1. Introduction
With the rapid advancement in data collection and storage, it has become increasingly common to encounter datasets characterized by a large number of features but a limited number of individuals. For instance, in financial studies, particularly those involving long-term data, each index often comprises hundreds or thousands of time points. However, due to constraints such as market capacity, policy restrictions, and other factors, resources are typically scarce, resulting in only a few subjects available for comparison across indexes. In such scenarios, the data dimension
p approaches or even surpasses the total sample size
n, a characteristic known as the “large
p, small
n” phenomenon. This feature renders many conventional methods inapplicable, necessitating specialized approaches. We refer to datasets exhibiting this characteristic as high-dimensional data, and the associated challenge as a “large
p, small
n” problem. A key focus of multivariate statistical analysis is to compare covariance matrices across several high-dimensional populations. The motivation for this paper partially stems from a financial dataset provided by the Credit Research Initiative of the National University of Singapore (NUS-CRI). In finance, contagion refers to a phenomenon observed through concurrent movements in exchange rates, stock prices, sovereign spreads, and capital flows [
1]. Identifying the presence of financial contagion is crucial, as it signifies potential risks for countries aiming to integrate their financial systems with international markets and institutions. Additionally, it aids in understanding economic crises that spread to neighboring countries or regions. A common approach to detecting contagion involves examining the variance–covariance relationships of financial indices across different regions or time periods, as demonstrated by [
2,
3,
4]. The Probability of Default (PD) serves as a metric for quantifying the likelihood of an obligor being unable to meet its financial obligations and forms the core of the credit product within the NUS-CRI corporate default prediction system, built on the forward intensity model of [
5]. A notable example is the financial contagion observed during the 1997 Asian Financial Crisis, described in
Section 4. Consequently, there is interest in investigating whether the covariance matrices of daily PD for neighboring countries during periods of stability and crisis are equal. This inquiry stimulates a
k-sample equal-covariance matrix testing problem tailored for high-dimensional data.
Mathematically, a
k-sample equal-covariance matrix testing problem for high-dimensional data is described as follows. Let us consider the following
k independent high-dimensional samples:
where the dimension
p is significantly large, potentially exceeding the total sample size
. The objective is to test whether the
k covariance matrices are equal:
When
, the
k-sample equal-covariance matrix testing problem in (
2) simplifies to a two-sample equal-covariance matrix testing problem, which has been the subject of several previous studies. Ref. [
6] devised a test based on an unbiased estimator using U-statistics of the usual squared Frobenius norm of the covariance matrix difference
. Under certain stringent conditions, ref. [
6] demonstrated that the null distribution of their test statistic is asymptotically normal, without relying on the normality assumption for the samples. However, this test may lack power when the entries of the covariance matrix difference
are sparse, due to its reliance on an
-norm-based approach. To address this limitation, ref. [
7] proposed an
-type test. They showed that under certain regularity conditions, their test statistic asymptotically follows an extreme-value distribution of Type I. Unfortunately, simulation results presented in [
8] reveal that [
7]’s test is excessively conservative, exhibiting notably small empirical sizes.
For a general
, the problem of testing for equality of covariance matrices across all groups has attracted significant attention from researchers. Extending the test to multiple groups necessitates careful consideration of the problem’s complexity and the potential trade-offs between power and Type I error control. Ref. [
9] addressed (2) by constructing an unbiased estimator for the sum of the usual squared Frobenius norm of the covariance matrix difference
, where
. However, to derive the asymptotic normal distribution of his test statistic, Schott imposed strong assumptions, including the assumption of Gaussian populations. Nevertheless, this assumption may not hold in real datasets, leading to inaccurate results. Specifically, empirical results in
Section 3.1 demonstrate that [
9]’s test is overly permissive, particularly when the
k samples (
1) are non-Gaussian. With a nominal size of 5%, the empirical sizes of [
9]’s test can exceed 9.61% and 10.08% for
and 4, respectively, when the samples are normally distributed. Conversely, when the samples are not normally distributed, the empirical sizes can soar to 32.14% and 41.86% for
and 4, respectively. To mitigate the reliance on normality assumptions, ref. [
10] proposed a test statistic to extend [
6]’s test for the
k-sample high-dimensional equal-covariance matrix testing problem. However, they also followed strong assumptions imposed by [
6], such as the existence of the samples’ eighth moments. According to the results from
Section 3.1, [
10]’s test may also be overly permissive, with empirical sizes reaching as high as 13.46% when the assumptions are not satisfied. This aligns with the simulation results presented in [
8], which suggested that [
6]’s test is overly permissive. Furthermore, both [
9]’s and [
10]’s tests are
-norm-based, which may yield poor performance when the entries of the covariance matrix difference are sparse. In an effort to address both sparse and dense alternatives, ref. [
11] combined two types of norms to characterize the distance among the covariance matrices: the Frobenius norm, as adopted by [
6], and the maximum norm, introduced by [
7]. However, empirical results displayed in
Section 3.1 indicate that [
11]’s test remains overly permissive in many cases. A common issue with these existing tests is their reliance on achieving normality of their null limiting distributions under certain strong conditions. However, in numerous scenarios, satisfying these conditions is challenging, rendering testing based on normal distribution inadequate.
From the preceding discussion, it is apparent that existing methods often struggle to control the size of the test effectively. In this paper, we address this issue by proposing and examining a normal-reference test for the
k-sample equal-covariance matrix testing problem for high-dimensional data as described in (2). Our primary contributions are outlined below. Firstly, leveraging the well-known Kronecker product, we transform the
k-sample equal-covariance matrix testing problem (2) on original high-dimensional samples (
1) into a
k-sample equal-mean vector testing problem on induced high-dimensional samples. This novel approach offers a fresh and innovative method tailored specifically for testing the equality of covariance matrices in high-dimensional data settings. Secondly, to address the
k-sample equal-mean vector problem, we adopt the methodology introduced by [
12] to construct a U-statistic-based test statistic on the induced high-dimensional samples. Under certain regularity conditions and the null hypothesis, it is demonstrated that the proposed test statistic and a chi-square-type mixture share the same normal or non-normal limiting distribution. Therefore, approximating the null distribution of the test statistic using the normal distribution, as carried out in the works of [
9,
10], may not always be appropriate. Our approach, termed the normal-reference approach, utilizes the chi-square-type mixture, obtained when the
k induced samples are normally distributed, to accurately approximate the null distribution of the test statistic. A key advantage of this approach is its elimination of the need to verify whether the limiting distribution is normal or non-normal. Thirdly, instead of estimating the unknown coefficients of the chi-square-type mixture, we employ the three-cumulant matched chi-square-approximation method proposed by [
13] to approximate the distribution of the chi-square-type mixture. The approximation parameters are consistently estimated from the data. Fourthly, we establish the asymptotic power under a local alternative. Fifthly, alongside the theoretical foundation, we conduct two simulation studies and a real data application to empirically demonstrate the superiority of our method over several competitors, such as the tests proposed by [
9,
10,
11]. It is worth highlighting that our adaptation of the normal-reference test to the
k-sample equal-covariance matrix testing problem is not a direct application of the results from [
8]. The asymptotic properties presented in Theorems 1–3 are not directly derived from the theoretical results of [
8,
14], as these were proposed for the two-sample testing problem. The proofs of Theorems 1–3 are significantly more complex than those in [
8].
The structure of this paper is organized as follows:
Section 2 presents the main results. Simulation studies are detailed in
Section 3. An application to a financial dataset is provided in
Section 4. Concluding remarks are offered in
Section 5. The technical proofs of the main results are outlined in
Appendix A.
4. Application to the Financial Data
In this section, we apply
,
,
, and
to the financial dataset briefly described in
Section 1. The dataset investigates financial contagion during the period of the well-known “1997 Asian financial crisis” and is accessible at
https://nuscri.org/en/datadownload/, accessed on 1 December 2024. This crisis originated in Thailand in 1997 and subsequently spread to neighboring countries such as Indonesia, Malaysia, and the Philippines, causing a ripple effect and raising concerns about a global economic downturn due to financial contagion. However, the recovery in 1998 was swift, and concerns about a meltdown quickly diminished.
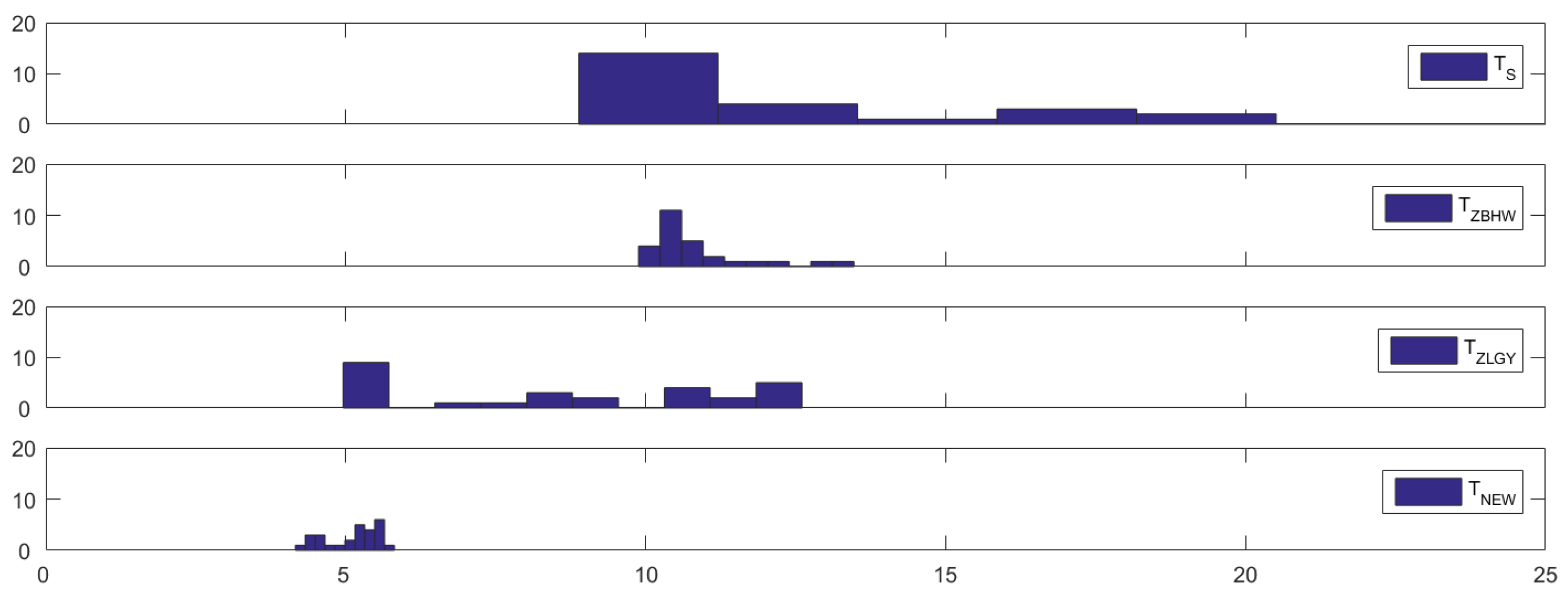
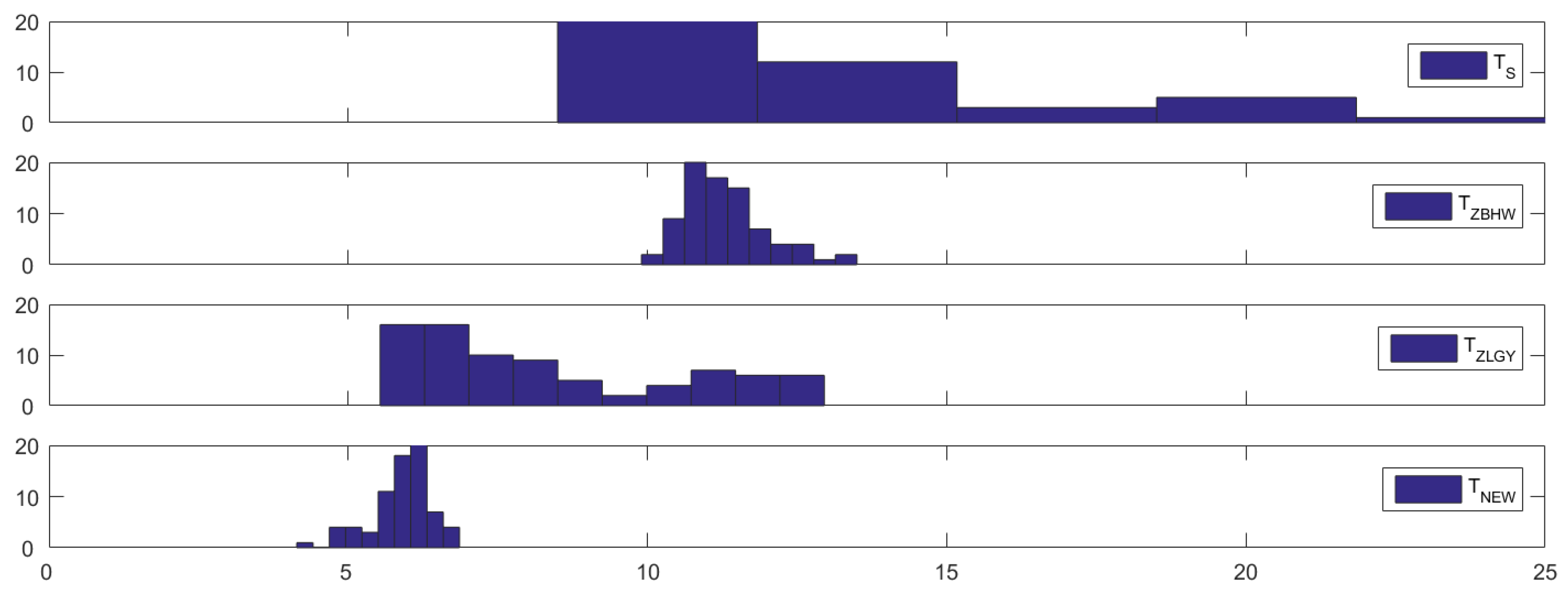
The dataset provides daily aggregated Probability of Default (PD) data for four sectors, energy, financials, real estate, and industrials, across the aforementioned four countries in 1997. Our interest lies in examining whether there were any structural breaks in the correlations (variance–covariance matrices) of the PDs for these countries and sectors during the crisis period. For this purpose, we divide the dataset into four groups labeled as , , , and . These groups represent the daily aggregated PD for each quarter of 1997, with each quarter spanning a three-month period and representing the 65 trading days in a quarter. Additionally, since we analyze the daily aggregated PD of the four sectors across the four countries, each group comprises 16 observations, i.e., .
To ensure that we have four independent samples, we conduct six pairwise independence tests by utilizing distance correlation-based tests proposed by [
26], implemented in the R package
energy. As all the
p-values exceed 0.05, we can conclude that there is insufficient evidence to reject the null hypothesis that any two groups are independent. Subsequently, we employ
,
,
, and
to test the equality of covariance matrices for this financial dataset.
Table 6 presents the
p-values of the four considered tests for testing the equality of covariance matrices, along with the corresponding estimated approximate degrees of freedom
of
under the column labeled “d.f.”. We initially apply the four considered tests to assess the equality of covariance matrices among the four groups. Given the small
p-values observed, there is compelling evidence to reject the null hypothesis of no difference between the covariance matrices of the four groups. This suggests significant divergence among the covariance matrices, potentially indicating the presence of financial contagion during the crisis period.
Subsequently, we aim to ascertain whether the inequality of the four covariance matrices is attributable to financial contagion. We commence by conducting the contrast test “
”, with the test results displayed in
Table 6. Notably, all considered tests yield consistent conclusions, as all
p-values exceed 0.05, implying that the covariance matrices for the first three quarters are equivalent. This finding is plausible, suggesting a gradual dissipation of financial contagion towards the end of the year. The equivalence of covariance matrices for the initial three quarters indicates a relatively stable level of financial contagion during that period. It is pertinent to mention that the estimated approximate degrees of freedom (d.f.) are relatively small, indicating that the normal approximation to the null distributions of
and
may not be adequate. Consequently, their
p-values may not be reliable.
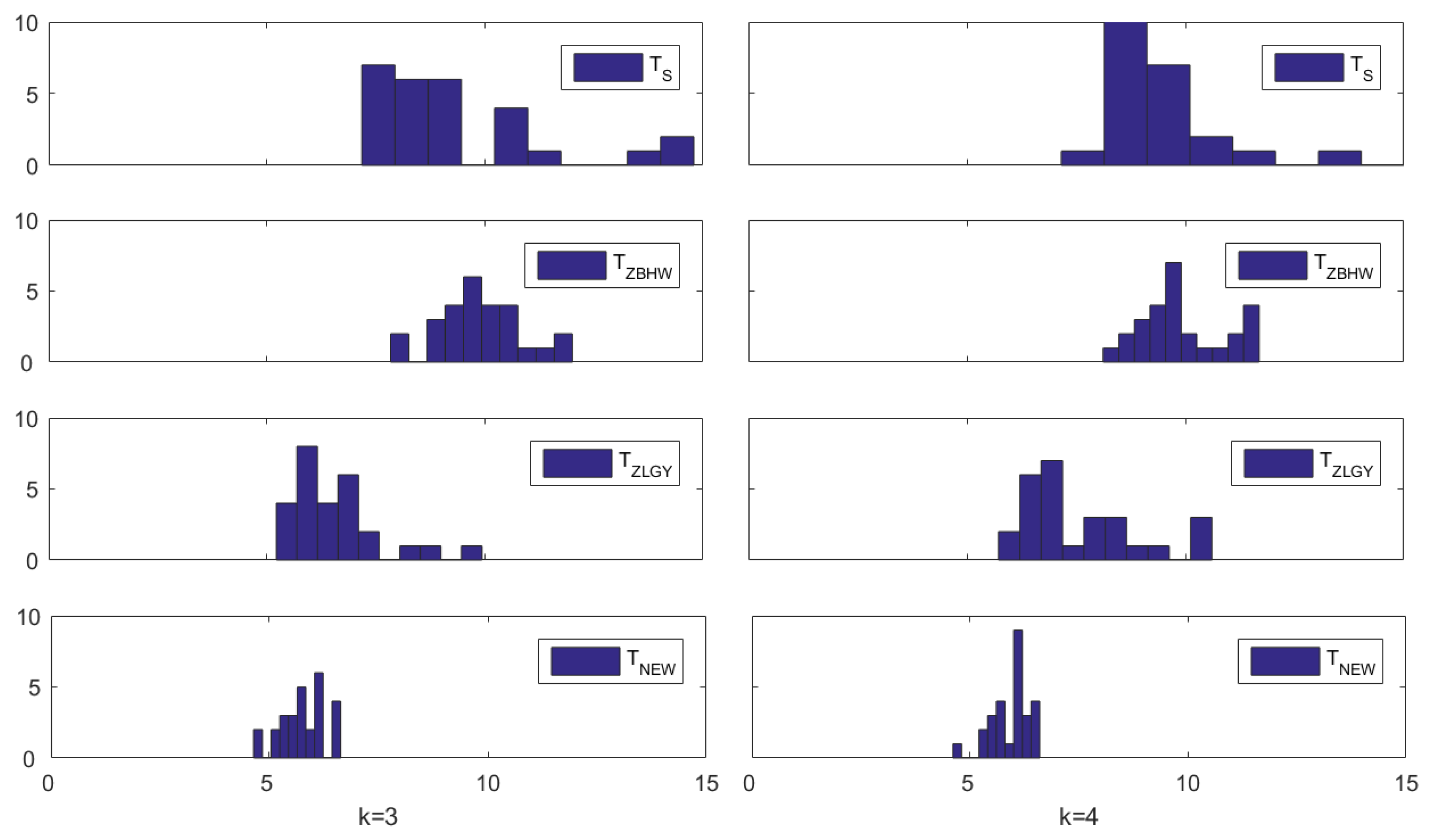
To further illustrate the finite-sample performance of
in terms of size control, we utilize this dataset to calculate the empirical sizes of these test procedures. The empirical size is computed from 10,000 runs. Building upon the testing results provided in
Table 6, where we have established that the first three quarters share the same covariance matrix, we proceed to calculate their empirical sizes based on the first two quarters (
) and the first three quarters (
). The procedures are outlined as follows: in each run, we randomly partition the
samples from the first
k quarters into
k sub-groups of equal size and then compute the
p-values to assess the equality of covariance structures among the
k sub-groups. The empirical size is determined as the proportion of times the
p-value is smaller than the nominal level
across the 10,000 independent runs.
Table 7 presents the empirical sizes of the four tests:
,
,
, and
. It is evident from this table that
exhibits significantly improved level accuracy compared to the other three tests, which tend to be quite liberal. This finding aligns with the conclusions drawn from the simulation studies presented in
Section 3.





{kind=link}
{kind=link}
{kind=link}