Mid-Infrared Spectroscopy with Variable Selection for the Rapid Quantification of Amylose Content in Starch

 and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Materials and Instruments
2.2. Samples Preparation and Apparent Amylose Content of Samples
2.3. Spectral Collection
2.4. Spectral Pretreatments
2.5. Multivariate Data Statistics
2.5.1. Modeling Method
2.5.2. Principal Component Analysis (PCA)
2.5.3. Competitive Adaptive Reweighted Sampling (CARS)
2.5.4. Uninformative Variable Elimination (UVE)
2.5.5. Bootstrapping Soft Shrinkage (BOSS)
2.6. Model’s Evaluation
2.7. Software
3. Results and Discussion
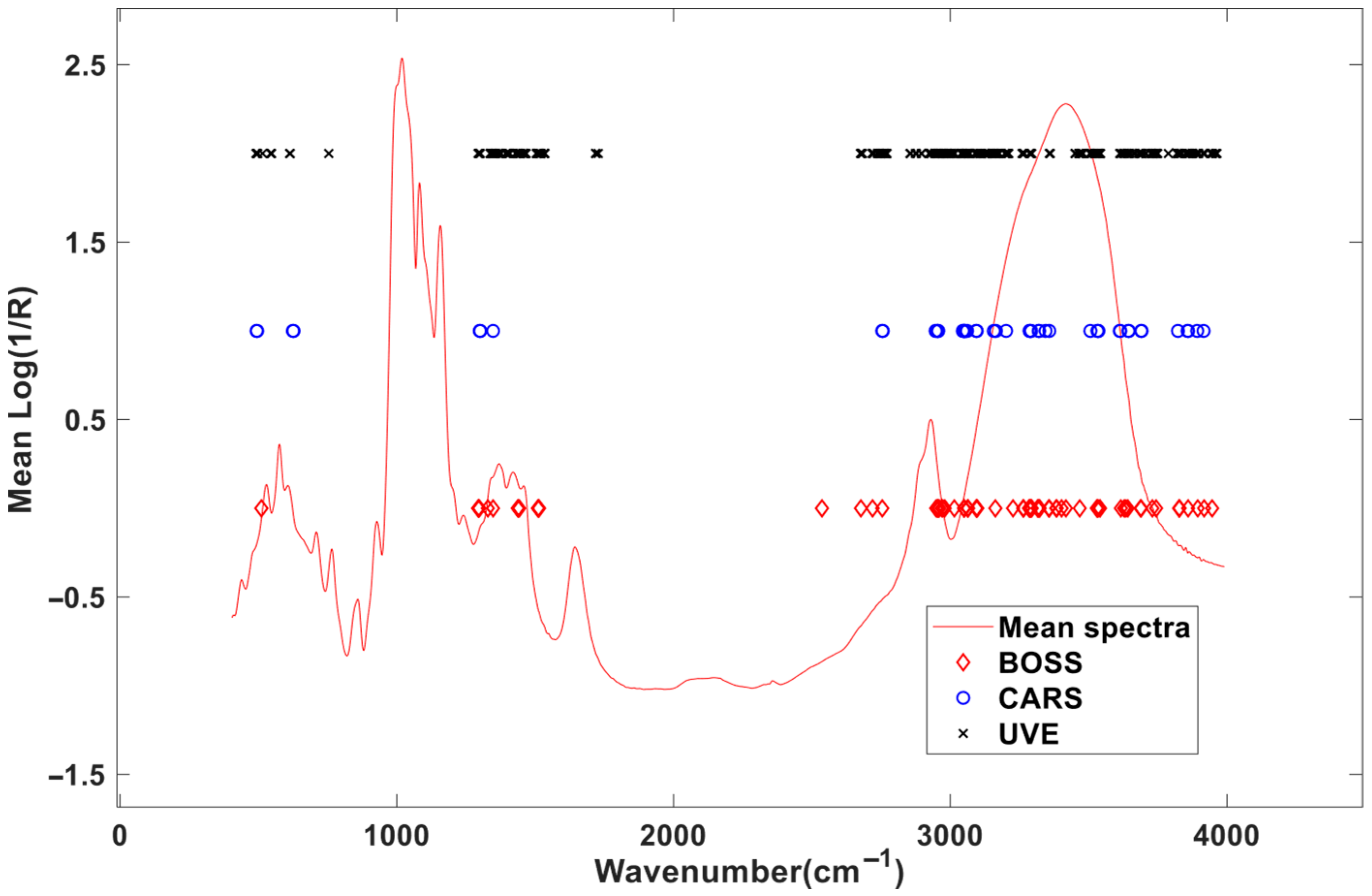
3.1. Analysis of Spectral Profile
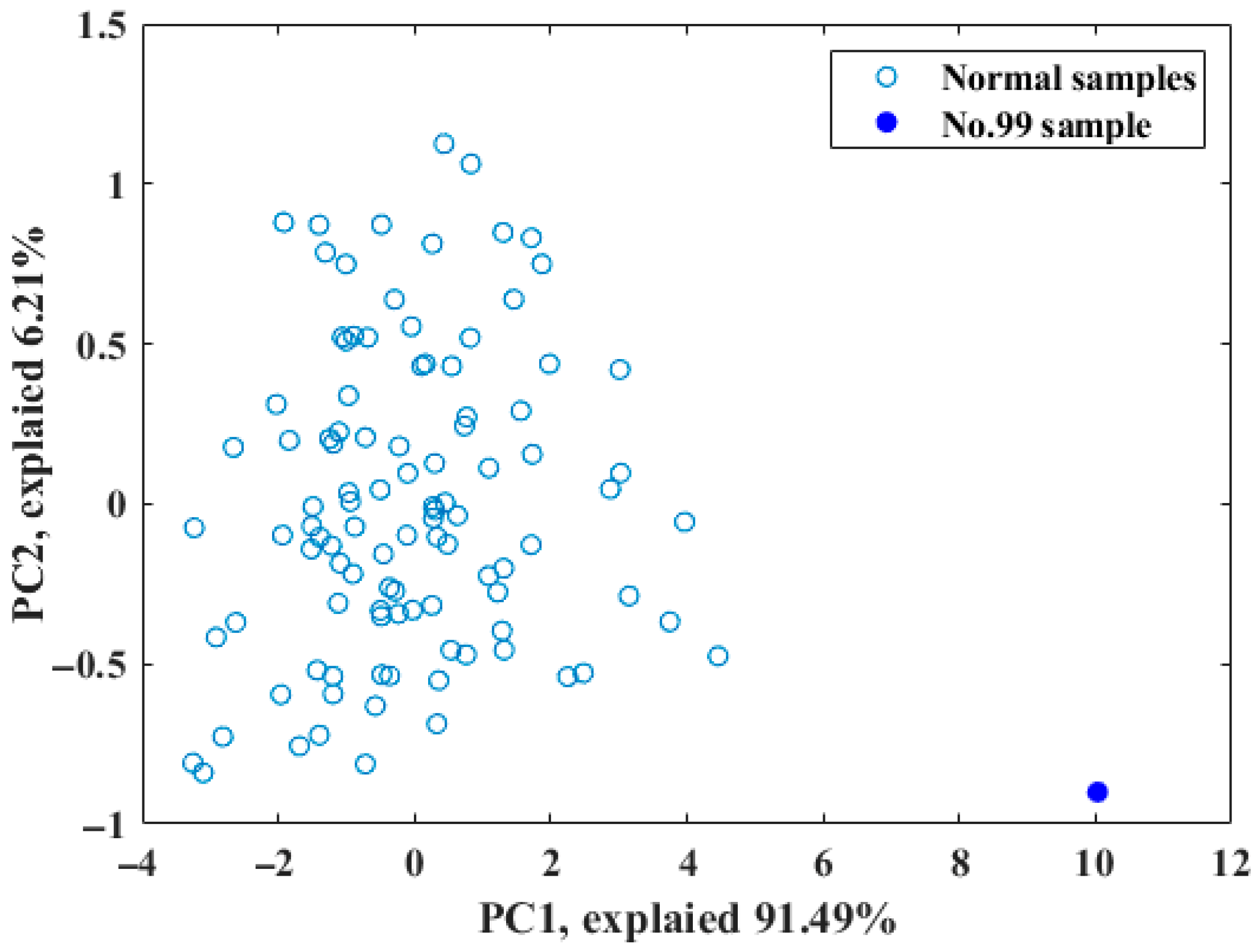
3.2. Division of Samples
3.3. Comparison of Spectra Pretreatments
3.4. Comparison of Spectral Variables Selections
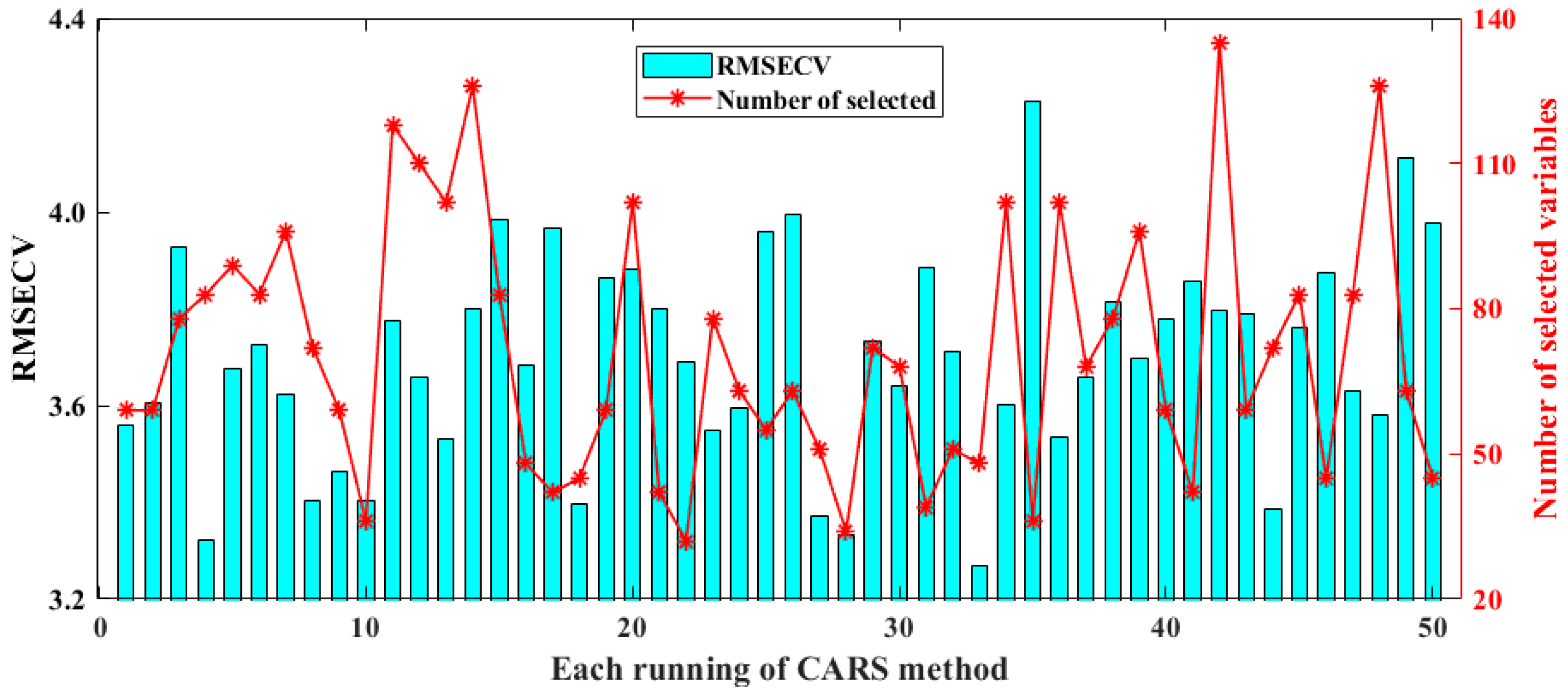
3.4.1. Optimization by BOSS
3.4.2. Optimization by CARS
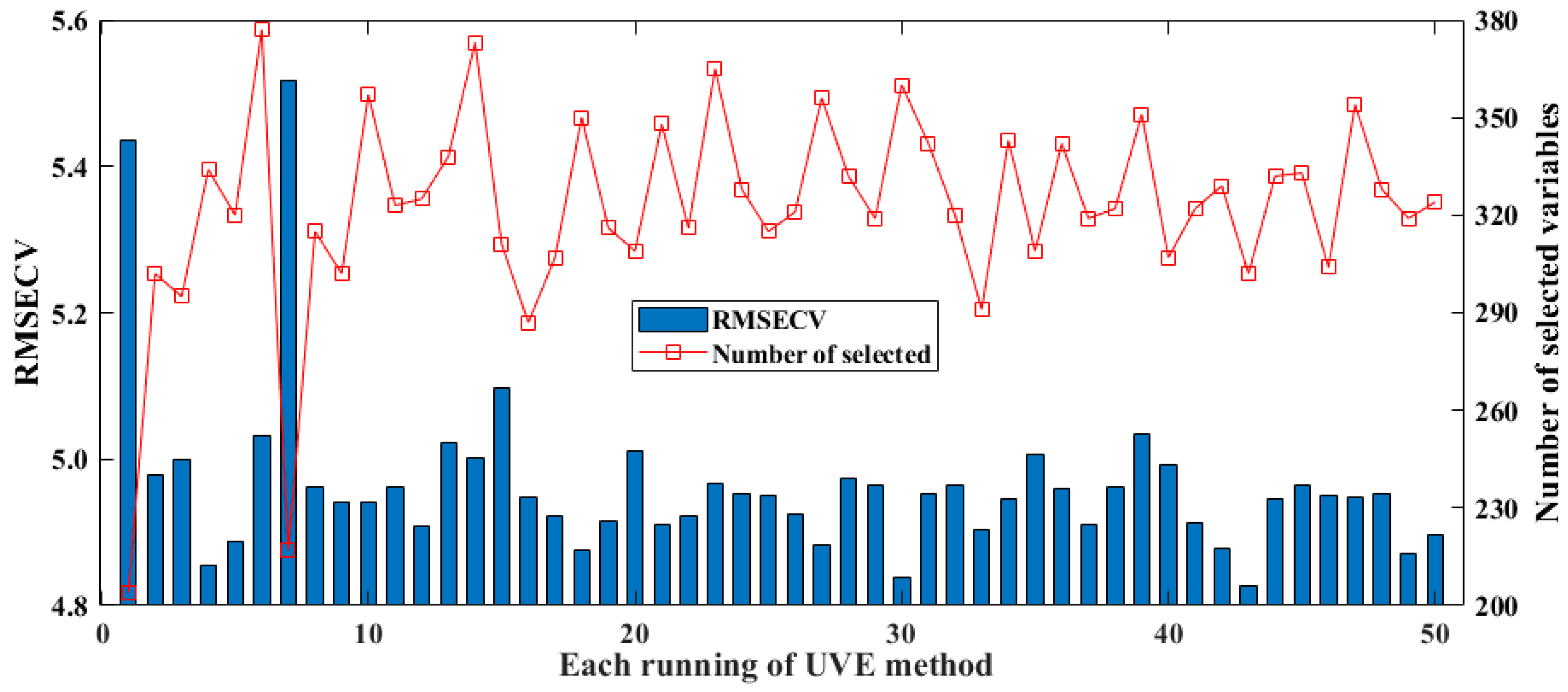
3.4.3. Optimization by UVE
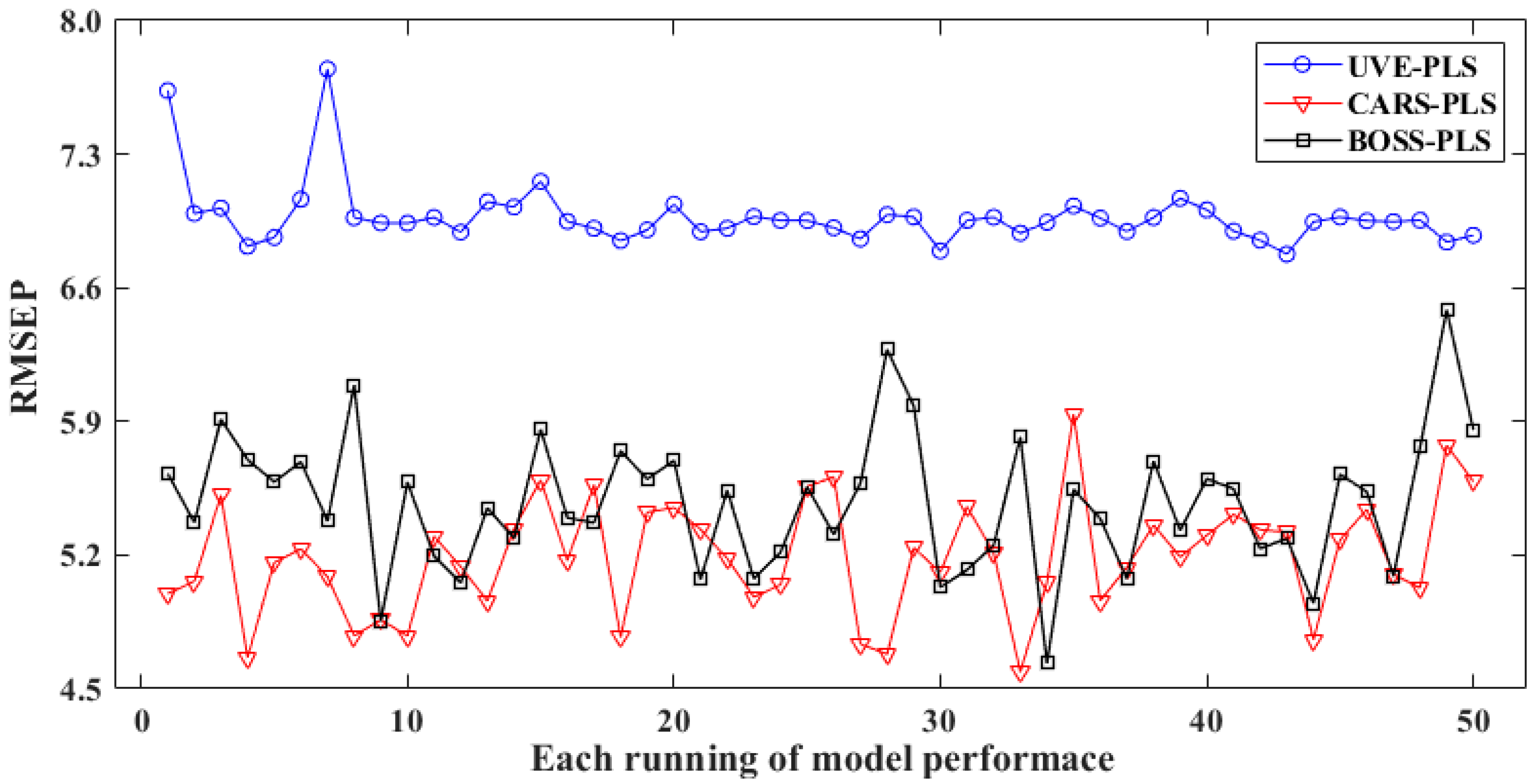
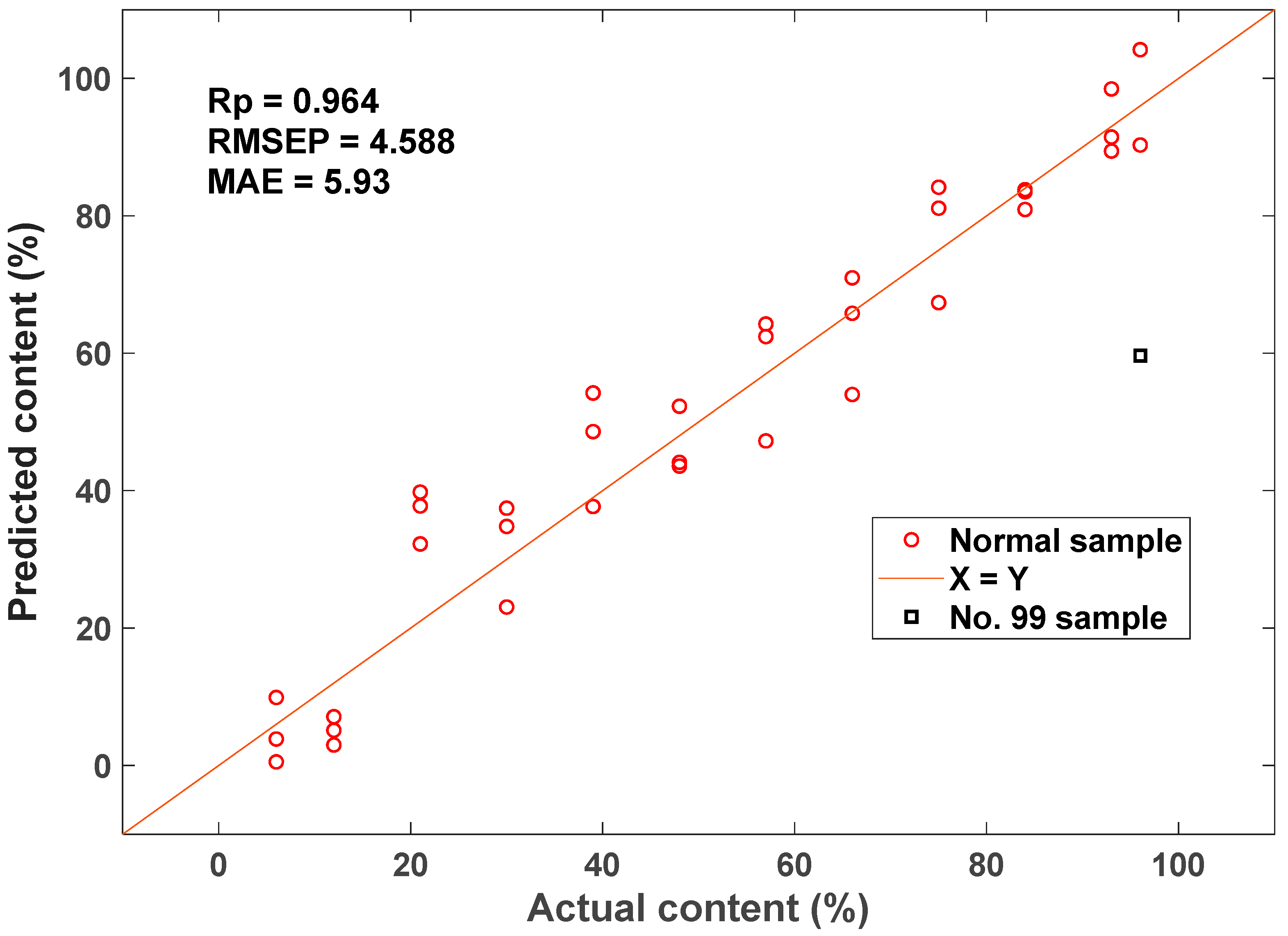
3.5. Predictions of the Optimized Regression Models
3.6. Discussions
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chi, C.; Xu, K.; Wang, H.; Zhao, L.; Zhang, Y.; Chen, B.; Wang, M. Deciphering multi-scale structures and pasting properties of wheat starch in frozen dough following different freezing rates. Food Chem. 2023, 405, 134836. [Google Scholar] [CrossRef]
- Cheng, W.; Sun, Y.; Xia, X.; Yang, L.; Fan, M.; Li, Y.; Wang, L.; Qian, H. Effects of β-amylase treatment conditions on the gelatinization and retrogradation characteristics of wheat starch. Food Hydrocoll. 2022, 124, 107286. [Google Scholar] [CrossRef]
- Sun, X.; Sun, Z.; Saleh, A.S.M.; Zhao, K.; Ge, X.; Shen, H.; Zhang, Q.; Yuan, L.; Yu, X.; Li, W. Understanding the granule, growth ring, blocklets, crystalline and molecular structure of normal and waxy wheat A- and B-starch granules. Food Hydrocoll. 2021, 121, 107034. [Google Scholar] [CrossRef]
- Liu, X.; Zhang, J.; Yang, X.; Sun, J.; Zhang, Y.; Su, D.; Zhang, H.; Wang, H. Combined molecular and supramolecular structural insights into pasting behaviors of starches isolated from native and germinated waxy brown rice. Carbohydr. Polym. 2022, 283, 119148. [Google Scholar] [CrossRef]
- Wang, H.; Liu, J.; Zhang, Y.; Li, S.; Liu, X.; Zhang, Y.; Zhao, X.; Shen, H.; Xie, F.; Xu, K.; et al. Insights into the hierarchical structure and physicochemical properties of starch isolated from fermented dough. Int. J. Biol. Macromol. 2024, 267, 131315. [Google Scholar] [CrossRef]
- Bian, X.; Chen, J.; Yang, Y.; Yu, D.; Ma, Z.; Ren, L.; Wu, N.; Chen, F.; Liu, X.; Wang, B.; et al. Effects of fermentation on the structure and physical properties of glutinous proso millet starch. Food Hydrocoll. 2022, 123, 107144. [Google Scholar] [CrossRef]
- Ma, M.; Gu, Z.; Cheng, L.; Li, Z.; Li, C.; Hong, Y. Chewing characteristics of rice and reasons for differences between three rice types with different amylose contents. Int. J. Biol. Macromol. 2024, 278, 134869. [Google Scholar] [CrossRef]
- Waterschoot, J.; Gomand, S.V.; Fierens, E.; Delcour, J.A. Production, structure, physicochemical and functional properties of maize, cassava, wheat, potato and rice starches. Starch-Stärke 2013, 67, 14–29. [Google Scholar] [CrossRef]
- Leal-Lazareno, C.; Agama-Acevedo, E.; Ibba, M.I.; Ammar, K.; Bello-Pérez, L. Structural, molecular, and physicochemical properties of starch in high-amylose durum wheat lines. Food Hydrocoll. 2025, 160, 110791. [Google Scholar] [CrossRef]
- Zhong, Y.; Tai, L.; Blennow, A.; Ding, L.; Herburger, K.; Qu, J.; Xin, A.; Guo, D.; Hebelstrup, K.; Liu, X. High-amylose starch: Structure, functionality and applications. Crit. Rev. Food Sci. 2023, 63, 8568–8590. [Google Scholar] [CrossRef] [PubMed]
- Obadi, M.; Qi, Y.; Xu, B. High-amylose maize starch: Structure, properties, modifications and industrial applications. Carbohydr. Polym. 2023, 299, 120185. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Zhu, F. Characterization of polymer chain fractions of kiwifruit starch. Food Chem. 2018, 240, 579–587. [Google Scholar] [CrossRef] [PubMed]
- Creek, J.A.; Benesi, A.; Runt, J.; Ziegler, G.R. Potential sources of error in the calorimetric evaluation of amylose content of starches. Carbohydr. Polym. 2007, 68, 465–471. [Google Scholar] [CrossRef]
- Mariotti, M.; Fongaro, L.; Catenacci, F. Alkali spreading value and image analysis. J. Cereal Sci. 2010, 52, 227–235. [Google Scholar] [CrossRef]
- Zhu, F.; Cui, R. Comparison of molecular structure of oca (Oxalis tuberosa), potato, and maize starches. Food Chem. 2019, 296, 116–122. [Google Scholar] [CrossRef]
- Shi, P.; Zhao, Y.; Qin, F.; Liu, K.; Wang, H. Understanding the multi-scale structure and physicochemical properties of millet starch with varied amylose content. Food Chem. 2023, 410, 135422. [Google Scholar] [CrossRef]
- Yang, X.; Chi, C.; Liu, X.; Zhang, Y.; Zhang, H.; Wang, H. Understanding the structural and digestion changes of starch in heat-moisture treated polished rice grains with varying amylose content. Int. J. Biol. Macromol. 2019, 139, 785–792. [Google Scholar] [CrossRef]
- Khoomtong, A.; Noomhorm, A. Development of a simple portable amylose content meter for rapid determination of amylose content in milled rice. Food Bioprocess Technol. 2015, 8, 1938–1946. [Google Scholar] [CrossRef]
- Lohumi, S.; Lee, S.; Lee, H.; Cho, B.K. A review of vibrational spectroscopic techniques for the detection of food authenticity and adulteration. Trends Food Sci. Technol. 2015, 46, 85–98. [Google Scholar] [CrossRef]
- Song, C.; Liu, J.; Wang, C.; Li, Z.; Zhang, D.; Li, P. Rapid identification of adulterated rice based on data fusion of near-infrared spectroscopy and machine vision. J. Food Meas. Charact. 2024, 18, 3881–3892. [Google Scholar] [CrossRef]
- Liu, L.; Zareef, M.; Wang, Z.; Li, H.; Chen, Q.; Ouyang, Q. Monitoring chlorophyll changes during Tencha processing using portable near-infrared spectroscopy. Food Chem. 2023, 412, 135505. [Google Scholar] [CrossRef]
- Pasquini, C. Near infrared spectroscopy: A mature analytical technique with new perspectives–A review. Anal. Chim. Acta 2018, 1026, 8–36. [Google Scholar] [CrossRef]
- Collell, C.; Gou, P.; Arnau, J.; Muñoz, I.; Comaposada, J. NIR technology for on-line determination of superficial aw and moisture content during the drying process of fermented sausages. Food Chem. 2012, 135, 1750–1755. [Google Scholar] [CrossRef]
- González-Muñoz, A.; Montero, B.; Enrione, J.; Matiacevich, S. Rapid prediction of moisture content of quinoa (Chenopodium quinoa Willd.) flour by Fourier transform infrared (FTIR) spectroscopy. J. Cereal Sci. 2016, 71, 246–249. [Google Scholar] [CrossRef]
- Amirvaresi, A.; Nikounezhad, N.; Amirahmadi, M.; Daraei, B.; Parastar, H. Comparison of near-infrared (NIR) and mid-infrared (MIR) spectroscopy based on chemometrics for saffron authentication and adulteration detection. Food Chem. 2021, 344, 128647. [Google Scholar] [CrossRef]
- Porep, J.U.; Kammerer, D.R.; Carle, R. On-line application of near infrared (NIR) spectroscopy in food production. Trends Food Sci. Technol. 2015, 46, 211–230. [Google Scholar] [CrossRef]
- Yuan, L.-M.; Mao, F.; Chen, X.; Li, L.; Huang, G. Non-invasive measurements of ‘Yunhe’ pears by vis-NIRS technology coupled with deviation fusion modeling approach. Postharvest Biol. Technol. 2020, 160, 111067–111073. [Google Scholar] [CrossRef]
- Borba, K.R.; Spricigo, P.C.; Aykas, D.P.; Mitsuyuki, M.C.; Colnago, L.A.; Ferreira, M.D. Non-invasive quantification of vitamin C, citric acid, and sugar in ‘Valência’oranges using infrared spectroscopies. J. Food Sci. Technol. 2021, 58, 731–738. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Wang, Y.; Wang, R.; Liu, X.; Zhang, Y.; Zhang, H.; Chi, C. Impact of long-term storage on multi-scale structures and physicochemical properties of starch isolated from rice grains. Food Hydrocoll. 2022, 124, 107255. [Google Scholar] [CrossRef]
- Yuan, L.-M.; Yang, X.; Fu, X.; Yang, J.; Chen, X.; Huang, G.; Chen, X.; Li, L.; Shi, W. Consensual Regression of Lasso-Sparse PLS models for Near-Infrared Spectra of Food. Agriculture 2022, 12, 1804. [Google Scholar] [CrossRef]
- Granato, D.; Santos, J.S.; Escher, G.B.; Ferreira, B.L.; Maggio, R.M. Use of principal component analysis (PCA) and hierarchical cluster analysis (HCA) for multivariate association between bioactive compounds and functional properties in foods: A critical perspective. Trends Food Sci. Technol. 2018, 72, 83–90. [Google Scholar] [CrossRef]
- Li, H.; Liang, Y.; Xu, Q.; Cao, D. Key wavelengths screening using competitive adaptive reweighted sampling method for multivariate calibration. Anal. Chim. Acta 2009, 648, 77–84. [Google Scholar] [CrossRef] [PubMed]
- Centner, V.; Massart, D.L.; de Noord, O.E.; de Jong, S.; Vandeginste, B.M.; Sterna, C. Elimination of uninformative variables for multivariate calibration. Anal. Chem. 1996, 68, 3851–3858. [Google Scholar] [CrossRef]
- Koshoubu, J.; Iwata, T.; Minami, S. Elimination of the uninformative calibration sample subset in the modified UVE (uninformative variable elimination)–PLS (partial least squares) method. Anal. Sci. 2001, 17, 319–322. [Google Scholar] [CrossRef]
- Deng, B.; Yun, Y.; Cao, D.; Yin, Y.; Wang, W.; Lu, H.; Luo, Y.; Liang, Y. A bootstrapping soft shrinkage approach for variable selection in chemical modeling. Anal. Chim. Acta 2016, 908, 63–74. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Lv, W.; Zhao, R.; Guo, H.; Liu, J.; Han, D. Non-destructive assessment of quality parameters in ‘Friar’plums during low temperature storage using visible/near infrared spectroscopy. Food Control 2017, 73, 1334–1341. [Google Scholar] [CrossRef]
- Glaucio, L.A.; Reis, A.S.; Besen, M.S.; Rodrigues, M.; Crusiol, L.; Falcioni, R.; Oliveira, R.; Batista, M.; Nanni, M. Spectral method for macro and micronutrient prediction in soybean leaves using interval partial least squares regression. Eur. J. Agron. 2023, 143, 126717. [Google Scholar] [CrossRef]
- Yuan, L.; Mao, F.; Huang, G.; Chen, X.; Wu, D.; Li, S.; Zhou, X.; Jiang, Q.; Lin, D.; He, R. Models fused with successive CARS-PLS for measurement of the soluble solids content of Chinese bayberry by vis-NIRS technology. Postharvest Biol. Technol. 2020, 169, 111308. [Google Scholar] [CrossRef]
- Gao, F.; Xing, Y.; Li, J.; Guo, L.; Sun, Y.; Shi, W.; Yuan, L. Prediction of Total Soluble Solids in Apricot Using Adaptive Boosting Ensemble Model Combined with NIR and High-Frequency UVE-Selected Variables. Molecules 2025, 30, 1543. [Google Scholar] [CrossRef]
- Yun, Y.-H.; Li, H.-D.; Deng, B.-C.; Cao, D.-S. An overview of variable selection methods in multivariate analysis of near-infrared spectra. TrAC Trends Anal. Chem. 2019, 113, 102–115. [Google Scholar] [CrossRef]
- Hearn, L.K.; Subedi, P.P. Determining levels of steviol glycosides in the leaves of Stevia rebaudiana by near infrared reflectance spectroscopy. J. Food Compos. Anal. 2009, 22, 165–168. [Google Scholar] [CrossRef]
- Du, G.; Cai, W.; Shao, X. A variable differential consensus method for improving the quantitative near-infrared spectroscopic analysis. Sci. China Chem. 2012, 55, 1946–1952. [Google Scholar] [CrossRef]
- Han, Q.; Wu, H.; Cai, C.; Xu, L.; Yu, R. An ensemble of Monte Carlo uninformative variable elimination for wavelength selection. Anal. Chim. Acta 2008, 612, 121–125. [Google Scholar] [CrossRef]
- Yuan, L.-M.; Liu, Y.; Gao, F.; Jiang, Q.; Ji, H.; Chen, X.; Chen, X.; Zhu, F. Prediction of bayberry SSC by ensemble model with random frog successively selected from the residual vis-NIR spectra. Food Control 2025, 178, 111525. [Google Scholar] [CrossRef]
- Mariana, R.A.; Laura, B.R.; Ronei, J.P. Determination of amylose content in starch using Raman spectroscopy and multivariate calibration analysis. Anal. Bioanal. Chem. 2010, 397, 2693–2701. [Google Scholar] [CrossRef]
- Xie, L.H.; Tang, S.Q.; Wei, X.J.; Sheng, Z.H.; Shao, G.N.; Jiao, G.A.; Hu, S.K.; Wang, L.; Hu, P.S. Simultaneous determination of apparent amylose, amylose and amylopectin content and classification of waxy rice using near-infrared spectroscopy (NIRS). J. Food Chem. 2022, 388, 132944. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Items | Sample Number | Mean | Std | C.V. a | Amylose Content Level b |
|---|---|---|---|---|---|
| Calibration set | 69 | 50.26 | 30.55 | 0.608 | 0, 3, 9, 15, 18, 24, 27, 33, 36, 42, 45, 51, 54, 60, 63, 69, 72, 78, 81, 87, 90, 99, 100 |
| Prediction set | 35 | 51 | 29.82 | 0.585 | 6, 12, 21, 30, 39, 48, 57, 66, 75, 84, 93, 96 c |
| Pretreatments | LVs | Rcv | RMSECV | MAE | Rp | RMSEP | MAE | RPD | Bias (No. 99) |
|---|---|---|---|---|---|---|---|---|---|
| None | 14 | 0.937 | 10.78 | 8.25 | 0.920 | 11.56 | 8.71 | 2.58 | −61.3 |
| Smooth a | 14 | 0.944 | 10.04 | 7.51 | 0.940 | 10.25 | 7.94 | 2.91 | −61.6 |
| z-score | 11 | 0.945 | 9.82 | 7.64 | 0.971 | 7.57 | 5.98 | 3.94 | −26.8 |
| De-mean b | 13 | 0.842 | 10.23 | 7.91 | 0.950 | 9.59 | 7.61 | 3.11 | −57.6 |
| Derivative c | 9 | 0.938 | 10.58 | 8.10 | 0.889 | 13.66 | 10.43 | 2.18 | −22.4 |
| Selection Method | Inputs | Calibration Set | Prediction Set | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Number | LVs | Rcv | RMSECV | Mean ± SD a | Rp | RMSEP | Mean ± SD b | RPD | Bias (No. 99) | |
| UVE-4th | 334 | 15 | 0.987 | 4.86 | 4.96 ± 0.12 | 0.969 | 6.82 | 6.97 ± 0.17 | 4.37 | −36.6 |
| CARS-33rd | 48 | 14 | 0.983 | 3.27 | 3.69 ± 0.21 | 0.964 | 4.59 | 5.19 ± 0.30 | 6.49 | −36.4 |
| BOSS-34th | 71 | 13 | 0.994 | 3.30 | 3.90 ± 0.25 | 0.952 | 4.63 | 5.48 ± 0.36 | 6.44 | −31.5 |
| none | 1860 | 14 | 0.937 | 10.78 | 0.920 | 11.56 | 2.58 | −61.3 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, J.; Wang, H.; Bai, J.; Liu, Y.; Liu, X.; Zhang, Y.; Yuan, L. Mid-Infrared Spectroscopy with Variable Selection for the Rapid Quantification of Amylose Content in Starch. Chemosensors 2025, 13, 287. https://doi.org/10.3390/chemosensors13080287
Qiao J, Wang H, Bai J, Liu Y, Liu X, Zhang Y, Yuan L. Mid-Infrared Spectroscopy with Variable Selection for the Rapid Quantification of Amylose Content in Starch. Chemosensors. 2025; 13(8):287. https://doi.org/10.3390/chemosensors13080287
Chicago/Turabian StyleQiao, Jingyue, Hongwei Wang, Jianing Bai, Yimin Liu, Xiaocheng Liu, Yanyan Zhang, and Leiming Yuan. 2025. "Mid-Infrared Spectroscopy with Variable Selection for the Rapid Quantification of Amylose Content in Starch" Chemosensors 13, no. 8: 287. https://doi.org/10.3390/chemosensors13080287
APA StyleQiao, J., Wang, H., Bai, J., Liu, Y., Liu, X., Zhang, Y., & Yuan, L. (2025). Mid-Infrared Spectroscopy with Variable Selection for the Rapid Quantification of Amylose Content in Starch. Chemosensors, 13(8), 287. https://doi.org/10.3390/chemosensors13080287