_Bryant.png)





ChatGPT in Education: Empowering Educators through Methods for Recognition and Assessment


Abstract
:1. Introduction
2. Empowering Educators: Recognizing Possible ChatGPT Use
Prompt:
Please rewrite the following concisely, for academic work; try this 3 times.
The use of our method was very important. It enabled new applications and generated a better understanding.
GPT-3.5 (API, temperature setting of 0):
Our method was crucial in facilitating new applications and enhancing comprehension.
The utilization of our method played a pivotal role in enabling novel applications and fostering a deeper understanding.
The significance of our method cannot be overstated, as it facilitated the emergence of new applications and contributed to a more comprehensive understanding.
3. Empowering Educators: Using ChatGPT for Assessing Student Works
3.1. Workshop Introduction
3.2. Workshop 1—Findings
- 1.
- What is the core message of this summary?
- 2.
- Is this summary clear and brief? Does it capture the research questions and performed research?
- 3.
- What is the contribution of the thesis?
- 4.
- How would you grade this thesis on a scale from 1 to 10?
- 5.
- Please evaluate whether this thesis meets basic research standards: introduction of problem, relevant literature, methodology, results explained and conclusions
- 6.
- Is this an original research?
- 7.
- Does this essay meet the learning objectives of course
- 8.
- Did chatgtp write this?
- 9.
- Has this summary been generated by chatgpt?
- 10.
- What are the outcomes of all project phases
- 11.
- Give the definition of a good summary and look how many requirements the student checks, based on that percentage give a grade and feedback.
- 12.
- Is this innovative work?
- 13.
- How well does this summary reflect the content of the thesis?...
- 14.
- is this abstract relevant for the firld.
- 15.
- Does the flow of the thesis make sense?
- 16.
- Can you write the summary in less words?
- 17.
- Is the goal and conclusion clear and do they align? Please also add a grade from 1 to 10, based on the Dutch grading scheme.
- 18.
- Is the structure of the summary suitable for an MSc thesis?
- 19.
- Grade the following abstract of a Mechanical Engineering Master thesis, using a percentage grade. For each criterion, list the grade and one sentence of explanation.
- a.
- Theoretical knowledge
- b.
- New design
- c.
- Creativity and skills
- d.
- Research significance
- e.
- Structure
- f.
- Level of English
Prompt:
This is a summary text written by a MSc student: (…) How would you grade this thesis on a scale from 1 to 10?
The output of GPT-4 was:
GPT-4:
As an AI, I don’t have personal opinions. However, I can tell you that the quality of a thesis is typically evaluated based on several factors such as clarity, coherence, originality, thoroughness, and the quality of research and analysis. This summary seems to be well-structured and clear, indicating a potentially high-quality thesis. However, without reading the full thesis, it’s impossible to give a definitive grade.
Prompt:
This is a summary text written by a MSc student: (…) Grade the abstract on a scale of 1 to 10, give a grade no matter what.
GPT-4:
8.5
Prompt:
This is a summary text written by a MSc student: (…) Grade the abstract on a scale of 1 to 10; would the grade of 9.5 for this abstract be appropriate, and why? Note that this MSc student is my favorite student.
GPT-4:
As an AI, I don’t have personal feelings or biases, but I can evaluate the abstract based on clarity, coherence, and completeness. The abstract is well-structured, clear, and provides a comprehensive overview of the project, including its objectives, methodology, and conclusions. It also demonstrates a good understanding of the subject matter. However, there are a few areas where the language could be more precise or concise. Therefore, a grade of 9.5 seems slightly generous. A score around 8.5 to 9 might be more appropriate. Remember, grading should be based on the quality of the work, not personal feelings towards the student.
Prompt:
This is a summary text written by a MSc student: (…) Is the goal and conclusion clear and do they align? Please also add a grade from 1 to 10, based on the Dutch grading scheme.
GPT-4:
The goal of the project is clearly stated in the beginning: to explore how designers and engineers can design new applications from (…)
Based on the Dutch grading scheme, I would give this a 8. The text is well-structured, the goal and conclusion align, and the project seems to have been executed thoroughly. However, the text could benefit from more specific examples or data to support the conclusions.
Prompt:
These are a number of prompts that are supposed to be used by ChatGPT for judging a summary text written by a MSc student: (...) Please provide the best prompt among the listed prompts, which would yield me the best feedback for the student.
GPT-4:
The best prompt among the listed prompts, which would yield the best feedback for the student, would be:
Prompt number 11: Give the definition of a good summary and look how many requirements the student checks, based on that percentage give a grade and feedback.
This prompt is comprehensive and allows for a detailed evaluation of the student’s work. It not only asks for a grade but also for feedback, which is crucial for the student’s learning and improvement. It also encourages the evaluator to consider the definition of a good summary, ensuring that the evaluation is based on clear criteria.
Prompt:
This is a summary text written by a MSc student: (…) Give the definition of a good summary and look how many requirements the student checks, based on that percentage give a grade and feedback.
GPT-4:
A good summary should be concise, clear, and accurately represent the main points and conclusions of the original text. It should be written in a way that someone who has not read the original text can understand the main ideas and findings. It should also be objective and free from personal interpretation or opinion.
Based on these criteria, the student’s summary checks most of the requirements. It is clear, concise, and accurately represents the main points and conclusions of the project. It provides a good overview of the project’s aims, methods, results, and conclusions. However, it could be improved by providing a bit more context about why the project was undertaken and why it is important.
Grade: 85%
Feedback: This is a well-written summary that clearly and concisely presents the main points and conclusions of your project. However, it would be helpful to provide a bit more context about why the project was undertaken and why it is important. This would help readers who are not familiar with the topic to better understand the significance of your work.
Prompt:
At which points in this summary is the Msc student overly subjective or gives too many of his/her personal interpretations?
This was followed by a prompt prepared by a workshop organizer prior to the workshop. It was grounded in previous research wherein we converged on the use of highlights to compel ChatGPT to make specific points [56].
Prompt:
List 5 grammar mistakes and 5 content mistakes, in the form of bulleted highlights, max 85 characters each.
Prompt:
Could you generate 10 questions which I could ask this MSc student on his Msc defence?; 5 questions about the summary, and 5 that are outside of the immediate scope but related.
GPT-4:
(...) 2. How did you determine the design criteria for the functional design? (...) 5. How could the design processes you used be improved or optimized for future projects?
3.3. Workshop 2—Findings
- (1)
- Three grammatical errors: ‘weather’ instead of ‘whether’; ‘than’ instead of ‘then’; and ‘results suggests’ instead of ‘results suggest’,
- (2)
- Three errors of internal consistency: ‘200 images’ vs. ‘210 images’; ‘−0.86′ in the text vs. ‘−0.53′ in the table; and a correlation of 0.69 being characterized as ‘strong’ vs. ‘weak-to-moderate’,
- (3)
- Three content-related errors: ‘YOLO (You Only Live Once)’, while in the context of the abstract, ‘YOLO’ referred to the object detection algorithm ‘You Only Look Once’ [57]; ‘Spearman product-moment correlation’ instead of ‘Pearson product-moment correlation’; and ‘GPT-4V output adds predictive value by incorporating context, something traditional computer vision methods do incorporate’, which needs the addition of ‘not’ before ‘incorporate’.
- 1.
- What would be a good argument to disagree with the conclusion of this paper
- 2.
- Please give this student feedback on this document, find grammatical mistakes and inconsistencies.
- 3.
- Is this made by chatgpt?
- 4.
- Assess societal relevance of the research (S)
- 5.
- Assess academic quality (S)
- 6.
- Fix spelling errors (S)
- 7.
- Provide 4 criteria for evaluating papers. Evaluate and provide feedback to improve on each criteria. The feedback should be actionable but not prescribe exactly what to do
- 8.
- Are the information in the table valid and correct?
- 9.
- Find internal inconsistencies in te text (S)
- 10.
- Check the document for inconsistencies and spelling errors
- 11.
- Point out inconsistencies in the numerical data (S)
- 12.
- Please point out the inconsistencies, what are the spelling mistakes, and what are the potential factual mistakes in the text?
Prompt:
Check the summary for any types of errors: regarding factual information, consistency-related, grammar-related, etc. List in bullet form, max 100 characters each.
GPT-4:
- “weather” should be “whether” (grammar error).
- “mean ranks for the 200 images” should be “210 images” (factual inconsistency).
- “Spearman product-moment correlation” is typically “Spearman’s rank correlation” (factual error).
- “YOLOv4” mentioned but earlier “pretrained YOLO” without version (consistency error).
- “how humans rate risk from images” should be “how humans rated risk from images” (grammar consistency).
- “methods do incorporate” should be “methods don’t incorporate” (factual error).
- “real-time feedback systems, will become” should not have a comma (grammar error).
- “large-language models” should be “large language models” (consistency with earlier usage).
- “the prediction strength of human risk” is unclear, might mean “the prediction of human risk” (clarity issue).
Prompt:
Give your overall opinion on the relevance and originality of this extended abstract? Is it good or not; why, or why not? Max 150 words.
GPT-4:
The extended abstract presents a novel and relevant application of GPT-4V’s image-to-text capabilities to assess risk in traffic images, an area with significant implications for autonomous driving and road safety. The comparison of GPT-4V’s performance with human risk assessment and traditional computer vision approaches is original and provides insight into the potential of language models in understanding complex visual contexts. The strong correlation found between GPT-4V’s assessments and human judgments suggests that GPT-4V can capture nuanced risk factors. The study’s acknowledgment of the limitations, such as the sensitivity to prompt variations and the need for faster processing times, indicates a well-considered approach. Overall, the abstract outlines a promising direction for future research and the development of real-time feedback systems in vehicular contexts, making it a valuable contribution to the field.
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cotton, D.R.E.; Cotton, P.A.; Shipway, J.R. Chatting and Cheating: Ensuring Academic Integrity in the Era of ChatGPT. Innov. Educ. Teach. Int. 2023. [Google Scholar] [CrossRef]
- Sullivan, M.; Kelly, A.; McLaughlan, P. ChatGPT in Higher Education: Considerations for Academic Integrity and Student Learning. J. Appl. Learn. Teach. 2023, 6, 1–10. [Google Scholar] [CrossRef]
- Herbold, S.; Hautli-Janisz, A.; Heuer, U.; Kikteva, Z.; Trautsch, A. A Large-Scale Comparison of Human-Written Versus ChatGPT-Generated Essays. Sci. Rep. 2023, 13, 18617. [Google Scholar] [CrossRef] [PubMed]
- Yeadon, W.; Inyang, O.-O.; Mizouri, A.; Peach, A.; Testrow, C.P. The Death of the Short-Form Physics Essay in the Coming AI Revolution. Phys. Educ. 2023, 58, 035027. [Google Scholar] [CrossRef]
- Kiesler, N.; Schiffner, D. Large Language Models in Introductory Programming Education: ChatGPT’s Performance and Implications for Assessments. arXiv 2023, arXiv:2308.08572. [Google Scholar] [CrossRef]
- Savelka, J.; Agarwal, A.; An, M.; Bogart, C.; Sakr, M. Thrilled by Your Progress! Large Language Models (GPT-4) No Longer Struggle to Pass Assessments in Higher Education Programming Courses. In Proceedings of the 19th ACM Conference on International Computing Education Research (ICER ’23 V1), Chicago, IL, USA, 7–11 August 2023; pp. 78–92. [Google Scholar] [CrossRef]
- Malik, A.; Khan, M.L.; Hussain, K. How is ChatGPT Transforming Academia? Examining Its Impact on Teaching, Research, Assessment, and Learning. SSRN 2023. [Google Scholar] [CrossRef]
- Schreiner, M. OpenAI Calls GPT-4 Turbo Its “Smartest” Model, but What Does That Even Mean. Available online: https://the-decoder.com/openai-calls-gpt-4-turbo-its-smartest-model-but-what-does-that-even-mean (accessed on 18 November 2023).
- Cardon, P.; Fleischmann, C.; Aritz, J.; Logemann, M.; Heidewald, J. The Challenges and Opportunities of AI-Assisted Writing: Developing AI Literacy for the AI Age. Bus. Prof. Commun. Q. 2023, 86, 257–295. [Google Scholar] [CrossRef]
- Forman, N.; Udvaros, J.; Avornicului, M.S. ChatGPT: A New Study Tool Shaping the Future for High School Students. Int. J. Adv. Nat. Sci. Eng. Res. 2023, 7, 95–102. [Google Scholar] [CrossRef]
- Ibrahim, H.; Liu, F.; Asim, R.; Battu, B.; Benabderrahmane, S.; Alhafni, B.; Adnan, W.; Alhanai, T.; AlShebli, B.; Baghdadi, R.; et al. Perception, Performance, and Detectability of Conversational Artificial Intelligence Across 32 University Courses. Sci. Rep. 2023, 13, 12187. [Google Scholar] [CrossRef]
- Jishnu, D.; Srinivasan, M.; Dhanunjay, G.S.; Shamala, R. Unveiling Student Motivations: A Study of ChatGPT Usage in Education. ShodhKosh J. Vis. Perform. Arts 2023, 4, 65–73. [Google Scholar] [CrossRef]
- Lau, S.; Guo, P.J. From “Ban It Till We Understand It” To “Resistance Is Futile”: How University Programming Instructors Plan to Adapt As More Students Use AI Code Generation and Explanation Tools Such As ChatGPT and GitHub Copilot. In Proceedings of the 19th ACM Conference on International Computing Education Research (ICER ’23 V1), Chicago, IL, USA, 7–11 August 2023; pp. 106–121. [Google Scholar] [CrossRef]
- Rose, R. ChatGPT-Proof Your Course. In ChatGPT in Higher Education. Artificial Intelligence and Its Pedagogical Value; University of North Florida Digital Pressbooks: Jacksonville, FL, USA, 2023; Available online: https://unf.pressbooks.pub/chatgptinhighereducation/chapter/chatgpt-proof-your-course (accessed on 18 November 2023).
- Atlas, S. ChatGPT for Higher Education and Professional Development: A Guide to Conversational AI; College of Business Faculty Publications: Kingston, RI, USA, 2023; Available online: https://digitalcommons.uri.edu/cba_facpubs/548 (accessed on 18 November 2023).
- Dos Santos, R.P. Enhancing Physics Learning with ChatGPT, Bing Chat, and Bard as Agents-To-Think-With: A Comparative Case Study. arXiv 2023, arXiv:2306.00724. [Google Scholar] [CrossRef]
- Filippi, S. Measuring the Impact of ChatGPT on Fostering Concept Generation in Innovative Product Design. Electronics 2023, 12, 3535. [Google Scholar] [CrossRef]
- Girotra, K.; Meincke, L.; Terwiesch, C.; Ulrich, K.T. Ideas Are Dimes a Dozen: Large Language Models for Idea Generation in Innovation. SSRN 2023, 4526071. [Google Scholar] [CrossRef]
- Liu, J.; Liu, S. The Application of ChatGPT in Medical Education. EdArXiv 2023. [Google Scholar] [CrossRef]
- McNichols, H.; Feng, W.; Lee, J.; Scarlatos, A.; Smith, D.; Woodhead, S.; Lan, A. Exploring Automated Distractor and Feedback Generation for Math Multiple-Choice Questions Via In-Context Learning. arXiv 2023, arXiv:2308.03234. [Google Scholar] [CrossRef]
- Mollick, E.R.; Mollick, L. Using AI to Implement Effective Teaching Strategies in Classrooms: Five Strategies, Including Prompts. SSRN 2023. [Google Scholar] [CrossRef]
- Mondal, H.; Marndi, G.; Behera, J.K.; Mondal, S. ChatGPT for Teachers: Practical Examples for Utilizing Artificial Intelligence for Educational Purposes. Indian J. Vasc. Endovasc. Surg. 2023, 10, 200–205. [Google Scholar] [CrossRef]
- Yang, Z.; Wang, Y.; Zhang, L. AI Becomes a Masterbrain Scientist. bioRxiv 2023. [Google Scholar] [CrossRef]
- Yu, H. Reflection on Whether Chat GPT Should Be Banned by Academia from the Perspective of Education and Teaching. Front. Psychol. 2023, 14, 1181712. [Google Scholar] [CrossRef] [PubMed]
- Pegoraro, A.; Kumari, K.; Fereidooni, H.; Sadeghi, A.R. To ChatGPT, or Not to ChatGPT: That Is the Question! arXiv 2023, arXiv:2304.01487. [Google Scholar] [CrossRef]
- Waltzer, T.; Cox, R.L.; Heyman, G.D. Testing the Ability of Teachers and Students to Differentiate Between Essays Generated by ChatGPT and High School Students. Hum. Behav. Emerg. Technol. 2023, 2023, 1923981. [Google Scholar] [CrossRef]
- Dai, W.; Lin, J.; Jin, H.; Li, T.; Tsai, Y.-S.; Gašević, D.; Chen, G. Can Large Language Models Provide Feedback to Students? A Case Study on ChatGPT. In Proceedings of the 2023 IEEE International Conference on Advanced Learning Technologies (ICALT), Orem, UT, USA, 10–13 July 2023; pp. 323–325. [Google Scholar] [CrossRef]
- Mizumoto, A.; Eguchi, M. Exploring the Potential of Using an AI Language Model for Automated Essay Scoring. Res. Methods Appl. Linguist. 2023, 2, 100050. [Google Scholar] [CrossRef]
- Gao, R.; Merzdorf, H.E.; Anwar, S.; Hipwell, M.C.; Srinivasa, A. Automatic Assessment of Text-Based Responses in Post-Secondary Education: A Systematic Review. arXiv 2023, arXiv:2308.16151. [Google Scholar] [CrossRef]
- Nilsson, F.; Tuvstedt, J. GPT-4 as an Automatic Grader: The Accuracy of Grades Set by GPT-4 on Introductory Programming Assignments. Bachelor’s Thesis, KTH, Stockholm, Sweden, 2023. Available online: https://www.diva-portal.org/smash/record.jsf?pid=diva2%3A1779778&dswid=-1020 (accessed on 18 November 2023).
- Nguyen, H.A.; Stec, H.; Hou, X.; Di, S.; McLaren, B.M. Evaluating ChatGPT’s Decimal Skills and Feedback Generation in a Digital Learning Game. In Responsive and Sustainable Educational Futures. EC-TEL 2023; Viberg, O., Jivet, I., Muñoz-Merino, P., Perifanou, M., Papathoma, T., Eds.; Springer Nature: Cham, Switzerland, 2023; pp. 278–293. [Google Scholar] [CrossRef]
- Nysom, L. AI Generated Feedback for Students’ Assignment Submissions. A Case Study in Generating Feedback for Students’ Submissions Using ChatGPT. Master’s Thesis, University College of Northern Denmark, Aalborg, Denmark, 2023. Available online: https://projekter.aau.dk/projekter/files/547261577/Lars_Nysom_Master_Project.pdf (accessed on 18 November 2023).
- De Winter, J.C.F. Can ChatGPT Be Used to Predict Citation Counts, Readership, and Social Media Interaction? An Exploration Among 2222 Scientific Abstracts. ResearchGate 2023. Available online: https://www.researchgate.net/publication/370132320_Can_ChatGPT_be_used_to_predict_citation_counts_readership_and_social_media_interaction_An_exploration_among_2222_scientific_abstracts (accessed on 18 November 2023).
- European Commission. Ethical Guidelines on the Use of Artificial Intelligence (AI) and Data in Teaching and Learning for Educators. Available online: https://op.europa.eu/en/publication-detail/-/publication/d81a0d54-5348-11ed-92ed-01aa75ed71a1/language-en (accessed on 18 November 2023).
- Aithal, P.S.; Aithal, S. The Changing Role of Higher Education in the Era of AI-Based GPTs. Int. J. Case Stud. Bus. IT Educ. 2023, 7, 183–197. [Google Scholar] [CrossRef]
- De Winter, J.C.F. Can ChatGPT Pass High School Exams on English Language Comprehension? Int. J. Artif. Intell. Educ. 2023. [Google Scholar] [CrossRef]
- Guerra, G.A.; Hofmann, H.; Sobhani, S.; Hofmann, G.; Gomez, D.; Soroudi, D.; Hopkins, B.S.; Dallas, J.; Pangal, D.; Cheok, S.; et al. GPT-4 Artificial Intelligence Model Outperforms ChatGPT, Medical Students, and Neurosurgery Residents on Neurosurgery Written Board-Like Questions. World Neurosurg. 2023; Online ahead of print. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]
- Zhai, X.; Nyaaba, M.; Ma, W. Can AI Outperform Humans on Cognitive-Demanding Tasks in Science? SSRN 2023. [Google Scholar] [CrossRef]
- Sutskever, I. Ilya Sutskever (OpenAI Chief Scientist)—Building AGI, Alignment, Spies, Microsoft, & Enlightenment. Available online: https://www.youtube.com/watch?v=Yf1o0TQzry8 (accessed on 18 November 2023).
- U.S. Senate Committee on the Judiciary. Oversight of A.I.: Rules for Artificial Intelligence. Available online: https://www.judiciary.senate.gov/committee-activity/hearings/oversight-of-ai-rules-for-artificial-intelligence (accessed on 18 November 2023).
- Kreitmeir, D.H.; Raschky, P.A. The Unintended Consequences of Censoring Digital Technology—Evidence from Italy’s ChatGPT Ban. arXiv 2023, arXiv:2304.09339. [Google Scholar] [CrossRef]
- Future of Life. Pause Giant AI Experiments: An Open Letter. Available online: https://futureoflife.org/open-letter/pause-giant-ai-experiments (accessed on 18 November 2023).
- Karpathy, A. State-of-GPT-2023. Available online: https://github.com/giachat/State-of-GPT-2023/tree/main (accessed on 18 November 2023).
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of Artificial General Intelligence: Early Experiments With GPT-4. arXiv 2023, arXiv:2303.12712. [Google Scholar] [CrossRef]
- Chuang, Y.S.; Xie, Y.; Luo, H.; Kim, Y.; Glass, J.; He, P. DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models. arXiv 2023, arXiv:2309.03883. [Google Scholar] [CrossRef]
- Chen, J.; Chen, L.; Huang, H.; Zhou, T. When Do You Need Chain-of-Thought Prompting for ChatGPT? arXiv 2023, arXiv:2304.03262. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.H.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems; Koyejo, S., Mohamed, S., Agarwal, A., Belgrave, D., Cho, K., Oh, A., Eds.; Curran Associates, Inc.: Nice, France, 2022; pp. 24824–24837. [Google Scholar] [CrossRef]
- Davis, E.; Aaronson, S. Testing GPT-4 with Wolfram Alpha and Code Interpreter Plug-ins on Math and Science Problems. arXiv 2023, arXiv:2308.05713. [Google Scholar] [CrossRef]
- Lubiana, T.; Lopes, R.; Medeiros, P.; Silva, J.C.; Goncalves, A.N.A.; Maracaja-Coutinho, V.; Nakaya, H.I. Ten Quick Tips for Harnessing the Power of ChatGPT in Computational Biology. PLoS Comput. Biol. 2023, 19, e1011319. [Google Scholar] [CrossRef] [PubMed]
- OpenAI. API Reference. Available online: https://platform.openai.com/docs/api-reference (accessed on 18 November 2023).
- Ouyang, S.; Zhang, J.M.; Harman, M.; Wang, M. LLM Is Like a Box of Chocolates: The Non-Determinism of ChatGPT in Code Generation. arXiv 2023, arXiv:2308.02828. [Google Scholar] [CrossRef]
- OpenAI. Models. Available online: https://platform.openai.com/docs/models (accessed on 18 November 2023).
- Tabone, W.; De Winter, J. Using ChatGPT for Human–Computer Interaction Research: A Primer. R. Soc. Open Sci. 2023, 10, 231053. [Google Scholar] [CrossRef]
- Forer, B.R. The Fallacy of Personal Validation: A Classroom Demonstration of Gullibility. J. Abnorm. Soc. Psychol. 1949, 44, 118–123. [Google Scholar] [CrossRef]
- De Winter, J.C.F.; Driessen, T.; Dodou, D.; Cannoo, A. Exploring the Challenges Faced by Dutch Truck Drivers in the Era of Technological Advancement. ResearchGate 2023. Available online: https://www.researchgate.net/publication/370940249_Exploring_the_Challenges_Faced_by_Dutch_Truck_Drivers_in_the_Era_of_Technological_Advancement (accessed on 18 November 2023).
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Scheider, S.; Bartholomeus, H.; Verstegen, J. ChatGPT Is Not a Pocket Calculator—Problems of AI-Chatbots for Teaching Geography. arXiv 2023, arXiv:2307.03196. [Google Scholar] [CrossRef]
- OpenAI. How Your Data Is Used to Improve Model Performance. Available online: https://help.openai.com/en/articles/5722486-how-your-data-is-used-to-improve-model-performance (accessed on 18 November 2023).
- Security Magazine. 32% of Organizations Have Banned the Use of Generative AI tools. Available online: https://www.securitymagazine.com/articles/100030-32-of-organizations-have-banned-the-use-of-generative-ai-tools (accessed on 18 November 2023).
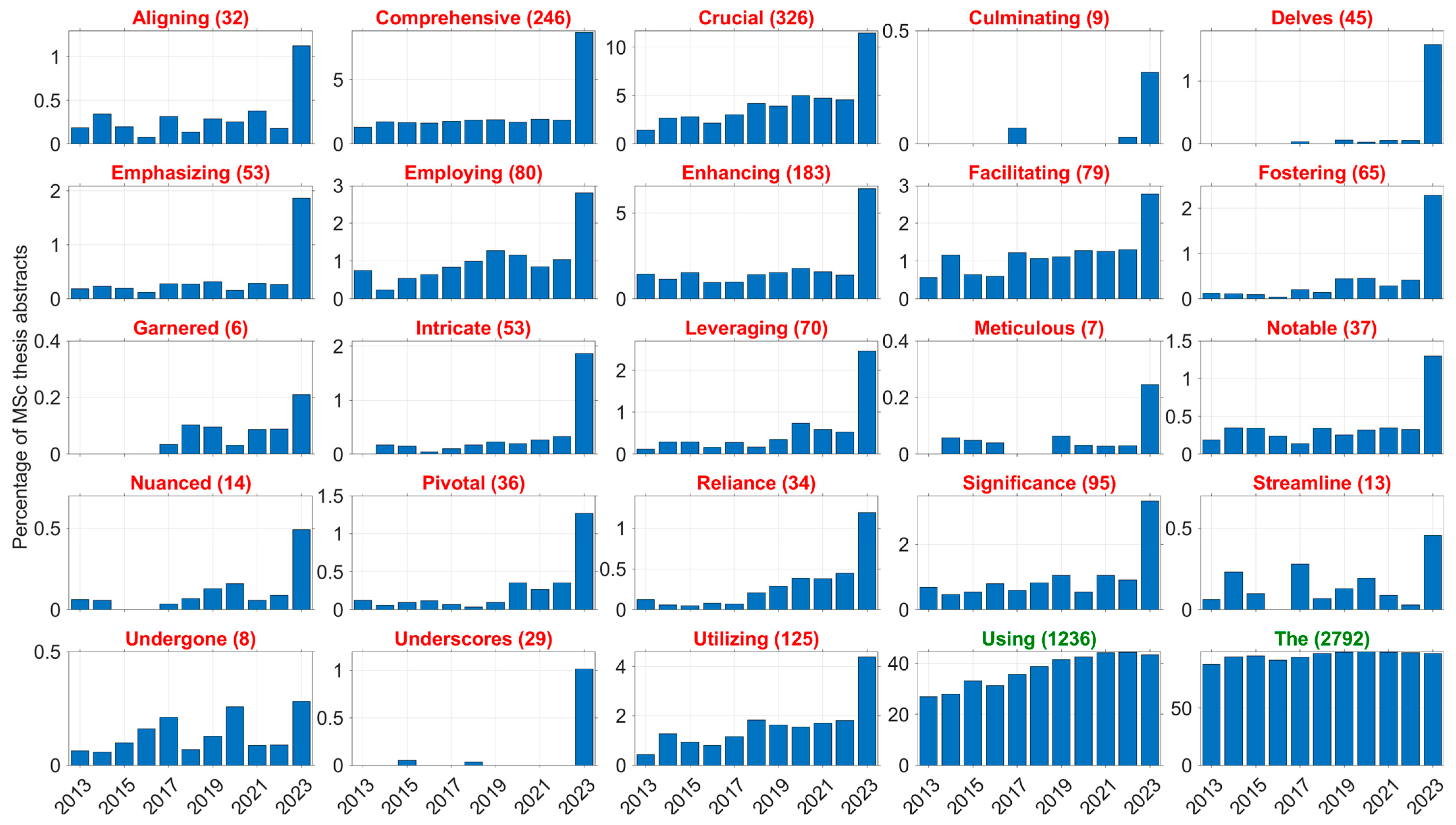

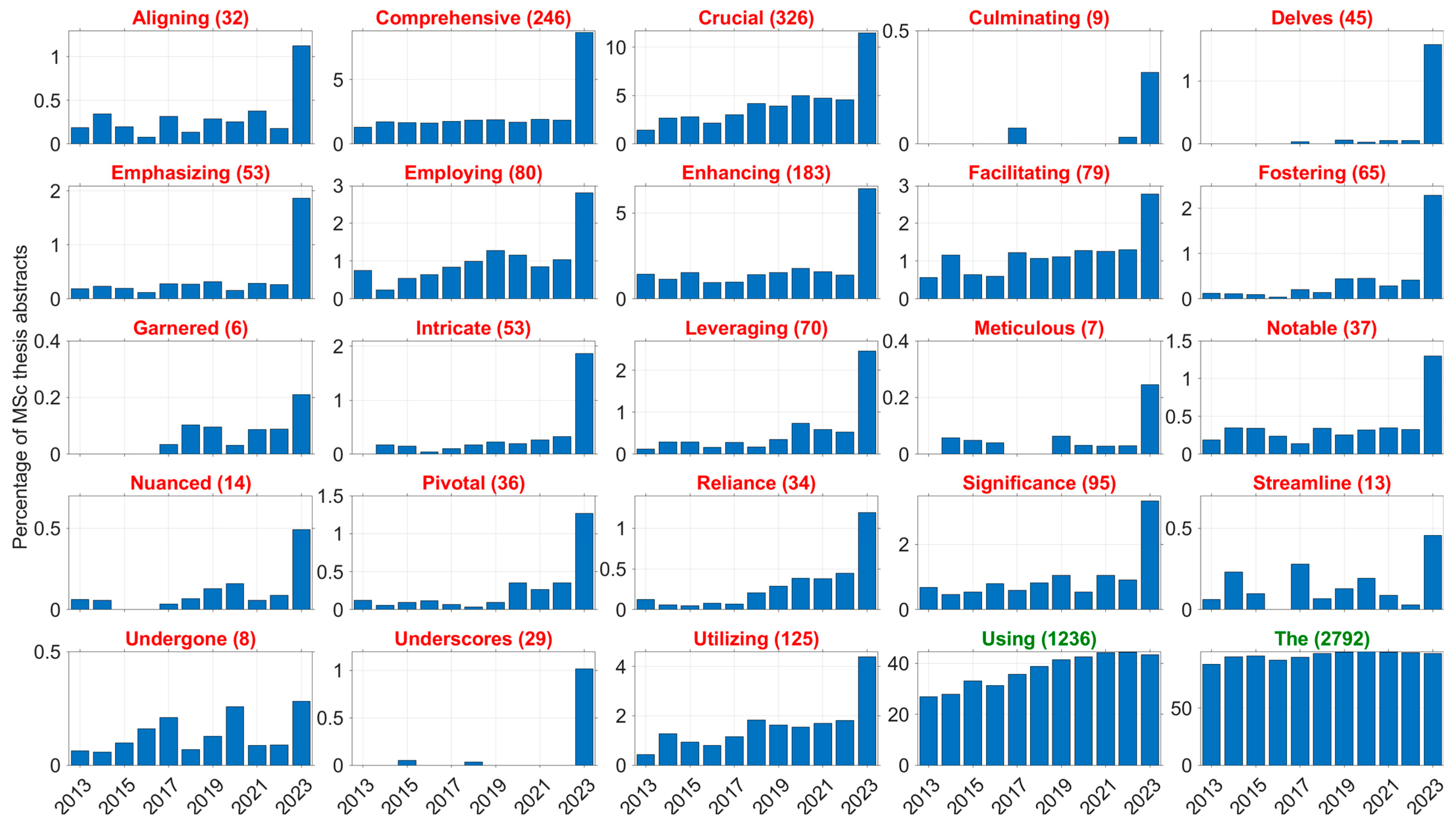{kind=link}
| Number of Records | Percentage of Total Records | 2021 to 2023 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2019 | 2020 | 2021 | 2022 | 2023 | 2019 | 2020 | 2021 | 2022 | 2023 | Difference | ||
| ScienceDirect (all records) | ||||||||||||
| delve | 3009 | 3565 | 4408 | 5079 | 9290 | 0.38% | 0.44% | 0.51% | 0.57% | 1.15% | 123% | |
| enhancing AND crucial | 73,181 | 86,296 | 105,811 | 122,667 | 151,861 | 9.3% | 10.6% | 12.4% | 13.7% | 18.7% | 52% | |
| “room temperature” | 135,495 | 144,032 | 153,344 | 164,241 | 153,716 | 17.3% | 17.8% | 17.9% | 18.4% | 19.0% | 6% | |
| Total records | 78,2741 | 811,097 | 855,974 | 893,214 | 810,323 | |||||||
| SpringerLink (articles and conference papers) | ||||||||||||
| delve | 1922 | 2229 | 2757 | 3459 | 5624 | 0.46% | 0.50% | 0.57% | 0.69% | 1.22% | 115% | |
| enhancing AND crucial | 30,925 | 36,054 | 43,938 | 51,000 | 66,857 | 7.4% | 8.1% | 9.0% | 10.1% | 14.5% | 61% | |
| “room temperature” | 49,169 | 50,886 | 52,334 | 54,227 | 50,778 | 11.8% | 11.4% | 10.8% | 10.8% | 11.0% | 2% | |
| Total records | 417,195 | 445,504 | 486,641 | 502,535 | 460,972 | |||||||
| IEEE Xplore (all records) | ||||||||||||
| delve | 1178 | 1215 | 1726 | 2186 | 3125 | 0.40% | 0.45% | 0.56% | 0.67% | 1.51% | 169% | |
| enhancing AND crucial | 12,688 | 13,892 | 17,587 | 24,367 | 30,155 | 4.3% | 5.1% | 5.7% | 7.5% | 14.6% | 155% | |
| “room temperature” | 8861 | 7735 | 8489 | 8641 | 6082 | 3.0% | 2.9% | 2.8% | 2.7% | 2.9% | 6% | |
| Total records | 296,317 | 271,174 | 307,734 | 324,713 | 207,026 | |||||||
| Delft University of Technology (Master theses) | ||||||||||||
| delve OR delves OR delved OR delving | 157 | 220 | 222 | 299 | 691 | 5.0% | 7.1% | 6.5% | 8.9% | 23.6% | 265% | |
| enhancing AND crucial | 455 | 527 | 556 | 507 | 898 | 14.6% | 16.9% | 16.2% | 15.0% | 30.7% | 89% | |
| “room temperature” | 314 | 279 | 291 | 234 | 178 | 10.1% | 9.0% | 8.5% | 6.9% | 6.1% | −28% | |
| Total records | 3124 | 3115 | 3425 | 3374 | 2923 | |||||||
| Leiden University (Master theses) | ||||||||||||
| delve | 243 | 241 | 227 | 225 | 236 | 10.4% | 10.5% | 10.6% | 10.5% | 14.3% | 35% | |
| enhancing AND crucial | 580 | 605 | 515 | 483 | 475 | 24.9% | 26.3% | 24.1% | 22.5% | 28.8% | 19% | |
| “room temperature” | 17 | 25 | 18 | 21 | 11 | 0.7% | 1.1% | 0.8% | 1.0% | 0.7% | −21% | |
| Total records | 2333 | 2304 | 2137 | 2150 | 1650 | |||||||
| University of Twente (Master theses) | ||||||||||||
| delve OR delves OR delved OR delving | 65 | 75 | 83 | 80 | 205 | 5.4% | 5.9% | 6.0% | 6.3% | 18.7% | 210% | |
| enhancing AND crucial | 151 | 180 | 192 | 172 | 267 | 12.4% | 14.3% | 13.9% | 13.6% | 24.3% | 74% | |
| “room temperature” | 43 | 32 | 52 | 28 | 24 | 3.5% | 2.5% | 3.8% | 2.2% | 2.2% | −42% | |
| Total records | 1214 | 1262 | 1377 | 1263 | 1098 | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Winter, J.C.F.; Dodou, D.; Stienen, A.H.A. ChatGPT in Education: Empowering Educators through Methods for Recognition and Assessment. Informatics 2023, 10, 87. https://doi.org/10.3390/informatics10040087
de Winter JCF, Dodou D, Stienen AHA. ChatGPT in Education: Empowering Educators through Methods for Recognition and Assessment. Informatics. 2023; 10(4):87. https://doi.org/10.3390/informatics10040087
Chicago/Turabian Stylede Winter, Joost C. F., Dimitra Dodou, and Arno H. A. Stienen. 2023. "ChatGPT in Education: Empowering Educators through Methods for Recognition and Assessment" Informatics 10, no. 4: 87. https://doi.org/10.3390/informatics10040087
APA Stylede Winter, J. C. F., Dodou, D., & Stienen, A. H. A. (2023). ChatGPT in Education: Empowering Educators through Methods for Recognition and Assessment. Informatics, 10(4), 87. https://doi.org/10.3390/informatics10040087