3.1. Game Design and Description
Based on information security knowledge, different attackers and defenders in the network will have different predictions and decisions, leading to them gaining different benefits. Over time, each participant is continuously able to improve their security strategy by learning from the experience of the more successful ones, and then a new attack and defense scenario can be formed. The network security state is essentially determined by the adversarial behavior of both attackers and defender and its results. For example, attackers can use various techniques such as poisoning attacks, evasion attacks, model stealing attacks, etc., to disrupt the machine learning of online service platforms. These attacks are conducted online, during which the costs induced by the attackers include the research cost to determine the use of different attack techniques besides labor costs and the equipment costs. The attack techniques with higher success rates require more calculation and a longer amount of time in order to run the algorithm, which means the cost of the attack increases. By analyzing the network attack and defense processes, we are able to come to some realistic assumptions and are better able to further set up the payoff for each participant in order to simplify the analysis of the evolutionary game.
Assumption 1. Both the defender and the attackers are bounded rationally and seek to maximize their profits. The two strategies that each participant can choose are mutually exclusive, and each participant will test their profits at all times to determine whether or not to change strategies.
Assumption 2. After increasing the defensive investment, the defender has a defensive capability that is strong enough to detect an attacker’s behavior once an attacker attacks, resulting in there being no means that the attackers can use to escape from the defender’s punishment.
In this multi-player game, the defender chooses ( as its strategy, where denotes the probability of strengthening the defense. The larger the value of is, the greater the probability that the defender will choose to increase the defensive investment. means that the defender maintains the original defensive strength, and the original defensive cost of the defender is . Conversely, indicates that the defender strictly strengthens the defense, and the defender needs to pay a higher defensive cost after strengthening the defense . In addition, the value of the defender’s information asset is , i.e., the value of the information asset is greater than the cost of its defense, and when the defender is breached, the defender’s reputation loss due to privacy leakage is .
The attackers choose ,) as their attack strategy, where denotes the probability that the attacker chooses to attack. or 1 denotes whether the attacker does not attack or attacks, respectively. During the attack, shows the cost of the attack for the attacker(), including the cost of equipment, manpower, etc.
Assumption 3. When, the attacker() can successfully breach the original defense strength but cannot successfully breach the reinforced defense strength and will be captured by the defender. If the defender captures the attacker(), the defender will punish the attacker() according to the attacker()’s attack level, which can be reflected from its attack cost. In particular, when more attackers than the number set by the defender all choose to attack, then the defender, in order to remedy the situation, penalizes each captured attacker according to its information asset value of, whereis the penalty factor. When the number of attackersis less than the number set by the defender, then the defender’s penalty for each captured attacker() is.
Assumption 4. To model a realistic scenario, according to the value of information theory [
40]
and Reinhard Selten’s fair reward portfolio [
41]
, for low timeliness information, the more people who obtain the same information, the lower the value of the information is. Moreover, the faster the person obtains information, i.e., the more costly it is, and the greater and benefit. Similarly, as more attackers that breach the defender’s defense, the lower the gain obtained by each attacker, and the one with higher attack cost can obtain the information faster and can achieve better gains; the gain needed for the attacker( ) to breach the defense is, where k is the gain factor of the value of information obtained by the attacker. Figure 2 shows the multi-player game between the defender and attackers during the network attack and defense process. Among them, the defender can be an individual, enterprises, or other organizations with a large amount of private information, such as the shopping preferences of users on shopping websites, the health information of patients in hospital databases, and algorithms and parameters used by the network itself in machine learning service platforms. All of the private information is stored in the defender’s cloud servers and cannot be leaked. The attackers want to steal the defender’s private information through cyber technology such as targeted false advertising, making adversarial samples to damage the machine learning service platform, and so on, after which it will be used to gain benefits. A defender may be attacked by multiple attackers in reality, and each participant’s decision will affect the decisions of the other participants, so we set multiple attackers in for this game. In the network attack and defense process, the attackers are not entirely independent of each other, and they have different conditions and aim for different interests. Therefore, as the number of attackers increases, the interrelationship between the variables becomes more and more complex. This increases the difficulty of analyzing their evolutionary stability under various strategies. Since the relationship between the
n attackers is non-cooperative, we can take any two attackers from the
n attackers and can form a three-player game framework with the defender. After mathematical reasoning and simulations, it is easy to analyze the impact between the attackers and the defender and to analyze the impact between different attackers. All of the variables in the simplified multi-player game are shown in
Table 1; among them, the defender will increase the penalty when the number of attackers is not less than 2. Additionally, the payoff matrices for the two non-cooperative attackers and the defender are shown in
Table 2 and
Table 3, respectively.
3.2. Game Solution
According to evolutionary game theory [
42] and the payoff matrix in
Table 2, the expected benefits
that are obtained when the attacker(1) attacks and the expected benefits
when it does not attack can be obtained separately as follows:
Therefore, the expected average benefits for attacker (1) is:
According to the ordinary differential equation algorithm [
26] in the replication dynamic model, the replication dynamic equation for attacker (1) is:
Likewise, the expected benefits
when attacker (2) attacks and the expected benefits
when it does not attack can be obtained separately as follows:
Therefore, the replication dynamic equation for attacker (2) is:
Likewise, according to
Table 3, the expected benefits
that are obtained when the defender strengthens the defense and the expected benefits
that are when the defender maintains the original defensive strength can be obtained as follows, respectively:
Therefore, the replication dynamic equation for the defender is:
In summary, the above multi-player evolutionary game in the network attack and defense process can be indicated by the following set of replicated dynamic equations:
Set , we can obtain the local equilibrium solution as: , , , , , , , , , , , , , and .
Friedman proposed that the stability of the system replicating the equilibrium point of the dynamic equations was obtained by analyzing the Jacobian matrix and the eigenvalues of the system at the equilibrium solution [
43]. According to Lyapunov’s stability theory, the system is stable if all of the characteristic values have non-positive real parts; otherwise, the system is unstable. The Jacobian matrix of the replicated dynamic equations (11) is:
Of which,
| Jacobian matrix definitions | Details |
| |
| |
| |
| |
| |
| |
| |
| |
| |
Then, by taking the eight pure strategy points as examples and by substituting them into the Jacobi matrix (12), the eigenvalues of the Jacobi matrix corresponding to the equilibrium solutions can be obtained separately, as shown in
Table 4.
If and only if
, then the above equilibrium solution will reach a steady state. This is because there are certain comparative relationships among variables in the real world, for example, the attackers’ attack cost
should be less than the maximum value
obtained when the attack is successful, i.e.,
; the defenders’ defense cost
after strengthening the defense should not be greater than the lost information value
, i.e.,
. According to the analysis of the results in
Table 4, it is clear that there is no evolutionary stabilization strategy (ESS) in
.
For the analysis of hybrid strategy , it is impossible to determine whether there is ESS in the above equilibrium solution because a variety of factors jointly influence the evolutionary equilibrium states of the defender and the attackers. As such it can be combined with computer simulation to analyze the evolution of the network security attack and defense in the real world. The primary function of the model analysis is to capture the essence of the problem, analyze the influence of various factors, and find the final solution to the problem. Therefore, when the model analysis cannot use theoretical analysis alone to achieve our purpose, simulation can simulate the effect of implementing different strategies and can conduct scientific predictive analysis.
3.3. Game Analysis Based on System Dynamics
The system dynamics approach is based on feedback control theory. It uses computer simulation technology as a tool that can effectively combine quantitative and qualitative analysis to establish a simulation platform. The system dynamics approach allows for the deep study of the information feedback behavior in complex systems through these methods as well as the search and study the relevant influencing factors within the system [
11]. The simulation of evolutionary games with system dynamics for related problems allows for a holistic examination of the dynamic properties behind the game equilibrium globally. In contrast, evolutionary game theory analysis plays a crucial role in modeling and formulating the corresponding decisions [
9,
44].
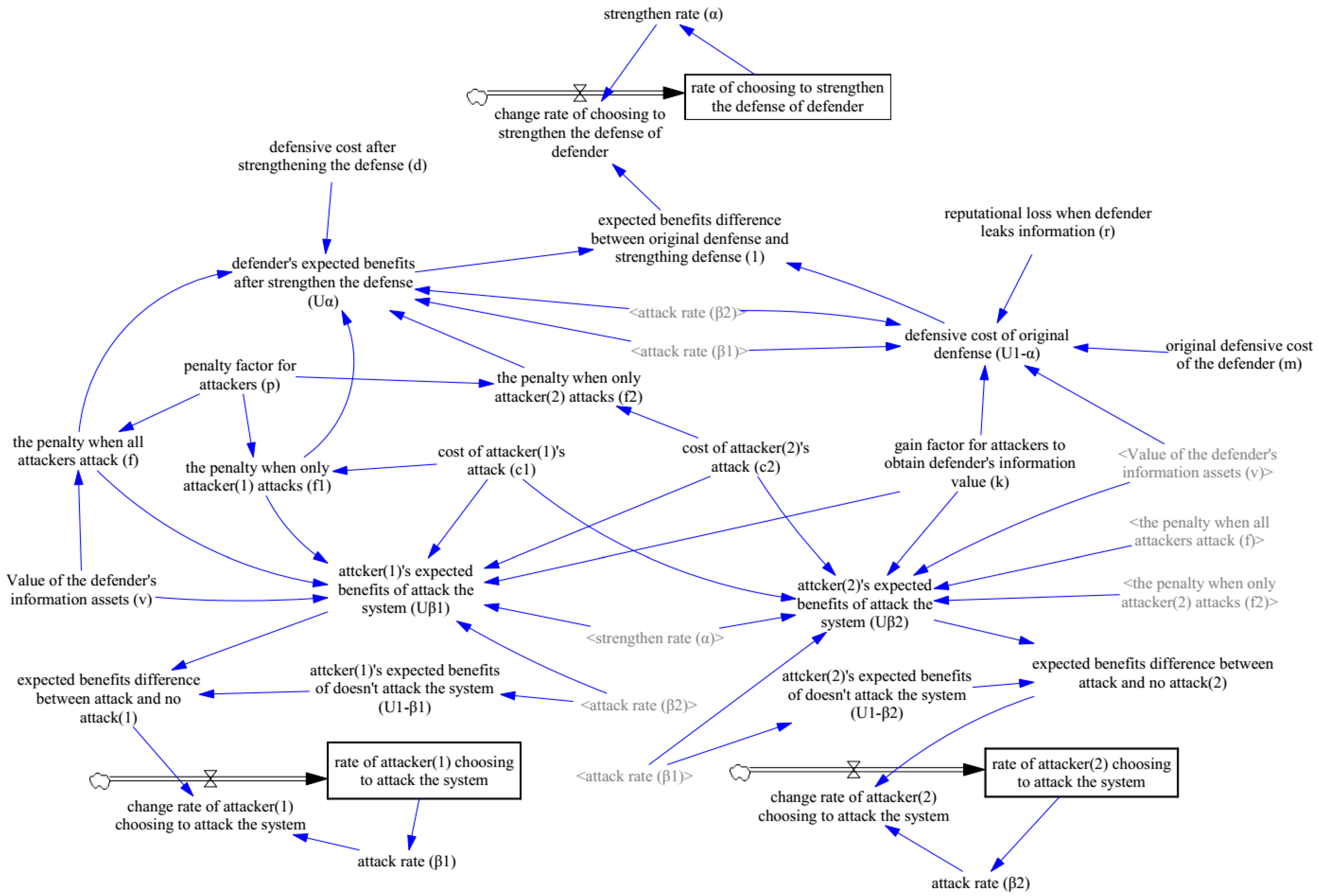
According to the above assumptions and analysis, this paper uses Vensim DSS v5.6a to construct an evolutionary game model for network attack and defense, which is comprised of three sub-systems: the defender, attacker (1), and attacker (2), as shown in
Figure 3. The rectangles represent level variables that show the cumulative results. The valves represent the rate variables showing the physical flows of the items feeding into or depleting the model. The other variables are exogenous and auxiliary variables. This model includes 3 level variables, 3 rate variables, 8 exogenous variables, and 15 auxiliary variables. Setting the functional relationship between all of the variables depends on the above equations, Equations (1)–(10).
The basic parameters of the model are set as follows: INITIAL TIME = 0, FINAL TIME = 50, TIME STEP = 0.25, Integration Type: Euler. The initial values of the exogenous variables in the SD model are shown in
Table 5.
In the set of replicated dynamic equations in (11), make ; ten equilibrium solutions can be obtained as follows: , , , , , , , , , , where are pure strategy equilibrium solutions, and and are mixed strategy equilibrium solutions.
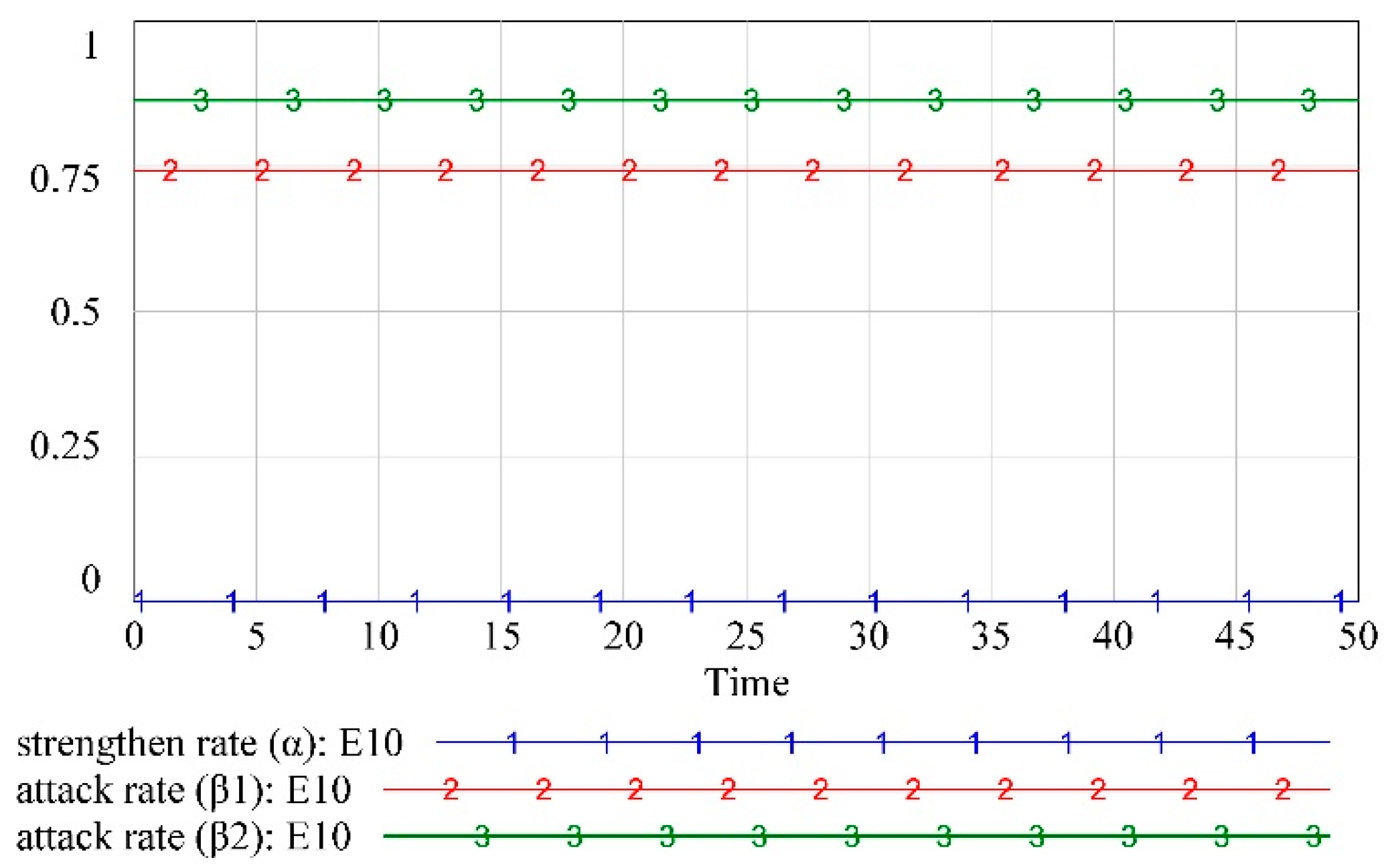
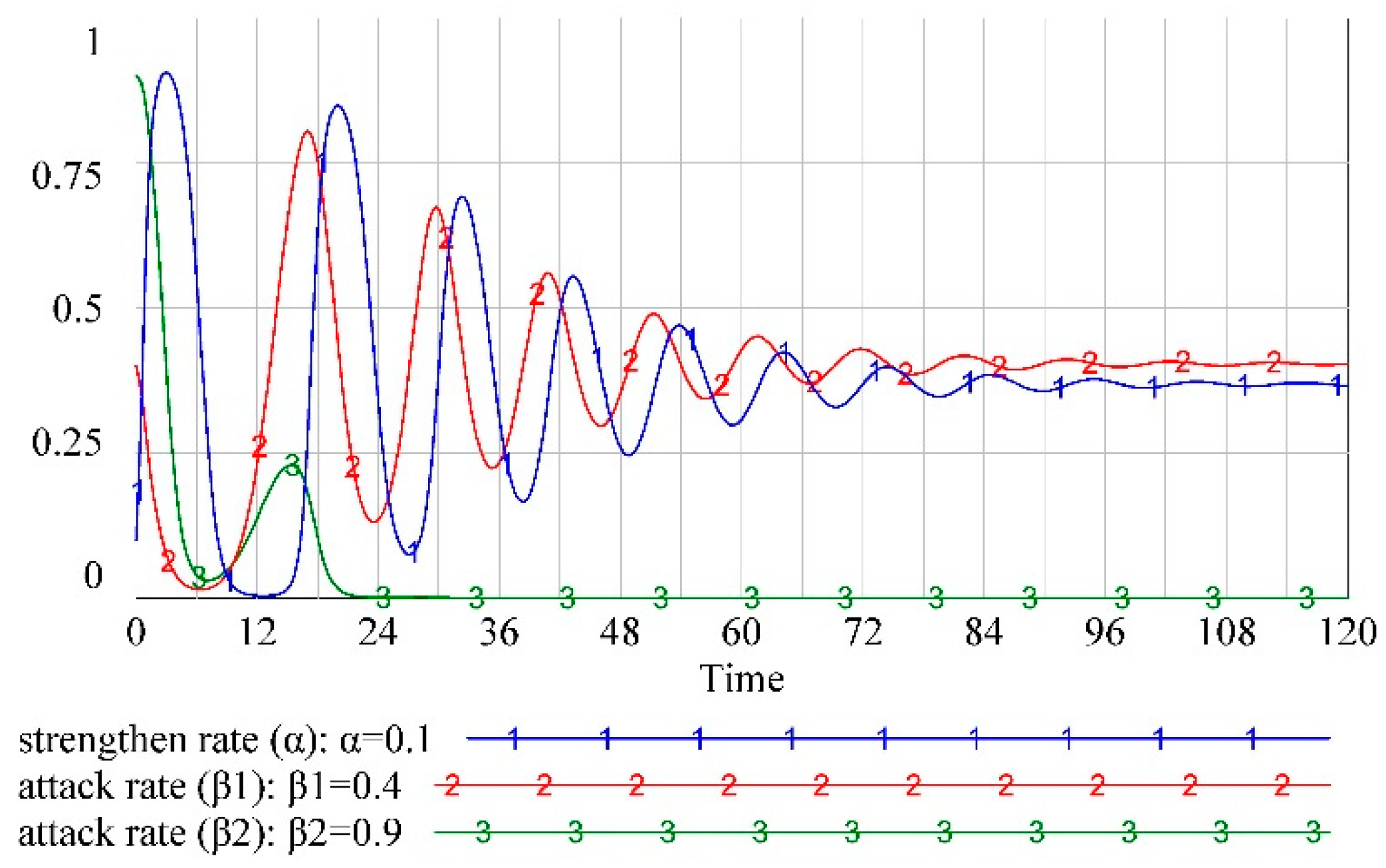
The simulation results that are obtained in the next step after substituting
into the system dynamics model as an example are shown in
Figure 4. This result demonstrates that the defender, attacker (1), and attacker (2) are not actively changing their own strategy choices and are in a relatively stable situation. However, whether
is an ESS still needs to be tested. A population adopting ESS should be sufficient to resist small mutations [
42]. We made a tiny mutation in the initial strategy of attacker (2), i.e., we changed the defender’s
from 0 to 0.01, and the model was re-simulated, the results of which are shown in
Figure 5.
It can be seen from
Figure 4 that when the defender maintains a low defense cost, that is, when they cannot prevent attackers from obtaining information, the attack probability of attacker (2) is greater than the attack probability of attacker (1) because the attack cost of attacker (2) is greater than the attack cost of attacker (1). This indicates that when the defenders are unable to act, more attackers will be attracted to the opportunity to choose to pay a higher attack cost. However, when defenders act, the attackers tend to adopt a lower-cost attack strategy. Further, the results in
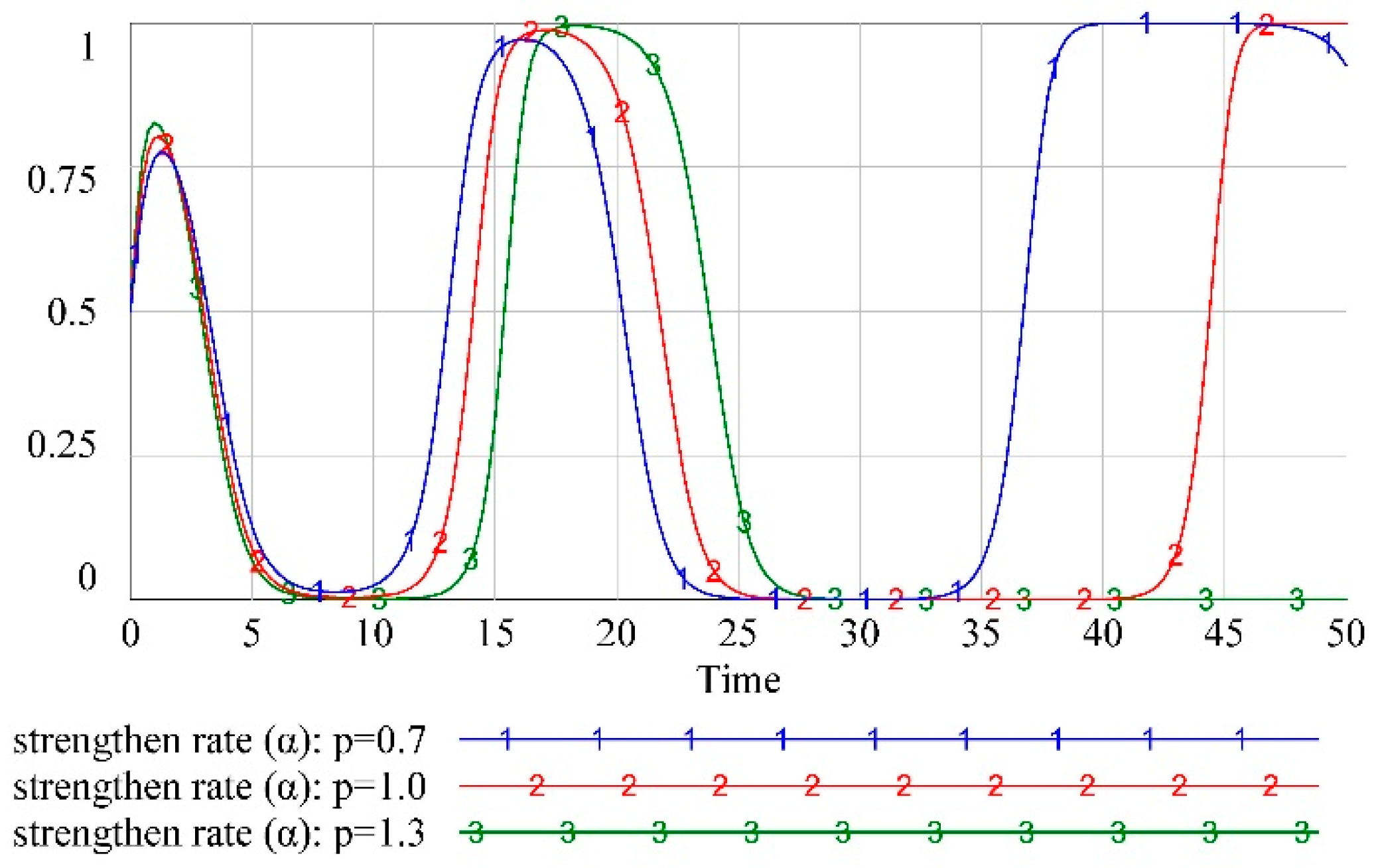
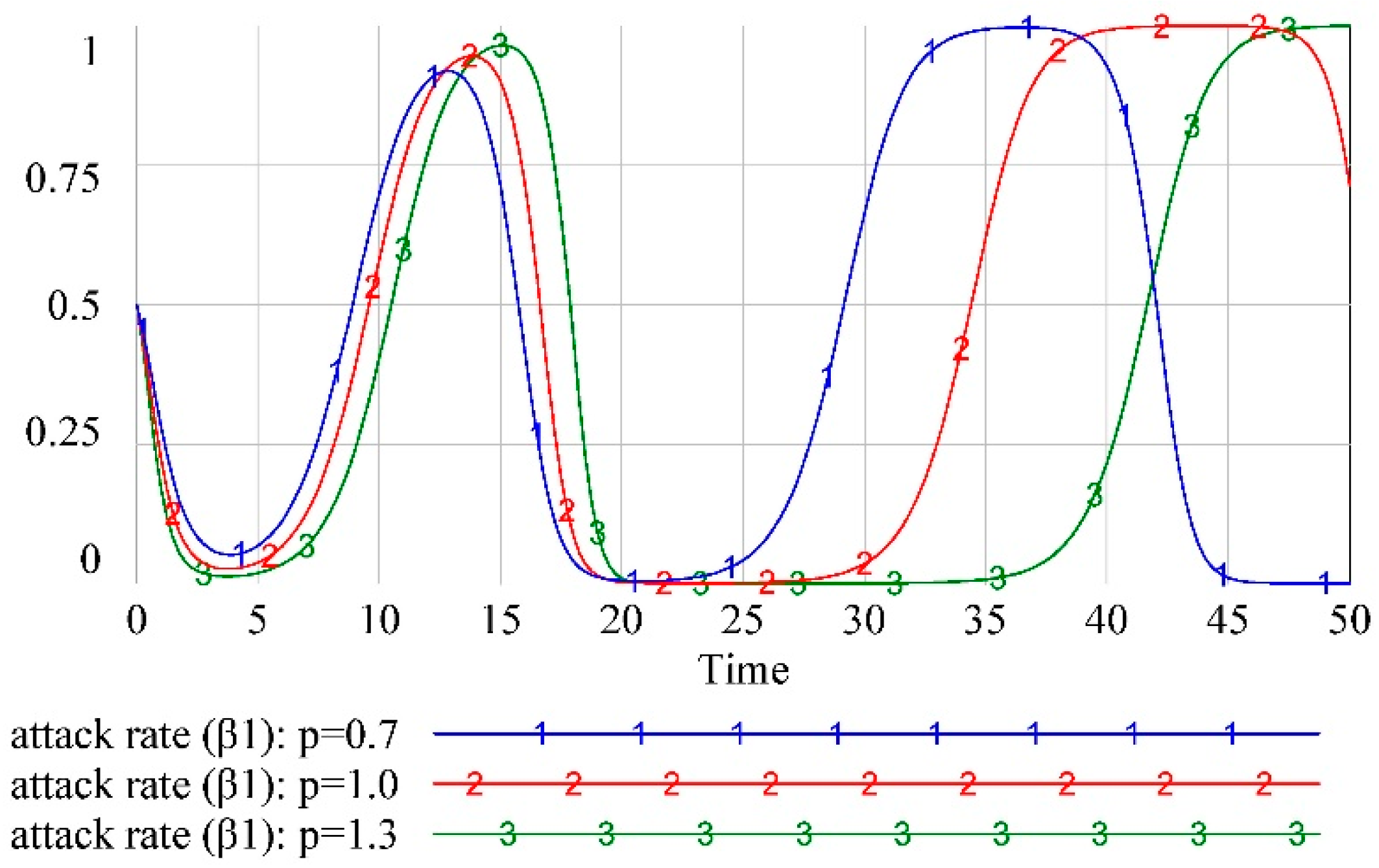
Figure 5 show that
is not an ESS, and the equilibrium state of
is broken when the defender’s initial value of
changes abruptly, and the strategic choices of the other two players are in a fluctuating and unstable state. The reason for this phenomenon is that the defender’s payoff increases after a sudden change in its strategy, and the defender keeps changing its strategy, causing attacker (1) and attacker (2) to change their strategies according to their payoffs. Similarly, we checked the equilibrium state of the other nine strategies and found that
are also not ESS according to the simulation results.
In summary, using SD when simulating multi-player evolutionary games to depict network attack and defense is a practical way to analyze the stability of equilibrium solutions. The state of the system is in equilibrium when the defender, attacker (1), and attacker (2) maintain their original strategies, and this state will not change based on an increase in the simulation time. By that time, the attacker with the high attack cost would rather attack the defender with a low defensive cost. However, this equilibrium is unstable and will be broken once a sudden change in one player’s strategy has been made, which indicates that all of the equilibria are not ESS. Therefore, there is no ESS in this game process, and the attackers’ behavior will not be effectively controlled the act at within a certain amount of time.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}