1. Introduction
In modern medical and epidemiological studies, identifying nonlinear relationships between covariates and clinical outcomes is crucial for understanding disease mechanisms and improving risk prediction. A particularly interpretable and practically meaningful form of nonlinearity is the change point effect, where the association between a continuous covariate and the outcome shifts once the covariate crosses an unknown threshold [
1,
2,
3,
4,
5,
6,
7]. For instance, Shapiro et al. [
6] showed that primary biliary cirrhosis patients can be divided into early and late phases via a change point parameter, with the effect of bilirubin level exhibiting a change point effect (differing above and below the parameter). Zhao et al. [
7] found evidence of a change point in the relationship between leukocyte telomere length (LTL) and the incidence of diabetes. Such threshold-based models are not only supported by empirical findings but also provide important methodological advantages. These models facilitate clearer clinical interpretation, such as identifying critical biomarker thresholds for intervention or surveillance. Compared to spline or polynomial regression models—which may lack biological interpretability, involve complex tuning procedures, or risk overfitting—change point models offer a more parsimonious and clinically intuitive framework for capturing nonlinear risk patterns. In many cases threshold models find breakpoints automatically and provide clearer clinical interpretation, while spline methods require pre-specified knots and often lack direct interpretability [
8,
9].
From a methodological standpoint, numerous statistical models have been developed to accommodate change points in survival data. For example, Pons [
10] introduced a Cox model with time-dependent covariates and an unknown change point, proposing a two-stage estimation procedure. Building on this, Kosorok and Song [
11] studied semiparametric transformation models with a change point under right-censored data. Deng et al. [
12] proposed a change point proportional hazards model for clustered survival data with estimation via pseudo-partial likelihood. Molinari et al. [
13] and Jensen and Lütkebohmert [
14] also discussed the detection of multiple change points. These foundational works provided important insights into the asymptotic properties of change point models under right censoring. Despite this progress, most existing methods are limited to right-censored settings, where either exact event times are observed or the only information available is that an event occurs after a certain time.
Interval censoring is a common feature in medical and epidemiological studies, especially in longitudinal designs where the exact timing of an event (e.g., disease onset or clinical progression) is unknown but known to occur within a follow-up interval. Such censoring mechanisms are prevalent in large-scale cancer screening programs [
15], AIDS clinical trials [
16], and pediatric transplantation studies [
17]. Unlike right censoring, interval censoring introduces greater methodological complexity, as the corresponding likelihood contributions involve integrals over time intervals rather than point observations, rendering standard survival models potentially biased or inapplicable. These challenges have motivated the development of a broad range of statistical methods tailored to interval-censored data [
18,
19,
20,
21,
22,
23,
24,
25,
26,
27]. For instance, Zeng et al. [
18] developed semiparametric maximum likelihood estimators under transformation models, and Wang et al. [
20] proposed a latent Poisson-based EM algorithm for interval-censored proportional hazards models.More recently, research has extended interval-censoring methodology to engineering and experimental sciences. Mohamed et al. [
25] proposed inference methods under adaptive progressive hybrid censoring in Gompertz models, while Elbahnasawi et al. [
26] introduced Bayesian and frequentist estimation procedures for the extended inverse Gompertz distribution under Type-II censoring. Despite these advances, most existing methods assume smooth covariate effects and do not account for possible threshold structures in risk modeling.
While change point models have been extensively studied under exact or right-censored survival data, their development under interval censoring remains largely unexplored. This gap is particularly salient given that threshold phenomena—where covariate effects change abruptly at unknown values—are of substantial interest in clinical and biological research, and that interval-censored outcomes are common in such studies. Our work aims to fill this gap by proposing a semiparametric transformation model with an unknown covariate threshold under interval censoring. The framework flexibly accommodates both proportional hazards and proportional odds models as special cases and allows interaction effects between covariates and the threshold variable. Estimation is performed via an EM algorithm adapted from Zeng et al. [
18], incorporating profile likelihood and grid search to estimate the change point. The proposed method is evaluated through simulation studies assessing bias, standard errors, and confidence interval coverage, and it is further illustrated using data from the PLCO cancer screening trial to examine whether age exhibits a threshold effect on colorectal cancer risk.
The remainder of this article is organized as follows.
Section 2 describes the model framework, censoring structure and the likelihood construction. In
Section 3, we detail the EM estimation algorithm.
Section 4 establishes the asymptotic properties of the proposed estimators.
Section 5 presents simulation results under various data-generating scenarios.
Section 6 applies our model to the PLCO data. Concluding discussions and potential future directions are provided in
Section 7 and
Section 8.
2. Notation, Models and Likelihood
To improve the clarity and accessibility of the proposed methodology, we provide a summary of the key notations used throughout this paper in
Table 1. This includes variables related to interval-censored observations, model components such as the transformation function and baseline hazard, as well as the unknown change point. The table is intended to assist readers, particularly those less familiar with semiparametric models, in navigating the mathematical formulation presented in the following sections.
Let
T denote the failure time of interest,
represent a
p-dimensional vector of possibly time-varying covariates, and
X be an additional covariate. We consider a class of transformation models with a threshold structure, where the conditional cumulative hazard function of
T given
and
X is expressed as
where
is a known, strictly increasing function satisfying
,
is a nonparametric baseline cumulative hazard [
28], and
is an unknown threshold constant. We assume that the change point is (1) unknown but fixed (i.e., the same for all individuals); (2) unique (i.e., only one threshold exists for the covariate); and (3) located within a pre-specified interval, over which a grid search is conducted. The regression coefficients include
, a
p-dimensional vector, along with scalar and vector components
and
that capture the effects associated with exceeding the threshold
.
This model framework is quite flexible and encompasses several widely used semiparametric models as special instances. For example, choosing yields a partly linear proportional hazards (PH) model, while corresponds to a partly linear proportional odds (PO) model.
We formulate the mixed-case interval censoring framework by allowing the number of monitoring times, denoted by K, to be a random variable. For each subject, there exists a random sequence of observation times . Define the augmented monitoring time vector as , where and , representing the initial and terminal boundaries of the observation window, respectively. Let , where with denoting the indicator function. This formulation ensures that exactly one component of equals one, indicating the interval in which the failure time T occurred. Thus, the observed data for a sample of n individuals consist of , where and represent the observed monitoring intervals and corresponding indicators for the ith subject, and is the vector of covariates (possibly time-dependent).
Assume that the pair
is conditionally independent of
T given
and
X. Under this assumption, the observed data likelihood function is given by the following:
Since exactly one
equals 1 for each subject, the likelihood can be simplified to the following:
where
is the interval containing the failure time
, defined as
It is worth noting that
corresponds to a left-censored observation, while
indicates right censoring. This general formulation accommodates all types of interval censoring: exact, left, right, and current status data, under a unified likelihood framework.
3. Estimation Procedures
To estimate the parameters
,
, and
, we adopt a semiparametric maximum likelihood estimation approach. In this framework, the cumulative baseline hazard function
is modeled as a non-decreasing step function, with positive jumps only at the observed interval boundaries that bracket failure times. We define the jump size function
such that
, where
denotes the size of the jump at time
[
18]. Let
denote the sorted set comprising 0 and all unique values of
and
for
. Then
is a piecewise constant function with jumps
at these points, and we set
.
Under this representation, the likelihood function can be rewritten as follows:
where
To facilitate estimation, we express the transformation function
through its associated frailty representation. Specifically, under the transformation model, the observed-data likelihood can be written as an integral over the unobserved frailty variable
for subject
i:
Following Zeng et al. [
18] and Wang et al. [
20], we adopt an Expectation-Maximization (EM) algorithm to maximize the likelihood in (
3). The integral can be further simplified by noting that the likelihood for each subject becomes the following:
This formulation accommodates left, interval, and right censored observations in a unified EM-based estimation framework. The latent frailty variable is treated as missing data, and the expectation step of the EM algorithm involves computing its conditional expectation given current parameter estimates. The maximization step updates , and the jump sizes .
To facilitate the implementation of the EM algorithm, we introduce latent variables
for
and
, where each
is assumed to follow an independent Poisson distribution with mean
. Define the aggregate counts
. Suppose that the observed data for subject
i include
, meaning that no events occur before
and at least one event occurs within
when
. Under this setup, the likelihood function can be written as
We maximize the likelihood in (
4) using the EM algorithm by treating
and
as latent variables. The complete data for subject i are defined as
. The complete-data log-likelihood takes the following form:
In the M-step, we update the jump sizes
by maximizing the expected complete-data log-likelihood with respect to
, leading to the following closed-form update:
where
denotes the posterior expectation given the observed data and current parameter estimates.
After obtaining the updated baseline hazard increments
, we incorporate Equation (
6) into the conditional expectation of the complete-data log-likelihood derived in Equation (
5). We then proceed to update the regression parameters
in the M-step via a one-step Newton–Raphson approach. The updates rely on solving the score equations, which are derived by taking the gradient of the expected complete-data log-likelihood with respect to each component of
. Specifically,
, which captures the covariate effects before the threshold
, the corresponding score equation is
, which governs the jump in the transformation at
, the score equation is
, which represents the interaction between post-threshold covariates and the threshold indicator, we solve
Each of the three estimating equations above intuitively compares the observed covariate (or covariate–threshold interaction) contributions to their model-based expectations, weighted by the latent class probabilities and the interval-based risk set weights . These moment-type conditions align the observed data with the implied likelihood structure under the current parameter values. Together, these updates ensure that the expected complete-data log-likelihood is maximized at each M-step. We alternate between updating and computing the latent expectations in the E-step until convergence is achieved—typically defined as the change in parameter estimates falling below a pre-specified threshold (e.g., ).
To clarify the role of the EM algorithm under the latent frailty formulation, we briefly outline its conceptual structure. In our model, a subject-specific frailty term
is introduced to capture unobserved heterogeneity in the hazard function. Due to interval censoring, the true event time is not directly observed but known to fall within a subject-specific interval
. The EM algorithm facilitates inference by treating the frailty terms
as latent variables and iteratively computing their conditional expectations given the observed data and current parameter estimates.In the E-step, we evaluate quantities such as
and
, which are required for updating the parameter estimates. To that end, define
The posterior density of
, up to a proportionality constant, is given by
which reflects the fact that the event time lies in the interval
.
Based on this posterior distribution, the conditional expectation of
can be computed as follows:
where
is the cumulant-generating function and
its derivative.
Next, we compute the conditional expectation of
. For
, the corresponding count is deterministically zero, so
For
, if
, the conditional expectation is obtained by integrating over the posterior distribution of
as follows (parameter estimation was performed using the R language. Numerical integration within the EM algorithm was carried out using the pracma package.):
To estimate the threshold parameter
, we maximize the observed-data log-likelihood as follows:
where
denotes the regression coefficients. We employ a two-step procedure for the optimization [
10,
12]. First, we fix
over a pre-specified grid and, for each value, maximize
with respect to
via the EM algorithm outlined above. This yields the profile likelihood function for
. In the second step, we perform a grid search to identify the maximizer of the profile likelihood. If multiple candidate values of
yield the same maximum, we adopt the smallest such value for stability as follows:
To enhance the clarity and reproducibility of the proposed estimation procedure, we summarize the implementation of the EM algorithm in the form of a step-by-step pseudocode given as follows:
Initialization: Set initial values and for . Set iteration index .
Construct Grid: Define a set of 100 candidate change points over .
Repeat for each candidate :
- (a)
E-step: Calculate and based on current estimates.
- (b)
M-step: Update
using Equation (
6); update
by solving Equations (
7)–(
9).
- (c)
Iterate E-step and M-step until convergence. Record the log-likelihood value.
Select the with the highest log-likelihood as the final estimate.
To estimate the covariance matrix of
, we adopt the profile likelihood approach [
29]. Define the profile log-likelihood function as
where
denotes the set of step functions with nonnegative jumps at the
’s, and
denotes a neighborhood of
, defined as
. The covariance matrix of
is estimated by the negative inverse of the matrix whose
-th element is given by
where
is the
d-dimensional unit vector with 1 in the
j-th position and 0 elsewhere, and
is a constant of order
. To evaluate
, we apply the proposed EM algorithm with
held fixed, so that only
and
need to be updated in the M-step. The algorithm converges rapidly when using the initial values
.
4. Asymptotic Properties
The asymptotic properties of are established under the following regularity conditions:
(C1) The true value of , denoted by , belongs to a known compact set in , where and the true value of , denoted by , is continuously differentiable with positive derivatives in , where is the union of the support of .
(C2) The vector is uniformly bounded with uniformly bounded total variation over , and its left limit exists for any t. In addition, for any continuously differentiable function , the expectations are continuously differentiable in , where and are increasing functions in the decomposition .
(C3) If for all with probability one, then for and .
(C4) The number of monitoring times, K, is positive, and . The conditional probability for some positive constant c. In addition, for some positive constant . Finally, the conditional densities of given Z, X and K, denoted by , have continuous second-order partial derivatives with respect to u and v when and are continuously differentiable with respect to Z.
(C5) The transformation function G is twice-continuously differentiable on with , and .
(C6) , for some known with and .
(C7) For some neighborhood of , (i) the denity of X, exists and is strictly positive, bounded and continuous for all ; and (ii) the conditional law of given , is left-continuous with right-hand limits over .
(C8) For some , both and are positive definite.
(C9) Either or .
Condition (C1) ensures the parameter space is well-behaved and compact, a common requirement for establishing consistency and asymptotic normality in survival analysis. Condition (C2) permits the covariate process
to have discontinuities, which reflects realistic data-generating mechanisms, while requiring the expectations of smooth functionals involving
to remain differentiable. This balance allows analytical tractability while retaining modeling flexibility [
18]. Condition (C3) relates to model identifiability and ensures that different combinations of covariates and baseline hazard components are distinguishable. In practice, it is satisfied when the design matrix formed by
and a constant term is non-singular for some
t [
18,
19]. Condition (C4) governs the observation process, requiring that monitoring times are sufficiently spaced (by at least
) and informative. This helps avoid excessive interval censoring that could undermine identifiability. Condition (C5) requires the transformation function
G to be smooth and strictly increasing, which is essential for valid modeling of survival time. It holds for commonly used transformations such as the logarithmic and Box-Cox families [
18]. Conditions (C6)–(C9) are critical for ensuring the identifiability of the change point parameter. These conditions require, for instance, that the covariates vary sufficiently around the change point and that the change point covariate
X has a well-behaved and informative distribution [
11].
To establish the asymptotic properties of the proposed estimator, we first demonstrate model identifiability. The following lemma ensures that the transformation model is well-defined under the given framework.
Lemma 1. Under the regularity conditions, the proposed transformation model is identifiable.
Building on the identifiability result, we next derive the consistency of the estimators for the regression coefficients, change point parameter, and baseline cumulative hazard function.
Theorem 1. Under the regularity conditions, almost surely as , where is the Euclidean norm.
5. Simulation Study
To assess the finite-sample performance of the proposed method, we conducted a comprehensive simulation study under a transformation model with interval-censored data. We generated the following two independent covariates:
and
. The failure time
T was simulated from the following transformation model:
where the transformation function is defined as
with
, and the baseline cumulative hazard function is
. For the simulation, we set the true regression coefficients as
,
, and
. We considered two scenarios for the true change point
, specifically
and
, to evaluate the model’s robustness under different threshold locations. To generate interval-censored failure times, we constructed two monitoring times
for each subject. First, we sampled an initial monitoring time
, then generated the second monitoring time as
, where
is the maximum follow-up time. If the true failure time occurred before
, the observation was left-censored; if it occurred after
, it was right-censored; and otherwise, it was interval-censored within
. This design yielded, on average, approximately 25–35% left-censored, 25–35% interval-censored, and 30–50% right-censored observations across simulations, ensuring a realistic mixture of censoring types.
The proposed estimation method was implemented using the EM algorithm combined with a grid search for the change point parameter . The search interval for was set to , discretized into 100 equally spaced grid points. A grid of 100 candidate values for the change point was used in our implementation, striking a balance between computational burden and numerical resolution. While a finer grid could potentially improve precision, our current setting is consistent with standard practice. For each fixed , the EM algorithm was applied to estimate the regression coefficients and baseline hazard function. The initial values were set as follows: the regression parameter was initialized at zero, and the discrete baseline hazard weights were set to , where m is the number of observed unique event times. The convergence criterion for the EM algorithm was set as a relative change in the log-likelihood smaller than . We considered the following two sample sizes: , and conducted 400 independent replications for each configuration (i.e., for each true change point and ). For each simulated dataset, we applied the full estimation procedure to obtain parameter estimates and to evaluate the accuracy of change point detection, parameter recovery, and algorithm convergence.
We summarize the results of the two simulation settings under different values of the transformation parameter
.
Table 2 presents the results for the scenario with the true change point
, while
Table 3 reports results for
. In both cases, we report the average bias, the standard error estimator (SEE), the sample standard deviation of the estimates across replications (SSE), and the empirical coverage probability (CP) of the 95% confidence intervals for each parameter. From
Table 2, we observe that the proposed method yields nearly unbiased estimates for the change point
, as well as for all regression coefficients
. As the sample size increases, both the bias and the variability (as measured by SSE) of the change point estimator decrease notably. The standard error estimates (SEE) closely approximate the empirical standard deviation (SSE), indicating good calibration of the variance estimation procedure. Moreover, the empirical coverage probabilities (CP) of the confidence intervals are close to the nominal level, further confirming the reliability of the inference. Similar patterns are observed in
Table 3, which summarizes the results when the true change point is
. The estimators remain nearly unbiased, variance estimates are accurate, and the coverage probabilities remain close to 95%. Comparing
Table 2 and
Table 3, we find that the finite-sample performance of the proposed method is robust to the location of the change point. That is, the accuracy of the change point estimator and the regression coefficient estimates is not substantially affected by whether the threshold occurs at 0.75 or 0.9.
To further illustrate the computational performance of our approach,
Table 4 reports the average number of EM iterations and total runtime across various simulation settings. As expected, increases in sample size or the transformation parameter r are associated with higher computational demands, reflecting the greater complexity of model structure. Nevertheless, the proposed algorithm remains computationally feasible and exhibits stable convergence across all settings examined. We further visualize the estimated baseline function
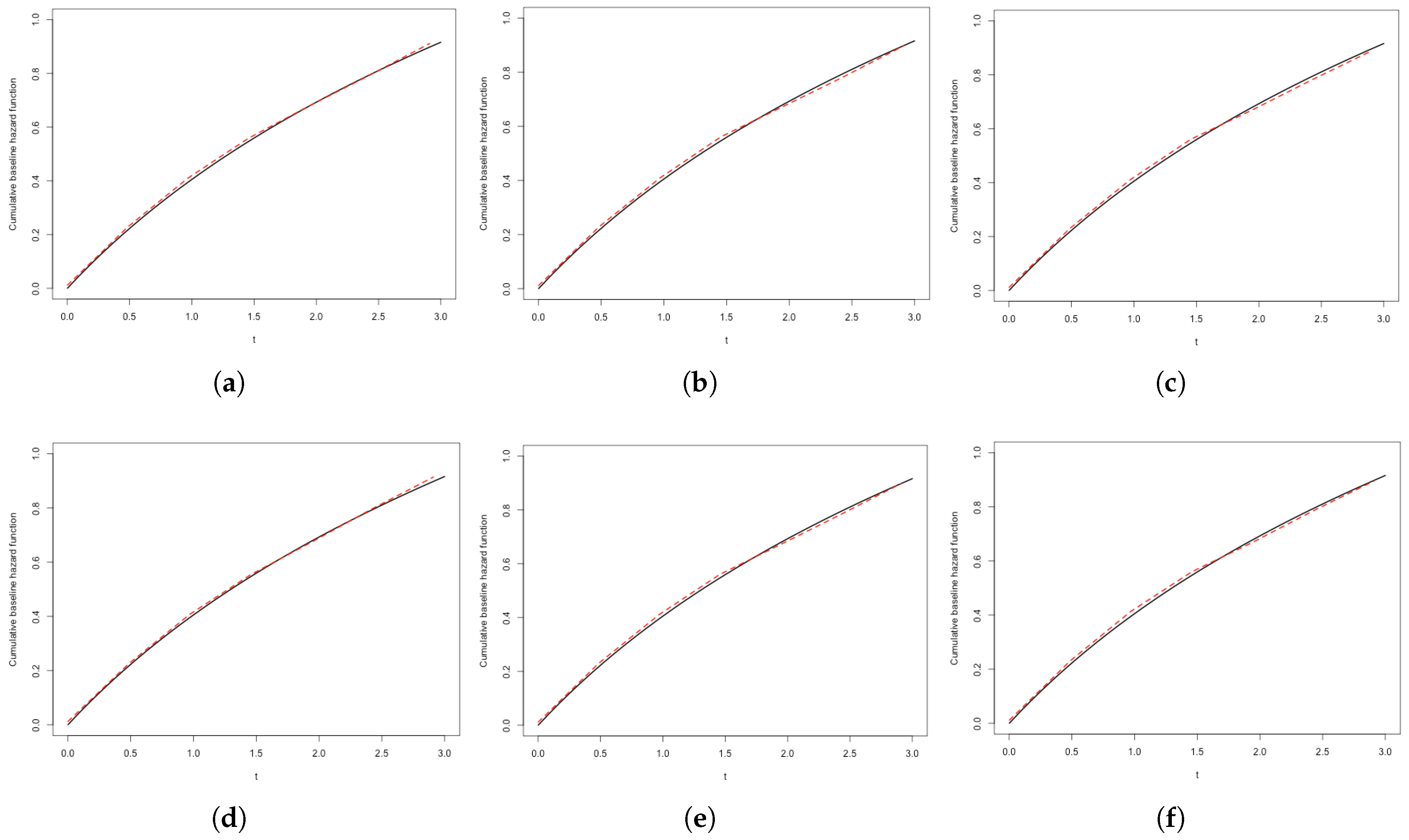
alongside the true function in
Figure 1, showing that the EM-based estimator effectively captures the underlying hazard dynamics. These findings collectively highlight the practical reliability and efficiency of our method in realistic interval-censored data contexts. While the simulation primarily focuses on moderate sample sizes and a fixed grid resolution for the change point, preliminary examinations suggest that the estimation results are relatively robust to alternative grid specifications.
6. Application
We applied the proposed EM-based transformation model to the PLCO (Prostate, Lung, Colorectal, and Ovarian) Cancer Screening Trial dataset to investigate whether a threshold effect exists in the relationship between age and colorectal cancer incidence, which has been widely accepted as a surrogate end point for disease progression [
30]. The PLCO is a large-scale, multicenter randomized controlled trial initiated by the U.S. National Cancer Institute in 1993, designed to evaluate the effectiveness of various cancer screening strategies on cancer-specific mortality [
31,
32].
Our analysis focused on the incidence of colorectal cancer. The dataset consists of 60,598 participants, among whom approximately 98.7% of observations are right-censored, indicating a high degree of incomplete follow-up. To account for this and capture potential nonlinear covariate effects, we employed a semiparametric transformation model for survival outcomes. To explore the possible nonlinear influence of age, we modeled it as a threshold (or change point) variable. Specifically, we allowed the effect of age to change once it crosses an unknown threshold , which was estimated from the data using a grid search procedure embedded within the EM algorithm. The grid search was conducted over all unique observed age values in the dataset, ensuring that the threshold is data-driven and captures meaningful shifts in risk. This formulation introduces a binary indicator into the linear predictor, allowing the model to detect and quantify a discrete change in risk associated with advancing age. Twelve covariates were included in the model: Race, Sex, Education, Employment, Cancer, Colorectal cancer, Diabetes, Stroke, Heart disease, Gallbladder disease, and Colorectal polyps. All variables were coded as binary indicators based on baseline questionnaire data. Initially, we also incorporated interaction terms between the thresholded age variable and all other covariates to test for potential effect modification. However, none of these interactions were statistically significant, and they were therefore omitted from the final model. To determine the most appropriate transformation structure, we varied the transformation parameter r over the interval in increments of 0.1 and evaluated model fit via the log-likelihood. The value corresponds to the Cox PH model, while corresponds to the PO model. We found that the log-likelihood increased monotonically with r, peaking at . Accordingly, was selected as the best-fitting model, though results for and are also reported for comparison.
Table 5 presents the estimated regression coefficients, standard errors, and
p-values under the three transformation specifications. The estimated age threshold was 62 years and was held fixed across all models. The age indicator
was found to be highly significant in all models (
), suggesting a substantial increase in colorectal cancer risk beyond this threshold. Notably, age 62 aligns with current clinical guidelines: most major organizations—including the U.S. Preventive Services Task Force—recommend initiating colorectal cancer screening at age 45, and strongly endorse routine screening between ages 50 and 75. The identification of 62 as a data-driven risk threshold offers a potentially meaningful refinement for stratifying individuals by risk and tailoring screening strategies. This reinforces not only the clinical relevance of our result, but also the interpretability and practical utility of the threshold model in guiding age-based prevention policies. Under the best-fitting transformation model (
), the estimated coefficient for the thresholded age variable was 0.653 (SE = 0.091), corresponding to an approximate 1.92-fold increase in relative risk (
) for individuals older than 62.
In addition to Age, both Race and Sex were consistently significant across all model specifications. Specifically, Race = 1 was associated with increased risk (coefficient = 0.521, ), as was Sex = 1 (coefficient = 0.326, ). These findings are consistent with existing epidemiological literature and may reflect differences in genetic predisposition, healthcare access, health behaviors, or screening participation across demographic groups. The variable Education = 1 showed a marginally protective effect (), suggesting that higher educational attainment may be associated with reduced risk, potentially through improved health literacy or greater utilization of preventive services. Other covariates, including prior cancer history, diabetes, cardiovascular conditions, and colorectal polyps, were not statistically significant at conventional levels, although the direction and magnitude of their coefficients remained clinically plausible. Residual diagnostics revealed no substantial violations of model assumptions, supporting the adequacy of the transformation model in this context.
We found that consistently yielded the best model fit in terms of log-likelihood, indicating that the effect of covariates on the event time distribution may deviate from the assumptions of standard proportional hazards () or proportional odds () models. This suggests that a more flexible transformation function is better suited to capture the underlying risk structure, particularly in the presence of threshold effects or subtle nonlinearities. In our application, such flexibility is especially relevant given the observed change point effect and the potential complexity of age-related risk dynamics. To assess the robustness of our conclusions, we conducted sensitivity analyses by fitting models at adjacent transformation parameters (e.g., , , and ). The results showed that the estimated effects and significance patterns remained stable, supporting both the interpretability and reliability of our modeling framework. In summary, our findings highlight the practical utility of transformation models with threshold components for analyzing complex, censored survival data. The estimated age cutoff of 62 years not only aligns with known clinical trends but also offers a data-driven refinement that may inform individualized screening strategies for colorectal cancer. The combination of transformation modeling and EM-based estimation thus provides a flexible and effective approach for uncovering nonlinear and heterogeneous risk patterns in survival analysis.
7. Discussion
In this paper, we developed a semiparametric transformation model that incorporates an unknown change point under interval-censored data. By combining a grid search technique for estimating the change point with an EM algorithm to handle the nonparametric baseline hazard, we proposed an effective estimation procedure tailored to this challenging data structure. Simulation studies demonstrated that the proposed method performs well in terms of bias, standard error, and confidence interval coverage across a range of settings, including different sample sizes and change point locations. Moreover, our application to real-world colorectal cancer screening data highlighted the practical utility of the approach in identifying interpretable threshold effects that may inform clinical guidelines.
Despite the encouraging performance of our proposed method, several avenues remain for future enhancement. First, the estimation of the change point via grid search—though widely adopted and effective in our simulations—may involve non-negligible computational cost and raise concerns about sensitivity to grid resolution. Our preliminary results suggest that the estimator remains stable even near boundary values, but a more systematic evaluation of grid resolution and its impact on estimation accuracy and efficiency is warranted. Developing adaptive or data-driven grid strategies could further enhance scalability for large datasets. Additionally, while we adopted a standard fixed initialization for the EM algorithm, exploring multiple or data-adaptive starting points may improve convergence in more complex or high-dimensional settings. Incorporating acceleration techniques such as quasi-Newton updates or PX-EM [
33,
34,
35] could also reduce computation time. From a theoretical perspective, it would be valuable to investigate the convergence rate of the estimated threshold
. Formal results on parameter existence and convergence remain an important direction for future theoretical work. Finally, while our model emphasizes interpretability via threshold detection, a direct empirical comparison with flexible alternatives (e.g., spline-based methods) could further clarify trade-offs in terms of estimation efficiency, interpretability, and computational cost.
In addition, extending our framework to accommodate mixture cure models could be particularly useful in clinical contexts involving long-term survivors or latent subpopulations [
36,
37,
38]. Incorporating change points in such settings may better capture heterogeneous risk patterns and improve understanding of treatment effects and disease dynamics. Finally, in the presence of high-dimensional covariates, model sparsity and multicollinearity may impact estimation stability. Incorporating regularization techniques such as Lasso or SCAD [
39,
40,
41] could improve variable selection and estimation accuracy. Moreover, systematic sensitivity analyses—including those on initial values, grid density, and transformation function specification—would provide deeper insight into the robustness and practical utility of the method across diverse scenarios [
42].




{kind=link}