
A Feature Engineering Framework for Smart Meter Group Failure Rate Prediction


Abstract
1. Introduction
1.1. Condition Assessment for Smart Meters
1.2. Multi-Objective Evolutionary Feature Selection
2. Materials and Methods
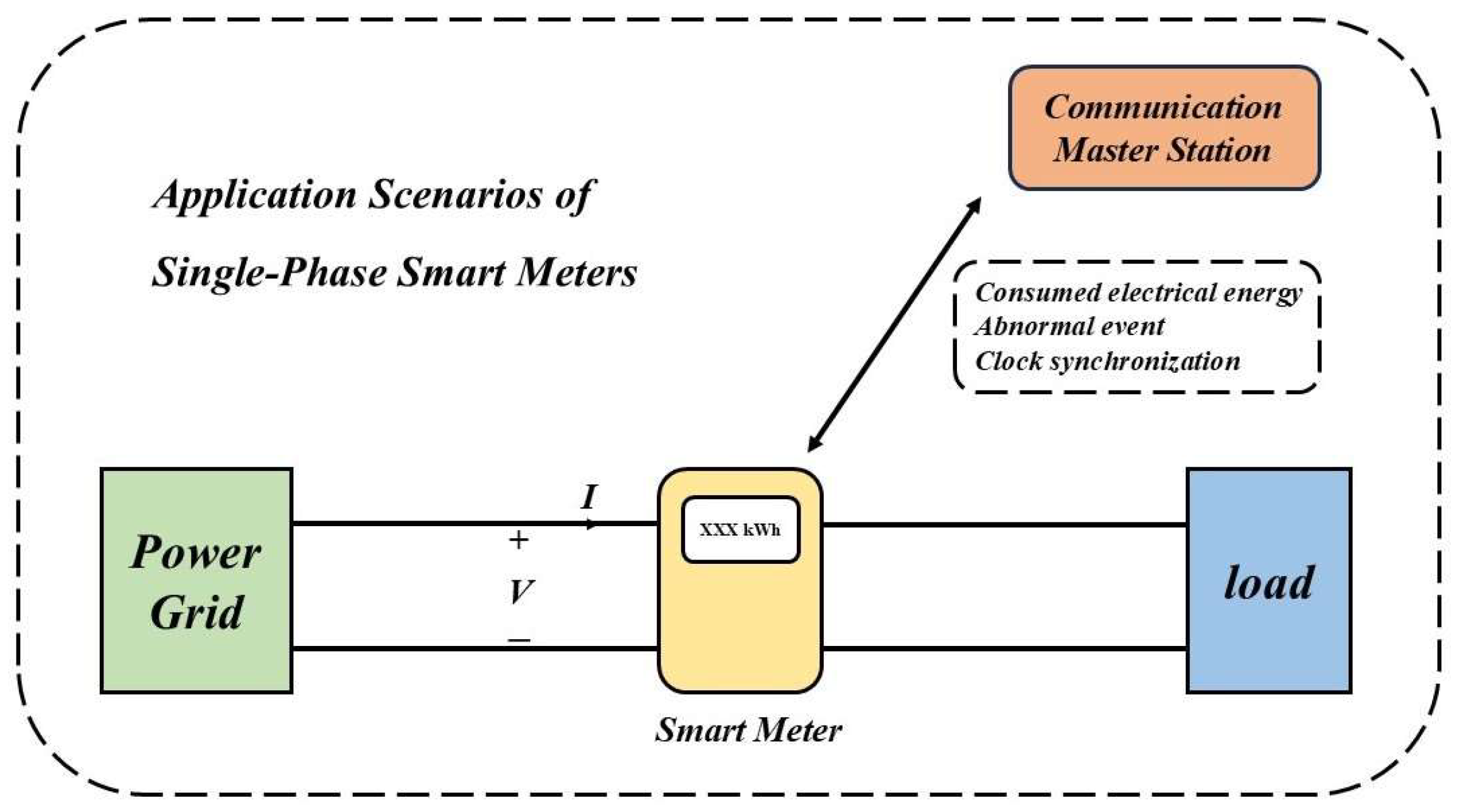
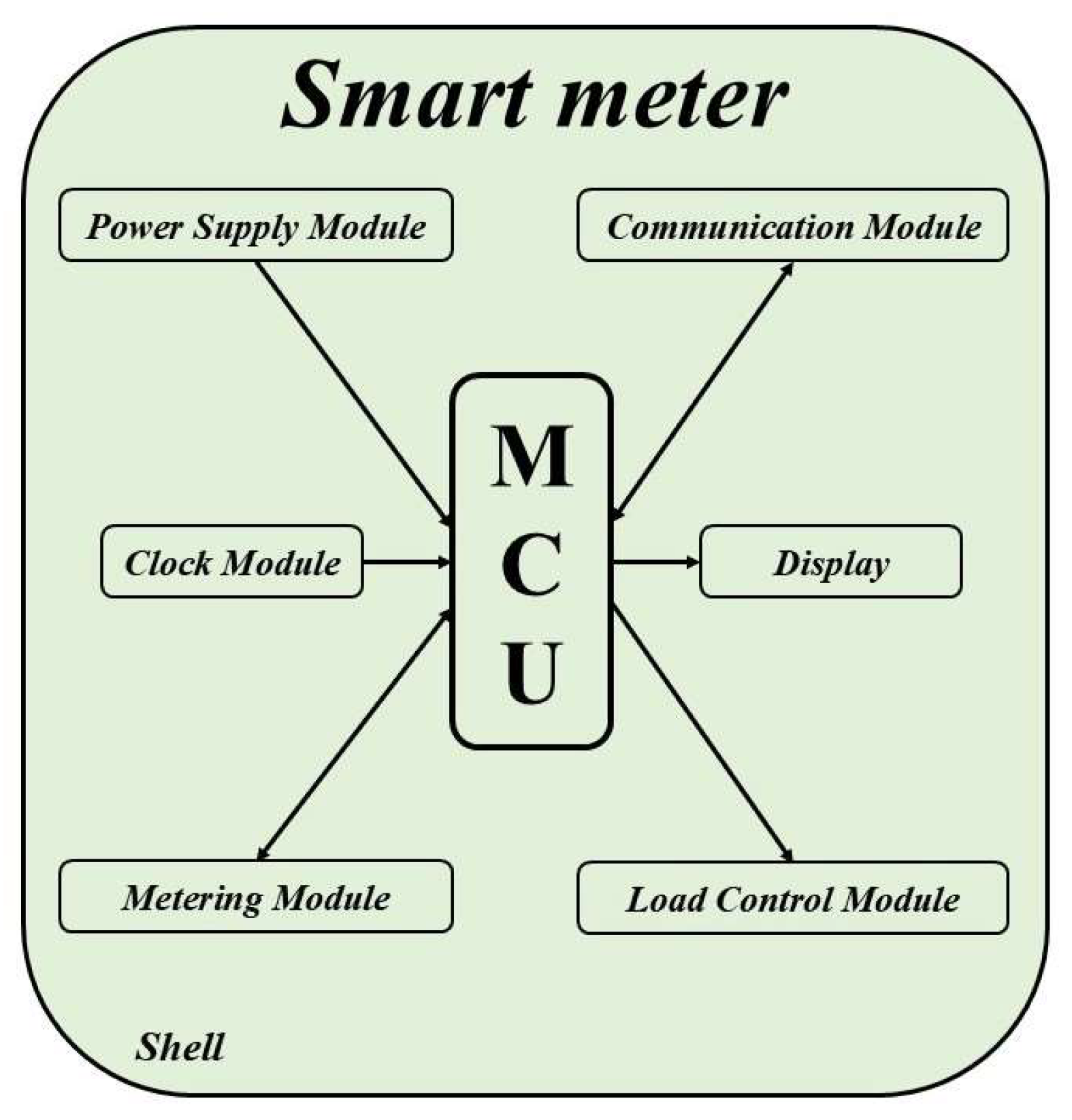
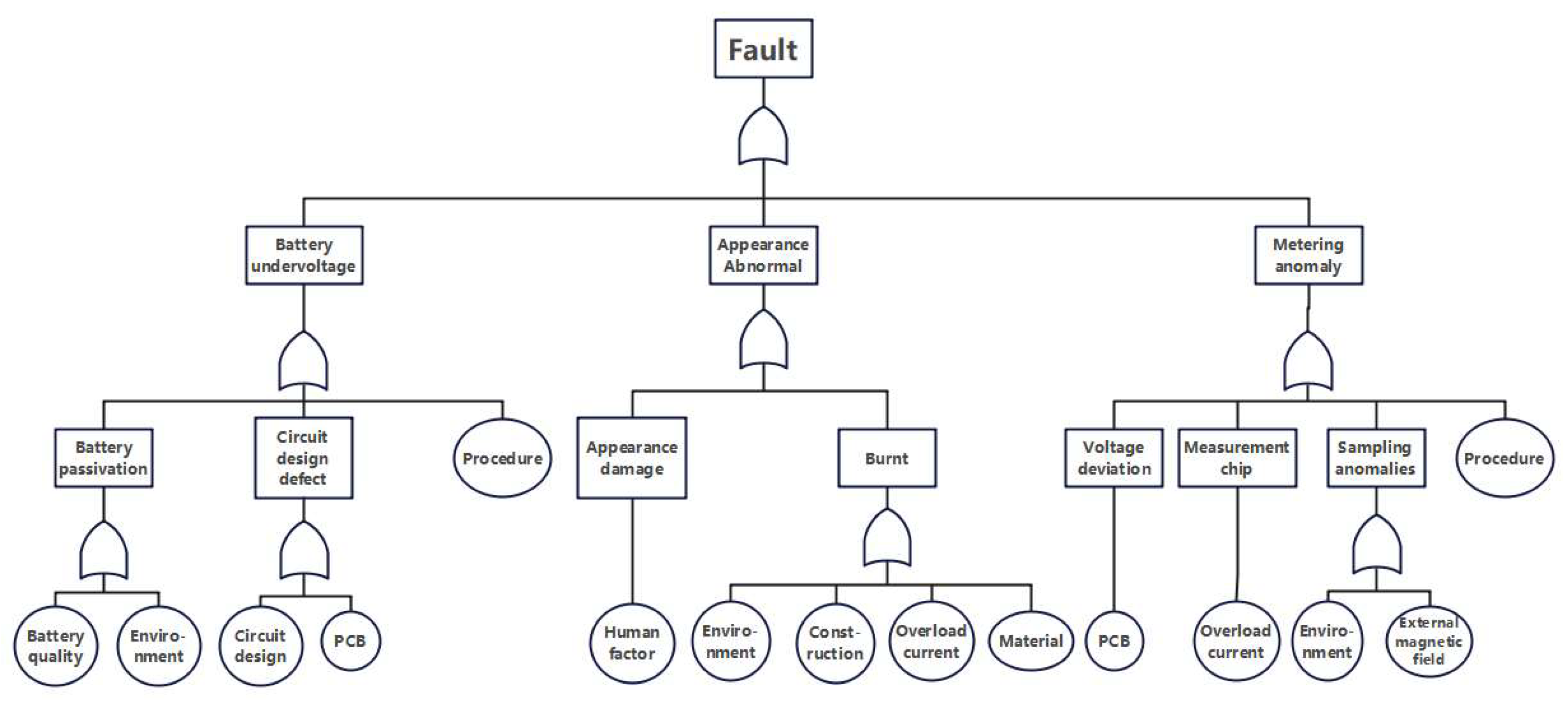
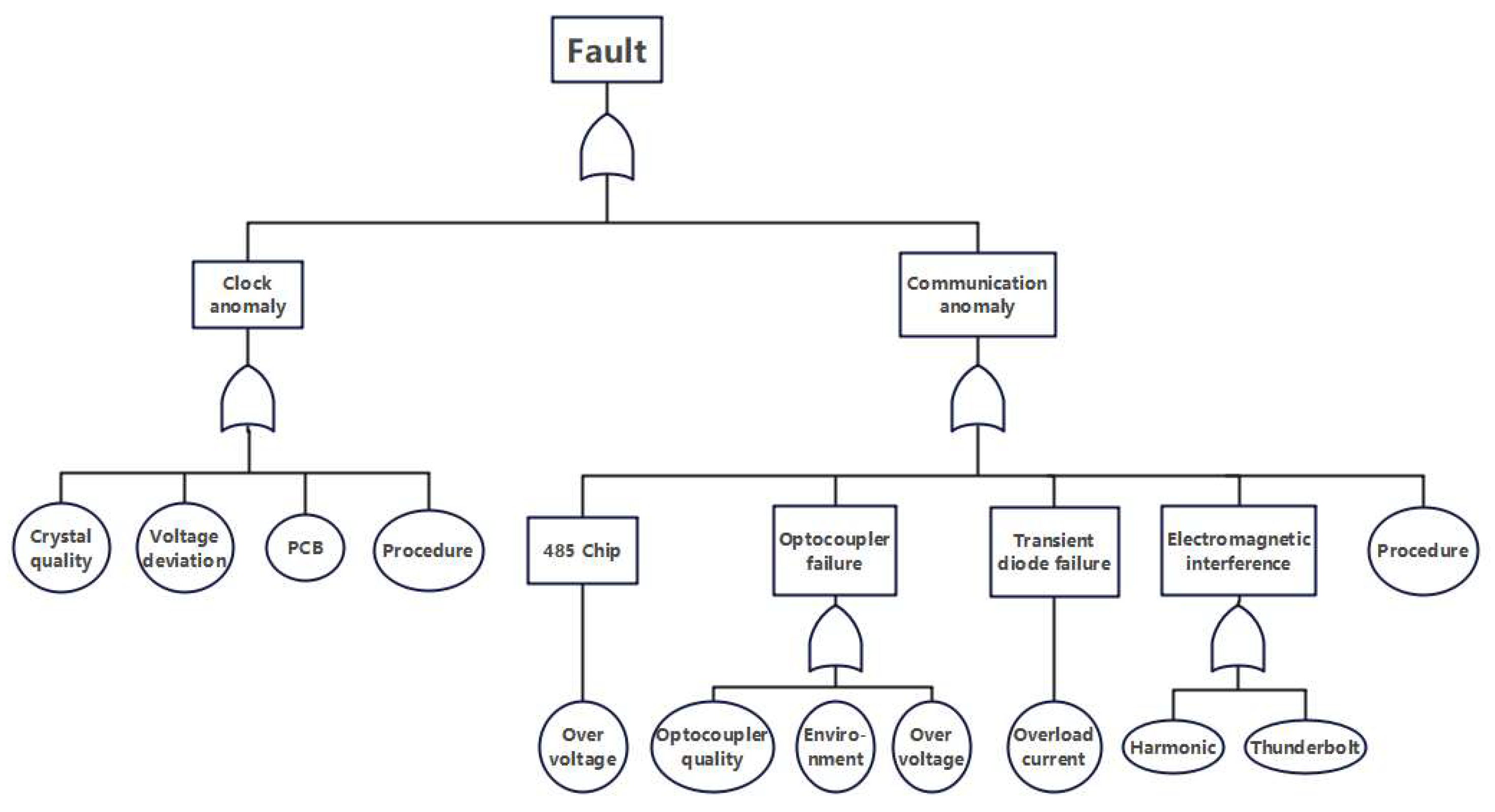
2.1. Basic Structure and Typical Faults of Smart Meters
2.2. Feature Construction for Smart Meter Group Condition Assessment
2.2.1. Physics-Knowledge-Based Construction of Smart Meter Condition Features
- (1)
- Component Quality: including battery quality, crystal oscillator quality, and optocoupler quality;
- (2)
- Electromagnetic Environment: comprising external magnetic fields, overvoltage, power grid harmonics, and lightning strikes;
- (3)
- Natural Environment: such as temperature and humidity;
- (4)
- Process Control: encompassing PCB manufacturing process, circuit design, installation quality, and software defects.
2.2.2. Expert-Experience-Based Construction of Smart Meter Condition Features
- Accuracy Tests
- External Influence Tests
- Climatic Impact Tests
- Mechanical Tests
- Electrical Performance Tests
- Insulation Tests
- Tariff Control Security Tests
- Reliability Verification Tests
- Communication Checks
2.2.3. Condition Features for Smart Meter Group
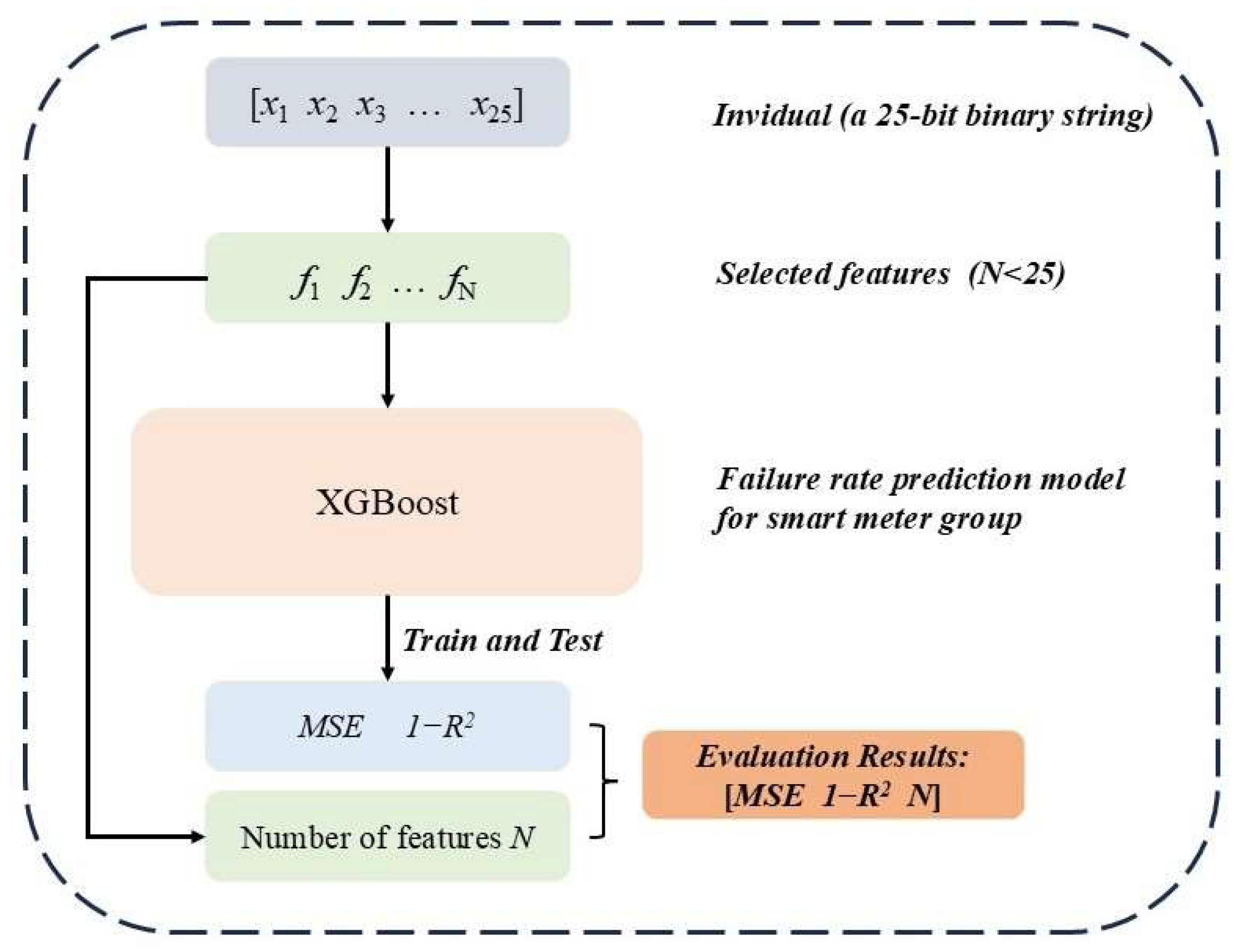
2.3. Feature Selection for Smart Meter Group Condition Assessment
2.3.1. Optimization Objectives for Feature Selection
- (1)
- Minimize MSE (reduce model prediction error)
- (2)
- Minimize 1 − R2 (reduce model prediction error)
- (3)
- Minimize N (reduce feature count)
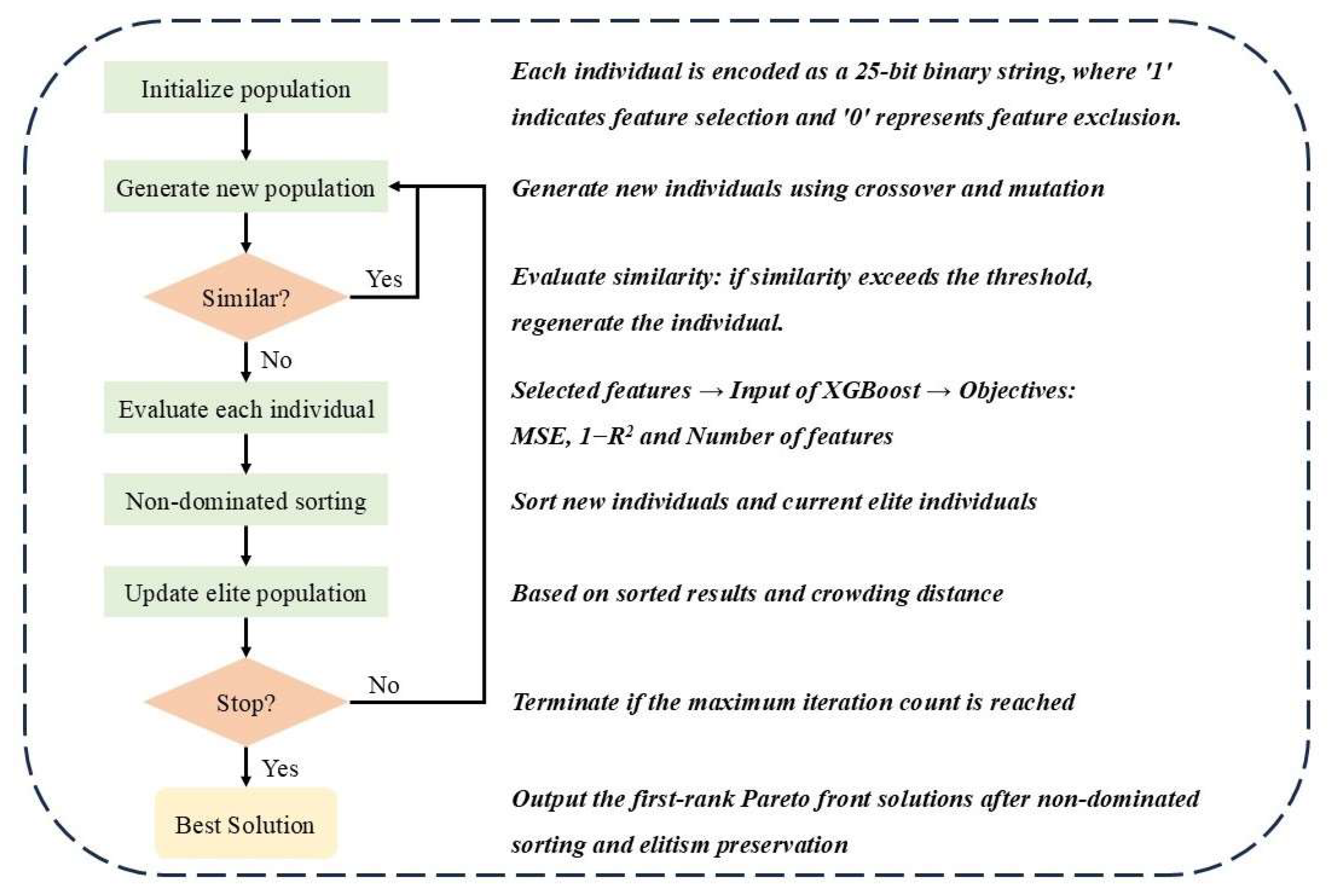
2.3.2. Optimization Algorithms for Feature Selection
- (1)
- Initialize population
- (2)
- Generate new population
- (3)
- Similar?
| Algorithm 1: Crossover | |
| Inputs: | Random parent individuals x1, x2 |
| Outputs: | Offspring individuals y1, y2 |
| 1. | y1 ← x1 AND x2 |
| 2. | y2 ← x1 OR x2 |
| 3. | return (y1, y2) |
| Algorithm 2: Mutation | |
| Inputs: | Offspring population X, Mutation rate m |
| Outputs: | Mutated populaton Y |
| 1. | While i < length(X) do |
| 2. | if random(0,1) < u then |
| 3. | X[i] ← 1 − X[i] |
| 4. | if sum(X) == 0 then |
| 5. | k ← random(0, length(X)−1) |
| 6. | X [k] ← 1 |
| 7. | end if |
| 8. | if sum(X) == length(X) then |
| 9. | k ← random(0, length(X)−1) |
| 10. | child[k] ← 0 |
| 11. | end if |
| 12. | end if |
| 13. | end while |
- (4)
- Evaluate each individual
- (5)
- Non-dominated sorting
- Front 1: All non-dominated solutions in the current population;
- Front k: Solutions only dominated by those in preceding fronts.
- Sort solutions along each objective axis;
- Assign infinite distance to boundary solutions;
- For intermediate solutions, compute normalized Manhattan distance between adjacent neighbors.
- (6)
- Update elite population
- (7)
- Stop?
- (8)
- Best Solution
2.4. Dataset Description
- Unique meter identifiers;
- Initial verification metrics (metering error and daily timing error);
- Installation locations;
- Binary fault status and fault type;
- Operational duration (5–9 years);
- Manufacturer specifications and production batch codes;
- Anomaly event logs (power interruptions, overcurrent incidents, undervoltage occurrences).
3. Results
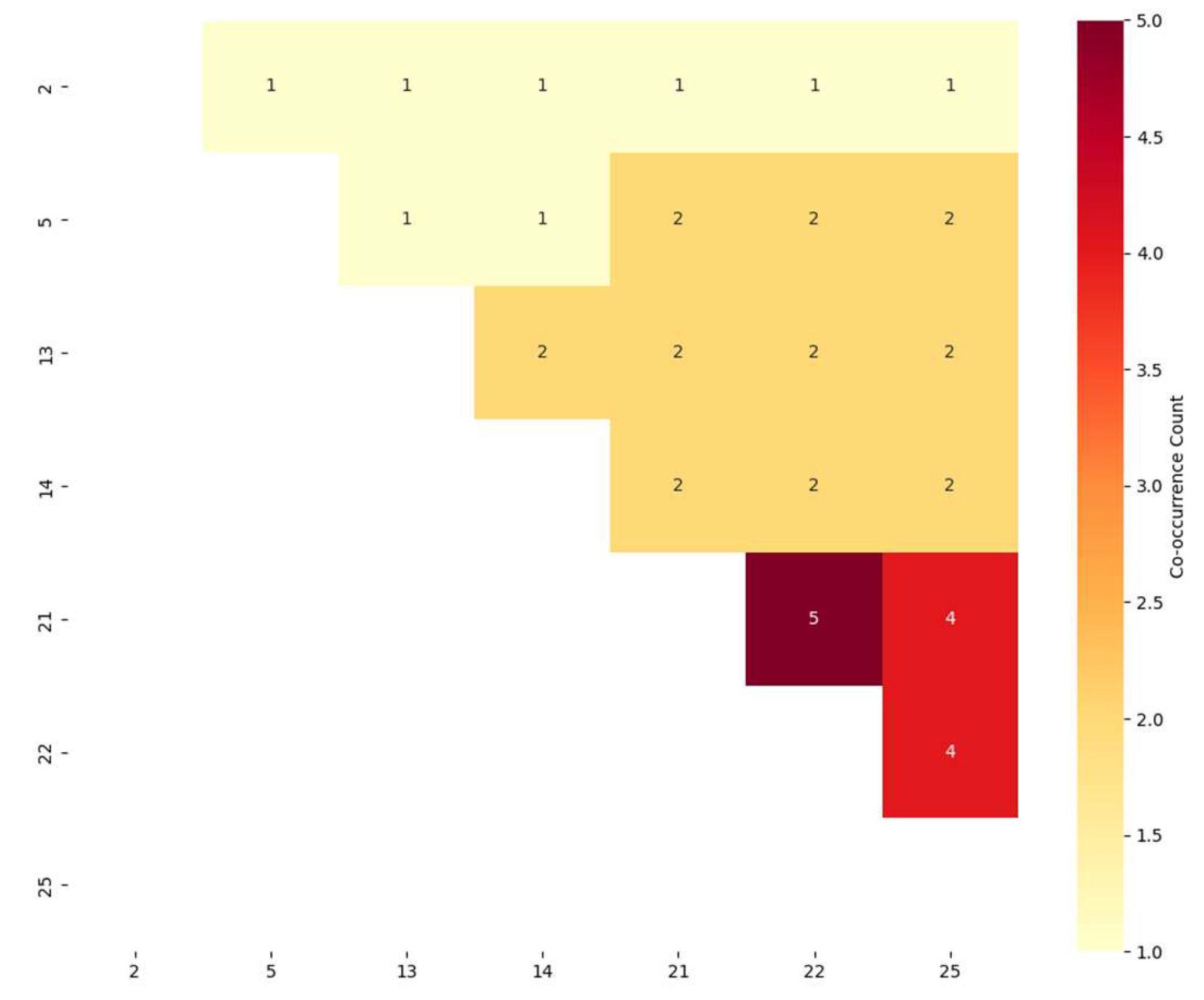
3.1. Optimal Feature Subset
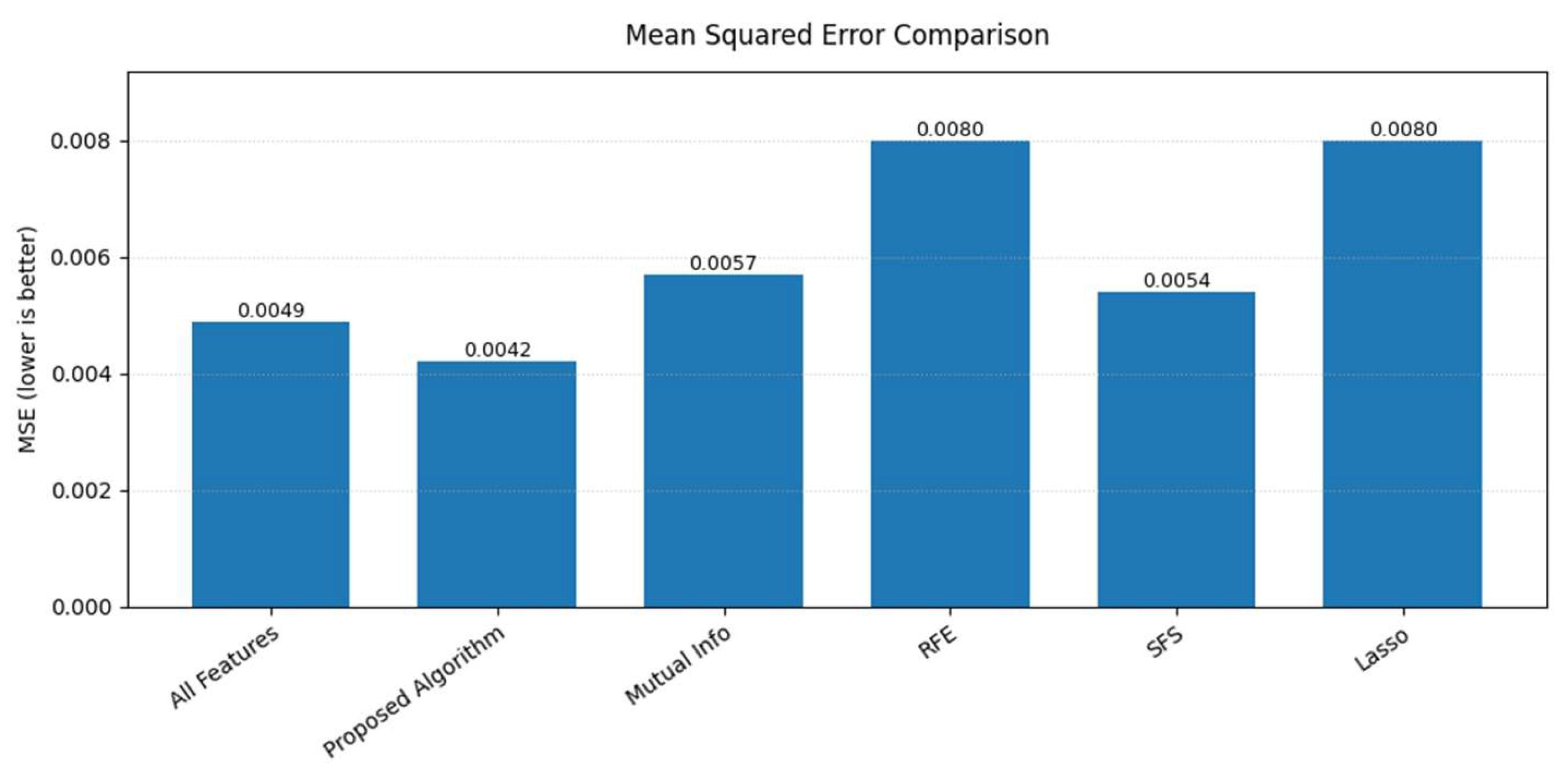
3.2. Comparative Analysis
4. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bibek, K.B.; Shiv, N.Y.; Shivam, K.; Sadhan, G. IoT Based Smart Energy Meter for Efficient Energy Utilization in Smart Grid. In Proceedings of the 2018 2nd International Conference on Power, Energy and Environment, Shillong, India, 1–2 June 2018; pp. 1–5. [Google Scholar]
- Tomasz, T.W. Who is Smart? Smart Metering and Billing System for Prosumer Microgrids With New-Type Multi-Source Energy Meters. In Proceedings of the 2024 IEEE 12th International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 18–20 August 2024; pp. 47–51. [Google Scholar]
- Sreedevi, S.V.; Prasannan, P.; Jiju, K.; Indu, L.I.J. Development of Indigenous Smart Energy Meter Adhering Indian Standards for Smart Grid. In Proceedings of the 2020 IEEE International Conference on Power Electronics, Smart Grid and Renewable Energy (PESGRE2020), Cochin, India, 2–4 January 2020; pp. 1–5. [Google Scholar]
- Chen, M.; Zhang, Y.; Zou, Y.; Xin, R.; Zhang, L.Y.; Gao, C.; Lin, H. A Medium-Voltage Stealing Type Detection Method Based on Robust Regression and Convolutional Neural Network. Power Syst. Technol. 2024, 48, 4729–4738. [Google Scholar]
- Yuan, B.; Liu, H.; Ge, S.Y. Optimal Construction Method for Advanced Metering Infrastructure of Power Grid Based on Multi-Dimensional Compressed Sensing. Autom. Electr. Power Syst. 2024, 48, 167–176. [Google Scholar]
- Santosh, K.; Suneetha, K.; Amandeep, G. Utilization of IoT and Smart Meters for Energy Management. In Proceedings of the 2023 International Conference on Power, Energy, Environment and Intelligent Control (PEEIC), Greater Noida, India, 19–23 December 2023; pp. 1254–1258. [Google Scholar]
- Tan, H.Y.; Yao, H.J.; Huang, Y.; Wang, H.; Zhao, Z.; He, Y. Temperature-Controlled Smart Energy Meter Field Calibration System Based on Measurement Risk Rating. In Proceedings of the 2019 3rd International Conference on Smart Grid and Smart Cities (ICSGSC), Berkeley, CA, USA, 25–28 June 2019; pp. 60–64. [Google Scholar]
- Xie, L.T.; Ma, Y.B.; Yang, L.; Zhou, L.H.; Ren, M.; Shu, Q.Q. Construction for Power Meter Condition Inspection Function. Electron. Meas. Technol. 2017, 40, 65–70. [Google Scholar]
- Luo, Q.; Liu, C.Y.; Zhang, J.A.; Zhang, J.; Wang, S.K.; Ge, L.J. Online Platform Development and Evaluation Indexes of State Inspection for Smart Meter. Electr. Meas. Instrum. 2017, 54, 94–99, 111. [Google Scholar]
- Liu, C.Y.; Liu, Z.F.; Luo, Q.; Ge, L.J.; Deng, W.; Wang, Y. A Comprehensive Evaluation and Trend Prediction Method of Health Degree for Electric Energy Measuring Devices. Power Syst. Prot. Control 2018, 46, 47–53. [Google Scholar]
- Cai, H.; Chen, H.; Ye, X.; Zhang, X.; Wen, H.; Li, J.; Guo, Q. An Online State Evaluation Method of Smart Meters Based on Information Fusion. IEEE Access 2019, 7, 163665–163676. [Google Scholar] [CrossRef]
- Cai, H.; Qiao, S.S.; Yuan, J.; Chen, H.Q.; Li, J.; Pan, Y.Z. Information Fusion Based Dynamic Evaluation Model of Low-Voltage Smart Electricity Meter. Autom. Electr. Power Syst. 2020, 44, 206–214. [Google Scholar]
- Ma, J.; Tang, Q.; Duan, J.F.; Liu, J.; Han, M.; Yi, K.Y.; Teng, Z.S. Measurement Error Evaluation Model for Smart Meter Under High Dry Heat Environment. Proc. CSEE 2023, 43, 4581–4589. [Google Scholar]
- Ye, J.B.; Zhu, D.S.; Wang, Y.J.; Chen, Y.L.; Zhang, Y.S. Research on Intelligent Electric Energy Meter State Inspection Technology. Process Autom. Instrum. 2020, 41, 51–55. [Google Scholar]
- Li, X.S.; Gao, Y. State Assessment Method of Electricity Meter Based on Grey Correlation Analysis. Process Integr. Optim. Sustain. 2023, 7, 1149–1156. [Google Scholar] [CrossRef]
- Ying, C.Y.; Jie, D.; Feng, Z.; Ji, X.; Xiao, Y.H. Application of Variable Weight Fuzzy Analytic Hierarchy Process in Evaluation of Electric Energy Meter. In Proceedings of the 2017 IEEE 2nd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 25–26 March 2017; pp. 1–5. [Google Scholar]
- Cheng, X.; Yu, M.; Liu, M.; Huang, R.; Xie, L.; Tan, H. Research on Comprehensive Performance Evaluation Method of Smart Energy Meter. In Proceedings of the 2018 3rd International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 14–16 September 2018; pp. 1–5. [Google Scholar]
- Chen, H.Q. Research on State Indicators and Modeling Method for Online Evaluation of Smart Meters. Master’s Thesis, China Jiliang University, Hangzhou, China, 2020. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature Selection Based on Mutual Information Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef]
- Han, Y.; Park, K.; Guan, D.; Halder, S.; Lee, Y. Topological Similarity-Based Feature Selection for Graph Classification. Comput. J. 2015, 58, 1884–1893. [Google Scholar] [CrossRef]
- Zhou, P.; Zhang, Y.; Ling, Z.; Yan, Y.; Zhao, S.; Wu, X. Online Heterogeneous Streaming Feature Selection Without Feature Type Information. IEEE Trans. Big Data 2024, 10, 470–485. [Google Scholar] [CrossRef]
- Taşkın, G.; Kaya, H.; Bruzzone, L. Feature Selection Based on High Dimensional Model Representation for Hyperspectral Images. IEEE Trans. Image Process. 2017, 26, 2918–2928. [Google Scholar] [CrossRef]
- Komeili, M.; Armanfard, N.; Hatzinakos, D. Multiview Feature Selection for Single-View Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3573–3586. [Google Scholar] [CrossRef] [PubMed]
- Castillo, C.F.C.; Coello, C.A. A Survey of Applications of Multi-Objective Evolutionary Algorithms in Biotechnology. In Proceedings of the 2024 IEEE Congress on Evolutionary Computation (CEC), Yokohama, Japan, 14–19 July 2024; pp. 1–8. [Google Scholar]
- Hong, W.; Chen, C.; Zhu, Z.; Tang, K. An Elite Archive-Assisted Multi-Objective Evolutionary Algorithm for mRNA Design. In Proceedings of the 2024 IEEE Congress on Evolutionary Computation (CEC), Yokohama, Japan, 14–19 July 2024; pp. 1–8. [Google Scholar]
- Hou, H.; He, Z.; Xiang, M.; Lu, Y.; Yang, J.; Huang, L.; Xie, C. Interval Multi-Objective Optimization for Low-Carbon Building Energy Management System Upon Deep Reinforcement Learning. IEEE Trans. Ind. Appl. 2025, 61, 2193–2202. [Google Scholar] [CrossRef]
- Yang, R.; Yi, Z.; Xu, Y.; Chen, G.; Yang, H.; Yi, R.; Li, T.; Shen, M.; Li, J.; Gao, H.; et al. Adaptive Multi-Objective Bayesian Optimization for Capacity Planning of Hybrid Heat Sources in Electric-Heat Coupling Systems of Cold Regions. IEEE Trans. Ind. Appl. 2025, 61, 4718–4729. [Google Scholar] [CrossRef]
- Zhang, Z.-X.; Chen, W.-N.; Shi, W.; Jeon, S.-W.; Zhang, J. An Individual Evolutionary Game Model Guided by Global Evolutionary Optimization for Vehicle Energy Station Distribution. IEEE Trans. Comput. Soc. Syst. 2024, 11, 1289–1301. [Google Scholar] [CrossRef]
- Gu, Y.-R.; Bian, C.; Li, M.; Qian, C. Subset Selection for Evolutionary Multiobjective Optimization. IEEE Trans. Evol. Comput. 2024, 28, 403–417. [Google Scholar] [CrossRef]
- Chen, W.; Ishibuchi, H.; Shang, K. Fast Greedy Subset Selection From Large Candidate Solution Sets in Evolutionary Multiobjective Optimization. IEEE Trans. Evol. Comput. 2022, 26, 750–764. [Google Scholar] [CrossRef]
- Buskulic, N.; Doerr, C. Maximizing Drift Is Not Optimal for Solving OneMax. Evol. Comput. 2021, 29, 521–541. [Google Scholar] [CrossRef]
- Li, T.; Meng, Y.; Tang, L. Scheduling of Continuous Annealing With a Multi-Objective Differential Evolution Algorithm Based on Deep Reinforcement Learning. IEEE Trans. Autom. Sci. Eng. 2024, 21, 1767–1780. [Google Scholar] [CrossRef]
- Xue, Y.; Tang, Y.; Xu, X.; Liang, J.; Neri, F. Multi-Objective Feature Selection With Missing Data in Classification. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 355–364. [Google Scholar] [CrossRef]
- Hua, Y.; Zhu, H.; Xu, Y. Multi-Objective Optimization Design of Bearingless Permanent Magnet Synchronous Generator. IEEE Trans. Appl. Supercond. 2020, 30, 1–5. [Google Scholar] [CrossRef]
- Li, Y.; Xie, Z.; Yang, S.; Ren, Z. A Novel Hybrid Multi-Objective Optimization Algorithm and Its Application to Designs of Electromagnetic Devices. IEEE Trans. Magn. 2025, 61, 1–4. [Google Scholar] [CrossRef]
- Li, Y.; Xie, Z.; Yang, S.; Ren, Z. A Hybrid Algorithm Based on NSGA-II and MOPSO for Multi-Objective Designs of Electromagnetic Devices. IEEE Trans. Magn. 2023, 59, 1–4. [Google Scholar] [CrossRef]
- Wang, Y.; van Stein, B.; Bäck, T.; Emmerich, M. A Tailored NSGA-III for Multi-objective Flexible Job Shop Scheduling. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 2746–2753. [Google Scholar]
- Wang, X.; Zhao, Y.; Tang, L.; Yao, X. MOEA/D With Spatial-Temporal Topological Tensor Prediction for Evolutionary Dynamic Multiobjective Optimization. IEEE Trans. Evol. Comput. 2025, 29, 764–778. [Google Scholar] [CrossRef]
- Xie, Y.; Yang, S.; Wang, D.; Qiao, J.; Yin, B. Dynamic Transfer Reference Point-Oriented MOEA/D Involving Local Objective-Space Knowledge. IEEE Trans. Evol. Comput. 2022, 26, 542–554. [Google Scholar] [CrossRef]
- Khajwaniya, K.K.; Tiwari, V. Satellite Image Denoising Using Wiener Filter With SPEA2 Algorithm. In Proceedings of the 2015 IEEE 9th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 9–10 January 2015; pp. 1–6. [Google Scholar]
- Liu, D.; Xu, X.; Ma, K.; Tao, L.; Suo, M. Fault Diagnosis Based on Fault Tree and Bayesian Network with Grey Optimization. In Proceedings of the 2022 34th Chinese Control and Decision Conference (CCDC), Hefei, China, 15–17 August 2022; pp. 1787–1792. [Google Scholar]
- Li, Y.; Wang, K.; Kang, Y.; Zhao, Y.; Bai, P. Board-level Functional Test Selection Based on Fault Tree Analysis. In Proceedings of the 2023 6th International Symposium on Autonomous Systems (ISAS), Nanjing, China, 12–14 May 2023; pp. 1–6. [Google Scholar]
- Wang, C.; Wang, L.; Chen, H.; Yang, Y.; Li, Y. Fault Diagnosis of Train Network Control Management System Based on Dynamic Fault Tree and Bayesian Network. IEEE Access 2021, 9, 2618–2632. [Google Scholar] [CrossRef]
- Q/GDW 10364-2020; Technical Specification for Single Phase Smart Electricity Meters. Ministry of Science and Technology, State Grid Corporation of China: Beijing, China, 2020.
- Saadatmand, H.; Akbarzadeh-T, M.-R. Many-Objective Jaccard-Based Evolutionary Feature Selection for High-Dimensional Imbalanced Data Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 8820–8835. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, X.; Jia, X. Scale-Adaptive NN-Based Similarity for Robust Template Matching. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Li, J.; Chen, R.; Huang, X.; Qu, Y. Development of Deep Residual Neural Networks for Gear Pitting Fault Diagnosis Using Bayesian Optimization. IEEE Trans. Instrum. Meas. 2022, 71, 1–15. [Google Scholar] [CrossRef]
- Ma, W.; Tan, L.; Feng, H.; Ma, S.; Cao, D.; Yin, C. A Data-Driven LSTM Soft Sensor Model Based on Bayesian Optimization for Hydraulic Pressure Measurement of Excavator. IEEE Sens. J. 2023, 23, 25749–25759. [Google Scholar] [CrossRef]
- Wei, L.; Sun, Y.; Diao, Q.; Xu, H.; Tan, X.; Fan, Y. State of Health Estimation of Lithium-Ion Batteries Based on Stacked-LSTM Transfer Learning With Bayesian Optimization and Multiple Features. IEEE Sens. J. 2024, 24, 37607–37619. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test | Interference Sources |
|---|---|
| Accuracy Tests | temperature |
| External Influence Tests | transient overvoltage, power supply quality, electromagnetic interference, temperature |
| Climatic Impact Tests | high temperature, low temperature, high humidity, sunlight radiation |
| Mechanical Tests | mechanical shock, dust, thermal overload |
| Electrical Performance Tests | overvoltage |
| Insulation Tests | overvoltage |
| Tariff Control Security Tests | power supply quality |
| Reliability Verification Tests | temperature, humidity, operating hours |
| Number | Feature |
|---|---|
| 1–5 | Mean, standard deviation, skewness, kurtosis, and range of metering error at 1.0 power factor |
| 6–10 | Mean, standard deviation, skewness, kurtosis, and range of metering error at 0.5 L power factor |
| 11–15 | Mean, standard deviation, skewness, kurtosis, and range of daily timing error |
| 16 | Urban area indicator (0 or 1) |
| 17 | Overcurrent frequency (times/year) |
| 18 | Power outage duration (hours) |
| 19 | Distance to coastline (km) |
| 20 | Manufacturer failure rate (%) |
| 21 | Batch failure rate (%) |
| 22 | Operating duration (year) |
| 23 | Temperature (℃) |
| 24 | Humidity (%RH) |
| 25 | Undervoltage frequency (times/year) |
| Parameter | Search Space |
|---|---|
| learning_rate | Real (0.01, 0.3), log-uniform |
| max_depth | Integer (3, 10) |
| n_estimators | Integer (50, 300) |
| γ | Real (0, 5) |
| subsample | Real (0.6, 1) |
| colsample_bytree | Real (0.6, 1) |
| reg_alpha | Real (0.001, 10), log-uniform |
| reg_lambda | Real (0.001, 10), log-uniform |
| n_iter | 50 |
| CV folds | 5 |
| Invidual | Features | N | MSE | R2 |
|---|---|---|---|---|
| 1 | [2, 5, 13, 14, 21, 22, 25] | 7 | 0.0043 | 0.7239 |
| 2 | [13, 14, 21, 22, 25] | 5 | 0.0059 | 0.7217 |
| 3 | [5, 21, 22, 25] | 4 | 0.0098 | 0.6425 |
| 4 | [21, 22, 25] | 3 | 0.0127 | 0.4759 |
| 5 | [21, 22] | 2 | 0.0948 | 0.1579 |
| 6 | [21] | 1 | 0.1548 | 0.0456 |
| Number | Feature |
|---|---|
| 2 | Standard deviation of metering error at 1.0 power factor |
| 5 | Range of metering error at 1.0 power factor |
| 13 | Skewness of daily timing error |
| 14 | Kurtosis of daily timing error |
| 21 | Batch failure rate (%) |
| 22 | Operating duration (year) |
| 25 | Undervoltage frequency (times/year) |
| Methods | Top 7 Features | N | MSE (95% CI) | R2 (95% CI) |
|---|---|---|---|---|
| All features | All features | 25 | 0.0049 [0.0039, 0.0055] | 0.6638 [0.6595, 0.7560] |
| Proposed algorithm | [21, 22, 25, 2, 13, 5, 14] | 7 | 0.0042 [0.0040, 0.0052] | 0.7228 [0.6485, 0.7458] |
| Mutual Information | [22, 21, 12, 6, 1, 11, 15] | 7 | 0.0057 [0.0050, 0.0063] | 0.6329 [0.5955, 0.6759] |
| RFE | [21, 24, 2, 1, 12, 15, 7] | 7 | 0.0080 [0.0078, 0.0081] | 0.4832 [0.4765, 0.4955] |
| SFS | [21, 24, 25, 22, 7, 16, 2] | 7 | 0.0054 [0.0047, 0.0073] | 0.6543 [0.5279, 0.7008] |
| Lasso regression | [21, 24, 23, 6, 2, 7, 10] | 7 | 0.0080 [0.0078, 0.0081] | 0.4869 [0.4821, 0.4963] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Xiao, X.; Zhang, Z.; Liu, W. A Feature Engineering Framework for Smart Meter Group Failure Rate Prediction. Mathematics 2025, 13, 2472. https://doi.org/10.3390/math13152472
Li Y, Xiao X, Zhang Z, Liu W. A Feature Engineering Framework for Smart Meter Group Failure Rate Prediction. Mathematics. 2025; 13(15):2472. https://doi.org/10.3390/math13152472
Chicago/Turabian StyleLi, Yihong, Xia Xiao, Zhengbo Zhang, and Wenao Liu. 2025. "A Feature Engineering Framework for Smart Meter Group Failure Rate Prediction" Mathematics 13, no. 15: 2472. https://doi.org/10.3390/math13152472
APA StyleLi, Y., Xiao, X., Zhang, Z., & Liu, W. (2025). A Feature Engineering Framework for Smart Meter Group Failure Rate Prediction. Mathematics, 13(15), 2472. https://doi.org/10.3390/math13152472