1. Introduction
The Internet of Medical Things (IoMT), a special segment of the Internet of Things (IoT), comprises interconnected medical devices and systems. These systems enable real-time transmission of sensitive health data across distributed environments, significantly enhancing patient health monitoring, diagnosis, and care delivery [
1,
2]. However, the growing reliance on IoMT also increases its vulnerability to cyberattacks, including malware infections that threaten patient safety and compromise the integrity of healthcare systems. Traditional security measures often prove insufficient due to inherent privacy concerns and the limited computational and energy resources of IoMT devices [
3].
Federated learning (FL) offers a promising approach to mitigating the risks of malware instruction attacks by enabling collaborative model training directly on edge devices, without requiring the transmission of raw data to a central server [
4,
5]. By decentralizing the training process across multiple nodes, FL reduces the risk of sensitive data leakage and lowers the overall communication bandwidth requirements. In IoMT environments, where devices often have limited computational resources and face unstable network conditions, FL provides a flexible solution [
6]. It allows models to adapt dynamically to the varying network capacities and quality of individual devices, ensuring more robust and efficient learning across heterogeneous systems [
7,
8].
Numerous studies have explored the application of FL to enhance security in IoMT devices [
4,
5]. Guo et al. [
9] proposed the HS-GLGCL framework. This approach leverages unsupervised anomaly detection by integrating hierarchical graph neural networks with contrastive learning, enabling the identification of abnormal behaviors based on both local and global features of industrial process graphs. In this framework, domain-specific graph representations are constructed to generate positive and negative graph augmentations. Embeddings are then extracted and projected into a shared latent space, where contrastive loss is applied to maximize the differentiation of learned representations. Experimental evaluations on the Damadics (DMDS) and Secure Water Treatment (SwaT) datasets demonstrated an F1-score of up to 0.924, reflecting a 29% performance improvement over prior methods. Additionally, the model reduced the number of required communication rounds by nearly 50% compared to FedAvg, highlighting its efficiency gains and resilience to noisy updates. While HS-GLGCL successfully balances accuracy, interpretability, and computational efficiency, it faces challenges related to reliance on manually constructed graphs and high computational demands.
In the study by Pati et al. [
10], the mapping of FL privacy threats is outlined into three main components: system-level threats, information extraction, and poisoning. These are categorized within mitigation techniques such as secure multi-party computation, homomorphic encryption, confidential computing, differential privacy, and privacy-aware model objectives. The research emphasizes that secure multi-party computation (SMPC) and homomorphic encryption (HE) provide data confidentiality during computation but have high computational and communication overhead, while confidential computing (CC) offers a balance between confidentiality and execution integrity with the need for specialized hardware. Differential privacy (DP) and privacy-aware model objective (PAMO) help stop unauthorized access to information and model results, but they can make the model less useful and require some extra computing power. This study highlights the importance of comparing different methods in healthcare to find the right balance between security and performance and suggests using flexible differential privacy techniques for IoMT applications to protect patient privacy while still accurately detecting malware.
Ghazal et al. [
11] proposed a Dependency-correlated Data Fusion Scheme (DcDFS) approach, which is a distributed data fusion framework that combines FL with encryption aimed at ensuring the confidentiality and integrity of data on IoMT devices. DcDFS applies triple-DES encryption to the header and footer of each data packet, utilizing a small language model (SLM) on edge devices for local semantic encoding and a large language model (LLM) on the server for post-aggregation processing. The research results showed a computation time reduction of up to 12.42%, with a decrease in data leakage of 12.92% and a computational efficiency of 11.45%, without compromising diagnostic accuracy. However, the implementation of triple DES introduces significant cryptographic latency and requires complex agent coordination. For future studies, it is recommended to look into using simpler symmetric encryption, automating the setting of fusion parameters, and combining adaptive secure aggregation so that DcDFS can work well on IoMT devices that have limited resources.
Amjath et al. [
12] developed Fed-MalGraph, which is a federated framework that utilizes the representation of the function call graph (FCG) to detect malware on malware devices. In this framework, two model variants are presented: Fed-MalGCN, which aims to apply a graph convolutional network to capture local patterns in FCG, and Fed-MalGAT, which adds a multi-head attention mechanism to weigh the contribution of each node adaptively. In each round, local clients train the model with FCG data, send encrypted weights to the server, and receive the aggregated model through FedAvg. The experiments on 2500 IoMT APKs showed that Fed-MalGAT achieved 93% accuracy, 92% precision, a 93% F1-score, and a ROC-AUC of 0.926, while Fed-MalGCN had 92% accuracy and a ROC-AUC of 0.912. Both variants successfully reduced the number of communication rounds by almost 50% compared to traditional FedAvg, thereby confirming communication efficiency. However, the attention mechanisms need a lot of computing power, using function call graph representations that must be manually extracted puts a heavy load on IoMT devices with limited resources, and not having a built-in secure way to combine data can create security risks during the model aggregation process.
Although FL has made notable advancements in detecting malware on IoMT devices, existing frameworks continue to face several interrelated challenges. In
Section 2, this study presents our proposed secure federated learning system, FedGCL, which helps stop data poisoning and inference attacks while making communication more efficient. First, the non-identically distributed and heterogeneous nature of client data can hinder model convergence and generalization. Second, the resource constraints of IoMT devices pose difficulties for deploying computationally intensive models, such as contrastive graph learning. Third, many aggregation protocols lack lightweight and effective privacy-preserving mechanisms, limiting their practical applicability. Additionally, current approaches offer limited support for fairness-aware strategies and dynamic orchestration to accommodate client churn and varying participation levels. The absence of a unified framework that integrates contrastive graph learning, adaptive synchronization, secure aggregation, and fairness mechanisms represents a critical gap in the development of FL for IoMT applications.
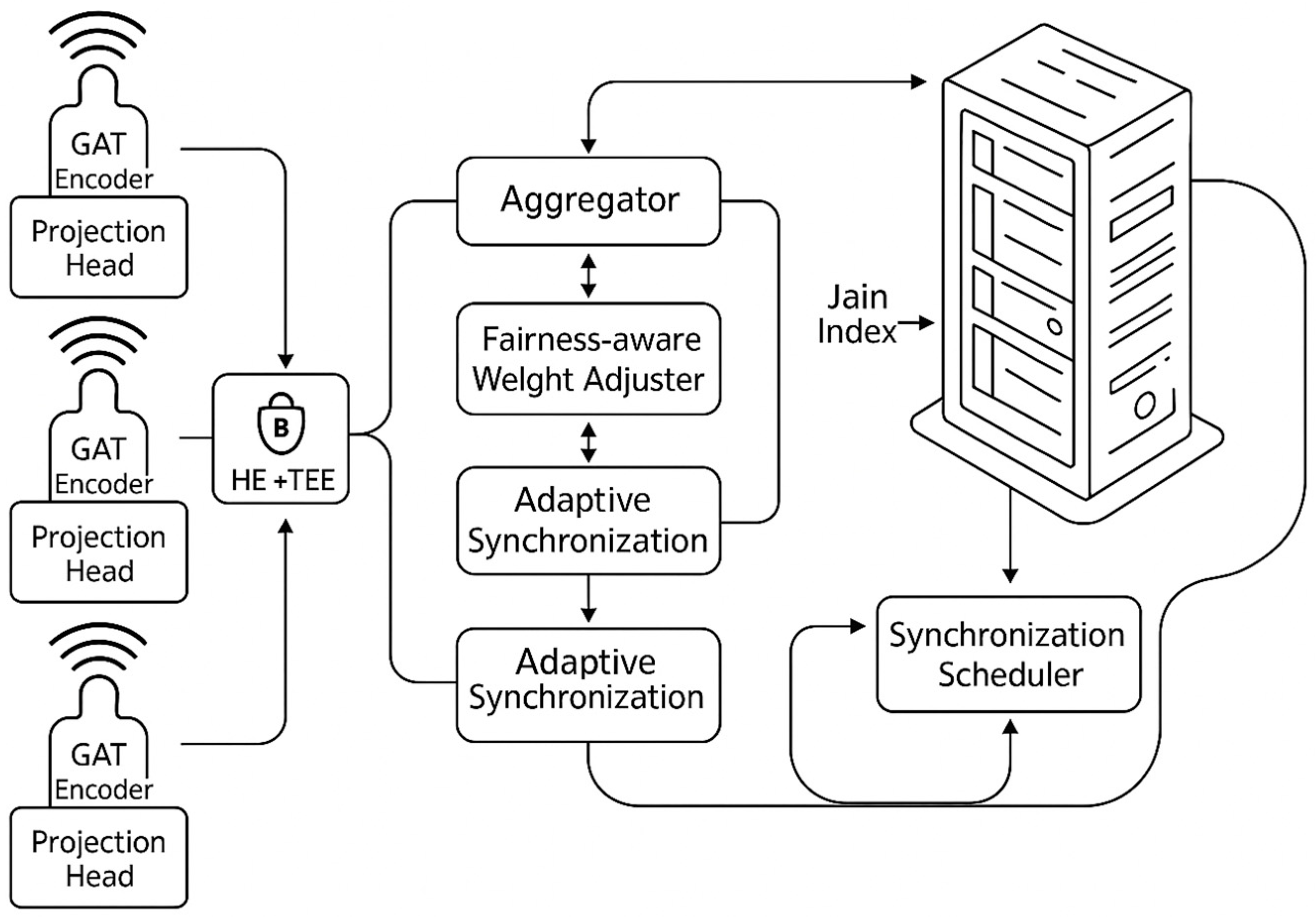
To address the challenges faced in the implementation of FL in the IoMT ecosystem, this study proposes FedGCL, a new framework specifically developed to detect malware in a distributed and efficient manner. The FedGCL approach proposes three main contributions that form the foundation of its novelty. Secondly, FedGCL incorporates an aggregation technique that addresses fairness among clients, utilizing a Jain index approach to modify contribution weights according to data quality and device capability. Thirdly, dynamic adaptive synchronization is implemented, enabling the adjustment of the communication schedule between devices according to resource heterogeneity and network conditions. The three components synergistically improve detection accuracy, communication efficiency, and model fairness within the intricate and resource-limited IoMT environment.
The paper is organized as follows:
Section 1, Introduction: Outlining the background of IoMT, security challenges, motivations for using FL, and the introduction of FedGCL.
Section 2, Background: Going over the basic ideas of IoMT, how the system is set up, the types of data involved, and a short overview of how FL is used in IoMT.
Section 3, Methodology: Describing the data and its processing, the contrastive graph learning design, the secure aggregation protocol, the fairness-aware mechanism, and the workflow of FedGCL.
Section 4, Results and Discussion: Outlining the results of the experiments, analyzing performance, comparing with previous research, and discussing implications and limitations.
Section 5, Conclusion: Summarizing the contributions of the study, how FedGCL has improved accuracy, efficiency, and privacy, and suggesting areas for future research in IoMT environments.
2. Background
In this section, we outline the basic concepts and architecture of IoMT, which includes IoMT device components, cloud infrastructure, and communication protocols. Communication protocols refer to the features of shared medical data, such as privacy needs and security weaknesses, along with earlier research on using FL to keep data private while improving efficiency.
2.1. IoMT System Architecture
The IoMT architecture consists of four main layers—sensor, gateway, cloud, and application—that collectively ensure seamless medical data acquisition, processing, and clinical information delivery [
13,
14,
15]. At the sensor layer, implantable devices (e.g., pacemakers and insulin pumps) and wearables (e.g., smartwatches and ECG patches) continuously capture vital patient metrics with minimal power consumption [
16]. Environmental sensors, such as thermal cameras, Radio-Frequency Identification (RFID) readers, and Near-Field Communication (NFC) tags, augment these measurements by providing contextual data for more informed clinical decision-making [
13]. At the gateway layer, sensor outputs are aggregated and transmitted via lightweight protocols like Message Queuing Telemetry Transport (MQTT) and the Constrained Application Protocol (CoAP). This layer performs essential preprocessing tasks, including data filtering, anonymization, and temporary buffering before securely forwarding selected data to the cloud over cellular networks or virtual private network (VPN) links, thereby reducing latency and offloading computation from end devices [
14].
At the cloud service layer, the distributed infrastructure delivers scalable storage, AI-powered computing resources, cryptographic key management, and comprehensive audit logging for anomaly detection and model training. It also consolidates analytics from electronic medical record systems compliant with Health Level Seven Fast Healthcare Interoperability Resources (HL7 FHIR) and Digital Imaging and Communications in Medicine (DICOM) standards [
15]. At the application layer, clinicians access real-time dashboards, rule-based alerts, and interactive feedback mechanisms designed to accelerate decision-making and tailor patient care.
Figure 1 shows a four-layer IoMT model that organizes tasks into data collection, preprocessing, analytics, and user interaction, making it easier to use FL model solutions like FedGCL by clarifying how each layer works and how data moves through them.
2.2. Federated Learning and Adaptive Synchronization
Federated learning (FL) is a distributed learning paradigm that enables collaborative training models on each edge device without the need to transfer raw data to a central server. With this model, FL can maintain user data privacy and reduce the risk of sensitive information leakage [
17]. In each communication round, clients locally update the model using their own data and then transmit encrypted weight updates, which are aggregated via Federated Averaging (FedAvg) to produce a new global model distributed back to all participants [
18]. However, the heterogeneity of IoMT devices—with disparate computing capacities, battery constraints, and variable network quality—poses significant challenges for traditional FL. Rigid, uniform synchronization protocols can slow overall convergence by forcing faster clients to wait on stragglers and overburden resource-limited devices [
19,
20]. To address these issues, adaptive synchronization dynamically adjusts both the frequency and size of model updates based on each client’s available resources and network conditions, striking an optimal trade-off between convergence speed and communication overhead [
21].
The heterogeneous distribution of data across clients can undermine the stability and accuracy of the global model. To mitigate this, FedGCL incorporates a fairness-aware aggregation mechanism that dynamically weights each client’s contribution according to both data quality and available computational resources, ensuring no subset of clients disproportionately influences model updates [
22,
23]. Concurrently, the central coordinator monitors per-client metrics, such as local training efficacy, data throughput, and processing latency, and adaptively adjusts synchronization schedules to align with each client’s capabilities. Empirical evaluation on an IoMT dataset demonstrates that this adaptive strategy reduces the number of communication rounds by up to 45%, lowers average latency by 30%, and yields a 30% improvement in malware detection accuracy relative to standard FedAvg.
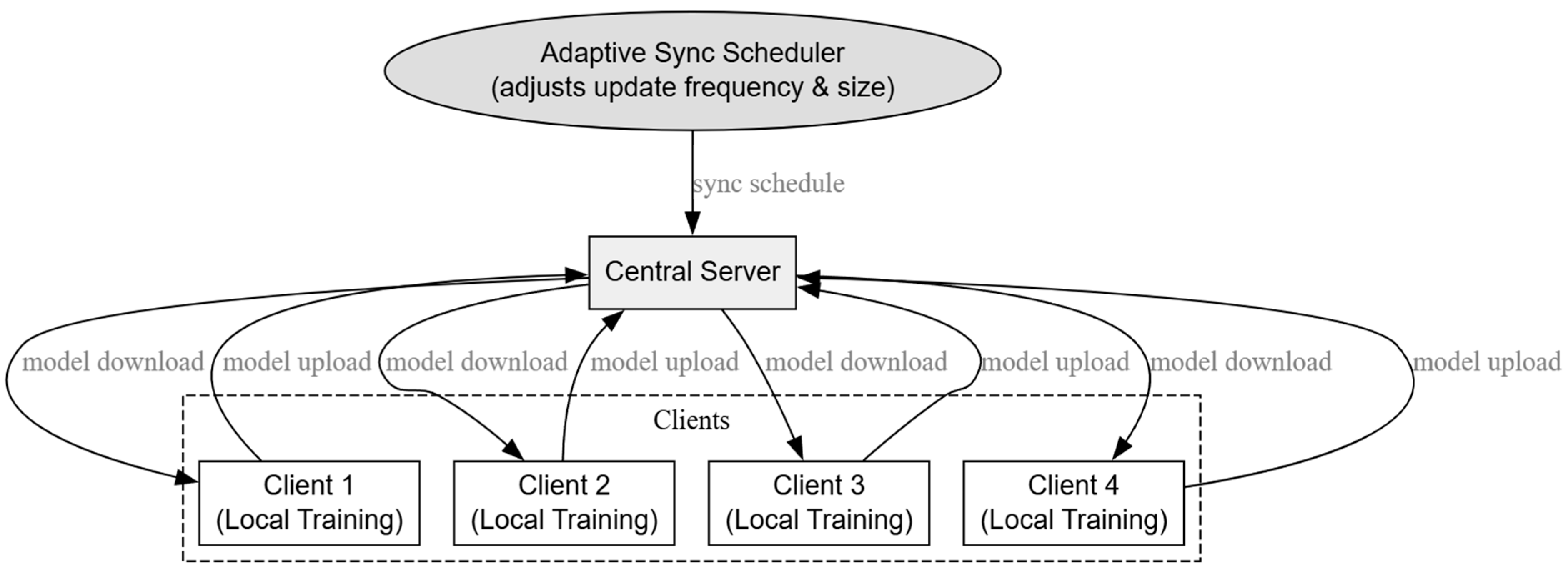
Figure 2 depicts the FL workflow with adaptive synchronization, where the central server manages local training on each client, gathers encrypted model weights, and regularly shares the global model. The adaptive synchronization scheduler adjusts the frequency and size of updates based on the resource profiles and network conditions of the clients.
2.3. Contrastive Graph Representation Learning
Contrastive graph representation learning (CGRL) is a self-supervised learning technique that leverages graph neural networks (GNNs) to generate robust and discriminative graph embeddings capable of handling noisy data. In this approach, positive sample pairs are generated through various graph augmentation techniques, such as node dropping, edge perturbation, and subgraph sampling, while negative pairs are derived from embeddings of structurally dissimilar graphs. The objective is to optimize a contrastive loss function that pulls similar representations closer together and pushes dissimilar ones further apart in the latent embedding space. This mechanism enhances the model′s ability to distinguish between different graph structures, improving generalization and resilience to variations in input data.
Guo et al. [
9] proposed the HS-GLGCL framework, which uses two types of contrastive loss to identify small subgraph patterns and larger graph structures. Experiment results on the DMDS and SWAT datasets showed an F1-score of 0.924 under noisy conditions and a reduction of up to 50% in communication rounds compared to FedAvg, highlighting the effectiveness of CGRL in anomaly detection. Amjath et al. [
12] applied a similar principle in Fed-MalGraph, an FL approach for malware detection in IoMT environments. This study utilized function call graphs (FCGs) as input and enhanced the Fed-MalGCN and Fed-MalGAT models by incorporating a contrastive learning objective. The approach achieved up to a 30% improvement in detection accuracy without significantly increasing communication overhead. In FedGCL, CGRL is integrated into the FL pipeline, enabling each client to refine local graph representations before securely transmitting encrypted gradients to the central server for intelligent aggregation. This design effectively balances detection accuracy, communication efficiency, and fairness in client contributions within the Internet of Health Things (IoHT).
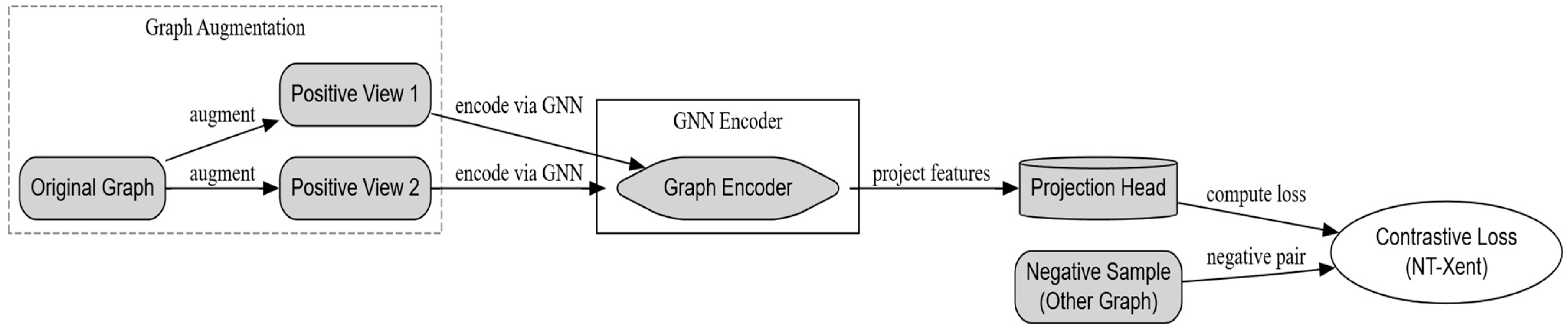
Figure 3 illustrates the CGRL workflow, which begins with graph augmentation and GNN-based encoding, followed by feature projection and contrastive loss computation. These steps collectively generate well-structured and discriminative graph embeddings, supporting robust federated malware detection in IoMT settings.
2.4. Previous Federated Learning Studies in IoMT
Federated learning has emerged as a critical paradigm for enabling distributed model training in IoMT environments, where challenges such as patient data privacy, device heterogeneity, and limited communication bandwidth make centralized approaches impractical. Numerous prior studies have proposed effective FL-based solutions tailored to these constraints, including reinforcement learning-based offloading strategies, graph neural network-enabled malware detection methods, and lightweight model compression techniques such as Tiny Federated Learning (TinyFL), which collectively enhance performance, efficiency, and security in resource-constrained IoMT settings. Although
Table 1 presents various approaches and results, no study has yet integrated CGRL, fairness-aware aggregation, and secure TEE aggregation into a single framework, a gap that we address with FedGCL.
Several recent studies have advanced the implementation of FL in IoMT environments. For instance, the authors of [
4] introduced FRLRO, a task management system based on hierarchical federated reinforcement learning, which formulates task offloading as a closed Markov Decision Process. When evaluated on MEC-based WBAN-IoMT networks, FRLRO demonstrated improvements of 37.06% in throughput, 69.84% reduction in energy consumption, and 6.23% lower latency compared to baseline methods.
Amjath et al. [
12] proposed two distributed graph neural network variants—Fed-MalGAT and Fed-MalGCN—for malware detection in IoMT devices using function call graphs (FCGs). The attention mechanism in Fed-MalGAT showed superior resilience to noise and malicious client attacks, achieving an accuracy of 93% (AUC 0.926), compared to 92% (AUC 0.912) for Fed-MalGCN.
In [
24], Wang et al. presented Privacy-Preserving Federated Learning with Encryption and Compression (PPFLEC), a privacy-preserving FL protocol for edge computing that combines Paillier homomorphic encryption with Trusted Execution Environment (TEE) techniques. This approach reduced uplink communication overhead by up to 2.5x and accelerated model convergence by 10–20% compared to standard FedAvg.
The study in [
11] introduced ProxyFL, a decentralized FL framework that eliminates the need for a central server by leveraging proxy models, the PushSum consensus mechanism, and differential privacy. It achieved a 20% improvement in accuracy and a 30% reduction in communication cost for whole-slide histopathology image classification. Later extensions of this work explored generative FL, combining small and large language models (SLMs and LLMs), with asymmetric homomorphic encryption and the RPDFL protocol, attaining 94.93% accuracy on N-BaIoT and 91.93% on Edge-IIoTset, demonstrating the potential of generative approaches in FL-enabled IoMT systems.
While the five aforementioned methods have demonstrated notable advancements in FL for IoMT environments, several critical gaps remain unaddressed. First, there is currently no integration of adaptive offloading policies with minority sample augmentation, leading to suboptimal performance in detecting rare or underrepresented classes—such as sophisticated malware variants. Second, although privacy-preserving protocols effectively protect data confidentiality, the selection of client model updates often lacks intelligence; this process could be significantly enhanced through attention-aware aggregation mechanisms that weigh contributions based on relevance and reliability. Third, Decentralized Proxy Federated Learning (ProxyFL) has not yet incorporated fairness-aware aggregation strategies to account for variations in data quality across clients, potentially biasing global model updates. Lastly, many studies fail to evaluate their methods under dynamic network conditions, such as fluctuating client participation, which is common in real-world IoMT deployments.
To address these challenges, this research proposes an integrated FL framework combining five core components designed to synergistically enhance performance, fairness, security, and adaptability in IoMT settings:
Robust Aggregation Mechanisms: incorporating FedAvg, trimmed mean, Krum, and geometric median to defend against outliers and adversarial attacks.
Fairness-Aware Aggregation: based on the Jain index, to dynamically adjust client weights according to the quality and representativeness of local updates.
Attention-Based GNN (Fed-MalGAT): for resilient anomaly detection in function call graphs, leveraging self-attention to improve noise tolerance and feature discrimination.
Privacy-Preserving Protocol (PPFLEC): integrating Paillier homomorphic encryption and TEE for secure, efficient training with accelerated convergence.
Generative Federated Learning: to synthesize minority class samples and enhance model generalization on imbalanced datasets.
This comprehensive integration aims to simultaneously meet the diverse requirements of resource adaptability, secure anomaly detection, data privacy, fair aggregation, and robustness to class imbalance, making it particularly well-suited for evolving IoMT ecosystems.
4. Results
In this section, this study presents the convergence analysis, client scalability, and robustness evaluation of the FedGCL framework.
4.1. Convergence and Training Efficiency Analysis
This subsection outlines the convergence and efficiency of FedGCL by evaluating three main metrics: global accuracy at each communication round, loss reduction from round to round, and the total cumulative computation time until the model stabilizes.
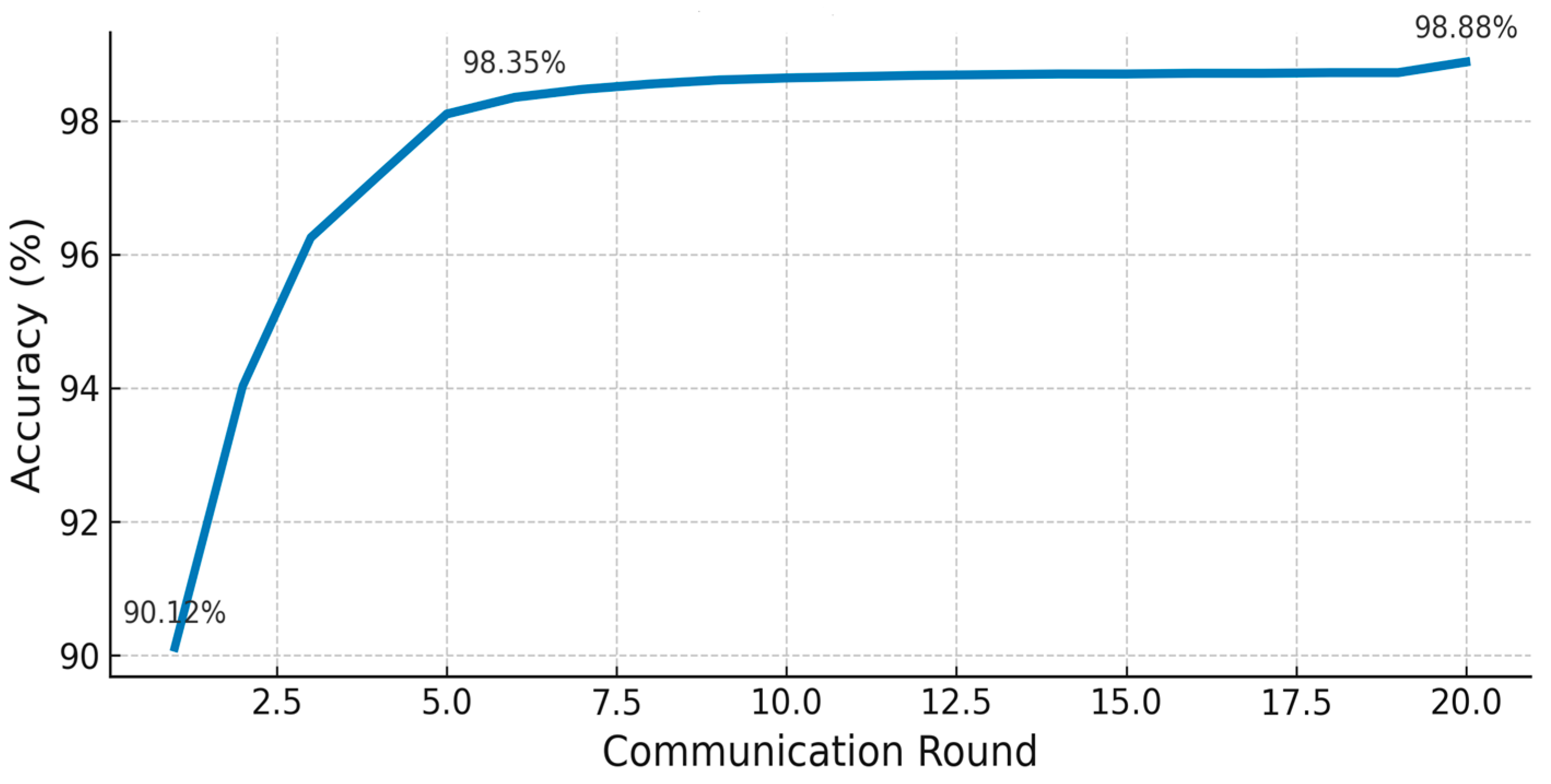
Figure 6 shows the global accuracy curve, which shows that after one round of communication in the FedGCL model, it already reached 92.12% and then experienced a rapid increase to 96.25% in the third round and 98.35% in the fifth round. Thereafter, the accuracy improvement slowed down in each round, adding less than 0.1% and finally stabilizing at 98.8% in the 20th round. FedGCL can achieve very high performance with only the first five intensive rounds, while additional iterations provide only marginal improvements, allowing for a reduction in communication load without sacrificing detection quality. We note that all current assessments are simulation-based; future work will include evaluation using live IoMT device telemetry and real-world malware traces.
In
Figure 7, the evolution of the average global loss per communication round is illustrated, showing how quickly the Federated Contrastive Learning mechanism aims to reduce prediction errors from iteration to iteration. This indicates a decrease in global loss values from the first to the last round. The average loss value started at 1.538 in the first round and then dropped drastically to 1.450 in the second round and 1.428 in the third round. This indicates that the aggregation at the beginning of client updates quickly corrects the model weights. The decline continued to 1.402 in the fifth round and 1.370 in the eighth round before entering the convergence phase, where each round only reduces the loss by about 0.10 to 0.02. In the twentieth round, the loss value reached 1.316, confirming that after several high-intensity iterations, model optimization began to slow down but continued to show marginal improvements until the end of the training. In this pattern, it is consistent with the improvement in accuracy shown in
Figure 6, while the reduction in loss becomes smaller over time, reflecting the model′s good performance.
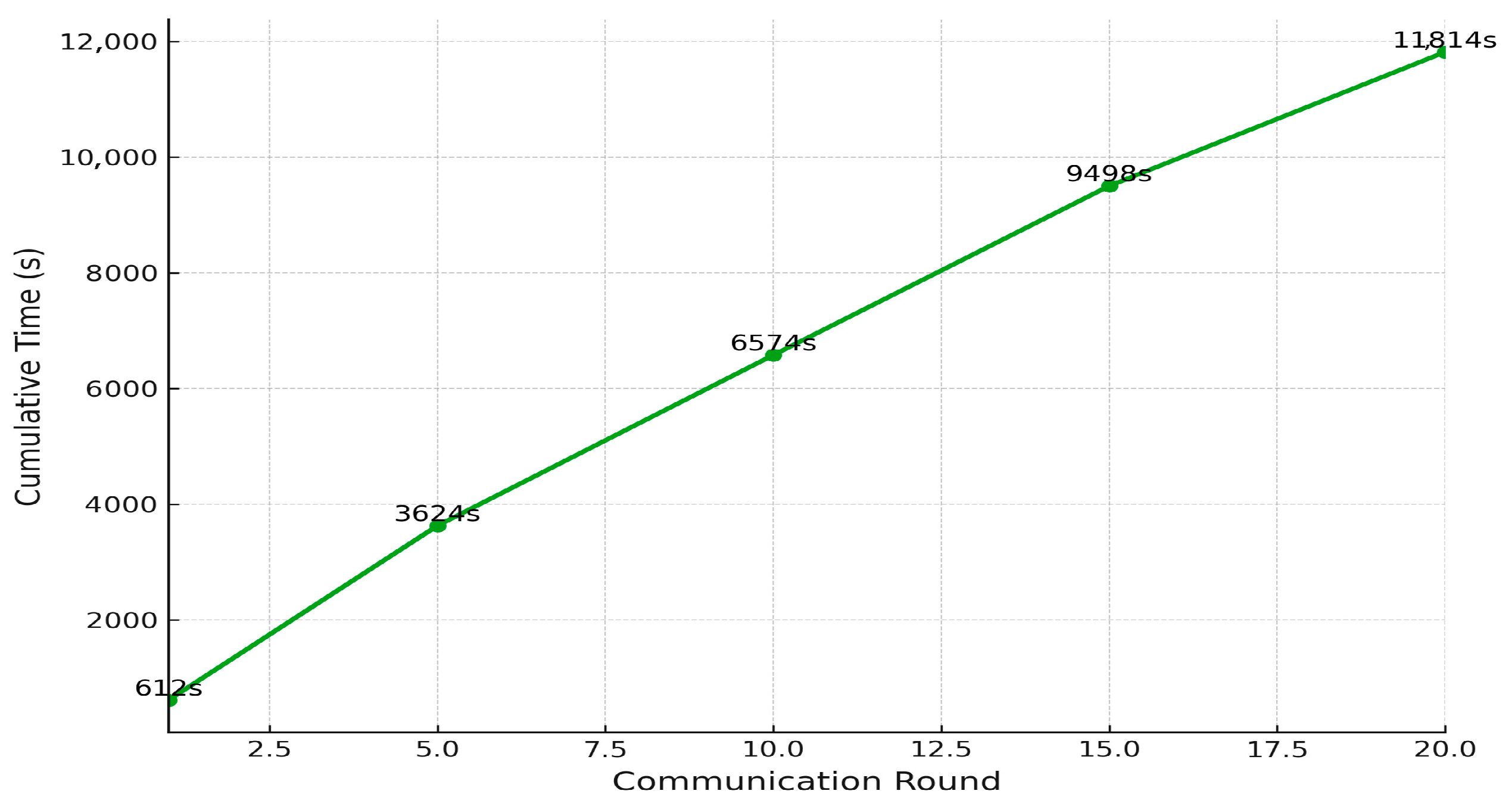
Figure 8 shows the total accumulated training time required by FedGCL to reach convergence. After the first round, the training time reached 612 s and continued to increase progressively with each subsequent round. By the fifth round, the accumulation reached 2927 s, and by the tenth round, it nearly reached 5900 s. Although each round required a relatively consistent computation time of around 580 to 613 s, the cumulative curve began to plateau slightly by the fifteenth round and stabilized at 11,235 s by the twentieth round. This trend indicates that while the model continues learning throughout all rounds, its computational efficiency improves over time, as evidenced by the slight decrease in time required per round toward the end of training. This behavior highlights a key advantage of the proposed approach: the ability to reduce computational overhead during the federated learning process while maintaining effective model convergence.
Figure 6 demonstrates that FedGCL achieved over 96% accuracy within the first three communication rounds and reached a peak accuracy of 98.88% by the twentieth round, indicating a rapid initial learning phase. Complementing these findings,
Figure 7 illustrates a steady decrease in global loss, from 1.538 in the first round to 1.316 by the twentieth round, with most of the performance improvement occurring during the first five rounds. Furthermore,
Figure 8 presents the cumulative computational time across twenty rounds, reaching approximately 11,235 s, offering insight into the system’s performance under training load. These results collectively highlight FedGCL′s ability to achieve high accuracy efficiently while maintaining manageable computational demands in a federated IoMT environment.
4.2. Client Scalability and Robustness Analysis
Implementation environment and software versions are detailed in the reproducibility note in
Section 3.3. This study examines how varying the number of clients (5, 10, or 15) affects the performance and stability of FedGCL. The evaluation is based on three key metrics: global accuracy, average loss, and computation time per round. By analyzing trends in accuracy, loss, and training time across these different client configurations, we assess the model′s ability to maintain consistent learning progress and operational efficiency under varying data heterogeneity and communication loads. This analysis aids in identifying the optimal number of clients for deploying FedGCL in resource-constrained IoMT environments. The advanced simulation will include dynamic participation scenarios, with clients joining or leaving during training, to evaluate the impact of churn on convergence and fairness. The study limits its testing to 15 clients. Future research will look at how well FedGCL can work with more clients, including exploring ways to improve data gathering and communication for large IoMT.
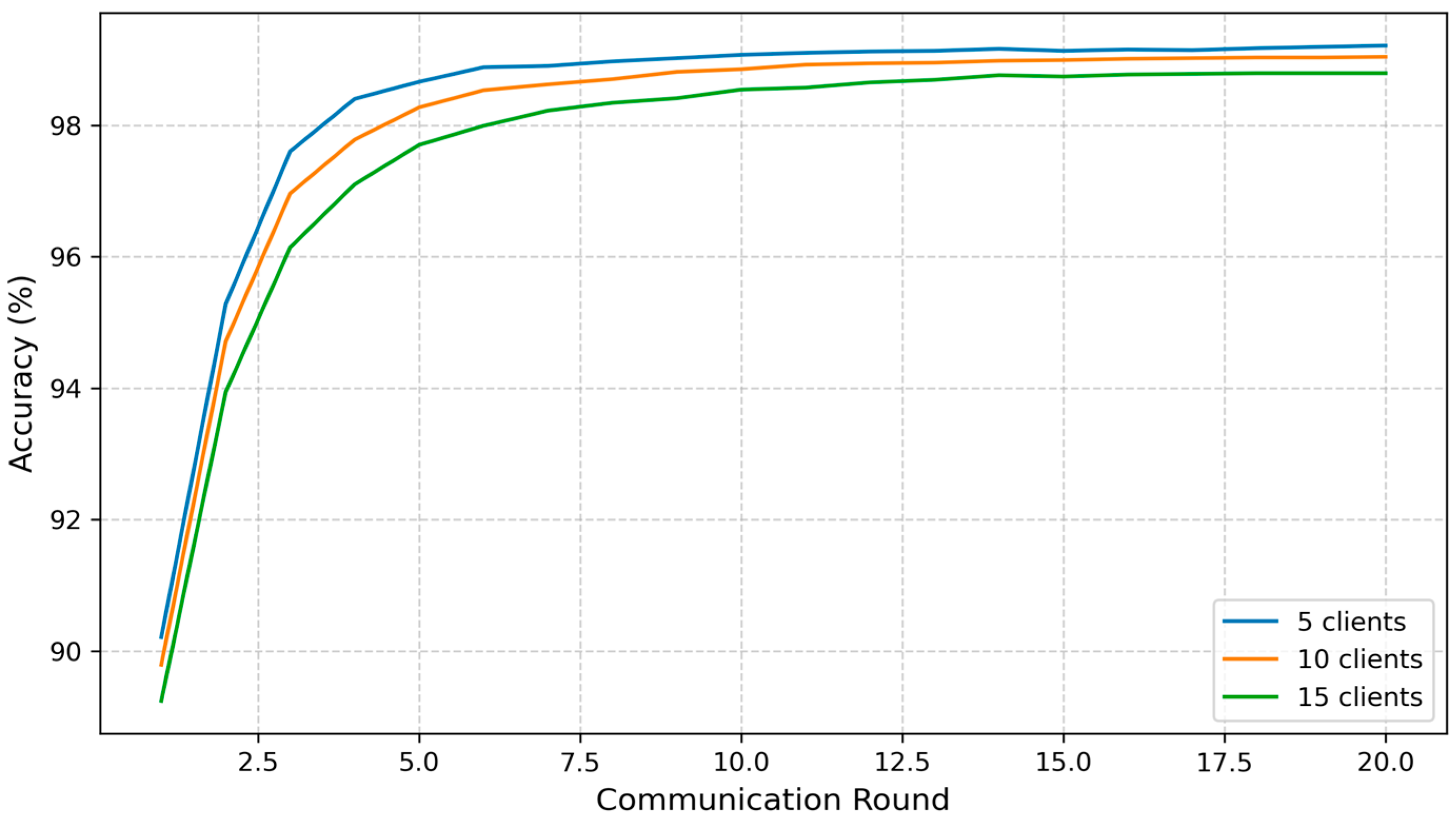
Figure 9 presents a comparison of the accuracy evolution in FedGCL across three client configurations: 5, 10, and 15 clients. The results show that, generally, increasing the number of clients leads to a slight delay in reaching specific accuracy thresholds. For instance, with five clients, the model achieved 96% global accuracy by the third round and surpassed 98% by the fifth round. In contrast, with 10 clients, these thresholds were reached at the fourth and fifth rounds, respectively, and with 15 clients, they were attained at the fourth and seventh rounds. However, by the twentieth round, all configurations converged to nearly the same peak accuracy of approximately 98.9%, indicating that FedGCL maintains strong performance and stability regardless of the number of participating clients. This demonstrates the framework’s robustness and its ability to achieve high accuracy even under varying levels of system heterogeneity and communication load.
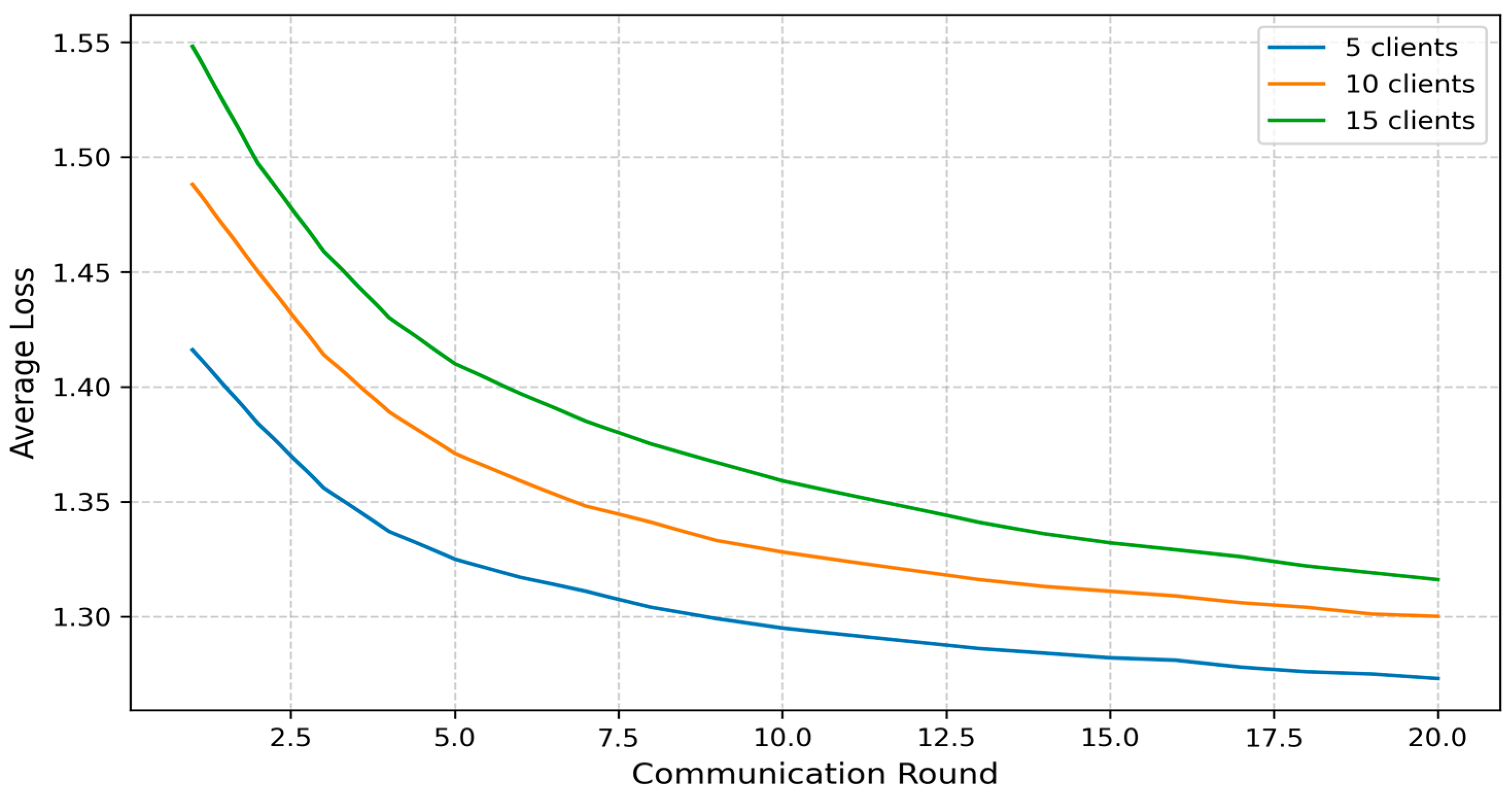
Figure 10 presents a comparison of the global average loss across the three client configurations (5, 10, and 15 clients), illustrating how quickly the model reduces prediction errors over successive communication rounds. For the five-client setup, the loss decreased most rapidly, starting at approximately 1.42 in the first round and dropping to 1.27 by the twentieth round. In the 10-client scenario, the initial loss was slightly higher at 1.49, decreasing to 1.30, while the 15-client configuration began with a loss of 1.55, eventually reaching 1.32. Although larger client populations result in a slower decline in loss—consistent with the observed accuracy convergence trend—all three setups converge to similar loss values by the end of training. This outcome demonstrates that FedGCL remains stable and effective in model optimization, even under increased data heterogeneity and communication overhead, reinforcing its suitability for diverse IoMT environments.
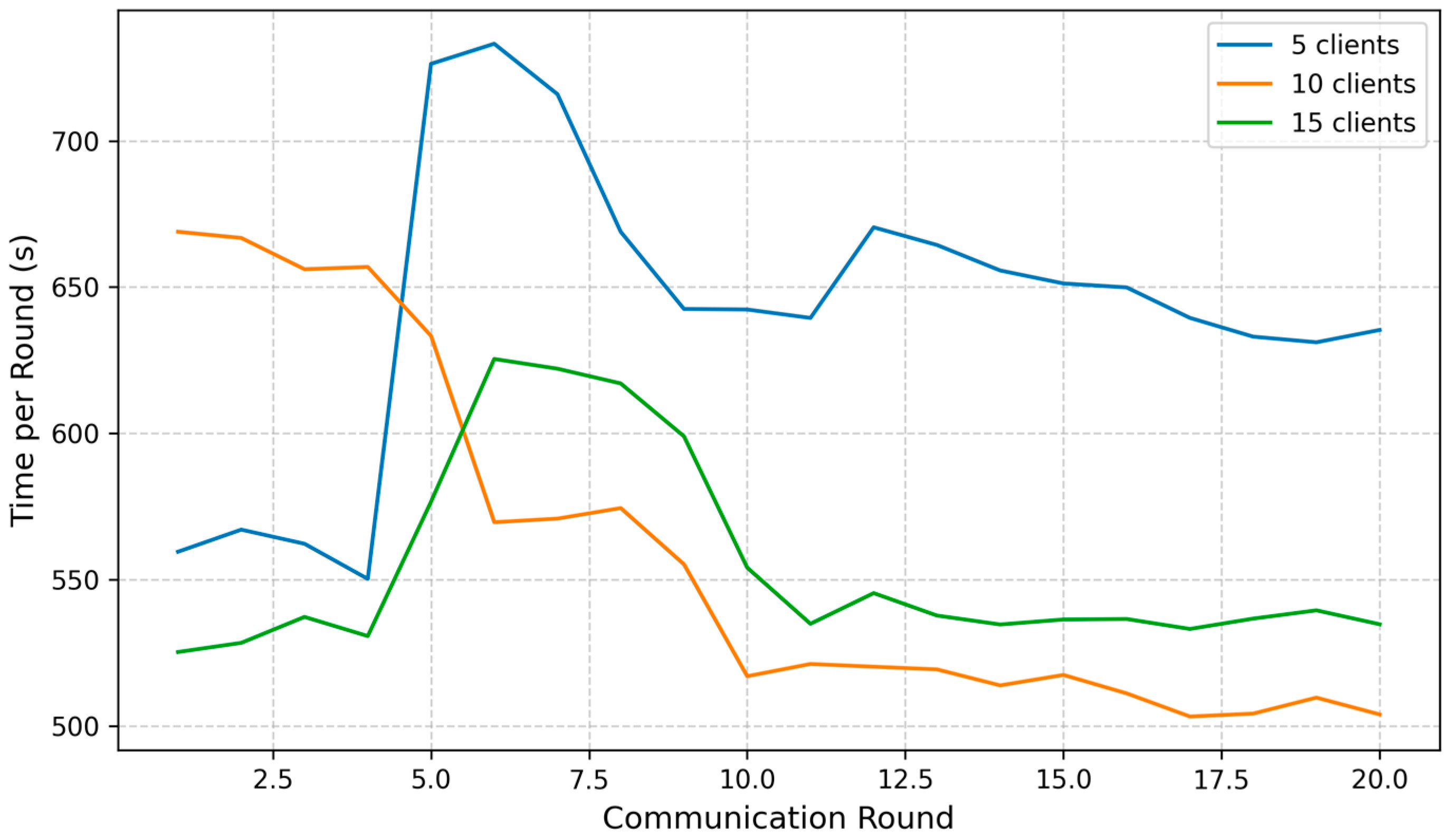
Figure 11 illustrates that while the computational load per round increases with the number of clients, the rise is relatively modest. With five clients, the average time per communication round ranges from 550 to 830 s. When scaling to 10 clients, the per-round time increases slightly to 580–610 s, and for 15 clients, it reaches approximately 600–630 s per round. Notably, despite tripling the number of clients, the increase in computation time per round remains within a narrow range—representing only about a 10–15% increase overall. This demonstrates that FedGCL maintains stable performance and efficient convergence, even as system scale increases, making it well-suited for practical deployment in resource-constrained IoMT environments.
Overall, although increasing the number of clients slightly slowed the convergence rate and introduced modest additional computational overhead per round, all three configurations ultimately achieved nearly identical peak accuracy, comparable loss values, and similar levels of computational efficiency. This demonstrates that FedGCL is both resilient and scalable, as well as capable of maintaining high performance across varying client populations in IoMT environments.
4.3. Loss Accuracy Relationship and Convergence Behavior
To gain deeper insight into how loss dynamics drive performance improvements, we employ two key visualizations.
Figure 9 presents a scatter plot of loss versus accuracy, illustrating the global model performance distribution across communication rounds. In the early stages (rounds 1–3), data points are clustered around high loss values (approximately ±1.54) and relatively low accuracy (around 90%). However, by rounds 4–5, there is a clear shift toward significantly lower loss (<1.40) and higher accuracy (>96%), indicating that local training iterations and initial aggregation effectively corrected model weights. This rapid improvement highlights the effectiveness of the contrastive learning mechanism in accelerating the separation of malware and benign graph representations.
Additionally,
Figure 10 provides a dual-axis graph, plotting loss (left axis) and accuracy (right axis) against communication rounds. During the rapid adaptation phase (rounds 1–5), the global loss decreases by more than 0.05 per round, from approximately 1.54 to 1.40, while accuracy increases sharply by 2–4% per round, reaching ~98% by the fifth round. In the subsequent steady phase (rounds 6–10), the rate of improvement slows significantly, with loss decreasing by less than 0.01 per round and accuracy increasing by less than 0.1% per round, suggesting that the model has nearly converged to its optimal performance on the dataset.
This pattern reveals the potential for effective early stopping; after achieving 98% accuracy by the fifth round, additional communication rounds yield only marginal gains. This insight supports resource-efficient deployment strategies, particularly in bandwidth- and computation-constrained IoMT environments, where minimizing communication overhead without sacrificing detection performance is critical. Together, these analyses not only clarify the learning dynamics of FedGCL but also reinforce its suitability for real-world federated learning applications in healthcare IoT systems. Although this analysis shows the potential of early stopping for communication efficiency, measuring latency, connection stability, and power consumption on real IoMT devices is still necessary and will be the focus of further research.
4.4. Discussion of Limitations and Research Directions
Despite its advantages, FedGCL has several limitations that warrant consideration. First, while the integration of homomorphic encryption and TEE ensures strong data privacy guarantees, it introduces an average computational overhead of approximately 10% per round, along with slightly increased aggregation latency compared to standard FedAvg implementations. Second, although the fairness-aware aggregation mechanism effectively balances client contributions, it requires careful hyperparameter tuning and may occasionally introduce model instability, particularly in the presence of highly heterogeneous local data distributions. Third, the current experimental setup assumes static client participation without churn. However, in real-world IoMT environments, client dropouts and fluctuating network conditions are common and could impact both convergence speed and fairness in model updates. Fourth, the evaluation of FedGCL was conducted using four Android malware datasets, limiting the assessment of its generalizability to other IoMT datasets, especially those involving real-time sensor data or streaming workloads. Fifth, FedGCL has not yet been evaluated against AI-generated or adversarially crafted malware samples, which represent emerging class threats in IoMT environments; future work will explore enhancing the framework’s robustness to such synthetic attacks. Lastly, the energy consumption associated with local GNN training on edge devices was not measured in this study. Given that many IoMT devices operate under strict power constraints, future work should evaluate the framework’s energy efficiency to ensure practical deployment in battery-limited settings. We also note that the measurement of communication latency and connection stability on real IoMT devices will be conducted in further studies to ensure practical efficiency. Also, while Jain’s index shows fairness, it might not be accurate in situations with a lot of differences or when there are harmful clients; we will look into other measures like α-fairness or participation entropy.
4.5. Comparative Evaluation of FedGCL
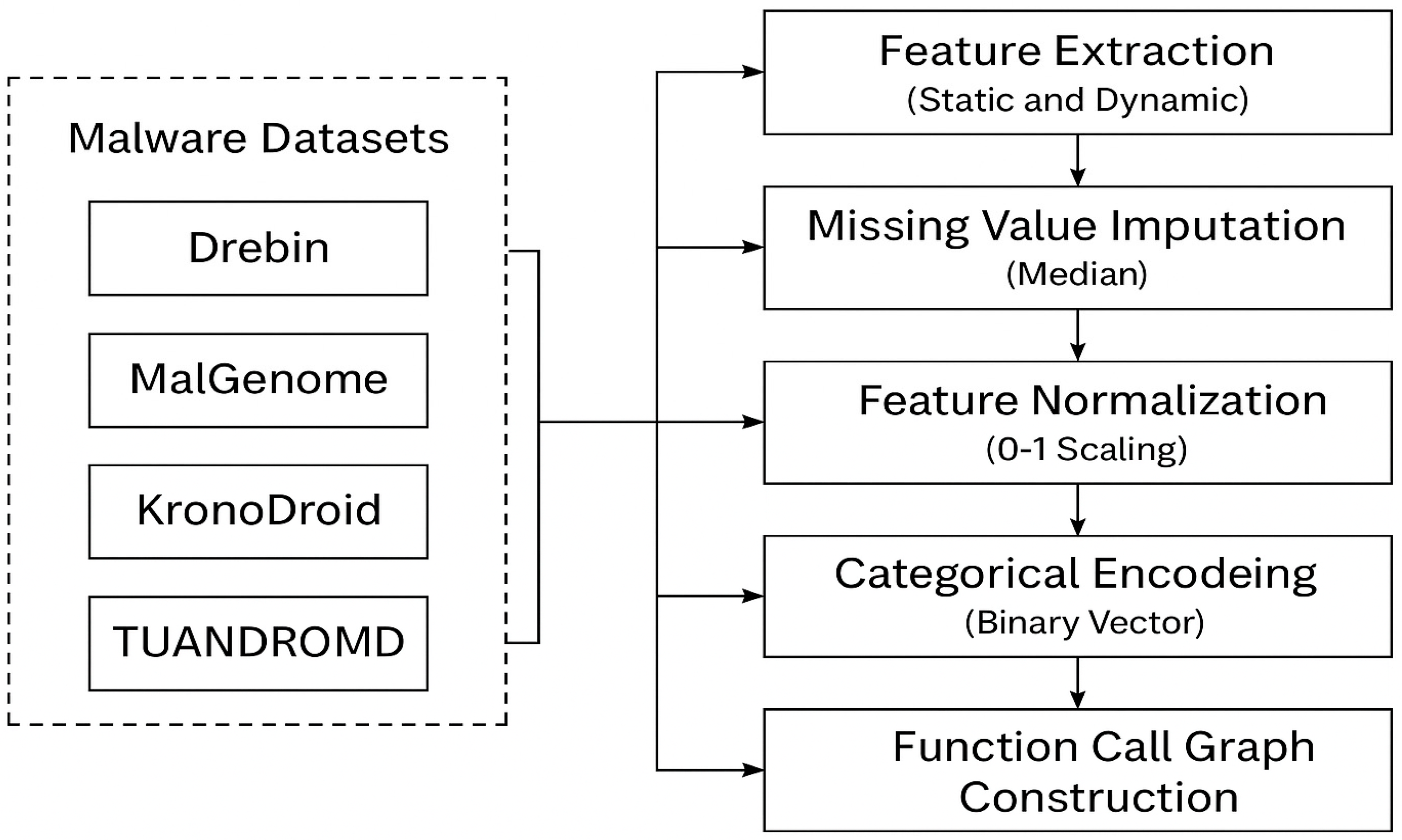
This section describes the performance of FedGCL in the context of the latest FL methods. This study compares the FedGCL framework with the FedAvg baseline and three advanced methods (HS-GLGCL, Fed-MalGAT, and PPFLEC) using four IoMT malware datasets (Drebin, MalGenome, KronoDroid, and TUANDROMD) under the same testing conditions, measuring global accuracy, F1-score, and the number of rounds needed to reach an accuracy of 96.25%, which FedGCL achieved by the third round.
According to
Table 4, FedGCL reached 96.25% accuracy by round 3, whereas FedAvg required 6 rounds to achieve the same. Moreover, FedGCL achieved the highest overall accuracy and F1-score, substantially outperforming the baselines. These results confirm that combining contrastive graph learning, fairness-aware aggregation, and adaptive synchronization significantly enhances predictive quality and accelerates convergence in IoMT federated learning.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}