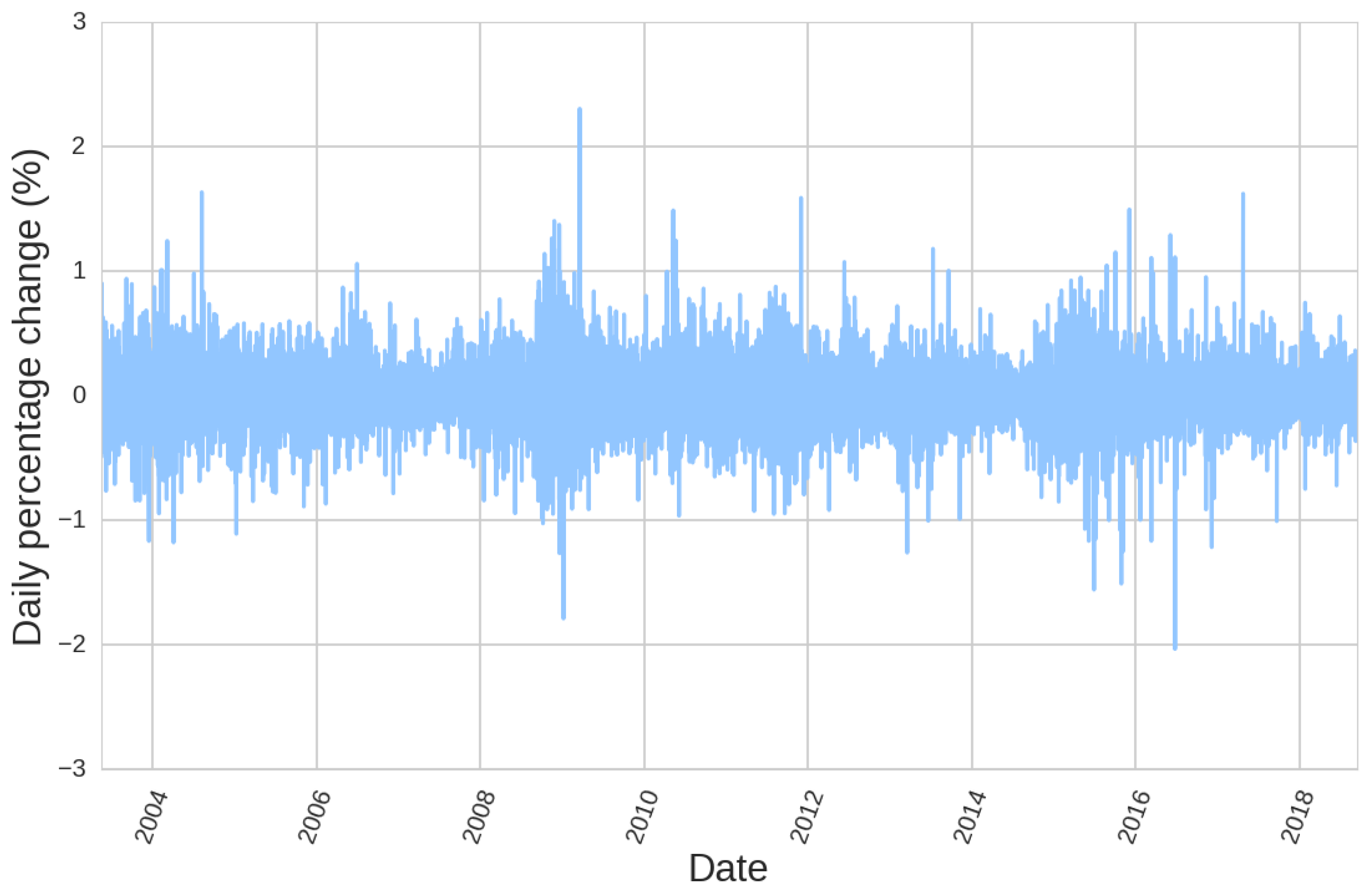
Figure 1.
Volatility clustering can be appreciated in EURUSD price history.
Figure 1.
Volatility clustering can be appreciated in EURUSD price history.
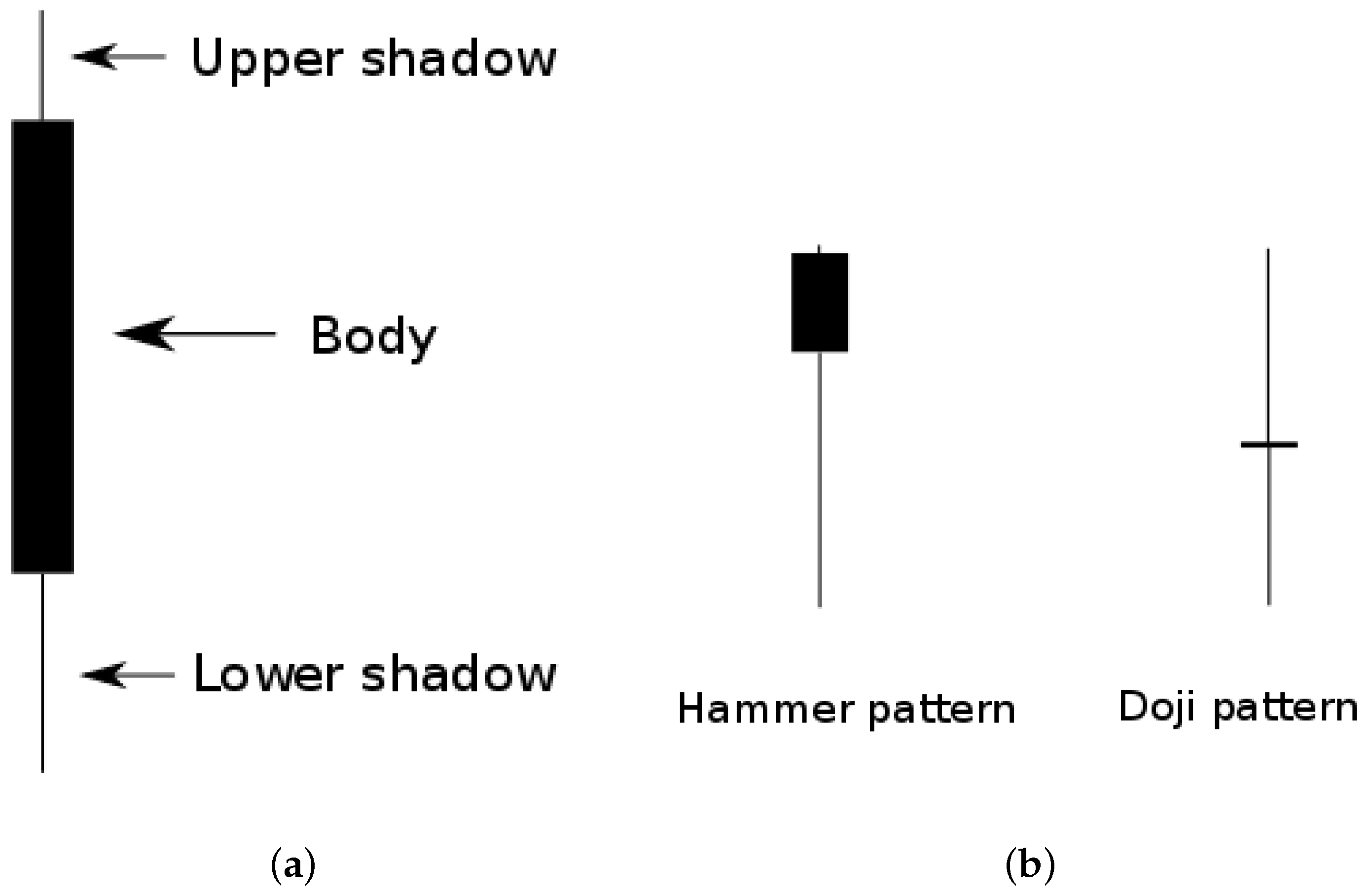
Figure 2.
(a) Different parts of a bearish candlestick. (b) A doji is a kind of candlestick where the size of the body is much smaller than both shadows, while a hammer has a small body, one small shadow, and one big shadow (depending on whether we are referring to an inverted hammer or not).
Figure 2.
(a) Different parts of a bearish candlestick. (b) A doji is a kind of candlestick where the size of the body is much smaller than both shadows, while a hammer has a small body, one small shadow, and one big shadow (depending on whether we are referring to an inverted hammer or not).
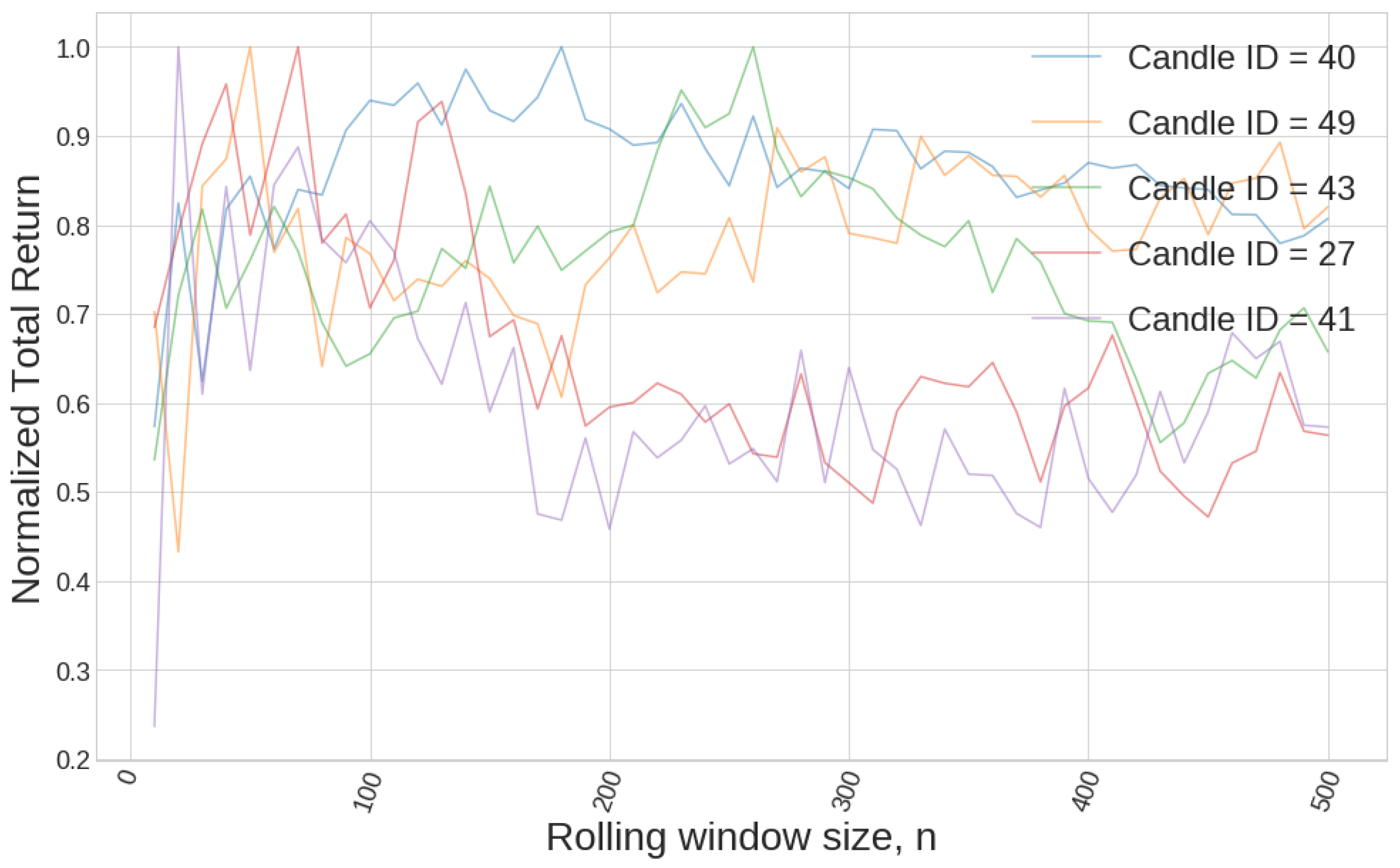
Figure 3.
There is not a clear pattern of how the parameter n affects the performance of different strategies.
Figure 3.
There is not a clear pattern of how the parameter n affects the performance of different strategies.
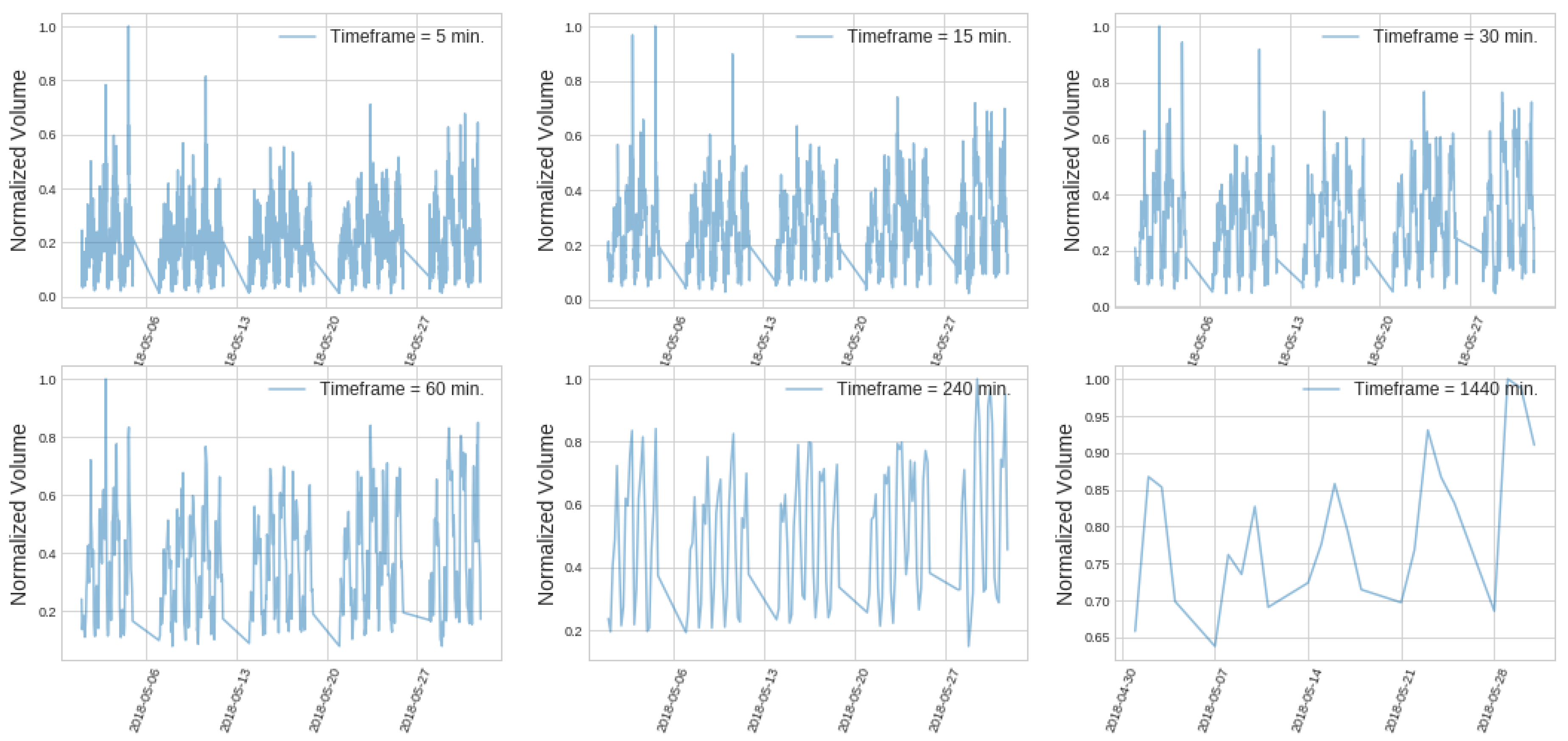
Figure 4.
Daily periodicity of volume data for EURUSD pair in May 2018.
Figure 4.
Daily periodicity of volume data for EURUSD pair in May 2018.
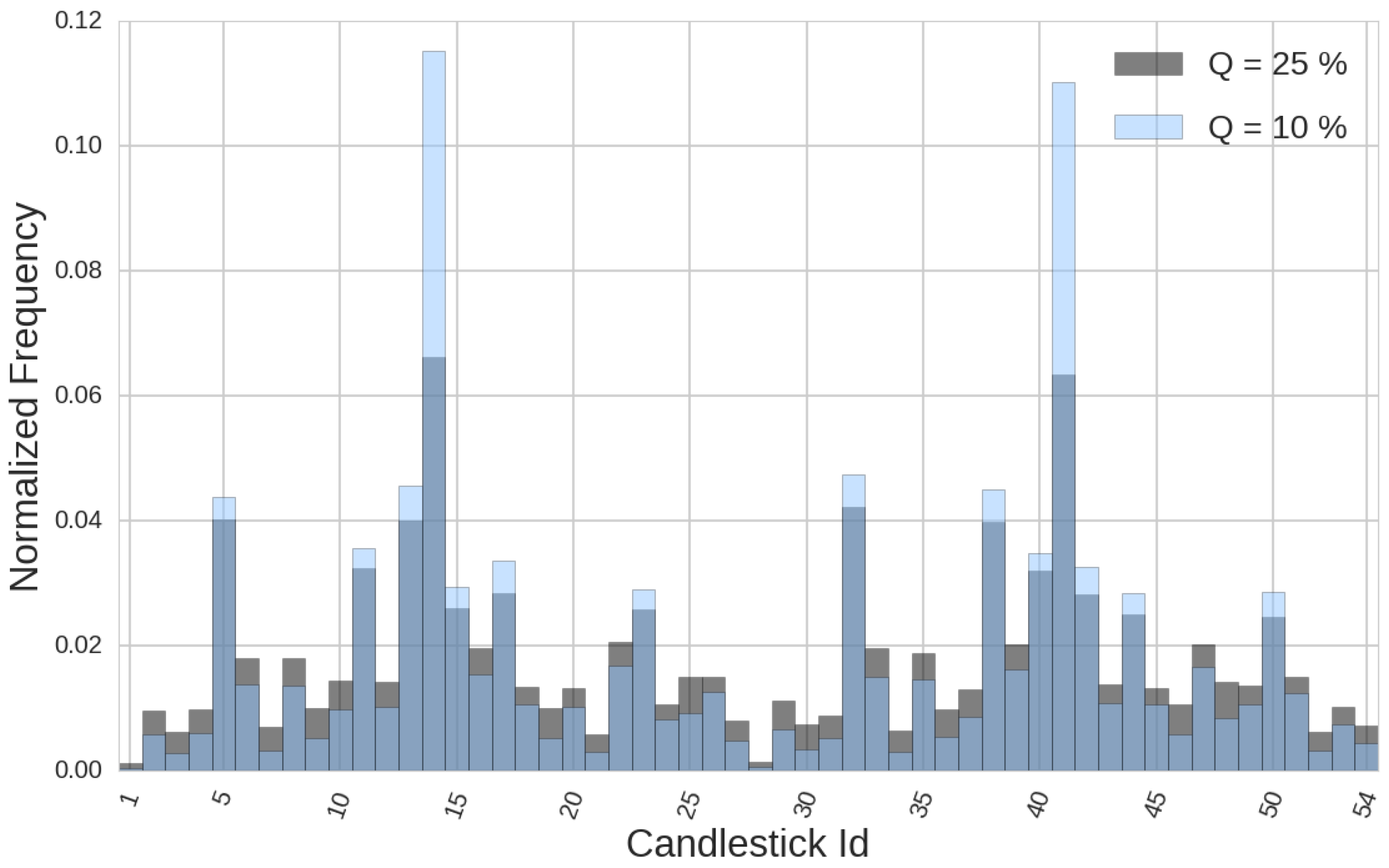
Figure 5.
When the quantile chosen is low, we see two peaks at those candlesticks which have medium size for all three parameters (body and shadows), one bullish and the other bearish. This concentration disappears as the quantile used as a threshold grows.
Figure 5.
When the quantile chosen is low, we see two peaks at those candlesticks which have medium size for all three parameters (body and shadows), one bullish and the other bearish. This concentration disappears as the quantile used as a threshold grows.
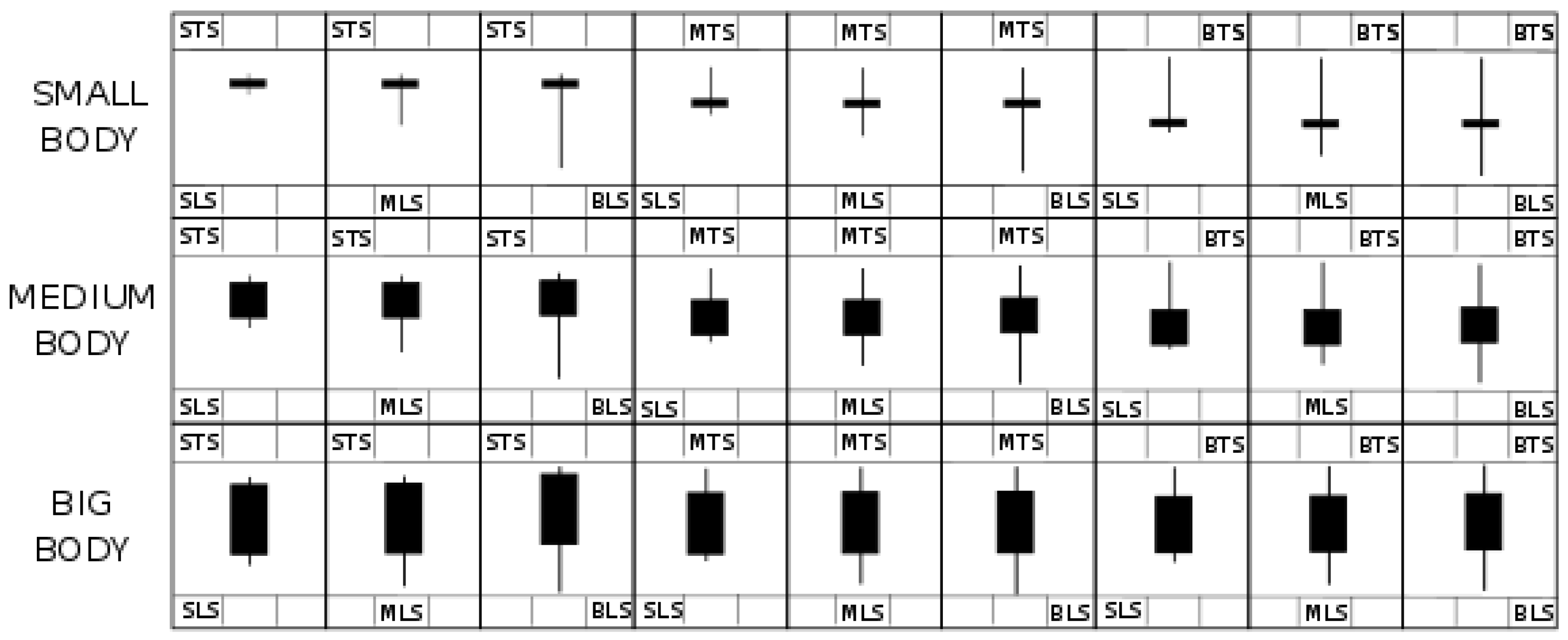
Figure 6.
Each box is identified by the size of each parameter defining the single-candlestick pattern. In the upper area of each box, we read the size of the top shadow (STS, MTS and BTS for small, medium and big sizes, respectively). Similarly, we find the information about the lower shadow in the lower part of each box.
Figure 6.
Each box is identified by the size of each parameter defining the single-candlestick pattern. In the upper area of each box, we read the size of the top shadow (STS, MTS and BTS for small, medium and big sizes, respectively). Similarly, we find the information about the lower shadow in the lower part of each box.
Figure 7.
The final out-of-sample period is comprised of all smaller out-of-sample periods coming from different folds.
Figure 7.
The final out-of-sample period is comprised of all smaller out-of-sample periods coming from different folds.
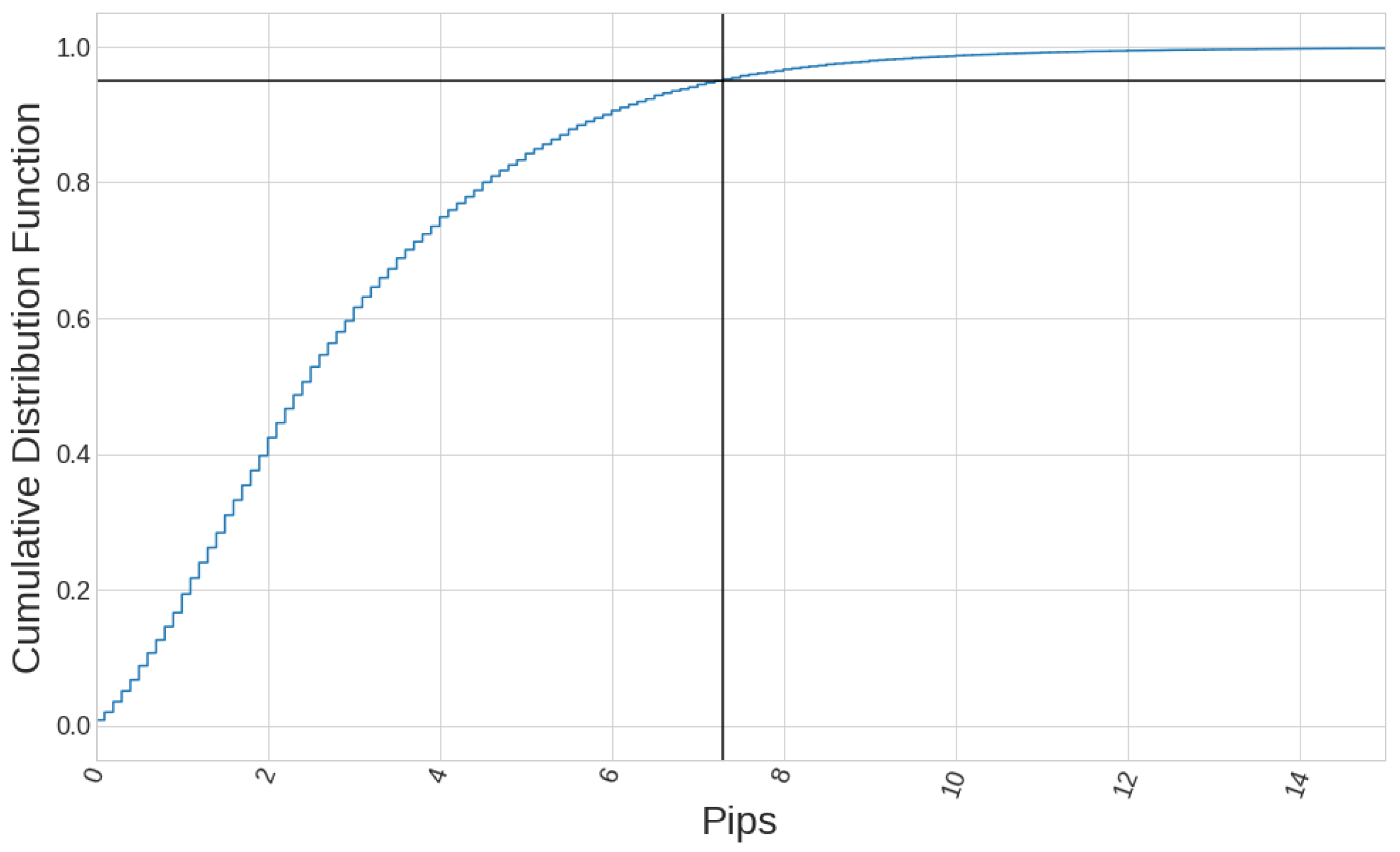
Figure 8.
The volatility of EURUSD in the 1-min timeframe experiences values above pips just of the time for the period considered.
Figure 8.
The volatility of EURUSD in the 1-min timeframe experiences values above pips just of the time for the period considered.
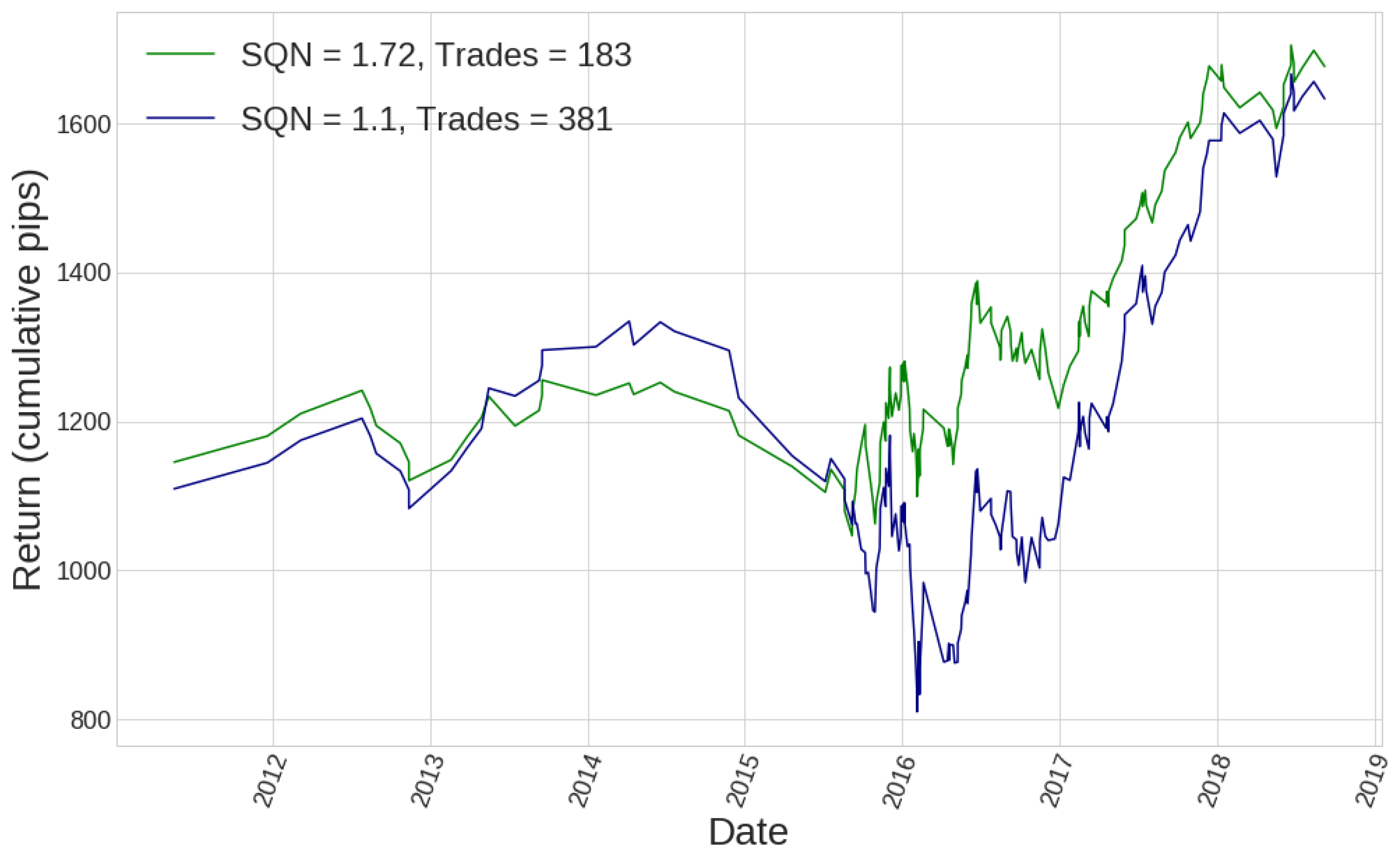
Figure 9.
Blue curve shows the out of sample equity curve arising from the optimal single candlestick pattern strategy. In green, we have the equity curve of the same strategy, where a AB classifier algorithm was used to define the signal for entering the market on the same training data used by the single candlestick pattern strategy.
Figure 9.
Blue curve shows the out of sample equity curve arising from the optimal single candlestick pattern strategy. In green, we have the equity curve of the same strategy, where a AB classifier algorithm was used to define the signal for entering the market on the same training data used by the single candlestick pattern strategy.
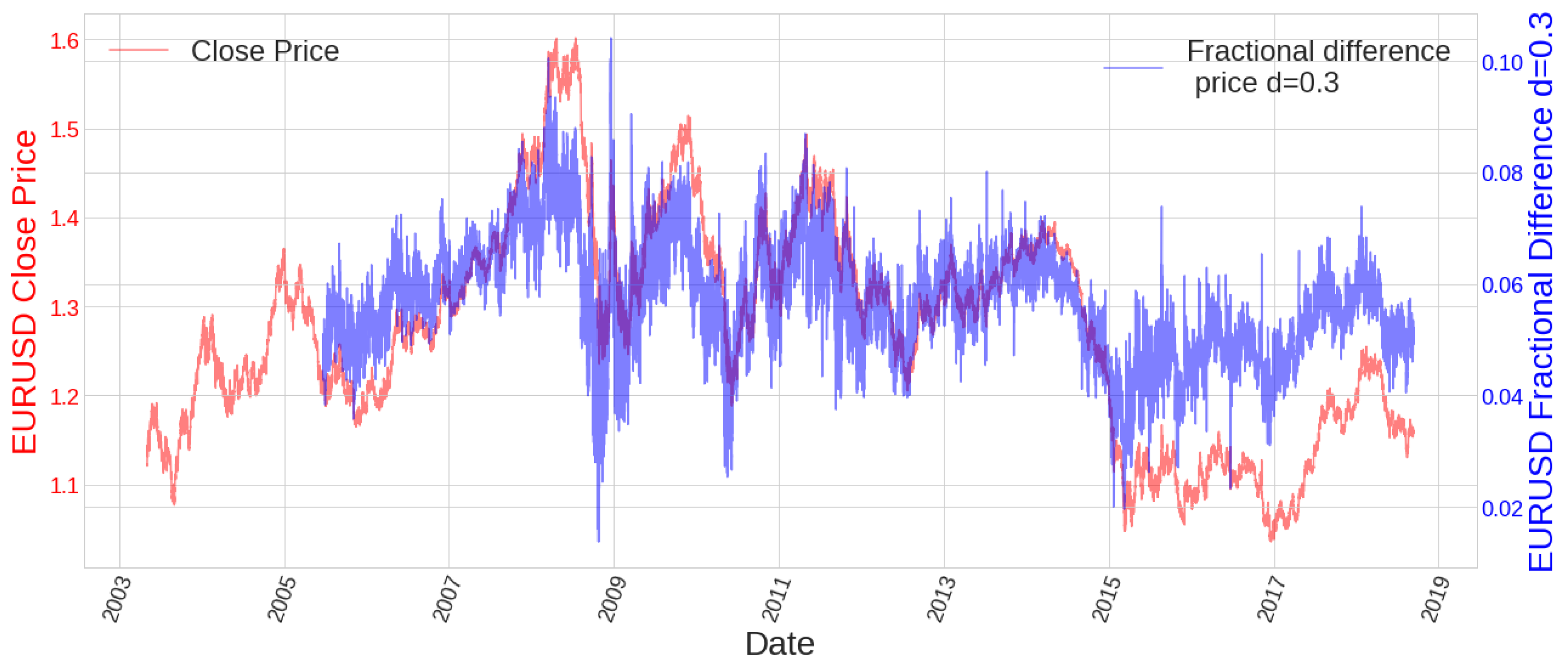
Figure 10.
The first two years of historical data are needed to compute the first value of the fractional difference. It can be seen how it is more stationary than the close price at the time it still preserves some memory since it is still correlated with the close price.
Figure 10.
The first two years of historical data are needed to compute the first value of the fractional difference. It can be seen how it is more stationary than the close price at the time it still preserves some memory since it is still correlated with the close price.
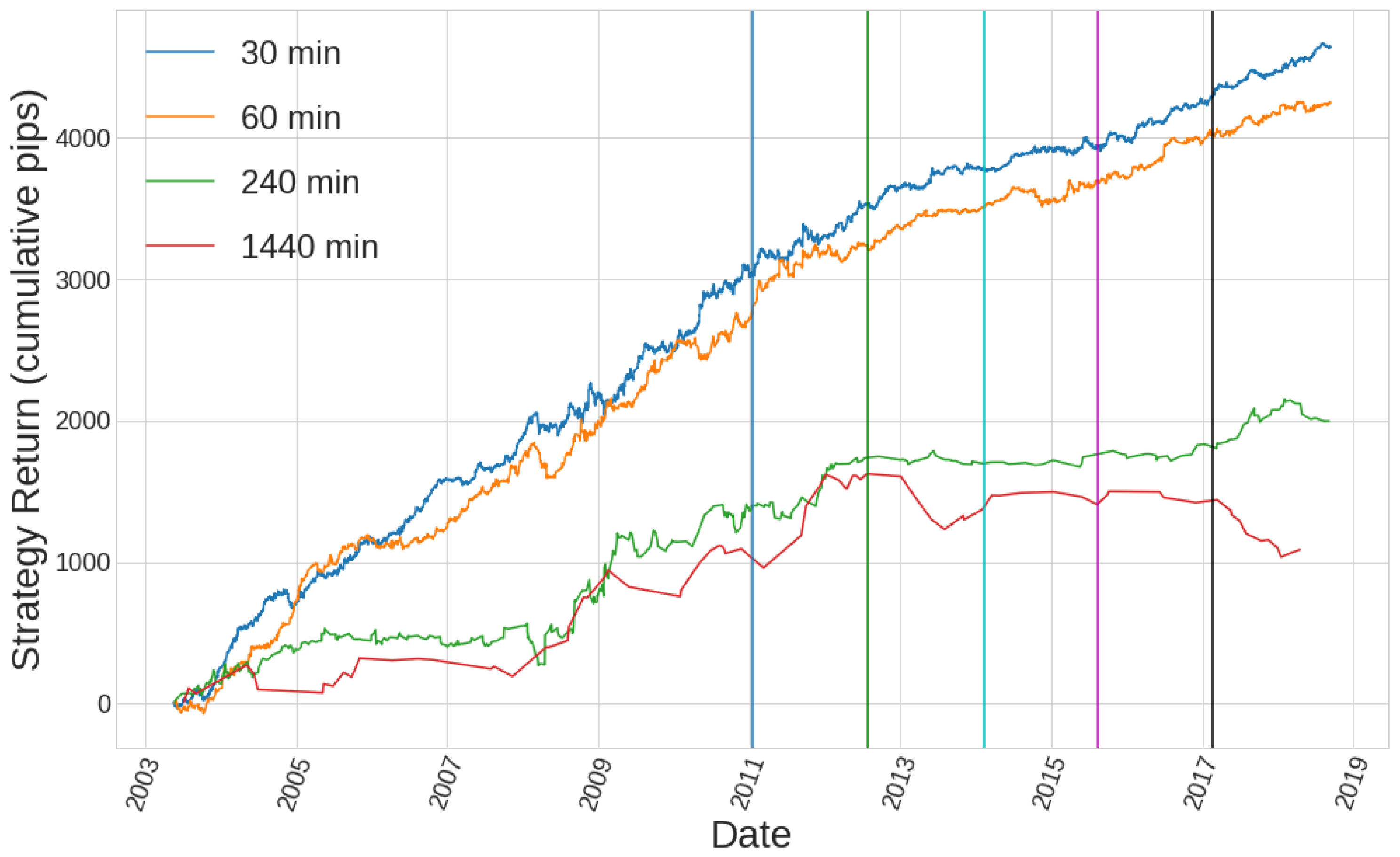
Figure 11.
Vertical lines are coloured for the beginning of each of the out of sample periods. It can be seen how the first half of the historical data coincides with the first in-sample period, while the second half coincides with the whole out-of-sample ensembled data.
Figure 11.
Vertical lines are coloured for the beginning of each of the out of sample periods. It can be seen how the first half of the historical data coincides with the first in-sample period, while the second half coincides with the whole out-of-sample ensembled data.
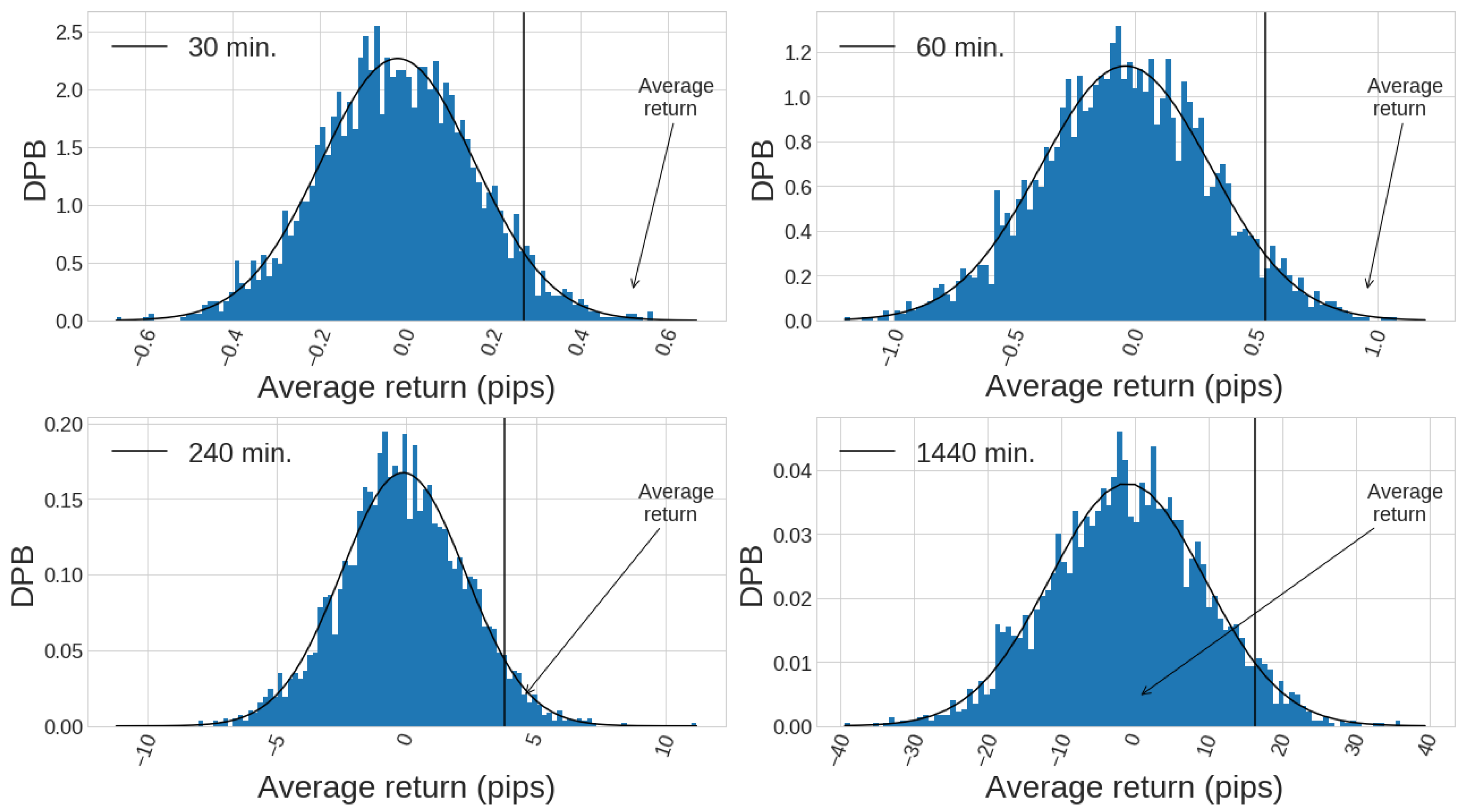
Figure 12.
Normalised histograms are shown for 3000 Monte Carlo distributions of average returns for each timeframe for the period considered (second half of the whole historical data, which is the total out of sample period). The y-axis represents the probability density function. A vertical line has been drawn for the quantile, to show which is the threshold above which a mean return is a reflection of predictive power. The mean return of each out-of-sample equity curves are marked in the figure with an arrow ( pips, pips, pips, pips).
Figure 12.
Normalised histograms are shown for 3000 Monte Carlo distributions of average returns for each timeframe for the period considered (second half of the whole historical data, which is the total out of sample period). The y-axis represents the probability density function. A vertical line has been drawn for the quantile, to show which is the threshold above which a mean return is a reflection of predictive power. The mean return of each out-of-sample equity curves are marked in the figure with an arrow ( pips, pips, pips, pips).
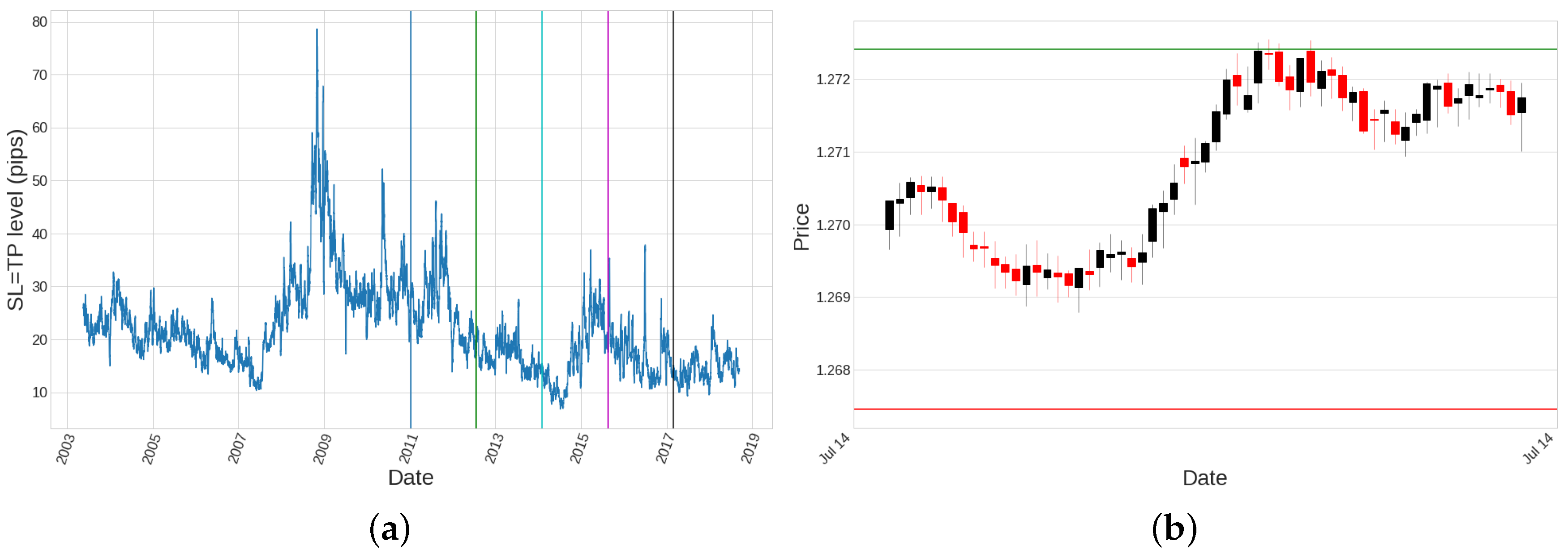
Figure 13.
(a) Average volatility for the 60-min timeframe experiences different periods during 2003–2018. Vertical lines have been drawn at the beginning of each out of sample period. This is the reason that, even though , the average amount of pips for the winning trades are not the same as the average amount of pips for the losing trades. (b) Example of a specific trade evolution in 1-min timeframe: it corresponds to candlestick ID 44, first out of sample period, timeframe of 60 min, operation number 1112, opened at the open price on 2010-07-14 at 09:00, and closed at 09:36, just when the high value of the price touched the TP level.
Figure 13.
(a) Average volatility for the 60-min timeframe experiences different periods during 2003–2018. Vertical lines have been drawn at the beginning of each out of sample period. This is the reason that, even though , the average amount of pips for the winning trades are not the same as the average amount of pips for the losing trades. (b) Example of a specific trade evolution in 1-min timeframe: it corresponds to candlestick ID 44, first out of sample period, timeframe of 60 min, operation number 1112, opened at the open price on 2010-07-14 at 09:00, and closed at 09:36, just when the high value of the price touched the TP level.
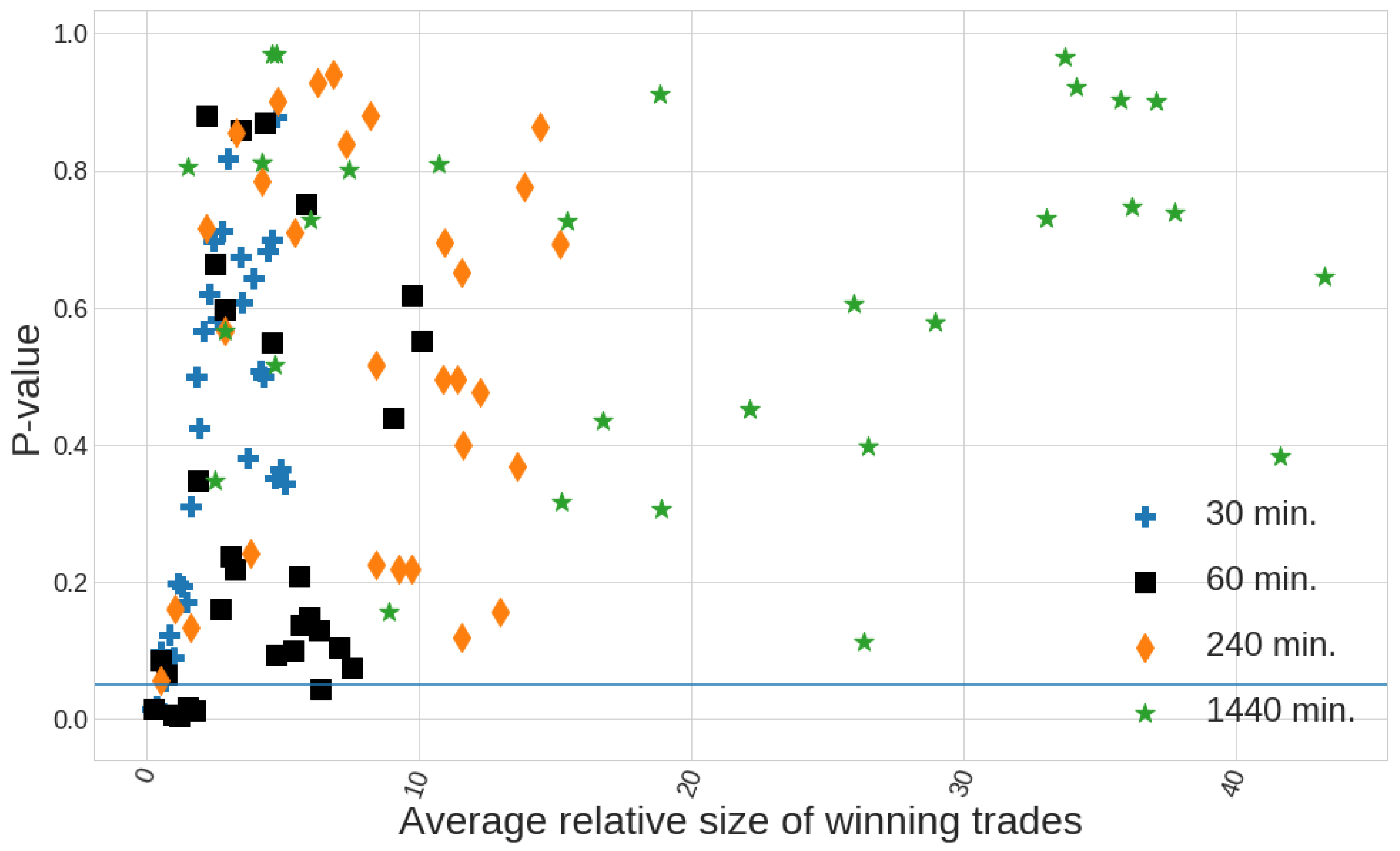
Figure 14.
A horizontal blue line is set at level, which defines the threshold for the p-values to be considered as statistically significant enough to reject the null hypothesis that the rule has no predictive power. The x-axis represents the average relative size of the winning trades, calculated as , being the mean return of the strategy analysed and the quantile for the volatility in the 1-min timeframe (which is equal to 7.3 pips). Values of this quotient close to 1 produces unreliable results.
Figure 14.
A horizontal blue line is set at level, which defines the threshold for the p-values to be considered as statistically significant enough to reject the null hypothesis that the rule has no predictive power. The x-axis represents the average relative size of the winning trades, calculated as , being the mean return of the strategy analysed and the quantile for the volatility in the 1-min timeframe (which is equal to 7.3 pips). Values of this quotient close to 1 produces unreliable results.
Figure 15.
The difference between the average winning pips per trade is clear, although they all follow similar curves due to similar choices of optimum candlestick patterns.
Figure 15.
The difference between the average winning pips per trade is clear, although they all follow similar curves due to similar choices of optimum candlestick patterns.
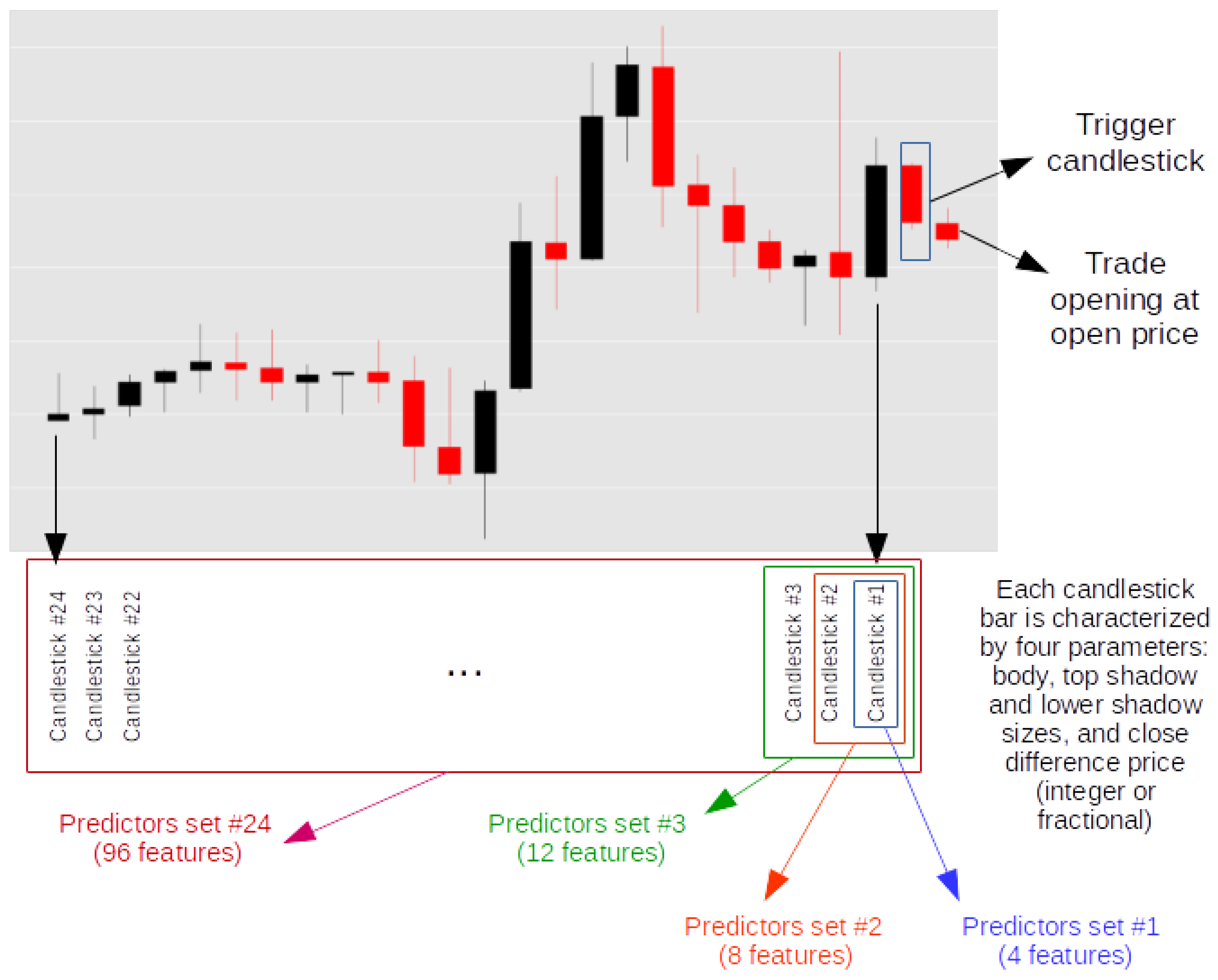
Figure 16.
Set of 24 feature subsets per feature set (A or B) per model (six models) per value of coefficient c.
Figure 16.
Set of 24 feature subsets per feature set (A or B) per model (six models) per value of coefficient c.
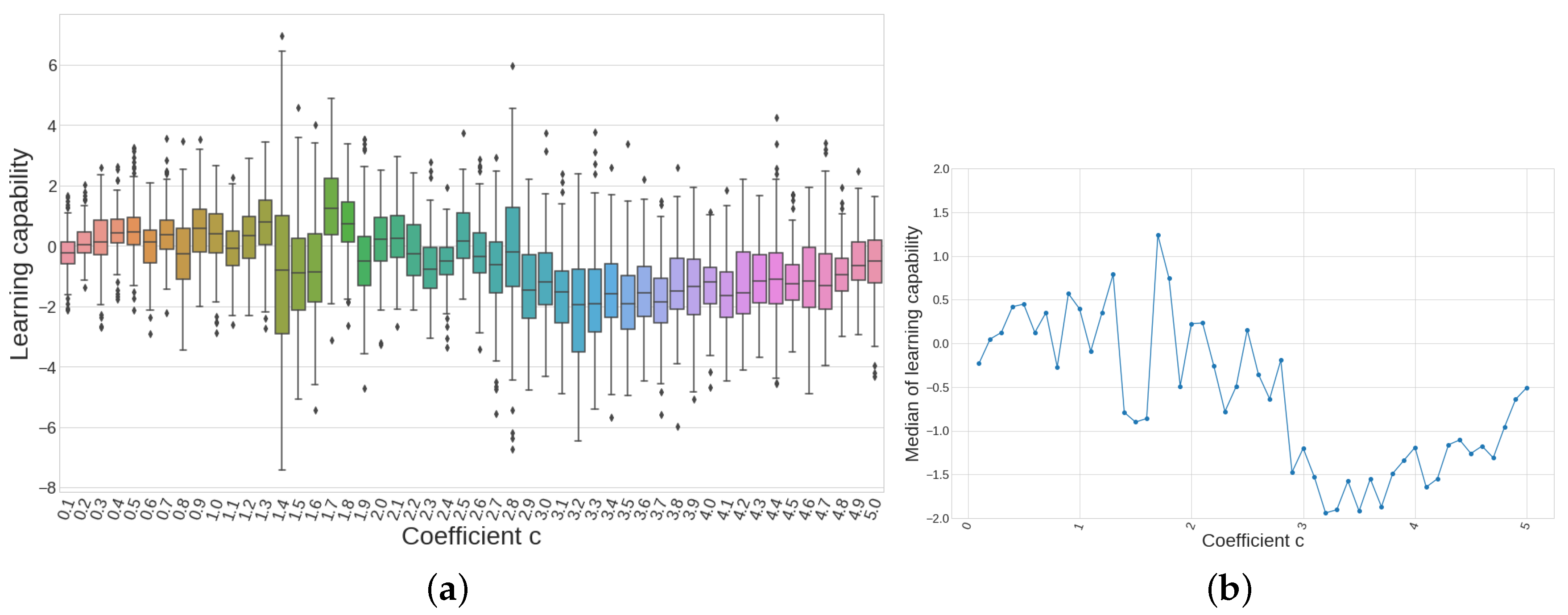
Figure 17.
(a) Although the variance of each boxplot is different, the median appears to have certain tendency, being below 0 for on; and (b) only coefficients below are considered.
Figure 17.
(a) Although the variance of each boxplot is different, the median appears to have certain tendency, being below 0 for on; and (b) only coefficients below are considered.
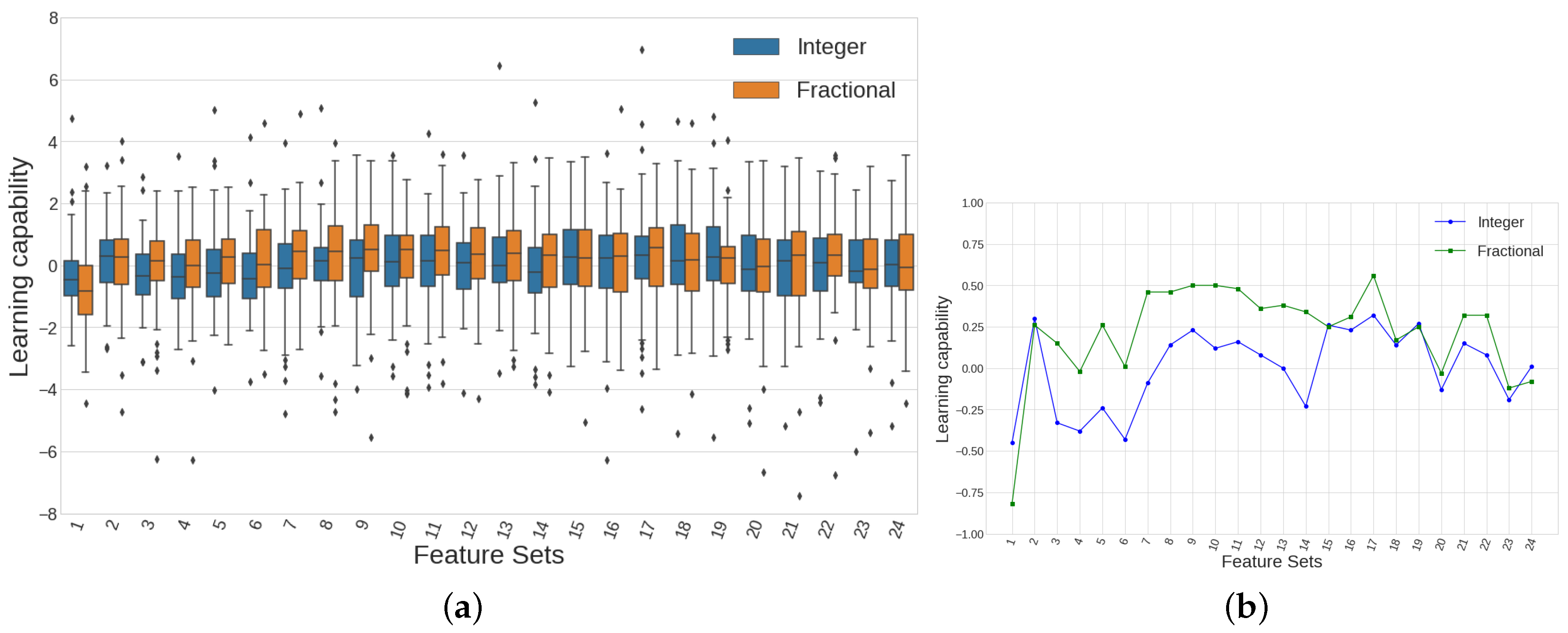
Figure 18.
(a) Learning capability boxplots show how those distributions where fractional differences have been used, present, mostly, higher values of first, second and third quartiles. (b) Line plots showing median values of learning capability offer a clearer representation where it can be easily seen that 19 out of 24 feature sets using fractional differences outperform the corresponding cases that use integer differences instead.
Figure 18.
(a) Learning capability boxplots show how those distributions where fractional differences have been used, present, mostly, higher values of first, second and third quartiles. (b) Line plots showing median values of learning capability offer a clearer representation where it can be easily seen that 19 out of 24 feature sets using fractional differences outperform the corresponding cases that use integer differences instead.
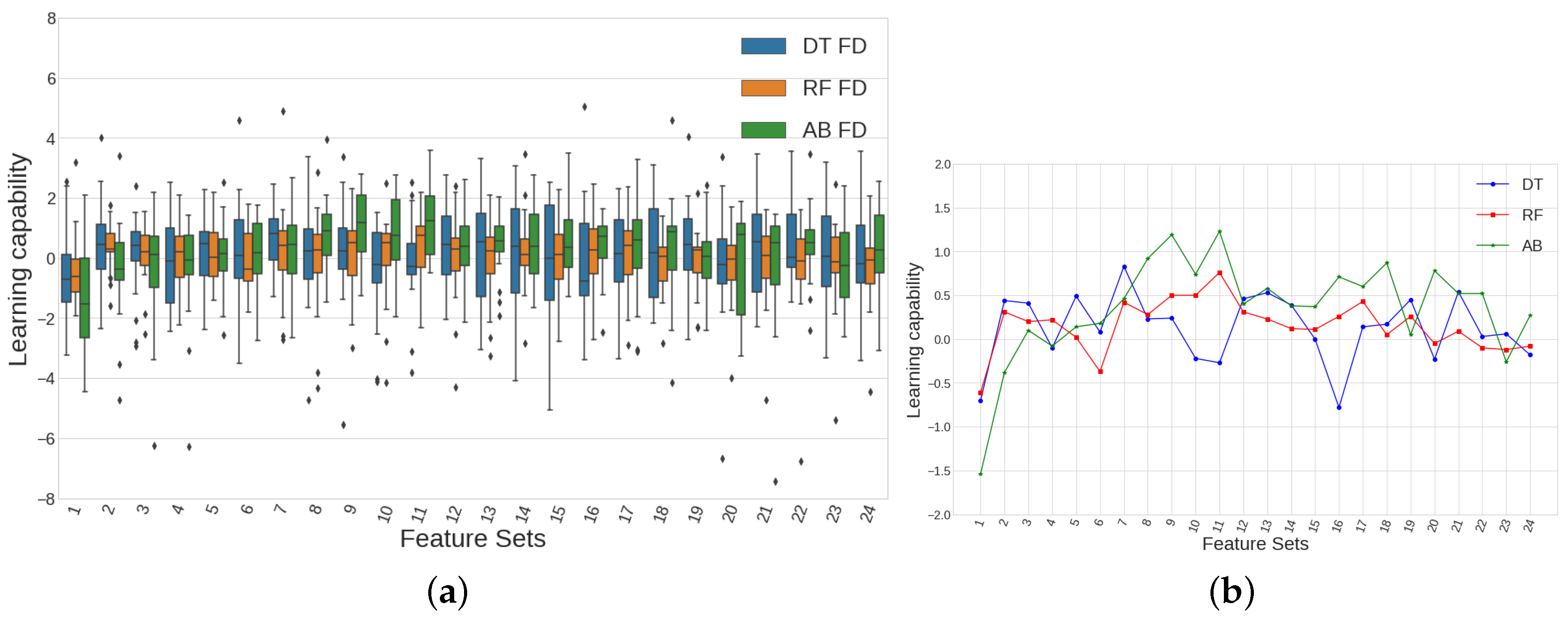
Figure 19.
(a) AdaBoost classifier performs better than RF and DT, possibly because it takes advantage of the fractional differences informative power in a more efficient way than the rest of the classifiers, since AdaBoost is based on one-predictor decision tree (the most informative one among all predictors given). (b) Line plots showing median values of learning capability show how the use of AB outperforms both DT and RF results in 13 out of 24 total feature sets.
Figure 19.
(a) AdaBoost classifier performs better than RF and DT, possibly because it takes advantage of the fractional differences informative power in a more efficient way than the rest of the classifiers, since AdaBoost is based on one-predictor decision tree (the most informative one among all predictors given). (b) Line plots showing median values of learning capability show how the use of AB outperforms both DT and RF results in 13 out of 24 total feature sets.
Table 1.
Rolling window size n shrinks as the timeframe expands.
Table 1.
Rolling window size n shrinks as the timeframe expands.
| Timeframe (min) | Rolling Window Size n |
|---|
| 30 | 240 |
| 60 | 120 |
| 240 | 30 |
| 1440 | 22 |
Table 2.
Trade returns of an hourly timeframe trading strategy and its
filtered version using AdaBoost classifier to learn which trades are profitable. Only the performance of the month of September is shown in this table.
Figure 9 shows both equity curves for all the out-of-sample data. Notice how the AB-filtered strategy shows 0 for the returns of all those trades which were predicted to yield negative returns and a non-zero value for all those trades which were predicted to yield positive returns. It can be seen that the prediction is not always good, since there are negative predictions for true positive returns and conversely.
Table 2.
Trade returns of an hourly timeframe trading strategy and its
filtered version using AdaBoost classifier to learn which trades are profitable. Only the performance of the month of September is shown in this table.
Figure 9 shows both equity curves for all the out-of-sample data. Notice how the AB-filtered strategy shows 0 for the returns of all those trades which were predicted to yield negative returns and a non-zero value for all those trades which were predicted to yield positive returns. It can be seen that the prediction is not always good, since there are negative predictions for true positive returns and conversely.
| Date of the Trade | Trade Returns of Base Strategy (Pips) | Trade Returns of AB-Filtered Strategy (Pips) |
|---|
| 2015-09-03 21:00:00 | −35.1 | 0 |
| 2015-09-07 11:00:00 | −33.2 | −33.2 |
| 2015-09-08 07:00:00 | 31.3 | 31.3 |
| 2015-09-08 16:00:00 | −29.8 | 0 |
| 2015-09-11 16:00:00 | −28.4 | 0 |
| 2015-09-15 11:00:00 | 28.5 | 28.5 |
| 2015-09-16 16:00:00 | −28.7 | 0 |
| 2015-09-18 12:00:00 | 28.5 | 28.5 |
| 2015-09-23 19:00:00 | −32.5 | 0 |
| 2015-09-24 14:00:00 | −33.9 | 0 |
| 2015-09-24 15:00:00 | −33.9 | 0 |
| 2015-09-25 13:00:00 | 33.3 | 0 |
| 2015-09-28 11:00:00 | 33.0 | 33.0 |
| TOTAL | −100.9 | 88.1 |
Table 3.
Results from a long-only strategy. Candlesticks IDs 1–27 are bullish, while Candlesticks IDs 28–54 are bearish. It is highlighted the best SQN-performing strategy, which corresponds to an entry condition defined by candlestick ID 40.
Table 3.
Results from a long-only strategy. Candlesticks IDs 1–27 are bullish, while Candlesticks IDs 28–54 are bearish. It is highlighted the best SQN-performing strategy, which corresponds to an entry condition defined by candlestick ID 40.
| ID | Body | TS | LS | Trades | Return | APpT | Drawdown | % W | % L | Winners | Losers | SQN |
|---|
| 1 | S | S | S | 64 | 194.75 | 3.04 | −34.52 | 35.94 | 64.06 | 11.43 | −11.66 | 1.56 |
| 2 | S | S | M | 385 | 87.52 | 0.23 | −164.86 | 45.45 | 54.55 | 9.18 | −7.23 | 0.31 |
| 3 | S | S | B | 342 | 36.55 | 0.11 | −282.31 | 48.83 | 51.17 | 10.61 | −9.92 | 0.12 |
| 4 | S | M | S | 366 | 38.73 | 0.11 | −240.14 | 50.55 | 49.45 | 8.45 | −8.42 | 0.16 |
| 5 | S | M | M | 1946 | 852.09 | 0.44 | −507.75 | 52.16 | 47.84 | 8.41 | −8.25 | 1.51 |
| 6 | S | M | B | 921 | 88.53 | 0.10 | −462.47 | 48.64 | 51.36 | 11.86 | −11.04 | 0.17 |
| 7 | S | B | S | 359 | 33.44 | 0.09 | −357.42 | 52.65 | 47.35 | 9.75 | −10.64 | 0.12 |
| 8 | S | B | M | 897 | −623.25 | −0.69 | −766.99 | 48.83 | 51.17 | 11.48 | −12.31 | −1.18 |
| 9 | S | B | B | 502 | 195.24 | 0.39 | −311.01 | 49.20 | 50.80 | 14.03 | −12.82 | 0.45 |
| 10 | M | S | S | 606 | −778.74 | −1.29 | −846.34 | 42.74 | 57.26 | 8.97 | −8.94 | −2.39 |
| 11 | M | S | M | 1514 | −651.90 | −0.43 | −1122.79 | 43.13 | 56.87 | 10.35 | −8.61 | −1.18 |
| 12 | M | S | B | 725 | −122.83 | −0.17 | −689.77 | 45.10 | 54.90 | 13.81 | −11.65 | −0.22 |
| 13 | M | M | S | 1911 | −268.29 | −0.14 | −1276.31 | 48.67 | 51.33 | 9.62 | −9.40 | −0.40 |
| 14 | M | M | M | 3245 | −907.66 | −0.28 | −1143.12 | 47.92 | 52.08 | 10.52 | −10.22 | −0.98 |
| 15 | M | M | B | 1240 | −572.40 | −0.46 | −909.52 | 45.48 | 54.52 | 14.06 | −12.58 | −0.82 |
| 16 | M | B | S | 1063 | 677.93 | 0.64 | −355.90 | 51.18 | 48.82 | 12.14 | −11.42 | 1.20 |
| 17 | M | B | M | 1337 | −890.17 | −0.67 | −1335.98 | 48.24 | 51.76 | 12.44 | −12.88 | −1.27 |
| 18 | M | B | B | 599 | −861.34 | −1.44 | −1223.49 | 46.91 | 53.09 | 15.50 | −16.41 | −1.46 |
| 19 | B | S | S | 522 | −319.08 | −0.61 | −588.77 | 39.46 | 60.54 | 13.51 | −9.82 | −0.83 |
| 20 | B | S | M | 704 | −1100.81 | −1.56 | −1516.04 | 40.77 | 59.23 | 13.76 | −12.11 | −2.11 |
| 21 | B | S | B | 296 | −703.52 | −2.38 | −752.88 | 41.22 | 58.78 | 14.66 | −14.32 | −1.98 |
| 22 | B | M | S | 1095 | −909.80 | −0.83 | −1335.43 | 44.29 | 55.71 | 13.55 | −12.27 | −1.42 |
| 23 | B | M | M | 1211 | 319.32 | 0.26 | −822.70 | 47.07 | 52.93 | 15.72 | −13.48 | 0.42 |
| 24 | B | M | B | 480 | 594.05 | 1.24 | −390.88 | 48.75 | 51.25 | 18.37 | −15.06 | 1.09 |
| 25 | B | B | S | 786 | 608.33 | 0.77 | −455.96 | 49.11 | 50.89 | 14.60 | −12.56 | 1.04 |
| 26 | B | B | M | 670 | 356.11 | 0.53 | −470.43 | 50.75 | 49.25 | 14.25 | −13.60 | 0.68 |
| 27 | B | B | B | 341 | 774.75 | 2.27 | −302.31 | 56.01 | 43.99 | 17.26 | −16.81 | 1.70 |
| 28 | S | S | S | 79 | −4.46 | −0.06 | −72.00 | 46.84 | 53.16 | 4.48 | −4.06 | −0.05 |
| 29 | S | S | M | 452 | −151.63 | −0.34 | −366.98 | 47.79 | 52.21 | 8.52 | −8.44 | −0.53 |
| 30 | S | S | B | 388 | −575.38 | −1.48 | −708.13 | 43.81 | 56.19 | 11.28 | −11.43 | −1.59 |
| 31 | S | M | S | 325 | −22.44 | −0.07 | −342.53 | 52.92 | 47.08 | 7.08 | −8.11 | −0.12 |
| 32 | S | M | M | 2041 | 282.42 | 0.14 | −722.18 | 51.64 | 48.36 | 8.42 | −8.71 | 0.47 |
| 33 | S | M | B | 994 | −1105.72 | −1.11 | −1480.98 | 47.18 | 52.82 | 11.98 | −12.80 | −1.77 |
| 34 | S | B | S | 337 | 383.86 | 1.14 | −209.93 | 55.49 | 44.51 | 10.44 | −10.46 | 1.24 |
| 35 | S | B | M | 972 | 572.19 | 0.59 | −319.46 | 50.41 | 49.59 | 12.42 | −11.44 | 1.00 |
| 36 | S | B | B | 495 | −581.96 | −1.18 | −663.13 | 48.08 | 51.92 | 14.04 | −15.26 | −1.23 |
| 37 | M | S | S | 545 | −10.10 | −0.02 | −211.02 | 53.58 | 46.42 | 8.22 | −9.53 | −0.03 |
| 38 | M | S | M | 1882 | 572.23 | 0.30 | −508.57 | 50.16 | 49.84 | 9.00 | −8.45 | 1.00 |
| 39 | M | S | B | 1020 | 133.36 | 0.13 | −733.85 | 52.35 | 47.65 | 11.14 | −11.97 | 0.24 |
| 40 | M | M | S | 1455 | 2717.64 | 1.87 | −249.93 | 59.24 | 40.76 | 9.24 | −8.86 | 5.34 |
| 41 | M | M | M | 3140 | 2157.72 | 0.69 | −513.82 | 54.17 | 45.83 | 10.65 | −11.09 | 2.19 |
| 42 | M | M | B | 1349 | 54.82 | 0.04 | −903.55 | 52.19 | 47.81 | 12.43 | −13.48 | 0.08 |
| 43 | M | B | S | 686 | 989.30 | 1.44 | −292.12 | 53.94 | 46.06 | 12.30 | −11.27 | 2.05 |
| 44 | M | B | M | 1206 | −1247.78 | −1.03 | −1387.62 | 49.17 | 50.83 | 12.90 | −14.52 | −1.76 |
| 45 | M | B | B | 567 | 440.79 | 0.78 | −441.16 | 53.62 | 46.38 | 14.78 | −15.41 | 0.87 |
| 46 | B | S | S | 577 | 38.78 | 0.07 | −548.94 | 53.73 | 46.27 | 11.30 | −12.97 | 0.09 |
| 47 | B | S | M | 998 | 69.38 | 0.07 | −529.02 | 54.46 | 45.54 | 11.86 | −14.00 | 0.11 |
| 48 | B | S | B | 715 | −107.02 | −0.15 | −456.95 | 49.93 | 50.07 | 13.53 | −13.79 | −0.21 |
| 49 | B | M | S | 723 | 1170.67 | 1.62 | −265.01 | 58.09 | 41.91 | 12.40 | −13.32 | 2.40 |
| 50 | B | M | M | 1092 | −241.49 | −0.22 | −789.93 | 55.40 | 44.60 | 12.60 | −16.15 | −0.35 |
| 51 | B | M | B | 641 | −965.07 | −1.51 | −1018.63 | 50.55 | 49.45 | 13.52 | −16.87 | −1.69 |
| 52 | B | B | S | 328 | 181.36 | 0.55 | −296.95 | 53.05 | 46.95 | 15.53 | −16.37 | 0.45 |
| 53 | B | B | M | 414 | 329.50 | 0.80 | −382.83 | 58.45 | 41.55 | 13.60 | −17.23 | 0.77 |
| 54 | B | B | B | 317 | −28.83 | −0.09 | −398.57 | 50.16 | 49.84 | 16.92 | −17.21 | −0.07 |
Table 4.
In-sample strategy results considering all different timeframes and all five in-sample periods. Each in-sample period comprises approximately eight years of data. The column says which candlestick performs best for that period of historical data, while the columns tells us whether we should go short-only or long-only to obtain the results shown.
Table 4.
In-sample strategy results considering all different timeframes and all five in-sample periods. Each in-sample period comprises approximately eight years of data. The column says which candlestick performs best for that period of historical data, while the columns tells us whether we should go short-only or long-only to obtain the results shown.
| IS Fold | TF | ID | Trades | Return | AppT | Drawdown | % W | % L | Winners | Losers | SQN | Direction |
|---|
| 1 | 30 | 11 | 3050 | 3040.34 | 1.00 | −3139.11 | 57.28 | 42.72 | 6.15 | −6.33 | 5.89 | Short |
| 2 | 30 | 11 | 3013 | 2807.62 | 0.93 | −2880.30 | 56.95 | 43.05 | 6.51 | −6.56 | 5.09 | Short |
| 3 | 30 | 40 | 2800 | 2700.37 | 0.96 | −314.93 | 58.04 | 41.96 | 6.37 | −6.51 | 4.81 | Long |
| 4 | 30 | 11 | 3000 | 2300.82 | 0.77 | −2324.61 | 56.80 | 43.20 | 6.36 | −6.19 | 4.25 | Short |
| 5 | 30 | 11 | 3059 | 2169.24 | 0.71 | −2180.44 | 57.14 | 42.86 | 5.31 | −5.23 | 4.69 | Short |
| 1 | 60 | 40 | 1455 | 2717.64 | 1.87 | −249.93 | 59.24 | 40.76 | 9.24 | −8.86 | 5.34 | Long |
| 2 | 60 | 40 | 1465 | 2677.83 | 1.83 | −249.93 | 58.57 | 41.43 | 9.68 | −9.27 | 4.93 | Long |
| 3 | 60 | 40 | 1452 | 2393.14 | 1.65 | −249.93 | 58.95 | 41.05 | 9.00 | −8.90 | 4.57 | Long |
| 4 | 60 | 40 | 1501 | 2001.11 | 1.33 | −249.93 | 56.70 | 43.30 | 8.81 | −8.46 | 3.84 | Long |
| 5 | 60 | 40 | 1555 | 1874.17 | 1.21 | −156.41 | 57.43 | 42.57 | 7.50 | −7.28 | 4.22 | Long |
| 1 | 240 | 22 | 295 | 1359.39 | 4.61 | −1409.79 | 53.56 | 46.44 | 22.81 | −28.38 | 2.06 | Short |
| 2 | 240 | 46 | 136 | 923.87 | 6.79 | −305.02 | 63.97 | 36.03 | 22.62 | −21.30 | 2.4 | Long |
| 3 | 240 | 3 | 105 | 793.52 | 7.56 | −158.21 | 57.14 | 42.86 | 27.95 | −19.64 | 2.26 | Long |
| 4 | 240 | 3 | 95 | 866.14 | 9.12 | −158.21 | 61.05 | 38.95 | 29.09 | −22.19 | 2.48 | Long |
| 5 | 240 | 24 | 126 | 925.59 | 7.35 | −168.14 | 54.76 | 45.24 | 27.26 | −16.76 | 2.68 | Long |
| 1 | 1440 | 46 | 36 | 1064.47 | 29.57 | −1118.44 | 52.78 | 47.22 | 42.19 | −93.78 | 1.93 | Short |
| 2 | 1440 | 46 | 41 | 1525.09 | 37.20 | −1547.60 | 56.10 | 43.90 | 41.16 | −98.52 | 2.46 | Short |
| 3 | 1440 | 12 | 39 | 1364.62 | 34.99 | −1407.49 | 71.79 | 28.21 | 52.85 | −69.50 | 2.42 | Short |
| 4 | 1440 | 9 | 34 | 1349.11 | 39.68 | −1562.74 | 73.53 | 26.47 | 74.85 | −80.91 | 2.5 | Short |
| 5 | 1440 | 22 | 57 | 1555.81 | 27.29 | −1839.28 | 70.18 | 29.82 | 49.52 | −59.94 | 2.76 | Short |
Table 5.
Results are better for those strategies with more trades. Each out of sample period runs for a period of over two years.
Table 5.
Results are better for those strategies with more trades. Each out of sample period runs for a period of over two years.
| OOS Fold | TF | ID | Trades | Return | APpT | Drawdown | % W | % L | Winners | Losers | SQN | Direction |
|---|
| 1 | 30 | 11 | 599 | 497.16 | 0.83 | −144.66 | 56.09 | 43.91 | 6.76 | −6.75 | 1.87 | Short |
| 2 | 30 | 11 | 600 | 231.56 | 0.39 | −58.79 | 57.83 | 42.17 | 3.85 | −4.37 | 1.56 | Short |
| 3 | 30 | 40 | 639 | 171.42 | 0.27 | −86.73 | 56.34 | 43.66 | 3.68 | −4.13 | 1.22 | Long |
| 4 | 30 | 11 | 623 | 367.27 | 0.59 | −80.85 | 55.38 | 44.62 | 4.24 | −3.94 | 2.55 | Short |
| 5 | 30 | 11 | 618 | 330.67 | 0.54 | −66.07 | 57.28 | 42.72 | 3.73 | −3.75 | 2.52 | Short |
| 1 | 60 | 40 | 279 | 519.40 | 1.86 | −122.35 | 54.12 | 45.88 | 11.57 | −9.59 | 1.90 | Long |
| 2 | 60 | 40 | 288 | 270.09 | 0.94 | −47.51 | 61.11 | 38.89 | 4.85 | −5.21 | 2.18 | Long |
| 3 | 60 | 40 | 365 | 191.63 | 0.53 | −136.47 | 54.25 | 45.75 | 5.59 | −5.48 | 1.21 | Long |
| 4 | 60 | 40 | 320 | 327.87 | 1.02 | −58.71 | 59.69 | 40.31 | 5.87 | −6.15 | 2.28 | Long |
| 5 | 60 | 40 | 349 | 225.55 | 0.65 | −76.52 | 57.59 | 42.41 | 5.56 | −6.02 | 1.45 | Long |
| 1 | 240 | 22 | 46 | 376.48 | 8.18 | −117.59 | 54.35 | 45.65 | 29.97 | −17.75 | 1.76 | Short |
| 2 | 240 | 46 | 23 | −33.74 | −1.47 | −94.31 | 43.48 | 56.52 | 13.43 | −12.92 | −0.44 | Long |
| 3 | 240 | 3 | 13 | 39.78 | 3.06 | −47.50 | 61.54 | 38.46 | 15.64 | −17.06 | 0.49 | Long |
| 4 | 240 | 3 | 20 | 77.67 | 3.88 | −69.42 | 60 | 40 | 18.46 | −17.99 | 0.72 | Long |
| 5 | 240 | 24 | 39 | 177.53 | 4.55 | −155.82 | 64.10 | 35.90 | 18.80 | −20.89 | 0.98 | Long |
| 1 | 1440 | 46 | 11 | 559.81 | 50.89 | −104.92 | 63.64 | 36.36 | 113.61 | −58.87 | 1.44 | Short |
| 2 | 1440 | 46 | 8 | −253.84 | −31.73 | −393.19 | 25 | 75 | 83.98 | −70.30 | −1.09 | Short |
| 3 | 1440 | 12 | 6 | 36.60 | 6.10 | −89.53 | 50 | 50 | 42.58 | −30.38 | 0.30 | Short |
| 4 | 1440 | 9 | 5 | 13.61 | 2.722 | −78.75 | 40 | 60 | 46.18 | −26.25 | 0.15 | Short |
| 5 | 1440 | 22 | 11 | −333.19 | −30.29 | −403.24 | 36.36 | 63.64 | 19.21 | −58.57 | −1.97 | Short |
Table 6.
The highest timeframe is not profitable out of sample. values are better for lower timeframes, where we have more trades. However, the APpT is smaller in these cases. The APpT shown here is the weighted average of the APpT, whose weights are the number of trades at each out of sample period.
Table 6.
The highest timeframe is not profitable out of sample. values are better for lower timeframes, where we have more trades. However, the APpT is smaller in these cases. The APpT shown here is the weighted average of the APpT, whose weights are the number of trades at each out of sample period.
| TF | Trades | Return | APpT | Drawdown | % W | % L | Winners | Losers | SQN | WFA Eff. |
|---|
| 30 | 3066 | 1618.59 | 0.52 | −144.66 | 56.62 | 43.38 | 4.42 | −4.56 | 4.20 | 0.53 |
| 60 | 1595 | 1444.14 | 0.96 | −136.47 | 57.24 | 42.76 | 6.39 | −6.44 | 3.69 | 0.53 |
| 240 | 138 | 597.91 | 4.52 | −155.82 | 55.80 | 44.20 | 21.56 | −17.42 | 1.90 | 0.44 |
| 1440 | 41 | 22.99 | 0.56 | −587.69 | 43.90 | 56.10 | 70.01 | −53.79 | 0.05 | 0.02 |
Table 7.
The highest timeframe is the only one exhibiting no predictive power at all. However, taking into account transaction costs of one pip per trade (taken as an average for the whole period ranging from 2003 to 2018), we see the net predictive power component of all four strategies is below 0, which makes them all unprofitable to trade.
Table 7.
The highest timeframe is the only one exhibiting no predictive power at all. However, taking into account transaction costs of one pip per trade (taken as an average for the whole period ranging from 2003 to 2018), we see the net predictive power component of all four strategies is below 0, which makes them all unprofitable to trade.
| TF | 95% Quantile | Avg. Return | p-Value | PP Component | Net PP Component |
|---|
| 30 | 0.27 | 0.52 | 0.00104 | 0.25 | −0.75 |
| 60 | 0.53 | 0.96 | 0.00199 | 0.43 | −0.57 |
| 240 | 3.80 | 4.52 | 0.02615 | 0.72 | −0.28 |
| 1440 | 10.96 | 0.56 | 0.44465 | −10.4 | −11.4 |
Table 8.
Coefficient c and respective p-values for timeframes of 30 and 60 min. Those strategies which present p-values lower than have been highlighted.
Table 8.
Coefficient c and respective p-values for timeframes of 30 and 60 min. Those strategies which present p-values lower than have been highlighted.
| TF | c | Avg. Winners | q | p-Value |
|---|
| 30 | 0.1 | 1.45 | 0.20 | 0.0161 |
| 30 | 0.2 | 2.58 | 0.35 | 0.0192 |
| 30 | 0.3 | 3.53 | 0.48 | 0.0974 |
| 30 | 0.4 | 4.62 | 0.63 | 0.0572 |
| 30 | 0.5 | 5.89 | 0.81 | 0.1244 |
| 30 | 0.6 | 7.07 | 0.97 | 0.0909 |
| 30 | 0.7 | 8.27 | 1.13 | 0.1983 |
| 30 | 0.8 | 9.28 | 1.27 | 0.1936 |
| 30 | 0.9 | 10.72 | 1.47 | 0.1718 |
| 30 | 1.0 | 11.86 | 1.62 | 0.3113 |
| 30 | 1.1 | 13.08 | 1.79 | 0.4994 |
| 30 | 1.2 | 14.04 | 1.92 | 0.4241 |
| 30 | 1.3 | 15.13 | 2.07 | 0.5660 |
| 30 | 1.4 | 16.57 | 2.27 | 0.6212 |
| 30 | 1.5 | 17.84 | 2.44 | 0.6977 |
| 30 | 1.6 | 18.97 | 2.60 | 0.5822 |
| 30 | 1.7 | 20.11 | 2.75 | 0.7112 |
| 30 | 1.8 | 21.49 | 2.94 | 0.8171 |
| 30 | 1.9 | 26.93 | 3.69 | 0.3816 |
| 30 | 2.0 | 25.38 | 3.48 | 0.6070 |
| 30 | 2.1 | 24.92 | 3.41 | 0.6747 |
| 30 | 2.2 | 31.03 | 4.25 | 0.4991 |
| 30 | 2.3 | 28.68 | 3.93 | 0.6425 |
| 30 | 2.4 | 30.35 | 4.16 | 0.5080 |
| 30 | 2.5 | 32.26 | 4.42 | 0.6830 |
| 30 | 2.6 | 33.46 | 4.58 | 0.7002 |
| 30 | 2.7 | 34.58 | 4.74 | 0.8786 |
| 30 | 2.8 | 34.39 | 4.71 | 0.3523 |
| 30 | 2.9 | 35.63 | 4.88 | 0.3642 |
| 30 | 3.0 | 36.86 | 5.05 | 0.3431 |
| 60 | 0.1 | 1.75 | 0.24 | 0.0152 |
| 60 | 0.2 | 3.48 | 0.48 | 0.0861 |
| 60 | 0.3 | 5.11 | 0.70 | 0.0661 |
| 60 | 0.4 | 7.17 | 0.98 | 0.0062 |
| 60 | 0.5 | 8.52 | 1.17 | 0.0041 |
| 60 | 0.6 | 10.83 | 1.48 | 0.0180 |
| 60 | 0.7 | 12.68 | 1.74 | 0.0139 |
| 60 | 0.8 | 13.76 | 1.88 | 0.3473 |
| 60 | 0.9 | 16.03 | 2.20 | 0.8804 |
| 60 | 1.0 | 18.27 | 2.50 | 0.6650 |
| 60 | 1.1 | 19.83 | 2.72 | 0.1612 |
| 60 | 1.2 | 22.26 | 3.05 | 0.2385 |
| 60 | 1.3 | 24.98 | 3.42 | 0.8589 |
| 60 | 1.4 | 21.00 | 2.88 | 0.5970 |
| 60 | 1.5 | 23.64 | 3.24 | 0.2192 |
| 60 | 1.6 | 33.46 | 4.58 | 0.5500 |
| 60 | 1.7 | 31.50 | 4.32 | 0.8700 |
| 60 | 1.8 | 34.67 | 4.75 | 0.0935 |
| 60 | 1.9 | 40.79 | 5.59 | 0.2081 |
| 60 | 2.0 | 39.14 | 5.36 | 0.1011 |
| 60 | 2.1 | 41.11 | 5.63 | 0.1385 |
| 60 | 2.2 | 43.61 | 5.97 | 0.1480 |
| 60 | 2.3 | 46.53 | 6.37 | 0.0438 |
| 60 | 2.4 | 46.22 | 6.33 | 0.1293 |
| 60 | 2.5 | 51.43 | 7.05 | 0.1044 |
| 60 | 2.6 | 54.75 | 7.50 | 0.0759 |
| 60 | 2.7 | 65.82 | 9.02 | 0.4392 |
| 60 | 2.8 | 42.60 | 5.84 | 0.7518 |
| 60 | 2.9 | 70.84 | 9.70 | 0.6184 |
| 60 | 3.0 | 73.49 | 10.07 | 0.5522 |
Table 9.
Coefficient c and respective p-values for timeframes of 240 and 1440 min.
Table 9.
Coefficient c and respective p-values for timeframes of 240 and 1440 min.
| TF | c | Avg. Winners | q | p-Value |
|---|
| 240 | 0.1 | 3.78 | 0.52 | 0.0575 |
| 240 | 0.2 | 7.36 | 1.01 | 0.1607 |
| 240 | 0.3 | 11.65 | 1.60 | 0.1346 |
| 240 | 0.4 | 15.96 | 2.19 | 0.7167 |
| 240 | 0.5 | 21.01 | 2.88 | 0.5670 |
| 240 | 0.6 | 24.09 | 3.30 | 0.8562 |
| 240 | 0.7 | 27.89 | 3.82 | 0.2424 |
| 240 | 0.8 | 31.00 | 4.25 | 0.7848 |
| 240 | 0.9 | 35.12 | 4.81 | 0.9021 |
| 240 | 1.0 | 39.65 | 5.43 | 0.7098 |
| 240 | 1.1 | 45.86 | 6.28 | 0.9286 |
| 240 | 1.2 | 50.13 | 6.87 | 0.9409 |
| 240 | 1.3 | 53.55 | 7.34 | 0.8391 |
| 240 | 1.4 | 61.50 | 8.42 | 0.5173 |
| 240 | 1.5 | 59.74 | 8.18 | 0.8813 |
| 240 | 1.6 | 61.50 | 8.42 | 0.2253 |
| 240 | 1.7 | 67.59 | 9.26 | 0.2198 |
| 240 | 1.8 | 71.14 | 9.74 | 0.2185 |
| 240 | 1.9 | 79.78 | 10.93 | 0.6953 |
| 240 | 2.0 | 79.35 | 10.87 | 0.4967 |
| 240 | 2.1 | 83.15 | 11.39 | 0.4953 |
| 240 | 2.2 | 84.54 | 11.58 | 0.1189 |
| 240 | 2.3 | 84.87 | 11.63 | 0.4004 |
| 240 | 2.4 | 84.53 | 11.58 | 0.6516 |
| 240 | 2.5 | 89.38 | 12.24 | 0.4776 |
| 240 | 2.6 | 99.29 | 13.60 | 0.3688 |
| 240 | 2.7 | 94.68 | 12.97 | 0.1558 |
| 240 | 2.8 | 101.20 | 13.86 | 0.7767 |
| 240 | 2.9 | 105.36 | 14.43 | 0.8629 |
| 240 | 3.0 | 110.91 | 15.19 | 0.6926 |
| 1440 | 0.1 | 10.86 | 1.49 | 0.8065 |
| 1440 | 0.2 | 18.08 | 2.48 | 0.3485 |
| 1440 | 0.3 | 20.80 | 2.85 | 0.5669 |
| 1440 | 0.4 | 31.00 | 4.25 | 0.8112 |
| 1440 | 0.5 | 43.90 | 6.01 | 0.7293 |
| 1440 | 0.6 | 34.17 | 4.68 | 0.5168 |
| 1440 | 0.7 | 54.25 | 7.43 | 0.8019 |
| 1440 | 0.8 | 64.97 | 8.90 | 0.1563 |
| 1440 | 0.9 | 78.36 | 10.73 | 0.8100 |
| 1440 | 1.0 | 112.78 | 15.45 | 0.7266 |
| 1440 | 1.1 | 110.98 | 15.20 | 0.3174 |
| 1440 | 1.2 | 122.24 | 16.75 | 0.4344 |
| 1440 | 1.3 | 138.03 | 18.91 | 0.3059 |
| 1440 | 1.4 | 137.56 | 18.84 | 0.9115 |
| 1440 | 1.5 | 161.46 | 22.12 | 0.4516 |
| 1440 | 1.6 | 189.48 | 25.96 | 0.6051 |
| 1440 | 1.7 | 192.25 | 26.34 | 0.1127 |
| 1440 | 1.8 | 193.18 | 26.46 | 0.3974 |
| 1440 | 1.9 | 211.36 | 28.95 | 0.5791 |
| 1440 | 2.0 | 315.89 | 43.27 | 0.6448 |
| 1440 | 2.1 | 241.24 | 33.05 | 0.7302 |
| 1440 | 2.2 | 303.94 | 41.64 | 0.3843 |
| 1440 | 2.3 | 264.22 | 36.19 | 0.7464 |
| 1440 | 2.4 | 275.70 | 37.77 | 0.7394 |
| 1440 | 2.5 | 249.27 | 34.15 | 0.9230 |
| 1440 | 2.6 | 246.00 | 33.70 | 0.9654 |
| 1440 | 2.7 | 260.96 | 35.75 | 0.9023 |
| 1440 | 2.8 | 270.62 | 37.07 | 0.9004 |
| 1440 | 2.9 | 33.53 | 4.59 | 0.9694 |
| 1440 | 3.0 | 34.69 | 4.75 | 0.9703 |
Table 10.
It can be seen that the vector comprising the optimum sequence of candlestick patterns is very similar for coefficient values which are very close.
Table 10.
It can be seen that the vector comprising the optimum sequence of candlestick patterns is very similar for coefficient values which are very close.
| c | OOS Fold | ID | Trades | Return | AppT | DD | % W | % L | Winners | Losers | SQN | Direction |
|---|
| 0.5 | 1 | 19 | 99 | 257.88 | 2.6 | −41.74 | 59.6 | 40.4 | 12.83 | −12.47 | 2.03 | Short |
| 0.5 | 2 | 40 | 285 | 469.07 | 1.65 | −70.47 | 59.65 | 40.35 | 8.45 | −8.41 | 3.32 | Long |
| 0.5 | 3 | 40 | 358 | 271.33 | 0.76 | −108.6 | 54.75 | 45.25 | 8.44 | −8.54 | 1.57 | Long |
| 0.5 | 4 | 40 | 313 | 766.4 | 2.45 | −62.69 | 63.26 | 36.74 | 8.72 | −8.34 | 5.06 | Long |
| 0.5 | 5 | 40 | 341 | 333.44 | 0.98 | −58.58 | 57.18 | 42.82 | 7.21 | −7.34 | 2.48 | Long |
| 0.6 | 1 | 40 | 277 | 371.4 | 1.34 | −137.08 | 54.15 | 45.85 | 15.51 | −15.4 | 1.41 | Long |
| 0.6 | 2 | 40 | 285 | 303.56 | 1.07 | −182.34 | 55.44 | 44.56 | 10.08 | −10.15 | 1.77 | Long |
| 0.6 | 3 | 40 | 358 | 472.73 | 1.32 | −159.05 | 55.87 | 44.13 | 10.29 | −10.04 | 2.3 | Long |
| 0.6 | 4 | 40 | 313 | 685.48 | 2.19 | −86.92 | 59.74 | 40.26 | 10.45 | −10.07 | 3.7 | Long |
| 0.6 | 5 | 40 | 341 | 238.46 | 0.7 | −88.5 | 54.84 | 45.16 | 8.59 | −8.88 | 1.47 | Long |
| 0.7 | 1 | 40 | 277 | 505.22 | 1.82 | −157.26 | 54.87 | 45.13 | 18.1 | −17.96 | 1.64 | Long |
| 0.7 | 2 | 40 | 285 | 304.07 | 1.07 | −172.46 | 54.74 | 45.26 | 11.75 | −11.86 | 1.51 | Long |
| 0.7 | 3 | 40 | 358 | 455.07 | 1.27 | −268.3 | 53.91 | 46.09 | 12.19 | −11.5 | 1.89 | Long |
| 0.7 | 4 | 40 | 313 | 853.25 | 2.73 | −104.73 | 60.38 | 39.62 | 12.2 | −11.72 | 3.96 | Long |
| 0.7 | 5 | 40 | 341 | 218.28 | 0.64 | −158.26 | 53.96 | 46.04 | 10.02 | −10.35 | 1.15 | Long |
| 2.3 | 1 | 38 | 399 | 1482.19 | 3.71 | −1230.44 | 51.13 | 48.87 | 62.61 | −57.9 | 1.2 | Long |
| 2.3 | 2 | 38 | 439 | 1918.11 | 4.37 | −1145.19 | 56.26 | 43.74 | 38.76 | −39.87 | 2.32 | Long |
| 2.3 | 3 | 4 | 146 | −194.24 | −1.33 | −430.41 | 47.26 | 52.74 | 41.32 | −39.55 | −0.37 | Long |
| 2.3 | 4 | 23 | 251 | 212.11 | 0.85 | −558.16 | 51 | 49 | 38.62 | −38.46 | 0.34 | Short |
| 2.3 | 5 | 1 | 21 | 152.01 | 7.24 | −96.85 | 61.9 | 38.1 | 34.43 | −36.95 | 0.94 | Short |
Table 11.
Columns
Return,
APpT,
% W,
% L,
Winners,
Losers,
SQN are calculated as a weighted average of the corresponding values shown in
Table 10, being the column
Trades the weights employed.
Table 11.
Columns
Return,
APpT,
% W,
% L,
Winners,
Losers,
SQN are calculated as a weighted average of the corresponding values shown in
Table 10, being the column
Trades the weights employed.
| c | Trades | Return | AppT | Drawdown | % W | % L | Winners | Losers | SQN |
|---|
| 0.5 | 1396 | 2098.12 | 1.50 | −108.60 | 58.60 | 41.40 | 8.52 | −8.45 | 2.96 |
| 0.6 | 1574 | 2071.63 | 1.32 | −182.34 | 56.04 | 43.96 | 10.83 | −10.76 | 2.15 |
| 0.7 | 1574 | 2335.89 | 1.48 | −268.30 | 55.53 | 44.47 | 12.68 | −12.50 | 2.03 |
| 2.3 | 1256 | 3570.18 | 2.84 | −1.230.44 | 52.63 | 47.37 | 46.53 | −45.23 | 1.23 |
Table 12.
None of the strategies selected show positive net predictive power after considering one pip per trade as an approximation for transaction costs.
Table 12.
None of the strategies selected show positive net predictive power after considering one pip per trade as an approximation for transaction costs.
| c | 95% Quantile | APpT | p-Value | PP Component | Net PP Component |
|---|
| 0.5 | 0.95 | 1.50 | 0.00413 | 0.55 | −0.45 |
| 0.6 | 0.99 | 1.32 | 0.01812 | 0.33 | −0.67 |
| 0.7 | 1.1 | 1.48 | 0.01391 | 0.38 | −0.62 |
| 2.3 | 2.76 | 2.84 | 0.04379 | 0.08 | −0.92 |
Table 13.
Predictors Sets 1–24 use integer difference close price as the last feature for each candlestick, while Predictors Sets 25–48 use fractional difference close prices instead.
Table 13.
Predictors Sets 1–24 use integer difference close price as the last feature for each candlestick, while Predictors Sets 25–48 use fractional difference close prices instead.
| Model ID | Model Name | c | Predictors Set |
|---|
| 1 | Decision Tree | 0.1 | 1 |
| 2 | | | 2 |
| ⋮ | | | ⋮ |
| 48 | | | 48 |
| 49 | | 0.2 | 1 |
| 50 | | | 2 |
| ⋮ | | | ⋮ |
| 96 | | | 48 |
| | ⋮ | ⋮ |
| 2353 | | 5 | 1 |
| 2354 | | | 2 |
| | | ⋮ |
| 2400 | | | 48 |
| 2401 | Random Forest | 0.1 | 1 |
| 2402 | | | 2 |
| ⋮ | | | ⋮ |
| 2448 | | | 48 |
| 2449 | | 0.2 | 1 |
| 2450 | | | 2 |
| ⋮ | | | ⋮ |
| 2496 | | | 48 |
| | ⋮ | ⋮ |
| 4753 | | 5 | 1 |
| 4754 | | | 2 |
| | | ⋮ |
| 4800 | | | 48 |
| 4801 | AdaBoost | 0.1 | 1 |
| 4802 | | | 2 |
| ⋮ | | | ⋮ |
| 4848 | | | 48 |
| 4849 | | 0.2 | 1 |
| 4850 | | | 2 |
| ⋮ | | | ⋮ |
| 4896 | | | 48 |
| | ⋮ | ⋮ |
| 7153 | | 5 | 1 |
| 7154 | | | 2 |
| | | ⋮ |
| 7200 | | | 48 |






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}