
A Bayesian Additive Regression Trees Framework for Individualized Causal Effect Estimation



Abstract
1. Introduction
2. Theoretical Foundations
2.1. Definition and Modeling Foundations of Causality
- (1)
- Association: There is a statistical association between the treatment variable and the outcome;
- (2)
- Time ordering: The treatment occurs before the outcome to ensure causal direction.
- (3)
- Non-spuriousness: The relationship between the treatment and the outcome cannot be explained by omitted variables. To this end, the ignorability assumption needs to be made, that is and are independent of given . Under this assumption, with adequate adjustment for the covariance , the expected function of the potential outcome can be identified.
- (4)
- Supporting theory: In addition to statistical modeling, there must be a theoretical or empirical background to support the causal direction of the treatment variables on the results.
2.2. BART Theory
- (1)
- Tree structure prior
- (2)
- Dividing variables a priori
- (3)
- Leaf node parameter prior
- (4)
- Error variance prior
- (1)
- Update the tree structure
- (2)
- Update leaf node parameters
- (3)
- Update error variance
2.3. Multivariable Contribution-Evaluation Method
2.4. ITE Estimation and Evaluation Methods
- (1)
- S-Learner: The treatment variable and the covariates are input into the same prediction model, and the ITE estimation is obtained by predicting and , respectively, that is:
- (2)
- X-Learner: It is a causal estimation framework based on meta-learning. This method first fits the potential outcome model to the treatment group and the control group, respectively, calculates the pseudo-ITE and then remodels them and finally obtains the individualized treatment effect through propensity score weighted fusion.
- (3)
- BCF: This method jointly models potential outcomes and treatment mechanisms in a Bayesian framework, explicitly considers the confounding of treatment assignments and outputs the posterior distribution of individual ITE, thereby achieving the unification of effect estimation and uncertainty quantification [29].
- (4)
- Interaction linear model: This model describes the linkage between individual characteristics and treatment effects by adding interaction terms between covariates and treatment variables . This model has strong interpretability, but its ability is limited when dealing with high-dimensional data or complex nonlinear relationships.
- (5)
- The dual-structure BART-ITE model proposed in this paper: Under the BART framework, prediction models for the treatment group and the control group are constructed, respectively, and the individual potential outcomes are modeled separately, and then the ITE is estimated based on this. This model not only has good nonlinear fitting ability, but can also output the posterior distribution of ITE through MCMC sampling, which has the advantages of robustness and uncertainty quantification.
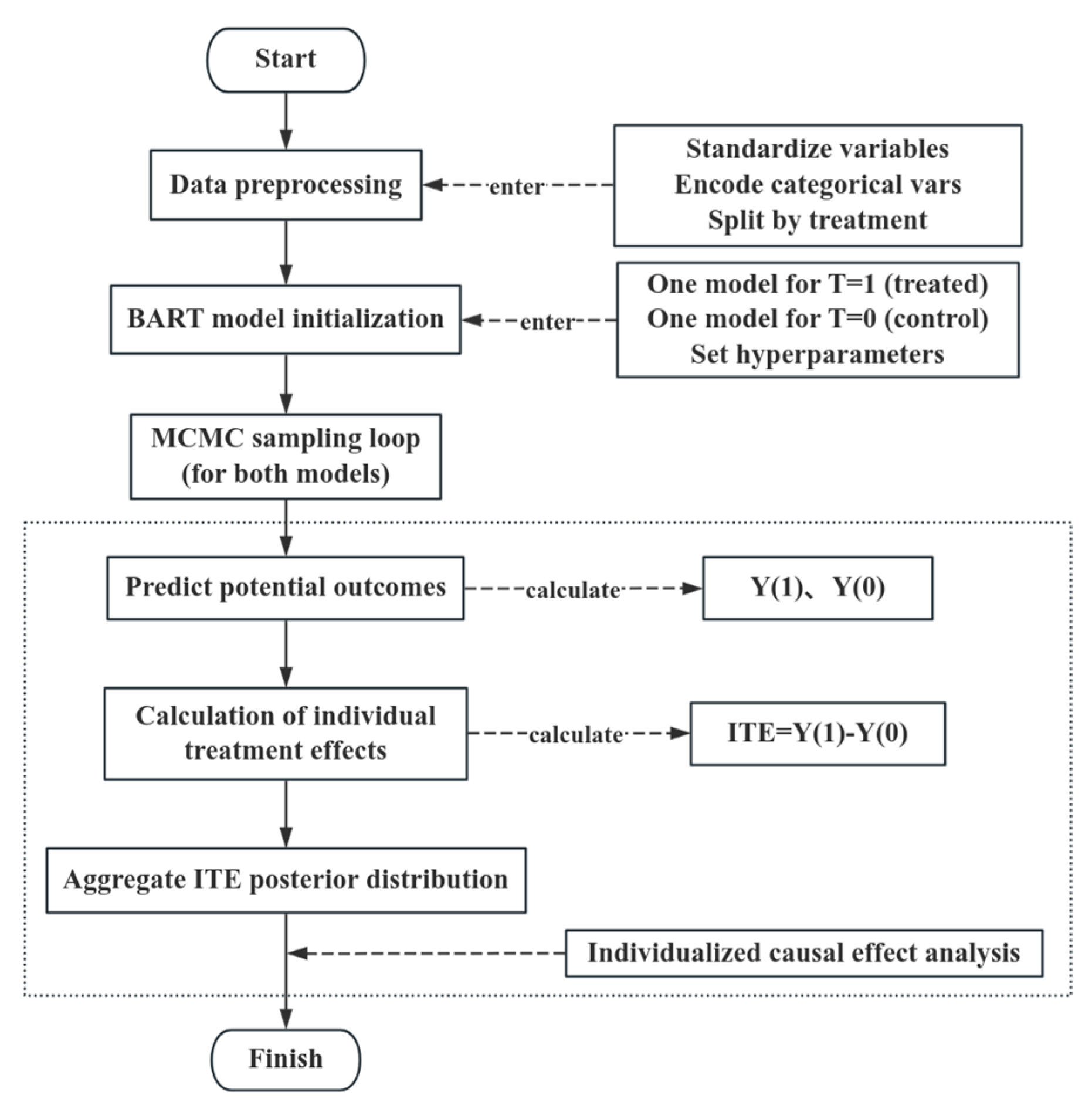
3. Individual Causal Effect Analysis Model Based on BART
3.1. Symbol Description
3.2. Construction of the BART-ITE Model
3.3. Model Solving Algorithm and Implementation
- (1)
- Update the tree structure , calculate the residual according to the prediction results of the current model and select a tree for structural adjustment. Structural operations include Grow, Prune and Change. By searching for the optimal splitting variables and splitting points among covariates, a candidate tree structure is constructed. Whether to accept the new structure is determined by the Metropolis-Hastings criterion. The acceptance probability is calculated by combining the likelihood values under the new and old structures and prior information, and sampling is based on this;
- (2)
- Update the leaf node mean . Given the tree structure , the leaf node mean is sampled through the Gaussian posterior distribution:where is the sample index that falls into leaf node ;
- (3)
- Update the noise variance . Given the current prediction residual, the noise variance is sampled from the inverse Gamma distribution based on its conjugate prior:
3.4. Computational Complexity and Scalability of the BART-ITE Model
- (1)
- Training phase: Two sets of BART models are trained independently on samples of the treatment group (treatment = 1) and the control group (treatment = 0);
- (2)
- Prediction phase: The two sets of BART models obtained through training are used to predict the potential treatment effects of all observed samples, i.e., the potential results and , and calculate the individual ITE.
- (1)
- Parallel computing: The tree structure update, MCMC iteration and prediction process in the BART model are highly parallel and can be accelerated by multi-core CPU or GPU. At present, the dbarts package is superior to the classic bartMachine in terms of multi-thread support and memory management, and can significantly improve computing efficiency on medium-sized datasets;
- (2)
- Efficient software implementation: The dbarts package used in this study has better memory management and parallel efficiency than the classic BART implementation, and can significantly improve the running speed on medium-sized datasets;
- (3)
- Approximate Bayesian inference: For example, Variational Bayesian BART (VB-BART) can significantly shorten the training time through approximate posterior inference and is suitable for ultra-large-scale data;
- (4)
- Data subsampling technique: In extremely large-scale scenarios, the BART model can be trained in stages through methods such as data subsampling or local weighted fitting;
- (5)
- Distributed computing framework: Explore the feasibility of expanding the BART model on a distributed platform, such as combining the Spark + MapReduce framework to implement data segmentation and parallel training of tree models [34], or the BART architecture based on a distributed GPU cluster, which has the potential to further improve the scale and speed of training under ultra-large-scale data.
4. Simulation Study on the ITE of Graduate Students’ Psychological Stress
4.1. Data Description and Structural Compatibility Test
- (i)
- Full-time enrollment in a graduate program.
- (ii)
- A minimum enrollment duration of three months.
- (iii)
- Clear consciousness and the ability to independently complete the questionnaire.
- (iv)
- Informed consent was obtained prior to participation.
4.2. Multivariable Contribution Analysis Based on BART and SHAP
4.3. Analysis of Group Differences in Employment Stress Among ITE Students
- (i)
- School 1 (non-elite Tier-2 university)—Female students (Gender 1) exhibit slightly higher ITEs than male students (Gender 2). Both genders show modest fluctuations with age. Female ITEs remain relatively stable, with narrow credible intervals, indicating reliable estimates; male ITEs are slightly lower and less sensitive to age.
- (ii)
- School 2 (non-elite Tier-1 university)—No meaningful gender difference is observed. ITEs for both males and females stay low and flat across ages, with minimal variation. Here, gender and age exert little moderating influence on intervention effects.
- (iii)
- School 3 (“211” university)—Female students display marginally higher ITEs than males and a gentle upward trend with age. Male ITEs are lower and fairly constant, suggesting that female students respond better to employment-stress interventions, whereas males experience greater baseline stress but weaker gains from the intervention.
- (iv)
- School 4 (“985” university)—Female students maintain consistently high, stable ITEs with minor age-related variation. By contrast, male students show a pronounced age-related increase: after age 25, their ITEs rise sharply, indicating that employment pressure exerts a growing psychological burden on male postgraduates at top-tier universities.
4.4. Analysis of the Dual-Structure BART-ITE Model
4.4.1. Hyperparameter Tuning
4.4.2. Model Prediction Performance and Robustness Evaluation
4.4.3. Comparative Analysis with Other ITE-Estimation Models
4.4.4. Operational Efficiency and Computing Resource Evaluation
- (a)
- Sample size : 100, 200 and 342;
- (b)
- Number of trees : 50, 100 and 200;
- (c)
- MCMC iteration number : 1000 and 2000, with burn-in set to 0.5.
- (1)
- The model training time increases approximately linearly with the number of trees and the number of MCMC iterations ;
- (2)
- When the sample size n increases, the training time also increases, but the increase is relatively mild, mainly due to the good processing efficiency of dbarts for sample size;
- (3)
- Under the maximum setting of the training time is about 2.23 s, which is generally controllable.
4.5. Local Interpretation of ITE Based on SHAP
5. Conclusions
- (1)
- Dynamic causal inference: With the growing availability of multimodal and time-series data, the dual-structure BART-ITE model can be extended to estimate time-varying treatment effects and incorporate temporal dependencies [37].
- (2)
- Integration with deep learning: By embedding the dual-structure BART-ITE model within deep learning architectures and incorporating automatic feature extraction, the framework can be further adapted to handle nonlinear, highly complex structures [38].
- (3)
- In terms of real-world applications, the dual-structure BART-ITE offers substantial value in domains such as precision medicine, policy evaluation and educational resource optimization. Future work may explore integrating the model with online learning algorithms to support real-time updates and adaptive causal analysis, thereby enhancing its responsiveness and practical utility in dynamic environments.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BART | Bayesian Additive Regression Trees |
| SHAP | Shapley Additive Explanations |
| ITE | Individualized Treatment Effect |
References
- Li, T.; Guan, J.; Huang, Y.; Jin, X. The Effect of Stress on Depression in Postgraduate Students: Mediating Role of Research Self-Efficacy and Moderating Role of Growth Mindset. Behav. Sci. 2025, 15, 266. [Google Scholar] [CrossRef]
- Soma, S.; Dipanjan, B.; Prasad, K.; Hariom, P.; Sourav, K. A Comparison of Stress, Coping, Empathy, and Personality Factors Among Post-Graduate Students of Behavioural Science and Engineering Courses. Indian J. Psychiatry 2023, 65, 113–114. [Google Scholar] [CrossRef]
- Prout, T.A.; Zilcha-Mano, S.; Aafjes-van Doorn, K.; Békés, V.; Christman-Cohen, I.; Whistler, K.; Kui, T.; Di Giuseppe, M. Identifying Predictors of Psychological Distress During COVID-19: A Machine Learning Approach. Front. Psychol. 2020, 11, 586202. [Google Scholar] [CrossRef] [PubMed]
- Adhikari, S.; Zheleva, E. Inferring Individual Direct Causal Effects under Heterogeneous Peer Influence. Mach. Learn. 2025, 114, 113. [Google Scholar] [CrossRef]
- Samuel, B.; Matias, B.; Michele, G. Helping Struggling Students and Benefiting All: Peer Effects in Primary Education. J. Public Econ. 2023, 224, 104925. [Google Scholar] [CrossRef]
- Xiao, Z.M.; Hauser, O.P.; Kirkwood, C.; Li, D.Z.; Jones, B.; Higgins, S. Uncovering Individualised Treatment Effect: Evidence from Educational Trials. OSF Preprints, 2020; preprint. [Google Scholar] [CrossRef]
- Xiang, Z.; Xie, Y. Propensity Score-Based Methods versus MTE-Based Methods in Causal Inference: Identification, Estimation, and Application. Sociol. Methods Res. 2016, 45, 3. [Google Scholar]
- Hettinger, G.; Lee, Y.; Mitra, N. Multiply robust difference-in-differences estimation of causal effect curves for continuous exposures. Biometrics 2025, 81, ujaf015. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, Y.; Li, Y.; Li, Y. Doubly robust estimation for non-probability samples with heterogeneity. J. Comput. Appl. Math. 2025, 465, 116567. [Google Scholar] [CrossRef]
- Mullainathan, S.; Spiess, J. Machine learning: An applied econometric approach. J. Econ. Perspect. 2017, 31, 87–106. [Google Scholar] [CrossRef]
- He, W.J.; You, D.F.; Zhang, R.Y.; Yu, H.; Chen, F.; Hu, Z.B.; Zhao, Y. Estimation on the Individual Treatment Effect among Heterogeneous Population, Using the Causal Forests Method. Zhonghua Liu Xing Bing Xue Za Zhi 2019, 40, 707–712. [Google Scholar] [CrossRef]
- Goedhart, M.J.; Klausch, T.; Janssen, J.; van de Wiel, M.A. Adaptive Use of Co-Data Through Empirical Bayes for Bayesian Additive Regression Trees. Stat. Med. 2025, 44, e70004. [Google Scholar] [CrossRef]
- Sparapani, R.A.; Logan, B.R.; McCulloch, R.E.; Laud, P.W. Nonparametric Survival Analysis Using Bayesian Additive Regression Trees (BART). Stat. Med. 2016, 35, 2741–2753. [Google Scholar] [CrossRef] [PubMed]
- Chipman, H.A.; George, E.I.; McCulloch, R.E. BART: Bayesian Additive Regression Trees. Ann. Appl. Stat. 2010, 4, 266–298. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, R.; Lin, J.; Chi, A.; Davies, S. DOD-BART: Machine Learning-Based Dose Optimization Design Incorporating Patient-Level Prognostic Factors via Bayesian Additive Regression Trees. J. Biopharm. Stat. 2024, 34, 11–16. [Google Scholar] [CrossRef]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Rossouw, R.F.; Coetzer, R.L.J.; Le Roux, N.J. Variable Contribution Identification and Visualization in Multivariate Statistical Process Monitoring. Chemom. Intell. Lab. Syst. 2020, 196, 103894. [Google Scholar] [CrossRef]
- Del Serrone, G.; Moretti, L. A Stepwise Regression to Identify Relevant Variables Affecting the Environmental Impacts of Clinker Production. J. Clean. Prod. 2023, 398, 136564. [Google Scholar] [CrossRef]
- Dubey, A.K.; Kumar, Y.; Kumar, S. Optimizing Parameters of AWJM for Ti-6Al-4V Grade 5 Alloy Using Grey Entropy Weight Method: A Multivariable Approach. J. Inst. Eng. Ser. C 2025, 106, 181–195. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.I. A Unified Approach to Interpreting Model Predictions. arXiv 2017. [Google Scholar] [CrossRef]
- Akter, R.; Susilawati, S.; Zubair, H.; Chor, W.T. Analyzing Feature Importance for Older Pedestrian Crash Severity: A Comparative Study of DNN Models, Emphasizing Road and Vehicle Types with SHAP Interpretation. Multimodal Transp. 2025, 4, 100203. [Google Scholar] [CrossRef]
- Ji, Y.; Shang, H.; Yi, J.; Zang, W.; Cao, W. Machine Learning-Based Models to Predict Type 2 Diabetes Combined with Coronary Heart Disease and Feature Analysis Based on Interpretable SHAP. Acta Diabetol. 2025, 62, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Neubauer, A.; Brandt, S.; Kriegel, M. Explainable Multi-Step Heating Load Forecasting: Using SHAP Values and Temporal Attention Mechanisms for Enhanced Interpretability. Energy AI 2025, 14, 100480. [Google Scholar] [CrossRef]
- Aman, N.; Panyametheekul, S.; Pawarmart, I.; Sudhibrabha, S.; Manomaiphiboon, K. A Visibility-Based Historical PM2.5 Estimation for Four Decades (1981–2022) Using Machine Learning in Thailand: Trends, Meteorological Normalization, and Influencing Factors Using SHAP Analysis. Aerosol Air Qual. Res. 2025, 25, 4. [Google Scholar] [CrossRef]
- Yu, L.; Jian, W.; Bing, L. EDVAE: Disentangled Latent Factors Models in Counterfactual Reasoning for Individual Treatment Effects Estimation. Inf. Sci. 2024, 652, 119578. [Google Scholar] [CrossRef]
- Marchezini, G.F.; Lacerda, A.M.; Pappa, G.L.; Meira, W.; Miranda, D.; Romano Silva, M.A.; Diniz, L.M. Counterfactual inference with latent variable and its application in mental health care. Data Min. Knowl. Discov. 2022, 36, 811–840. [Google Scholar] [CrossRef]
- Winship, C.; Morgan, S.L. The estimation of causal effects from observational data = L’évaluation des effets de causalité à partir de données d’observation. Annu. Rev. Sociol. 1999, 25, 659–706. [Google Scholar] [CrossRef]
- Hill, J.L. Bayesian nonparametric modeling for causal inference. J. Comput. Graph. Stat. 2011, 20, 217–240. [Google Scholar] [CrossRef]
- Carone, M.; Bignozzi, G.; Manolopoulou, I. Shrinkage Bayesian causal forests for heterogeneous treatment effects estimation. J. Comput. Graph. Stat. 2022, 31, 1202–1214. [Google Scholar] [CrossRef]
- Kalu, C.; Stephen, B.U.A.; Uko, M.C. Empirical valuation of multi-parameters and RMSE-based tuning approaches for the basic and extended Stanford University Interim (SUI) propagation models. Math. Softw. Eng. 2017, 3, 1–12. [Google Scholar]
- Macedo, F.L.; Reverter, A.; Legarra, A. Behavior of the linear regression method to estimate bias and accuracies with correct and incorrect genetic evaluation models. J. Dairy Sci. 2020, 103, 529–544. [Google Scholar] [CrossRef]
- Marvald, J.; Love, T. Detecting interactions using Bayesian additive regression trees. Pattern Anal. Appl. 2024, 27, 153. [Google Scholar] [CrossRef]
- Ročková, V.; van der Pas, S. Posterior concentration for Bayesian regression trees and forests. Ann. Stat. 2020, 48, 2108–2131. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, Z.; Jiang, J.; Wu, W.; Zhang, C.; Cui, B.; Li, J. Model averaging in distributed machine learning: A case study with Apache Spark. VLDB J. 2021, 30, 693–712. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, F.; Zhao, J.; Du, J. Reliability and validity of the positive mental health literacy scale in Chinese adolescents. Front. Psychol. 2023, 14, 1150293. [Google Scholar] [CrossRef]
- Mirhaghi, A.; Sittichanbuncha, S. Observer heterogeneity can be thought of as a confounding variable. Asian Biomed. 2016, 10, 393. [Google Scholar] [CrossRef]
- Papaspyropoulos, K.G.; Kugiumtzis, D. On the validity of Granger causality for ecological count time series. Econometrics 2024, 12, 13. [Google Scholar] [CrossRef]
- He, R.; Liu, M.; Lin, Z.; Zhuang, Z.; Shen, X.; Pan, W. DeLIVR: A deep learning approach to IV regression for testing nonlinear causal effects in transcriptome-wide association studies. Biostatistics 2023, 25, 468–485. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Symbol Meaning |
|---|---|
| Potential outcomes for individual i when receiving treatment. | |
| Potential outcomes for individual i when they do not receive treatment (Control). | |
| Treatment indicator variable, if the individual accepts the treatment, then T = 1, otherwise T = 0. | |
| Individual covariate eigenvector, dimension p. | |
| The number of regression trees in each BART model. | |
| The j-th regression tree is used to fit . | |
| The j-th regression tree is used to fit . | |
| , | The structure of the j-th tree during the s-th MCMC iteration sampling. |
| The predicted value of the outcome of the individual under the treatment state based on the model. | |
| The predicted value of the individual’s outcome under control conditions based on the model. | |
| ITE estimation of individuals in the s-th sampling. | |
| MCMC sampling rounds. | |
| The variance of the noise term, updated in the posterior. | |
| Prior hyperparameters for tree growth. | |
| Prior distribution parameters of leaf node output values. |
| KMO Test and Bartlett Test | ||
|---|---|---|
| Kaiser–Meyer–Olkin measure of sampling adequacy | 0.9010274 | |
| Bartlett’s test of sphericity | chisq | 2272.322 |
| p-value | 0.000 | |
| df | 55 | |
| Metric | Mean | SD |
|---|---|---|
| 0.890 | 0.061 | |
| 8.615 | 1.820 | |
| Overall | 0.896 | |
| Overall | 8.773 |
| Feature | SHAP Value | Interpretation |
|---|---|---|
| Employment Stress () | 2.4942 | The most influential factor significantly increases psychological stress. |
| Peer Stress () | 2.3384 | Strong negative influence, the strongest protective factor, lower peer pressure reduced psychological distress. |
| Research Stress () | 2.0425 | Substantial contributor to stress, consistent with academic workload challenges. |
| Family Stress () | 1.8182 | Lower family stress acts as a buffer, helping reduce overall stress. |
| Financial Stress () | 1.3256 | Suggests moderate financial stress may be less harmful. |
| Anxiety Frequency () | 1.3037 | Frequent anxiety symptoms are naturally linked to higher psychological stress. |
| Supervisor Stress () | 1.1351 | The greater pressure from the tutor leads to increased mental tension and stress. |
| Health Stress () | 0.5370 | Mild health stress contributes only slightly to psychological burden |
| Social Stress () | 0.0929 | A slightly negative value indicates that social pressure has little impact on the individual. |
| Negation Frequency () | 0.0673 | Negative frequencies play a weaker role. |
| Personality Stress () | 0.0231 | The effects of personality-related stress were minimal. |
| Variable | Estimated Coefficient | p Value | Explain |
|---|---|---|---|
| Intercept | 60.5448 | <2 × 10−16 | Benchmark group ITE (gender1, school1, grade = 0, age = 0) |
| age | −1.2037 | 1.45 × 10−13 | For every additional year of age, female ITE decreases by about 1.20 |
| gender2 | 17.4908 | 0.00207 | When the gender is male, the baseline ITE increases by about 17.49 |
| age × gender2 | −0.6495 | 0.00656 | For males, ITE decreased by an additional 0.65 for every additional year of age. |
| Verification Method | RMSE | Bias |
|---|---|---|
| Bootstrap | 10.71 | 23.15 |
| Cross-validation | 7.67 | - |
| Pseudo-ITE comparison by matching method | 21.77 | 1.72 |
| n | m | S | Training Time (Seconds) |
|---|---|---|---|
| 100 | 50 | 1000 | 0.27 |
| 100 | 50 | 2000 | 0.47 |
| 100 | 100 | 1000 | 0.47 |
| 100 | 100 | 2000 | 0.93 |
| 100 | 200 | 1000 | 0.92 |
| 100 | 200 | 2000 | 1.77 |
| 200 | 50 | 1000 | 0.28 |
| 200 | 50 | 2000 | 0.51 |
| 200 | 100 | 1000 | 0.50 |
| 200 | 100 | 2000 | 1.00 |
| 200 | 200 | 1000 | 0.98 |
| 200 | 200 | 2000 | 1.94 |
| 342 | 50 | 1000 | 0.30 |
| 342 | 50 | 2000 | 1.09 |
| 342 | 100 | 1000 | 0.59 |
| 342 | 100 | 2000 | 1.14 |
| 342 | 200 | 1000 | 1.11 |
| 342 | 200 | 2000 | 2.23 |
| Group | Feature | SHAP Value (ϕ) | Contribution Variance (ϕ.var) | Feature Value |
|---|---|---|---|---|
| Treated | gender | 0.390 | 0.412 | gender = 1 |
| age | 0.026 | 2.938 | age = 25 | |
| grade | 1.120 | 1.050 | grade = 2 | |
| school | 2.717 | 7.296 | school = 3 | |
| Control | grade | 3.086 | 9.228 | grade = 2 |
| school | 1.391 | 3.671 | school = 3 | |
| gender | 1.010 | 2.852 | gender = 1 | |
| age | 1.038 | 20.668 | age = 25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, L.; Cao, L.; Wang, T.; Cao, Z.; Shi, X. A Bayesian Additive Regression Trees Framework for Individualized Causal Effect Estimation. Mathematics 2025, 13, 2195. https://doi.org/10.3390/math13132195
He L, Cao L, Wang T, Cao Z, Shi X. A Bayesian Additive Regression Trees Framework for Individualized Causal Effect Estimation. Mathematics. 2025; 13(13):2195. https://doi.org/10.3390/math13132195
Chicago/Turabian StyleHe, Lulu, Lixia Cao, Tonghui Wang, Zhenqi Cao, and Xin Shi. 2025. "A Bayesian Additive Regression Trees Framework for Individualized Causal Effect Estimation" Mathematics 13, no. 13: 2195. https://doi.org/10.3390/math13132195
APA StyleHe, L., Cao, L., Wang, T., Cao, Z., & Shi, X. (2025). A Bayesian Additive Regression Trees Framework for Individualized Causal Effect Estimation. Mathematics, 13(13), 2195. https://doi.org/10.3390/math13132195