Modelling Unobserved Heterogeneity in Claim Counts Using Finite Mixture Models



Abstract
1. Introduction and Aims
2. Finite Mixture of Regression Models
2.1. Finite Mixture of Poisson Regressions
2.2. Finite Mixture of Negative Binomial Regressions
2.3. Other Models
2.4. Estimation via EM Algorithm
- M1
- Update the mixing proportions using
- M2
- Update the regression coefficients and the component-specific parameters by fitting a single regression model for the j-th component with response , covariates using a weighted likelihood approach with weights .
2.5. Computational Details
3. Data and Results
3.1. Data Description
3.2. Fitted Models
3.3. Usage of FM Models for Actuarial Purposes
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Aitkin, Murray. 1999. A general maximum likelihood analysis of variance components in generalized linear models. Biometrics 55: 117–28. [Google Scholar] [CrossRef] [PubMed]
- Bermúdez, Lluís. 2009. A priori ratemaking using bivariate Poisson regression models. Insurance: Mathematics and Economics 44: 135–41. [Google Scholar] [CrossRef]
- Bermúdez, Lluís, and Dimitris Karlis. 2012. A finite mixture of bivariate Poisson regression models with an application to insurance ratemaking. Computational Statistics & Data Analysis 56: 3988–99. [Google Scholar]
- Bolancé, Catalina, Montserrat Guillén, and Jean Pinquet. 2003. Time-varying credibility for frequency risk models: Estimation and tests for autoregressive specifications on the random effects. Insurance: Mathematics and Economics 33: 273–82. [Google Scholar] [CrossRef]
- Bolancé, Catalina, Montserrat Guillén, and Jean Pinquet. 2008. On the link between credibility and frequency premium. Insurance: Mathematics and Economics 43: 209–13. [Google Scholar] [CrossRef]
- Boucher, Jean-Philippe, and Michel Denuit. 2008. Credibility premiums for the zero inflated Poisson model and new hunger for bonus interpretation. Insurance: Mathematics and Economics 42: 727–35. [Google Scholar] [CrossRef]
- Boucher, Jean-Philippe, Michel Denuit, and Montserrat Guillén. 2007. Risk classification for claim counts: A comparative analysis of various zero-inflated mixed Poisson and hurdle models. North American Actuarial Journal 11: 110–31. [Google Scholar] [CrossRef]
- Boucher, Jean-Philippe, Michel Denuit, and Montserrat Guillén. 2009. Number of accidents or number of claims? an approach with zero-inflated Poisson models for panel data. Journal of Risk and Insurance 76: 821–46. [Google Scholar] [CrossRef]
- Breslow, Norman E. 1984. Extra-Poisson variation in log-linear models. Applied Statistics 33: 38–44. [Google Scholar] [CrossRef]
- Brouhns, Natacha, Montserrat Guillén, Michael Denuit, and Jean Pinquet. 2003. Bonus-malus scales in segmented tariffs with stochastic migration between segments. Journal of Risk and Insurance 70: 577–99. [Google Scholar] [CrossRef]
- Byung-Jung, Park, Dominique Lord, and Chungwon Lee. 2014. Finite mixture modeling for vehicle crash data with application to hotspot identification. Accident Analysis & Prevention 71: 319–26. [Google Scholar]
- Dean, Charmaine, Jerald Lawless, and Gordon Willmot. 1989. A mixed Poisson-inverse-gaussian regression model. Canadian Journal of Statistics 17: 171–81. [Google Scholar] [CrossRef]
- Denuit, Michael, Xavier Marechal, Sandra Pitrebois, and Jean-François Walhin. 2007. Actuarial Modelling of Claim Counts: Risk Classification, Credibility and Bonus-Malus Systems. New York: Wiley. [Google Scholar]
- Dionne, George, and Charles Vanasse. 1989. A generalization of actuarial automobile insurance rating models: The negative binomial distribution with a regression component. ASTIN Bulletin 19: 199–212. [Google Scholar] [CrossRef]
- Dionne, George, and Charles Vanasse. 1992. Automobile insurance ratemaking in the presence of asymmetrical information. Journal of Applied Econometrics 7: 149–65. [Google Scholar] [CrossRef]
- Grun, Bettina, and Friedrich Leisch. 2007. Fitting finite mixtures of generalized linear regressions in R. Computational Statistics and Data Analysis 51: 5247–52. [Google Scholar] [CrossRef]
- Grun, Bettina, and Friedrich Leisch. 2008. Flexmix version 2: Finite mixtures with concomitant variables and varying and constant parameters. Journal of Statistical Software 28: 1–35. [Google Scholar] [CrossRef]
- Guillén, Montserrat, Jens Perch Nielsen, Mercedes Ayuso, and Ana Pérez-Marín. 2019. The use of telematics devices to improve automobile insurance rates. Risk Analysis 39: 662–72. [Google Scholar] [CrossRef]
- Hennig, Christian. 2000. Identifiablity of models for clusterwise linear regression. Journal of Classification 17: 273–96. [Google Scholar] [CrossRef]
- Lambert, Diane. 1992. Zero-inflated Poisson regression, with an application to defects in manufacturing. Technometrics 34: 1–14. [Google Scholar] [CrossRef]
- Lord, Dominique, Simon Washington, and John N. Ivan. 2007. Further notes on the application of zero-inflated models in highway safety. Accident Analysis & Prevention 39: 53–57. [Google Scholar]
- Mullahy, John. 1986. Specification and testing of some modified count data models. Journal of Econometrics 33: 341–65. [Google Scholar] [CrossRef]
- Papastamoulis, Panagiotis, Marie-Laure Martin-Magniette, and Cathy Maugis-Rabusseau. 2016. On the estimation of mixtures of Poisson regression models with large number of components. Computational Statistics & Data Analysis 93: 97–106. [Google Scholar]
- Park, Byung-Jung, and Dominique Lord. 2009. Application of finite mixture models for vehicle crash data analysis. Accident Analysis and Prevention 41: 683–91. [Google Scholar] [CrossRef] [PubMed]
- Pinquet, Jean, Montserrat Guillén, and Catalina Bolancé. 2001. Long-range contagion in automobile insurance data: Estimation and implications for experience rating. ASTIN Bulletin 31: 337–48. [Google Scholar] [CrossRef]
- Wang, Peiming, Martin L. Puterman, Iain Cockburn, and Nhu Le. 1996. Mixed Poisson regression models with covariate dependent rates. Biometrics 52: 381–400. [Google Scholar] [CrossRef]
- Winkelmann, Rainer. 2008. Econometric Analysis of Count Data, 4th ed. New York: Springer. [Google Scholar]
- Zou, Yajie, Yunlong Zhang, and Dominique Lord. 2013. Application of finite mixture of negative binomial regression models with varying weight parameters for vehicle crash data analysis. Accident Analysis & Prevention 50: 1042–51. [Google Scholar]


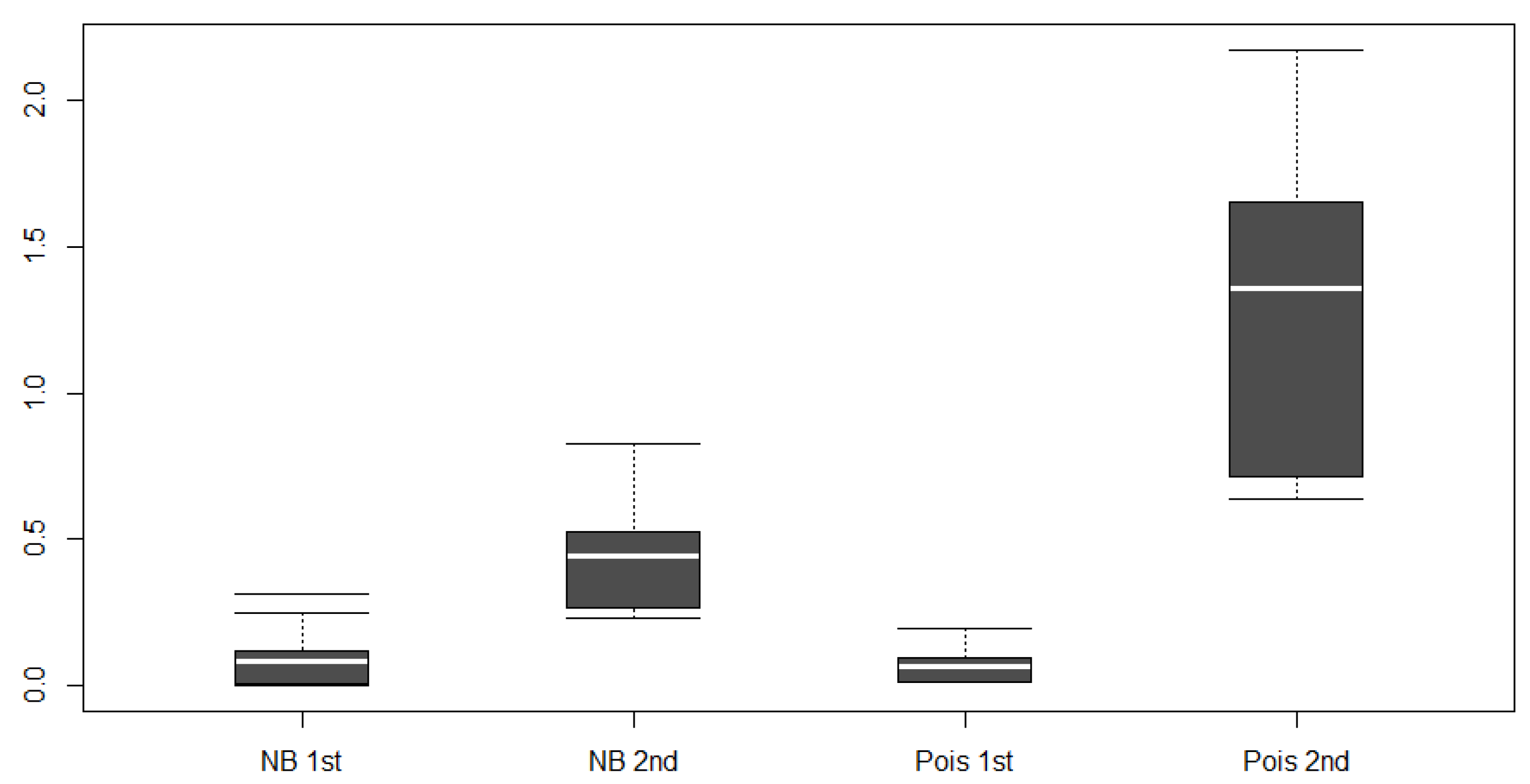{kind=link}
| Variable | Definition | Mean | St. dev. |
|---|---|---|---|
| N | total number of claims reported by policyholders | 0.1833 | 0.5873 |
| (0: 71,087; 1: 6,744; 2: 2,067; 3: 690; 4: 248; 5: 95; 6: 34; >6: 29) | |||
| GEN | equals 1 for women and 0 for men | 0.1600 | 0.3666 |
| URB | equals 1 when driving in urban area, 0 otherwise | 0.6690 | 0.4706 |
| ZON | equals 1 when driving in Madrid, Catalonia or northern Spain, 0 otherwise | 0.4326 | 0.4954 |
| LIC | equals 1 if the driving license is 4 or more years old, 0 otherwise | 0.9766 | 0.1511 |
| LOY | equals 1 if the client is in the company for more than 5 years, 0 otherwise | 0.1441 | 0.3512 |
| COV | equals 1 if includes comprehensive and collision coverage, 0 otherwise | 0.5087 | 0.4999 |
| POW | equals 1 if horsepower is greater than or equal to 5500cc, 0 otherwise | 0.8058 | 0.3955 |
| Model | Log-Likelihood | Parameters | AIC | BIC |
|---|---|---|---|---|
| Poisson | −42,585.08 | 8 | 85,186.15 | 85,260.57 |
| Negative binomial | −38,453.13 | 9 | 76,924.27 | 77,007.98 |
| Zero-inflated Poisson | −38,836.59 | 9 | 77,691.19 | 77,774.91 |
| Zero-inflated negative binomial | −38,453.13 | 10 | 76,926.27 | 77,019.28 |
| 2-Finite Poisson mixture | −38,449.61 | 17 | 76,933.21 | 77,091.36 |
| 2-Finite negative binomial mixture | −38,347.81 | 19 | 76,733.62 | 76,910.36 |
| 2FMNB | Negative Binomial | ||||||
|---|---|---|---|---|---|---|---|
| 1st comp. | 2nd comp. | p-Value | Estimate | p-Value | |||
| Intercept | −6.1420 | −1.1364 | <0.0001 | Intercept | −2.4144 | <0.0001 | |
| GEN | 0.2633 | 0.0086 | 0.0124 | GEN | 0.0774 | 0.0103 | |
| URB | 0.3407 | −0.0762 | 0.0017 | URB | 0.0165 | 0.4870 | |
| ZON | 0.3745 | 0.0564 | <0.0001 | ZON | 0.1324 | <0.0001 | |
| LIC | 0.2413 | −0.2423 | 0.0448 | LIC | −0.1610 | 0.0230 | |
| LOY | 0.3707 | 0.1289 | <0.0001 | LOY | 0.2019 | <0.0001 | |
| COV | 3.1438 | 0.6373 | <0.0001 | COV | 1.0024 | <0.0001 | |
| POW | 0.2502 | 0.1148 | <0.0001 | POW | 0.1440 | <0.0001 | |
| 0.2321 | 0.6051 | 0.2527 | |||||
| 0.6686 | 0.3314 | ||||||
| Profile Name | GEN | URB | ZON | LIC | LOY | COV | POW |
|---|---|---|---|---|---|---|---|
| Best | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| Good | 1 | 1 | 0 | 0 | 0 | 0 | 1 |
| Average | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
| Bad | 1 | 1 | 0 | 0 | 0 | 1 | 1 |
| Worst | 1 | 1 | 1 | 0 | 1 | 1 | 1 |
| Profile | Mean | Variance | |||||||
|---|---|---|---|---|---|---|---|---|---|
| NB | 2FMNB | 2FMNB-1 | 2FMNB-2 | NB | 2FMNB | 2FMNB-1 | 2FMNB-2 | ||
| Best | 0.077 | 0.080 | 0.004 | 0.233 | 0.101 | 0.183 | 0.004 | 0.323 | |
| Good | 0.113 | 0.115 | 0.005 | 0.336 | 0.164 | 0.279 | 0.005 | 0.524 | |
| Average | 0.207 | 0.200 | 0.063 | 0.476 | 0.378 | 0.496 | 0.081 | 0.852 | |
| Bad | 0.309 | 0.289 | 0.117 | 0.636 | 0.688 | 0.756 | 0.176 | 1.306 | |
| Worst | 0.432 | 0.419 | 0.247 | 0.766 | 1.170 | 1.159 | 0.509 | 1.735 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bermúdez, L.; Karlis, D.; Morillo, I. Modelling Unobserved Heterogeneity in Claim Counts Using Finite Mixture Models. Risks 2020, 8, 10. https://doi.org/10.3390/risks8010010
Bermúdez L, Karlis D, Morillo I. Modelling Unobserved Heterogeneity in Claim Counts Using Finite Mixture Models. Risks. 2020; 8(1):10. https://doi.org/10.3390/risks8010010
Chicago/Turabian StyleBermúdez, Lluís, Dimitris Karlis, and Isabel Morillo. 2020. "Modelling Unobserved Heterogeneity in Claim Counts Using Finite Mixture Models" Risks 8, no. 1: 10. https://doi.org/10.3390/risks8010010
APA StyleBermúdez, L., Karlis, D., & Morillo, I. (2020). Modelling Unobserved Heterogeneity in Claim Counts Using Finite Mixture Models. Risks, 8(1), 10. https://doi.org/10.3390/risks8010010