
Bayesian Prototypical Pruning for Transformers in Human–Robot Collaboration †


Abstract
:1. Introduction
- ProtoPrune: a Bayesian token pruning method that automatically selects task-relevant features with a refined self-attention mechanism.
- Theoretical analysis for the convergence of the Prototypical Pruning method with mathematical proof.
- Experimental analysis on two off-the-shelf video Transformers, demonstrating that task-awareness supervision can efficiently guide token pruning.
2. Related Works
2.1. Human–Robot Collaboration
2.2. Keyframe Extraction
2.3. Automatic Action Recognition
2.4. Optical Flow and Action Recognition
2.5. Structured Pruning
3. Methodology
3.1. Problem Formulation
3.2. Bayesian Action Recognition
3.3. Bayesian Token Pruning
3.4. Summary of the Algorithm
| Algorithm 1 Prototype-Aware Token Pruning (ProtoPrune) |
|
4. Convergence Analysis
5. Experiments
5.1. Datasets and Metrics
5.2. Implementation Details
5.3. Results
6. Conclusions
6.1. Main Contributions
6.2. Main Results
6.3. Limitation and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Orsag, L.; Koren, L. Towards a Safe Human–Robot Collaboration Using Information on Human Worker Activity. Sensors 2023, 23, 1283. [Google Scholar] [CrossRef] [PubMed]
- Peng, B.; Chen, B.; He, W.; Kadirkamanathan, V. Prototype-aware Feature Selection for Multi-view Action Prediction in Human-Robot Collaboration. In Proceedings of the 2024 IEEE 29th International Conference on Emerging Technologies and Factory Automation (ETFA), Padova, Italy, 10–13 September 2024; pp. 1–7. [Google Scholar] [CrossRef]
- Yan, Y.; Su, H.; Jia, Y. Modeling and analysis of human comfort in human–robot collaboration. Biomimetics 2023, 8, 464. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010.
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. Video action transformer network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 244–253. [Google Scholar]
- Lou, S.; Hu, Z.; Zhang, Y.; Feng, Y.; Zhou, M.; Lv, C. Human-cyber-physical system for Industry 5.0: A review from a human-centric perspective. IEEE Trans. Autom. Sci. Eng. 2024, 22, 494–511. [Google Scholar] [CrossRef]
- Ramirez-Amaro, K.; Yang, Y.; Cheng, G. A survey on semantic-based methods for the understanding of human movements. Robot. Auton. Syst. 2019, 119, 31–50. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, X.; Zhao, Y. Exploring sub-action granularity for weakly supervised temporal action localization. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2186–2198. [Google Scholar] [CrossRef]
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale video classification with convolutional neural networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1725–1732. [Google Scholar]
- Jahanmahin, R.; Masoud, S.; Rickli, J.; Djuric, A. Human–robot interactions in manufacturing: A survey of human behavior modeling. Robot. Comput. Integr. Manuf. 2022, 78, 102404. [Google Scholar] [CrossRef]
- Tian, Y.; Krishnan, D.; Isola, P. Contrastive Multiview Coding. In Proceedings of the European Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Chen, Z.; Wan, Y.; Liu, Y.; Valera-Medina, A. A knowledge graph-supported information fusion approach for multi-faceted conceptual modelling. Inf. Fusion 2023, 101, 101985. [Google Scholar] [CrossRef]
- Richard, A.; Kuehne, H.; Gall, J. Weakly supervised action learning with rnn based fine-to-coarse modeling. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 754–763. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhang, P.; Tian, C.; Zhao, L.; Duan, Z. A multi-granularity CNN pruning framework via deformable soft mask with joint training. Neurocomputing 2024, 572, 127189. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, Z.; Han, S. Spatten: Efficient sparse attention architecture with cascade token and head pruning. In Proceedings of the 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Republic of Korea, 27 February–3 March 2021; pp. 97–110. [Google Scholar]
- Chitty-Venkata, K.T.; Mittal, S.; Emani, M.; Vishwanath, V.; Somani, A.K. A survey of techniques for optimizing transformer inference. J. Syst. Archit. 2023, 144, 102990. [Google Scholar] [CrossRef]
- Kim, S.; Shen, S.; Thorsley, D.; Gholami, A.; Kwon, W.; Hassoun, J.; Keutzer, K. Learned token pruning for transformers. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 784–794. [Google Scholar]
- Peng, B.; Islam, M.; Tu, M. Angular Gap: Reducing the Uncertainty of Image Difficulty through Model Calibration. In Proceedings of the 30th ACM International Conference on Multimedia, New York, NY, USA, 10–14 October 2022; MM ’22. pp. 979–987. [Google Scholar] [CrossRef]
- Hu, J.F.; Zheng, W.S.; Lai, J.; Zhang, J. Jointly learning heterogeneous features for RGB-D activity recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5344–5352. [Google Scholar]
- Molchanov, D.; Ashukha, A.; Vetrov, D. Variational dropout sparsifies deep neural networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2498–2507. [Google Scholar]
- Liu, Y.; Dong, W.; Zhang, L.; Gong, D.; Shi, Q. Variational bayesian dropout with a hierarchical prior. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7124–7133. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2017, arXiv:1611.01144. [Google Scholar]
- Patalas-Maliszewska, J.; Dudek, A.; Pajak, G.; Pajak, I. Working toward solving safety issues in human–robot collaboration: A case study for recognising collisions using machine learning algorithms. Electronics 2024, 13, 731. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, W.; Cheng, Q.; Ming, D. Efficient Reachable Workspace Division under Concurrent Task for Human-Robot Collaboration Systems. Appl. Sci. 2023, 13, 2547. [Google Scholar] [CrossRef]
- Tuli, T.B.; Kohl, L.; Chala, S.A.; Manns, M.; Ansari, F. Knowledge-Based Digital Twin for Predicting Interactions in Human-Robot Collaboration. In Proceedings of the 2021 26th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Västerås, Sweden, 7–10 September 2021; pp. 1–8. [Google Scholar]
- Malik, A.A.; Masood, T.; Bilberg, A. Virtual reality in manufacturing immersive and collaborative artificial-reality in design of human–robot workspace. Int. J. Comput. Integr. Manuf. 2020, 33, 22–37. [Google Scholar] [CrossRef]
- Guerra-Zubiaga, D.A.; Kuts, V.; Mahmood, K.; Bondar, A.; Esfahani, N.N.; Otto, T. An approach to develop a digital twin for industry 4.0 systems: Manufacturing automation case studies. Int. J. Comput. Integr. Manuf. 2021, 34, 933–949. [Google Scholar] [CrossRef]
- Hanna, A.; Bengtsson, K.; Götvall, P.L.; Ekström, M. Towards safe human robot collaboration - Risk assessment of intelligent automation. In Proceedings of the 2020 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA), Vienna, Austria, 8–11 September 2020; Volume 1, pp. 424–431. [Google Scholar] [CrossRef]
- Inaba, M.; Guo, H.J.; Nakao, K.; Abe, K. Adaptive control systems switched by control and robust performance criteria. In Proceedings of the 1996 IEEE Conference on Emerging Technologies and Factory Automation (ETFA ’96), Kauai Marriott, HI, USA, 18–21 November 1996; Volume 2, pp. 690–696. [Google Scholar] [CrossRef]
- Demir, K.A.; Döven, G.; Sezen, B. Industry 5.0 and Human-Robot Co-working. Procedia Comput. Sci. 2019, 158, 688–695. [Google Scholar] [CrossRef]
- Pini, F.; Ansaloni, M.; Leali, F. Evaluation of operator relief for an effective design of HRC workcells. In Proceedings of the 2016 IEEE 21st International Conference on Emerging Technologies and Factory Automation (ETFA), Berlin, Germany, 6–9 September 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Likitlersuang, J.; Sumitro, E.R.; Cao, T.; Visée, R.J.; Kalsi-Ryan, S.; Zariffa, J. Egocentric video: A new tool for capturing hand use of individuals with spinal cord injury at home. J. Neuroeng. Rehabil. 2019, 16, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, Y.; Rui, Y.; Huang, T.S.; Mehrotra, S. Adaptive key frame extraction using unsupervised clustering. In Proceedings of the 1998 International Conference on Image Processing. icip98 (cat. no. 98cb36269), Chicago, IL, USA, 7 October 1998; Volume 1, pp. 866–870. [Google Scholar]
- De Avila, S.E.F.; Lopes, A.P.B.; da Luz, A.; de Albuquerque Araújo, A. VSUMM: A mechanism designed to produce static video summaries and a novel evaluation method. Elsevier PRL 2011, 32, 56–68. [Google Scholar] [CrossRef]
- Kuanar, S.K.; Panda, R.; Chowdhury, A.S. Video key frame extraction through dynamic Delaunay clustering with a structural constraint. J. Vis. Commun. Image Represent. 2013, 24, 1212–1227. [Google Scholar] [CrossRef]
- Gharbi, H.; Bahroun, S.; Massaoudi, M.; Zagrouba, E. Key frames extraction using graph modularity clustering for efficient video summarization. In Proceedings of the ICASSP, New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Wang, Q.; He, X.; Jiang, X.; Li, X. Robust bi-stochastic graph regularized matrix factorization for data clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 390–403. [Google Scholar] [CrossRef]
- Lucci, N.; Preziosa, G.F.; Zanchettin, A.M. Learning Human Actions Semantics in Virtual Reality for a Better Human-Robot Collaboration. In Proceedings of the 2022 31st IEEE International Conference on Robot and Human Interactive Communication (RO-MAN), Napoli, Italy, 29 August–1 September 2022; pp. 785–791. [Google Scholar]
- Guo, K.; Ishwar, P.; Konrad, J. Action recognition from video using feature covariance matrices. IEEE Trans. Image Process. 2013, 22, 2479–2494. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Neimark, D.; Bar, O.; Zohar, M.; Asselmann, D. Video transformer network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3163–3172. [Google Scholar]
- Choi, J.; Gao, C.; Messou, J.C.E.; Huang, J.B. Why cannot I dance in a mall? Learning to mitigate scene bias in action recognition. In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 8–14 December 2019; pp. 77–89. [Google Scholar]
- Korban, M.; Li, X. DDGCN: A Dynamic Directed Graph Convolutional Network for Action Recognition. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Part XX. Volume 16. [Google Scholar]
- Hussain, T.; Muhammad, K.; Ding, W.; Lloret, J.; Baik, S.W.; De Albuquerque, V.H.C. A comprehensive survey of multi-view video summarization. Pattern Recognit. 2021, 109, 107567. [Google Scholar] [CrossRef]
- Wang, H.; Yang, J.; Yang, L.T.; Gao, Y.; Ding, J.; Zhou, X.; Liu, H. MvTuckER: Multi-view knowledge graphs representation learning based on tensor tucker model. Inf. Fusion 2024, 106, 102249. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981. [Google Scholar]
- Sevilla-Lara, L.; Liao, Y.; Güney, F.; Jampani, V.; Geiger, A.; Black, M.J. On the Integration of Optical Flow and Action Recognition. In Proceedings of the German Conference on Pattern Recognition, Basel, Switzerland, 13–15 September 2017. [Google Scholar]
- Wang, L.; Xiong, Y.; Wang, Z.; Qiao, Y.; Lin, D.; Tang, X.; Gool, L.V. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Sun, D.; Roth, S.; Black, M.J. Secrets of Optical Flow Estimation and Their Principles. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Candès, E.J.; Romberg, J.; Tao, T. Robust uncertainty principles: Exact signal reconstruction from highly incomplete frequency information. IEEE Trans. Inf. Theory 2006, 52, 489–509. [Google Scholar] [CrossRef]
- Zheng, C.; Li, Z.; Zhang, K.; Yang, Z.; Tan, W.; Xiao, J.; Ren, Y.; Pu, S. SAViT: Structure-Aware Vision Transformer Pruning via Collaborative Optimization. In Proceedings of the Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- Frantar, E.; Alistarh, D. SparseGPT: Massive language models can be accurately pruned in one-shot. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023. [Google Scholar]
- Liu, Z.; Wang, J.; Dao, T.; Zhou, T.; Yuan, B.; Song, Z.; Shrivastava, A.; Zhang, C.; Tian, Y.; Re, C.; et al. Deja vu: Contextual sparsity for efficient llms at inference time. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 22137–22176. [Google Scholar]
- Feng, Z.; Zhang, S. Efficient vision transformer via token merger. IEEE Trans. Image Process. 2023, 32, 4156–4169. [Google Scholar] [CrossRef] [PubMed]
- Park, S.H.; Tack, J.; Heo, B.; Ha, J.W.; Shin, J. K-centered patch sampling for efficient video recognition. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022; pp. 160–176. [Google Scholar]
- Bolya, D.; Fu, C.Y.; Dai, X.; Zhang, P.; Feichtenhofer, C.; Hoffman, J. Token Merging: Your ViT but Faster. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Kim, M.; Gao, S.; Hsu, Y.C.; Shen, Y.; Jin, H. Token fusion: Bridging the gap between token pruning and token merging. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 1383–1392. [Google Scholar]
- Ishibashi, R.; Meng, L. Automatic pruning rate adjustment for dynamic token reduction in vision transformer. Appl. Intell. 2025, 55, 1–15. [Google Scholar] [CrossRef]
- Gao, S.; Tsang, I.W.H.; Chia, L.T. Sparse representation with kernels. IEEE Trans. Image Process. 2012, 22, 423–434. [Google Scholar]
- Nitanda, A. Stochastic proximal gradient descent with acceleration techniques. In Proceedings of the 28th International Conference on Neural Information Processing Systems (NIPS’14), Montreal, QC, Canada, 8–13 December 2014; pp. 1574–1582. [Google Scholar]
- Deisenroth, M.; Faisal, A.A.; Ong, C.S. Mathematics for Machine Learning; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Li, J.; Zhou, P.; Xiong, C.; Hoi, S.C. Prototypical contrastive learning of unsupervised representations. arXiv 2020, arXiv:2005.04966. [Google Scholar]
- Kay, W.; Carreira, J.; Simonyan, K.; Zhang, B.; Hillier, C.; Vijayanarasimhan, S.; Viola, F.; Green, T.; Back, T.; Natsev, P.; et al. The kinetics human action video dataset. arXiv 2017, arXiv:1705.06950. [Google Scholar]
- Goyal, R.; Ebrahimi Kahou, S.; Michalski, V.; Materzynska, J.; Westphal, S.; Kim, H.; Haenel, V.; Fruend, I.; Yianilos, P.; Mueller-Freitag, M.; et al. The “something something” video database for learning and evaluating visual common sense. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5842–5850. [Google Scholar]
- Wang, S.; Zhang, J.; Wang, P.; Law, J.; Calinescu, R.; Mihaylova, L. A deep learning-enhanced Digital Twin framework for improving safety and reliability in human–robot collaborative manufacturing. Robot. Comput. Integr. Manuf. 2024, 85, 102608. [Google Scholar] [CrossRef]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. In Proceedings of the 29th International Conference on Neural Information Processing Systems (NIPS’15), Montreal, QC, Canada, 7–12 December 2015; pp. 1135–1143. [Google Scholar]
- Li, K.; Wang, Y.; Zhang, J.; Gao, P.; Song, G.; Liu, Y.; Li, H.; Qiao, Y. Uniformer: Unifying convolution and self-attention for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12581–12600. [Google Scholar] [CrossRef]
- Wang, M.; Xing, J.; Liu, Y. ActionCLIP: A New Paradigm for Video Action Recognition. arXiv 2021, arXiv:2109.08472. [Google Scholar]
- Jeff, R. Experiment Tracking with Weights & Biases. 2020. Available online: https://wandb.ai/site/ (accessed on 21 April 2025).
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
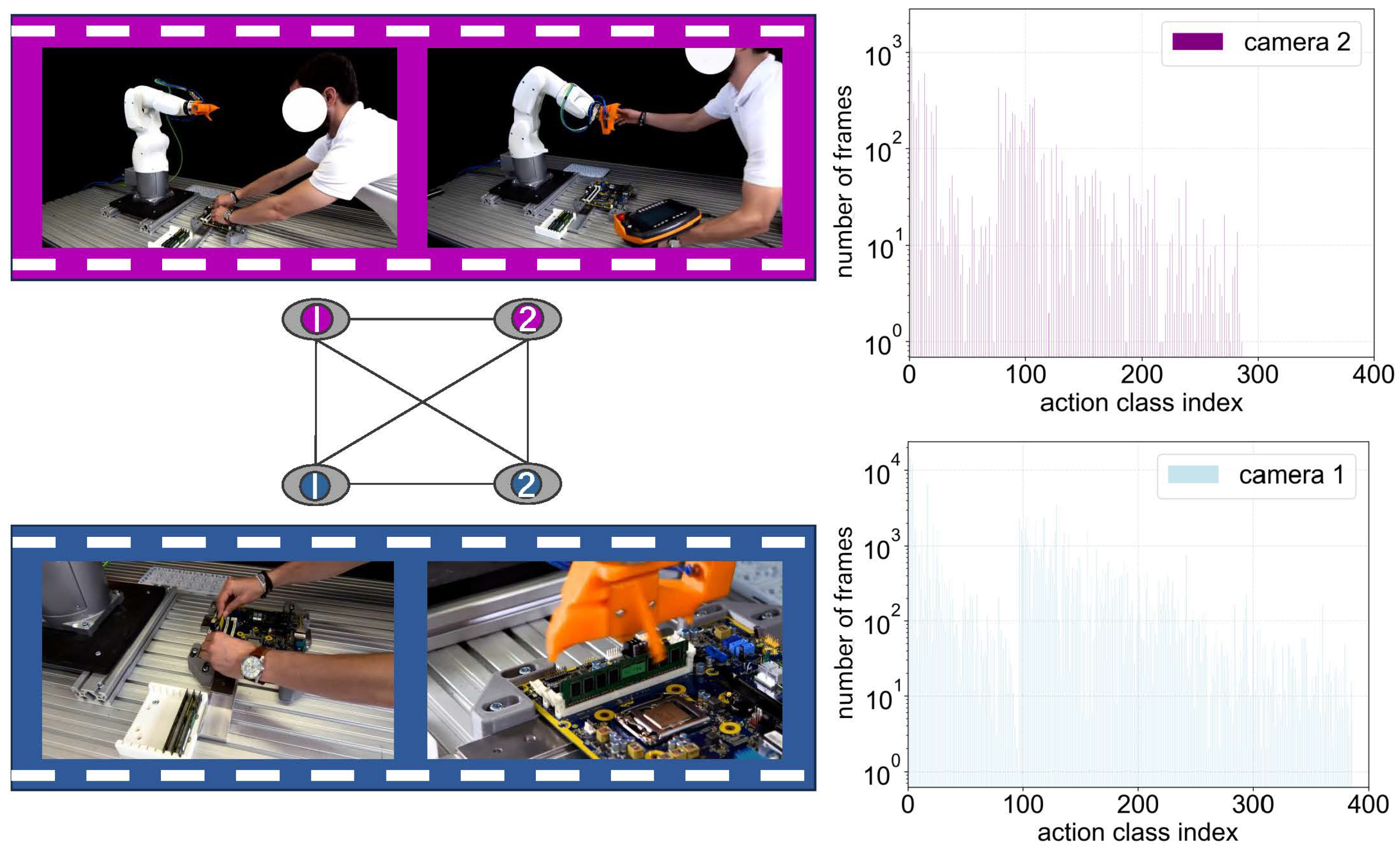
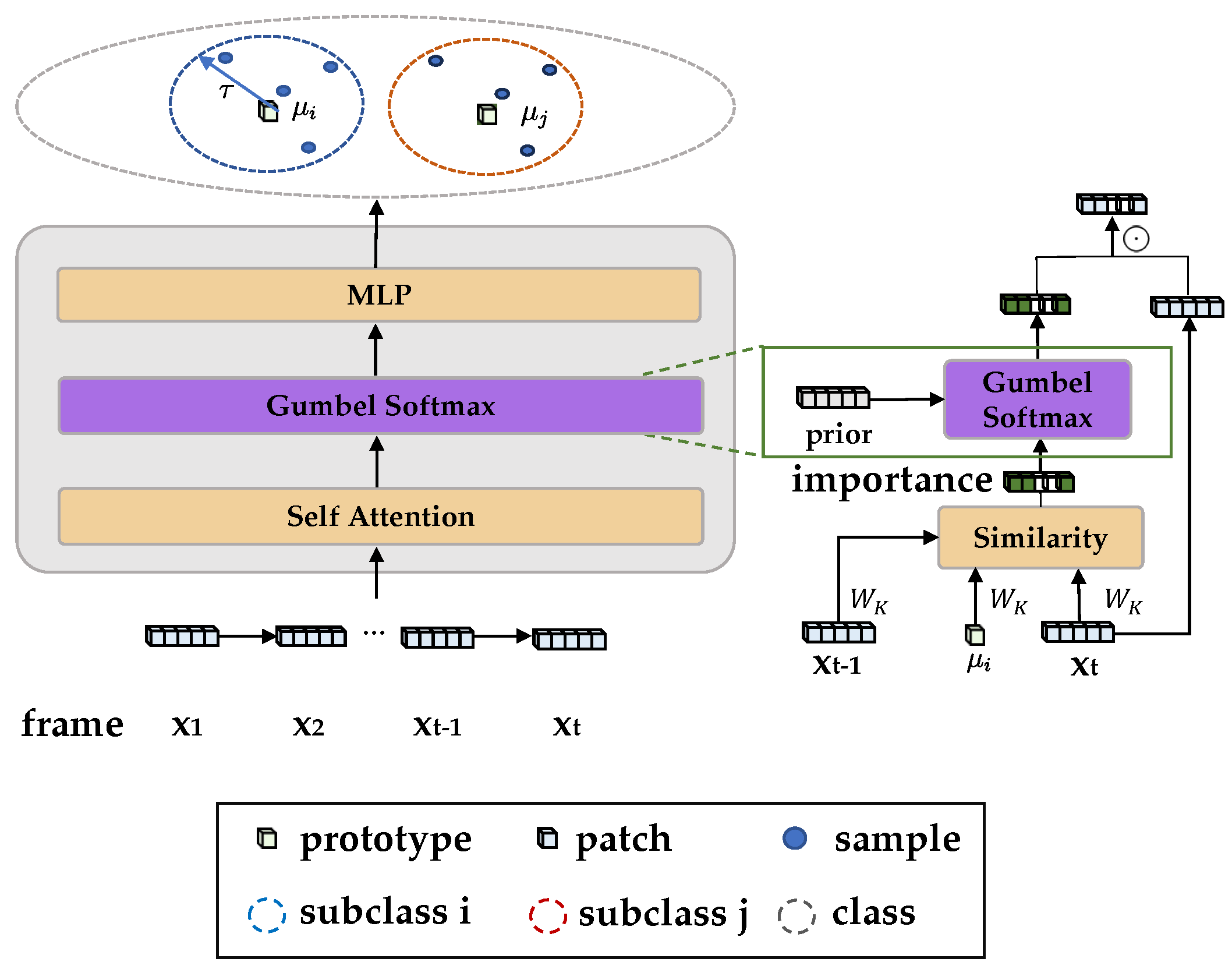





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Summarization | Key Element |
|---|---|---|
| EVit [57] | Token merging via fusion | Self-attention Fusion |
| K-centered [58] | Efficient patch-based sampling | K-center Search |
| ToMe [59] | Image token merging | Bipartite Matching |
| ToFu [60] | Combine merging and pruning | Bipartite Soft Matching |
| Adjust [61] | Adaptive pruning rate | Gradient Aware Scaling |
| ProtoPrune (ours) | Pruning weakly labeled sub-actions | Prototypical learning |
| Symbol | Description |
|---|---|
| A video clip recording one action | |
| The embedding of the i-th frame, with | |
| d | The number of hidden dimensions |
| x | Feature summed over the hidden dimension |
| The keyframe (prototype) in multi-views | |
| T | Hard threshold for token pruning operations |
| Temperature for Gumbel-Softmax operations | |
| The margin to discriminate the representations | |
| Concentration level of the feature distribution in prototypes | |
| f | The raw likelihood function used in the Bayesian inference |
| The modified likelihood function in Bayesian Prototypical Pruning | |
| Gumbel sample from a prior distribution | |
| w | Aggregating feature magnitudes on the l th layer |
| The [CLS] token from a video Transformer | |
| Performance retention ratio measures accuracy of pruned models | |
| GFLOPs | Giga floating point operations measure inference computation |
| Feature | Kinetics-400 | SSV2 | HRC |
|---|---|---|---|
| Classes | 400 | 174 | 4 |
| #Videos/Images | ∼260,000 | ∼200,000 | 13,926 |
| Duration | ∼10 s | ∼ 2–6 s | ∼2 min |
| Frame Rate | 25 fps | 12 fps | 30 fps |
| Focus | general | egocentric, FPV | illumination |
| Source | YouTube | crowd-sourced | laboratory |
| Hyperparameter | Value | Description |
|---|---|---|
| Number of Prototypes | 4 | #views that limit the granularity of actions |
| Temperature | 0.5 | Gumbel-Softmax’s hyperparameter for sparsity |
| Learning Rate (LR) | Base LR with cosine decay | |
| Batch Size | 1024 | Number of samples in a mini-batch |
| Weight Decay | 0.05 | Weight regularization term |
| Warmup Epochs | 5 | Epochs to stabilize early training |
| Total Epochs | 100/30 | Epochs on Kinetics-400/SSV2 |
| Method | Kinetics-400 | SSV2 | PRR | |||||
|---|---|---|---|---|---|---|---|---|
| #frame | GFLOPs↓ | Top-1↑ | #frame | GFLOPs↓ | Top-1↑ | |||
| I3D [42] | 16×1×10 | 108 | 72.1 | 16×2×8 | 167.8 | 62.8 | - | |
| SlowFast [73] | 32×3×10 | 12,720 | 77.0 | 32×3×10 | 12,720 | 58.4 | - | |
| CLIP [74] | 8×1×1 | 149.1 | 57.5 | 8×1×1 | 149.1 | 5.1 | - | |
| ActionCLIP [71] | 8×1×1 | 149.1 | 52.6 | 8×1×1 | 149.1 | 69.6 | - | |
| Dropout [21] | 8×1×1 | 92.6↓37.9% | 18.3 | 8×1×1 | 92.6↓37.9% | 10.3 | 17.9 | |
| ProtoPrune | 8×1×1 | 92.6↓37.9% | 74.1 | 8×1×1 | 92.6↓37.9% | 62.7 | 91.0 | |
| UniFormer [70] | 16×1×4 | 389 | 82.0 | 16×3×1 | 290 | 70.2 | - | |
| Dropout [21] | 16×1×4 | 244.3↓37.2% | 24.7 | 16×3×1 | 182.7↓37% | 10.9 | 20.5 | |
| Ablation | 16×1×4 | 244.3↓37.2% | 49.2 | 16×3×1 | 182.7↓37% | 47.3 | 63.5 | |
| ProtoPrune | 16×1×4 | 244.3↓37.2% | 75.9 | 16×3×1 | 182.7↓37% | 65.4 | 92.9 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peng, B.; Chen, B. Bayesian Prototypical Pruning for Transformers in Human–Robot Collaboration. Mathematics 2025, 13, 1411. https://doi.org/10.3390/math13091411
Peng B, Chen B. Bayesian Prototypical Pruning for Transformers in Human–Robot Collaboration. Mathematics. 2025; 13(9):1411. https://doi.org/10.3390/math13091411
Chicago/Turabian StylePeng, Bohua, and Bin Chen. 2025. "Bayesian Prototypical Pruning for Transformers in Human–Robot Collaboration" Mathematics 13, no. 9: 1411. https://doi.org/10.3390/math13091411
APA StylePeng, B., & Chen, B. (2025). Bayesian Prototypical Pruning for Transformers in Human–Robot Collaboration. Mathematics, 13(9), 1411. https://doi.org/10.3390/math13091411