1. Introduction
B-spline functions, curves, and surfaces are widely used for approximation [
1,
2,
3] and for defining the trajectories of vehicles [
4,
5], robots [
6,
7] and industrial machines [
8]. Furthermore, they are common in computer graphics [
9,
10] and signal processing for filter design and signal representation [
11,
12,
13,
14,
15].
We address the approximation of a set of data points by a B-spline function in the nonlinear weighted least squares (NWLS) sense as well as the nonlinear optimization of a B-spline trajectory. In both cases, a Bayesian filter determines the coefficients of the B-spline function.
1.1. Nonlinear Weighted Least Squares Data Approximation
In NWLS approximation problems, the solution depends on the function coefficients in a nonlinear fashion. Based on the results of numerical experiments, Reference [
16] reported that a B-spline function was beneficial in solving NWLS problems because of its piecewise polynomial character and smoothness.
In offline applications, a bounded number of data points needs to be processed and all data points are known at the same time. Therefore, the problem can be solved using a batch method. Batch methods for NWLS problems include the Gauss–Newton algorithm and the Levenberg-Marquardt (LM) algorithm. None of these algorithms is an exact method [
16]. The LM algorithm solves in each iteration a linearized NWLS problem [
17]. A method for separable NWLS problems, in which some parameters affect the solution linearly, is derived in References [
18,
19].
In contrast, in online applications such as signal processing, data points become available consecutively and their number is often unbounded. Sliding window algorithms keep the required memory constant by processing only a subset consisting of the latest data points [
20]. A sliding window implementation of the LM algorithm for online applications is proposed in [
21].
Recursive methods only store an already existing solution and update it with each additional data point. Therefore, they are suitable for online applications and usually require less memory and computational effort than batch algorithms that have been adapted for online applications.
NWLS approximation problems are nonlinear optimization problems. Therefore, recursive algorithms for NWLS problems can be based on nonlinear Bayesian filters.
1.2. Trajectory Optimization
Many driver assistance systems calculate a desired vehicle movement, also denoted trajectory, by solving a multiobjective optimization problem with respect to target criteria such as comfort, safety, energy consumption, and travel time. The trajectory optimization methods can be divided into Dynamic Programming (DP), direct methods (DM), and indirect methods (IM).
DP is based on Bellmann’s principle of optimality and determines globally optimal solutions. Its computational effort grows linearly with the temporal length of the trajectory and exponentially with the dimensions of the optimization problem. An adaptive cruise control based on DP is proposed in Reference [
22]. DP-based algorithms for energy-efficient automated vehicle longitudinal control exist for vehicles with an internal combustion engine [
23], hybrid electric vehicles [
24], and plug-in hybrid electric vehicles [
25]. In vehicles with a conventional powertrain, one dimension of the optimization problem refers to the selected gear. In case of a vehicle with a hybrid powertrain, there is at least one additional dimension for the operating mode, i.e., how power flows between the combustion engine, electric motor, and wheels. These degrees of freedom come along with various constraints, and frequently, the optimization problem needs to be simplified such that it can be solved in real-time.
DM lead to an optimization problem, in which the optimization variables are the parameters of a functional trajectory representation. The problem is usually nonlinear and solved using sequential quadratic programming methods or interior point methods. An example for a DM is the model predictive control, which solves the trajectory optimization problem on a receding horizon. DM are locally optimal, and their computational effort grows polynomially with the dimensions but mostly exponentially with the temporal trajectory length. Therefore, the optimization horizon is usually restricted to a few seconds.
IM are based on variational calculus and require solving a nonlinear equation system. They offer a polynomial complexity increase with the number of dimensions and the time horizon.
In practice, mainly the two first approaches are used and combined for solving difficult, farsighted trajectory optimization problems because of their complementary properties. Then DP provides a rough long-term reference trajectory for a DM that computes feasible trajectories within a short horizon [
26,
27].
1.3. Bayesian Filters
The Bayesian approach to a state estimation for dynamic systems calculates the probability density function (pdf) of the unknown system state. The required information stems partly from a system model and partly from previous measurements. The state estimation is performed by a recursive filter that alternates between a time update that predicts the state via the system model and a measurement update that corrects the estimate with the current measurement.
The Kalman filter (KF) computes an optimal state estimate for systems with linear system and measurement equations and Gaussian system and measurement noises [
28]. Use cases include path planning applications [
29]. However, in many scenarios, the linear Gaussian assumptions do not apply and suboptimal approximate nonlinear Bayesian filters such as the extended Kalman filter (EKF), unscented Kalman filter (UKF), or particle filter (PF) are required [
30].
The EKF applies a local first order Taylor approximation to the nonlinear system and measurement functions via Jacobians in order to keep the linear state and measurement equations. The system and measurement noises are both approximated with Gaussian pdfs [
28]. Although the EKF is not suitable for systems with a strong nonlinearity or non-Gaussian noise, it is still often successfully used for a nonlinear state estimation [
31]. For example, an NWLS approximation via a modified EKF is presented in Reference [
32].
An alternative to the approximation of the nonlinear state and measurement functions is the approximation of the pdfs. This can be done by propagating a few state samples called sigma points through the nonlinear functions. A filter that follows this approach is referred to as a sigma point Kalman filter. One of the most well-known representatives is the UKF. It uses
deterministically chosen sigma points, whereby
J denotes the dimensions of the system state. The pdfs are approximated as Gaussians of which the means and variances are determined from the propagated sigma points [
28].
Compared to the EKF, the UKF offers at least a second-order accuracy [
33] and is a derivative-free filter [
28], meaning that it does not require the evaluation of Jacobians, which is often computationally expensive in the EKF [
31]. Several publications report nonlinear problems in which the UKF performs better than the EKF, e.g., for a trajectory estimation [
33,
34]. However, if the pdf cannot be well-approximated by a Gaussian because the pdf is multimodal or has a strong skew, the UKF will also not perform well. Under such conditions, sequential Monte Carlo methods like the PF outperform Gaussian filters like EKF and UKF [
30].
The PF approximates the pdf by a large set of randomly chosen state samples called particles. The state estimate is a weighted average of the particles. With increasing number of particles, the pdf approximation by the particles becomes equivalent to the functional pdf representation and the estimate converges against the optimal estimate [
30]. For nonlinear and non-Gaussian systems, the PF allows the determination of various statistical moments, whereas EKF and UKF are limited to the approximation of the first two moments [
31]. However, the number of particles that is needed for a sufficient approximation of the pdf increases exponentially with the state dimension [
35]. The PF has been applied to the optimization [
36] and prediction [
37] of trajectories successfully as well.
Many use cases involve a mixed linear/nonlinear system. Typically, there are few nonlinear state dimensions and comparatively many linear Gaussian state dimensions. The marginalized particle filter (MPF) is beneficial for such problems as it combines KF and PF. The PF is only applied to the nonlinear states because the linear part of the state vector is marginalized out and optimally filtered with the KF. This approach is known as Rao–Blackwellization and can be described as an optimal Gaussian mixture approximation. Therefore, the MPF is also called a Rao–Blackwellized particle filter or mixture Kalman filter. Marginalizing out linear states from the PF strongly reduces the computational effort because less particles suffice and often enables real-time applications. Simultaneously, the estimation accuracy usually increases [
31,
38].
In the recent past, several publications have proposed approaches for localization [
39,
40] and trajectory tracking [
38,
41] that are based on the MPF because of its advantages for mixed linear/nonlinear systems. Automotive use cases include a road target tracking application, of which the multimodality requires using a PF or MPF [
42]. The MPF is chosen as it allows a reduction in the number of particles for less computational effort. Similarly, Reference [
35] presents a MPF application for lane tracking, in which the achieved particle reduction compared to a pure PF enables the execution of the algorithm in real-time in an embedded system.
1.4. Contribution
By definition, a B-spline function with a bounded number of coefficients has a bounded definition range. Usually, approximation algorithms require a bounded number of coefficients which restricts the approximation of data points with a B-spline function to a bounded interval that needs to be determined in advance.
In online applications, the required B-spline function definition range might not be precisely known or vary. This can result in the issuse of unprocessable data points outside the selected definition range.
In Reference [
43], we presented the recursive B-spline approximation (RBA) algorithm, which iteratively approximates an unbounded set of data points in the linear weighted least squares (WLS) sense with a B-spline function using a KF. A novel shift operation enables an adaptation of the definition range during run-time such that the latest data point can always be approximated.
However, recursive NWLS B-spline approximation methods are still restricted to a constant approximation interval. We contribute to closing this research gap by proposing and investigating an algorithm termed nonlinear recursive B-spline approximation (NRBA) for the case of NWLS approximation problems.
NRBA comprises an MPF that addresses nonlinear target criteria with its PF while it determines the optimal solution for linear target criteria with a KF [
44]. The target criteria that refer to the value of the B-spline function or its derivatives directly are linear criteria. Hereby, the benefit of using MPF is that it can deal with strong nonlinearities, that its computational effort can be adapted by changing the number of particles in order to meet computation time constraints, and that it accepts the known measurement matrix for linear target critera as an input, whereas other nonlinear filters estimate the relationship between measurements and function coefficients.
In automotive applications, the exponential growth of the computational effort with an increasing time horizon limits the application of DM to short time horizons. Hence, the research gap regarding trajectory optimization consists of available DM with a lower complexity. Compared to conventional and hybrid vehicles, the powertrain of a battery electric vehicle (BEV) often only has a constant gear ratio which enables savings in computational effort.
Since the NWLS approximation problem that NRBA solves is an unconstrained nonlinear optimization problem, NRBA can be applied for multiobjective trajectory optimization. Our contribution regarding trajectory optimization is an iterative local direct optimization method for B-spline trajectories of which the computational effort only grows linearly with the time horizon instead of exponentially. Due to the iterative nature of NRBA, the optimization can be paused, and if computation time is available, the temporal length of the trajectory can be extended by calculating additional coefficients.
1.5. Structure of the Data Set
Analogous to Reference [
43], we consider the data point sequence
. The index
t indicates the time step at which the data point
becomes available.
denotes the value of the independent variable
s at
t. The vector
summarizes
scalar measurements
y. The superscript
indicates transposed quantities.
can vary with
t, but we suppose that
. The vector
comprises all measurements and is given by
1.6. Outline
Section 2.1 states the used B-spline function definition. In
Section 2.2, we specify the MPF and the chosen state-space model.
Section 2.3 proposes the NRBA algorithm for an NWLS approximation. The numerical experiments in
Section 3 investigate the capabilities of NRBA compared to the LM algorithm as well as the influences of the NRBA parameters on the result and convergence before we demonstrate how NRBA can be applied for a multiobjective trajectory optimization in
Section 4. In
Section 5, we recapitulate the features of NRBA and conclude.
2. Methods
2.1. B-Spline Function Representation
The value of a B-spline function results from the weighted sum of J polynomial basis functions called B-splines. All B-splines possess the same degree d. The B-splines are defined by d, and the knot vector . We suppose that the values of the knots grow strictly monotonously (). with is the spline interval index and is the corresponding spline interval of the B-spline function.
In the jth B-spline is positive for and diminishes everywhere else. This feature is referred to as local support and causes the B-spline function to be piecewise defined for each spline interval. For , only the B-splines can be positive.
Their values for a specific
s are comprised in the B-spline vector
which is calculated according to Equation (
2):
The B-spline matrix
with
and
reads
is the definition range of the B-spline function
. For
,
f is defined by
with coefficient vector
f has
continuous derivatives. For
, the
rth derivative
of
f reads
with B-spline vector
is a
zero matrix. The matrix
results from computing the derivative with respect to
s for each element of
[
43,
45]:
2.2. Marginalized Particle Filter
The marginalized particle filter (MPF) is an iterative algorithm for estimating the unknown state vector of a system at time step .
In the MPF,
is subdivided into
whereby the KF optimally estimates the linear state vector
and a PF estimates the nonlinear state vector
. Exploiting linear substructures allows for better estimates and a reduction of the computational effort. Therefore, the MPF is beneficial for mixed linear/nonlinear state-space models [
46]. Due to Equations (
4) and (
6), linear substructures will occur in approximation problems as long as there are target criteria that refer to the value of the B-spline function or its derivatives directly.
MPF algorithms for several state-space models can be found in Reference [
46] along with a
Matlab example that can be downloaded from [
47]. An equivalent but new formulation of the MPF that allows for reused, efficient, and well-studied implementations of standard filtering components is stated in Reference [
44].
For an NWLS approximation, we apply the following state-space model derived from Reference [
44]:
The superscripts
and
indicate that the corresponding quantity refers to linear or nonlinear state variables, respectively.
denotes the state transition matrix,
is the known input vector,
is the vector of measurements,
is the measurement matrix, and
is the nonlinear measurement function that depends on
.
denotes the process noise of the linear state vector with a covariance matrix , is the process noise of the nonlinear state vector with a covariance matrix , and is the measurement noise with a covariance matrix .
The model of the conditionally linear subsystem in the KF has the state vector
, whereby
describes the linear dynamics of
:
The covariance matrix of process noise is
, and
denotes a zero matrix with a suitable size.
A PF with the model
deals with the remaining nonlinear effects. The noise depends on the estimates indicated by ^ from the conditionally linear model:
with
where the superscript
refers to a priori quantities that are computed in the time update which is based on the state of Equations (
9) and (
10). In contrast,
denotes a posteriori quantities that are calculated in the following measurement update based on the measurement of Equation (
11).
and are the covariance matrices of the estimation errors that belong to and , respectively.
The PF uses multiple state estimates called particles simultaneously. The superscript
with
is the particle index and
is the particle count. In general, a KF is used for each particle. In the chosen state-space model, however,
,
,
, and
are independent of
and
. This implies that
and
are identical for all KFs which reduces the computational effort substantially [
44,
46].
Algorithm 1 states the equations for one MPF iteration and was derived from References [
44,
46]. For an implementation in
Matlab, we adapted the example from Reference [
47]. Note that, in Algorithm 1, the measurement update of the previous time step
occurs before the time update for the current time step
, similar to the algorithm in Reference [
48].
In line 4 of Algorithm 1, linear particles are resampled according to their corresponding normalized importance weights. After resampling, particles with a low measurement error occur more frequently in the set of particles. Subsequently, all particles are aggregated in line 5 to a single estimate by calculating their mean.
After both KF and PF have been time updated, the KF is adjusted based on the PF estimates in a mixing step with the cross-covariances of the estimation errors, and .
In the new formulation from Reference [
44], resampling occurs after the measurement update of both PF and KF. Therefore, the quantities computed for the measurement update of the PF can be reused for the KF measurement update. In particular, each particle is only evaluated once in line 1 of each MPF iteration instead of twice as with the previous formulation in Reference [
46].
| Algorithm 1: The marginalized particle filter derived from References [44,46] |
 |
2.3. Nonlinear Recursive B-Spline Approximation
The Nonlinear recursive B-spline approximation (NRBA) iteratively adapts a B-spline function
with degree
d to the data set from
Section 1.5. Algorithm 2 states the instructions for one iteration of NRBA, which is based on the MPF.
In each iteration t, NRBA modifies f in consecutive spline intervals. Each linear particle and each nonlinear particle contains estimates for function coefficients of f. denotes the knot vector comprising knots. The resulting definition range of f is given by . NRBA checks if is in the definition range of the previous time step, . If not, needs to be shifted such that . A shift can be conducted in the MPF time update. The result of the time update is the a priori estimate . In the following measurement update, we need again to compute the measurement matrix , and then, to take into account . The result of the measurement update is the a posteriori estimate .
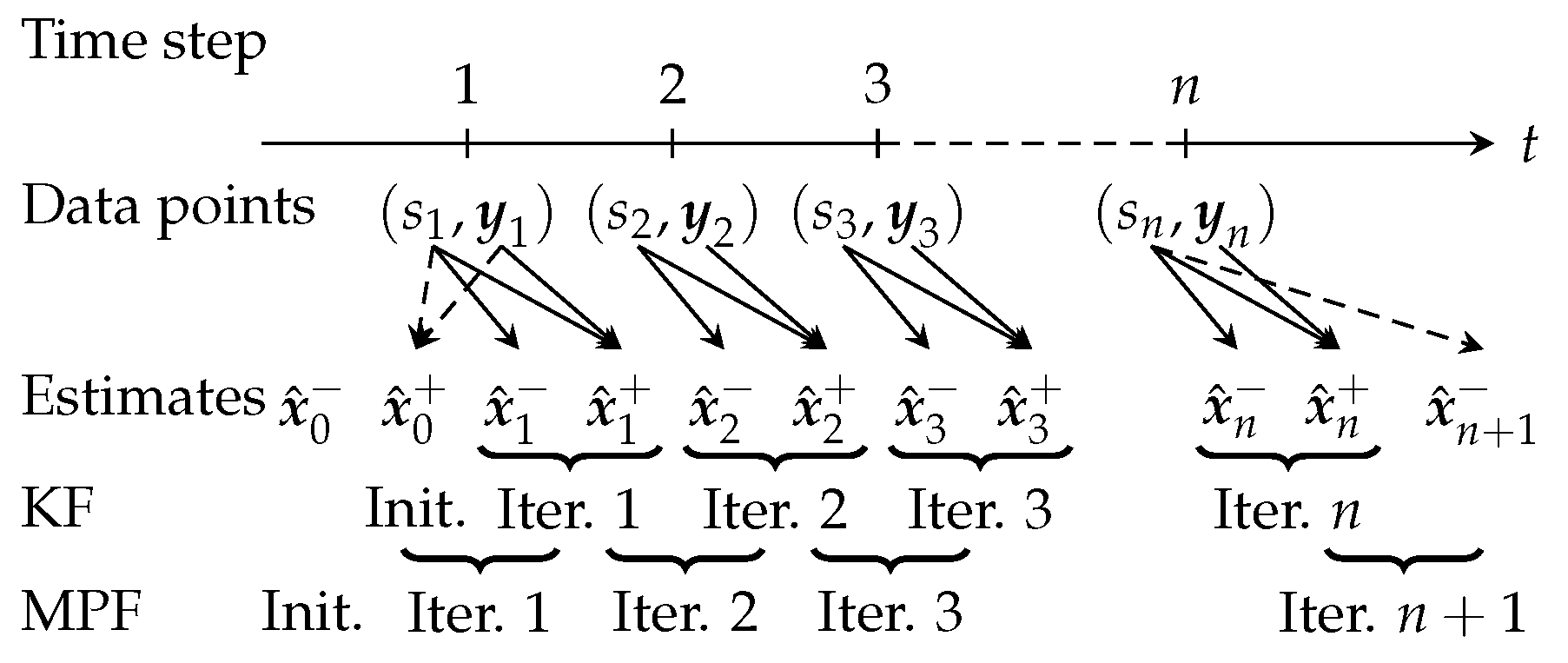
Figure 1 depicts the allocation of available data points and computed estimates
to KF iterations in RBA versus MPF iterations in NRBA. The arrows indicate the needed information for computing the estimates. The KF is initialized with
and conducts in each iteration a time update first and then a measurement update. Therefore, we need
iterations for
data points. In contrast, the MPF performs the measurement update first and is initialized with
. Therefore, we have to save
and provide
,
, and
for iteration
. Hence, we need one iteration more than with the KF in order to take into account all data points. By definition, we use
for computing
and
for
as indicated by the dashed arrows.
2.3.1. Initialization
Each linear particle is initialized with , and each nonlinear particle is initialized with . Hereby, is a matrix of ones and indicates an initial value equal to the scalar measurement referring to f. computes the Cholesky factorization, and is a vector of random values drawn from the standard normal distribution. The covariance matrix of a priori estimation error of linear states, , is initialized with . denotes a identity matrix.
The large scalar value causes to quickly change such that f adapts to the data. Provided that the values in are small, the values in decrease as t grows because of line 8 of Algorithm 1. Small elements in correspond to certain estimates. Therefore, the particles and are slower to be updated using measurements such that f converges. Analogous statements hold for because of line 9 of Algorithm 1.
Hence, the process noises are defined as and with small positive values and , respectively.
2.3.2. Measurement Update
The measurement update from line 1 to line 4 of Algorithm 1 adapts based on .
The
vth dimension of
refers to either
f itself or a derivative of
f. Therefore, the
vth row of the
measurement matrix
reads
whereby
and
. Algorithm 2 computes
in line 7 using Equation (
16).
The value of the nonlinear measurement function depends on the nonlinear particles . Furthermore, can depend on additional quantities that vary with the application and are not stated in Algorithm 1.
The diagonal covariance matrix of measurement noise enables a relative weighting of the dimensions of because the influence of the vth dimension of the measurement error on and decreases with a growing positive value .
| Algorithm 2: Nonlinear recursive B-spline approximation |
 |
2.3.3. Time Update with Shift Operation
Based on a comparison between and , NRBA decides if a shift operation of the B-spline function definition range is required to achieve that .
The variable calculated from line 8 to line 21 of Algorithm 2 states the shift direction of and by how many positions components in , and need to be moved for that purpose. indicates a right shift of , indicates a left shift, and means that no shift is conducted because .
Algorithm 2 expects that, for , the additionally needed knots are the last entries of the knot vector and that they are the first entries of if .
Case 1: Right shift of definition range ()
The updated knot vector reads
and line 6 of Algorithm 1 updates
to
using the state transition matrix
with
and the input signal vector
with
Thereby all entries of
are moved to the left and the last
entries of
have an arbitrary initial value
:
During a right shift of the definition range, we set
to the last element of
, which is determined during the preceding call of Algorithm 1 in line 5. This is based on the assumption that
is a good initial value in the magnitude of the data.
Additionally, line 8 of Algorithm 1 updates
to
using Equation (
18) and
with
The update operation moves the elements in
to the top left and replaces the zeros on the last
σ main diagonal elements of
with
in order to get large values on the last
σ main diagonal elements of
and a fast adaption of the initial estimates
to the data points.
In line 7 and line 9, Algorithm 1 computes the the quantities
and
that are needed for the PF time update. The calculations of the state transition matrix
with
and the input signal vector
with
are analogous to those for the linear quantities.
uses
instead of
:
Case 2: Left shift of definition range ()
The updated knot vector is
the input signal vector for linear states
reads
and the input signal vector for nonlinear states
is given by
with
Additionally, we set
to the first component of
.
Note that since and are identical in the chosen state-space model, we can save computational effort when calculating the covariances and cross-covariances from line 8 to line 11 in Algorithm 1.
2.3.4. Effect of the Shift Operation
The shift operation decouples the dimension of the state vector from the total number of estimated coefficients. As a result, NRBA can determine an unknown and unbounded number of coefficients while the effort per iteration only depends on the number of spline intervals in which the approximating function can be adapted simultaneously.
However, the shift operation causes NRBA to partially forget the approximation result in order to keep the dimensions of matrices and vectors constant. and only allow an evaluation of for . The forgetting mechanism can be circumvened by copying old NRBA elements before they are overwritten.
3. Numerical Experiments
We apply Algorithm 2 in numerical experiments. Thereby, we also investigate the effects of the number of simultaneously adaptable spline intervals and the particle count on the NRBA solution. An implementation in
Matlab is provided in [
49]. The LM algorithm [
50] with
Matlab standard settings serves as a benchmark.
3.1. General Experimental Setup
The data set
is defined according to
Section 1.5, whereby
A B-spline function
of degree
and with knot vector
approximates the data. Thereby, we suppose that
refers to
f,
to the first derivative of
f,
to the second derivative of
f, and
to the value of the nonlinear measurement function
.
The nonlinear measurement function
is defined as a quadratic B-spline function with
and
.
depends on the value of the approximating function
and is displayed in
Figure 2. The input variable
of
is restricted to the definition range
of
.
The diagonal measurement covariance matrix with , , and or , respectively, comprises the reciprocal weights of , , and . The reciprocal weight values for the first three dimensions of avoid that f oscillates and cause that f smooths the jumps in the first dimension of the measurements. With , we weight the nonlinear target criterion heavily, whereas with , it is almost completely neglected.
Depending on the applied algorithm, solutions for the former weighting case are denoted with or , indicating the nonlinear approximation. Solutions for the latter case are denoted with or , indicating that we apply the corresponding algorithm to a quasi-linear approximation problem.
We analyze solutions for two different numbers of spline intervals . For , we initialize with , which leads to an initial definition range of f. For , we initialize with , and the resulting definition range is . In both cases, NRBA approximates the data by repeatedly shifting the function definition range to the right. Each time, an additional knot value needs to be provided in the vector . For , these values are , and for , they read .
In order to display the NRBA results for the whole data set, we store all values that are moved out of NRBA matrices and vectors elsewhere. The remaining NRBA parameters are , , and . The LM algorithm uses as the initial value for each coefficient.
Due to the included PF, NRBA is a sampling-based, nondeterministic method and its results vary between different approximation runs. Therefore, we apply a Monte Carlo analysis and perform 50 runs for each approximation setting. For each run, we calculate the normalized root mean square error (NRMSE) between the B-spline function determined by NRBA,
, and the B-spline function according to LM,
, as follows:
With the notation , , and , we refer to the NRBA solution with the minimum, median, or maximum NRMSE, respectively, in each set of 50 runs.
3.2. Effect of Weighting and Nonlinear Measurement Function
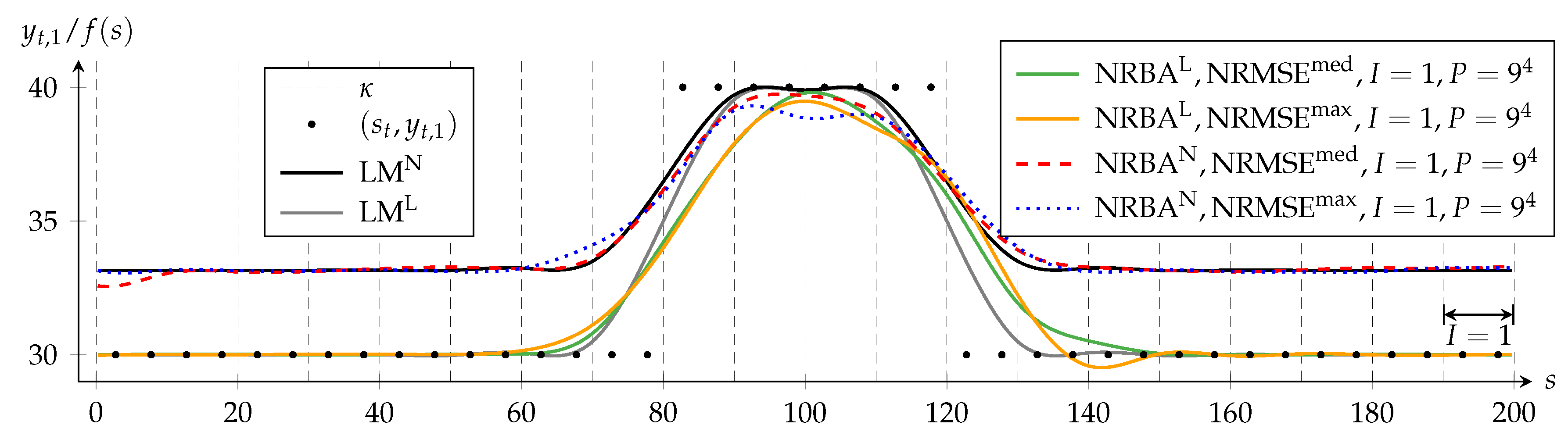
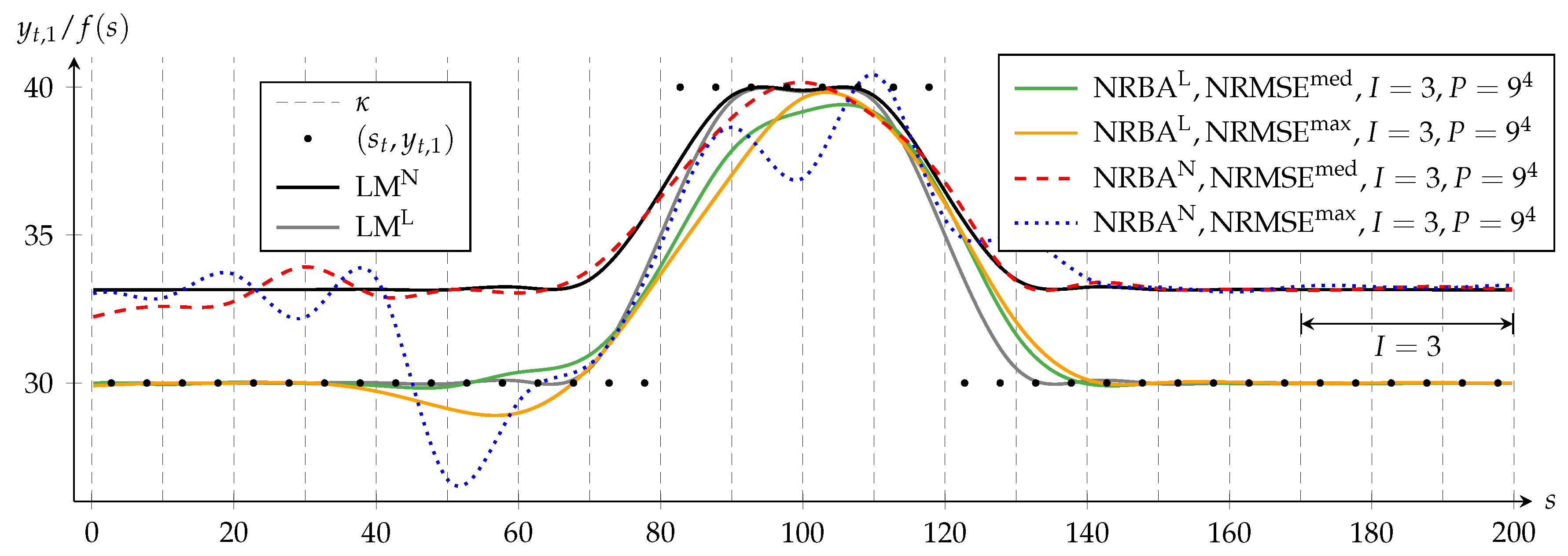
Figure 3 shows the approximating functions of each algorithm for both
and
. It displays for each weighting the NRBA solutions that achieve the median and the maximum NRMSE compared to the LM solution with a same weighting.
is set to one for all NRBA approximations; hence, the MPF state vector comprises four linear and four nonlinear components. Furthermore, we choose
; therefore, the PF creates nine samples per nonlinear state dimension.
The black dots depict the first component
yt,1 of the data points (
st,
yt). For a better visualization of the approximating functions, only two representative data dots per spline interval are displayed. For
f (
s) = 30, the deviation between the value of
c and its target value
yt,4 = 0 has a local maximum (c.f.
Figure 2). In NRBA
N and LM
N, this deviation is penalized strongly; hence, these solutions avoid
f (
s) = 30. In contrast, NRBA
L and LM
L approximate data with
yt,1 = 30 closely because the nonlinear criterion is weighted only to a negligible extent.
Dashed vertical lines indicate knots, whereby the first and last knots are not shown. Data and knot vector are symmetrical to the straight line defined by
s = 100. Since the LM algorithm processes all data simultaneously in each iteration, the solutions LM
L and LM
N in
Figure 3 reflect this symmetry.
In contrast, NRBA processes the data from left to right and can only adapt some coefficients at a time. For
I = 1, these are the four coefficients that influence the B-spline function in the spline interval in which the current data point lies. The double-headed arrow in
Figure 3 visualizes the range in which NRBA can adapt
f simultaneously while (
sn,
yn) is taken into account.
The solutions NRBAL and NRBAN are both asymmetrical and mostly delayed with respect to LML and LMN. However, with NRBAN, the asymmetry is less distinct. The reason for this is that, in the nonlinear problem, the PF removes states with a high delay more quickly from the particle set because they create a larger error. Additionally, the range of values in NRBAN is smaller than in NRBAL so that a present lag is less obvious.
Furthermore, we see that, for the same weighting, NRMSEmed and NRMSEmax differ only slightly. This suggests that, for the investigated settings, P = 6561 suffices for a convergence of NRBA solutions.
3.3. Effect of Interval Count
The number of spline intervals determines the number of intervals in which NRBA can adapt the approximating B-spline function simultaneously.
When we proposed the algorithm RBA for a linear-weighted least squares approximation in Reference [
43], we conducted numerical experiments similiar to the ones in this publication but without any nonlinear approximation criterion. For
, we observed a strong asymmetry and delay with RBA, analogous to
in
Figure 3. The filter delay diminished when
was increased to seven. This is because the filter is then able to update more coefficient estimates with hinsight based on
.
In this subsection, we investigate the effect of increasing from one to three with NRBA. With , NRBA can simultaneously adapt not only the coefficients that are relevant for the spline interval in which the current data point lies but also the two coefficients that affect the two spline intervals to the left. However, also determines the dimension of the state space. With , there are six linear and six nonlinear components. The PF samples the state space less densely unless the particle count is increased exponentially with .
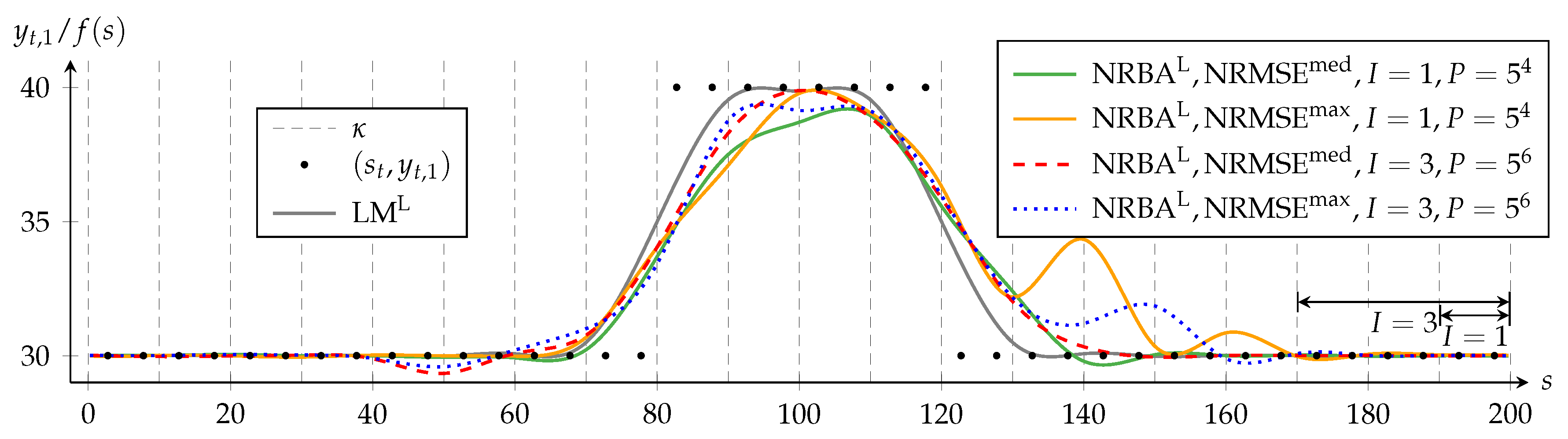
First, we keep the sampling density per nonlinear state space dimension constant by choosing for and = 15,625 = for .
Figure 4 displays the results for the quasi-linear approximation problem. With
, the NRBA solution is more symmetrical than with
for
as it follows the increase of
more closely. However, a comparison of
for
and
indicates that the increase of
does not translate to a reduction of the delay for
. The ability to adapt more coefficient estimates with hinsight can also lead not necessarily to beneficial effects. The examples are the too low course of NRBA for
between
and
and the overcompensation of the delay between
and
.
For
I = 1, NRMSE
max differs more from NRMSE
med and shows larger oscillation amplitudes between
s = 130 and
s = 170 than for
I = 3. This suggests that
P = 625 is not sufficient for a convergence of NRBA for
I = 1. Although we use only 625 particles for
I = 1, the required increase to
P = 15,625 for
I = 3 is quite strong. This illustrates that keeping the sampling density constant quickly becomes infeasible, especially if computation time constraints are present [
44].
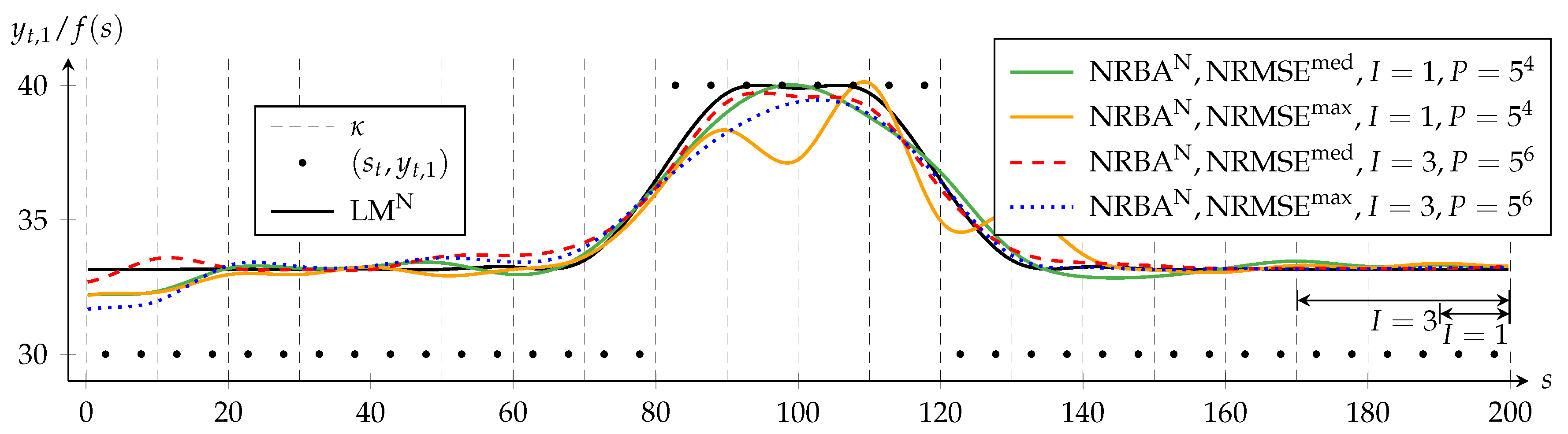
Figure 5 shows the results for the nonlinear approximation problem and supports the previously drawn conclusions. Additionally, we see for
s ≤ 20, that the conflicting target criteria in the nonlinear approximation problem cause a larger period for stabilization.
Second, we investigate the effect of an exclusive
I increase from
I = 1 to
I = 3 while maintaining the particle count of
Section 3.2.
Figure 3 then depicts the case for
I = 1, and
Figure 6 depicts the results for
I = 3. When we compare in both figures the NRMSE
max solution to the corresponding NRMSE
med solution, we notice that they differ much more for
I = 3. This indicates that more particles are needed for convergence for
I = 3. Especially, we notice that, with
I = 3, these differences are much larger for NRBA
N than for NRBA
L.
With the chosen setup, an increasing
I yields no clear approximation improvement when we compare corresponding NRMSE
med solutions in both figures.
Figure 6 also shows that NRBA
N temporarily decreases below
f (
s) = 30, the position of the maximum of
c (c.f.
Figure 2). This illustrates how the sequential data processing of filter-based methods can lead to solutions that differ from those of a batch method.
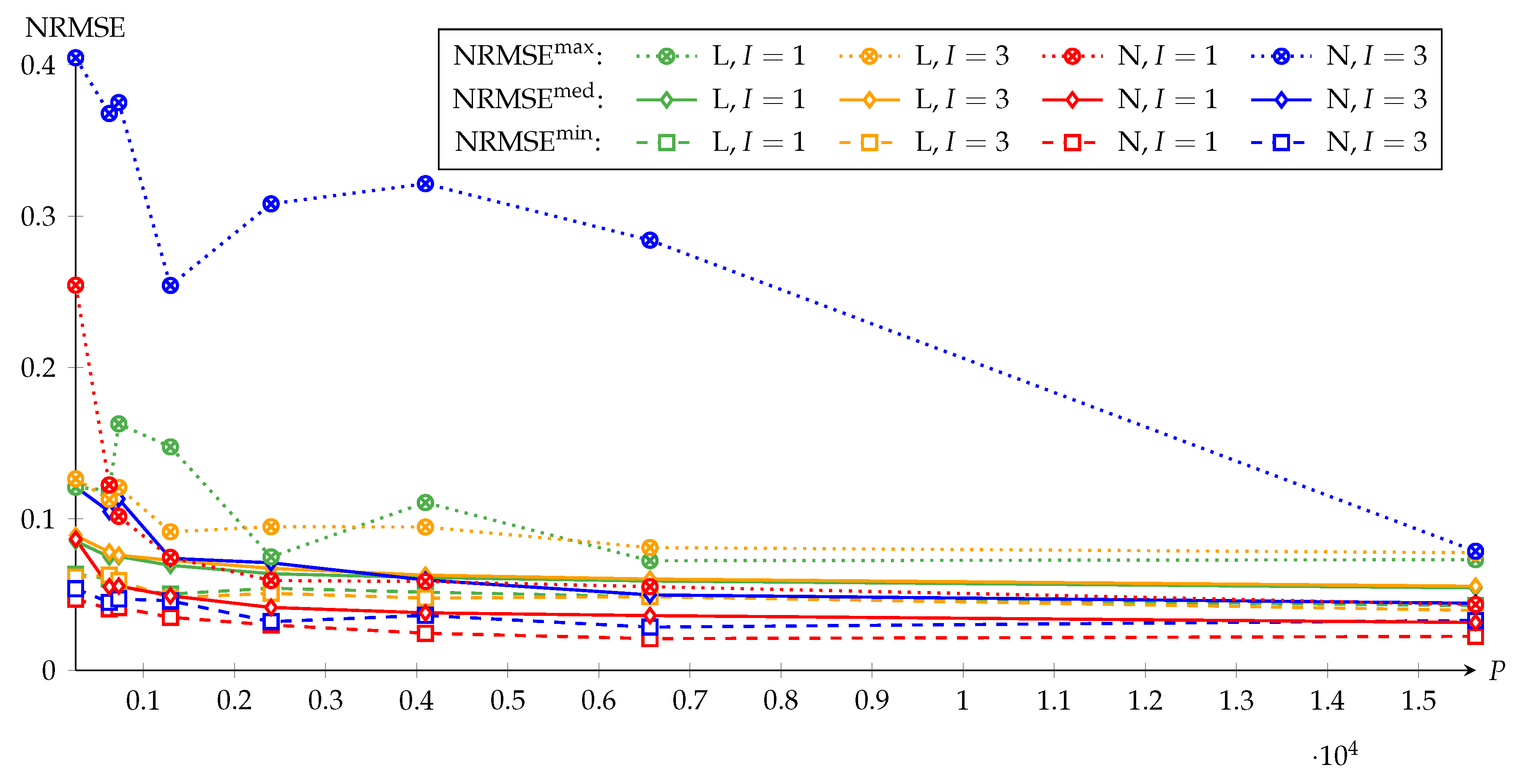
3.4. Effect of Particle Count on Convergence
The computational effort of MPF increases linearly with the particle count
. For an example with seven linear and two nonlinear state vector components, Reference [
46] chooses
and reports that, up to this particle count, increasing
reduces the convergence time significantly and leads to better estimates. Other examples in References [
44,
51] with four linear and two nonlinear state vector components uses
. The
Matlab example in Reference [
47] with three linear components and one nonlinear component uses only
.
Figure 7 depicts the effect of
on the convergence of NRBA. For each combination of quasi-linear approximation problem L and nonlinear approximation problem N with
and
, the figure shows the courses of
,
, and
versus
. The investigated particle counts are
, and 15,625
.
Between
and
, the NRMSE values are on different levels because the LM reference in the NRMSE from Equation (
36) differs between
and
and the normalization factor in Equation (
36) does not fully compensate for this. For
with
and
and
with
,
and
decrease quickly and remain almost constant when
is further increased from
on. For
with
, the courses of
and
suggest using
.
are the observed worst case results. According to the
courses,
should be used for
,
15,625 for
with
and at least
15,625 for
with
.
For
with
,
remains comparatively large because, in some runs, the approximating functions are below
as shown in
Figure 6. Only for
15,625, such results are not observed anymore (c.f.
Figure 5) and the
value is similar to that for
. As stated, the heavy penalization of the nonlinear criterion causes the MPF to remove bad particles quickly from the particle set, which reduces the filter lag. However, the MPF then relies more on the state-space sampling on the suboptimal PF than on the optimal KF. In combination with too few particles, this affects the results very negatively in the experiments.
3.5. Mean and Standard Deviation of NRBA Error
For insights into the statistical features of NRBA, we determine the mean and standard deviation of the error vector between the NRBA and LM solutions over all 50 Monte Carlo runs for each approximation setting. Hereby, we consider the error vector of function values between NRBA and LM, , as well as the error vector of coefficient values between NRBA and LM, . The mean with is an indicator for a bias of NRBA estimates, whereas the sample standard deviation with is a measure for bias stability. is a single error vector component, and denotes the number of components in the error vector.
Table 1 displays the mean and standard deviation of
, and
Table 2 shows these statistic measures for
. Both tables enable the following statements:
The mean of the error vector of the quasi-linear approximation problem is not clearly influenced by the particle count. Furthermore, the varying signs of the means close to zero speak against a bias for the quasi-linear approximation problem. In contrast, for the nonlinear approximation problem, the means are always negative and, therefore, biased. The negative sign is a problem-specific result and means that the solution is, in general, between and . The bias itself, however, seems to be a systematic effect of the interaction of KF and PF of which the system models are weighted relative to each other according to the covariance matrix of process noise for linear states and the covariance matrix of process noise for nonlinear states . Decreasing might help to reduce the magnitude of this bias. Moreover, we note that the absolute values of the means become smaller as the particle count is increased. As the NRBA results for nonlinear approximation problem rely heavily on the PF, this relation is comprehensible.
The standard deviation, in general, decreases for all investigated settings as the particle count is increased. With 15,625 particles, the standard deviations of the quasi-linear approximation problems are two to three times larger than those of the nonlinear approximation problems. This also is a problem-specific effect. For the nonlinear approximation problem, the range of the function values is considerably smaller than that of the quasi-linear problem, which favors lower standard deviations. For the nonlinear problem with the number of spline intervals equal to three, the relatively large standard deviations reflect the often disadvantageous courses of the approximating functions again as depicted in
Figure 6.
4. Trajectory Optimization
This section demonstrates how NRBA can be applied for a multiobjective trajectory optimization. The trajectory represents the planned vehicle velocity with respect to time
measured from present into the future and is a B-spline function as defined in Equation (
4) with degree
, knot vector
, and coefficient vector
. Due to its interpretation as a temporal velocity trajectory, we refer to the B-spline function as
instead of
.
has equidistant and strictly monotonously increasing entries
where
denotes the constant temporal distance of neighboring knots. Due to the choice of
,
can be evaluated for
.
is discretized using a positive constant temporal distance of neighboring data points
:
Each component of the vector of measurements
of the data set in
Section 1.5 is interpreted as a target value of an optimization goal.
is assumed to be a suggested time-discrete course of velocity with a velocity set point
which comes from a preceding planning method:
The remaining components
,
, and
of
are assumed zero as before. NRBA solves the optimization problem
Each summand of the optimization function refers to an optimization goal. Under the assumption that
takes into account driving dynamics, the first summand can be interpreted as driving safety and the optimized trajectory should remain close to the course of
.
denotes the trajectory acceleration and
the trajectory jerk. These quantities are the first and second derivatives of
and can be derived according to Equation (
6). The second and third summands demand a smooth drive with a low acceleration and acceleration changes and, thus, refer to driving comfort. The last summand penalizes the absolute values of the estimated electric traction power
, which is used as a measure for driving efficiency.
Each optimization goal has a corresponding weight. denotes the weight of velocity error square, denotes the weight of acceleration error square, denotes the weight of jerk error square, and denotes the weight of power error square. The reciprocals of the weights follow the interpretation of the filter algorithms and refer to the variances of the artificial measurements. is the variance of velocity measurement, is the variance of acceleration measurement, is the variance of jerk measurement, and is the variance of power measurement.
Without the fourth goal, RBA would suffice for solving the problem because the first three goals are all linear in the coefficients. However, the energy consumption minimization goal requires a nonlinear method. In the following, we consider a BEV based on the Porsche Boxster (type 981), which is described in References [
52,
53,
54]. Like most BEVs, its powertrain has a fixed gear ratio, which simplifies the optimization problem and allows us to apply NRBA.
In a BEV, the powertrain converts electric traction power provided by the battery into mechanic traction power for vehicle propulsion. During recuperative braking, the power flow is vice versa. We will neglect the additional power for auxillaries such as air conditioning because it depends on environmental conditions and comfort requirements strongly. equals the product of the traction force and the vehicle velocity , whereby equals the sum of driving resistances. The dominant driving resistances are air resistance. which increases quadratically with , the inertial force which is a linear function of the vehicle acceleration and the climbing force which depends on the road slope angle .
During this power conversion, losses occur in various components of the powertrain. In order to provide sufficient
for a high acceleration or high velocity, the electric motor must generate a high torque which requires a large electric current
. The internal ohmic resistance
of electric components such as the battery causes an ohmic traction power loss
which is given by
. Furthermore, friction losses in the gearbox increase with rotation speed and transmitted torque [
55].
can be computed in the vehicle from voltage and current sensor data. However, due to a lack of sensors,
and
cannot be calculated, and therefore, power losses cannot be determined in the vehicle during its operation. As power losses increase with the absolute value of
, we use
as a measure for power losses and create a mathematical model of
that outputs the estimated electric traction power
based on the inputs
,
, and
. The mathematical model can adapt its parameters during vehicle operation because both model outputs and model inputs are known quantities during vehicle operation. The adaption is neccessary for accurate estimates because vehicle parameters such as mass or air drag coefficient can change and the driving resistances also depend on these parameters. The mathematical model serves as nonlinear measurement function for NRBA, whereby we assume that
and
. By penalizing the absolute value of
in Equation (
40), we encourage NRBA to determine energy-efficient velocity trajectories.
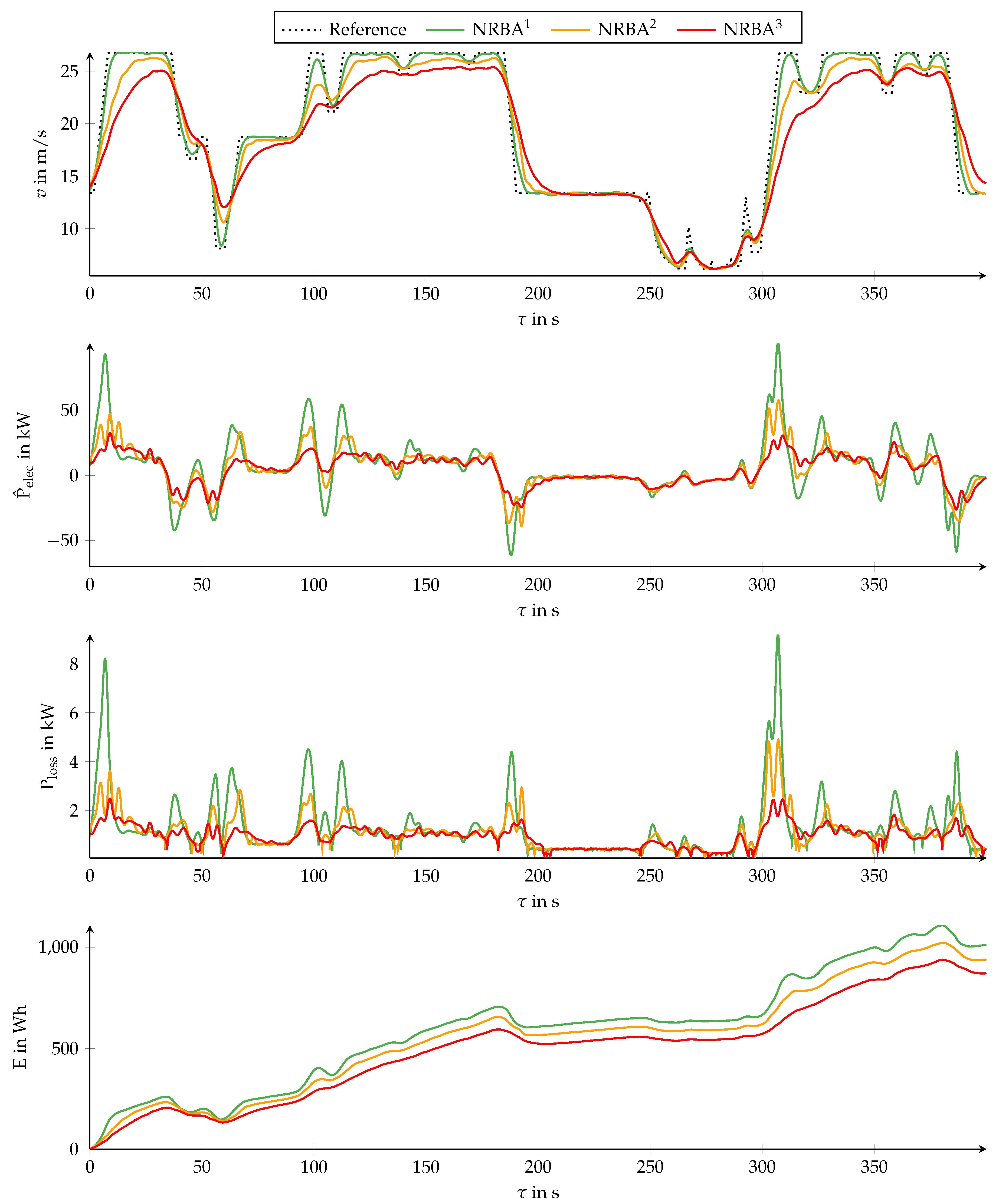
The first diagram of
Figure 8 displays the velocity
v versus the time
according to the velocity set points
of the reference as well as three trajectories optimized by NRBA. The NRBA trajectories are denoted
,
, and
and differ in the choice of
. We use
for
,
for
, and
for
. The remaining parameter values are
,
,
,
,
,
,
,
,
, and
.
The second diagram shows the estimated electric traction power
according to the mathematical model. The traction power loss
and traction energy
depicted in the third and fourth diagram originate from a detailed vehicle model. The detailed vehicle model includes parameters for all relevant power losses. These parameters were derived from component tests on test benches. The detailed model requires
as an input and, therefore, assumptions concerning the driving resistance parameters. For simplicity, we assume a slope-free road in this example. An implementation of this example in
Matlab is also provided in Reference [
49].
The trajectory follows the reference closely apart from some short and large changes of between and . Staying close to the reference requires several positive and negative peaks in , which are almost not penalized because of the high variance of power measurement . As is decreased, the trajectories exhibit lower velocities and absolute values of acceleration in order to avoid large absolute values of . Between and decreasing, has almost no effect because is close to zero because the velocity is low.
The last three diagrams show that is a suitable measure for the goal of a lower energy consumption. A comparison of the peaks in and at illustrates that increases with more than linearly.
Note that there are some situations in which the trajectories exceed . Depending on the exact application, interpreting as an upper velocity limit might be more suitable. By penalizing positive deviations more strongly than negative ones in each NRBA iteration using a sign-dependent value, exceeding can be avoided.
5. Conclusions
We presented a filter-based algorithm denoted nonlinear recursive B-spline approximation (NRBA) that determines a B-spline function such that it approximates an unbounded number of data points in the nonlinear weighted least squares sense. NRBA uses a marginalized particle filter (MPF), also denoted a Rao–Blackwellized particle filter, for solving the approximation problem iteratively. In the MPF, a particle filter (PF) takes into account the approximation criteria that relate to the function coefficients in a nonlinear fashion whereas a Kalman filter (KF) solves any linear subproblem optimally. Thus, the particle count in the PF can be reduced.
As the value of the B-spline function and its derivatives depend linearly on the coefficient values, linear approximation criteria will occur in most approximation applications. The MPF accepts the exactly known values of the B-spline function basis functions as an input and does not need to estimate them like many other nonlinear filters do. Therefore, the MPF enables a reduction in the computational effort and an achievement of better results compared to purely nonlinear filters [
46].
NRBA can shift estimated coefficients in the MPF state vector which allows an adaptation of the bounded B-spline function definition range during run-time such that, regardless of the initially selected definition range, all data points can be processed. Additionally the shift operation enables a decrease in the dimension of the state vector for less computational effort.
In numerical experiments, we compared NRBA to the Levenberg-Marquardt (LM) algorithm and investigated the effects of NRBA parameters on the approximation result using a Monte Carlo simulation. Provided that the NRBA parameters are chosen appropriately, the NRBA solution is close to the LM solution apart from some filter-typical delay. For a strong weighting of the nonlinear approximation criteria, the result relies more on the state-space sampling of the PF than on the KF. In combination with too few particles, the approximating function tends to oscillate.
NRBA use cases are nonlinear weighted least squares (NWLS) problems in which a linearization of nonlinear criteria is not desired or promising, for example, because of strong nonlinearities. For linear weighted least squares problems, the recursive B-spline approximation (RBA) algorithm proposed in Reference [
43] should be used instead of NRBA. RBA is based on the KF, which computes an optimal solution [
38]. In contrast, the PF in NRBA causes NRBA to, at best, reach the same approximation quality provided that the particle count is large enough, which requires more computational effort.
Furthermore, with NRBA, the approximation depends more heavily on the parameterization of the underlying filter algorithm than with RBA. An increase of the number of coefficients that NRBA can adapt simultaneously is not as unambiguously beneficial as with RBA and usually needs to be combined with an exponential increase of the particle count in the PF for an improvement of the approximation.
As demonstrated, NRBA is suitable for an unconstrained multiobjective trajectory optimization. Thereby, a major advantage of NRBA is a linear increase of the computational effort with the number of processed data points as opposed to an exponential increase with most other direct trajectory optimization methods. NRBA can also be applied during the processing of discrete signals in a time domain. Then NRBA can provide a sparse, continuous, and smoothed representation of the signals themselves or of their derivatives.
The chosen MPF formulation allows an easy replacement of the standard KF and PF. For example, Reference [
56] presents a PF, in which the particles are determined with a particle swarm optimization, and reports that less particles are needed compared with the standard PF. An improvement of the MPF is proposed by Reference [
57]. Investigating these algorithms in combination with NRBA can be the subject of further research.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}