
A Fast Proximal Alternating Method for Robust Matrix Factorization of Matrix Recovery with Outliers

Abstract
1. Introduction
2. Preliminaries
2.1. Notations
2.2. Stationary Points and -Global Optimal Solutions
2.3. Kurdyka–Łojasiewicz Property
- (i)
- and φ is continuously differentiable on , and
- (ii)
- , ;
3. Relationship Between Problems (2) and (3)
4. A PALM Method for Solving Problem (3)
| Algorithm 1 (PALM Method for Solving (3)) |
|
- (i)
- For each , it holds that Hence, the sequence is convergent.
- (ii)
- For each , withAssume that is bounded. Then, there exists constant , such that
5. Numerical Experiments
5.1. Implementation Details of Algorithms
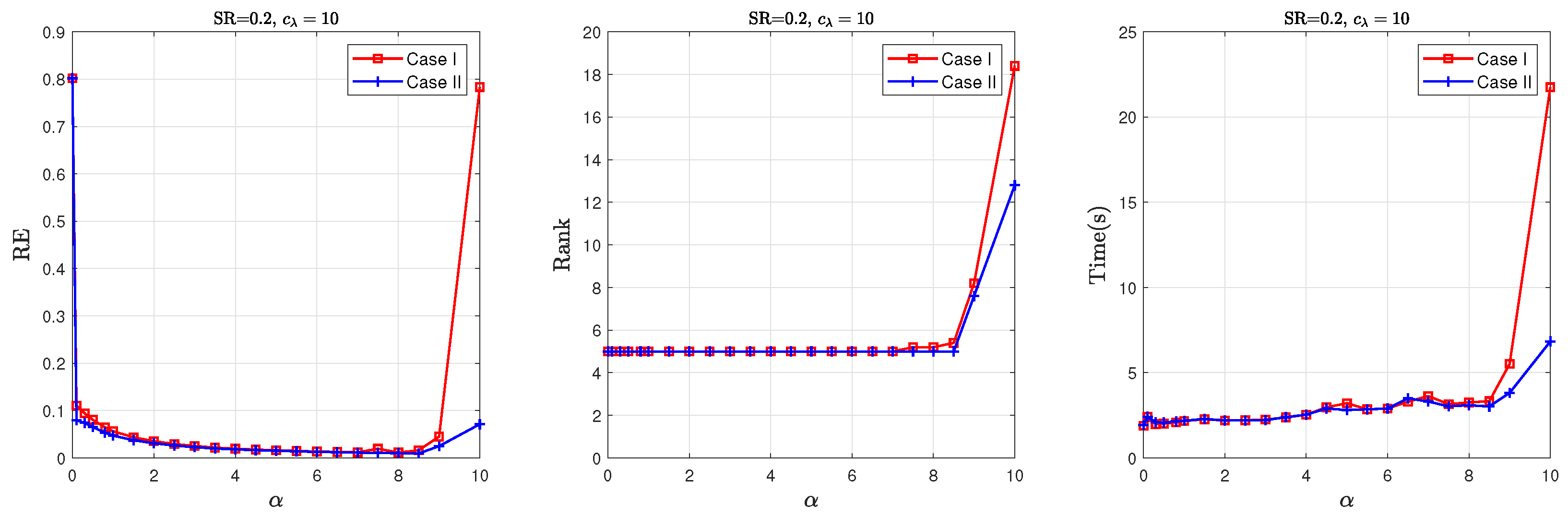
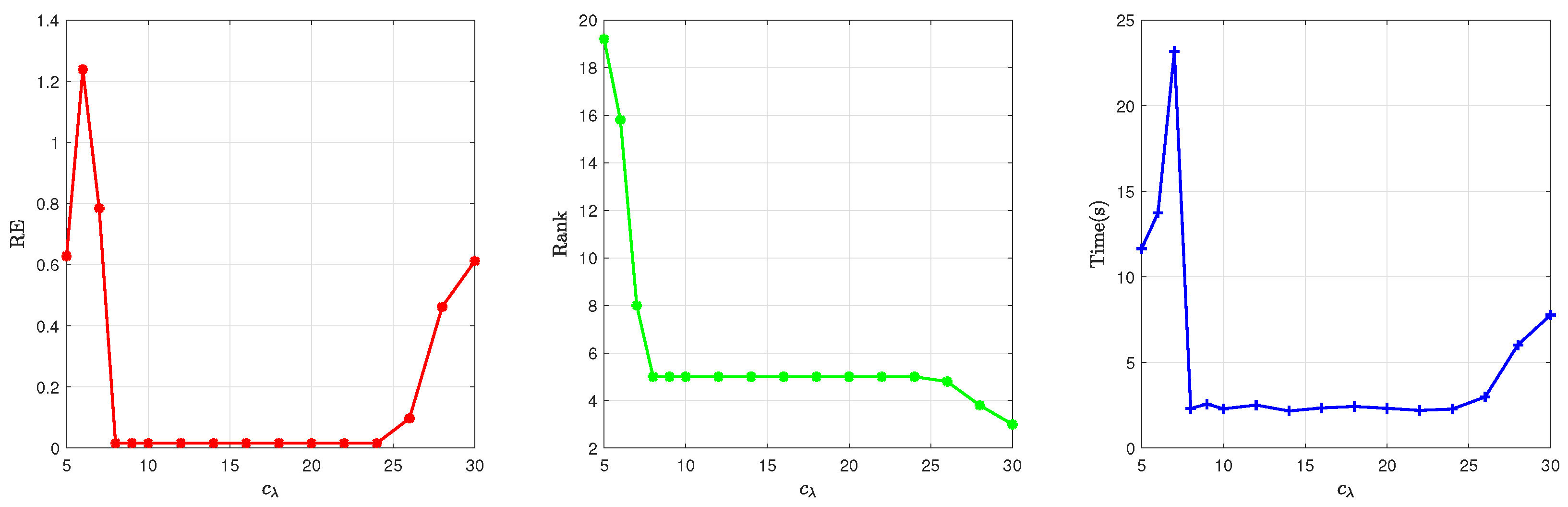
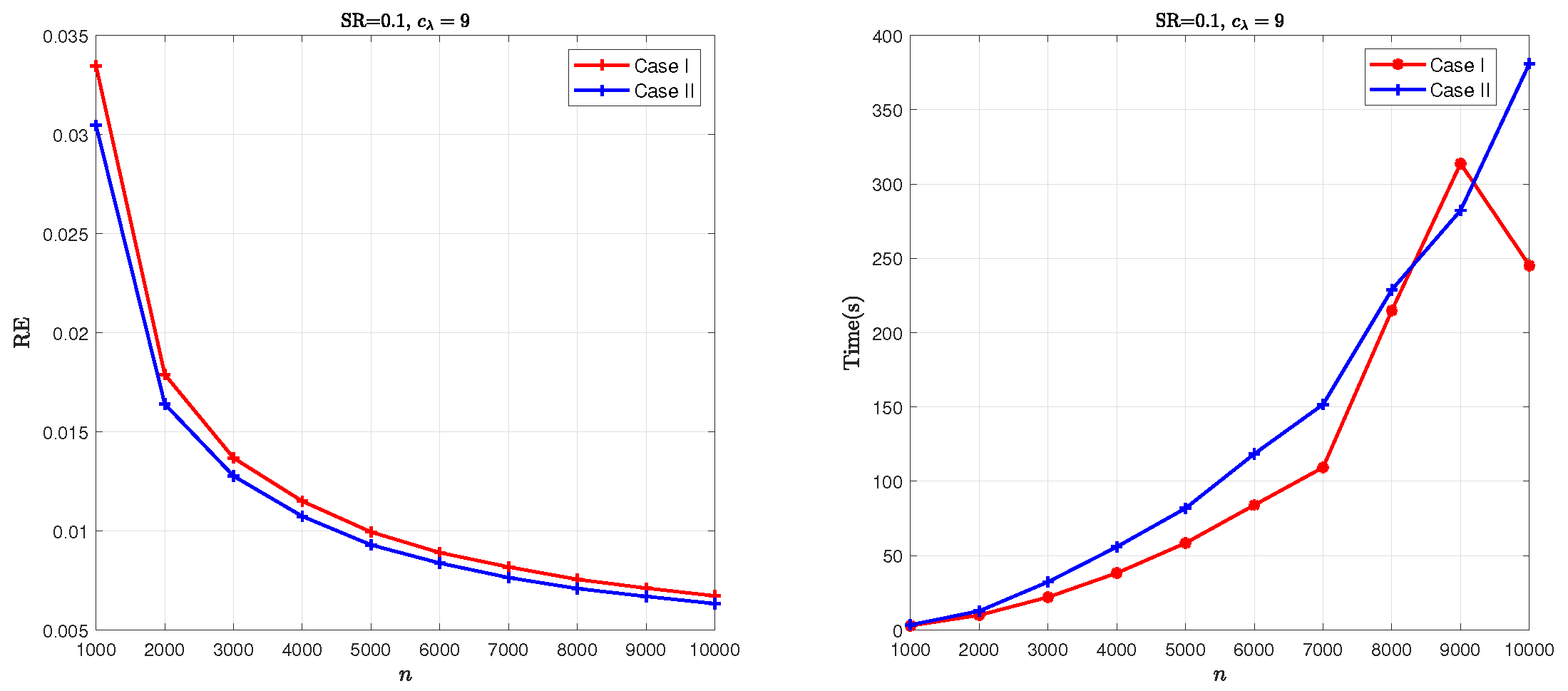
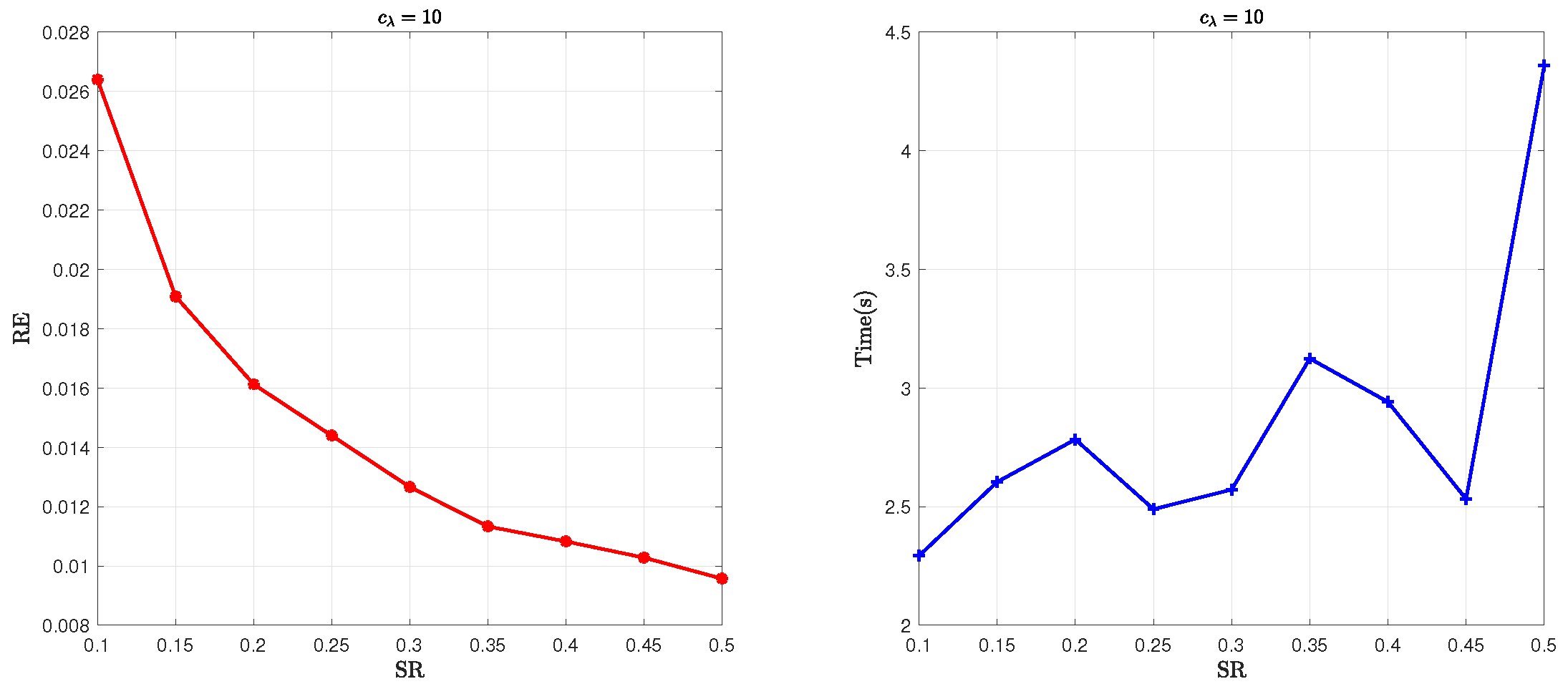
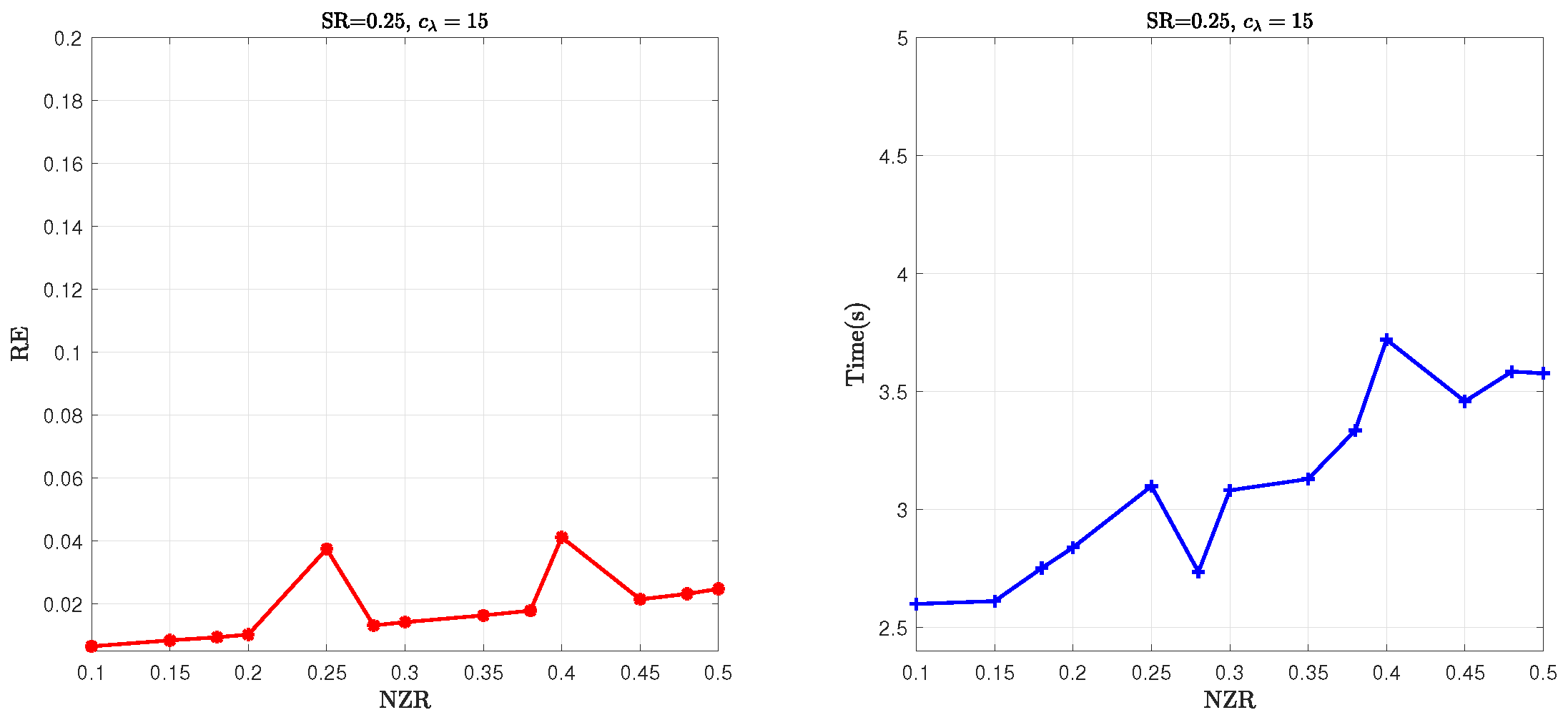
5.2. Parameter Sensitivity Analysis
5.3. Numerical Comparisons with SubGM
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Candès, E.J.; Recht, B. Exact matrix completion via convex optimization. Found. Comput. Math. 2009, 9, 717–772. [Google Scholar] [CrossRef]
- Davenport, M.A.; Romberg, J. An overview of low-rank matrix recovery from incomplete observations. IEEE J. Sel. Top. Signal Process. 2016, 10, 608–622. [Google Scholar] [CrossRef]
- Fazel, M.; Hindi, H.; Boyd, S. Rank Minimization and Applications in System Theory. Proc. 2004 Am. Control Conf. 2004, 4, 3273–3278. [Google Scholar]
- Gross, D.; Liu, Y.K.; Flammia, S.T.; Becker, S.; Eisert, J. Quantum state tomography via compressed sensing. Phys. Rev. Lett. 2010, 105, 150401. [Google Scholar] [CrossRef] [PubMed]
- Negahban, S.; Wainwright, M.J. Estimation of (near) low-rank matrices with noise and high-dimensional scaling. Ann. Stat. 2011, 39, 1069–1097. [Google Scholar] [CrossRef]
- Charisopoulos, V.; Chen, Y.; Davis, D.; Díaz, M.; Ding, L.; Drusvyatskiy, D. Low-Rank Matrix Recovery with Composite Optimization: Good Conditioning and Rapid Convergence. Found. Comput. Math. 2021, 21, 1505–1593. [Google Scholar] [CrossRef]
- Li, X.; Zhu, Z.H.; So, A.M.; Vidal, R. Nonconvex Robust Low-Rank Matrix Recovery. SIAM J. Optim. 2020, 30, 660–686. [Google Scholar] [CrossRef]
- Ma, J.H.; Fattahi, S. Global Convergence of Sub-gradient Method for Robust Matrix Recovery: Small Initialization, Noisy Measurements, and Over-parameterization. J. Mach. Learn. Res. 2023, 24, 1–84. [Google Scholar]
- Wang, Z.Y.; So, H.C.; Liu, Z.F. Fast and robust rank-one matrix completion via maximum correntropy criterion and half-quadratic optimization. Signal Process. 2022, 198, 108580. [Google Scholar] [CrossRef]
- Tao, T.; Qian, Y.T.; Pan, S.H. Column ℓ2,0-norm regularized factorization model of low-rank matrix recovery and its computation. SIAM J. Optim. 2022, 32, 959–988. [Google Scholar] [CrossRef]
- Candès, E.J.; Li, X.; Ma, Y.; Wright, J. Robust principal component analysis. J. ACM 2011, 11, 1–37. [Google Scholar] [CrossRef]
- Josz, C.; Ouyang, Y.; Zhang, R.; Lavaei, J.; Sojoudi, S. A theory on the absence of spurious solutions for nonconvex and nonsmooth optimization. Adv. Neural Inf. Process. Syst. 2018, 31, 2441–2449. [Google Scholar]
- Li, Y.; Sun, Y.; Chi, Y. Low-rank positive semidefinite matrix recovery from corrupted rank-one measurements. IEEE Trans. Signal Process. 2017, 65, 397–408. [Google Scholar] [CrossRef]
- Rockafellar, R.T.; Wets, R.J.-B. Variational Analysis; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Attouch, H.; Bolte, J.; Redont, P.; Soubeyran, A. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-Łojasiewicz inequality. Math. Oper. Res. 2010, 35, 438–457. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Bolte, J.; Sabach, S.; Teboulle, M. Proximal alternating linearized minimization for nonconvex and nonsmooth problems. Math. Program. 2014, 146, 459–494. [Google Scholar] [CrossRef]
- Polyak, B.T. Minimization of unsmooth functions. USSR Comput. Math. Math. Phys. 1969, 9, 14–29. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, D.; Ye, J.; Li, X.; He, X. Fast and accurate matrix completion via truncated nuclear norm regularization. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2117–2130. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm 1 | SubGM | |||||||
|---|---|---|---|---|---|---|---|---|
| (r*, SR) | RE | Rank | Time (s) | RE | Rank | Time (s) | ||
| 1000 | (5, 0.10) | 10 | 2.61 | 5 | 1.50 | 1.26 | 15 | 4.04 |
| (5, 0.15) | 10 | 1.94 | 5 | 1.48 | 7.71 | 15 | 4.71 | |
| (5, 0.20) | 10 | 1.59 | 5 | 1.60 | 6.13 | 15 | 5.28 | |
| (5, 0.20) | 10 | 1.40 | 5 | 1.73 | 4.93 | 15 | 5.56 | |
| (10, 0.10) | 6 | 3.34 | 10 | 1.88 | 2.58 | 30 | 4.35 | |
| (10, 0.15) | 6 | 2.26 | 10 | 2.88 | 1.38 | 30 | 5.26 | |
| (10, 0.20) | 6 | 2.15 | 10 | 2.34 | 8.20 | 30 | 5.92 | |
| (10, 0.20) | 6 | 1.54 | 10 | 2.33 | 5.88 | 30 | 6.26 | |
| 3000 | (10, 0.10) | 6 | 1.36 | 10 | 15.0 | 3.61 | 30 | 40.6 |
| (10, 0.15) | 6 | 1.05 | 10 | 17.1 | 2.91 | 30 | 50.6 | |
| (10, 0.20) | 6 | 8.95 | 10 | 18.3 | 2.23 | 30 | 51.4 | |
| (10, 0.20) | 6 | 1.24 | 10 | 20.5 | 2.64 | 30 | 56.3 | |
| (20, 0.10) | 6 | 1.57 | 20 | 20.3 | 7.73 | 60 | 44.1 | |
| (20, 0.15) | 6 | 1.15 | 20 | 20.0 | 3.41 | 60 | 49.6 | |
| (20, 0.20) | 6 | 9.52 | 20 | 22.4 | 2.42 | 60 | 55.5 | |
| (20, 0.20) | 6 | 8.33 | 20 | 23.2 | 2.07 | 60 | 61.6 | |
| 5000 | (10, 0.10) | 10 | 9.92 | 10 | 45.8 | 2.29 | 30 | 140.9 |
| (10, 0.15) | 10 | 7.87 | 10 | 50.0 | 1.93 | 30 | 138.8 | |
| (10, 0.20) | 10 | 6.73 | 10 | 46.9 | 1.87 | 30 | 141.4 | |
| (10, 0.20) | 10 | 6.01 | 10 | 50.1 | 1.61 | 30 | 157.7 | |
| 8000 | (10, 0.10) | 10 | 7.63 | 10 | 121.3 | 1.53 | 30 | 312.1 |
| (10, 0.15) | 10 | 8.21 | 10 | 140.2 | 1.62 | 30 | 387.8 | |
| (10, 0.20) | 10 | 5.21 | 10 | 144.9 | 1.40 | 30 | 432.9 | |
| (10, 0.20) | 10 | 4.71 | 10 | 154.7 | 1.49 | 30 | 475.7 | |
| Algorithm 1 | SubGM | |||||||
|---|---|---|---|---|---|---|---|---|
| (r*, SR) | RE | Rank | Time (s) | RE | Rank | Time (s) | ||
| 1000 | (5, 0.10) | 10 | 2.42 | 5 | 1.37 | 8.76 | 15 | 3.85 |
| (5, 0.15) | 10 | 1.82 | 5 | 1.43 | 6.14 | 15 | 4.81 | |
| (5, 0.20) | 10 | 1.49 | 5 | 1.39 | 5.03 | 15 | 5.49 | |
| (5, 0.20) | 10 | 1.31 | 5 | 1.28 | 4.61 | 15 | 5.70 | |
| 1000 | (10, 0.10) | 6 | 3.00 | 10 | 1.86 | 1.85 | 30 | 4.31 |
| (10, 0.15) | 6 | 2.07 | 10 | 1.88 | 9.23 | 30 | 4.26 | |
| (10, 0.20) | 6 | 1.65 | 10 | 2.24 | 6.02 | 30 | 5.92 | |
| (10, 0.20) | 6 | 1.42 | 10 | 2.28 | 4.71 | 30 | 6.26 | |
| 3000 | (10, 0.10) | 6 | 1.27 | 10 | 15.5 | 3.11 | 30 | 40.6 |
| (10, 0.15) | 6 | 9.85 | 10 | 16.1 | 2.71 | 30 | 45.6 | |
| (10, 0.20) | 6 | 8.33 | 10 | 17.3 | 2.27 | 30 | 50.4 | |
| (10, 0.20) | 6 | 7.40 | 10 | 18.5 | 2.11 | 30 | 55.3 | |
| 3000 | (20, 0.10) | 6 | 1.44 | 20 | 20.3 | 5.30 | 60 | 44.1 |
| (20, 0.15) | 6 | 1.07 | 20 | 22.0 | 2.79 | 60 | 49.6 | |
| (20, 0.20) | 6 | 8.82 | 20 | 22.4 | 2.11 | 60 | 54.5 | |
| (20, 0.20) | 6 | 7.73 | 20 | 23.2 | 1.85 | 60 | 59.6 | |
| 5000 | (10, 0.10) | 10 | 9.29 | 10 | 40.8 | 2.07 | 30 | 110.9 |
| (10, 0.15) | 10 | 7.37 | 10 | 48.0 | 1.84 | 30 | 126.8 | |
| (10, 0.20) | 10 | 6.29 | 10 | 46.9 | 1.75 | 30 | 141.4 | |
| (10, 0.20) | 10 | 5.62 | 10 | 50.1 | 1.61 | 30 | 156.7 | |
| 8000 | (10, 0.10) | 10 | 7.13 | 10 | 99.3 | 1.51 | 30 | 283.1 |
| (10, 0.15) | 10 | 5.71 | 10 | 114.2 | 1.56 | 30 | 337.8 | |
| (10, 0.20) | 10 | 4.91 | 10 | 114.9 | 1.50 | 30 | 353.9 | |
| (10, 0.20) | 10 | 4.38 | 10 | 124.7 | 1.48 | 30 | 395.7 | |
| Algorithm | RE | PSNR | Time (s) | |
|---|---|---|---|---|
| Sampling Ratio = 50% | Algorithm 1 | 0.0708 | 30.57 | 1.72 |
| SubGM | 0.0991 | 27.82 | 2.60 | |
| Sampling Ratio = 20% | Algorithm 1 | 0.1178 | 24.22 | 0.76 |
| SubGM | 0.1361 | 23.07 | 1.84 | |
| Sampling Ratio = 10% | Algorithm 1 | 0.0369 | 33.61 | 0.59 |
| SubGM | 0.1113 | 24.06 | 1.49 | |
| Image with text mask | Algorithm 1 | 0.1639 | 21.10 | 0.48 |
| SubGM | 0.1700 | 20.82 | 4.84 | |
| Image with cross mask | Algorithm 1 | 0.0934 | 16.71 | 1.34 |
| SubGM | 0.1811 | 7.40 | 5.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tao, T.; Xiao, L.; Zhong, J. A Fast Proximal Alternating Method for Robust Matrix Factorization of Matrix Recovery with Outliers. Mathematics 2025, 13, 1466. https://doi.org/10.3390/math13091466
Tao T, Xiao L, Zhong J. A Fast Proximal Alternating Method for Robust Matrix Factorization of Matrix Recovery with Outliers. Mathematics. 2025; 13(9):1466. https://doi.org/10.3390/math13091466
Chicago/Turabian StyleTao, Ting, Lianghai Xiao, and Jiayuan Zhong. 2025. "A Fast Proximal Alternating Method for Robust Matrix Factorization of Matrix Recovery with Outliers" Mathematics 13, no. 9: 1466. https://doi.org/10.3390/math13091466
APA StyleTao, T., Xiao, L., & Zhong, J. (2025). A Fast Proximal Alternating Method for Robust Matrix Factorization of Matrix Recovery with Outliers. Mathematics, 13(9), 1466. https://doi.org/10.3390/math13091466