texts using transfer learning. Expert Syst. Appl. 2023, 213, 118534. [Google Scholar] [CrossRef]
- Dong, X.; Chen, X.; Li, Y.; Liu, J.; Du, Y.; Li, X. Mutual Attention Network for Multi-label Emotion Recognition with Graph-Structured Label Representations. In Proceedings of the 2024 International Conference on Ubiquitous Computing and Communications (IUCC), Chengdu, China, 20–22 December 2024; pp. 168–175. [Google Scholar]
- Malik, U.; Bernard, S.; Pauchet, A.; Chatelain, C.; Picot-Clemente, R.; Cortinovis, J. Pseudo-Labeling with Large Language Models for Multi-Label Emotion Classification of French Tweets. IEEE Access 2024, 12, 15902–15916. [Google Scholar] [CrossRef]
- Siddiqui, M.H.F.; Inkpen, D.; Gelbukh, A.F. Instruction Tuning of LLMs for Multi-label Emotion Classification in Social Media Content. In Proceedings of the Canadian AI, Guelph, ON, Canada, 27–31 May 2024. [Google Scholar]
- Brynielsson, J.; Johansson, F.; Jonsson, C.; Westling, A. Emotion classification of social media posts for estimating people’s reactions to communicated alert messages during crises. Secur. Inform. 2014, 3, 1–11. [Google Scholar] [CrossRef]
- Anthony, P.; Hoi Ki Wong, J.; Joyce, Z. Identifying emotions in earthquake tweets. AI Soc. 2025, 40, 2909–2926. [Google Scholar] [CrossRef]
- He, C.; Hu, D. Social Media Analytics for Disaster Response: Classification and Geospatial Visualization Framework. Appl. Sci. 2025, 15, 4330. [Google Scholar] [CrossRef]
- Zou, L.; He, Z.; Zhou, C.; Zhu, W. Multi-class multi-label classification of social media texts for typhoon damage assessment: A two-stage model fully integrating the outputs of the hidden layers of BERT. Int. J. Digit. Earth 2024, 17, 2348668. [Google Scholar] [CrossRef]
- Stojanovski, D.; Strezoski, G.; Madjarov, G.; Dimitrovski, I. Emotion identification in FIFA world cup tweets using convolutional neural network. In Proceedings of the 2015 11th International Conference on Innovations in Information Technology (IIT), Dubai, United Arab Emirates, 1–3 November 2015; pp. 52–57. [Google Scholar]
- Fagbola, T.M.; Abayomi, A.; Mutanga, M.B.; Jugoo, V.R. Lexicon-Based Sentiment Analysis and Emotion Classification of Climate Change Related Tweets. In Proceedings of the 13th International Conference on Soft Computing and Pattern Recognition (SoCPaR 2021), Online, 15–17 December 2022. [Google Scholar]
- Deniz, E.; Erbay, H.; Cosar, M. Multi-Label Classification of E-Commerce Customer Reviews via Machine Learning. Axioms 2022, 11, 436. [Google Scholar] [CrossRef]
- Adesokan, A.; Madria, S.K.; Nguyen, L. HatEmoTweet: Low-level emotion classifications and spatiotemporal trends of hate and offensive COVID-19 tweets. Soc. Netw. Anal. Min. 2023, 13, 136. [Google Scholar] [CrossRef]
- Cabral, R.C.; Han, S.C.; Poon, J.; Nenadic, G. MM-EMOG: Multi-Label Emotion Graph Representation for Mental Health Classification on Social Media. Robotics 2024, 13, 53. [Google Scholar] [CrossRef]
- Farasalsabila, F.; Utami, E.; Raharjo, S. Multi-Label Classification using BERT for Cyberbullying Detection. In Proceedings of the 2024 4th International Conference of Science and Information Technology in Smart Administration (ICSINTESA), Balikpapan, Indonesia, 12–13 July 2024; pp. 195–200. [Google Scholar]
- Meder, T.; Meertens Instituut, A.N. Online Coping with the First Wave: Covid Humor and Rumor on Dutch Social Media (March–July 2020). Folk.-Electron. J. Folk. 2021, 82, 135–158. [Google Scholar] [CrossRef]
- Oliveira, F.B.; Haque, A.; Mougouei, D.; Sichman, J.S.; Singh, M.P.; Evans, S. Investigating the Emotional Response to COVID-19 News on Twitter: A Topic Modelling and Emotion Classification Approach. IEEE Access 2022, 10, 16883–16897. [Google Scholar] [CrossRef]
- Olusegun, R.; Oladunni, T.; Audu, H.; Houkpati, Y.; Bengesi, S. Text Mining and Emotion Classification on Monkeypox Twitter Dataset: A Deep Learning-Natural Language Processing (NLP) Approach. IEEE Access 2023, 11, 49882–49894. [Google Scholar] [CrossRef]
- He, P.; Gao, J.; Chen, W. DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing. arXiv 2023, arXiv:2111.09543. [Google Scholar]
- Plutchik, R. A psychoevolutionary theory of emotions. Soc. Sci. Inf. 1982, 21, 529–553. [Google Scholar] [CrossRef]
- Klucken, T.; Schweckendiek, J.; Koppe, G.; Merz, C.J.; Kagerer, S.; Walter, B.; Sammer, G.; Vaitl, D.; Stark, R. Neural correlates of disgust- and fear-conditioned responses. Neuroscience 2012, 201, 209–218. [Google Scholar] [CrossRef]








Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).