1. Introduction
With the increasing reliability of modern products, censored data have become essential in survival analysis, reliability assessments, and medical research. They play a crucial role in minimizing both the time and cost of life-testing experiments. Depending on the study’s objectives, different censoring strategies can be employed, with Type-I and Type-II censoring being the most widely used.
However, neither of these schemes permits the removal of experimental units during life testing. To address this limitation, the progressive censoring scheme introduces flexibility by allowing units to be withdrawn throughout the experiment. In particular, the progressive Type-II censoring scheme enables unit removal while ensuring that a predetermined number of failures are recorded, thereby improving the efficiency of the experiment. Kyeongjun and Youngseuk [
1] explored both classical and Bayesian approaches to estimate parameters, hazard functions, and reliability functions of the inverted exponentiated half-logistic distribution within a progressive Type-II censoring scheme. Gürünlü Alma and Arabi Belaghi [
2] focused on the complementary exponential geometric distribution under the same censoring framework, employing the Structural Equation Modeling algorithm alongside the Markov Chain Monte Carlo (MCMC) method for parameter estimation. The inference of the inverted exponentiated Rayleigh distribution using an adaptive Type-II progressive hybrid censored sample, along with Bayesian estimation via the MCMC method and the Metropolis–Hastings (M-H) algorithm, was presented in Panahi and Moradi’s study [
3]. Panahi and Asadi’s work [
4] featured parameter estimation for the Burr Type-III distribution under the same censoring model, where Bayesian estimates were derived through the Lindley method and the M-H sampling technique.
Previous studies have primarily focused on analyzing a single population, with relatively little attention given to research involving multiple samples. However, in recent years, two-sample joint censoring schemes have gained increasing attention due to their ability to effectively reduce time and costs in life-testing experiments. Under the Type-II joint censoring scheme, two independent samples are tested simultaneously until a predetermined number of failures occur. This approach allows for more efficient data collection on the lifetimes of different samples, enabling more comprehensive comparisons and analyses under the same experimental conditions. Not only does this method improve data utilization efficiency, but it also enhances the practical applicability of experiments, making it widely valuable in fields such as reliability analysis and product quality assessment. Balakrishnan and Rasouli [
5] proposed a Type-II censoring scheme for two populations and developed a parameter estimation method for two exponential distributions. Ashour and Abo-Kasem [
6] applied this approach to conduct classical inference for two Weibull populations. Expanding on this, Mondal and Kundu [
7] extended the framework to generalized exponential distributions with two parameters, employing both maximum likelihood and Bayesian estimation. Furthermore, the issue of interval estimation for two Weibull populations under a joint Type-II progressive censoring scheme was addressed in Parsi and Ganjali’s study [
8]. Balakrishnan [
9] established the conditional maximum likelihood estimates and Bayesian estimates for the
k exponential mean parameters, utilizing a joint progressively Type-II censored sample from
k independent exponential populations. Similarly, statistical inference for the three-parameter Burr-XII distribution under a joint progressive Type-II censoring scheme for two independent samples was explored in Mohamed and Mustafa’s paper [
10], where both maximum likelihood and Bayesian estimation methods were applied. Ismail [
11] introduces an adaptive Type-I progressively hybrid censoring scheme under a step-stress partially accelerated test model, offering advantages over existing schemes.
More recently, Mondal and Kundu [
12] introduced the balanced joint progressive Type-II censoring (B-JPC) scheme, considering it superior to the conventional JPC method. In contrast to the traditional approach, the B-JPC scheme is more practical and easier to implement. Moreover, estimators derived from this scheme are not only simpler to compute but also demonstrate better performance compared to those obtained using the JPC method. It has drawn much attention in comparative lifetime testing in reliability engineering. As pointed out by Mondal and Kundu [
13], Bayesian inference for two Weibull populations sharing a common shape parameter but with different scale parameters was examined under the B-JPC scheme. Statistical inference for two Lindley populations, along with criteria for optimal censoring design, was presented in Goel and Krishna’s study [
14]. Similarly, Shi and Gui’s paper [
15] addressed parameter estimation for two Gompertz populations.
The Lomax distribution (LD), introduced by Lomax [
16], also known as the Pareto II distribution, was initially designed to model business failures. However, its applications extend far beyond this original use. Over the years, it has proven to be a useful tool in various fields, particularly reliability modeling and life testing, as emphasized by Hassan and Al-Ghamdi [
17]. The LD has become widely adopted to analyze diverse datasets. Moreover, as highlighted by Holland [
18], the LD is applicable across a wide range of fields, including biological sciences and the distribution of computer file sizes on servers. Mahmoud [
19] proposed a lifetime performance index based on progressive Type-II sampling under the Lomax distribution and evaluated the performance of the maximum likelihood and Bayesian methods in estimating the lifetime performance index. Pak and Mahmoudi [
20] applied the Newton–Raphson method and the EM algorithm to obtain the maximum likelihood estimates of the Lomax distribution parameters under the progressive Type-II censoring scheme. Furthermore, Bayesian estimates were computed and compared using Monte Carlo simulations in terms of estimation bias and mean squared error. Mustafa [
21] performed Bayesian inference for two Lomax populations under joint progressive Type-II censoring, with an emphasis on engineering applications.
This paper addresses the estimation challenges related to the LD. We derive maximum likelihood estimators (MLEs) for the unknown parameters; however, we find that the MLEs cannot be expressed in closed form. To resolve this, we propose approximate maximum likelihood estimators (AMLEs) that can be explicitly calculated. We also employ the asymptotic distribution of the MLEs and the bootstrap method to construct confidence intervals (CIs) for the unknown parameters. In addition, we perform Bayesian inference, assuming independent Gamma priors, and compute Bayesian estimators under squared error (SE) and linear exponential (LINEX) loss functions. To assess the performance of these estimators, we conduct Monte Carlo simulations and compare point estimates based on their mean values and mean squared error (MSE). Furthermore, we evaluate the effectiveness of 95% two-sided interval estimates by analyzing their average confidence lengths, ensuring a comprehensive assessment of interval estimation precision. To further validate our methodology, we conduct a comparative analysis between frequentist and Bayesian approaches, highlighting their respective advantages and limitations in different parameter settings. Lastly, we apply our methodology to real data to demonstrate its practical application and effectiveness, illustrating its potential use in real statistical inference problems.
The structure of this paper is as follows:
Section 2 outlines the B-JPC scheme and formulates the model. The maximum likelihood estimation and the coverage probabilities of the model parameters are discussed, deriving asymptotic confidence intervals using the observed Fisher information matrix (FIM) in
Section 3.
Section 4 presents Bayesian estimation methods, employing the Metropolis–Hastings algorithm.
Section 5 provides numerical simulations and real data analysis. Lastly,
Section 6 summarizes the findings and concludes this study.
2. Model Description
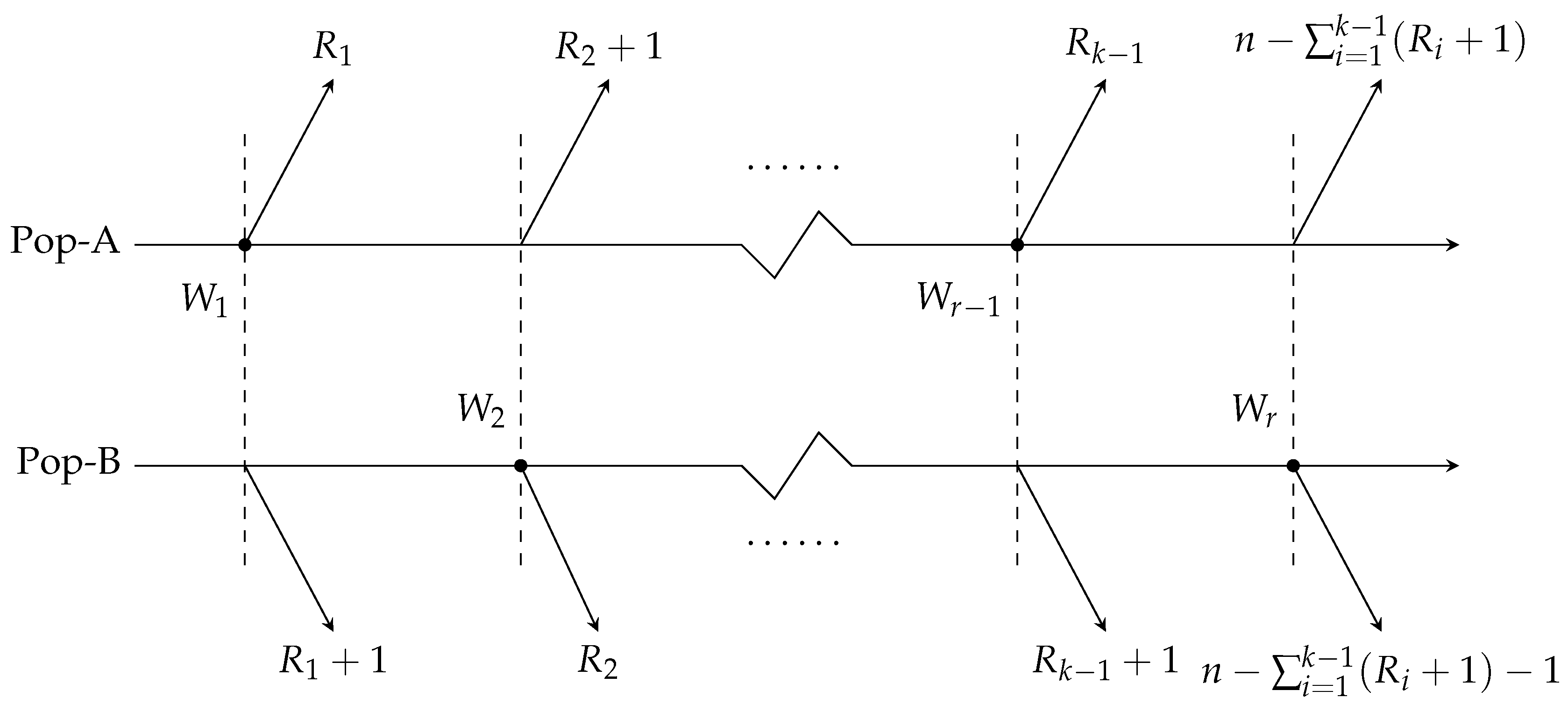
The B-JPC scheme is described as follows. Consider two similar products, denoted as A and B, for which we need to compare their relative performance. We draw a sample of size n from each product population, known as Pop-A and Pop-B. Let k denote the total number of failures observed in the life-testing experiment, where . The removal pattern R, given by , consists of non-negative integers such that , and each .
In the B-JPC scheme, both populations undergo testing simultaneously. When the first failure occurs in Pop-A at time , units are randomly removed from its remaining surviving units, while units are removed from the n surviving units of Pop-B. If the second failure occurs in Pop-B at time , then units are withdrawn from the remaining units of Pop-A, and units are removed from the remaining units of Pop-B. This process continues, with each subsequent failure triggering the removal of units from either Pop-A or Pop-B, until a total of k failures are observed, at which point the experiment concludes.
This life-testing experiment introduces a new set of random variables,
Z.
Let
and
denote the number of failures from Pop-
A and Pop-
B, respectively. The random variables
indicate whether the
i-th failure is from Pop-
A (
) or Pop-
B (
). The total number of failures from Pop-
A and Pop-
B is
and
, respectively. A schematic of the B-JPC scheme is provided in
Figure 1.
Suppose that the random variable
W follows the Lomax distribution, denoted as
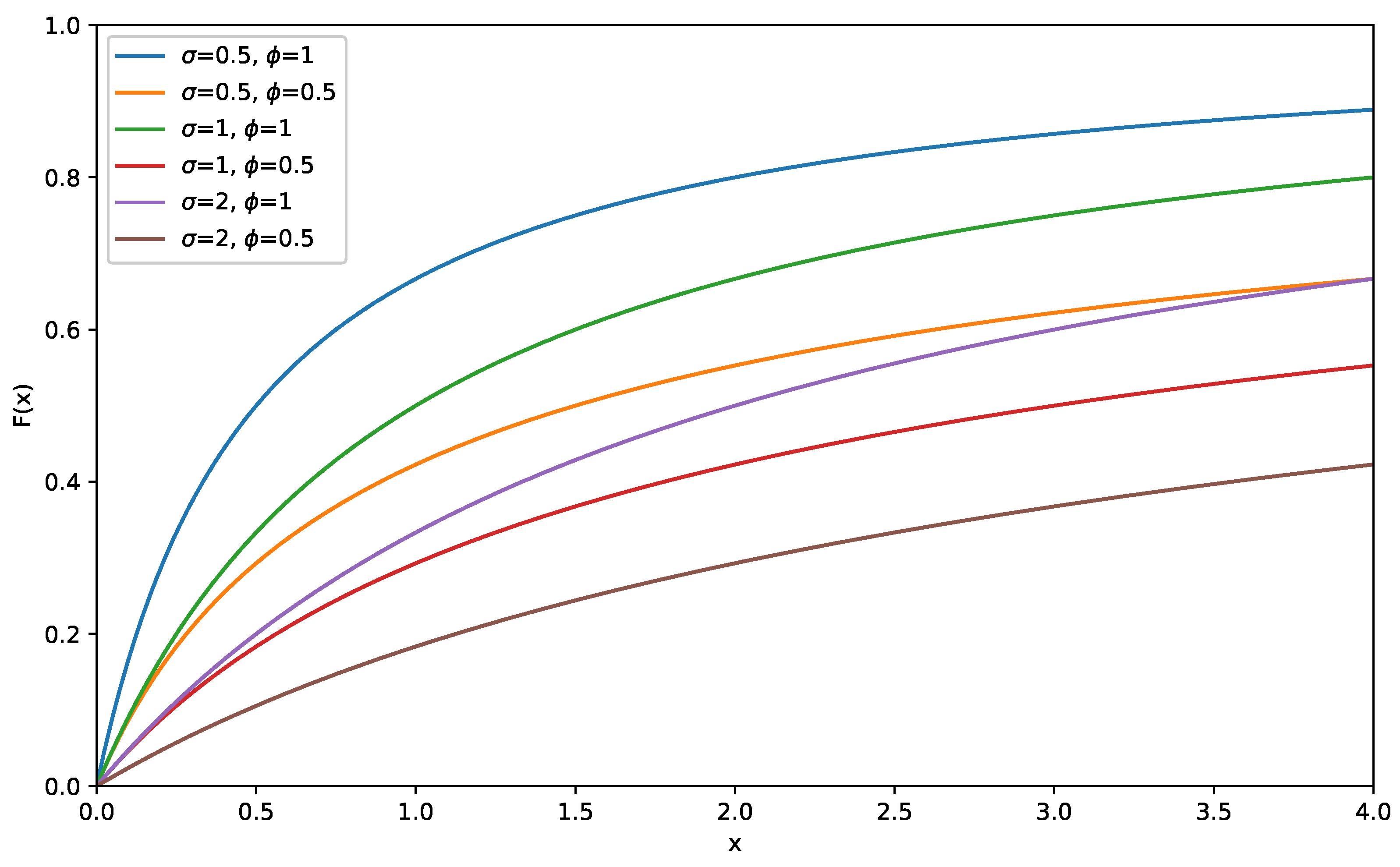
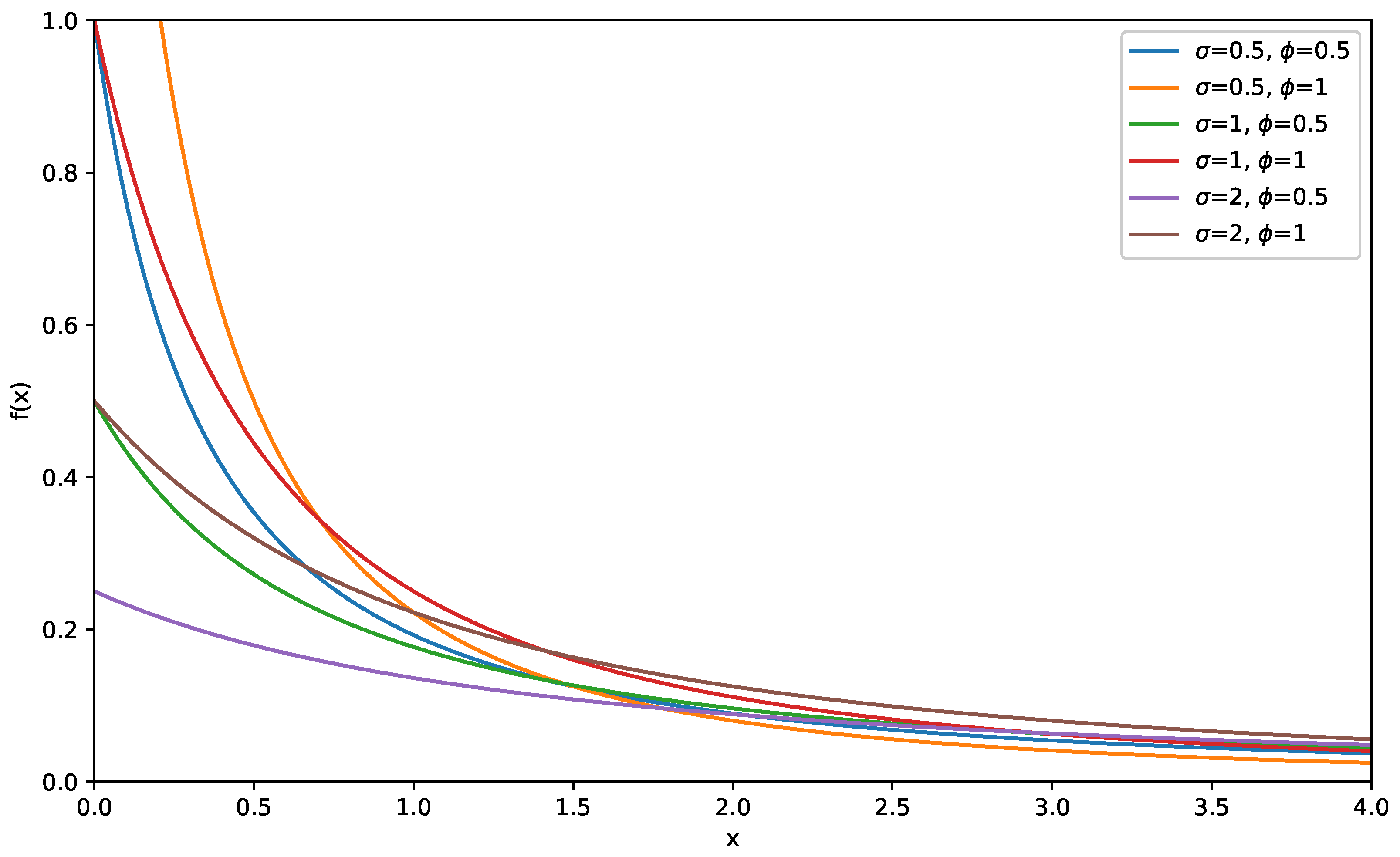
. The cumulative distribution function (CDF) is defined as follows:
Moreover, its corresponding probability density function (PDF) is expressed as follows:
In these functions,
represents the scale parameter, while
denotes the shape parameter.
Figure 2 and
Figure 3 present graphs illustrating the CDF and PDF of the LD for various values of
and
.
We assume that the lifetimes of the n units from product Pop-A, denoted as , are independent and identically distributed (i.i.d.) random variables that follow the Lomax distribution, LD. Similarly, the lifetimes of the n units from product Pop-B, denoted as , are i.i.d. random variables following the Lomax distribution, LD. For a given B-JPC scheme R, the observed sample data are expressed as , where represents the failure time at the i-th instance. The indicator denotes the population from which the failure originates: corresponds to a failure occurring in Pop-A, while indicates a failure in Pop-B. The total number of failures in Pop-A is given by , whereas the number of failures in Pop-B is .
3. Classical Estimation
3.1. Maximum Likelihood Estimators
Based on the censoring mechanism described above, the contribution of
to the likelihood is
The contribution of
to the likelihood is given by
Hence, the contribution of a general
can be written as
Therefore, the likelihood function of the unknown parameters
based on the removal pattern
R and the observed data is given by
The log-likelihood function corresponding to (
3) can be expressed as follows:
Therefore, the normal equations are derived by computing the partial derivatives of the log-likelihood function (
4) and equating them to zero, as demonstrated below.
To obtain the MLEs of
,
,
, and
, we need to solve Equations (
5) to (
8) simultaneously. However, due to their complexity, deriving closed-form solutions for each parameter is not practical. Hence, numerical approaches like the Newton–Raphson method are commonly employed for parameter estimation.
3.2. Approximate Confidence Interval
The second-order partial derivatives of the log-likelihood function (
4) with respect to
,
,
, and
result in
.
Thus, we obtain the Fisher information matrix. Furthermore, by inverting the observed Fisher information matrix, we obtain the observed variance–covariance matrix of
, which provides the estimated variances of the MLEs. Based on the asymptotic normality of the MLEs, we can further compute the approximate
ACIs for
as
where
is the percentile of the standard normal distribution with right-tail probability
.
3.3. Bootstrap Confidence Interval
Bootstrap resampling is a powerful technique used to estimate the statistical accuracy of a sample by repeatedly sampling from the original dataset, with replacement, to create multiple resampled datasets. These resamples allow researchers to estimate the variability of various statistics, including biases, standard errors, and confidence intervals, without making strict assumptions about the underlying data distribution.
In cases with small sample sizes, traditional methods like normal approximations may fail, but bootstrap methods can be particularly effective as they do not require large sample sizes or specific distributional assumptions. This makes bootstrap a valuable tool when large samples are not feasible or when traditional methods are unreliable.
Specialized bootstrap algorithms, such as bootstrap-P (Boot-P) and bootstrap-T (Boot-T), are commonly used to construct confidence intervals for unknown parameters. Algorithms 1 and 2 offer a non-parametric approach to statistical inference, providing more flexibility and robustness in estimating uncertainty.
Boot-P is a straightforward method for quickly estimating confidence intervals, particularly useful when bias correction is not a primary concern. It is simple to implement and provides confidence intervals based on percentiles, which makes it easy to interpret and understand. However, its main limitations lie in its potential imprecision, especially when applied to small sample sizes or skewed data, which can lead to less accurate estimates. Additionally, Boot-P does not address any bias present in the original estimator, making it less suitable in situations where bias correction is important. The steps for implementing Boot-P are outlined in Algorithm 1.
| Algorithm 1 Boot-P method |
- 1:
Based on the original sample , the MLEs of the parameters , , and can be estimated by solving Equations ( 5)–( 8). - 2:
Using the estimated values and , a bootstrap B-JPC sample, denoted as , is generated. - 3:
Compute the bootstrap estimates of , , and from the bootstrap sample, denoted as and . - 4:
Repeat steps 2 and 3 N times to obtain and , where . - 5:
Arrange and in ascending order as and , where . - 6:
The approximate Boot-P CI for , , and is given by The symbol [] is used here to denote the floor function, rounding down to the greatest integer less than or equal to the given value.
|
Boot-T is used when dealing with small sample sizes or when there is suspicion that the distribution of the statistic is not symmetric. Boot-T is more robust for small samples compared to Boot-P and provides improved accuracy, particularly when the distribution of the statistic deviates from symmetry. However, it is somewhat more complex to implement than Boot-P, requiring additional steps. While it still may introduce some bias, it tends to result in less bias compared to Boot-P. The steps for implementing Boot-T are outlined in Algorithm 2. Our samples are independent; thus, the Bootstrap methods are valid in analysis.
| Algorithm 2 Boot-T method |
- 1:
Follow the same steps 1 to 3 as in the Boot-P procedure outlined in Algorithm 1. - 2:
Calculate the bootstrap-T statistics , , and as follows:
where is given by using FIM like function (??). - 3:
Repeat Steps 1 and 2 N times to obtain , , for . - 4:
Sort in ascending order as , , . - 5:
The approximate Boot-T CI for , , and are given by
|
4. Bayes Estimation
In this section, we consider the lifetimes of n units from product Pop-A, denoted as , which are i.i.d. random variables following the Lomax distribution, LD(). Similarly, the lifetimes of n units from product Pop-B, represented as , are also i.i.d. and follow the Lomax distribution, LD().
Under a given B-JPC scheme R, defined by , the observed sample data are recorded as , where denotes the failure time at the i-th instance. The indicator specifies the population of origin: signifies a failure from Pop-A, whereas indicates a failure from Pop-B. The total number of failures from Pop-A is given by , while the failures from Pop-B amount to .
4.1. Prior and Posterior Distribution
In Bayesian inference, prior and posterior distributions are fundamental tools for managing uncertainty and enhancing our understanding of model parameters. Prior distributions capture our initial beliefs about the parameters before any data are observed, allowing us to incorporate domain-specific knowledge into the analysis. Once we observe data, Bayes’ theorem helps us update these beliefs, producing posterior distributions that reflect the revised understanding of the parameters based on new evidence. This process is vital for making informed decisions and achieving more accurate estimates. Prior distributions integrate external knowledge, while posterior distributions reveal insights not only about the parameter estimates but also the uncertainties associated with them. Ultimately, the proper use of both prior and posterior distributions is at the heart of Bayesian inference, offering a powerful and flexible framework for statistical analysis across diverse fields.
As all parameters are inherently unobservable, joint conjugate priors are excluded. Since the parameters must be non-negative, which aligns with the value range of the Gamma distribution, we assume that
,
,
, and
follow Gamma distributions. Furthermore, we assume
, where
i = 1, 2, 3, 4. From these assumptions, we derive the following relationships:
By using the prior distribution for
,
,
, and
, we obtain the joint prior distribution as follows:
Given
R and data, the joint posterior density function of
,
,
, and
can be expressed as follows:
However, it is important to note that the conditional posterior distributions of
,
,
, and
, as outlined in the functions (
11)–(
14), cannot be analytically simplified into standard distributions. As a result, direct sampling using conventional methods may be difficult. Nevertheless, these distributions resemble the normal distribution.
Evidently, directly solving the equation is impractical. Therefore, we utilize MCMC sampling to obtain Bayesian estimates, incorporating both the SE and LINEX loss functions.
4.2. Estimation Under SE and LINEX Loss Function
The SE loss function is expressed as follows:
In this function,
is a function of
denotes the SE estimate of
The Bayes estimator under a quadratic loss function is obtained as the expectation of the posterior distribution.
The SE loss function is widely used due to its broad applicability. Its symmetry ensures that overestimation and underestimation are penalized equally. However, in life-testing situations, the impact of estimation errors can vary, with one type potentially causing more significant consequences than the other. To address this asymmetry, the LINEX loss function is introduced, which is formulated as follows:
retains its previous definition, while represents the LINEX estimate of . The shape parameter l controls both the direction and degree of asymmetry in the loss function. When , overestimation is penalized more than underestimation, while the opposite occurs for . As l approaches zero, the LINEX loss function becomes similar to the symmetric SE loss function. At , the asymmetry is significant, heavily penalizing overestimation. For , the loss function increases nearly exponentially when , but decreases almost linearly when .
The corresponding Bayes estimate
is determined as follows:
As analytical solutions are unattainable, the Metropolis–Hastings algorithm is used to approximate explicit expressions for and and to construct their confidence intervals.
4.3. Metropolis–Hastings Algorithm
We assume that the joint posterior density function (
10) follows a multivariate normal distribution, with MCMC samples generated using the Metropolis–Hastings method, as outlined in Algorithm 3.
The initial burn-in period consists of
samples. Next, the Bayes estimates of
are obtained based on the SE loss function, as given by
Finally, the Bayes estimates of
are computed using the LINEX loss function:
| Algorithm 3 Outlines the procedure steps for the M-H algorithm |
- 1:
- 2:
Set j to 1. - 3:
Generate from a Gamma distribution with parameters - 4:
Generate from a Gamma distribution with parameters - 5:
Use the M-H algorithm to sample and from the normal proposals and , where and are derived from the main diagonal of the inverse FIM. (i) Generate proposal values from their respective normal distributions. (ii) Calculate the acceptance probabilities as follows: (iii) Sample u from a uniform distribution over the interval (0,1). (iv) Update ,and based on the acceptance probabilities: If , accept and update ; otherwise, keep . If , accept and update ; otherwise, keep . - 6:
Put j = j + 1. - 7:
- 8:
To compute the credible intervals (CRIs) for and , arrange and , for , in ascending orden as follows: and Then, calculate the CRIs for or as .
|
5. Simulation Study and Data Analysis
In this section, we assess the outcomes of a Monte Carlo simulation study designed to evaluate the effectiveness of the inference techniques discussed earlier. Additionally, we provide an example to illustrate the inference methods presented.
The experiment was carried out using R, with the code written in RStudio version 2024.12.0+467. The RStudio environment runs on Windows 10 (64-bit), and the experimental computer was equipped with an 11th Gen Intel i5-11320H CPU.
5.1. Simulation Study
This study aims to evaluate the efficiency and accuracy of different estimation methods for balanced joint progressively Type-II censored Lomax populations. To achieve this, a comprehensive simulation study is conducted. The study focuses on evaluating the accuracy and efficiency of different estimation techniques when applied to censored data from Lomax distributions with varying scale and shape parameters. The detailed procedure for generating the B-JPC data is outlined in Algorithm 4.
| Algorithm 4 Generate the B-JPC sample from Lomax distribution |
- 1:
Initialize parameters and . - 2:
Generate from Lomax and sort as . - 3:
Generate from Lomax and sort as . - 4:
Compute , set if , otherwise set . - 5:
Compute , where . Set if , otherwise set , - 6:
Thus, represent the required B-JPC sample derived from the Lomax distribution.
|
Let the sample sizes be . Additionally, various selections are made for the B-JPC, particularly with k values of , and 75.
We initialize the unknown parameters as
and then compute the MLEs along with the 95% confidence intervals for these parameters across all specified scenarios. We use the true parameter values as the initial values for the MLEs and confidence intervals. This process is repeated 1000 times, and the mean values of the MLEs, along with their corresponding intervals, are calculated. Additionally, we report the average length (AL) and coverage percentages (CPs) for each scenario. The results are presented in
Table 1,
Table 2,
Table 3 and
Table 4, with specific notations used to represent different censoring schemes. For example,
means
Furthermore, informative Gamma priors are utilized for
in Bayesian estimation under SE and LINEX loss functions, with calculations performed using the M-H algorithm. For informative priors, the hyperparameters are specified as
and
. We adopted the approach outlined by Almuhayfith [
22], where the prior mean is aligned with the true parameter value. For the non-informative priors, all hyperparameters are set to
. We set the step size to 1.5, and since the posterior distribution in our study is unimodal and relatively symmetric, we used a normal distribution as the proposal distribution. To ensure algorithm efficiency, we performed 20,000 iterations, with the initial value set to the log of the true value. Additionally, we controlled the acceptance probability to approximately 30% to balance the acceptance rate and improve the convergence of the Markov chain.
Through simulations, Bayes estimates and 95% CRIs for
are obtained via MCMC with 10,000 samples.
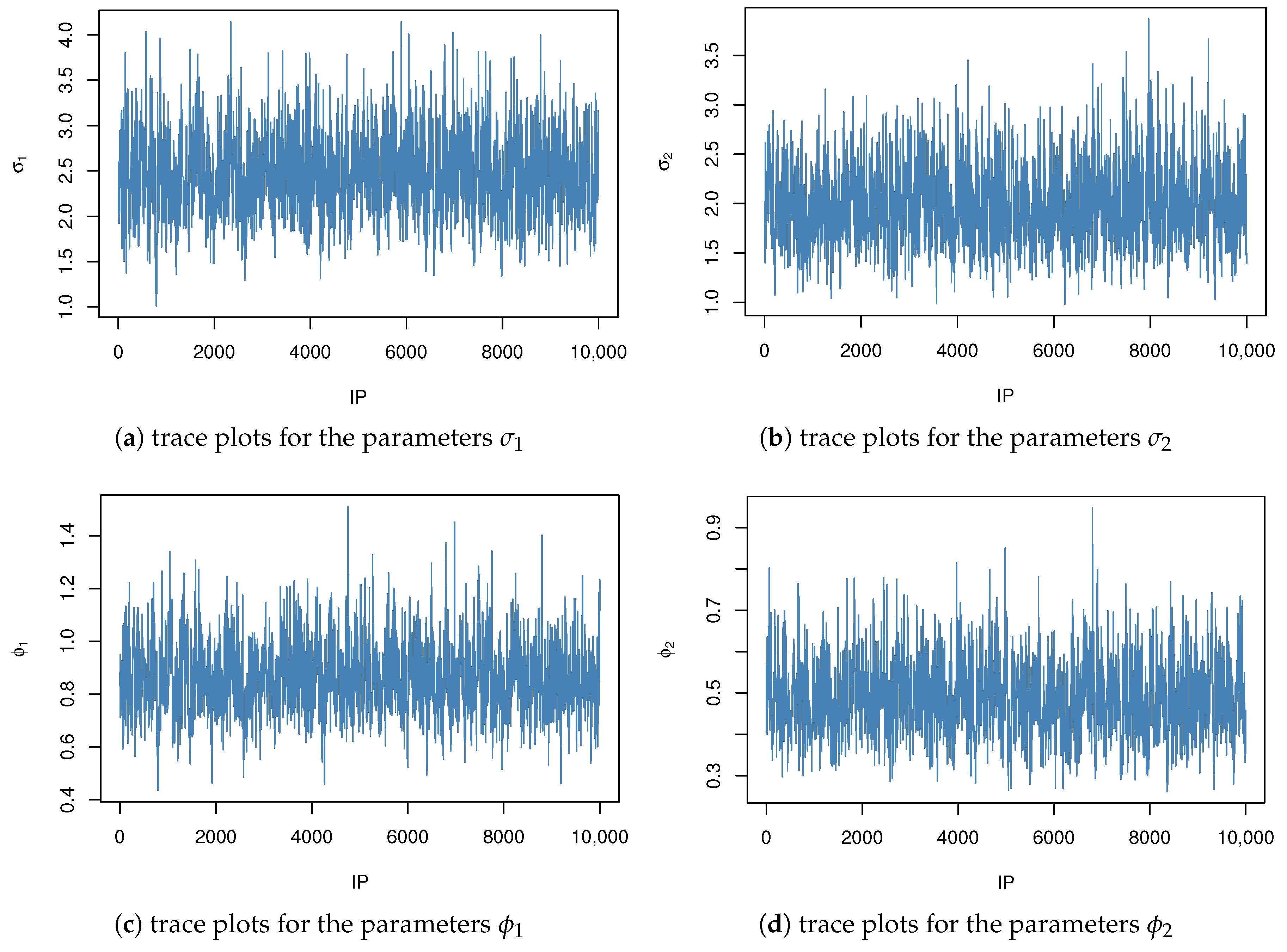
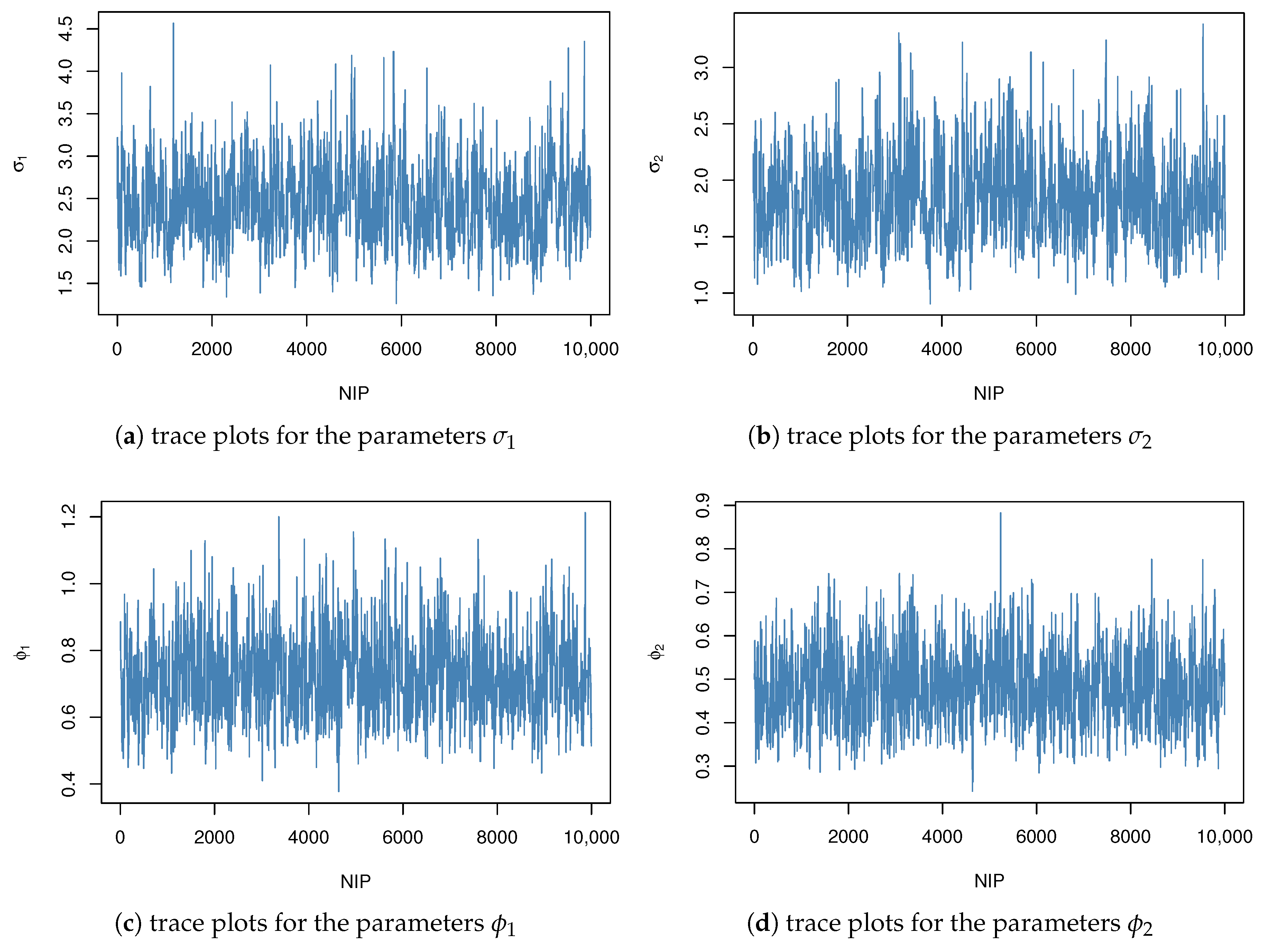
Figure 4 and
Figure 5 display the trace plots of the posterior samples under informative and non-informative priors, respectively. The convergence of the Markov chains was assessed using the Gelman–Rubin diagnostic, yielding a potential scale reduction factor of
. This value, being sufficiently close to 1, indicates satisfactory convergence and reliable mixing of the chains.
Table 1,
Table 2,
Table 3 and
Table 4 reflect that the MSEs of the unknown parameter estimation become smaller as the sample size increases and the lengths of the confidence intervals also decrease. The MSEs of
and
are smaller than those of
and
in most cases. The confidence intervals of
and
are generally longer than those of
and
. Among the two types of bootstrap confidence intervals, the approximate confidence intervals have a longer AL, while the bootstrap confidence intervals exhibit higher coverage probabilities. Furthermore, the Boot-T method demonstrates better accuracy than the Boot-P method, and we recommend using the Boot-T method for calculating confidence intervals.
From
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11 and
Table 12, it can be seen that in the Bayesian statistical method, across different censoring schemes, the MSEs of the unknown parameter estimates remain relatively consistent, indicating that variations in censoring schemes have minimal impact on estimation accuracy. Additionally, the estimates of
and
exhibit relatively small biases and MSEs, suggesting that these parameters are estimated with high accuracy and stability. In contrast,
consistently has the highest MSE, indicating greater uncertainty in its estimation, which may require more refined methods to improve precision. When comparing estimation methods, the SE and LINEX methods yield similar MSEs and ALs. Furthermore, MLEs exhibit lower biases and MSEs than Bayesian estimates and demonstrate greater stability across different censoring schemes, further highlighting their superiority in practical applications. Regarding the Bayesian estimates with non-informative priors, as the sample size increases, we observe that the MSE decreases and the coverage rate increases. However, the results do not outperform those obtained using informative priors. This finding underscores the importance of selecting appropriate priors in Bayesian inference to achieve optimal results.
5.2. Real Data Analysis
This section presents an analysis of the real dataset to illustrate the practical application of the proposed methods.
The first dataset represents the breakdown times of an insulating fluid between electrodes at a voltage of 34 kV, measured in minutes. This dataset, sourced from [
23], is widely used in reliability analysis and serves as a standard example for studying the breakdown behavior of insulating materials under controlled electrical stress.
The second dataset records the time in months to the first failure of various small electric carts used for internal transportation and delivery within a large manufacturing facility. This dataset, which was initially sourced from Zimmer [
24], provides valuable real-world failure data for mechanical systems in industrial environments, making it particularly relevant to our analysis of system reliability in operational settings.
Hasaballah [
21] also analyzes these data. To conform with the assumptions of this study, only the first 19 failure times are utilized. The dataset provided in
Table 13 comprises the following.
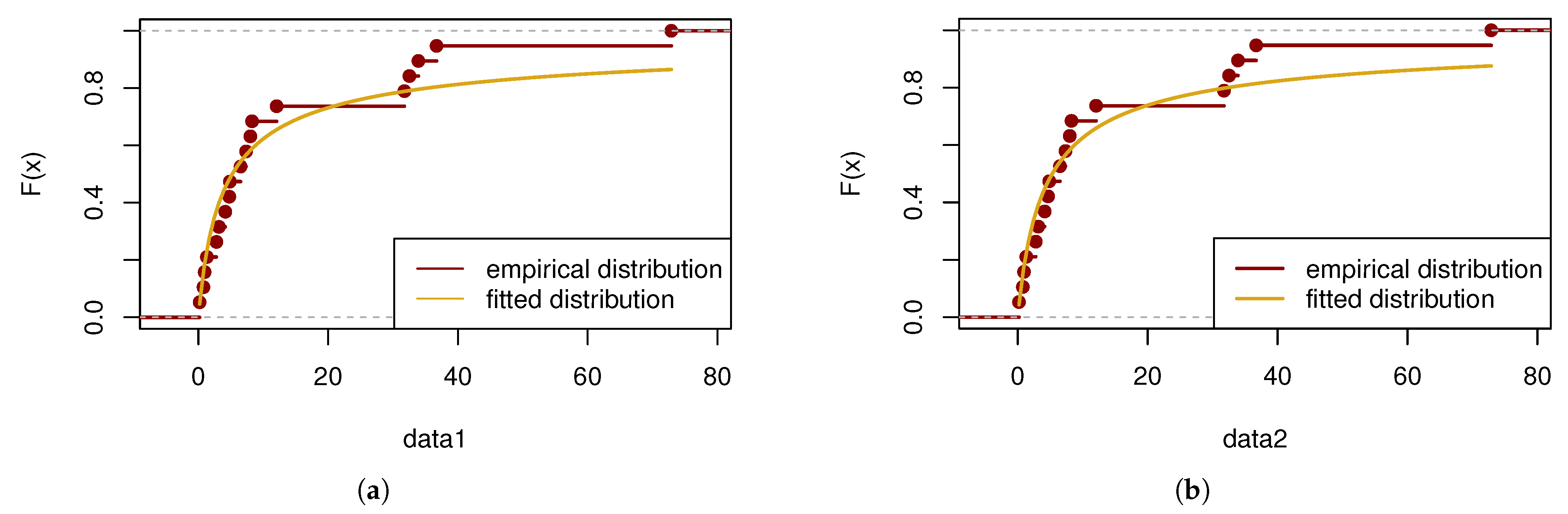
In this part, a goodness-of-fit test is performed using the Kolmogorov–Smirnov (K-S) statistic. The calculated
p value for the first sample is 0.7998, while for the second sample, the
p value is 0.5906. The results of the test are visually presented in
Figure 6.
Using Algorithm 5 to analyze real data, the following statistical inferences were obtained.
Among the various censoring schemes, the one described above achieves the smallest MSEs for
,
,
, and
, along with the highest accuracy.
| Algorithm 5 Pseudocode for classical statistical and Bayesian estimation methods on real data |
- 1:
Perform Kolmogorov-Smirnov (K-S) test to verify if both populations follow Lomax distribution. - 2:
Set and R. Generate the B-JPC sample from Lomax distribution in Algorithm 4. - 3:
Calculate the likelihood function based on Fnction ( 3). - 4:
Use R language’s ‘optim’ function to compute the MLE for the parameters. - 5:
Compute the Fisher information matrix and take its inverse to obtain the covariance matrix for the ACI. - 6:
Set a gamma prior such that the prior mean is close to the MLE estimate. Apply Algorithm 3 to compute the Bayesian estimate using the information prior.
|
Using the MLE method, we estimate
,
,
, and
based on the data type in this study. The results are summarized in
Table 14.
For Bayesian estimation, the MCMC method is implemented with 10,000 iterations.The Bayesian estimates of
, and
are computed under both SE and LINEX loss functions, with the results summarized in
Table 14.
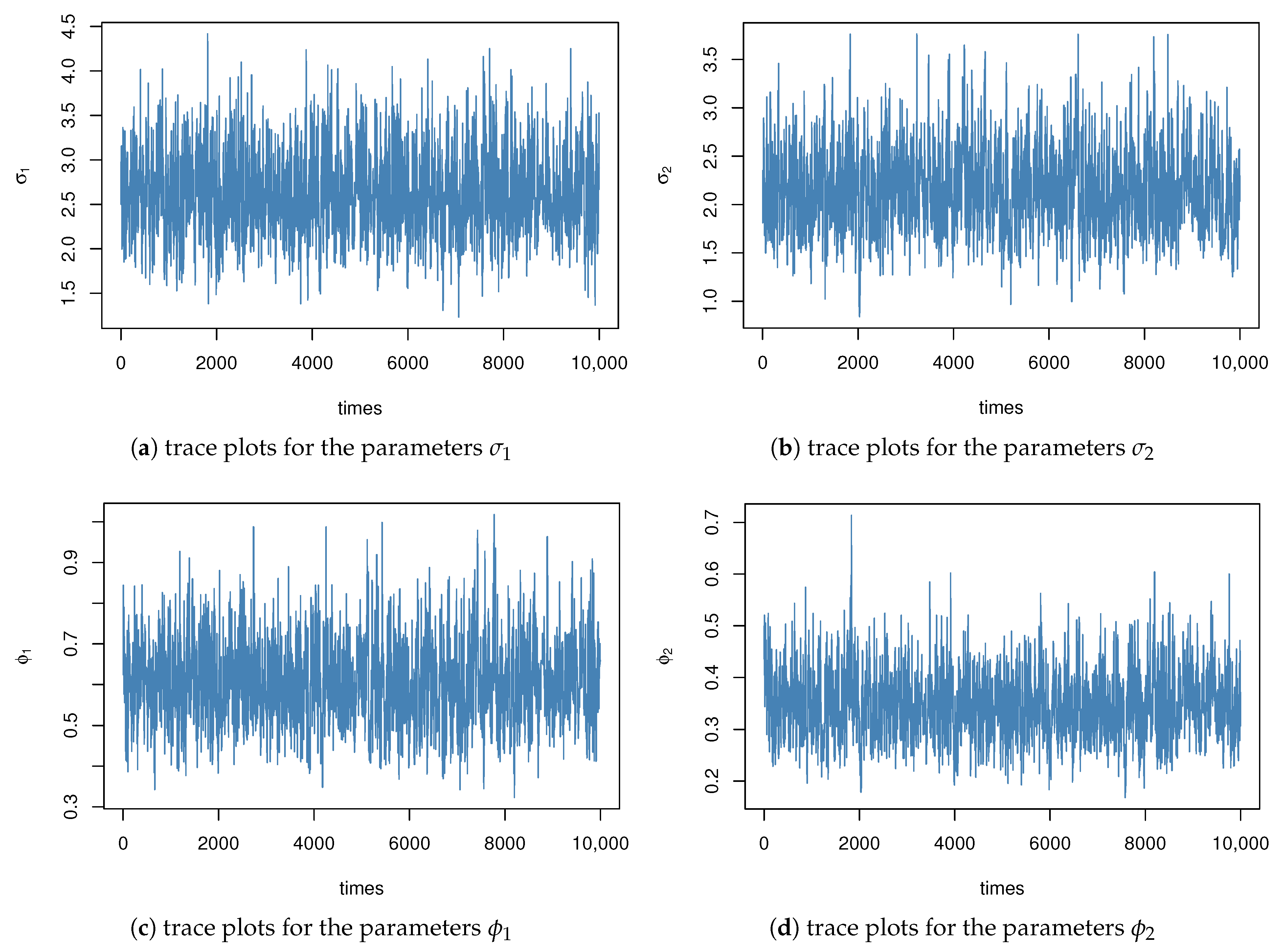
Figure 7 displays the trace plots of the posterior samples under informative priors.
The data indicate that the AMLE values are reasonable and closely align with previous studies. Additionally, our method produces narrower 95% confidence intervals, which highlights its advantages in practical applications. Furthermore, the Bayesian estimates calculated using two different loss functions are quite similar, demonstrating the robustness of our method.
6. Conclusions
This study employs both maximum likelihood estimation and Bayesian inference to estimate unknown parameters under the B-JPC framework. Since explicit MLE solutions and closed-form Bayesian estimators are unavailable, numerical methods are utilized alongside Gamma priors to facilitate parameter estimation. The Markov Chain Monte Carlo method is implemented under both squared error and linear exponential loss functions, ensuring a comprehensive analysis of parameter behavior under different estimation criteria.
To validate the proposed methods, real datasets are analyzed, and extensive simulation studies are conducted to assess their performance across varying sample sizes. The results indicate that as the sample size increases, the MSEs of the unknown parameters decrease, and the lengths of the confidence intervals shorten accordingly. When comparing the two types of bootstrap confidence intervals, the Boot-T method demonstrates better accuracy, and it is recommended for practical use. The Bayesian method shows stability across different censoring schemes. Although Bayesian estimates with non-informative priors improve as the sample size increases, they are still less precise compared to those obtained with informative priors. This finding emphasizes the importance of selecting appropriate priors in Bayesian inference to achieve more accurate estimation results.
Moving forward, this research will be extended to two distinct populations characterized by different Lomax distribution parameters and sample sizes. Additionally, sensitivity analysis will be conducted for the Bayesian statistical inference, further enhancing the robustness of the results. This study aims to explore parameter estimation under a balanced joint progressive Type-II censoring scheme, further expanding the applicability of comparative lifetime experiments. A comprehensive comparison between traditional methods and the BJPC method, including performance metrics such as accuracy, efficiency, and robustness, is a valuable next step.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}