1. Introduction
In this paper, we show that a class of uniformity-preserving transformations for uniform random variables can facilitate the application of copula modelling to time series exhibiting the serial dependence characteristics that are typical of volatile financial return data. Our main aims are twofold: to establish the fundamental properties of v-transforms and show that they are a natural fit to the volatility modelling problem; to develop a class of processes using the implied copula process of a Gaussian ARMA model that can serve as an archetype for copula models using v-transforms. Although the existing literature on volatility modelling in econometrics is vast, the models we propose have some attractive features. In particular, as copula-based models, they allow the separation of marginal and serial dependence behaviour in the construction and estimation of models.
A distinction is commonly made between genuine stochastic volatility models, as investigated by
Taylor (
1994) and
Andersen (
1994), and GARCH-type models as developed in a long series of papers by
Engle (
1982),
Bollerslev (
1986),
Ding et al. (
1993),
Glosten et al. (
1993) and
Bollerslev et al. (
1994), among others. In the former an unobservable process describes the volatility at any time point while in the latter volatility is modelled as a function of observable information describing the past behaviour of the process; see also the review articles by
Shephard (
1996) and
Andersen and Benzoni (
2009). The generalized autoregressive score (GAS) models of
Creal et al. (
2013) generalize the observation-driven approach of GARCH models by using the score function of the conditional density to model time variation in key parameters of the time series model. The models of this paper have more in common with the observation-driven approach of GARCH and GAS but have some important differences.
In GARCH-type models, the marginal distribution of a stationary process is inextricably linked to the dynamics of the process as well as the conditional or innovation distribution; in most cases, it has no simple closed form. For example, the standard GARCH mechanism serves to create power-law behaviour in the marginal distribution, even when the innovations come from a lighter-tailed distribution such as Gaussian (
Mikosch and Stărică 2000). While such models work well for many return series, they may not be sufficiently flexible to describe all possible combinations of marginal and serial dependence behaviour encountered in applications. In the empirical example of this paper, which relates to log-returns on the Bitcoin price series, the data appear to favour a marginal distribution with sub-exponential tails that are lighter than power tails and this cannot be well captured by standard GARCH models. Moreover, in contrast to much of the GARCH literature, the models we propose make no assumptions about the existence of second-order moments and could also be applied to very heavy-tailed situations where variance-based methods fail.
Let
be a time series of financial returns sampled at (say) daily frequency and assume that these are modelled by a strictly stationary stochastic process
with marginal distribution function (cdf)
. To match the stylized facts of financial return data described, for example, by
Campbell et al. (
1997) and
Cont (
2001), it is generally agreed that
should have limited serial correlation, but the squared or absolute processes
and
should have significant and persistent positive serial correlation to describe the effects of volatility clustering.
In this paper, we refer to transformed series like , in which volatility is revealed through serial correlation, as volatility proxy series. More generally, a volatility proxy series is obtained by applying a transformation which (i) depends on a change point that may be zero, (ii) is increasing in for and (iii) is increasing in for .
Our approach in this paper is to model the probability-integral transform (PIT) series of a volatility proxy series. This is defined by for all t, where denotes the cdf of . If is the PIT series of the original process , defined by for all t, then a v-transform is a function describing the relationship between the terms of and the terms of . Equivalently, a v-transform describes the relationship between quantiles of the distribution of and the distribution of the volatility proxy . Alternatively, it characterizes the dependence structure or copula of the pair of variables . In this paper, we show how to derive flexible, parametric families of v-transforms for practical modelling purposes.
To gain insight into the typical form of a v-transform, let
represent the realized data values and let
and
be the samples obtained by applying the transformations
and
, where
and
denote scaled versions of the empirical distribution functions of the
and
samples, respectively. The graph of
gives an empirical estimate of the v-transform for the random variables
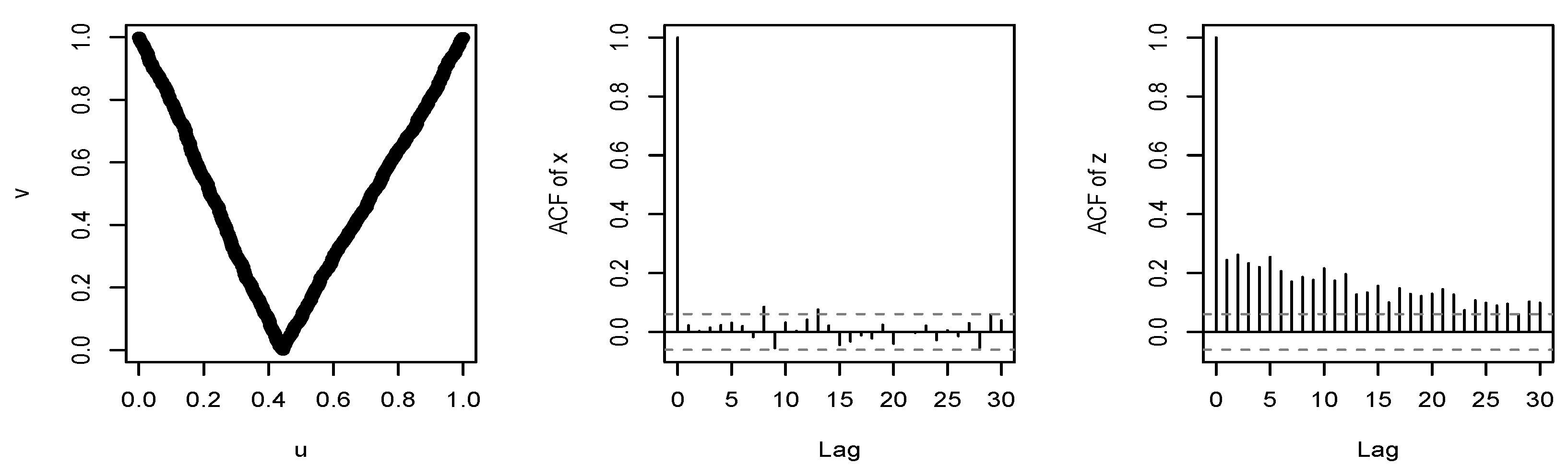
. In the left-hand plot of
Figure 1 we show the relationship for a sample of
daily log-returns of the Bitcoin price series for the years 2016–2019. Note how the empirical v-transform takes the form of a slightly asymmetric ‘V’.
The right-hand plot of
Figure 1 shows the sample autocorrelation function (acf) of the data given by
where
is the standard normal cdf. This reveals a persistent pattern of positive serial correlation which can be modelled by the implied ARMA copula. This pattern is not evident in the acf of the raw
data in the centre plot.
To construct a volatility model for using v-transforms, we need to specify a process for . In principle, any model for a series of serially dependent uniform variables can be applied to . In this paper, we illustrate concepts using the Gaussian copula model implied by the standard ARMA dependence structure. This model is particularly tractable and allows us to derive model properties and fit models to data relatively easily.
There is a large literature on copula models for time series; see, for example, the review papers by
Patton (
2012) and
Fan and Patton (
2014). While the main focus of this literature has been on cross-sectional dependencies between series, there is a growing literature on models of serial dependence. First-order Markov copula models have been investigated by
Chen and Fan (
2006),
Chen et al. (
2009) and
Domma et al. (
2009) while higher-order Markov copula models using D-vines are applied by
Smith et al. (
2010). These models are based on the pair-copula apporoach developed in
Joe (
1996),
Bedford and Cooke (
2001,
2002) and
Aas et al. (
2009). However, the standard bivariate copulas that enter these models are not generally effective at describing the typical serial dependencies created by stochastic volatility, as observed by
Loaiza-Maya et al. (
2018).
The paper is structured as follows. In
Section 2, we provide motivation for the paper by constructing a symmetric model using the simplest example of a v-transform. The general theory of v-transforms is developed in
Section 3 and is used to construct the class of VT-ARMA processes and analyse their properties in
Section 4.
Section 5 treats estimation and statistical inference for VT-ARMA processes and provides an example of their application to the Bitcoin return data;
Section 6 presents the conclusions. Proofs may be found in the
Appendix A.
2. A Motivating Model
Given a probability space , we construct a symmetric, strictly stationary process such that, under the even transformation , the serial dependence in the volatility proxy series is of ARMA type. We assume that the marginal cdf of is absolutely continuous and the density satisfies for all . Since and are both continuous, the properties of the probability-integral (PIT) transform imply that the series and given by and both have standard uniform marginal distributions. Henceforth, we refer to as the volatility PIT process and as the series PIT process.
Any other volatility proxy series that can be obtained by a continuous and strictly increasing transformation of the terms of , such as , yields exactly the same volatility PIT process. For example, if , then it follows from the fact that for that . In this sense, we can think of classes of equivalent volatility proxies, such as , , and . In fact, is itself an equivalent volatility proxy to since is a continuous and strictly increasing transformation.
The symmetry of
implies that
for
. Hence, we find that
which implies that the relationship between the volatility PIT process
and the series PIT process
is given by
where
is a perfectly symmetric v-shaped function that maps values of
close to 0 or 1 to values of
close to 1, and values close to
to values close to 0.
is the canonical example of a v-transform. It is related to the so-called tent-map transformation
by
.
Given
, let the process
be defined by setting
so that we have the following chain of transformations:
We refer to
as a
normalized volatility proxy series. Our aim is to construct a process
such that, under the chain of transformations in (
2), we obtain a Gaussian ARMA process
with mean zero and variance one. We do this by working back through the chain.
The transformation is not an injection and, for any , there are two possible inverse values, and . However, by randomly choosing between these values, we can ‘stochastically invert’ to construct a random variable such that , This is summarized in Lemma 1, which is a special case of a more general result in Proposition 4.
Lemma 1. Let V be a standard uniform variable. If , set . Otherwise, let with probability 0.5 and with probability 0.5. Then, U is uniformly distributed and .
This simple result suggests Algorithm 1 for constructing a process
with symmetric marginal density
such that the corresponding normalized volatility proxy process
under the absolute value transformation (or continuous and strictly increasing functions thereof) is an ARMA process. We describe the resulting model as a VT-ARMA process.
| Algorithm 1: |
Generate as a causal and invertible Gaussian ARMA process of order with mean zero and variance one. Form the volatility PIT process where for all t. Generate a process of iid Bernoulli variables such that . Form the PIT process using the transformation . Form the process by setting .
|
It is important to state that the use of the Gaussian process as the fundamental building block of the VT-ARMA process in Algorithm 1 has no effect on the marginal distribution of , which is as specified in the final step of the algorithm. The process is exploited only for its serial dependence structure, which is described by a family of finite-dimensional Gaussian copulas; this dependence structure is applied to the volatility proxy process.
Figure 2 shows a symmetric VT-ARMA(1,1) process with ARMA parameters
and
; such a model often works well for financial return data. Some intuition for this observation can be gained from the fact that the popular GARCH(1,1) model is known to have the structure of an ARMA(1,1) model for the squared data process; see, for example,
McNeil et al. (
2015) (
Section 4.2) for more details.
3. V-Transforms
To generalize the class of v-transforms, we admit two forms of asymmetry in the construction described in
Section 2: we allow the density
to be skewed; we introduce an asymmetric volatility proxy.
Definition 1 (Volatility proxy transformation and profile)
. Let and be strictly increasing, continuous and differentiable functions on such that . Let . Any transformation of the form is a volatility proxy transformation. The parameter is the change point of T and the associated function , is the profile function of T. By introducing
, we allow for the possibility that the natural change point may not be identical to zero. By introducing different functions
and
for returns on either side of the change point, we allow the possibility that one or other may contribute more to the volatility proxy. This has a similar economic motivation to the
leverage effects in GARCH models (
Ding et al. 1993); falls in equity prices increase a firm’s leverage and increase the volatility of the share price.
Clearly, the profile function of a volatility proxy transformation is a strictly increasing, continuous and differentiable function on such that . In conjunction with , the profile contains all the information about T that is relevant for constructing v-transforms. In the case of a volatility proxy transformation that is symmetric about , the profile satisfies .
The following result shows how v-transforms
can be obtained by considering different continuous distributions
and different volatility proxy transformations
T of type (
3).
Proposition 1. Let X be a random variable with absolutely continuous and strictly increasing cdf on and let T be a volatility proxy transformation. Let and . Then, where The result implies that any two volatility proxy transformations
T and
which have the same change point
and profile function
belong to an equivalence class with respect to the resulting v-transform. This generalizes the idea that
and
give the same v-transform in the symmetric case of
Section 2. Note also that the volatility proxy transformations
and
defined by
are in the same equivalence class as
T since they share the same change point and profile function.
Definition 2 (v-transform and fulcrum)
. Any transformation that can be obtained from Equation (4) by choosing an absolutely continuous and strictly increasing cdf on and a volatility proxy transformation T is a v-transform. The value is the fulcrum of the v-transform. 3.1. A Flexible Parametric Family
In this section, we derive a family of v-transforms using construction (
4) by taking a tractable asymmetric model for
using the construction proposed by
Fernández and Steel (
1998) and by setting
and
for
and
. This profile function contains the identity profile
(corresponding to the symmetric volatility proxy transformation) as a special case, but allows cases where negative or positive returns contribute more to the volatility proxy. The choices we make may at first sight seem rather arbitrary, but the resulting family can in fact assume many of the shapes that are permissible for v-transforms, as we will argue.
Let
be a density that is symmetric about the origin and let
be a scalar parameter. Fernandez and Steel suggested the model
This model is often used to obtain skewed normal and skewed Student distributions for use as innovation distributions in econometric models. A model with is skewed to the right while a model with is skewed to the left, as might be expected for asset returns. We consider the particular case of a Laplace or double exponential distribution which leads to particularly tractable expressions.
Proposition 2. Let be the cdf of the density (6) when . Set and let for . The v-transform (4) is given bywhere and . It is remarkable that (
7) is a uniformity-preserving transformation. If we set
and
, we get
which obviously includes the symmetric model
. The v-transform
in (
8) is a very convenient special case, and we refer to it as the
linear v-transform.
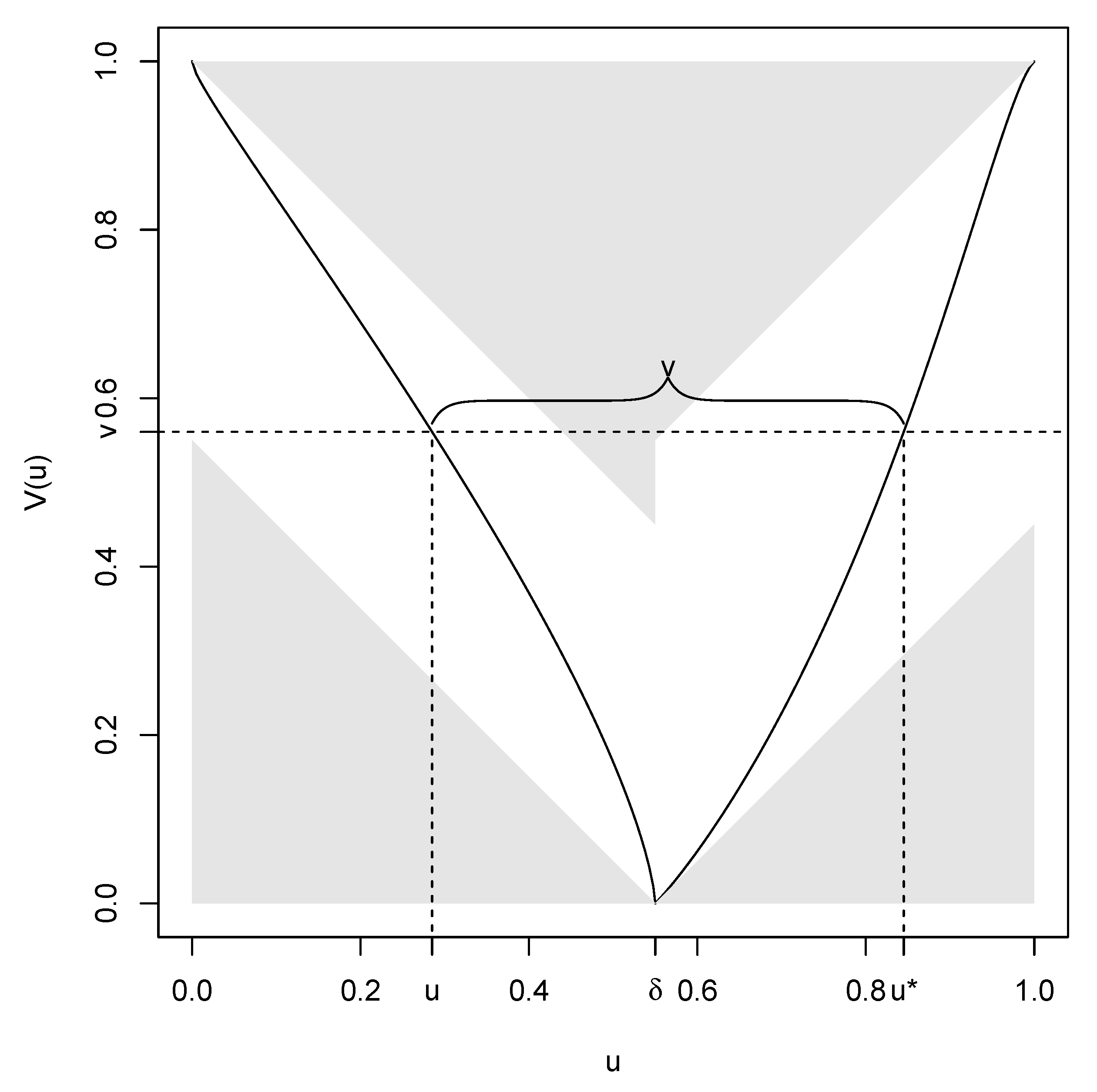
In
Figure 3, we show the v-transform
when
,
and
. We will use this particular v-transform to illustrate further properties of v-transforms and find a characterization.
3.2. Characterizing v-Transforms
It is easily verified that any v-transform obtained from (
4) consists of two arms or branches, described by continuous and strictly monotonic functions; the left arm is decreasing and the right arm increasing. See
Figure 3 for an illustration. At the fulcrum
, we have
. Every point
has a
dual point on the opposite side of the fulcrum such that
. Dual points can be interpreted as the quantile probability levels of the distribution of
X that give rise to the same level of volatility.
We collect these properties together in the following lemma and add one further important property that we refer to as the
square property of a v-transform; this property places constraints on the shape that v-transforms can take and is illustrated in
Figure 3.
Lemma 2. A v-transform is a mapping with the following properties:
- 1.
;
- 2.
There exists a point δ known as the fulcrum such that and ;
- 3.
is continuous;
- 4.
is strictly decreasing on and strictly increasing on ;
- 5.
Every point has a dual point on the opposite side of the fulcrum satisfying and (square property).
It is instructive to see why the square property must hold. Consider
Figure 3 and fix a point
with
. Let
and let
. The events
and
are the same and hence the uniformity of
V under a v-transform implies that
The properties in Lemma 2 could be taken as the basis of an alternative definition of a v-transform. In view of (
9), it is clear that any mapping
that has these properties is a uniformity-preserving transformation. We can characterize the mappings
that have these properties as follows.
Theorem 1. A mapping has the properties listed in Lemma 2 if and only if it takes the formwhere Ψ is a continuous and strictly increasing distribution function on . Our arguments so far show that every v-transform must have the form (
10). It remains to verify that every uniformity-preserving transformation of the form (
10) can be obtained from construction (
4), and this is the purpose of the final result of this section. This allows us to view Definition 2, Lemma 2, and the characterization (
10) as three equivalent approaches to the definition of v-transforms.
Proposition 3. Let be a uniformity-preserving transformation of the form (10) and a continuous distribution function. Then, can be obtained from construction (4) using any volatility proxy transformation with change point and profile Henceforth, we can view (
10) as the general equation of a v-transform. Distribution functions
on
can be thought of as
generators of v-transforms. Comparing (
10) with (
7), we see that our parametric family
is generated by
. This is a 2-parameter distribution whose density can assume many different shapes on the unit interval including increasing, decreasing, unimodal, and bathtub-shaped forms. In this respect, it is quite similar to the beta distribution which would yield an alternative family of v-transforms. The uniform distribution function
gives the family of linear v-transforms
.
In applications, we construct models starting from the building blocks of a tractable v-transform
such as (
7) and a distribution
; from these, we can always infer an implied profile function
using (
11). The alternative approach of starting from
and
and constructing
via (
4) is also possible but can lead to v-transforms that are cumbersome and computationally expensive to evaluate if
and its inverse do not have simple closed forms.
3.3. V-Transforms and Copulas
If two uniform random variables are linked by the v-transform , then the joint distribution function of is a special kind of copula. In this section, we derive the form of the copula, which facilitates the construction of stochastic processes using v-transforms.
To state the main result, we use the notation and for the the inverse function and the gradient function of a v-transform . Although there is no unique inverse (except when ), the fact that the two branches of a v-transform mutually determine each other allows us to define to be the inverse of the left branch of the v-transform given by . The gradient is defined for all points , and we adopt the convention that is the left derivative as .
Theorem 2. Let V and U be random variables related by the v-transform .
- 1.
The joint distribution function of is given by the copula - 2.
Conditional on , the distribution of U is given bywhere - 3.
.
Remark 1. In the case of the symmetric v-transform , the copula in (12) takes the form . We note that this copula is related to a special case of the tent map copula family in Rémillard (2013) by . For the linear v-transform family, the conditional probability
in (
14) satisfies
. This implies that the value of
V contains no information about whether
U is likely to be below or above the fulcrum; the probability is always the same regardless of
V. In general, this is not the case and the value of
V does contain information about whether
U is large or small.
Part (2) of Theorem 2 is the key to stochastically inverting a v-transform in the general case. Based on this result, we define the concept of stochastic inversion of a v-transform. We refer to the function as the conditional down probability of .
Definition 3 (Stochastic inversion function of a v-transform)
. Let be a v-transform with conditional down probability Δ. The two-place function defined byis the stochastic inversion function of . The following proposition, which generalizes Lemma 1, allows us to construct general asymmetric processes that generalize the process of Algorithm 1.
Proposition 4. Let V and W be iid variables and let be a v-transform with stochastic inversion function . If , then and .
In
Section 4, we apply v-transforms and their stochastic inverses to the terms of time series models. To understand the effect this has on the serial dependencies between random variables, we need to consider multivariate componentwise v-transforms of random vectors with uniform marginal distributions and these can also be represented in terms of copulas. We now give a result which forms the basis for the analysis of serial dependence properties. The first part of the result shows the relationship between copula densities under componentwise v-transforms. The second part shows the relationship under the componentwise stochastic inversion of a v-transform; in this case, we assume that the stochastic inversion of each term takes place independently given
so that all serial dependence comes from
.
Theorem 3. Let be a v-transform and let and be vectors of uniform random variables with copula densities and , respectively.
- 1.
If , thenwhere and for all . - 2.
If where are iid uniform random variables that are also independent of , then
4. VT-ARMA Copula Models
In this section, we study some properties of the class of time series models obtained by the following algorithm, which generalizes Algorithm 1. The models obtained are described as VT-ARMA processes since they are stationary time series constructed using the fundamental building blocks of a v-transform and an ARMA process.
We can add any marginal behaviour in the final step, and this allows for an infinitely rich choice. We can, for instance, even impose an infinite-variance or an infinite-mean distribution, such as the Cauchy distribution, and still obtain a strictly stationary process for . We make the following definitions.
Definition 4 (VT-ARMA and VT-ARMA copula process). Any stochastic process that can be generated using Algorithm 2 by choosing an underlying ARMA process with mean zero and variance one, a v-transform , and a continuous distribution function is a VT-ARMA process. The process obtained at the penultimate step of the algorithm is a VT-ARMA copula process.
| Algorithm 2: |
Generate as a causal and invertible Gaussian ARMA process of order with mean zero and variance one. Form the volatility PIT process where for all t. Generate iid random variables . Form the series PIT process by taking the stochastic inverses . Form the process by setting for some continuous cdf .
|
Figure 4 gives an example of a simulated process using Algorithm 2 and the v-transform
in (
7) with
and MA parameter
. The marginal distribution is a heavy-tailed skewed Student distribution of type (
6) with degrees-of-freedom
and skewness
, which gives rise to more large negative returns than large positive returns. The underlying time series model is an ARMA(1,1) model with AR parameter
and MA parameter
. See the caption of the figure for full details of parameters.
In the remainder of this section, we concentrate on the properties of VT-ARMA copula processes from which related properties of VT-ARMA processes may be easily inferred.
4.1. Stationary Distribution
The VT-ARMA copula process of Definition 4 is a strictly stationary process since the joint distribution of for any set of indices is invariant under time shifts. This property follows easily from the strict stationarity of the underlying ARMA process according to the following result, which uses Theorem 3.
Proposition 5. Let follow a VT-ARMA copula process with v-transform and an underlying ARMA(p,q) structure with autocorrelation function . The random vector for has joint density , where denotes the density of the Gaussian copula and is a correlation matrix with element given by .
An expression for the joint density facilitates the calculation of a number of dependence measures for the bivariate marginal distribution of
. In the bivariate case, the correlation matrix of the underlying Gaussian copula
contains a single off-diagonal value
and we simply write
. The Pearson correlation of
is given by
This value is also the value of the Spearman rank correlation
for a VT-ARMA process
with copula process
(since the Spearman’s rank correlation of a pair of continuous random variables is the Pearson correlation of their copula). The calculation of (
18) typically requires numerical integration. However, in the special case of the linear v-transform
in (
8), we can get a simpler expression as shown in the following result.
Proposition 6. Let be a VT-ARMA copula process satisfying the assumptions of Proposition 5 with linear v-transform . Let denote the underlying Gaussian ARMA process. Then, For the symmetric v-transform
, Equation (
19) obviously yields a correlation of zero so that, in this case, the VT-ARMA copula process
is a white noise with an autocorrelation function that is zero, except at lag zero. However, even a very asymmetric model with
or
gives
so that serial correlations tend to be very weak.
When we add a marginal distribution, the resulting process
has a different auto-correlation function to
, but the same rank autocorrelation function. The symmetric model of
Section 2 is a white noise process. General asymmetric processes
are not perfect white noise processes but have only very weak serial correlation.
4.2. Conditional Distribution
To derive the conditional distribution of a VT-ARMA copula process, we use the vector notation and to denote the history of processes up to time point t and and for realizations. These vectors are related by the componentwise transformation . We assume that all processes have a time index set given by .
Proposition 7. For , the conditional density is given bywhere and is the standard deviation of the innovation process for the ARMA model followed by . When
is iid white noise
,
and (
20) reduce to the uniform density
as expected. In the case of the first-order Markov AR(1) model
, the conditional mean of
is
and
. The conditional density (
20) can be easily shown to simplify to
where
denotes the copula density derived in Proposition 5. In this special case, the VT-ARMA model falls within the class of first-order Markov copula models considered by
Chen and Fan (
2006), although the copula is new.
If we add a marginal distribution
to the VT-ARMA copula model to obtain a model for
and use similar notational conventions as above, the resulting VT-ARMA model has conditional density
with
as in (
20). An interesting property of the VT-ARMA process is that the conditional density (
21) can have a pronounced bimodality for values of
in excess of zero that is in high volatility situations where the conditional mean of
is higher than the marginal mean value of zero; in low volatility situations, the conditional density appears more concentrated around zero. This phenomenon is illustrated in
Figure 4. The bimodality in high volatility situations makes sense: in such cases, it is likely that the next return will be large in absolute value and relatively less likely that it will be close to zero.
The conditional distribution function of
is
and hence the
-quantile
of
can be obtained by solving
For , the negative of this value is often referred to as the conditional -VaR (value-at-risk) at time t in financial applications.
5. Statistical Inference
In the copula approach to dependence modelling, the copula is the object of central interest and marginal distributions are often of secondary importance. A number of different approaches to estimation are found in the literature. As before, let represent realizations of variables from the time series process .
The semi-parametric approach developed by
Genest et al. (
1995) is very widely used in copula inference and has been applied by
Chen and Fan (
2006) to first-order Markov copula models in the time series context. In this approach, the marginal distribution
is first estimated non-parametrically using the scaled empirical distribution function
(see definition in
Section 1) and the data are transformed onto the
scale. This has the effect of creating pseudo-copula data
where
denotes the rank of
within the sample. The copula is fitted to the pseudo-copula data by maximum likelihood (ML).
As an alternative, the inference-functions-for-margins (IFM) approach of
Joe (
2015) could be applied. This is also a two-step method although in this case a parametric model
is estimated under an iid assumption in the first step and the copula is fitted to the data
in the second step.
The approach we adopt for our empirical example is to first use the semi-parametric approach to determine a reasonable copula process, then to estimate marginal parameters under an iid assumption, and finally to estimate all parameters jointly using the parameter estimates from the previous steps as starting values.
We concentrate on the mechanics of deriving maximum likelihood estimates (MLEs). The problem of establishing the asymptotic properties of the MLEs in our setting is a difficult one. It is similar to, but appears to be more technically challenging than, the problem of showing consistency and efficiency of MLEs for a Box-Cox-transformed Gaussian ARMA process, as discussed in
Terasaka and Hosoya (
2007). We are also working with a componentwise transformed ARMA process, although, in our case, the transformation
is via the nonlinear, non-increasing volatility proxy transformation
in (
5), which is not differentiable at the change point
. We have, however, run extensive simulations which suggests good behaviour of the MLEs in large samples.
5.1. Maximum Likelihood Estimation of the VT-ARMA Copula Process
We first consider the estimation of the VT-ARMA copula process for a sample of data
. Let
and
denote the parameters of the v-transform and ARMA model, respectively. It follows from Theorem 3 (part 2) and Proposition 5 that the log-likelihood for the sample
is simply the log density of the Gaussian copula under componentwise inverse v-transformation. This is given by
where the first term
is the log-likelihood for an ARMA model with a standard N(0,1) marginal distribution. Both terms in the log-likelihood (
23) are relatively straightforward to evaluate.
The evaluation of the ARMA likelihood for parameters and data can be accomplished using the Kalman filter. However, it is important to note that the assumption that the data are standard normal requires a bespoke implementation of the Kalman filter, since standard software always treats the error variance as a free parameter in the ARMA model. In our case, we need to constrain to be a function of the ARMA parameters so that . For example, in the case of an ARMA(1,1) model with AR parameter and MA parameter , this means that . The constraint on must be incorporated into the state-space representation of the ARMA model.
Model validation tests for the VT-ARMA copula can be based on residuals
where
denotes the implied realization of the normalized volatility proxy variable and where an estimate
of the conditional mean
may be obtained as an output of the Kalman filter. The residuals should behave like an iid sample from a normal distribution.
Using the estimated model, it is also possible to implement a likelihood-ratio (LR) test for the presence of stochastic volatility in the data. Under the null hypothesis that
, the log-likelihood (
23) is identically equal to zero. Thus, the size of the maximized log-likelihood
provides a measure of the evidence for the presence of stochastic volatility.
5.2. Adding a Marginal Model
If
and
denote the cdf and density of the marginal model and the parameters are denoted
, then the full log-likelihood for the data
is simply
where the first term is the log-likelihood for a sample of iid data from the marginal distribution
and the second term is (
23).
When a marginal model is added, we can recover the implied form of the volatility proxy transformation using Proposition 3. If
is the estimated fulcrum parameter of the v-transform, then the estimated change point is
and the implied profile function is
Note that is is possible to force the change point to be zero in a joint estimation of marginal model and copula by imposing the constraint on the fulcrum and marginal parameters during the optimization. However, in our experience, superior fits are obtained when these parameters are unconstrained.
5.3. Example
We analyse
daily log-returns for the Bitcoin price series for the period 2016–2019; values are multiplied by 100. We first apply the semi-parametric approach of
Genest et al. (
1995) using the log-likelihood (
23) which yields the results in
Table 1. Different models are referred to by VT(
n)-ARMA(
p,
q), where
refers to the ARMA model and
n indexes the v-transform: 1 is the linear v-transform
in (
8); 3 is the three-parameter transform
in (
7); 2 is the two-parameter v-transform given by
. In unreported analyses, we also tried the three-parameter family based on the beta distribution, but this had negligible effect on the results.
The column marked L gives the value of the maximized log-likelihood. All values are large and positive showing strong evidence of stochastic volatility in all cases. The model VT(1)-ARMA(1,0) is a first-order Markov model with linear v-transform. The fit of this model is noticeably poorer than the others suggesting that Markov models are insufficient to capture the persistence of stochastic volatility in the data. The column marked SW contains the p-value for a Shapiro–Wilks test of normality applied to the residuals from the VT-ARMA copula model; the result is non-significant in all cases.
According to the AIC values, the VT(2)-ARMA(1,1) is the best model. We experimented with higher order ARMA processes, but this did not lead to further significant improvements.
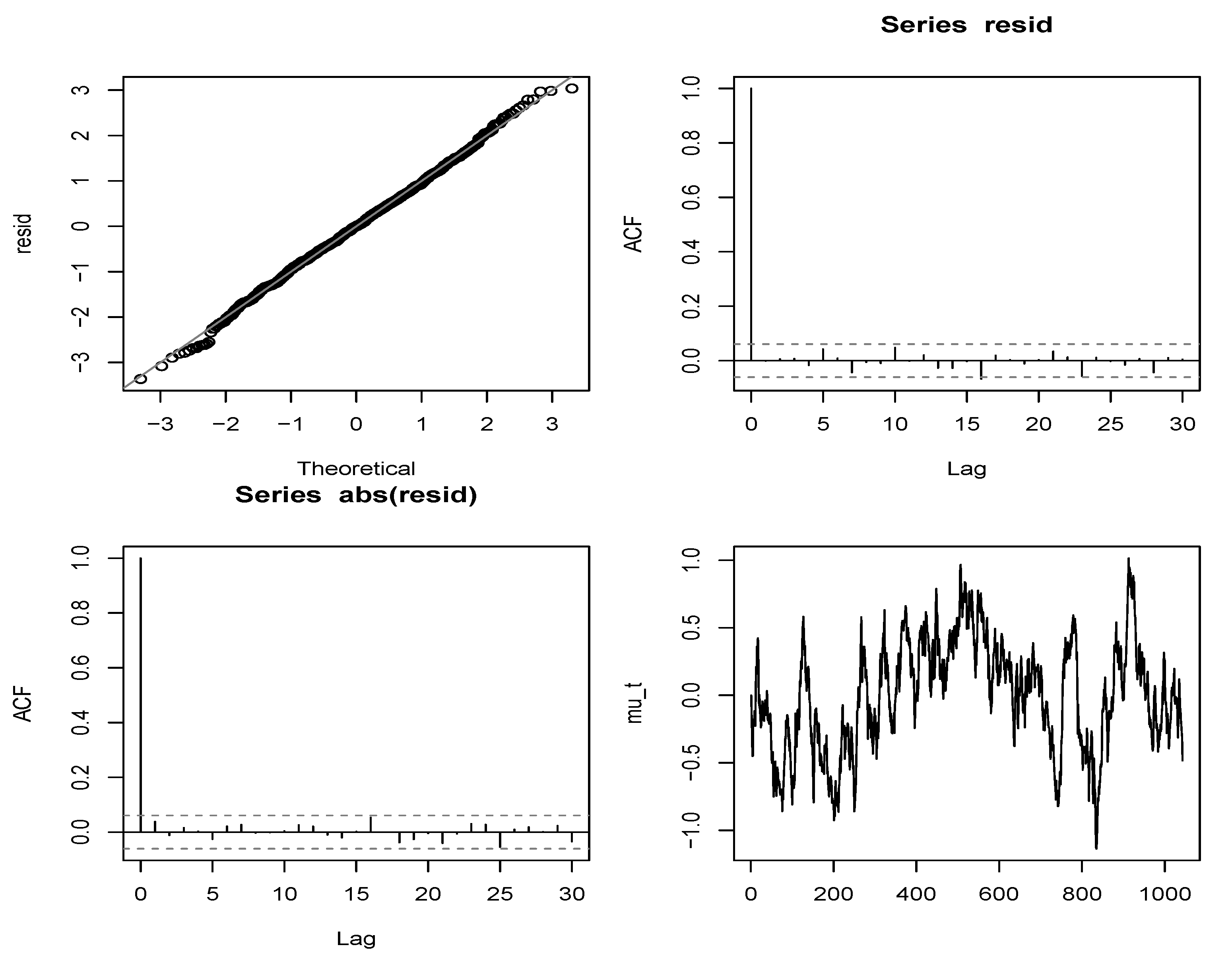
Figure 5 provides a visual of the fit of this model. The pictures in the panels show the QQplot of the residuals against normal, acf plots of the residuals and squared residuals and the estimated conditional mean process
, which can be taken as an indicator of high and low volatility periods. The residuals and absolute residuals show very little evidence of serial correlation and the QQplot is relatively linear, suggesting that the ARMA filter has been successful in explaining much of the serial dependence structure of the normalized volatility proxy process.
We now add various marginal distributions to the VT(2)-ARMA(1,1) copula model and estimate all parameters of the model jointly. We have experimented with a number of location-scale families including Student-t, Laplace (double exponential), and a double-Weibull family which generalizes the Laplace distribution and is constructed by taking back-to-back Weibull distributions. Estimation results are presented for these three distributions in
Table 2. All three marginal distributions are symmetric around their location parameters
, and no improvement is obtained by adding skewness using the construction of
Fernández and Steel (
1998) described in
Section 3.1; in fact, the Bitcoin returns in this time period show a remarkable degree of symmetry. In the table, the shape and scale parameters of the distributions are denoted
and
, respectively; in the case of Student, an infinite-variance distribution with degree-of-freedom parameter
is fitted, but this model is inferior to the models with Laplace and double-Weibull margins; the latter is the favoured model on the basis of AIC values.
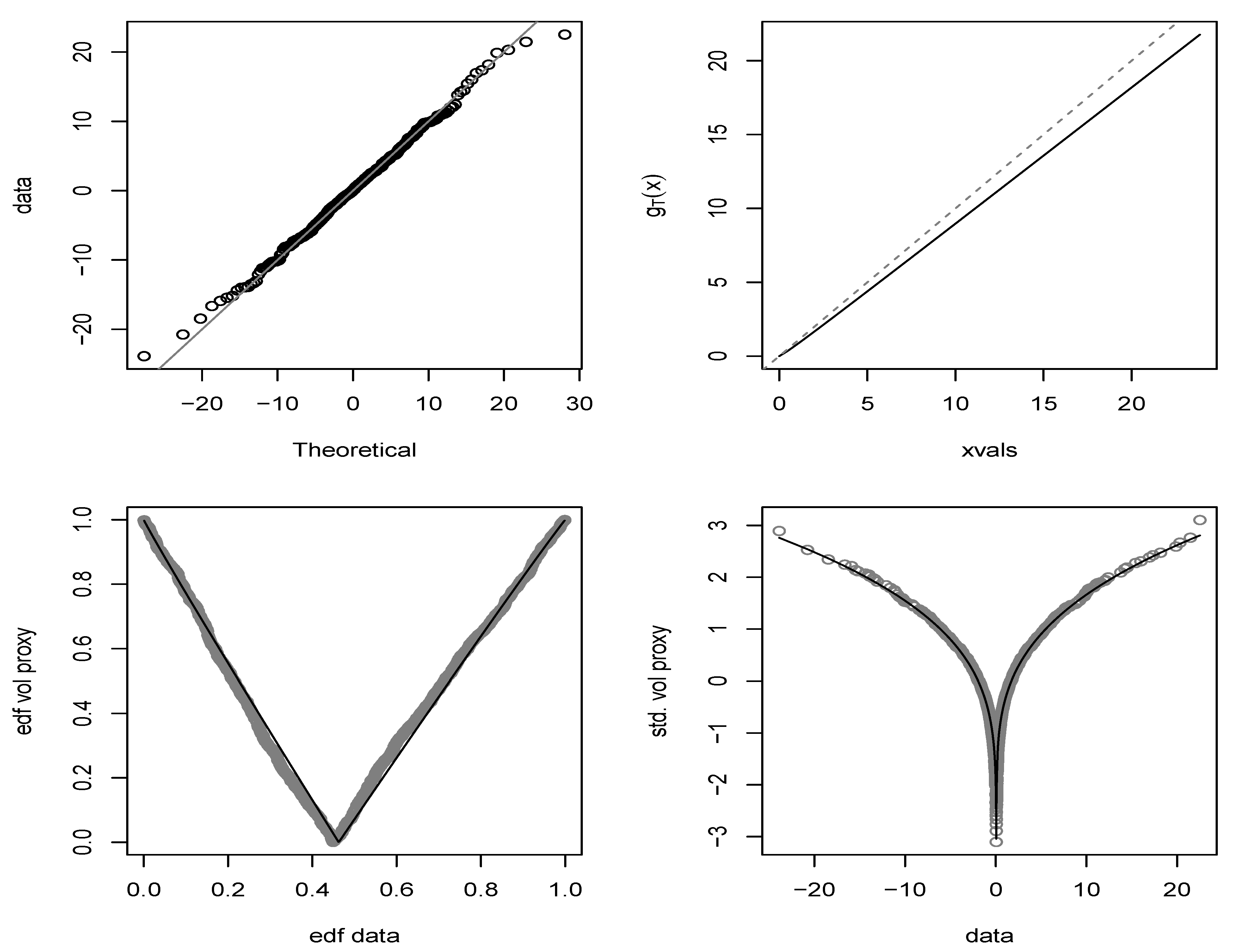
Figure 6 shows some aspects of the joint fit for the fully parametric VT(2)-ARMA(1,1) model with double-Weibull margin. A QQplot of the data against the fitted marginal distribution confirms that the double-Weibull is a good marginal model for these data. Although this distribution is sub-exponential (heavier-tailed than exponential), its tails do not follow a power law and it is in the maximum domain of attraction of the Gumbel distribution (see, for example,
McNeil et al. 2015, Chapter 5).
Using (
26), the implied volatility proxy profile function
can be constructed and is found to lie just below the line
as shown in the upper-right panel. The change point is estimated to be
. We can also estimate an implied volatility proxy transformation in the equivalence class defined by
and
. We estimate the transformation
in (
5) by taking
. In the lower-left panel of
Figure 6, we show the empirical v-transform formed from the data
together with the fitted parametric v-transform
. We recall from
Section 1 that the empirical v-transform is the plot
where
and
. The empirical v-transform and the fitted parametric v-transform show a good degree of correspondence. The lower-right panel of
Figure 6 shows the volatility proxy transformation
as a function of
x superimposed on the points
. Using the curve, we can compare the effects of, for example, a log-return (× 100) of −10 and a log-return of 10. For the fitted model, these are 1.55 and 1.66 showing that the up movement is associated with slightly higher volatility.
As a comparison to the VT-ARMA model, we fit standard GARCH(1,1) models using Student-t and generalized error distributions for the innovations; these are standard choices available in the popular
rugarch package in R. The generalized error distribution (GED) contains normal and Laplace as special cases as well as a model that has a similar tail behaviour to Weibull; note, however, that, by the theory of
Mikosch and Stărică (
2000), the tails of the marginal distribution of the GARCH decay according to a power law in both cases. The results in
Table 3 show that the VT(2)-ARMA(1,1) models with Laplace and double-Weibull marginal distributions outperform both GARCH models in terms of AIC values.
Figure 7 shows the in-sample 95% conditional value-at-risk (VaR) estimate based on the VT(2)-ARMA(1,1) model which has been calculated using (
22). For comparison, a dashed line shows the corresponding estimate for the GARCH(1,1) model with GED innovations.
Finally, we carry out an out-of-sample comparison of conditional VaR estimates using the same two models. In this analysis, the models are estimated daily throughout the 2016–2019 period using a 1000-day moving data window and one-step-ahead VaR forecasts are calculated. The VT-ARMA model gives 47 exceptions of the 95% VaR and 11 exceptions of the 99% VaR, compared with expected numbers of 52 and 10 for a 1043 day sample, while the GARCH model leads to 57 and 12 exceptions; both models pass binomial tests for these exception counts. In a follow-up paper (
Bladt and McNeil 2020), we conduct more extensive out-of-sample backtests for models using v-transforms and copula processes and show that they rival and often outperform forecast models from the extended GARCH family.
6. Conclusions
This paper has proposed a new approach to volatile financial time series in which v-transforms are used to describe the relationship between quantiles of the return distribution and quantiles of the distribution of a predictable volatility proxy variable. We have characterized v-transforms mathematically and shown that the stochastic inverse of a v-transform may be used to construct stationary models for return series where arbitrary marginal distributions may be coupled with dynamic copula models for the serial dependence in the volatility proxy.
The construction was illustrated using the serial dependence model implied by a Gaussian ARMA process. The resulting class of VT-ARMA processes is able to capture the important features of financial return series including near-zero serial correlation (white noise behaviour) and volatility clustering. Moreover, the models are relatively straightforward to estimate building on the classical maximum-likelihood estimation of an ARMA model using the Kalman filter. This can be accomplished in the stepwise manner that is typical in copula modelling or through joint modelling of the marginal and copula process. The resulting models yield insights into the way that volatility responds to returns of different magnitude and sign and can give estimates of unconditional and conditional quantiles (VaR) for practical risk measurement purposes.
There are many possible uses for VT-ARMA copula processes. Because we have complete control over the marginal distribution, they are very natural candidates for the innovation distribution in other time series models. For example, they could be applied to the innovations of an ARMA model to obtain ARMA models with VT-ARMA errors; this might be particularly appropriate for longer interval returns, such as weekly or monthly returns, where some serial dependence is likely to be present in the raw return data.
Clearly, we could use other copula processes for the volatility PIT process . The VT-ARMA copula process has some limitations: the radial symmetry of the underlying Gaussian copula means that the serial dependence between large values of the volatility proxy must mirror the serial dependence between small values; moreover, this copula does not admit tail dependence in either tail and it seems plausible that very large values of the volatility proxy might have a tendency to occur in succession.
To extend the class of models based on v-transforms, we can look for models for the volatility PIT process
with higher dimensional marginal distributions given by asymmetric copulas with upper tail dependence. First-order Markov copula models as developed in
Chen and Fan (
2006) can give asymmetry and tail dependence, but they cannot model the dependencies at longer lags that we find in empirical data. D-vine copula models can model higher-order Markov dependencies and
Bladt and McNeil (
2020) show that this is a promising alternative specification for the volatility PIT process.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}