
INF-GAN: Generative Adversarial Network for Illumination Normalization of Finger-Vein Images



Abstract
:1. Introduction
- -
- This study is the first to restore finger-vein images with nonuniform illumination using a GAN.
- -
- The INF-GAN is newly proposed for the restoration of a finger-vein image with nonuniform illumination.
- -
- The INF-GAN is based on the conventional Pix2Pix-HD, but uses a ResNet generator and only one PatchGAN discriminator, unlike the Pix2Pix-HD. A residual image-generation block (RIGB) is newly proposed for highlighting the vein texture of images distorted by the severe nonuniformity of illumination. In the INF-GAN, a one-channel residual image containing the finger-vein texture information is generated to be concatenated onto the input, thus improving the restoration performance. Furthermore, a feature encoder network was not used, unlike in Pix2Pix-HD.
- -
- For a fair performance assessment by other researchers, the nonuniform finger-vein images, INF-GAN, and algorithm proposed in this study are disclosed through [10].
2. Related Work
2.1. Finger-Vein Recognition without Illumination Compensation
2.2. Finger-Vein Recognition with Illumination Compensation
2.2.1. Finger-Vein Recognition with Images Including Weak Nonuniformity of Illumination
2.2.2. Finger-Vein Recognition with Images Including Severe Nonuniformity of Illumination
3. Proposed Methods
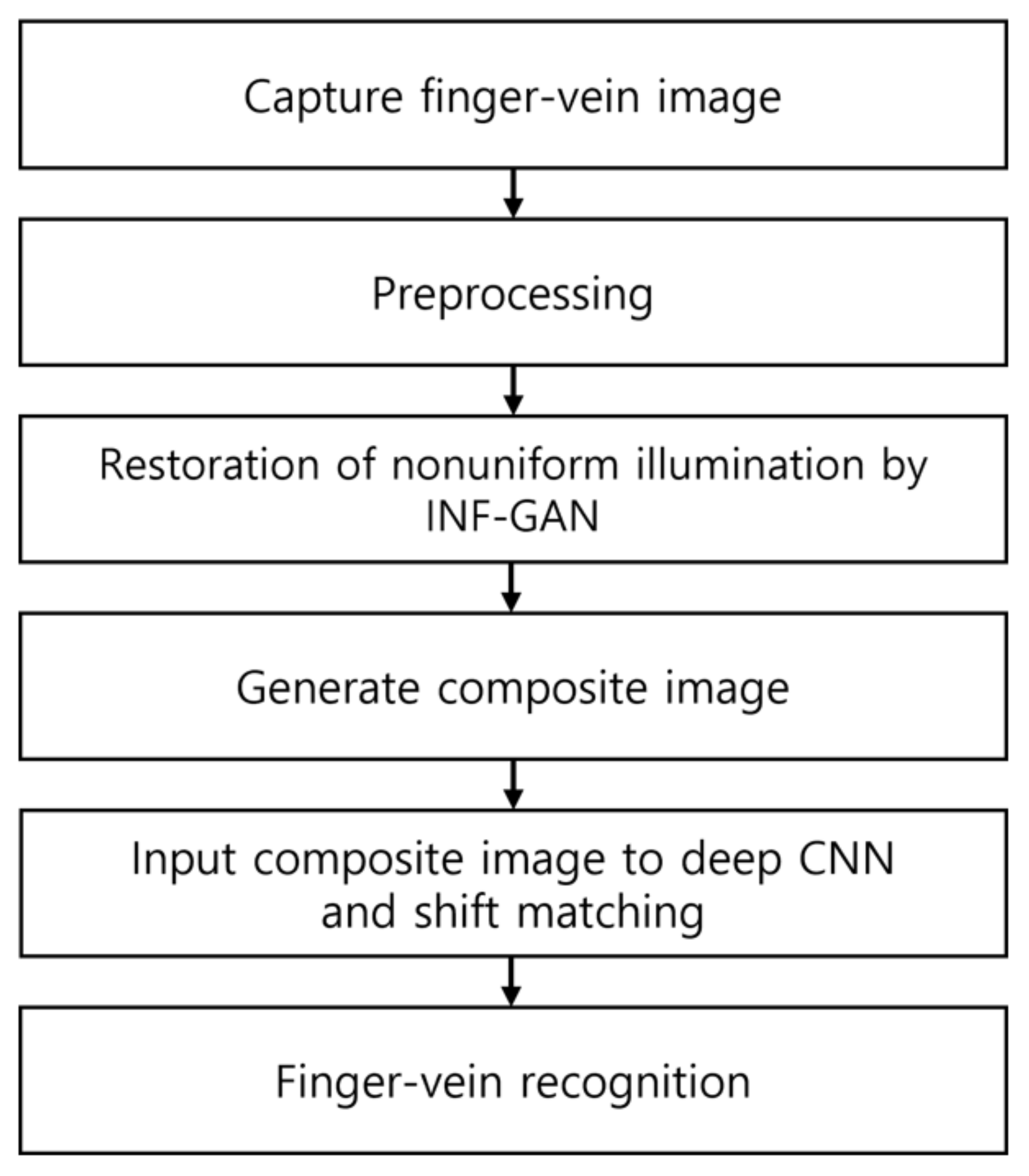
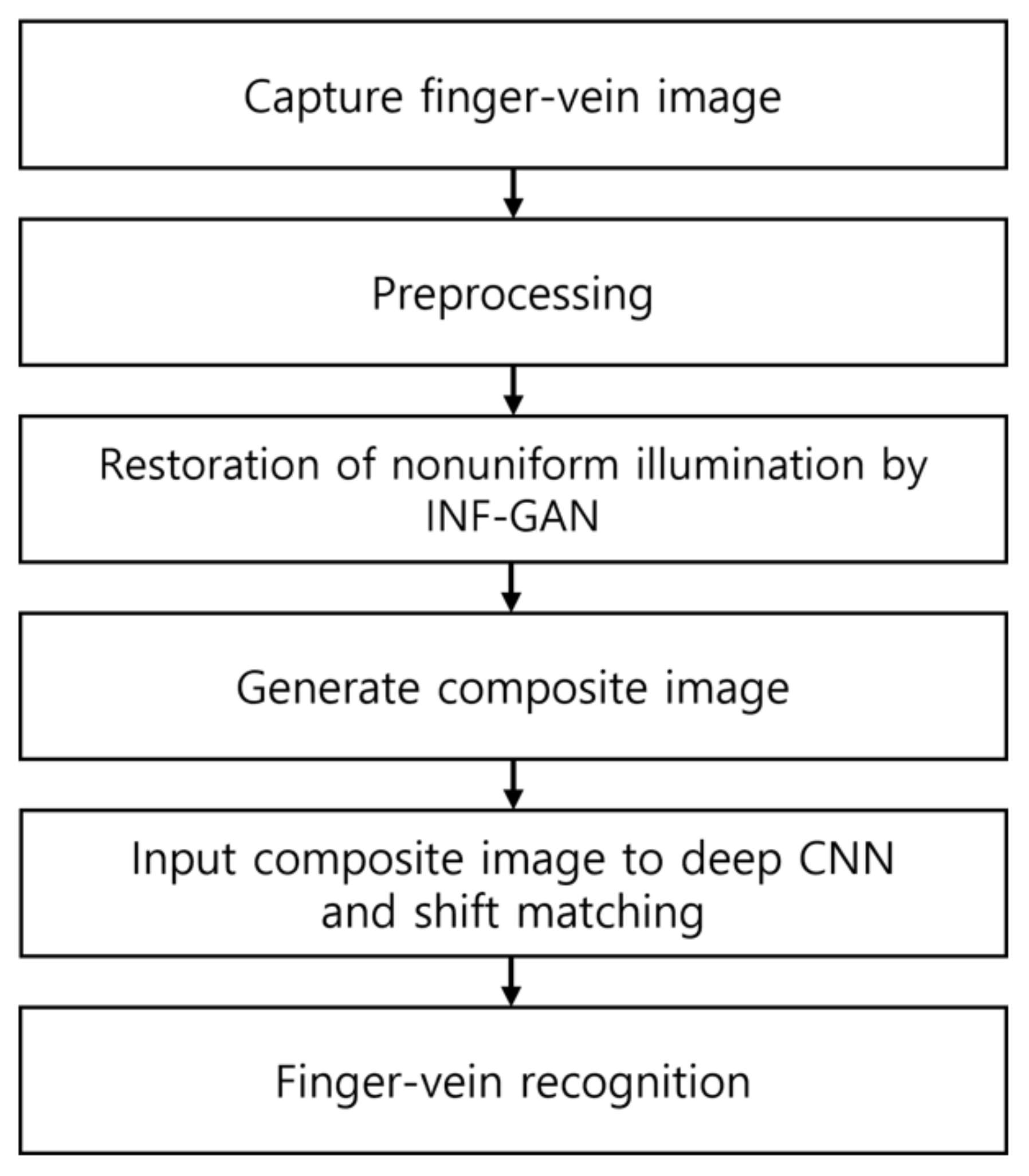
3.1. Overview of the Proposed Method
3.2. Preprocessing
3.3. Restoration of Nonuniform Illumination by INF-GAN
3.3.1. Generator of INF-GAN
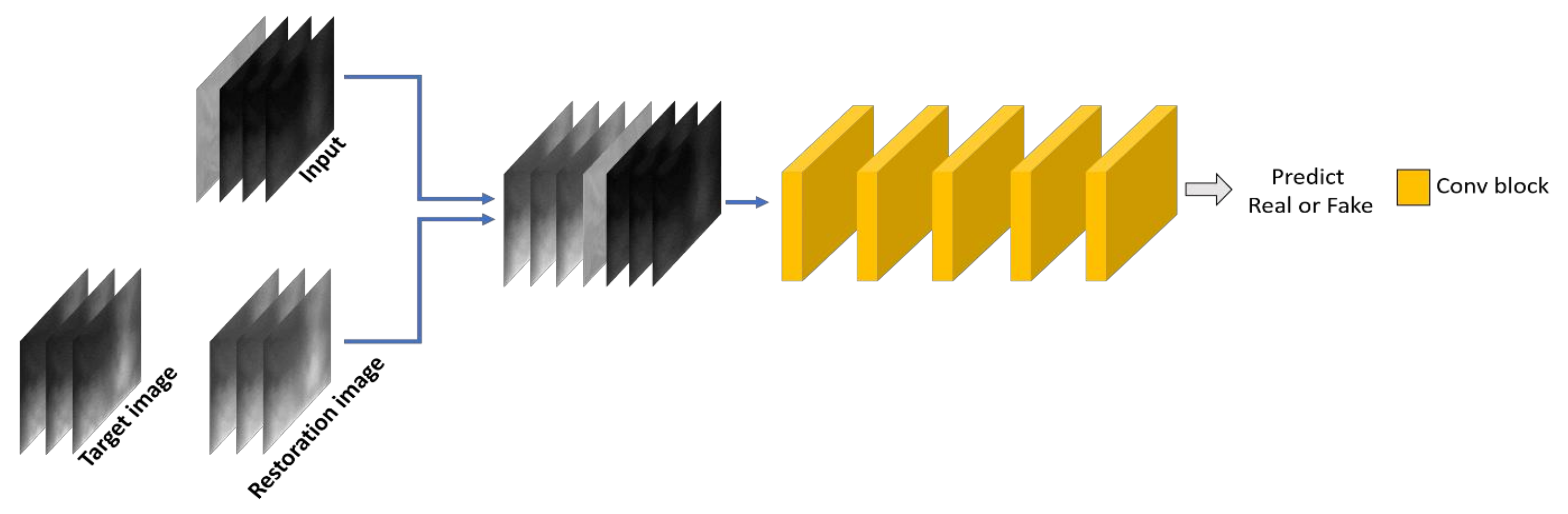
3.3.2. Discriminator of INF-GAN
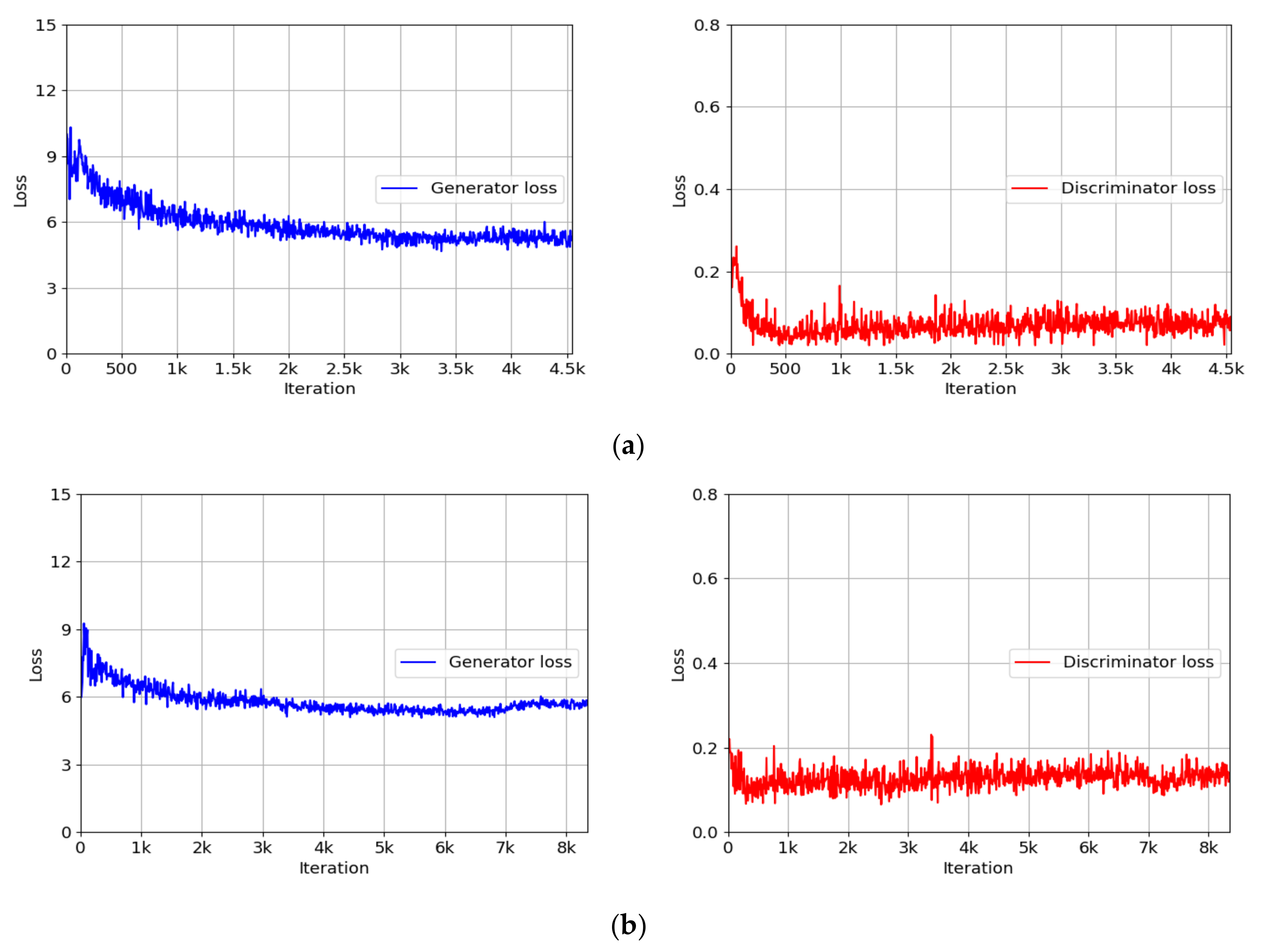
3.3.3. Loss Function of INF-GAN
3.4. Differences between the Proposed INF-GAN and Pix2Pix-HD
- -
- The generator of the Pix2Pix-HD was configured with a global generator, which is a ResNet generator, and a multiresolution pipeline as an additional local generator to transform low-resolution images into high-resolution images. The INF-GAN proposed in this study only used the ResNet generator, as it is a translation of nonuniform illumination to the uniform illumination of the images with an identical resolution.
- -
- Pix2Pix-HD used three multiscale discriminators to use three PatchGAN discriminators with different receptive field sizes, whereas the INF-GAN used one PatchGAN discriminator.
- -
- Pix2Pix-HD used a one-channel instance map containing the boundary region information of an object to ensure objects are distinguished for translation. In contrast, the newly proposed RIGB was used in the INF-GAN to highlight the vein texture of images distorted by severe nonuniformity of illumination. In the INF-GAN, a one-channel residual image containing the vein texture information was generated to be concatenated onto the input, thus improving the restoration performance.
- -
- Pix2Pix-HD used a feature encoder network to generate images of various styles to obtain output diversity. In contrast, the INF-GAN did not use a feature encoder network, as it focused on an accurate restoration of nonuniform illumination rather than output diversity.
3.5. Generation of Composite Image and Recognition by DenseNet-161 with Shift Matching
4. Experimental Results and Analysis
4.1. Dataset and Experimental Environments
4.2. Generation of the Nonuniform Illumination Dataset
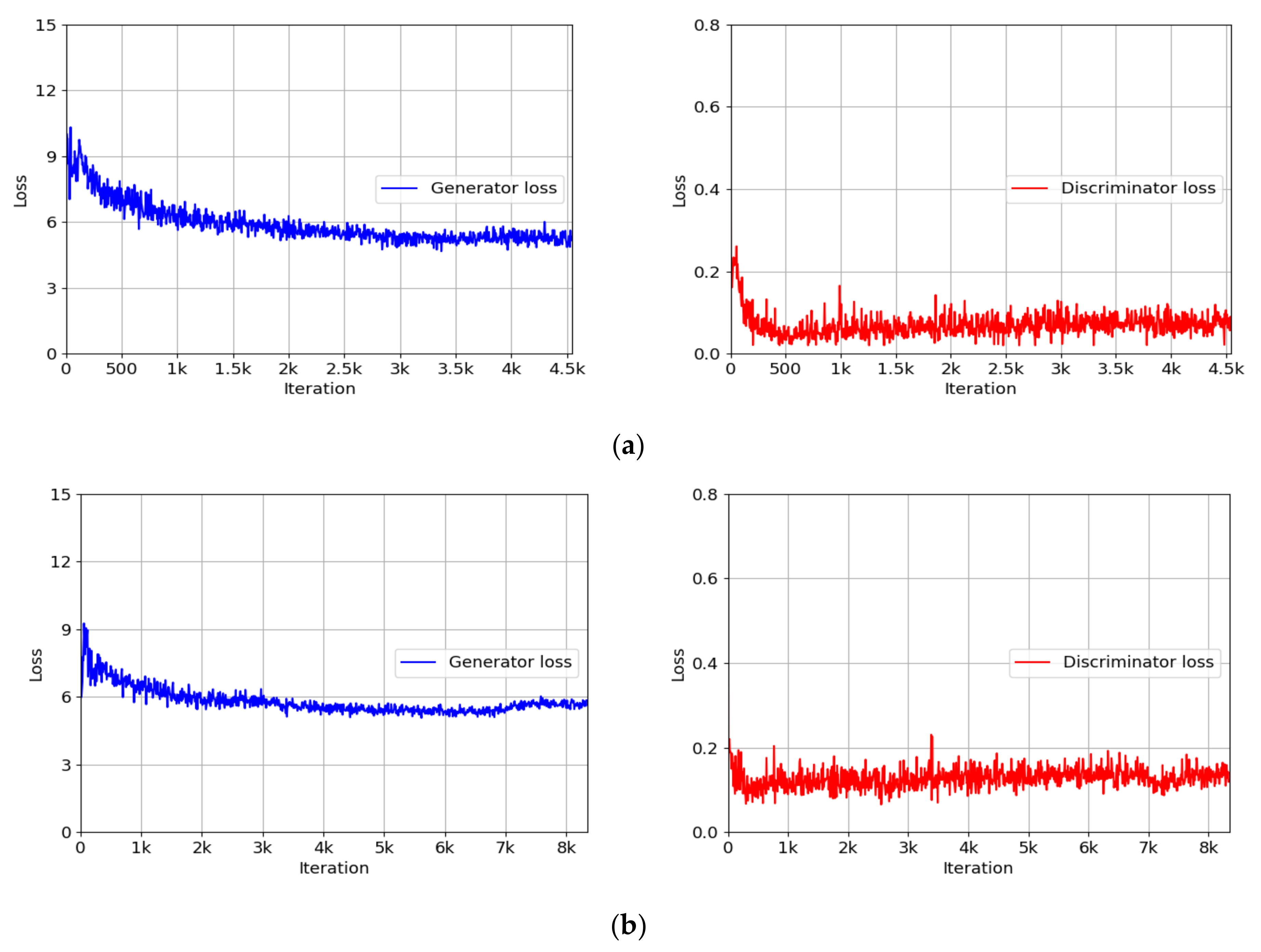
4.3. Training of INF-GAN
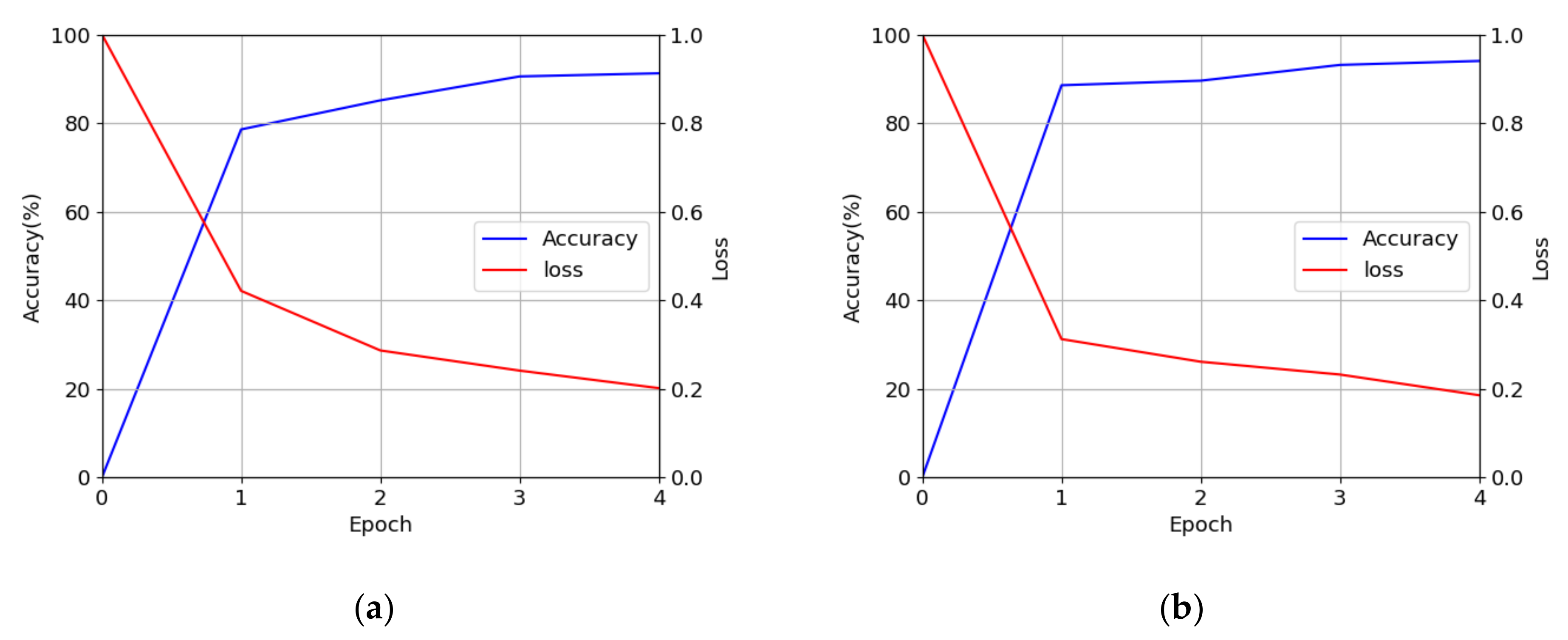
4.4. Training of the CNN Model for Finger-Vein Recognition
4.5. Testing of the Proposed Method
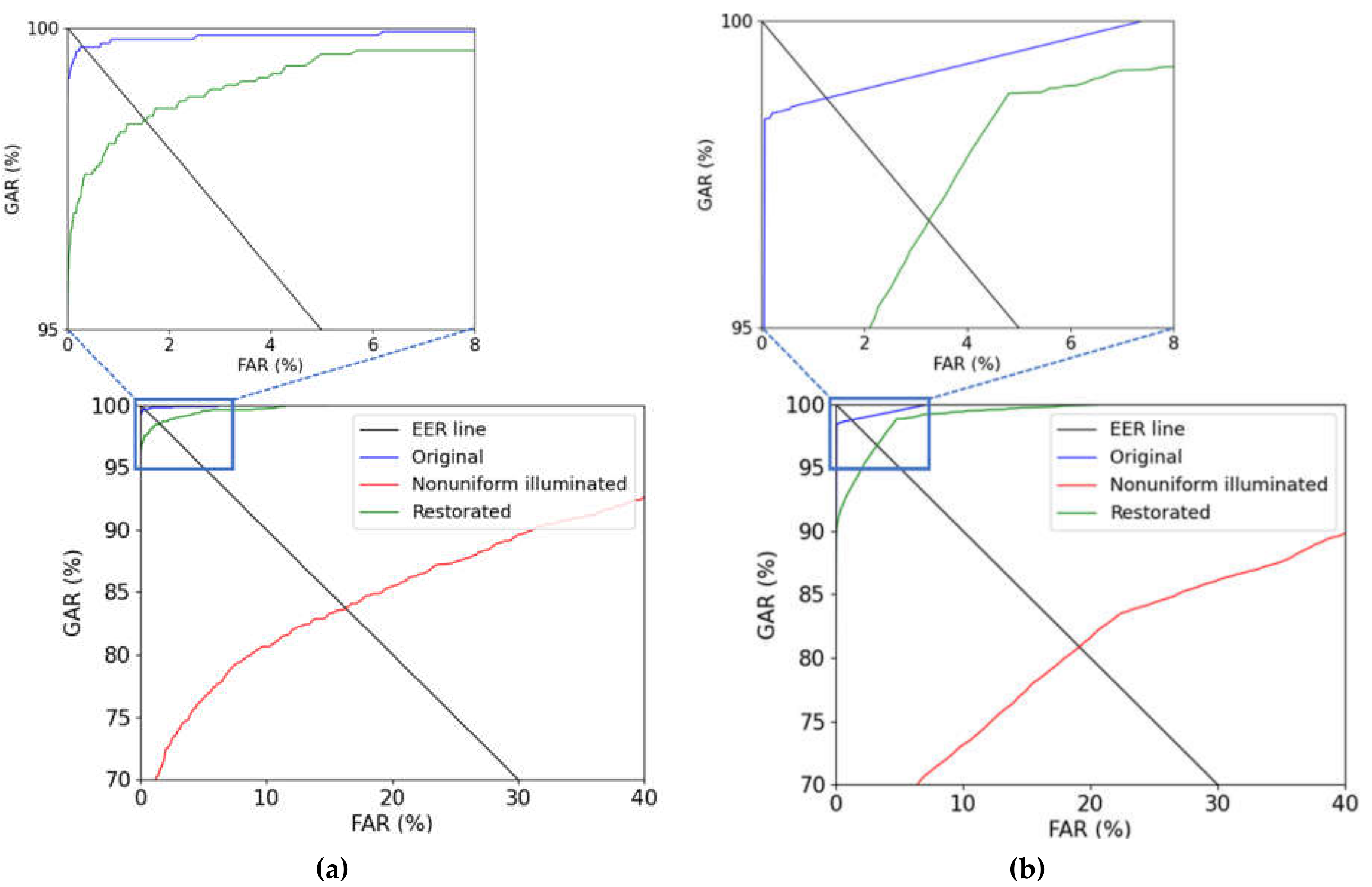
4.5.1. Ablation Study
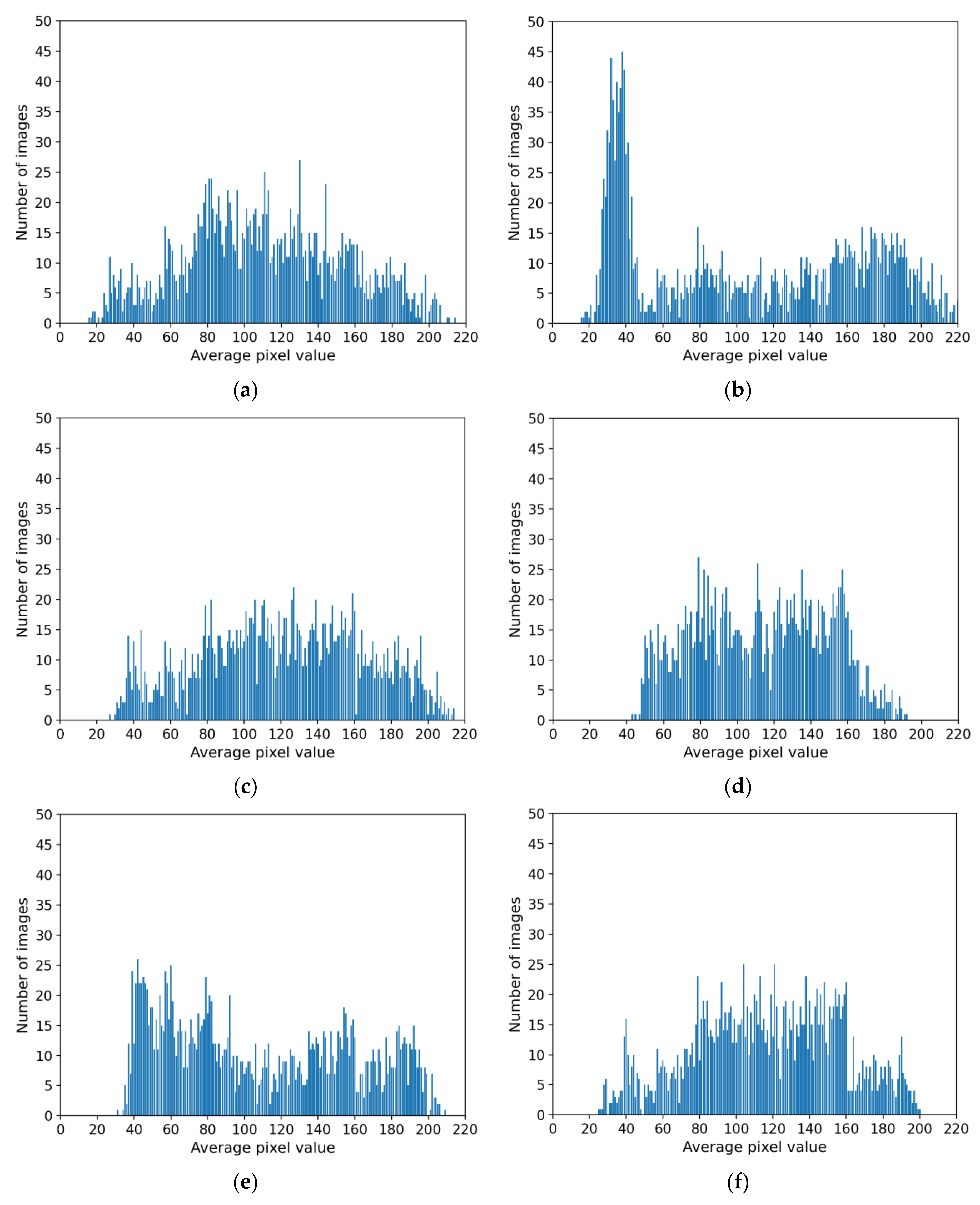
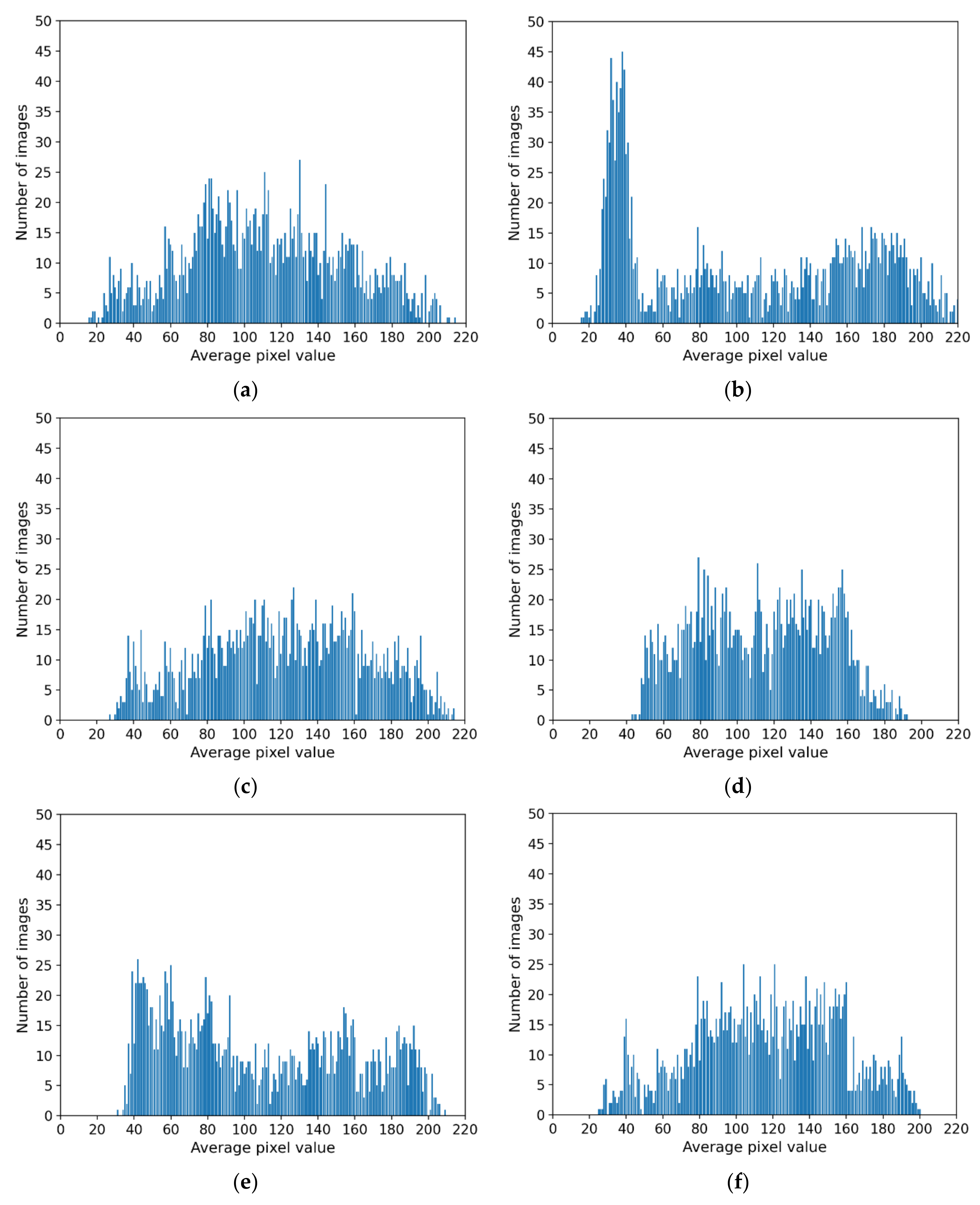
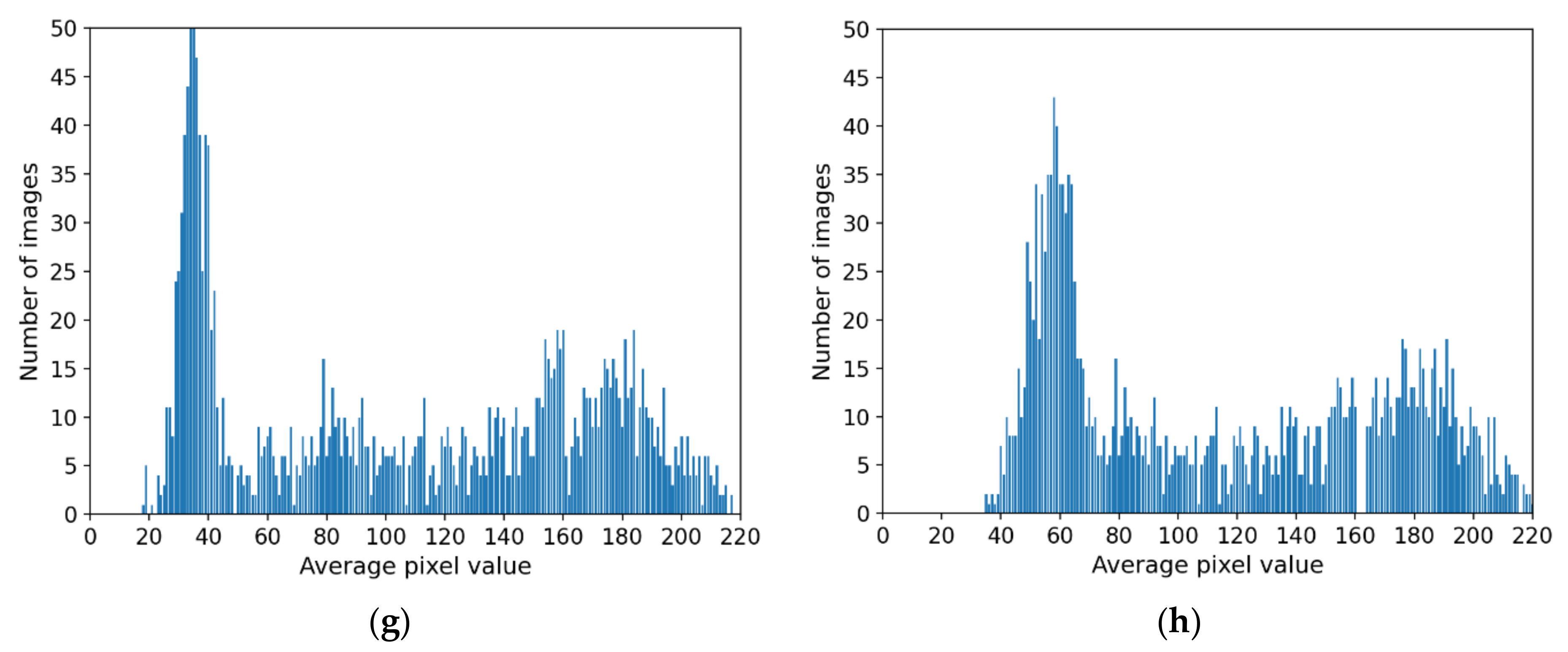
4.5.2. Comparison of Distribution of Generated Images by INF-GAN and Original Images
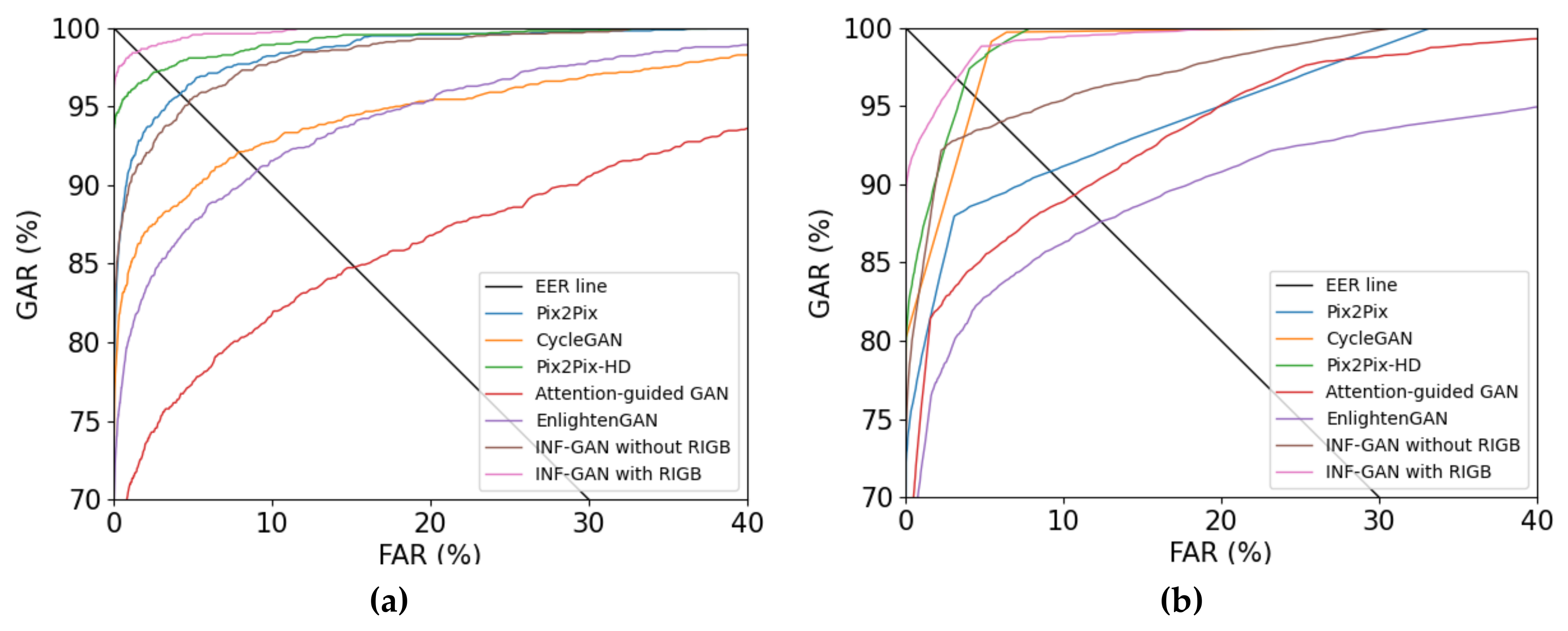
4.5.3. Comparisons of Finger-Vein Recognition Accuracies by the Proposed Method
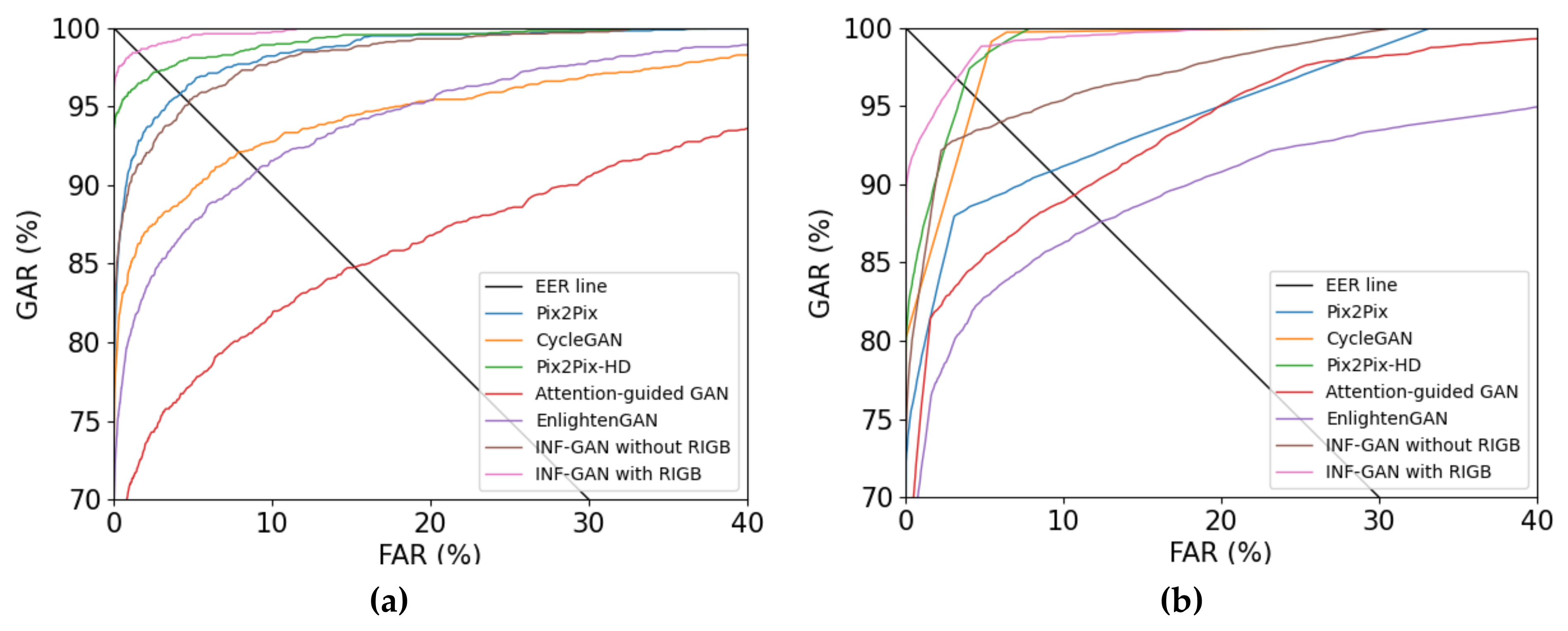
4.5.4. Comparisons of the Proposed Method and State-of-the-Art Methods
4.5.5. Testing on the Unseen Dataset
4.5.6. Analysis of Feature Maps by Grad-CAM
4.5.7. Processing Time of the Proposed Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mohsin, A.; Zaidan, A.; Zaidan, B.; Albahri, O.; Ariffin, S.A.B.; Alemran, A.; Enaizan, O.; Shareef, A.H.; Jasim, A.N.; Jalood, N. Finger Vein Biometrics: Taxonomy Analysis, Open Challenges, Future Directions, and Recommended Solution for Decentralised Network Architectures. IEEE Access 2020, 8, 9821–9845. [Google Scholar] [CrossRef]
- Akila, D.; Jeyalaksshmi, S.; Jayakarthik, R.; Mathivilasini, S.; Suseendran, G. Biometric Authentication with Finger Vein Im-ages Based on Quadrature Discriminant Analysis. In Proceedings of the 2nd International Conference on Computation, Auto-mation and Knowledge Management, Dubai, United Arab Emirates, 19–21 January 2021; pp. 118–122. [Google Scholar]
- Ma, H.; Hu, N.; Fang, C. The biometric recognition system based on near-infrared finger vein image. Infrared Phys. Technol. 2021, 116, 103734. [Google Scholar] [CrossRef]
- Lee, Y.H.; Khalil-Hani, M.; Bakhteri, R. FPGA-based finger vein biometric system with adaptive illumination for better image acquisition. In Proceedings of the IEEE International Symposium on Computer Applications and Industrial Electronics, Kota Kinabalu, Malaysia, 3–5 December 2012; pp. 107–112. [Google Scholar]
- Gil Hong, H.; Lee, M.B.; Park, K.R. Convolutional Neural Network-Based Finger-Vein Recognition Using NIR Image Sensors. Sensors 2017, 17, 1297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Noh, K.J.; Choi, J.; Hong, J.S.; Park, K.R. Finger-Vein Recognition Based on Densely Connected Convolutional Network Using Score-Level Fusion with Shape and Texture Images. IEEE Access 2020, 8, 96748–96766. [Google Scholar] [CrossRef]
- Choi, J.H.; Noh, K.J.; Cho, S.W.; Nam, S.H.; Owais, M.; Park, K.R. Modified Conditional Generative Adversarial Net-work-Based Optical Blur Restoration for Finger-Vein Recognition. IEEE Access 2020, 8, 16281–16301. [Google Scholar]
- Yang, S.; Qin, H.; Liu, X.; Wang, J. Finger-Vein Pattern Restoration with Generative Adversarial Network. IEEE Access 2020, 8, 141080–141089. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, Z.; Li, M.; Wu, H. GAN-Based Image Augmentation for Finger-Vein Biometric Recognition. IEEE Access 2019, 7, 183118–183132. [Google Scholar] [CrossRef]
- INF-GAN with Algorithm and Nonuniform Finger-Vein Images. Available online: http://dm.dgu.edu/link.html (accessed on 10 June 2021).
- Lee, E.C.; Lee, H.C.; Park, K.R. Finger vein recognition using minutia-based alignment and local binary pattern-based feature extraction. Int. J. Imaging Syst. Technol. 2009, 19, 179–186. [Google Scholar] [CrossRef]
- Song, W.; Kim, T.; Kim, H.C.; Choi, J.H.; Kong, H.-J.; Lee, S.-R. A finger-vein verification system using mean curvature. Pattern Recognit. Lett. 2011, 32, 1541–1547. [Google Scholar] [CrossRef]
- Wu, J.-D.; Liu, C.-T. Finger-vein pattern identification using SVM and neural network technique. Expert Syst. Appl. 2011, 38, 14284–14289. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Peng, J.; Wang, N.; El-Latif, A.A.A.; Li, Q.; Niu, X. Finger-vein Verification Using Gabor Filter and SIFT Feature Matching. In Proceedings of the 2012 Eighth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Piraeus-Athens, Greece, 18–20 July 2012; pp. 45–48. [Google Scholar]
- Van, H.T.; Thai, T.T.; Le, T.H. Robust Finger Vein Identification Base on Discriminant Orientation Feature. In Proceedings of the Seventh IEEE International Conference on Knowledge and Systems Engineering, Ho Chi Minh, Vietnam, 8–10 October 2015; pp. 348–353. [Google Scholar]
- Qin, H.; Qin, L.; Xue, L.; He, X.; Yu, C.; Liang, X. Finger-Vein Verification Based on Multi-Features Fusion. Sensors 2013, 13, 15048–15067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Kumar, A.; Zhou, Y. Human Identification Using Finger Images. IEEE Trans. Image Process. 2012, 21, 2228–2244. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.-C.; Liu, M.-Y.; Zhu, J.-Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-resolution Image Synthesis and Semantic Manipula-tion with Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8798–8807. [Google Scholar]
- He, K.M.; Zhang, X.Y.; Ren, S.Q.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Van der Ouderaa, T.F.; Worrall, D.E. Reversible GANs for Memory-efficient Image-to-image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4720–4728. [Google Scholar]
- Awasthi, P.; Tang, A.; Vijayaraghavan, A. Efficient Algorithms for Learning Depth-2 Neural Networks with General ReLU Activations. arXiv 2021, arXiv:2107.10209. [Google Scholar]
- Li, M.; Lin, J.; Ding, Y.; Liu, Z.; Zhu, J.-Y.; Han, S. GAN Compression: Efficient Architectures for Interactive Conditional GANs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 5284–5294. [Google Scholar]
- Hui, Z.; Li, J.; Wang, X.; Gao, X. Image Fine-grained Inpainting. arXiv 2020, arXiv:2002.02609. [Google Scholar]
- Javed, K.; Din, N.U.; Bae, S.; Maharjan, R.S.; Seo, D.; Yi, J. UMGAN: Generative adversarial network for image unmosaicing using perceptual loss. In Proceedings of the 16th International Conference on Machine Vision Applications, Tokyo, Japan, 27–31 May 2019; pp. 1–5. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. arXiv 2016, arXiv:1606.03498. [Google Scholar]
- Yang, G.; Pennington, J.; Rao, V.; Sohl-Dickstein, J.; Schoenholz, S.S. A mean field theory of batch normalization. arXiv 2019, arXiv:1902.08129. [Google Scholar]
- Yin, Y.; Liu, L.; Sun, X. SDUMLA-HMT: A Multimodal Biometric Database. In Proceedings of the Chinese Conference on Biometric Recognition, Beijing, China, 3–4 December 2011; pp. 260–268. [Google Scholar]
- Lu, Y.; Xie, S.J.; Yoon, S.; Wang, Z.; Park, D.S. An available database for the research of finger vein recognition. In Proceedings of the 6th International Congress on Image and Signal Processing, Hangzhou, China, 16–18 December 2013; pp. 410–415. [Google Scholar]
- THU-FVFDT1. Available online: https://www.sigs.tsinghua.edu.cn/labs/vipl/thu-fvfdt.html (accessed on 10 October 2021).
- NVIDIA GeForce GTX 1070. Available online: https://www.geforce.com/hardware/desktop-gpus/geforce-gtx-1070/specifications (accessed on 10 June 2021).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An Imperative Style, High-performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Loh, Y.P.; Liang, X.; Chan, C.S. Low-light image enhancement using Gaussian Process for features retrieval. Signal. Process. Image Commun. 2019, 74, 175–190. [Google Scholar] [CrossRef]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. MSR-net: Low-light Image Enhancement Using Deep Convolutional Network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; Volume 2242–2251. [Google Scholar] [CrossRef] [Green Version]
- Mejjati, Y.A.; Richardt, C.; Tompkin, J.; Cosker, D.; Kim, K.I. Unsupervised Attention-Guided Image to Image Translation. arXiv 2018, arXiv:1806.02311. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. EnlightenGAN: Deep Light Enhance-ment Without Paired Supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef]
- Herzog, M.H.; Francis, G.; Clarke, A. Experimental Design and the Basics of Statistics: Signal Detection Theory (SDT). In Basic Concepts on 3D Cell Culture; Springer: Berlin, Germany, 2019; pp. 13–22. [Google Scholar]
- Ramdas, A.; Trillos, N.G.; Cuturi, M. On Wasserstein Two-Sample Testing and Related Families of Nonparametric Tests. Entropy 2017, 19, 47. [Google Scholar] [CrossRef]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. GANs Trained by a Two Time-Scale Update Rule Con-verge to a Local Nash Equilibrium. arXiv 2018, arXiv:1706.08500. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Net-works via Gradient-based Localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Jetson TX2 Module. Available online: https://developer.nvidia.com/embedded/jetson-tx2 (accessed on 2 January 2021).




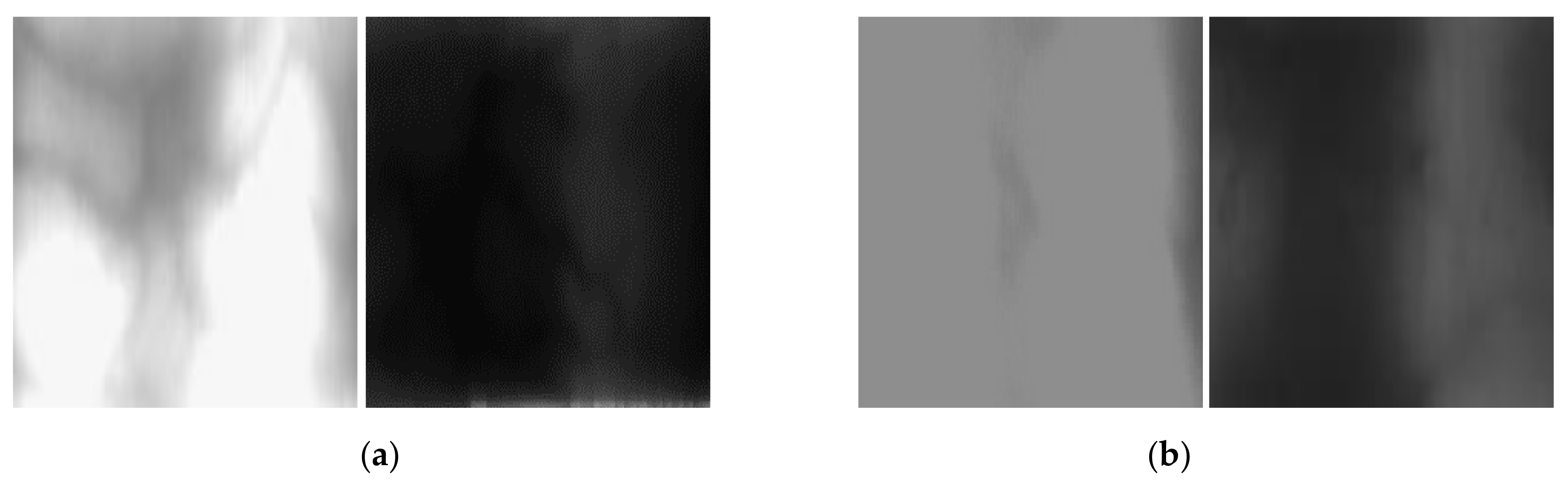
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
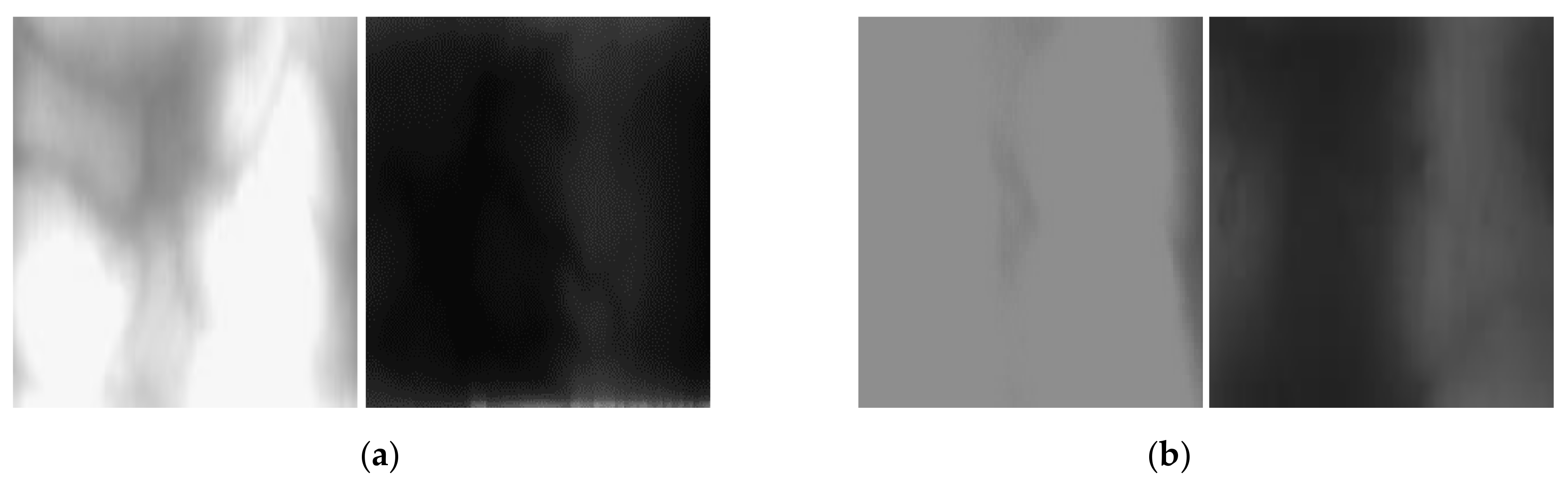{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Method | Advantage | Disadvantage | ||
|---|---|---|---|---|---|
| Without illumination compensation | Non-training-based | Minutia-based alignment and LBP [11] | Misalignment compensation through minutia-based alignment | Performance is affected by illumination quality, because there is no illumination compensation | |
| Mean curvature and MPR [12] | Misalignment compensation through in-plane rotation during finger-vein matching | ||||
| Training-based | ANFIS and SVM [13] | More robust recognition than non-training-based methods | |||
| CNN with difference image [5] | |||||
| With illumination compensation | Including weak nonuniformity of illumination | Non-training-based | Gabor filter and SIFT [15] | Illumination compensation through grayscale normalization | Recognition performance is difficult to improve in the case of severe nonuniformity of illumination |
| Training-based | MFRAT, GridPCA, and k-nearest classifier [16] | Robust feature extraction through MFRAT | |||
| Shape feature and orientation feature fusion [17] | Robust recognition through score-level feature fusion | ||||
| CNN with shape feature and texture feature using composite image and score level fusion [6] | |||||
| Including severe nonuniformity of illumination | Hardware-based | Hardware-based adaptive illumination [4] | Solves the problem of severe nonuniformity of illumination | Requires additional hardware devices and cannot be used in general finger-vein image acquisition devices | |
| Software-based (training-based) | INF-GAN-based illumination compensation (Proposed method) | Does not require additional hardware devices and can be used in general finger-vein image acquisition devices | Requires additional procedure of training of INF-GAN, including RIGB | ||
| Layer | Filter (Number of Filters, Size, Stride) (Number of Blocks) | Padding | Input | Output |
|---|---|---|---|---|
| Input layer | 224 × 224 × 3 | 224 × 224 × 3 | ||
| RIGB | 64, 3 × 3 × 3, 1 (1) 64, 1 × 1 × 64, 1 (2) 64, 3 × 3 × 64, 1 (3) 1, 1 × 1 × 64, 1 (1) | 224 × 224 × 3 | 224 × 224 × 4 (Channel-wise concatenation) | |
| Conv block 1 | 64, 7 × 7 × 4,1 | 3 × 3 | 224 × 224 × 4 | 224 × 224 × 64 |
| Downsampling 1 | 128, 3 × 3 × 64, 2 | 1 × 1 | 224 × 224 × 64 | 112 × 112 × 128 |
| Downsampling 2 | 256, 3 × 3 × 128, 2 | 1 × 1 | 112 × 112 × 128 | 56 × 56 × 256 |
| Downsampling 3 | 512, 3 × 3 × 256, 2 | 1 × 1 | 56 × 56 × 256 | 28 × 28 × 512 |
| Downsampling 4 | 1024, 3 × 3 × 512, 2 | 1 × 1 | 28 × 28 × 512 | 14 × 14 × 1024 |
| Residual blocks (9) | 1024, 3 × 3 × 1024, 1 | 1 × 1 | 14 × 14 × 1024 | 14 × 14 × 1024 |
| Upsampling 1 | 512, 3 × 3 × 1024, 2 | 1 × 1 | 14 × 14 × 1024 | 28 × 28 × 512 |
| Upsampling 2 | 256, 3 × 3 × 512, 2 | 1 × 1 | 28 × 28 × 512 | 56 × 56 × 256 |
| Upsampling 3 | 128, 3 × 3 × 256, 2 | 1 × 1 | 56 × 56 × 256 | 112 × 112 × 128 |
| Upsampling 4 | 64, 3 × 3 × 128, 2 | 1 × 1 | 112 × 112 × 128 | 224 × 224 × 64 |
| Conv block 2 | 3, 7 × 7 × 64, 1 | 3 × 3 | 224 × 224 × 64 | 224 × 224 × 3 |
| Layer | Filter (Number of Filters, Size, Stride) | Padding | Input | Output |
|---|---|---|---|---|
| Input layer | 224 × 224 × 3 | 224 × 224 × 3 | ||
| Conv block 1 | 64, 3 × 3 × 3, 1 | 1 × 1 | 224 × 224 × 3 | 224 × 224 × 64 |
| Conv block 2 | 64, 1 × 1 × 64, 1 | 1 × 1 | 224 × 224 × 64 | 224 × 224 × 64 |
| Residual block 1 | 64, 3 × 3 × 64, 1 | 1 × 1 | 224 × 224 × 64 | 224 × 224 × 64 |
| Conv block 3 | 64, 3 × 3 × 64, 1 | 1 × 1 | 224 × 224 × 64 | 224 × 224 × 64 |
| Conv block 4 | 64, 1 × 1 × 64, 1 | 1 × 1 | 224 × 224 × 64 | 224 × 224 × 64 |
| Residual block 2 | 64, 3 × 3 × 64, 1 | 1 × 1 | 224 × 224 × 64 | 224 × 224 × 64 |
| Conv 1 | 1, 1 × 1 × 64, 1 | 1 × 1 | 224 × 224 × 64 | 224 × 224 × 1 |
| Layer | Filter (Number of Filters, Size, Stride) | Padding | Input | Output |
|---|---|---|---|---|
| Input layer | 224 × 224 × 4 224 × 224 × 3 (channel-wise concatenation) | 224 × 224 × 7 | ||
| Conv block 1 * | 64, 4 × 4 × 7, 2 | 2 × 2 | 224 × 224 × 7 | 113 × 113 × 64 |
| Conv block 2 ** | 128, 4 × 4 × 64, 2 | 2 × 2 | 113 × 113 × 64 | 57 × 57 × 128 |
| Conv block 3 ** | 256, 4 × 4 × 128, 2 | 2 × 2 | 57 × 57 × 128 | 29 × 29 × 256 |
| Conv block 4 ** | 512, 4 × 4 × 256, 1 | 2 × 2 | 29 × 29 × 256 | 30 × 30 × 512 |
| Conv block 5 *** | 1, 4 × 4 × 512, 1 | 2 × 2 | 30 × 30 × 512 | 31 × 31 × 1 |
| Layer | Filter (Number of Filters, Size, Stride) | Padding | Input | Output |
|---|---|---|---|---|
| Input layer | 224 × 224 × 3 | 224 × 224 × 3 | ||
| Conv block | 96, 7 × 7 × 3, 2 | 3 × 3 | 224 × 224 × 3 | 112 × 112 × 96 |
| Max Pooling | 96, 3 × 3 × 96, 2 | 1 × 1 | 112 × 112 × 96 | 56 × 56 × 96 |
| Dense Block 1 | 6 × 192, 1 × 1 × 96, 1 | 56 × 56 × 96 | 56 × 56 × 384 | |
| 6 × 48, 3 × 3 × 192, 1 | 1 × 1 | |||
| Transition Block 1 | 192, 1 × 1 × 384, 1 192, 2 × 2 × 192, 2 | 56 × 56 × 384 | 28 × 28 × 192 | |
| Dense Block 2 | 12 × 192, 1 × 1 × 192, 1 | 28 × 28 × 192 | 28 × 28 × 768 | |
| 12 × 48, 3 × 3 × 48, 1 | 1 × 1 | |||
| Transition Block 2 | 384, 1 × 1 × 768, 1 384, 2 × 2 × 384, 2 | 28 × 28 × 768 | 14 × 14 × 384 | |
| Dense Block 3 | 36 × 192, 1 × 1 × 384, 1 | 14 × 14 × 384 | 14 × 14 × 2112 | |
| 36 × 48, 3 × 3 × 192, 1 | 1 × 1 | |||
| Transition Block 3 | 1056, 1 × 1 × 2112, 1 1056, 2 × 2 × 1056, 2 | 14 × 14 × 2112 | 7 × 7 × 1056 | |
| Dense Block 4 | 24 × 192, 1 × 1 × 1056, 1 | 7 × 7 × 1056 | 7 × 7 × 2208 | |
| 24 × 48, 3 × 3 × 192, 1 | 1 × 1 | |||
| Global average pooling | 2208, 7 × 7 × 2208, 1 | 7 × 7 × 2208 | 1 × 1 × 2208 | |
| Fully connected layer | 1 × 1 × 2208 | 1 × 1 × 2 |
| Database | People | Hands | Fingers | Classes | Images | Augmented Images | |
|---|---|---|---|---|---|---|---|
| INF-GAN Training | DenseNet-161 Training | ||||||
| HKPU-DB | 156 | 1 | 2 | 312 | 1872 | 2600 | 9360 |
| SDU-DB | 106 | 2 | 3 | 636 | 3816 | 4580 | 19,080 |
| Number of Residual Blocks | EER | |
|---|---|---|
| HKPU-DB | SDU-DB | |
| 1 | 4.78 | 2.95 |
| 2 | 1.65 | 3.17 |
| 3 | 3.09 | 5.55 |
| 4 | 3.82 | 5.61 |
| Method | EER | |
|---|---|---|
| HKPU-DB | SDU-DB | |
| Without RIGB | 4.87 | 5.83 |
| With RIGB | 1.65 | 3.17 |
| Database | Metric | Nonuniform Illumination | Pix2Pix [39] | CycleGAN [40] | Pix2Pix-HD [21] | Attention-Guided Image-to-Image Translation GAN [41] | EnlightenGAN [42] | INF-GAN |
|---|---|---|---|---|---|---|---|---|
| HKPU-DB | d′ | 0.0689 | 0.0624 | 0.0489 | 0.1455 | 0.0841 | 0.0775 | 0.2482 |
| Wasserstein distance | 21.154 | 6.8135 | 10.705 | 6.63 | 20.03 | 16.734 | 10.728 | |
| FID | 7.93 | 8.44 | 28.8 | 2.89 | 5.92 | 4.72 | 4.82 | |
| SDU-DB | d′ | 0.191 | 0.502 | 0.031 | 0.215 | 0.030 | 0.490 | 0.171 |
| Wasserstein distance | 24.314 | 10.774 | 2.83 | 4.25 | 11.77 | 19.53 | 3.545 | |
| FID | 4.61 | 6.48 | 4.18 | 2.03 | 9.33 | 3.81 | 3.37 |
| Database | Original Image | Nonuniformly Illuminated Image | Restored Image by INF-GAN |
|---|---|---|---|
| HKPU-DB | 0.37 | 16.23 | 1.65 |
| SDU-DB | 1.65 | 19.3 | 3.17 |
| Database | Pix2Pix [39] | CycleGAN [40] | Pix2Pix-HD [21] | Attention-Guided Image-to-Image Translation GAN [41] | EnlightenGAN [42] | INF-GAN (without RIGB) | INF-GAN (with RIGB) |
|---|---|---|---|---|---|---|---|
| HKPU-DB | 4.24 | 8.31 | 2.84 | 15.48 | 8.72 | 4.87 | 1.65 |
| SDU-DB | 8.81 | 4.28 | 3.66 | 10.39 | 12.52 | 5.83 | 3.17 |
| INF-GAN | DenseNet-161 | Total | |
|---|---|---|---|
| Desktop computer | 15.62 | 13.12 | 28.74 |
| Jetson TX2 | 33.77 | 227.45 | 261.22 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, J.S.; Choi, J.; Kim, S.G.; Owais, M.; Park, K.R. INF-GAN: Generative Adversarial Network for Illumination Normalization of Finger-Vein Images. Mathematics 2021, 9, 2613. https://doi.org/10.3390/math9202613
Hong JS, Choi J, Kim SG, Owais M, Park KR. INF-GAN: Generative Adversarial Network for Illumination Normalization of Finger-Vein Images. Mathematics. 2021; 9(20):2613. https://doi.org/10.3390/math9202613
Chicago/Turabian StyleHong, Jin Seong, Jiho Choi, Seung Gu Kim, Muhammad Owais, and Kang Ryoung Park. 2021. "INF-GAN: Generative Adversarial Network for Illumination Normalization of Finger-Vein Images" Mathematics 9, no. 20: 2613. https://doi.org/10.3390/math9202613
APA StyleHong, J. S., Choi, J., Kim, S. G., Owais, M., & Park, K. R. (2021). INF-GAN: Generative Adversarial Network for Illumination Normalization of Finger-Vein Images. Mathematics, 9(20), 2613. https://doi.org/10.3390/math9202613