Abstract
Ensuring the structural continuity and completeness of road networks in high-resolution remote sensing imagery remains a major challenge for current deep learning methods, especially under conditions of occlusion caused by vegetation, buildings, or shadows. To address this, we propose a novel post-processing enhancement framework that improves the connectivity and accuracy of initial road extraction results produced by any segmentation model. The method employs a dual-stream encoder architecture, which jointly processes RGB images and preliminary road masks to obtain complementary spatial and semantic information. A core component is the MAF (Multi-Modal Attention Fusion) module, designed to capture fine-grained, long-range, and cross-scale dependencies between image and mask features. This fusion leads to the restoration of fragmented road segments, the suppression of noise, and overall improvement in road completeness. Experiments on benchmark datasets (DeepGlobe and Massachusetts) demonstrate substantial gains in precision, recall, F1-score, and mIoU, confirming the framework’s effectiveness and generalization ability in real-world scenarios.
MSC:
68U05
1. Introduction
In remote sensing image analysis, road extraction is a crucial task, with road information widely applied in fields such as geographic information system construction [1], urban planning [2], and disaster assessment [3]. However, remote sensing images are often affected by complex surface features, shadows, and diverse climatic conditions, resulting in blurred road boundaries or confusion with surrounding environments. These challenges make it extremely difficult to accurately extract roads from high-resolution remote sensing images [4,5,6].
Traditional road extraction methods include threshold segmentation [7], edge detection [8], and machine learning [9]. Threshold segmentation methods calculate the grayscale value of each pixel based on image grayscale characteristics, setting appropriate thresholds according to specific scenes to distinguish pixels and extract road information. Bajcsy et al. [10] used high and low grayscale thresholds and road width thresholds to segment road areas in images. The road width threshold was derived from image resolution and actual road width, while high and low grayscale thresholds were determined by histogram analysis. Edge detection methods use operators such as Canny, Sobel, and Roberts to identify road edges. For instance, Ma et al. [11] employed a Retinex-based algorithm to enhance high-resolution but low-contrast images, followed by segmentation with an improved Canny edge detector. Although edge detection performs well in certain scenarios, its effectiveness typically declines in complex environments. Road extraction methods based on machine learning usually rely on manually extracted features, with support vector machines (SVM) being commonly used. Yang et al. [12] achieved high completeness and accuracy in road extraction from high-resolution remote sensing images in industrial park scenes by combining 3D wavelet transform with an optimized support vector machine method. Soni et al. [13] proposed a multistage framework based on LS-SVM, mathematical morphology, and road shape features to accurately extract road networks from remote sensing images, removing non-road elements through morphological processing. Experimental results show this method outperforms others. However, due to the spectral similarity of objects such as roads, buildings, and parking lots, along with limitations in model generalization, these traditional methods are inefficient in complex road scenes and often fail to yield satisfactory results.
With the rapid development of deep learning technology in fields such as image classification [14,15,16], image segmentation [17], and object detection [18], deep learning technology has also offered novel and innovative approaches for the task of road extraction. Sofal et al. [19] proposed a method combining UNet [20] with a spatial channel weighting (SE) module for road recognition, where the Squeeze-and-Excitation (SE) module reweights UNet feature maps to emphasize useful channels Wang et al. [21] proposed a Deeplabv3+ [22] based road extraction method, using ResNeSt [23] as the backbone and incorporating the Atrous Spatial Pyramid Pooling (ASPP) module for multi-scale feature extraction, thereby enhancing extraction accuracy. To retain more spatial information on roads, Zhou et al. [24] proposed D-LinkNet based on LinkNet [25], adding dilated convolution layers to expand the receptive field and facilitate multi-scale feature fusion, though it shows limited performance when roads are occluded. Consequently, Wu et al. [26] introduced a coordinate attention module to enhance feature representation in the central part of D-LinkNet and replaced linear feature fusion with an attention feature fusion module to improve detail extraction. Kampffmeyer et al. [27] introduced a directional awareness module to predict pixel connectivity with neighboring pixels, while Maji et al. [28] proposed a deep learning generator with a guided decoder, enhancing the predictive capability of the decoding layer through weighted guided loss to improve output precision and road connectivity.
Although deep learning methods have achieved notable success in road extraction, many methods still fall short in capturing deeper-level detail expressions and are limited by occlusions from trees or buildings. Even with specifically designed modules to address these issues [29,30,31,32,33,34], serious omissions and misclassifications in road extraction persist, which impacts road morphology and compromises the suitability of the extraction results for spatial decision-making and analysis. To optimize deep learning-based extraction results, several studies have combined deep learning with traditional post-processing methods. For instance, Wang et al. [35] aimed to improve road connectivity by using augmented and expanded sample data as input for UNet to train the model for optimal road extraction. They then applied polynomial curve fitting to correct road discontinuities in the extraction results, compensating for the network’s limitations in road completeness. Gao et al. [36] proposed a refined deep residual convolutional neural network for road extraction from optical satellite images, utilizing residual connection and dilated perception units for symmetric output, and optimizing post-processing with mathematical morphology and tensor voting algorithms. Experimental results show that this method outperforms other network architectures in complex scenes.
Although traditional post-processing combined with deep learning can improve road connectivity to some extent, such approaches still struggle to capture complex road topologies. For severely fragmented, misclassified, or terrain-complicated roads, the effectiveness of post-processing corrections is limited, as these methods heavily rely on hand-crafted rules and are thus vulnerable to noise. Furthermore, despite the notable success of deep learning methods in recent years, they continue to face significant limitations. For example, under occlusions caused by trees or buildings, models often produce broken or missing segments; in complex backgrounds, false positives and misclassifications frequently occur. These challenges reveal that existing approaches remain inadequate in achieving global consistency and generalization. Therefore, there is a pressing need for a new framework that can effectively fuse multi-modal information, thereby enhancing road connectivity, robustness, and adaptability to diverse scenarios. To address these challenges, we propose DRMNet, a deep learning model specifically designed to optimize road extraction results. The model’s encoder adopts a dual-branch structure, with RGB images as input for one branch and a coarse road prediction MASK for the other. Through this dual-branch setup, it achieves fine-grained road extraction by fusing both modalities. To achieve better modality fusion, we introduce an attention-based MAF module, which fuses information across multiple scales, further enhancing road contextual information and feature consistency. To further improve road connectivity, we use multi-loss function weighting to balance BCE loss [37] and Dice loss [38], thus addressing the issue of sparse road target pixels and achieving optimal segmentation performance.
In conclusion, our contributions are listed as follows:
- Dual-branch encoder architecture:
We propose a novel dual-branch encoder that jointly processes RGB images and preliminary road masks (MASK), effectively fusing spatial and semantic information to enhance road extraction capability in complex scenarios.
- Multi-modal Attention Fusion (MAF) module:
We design the MAF module, which dynamically refines feature fusion through channel and spatial attention mechanisms, significantly recovering fragmented roads while suppressing noise and improving global consistency.
- End-to-end optimization framework:
We propose DRMNet, an end-to-end model that directly refines initial segmentation results without relying on traditional post-processing, thereby achieving substantial improvements in both road connectivity and accuracy on public benchmarks. More importantly, DRMNet demonstrates strong robustness in handling occlusions and complex backgrounds, effectively restoring broken road segments and enhancing the structural integrity of road networks. Since the practical value of road extraction lies not only in pixel-level accuracy but also in maintaining the topological connectivity of road networks, recovering fragmented or disconnected roads is crucial for applications such as path planning, urban development, emergency response, and automated mapping. Compared with traditional post-processing methods that depend heavily on hand-crafted rules, the proposed framework exhibits greater generalization ability and adaptability, making it well-suited for practical applications such as geographic information system (GIS) construction and disaster emergency response.
2. Materials and Methods
The DRMNet road extraction model was developed based on the LinkNet framework. First, we proposed a dual-branch encoder structure, with each encoder comprising a 7 × 7 convolution layer with a stride of 2 and five ResNet [39] residual modules. The dual-branch encoder takes a 512 × 512 RGB image and a coarse MASK image as inputs; this coarse MASK can be generated either by a single-branch DRMNet or by other road segmentation models. The pretrained network uses ResNet-34, and each Encoder-block in both encoders employs the MAF module for refined feature extraction. The fused features are then passed to the next block in the RGB branch. The MAF module enhances the model’s information extraction ability from both channel and spatial perspectives, improving multi-level feature extraction and integration. In the decoding stage, a residual structure is used with 1x1 convolution kernels to reduce computational complexity, while full convolution restores the image to its original size. The DRMNet network structure is shown in Figure 1.
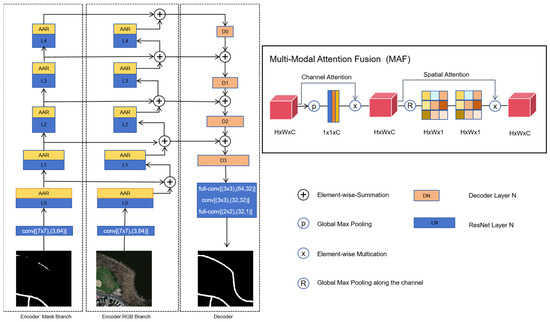
Figure 1.
Model Structure of DRMNet.
2.1. Encoder
In the proposed DRMNet, RGB and MASK features are extracted simultaneously through dual-branch encoders. Each branch consists of five ResNet convolutional blocks, with an MAF module added after each block. Since standard ResNet models are designed for three-channel RGB images, they are not suitable for single-channel MASK images. To address this issue, we modified the first convolutional layer to accept a single-channel input, ensuring compatibility with MASK images.
By using a coarse MASK as input, combined with the RGB image to generate a refined MASK, the main purpose is to provide preliminary positional information, enabling the model to focus on fine feature extraction in key areas. Compared to a single-branch model, this dual-branch structure enables refinement based on the coarse localization, reducing the search space and improving computational efficiency and edge precision. Additionally, this design provides extra contextual information when image quality is poor or background complexity is high, enhancing model robustness.
Effectively extracting features from RGB images and coarse MASK images is the focus of this study. Inspired by [40], we designed an MAF module that leverages attention components to learn discriminative features from the fused data, thereby improving prediction accuracy. As shown in Figure 1, the MAF module is applied after each convolutional layer in both encoder streams to enhance feature compatibility. The MAF module consists of two sequential components: channel attention and spatial attention.
Let the input feature map be denoted as . The channel attention mechanism aims to generate a channel-wise weighting vector to recalibrate the importance of each feature channel. First, global max pooling is applied to compress spatial information:
A non-linear transformation , typically implemented as a fully connected layer followed by a sigmoid activation, is used to compute the attention weights:
where and are learnable parameters, and denotes the sigmoid function. The input features are then reweighted accordingly:
Next, the spatial attention component focuses on enhancing region-level responses. It begins by applying average and max pooling across the channel dimension to generate two spatial descriptors:
These descriptors are concatenated and fed into a convolutional layer with a kernel, followed by a sigmoid activation to obtain a spatial attention map:
This spatial attention is broadcast across all channels and applied to the intermediate feature map:
In summary, the MAF module utilizes both channel-wise and spatial-wise recalibration to progressively enhance feature representations. The channel attention focuses on foreground semantic cues extracted by the convolutional layers, while the spatial attention strengthens contextual awareness across global regions, improving continuity in occluded road sections.
2.2. Decoder
After computing the multi-level features from the two encoder streams, we obtained the final feature maps for the RGB and coarse MASK inputs. The decoder is designed primarily to make efficient use of multi-layer information to refine pixel details. Our decoder architecture is an improvement upon the LinkNet decoder, allowing feature maps to be restored to the original image size.
Multiple downsampling operations in the encoder result in the loss of some spatial information, and relying solely on the encoder’s downsampling output makes it difficult to recover this lost information. To address this, we bypass the input of each encoder layer to the corresponding output of the decoder. This design aims to recover the lost spatial information, which can then be utilized by the decoder and its upsampling operations. Additionally, because the decoder shares the knowledge learned at each encoder layer, it can achieve this with fewer parameters.
Each decoder consists of two 1 × 1 convolutions and one 3 × 3 full convolution, as shown in Figure 2. Each convolution layer takes three parameters as input, with Table 1 listing the values of m and n for each decoder layer, allowing the corresponding convolutional layer parameters to be derived.
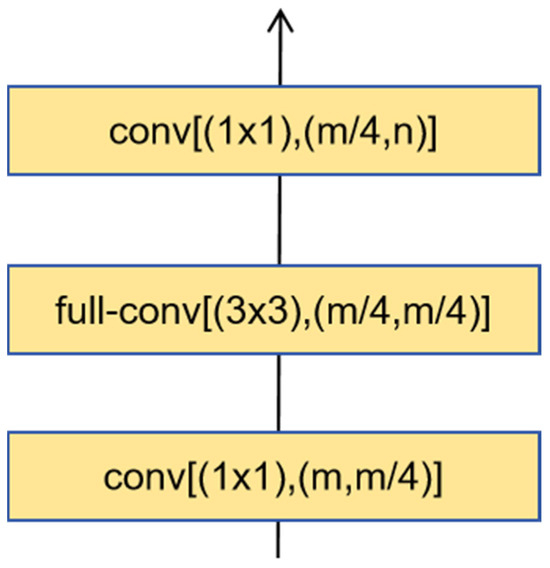
Figure 2.
Decoder Structure.

Table 1.
Decoder Convolution Layer Parameters.
To provide a clearer overview of the entire DRMNet pipeline, we summarize the complete processing steps in Algorithm 1. The pseudocode illustrates the overall workflow, including feature extraction, multi-modal attention fusion, decoding, and optimization.
| Algorithm 1. DRMNet Road Extraction Framework |
| 1 Inputs: RGB image I_rgb, coarse mask M_coarse |
| 2 Outputs: Refined road mask M_refined |
| 3 Feature Extraction: |
| 4 F_rgb ← Encoder_RGB(I_rgb) |
| 5 F_mask ← Encoder_MASK(M_coarse) |
| 6 Feature Fusion: |
| 7 For each stage l do |
| 8 F_rgb[l] ← MAF(F_rgb[l], F_mask[l]) |
| 9 End For |
| 10 Decoding: |
| 11 F_dec ← Decoder(F_rgb, F_mask) |
| 12 M_pred ← Conv(F_dec) |
| 13 Loss Calculation: |
| 14 L_bce ← BCE(M_pred, GroundTruth) |
| 15 L_dice ← Dice(M_pred, GroundTruth) |
| 16 L_total ← α×L_bce + β× L_dice |
| 17 Optimization: |
| 18 Update network parameters using Adam optimizer |
| 19 Return: M_refined = Sigmoid(M_pred) |
2.3. Loss Function
The algorithm in this paper employs both the BCE loss function and the DICE loss function. The BCE loss function calculates the difference using cross-entropy, as shown in Equation (7). When the “penalty” on the current model increases, the logarithmic function used causes the loss value to exhibit an exponential growth pattern. This characteristic encourages the model to adjust the prediction output y to be closer to the true label.
where is the real category of pixel I, and is the prediction of the corresponding pixel.
The Dice loss function is a similarity metric, as shown in Equation (8), with a range from 0 to 1. A higher value indicates a greater number of intersecting elements between the two sets.
where is the real category of pixel I, and is the prediction of the corresponding pixel.
The total loss function is defined in Equation (9). Through a series of comparative experiments, we found that setting the weights to α = 1 and β = 4 yields the best performance. Therefore, unless otherwise specified, subsequent experiments in this paper adopt α = 1 and β = 4.
3. Results
3.1. Dataset
This paper conducted experiments using two remote sensing datasets: the Massachusetts dataset [41] and the DeepGlobe dataset [42].
The Massachusetts road dataset contains 1171 images, each with a size of 1500 × 1500 pixels and a resolution of 1.2 m. The samples in this dataset were cropped into 10,854 images of size 512 × 512. Based on experimental requirements, the dataset was divided into a training set and a validation set, with 8684 images in the training set and 2170 images in the validation set. The example image from the Massachusetts Roads Dataset is shown in Figure 3.

Figure 3.
Examples of the Massachusetts dataset.
The DeepGlobe road dataset contains 6226 images, each sized 1024 × 1024 pixels with a resolution of 0.5 m. These images were cropped into 24,904 smaller images of 512 × 512 pixels. A total of 308 images were designated as the test set, while the remaining samples were split into a training set and a validation set in an approximate 4:1 ratio, with 19,676 images in the training set and 4920 in the validation set. The example image from the DeepGlobe dataset is shown in Figure 4.
Figure 4.
Examples of the DeepGlobe dataset.
3.2. Experimental Setup
The experimental setup utilized an NVIDIA GeForce RTX 3090 GPU (24 GB memory) sourced from Gigabyte, Ningbo, China, and the network model was built using Python 3.8 and the PyTorch 1.8.2 deep learning framework. The learning rate was set to 2 × 10−4, the batch size to 16, and the number of epochs to 200. The Adam optimizer was used to update weights, with a learning rate decay strategy employed during training to enhance model performance. The learning rate automatically decreases as the number of epochs increases, helping the model converge more quickly. The input size for the Massachusetts dataset was 256 × 256, and for the DeepGlobe dataset, it was 512 × 512. The source code is publicly available at: https://github.com/panbo-bridge/DRMNet (accessed on 22 September 2025).
In both the training and testing stages, the coarse masks were generated by the same baseline model used for comparison. Specifically, when comparing DRMNet with UNet, DeepLabV3, LinkNet, or D-LinkNet, we first trained the corresponding baseline model and then used its predicted masks as the coarse inputs to DRMNet. This design ensures that the training and inference processes remain consistent, and that the performance improvements of DRMNet can be fairly attributed to its refinement capability rather than to discrepancies between training and testing conditions.
3.3. Model Evaluation Metrics
The experiment evaluates the model’s effectiveness using four metrics: Precision, Recall, F1-score, and mean intersection over union (mIoU). Precision measures the ratio of correctly predicted road pixels to all predicted road pixels. Recall reflects the proportion of actual road pixels identified by the model. The mIou quantifies the overlap between predicted and true road areas. Finally, the F1-score, as the harmonic mean of Precision and Recall, provides a comprehensive measure of the model’s performance. The evaluation metric formulas are as follows:
In the above equation, k represents the total number of categories, including the background class. TP refers to the count of samples accurately predicted as road pixels by the model; FP denotes the number of samples incorrectly classified as road pixels; FN is the number of actual road pixels misclassified as non-road pixels; and TN signifies the number of non-road pixels correctly identified by the model.
3.4. Road Extraction Comparative Experiments
To validate the effectiveness of the algorithm, the performance of DRMNet was compared with UNet, DeepLabv3, LinkNet, and D-LinkNet models on the Massachusetts road dataset and the DeepGlobe road dataset. The model performance was evaluated from both qualitative and quantitative perspectives.
3.4.1. Results on the Massachusetts Dataset
A comparison of road extraction results for the DRMNet model and other models on the Massachusetts dataset is shown in Figure 5. Overall, all these networks can extract the basic contours of road networks, but DRMNet produces more complete results than other networks. In Figure 5a,c, there are instances of missed extractions. LinkNet, D-LinkNet, and UNet exhibit varying degrees of omission, whereas DRMNet refinement achieves a more complete road extraction. In image c, for instance, there is a small road within the frame that LinkNet, D-LinkNet, and UNet fail to extract entirely, but DRMNet captures it accurately.
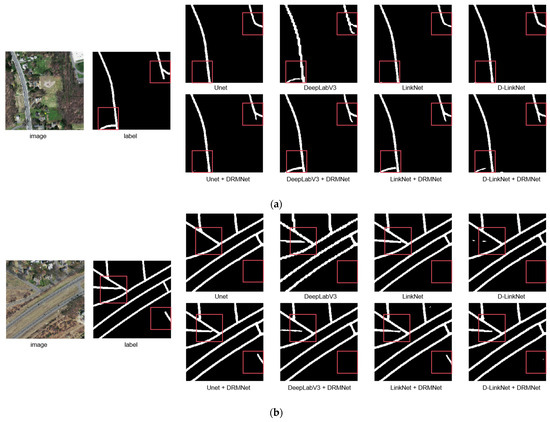
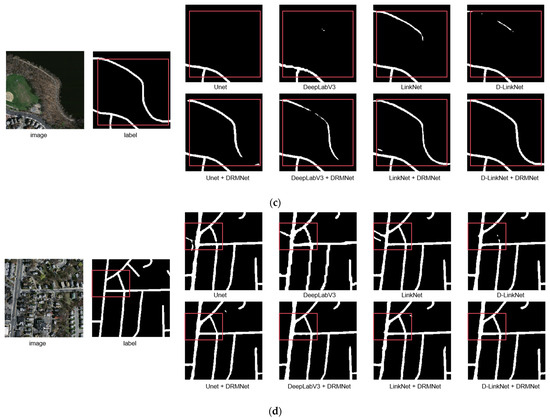
Figure 5.
The figure showcases the comparative results of representative images (a–d) from the Massachusetts dataset before and after applying the DRMNet model. The red bounding boxes emphasize the differences among various methods.
Regarding fragmentation in the extraction results, DeepLabv3, LinkNet, D-LinkNet, and UNet all display fragmentation, especially in Figure 5b,d. However, after processing with DRMNet, these fragmented sections are connected, effectively improving the continuity of the roads. In DeepLabV3’s results, the road integrity in each image is generally better than that of LinkNet, D-LinkNet, and UNet. However, its road boundaries are significantly jagged and uneven. After refinement with DRMNet, the jagged edges are noticeably smoothed, resulting in a more precise and smooth boundary.
Table 2 presents the quantitative evaluation results on the entire test dataset. In this paper, we input the coarse masks from UNet, DeepLabV3, LinkNet, and D-LinkNet into our DRMNet model for refined extraction. After using DRMNet, the improvements in each metric are as follows: For precision, the minimum improvement is 6.5%, observed in the UNet model, while the maximum improvement is 18.3%, observed in the DeepLabv3 model, with an average improvement of 11.88%. For recall, the minimum improvement is 2.2%, observed in the DeepLabv3 model, and the maximum improvement is 15.8%, observed in the UNet model, with an average improvement of 11.63%. For F1-score, the minimum improvement is 10.1%, observed in the DeepLabv3 model, and the maximum improvement is 13.5%, observed in the D-LinkNet model, with an average improvement of 11.75%. For mIoU, the minimum improvement is 7.6%, observed in the DeepLabv3 model, and the maximum improvement is 11.0%, observed in the D-LinkNet model, with an average improvement of 9.25%. Overall, the improvements in each metric are around 10%, with precision showing the largest improvement, and recall showing the smallest minimum improvement.
Table 2.
Metric Evaluation of Comparative Experiments on the Massachusetts Dataset.
Both qualitative and quantitative analyses indicate that DRMNet not only enhances overall accuracy but also improves road consistency, capturing more road details and demonstrating better connectivity. It can extract road surfaces obscured by shadows from buildings or trees and reduces jagged edges along road boundaries, making them smoother.
3.4.2. Results on the DeepGlobe Dataset
A comparison of road extraction results for the DRMNet model and other models on the DeepGlobe dataset is shown in Figure 6. In the figure, “refine” indicates that DRMNet was used for fine-grained road extraction. The test results within the outlined images show that, although UNet, DeepLabV3, LinkNet, and D-LinkNet can extract the general road outlines, there are varying degrees of fragmentation and omission. However, after refinement with DRMNet, the connectivity improves significantly. In Figure 6a,d, all models show considerable omission, but when these models’ outputs are fed into DRMNet for refinement, the results yield relatively complete and continuous extractions. In Figure 6b,c, the road network within some outlined regions appears fragmented; however, DRMNet helps to restore these fragmented areas into more complete roads to some extent.
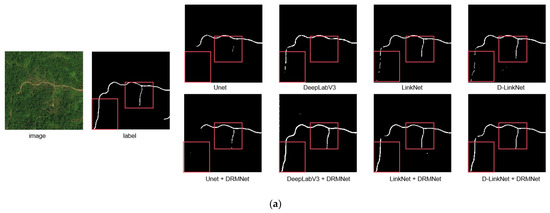
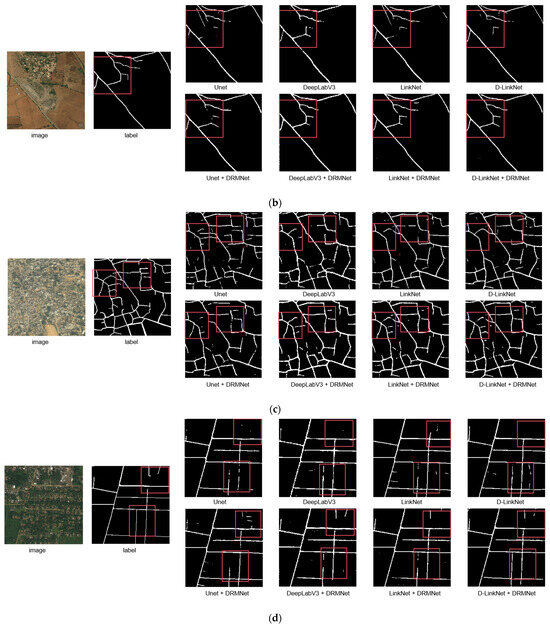
Figure 6.
The figure showcases the comparative results of representative images (a–d) from the DeepGlobe dataset before and after applying the DRMNet model. The red bounding boxes emphasize the differences among various methods.
Table 3 presents the quantitative evaluation results on the entire test dataset. After using DRMNet, the improvements in each metric are as follows: For precision, the minimum improvement is 0.6%, observed in the LinkNet model, while the maximum improvement is 3.7%, observed in the UNet model, with an average improvement of 1.55%. For recall, the minimum improvement is 7.5%, observed in the DeepLabv3 model, and the maximum improvement is 10.2%, observed in the UNet model, with an average improvement of 9.15%. For F1-score, the minimum improvement is 2.4%, observed in the DeepLabv3 model, and the maximum improvement is 7.1%, observed in the UNet model, with an average improvement of 4.78%. For mIoU, the minimum improvement is 1.5%, observed in the DeepLabv3 model, and the maximum improvement is 4.9%, observed in the UNet model, with an average improvement of 3.43%. Overall, recall shows the largest improvement, with an average of 9.15%, while precision shows relatively smaller improvements. It is worth noting that the precision of D-LinkNet + DRMNet is slightly lower than that of the original D-LinkNet. However, recall increases substantially, resulting in higher F1-score and mIoU. This trade-off suggests that DRMNet is more effective at recovering missing road segments, even at the cost of introducing a small number of false positives, thereby ultimately enhancing overall performance. Based on the qualitative and quantitative analysis above, DRMNet achieved outstanding results on the DeepGlobe public dataset, with an improvement in overall road extraction accuracy. The experimental results demonstrate that DRMNet can extract smoother and more complete road networks, confirming its feasibility.
Table 3.
Metric Evaluation of Comparative Experiments on the DeepGlobe Dataset.
3.5. Results Analysis
Analysis of the experimental results indicates that DRMNet demonstrates significant advantages in handling occlusions caused by trees, buildings, and shadows. In the Massachusetts and DeepGlobe datasets, other models often produce noticeable road discontinuities in occluded areas, whereas DRMNet can restore the missing segments through cross-modal fusion of RGB and MASK information. For example, Figure 5a,d illustrate scenes with building shadow occlusions, where traditional methods yield fragmented roads, while DRMNet provides much more complete connectivity. This shows that the proposed MAF module is capable of capturing long-range dependencies and global contextual information, thereby effectively mitigating the negative impact of occlusions on road extraction.
We further analyzed the model’s performance across different scenarios. The results show that DRMNet exhibits strong robustness when dealing with shadow occlusions and complex background interference, maintaining high road connectivity. However, in extremely narrow roads (less than 3 pixels wide) and regions with strong illumination leading to low contrast, the model may still suffer from missed detections and blurred boundaries. In addition, a small number of false positives occur in cases where the background texture is highly similar to that of the road. Overall, DRMNet demonstrates clear advantages under occlusion and complex background conditions, but there remains room for improvement in extracting extremely fine-grained road structures.
4. Discussion
To validate the effectiveness of the dual-branch structure and the MAF module, we designed comparative experiments to assess the impact of single-branch structure, dual-branch structure, and the presence of the MAF module on the road mIoU metric.
Table 4 presents the quantitative comparison results of different model variants on the DeepGlobe dataset. In the test set of the LinkNet model, the mIoU result is 0.797. The performance of the RGB model is similar to that of LinkNet, with a mIoU of 0.799, as DRMNet is based on LinkNet. After incorporating the MAF structure into the RGB model, the mIoU improves to 0.809. Similarly, in the MASK model, adding the MAF structure leads to a significant improvement in mIoU, rising from 0.806 to 0.820. The RGB-MASK model with a dual-branch encoder structure outperforms the single-branch RGB model by 1.6%, and the mIoU in the dual-branch RGB-MASK model increases by 2.2% after incorporating the MAF module.
Table 4.
Quantitative comparison of mIoU results after refining the LinkNet output using DRMNet and its variants on the DeepGlobe test set.
The variant models are shown in the “variants” column of Table 5. “RGB” indicates the encoder uses only the RGB branch; “RGB-MAF” means the MAF module is added to the RGB branch; “MASK” indicates the encoder uses only the MASK branch; “MASK-MAF” means the MAF module is added to the MASK branch; “RGB-MASK” refers to using the dual-branch structure of RGB and MASK without the MAF module; “RGB-MAF-MASK” uses the dual-branch structure of RGB and MASK with the MAF module added to the RGB branch; “RGB-MASK-MAF” uses the dual-branch structure of RGB and MASK with the MAF module added to the MASK branch; “RGB-MAF” refers to the structure proposed in this paper, which uses the dual-branch structure of RGB and MASK, with MAF modules added to both branches.
Table 5.
Quantitative evaluation of DRMNet on the DeepGlobe dataset under different types and levels of perturbations, including Gaussian noise with varying probabilities and random occlusion with different block sizes.
Table 5 further reports the robustness evaluation of DRMNet on the DeepGlobe dataset under different perturbation scenarios, including Gaussian noise with varying probabilities and random occlusion with different block sizes. As can be observed, the mIoU decreases slightly as the noise probability or occlusion size increases, but the overall performance degradation remains limited. For example, under 10% noise, the mIoU only drops from 0.835 to 0.778, and even with a large occlusion of 256 × 256, the mIoU is still maintained at 0.803. These results demonstrate that DRMNet exhibits strong robustness against noise interference and partial occlusion, ensuring reliable performance in real-world applications.
Table 6 shows the quantitative comparison results of different model variants on the Massachusetts dataset. In the test set of the LinkNet model, the mIoU result is 0.793. The RGB model yields a similar performance, with a mIoU of 0.795. After adding the MAF structure to the RGB model, the mIoU increases to 0.823. In the MASK model, incorporating the MAF structure similarly leads to a substantial improvement, with the mIoU rising from 0.819 to 0.858. The RGB-MASK model with a dual-branch encoder structure improves the performance by 5% compared to the single-branch RGB model, and the mIoU in the dual-branch RGB-MASK model improves by 4.4% after incorporating the MAF module.
Table 6.
Quantitative comparison of mIoU results after refining the LinkNet output using DRMNet and its variants on the Massachusetts test set.
Table 7 further presents the robustness evaluation of DRMNet on the Massachusetts dataset under different perturbation conditions. Specifically, Gaussian noise with different probabilities and random occlusion with varying block sizes were applied to the test images. As shown in the results, the mIoU only decreases slightly as the noise level or occlusion size increases. For instance, under 10% Gaussian noise, the mIoU drops from 0.904 to 0.881, while with a large occlusion of 128 × 128, the mIoU remains as high as 0.896. Even when noise and occlusion are combined, the performance degradation is limited, with the mIoU still reaching 0.883. These findings indicate that DRMNet exhibits strong robustness against both noise interference and partial occlusion on the Massachusetts dataset, maintaining reliable segmentation accuracy under challenging conditions.
Table 7.
Quantitative evaluation of DRMNet on the Massachusetts dataset under different types and levels of perturbations, including Gaussian noise with varying probabilities and random occlusion with different block sizes.
Table 8 summarizes the comparison of model complexity and performance with different baselines under an input size of 256 × 256. Although DRMNet requires relatively higher computational cost (44.57M parameters and 52.89 G FLOPs) compared with the baseline models, it achieves the highest segmentation accuracy, reaching an mIoU of 0.904. Specifically, DRMNet outperforms D-LinkNet by 11%, demonstrating its superiority in restoring fragmented and occluded roads and ensuring global connectivity. The higher FLOPs are the main drawback of DRMNet. Nevertheless, the substantial improvements in connectivity and accuracy make this trade-off worthwhile. In particular, the FLOPs of DRMNet scale quadratically with input size which is consistent with the quadratic growth expected when doubling input resolution: approximately 211 G at 512 × 512 and 846 G at 1024 × 1024. Despite this increase in computational cost, DRMNet consistently delivers robust performance and practical feasibility, underscoring the effectiveness of the proposed dual-branch multi-modal attention fusion design under real-world conditions.
Table 8.
Computational complexity and mIoU comparison on the Massachusetts dataset.
Overall, the results in Table 4, Table 5, Table 6, Table 7 and Table 8 comprehensively demonstrate the effectiveness and robustness of DRMNet. On both the DeepGlobe and Massachusetts datasets, incorporating the MAF module and adopting the dual-branch encoder consistently improve segmentation accuracy compared with baseline models. Under perturbation scenarios with Gaussian noise and random occlusion, DRMNet maintains stable performance, with only slight decreases in mIoU, thereby validating its robustness against noise interference and partial missing information. Although DRMNet introduces higher computational cost, the improvements in connectivity and accuracy make this trade-off worthwhile. Moreover, ablation studies confirm that the MASK branch contributes more significantly than the RGB branch, while cross-modal fusion through the MAF module further refines road extraction. Taken together, these findings highlight that DRMNet achieves superior road extraction performance with strong robustness and practical feasibility in real-world applications.
5. Conclusions
Existing methods often lack global consistency in road feature perception, leading to fragmentation and omission in road extraction results. To address this issue, we propose the DRMNet model for fine-grained road extraction. The model consists of two main components: the RGB-MASK dual-branch encoder structure and the MAF feature enhancement module. The RGB-MASK dual-branch encoder extracts features from the input RGB image and coarse MASK, enabling the fusion of two modalities of data. The MAF module enhances the features extracted from each branch via an attention mechanism, optimizing the feature fusion of the two modalities.
Comparative experiments and analysis were conducted on the Massachusetts and DeepGlobe datasets. The results show that DRMNet effectively reduces fragmentation in road extraction, capturing finer roads and producing smoother road boundaries. After inputting the coarse masks from Unet, DeepLabV3, LinkNet, and D-LinkNet into the DRMNet model for refined extraction, the average improvements in Precision, Recall, F1-score, and mIoU in the Massachusetts dataset were 11.88 percentage points, 11.63 percentage points, 11.75 percentage points, and 9.25 percentage points, respectively. In the DeepGlobe dataset, the average improvements in Precision, Recall, F1-score, and mIoU were 2.33 percentage points, 9.15 percentage points, 4.78 percentage points, and 3.35 percentage points, respectively.
To further validate the effectiveness of the proposed dual-branch structure and MAF module, ablation experiments were conducted comparing single-branch structures, multi-branch structures, and the presence or absence of the MAF module. The results show that in the Massachusetts dataset, the RGB-MASK dual-branch structure outperforms the RGB single-branch model by 5% in mIoU, and incorporating the MAF module into the RGB-MASK dual-branch structure improves the mIoU by 4.4%. In the DeepGlobe dataset, the RGB-MASK dual-branch structure outperforms the RGB single-branch model by 1.6% in mIoU, and adding the MAF module to the RGB-MASK dual-branch structure results in a 2.2% improvement in mIoU.
The experimental results demonstrate that the DRMNet model effectively addresses issues such as omission, fragmentation, and jagged boundaries in current remote sensing road extraction methods. This confirms the feasibility of using DRMNet for fine-grained road extraction in high-resolution remote sensing images. Looking ahead, future research will focus on further enhancing the model’s ability to recover extremely narrow road segments with widths of only a few pixels, reducing computational complexity to improve efficiency, and exploring lightweight architectures that can be more readily deployed in large-scale or real-time applications. In addition, integrating self-supervised learning or domain adaptation strategies may help reduce reliance on extensive labeled data and improve generalization across diverse geographic environments.
Author Contributions
Conceptualization: Y.Y. and Y.C.; Methodology: Y.Y., Y.C. and B.P.; Software: Y.Y., Y.C., G.J. and Q.Z.; Validation: Y.Y., Y.C., B.P., G.J., D.Y. and M.Y.; Writing—Original Draft Preparation: Y.Y., Y.C. and B.P.; Writing—Review & Editing: Y.Y., Y.C., B.P., G.J., D.Y. and M.Y.; Funding Acquisition: G.J. and Q.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the National Natural Science Foundation of China (Grant No. 62206114) and the Jiangsu Education Department (via the Natural Science Foundation of the Jiangsu Higher Education Institutions of China, Grant No. 24KJB520005).
Data Availability Statement
The datasets used in this study are available as follows: the Massachusetts Roads Dataset can be accessed at https://www.cs.toronto.edu/~vmnih/data/ (accessed on 7 October 2025), and the DeepGlobe dataset can be found at https://competitions.codalab.org/competitions/18467 (accessed on 7 October 2025).
Conflicts of Interest
Author Bo Pan was employed by the company Beijing GreenValley Technology Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Zhao, K.; Liu, J.; Wang, Q.; Wu, X.; Tu, J. Road damage detection from post-disaster high-resolution remote sensing images based on tld framework. IEEE Access 2022, 10, 43552–43561. [Google Scholar] [CrossRef]
- Chen, R.; Li, X.; Hu, Y.; Wen, C.; Peng, L. Road extraction from remote sensing images in wildland–urban interface areas. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Zhang, X.; Jiang, Y.; Wang, L.; Han, W.; Feng, R.; Fan, R.; Wang, S. Complex mountain road extraction in high-resolution remote sensing images via a light roadformer and a new benchmark. Remote Sens. 2022, 14, 4729. [Google Scholar] [CrossRef]
- Zhou, K.; Xie, Y.; Gao, Z.; Miao, F.; Zhang, L. FuNet: A novel road extraction network with fusion of location data and remote sensing imagery. ISPRS Int. J. Geo-Inf. 2021, 10, 39. [Google Scholar] [CrossRef]
- Tao, C.; Qi, J.; Li, Y.; Wang, H.; Li, H. Spatial information inference net: Road extraction using road-specific contextual information. ISPRS J. Photogramm. Remote Sens. 2019, 158, 155–166. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Liu, Y.; Zhao, J.; Ma, A.; Yang, J. Multi-scale and multi-task deep learning framework for automatic road extraction. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9362–9377. [Google Scholar] [CrossRef]
- Zhou, T.; Sun, C.; Fu, H. Road information extraction from high-resolution remote sensing images based on road reconstruction. Remote Sens. 2019, 11, 79. [Google Scholar] [CrossRef]
- Li, R.; Gao, B.; Xu, Q. Gated auxiliary edge detection task for road extraction with weight-balanced loss. IEEE Geosci. Remote Sens. Lett. 2020, 18, 786–790. [Google Scholar] [CrossRef]
- Xu, Y.; Xie, Z.; Wu, L.; Chen, Z. Multilane roads extracted from the OpenStreetMap urban road network using random forests. Trans. GIS 2019, 23, 224–240. [Google Scholar] [CrossRef]
- Bajcsy, R.; Tavakoli, M. Computer recognition of roads from satellite pictures. IEEE Trans. Syst. Man Cybern. 1976, SMC-6, 623–637. [Google Scholar] [CrossRef]
- Ronggui, M.; Weixing, W.; Sheng, L. Extracting roads based on Retinex and improved Canny operator with shape criteria in vague and unevenly illuminated aerial images. J. Appl. Remote Sens. 2012, 6, 063610. [Google Scholar] [CrossRef]
- Yang, Y.; Wu, Q.; Yu, R.; Wang, L.; Zhao, Y.; Ding, C.; Yin, Y. Intelligent road extraction from high resolution remote sensing images based on optimized SVM. J. Radiat. Res. Appl. Sci. 2024, 17, 101069. [Google Scholar] [CrossRef]
- Soni, P.K.; Rajpal, N.; Mehta, R. Semiautomatic road extraction framework based on shape features and LS-SVM from high-resolution images. J. Indian Soc. Remote Sens. 2020, 48, 513–524. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhu, Y.; Yang, M.; Jin, G.; Zhu, Y.; Chen, Q. Cross-to-merge training with class balance strategy for learning with noisy labels. Expert Syst. Appl. 2024, 249, 123846. [Google Scholar] [CrossRef]
- Zhang, Q.; Jin, G.; Zhu, Y.; Wei, H.; Chen, Q. BPT-PLR: A Balanced Partitioning and Training Framework with Pseudo-Label Relaxed Contrastive Loss for Noisy Label Learning. Entropy 2024, 26, 589. [Google Scholar] [CrossRef]
- Zhang, Q.; Zhu, Y.; Cordeiro, F.R.; Chen, Q. PSSCL: A progressive sample selection framework with contrastive loss designed for noisy labels. Pattern Recognit. 2025, 161, 111284. [Google Scholar] [CrossRef]
- Yuan, Y.; Tian, Y. Semantic Segmentation Algorithm of Underwater Image Based on Improved DeepLab v3+. In Proceedings of the 2022 International Conference on Computer Graphics, Artificial Intelligence, and Data Processing, ICCAID 2022, Guangzhou, China, 23–25 December 2022. [Google Scholar]
- Yuan, Y.; Sun, J.; Zhang, Q. An Enhanced Deep Learning Model for Effective Crop Pest and Disease Detection. J. Imaging 2024, 10, 279. [Google Scholar] [CrossRef]
- Sofla, R.A.D.; Alipour-Fard, T.; Arefi, H. Road extraction from satellite and aerial image using SE-Unet. J. Appl. Remote Sens. 2021, 15, 014512. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Wang, H.; Yu, F.; Xie, J.; Zheng, H. Road extraction based on improved DeepLabv3 plus in remote sensing image. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 48, 67–72. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; CV, A.; Adam, H. Deeplabv3+: Encoderdecoder with atrous separable convolution for semantic image segmentation. In ECCV; Ferrari, V., Hebert, M., Sminchisescu, C., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R. Resnest: Split-attention networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2736–2746. [Google Scholar]
- Zhou, L.; Zhang, C. Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 2018 IEEE, Salt Lake City, UT, USA, 18–22 June 2018; pp. 192–1924. [Google Scholar]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Wu, K.; Cai, F. Dual Attention D-LinkNet for Road Segmentation in Remote Sensing Images. In Proceedings of the 2022 IEEE 14th International Conference on Advanced Infocomm Technology (ICAIT), Chongqing, China, 8–11 July 2022; pp. 304–307. [Google Scholar]
- Kampffmeyer, M.; Dong, N.; Liang, X.; Zhang, Y.; Xing, E.P. ConnNet: A long-range relation-aware pixel-connectivity network for salient segmentation. IEEE Trans. Image Process. 2018, 28, 2518–2529. [Google Scholar] [CrossRef] [PubMed]
- Maji, D.; Sigedar, P.; Singh, M. Attention Res-UNet with Guided Decoder for semantic segmentation of brain tumors. Biomed. Signal Process. Control 2022, 71, 103077. [Google Scholar] [CrossRef]
- Soni, Y.; Meena, U.; Mishra, V.K.; Soni, P.K. AM-UNet: Road Network Extraction from high-resolution Aerial Imagery Using Attention-Based Convolutional Neural Network. J. Indian Soc. Remote Sens. 2024, 53, 135–147. [Google Scholar] [CrossRef]
- Yang, H.; Zhou, C.; Xing, X.; Wu, Y.; Wu, Y. A High-Resolution Remote Sensing Road Extraction Method Based on the Coupling of Global Spatial Features and Fourier Domain Features. Remote Sens. 2024, 16, 3896. [Google Scholar] [CrossRef]
- Kumar, K.M.; Velayudham, A. CCT-DOSA: A hybrid architecture for road network extraction from satellite images in the era of IoT. Evol. Syst. 2024, 15, 1939–1955. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Zhou, H.; Wang, R.; Yang, J. Road segmentation for remote sensing images using adversarial spatial pyramid networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 4673–4688. [Google Scholar] [CrossRef]
- Lu, X.; Zhong, Y.; Zheng, Z.; Chen, D.; Su, Y.; Ma, A.; Zhang, L. Cascaded multi-task road extraction network for road surface, centerline, and edge extraction. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.; Zhang, X.; Huang, X. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Bin, W.; Zhanlong, C.; Liang, W.; Peng, X.; Donglin, F.; Bolin, F. Road extraction of high-resolution satellite remote sensing images in U-Net network with consideration of connectivity. National Remote Sens. Bull. 2021, 24, 1488–1499. [Google Scholar]
- Gao, L.; Song, W.; Dai, J.; Chen, Y. Road extraction from high-resolution remote sensing imagery using refined deep residual convolutional neural network. Remote Sens. 2019, 11, 552. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zhou, Z.; Rahman Siddiquee, M.M.; Tajbakhsh, N.; Liang, J. Unet++: A nested u-net architecture for medical image segmentation. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support, Proceedings of the 4th International Workshop, DLMIA 2018, and 8th International Workshop, ML-CDS 2018, Held in Conjunction with MICCAI 2018, Granada, Spain, 20 September 2018; Springer: Cham, Switzerland, 2018; pp. 3–11. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, F.; Feng, H.; Liang, M.; Wang, H.; Yang, Y.; Gao, Y.; Chen, J.; Hu, J.; Guo, X.; Lam, T.L. FEANet: Feature-enhanced attention network for RGB-thermal real-time semantic segmentation. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4467–4473. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; pp. 210–223. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).