
A High-Dimensional Counterpart for the Ridge Estimator in Multicollinear Situations



Abstract
:1. Introduction
An Existing Two-Parameter Biased Estimator
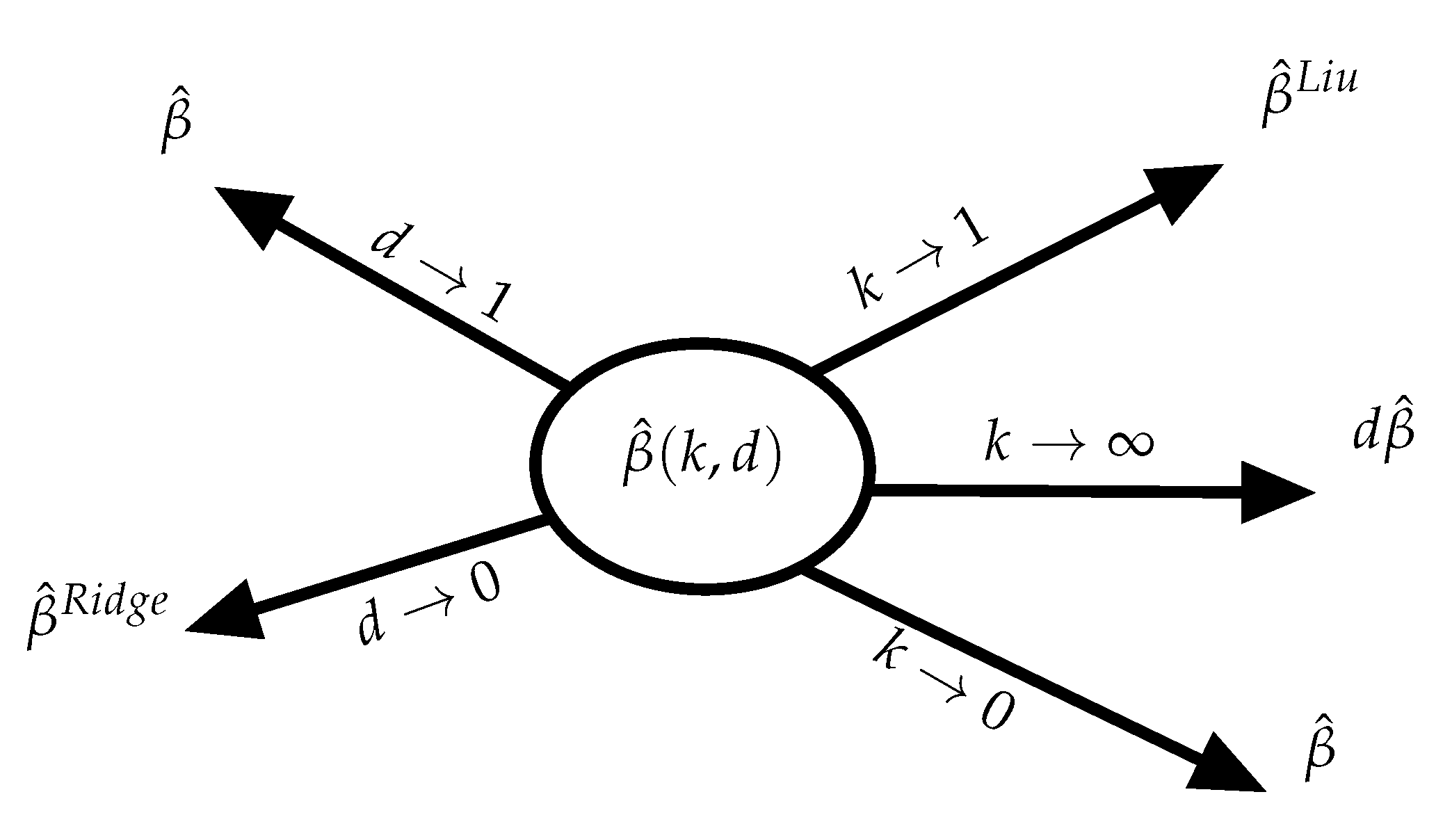
2. The Proposed Estimator
- (A1)
- . There exists a constant , such that a component of is .
- (A2)
- . There exists a constant , such that a component of is .
- (A3)
- For sufficiently large p, there is a vector , such that , and there exists a constant , such that each component of the vector is , and , with . (An example of such choice is and ).
- (A4)
- For sufficiently large p, there exists a constant , such that each component of is and . Further, .
3. Generalized cross Validation
4. Numerical Investigations
4.1. Simulation
4.2. Review of Results
- (1)
- The performance of the estimators is affected by the number of observations (n), the number of variables (p), the signal to noise ratio (c), and the degree of multicollinearity ().
- (2)
- By increasing the degree of multicollinearity, , although for both cases of error distributions, the QB of the proposed estimator increases for and 1, its MSE decreases dramatically since the RMSE increases.
- (3)
- The signal-to-noise shows the effect of in the model. Lower values (less than 1) are a sign of model sparsity, since, when c is small, the proposed estimator performs better than the ridge. This is evidence that our estimator is a better candidate as an alternative in sparse models in the MSE sense. However, the QB increases for large c values, which forces the model to overestimate the parameters.
- (4)
- As p increases, although the proposed estimator is superior to the ridge in sparse models (small c values), the efficiency decreases. This is more evident when the ratio becomes larger. This fact may come as poor performance of the proposed estimators, but our estimator is still preferred in high dimensions for sparse models.
- (5)
- Obviously, as n increases, so does the RMSE; however, the QB becomes very large, and it is due to the nature of the proposed estimators because of its complicated form. It must be noted that this does not contradict the results of Theorem 2, since the simulation scheme does not obey the regularity condition.
- (6)
- There is evidence of robustness for the distribution tail for sparse models, i.e., the QB and RMSE are the same for both normal and t distributions. However, as c increases, the QB of the proposed estimator explodes for the heavier tail distribution. This may be seen as a disadvantage of the proposed estimators, but even for large values of c, the RMSE stays the same, evidence of relatively small variance for the heavier tail distribution.
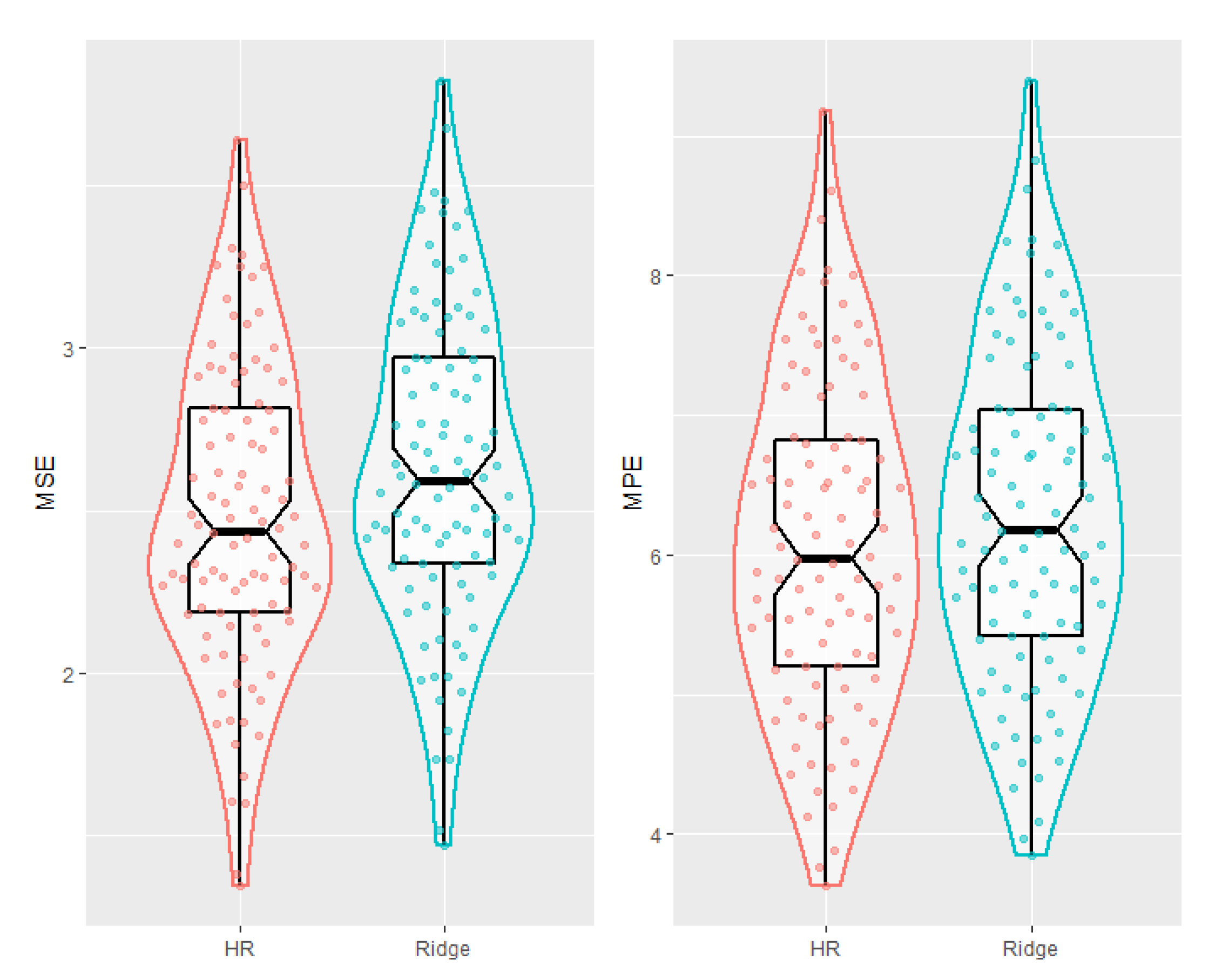
4.3. AML Data Analysis
- (1)
- Using the GCV, the proposed estimator is shown to be consistently superior to the ridge estimator, relative to RMSE and RMPE criteria.
- (2)
- Similarly to the results of simulations, with growing p, the MSE of the proposed estimator increases compared to the ridge estimator. However, as p gets larger the mean prediction error becomes smaller, which shows the superiority for prediction purposes.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Proof of the Main Results
References
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for non-orthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tikhonov, A.N. Solution of incorrectly formulated problems and the regularization method. Sov. Math. Dokl. 1963, 4, 1035–1038. [Google Scholar]
- Saleh, A.K.M.E.; Arashi, M.; Kibria, B.M.G. Theory of Ridge Regression Estimation with Applications; John Wiley: Hoboken, NJ, USA, 2019. [Google Scholar]
- Wang, X.; Dunson, D.; Leng, C. No penalty no tears: Least squares in high-dimensional models. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1814–1822. [Google Scholar]
- Bühlmann, P. Statistical significance in high-dimensional linear models. Bernoulli 2013, 19, 1212–1242. [Google Scholar] [CrossRef] [Green Version]
- Shao, J.; Deng, X. Estimation in high-dimensional linear models with deterministic design matrices. Ann. Stat. 2012, 40, 812–831. [Google Scholar] [CrossRef] [Green Version]
- Dicker, L.H. Ridge regression and asymptotic minimum estimation over spheres of growing dimension. Bernoulli 2016, 22, 1–37. [Google Scholar] [CrossRef]
- Liu, K. A new class of biased estimate in linear regression. Commun. Stat. Theory Methods 1993, 22, 393–402. [Google Scholar]
- Ozkale, M.R.; Kaciranlar, S. The restricted and unrestricted two-parameter estimators. Commun. Stat. Theory Methods 2007, 36, 2707–2725. [Google Scholar] [CrossRef]
- Wang, X.; Leng, C. High dimensional ordinary least squares projection for screening variables. J. R. Stat. Soc. Ser. B 2015. [Google Scholar] [CrossRef] [Green Version]
- Luo, J. The discovery of mean square error consistency of ridge estimator. Stat. Probab. Lett. 2010, 80, 343–347. [Google Scholar] [CrossRef]
- Amini, M.; Roozbeh, M. Optimal partial ridge estimation in restricted semiparametric regression models. J. Multivar. Anal. 2015, 136, 26–40. [Google Scholar] [CrossRef]
- Akdeniz, F.; Roozbeh, M. Generalized difference-based weighted mixed almost unbiased ridge estimator in partially linear models. Stat. Pap. 2019, 60, 1717–1739. [Google Scholar] [CrossRef]
- McDonald, G.C.; Galarneau, D.I. A Monte Carlo of Some Ridge-Type Estimators. J. Am. Stat. Assoc. 1975, 70, 407–416. [Google Scholar] [CrossRef]
- Zhu, L.P.; Li, L.; Li, R.; Zhu, L.X. Model-free feature screening for ultrahigh dimensional data. J. Am. Stat. Assoc. 2011, 106, 1464–1475. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Metzeler, K.H.; Hummel, M.; Bloomfield, C.D.; Spiekermann, K.; Braess, J.; Sauerl, M.C.; Heinecke, A.; Radmacher, M.; Marcucci, G.; Whitman, S.P.; et al. An 86 Probe Set Gene Expression Signature Predicts Survival in Cytogenetically Normal Acute Myeloid Leukemia. Blood 2008, 112, 4193–4201. [Google Scholar] [CrossRef] [PubMed]
- Sill, M.; Hielscher, T.; Becker, N.; Zucknick, M. c060: Extended Inference for Lasso and Elastic-Net Regularized Cox and Generalized Linear Models; R Package Version 0.2-4; 2014. Available online: http://CRAN.R-project.org/package=c060 (accessed on 1 January 2021).
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis, 5th ed.; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]

{kind=link}
{kind=link}
| diff | diff | diff | diff | |||
| 256 | 30 | 5.7657 | 5.7643 | 10.0535 | 10.1134 | |
| 50 | 6.4911 | 6.4941 | 11.4722 | 11.5088 | ||
| 100 | 17.8314 | 17.8493 | 30.1008 | 30.4137 | ||
| 1 | 30 | 22.9671 | 487.4169 | 39.6556 | 459.3473 | |
| 50 | 25.8621 | 522.6298 | 45.1138 | 480.5501 | ||
| 100 | 70.8693 | 798.6551 | 118.1326 | 676.1919 | ||
| 2 | 30 | 91.7526 | 2413.9746 | 158.0026 | 2256.1664 | |
| 50 | 103.3996 | 2587.7382 | 179.8509 | 2357.4111 | ||
| 100 | 283.0549 | 3922.0057 | 470.4114 | 3259.2211 | ||
| 512 | 30 | 3.1943 | 3.2012 | 6.5528 | 6.6001 | |
| 50 | 4.4800 | 4.4781 | 9.5861 | 9.6151 | ||
| 100 | 10.2121 | 10.2489 | 20.1828 | 20.3366 | ||
| 1 | 30 | 12.7657 | 926.7540 | 26.0911 | 916.2663 | |
| 50 | 17.8861 | 1009.3595 | 38.0549 | 969.4353 | ||
| 100 | 40.7254 | 1192.4455 | 79.9094 | 1095.9628 | ||
| 2 | 30 | 51.0605 | 4621.0862 | 104.2892 | 4555.0569 | |
| 50 | 71.5157 | 5029.3107 | 151.9461 | 4809.2595 | ||
| 100 | 162.7616 | 5920.6337 | 318.7343 | 5397.7878 | ||
| 1024 | 30 | 1.7594 | 1.7584 | 3.7384 | 3.7410 | |
| 50 | 3.9188 | 3.9345 | 9.2523 | 9.3437 | ||
| 100 | 5.1236 | 5.1189 | 12.6469 | 12.6455 | ||
| 1 | 30 | 7.0318 | 1637.6798 | 14.8960 | 1636.5664 | |
| 50 | 15.6758 | 1804.8548 | 36.9649 | 1763.7468 | ||
| 100 | 20.4564 | 1940.6091 | 50.2993 | 1856.0197 | ||
| 2 | 30 | 28.1221 | 8181.4255 | 59.5312 | 8167.9835 | |
| 50 | 62.7157 | 9008.4246 | 147.8715 | 8781.1968 | ||
| 100 | 81.7756 | 9682.7404 | 147.8715 | 9229.7803 | ||
| RMSE | RMSE | RMSE | RMSE | |||
| 256 | 30 | 1.0050 | 1.0050 | 1.0140 | 1.0139 | |
| 50 | 1.0058 | 1.0058 | 1.0161 | 1.0160 | ||
| 100 | 1.0222 | 1.0222 | 1.0543 | 1.0539 | ||
| 1 | 30 | 1.0032 | 1.0032 | 1.0179 | 1.0178 | |
| 50 | 1.0039 | 1.0039 | 1.0209 | 1.0209 | ||
| 100 | 1.0221 | 1.0220 | 1.0883 | 1.0876 | ||
| 2 | 30 | 0.9816 | 0.9816 | 0.9852 | 0.9851 | |
| 50 | 0.9793 | 0.9793 | 0.9829 | 0.9829 | ||
| 100 | 0.9434 | 0.9435 | 0.9587 | 0.9584 | ||
| 512 | 30 | 1.0011 | 1.0011 | 1.0031 | 1.0031 | |
| 50 | 1.0016 | 1.0016 | 1.0048 | 1.0048 | ||
| 100 | 1.0041 | 1.0041 | 1.0119 | 1.0119 | ||
| 1 | 30 | 1.0004 | 1.0004 | 1.0029 | 1.0029 | |
| 50 | 1.0007 | 1.0007 | 1.0048 | 1.0048 | ||
| 100 | 1.0023 | 1.0023 | 1.0139 | 1.0139 | ||
| 2 | 30 | 0.9948 | 0.9948 | 0.9924 | 0.9924 | |
| 50 | 0.9929 | 0.9929 | 0.9895 | 0.9895 | ||
| 100 | 0.9843 | 0.9843 | 0.9810 | 0.9809 | ||
| 1024 | 30 | 1.0003 | 1.0003 | 1.0009 | 1.0009 | |
| 50 | 1.0007 | 1.0007 | 1.0022 | 1.0022 | ||
| 100 | 1.0009 | 1.0009 | 1.0031 | 1.0031 | ||
| 1 | 30 | 1.0001 | 1.0001 | 1.0006 | 1.0006 | |
| 50 | 1.0002 | 1.0002 | 1.0017 | 1.0017 | ||
| 100 | 1.0003 | 1.0003 | 1.0025 | 1.0025 | ||
| 2 | 30 | 0.9984 | 0.9984 | 0.9973 | 0.9973 | |
| 50 | 0.9964 | 0.9964 | 0.9933 | 0.9933 | ||
| 100 | 0.9954 | 0.9954 | 0.9910 | 0.9911 | ||
| Criterion | ||
|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arashi, M.; Norouzirad, M.; Roozbeh, M.; Khan, N.M. A High-Dimensional Counterpart for the Ridge Estimator in Multicollinear Situations. Mathematics 2021, 9, 3057. https://doi.org/10.3390/math9233057
Arashi M, Norouzirad M, Roozbeh M, Khan NM. A High-Dimensional Counterpart for the Ridge Estimator in Multicollinear Situations. Mathematics. 2021; 9(23):3057. https://doi.org/10.3390/math9233057
Chicago/Turabian StyleArashi, Mohammad, Mina Norouzirad, Mahdi Roozbeh, and Naushad Mamode Khan. 2021. "A High-Dimensional Counterpart for the Ridge Estimator in Multicollinear Situations" Mathematics 9, no. 23: 3057. https://doi.org/10.3390/math9233057
APA StyleArashi, M., Norouzirad, M., Roozbeh, M., & Khan, N. M. (2021). A High-Dimensional Counterpart for the Ridge Estimator in Multicollinear Situations. Mathematics, 9(23), 3057. https://doi.org/10.3390/math9233057