Principle of Duality in Cubic Smoothing Spline


Abstract
1. Introduction
2. Preliminaries
2.1. Notations
2.2. Key Preliminary Results
- (i)
- can be factorized as .
- (ii)
- We have the following inequalities:
- (i)
- Let be an n-dimensional column vector. Then, by definition of , it follows thatwhich leads to .
- (ii)
- The first inequality follows by applying the Gershgorin circle theorem and the second inequality holds from for .
- (i)
- equals and
- (ii)
- equals .
- (i)
- Given that for , both and are of full column rank. In addition, is a square matrix. Thus, if , then it follows that . From , we have . Likewise, from and , we obtain . Accordingly, we have , which completes the proof.
- (ii)
- Recall that . It is clear that is a full-column-rank matrix such that is a square matrix. In addition, . Thus, it follows that .
- (i)
- equals and
- (ii)
- equals .
- (i)
- equals ,
- (ii)
- equals , and
- (iii)
- equals .
- (i)
- equals and
- (ii)
- equals .
- (i)
- ,
- (ii)
- ,
- (iii)
- both and are nonsingular, and
- (iv)
- .
3. Several Regressions Relating to (6) and Principle of Duality in Them
3.1. Penalized Regressions to Compute
3.2. Penalized Regressions to Compute
3.3. Penalized Regressions to Compute
3.4. Penalized Regression to Compute
3.5. Ordinary Regressions to Compute and
- (i)
- Let , whereThen, it follows that
- (ii)
- It follows that , where
3.6. Principle of Duality in the Penalized Regressions
4. Results That Are Obtainable from the Regressions
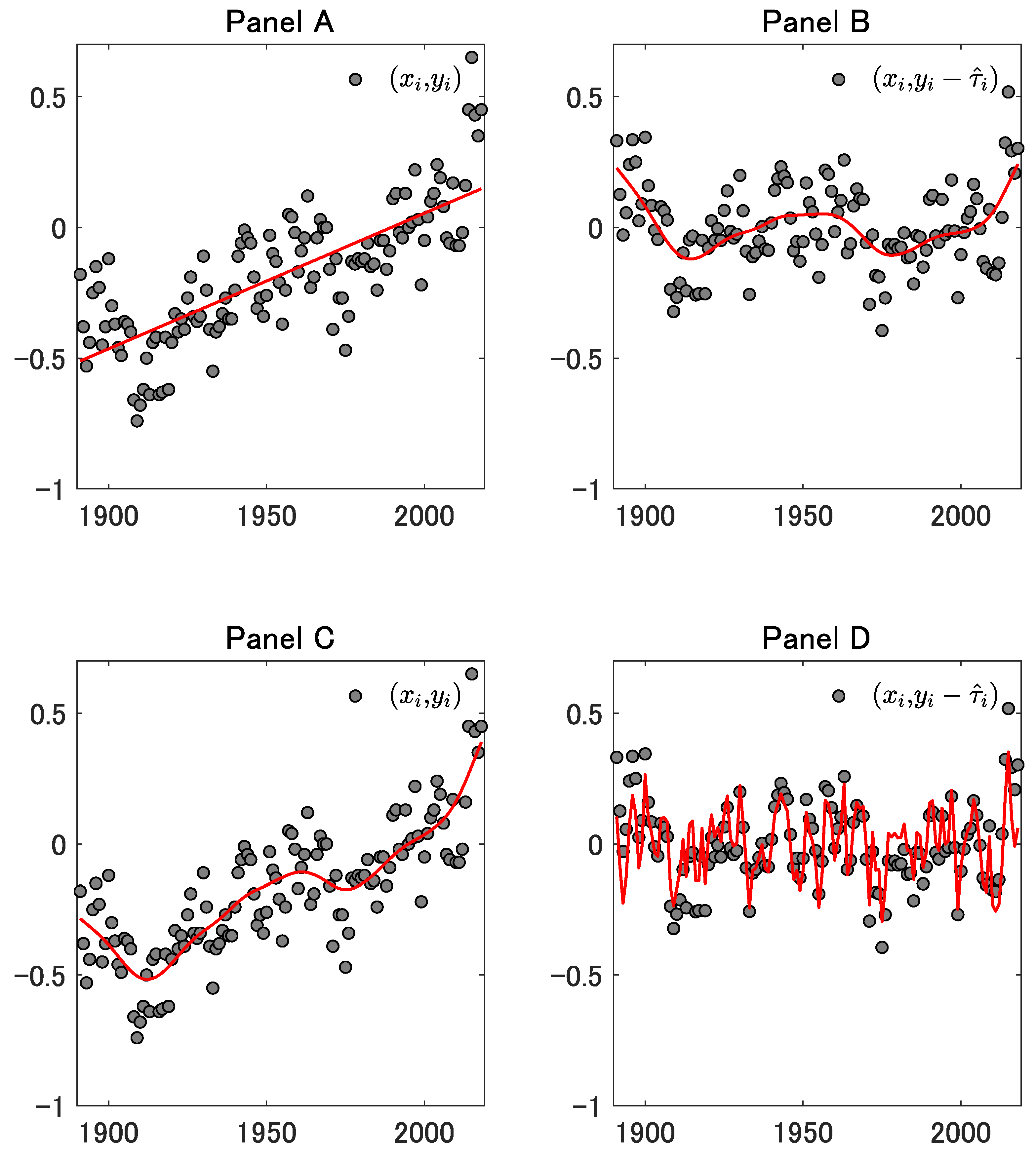
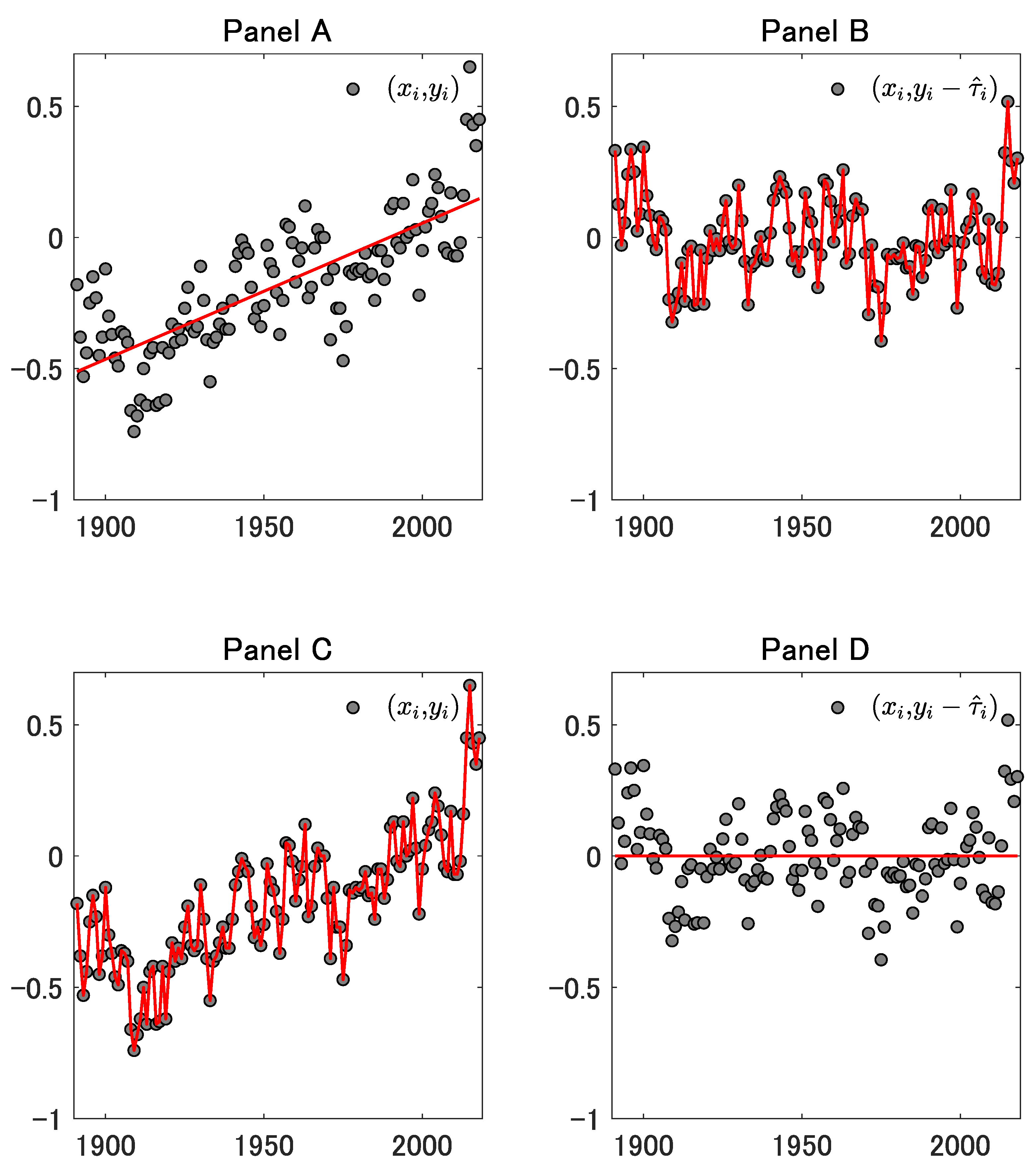
5. Illustrations of Some Results
6. The Cases Such That the Other Right-Inverse Matrices Are Used
7. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Some Remarks on a Special Case Such That x = [1,…,n]⊤
- (i)
- If , then , which is a Toeplitz matrix of which the first (resp. last) row is (resp. ).
- (ii)
- If , then is bisymmetric (i.e., symmetric centrosymmetric), which may be proved as in Yamada (2020a).
- (iii)
- (iv)
Appendix A.2. User-Defined Functions
Appendix A.2.1. A Matlab/GNU Octave Function to Make in (7)

Appendix A.2.2. A Matlab/GNU Octave Function to Make in (8)

Appendix A.2.3. A Matlab/GNU Octave Function to Make in (9)

Appendix A.2.4. A R Function to Make in (7)


Appendix A.2.5. A R Function to Make in (8)

Appendix A.2.6. A R Function to Make in (9)

References
- Schoenberg, I.J. Spline functions and the problem of graduation. Proc. Natl. Acad. Sci. USA 1964, 52, 947–950. [Google Scholar] [CrossRef] [PubMed]
- Reinsch, C. Smoothing by spline functions. Numer. Math. 1967, 10, 177–183. [Google Scholar] [CrossRef]
- Green, P.J.; Silverman, B.W. Nonparametric Regression and Generalized Linear Models: A roughness Penalty Approach; Chapman and Hall/CRC: Boca Raton, FL, USA, 1994. [Google Scholar]
- Wood, S.N. Generalized Additive Models: An Introduction with R, 2nd ed.; Chapman & Hall/CRC: Boca Raton, FL, USA, 2017. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Verbyla, A.P.; Cullis, B.R.; Kenward, M.G.; Welham, S.J. The analysis of designed experiments and longitudinal data by using smoothing splines. J. R. Stat. Soc. 1999, 48, 269–311. [Google Scholar] [CrossRef]
- Høyer, J.L.; Karagali, I. Sea surface temperature climate data record for the North Sea and Baltic Sea. J. Clim. 2016, 29, 2529–2541. [Google Scholar] [CrossRef]
- Yamada, H. The Frisch–Waugh–Lovell theorem for the lasso and the ridge regression. Commun. Stat. Theory Methods 2017, 46, 10897–10902. [Google Scholar] [CrossRef]
- Pesaran, M.H. Exact maximum likelihood estimation of a regression equation with a first-order moving-average error. Rev. Econ. Stud. 1973, 40, 529–535. [Google Scholar] [CrossRef]
- Bohlmann, G. Ein ausgleichungsproblem. Nachrichten von der Gesellschaft der Wissenschaften zu Gottingen, Mathematisch-Physikalische Klasse 1899, 1899, 260–271. [Google Scholar]
- Whittaker, E.T. On a new method of graduation. Proc. Edinb. Math. Soc. 1923, 41, 63–75. [Google Scholar] [CrossRef]
- Weinert, H.L. Efficient computation for Whittaker–Henderson smoothing. Comput. Stat. Data Anal. 2007, 52, 959–974. [Google Scholar] [CrossRef]
- Hodrick, R.J.; Prescott, E.C. Postwar U.S. business cycles: An empirical investigation. J. Money Credit. Bank. 1997, 29, 1–16. [Google Scholar] [CrossRef]
- Schlicht, E. Estimating the smoothing parameter in the so-called Hodrick–Prescott filter. J. Jpn. Stat. Soc. 2005, 35, 99–119. [Google Scholar] [CrossRef]
- Kim, S.; Koh, K.; Boyd, S.; Gorinevsky, D. ℓ1 trend filtering. SIAM Rev. 2009, 51, 339–360. [Google Scholar] [CrossRef]
- Paige, R.L.; Trindade, A.A. The Hodrick–Prescott filter: A special case of penalized spline smoothing. Electron. J. Stat. 2010, 4, 856–874. [Google Scholar] [CrossRef]
- Yamada, H. Ridge regression representations of the generalized Hodrick–Prescott filter. J. Jpn. Stat. Soc. 2015, 45, 121–128. [Google Scholar] [CrossRef]
- Yamada, H. Why does the trend extracted by the Hodrick–Prescott filtering seem to be more plausible than the linear trend? Appl. Econ. Lett. 2018, 25, 102–105. [Google Scholar] [CrossRef]
- Yamada, H. Several least squares problems related to the Hodrick–Prescott filtering. Commun. Stat. Theory Methods 2018, 47, 1022–1027. [Google Scholar] [CrossRef]
- Yamada, H. A note on Whittaker–Henderson graduation: Bisymmetry of the smoother matrix. Commun. Stat. Theory Methods 2020, 49, 1629–1634. [Google Scholar] [CrossRef]
- Yamada, H. A smoothing method that looks like the Hodrick–Prescott filter. Econom. Theory 2020. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Regressions Relating to the Cubic Smoothing Spline | Average | Sum | ⊥ | ||||
|---|---|---|---|---|---|---|---|
| (P1) | 1 | ||||||
| (D1) | 1 | ||||||
| (P2) | , where | 0 | 0 | ∘ | |||
| (D2) | , where | 0 | 0 | ∘ | |||
| (P3) | 0 | 0 | ∘ | ||||
| (D3) | 0 | 0 | ∘ | ||||
| (P4) | , where | 0 | 0 | ∘ | |||
| (D4) | , where | 0 | 0 | ∘ | |||
| , where | 1 |
| Regressions Relating to the Cubic Smoothing Spline | Average | Sum | ⊥ | ||||
|---|---|---|---|---|---|---|---|
| (P5) | 1 | ||||||
| (D5) | 1 | ||||||
| (P6) | , where | 0 | 0 | ∘ | |||
| (D6) | , where | 0 | 0 | ∘ | |||
| (P7) | 0 | 0 | ∘ | ||||
| (D7) | 0 | 0 | ∘ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, R.; Yamada, H. Principle of Duality in Cubic Smoothing Spline. Mathematics 2020, 8, 1839. https://doi.org/10.3390/math8101839
Du R, Yamada H. Principle of Duality in Cubic Smoothing Spline. Mathematics. 2020; 8(10):1839. https://doi.org/10.3390/math8101839
Chicago/Turabian StyleDu, Ruixue, and Hiroshi Yamada. 2020. "Principle of Duality in Cubic Smoothing Spline" Mathematics 8, no. 10: 1839. https://doi.org/10.3390/math8101839
APA StyleDu, R., & Yamada, H. (2020). Principle of Duality in Cubic Smoothing Spline. Mathematics, 8(10), 1839. https://doi.org/10.3390/math8101839