To verify the effectiveness of the proposed approach, we experimented with five different problem types, and measured cpu times to make a comparison possible. We have implemented BoxCQP in Fortan 77 and used a recent Intel processor with a Linux operating system and employed the suite of the GNU gfortran compiler.
In the subsections that follow, we describe in brief the different test problems used for the experiments, and report our results.
4.1. Random Problems
The first set of experiments treats randomly generated problems. We generate problems following the general guidelines of [
32]. Specific details about creating these random problems are provided in the
Appendix A.1.
For every random problem class, we have created Hessian matrices with three different condition numbers:
Using = 0.1 and hence, ;
Using = 1 and hence, ;
Using = 5 and hence, .
The results for the three variants of BoxCQP against the other quadratic codes for the classes (a), (b), and (c) and for three different condition numbers are shown in
Table 1,
Table 2, and
Table 3, respectively. In each table, alongside the execution times of the competing solvers, we include additional columns presenting their rankings for the specific case. These rankings serve to facilitate a more general interpretation and comparison of the results.
The results presented in
Table 3 show that across all conditioning levels, computational time increases with problem size, as expected. Variant 1 (
decomposition) performs well for small-to-moderate problem sizes but suffers from scalability issues as the problem dimension increases, particularly in ill-conditioned cases where factorization becomes computationally expensive. In contrast, Variant 2 (conjugate gradient) exhibits greater robustness for ill-conditioned problems but is slower than direct decomposition for well-conditioned cases. The hybrid Variant 3 provides the best overall performance, maintaining lower runtimes across different problem sizes and conditioning levels.
Comparing BoxCQP to the antagonistic solvers, QUACAN performs well on small problems but becomes inefficient for large-scale and ill-conditioned cases. QPBOX and QLD exhibit competitive runtimes, with QLD showing the best efficiency in large, ill-conditioned scenarios. BoxCQP Variants 2 and 3 consistently outperform QUACAN, making them preferable for difficult optimization problems. In this case, BoxCQP Variant 3 emerges as the most effective approach, striking a balance between computational efficiency and robustness to ill-conditioning.
Considering the results presented in
Table 4 and
Table 5, we can see that for the most ill-conditioned cases, Variant 1 (LDL) becomes prohibitively expensive, and methods using iterative methods (Variants 2 and 3) become more favorable. On the other hand, for the well-conditioned cases, iterative BoxCQP variants outperform the LDL one. Among the other solvers, QUACAN struggles significantly with ill-conditioned problems and large problem sizes, often displaying dramatically increased runtime, particularly for
. QPBOX and QLD scale more effectively, with QLD consistently outperforming QUACAN in all problem sizes. However, BoxCQP Variants 2 and 3 maintain superior performance over QUACAN and, in all cases, are better than QPBOX and QLD.
Overall, the results confirm that when most variables reside on the bounds, BoxCQP Variant 3 is the most practical choice, as it combines the advantages of both and CG, adapting well to different problem conditions. Variant 1 remains suitable for well-conditioned small problems, whereas Variant 2 is preferable for handling ill-conditioned, large-scale problems.
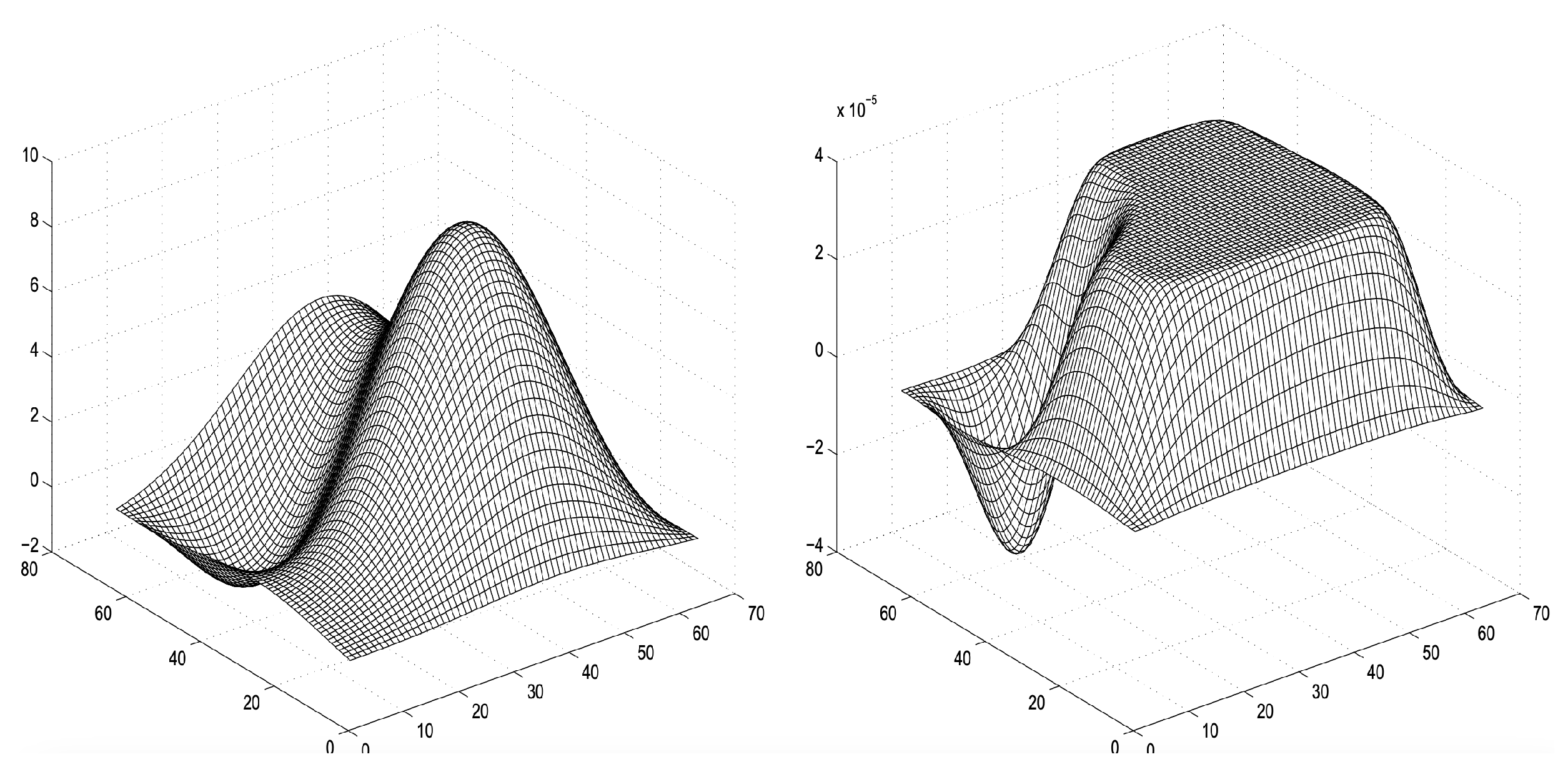
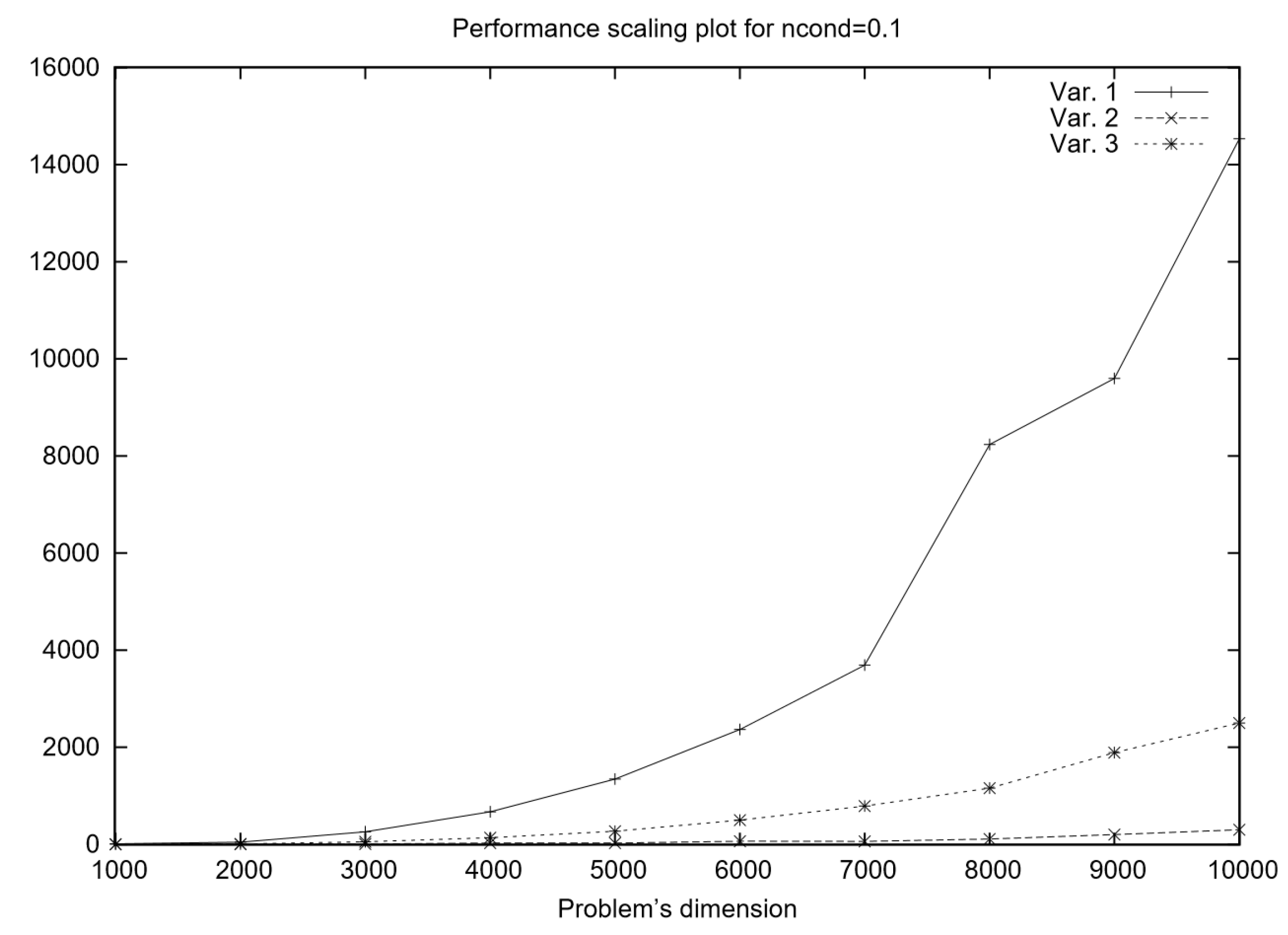
The performance scaling plot in
Figure 2 compares the runtime of three algorithmic variants for solving well-conditioned problems, where half of the variables are fixed on bounds. The primary computational task in the algorithm is solving a linear system at each iteration, and the three variants differ in their approach to this task. We can an infer that for small problem sizes, the differences between the three variants are relatively minor. However, as the problem size grows, Variant 1 (
decomposition at every iteration) exhibits the steepest runtime increase due to the high cost of repeated factorizations. Meanwhile, Variant 2 (CG throughout) shows much better scalability, with its runtime growing at a slower rate, making it preferable for large-scale problems. Variant 3 (hybrid) likely demonstrates an intermediate performance profile, outperforming Variant 1 in terms of efficiency while maintaining better numerical robustness than Variant 2.
In summary, if computational speed is the primary concern, Variant 2 (CG) is the most scalable option, particularly for large problem sizes. If numerical stability and accuracy are the priority, Variant 1 () is the most robust but at the cost of significantly higher computation time. Variant 3 (hybrid) emerges as an optimal middle-ground approach, balancing efficiency and stability by combining iterative and direct methods. The performance-scaling trends confirm these expectations, with Variant 1 becoming increasingly costly, Variant 2 scaling efficiently, and Variant 3 offering a competitive compromise.
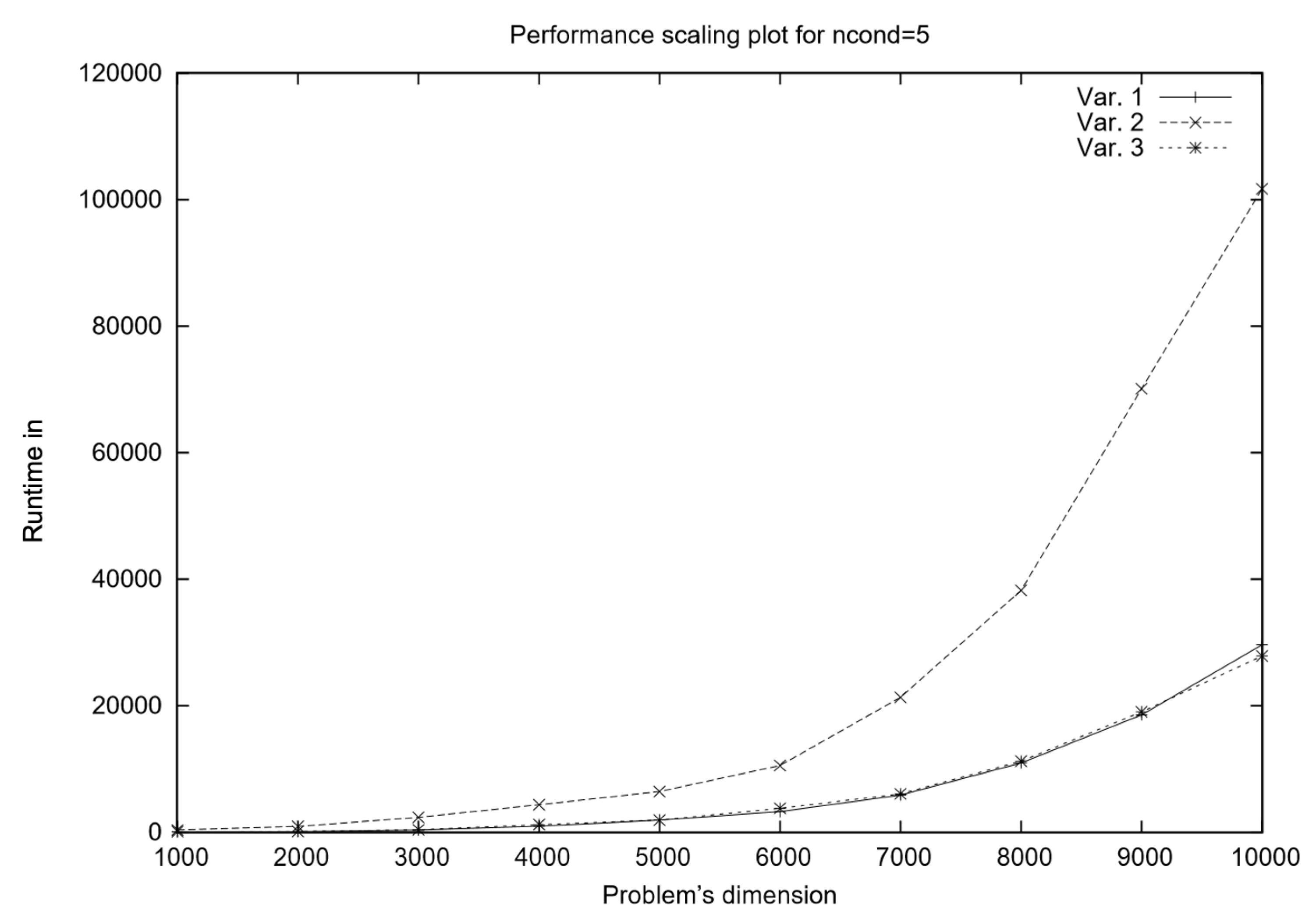
For ill-conditioned problems (see
Figure 3, the performance-scaling behavior of the three algorithmic variants shifts significantly compared to well-conditioned problems. In such cases, the system matrix exhibits a high condition number, which impacts both direct and iterative solution methods differently.
From the runtime trends observed in
Figure 3 in the new performance scaling plot, it appears that Variant 1 (
) performs better than in the well-conditioned scenario. This is likely due to the fact that
decomposition, being a direct method, remains robust even when the system matrix is poorly conditioned. Unlike iterative methods, which suffer from slow convergence or numerical instability when the condition number is large,
maintains accuracy at the cost of higher computational effort per iteration. However, in ill-conditioned problems, iterative solvers such as the conjugate gradient (CG) method (used in Variant 2) may require significantly more iterations to converge, making them less efficient overall. This explains why Variant 1, despite its higher theoretical complexity, outperforms the other two methods in this setting.
Variant 3 balances these trade-offs effectively by leveraging the fast initial approximations of CG while maintaining the stability of in subsequent iterations. While CG may struggle with slow convergence in ill-conditioned problems, using it only in the first iteration can still provide a useful initial guess that reduces the effort needed for decomposition later on. This reduces the total computational burden of while still ensuring that subsequent iterations remain numerically stable.
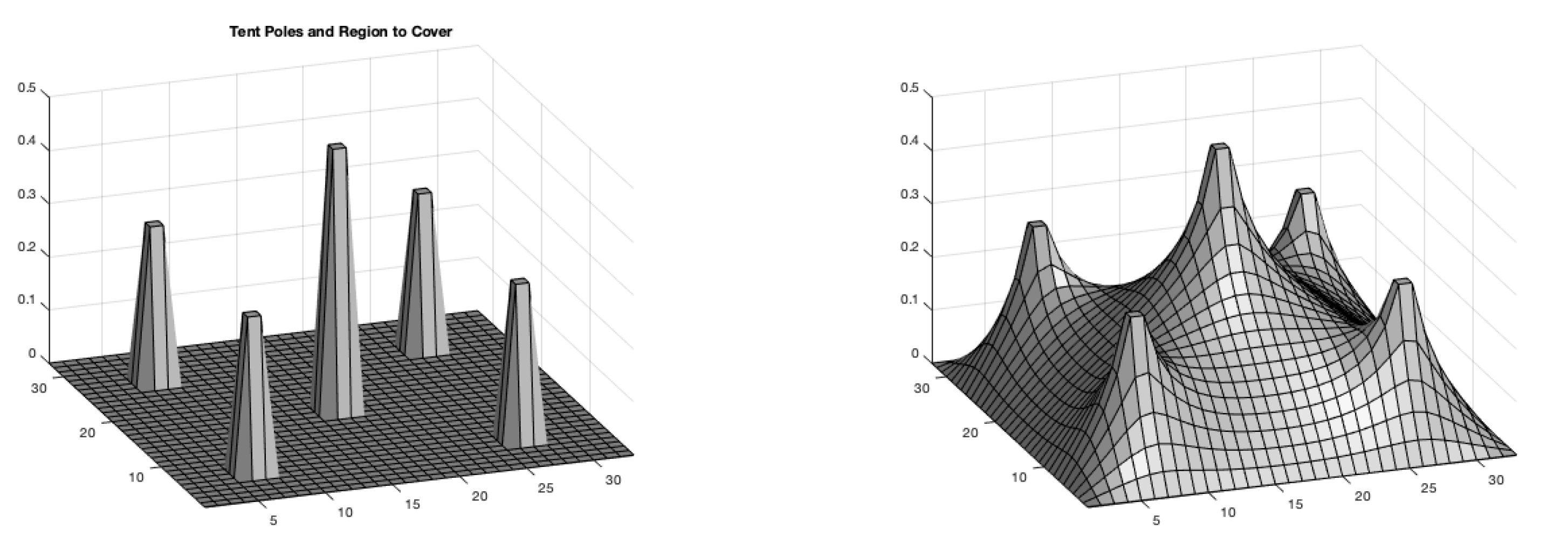
4.2. Circus-Tent Problem
The circus-tent problem serves as a foundational case that highlights how mathematical optimization techniques can be applied to real-world engineering challenges. Its formulation as box-constrained quadratic programming problem is described in detail in
Appendix A.2.
Table 6 presents execution times for different solution approaches to the circus-tent problem across increasing problem sizes, measured in seconds. As the problem size grows, Variant 1 becomes increasingly expensive due to the repeated direct factorization, reaching 1333.51 s for
. Variant 2, relying entirely on the iterative CG method, exhibits significantly better scalability, with execution time increasing more gradually to
s at
. Variant 3, which blends iterative and direct methods, initially performs better than Variant 1 but eventually shows similar growth in execution time, reaching
s for the largest problem size. Among the solvers compared, QUACAN successfully solves only the smallest in negligible time but fails for larger cases. QPBOX is unable to solve any instance, as indicated by the NC values across all entries. QLD, however, demonstrates competitive performance, outperforming Variant 1 and Variant 3 for larger problems, reaching
s for
.
From these results, Variant 2 (conjugate gradient method) proves to be the most efficient and scalable, particularly for larger problem sizes, making it the preferred choice for large-scale computations. Variant 3 (hybrid approach) offers a reasonable compromise between iterative and direct methods, performing well for small-to-medium problems before exhibiting similar computational demands to Variant 1. Variant 1 ( decomposition), while accurate, is computationally expensive and less suitable for large-scale applications. Among the solvers, QLD remains the most competitive alternative, performing consistently better than -based methods for larger problem sizes.
4.3. Biharmonic Equation Problem
The biharmonic equation arises in elasticity theory and describes the small vertical deformations of a thin elastic membrane. In this work, we consider an elastic membrane clamped on a rectangular boundary and subject to a vertical force while being constrained to remain below a given obstacle. This leads to a constrained variational problem that can be formulated as a convex quadratic programming (QP) problem with bound constraints. For more details about the formulation, see
Appendix A.3.
Table 7 presents execution times (in seconds) for different numerical methods applied to the biharmonic equation problem across increasing problem sizes. As the problem size increases, Variant 1 exhibits the steepest growth in execution time, reaching
s for the largest case (
). Variant 2, which leverages iterative solvers, scales better, achieving a significantly lower execution time of
s for the same problem size. Variant 3 strikes a balance between direct and iterative methods, showing better performance than Variant 1 but remaining slightly less efficient than Variant 2, with
s for the case
.
In the series of solver tests, QLD demonstrates superior performance compared to QUACAN and QPBOX, solving the largest problem in 1837.66 s. By contrast, QUACAN and QPBOX exhibit considerably worse scalability, with times of 8282.04 s and 3067.21 s, respectively, for . QUACAN shows effectiveness with smaller problems but becomes very inefficient as the problem size grows, whereas QPBOX follows a similar pattern, though it performs somewhat better. The findings emphasize that Variant 3 is the most scalable method, making it the optimal choice for large-scale biharmonic problems. Additionally, all BoxCQP variants outperform the competition in this scenario.
4.4. Intensity-Modulated Radiation Therapy
Intensity-Modulated Radiation Therapy (IMRT) is an advanced radiotherapy technique that optimizes the spatial distribution of radiation to maximize tumor control while minimizing damage to surrounding healthy tissues and vital organs. The goal is to deliver a precisely calculated radiation dose that conforms to the tumor shape, reducing side effects and improving treatment effectiveness.
This problem is typically formulated as a quadratic programming (QP) task, where the objective is to determine the optimal fluence intensity profile for a given set of beam configurations. The radiation dose distribution can be represented as a linear combination of beamlet intensities, allowing for a mathematical optimization approach. Given a set of desired dose levels, the optimal beamlet intensities are computed by solving a quadratic objective function that minimizes the difference between the prescribed and delivered doses. The optimization constraints include dose limits for critical organs and physical feasibility conditions. In
Appendix A.4, we present in some details the derivation of the formulation.
In practical applications, inverse treatment planning in IMRT requires solving a quadratic optimization problem of the form shown in Equation (
9) multiple times, as beam configurations are iteratively adjusted to meet clinical constraints. Since the process involves large-scale quadratic systems, efficient solvers are essential to ensure fast and accurate treatment planning.
Table 8 showcases findings derived from actual data generously shared by S. Breedveld [
34]. In this scenario, seven beams are integrated, leading to a quadratic problem comprising 2342 parameters. In this instance, Variants 2 and 3 exhibit superior performance, outperforming their counterparts by a factor of two.
4.5. Support Vector Classification
To create the problem for the case of Support Vector Classification, we used the CLOUDS dataset [
35] a well-estabalished two dimensional and two-class classification task. The specifics of the quadratic programming formulation are provided in the
Appendix A.5. We run different experiments for an increasing number of CLOUDS datapoints. From
Table 9, we can see that Variant 1 experiences significant growth in execution time, reaching
s for
, making it the least efficient among the three variants. In contrast, Variant 2 scales much better due to its reliance on iterative methods, requiring
s for the largest problem. Variant 3, which combines both iterative and direct methods, shows even better performance than Variant 1 for larger problems, reducing execution time to
s at. When comparing solver performance, QUACAN, QPBOX, and QLD also display increasing execution times as problem sizes grow. QUACAN shows relatively poor scalability, requiring
s for
, making it the slowest solver in the test. QPBOX, while performing better, still struggles with larger problem sizes, reaching
s at
. QLD, is completing the largest problem in
s, yet still significantly slower than Variants 2 and 3. These results highlight that Variant 2 (conjugate gradient method) is the most scalable approach, making it the preferred choice for large-scale SVM problems. Variant 3 (hybrid approach) still offers the best balance between iterative and direct solvers. Therefore, the findings suggest that a combination of CG-based techniques is optimal for solving large-scale SVM optimization problems efficiently.
4.6. Summarizing Fortran Experimental Results
The performance of the six solver variants—Variant 1, Variant 2, Variant 3 versus QUACAN, QPBOX, and QLD—was evaluated across a diverse set of convex quadratic programming problems.
Each case revealed different characteristics of the solver behavior. In the random problem set, Variant 3 and Variant 2 consistently achieved the lowest average rankings ( and , respectively, on all 90 cases), indicating robust and efficient performance, especially under varying condition numbers. QUACAN followed with an average rank of , while QPBOX and QLD were generally slower ( and , respectively), reflecting their higher computational overheads.
In the context of the biharmonic scenario, characterized by structured sparse problems, Variant 3 emerged as the leader, boasting the top average rank (), with Variant 2 not far behind (). A similar pattern occurred in the circus-tent problem, where Variant 2 was clearly the standout performer, achieving the highest average rank (), while QLD followed in second place (), demonstrating its effectiveness for structured geometric problems when feasible. For SVM classification tasks, Variant 2 excelled, with an average rank of , and was trailed by Variant 3 and Variant 1. Meanwhile, QLD and QPBOX showed inferior performance, especially with large datasets, due to scaling challenges. In the singular IMRT instance, Variant 2 along with Variant 3 were rated highest, emphasizing their competitiveness even in substantial real-world applications.
In
Table 10 we present aggregated ranking results for all the test problem cases. When evaluating all problems together, the aggregate average ranking supports the prior findings. Variant 3 and Variant 2 secured top overall rankings of
and
, respectively, with Var.1 following at
. Among the other solvers, QUACAN occupied a central rank of
, while QPBOX and QLD frequently ranked lower at
and
, respectively. These outcomes highlight the robustness and versatility of the proposed BoxCQP variants, particularly Var.2 and Var.3, which effectively balance speed and dependability across diverse problem categories.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}