1. Introduction
Consider a second-order stationary sequence of stochastic processes
defined on a probability space
, having zero mean and covariance function
. For a given functional sample
consider the model:
where the function
is deterministic, but unobserved. Our main aim is in testing the hypothesis:
with emphasis on a case of change-point detection, which corresponds to a piecewise-constant function
g with respect to the first argument.
This model covers a broad range of real-world problems such as climate change detection, image analysis, analysis of medical treatments, especially magnetic resonance images of brain activities, and speech recognition, to name a few. Besides, the change-point detection model (
1) can be used for knot selection in spline smoothing as well for trend changes in functional time series analysis.
There is a huge list of references on testing for change-points or structural changes for a sequence of independent random variables/vectors. We refer to Csörgő and Horváth [
1], Brodsky and Darkhovsky [
2], Basseville and Nikiforov [
3], and Chen and Gupta [
4] for accounts of various techniques.
Within the functional data analysis literature, change-point detection has largely focused on one change-point problem. In Berkes et al. [
5], a cumulative sum (CUSUM) test was proposed for independent functional data by using projections of the sample onto some principal components of covariance
. Later, the problem was studied in Aue et al. [
6], where its asymptotic properties were developed. This test was extended to weakly dependent functional data and epidemic changes by Aston and Kirch [
7]. Aue et al. [
8] proposed a fully functional method for finding a change in the mean without losing information due to dimension reduction, T. Harris, Bo Li, and J. D. Tucker [
9] propose the multiple change-point isolation method for detecting multiple changes in the mean and covariance of a functional process.
The methodology we propose is based on some measures of variation of the process:
where
.
Since this process is infinite-dimensional, we used the projections technique to reduce the dimension. To this aim, we assumed that is mean-squared continuous and jointly measurable and that has finite trace: . In this case, is also an -valued random element, where is a Hilbert space of Lebesgue square integrable functions on endowed with the inner product and the norm .
In the case where the number of change-points is known to be no bigger than m, our test statistics are constructed from -variation (see the definition below) of the processes , where runs through a finite set of possibly random directions in . In particular, consists of estimated principal components. If the number of change-points is unknown, we consider the p-variation of the processes and estimate the possible number of change-points.
The paper is organized as follows. In
Section 2,
-sum and
-CUSUM processes are defined and their asymptotic behavior is considered in a framework of the
space. The results presented in this section are used to derive the asymptotic distributions of the test statistics presented in
Section 3.
Section 4 is devoted to simulation studies of the proposed test algorithms.
Section 5 contains a case study. Finally,
Section 6 is devoted to the proofs of our main theoretical results.
2. -Sum Process and Its Asymptotic
Let
be the set of all probability measures on (
. For any
and
Q-integrable function
f,
As usual,
is a set of measurable functions on
, which are square-integrable for the measure
Q, and
is an associated Hilbert space endowed with the inner product:
and corresponding distance
,
. We abbreviate
to
and
to
for Lebesgue measure
. We use the norm
and the distance
for the elements
. On the set
, we use the inner product:
and the corresponding distance:
For two given sets
, we consider the
-sum process:
where
,
is a uniform probability on the interval
and
. A natural framework for stochastic process
is the space
, where
. Recall for a class
that
is a Banach space of all uniformly bounded real-valued functions
on
endowed with the uniform norm:
Given a pseudometric d on , is a set of all , which are uniformly d-continuous. The set is a separable subspace of if and only if is totally bounded. The pseudometric space is totally bounded if is finite for every , where is the minimal number of open balls of d-radius , which are necessary to cover .
It is worth noting that the process
is continuous when
is endowed with the metric
. Indeed,
since
for every
If both sets
and
are totally bounded, then the process
is uniformly continuous so that
takes values in the subspace
.
Next, we specify the set
. To this aim, we recall some definitions. For a function
, a positive number
, and an integer
, the
-variation of
f on the interval
is
where the supremum is taken over all partitions
of the interval
. We abbreviate
. If
, then we say that
f has finite
p-variation and
is the set of all such functions. The set
,
, is a (non-separable) Banach space with the norm:
The embedding
is continuous and
For more information on the space
, we refer to [
10].
The limiting zero mean Gaussian process
is defined via covariance:
where
is the covariance operator corresponding to the kernel
. The function
is positive definite:
for all
,
, and
. Indeed, if we denote by
the isonormal Gaussian process on the Hilbert space
, we see that
hence,
and (
3) follows. This justifies the existence of the process
.
Throughout, we shall exploit the following.
Assumption 1. Random processes are i.i.d. mean square continuous, jointly measurable, with mean zero and covariance γ such that .
For the model (1), we consider null hypothesis and two possible alternatives:andIn both alternatives, the function is responsible for the configuration of a drift within the sample, whereas the function estimates a magnitude of the drift. Our main theoretical results are Theorems 1 and 3, which are proven in
Section 6.
Theorem 1. Let the random processes be defined by , where satisfy Assumption 1. Assume that, for some , the set is bounded and the set satisfiesThen, there exists a version of a Gaussian process on such that its restriction on , is continuous and the following hold: If , then the alternative corresponds to the presence of a signal in a noise. In this case, Therefore, the use of this theorem for testing a signal in a noise is meaningful provided .
As a corollary, Theorem 1 combined with the continuous mapping theorem gives the following result.
Theorem 2. Assume that conditions of Theorem 1 are satisfied. Then, the following hold:
Proof. Since both (2a) and (2b) are by-products of Theorem 1 and continuous mappings, we need to prove only (2c). First, we observe that
by (2a). Consider
We have
By the Hölder inequality,
Since
, we deduce
Hence,
and this completes the proof of (2c). □
Next, we consider
-sum process
defined by
where
. Its limiting zero mean Gaussian process
is defined via covariance:
The existence of Gaussian process
can be justified as that of
above. Just notice that
where
.
Theorem 3. Assume that the conditions of Theorem 1 are satisfied. Then, there exists a version of the Gaussian process on such that its restriction on , is continuous and the following hold:
- (3a)
- (3b)
Under alternative ,where
We see that the limit distribution of the -sum process separates the null and alternative hypothesis provided . As a corollary, Theorem 3 combined with the continuous mapping theorem gives the following results.
Theorem 4. Assume that the conditions of Theorem 1 are satisfied. Then, the following hold:
Proof. Both (4a) and (4b) are by-products of Theorem 3 and continuous mappings, whereas the proof of (4c) follows the lines of the proof of Theorem 2 (2c). □
3. Test Statistics
Several useful test statistics can be obtained from the -sum process by considering concrete examples of sets and .
Throughout this section, we assume that the sample
follows the model (
1) and
satisfies Assumption 1.
By
, we denote the covariance operator of
Y:
. Recall
According to Mercer’s theorem, the covariance
has then the following singular-value decomposition:
where
are all the decreasingly ordered positive eigenvalues of
and
are the associated eigenfunctions of
such that
and
m is the smallest integer such that, when
,
. If
, then all the eigenvalues are positive, and in this case,
. Note that
Besides, we shall assume the following.
Assumption 2. The eigenvalues satisfy, for some In statistical analysis, the eigenvalues and eigenfunctions of Γ are replaced by their estimated versions. Noting that, for each k,one estimates Γ bywhere We denote the eigenvalues and eigenfunctions of by and , respectively. In order to ensure that may be viewed as an estimator of rather than of , we will in the following assume that the signs are such that . Note thatand The use of the estimated eigenfunctions and eigenvalues in the test statistics is justified by the following result. For a Hilbert–Schmidt operator T on , we denote by its Hilbert–Schmidt norm.
Lemma 1. Assume that Assumption 1 holds. Then, under , Proof. First, we observe that
where
It is well known that
as
. By the moment inequality for sums of independent random variables, we deduce
for both
. This yields
. Next, we have
as
due to assumption
. This completes the proof. □
Lemma 2. Assume that Assumptions 1 and 2 for some finite d hold and Then, under , as well as under :for each , where . Proof. If the null hypothesis is satisfied, then
and the asymptotic results for the eigenvalues and eigenfunctions of
are well known (see, e.g., [
11]). Under alternative
, the results follow from Lemma 1 and Lemmas 2.2 and 2.3 in [
11]. □
Next, we consider separately the test statistics for at most one, at most m, and for an unknown number of change-points.
3.1. Testing at Most One Change-Point
This statistic is designed for at most one change-point alternative. Its limiting distribution is established in the following theorem.
Theorem 5. Let random functional sample be defined by where satisfies Assumptions 1 and 2. Then,
- (a)
Under , it holds thatwhere are independent standard Brownian bridge processes; - (b)
Under , it holds thatwhere - (c)
Under , it holds that
Proof. Consider the sets
Observing that
and
is a bounded set in
, we complete the proof by applying Theorem 3. □
Based on this result, we construct the testing procedure in a classical way. Choose for a given
,
such that
According to Theorem 5, the test:
will have asymptotic level
. Under the alternative
, we have
when
Hence, if
and
as
, then the test (
20) is asymptotically consistent.
Let us note that, due to the independence of Brownian bridges
, we have
This yields
Hence,
is the
-quantile of the distribution of
. This observation simplifies the calculations of critical values
.
In particular, if there is
such that
then we have one change-point model:
In this case,
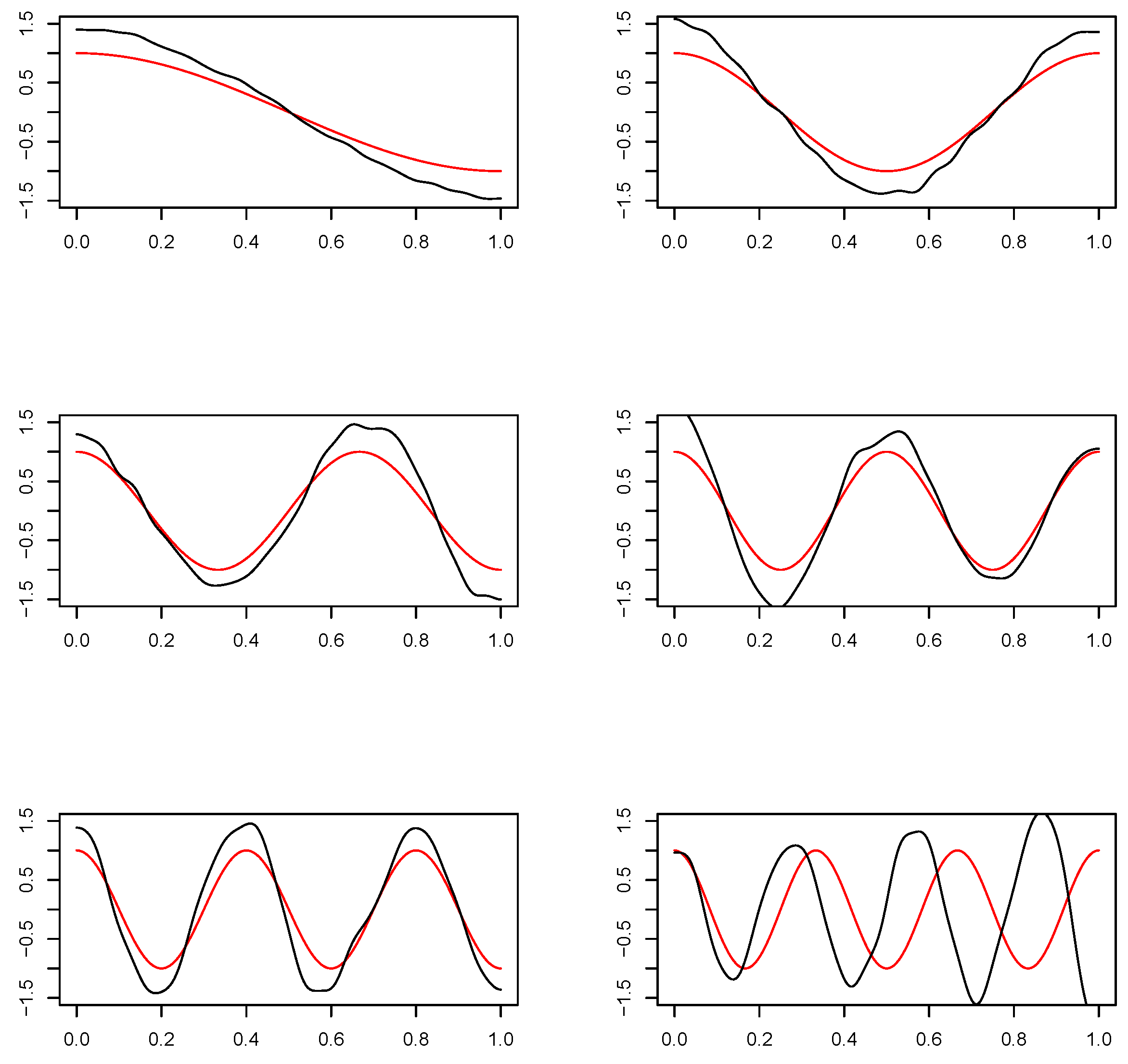
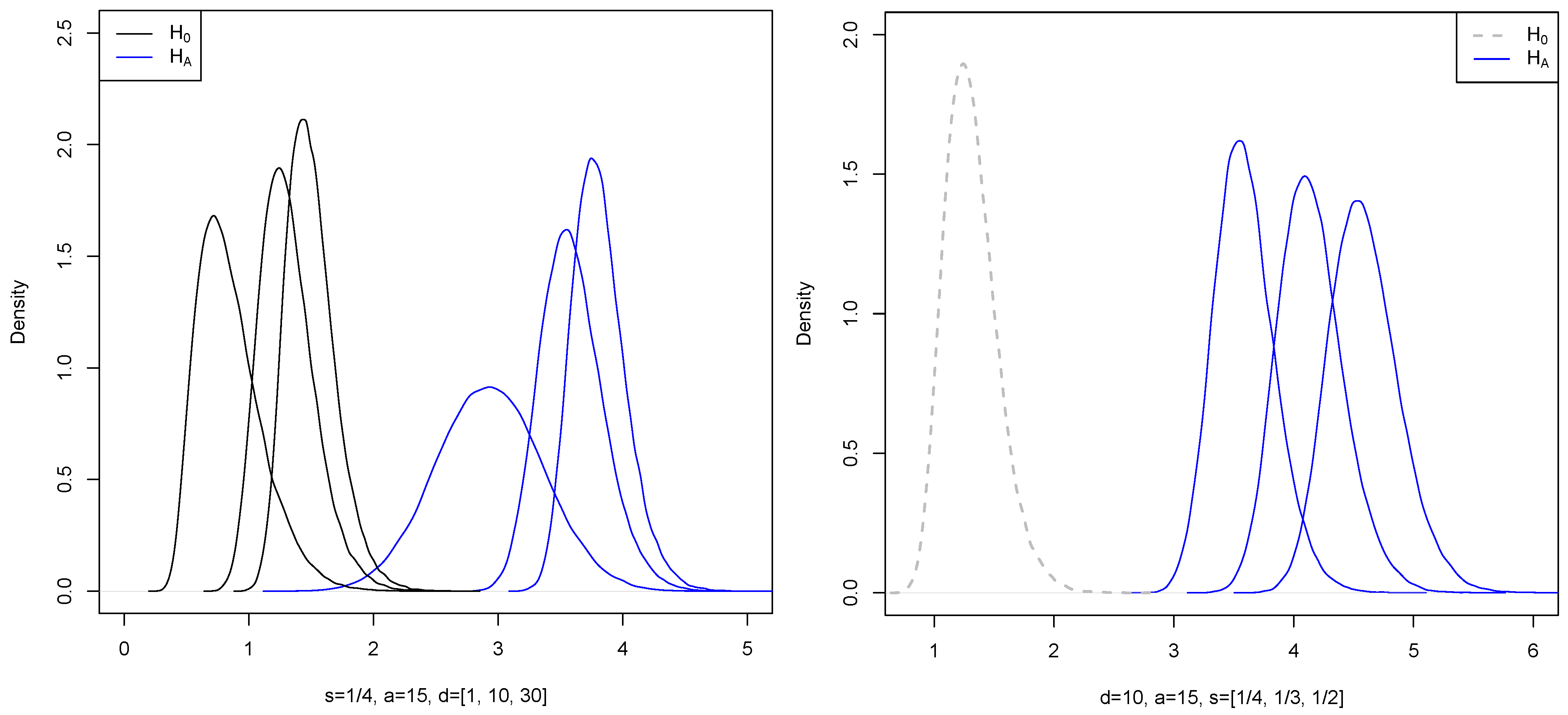
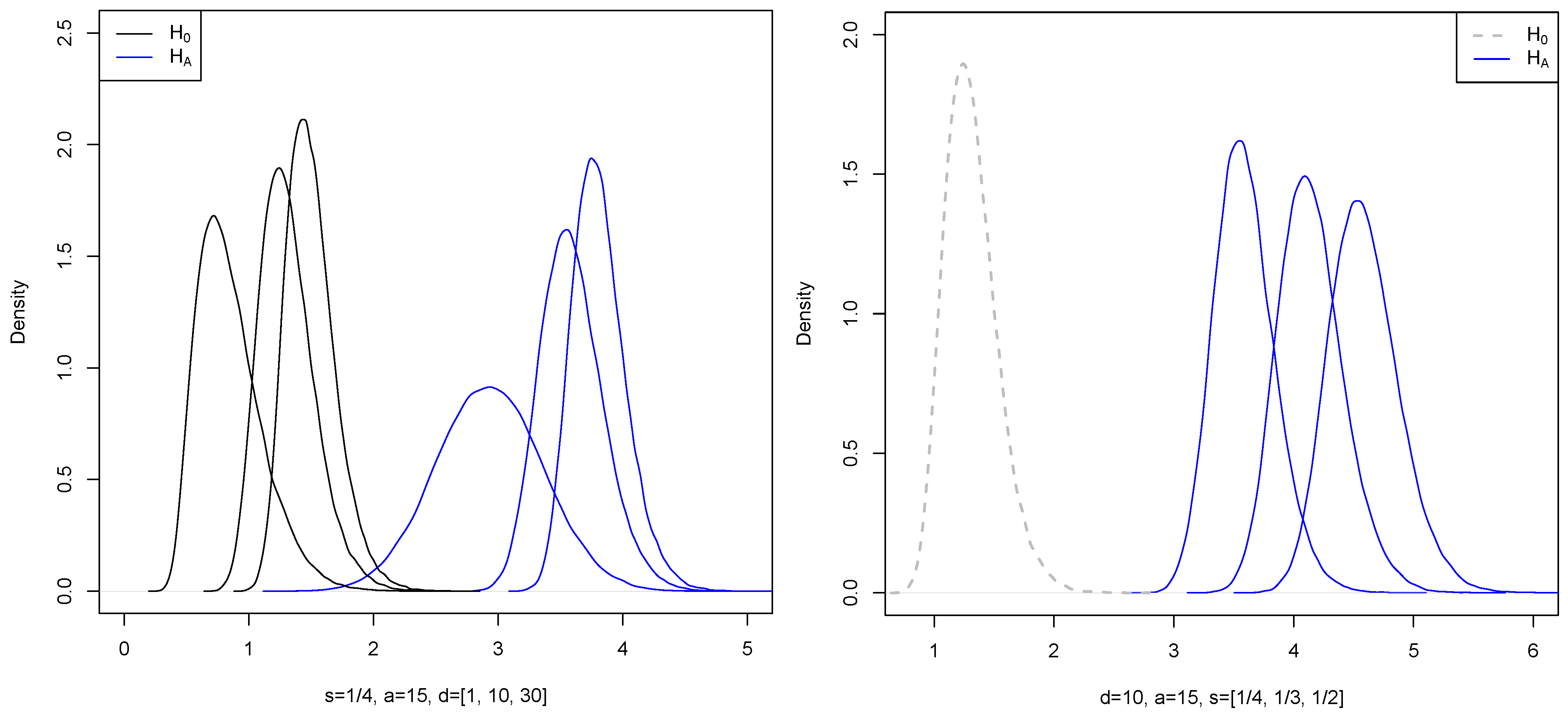
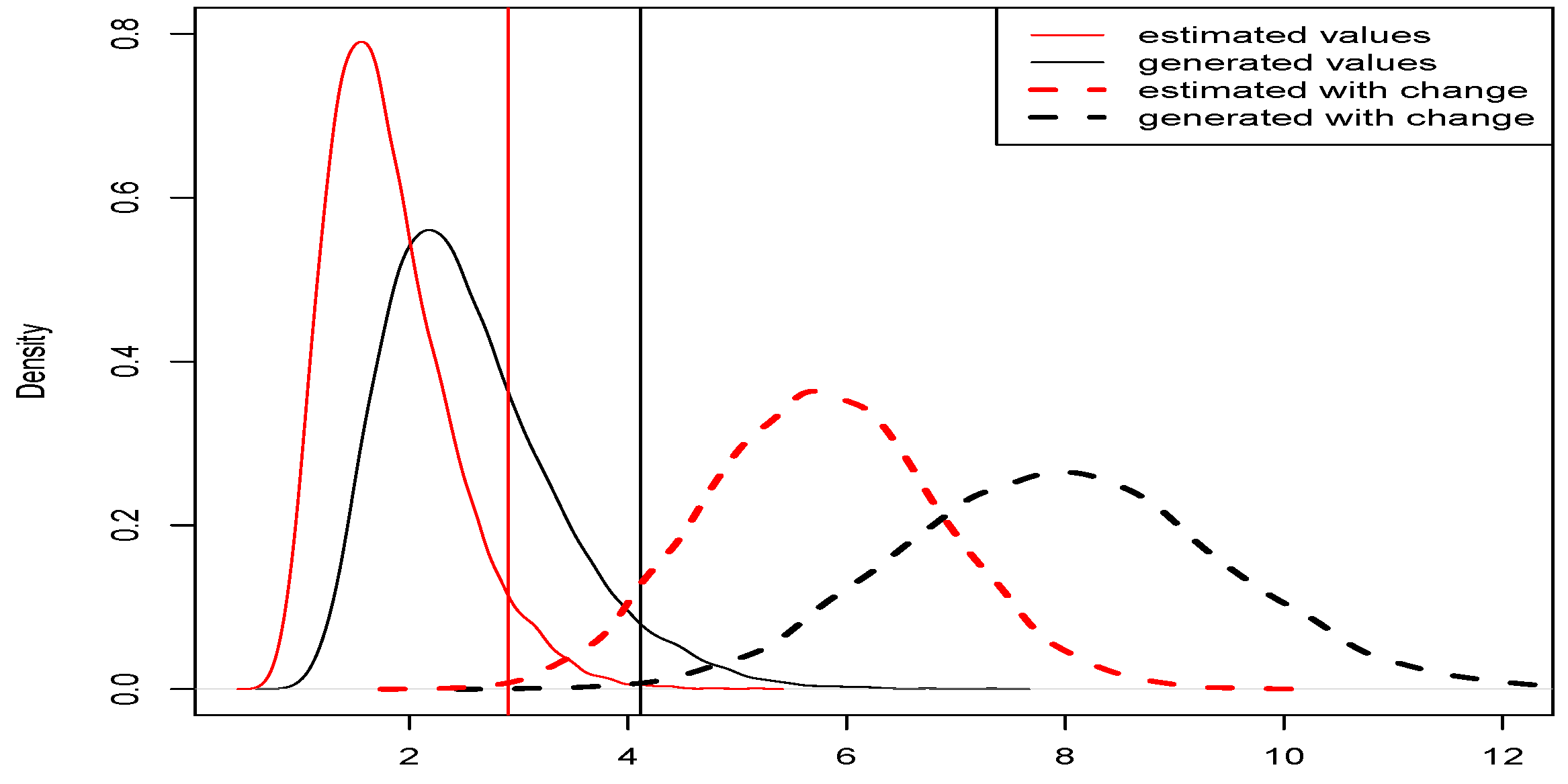
Figure 1 below shows generated density functions of
and
for
,
where
for a fixed
k.
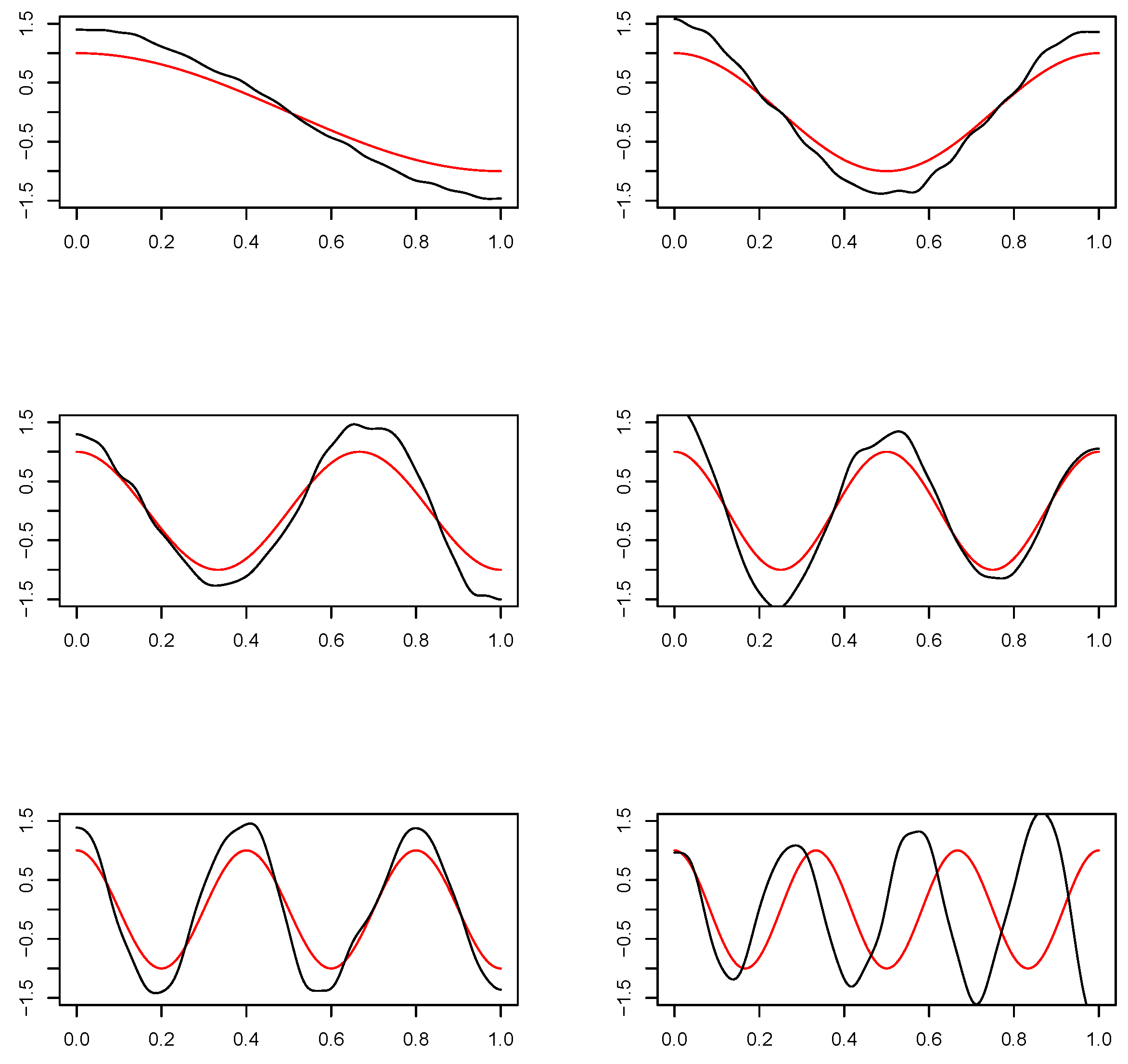
Let us observe that test statistic tends to infinity when . On the other hand, with larger d, the approximation of by series is better and leads to better testing power. The following result establishes the asymptotic distribution of as .
Theorem 6. Let random functional sample be defined by where satisfies Assumption 1. Then, under ,where Proof. By Theorem 5, the proof reduces to
It is known that
Since Brownian bridges
are independent, we have
and
This proves (
24). □
When
d is large, the test (
20) becomes
and has asymptotic level
as
n and
d tend to infinity.
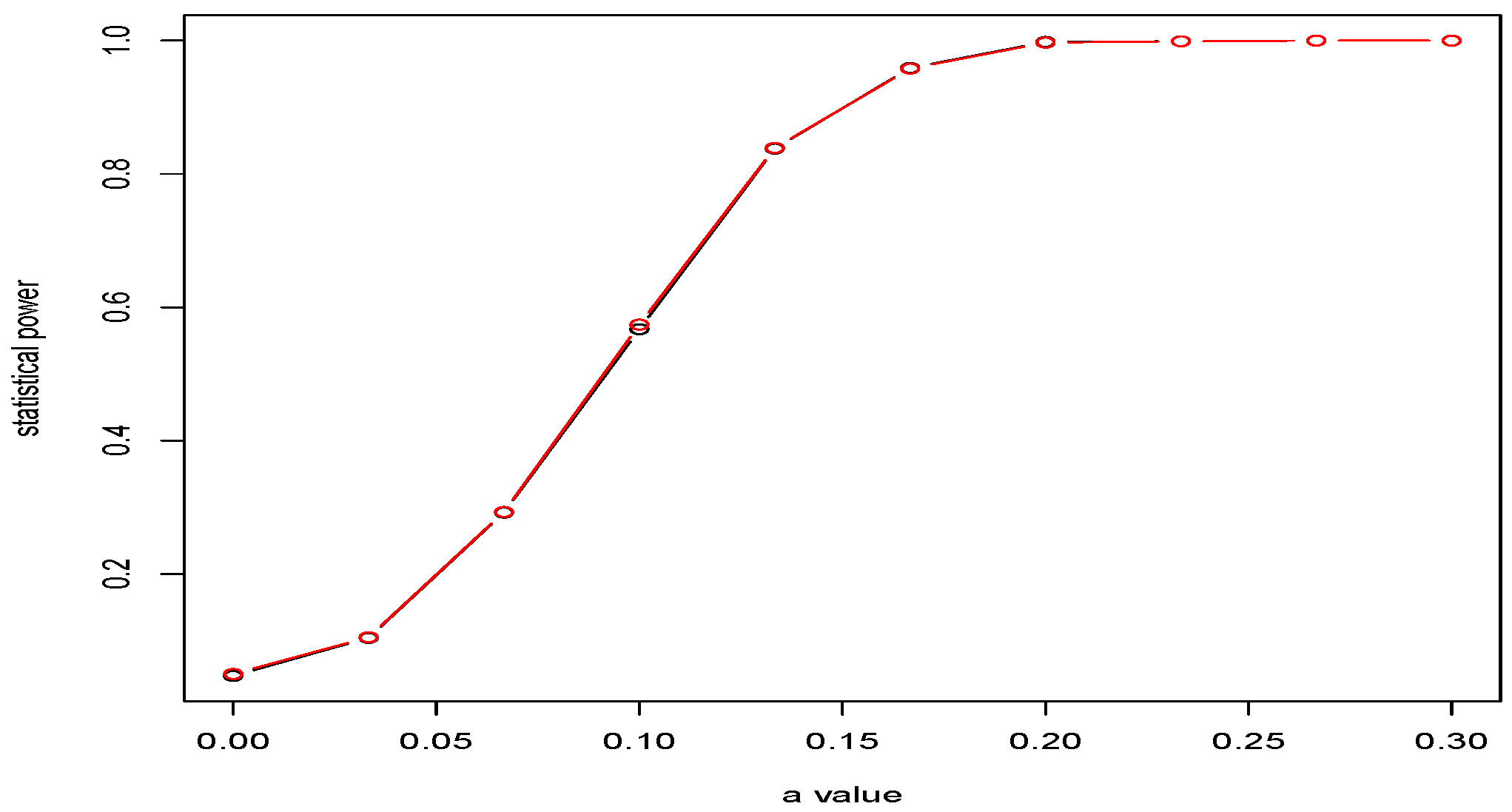
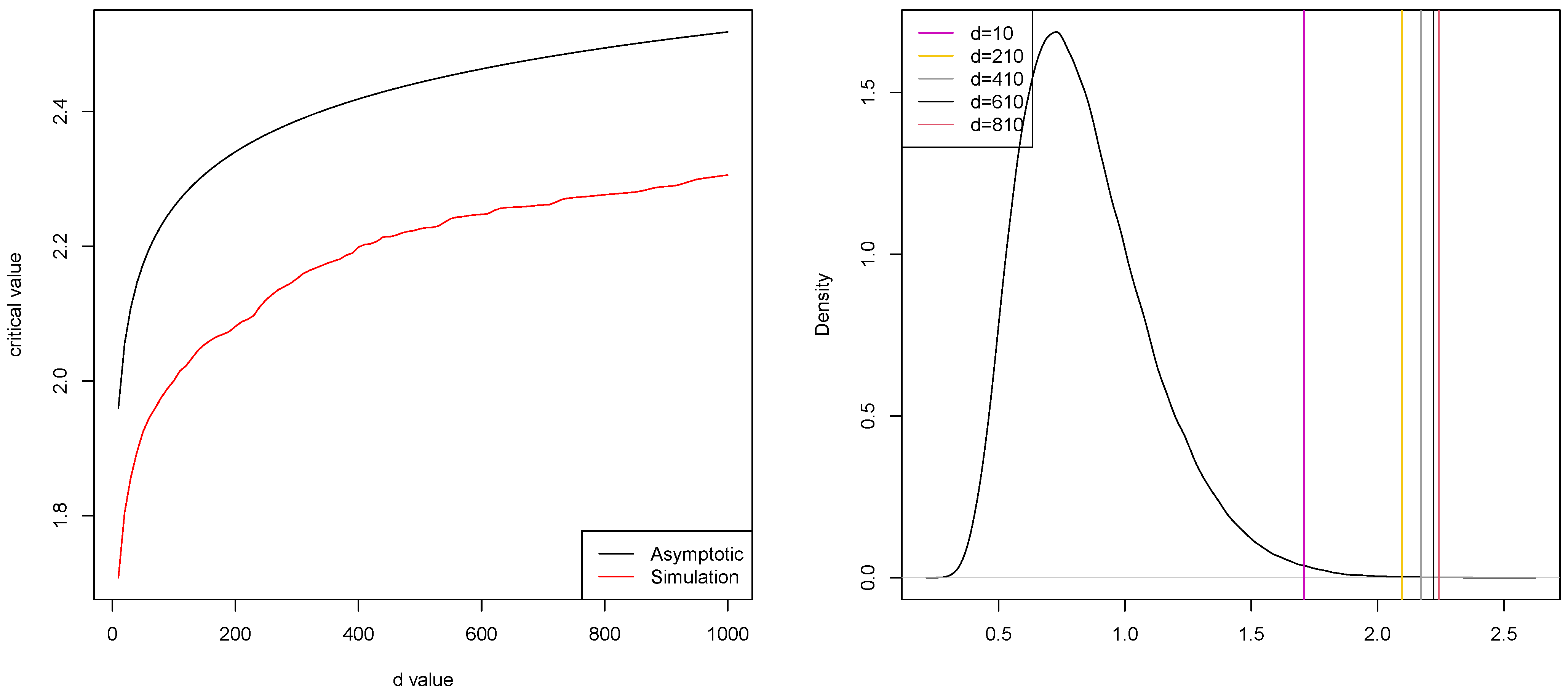
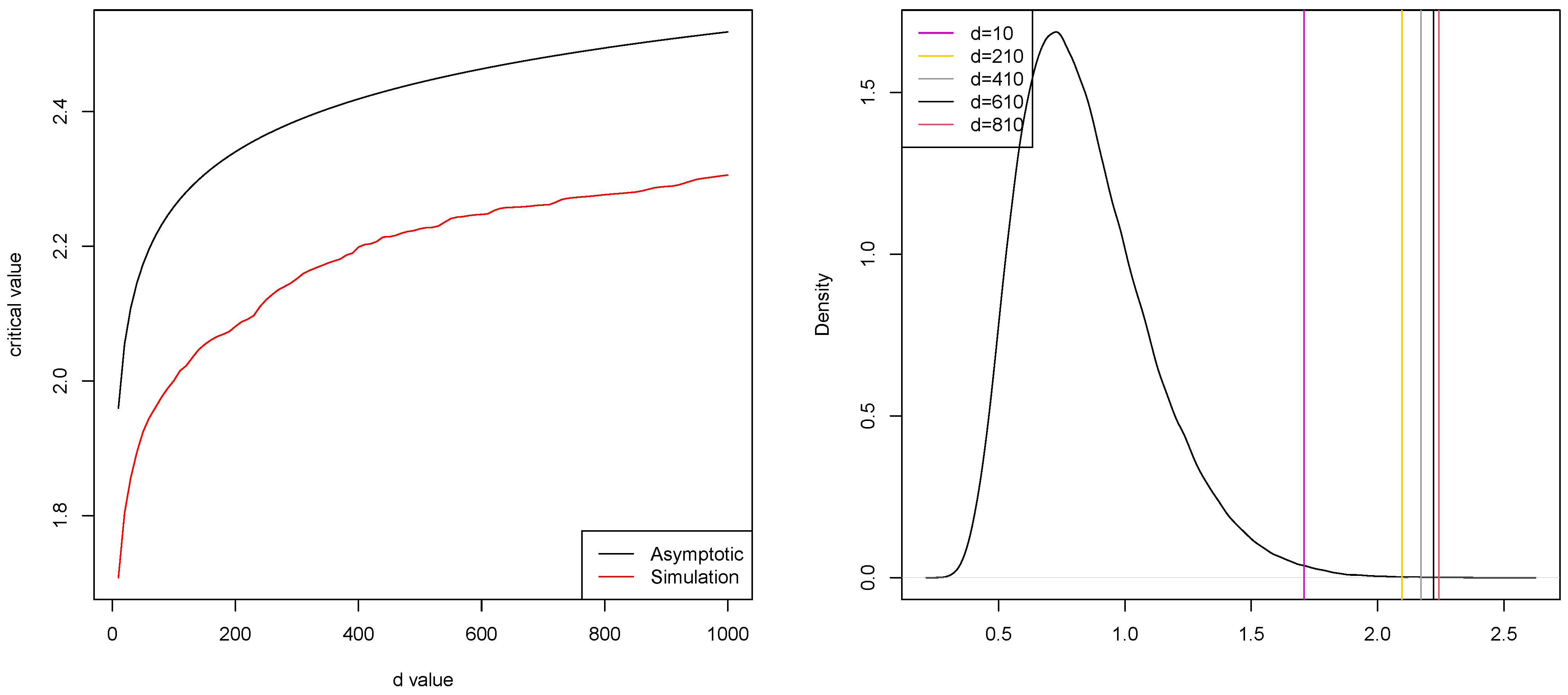
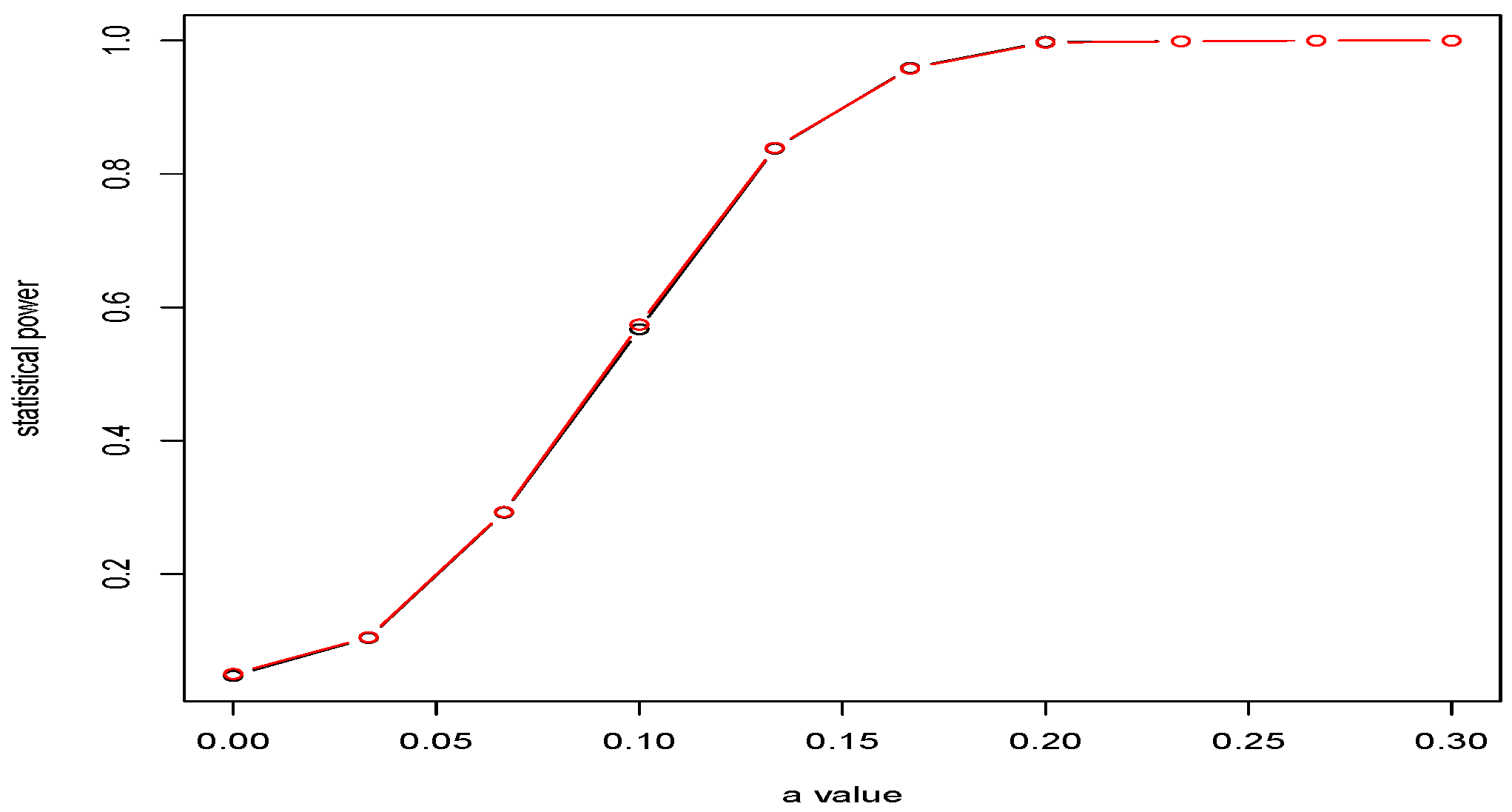
The dependence on
d of critical values of the tests (
20) and (
25) is shown in
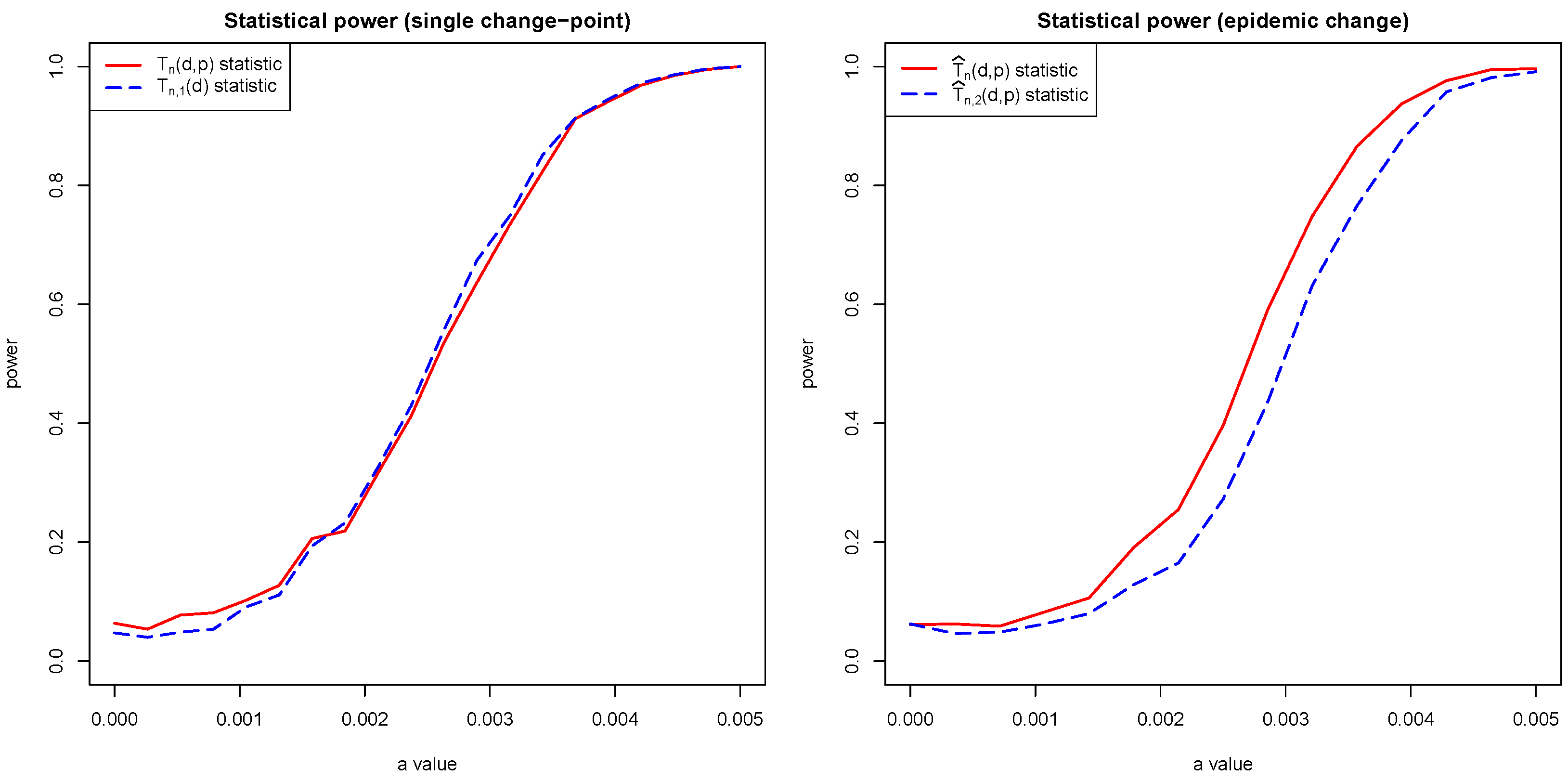
Figure 2. A comparison was made for asymptotic level
. From
Figure 2, we see that the critical values in (
25) are smaller than those in (
20). This means that the error of the first kind is more likely with the test (
25), rather than with (
36). This is confirmed by simulations.
If the eigenfunctions
are unknown, we use the statistics:
Theorem 7. Let random functional sample be defined by , where satisfies Assumptions 1 and 2. Then:
- (a)
Under ,where are independent standard Brownian bridge processes; - (b)
Under , if , it holds thatwhere . - (c)
Under , if , it holds that
Proof. The result follows from Theorem 5 if we show that
On the set
and for
such that
, simple algebra gives
where
and
by the law of large numbers. Lemma 2 concludes the proof. □
Test (
20) now becomes
and has asymptotic level
by Theorem 7.
3.2. Testing at Most m Change-Points
For
, let
be a set of all partitions
of the set
such that
. Next, consider for fixed integers
d,
and real
,
The statistics
are designed for testing at most
m change-points in a sample.
Theorem 8. Let the random sample be as in Theorem 1. Then:
- (a)
Under ,where are independent standard Brownian bridges. - (b)
Under ,where is as defined in Theorem 2. - (c)
Proof. For
and
, set
It is easy to check that
. Since
we have
and the results follow from Theorem 2. □
In particular, if there is
such that
then (
1) corresponds to the so-called changed segment model. In this case, we have
.
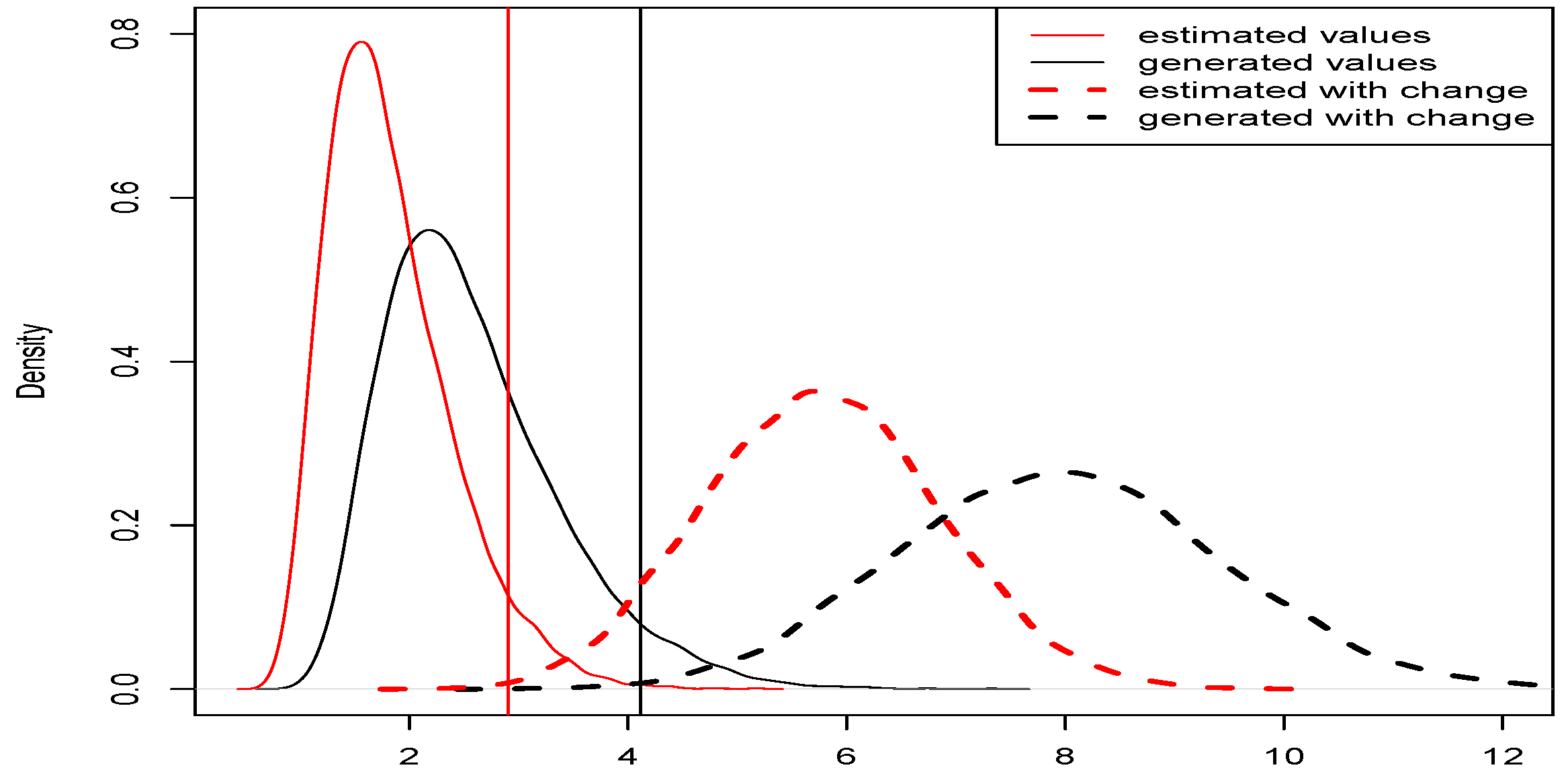
Figure 3) shows the generated density functions of
and
for different values of
,
, and
. The numbers
were sampled from the uniform distribution on
.
With the estimated eigenvalues and eigenfunctions, we define
Theorem 9. Let the functional sample be defined by where satisfies Assumptions 1 and 2. Then:
- (a)
Under ,where are independent standard Brownian bridges. - (b)
Under ,where is as defined in Theorem 2. - (c)
Proof. This goes along the lines of the proof of Theorem 7. □
According to Theorems 8 and 9, the tests:
respectively, will have asymptotic level
, if
is such that
3.3. Testing Unknown Number of Change-Points
Next, consider for fixed integers
d as above and real
,
The statistics
are designed for testing an unknown number of change-points in a sample.
Theorem 10. Let random sample be as in Theorem 1. Then:
- (a)
Under ,where are independent standard Brownian bridges. - (b)
Under where is as defined in Theorem 1. - (c)
Proof. For
, set
It is easy to check that
. Since
we have
and both statements (a) and (b) follow from Theorem 1. □
With the estimated eigenvalues and eigenfunctions, we define:
Theorem 11. Let random sample be as in Theorem 1. Then:
- (a)
Under ,where are independent standard Brownian bridges. - (b)
Under where is as defined in Theorem 1. - (c)
Proof. This goes along the lines of the proof of Theorem 7. □
According to Theorems 10 and 11, the tests:
respectively, will have asymptotic level
, if
is such that
The quantiles of distribution function of
were estimated in [
12].
5. Application to Brain Activity Data
The findings of real data analysis to show the performance of the proposed test are demonstrated in this section. The data were collected during a long-term study on voluntary alcohol- consuming rats following chronic alcohol experience. The data consist of two sets: neurophysiological activity from the two brain centers (the dorsal and ventral striatum) and data from the lickometer device. The lickometer devices were used to monitor the drinking bouts. During the single trial, two locations of the brain were monitored for each rat. Rats were given two drinking bouts, one with alcohol and the other with water. Any time, they were able to freely choose what to drink. Electrodes were attached to the brains, and neurophysiological data were sampled at 1kHz intervals. It was not the goal of this study to confirm nor reject the findings, but to show the advantages of the functional approach for change-point detection. For this reason, the data are well suited to illustrate the behavior of the test in real-world settings.
In our analysis, we took the first alcohol drinking event, which lasted around 27 s. We also included 10 s before the drinking event and 10 s after the event. The total time was 47 s long. The time series was broken down into processes of 100 ms. Each process had 100 data points.
All the processes were smoothed to the functions using 50 B-spline basis functions. The overall functional sample contained 470 functions
. The functional sample was separated into sub-samples
,
. For each sub-sample
, two statistics were calculated (
(
35) and
(
31),
).
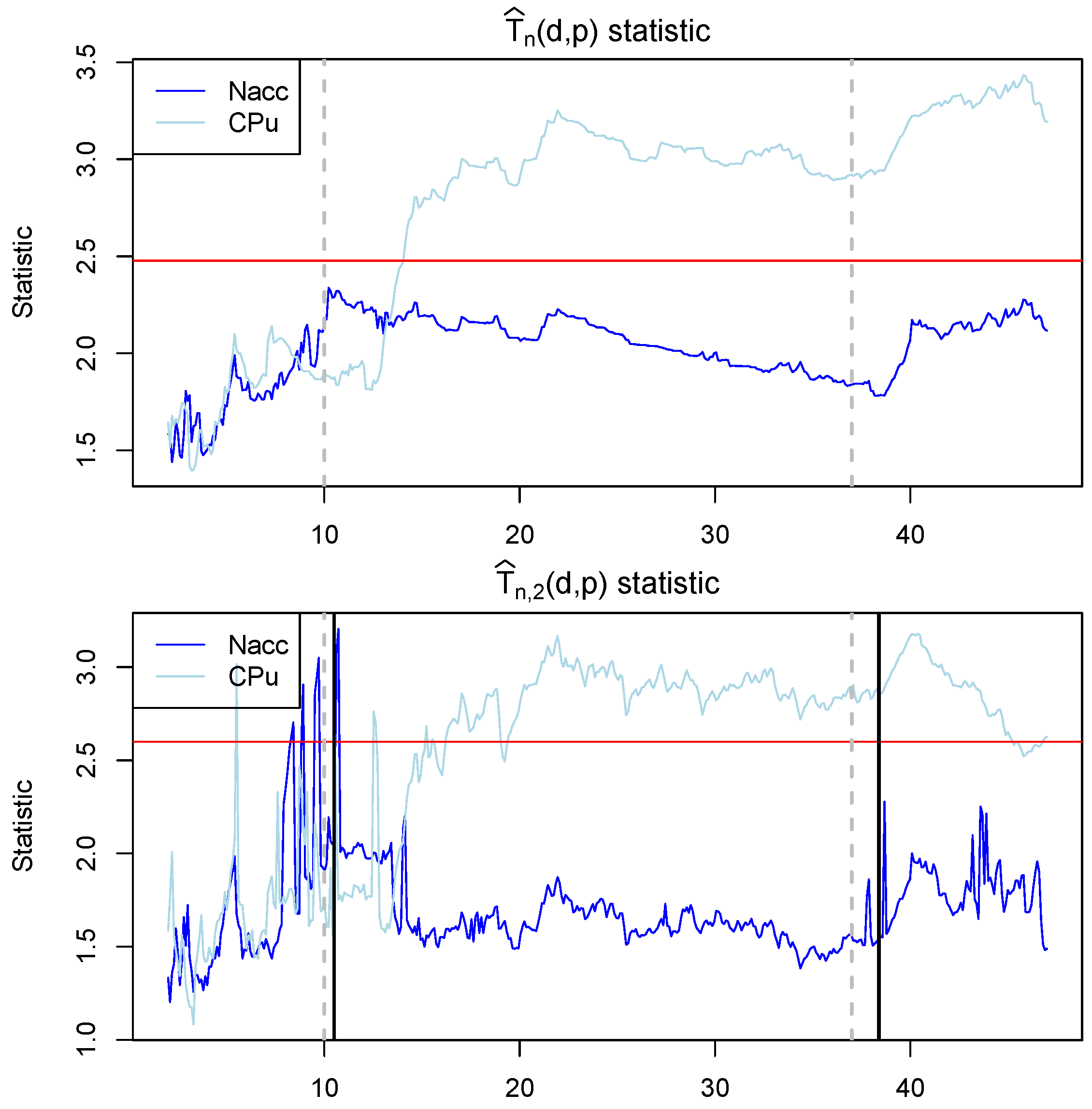
The results are visualized in
Figure 11. We can see that tests with statistics
and
strongly rejected the null hypothesis at around 2 s and onward after the rat started to consume the alcohol, which suggests that the changes in the brain activity can be observed. However, the changes appear to happen only for the CPu brain region. Interestingly, the statistic
has much larger volatility compared to the unrestricted
in the Nacc brain region before the drinking event and lower volatility just after the drinking event started. However, it is not fully clear if this is the expected behavior or a Type I error.
Finally, the locations of the restricted (
)
p-variation partition points nearly matched the beginning and the end of the drinking period. In
Figure 11, the gray vertical dashed lines indicate the actual beginning and the actual end of the drinking period measured by the lickometer and the black vertical lines indicate the location of the partitions calculated from the functional sample
. The first partition is located at 10.5 s and the second partition point at 38.4 s, which aligns well with the data collected from the lickometer.
The test with a restricted partition count showed weaker statistical power, but it did help determine the location of the change-points.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}