4.4. Results
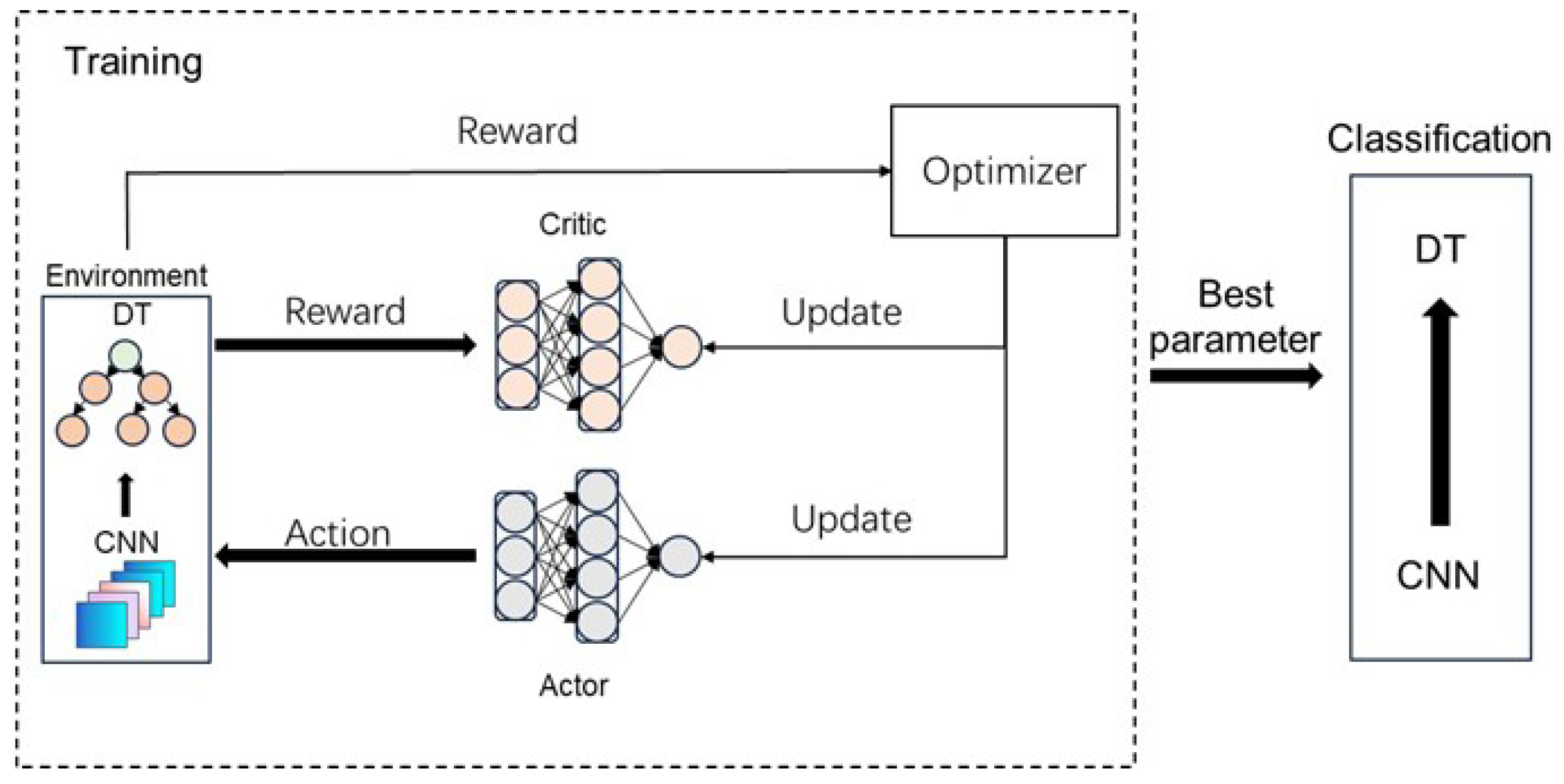
It is first necessary to clarify the distinction between the CNN-DT and DT-CNN model structures. CNN-DT refers to a hybrid model structure that first uses CNN networks to extract features, then inputs these high-level features into a decision tree (DT) for final classification, while DT-CNN refers to a model structure that first uses decision trees to extract or select features, then inputs these features into CNN networks for classification. This structural difference has a significant impact on model performance, as shown in
Table 3.
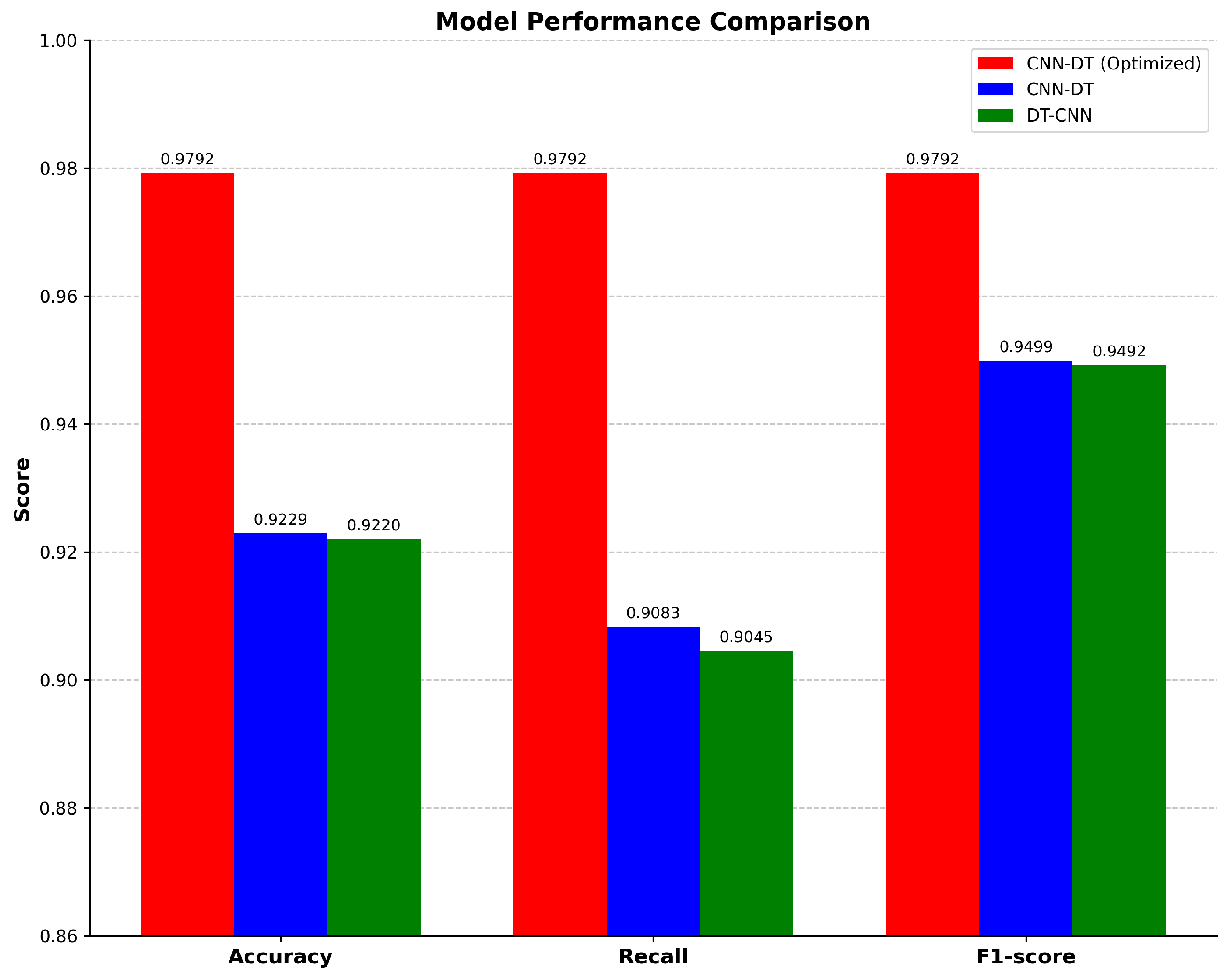
The experimental results fully verified the superiority of the CNN-DT structure and the effectiveness of the hyperparameter optimization strategy based on the actor–critic (AC) algorithm. The specific analysis was as follows (
Figure 4):
First, from the comparison of the underlying structures, CNN-DT showed better performance compared to DT-CNN in all evaluation metrics. Specifically, CNN-DT achieved higher scores in three metrics: accuracy (0.9229 vs. 0.9220), recall (0.9083 vs. 0.9045), and F1-score (0.9499 vs. 0.9492). This indicated that the structural design of feature extraction by CNN followed by decision tree classification could obtain better feature representation and decision boundaries.
Second, the hyperparameter optimization using the actor–critic algorithm significantly improved the performance of the CNN-DT model. The actor–critic algorithm, as a deep reinforcement learning method, combines the advantages of policy gradient (actor) and value function estimation (critic), where the actor is responsible for selecting the hyperparameters for the action strategy, and the critic is responsible for evaluating the value of the selected strategy, and the two work together to optimize the model hyperparameters. The optimized CNN-DT model achieved a high score of 0.9792 on all the metrics, which was an improvement of 5.63%, 7.09%, and 2.93% in accuracy, recall, and F1-score, respectively, compared to the unoptimized CNN-DT model. Achieving the same high scores for all evaluation metrics indicated that the optimization process based on the AC algorithm not only successfully improved the overall performance of the model but also achieved a perfect balance of the metrics.
These results validated two important design choices: (1) the CNN-DT architectural design had obvious advantages over DT-CNN; and (2) the actor–critic algorithm demonstrated excellent performance in hyperparameter optimization tasks. Through the dual learning mechanism of actor and critic, the algorithm was able to effectively find the optimal configuration in the complex hyperparameter space, which enabled the optimized CNN-DT model to achieve a consistently high score of 0.9792 in all the metrics.
In addition, the significant performance improvement obtained by the actor–critic algorithm also highlighted the importance of reinforcement learning optimization methods in deep learning applications. The AC algorithm not only effectively improved the performance of the model but also achieved a perfect balance of the indicators through dynamic adjustment of the strategy and continuous evaluation of the improvement, which demonstrated that the hyperparameter optimization methods based on reinforcement learning could well deal with complex optimization problems and help the model obtain a better generalization ability.
In addition to the performance metrics shown in
Table 3, this study also calculated Cohen’s Kappa coefficient to evaluate the classification consistency of the model. The CNN-DT model optimized by the actor–critic network achieved a Kappa coefficient of 0.7947, indicating high consistency and reliability in classification tasks. This result further validated the effectiveness of the proposed model, especially in handling network intrusion detection tasks with imbalanced class distributions.
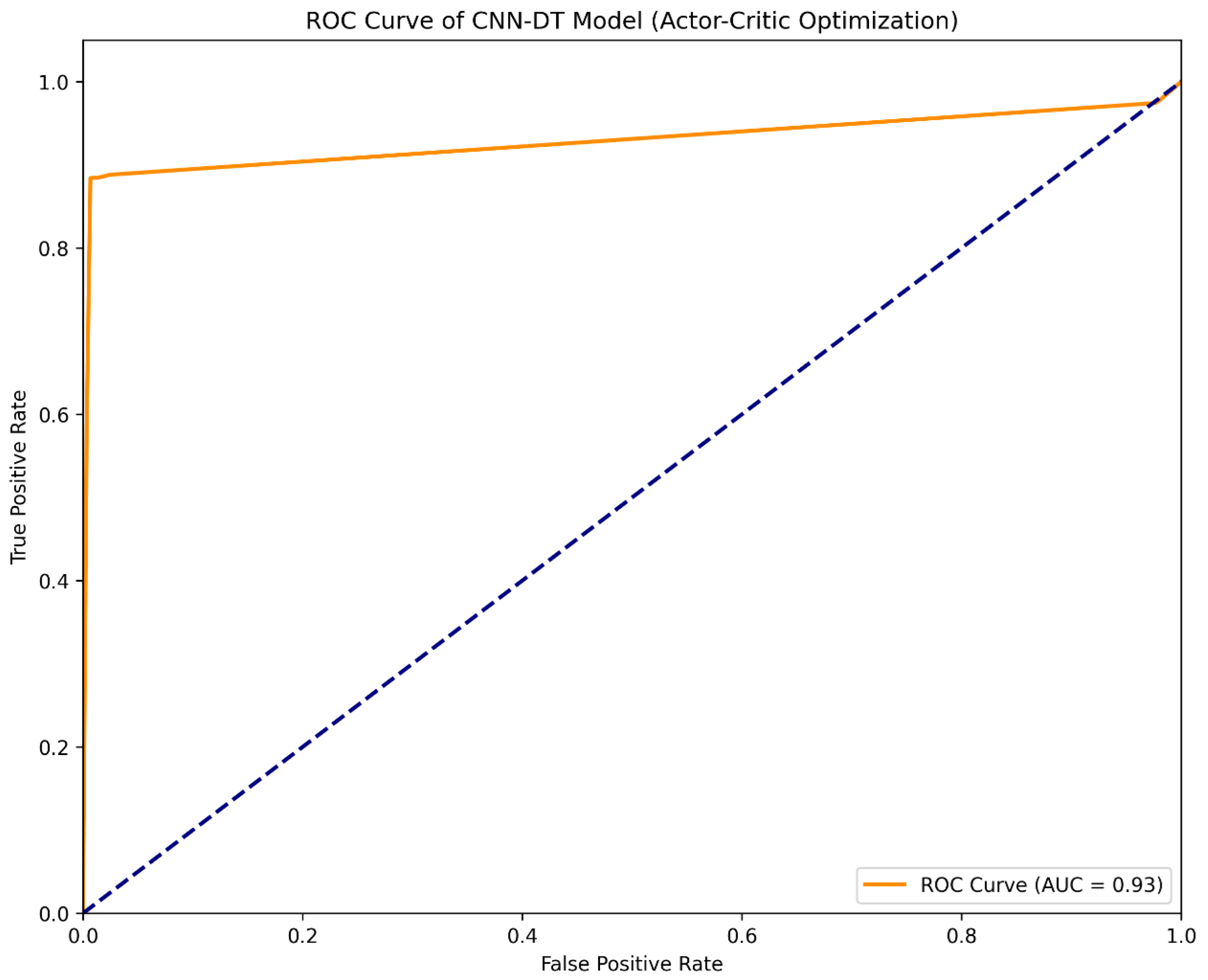
Furthermore, the ROC curve analysis (as shown in
Figure 5) demonstrated that the model achieved an AUC (Area Under the Curve) of 0.93, indicating excellent performance in distinguishing normal traffic from intrusion attacks. These evaluation metrics collectively confirmed the significant advantages of combining the CNN-DT structure with actor–critic optimization in improving intrusion detection performance.
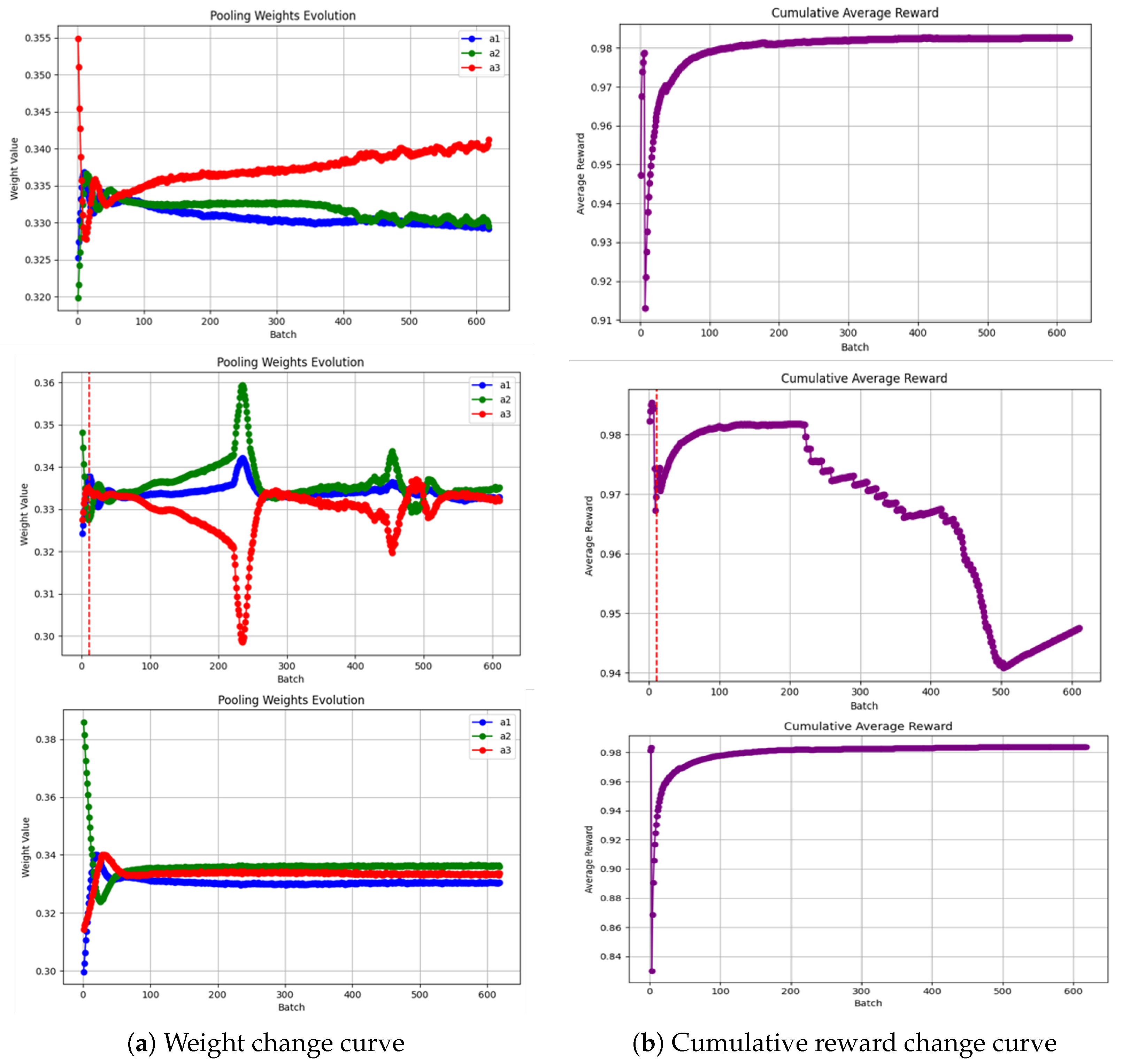
The experimental results in
Figure 6 indicated the decision tree’s depth significantly impacted model performance. The model with a depth of 3 demonstrated stable weight changes and sustained cumulative rewards; the model with a depth of 5 showed severe weight fluctuations throughout training, particularly extreme values near 200 batches, with cumulative rewards declining after the initial increase; while the depth-10 model, despite large initial weight adjustments, converged quickly and maintained high reward levels similar to the lesser-depth model. This suggested optimal tree depth was not simply “deeper is better” but required balancing between complexity and stability, where lesser-depth or larger-depth configurations may outperform medium-depth settings.
The weight change curves revealed how pooling parameters
evolved during training across different tree depths. The depth-3 tree showed stable weight trends with minor parameter adjustments, indicating smooth learning and gradual optimization. The depth-5 tree exhibited dramatic weight fluctuations, especially extreme values near 200 batches, suggesting medium-depth trees were unstable when combined with CNNs. This instability likely stemmed from mismatches between model complexity and data characteristics, causing learning oscillations. The non-convergence in
Figure 6b demonstrated the actor–critic deep learning algorithm struggled to find stable parameter combinations at that depth, and a noteworthy finding that contradicted the intuition that “moderately complex models perform best”. The depth-10 tree, despite larger initial weight adjustments, converged rapidly and stably, indicating deeper trees could form more stable synergies with CNNs, possibly by capturing more complex decision boundaries from high-level CNN features.
The cumulative reward curves reflected performance changes during training. The depth-3 model showed steady improvement, indicating shallow trees continuously benefited from CNN-extracted features. The depth-5 model’s rewards declined significantly after initial gains, corresponding to the observed weight instability and suggesting medium-depth trees may overfit CNN-extracted features. The depth-10 model maintained high reward levels similar to shallow models, demonstrating deep trees could effectively utilize complex CNN features while avoiding the instability of medium-depth models.
The non-convergence in
Figure 6b deserves special attention. In the depth-5 configuration, severe weight fluctuations and extreme values near 200 batches indicated the actor–critic algorithm struggled to find stable pooling weights. This may result from decision boundary complexity mismatches, where depth-5 trees inadequately expressed the required boundaries while being more complex than depth-3 models; gradient instability at this specific depth causing actor network convergence difficulties; and exploration–exploitation imbalance issues causing performance fluctuations.
This finding has significant practical implications: when designing hybrid CNN-DT models, tree depth selection should avoid the “middle ground”, favoring either shallow (simple but stable) or deep (complex but expressive) configurations. Careful depth selection and validation are crucial for both accuracy and training stability. By selecting appropriate tree depth (10 in this study) combined with early stopping, we successfully overcame the non-convergence shown in
Figure 6b, ultimately achieving a stable, high-performance intrusion detection model.
Table 4 shows the effect of different learning rates on the model reward values: the learning rate of 3 × 10
−4 performed the best, not only reaching the highest maximum reward value (0.9923) but also maintaining a near-optimal final reward value (0.9830); the performance of the learning rate of 1 × 10
−4 was relatively stable, and although the maximum reward was a little lower (0.9874), the final reward was maintained at a high level (0.9787); while a learning rate of 3 × 10
−3 achieves a high maximum reward (0.9896), but the final reward decreased (0.9562); the most significant instability occurred in the configuration with a learning rate of 1 × 10
−3, which had a high maximum reward value (0.9896), but the final reward decreased dramatically to a mere 0.5189. This suggests that appropriately lowering the learning rate helps the model to maintain stability, while too high a learning rate may cause the model to fail to converge to the optimal solution, and in particular, a moderate learning rate (1 × 10
−3) may trigger the most severe performance degradation.
To verify the effectiveness of the hybrid pooling mechanism, we conducted ablation experiments and tested the performance of models using max pooling, average pooling, global average pooling, and hybrid pooling separately. The experimental results are shown in
Table 5:
The experimental results showed that although a single pooling method could achieve high performance indicators, the hybrid pooling mechanism achieved better results in accuracy, recall, and F1-score by dynamically adjusting the weights of different pooling methods. Especially in terms of F1-score, hybrid pooling improved by 0.42 percentage points compared to the best single pooling method (max pooling). This confirmed that the hybrid pooling mechanism could more comprehensively capture complex feature patterns in network traffic, improving the model’s ability to detect different types of network attacks.
To validate the feasibility of using classification accuracy as the reward function in our reinforcement learning framework for network intrusion detection, we provide experimental justification. Accuracy is a direct and computationally efficient metric that aligns with the primary goal of accurately identifying intrusions, offering a clear learning signal for the agent. Comparative experiments, detailed in
Table 6, evaluated accuracy, F1-score, and a combined accuracy+F1-score reward function, yielding nearly identical performance (accuracy, recall, and F1-score of 0.9792 for the accuracy-based model), confirming its effectiveness. Furthermore, our approach mitigated class imbalance in intrusion detection datasets by leveraging CNN-extracted high-quality features, which created balanced, linearly separable representations for decision tree classification, as evidenced by strong recall and F1-scores (0.9792). The decision tree’s tendency to maximize information gain and balance class importance under depth constraints complemented accuracy as a reward signal, enhancing optimization in the CNN-derived feature space. Thus, experimental results collectively demonstrated that using accuracy as the reward function was both feasible and effective, simplifying model design while achieving superior detection performance.
The experimental results in
Table 7 clearly demonstrate the superiority of our proposed CNN-DT hybrid model based on deep reinforcement learning optimization in network intrusion detection tasks. We can analyze them from the following aspects:
Firstly, from the comparison of deep reinforcement learning optimization methods, all three deep reinforcement learning methods (actor critic, DQN, and DDQN) achieved significant performance improvements, with the actor–critic method achieving the best results (accuracy of 0.9792), slightly better than DQN (0.9787) and DDQN (0.9783). This result indicated that the actor–critic framework had advantages in handling continuous action spaces (pooling layer weights) and could more finely adjust model parameters. Although DQN and DDQN achieved similar results by discretizing the action space, they had some shortcomings in terms of precise optimization. Secondly, compared to traditional machine learning methods, our approach significantly improved performance. The accuracy of the best traditional method XGBoost was 0.9283, and our method improved it by 5.09 percentage points. Compared to Random Forest (0.9261) and LightGBM (0.9271), the improvement rates were 5.31% and 5.21%, respectively. Compared to SVM (0.8108), the improvement was as high as 16.84%. This indicated that our hybrid model structure could effectively combine the feature extraction capability of CNNs and the classification advantage of decision trees. Thirdly, compared to pure deep learning methods, our approach also demonstrated significant advantages. The accuracy of both CNN and Conv-LSTM was 0.9047, and our method improved it by approximately 7.45 percentage points. Compared to FT Transformer (0.8052), the improvement was as high as 17.4%. This result suggests that a reasonable hybrid model structure may be more effective than a single deep model in specific tasks such as network intrusion detection. Finally, it is worth noting that among all traditional and deep learning methods, ensemble learning methods (XGBoost, Random Forest, LightGBM) performed better overall than pure deep neural network methods, indicating that feature combination and decision boundary learning may be more important than deep feature extraction in network intrusion detection problems. Our method successfully overcame the limitations of a single model by combining the feature extraction ability of the CNN and the decision boundary learning ability of the decision tree, using deep reinforcement learning to optimize the weights.
Overall, the experimental results fully validated the effectiveness of our proposed CNN-DT hybrid model architecture and the advantages of using deep reinforcement learning to optimize model hyperparameters. All three deep reinforcement learning methods could effectively improve model performance, providing new directions for intelligent algorithm design in the field of network security.
While the KDD Cup 1999 dataset serves as a classic benchmark for intrusion detection systems, it is admittedly dated and may not fully reflect the characteristics of modern network attacks. To address this limitation and further validate the effectiveness of the proposed CNN-DT model with AC optimization, additional experiments were conducted on two more recent benchmark datasets: CICIDS2017 and UNSW-NB15.
The CICIDS2017 dataset contains modern attack scenarios including brute force attacks, DoS, DDoS, Web attacks, and insider threats collected in a realistic network environment. The UNSW-NB15 dataset comprises nine types of modern attacks, providing a more diverse and challenging evaluation scenario. As shown in
Table 8, the proposed model demonstrated exceptional performance on these modern datasets, achieving even higher metrics than on the KDD dataset in some cases. The near-perfect performance on the CICIDS2017 dataset with a remarkable 1.0000 recall rate indicated that the model could identify virtually all attacks without missing legitimate instances. The slightly lower but still impressive performance on UNSW-NB15 (accuracy of 0.9491 and Kappa of 0.8851) demonstrated the model’s robustness against more diverse and complex attack patterns.
These results further confirm that the CNN-DT structure with AC optimization maintains its effectiveness when faced with modern attack scenarios, suggesting strong generalization capabilities across different network security contexts and time periods.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}