Abstract
Maritime mobile edge computing (MMEC) technology enables the deployment of high-precision, computationally intensive object detection tasks on resource-constrained edge devices. However, dynamic network conditions and limited communication resources significantly degrade the performance of static offloading strategies, leading to increased task blocking probability and delays. This paper proposes a scheduling and offloading strategy tailored for MMEC scenarios driven by object detection tasks, which explicitly considers (1) the hierarchical structure of object detection models, and (2) the sporadic nature of maritime observation tasks. To minimize average task completion time under varying task arrival patterns, we formulate the average blocking delay minimization problem as a Markov Decision Process (MDP). Then, we propose an Orthogonalization-Normalization Proximal Policy Optimization (ON-PPO) algorithm, in which task category states are orthogonally encoded and system states are normalized. Experiments demonstrate that ON-PPO effectively learns policy parameters, mitigates interference between tasks of different categories during training, and adapts efficiently to sporadic task arrivals. Simulation results show that, compared to baseline algorithms, ON-PPO maintains stable task queues and achieves a reduction in average task latency.
Keywords:
Maritime Internet of Things; maritime mobile edge computing; reinforcement learning; PPO; object detection task MSC:
68M10
1. Introduction
Developments in deep learning facilitate its integration with Maritime Internet of Things (MIoT) across various marine industries. Specifically, object detection technologies with Convolutional Neural Network (CNN) play a critical role in MIoT applications such as maritime search and rescue, ship detection, and aquaculture [1,2,3,4]. However, current object detection models with high accuracy and robustness are plagued by overly parameterized architectures and demand significant computational overhead [5,6]. These constraints preclude the effective deployment of large-scale, high-precision object detection models in maritime environments due to limited network resources, such as communication bandwidth and computational capacity. Against this backdrop, it is imperative to investigate the maritime object data sensing, transmission, and processing, and to develop efficient maritime communication and computing systems.
Model compression, structured pruning, and lightweight architecture design are established approaches for alleviating the computational and communication burdens inherent in object detection networks [7,8,9,10]. Nevertheless, aggressive compression or pruning frequently precipitates non-negligible degradation in detection accuracy, thereby compelling practitioners to navigate a stringent accuracy–efficiency trade-off. Fortunately, mobile edge computing (MEC) technology has proven to be effective in providing computing resources for resource-constrained locals and improving resource utilization [11]. Therefore, the emergence of maritime mobile edge computing (MMEC) offers a new solution to the aforementioned challenges [12]. Edge computing architectures, such as aerial mobile edge computing systems supported by High Altitude Platforms and Unmanned Aerial Vehicles (UAVs), aim to minimize local device energy consumption [13]. Similarly, in maritime contexts, low earth orbit satellites can serve as edge servers for multi-access computing to assist vessels [14], while Unmanned Surface Vehicles (USVs) aid in the mobile edge deployment and resource management of maritime wireless networks, thereby satisfying computational requirements [15]. The current studies mentioned above have primarily focused on resource allocation and the selection of offloading targets. However, due to the complex structure of object detection models and the sporadic nature of maritime tasks, existing offloading strategies fail to effectively implement hierarchical offloading for object detection models and do not take into account the arrival characteristics of sporadic tasks. To address these challenges, this paper develops a maritime monitoring scenario implemented on resource-constrained edge devices, specifically targeting the offloading issues of sporadic object detection tasks.
By analyzing the sporadic object detection model, we can derive the following characteristics. Firstly, current mainstream object detection networks possess both sequentiality and divisibility. Sequentiality means that each layer requires the computational results of the previous layer. In contrast, divisibility implies that the computations of subsequent layers are independent of the processing of previous layers [16]. By selecting model layers, we can decide on the computing loads for local and cloud-end processing, as well as the size of the transmitted data. This approach allows us to fully leverage the computing resources of each node. Second, the sporadic nature of tasks means that they arrive infrequently. When tasks arrive sparsely, the usage of local resources can be increased to alleviate the pressure on cloud resources [17]. Conversely, when tasks arrive densely, the system must formulate more precise strategies based on task and network characteristics to mitigate the risk of system task blocking.
Faced with the dynamic maritime environment’s challenges for decision making, reinforcement learning iteratively interacts with the environment. It considers long-term task optimization and dynamically adjusts decisions [18]. For instance, Qu et al. utilized a Deep Q-Network (DQN) algorithm. By analyzing the deep neural network (DNN) model structure, they minimized network resources and local energy consumption [19]. Kim et al. developed a DRL-based offloading algorithm to minimize end-to-end inference delay by computing DNN layers [20]. According to the structure of object detection models and the sporadic nature of tasks, we build a time-series task blocking model and present an improved Proximal Policy Optimization (PPO) algorithm to minimize the total blocking delay of the task queue.
Specifically, this paper focuses on the sporadic nature of maritime observation tasks and the resource constraints of edge devices in MIoT, constructing an MMEC offloading scenario driven by object detection tasks. For this scenario, we propose a scheduling and offloading strategy based on the structure of object detection models and the sporadic nature of tasks. By vertically partitioning the object detection model, we reduce the number of transmissions between layers, which is suitable for the limited maritime communication resources. The strategy reasonably allocates the load between local devices, cloud platforms, and task transmissions by combining the intermittent characteristics of tasks with the structure of object detection models. By constructing a time-series task blocking model, the optimization objective is defined as minimizing the total blocking delay of the task queue. We further transform the above problem into a Markov Decision Process (MDP) and propose the Orthogonalization-Normalization Proximal Policy Optimization (ON-PPO) algorithm, in which task category states are orthogonally encoded and system states are normalized. Specifically, due to the use of different numerical representations for task category states, there are issues of weight conflicts and parameter oscillations, which affect the convergence speed and algorithm performance. By employing one-hot encoding for task category states, we reduce the interference between different task categories. Normalization of states effectively reduces the dimensional differences in state inputs, allowing for efficient extraction of feature information from each input state and enabling an effective offloading strategy.
The main contributions of this paper are as follows:
- (1)
- In order to address the limited communication capabilities and inadequate processing power of MIoT edge devices, we integrated the structures of object detection models with the sporadic nature of maritime observation tasks. This integration helped construct a marine-edge-computing scenario driven by object-detection tasks.
- (2)
- To address the sporadic nature of maritime observation tasks, this paper proposes a vertical partitioning-based offloading and dynamic scheduling strategy for task models, which is grounded in the structure of object detection and the sporadic characteristics of tasks. By constructing a time-series task blocking model, the optimization objective is formulated to minimize the total blocking delay of the task queue.
- (3)
- We formulate the problem of minimizing the total blocking delay of the task queue as an MDP and propose the ON-PPO algorithm. The application of orthogonal encoding for task category states and state normalization has mitigated the update conflicts that PPO encounters when dealing with different task categories and enhanced its ability to extract features from different dimensions. Experimental results demonstrate that the proposed algorithm can maintain the lowest blocking time and total delay under varying task intervals.
This paper is organized as follows. Section 2 reviews the related work. The system model is described in Section 3. Section 4 presents the Markov decision process formulation and the design of the ON-PPO algorithm. Simulation results are provided in Section 5, and conclusions are drawn in Section 6.
2. Materials and Methods
Object detection models are highly resource-demanding, making direct deployment on most marine IoT devices difficult. To solve this, some existing studies compress models to cut computational complexity and enhance adaptability for resource-constrained devices [21,22]. Common approaches include model pruning, compression, and designing specialized lightweight network architectures [23,24,25]. On the other hand, some studies have sought to fully utilize the system resources of edge computing through task offloading strategies.
Some research partitions the structure of object detection models and deploys them on different resource nodes for collaborative computing. Liu et al. proposed an adaptive DNN inference acceleration framework. It partitions and deploys tasks on end, edge, and cloud nodes for collaborative computing, accelerating model inference [26]. G et al. studied adaptive offloading based on early-exit models. They inserted branches at the outputs of intermediate layers to offer flexible offloading schemes [27]. Liu et al., leveraging the convolutional process of CNNs, proposed a distributed partitioning and offloading solution. Based on a stacked partitioning strategy, it aids clients in making partitioning decisions [28]. Due to the impact of dynamic weather on maritime channels, we adopt a vertical partitioning approach to reduce inter-layer number of data transfers and ensure stable task transmission.
To address the sporadic nature of maritime tasks, task-offloading strategies need to be combined with task characteristics. Duan et al. analyzed model scheduling for homogeneous and heterogeneous chains to reduce inference latency, offering an optimal partitioning strategy [29]. Fan et al. employed model partitioning and resource allocation to collaboratively optimize and minimize processing delays for all deep-learning tasks in the system [30]. Huang et al. proposed a policy-gradient-based deep-neural–model partitioning and scheduling scheme (PG-MPSS) to reduce model runtime waiting time and decrease per-iteration training time [31]. However, the above offloading strategies focus on optimal partitioning in static environments or short-term optimal offloading. The dynamic nature of the maritime environment can affect the effectiveness of these static strategies.
Faced with the challenges of dynamic maritime environments for decision making, reinforcement learning stands out as an effective solution. By interacting with the environment iteratively, it considers long-term task optimization and produces dynamic decisions. Feng et al. employed a Deep Reinforcement Learning (DRL) algorithm to determine the optimal task-model scheduling order and task-execution locations, focusing on long-term optimal strategies [16]. Xu et al. proposed the SA-MADDPG algorithm. For heterogeneous target models, it selects appropriate partitioning strategies to adapt to dynamic maritime environments [32]. Xu et al. proposed the COSREL online collaborative scheduling framework based on DRL to leverage heterogeneous computing resources and enable concurrent DNN model inference on edge devices [33].
Based on the above research, we propose a scheduling and offloading strategy that combines the structure of object detection models with the temporal characteristics of sporadic tasks. The introduction of the ON-PPO algorithm optimizes task blocking in time-series scenarios. It is based on task normalization and orthogonal forms of task-category states, helping obtain long-term optimal strategies for task models.
3. System Model
3.1. System Architecture
We consider a near-shore image sensing MIoT scenario, as shown in Figure 1. It has an image capture device connected to an edge device. The image capture device collects and preliminarily processes image data and implements offloading decisions. The edge device is connected via a wireless link to a cloud device connected to an onshore base station. Specifically, the edge device is within the wireless coverage range of the base station.
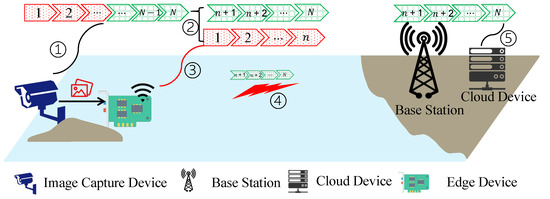
Figure 1.
Ocean remote sensing and computation offloading model: ➀ Image-target-recognition computational task model. ➁ Computational-task split into local and cloud parts. ➂ Local execution of the task. ➃ Data transmission of the computational task. ➄ Cloud execution of the computational task.
In the process of the edge device using the object detection model to process images captured by the image capture device, we conduct an in-depth analysis of the model given its sequentiality and divisibility. Based on the requirements of maritime object detection applications, we denote the set of model categories deployed on the edge device as = . We assume that each model category l can be divided into layers. The set of layers for l is defined as , where each set of layers has the same number of elements in different model categories l. We assume that layer n serves as the offloading point. Layers 1 to n are computed on the edge device, while layers to are offloaded to the cloud device via a wireless link for computation. Specifically, when , the model is fully computed on the edge device and when , the model is fully offloaded to the cloud device for computation. We define the model-layer sets on the edge and cloud devices as and , respectively, where , . The specific structures of the model layer are shown in Figure 2.
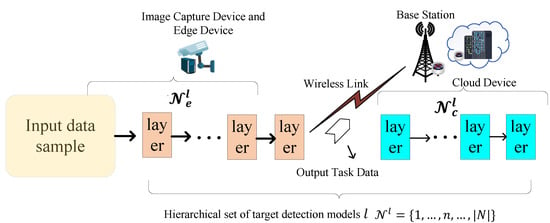
Figure 2.
Schematic diagram of target detection model partitioning and offloading.
In the scenario above, different offloading decisions alter the data processed by the edge device, transmitted, and processed by the cloud device. These changes affect the edge processing delay, transmission delay, and cloud device processing delay.
3.2. Computing Model
Considering the sporadic nature of the detection tasks, we denote the task set throughout the device’s operation as , where each task belongs to a category drawn from the task set L. During the computation of , layers of different tasks are mutually independent; a layer must wait only for the preceding layer that belongs to the same task. Let denote the Floating Point Operations (FLOPs) requirement in a layer n of model l and denote as the Floating Point Operation Per Second (FLOPS) of edge device for task k. Thus, the computational latency of the edge device with task k given by [32]
where represents the set of model layers with task k in model l on edge device, and represents the sum of the FLOPs of all model layers on the edge device.
Meanwhile, the computational latency of cloud device task k is given by [32]
where is the set of model layers in model l with task k on the cloud device, and is the sum of the FLOPs of all model layers on the edge device. Obviously, for task , we have , and denotes FLOPS of cloud device allocated for task k.
3.3. Communication Model
This paper only considers the uplink transmission process from the edge device to the base station. Given the negligible data size of detection results compared to sample data, this paper disregards wired transmission and downlink latency. This paper only considers the uplink transmission process from the edge device to the base station.
Let denote the size (in bits) of the output data of layer n in model l. The transmission rate from the edge device to the base station can be expressed as follows [34]:
where B is the transmission bandwidth, is the transmission power of edge device, is the noise power and is the large-scale attenuation coefficient of maritime communication.
The transmission time for the edge device to send the intermediate data of task k to the Base Station, denoted as , is given by
3.4. Task Queue Model
Due to the sequential nature of the image detection model, we divided the task into three phases: edge computing, data transmission, and cloud device processing. Each phase of the device can only process one task at a time. If a new task arrives while a phase is still processing the previous task, blocking occurs, as shown in Figure 3.
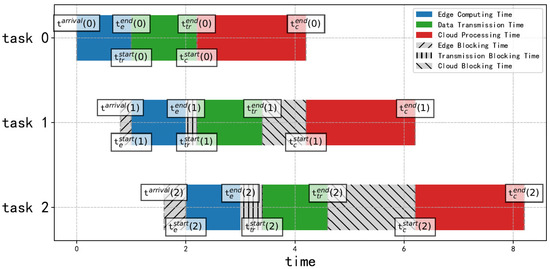
Figure 3.
Task queue status.
Consider that each of the three phases has a corresponding blocking time, namely, edge computing blocking time , transmission blocking time , and cloud computing blocking time . We denote the arrival time of task k of the edge device as . The start time for executing task k on the edge device is represented by . The end time of task k of on the edge device, , along with the blocking time , can be expressed as
Similarly, for the transmission phase of task k, the start time , blocking time , and end time can be expressed as
For the cloud device processing phase of task k, the start time , the blocking time , and the end time can be represented as follows:
By recording the time-related information of each device and its operational status, we can further analyze how different tasks, segmentation methods, and environmental conditions impact the system’s total latency in the dynamic MIoT scenario of nearshore image sensing.
3.5. Problem Definition
In this work, we aim to identify the optimal partitioning points in object detection models and offload specific model layers to suitable cloud devices to optimize system latency. As system blocking prolongs user waiting times and degrades task service quality, we use the system’s total blocking time as the total cost. The total cost for task k, , is expressed as
where , and are the weights for edge computing blocking, transmission blocking, and cloud computing blocking, respectively, with . Adjusting these weight values can further adapt to the varying demands of tasks in different environments.
Given that different task partitioning alters the computational load between edge and cloud computing, and each layer produces varying outputs, we can adjust task partitioning points to influence system blocking. Hence, our objective is to minimize the total blocking time of the task set in the system, given by:
where means the local FLOPs allocated by the edge device to task k cannot exceed the edge device’s maximum FLOPs , means the FLOPs allocated by the cloud device to task k cannot exceed the cloud device’s maximum FLOPs , means all object detection task types belong to the task type set , means the set of layers processed on edge and cloud devices are allocated from , means no overlap exists between the layer sets of edge and cloud devices and means the sum of weights for various blocking types equals 1.
4. Algorithm Design
In the dynamic MIoT scenario, the environment’s unpredictability, sporadic tasks, and high-dimensional state space make it tough for conventional static convex optimization and heuristic algorithms to find proper solutions for the above optimization problem. Given that the initial state of each task in this paper is solely related to the decision making of its previous task, we further transform the problem into a Markov decision process, as shown in Section 4.1. Furthermore, considering the significant differences in state dimensions within the system and the lack of dependencies among different task types, we propose the ON-PPO reinforcement learning algorithm framework to address the problem we have presented.
4.1. Markov Decision Process Construction
The system’s total cost is jointly determined by the current task state and action, which trigger the environment and lead to a new random state. In this context, we model the adaptive offloading problem as an MDP. In this MDP, we adaptively determine the offloading decisions for edge devices based on the dynamic system environment state, with the aim of minimizing the long-term system blocking delay. The MDP is represented by the tuple , where S is the state space, A is the action space, P is the state transition probability matrix, R is the reward function, and is the discount factor. The MDP state, action, and reward in this paper are as follows:
- (1)
- State: As edge devices continuously receive new tasks, the system’s blocking delay dynamically changes with task progression through decision making. Aiming to reduce task blocking time, the factors with task k are the task data transmission rate , the edge device’s computing resource , the cloud device’s computing resource , the computational demand and data output volume , and . Therefore, the state is represented aswhere and are the set computational demand and data output volume of all layers from model category l, respectively.
- (2)
- Action: The device influences the environment through actions. In this paper, based on the environmental state of task k, we determine the layer sets on the edge device and on the cloud device. Therefore, the action for processing task k can be represented as
- (3)
- Reward: In the MDP framework, the reward represents the system gain achieved at state k. Upon the arrival of each new task k, we can calculate the blocking time for task k by analyzing the state information of tasks 1 to . To minimize this blocking time, the reward for state is defined as the negative value of the blocking time. Thus, the reward can be expressed as
4.2. Deep Reinforcement Learning Solutions
4.2.1. Structure ON-PPO
As shown in Figure 4, the ON-PPO algorithm workflow involves the actor and critic networks interacting with the environment to determine the optimal computation offloading strategy. We adopt online training instead of a memory pool to save memory. When implementing the PPO algorithm, we maintain two policy networks: the current policy to be improved and the old policy used for sample collection but not yet updated. Then, based on the collected samples, we calculate the estimated advantage function . Finally, we update the network parameters by maximizing the objective function to optimize the strategy .
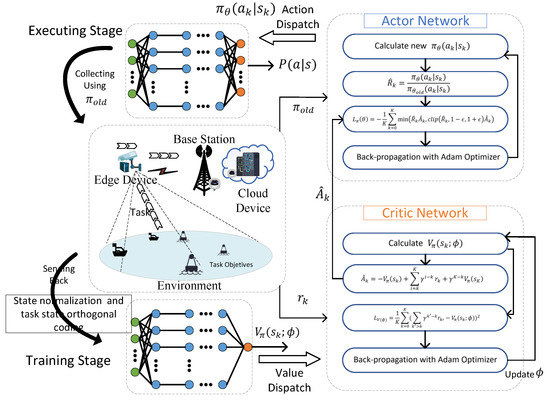
Figure 4.
Workflow of the ON-PPO-based offloading algorithm.
In each episode, the actor network and critic network are updated with iteration. Regarding the actor network, its objective function is
The clipping function is used for importance sampling calculations and can be expressed as
The sample ration measures the different between the two policies and can be calculated as
We calculate the advantage function using the state value function , which only takes the state s as input. This approach avoids over-parameterization issues that could arise from differences in action dimensions. The advantage function can be expressed as
In the formula, K represents the number of time periods for which the strategy is executed, and it should not exceed the length of an episode.
In each iteration, the actor network calculates the loss , and uses Adam optimizer concerning . The loss can be obtained as
Similarly, the critic network also updates its parameters with the Adam optimizer. To enhance the accuracy of evaluating the Actor network, its loss function is calculated based on the long-term rewards provided by the environment.
During the episode iteration, the parameters of the actor and critic networks are updated via loss functions. This enables the ON-PPO-based offloading algorithm to achieve faster convergence and more accurate decision making; see Algorithm 1 for details.
| Algorithm 1 The ON-PPO algorithm. |
|
4.2.2. Task Category Orthogonality and State Normalization
In the MIoT environment, the task state dimensions input to the ON-PPO algorithm vary. If the dimensional differences are too large, features with larger dimensions may dominate the update direction, ignoring state features with smaller numerical values, and causing training instability. To accelerate the algorithm’s convergence and enhance the model’s generalization ability, we added a feature normalization step before training.
First, we scale the state according to Equation (22) of the k-th task and get the scaled state with
where is the min-max scaling factor and , are the maximum and minimum values of the state features, respectively.
When edge devices handle diverse tasks, representing distinct task categories with different numerical values can cause interference during network weight updates. Orthogonal encoding addresses this by introducing orthogonality between category representations, effectively decoupling them and reducing interference during training. This orthogonality, while achieved through linear transformations, enables the network to more readily separate the internal states associated with different tasks, ultimately enhancing its policy representation capability.
In this paper, given the relatively small number of maritime task categories, the increase in input dimensionality resulting from using one-hot encoding is negligible. Therefore, we employ this encoding method to orthogonalize the task category states. For instance, the task category is represented as the vector . This approach helps to alleviate interference between different task categories.
4.2.3. Complexity Analysis
During the training phase, operations such as state normalization, orthogonal encoding of task category states, and hyperparameter configuration have constant complexity. The training phase is executed through a double loop. The outer loop iterates over the set , and the inner loop performs iterations for each element in . The complexity of these iterations primarily depends on the network’s architecture and the size of the data being processed. Assuming represents the number of parameters in the original network and denotes the number of network layers, the computational complexity for a single iteration can be approximated as . Updating the network weights is a constant-time operation, denoted as . Therefore, the total computational complexity for training can be expressed as .
5. Simulation Results
5.1. Simulation Setup
In our setup, an image capture device sporadically collects maritime images and performs tasks independently within the base station’s communication range. In our example, four object detection models: YOLOv5s, YOLOv5s-Mobilenetv3, YOLOv5s-shufflenetv2, and YOLOv5s-EfficientNet, are deployed on both edge and cloud devices [35,36,37,38]. We perform a hierarchical classification of the models based on their FLOPs and data output volumes, with six hierarchical classifications for each model. Tasks are assumed to emerge with certain random probabilities, namely , and . The offloading strategy guides the edge device to execute and offload tasks dynamically based on the current state. The computational capacity of the edge device ranges from 10 to 15 FLOPs, while the cloud device allocates 20 to 30 FLOPs of computing resources to the edge device. We assume that large-scale attenuation coefficient follows a normal distribution. These resources dynamically change to reflect real-world conditions. The remaining simulation parameters for the communication, computation, and load of the system model are listed in Table 1.

Table 1.
System parameters in simulation.
5.2. Convergence Analysis
PPO adopts an Actor–Critic architecture. In the ON-PPO network designed in this paper, the actor and critic networks share the feature extraction layer. The input layer size of the actor and critic corresponds to the size of state , and the LeakyReLU activation function is used in the feature extraction layer. Both of their hidden layers have a size of 64. We have already developed the ON-PPO-based computation offloading method using Python 3.8 and Pytorch 1.31.1. The other network parameters are determined through ablation experiments, and the remaining parameters are shown in Table 2.
Table 2.
Simulation parameters in the ON-PPO algorithm.
Figure 5 shows how different learning rates affect algorithm convergence and performance. A smaller learning rate can trap the algorithm in local minima, worsening the policy. So, with a learning rate of 0.0001, rewards are lower than with 0.001. Conversely, a higher learning rate can cause excessively large policy updates. As shown in Figure 5, when the learning rate is 0.01 and 0.1, the reward fluctuates sharply at episode 820, hindering short-term algorithm convergence. This is unlike other learning rates. The results indicate that a 0.001 learning rate balances convergence speed and the average performance of the system well. Thus, it is set as the default initial learning rate for later experiments.
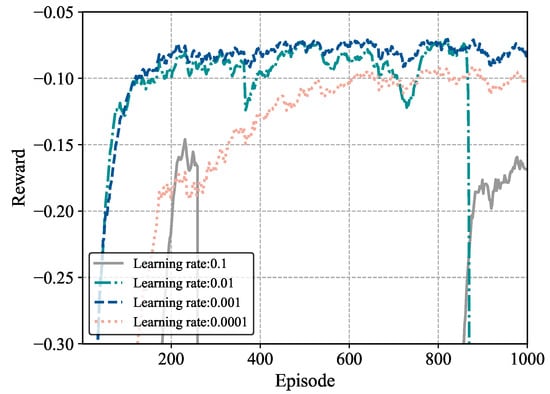
Figure 5.
Training process with different learning rate settings.
Figure 6 illustrates the impact of different gamma values on algorithm convergence and performance. When gamma is 0.5, the training outcome is the worst as the agent focuses excessively on immediate rewards. In contrast, when gamma is 0.99 or 0.999, the agent’s overemphasis on long-term rewards results in poor algorithm performance and a failure to converge. Results show that a gamma of 0.9 balances convergence speed and average performance well, so it is used as the default gamma for later experiments.
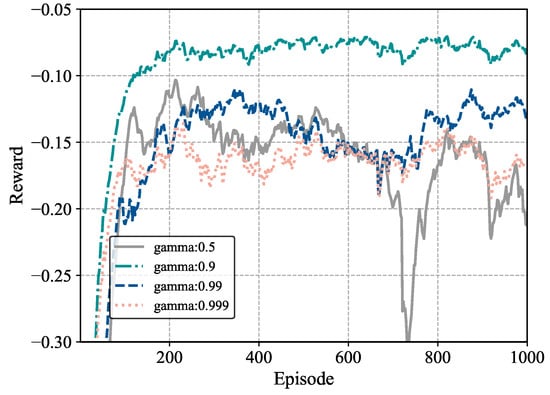
Figure 6.
Training process with different gamma parameters.
Figure 7 presents a comparison of convergence speed and performance among the ON-PPO algorithm, the algorithm (without orthogonal encoding), and the algorithm (without state normalization). From the analysis, it can be observed that the algorithm exhibits policy degradation and fails to converge to an optimal outcome in later stages. This demonstrates that orthogonal task state encoding enhances long-term policy optimization by improving feature representation. The algorithm without state normalization shows slow initial convergence and significant oscillations during training compared to other algorithms. This highlights the significant impact of input normalization on training efficiency. As shown in Figure 7, there is a synergistic effect between the algorithm’s optimization components, which together create a high-performing policy learning advantage.
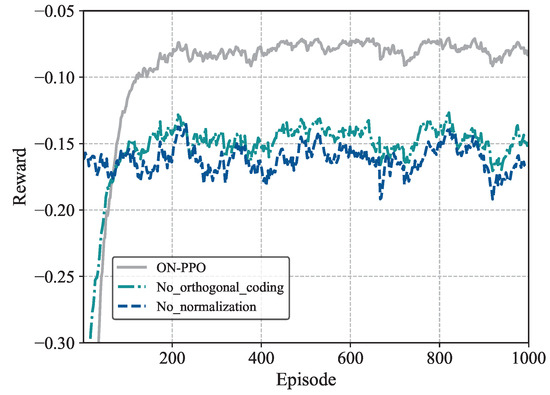
Figure 7.
Comparison of reward with ON-PPO, and .
5.3. Performance Evaluation
In this section, we verify the superior performance of the ON-PPO algorithm in handling sudden tasks. By comparing the blocking time and runtime of the random, DQN, DDPG, and ON-PPO algorithms, we further highlight the advantages of the ON-PPO algorithm in dynamic maritime scenarios involving sporadic target detection.
Figure 8 illustrates the reward comparison of different algorithms under low task burst conditions. Compared to the random algorithm, the other three algorithms in this study show varying degrees of improvement, highlighting the positive impact of reinforcement learning on system strategies. The analysis of the training curves indicates that the ON-PPO algorithm converges to a high reward value close to −0.1 within 1000 training epochs with minimal fluctuation. This is because, in the dynamic marine low-task burst environment, the ON-PPO algorithm mitigates numerical interference between different task categories through its state orthogonalization mechanism and reduces state dimensionality differences via state normalization, thereby minimizing training instability. In contrast, DDPG experiences policy oscillation due to delayed target network updates and is at risk of quantization errors during action discretization, resulting in lower rewards than ON-PPO in the later stages. The overestimation of Q-values in DQN is exacerbated in high-dimensional dynamic states, leading to suboptimal performance.
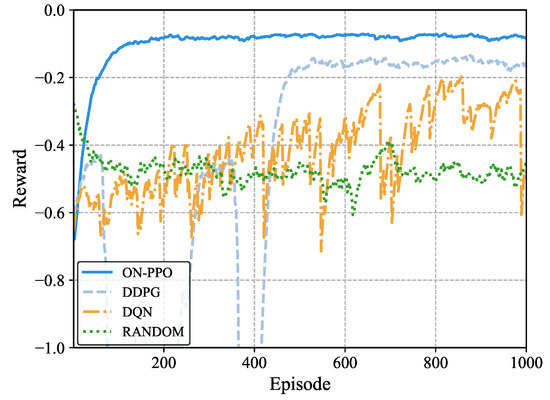
Figure 8.
Reward comparison with different algorithms in low task burst environment.
Figure 9 illustrates the training performance of various algorithms under high-intensity task burst scenarios. All algorithms show improvement compared to the random algorithm. However, such high-intensity task burst scenarios pose higher demands on algorithm decision making. Compared to the ON-PPO algorithm, the high-intensity task burst environment poses a greater challenge to the value estimation of the DDPG algorithm, and there is a risk of quantization errors during action discretization in high task burst states. The Q-network of the DQN algorithm lacks sufficient generalization ability, and its greedy operation strategy is prone to causing the system to obtain excessively low rewards. In the task burst environment, ON-PPO maintains stability through the clipping function, avoiding the policy imbalance caused by delayed network updates in DDPG, thereby improving data efficiency and performance.
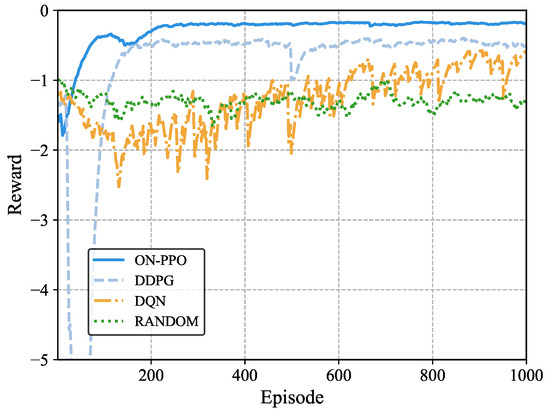
Figure 9.
Reward comparison with different algorithms in high task burst environment.
Figure 10 presents the blocking delay of each algorithm in a low task-burst scenario. is the blocking delay from computation on the edge device. is the transmission blocking delay during task offloading. results from computation on the cloud device. From the results, the ON-PPO algorithm shows excellent performance, with all blocking-related time around 0.04. Compared to the random algorithm, DDPG and DQN show some improvement. However, edge device-based edge-blocking significantly impacts performance. Even DDPG has a blocking delay as high as 0.12, while ON-PPO reduces it to 0.04. This clearly shows that ON-PPO has a significant advantage in reducing various blocking times, with the most prominent optimization in edge-blocking scenarios.
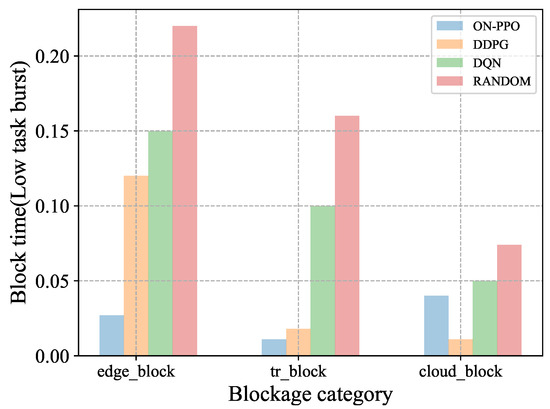
Figure 10.
Comparison of blocking times for various algorithms in low-task burst environments.
As shown in Figure 11, under high task burst scenarios, blocking delays of all algorithms are prolonged compared to Figure 10. However, the ON-PPO algorithm still leads in optimizing blocking delay. Similar to Figure 10, except for ON-PPO, other algorithms have the longest blocking time in edge-blocking delay, while ON-PPO keeps it at around 0.015. The random strategy, lacking dynamic adjustment ability, performs the worst. This further confirms the adaptability of reinforcement learning algorithms in complex and dynamic networks.
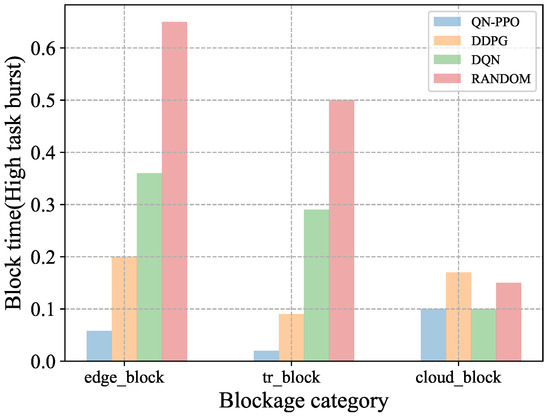
Figure 11.
Comparison of blocking times for various algorithms in high-task burst environments.
Figure 12 compares the average total time of different algorithms under varying task burst intensities. The ON-PPO algorithm maintains the lowest total processing time across all scenarios, with times of 0.8, 0.9, and 0.97 in low, medium, and high burst scenes, respectively. Its robustness in dynamic task scheduling is evident. Due to the random strategy’s lack of dynamic environmental adaptation, it performs the worst. The data also confirm that task burst intensity is a key factor influencing system latency, and ON-PPO effectively enhances the system’s ability to resist sudden loads.
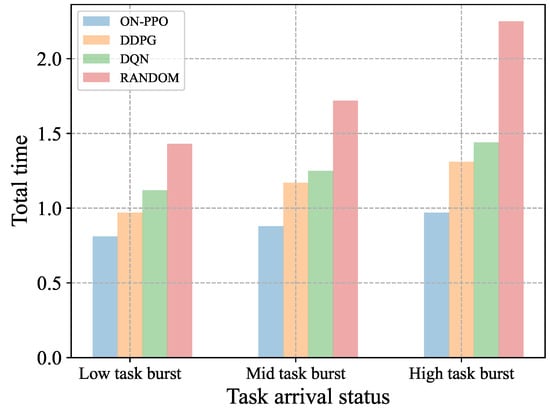
Figure 12.
Comparison of total time for each algorithm under different task burst conditions.
Figure 13 illustrates the operation of the ON-PPO algorithm compared to the random algorithm for the first five tasks. The task timeline of the ON-PPO algorithm is highly ordered, stepwise, continuous, and characterized by minimal blocking, completing within 3 s. In contrast, the random strategy results in varying degrees of task congestion at different processing stages, taking over 4.0 s. This indicates that ON-PPO enhances inter-layer parallelism through intelligent scheduling, effectively avoiding blocking delays. The random algorithm, lacking dynamic adjustment, leads to severe congestion. This is because the Markov state modeling of the ON-PPO algorithm considers historical information and predicts the next state based on the transition probabilities between states. This confirms the key value of reinforcement learning in reducing blocking in dynamic task scheduling.
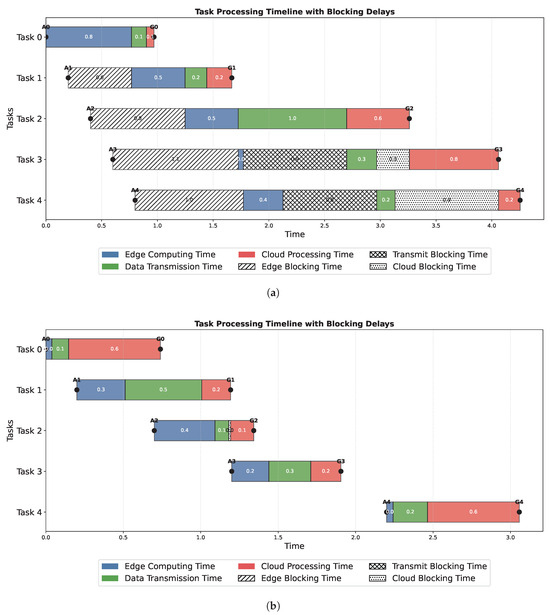
Figure 13.
Task in the operating conditions of different algorithms, (a) random, (b) ON-PPO.
6. Conclusions
Targeting image detection tasks in maritime IoT scenarios, we combine the structure of object detection models and the sporadic nature of maritime observation tasks to design a maritime edge-computing scenario driven by object detection tasks. We propose a scheduling and offloading strategy based on the structure of object-detection models and task sporadicity, considering the limited resources of maritime equipment and communication. Under the strategy of an ON-PPO algorithm based on task normalization and orthogonal task state form, this strategy provides edge devices with scheduling for object detection tasks. Simulation results verify that this strategy minimizes the system’s total operation time while maintaining consistently low task queue blocking delay in the long term. Compared to other methods, it reduces average task delay by and average blocking time by , offering a solution for maritime task queuing on marine edge devices. In the future, we will enhance the model’s sensitivity to time-series tasks, better predict task trends, further lower task blocking delay, and improve task quality of service.
Author Contributions
Conceptualization, methodology, resources, writing—original draft, writing—review, Y.S.; data curation, formal analysis, writing—original draft, software, W.L. (Wenqian Luo); methodology, writing–original draft, Z.X.; investigation, software, B.L.; funding acquisition, project administration, data curation, W.X.; visualization, writing—review, editing, W.L. (Weipeng Liu). All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Jimei University Startup Research Project (No. ZQ2024099, No. ZQ2022015); the Project of the Xiamen Science and Technology Bureau (No. 2024CXY0316); the Fujian Provincial Natural Science Foundation of China (No. 2024J01120); the National Science Foundation of Xiamen, China (No. 3502Z202372013); the Open Project of the Key Laboratory of Underwater Acoustic Communication and Marine In-formation Technology (Xiamen University) of the Ministry of Education, China (No. UAC202304); the Fujian Province Young and Middle-aged Teacher Education Research Project (No. JAT220182); the Jimei University Startup Research Project (No. ZQ2022015); the Scientific Research Foundation of Jimei University (No. ZP2023010).
Data Availability Statement
The data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MMEC | Maritime mobile edge computing |
| MDP | Markov Decision Process |
| ON-PPO | Orthogonalization-Normalization Proximal Policy Optimization |
| MIoT | Maritime Internet of Things |
| CNN | Convolutional Neural Network |
References
- Su, J.; Xu, D.; Qiu, L.; Xu, Z.; Lin, L.; Zheng, J. A High-Accuracy Underwater Object Detection Algorithm for Synthetic Aperture Sonar Images. Remote Sens. 2025, 17, 2112. [Google Scholar] [CrossRef]
- Yang, Z.; Yu, Q.; Yang, Z.; Wan, C. A data-driven Bayesian model for evaluating the duration of detention of ships in PSC inspections. Transp. Res. Part E Logist. Transp. Rev. 2024, 181, 103371. [Google Scholar] [CrossRef]
- Hemal, M.M.; Rahman, A.; Nurjahan.; Islam, F.; Ahmed, S.; Kaiser, M.S.; Ahmed, M.R. An Integrated Smart Pond Water Quality Monitoring and Fish Farming Recommendation Aquabot System. Sensors 2024, 24, 3682. [Google Scholar] [CrossRef] [PubMed]
- Xu, Z.; Xu, D.; Lin, L.; Song, L.; Song, D.; Sun, Y.; Chen, Q. Integrated Object Detection and Communication for Synthetic Aperture Radar Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 294–307. [Google Scholar] [CrossRef]
- Yuan, Y.; Gao, S.; Zhang, Z.; Wang, W.; Xu, Z.; Liu, Z. Edge-Cloud Collaborative UAV Object Detection: Edge-Embedded Lightweight Algorithm Design and Task Offloading Using Fuzzy Neural Network. IEEE Trans. Cloud Comput. 2024, 12, 306–318. [Google Scholar] [CrossRef]
- Li, H.; Wu, S.; Jiao, J.; Lin, X.H.; Zhang, N.; Zhang, Q. Energy-Efficient Task Offloading of Edge-Aided Maritime UAV Systems. IEEE Trans. Veh. Technol. 2023, 72, 1116–1126. [Google Scholar] [CrossRef]
- Huyan, L.; Li, Y.; Jiang, D.; Zhang, Y.; Zhou, Q.; Li, B.; Wei, J.; Liu, J.; Zhang, Y.; Wang, P.; et al. Remote Sensing Imagery Object Detection Model Compression via Tucker Decomposition. Mathematics 2023, 11, 856. [Google Scholar] [CrossRef]
- Guo, S.; Chen, Y.; Xu, L.; Deng, J.; Chen, H.; Heidari, A.A. Multiscale attention feature deep fusion network for iris region localization and segmentation from dual-spectral iris image. Appl. Soft Comput. 2025, 179, 113334. [Google Scholar] [CrossRef]
- Qian, Y.; Rao, L.; Ma, C.; Wei, K.; Ding, M.; Shi, L. Toward Efficient and Secure Object Detection With Sparse Federated Training Over Internet of Vehicles. IEEE Trans. Intell. Transp. Syst. 2024, 25, 14507–14520. [Google Scholar] [CrossRef]
- Li, C.; Lyu, H.; Duan, K. A lightweight and efficient detector for concealed object in active millimeter wave images. Knowl.-Based Syst. 2025, 310, 112995. [Google Scholar] [CrossRef]
- Zhou, T.; Liu, K.; Li, X.; Jiang, N.; Li, C. Joint Data Compression, Secure Multi-Part Collaborative Task Offloading and Resource Assignment in Ultra-Dense Networks. IEEE Trans. Netw. Sci. Eng. 2025, 1–18. [Google Scholar] [CrossRef]
- Li, M.; Qian, L.P.; Dong, X.; Lin, B.; Wu, Y.; Yang, X. Secure Computation Offloading for Marine IoT: An Energy-Efficient Design via Cooperative Jamming. IEEE Trans. Veh. Technol. 2023, 72, 6518–6531. [Google Scholar] [CrossRef]
- Chen, X.; Liu, G. Energy-Efficient Task Offloading and Resource Allocation via Deep Reinforcement Learning for Augmented Reality in Mobile Edge Networks. IEEE Internet Things J. 2021, 8, 10843–10856. [Google Scholar] [CrossRef]
- Wang, Z.; Lin, B.; Ye, Q.; Peng, H. Two-Tier Task Offloading for Satellite-Assisted Marine Networks: A Hybrid Stackelberg–Bargaining Game Approach. IEEE Internet Things J. 2025, 12, 13047–13060. [Google Scholar] [CrossRef]
- Zhang, C.; Lin, B.; Chen, Z.; Cai, L.X.; Duan, J. Mobile Edge Deployment and Resource Management for Maritime Wireless Networks. IEEE Trans. Veh. Technol. 2025, 74, 7928–7939. [Google Scholar] [CrossRef]
- Feng, Y.; Hu, S.; Chen, L.; Li, G. An intelligent scheduling framework for DNN task acceleration in heterogeneous edge networks. Comput. Commun. 2023, 201, 91–101. [Google Scholar] [CrossRef]
- Mondal, M.K.; Banerjee, S.; Das, D.; Ghosh, U.; Al-Numay, M.S.; Biswas, U. Toward Energy-Efficient and Cost-Effective Task Offloading in Mobile Edge Computing for Intelligent Surveillance Systems. IEEE Trans. Consum. Electron. 2024, 70, 4087–4094. [Google Scholar] [CrossRef]
- Chu, Z.; Wang, F.; Lei, T.; Luo, C. Path Planning Based on Deep Reinforcement Learning for Autonomous Underwater Vehicles Under Ocean Current Disturbance. IEEE Trans. Intell. Veh. 2023, 8, 108–120. [Google Scholar] [CrossRef]
- Qu, K.; Zhuang, W.; Wu, W.; Li, M.; Shen, X.; Li, X.; Shi, W. Stochastic Cumulative DNN Inference with RL-Aided Adaptive IoT Device-Edge Collaboration. IEEE Internet Things J. 2023, 10, 18000–18015. [Google Scholar] [CrossRef]
- Kim, S.; Jung, S.; Lee, H.W. Distributed Computation of DNN via DRL With Spatiotemporal State Embedding. IEEE Internet Things J. 2024, 11, 12686–12701. [Google Scholar] [CrossRef]
- Xing, B.; Wang, W.; Qian, J.; Pan, C.; Le, Q. A Lightweight Model for Real-Time Monitoring of Ships. Electronics 2023, 12, 3804. [Google Scholar] [CrossRef]
- Yang, S.; Xue, L.; Hong, X.; Zeng, X. A Lightweight Network Model Based on an Attention Mechanism for Ship-Radiated Noise Classification. J. Mar. Sci. Eng. 2023, 11, 432. [Google Scholar] [CrossRef]
- Yang, Y.; Xiao, S.; Yang, J.; Cheng, C. A Tiny Model for Fast and Precise Ship Detection via Feature Channel Pruning. Sensors 2022, 22, 9331. [Google Scholar] [CrossRef]
- Chen, S.; Zhan, R.; Wang, W.; Zhang, J. Learning Slimming SAR Ship Object Detector Through Network Pruning and Knowledge Distillation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1267–1282. [Google Scholar] [CrossRef]
- Sun, S.; Xu, Z.; Cao, X.; Zheng, J.; Yang, J.; Jin, N. A High-Performance and Lightweight Maritime Target Detection Algorithm. Remote Sens. 2025, 17, 1012. [Google Scholar] [CrossRef]
- Liu, G.; Dai, F.; Xu, X.; Fu, X.; Dou, W.; Kumar, N.; Bilal, M. An adaptive DNN inference acceleration framework with end–edge–cloud collaborative computing. Future Gener. Comput. Syst. 2023, 140, 422–435. [Google Scholar] [CrossRef]
- Pacheco, R.G.; Couto, R.S.; Simeone, O. On the impact of deep neural network calibration on adaptive edge offloading for image classification. J. Netw. Comput. Appl. 2023, 217, 103679. [Google Scholar] [CrossRef]
- Liu, C.; Liu, K. Toward Reliable DNN-Based Task Partitioning and Offloading in Vehicular Edge Computing. IEEE Trans. Consum. Electron. 2024, 70, 3349–3360. [Google Scholar] [CrossRef]
- Duan, Y.; Wu, J. Optimizing Job Offloading Schedule for Collaborative DNN Inference. IEEE Trans. Mob. Comput. 2024, 23, 3436–3451. [Google Scholar] [CrossRef]
- Fan, W.; Gao, L.; Su, Y.; Wu, F.; Liu, Y. Joint DNN Partition and Resource Allocation for Task Offloading in Edge–Cloud-Assisted IoT Environments. IEEE Internet Things J. 2023, 10, 10146–10159. [Google Scholar] [CrossRef]
- Huang, B.; Huang, X.; Liu, X.; Ding, C.; Yin, Y.; Deng, S. Adaptive partitioning and efficient scheduling for distributed DNN training in heterogeneous IoT environment. Comput. Commun. 2024, 215, 169–179. [Google Scholar] [CrossRef]
- Xu, W.; Luo, W.; Sun, Y.; Gao, Z.; Wu, B.; Lai, L. MADRL-Based Edge Computing: Joint Energy-Latency Optimization for Marine Internet of Things. IEEE Internet Things J. 2025, 12, 30228–30241. [Google Scholar] [CrossRef]
- Xu, Z.; Yang, D.; Yin, C.; Tang, J.; Wang, Y.; Xue, G. A Co-Scheduling Framework for DNN Models on Mobile and Edge Devices With Heterogeneous Hardware. IEEE Trans. Mob. Comput. 2023, 22, 1275–1288. [Google Scholar] [CrossRef]
- Wang, Z.; Lin, B.; Ye, Q.; Fang, Y.; Han, X. Joint Computation Offloading and Resource Allocation for Maritime MEC With Energy Harvesting. IEEE Internet Things J. 2024, 11, 19898–19913. [Google Scholar] [CrossRef]
- Zhang, P.; Li, D. Automatic counting of lettuce using an improved YOLOv5s with multiple lightweight strategies. Expert Syst. Appl. 2023, 226, 120220. [Google Scholar] [CrossRef]
- Liu, K.; Wang, J.; Zhang, K.; Chen, M.; Zhao, H.; Liao, J. A Lightweight Recognition Method for Rice Growth Period Based on Improved YOLOv5s. Sensors 2023, 23, 6738. [Google Scholar] [CrossRef]
- Yang, Y.; Liu, Z.; Chen, J.; Gao, H.; Wang, T. Railway Foreign Object Intrusion Detection Using UAV Images and YOLO-UAT. IEEE Access 2025, 13, 18498–18509. [Google Scholar] [CrossRef]
- Qi, S.; Lin, B.; Deng, Y.; Chen, X.; Fang, Y. Minimizing Maximum Latency of Task Offloading for Multi-UAV-Assisted Maritime Search and Rescue. IEEE Trans. Veh. Technol. 2024, 73, 13625–13638. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).