1. Introduction
During the COVID-19 pandemic, traffic on almost all popular Social Media (SMs) has increased by over 10%, mainly due to regional lockdowns and the need for additional information regarding the virus. Posts on SMs have circulated expressing the positive attitudes of those who believe that we are indeed dealing with a dangerous virus outbreak, the negative attitudes of skeptics or even virus deniers, and neutral attitudes.
This study explored the fluctuation of sentiments on Twitter by examining the attitudes towards officially reported COVID-19 cases and deaths. The subsequent sections will guide the readers through an analysis of other similar studies, the methodology and findings of the research, possible obstacles, consequences, and future enhancements to facilitate a probable incorporation into a widely accepted solution.
SMs, such as Twitter, have allowed the global community to deal with COVID-19 by offering reliable information, online connectivity, and real-time event tracking. However, as later studies demonstrated, there have also been disadvantages in using SMs as a source of information, for example due to fake news [
1]. Moreover, the online anti-vaccination movement shares many ties with COVID-19 deniers and conspiracy theorists [
2].
The foundations for opinion mining and Sentiment Analysis (SA) were laid by Pang and Lee [
3]. According to them, opinion mining, emotion analysis, and/or subjectivity analysis are defined as: “the areas that deal with the computational processing of opinion, emotion, and subjectivity in the text”. SA is utilized for extracting knowledge [
4,
5,
6,
7,
8,
9,
10] from the Internet and SMs, which have been established as multi-functional networking tools [
11], enabling various mining tasks in complex information networks [
12].
Today, more than ever, we need ways and approaches to manage massive amounts of data and mitigate global disasters like COVID-19. Governments, corporations, and organizations require tools to evaluate such situations. The significance of this work is attributed to the fact that COVID-19 has caused economic and psychological problems to individuals and societies, on top of medical ones [
13,
14]. By addressing these points, we can improve the knowledge-extraction capabilities by utilizing SMs’ data and elaborating on trends or correlations between different data sources. For example integrating SMs’ data with other crucial data, such as travel patterns, demographic information, or socioeconomic characteristics, might yield a more-holistic comprehension of the circumstances underlying COVID-19. This enhances the predictive, descriptive, and diagnostic analytics of this study [
15]. Moreover, SA can help indicate which topics are being discussed most on SMs about the COVID-19 pandemic and can be used to explore trends on vaccination decisions and, thus, aid policymakers to make targeted decisions [
16].
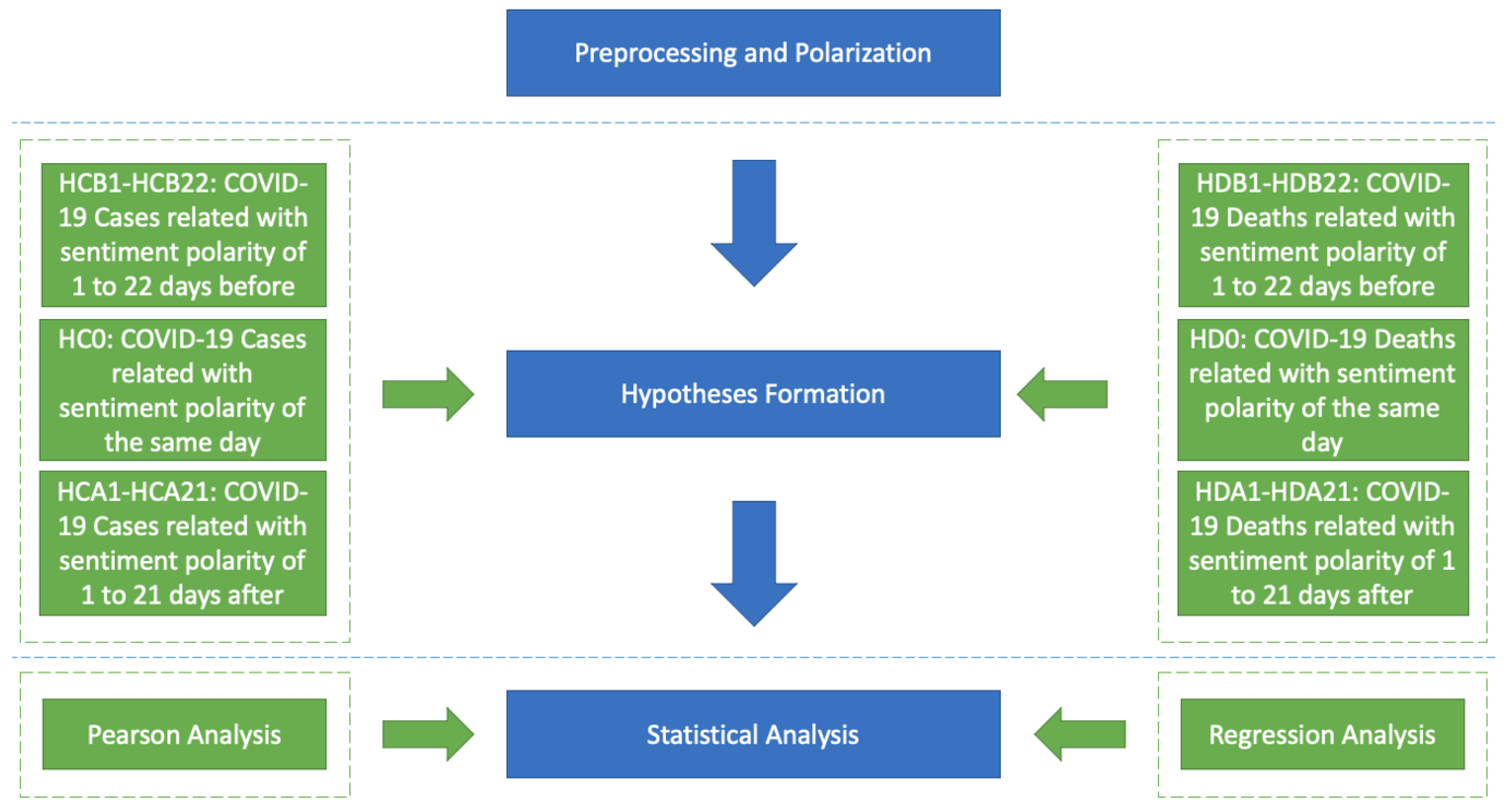
The conceived approach builds upon three contextual processes: preprocessing and polarization, hypothesis formation, and statistical analysis. The first process attempts to assess the sentiment of posts on Twitter. The second process aims to form hypotheses related to COVID-19 cases and deaths. The third process validates the existence of correlations between the time series of these three variables (tweet sentiment, cases, and deaths). This is achieved by addressing the following objectives:
Improve the sentiment polarization output by utilizing text preprocessing for accurate and reliable results.
Validate trends on Twitter sentiment in relation to the actual number of COVID-19 cases and deaths to retrieve useful insights.
Develop an approach/methodology that creates opportunities for disease forecasting by discovering and monitoring multivariable correlations, such as cases vs. polarity or deaths vs. polarity.
Moreover, this study addressed the following research questions: Can tweets act as an indicator for predicting polarity related to COVID-19 cases and deaths? Is there a correlation between these three data labels (tweets, cases, deaths)? If yes, to what extent? Are there any trends in these data labels? This study attempted to answer these questions envisioning future improvements involving localization and multilingual aspects, association rule mining, forecasting (the generated correlations may be used as input features for improving forecasting accuracy), and comparative reporting of various similar approaches.
The next sections of this work are organized as follows.
Section 2 presents a literature review on relevant SA research attempts. The approach employed in this study is outlined in
Section 3, while the findings obtained are presented and analyzed along with possible implications in
Section 4. Lastly, the concluding part (
Section 5) provides a summary of the main findings and engages in a discussion on the limitations and potential future directions of this study.
2. Background
COVID-19 research is one of the hottest trends since 2020. Multiple studies related to SMs’ data and potential capabilities, such as forecasting outcomes, have been reported and categorized according to the application domain (e.g., healthcare, politics, etc.) [
17]. Other studies combined SA, mainly using data from SMs and COVID-19. The most-representative ones that are related to this study are reported here. They deal with topic/theme extraction [
18], political interventions [
19], sentiment extraction/categorization [
20], news-sharing behavior and communication trends [
21], information diffusion and user interaction patterns [
22], multi-lingual misinformation [
23], the sentiment context during lockdowns [
24], geo-tagged network analysis [
25], and tools for improving SA [
26] and tracking/predicting worldwide outbreaks [
27].
However, to the best of our knowledge, there are no similar published efforts that have used SA on data from Twitter to find potential links between the polarity of sentiments and the number of reported COVID-19 cases or deaths. Furthermore, this study introduces a fresh approach by utilizing hypothesis formation and statistical analysis to uncover the dynamics of sentiment in microblogs, for which there is currently no similar established methodology.
More specifically, in [
18], the authors retrieved the main topics related to COVID-19 posted on Twitter. From 2.8 million tweets, they identified around 167k related posts. According to their categorization, there were four main themes about COVID-19: (i) its origin (location), (ii) its source (causes that led to its transmission to humans), (iii) its impact on people and countries, and (iv) methods for controlling its spread.
Political leaders have been using SMs for information dissemination since 2008. In 2020, a 23% growth in Twitter users was observed. They also communicate COVID-19 emotions related to informing the public. A data source of 12,128 tweets regarding 29 Indian political leaders was utilized. The data analysis involved NRC-based (emotion lexicon) SA. The retrieved emotions included “anger”, “disgust”, “fear”, “joy”, “negative”, “positive”, and more. The findings showcased that “positive” and “trust” are the most common when authorities choose to intervene by posting guidelines [
19].
SA was also conducted on tweets from India after the lockdown, using a dataset of 24k tweets for 4 days, from 25 March 2020 until 28 March 2020 [
20]. The most-dominant stems were “consult”, “manag”, and “disast”. An analysis was conducted by categorizing the sentiments via 10 words (“anger”, “anticipation”, “disgust”, “fear”, “joy”, “negative”, “positive”, “sadness”, “surprise”, and “trust”). The most-popular tweet sentiments were “positive”, “trust”, and “negative” with a count of 24k, 16k, and 9.5k, respectively.
Park et al. investigated news-sharing behavior, along with information-transmission networks from data related to COVID-19, gathered from 44k Korean Twitter users [
21]. They identified more than 78k relationships and found that communication regarding COVID-19 amongst users was more frequent and faster in terms of the spread of information.
Cinelli et al. investigated the diffusion of COVID-19 information by using data from five different SMs (Gab, Instagram, Reddit, Twitter, and YouTube) [
22]. They gathered 1.3 m posts in total, with 7.4 m comments from 3.7 m users for 45 days from 1 January 2020 until 14 February 2020. Of these posts, 88.5% came from Twitter, and 94.5% of comments and 85.7% of users came from YouTube. After analyzing the spread of debatable information or even misinformation, they concluded that Gab was the SM most prone to misinformation spread. Finally, they concluded that the channels of information dissemination and their contents depend on two factors: (i) the SM itself and (ii) the interaction patterns of groups of users that discuss the topic.
In a similar study, Singh et al. attempted to investigate the sharing of COVID-19 information and misinformation on Twitter [
23]. For a two-month period, from 16 January to 15 March 2020, they collected 2.8 million tweets, along with 457k quotes and 18.2 million retweets. The language of the tweets was predominately English (55.2%), followed by Spanish (12.5%) and French (7.4%). Overall, 32 languages were recognized. The countries that suffered the most demonstrated an increase in COVID-19-related tweets compared to the pre-COVID-19 period. They also provided a worldwide tweet geo-location distribution and compared it to the reported cases. Lastly, they summarized the identified themes using the most-frequent words in the tweets, finding that just 0.6% of the tweets discussed myths or conspiracy theories.
Sentiment within comments, hashtags, and posts from Twitter may be analyzed according to trends by keywords such as “covid” and “coronavirus”. Common tools/methods are Natural Language Processing (NLP) and sentiment classification with a Recurrent Neural Network (RNN). The authors in [
24] offered a solution for identifying the emotional manifestations from Twitter data according to a specific topic and time interval. Another study dealt with COVID-19 Twitter data collection from India. A total of 410,643 English tweets were gathered from 22 March to 21 April 2020, to investigate the public sentiment context during a lockdown period. Retrieving sentiment and emotions over time may improve the understanding of public contexts and expressions during a crisis such as a pandemic [
28].
Lopez et al. used text mining, NLP, and network analysis to investigate the perception of COVID-19 policies by mining a COVID-19-related multi-language Twitter dataset [
25]. From 22 January to 13 March 2020 (a 52-day period), they collected around 6.5 million tweets. Of these, 63.4% were written in English, 12.7% in Spanish/Castilian, and the rest in 64 other languages. Extreme retweet bursts were observed in Europe in late February and early March. Finally, they provided a geo-located distribution of 1625 tweets.
Samuel et al. tried to identify public sentiment associated with the pandemic using COVID-19-related tweets in the U.S. and the R [
29] statistical software 4.0.0 [
26]. They downloaded tweets from February to March 2020, and by using geo-tagged analytics, the association with non-textual variables, SA, and classification methods, they found that Naive Bayes performed better (91%) for sentiment classification of short (in length) COVID-19 tweets compared to logistic regression (74%). Better performance was also identified for long tweets, but with worse accuracy (57% and 52%, respectively).
Finally, another study by Hamzah et al. introduced the CoronaTracker, a worldwide COVID-19 outbreak data analysis and prediction tool [
27]. They utilized Susceptible–Exposed–Infectious–Recovered (SEIR) predictive modeling to forecast the COVID-19 outbreak based on daily observations. In their methodology, they included SA on articles from the news (561 positives and 2548 negatives) to further understand public reaction towards the pandemic.
4. Results
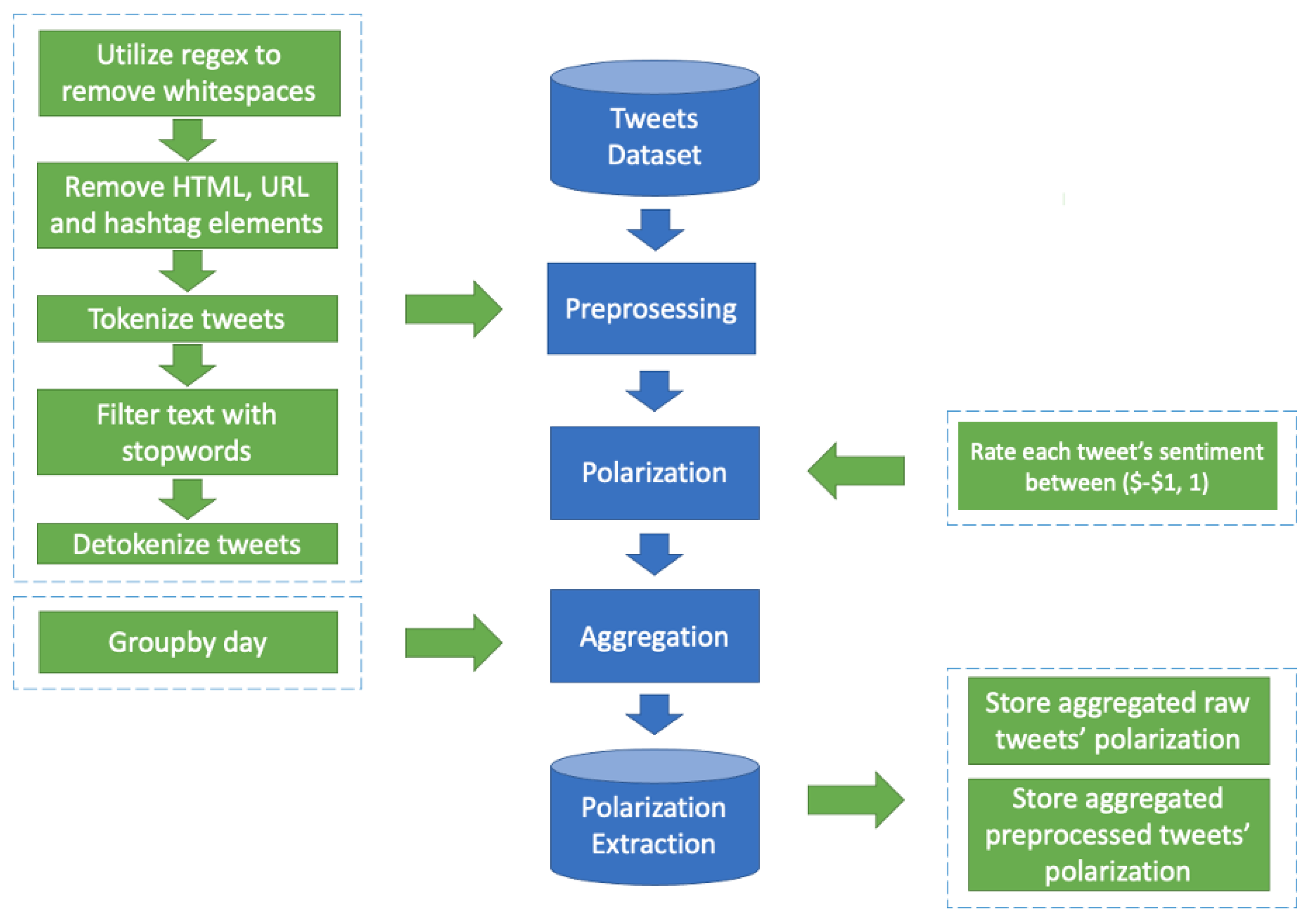
This section presents the outputs from preprocessing and polarization, as well as the statistical analysis for validating the hypothesis processes.
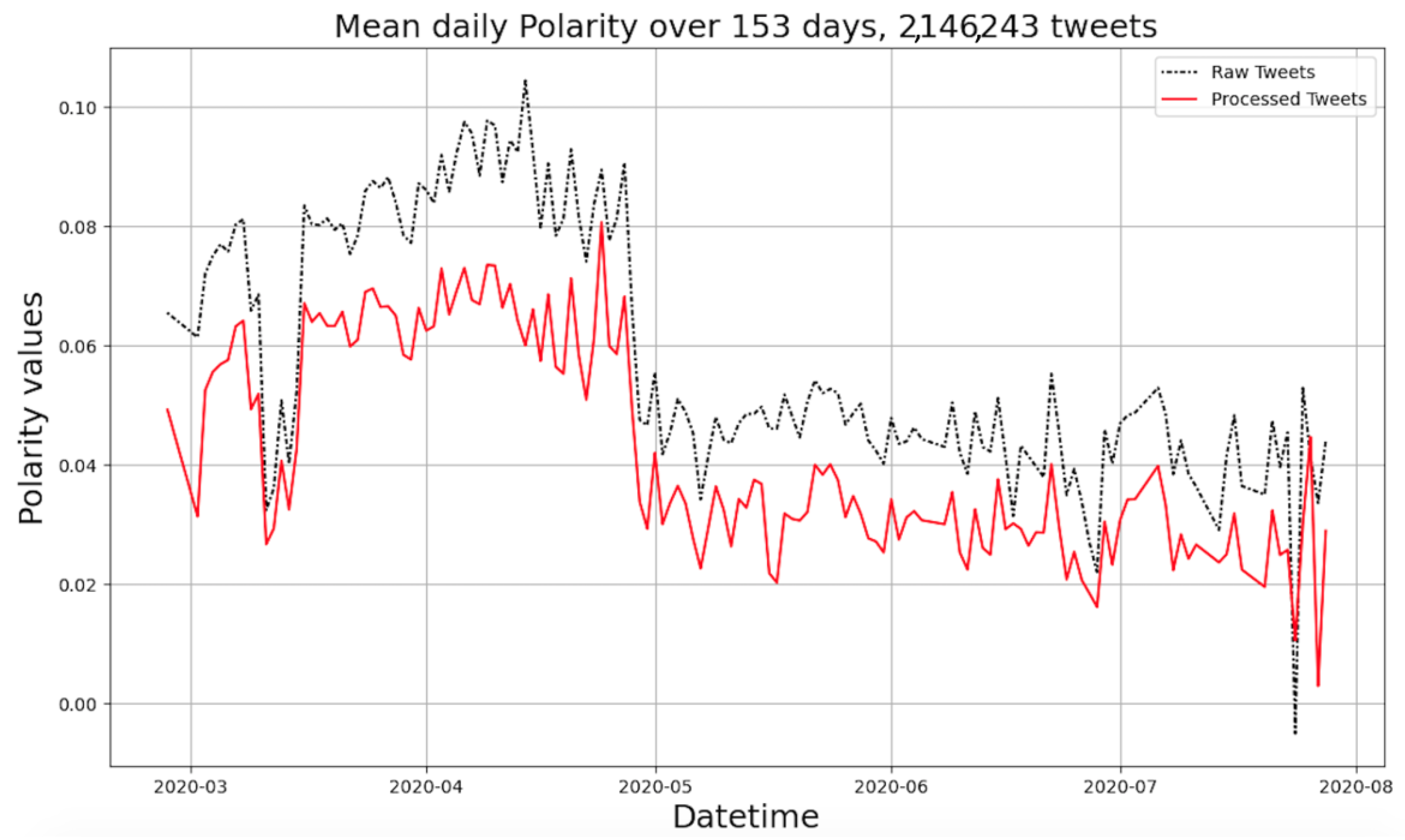
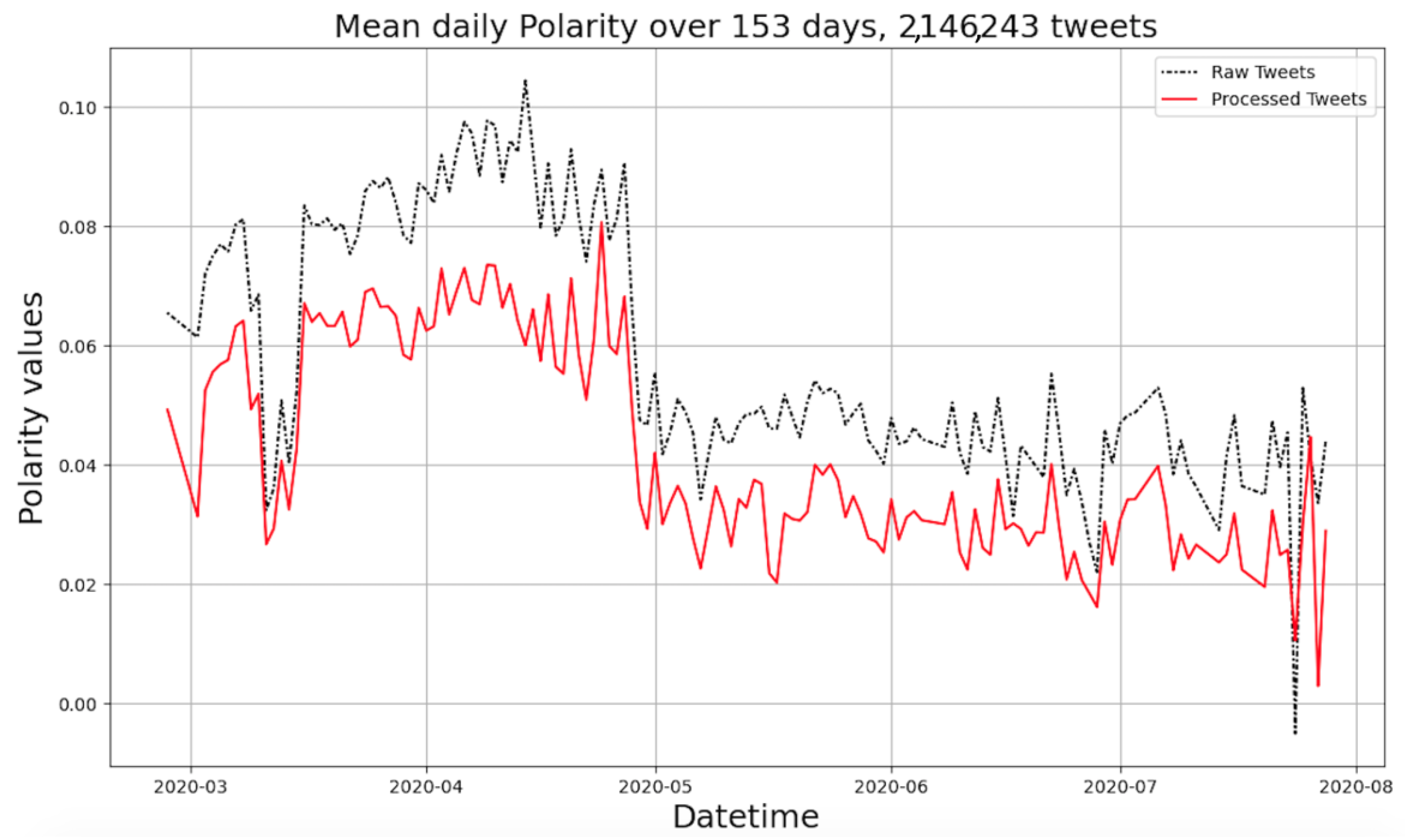
Figure 3 reports on the output from the preprocessing and polarization process, highlighting the sentiment polarization analysis on raw tweets with no preprocessing (raw tweets) and preprocessing (processed tweets) in daily resolution.
Figure 3 shows how the polarity values were adjusted after applying preprocessing (
Section 3.2) to the gathered tweets. Moreover, according to
Figure 3, it is evident that, after preprocessing the tweets, the polarity levels tended to follow the same value patterns, yet exposing reduced polarity values. It is noted that the statistical analysis process received as an input the processed tweets’ values.
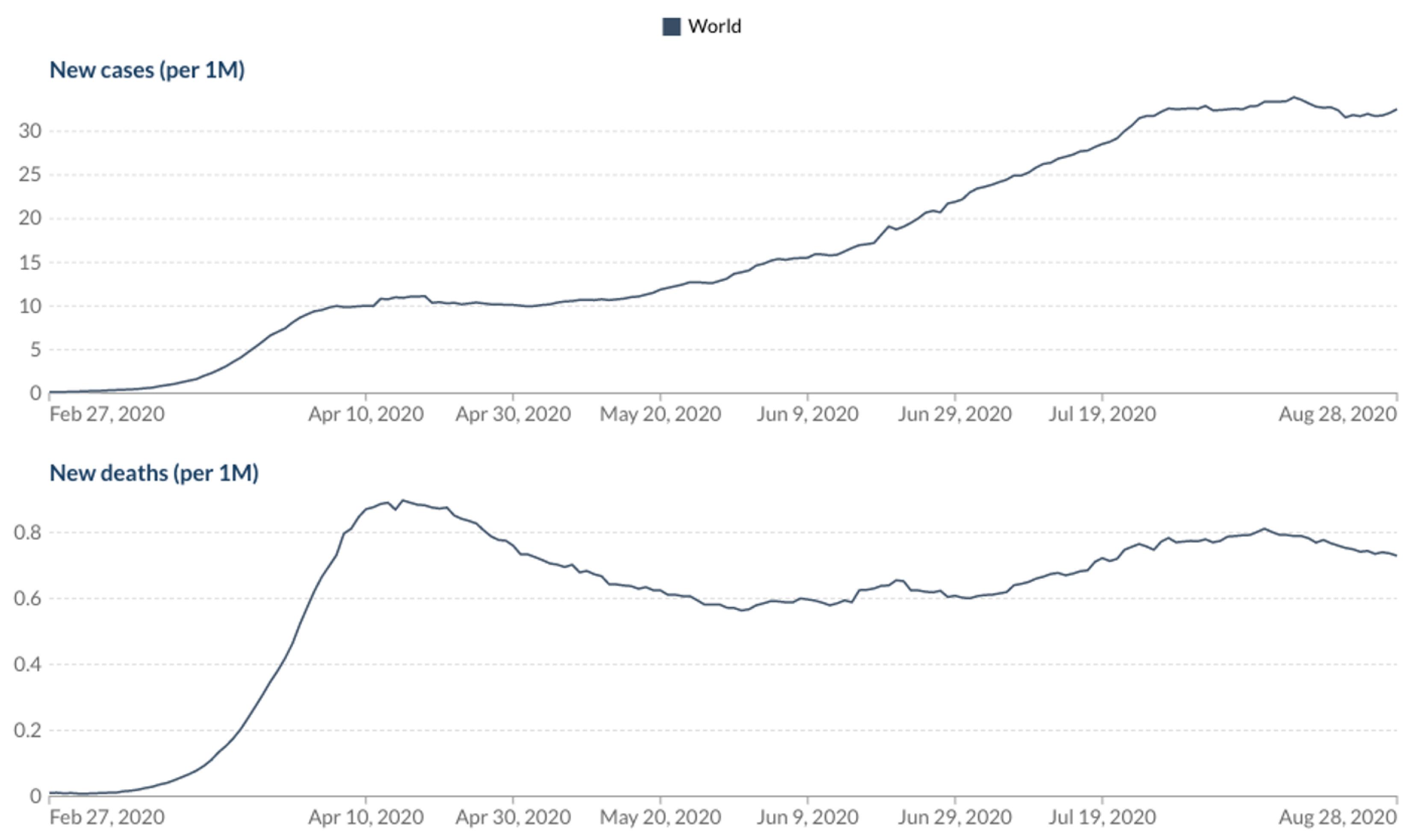
Figure 4 shows the world-wide daily new cases and deaths for the investigated period (27 February 2020 to 28 August 2020).
The Pearson correlation was calculated for the time series of the processed tweets. This process attempted to distinguish possible relationships between the variables cases vs. polarity and deaths vs. polarity for the 153 investigated days. The goal was to discover a qualitative measure of whether SMs’ data can be correlated with COVID-19, and, therefore, expose predictive opportunities regarding cases and deaths.
Based on the
p-values from
Table 6,
Table 5 depicts the status of the conceived hypotheses. For each column in
Table 6, the maximum and minimum Pearson correlation absolute values are in bold. For each row in
Table 5, when observed along with
Table 6, several findings can be extracted. For example, for the first row related to hypotheses HCB22 and HDB22 (22 days before), we can conclude that:
New cases exhibited a strong negative correlation with polarity (cases increased, while polarity dropped).
New deaths exhibited a very weak positive correlation with polarity (deaths increased and polarity increased, as well as deaths decreased and polarity decreased).
New cases p-value < 0.05; therefore, the null hypothesis (HCB22) was rejected. HCB22: The number of cases in a day was not correlated with a higher-on-average positive sentiment polarity 22 days ahead.
New deaths p-value > 0.05; therefore the null hypothesis (HDB22) was accepted. HDB22: The number of deaths in a day was not correlated with a higher-on-average positive sentiment polarity 22 days ahead.
For entries related to HC0 and HD0 (0 days):
New cases exhibited a very strong negative correlation with polarity (cases increased, while polarity dropped).
New deaths exhibited a very weak negative correlation with polarity (deaths increased and polarity decreased, as well as deaths decreased and polarity increased).
New cases p-value < 0.05; therefore, the null hypothesis (HC0) was rejected. HC0: The number of cases in a day was not correlated with a higher-on-average positive sentiment polarity 0 days before/after.
New deaths p-value > 0.05; therefore, the null hypothesis (HD0) was accepted. HD0: The number of deaths in a day was not correlated with a higher-on-average positive sentiment polarity 0 days before/after.
Despite their simplicity, Pearson correlation and
p-value are well recognized and extensively used in scientific research because of their wide application and maturity [
33]. As discussed in
Section 3.4, the Pearson coefficient may be utilized to quantify a correlation. On the other hand, the
p-value serves as a metric for determining the statistical significance of a correlation. In our case, this threshold was set to 0.05. This means that for a
p-value < 0.05 it is considered that the null hypothesis is rejected, while for a
p-value > 0.05 the null hypothesis is accepted due to insufficient evidence or arguments in opposition. For example, the statuses of “Hypotheses New Cases” in both
Table 5 and
Table 7 are all “Rejected”. This happens, since the
p-values of “New Cases” in
Table 6 are all nearly 0, satisfying the case that
p-value < 0.05. Therefore, it is imperative to interpret the Pearson coefficient and
p-value in conjunction rather than separately.
4.1. Discussion
This section discusses the knowledge extracted by the results’ interpretation. It informs about the insights regarding the COVID-19 crisis by utilizing data from Twitter. We focused on extracting and reporting on the polarity from tweets and examining the correlation strength of the polarity with the number of COVID-19 cases and deaths.
According to
Figure 3, it is evident that the overall polarity of evaluated tweets from 27 February 2020 to 28 August 2020 with 2,146,243 harvested tweets showed a negative trend, as the polarity values dropped. More specifically, the polarity values started dropping after mid-April 2020. This can be attributed to the fact that, since the start of official data reporting of COVID-19 (February 2020), people had been reluctant to accept that there was indeed a pandemic [
34]. Yet, on 17 April 2020, there was a greater number of reported daily deaths (12,430). So, this was the triggering point for an established long-term negative overall polarity trend.
According to
Table 6, tweets before and after a day were strongly negatively correlated with COVID-19 cases on average. However, tweets’ “after” correlation with COVID-19 cases exhibited a slightly stronger negative correlation. The average correlation values for tweets “before” and tweets “after” with new cases were −0.624 and −0.640, respectively. For both cases, the findings are sound since new cases increased, while polarity dropped (negative trend). The strongest correlation between polarity and new cases was on the same day with a Pearson value of −1, while the weakest correlation was 1 day after, with a Pearson value of −0.589327552. Overall, there was a strong correlation between COVID-19 Twitter conversations’ polarity with reported cases.
Moreover, tweets before and after a day were very weakly to weakly correlated with COVID-19 deaths on average. Tweets’ “before” correlation with COVID-19 deaths exhibited a very weak positive correlation, while tweets “after” exhibited a weak negative correlation with COVID-19 deaths. The average correlation values for these periods were +0.056 and −0.341, respectively. These findings can be interpreted as tweets’ “before” polarity increased related to a day’s deaths, and then, there was a trend reversal for tweets’ “after” with a much greater negative correlation increase (after deaths were announced, the polarity decreased further). More precisely, this trend reversal happened 4 days “before” and negatively increased until 21 days “after”. It was also evident that the strongest correlation between polarity and new deaths was at 21 days after, while the weakest was at five days before. Overall, there was a weak correlation between COVID-19 Twitter conversations’ polarity with reported new deaths.
In case the utilization of
p-values as expressed in
Section 3.4 was not disputed, all hypotheses associating new cases with tweets’ polarization had a
p-value < 0.05; therefore, they were rejected (
Table 5). This was expected since new cases had an overall increasing trend, while sentiment polarity exhibited a negative trend. As for the hypotheses associating new deaths with tweets’ polarization, the values diversified. Yet, there was cohesion in the observed trends. From HDB1-HDB22, HD0, and HD1-HD3, there was a
p-value > 0.05; therefore, these hypotheses were accepted. The remaining ones were rejected. This observation suggested that, as the number of deaths on a date increased, there was a higher-on-average positive sentiment polarity for 22 days before to 3 days after (a sum of 25 days).
As an expansion to
Table 5, we checked the
p-values for new cases and new deaths up to 50 days before to identify the threshold of the day when the hypotheses’ status change. According to
Table 7, the hypotheses regarding new cases remained “rejected”, while the hypotheses regarding new deaths changed from “accepted” to “rejected” 42 days before the tweets. Therefore, the previously mentioned period of 25 days (according to
Table 5) was expanded to a period of 6.5 weeks or 45 days, starting from 3 days “after” tweets and ending at tweets 41 days “before” the reported deaths. This suggests that people tended to start posting tweets four days after a day when deaths increased with diminished, yet positive polarization. Also, this means that the negativity in the tweets remained connected with the daily deaths, i.e., the hypotheses remained accepted for a very long period (45 days). When compared with the daily cases, the hypotheses remained rejected for the initial and the expanded period under scrutiny.









{kind=link}
{kind=link}
{kind=link}
{kind=link}