Figure 1.
High-Level Architecture of the Harmonizer Framework. This schematic shows the end-to-end pipeline: (1) Input Preprocessing: raw text, audio, and video are converted into STFT spectrograms, analytic signals via the Hilbert transform, and contrast-enhanced via SCLAHE; (2) Feature Encoding: FluxHead applies streaming multi-head attention to extract temporal and spectral cues; (3) Tokenization: FusionQuantizer vector-quantizes these features into discrete tokens, building a learned signal vocabulary; (4) Streaming Inference: FluxFormer uses sliding-window transformers to generate tokens on-the-fly with minimal latency; (5) Optimization: a multi-objective loss (adversarial, L1/L2 time-domain, STFT/Hilbert/SCLAHE spectral, and perceptual) refines reconstruction quality. The final output is a unified token sequence that any multimodal LLM can consume without additional modality-specific encoders.
Figure 1.
High-Level Architecture of the Harmonizer Framework. This schematic shows the end-to-end pipeline: (1) Input Preprocessing: raw text, audio, and video are converted into STFT spectrograms, analytic signals via the Hilbert transform, and contrast-enhanced via SCLAHE; (2) Feature Encoding: FluxHead applies streaming multi-head attention to extract temporal and spectral cues; (3) Tokenization: FusionQuantizer vector-quantizes these features into discrete tokens, building a learned signal vocabulary; (4) Streaming Inference: FluxFormer uses sliding-window transformers to generate tokens on-the-fly with minimal latency; (5) Optimization: a multi-objective loss (adversarial, L1/L2 time-domain, STFT/Hilbert/SCLAHE spectral, and perceptual) refines reconstruction quality. The final output is a unified token sequence that any multimodal LLM can consume without additional modality-specific encoders.
Figure 2.
Overlaid left-channel waveforms for a 0.25 s excerpt of low-tempo, low-dynamic vocal music (3.50–3.75 s). The solid blue trace shows the ground-truth signal, while the dashed red trace shows the Harmonizer reconstruction. The near-perfect alignment of peaks, troughs, and transient edges demonstrates high temporal fidelity and minimal phase distortion introduced by the quantization and decoding pipeline.
Figure 2.
Overlaid left-channel waveforms for a 0.25 s excerpt of low-tempo, low-dynamic vocal music (3.50–3.75 s). The solid blue trace shows the ground-truth signal, while the dashed red trace shows the Harmonizer reconstruction. The near-perfect alignment of peaks, troughs, and transient edges demonstrates high temporal fidelity and minimal phase distortion introduced by the quantization and decoding pipeline.
Figure 3.
Overlaid right-channel waveforms for a 0.25 s excerpt of low-tempo, low-dynamic vocal music (3.50–3.75 s). The solid green trace shows the ground-truth signal, while the dashed purple trace shows the Harmonizer reconstruction. The near-complete overlap of the two traces indicates excellent amplitude and phase fidelity across stereo channels.
Figure 3.
Overlaid right-channel waveforms for a 0.25 s excerpt of low-tempo, low-dynamic vocal music (3.50–3.75 s). The solid green trace shows the ground-truth signal, while the dashed purple trace shows the Harmonizer reconstruction. The near-complete overlap of the two traces indicates excellent amplitude and phase fidelity across stereo channels.
Figure 4.
Pixelwise spectrogram error percentage for the left channel of a low-tempo, low-dynamic music excerpt (clamped at the 95th percentile). The color scale indicates reconstruction error in each time-frequency bin, with most bins below 18%, demonstrating that Harmonizer maintains spectral integrity with only minor deviations.
Figure 4.
Pixelwise spectrogram error percentage for the left channel of a low-tempo, low-dynamic music excerpt (clamped at the 95th percentile). The color scale indicates reconstruction error in each time-frequency bin, with most bins below 18%, demonstrating that Harmonizer maintains spectral integrity with only minor deviations.
Figure 5.
Pixelwise spectrogram error percentage for the right channel of low-tempo, low-dynamic music (values clamped at the 95th percentile). The majority of time-frequency bins exhibit reconstruction errors below 18%, demonstrating consistent spectral fidelity across both stereo channels.
Figure 5.
Pixelwise spectrogram error percentage for the right channel of low-tempo, low-dynamic music (values clamped at the 95th percentile). The majority of time-frequency bins exhibit reconstruction errors below 18%, demonstrating consistent spectral fidelity across both stereo channels.
Figure 6.
Absolute pixelwise spectrogram error for low-dynamic music’s left channel, displayed on a logarithmic color scale to highlight subtle discrepancies across time and frequency.
Figure 6.
Absolute pixelwise spectrogram error for low-dynamic music’s left channel, displayed on a logarithmic color scale to highlight subtle discrepancies across time and frequency.
Figure 7.
Absolute pixelwise spectrogram error for low-dynamic music (right channel), shown on a logarithmic color scale to amplify subtle discrepancies across time and frequency bins.
Figure 7.
Absolute pixelwise spectrogram error for low-dynamic music (right channel), shown on a logarithmic color scale to amplify subtle discrepancies across time and frequency bins.
Figure 8.
Comparison of Mel-Frequency Cepstral Coefficients for ground truth and regenerated low-tempo, low-dynamic music in left and right channels. Near-identical envelope shapes and temporal patterns indicate accurate preservation of timbral characteristics across both channels.
Figure 8.
Comparison of Mel-Frequency Cepstral Coefficients for ground truth and regenerated low-tempo, low-dynamic music in left and right channels. Near-identical envelope shapes and temporal patterns indicate accurate preservation of timbral characteristics across both channels.
Figure 9.
Difference between ground-truth and regenerated MFCCs for low-tempo, low-dynamic music. Light regions indicate near-zero deviation in cepstral coefficients across time and frequency, while the subtle band of warmer hues in lower frequencies highlights a minor residual mismatch that remains perceptually negligible.
Figure 9.
Difference between ground-truth and regenerated MFCCs for low-tempo, low-dynamic music. Light regions indicate near-zero deviation in cepstral coefficients across time and frequency, while the subtle band of warmer hues in lower frequencies highlights a minor residual mismatch that remains perceptually negligible.
Figure 10.
MFCC error percentage (GT vs. Gen) for low-tempo, low-dynamic music with logarithmic color-bar. The predominantly blue color indicates negligible errors after clamping the 95th percentile to avoid outliers, with the maximum error reaching only about 5%.
Figure 10.
MFCC error percentage (GT vs. Gen) for low-tempo, low-dynamic music with logarithmic color-bar. The predominantly blue color indicates negligible errors after clamping the 95th percentile to avoid outliers, with the maximum error reaching only about 5%.
Figure 11.
Ground truth (GT) vs. generated (Gen) spectrograms for low-tempo, low-dynamic music. The top row represents left-channel spectrograms, while the bottom row represents right-channel spectrograms. Harmonizer preserves both broad spectral contours and finer harmonic details in low-amplitude passages. Quantitatively, over the full 288 s excerpt: left channel: PMSE = 1.4323, SSIM = 0.9887, PSNR = 47.96 dB; right channel: PMSE = 1.2548, SSIM = 0.9881, PSNR = 47.67 dB.
Figure 11.
Ground truth (GT) vs. generated (Gen) spectrograms for low-tempo, low-dynamic music. The top row represents left-channel spectrograms, while the bottom row represents right-channel spectrograms. Harmonizer preserves both broad spectral contours and finer harmonic details in low-amplitude passages. Quantitatively, over the full 288 s excerpt: left channel: PMSE = 1.4323, SSIM = 0.9887, PSNR = 47.96 dB; right channel: PMSE = 1.2548, SSIM = 0.9881, PSNR = 47.67 dB.
Figure 12.
Overlaid waveforms—left channel (section 15: 3.50–3.75 s) for high-tempo, high-dynamic music. The red regenerated waveform tracks the blue ground truth waveform closely, indicating minimal temporal or amplitude distortion.
Figure 12.
Overlaid waveforms—left channel (section 15: 3.50–3.75 s) for high-tempo, high-dynamic music. The red regenerated waveform tracks the blue ground truth waveform closely, indicating minimal temporal or amplitude distortion.
Figure 13.
Overlaid waveforms—right channel (section 15: 3.50–3.75 s) for high-tempo, high-dynamic music. The purple regenerated waveform remains nearly indistinguishable from the green ground truth, reflecting robust transient alignment.
Figure 13.
Overlaid waveforms—right channel (section 15: 3.50–3.75 s) for high-tempo, high-dynamic music. The purple regenerated waveform remains nearly indistinguishable from the green ground truth, reflecting robust transient alignment.
Figure 14.
Ground truth (GT) vs. venerated (Gen) spectrograms for high-tempo, high-dynamic music. Harmonizer captures the broad dynamic range and maintains transient accuracy, matching key spectral features from 0 Hz to 16 kHz. Quantitatively, over the full 231 s excerpt: left channel: PMSE = 5.2295, SSIM = 0.9889, PSNR = 45.98 dB; right channel: PMSE = 5.4055, SSIM = 0.9892, PSNR = 46.09 dB; mean clamped spectrogram error = 15.2% (≈3.9%).
Figure 14.
Ground truth (GT) vs. venerated (Gen) spectrograms for high-tempo, high-dynamic music. Harmonizer captures the broad dynamic range and maintains transient accuracy, matching key spectral features from 0 Hz to 16 kHz. Quantitatively, over the full 231 s excerpt: left channel: PMSE = 5.2295, SSIM = 0.9889, PSNR = 45.98 dB; right channel: PMSE = 5.4055, SSIM = 0.9892, PSNR = 46.09 dB; mean clamped spectrogram error = 15.2% (≈3.9%).
Figure 15.
Pixelwise Spectrogram error percentage (clamped at 95th percentile)—left channel for high-tempo, high-dynamic music. The primary error range near 10–15% underscores Harmonizer’s capacity for accurate spectral reconstruction in rapidly changing signals. Mean clamped error = 15.2% ( ≈ 3.9%).
Figure 15.
Pixelwise Spectrogram error percentage (clamped at 95th percentile)—left channel for high-tempo, high-dynamic music. The primary error range near 10–15% underscores Harmonizer’s capacity for accurate spectral reconstruction in rapidly changing signals. Mean clamped error = 15.2% ( ≈ 3.9%).
Figure 16.
Pixelwise spectrogram error percentage (clamped at 95th percentile)—right channel for high-tempo, high-dynamic music. Similar to the left channel, most bins remain in a modest error range, corroborating stereo consistency. Quantitatively, the mean clamped error is 15.2% ( ≈ 3.9%).
Figure 16.
Pixelwise spectrogram error percentage (clamped at 95th percentile)—right channel for high-tempo, high-dynamic music. Similar to the left channel, most bins remain in a modest error range, corroborating stereo consistency. Quantitatively, the mean clamped error is 15.2% ( ≈ 3.9%).
Figure 17.
Absolute pixelwise spectrogram error for high-dynamic music’s left channel, shown on a logarithmic color scale to emphasize subtle reconstruction deviations across frequency and time.
Figure 17.
Absolute pixelwise spectrogram error for high-dynamic music’s left channel, shown on a logarithmic color scale to emphasize subtle reconstruction deviations across frequency and time.
Figure 18.
Absolute pixelwise spectrogram error for high-dynamic music’s right channel, depicted on a logarithmic color scale to highlight subtle reconstruction deviations across time and frequency.
Figure 18.
Absolute pixelwise spectrogram error for high-dynamic music’s right channel, depicted on a logarithmic color scale to highlight subtle reconstruction deviations across time and frequency.
Figure 19.
Ground truth (GT) vs. generated (Gen) MFCCs for high-tempo, high-dynamic music. Harmonizer successfully captures complex spectral envelopes and abrupt changes, ensuring high perceptual fidelity. MFCC similarity = 0.9928.
Figure 19.
Ground truth (GT) vs. generated (Gen) MFCCs for high-tempo, high-dynamic music. Harmonizer successfully captures complex spectral envelopes and abrupt changes, ensuring high perceptual fidelity. MFCC similarity = 0.9928.
Figure 20.
MFCC difference (GT − Gen) for high-tempo, high-dynamic music. The near-zero difference across most frames confirms robust cepstral alignment, even in demanding signal contexts.
Figure 20.
MFCC difference (GT − Gen) for high-tempo, high-dynamic music. The near-zero difference across most frames confirms robust cepstral alignment, even in demanding signal contexts.
Figure 21.
MFCC error percentage (GT vs. Gen) for high-tempo, high-dynamic music with logarithmic color-bar. The predominantly blue regions reflect near-zero error, with a maximum deviation of about 5%.
Figure 21.
MFCC error percentage (GT vs. Gen) for high-tempo, high-dynamic music with logarithmic color-bar. The predominantly blue regions reflect near-zero error, with a maximum deviation of about 5%.
Figure 22.
Comparison of original (blue) and reconstructed (red dashed) ASCII-encoded-Sinusoidal signals for text inputs of increasing length. Panels (a–c) correspond, respectively, to single-word, two-token, and longer-sentence reconstructions.
Figure 22.
Comparison of original (blue) and reconstructed (red dashed) ASCII-encoded-Sinusoidal signals for text inputs of increasing length. Panels (a–c) correspond, respectively, to single-word, two-token, and longer-sentence reconstructions.
Figure 23.
Select frame comparisons and video link. (
a) First frame—note crisp shapes and clear text with only minor block artifacts. (
b) Last frame—demonstrates consistent reconstruction quality across the clip. (
c) QR code linking to the full demonstration of all 16 frames, highlighting temporal coherence and overall video performance. The link to this video can be found in [
134]. These preliminary results confirm that Harmonizer can process video inputs end-to-end; future work will focus on artifact reduction and temporal smoothing.
Figure 23.
Select frame comparisons and video link. (
a) First frame—note crisp shapes and clear text with only minor block artifacts. (
b) Last frame—demonstrates consistent reconstruction quality across the clip. (
c) QR code linking to the full demonstration of all 16 frames, highlighting temporal coherence and overall video performance. The link to this video can be found in [
134]. These preliminary results confirm that Harmonizer can process video inputs end-to-end; future work will focus on artifact reduction and temporal smoothing.
Figure 24.
Overall token distribution. Token–ID bins (34 equal–width intervals spanning 0–1023) on the horizontal axis versus cumulative emission count across all 16 codebooks on the vertical axis. The pronounced peak at the highest bin (IDs 992–1023; 9000 counts) and the long tail toward low IDs are evident.
Figure 24.
Overall token distribution. Token–ID bins (34 equal–width intervals spanning 0–1023) on the horizontal axis versus cumulative emission count across all 16 codebooks on the vertical axis. The pronounced peak at the highest bin (IDs 992–1023; 9000 counts) and the long tail toward low IDs are evident.
Figure 25.
Codebooks 0–3. Codebook 0 exhibits a distinct peak around ID ≈ 500, deviating from the patterns observed in the others. Codebooks 1 through 3 all terminate with a pronounced spike at ID 1023. Notably, Codebook 1 displays two intermediate peaks prior to the terminal spike, Codebook 2 demonstrates a generally increasing trend with minor fluctuations, and Codebook 3 maintains a near-plateaued distribution before the final surge at ID 1023.
Figure 25.
Codebooks 0–3. Codebook 0 exhibits a distinct peak around ID ≈ 500, deviating from the patterns observed in the others. Codebooks 1 through 3 all terminate with a pronounced spike at ID 1023. Notably, Codebook 1 displays two intermediate peaks prior to the terminal spike, Codebook 2 demonstrates a generally increasing trend with minor fluctuations, and Codebook 3 maintains a near-plateaued distribution before the final surge at ID 1023.
Figure 26.
Codebooks 4–7. Codebook 4 exhibits an almost linear rise across IDs; Codebook 5 shows a moderate ramp before the final spike; Codebook 6 and 7 remain almost flat with some fluctuations until a steep jump near the end.
Figure 26.
Codebooks 4–7. Codebook 4 exhibits an almost linear rise across IDs; Codebook 5 shows a moderate ramp before the final spike; Codebook 6 and 7 remain almost flat with some fluctuations until a steep jump near the end.
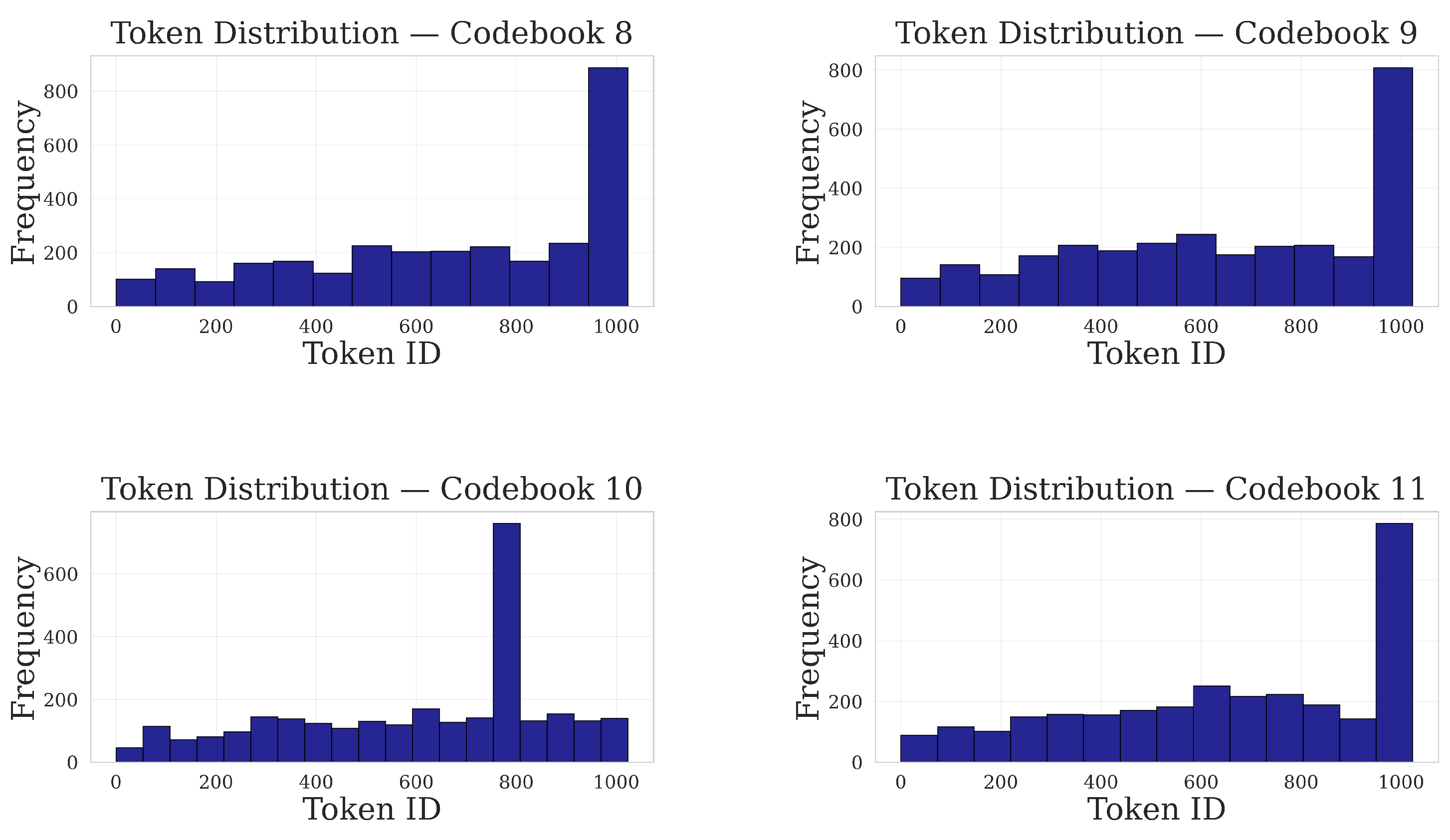
Figure 27.
Codebooks 8–11. Codebook 8 shows a smooth, gentle rise; Codebook 9 is flat until a sharp final ascent; Codebook 10 features a different peak at ID ≈ 800; Codebook 11 presents a gradual midrange build then a pronounced spike.
Figure 27.
Codebooks 8–11. Codebook 8 shows a smooth, gentle rise; Codebook 9 is flat until a sharp final ascent; Codebook 10 features a different peak at ID ≈ 800; Codebook 11 presents a gradual midrange build then a pronounced spike.
Figure 28.
Codebooks 12–15. Codebooks 12 and 15 feature gradual ramps with moderate slope before the significant terminal jump bar; Codebooks 13 and 14 exhibit small secondary peaks before the dominant terminal bar.
Figure 28.
Codebooks 12–15. Codebooks 12 and 15 feature gradual ramps with moderate slope before the significant terminal jump bar; Codebooks 13 and 14 exhibit small secondary peaks before the dominant terminal bar.
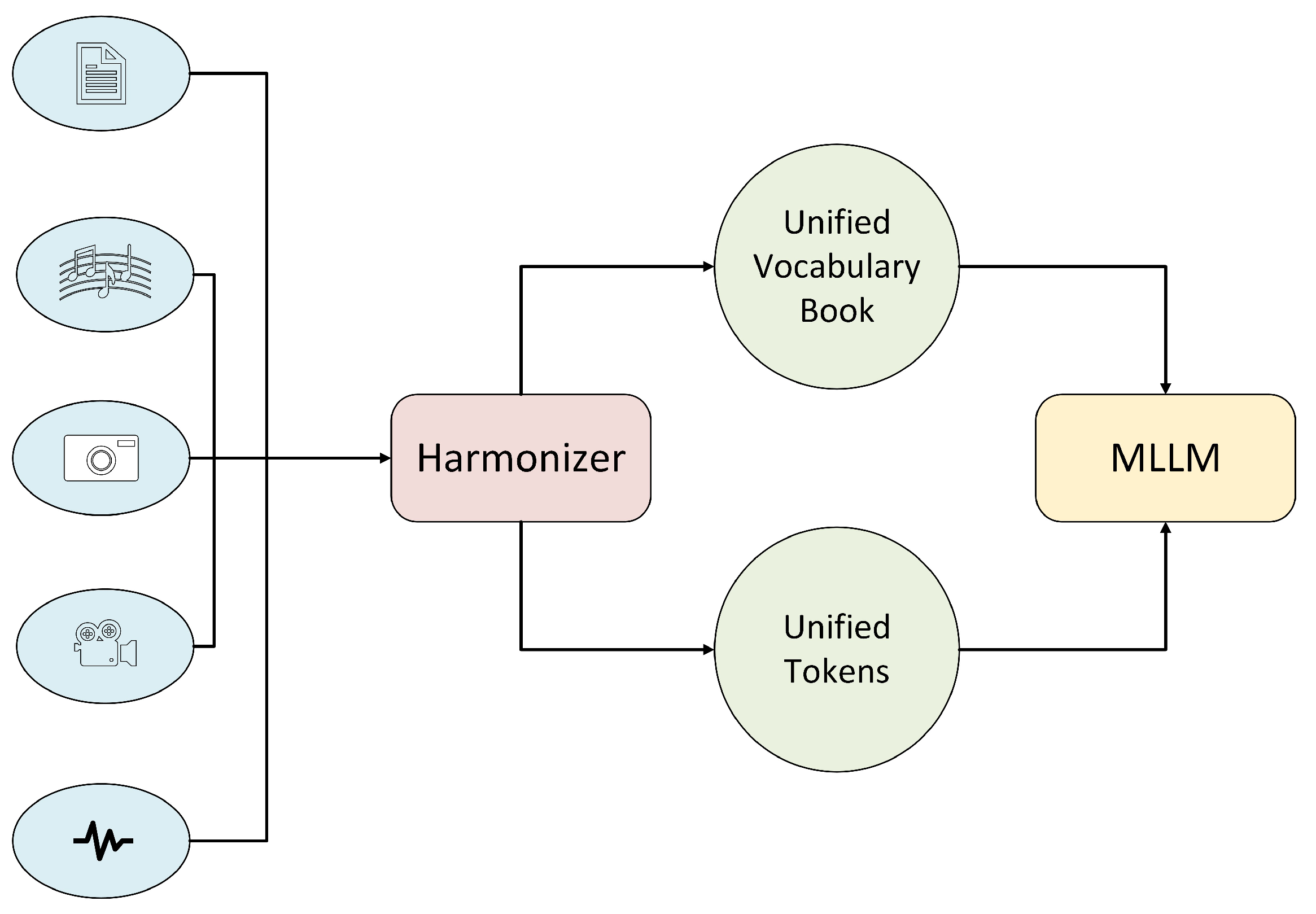
Figure 29.
Application of Harmonizer as a Universal Multimodal Tokenizer in Large Language Models. The pipeline converts raw inputs—(a) text (ASCII → sine-encoded vectors), (b) audio (STFT → Hilbert → SCLAHE feature maps), and (c) video (spatiotemporal patches)—into a shared feature space. The FusionQuantizer then maps these continuous features to discrete token IDs via a learned codebook. During Streaming Inference, FluxFormer generates token sequences on the fly, which are interleaved or concatenated with standard text tokens and fed into cross-modal attention layers of the LLM. This unified token stream enables a single model to perform context-aware reasoning over text, audio, and video without separate modality-specific encoders.
Figure 29.
Application of Harmonizer as a Universal Multimodal Tokenizer in Large Language Models. The pipeline converts raw inputs—(a) text (ASCII → sine-encoded vectors), (b) audio (STFT → Hilbert → SCLAHE feature maps), and (c) video (spatiotemporal patches)—into a shared feature space. The FusionQuantizer then maps these continuous features to discrete token IDs via a learned codebook. During Streaming Inference, FluxFormer generates token sequences on the fly, which are interleaved or concatenated with standard text tokens and fed into cross-modal attention layers of the LLM. This unified token stream enables a single model to perform context-aware reasoning over text, audio, and video without separate modality-specific encoders.
Table 1.
Normalized weights assigned to each component of the multi-objective loss function, ensuring their sum equals 1.0.
Table 1.
Normalized weights assigned to each component of the multi-objective loss function, ensuring their sum equals 1.0.
| Loss Term | Weight |
|---|
| (Adversarial) | 0.10 |
| () | 0.40 |
| () | 0.20 |
| (Perceptual) | 0.10 |
| (STFT) | 0.05 |
| (Hilbert) | 0.05 |
| (SCLAHE) | 0.10 |
| Total | 1.00 |
Table 2.
Detailed hyperparameter settings and hardware configurations used for training and evaluating the Harmonizer framework.
Table 2.
Detailed hyperparameter settings and hardware configurations used for training and evaluating the Harmonizer framework.
| Aspect | Setting |
|---|
| Model size | ≈65 million parameters |
| Optimizer | AdamW, |
| Audio framing | 96 kHz stereo, 1 s segments, 0.5% overlap |
| Feature backbone | 128-dim features, 32 base channels |
| Quantization | 16 codebooks, 1024 entries each |
| Sequence model | 512-dim embeddings, 10 layers, 16 heads |
| Mixed precision | FP16/BF16 on A100 GPUs (TF32 fallback on P100) |
Table 3.
Quantitative evaluation metrics for audio reconstruction, listing each abbreviation, its full name, the numerical range of values, and the criterion for optimal performance; the lower section presents pixel-wise image-based metrics computed on spectrograms.
Table 3.
Quantitative evaluation metrics for audio reconstruction, listing each abbreviation, its full name, the numerical range of values, and the criterion for optimal performance; the lower section presents pixel-wise image-based metrics computed on spectrograms.
| Abbr. | Expanded Version | Range | Optimal Value |
|---|
| MSE | Mean Squared Error | | |
| CC | Correlation Coefficient | | |
| CS | Cosine Similarity | | |
| DTW | Dynamic Time Warping Distance | | |
| SC | Spectral Convergence | | |
| SNR | Signal-to-Noise Ratio | Typically (dB) | |
| LSD | Log-Spectral Distance | | |
| MFCC | MFCC Similarity | | |
| PMSE | Pixelwise MSE | | |
| SSIM | Structural Similarity Index Measure | | |
| PSNR | Peak Signal-to-Noise Ratio | (dB) | |
Table 4.
Quantitative performance metrics for low-tempo, low-dynamic vocal music signals (≈288 s), covering time-domain error (MSE, CC, CS), temporal alignment (DTW), spectral fidelity (SC, LSD, MFCC), signal-to-noise ratios (SNRs), and pixelwise spectrogram measures (PMSE, SSIM, PSNR) for both stereo channels.
Table 4.
Quantitative performance metrics for low-tempo, low-dynamic vocal music signals (≈288 s), covering time-domain error (MSE, CC, CS), temporal alignment (DTW), spectral fidelity (SC, LSD, MFCC), signal-to-noise ratios (SNRs), and pixelwise spectrogram measures (PMSE, SSIM, PSNR) for both stereo channels.
| Metric | Value |
|---|
| MSE | |
| Correlation Coefficient (CC) | |
| Cosine Similarity (Left/Right) | / |
| DTW Distance (Left/Right) | / |
| Spectral Convergence (Left/Right) | / |
| SNR (Reconstructed) | dB |
| LSD (Left/Right) | / |
| MFCC Similarity | |
| SNR (Ground Truth/Generated) | dB/ dB |
| Left Pixelwise MSE | |
| Left Pixelwise SSIM | |
| Left Pixelwise PSNR | dB |
| Right Pixelwise MSE | |
| Right Pixelwise SSIM | |
| Right Pixelwise PSNR | dB |
Table 5.
Quantitative performance metrics for high-tempo, high-dynamic vocal music signals (≈231 s), covering time-domain error (MSE, CC, CS), temporal alignment (DTW), spectral fidelity (SC, LSD, MFCC), signal-to-noise ratios (SNRs), and pixelwise spectrogram measures (PMSE, SSIM, PSNR) for both stereo channels.
Table 5.
Quantitative performance metrics for high-tempo, high-dynamic vocal music signals (≈231 s), covering time-domain error (MSE, CC, CS), temporal alignment (DTW), spectral fidelity (SC, LSD, MFCC), signal-to-noise ratios (SNRs), and pixelwise spectrogram measures (PMSE, SSIM, PSNR) for both stereo channels.
| Metric | Value |
|---|
| MSE | |
| Correlation Coefficient (CC) | |
| Cosine Similarity (Left/Right) | / |
| DTW Distance (Left/Right) | / |
| Spectral Convergence (Left/Right) | / |
| SNR (Reconstructed) | dB |
| LSD (Left/Right) | / |
| MFCC Similarity | |
| SNR (Ground Truth/Generated) | dB/ dB |
| Left Pixelwise MSE | |
| Left Pixelwise SSIM | |
| Left Pixelwise PSNR | dB |
| Right Pixelwise MSE | |
| Right Pixelwise SSIM | |
| Right Pixelwise PSNR | dB |
Table 6.
Comparison of speech reconstruction quality on the VCTK test set, showing Short-Time Objective Intelligibility (STOI) and Perceptual Evaluation of Speech Quality (PESQ), where higher values indicate better performance.
Table 6.
Comparison of speech reconstruction quality on the VCTK test set, showing Short-Time Objective Intelligibility (STOI) and Perceptual Evaluation of Speech Quality (PESQ), where higher values indicate better performance.
| Model | STOI (↑) | PESQ (↑) |
|---|
| Encodec [125] | 0.81 | 2.00 |
| DAC [132] | 0.81 | 2.10 |
| WavTokenizer [128] | 0.79 | 1.90 |
| StableCodec [133] | 0.76 | 1.80 |
| ALMTokenizer [131] | 0.81 | 2.00 |
| SemantiCodec [130] | 0.81 | 1.76 |
| Harmonizer (ours) | 0.90 | 2.30 |
Table 7.
Music reconstruction performance on the MusicCaps dataset, reporting mean Mel-spectrogram loss and STFT reconstruction loss (↓).
Table 7.
Music reconstruction performance on the MusicCaps dataset, reporting mean Mel-spectrogram loss and STFT reconstruction loss (↓).
| Model | Mel-Spectrogram Loss (↓) | STFT Reconstruction Loss (↓) |
|---|
| Encodec [125] | 34.8 | 1.26 |
| DAC [132] | 35.9 | 1.28 |
| WavTokenizer [128] | 48.2 | 1.47 |
| ALMTokenizer [131] | 34.4 | 1.32 |
| SemantiCodec [130] | 47.9 | 1.58 |
| Harmonizer (ours) | 16.9 | 1.34 |
Table 8.
Comparison of key reconstruction metrics between low-tempo/low-dynamic and high-tempo/high-dynamic music signals.
Table 8.
Comparison of key reconstruction metrics between low-tempo/low-dynamic and high-tempo/high-dynamic music signals.
| Metric | Low-Tempo
Low-Dynamic | High-Tempo
High-Dynamic |
|---|
| MSE | | |
| Correlation Coefficient (CC) | | |
| Cosine Similarity (L/R) | | |
| DTW Distance (L/R) | | |
| Spectral Convergence (L/R) | | |
| MFCC Similarity | | |
| Mean Pixelwise MSE (L/R) | | |
| Mean Pixelwise SSIM (L/R) | | |
| Mean Pixelwise PSNR (dB) (L/R) | | |































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}