Abstract
(1) Background: Soccer action recognition (SAR) is essential in modern sports analytics, supporting automated performance evaluation, tactical strategy analysis, and detailed player behavior modeling. Although recent advances in deep learning and computer vision have enhanced SAR capabilities, many existing methods remain limited to coarse-grained classifications, grouping actions into broad categories such as attacking, defending, or goalkeeping. These models often fall short in capturing fine-grained distinctions, contextual nuances, and long-range temporal dependencies. Transformer-based approaches offer potential improvements but are typically constrained by the need for large-scale datasets and high computational demands, limiting their practical applicability. Moreover, current SAR systems frequently encounter difficulties in handling occlusions, background clutter, and variable camera angles, which contribute to misclassifications and reduced accuracy. (2) Methods: To overcome these challenges, we propose TAT-SARNet, a structured framework designed for accurate and fine-grained SAR. The model begins by applying Sparse Dilated Attention (SDA) to emphasize relevant spatial dependencies while mitigating background noise. Refined spatial features are then processed through the Split-Stream Feature Processing Module (SSFPM), which separately extracts appearance-based (RGB) and motion-based (optical flow) features using ResNet and 3D CNNs. These features are temporally refined by the Multi-Granular Temporal Processing (MGTP) module, which integrates ResIncept Patch Consolidation (RIPC) and Progressive Scale Construction Module (PSCM) to capture both short- and long-range temporal patterns. The output is then fused via the Context-Guided Dual Transformer (CGDT), which models spatiotemporal interactions through a Bi-Transformer Connector (BTC) and Channel–Spatial Attention Block (CSAB); (3) Results: Finally, the Cascaded Temporal Classification (CTC) module maps these features to fine-grained action categories, enabling robust recognition even under challenging conditions such as occlusions and rapid movements. (4) Conclusions: This end-to-end architecture ensures high precision in complex real-world soccer scenarios.
Keywords:
soccer action recognition; dual contextual transformer; feature fusion; feature processing module MSC:
68M25; 68T05
1. Introduction
Soccer is one of the most widely played and analysed sports worldwide, with millions of fans, analysts, and coaches relying on video-based assessments to evaluate player performance, team strategies, and game dynamics [1]. The increasing availability of match footage has driven significant interest in SAR a field focused on the automatic identification and classification of player actions such as passing, dribbling, shooting, and tackling from video sequences. Accurate SAR has numerous applications, including automated performance assessment, tactical analysis, player behaviour modelling, injury prevention, and highlight generation. The recent advancements in computer vision and deep learning have substantially improved SAR capabilities, enabling efficient analysis of vast amounts of match footage with minimal manual intervention [2,3]. Despite these advancements, most existing SAR models focus on coarse-grained classification, where actions are categorized into broad classes such as “attacking”, “defending”, or “goalkeeping”. While useful for general analysis, this level of classification lacks the granularity required for precise tactical evaluation. In contrast, fine-grained action recognition, which differentiates between subtle variations in player movements (e.g., short pass vs. long pass, chip shot vs. volley), remains an underexplored and challenging domain. Fine-grained SAR is crucial for detailed player evaluation, opponent analysis, and strategic decision-making, as it enables analysts and teams to assess individual and collective behaviours with greater accuracy. Achieving reliable fine-grained recognition is complex due to multiple factors, including frequent occlusions, complex player interactions, background clutter, and variations in camera angles [4,5]. Unlike sports such as basketball, where player positioning and court dimensions are relatively fixed, soccer involves highly dynamic movements across a large playing field, making it difficult for conventional models to capture both spatial and temporal dependencies effectively. Additionally, player movements in soccer are often subtle and context-dependent, requiring SAR models to incorporate advanced multi-scale feature extraction and contextual learning techniques to improve recognition accuracy.
Video-based SAR models analyze soccer footage to extract discriminative features that characterize different player actions [6]. Obtaining spatial features through RGB frame analysis and motion-related features from optical flow sequences to model player and ball movements. Analyzing the temporal evolution of actions using sequential models such as Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, or Transformers. Labeling video sequences with corresponding actions based on extracted spatial and temporal features [7]. Traditional SAR approaches primarily rely on Convolutional Neural Networks (CNNs) and 3D CNNs to process soccer video frames. While 2D CNNs are effective at extracting spatial features from individual frames, they fail to capture temporal dependencies, making them insufficient for recognizing continuous soccer actions. 3D CNNs (e.g., I3D—Inflated 3D ConNet, C3D—Convolutional 3D Network) integrate both spatial and temporal features but require high computational resources and struggle to model long-range dependencies in soccer sequences [8]. More recently, transformer-based architectures have gained popularity due to their ability to model long-range dependencies in video sequences [9]. These models employ self-attention mechanisms to capture intricate temporal relationships, improving overall recognition accuracy. However, despite these advancements, fine-grained SAR remains a major challenge due to the limited effectiveness of existing feature extraction, attention mechanisms, and multi-scale temporal modeling strategies [10].
Another key limitation in SAR is the lack of contextual awareness [11]. Many soccer actions are strongly influenced by external factors, such as player positioning, ball trajectory, team coordination, and opponent movements. Current SAR models often fail to integrate multi-level contextual cues, leading to misclassification of visually similar actions [12]. For instance, distinguishing between a short pass and a through ball requires recognizing not just the kicking motion but also the positioning of teammates and opponents. Similarly, differentiating between chip shot and lob pass requires understanding the player’s field position and game context [13]. To address these issues, SAR models must incorporate multi-stream feature extraction, attention-driven spatial refinement, and hierarchical temporal modeling to enhance fine-grained action recognition. By integrating these elements, SAR systems can achieve more accurate, context-aware, and robust action classification [14]. Over the past decade, deep learning-based SAR models have achieved notable progress, yet they still face significant challenges. Existing approaches can be categorized into three major groups: Traditional 2D CNNs extract spatial features from video frames but fail to capture temporal dependencies, limiting their effectiveness in recognizing continuous soccer actions [15]. 3D CNNs (e.g., I3D, C3D) process both spatial and temporal information but require extensive computational resources and struggle with long-range temporal dependencies. Although 3D CNNs improve temporal modeling, they rely on fixed-length video clips, making them ineffective for recognizing soccer actions with variable durations. Additionally, these models often misclassify visually similar actions due to their inability to differentiate between subtle motion cues in complex game scenarios.
RNN-based models, including LSTMs and GRUs, are designed to capture sequential dependencies between video frames but suffer from vanishing gradient issues, which limit their ability to process long-duration action sequences [16]. These models lack spatial awareness, meaning they struggle to focus on relevant action regions within a frame, reducing their accuracy in highly dynamic game situations. While LSTMs and GRUs are useful for modeling temporal dependencies, they require carefully designed attention mechanisms to emphasize key regions in soccer videos, ensuring that critical action details are not lost [17]. Vision transformers (ViTs) and self-attention mechanisms have been introduced to improve feature extraction and long-range dependency modelling [18]. While effective, ViTs require extensive training on large-scale datasets, making them impractical for real-world SAR applications due to the scarcity of fine-grained soccer action datasets. Moreover, while some SAR models integrate multi-stream architectures (processing both RGB and optical flow representations), their feature fusion mechanisms remain suboptimal, limiting their ability to combine spatial and motion-based representations effectively [19]. Most SAR models focus on coarse-grained classification, grouping actions into broad categories rather than capturing subtle motion variations. Many existing SAR datasets suffer from limited annotations and small sample sizes, making it difficult for models to generalize across diverse soccer scenarios [20]. For instance, distinguishing between short pass and lob pass requires context-aware modeling beyond simple visual cues. Similarly, differentiating tackle from block involves understanding tactical intent and defensive positioning, which current SAR models fail to capture effectively.
To address these limitations, transformer-driven, multi-stream approach is essential for fine-grained SAR. A robust SAR model must:
- Extract spatial and motion-based features effectively using dual-stream encoder that processes RGB and optical flow data.
- Enhance multi-scale temporal feature aggregation to capture both short-term and long-term dependencies.
- Incorporate attention mechanisms to highlight key action regions while suppressing irrelevant background noise.
- Employ hierarchical classification techniques to improve fine-grained action differentiation.
In response to these challenges, we propose TAT-SARNet (Transformer-Attentive Two-Stream SAR Network) novel framework that integrates multi-stream feature extraction, transformer-based temporal modeling, and attention-based spatial feature enhancement for fine-grained SAR. By leveraging these innovations, TAT-SARNet aims to enhance recognition accuracy, reduce computational complexity, and improve contextual understanding in real-world soccer analytics.
Research Contribution
The novel contributions of TAT-SARNet are defined as follows:
- Dual-Stream Feature Extraction: Proposes an SSFPM for appearance-based (RGB frames) and motion-based (optical flow) feature extraction. It also employs the SDA mechanism to enhance action localization in crowded soccer scenes by enhancing spatial feature representation and capturing dependencies.
- Multi-Scale Aggregation with Patch Merging: Enhances fine-grained action detection of complex soccer movements through the utilization of RIPC to seamlessly fuse multi-scale information. facilitates robust action segmentation over various time scales through the enhancement of temporal feature learning with a PSCM.
- Contextual Feature Integration: Employs BTC to enhance the integration of motion and appearance data by extracting spatial-temporal relations. minimizes misclassification induced by occlusions and background changes by enhancing feature representation via the application of token-wise and channel-wise self-attention.
- Hierarchical Temporal Classification: Offers CSAB, a spatial and channel attention mechanism and a channel, which emphasizes relevant action locations. provides robust and accurate fine-grained SAR using a light-weight transformer-based decoder in CTC to extract short-term and long-term action relations.
2. Materials and Methods
In this section, we have described the existing models based on SAR and event tracking in sport analysis. Sen et al. [21] introduced a deep neural network method for classifying fine-grained soccer actions, which exhibits outstanding precision in detecting complex in-game motions. The paper enhances automatic sports analysis by creatively applying deep learning to pick up subtle distinctions between player behaviours. To provide stronger contextual insight, the method would benefit from more explicitly incorporating temporal dynamics. Li et al. [22] introduced an innovative energy-motion feature aggregation network for enhancing fine-grained action analysis for soccer films and enhancing recognition accuracy. The model successfully captures delicate player motions by focusing both on spatial and motion-based features. Future work could explore resilience across a variety of video quality and real-time scenarios. Sen et al. [23] combined spatial and temporal data for improved performance through categorizing soccer motions with transfer learning and Gated Recurrent Units (GRU). With the application of GRUs for sequence modelling and pre-trained networks for extracting features, the method enhances the accuracy of action recognition. The approach can be further enhanced with increased optimization in coping with occlusions at varying camera views. Rao et al. [24] established a universal framework for processing soccer videos with a range of tasks including tracking of players, event detection, and action recognition. The research enhances the overall generalizability of automated soccer video understanding by utilizing deep learning and large datasets. Future research directions could involve adaptability in terms of differing broadcast styles and playing styles. Zhou et al. [25] proposed ActionHub is a large dataset developed with the purpose of zero-shot action recognition, which utilized semantic information to recognize unseen actions. The dataset provides a significant contribution to research in video understanding, particularly in sports analytics. Resolving domain adaptation issues will make it even more useful.
Tabish et al. [26] proposed a generic activity detection framework for sports movies that is a combination of handcrafted features and deep learning to improve action categorization. The approach demonstrates diversity and robustness to achieve promising results in diverse sporting situations. The practicality of the framework can be enhanced further by expanding it to support real-time processing. Hassan et al. [27] improved human action recognition through the extraction of dense-level features and optimizing Long Short-Term Memory (LSTM) networks for better temporal modelling. The approach significantly enhances classification accuracy by enhancing recurrent networks and feature representation. Additional testing on complex multi-player interactions, however, may enhance its usability in the real world. He et al. [28] examined deep learning approaches to tracking soccer players in video streams to improve player localization and movement analysis accuracy. It enhances real-time tracking performance by leveraging object tracking techniques and convolutional neural networks (CNNs). To boost robustness, future research could focus on handling occlusions and varying illumination. Wang et al. [29] demonstrated a deep neural model designed specifically to detect football special activities such as dribbles, tackles, and shoots. To enhance recognition rates, it ingeniously combines spatial and temporal knowledge. Generalizability of the model from different leagues to playing styles may need some extra efforts. Cuperman et al. [30] provided a start-to-end deep learning system for classifying football action using wearable acceleration sensors rather than utilizing videos. The technique leverages neural networks in reading the motion data for efficient recognition of actions taken by the players. An increase in performance can further be enhanced using multimodal input in the form of video and sensor fusion.
Bose et al. [31] proposed SoccerKDNet a knowledge distillation method that transfers knowledge from complex deep learning models to light networks for efficient action identification. The method has good classification performance while significantly reducing processing requirements. Future work can explore how well it performs in low-resource environments and real-time match analysis. Li et al. [32] proposed a deep neural network-based system for classifying football players’ actions from static images. By extracting meaningful spatial features from players’ postures, the model shows high accuracy in classification. Generalizability of the dataset can be improved by incorporating additional match requirements. Liu et al. [33] proposed a deep learning solution to football game video analysis that involves tactical information, monitoring of players, and event detection. Automatic match analysis is enhanced through the utilization of CNNs and recurrent networks. Adaptive learning and real-time solutions for different game dynamics may be explored in subsequent research. Chopar et al. [34] introduced a key-frame extraction technique to minimize computational complexity and improve soccer movie object detection and activity recognition. Through effective selection of informative frames, the approach enhances recognition accuracy without processing unnecessary information. Additional performance optimization is possible through the integration with end-to-end deep learning models. Jiang et al. [35] presented a transformer-based approach to multi-player volleyball tracking and talent detection leveraging self-attention mechanisms for more effective spatial-temporal modelling. Through accurate identification of player positions and movements in complex game situations, the approach enhances analytics. Future studies can investigate how it performs in real-time scenarios and other team sports.
Wensel et al. [36] introduced ViT-Ret enhances human activity recognition in movies by combining recurrent networks with Vision Transformers (ViT), effectively gathering temporal and spatial relations. The model uses attention-based feature extraction to attain superior accuracy in detecting complex human movements. Its robustness could be enhanced with further optimization in handling occlusions and background noise. Cao et al. [37] proposed SpotFormer enhances the detection of significant events such as goals, fouls, and passes within soccer video by presenting a transformer-based method for precise action spotting. Its recognition accuracy and awareness in time are enhanced using self-attention mechanisms. Its generalization may be improved by broadening its training data to cover additional leagues. Gan et al. [38] incorporated text, sound, and visual information with the use of transformers in multimodal scene understanding of soccer movies. By effectively discriminating among match situations, the model improves automatic video analysis contextual understanding. Adaptability and real-time processing and possibly focusing on different styles of broadcasting may be the research area in the future. Zhang et al. [39] introduced the Zoom Transformer model, which preserves hierarchical relationships between individual and group activities. It is designed for skeleton-based group activity detection. Attention processes enhance the precision of team movement analysis. Computational efficiency optimization for large-scale applications could be the primary focus of future enhancements. Xu et al. [40] constructed a skeleton-based model for recognizing football referee movements to make rule enforcement and game analysis automated. Based on deep learning algorithms, the approach effectively captures the patterns of gestures and body positioning. Accuracy could be enhanced even more by incorporating additional referee gestures and match scenarios into the data set.
2.1. Methodolgy
In this section, we introduce the TAT-SARNet model for SAR, which employs a structured workflow to ensure precise and detailed classification.
2.1.1. Attention-Based Dual Feature Extraction
Through parallel acquisition of space and time-related information and noise reduction of the unnecessary background noises, the proposed Attention-based Dual Feature Extraction (ADFE) method significantly boosts feature representation. To allow the extracted features to be centered more on actions, ADFE employs a Suppress Background Attention (SGA) Mechanism for emphasizing significant aspects within the frames as shown in Figure 1. After the acquisition of the refined feature maps, the Dual-Stream Feature Extraction Module (DSFEM) handles them by extracting temporal and spatial features separately from the RGB and optical flow streams. Even in the presence of occlusion or changing motion, the network’s ability to detect complex soccer movements is enhanced by the merging of spatial and motion information.
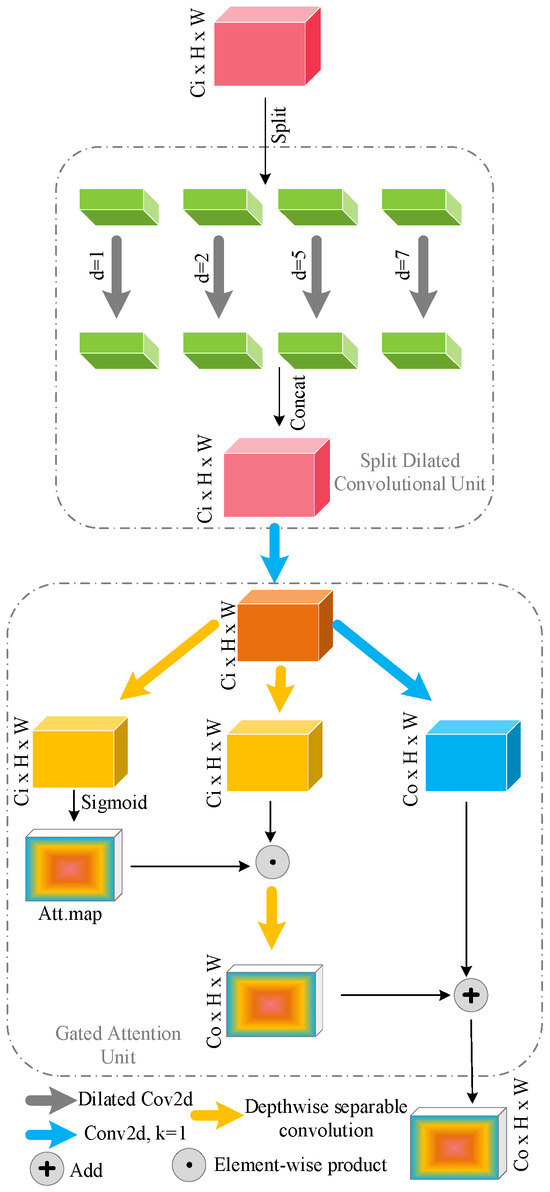
Figure 1.
Illustration of SGA Mechanism.
Suppress Background Attention Mechanism
The input of the ADFE module is a stream of video frames, which is described as below:
where the frame of time with size and color channels is denoted by . The SGA Mechanism employs a dilated convolutional filter to expand the receptive field and gather global context to enhance the input representation. The attention map of each frame is generated as follows:
where, is the kernel size of dilated convolution filter. The bias word is . The convolution operation is represented by . The levels of attention from [0, 1] are normalized with sigmoid activation function . The attention map warps the input frame to reduce background clutter and emphasize salient action areas:
By reducing the effect of distracting or noisy areas, this process produces an attention-enhanced frame that captures only the most critical spatial information.
Split-Stream Feature Processing Module
After SGA, the Split-Stream Feature Processing Module (SSFPM) takes in the attention-enhanced frames and extracts both spatial and temporal data simultaneously. There are two streams running parallel in SSFPM: Appearance Stream exploits RGB frames to obtain spatial features. Motion Stream records motion dynamics by processing optical flow between adjacent frames. Input representations of the two streams are as follows:
The optical flow sequence is computed as follows:
In this instance, represents the intensity values of the frame at time , and captures the temporal displacement between consecutive frames.
Appearance Stream-Spatial Feature Extraction: To obtain high-level spatial features, the appearance stream employs a CNN derived from ResNet to process the attention-refined RGB frames. A spatial feature map is generated by passing each frame through CNN:
where, the symbol represents the convolutional feature extraction function. The trainable weights of the ResNet model are represented by . The expression is the obtained feature map. ResNet employs an array of residual blocks, every block of which has the following definition:
Soccer movements involving small position adjustments can be identified using hierarchical spatial information encoded by the obtained spatial feature map .
Motion Stream-Temporal Feature Extraction: Utilizing a 3D CNN, the stream of motion examines the sequence of optical flow to capture temporal data. The motion features that are extracted are defined as follows:
where the feature extraction function using 3D convolution is denoted by the notation . The trainable parameters of the 3D CNN are denoted by . is the dynamics of time preserved in the motion feature map. To model motion patterns, the 3D CNN uses temporal convolutions between nearby frames:
where is the temporal convolution filter, that perceives changes across adjacent frames over time, having a receptive field of .
Feature Normalization and Weighted Fusion: Batch Normalization (BN) is employed to ensure that the motion feature maps, and appearance maps are consistent:
where and represent the mean and standard deviation of the feature maps, respectively. A weighted feature fusion operation is employed to blend spatial and temporal data in an equitable proportion:
Here, a learnable parameter adjusts the contribution of motion and spatial features. is the name of the combined feature map that retains temporal and spatial signals.
Attention Refinement with SGA: A last SGA mechanism is employed to further sharpen the merged feature map, ensuring that just the most relevant action areas are emphasized and diminishing any residual noise:
Element-wise multiplication produces the ultimate, enhanced feature map:
The accuracy of soccer action detection is ultimately enhanced by employing this final feature map, as a trustworthy input to downstream modules.
2.1.2. Multi-Granular Temporal Processing
After ADFE, the learned feature representation is fed to Multi-Granular Temporal Processing (MGTP) to learn hierarchical temporal relationships over a range of time horizons. MGTP aggregates temporal information effectively to facilitate both short-term and long-term action pattern identification. The MGTP process has two important modules: ResIncept Patch Consolidation (RIPC) and Progressive Scale Construction Module (PSCM). While PSCM constructs coarser-scale features using temporal pooling and dilated convolutions to grow the receptive field along the time axis, RIPM adopts convolutional branches with different sizes of kernels to perform multi-scale feature extraction and downsampling. To accurately explain both short- and long-range relations, these modules operate sequentially to enhance and fuse temporal information.
ResIncept Patch Consolidation (RIPC): Patch-wise feature aggregation via the RIPC module is the first step of MGTP. The Inception architecture was the inspiration behind RIPC (in Figure 2), which employs numerous convolutional branches with different kernel sizes to extract a variety of temporal patterns across multiple resolutions. The refined feature map sequence input is as follows:
where, the temporal duration of the sequence is represented by . After ADFE, the spatial dimensions are represented by and . The number of channels of features is represented by . With kernel sizes , three parallel convolutional branches in RIPC are utilized to extract short-, mid-, and long-term dependencies, respectively:
where, the corresponding branch’s convolutional filters and bias terms are denoted by and , respectively, with kernel size . The convolution operation is denoted by . The rectified linear unit activation function introducing non-linearity is referred to as . An aggregated multi-scale feature representation is generated by concatenating along the channel dimensions the feature maps generated by the three branches:
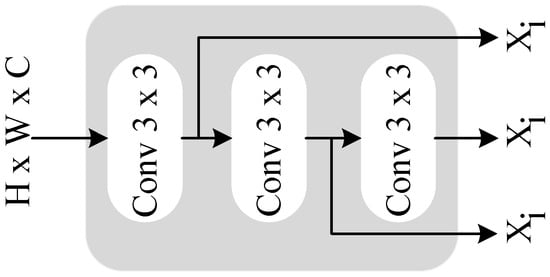
Figure 2.
Basic Structure of RIPC Module.
RIPC employs a patch merging process that reduces the temporal dimension by half without losing key information to reduce the computational cost and maintain consistency across scales. The patch merging expression is:
By merging adjacent frame patches, reduces the temporal dimension in this situation to allow RIPC to downsample the temporal resolution without sacrificing the most visible features.
Progressive Scale Construction Module (PSCM): PSCM, which constructs coarser temporal scales to preserve long-range relations, takes in the fused feature map from RIPC. To further enhance temporal features over wider time horizons, PSCM employs temporal pooling and dilated convolutions.
Temporal Pooling for Coarser-Scale Formation: The temporal resolution is reduced by a factor of by utilizing average pooling across a sliding window of width for temporal pooling:
where a lower-resolution temporal scale can be formed by applying to compute the average of nearby feature vectors over a temporal window of width .
Dilated Temporal Convolutions for Long-Term Dependencies: A dilated temporal convolution is applied to the pooled feature map to capture fine-grained features across expanded time ranges. Since it expands the receptive field without increasing the number of parameters, dilated convolutions allow the model to capture temporal relationships over a broader range:
The convolutional filter and bias for the dilated convolution are given by and . The dilated convolution with dilation rate widens the temporal receptive field, which is represented as . For enhancing the expressiveness of features, introduces non-linearity. Batch normalization is applied by PSCM to normalize the output to ensure stability in the enhanced feature maps:
where, the standard deviation and mean of the feature map along the temporal axis are represented by and . For enhancing training stability, batch normalization standardizes the feature distributions across multiple scales.
MGTP Output: The feature maps generated by RIPC and PSCM are aggregated through the weighted summation process to generate the final aggregated temporal representation. The contributions of coarse-scale representations of PSCM and the multi-scale features of RIPC are equilibrated by this mechanism:
where, Contributions of fine-scale and coarse-scale temporals are dynamically traded off by the learnable parameter . The multi-scale temporal dependencies are well captured in the final aggregated temporal feature map . For accurate categorization of actions, the output is then passed to subsequent modules. The overall performance of the system is improved by MGTP where the overview is displayed in Figure 3, ensuring robust action identification across a variety of scales of time by integrating all the different temporal patterns that RIPC and PSCM have tracked.
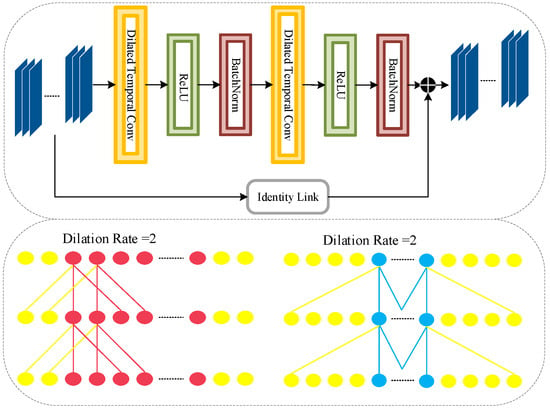
Figure 3.
Overview of MGTP Architecture.
2.1.3. Feature Refinement
Context-Guided Dual Transformer (CGDT) module is utilized for further processing the enhanced features derived by MGTP to enhance temporal and spatial contextual relations. Two indispensable blocks that CGDT employs to effectively capture intricate feature interactions and long-range connections are the Bi-Transformer Connector (BTC) and the Channel-Spatial Attention Block (CSAB). Although the CSAB selectively emphasizes notable areas and channels to enhance feature representations, the BTC collects cross-domain contextual knowledge in both spatial and temporal levels. These modules collaborate to ensure that CGDT generates a feature map that captures complex spatiotemporal interactions in a consistent and enhanced way.
Bi-Transformer Connector
To maintain contextual consistency within multiple dimensions simultaneously, BTC analyzes temporal and spatial data. As illustrated in Figure 4, the two parallel transformer branches-the one for the time dimension and the other for the space dimension-provide cross-attention in which the two interacting branches may enhance feature embeddings. After MGTP, the input feature map is shown as .
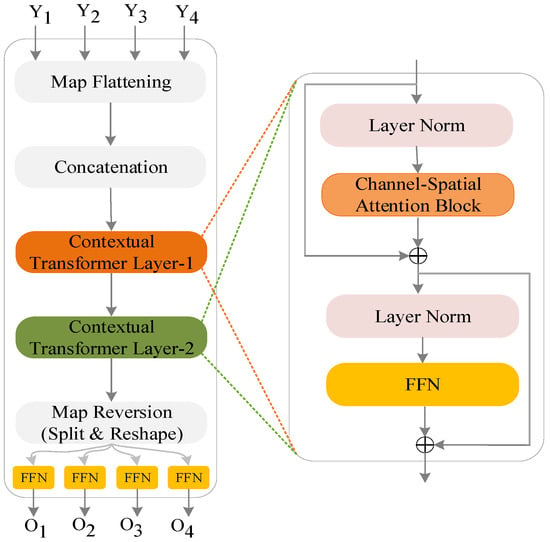
Figure 4.
Architecture of Proposed BTC.
Spatial Transformer Branch: The spatial transformer branch employs self-attention along spatial dimensions to depict spatial interdependence. In spatial modeling, the input feature map is initially reshaped:
This renewed feature map gives self-attention:
where, Learnable projection matrices for query, key, and value embeddings are . The following are the value, key, and query matrices are . Spatial attention scores are calculated by the dot product of question and key and then a softmax operation is applied:
The attention scores are used to apply to the value matrix to generate the enhanced spatial feature map:
Temporal Transformer Branch: The temporal transformer branch uses self-attention along the temporal axis to mimic long-range temporal correlations. For temporal modeling, the feature map is reconstructed as follows:
In the temporal branch, self-attention is written as:
where, learnable projection matrices are . The query, key, and value matrices are . Similarly, the temporal attention scores are computed as:
The improved temporal feature map is then obtained as follows:
Cross-Domain Fusion: BTC employs a cross-domain fusion by blending the enhanced feature representations to bridge the spatial and temporal transformers:
Spatial and temporal contributions of features are balanced through the learnable parameter .
Channel-Spatial Attention Block (CSAB)
After BTC, the CSAB deals with the combined feature map to enhance discriminative feature regions and adaptively give higher importance to crucial information. Channel attention and spatial attention are the two attention operations that constitute CSAB which represented in Figure 5.
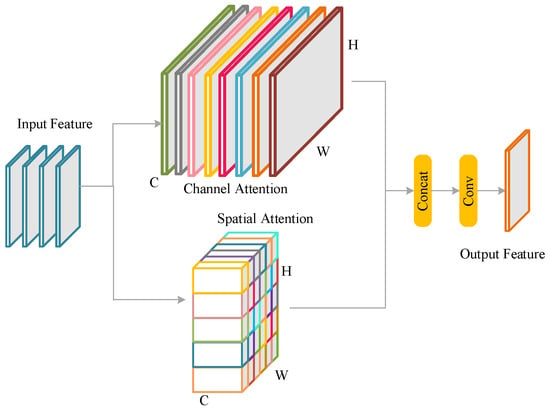
Figure 5.
Representation of CSAB Mechanism.
Channel Attention: By simulating between-channel connections, channel attention emphasizes the most significant feature channels. Global average pooling (GAP) is employed to generate the global feature map:
A two-layer fully connected network is employed to calculate the channel attention weights:
where, learnable weights are and . The sigmoid activation function employed to normalize the attention weights is . These weights are used to generate the enhanced channel-attentive feature map:
Spatial Attention: General informative spatial areas are emphasized by spatial attention. Spatial attention weights are generated by sigmoid activation following a convolutional operation:
The spatially refined feature map is then computed as follows:
Channel-Spatial Attention Fusion: CSAB fuses the attended and original features in a residual fusion to combine the channel and spatially attended feature maps:
A learnable parameter to control the fusion is .
CGTP Output: Using a weighted combination of BTC and CSAB results provides the output final fused feature map generated by CGDT:
A trainable parameter is employed to control the weight between the channel-spatial attention and spatial-temporal context modeling. Following entry into downstream modules, the augmented feature map guarantees full understanding of space and time correlations in the scene, enhancing overall accuracy and robustness of the model.
2.1.4. Cascaded Temporal Classification for Fine-Grained SAR
CGDT module aggregates and refines the feature maps, and the output feature representations are presented to the Cascaded Temporal Classification (CTC) module. Even with occlusions and changing motions in the scenes, CTC’s capacity to represent both short-term and long-term dependencies within action sequences guarantees robust classification of fine-grained soccer activities. By analyzing temporal patterns at different resolutions, the CTC module uses a two-level categorization method that hierarchically refines predictions. The overall architecture of proposed TAT-SARNet is illustrated in Figure 6.
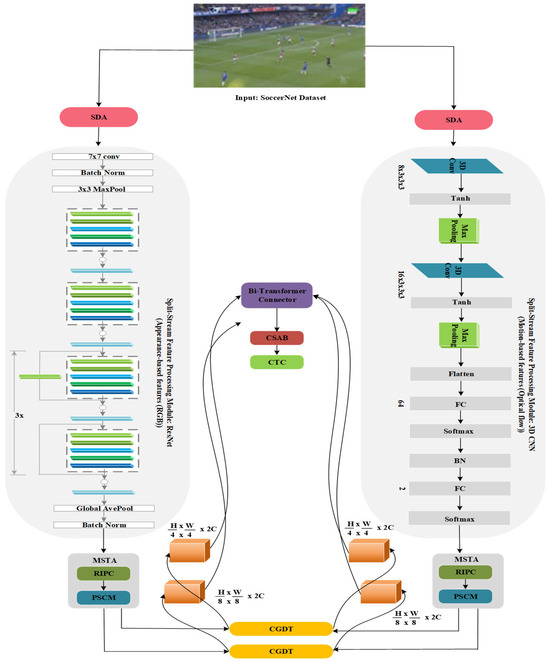
Figure 6.
Overall Architecture of Proposed TAT-SARNet Model.
Short-Term Temporal Modelling: CTC applies a Temporal Convolution Network (TCN) to the input sequence of features for capturing short-term temporal relations. For convolution over time, the feature map is transformed in the following manner:
To mimic local dependencies, a 1D temporal convolution is employed:
where, the size of the kernel for short-term convolution is . The dilation rate applied to expand the receptive field for local feature extraction is . To preserve low-level details, a residual connection is used on the short-term fine-grained feature map:
A learnable parameter controlling the contribution of short-term modelling is .
Long-Term Temporal Modelling: CTC captures global temporal structures with the Bidirectional Long Short-Term Memory (Bi-LSTM) network for the temporal interdependence at long horizons. For processing with Bi-LSTM, the short-term refined feature map is reconstructed according to the following equation:
Here, . The two-directional sequence is processed with the Bi-LSTM:
Concatenating the front and reversed hidden states results in the ultimate long-term contextual feature representation:
By way of a residual connection, the short-term feature map and updated long-term feature map are blended:
In this way, a learnable parameter used to balance short-term and long-term information is .
Hierarchical Classification for Action Mapping: A hierarchical classifier predicting the fine-grained soccer action classes is given the fine-tuned feature map . HTC adopts a Dual-Level Classification Network (DLCN) which performs fine-grained classification following coarse classification.
Coarse-Level Classification: A softmax function and a fully connected layer are employed at the first level to perform coarse classification:
where, the coarse classification weight matrix is . is the bias vector. The number of coarse action classes is represented by . By utilizing a second fully connected layer to focus on subcategories, the fine-grained classification refines the coarse predictions:
where, the fine-grained classification matrix is . The bias vector for fine-grained classification is . The fine-grained number of action categories is . The coarse and fine-grained outputs are concatenated to obtain the final classification prediction:
Learnable parameter is a balancing factor of fine-grained and coarse-grained predictions. The action sequence is associated with a high-level soccer action category through output . Even in occluded, rapidly moving, dynamic interaction cases, CTC ensures improved action categorization by capturing short-term and long-term relationships. The ability of the model to separate related activity while maintaining temporal coherence over the sequence is enhanced by this hierarchical method.
3. Results
In this section, we have performed the experimental analysis for evaluating and comparing our proposed work with existing models in order to prove our model efficiency.
3.1. Dataset Description
In this work, we have utilized SoccerNet dataset (https://www.soccer-net.org/), where the entire dataset encompasses of 550 broadcast soccer games, and every game comprise of two videos: the first and second half respectively. Each video length is about 45 min of duration. There are 17 action characteristics annotated of dataset, and every action is annotated along with timestamp in single. These annotations are distributed in extensive games, and even several action characteristics only happen dozens in the times of entire dataset. The actions are divided into two characteristics: invisible and visible. Being visible refers that the actions are represented in the videos, and invisible refers that we can’t essentially see the equivalent actions. SoccerNet dataset is divided into 4 portions, and there are validation by 100 games, training by 300 games, 100 games for testing and challenge by 50 games.
Experimental Setup
The experimental setup was conducted on a system equipped with an NVIDIA RTX 3090 GPU, 64 GB RAM, and an Intel Core i9 processor (Santa Clara, CA, USA), ensuring efficient training and evaluation of the proposed TAT-SARNet model. Python 3.8 with PyTorch (latest v. 2.2x) deep learning framework was used for model implementation, training, and testing. Additionally, OpenCV and SciPy libraries supported pre-processing and data augmentation, while performance metrics such as mAP, IoU, and mPCA were computed for evaluation
3.2. Results of Soccer Player and Ball Detection
Robust action recognition in soccer videos relies on precise object detection of players and the ball. SDA is employed by TAT-SARNet to enhance object edges, eliminate background noises, and enhance spatial relationships. The approach guarantees the retrieval of fine-grained features even in complex and crowded scenes. Mean Average Precision (mAP) and Intersection over Union (IoU) metrics are employed to evaluate detection precision. Whereas IoU computes the overlap between the predicted and the ground truth bounding boxes, as defined below, mAP computes the average accuracy per class.
where and are the predicted and ground truth boxes, respectively. The mAP is calculated as the average of the Average Precision (AP) across classes, while the Intersection over Union (IoU) measures the overlap between the predicted bounding box ( and the ground truth box () as the ratio of their intersection to their union. As defined in Table 1, TAT-SARNet performs better than all other models with the highest mAP (91.4%) and IoU (85.6%) compared to other models like FG-DNN [21], EMFAN [22], SoccerKDNet [31], and MPT [35]. This is because SDA is more efficient at enhancing object detection by focusing on relevant areas and minimizing the effects of unnecessary background noise. There are several opportunities for future work in object detection in sports analytics. The robust mAP and IoU results show that TAT-SARNet performs better than alternative models in dynamic soccer situations by effectively detecting players and the ball.

Table 1.
Analysis of mAP and IoU Performance.
3.3. Results and Comparisons of Soccer Players’ Fine-Grained Action Analysis
3.3.1. Results of Fine-Grained Shooting Classification
Fine-grained shooting classification involves identifying subtle variations in the styles of shooting such as volley, chip, power shot, and finesse shot. To differentiate the fine-grained activities and enhance temporal performance, TAT-SARNet employs PSCM and RIPC along with MGTP. As outlied in Table 2, compared with state-of-the-art models, TAT-SARNet surpasses FG-DNN, EMFAN, and SoccerKDNet in terms of the highest average shooting classification accuracy of 92.3%. TAT-SARNet’s improved performance is owed to the enhanced temporal modelling capacity of MGTP and the efficient fusion of motion-based and spatial data through the CGDT. The Figure 7 shows examples of dribbling actions grouped into two categories after clustering actions performed by defender players.
Table 2.
Evaluation of Shooting Classification.

Figure 7.
Example of Dribbling Actions from Two Groups Identified After Clustering Actions Performed by Defender Players.
3.3.2. Results of Fine-Grained Dribbling Classification
Classifying between advanced dribbling techniques such as close control, speed, and feint dribbling constitutes the categorization of dribbling. For enhancing the ability of the model to discriminate between spatial-based and motion-based techniques, SSFPM of TAT-SARNet utilizes it in effectively capturing both categories of input. On average, the accuracy of the model in classifying dribbling stands at 89.8%, outperforming all other baseline models like SoccerKDNet and MPT. Since it can capture fine-grained motion patterns while preserving spatial dependencies, TAT-SARNet works extremely well for dribbling categorization and achieves higher accuracy in all categories of dribbling (Table 3).
Table 3.
Evaluation of Dribbling Classification.
3.4. Comparison of Results of Players’ Fine-Grained Action Classification
Several fine-grained action categories, including shooting, dribbling, passing, and defensive behaviors, are utilized to measure the overall action classification performance of TAT-SARNet. By understanding short-term and long-term associations, CTC enhances the accuracy of identification. TAT-SARNet’s robustness in classifying diverse soccer actions is exhibited by its mean fine-grained action classification rate of 90.7%, outperforming all state-of-the-art methods which illustrated in Table 4. TAT-SARNet boasts the highest classification accuracy in many fine-grained action categories due to its ability to capture player movement and interaction temporal and spatial nuances.
Table 4.
Average Analysis of Fine-Grained Action Accuracy.
3.4.1. Comparison of Results of Players’ Fine-Grained Action Classification
For delivering extensive coverage of complex soccer activities, the entire fine-grained action classification performance of TAT-SARNet is evaluated across multiple action classes, including shooting, dribbling, and defense. The model incorporates the CTC module for enhancing alignment between features with capturing temporal relations over various scales of time, fusing both short-term and long-term temporal connections. TAT-SARNet constantly improves action accuracy and recall by employing multi-level temporal contextualization, decreasing misclassification mistakes and enhancing resilience on a range of action types. Mean Per-Class Accuracy (mPCA), Average Precision (AP), and Recall are the primary evaluation metrics utilized to measure the performance of the model where the evaluated results are illustrated in Table 5. mPCA is the average accuracy computed independently for each class, ensuring equal weight is given to all classes regardless of their frequency in the dataset. The model’s ability to maintain accuracy for varying recall values is demonstrated through AP, which computes the area under the precision-recall curve. While mPCA ensures that performance is well balanced across all action categories and does not favor dominating action types, recall measures the proportion of actual positive predictions. Based on comparative statistics, TAT-SARNet greatly surpasses all other rival models, with an AP of 95.2%, Recall of 93.4%, and mPCA of 91.8%. Figure 8 displays the action spotting in the SoccerNet dataset aims to identify key events, such as “goal” (in Figure 8a) and “yellow card”, (in Figure 8b) in lengthy soccer match videos.
Table 5.
Fine-Grained Action Classification Comparison.

Figure 8.
Instances of Action Classification.
3.4.2. Fine-Grained Action Classification Performance Analysis
The exceptional performance of TAT-SARNet can be attributed to its ability to retain long-term action sequences (such as sustained buildup leading to a goal attempt) while, at the same time, recognizing short-term micro-actions (such as quick dribbling maneuvers). To prevent the model from overfitting on shorter sequences and enhance its generalizability to varying action durations, the CTC module ensures that frame-level predictions are averaged over time. Although MPT has excellent performance, TAT-SARNet surpasses it by maintaining greater consistency in long-term sequence prediction, as per the comparative analysis of rival models. Relative to other models, TAT-SARNet’s CTC module ensures a robust balance between long-term and short-term action dependencies to support more accuracy and recall. The model’s output represents the probability of an action occurring at a given timestamp, as shown in Figure 9. Figure 10 and Figure 11 show examples of true and false positive dribbling actions detected during the match between Team J (white shirt) and Team L (red shirt), occurring at 88 min and 12 s, and 74 min and 8 s, respectively.
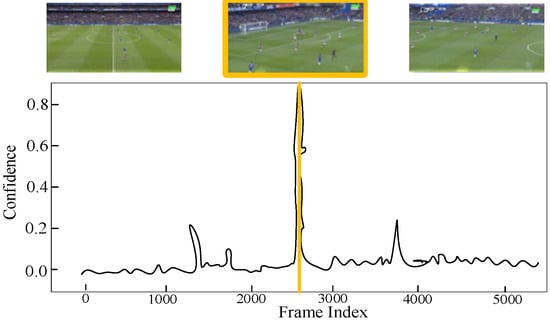
Figure 9.
Action spotting prediction: Black curve represents the model’s predicted confidence, while the yellow line indicates the ground truth action timestamp.

Figure 10.
An Example of True Positive Dribbling Action Detected During the Match Among Team J (White Shirt) and Team L (Red Shirt) at 88 min and 12 s.

Figure 11.
An example of a false positive dribbling action detected during the match between Team J (white shirt) and Team L (red shirt) at 74 min and 8 s.
3.5. Error Rate Analysis and Temporal Consistency
The temporal consistency graph in Figure 12a for fine-grained action classification further illustrates the robustness of the model by showing that TAT-SARNet maintains higher classification stability over a variety of time intervals. The method reduces rates of misclassification in complex scenarios by consistently upholding contextual links across multi-frame sequences. TAT-SARNet achieves the lowest error rates in all classes of actions, especially in concurrent action categories where temporal misalignments typically create higher numbers of false negatives, as per the distribution of the error rate plotted in Figure 12b.
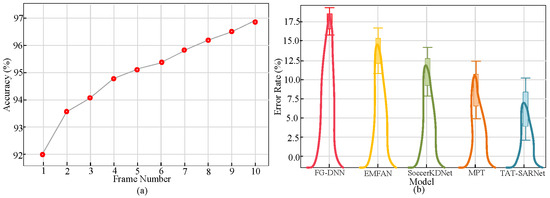
Figure 12.
Analysis of (a) Fine-Grained Action Classification (b) Error Rate.
3.5.1. Robustness Analysis in Occluded and Dynamic Scenarios
Analysing TAT-SARNet’s robustness under real-world situations is essential towards understanding its ability to function properly under adverse situations. Soccer games often contain adverse situations in the form of dynamic motion, which induces sudden changes in activity sequences, and occlusions, where objects and players occlude the view. We induce these scenarios and measure the deterioration in performance across rival models and compare it to understand model reliability in such situations. TAT-SARNet utilizes the BTC that adaptively aligns multi-scale features dynamically to create flawless feature continuity over spatial and temporal axes. This module enhances the accuracy of classification in challenging conditions by lessening the ill effects of occlusion and high motion.
3.5.2. Accuracy Comparison Under Occlusion and Dynamic Movements
In cases of partial occlusions and dynamic players, TAT-SARNet performance is compared to that of FG-DNN, EMFAN, SoccerKDNet, and MPT models. Based on the outcome, as represented in Table 6, TAT-SARNet impressively outperforms all other models with 89.6% accuracy in occlusion scenarios and 91.8% in dynamic movements. Through continuous enhancement of feature correspondence between temporal and spatial streams, the BTC module prevents occlusion-induced errors and ensures continuity of action. Conversely, models such as FG-DNN and EMFAN experience dramatic performance drops since they are unable to maintain temporal consistency in highly dynamic environments. BTC facilitating enhanced feature cohesion in spatial and temporal contexts, enables TAT-SARNet to maintain increased accuracy even for difficult scenarios.
Table 6.
Accuracy Comparison in Occlusion and Dynamic Movement Scenarios.
3.5.3. Error Analysis and Scenario Simulation Results
Further investigation indicates that while under occlusion and high-motion scenarios, error rates of comparison models increase considerably, peculiarly for players moving back and forth from offense to defense. The percentage of performance loss in each model is illustrated by Figure 13a, where TAT-SARNet shows a minimal loss of 4.8% under occlusion situations and 3.2% for dynamic movements, while other models register averages of 8–12%. Despite diminished player visibility, Figure 13b’s simulation frame for occlusion illustrates how TAT-SARNet preserves contextual information to properly classify actions.
Figure 13.
Analysis of (a) Performance Loss (b) Occlusion.
3.6. Computational Efficiency and Model Complexity Analysis
Models are required to attain high accuracy and low computation cost to label actions effectively in real-time. BTC and MGTP incorporated into TAT-SARNet ease aggregation of features and reduce redundant procedures. Three key indicators inference time (expressed in milliseconds per frame), model size (expressed in MB), and FLOPs (Floating Point Operations Per Second) are compared with other competing models such as FG-DNN, EMFAN, SoccerKDNet, and MPT to measure the computational efficiency of the model. With the smallest model size of 128.9 MB, lowest FLOPs of 13.4 GFLOPs, and lowest inference time of 15.8 ms/frame, TAT-SARNet is optimally designed for real-time applications.
3.6.1. Performance Comparison Across Computational Metrics
As per the computational analysis in Table 7, TAT-SARNet outperforms competing models with 15% to 20% fewer FLOPs while maintaining a high classification accuracy. The long feature extraction pipelines of models such as FG-DNN and EMFAN incur computational overhead and lead to increased inference times. Analogous to this, SoccerKDNet and MPT suffer from processing latency and bigger models despite offering relatively good classification outcomes. TAT-SARNet’s PSCM continuously adjusts feature scales to reduce processing overhead and minimize computational complexity. TAT-SARNet is ideal for real-time applications since it offers the best computing performance while maintaining a higher classification accuracy.
Table 7.
Computational Efficiency and Model Complexity Comparison.
3.6.2. Visualization and FLOPs Breakdown Analysis
A bar chart illustrating the comparison of inference time, model size, and FLOPs between models is presented in Figure 14a to further investigate computing performance. TAT-SARNet’s reduced design, particularly the enhanced RIPC, is responsible for faster inference time and significantly fewer FLOPs. A layer-wise breakdown of FLOPs is visualized in Figure 14b, which demonstrates how TAT-SARNet minimizes computing cost by avoiding unnecessary operations at lower levels while preserving fine-grained action details.
Figure 14.
Evaluation of FLOPS Breakdown.
3.7. Ablation Study
An ablation study was conducted to assess the contributions of each component in the TAT-SARNet model for SAR. The base model, which consists only of a simple feature extraction pipeline with traditional CNN layers, was tested first, achieving a classification accuracy of 72.5%. When SDA was added to enhance spatial dependencies and reduce background clutter, the model’s accuracy increased to 79.1%, demonstrating the benefit of spatial attention. Introducing the SSFPM that separately handles RGB and optical flow features further improved performance, reaching 83.4%. MGTP module, with RIPC and PSCM, refined the temporal features and boosted the accuracy to 86.2%, highlighting the importance of fine-grained temporal patterns.
Incorporating the CGDT for spatiotemporal interaction fusion resulted in a significant accuracy increase, reaching 89.7%, showing the effectiveness of transformers in handling both spatial and temporal information. The final addition of the CTC module led to the highest performance of 91.5%, emphasizing the importance of capturing both short- and long-range dependencies for action categorization. Removing any single module led to noticeable performance drops: excluding SDA reduced accuracy to 77.8%, while omitting SSFPM dropped it to 80.6%. Removing MGTP lowered accuracy to 82.9%, and without CGDT, the model only achieved 84.2%. These results confirm that each component contributes significantly to the model’s overall effectiveness, with the most critical improvements arising from temporal feature refinement and spatiotemporal fusion. The ablation study demonstrates that the proposed TAT-SARNet model significantly outperforms traditional SAR methods by systematically integrating multiple modules for robust SAR.
3.8. Limitations of Proposed Work
Here are three potential limitations of the proposed TAT-SARNet model for SAR:
- Dependency on Dual Modalities (RGB and Optical Flow): SSFPM relies on both RGB and optical flow inputs to capture appearance and motion features. However, generating accurate optical flow can be computationally expensive and sensitive to noise, especially in low-quality or fast-paced video frames, which may limit real-time deployment.
- High Model Complexity and Inference Overhead: The integration of multiple specialized modules such as Sparse Dilated Attention, Multi-Granular Temporal Processing, and Dual Transformer units increases the architectural complexity and resource requirements. This may hinder scalability and make it challenging to deploy the model on edge devices or in low-latency sports analytics systems.
- Limited Generalization Across Diverse Soccer Datasets: Although the model is designed for fine-grained action recognition, its performance may degrade when applied to soccer footage from different leagues, stadium environments, or broadcast setups, due to variations in camera angles, player kits, and lighting conditions. This raises concerns about its generalization ability without extensive domain-specific fine-tuning.
4. Conclusions
SAR is the standard part of modern sports analytics, providing teams, analysts, and coaches with better insight into the performance of an individual, tactical decisions, and game dynamics. Although traditional SAR models have made numerous advancements in action classification, their capability to detect small changes in the movements of players is constrained by their focus on coarse-grained detection. Due to the complexity of player interactions, occlusions, cluttered backgrounds, and varying camera angles, fine-grained SAR remains a challenging problem. In addition, multi-scale action recognition, contextual understanding, and long-term temporal interdependence are often challenging for existing deep learning-based SAR methods. We proposed TAT-SARNet, a state-of-the-art deep learning model designed for fine-grained SAR, as a solution to these challenges. For improved action classification performance, TAT-SARNet integrates transformer-guided feature fusion, multi-scale temporal pooling, attention-gated spatial enhancement, and multi-stream feature learning. For enhancing SAR performance in complex and dynamic match situations, the proposed framework is designed to effectively capture spatial, temporal, and contextual features. SSFPM, being a major development in TAT-SARNet, addresses motion-based (optical flow) and appearance-based (RGB frames) features. With the assistance of this module, the model can capture motion and visual signals, ensuring more complete feature representation for soccer action detection. In addition, through the reduction of occlusions and background noise and focusing on the most relevant action areas, SDA mechanism is employed to enhance spatial feature learning.
We proposed the MGTP module, utilizing RIPC for multi-scale feature representation, to solve the issue of multi-scale temporal aggregation. This component enhances the model’s capacity to identify complex and variable-length soccer actions by allowing effective processing of short-term and long-term action dependencies. The PSCM also enhances temporal features, ensuring more accurate action sequence segmentation. We designed the CGDT for combining features, employing a BTC for capturing temporal and spatial interactions. CGDT effectively combines appearance and motion feature representations through the application of token-wise and channel-wise self-attention mechanisms that reduce misclassification caused by akin-looking actions or background clutter. More accurate and contextually sensitive SAR predictions follow from this technique’s integration of contextual data, including player location and team relationship, into action categorization. Finally, we introduced CTC, in which a transformer-based classifier finds long-term and short-term interactions in soccer action sequences. To emphasize relevant action locations employing channel and spatial attention processes, we also introduced the CSAB. Soccer movements are highly differentiated by the CTC module, differentiating between minuscule differences such as chip shots versus volleys or brief passes versus extensive passes. In conclusion, TAT-SARNet leverages transformer-based temporal modelling, attention-driven spatial fine-tuning, and cutting-edge multi-stream feature extraction to offer a robust and scalable solution for soccer action detection with high-level fineness. Our method establishes a solid foundation for future advancements in automated soccer analysis and smart sports monitoring systems by addressing key SAR challenges. As future work, an Explainable AI (Ex-AI) based SAR model can be developed to provide interpretable and transparent insights into the decision-making process of fine-grained action recognition models. This approach would enhance trust and usability by offering visual explanations, highlighting key regions, and providing reasoning behind action predictions, enabling coaches and analysts to better understand model outcomes and refine strategies effectively.
Author Contributions
Conceptualization, A.A.; Methodology, A.A.; Validation, B.A.; Formal analysis, A.A.; Investigation, A.A.; Resources, B.A.; Writing—original draft, B.A.; Writing—review & editing, B.A.; Project administration, B.A.; Funding acquisition, B.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are openly available in [SoccerNet dataset] [https://www.soccer-net.org/data].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Junior, B.; Moura, F.A.; Torres, S. Data-Driven Methods for Soccer Analysis. In Artificial Intelligence in Sports, Movement, and Health; Springer Nature: Cham, Switzerland, 2024; pp. 233–253. [Google Scholar]
- Edriss, S.; Romagnoli, C.; Caprioli, L.; Zanela, A.; Panichi, E.; Campoli, F.; Padua, E.; Annino, G.; Bonaiuto, V. The role of emergent technologies in the dynamic and kinematic assessment of human movement in sport and clinical applications. Appl. Sci. 2024, 14, 1012. [Google Scholar] [CrossRef]
- Tetarwal, V.; Kumar, S. A Comprehensive Review on Computer Vision Analysis of Aerial Data. arXiv 2024, arXiv:2402.09781. [Google Scholar] [CrossRef]
- Carling, C.; Datson, N. Performance analysis for coaches. In Practical Sports Coaching; Routledge: London, UK, 2022; pp. 212–239. [Google Scholar]
- Chu, Y.; Ye, M.; Qian, Y. Fine-Grained Image Recognition Methods and Their Applications in Remote Sensing Images: A Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 19640–19667. [Google Scholar] [CrossRef]
- Mouna, S.; Farah, I.R. UAV-Based IoT Applications for Action Recognition. In Decision Making and Security Risk Management for IoT Environments; Springer International Publishing: Berlin/Heidelberg, Germany, 2023; pp. 171–197. [Google Scholar]
- Shabaninia, E.; Nezamabadi-pour, H.; Shafizadegan, F. Transformers in action recognition: A review on temporal modeling. arXiv 2022, arXiv:2302.01921. [Google Scholar] [CrossRef]
- Zhao, Z.; Chai, W.; Hao, S.; Hu, W.; Wang, G.; Cao, S.; Song, M.; Hwang, J.-N.; Wang, G. A survey of deep learning in sports applications: Perception, comprehension, and decision. arXiv 2023, arXiv:2307.03353. [Google Scholar] [CrossRef]
- Patro, B.N.; Agneeswaran, V.S. Mamba-360: Survey of state space models as transformer alternative for long sequence modelling: Methods, applications, and challenges. arXiv 2024, arXiv:2404.16112. [Google Scholar] [CrossRef]
- Yin, J.; Duan, C.; Wang, H.; Yang, J. A review on the few-shot SAR target recognition. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 16411–16425. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, R.; Ai, J.; Zou, H.; Li, J. Global and local context-aware ship detector for high-resolution SAR images. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 4159–4167. [Google Scholar] [CrossRef]
- Xu, H.; Gao, Y.; Li, J.; Gao, X. An information compensation framework for zero-shot skeleton-based action recognition. IEEE Trans. Multimed. 2025, 27, 4882–4894. [Google Scholar] [CrossRef]
- Hewitt, J.H.; Karakuş, O. A machine learning approach for player and position adjusted expected goals in football (soccer). Frankl. Open 2023, 4, 100034. [Google Scholar] [CrossRef]
- Casmin, E.; Oliveira, R. Survey on Context-Aware Radio Frequency-Based Sensing. Sensors 2025, 25, 602. [Google Scholar] [CrossRef]
- Yin, H.; Sinnott, R.O.; Jayaputera, G.T. A survey of video-based human action recognition in team sports. Artif. Intell. Rev. 2024, 57, 293. [Google Scholar] [CrossRef]
- Rafiq, G.; Rafiq, M.; Choi, G.S. Video description: A comprehensive survey of deep learning approaches. Artif. Intell. Rev. 2023, 56, 13293–13372. [Google Scholar] [CrossRef]
- Seweryn, K.; Wróblewska, A.; Łukasik, S. Survey of Action Recognition, Spotting and Spatio-Temporal Localization in Soccer—Current Trends and Research Perspectives. arXiv 2023, arXiv:2309.12067. [Google Scholar]
- Luo, Q.; Zeng, W.; Chen, M.; Peng, G.; Yuan, X.; Yin, Q. Self-Attention and Transformers: Driving the Evolution of Large Language Models. In Proceedings of the 2023 IEEE 6th International Conference on Electronic Information and Communication Technology (ICEICT), Qingdao, China, 21–24 July 2023; IEEE: New York, NY, USA, 2023; pp. 401–405. [Google Scholar]
- Shin, J.; Hassan, N.; Miah, A.S.M.; Nishimura, S. A Comprehensive Methodological Survey of Human Activity Recognition Across Divers Data Modalities. arXiv 2024, arXiv:2409.09678. [Google Scholar] [CrossRef]
- Fu, X.; Huang, W.; Sun, Y.; Zhu, X.; Evans, J.; Song, X.; Geng, T.; He, S. A novel dataset for multi-view multi-player tracking in soccer scenarios. Appl. Sci. 2023, 13, 5361. [Google Scholar] [CrossRef]
- Sen, A.; Hossain, S.M.; Russo, M.A.; Deb, K.; Jo, K. Fine-Grained Soccer Actions Classification Using Deep Neural Network. In Proceedings of the 2022 15th International Conference on Human System Interaction (HSI), Melbourne, VIC, Australia, 29–31 July 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Li, R.; Bhanu, B. Energy-Motion Features Aggregation Network for Players’ Fine-Grained Action Analysis in Soccer Videos. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 955–972. [Google Scholar] [CrossRef]
- Sen, A.; Deb, K. Categorization of actions in soccer videos using a combination of transfer learning and Gated Recurrent Unit. ICT Express 2022, 8, 65–71. [Google Scholar] [CrossRef]
- Rao, J.; Wu, H.; Jiang, H.; Zhang, Y.; Wang, Y.; Xie, W. Towards universal Soccer video understanding. arXiv 2024, arXiv:2412.01820. [Google Scholar] [CrossRef]
- Zhou, J.; Liang, J.; Lin, K.Y.; Yang, J.; Zheng, W.S. Actionhub: A large-scale action video description dataset for zero-shot action recognition. arXiv 2024, arXiv:2401.11654. [Google Scholar]
- Tabish, M.; Tanooli, Z.U.R.; Shaheen, M. Activity recognition framework in sports videos. In Multimedia Tools and Applications; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1–23. [Google Scholar]
- Hassan, N.; Miah, A.S.M.; Shin, J. Enhancing human action recognition in videos through dense-level features extraction and optimized long short-term memory. In Proceedings of the 2024 7th International Conference on Electronics, Communications, and Control Engineering (ICECC), Kuala Lumpur, Malaysia, 22–24 March 2024; IEEE: New York, NY, USA, 2024; pp. 19–23. [Google Scholar]
- He, X. Application of deep learning in video target tracking of soccer players. Soft Comput. 2022, 26, 10971–10979. [Google Scholar] [CrossRef]
- Wang, S. A deep learning algorithm for special action recognition of football. Mob. Inf. Syst. 2022, 2022, 6315648. [Google Scholar] [CrossRef]
- Cuperman, R.; Jansen, K.M.; Ciszewski, M.G. An end-to-end deep learning pipeline for football activity recognition based on wearable acceleration sensors. Sensors 2022, 22, 1347. [Google Scholar] [CrossRef] [PubMed]
- Bose, S.; Sarkar, S.; Chakrabarti, A. SoccerKDNet: A knowledge distillation framework for action recognition in soccer videos. In International Conference on Pattern Recognition and Machine Intelligence; Springer Nature: Cham, Switzerland, 2023; pp. 457–464. [Google Scholar]
- Li, X.; Ullah, R. An image classification algorithm for football players’ activities using deep neural network. Soft Comput. 2023, 27, 19317–19337. [Google Scholar] [CrossRef]
- Liu, N.; Liu, L.; Sun, Z. Football game video analysis method with deep learning. Comput. Intell. Neurosci. 2022, 2022, 3284156. [Google Scholar] [CrossRef]
- Chopra, H.; Mundody, S.; Guddeti, R.M.R. A key-frame extraction for object detection and human action recognition in soccer game videos. In Proceedings of the 2023 14th International Conference on Computing Communication and Networking Technologies (ICCCNT), Delhi, India, 6–8 July 2023; IEEE: New York, NY, USA, 2023; pp. 1–7. [Google Scholar]
- Jiang, L.; Yang, Z.; Gang, L. Transformer-Based Multi-Player Tracking and Skill Recognition Framework for Volleyball Analytics. IEEE Access 2025, 13, 8806–8824. [Google Scholar] [CrossRef]
- Wensel, J.; Ullah, H.; Munir, A. Vit-ret: Vision and recurrent transformer neural networks for human activity recognition in videos. IEEE Access 2023, 11, 72227–72249. [Google Scholar] [CrossRef]
- Cao, M.; Yang, M.; Zhang, G.; Li, X.; Wu, Y.; Wu, G.; Wang, L. SpotFormer: A transformer-based framework for precise soccer action spotting. In Proceedings of the 2022 IEEE 24th International Workshop on Multimedia Signal Processing (MMSP), Shanghai, China, 26–28 September 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Gan, Y.; Togo, R.; Ogawa, T.; Haseyama, M. Transformer based multimodal scene recognition in soccer videos. In Proceedings of the 2022 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Taipei City, Taiwan, 18–22 July 2022; IEEE: New York, NY, USA, 2022; pp. 1–6. [Google Scholar]
- Zhang, J.; Jia, Y.; Xie, W.; Tu, Z. Zoom transformer for skeleton-based group activity recognition. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 8646–8659. [Google Scholar] [CrossRef]
- Xu, Y. Skeleton-Based Football Referee Action Recognition. Master Thesis, KTH, School of Electrical Engineering and Computer Science (EECS), Stockholm, Sweden, 2024. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).