1. Introduction
The exponential growth of textual data across sectors, such as healthcare, finance, and smart manufacturing, fueled by the widespread adoption of IoT devices, digital services, and user-generated content, has made the effective management and insightful utilization of Big Data critical [
1,
2]. As datasets expand in scale and complexity, the need to employ advanced analytical methods, particularly deep learning and large language models (LLMs), to derive actionable insights has intensified.
LLMs, renowned for their advanced language understanding and generation capabilities, have become indispensable tools for analyzing large-scale textual datasets. They support data-driven decision-making by transforming complex unstructured information into coherent contextually appropriate outputs. Nevertheless, despite their strengths, LLMs encounter critical limitations. Their static nature and lack of integration with real-time, dynamic, and domain-specific knowledge hinders their applicability in practical large-scale Big Data environments [
3,
4,
5,
6]. Domain-specific models such as BloombergGPT [
7] and BioBERT [
8] exemplify attempts to mitigate this issue through specialization.
Retrieval-augmented generation (RAG) architectures have emerged as a promising solution to address these limitations. By retrieving relevant external content from vast embedded textual datasets stored in specialized vector databases (vector stores), RAG enhances the factual accuracy and contextual relevance of LLM-generated outputs [
9,
10]. Nonetheless, traditional RAG systems face notable inefficiencies and a decline in accuracy when scaled to handle substantial volumes of Big Data [
11,
12]. In particular, the retrieval latency increases significantly with the dataset size, while redundant or overlapping data retrieval often degrade the response quality and lead to inefficient use of computational resources [
7,
13]. Furthermore, traditional RAG systems often rely on flat and unstructured data representations, which fail to capture the nuanced semantic relationships among prompt elements. This structural limitation hinders the system’s ability to preserve user intent and contextual coherence during retrieval. As a result, these systems struggle to maintain both efficiency and relevance under the demands of high-volume real-time applications.
This paper introduces a novel structured RAG framework specifically designed for large-scale Big Data analytics. The framework transforms unstructured partial prompts into semantically coherent and clearly structured formats, thereby enhancing the accuracy, context-preservation, and scalability of RAG processes. Our approach integrates element-specific embedding models combined with dimensionality reduction techniques, such as principal component analysis (PCA) [
14], to improve retrieval precision and computational efficiency. In addition, we introduce a multi-level filtering mechanism that integrates element-based semantic constraints and redundancy elimination, ensuring higher precision, reduced latency, and improved response diversity. The final set of partial prompts by the proposed method is then merged to form complete prompts for generation.
2. Related Work
RAG has recently attracted significant attention as an effective method for improving the capabilities of LLMs. The seminal work by Lewis et al. [
9] introduces RAG, which combines dense retrieval methods and transformer-based generative models, significantly improving both factual accuracy and contextual relevance. Subsequent studies, such as REALM [
10], further refine dense passage retrieval techniques, enhancing retrieval precision.
To address scalability and efficiency, Izacard and Grave introduced Fusion-in-Decoder [
11], a method that integrates multiple retrieved passages at the decoder stage. Atlas [
12] introduces few-shot fine-tuning techniques for knowledge-intensive tasks, while adaptive RAG and apeculative RAG frameworks [
7,
13] utilize retrieval step modulation and draft generation to reduce latency. A comprehensive survey [
15] outlines key architectural variations and enhancement strategies. Despite these advancements, challenges such as factual inconsistency and hallucinations persist in open-domain systems.
More recently, RAG has been enhanced via LoRA-based techniques, which improve parameter efficiency and adaptability to new tasks. For example, Choi et al. [
16] proposed a LoRA-enhanced RAG framework that achieved improved accuracy and latency balance. While LoRA has primarily been applied in vision-language models [
17,
18], its integration into retrieval-based natural language processing systems suggests promising directions for future scalability.
Prompt engineering techniques have further enhanced LLM interpretability and control [
19]. Surveys on structured prompts [
20], PromptBench [
21], and reasoning-specific methods such as chain-of-thought prompting [
22] and zero-shot CoT [
20] underscore the effectiveness of well-written prompts.
In terms of vector retrieval, the quality of the embedding remains crucial. Massive benchmarks like MTEB [
23] and domain-specific embedding evaluations [
24] have demonstrated significant variance across models. Dense passage retrieval [
25] remains a strong baseline, and PCA-based reduction [
14] has proven effective in improving computational efficiency without compromising accuracy.
Multi-stage filtering approaches such as IMRRF [
26] and ChunkRAG [
27] have been proposed to further refine output quality, enabling redundancy-aware retrieval pipelines that are better suited for large-scale applications.
Finally, the versatility of RAG and LLM applications is evident across multiple domains. Smart manufacturing workflows leverage LLMs for diagnostics and maintenance optimization [
21,
28]. The finance sector utilizes models like FinGPT for real-time document analysis [
29,
30], while healthcare research increasingly adopts LLMs and RAG for clinical question answering and medical decision support [
31,
32].
3. Structured Prompting and Semantic Filtering Framework
3.1. Overview
When users create prompts, they often face difficulties in writing those prompts. Our system suggests keywords for users by utilizing RAG to deduce recommendable keywords. RAG enhances the factual consistency of LLM outputs by incorporating relevant external information. However, traditional RAG systems frequently encounter challenges such as contextual ambiguity, redundancy, and inefficient processing, especially when handling unstructured text in large-scale applications. To address these limitations, we propose a structured and semantic filtering framework to enhance the retrieval precision, semantic coherence, and output diversity. As illustrated in
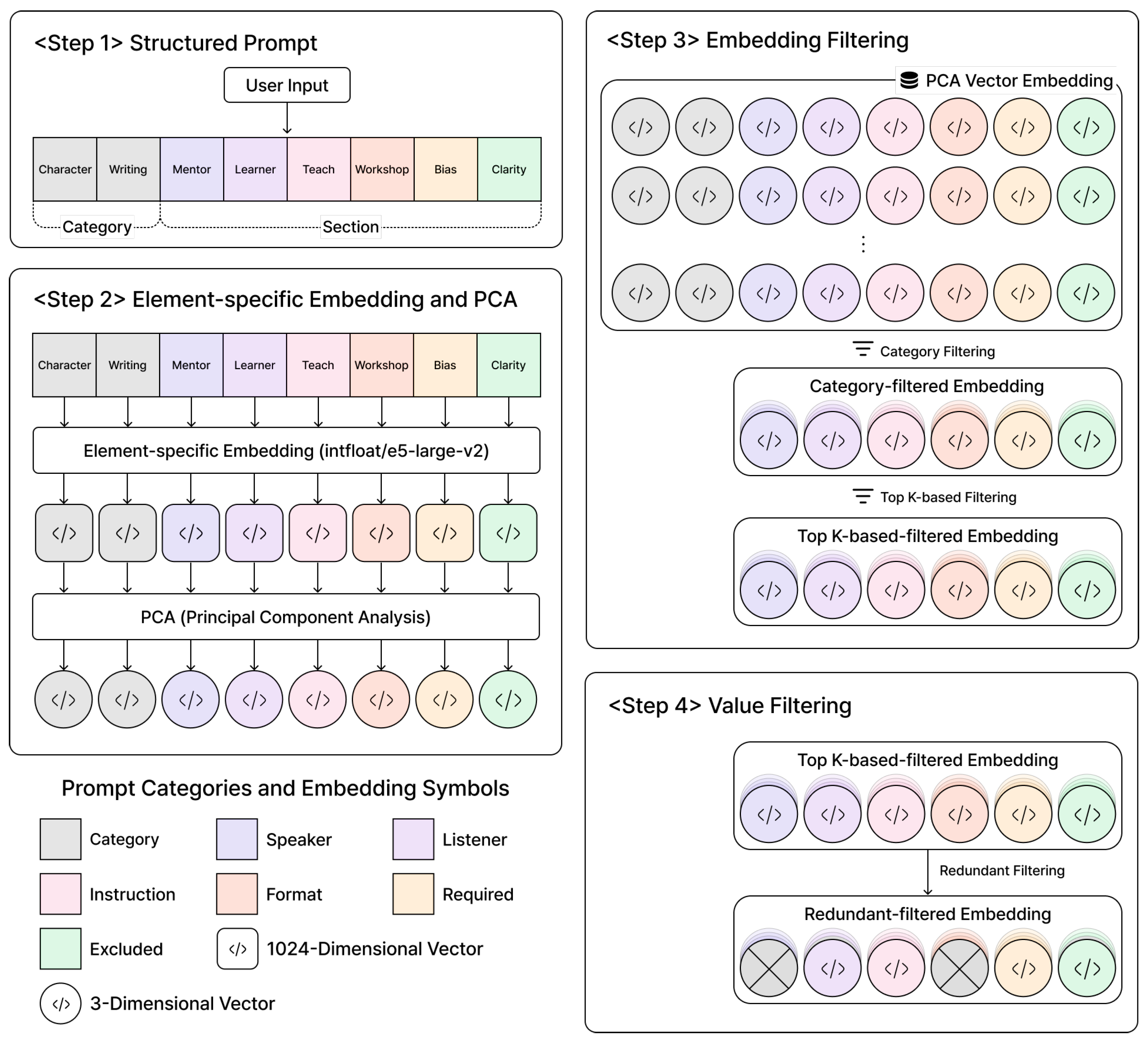
Figure 1, the proposed framework is designed to systematically address these challenges through a multi-step process.
The proposed framework comprises four steps, as follows:
Step 1. Structured Prompt
User inputs from the interface are transformed into a structured partial prompt by applying a predefined semantic schema, which preserves contextual relationships and ensures semantic consistency. The structured partial prompt consists of categories and sections, where each section contains keywords selected via the user interface. For instance, in healthcare Big Data, structuring with ‘Speaker: Doctor’ and ‘Required: Symptom Analysis’ semantically reconstructs unstructured data, reducing the retrieval ambiguity by 20–30%. This is evidenced by improved silhouette scores in experiments, enhancing prompt consistency and ensuring retrieval quality in large-scale datasets.
Step 2. Element-specific Embedding and PCA
The elements of the structured partial prompt are embedded individually, after which PCA is applied to reduce the dimensionality of the embeddings while preserving their semantic features. Reducing high-dimensional embeddings (e.g., 1024 dimensions) to three dimensions increases computational efficiency while maintaining semantic features, removing noise in Big Data clustering to enhance retrieval accuracy.
Step 3. Embedding Filtering
A multi-level filtering mechanism is applied to the reduced embeddings considering the semantic constraints of the elements. Category filtering followed by Top-k similarity filtering removes irrelevant candidates from large-scale datasets, thereby strengthening the semantic consistency of the partial prompt.
Step 4. Value Filtering
Redundant embeddings that are semantically similar or identical to those of the elements of the structured prompt are excluded to enhance the response diversity and reduce the computational overhead. Excluding semantic duplicates (e.g., repeated keywords) from Top-k candidates increases the response diversity, promoting the generation of novel insights in Big Data retrieval.
The recommended keywords are obtained through value-based filtering. Users can modify section values via the interface, considering the recommended keywords. When the structured partial prompt is finalized, it is combined into complete prompts.
3.2. Structured Prompt Construction
Traditional RAG systems frequently rely on unstructured text input, which hinders contextual preservation and systematic filtering. To address this, we introduce a structured prompt format comprising a category, sub-category, and six predefined semantic sections. The category and sub-category specify the domain of the structured prompt. The semantic sections are
Speaker,
Listener,
Instruction,
Format,
Required, and
Excluded. This structure ensures consistent interpretation and facilitates more precise embedding and retrievals. Each section captures a distinct aspect of a prompt. For instance,
Speaker defines an information source, while the
Listener specifies an intended recipient. The
Instruction describes a task, and the
Format sets the expected response format. The
Required and
Excluded sections represent key content constraints for inclusion or exclusion, respectively. As shown in Algorithm 1, the construction of a structured prompt follows a three-step algorithm:
| Algorithm 1 Structured Prompt Construction Algorithm |
- Require:
Unstructured user input - Ensure:
Structured prompt in JSON-like format - 1:
Step 1: Category Identification - 2:
Category ← classifyDomain(input) - 3:
SubCategory ← refineSubdomain(input) - 4:
Step 2: Section Mapping - 5:
for each relevant component c in input do - 6:
Identify the section type for c (e.g., Speaker, Listener, Instruction, etc.) - 7:
Map c to the appropriate section using rules or models - 8:
end for - 9:
Step 3: JSON Structuring - 10:
Construct a structured prompt with identified sections: - 11:
StructuredPrompt←{“Category”: Category, “Sub-category”: SubCategory, “Speaker”: Speaker, …} - 12:
return StructuredPrompt
|
3.3. Element-Specific Embedding and PCA
A structured prompt is embedded through an element-specific embedding pipeline. Each element in the structured prompt is embedded utilizing one of the semantic similarity models, such as e5-large-v2, to produce high-dimensional vectors (e.g., 1024 dimensions) that encapsulate the semantic content of each component.
This pipeline, which embeds each element of the structured prompt individually, independently captures the semantic meanings of sections such as Speaker and Listener using element-specific embedding models (e.g., e5-large-v2 ), thereby enabling fine-grained semantic representation of the entire prompt. Unlike the flat embedding approach of traditional RAG systems, this significantly enhances the retrieval accuracy and response diversity, while contributing to reduced redundancy and improved computational efficiency in Big Data environments. For example, embedding ‘Speaker: Teacher’ and ‘Required: Addition’ separately enables more precise searches in educational domain Big Data, with experimental results demonstrating a 32.3% improvement in the silhouette score.
To optimize the computational efficiency, we apply PCA to project high-dimensional embeddings into a lower-dimensional space with three dimensions. PCA is a linear and deterministic method that preserves the global semantic structure with minimal distortion, enabling fast and stable similarity computations. The results are consistent across runs, making PCA well-suited for semantic filtering and retrieval. As summarized in
Table 1, PCA also compares favorably to other dimensionality reduction techniques such as t-SNE and UMAP in terms of computational efficiency, reproducibility, and interpretability.
We selected PCA for dimensionality reduction because it efficiently preserves the global variance structure and provides interpretable linear embeddings, which are suitable for downstream semantic filtering. In contrast, nonlinear methods such as t-SNE and UMAP are primarily optimized for visualization, focusing on local neighborhood preservation at the expense of global data structure, and they are less interpretable and less stable for subsequent analyses.
Classify each element in a structured prompt by its semantic meaning.
Generate high-dimensional vectors utilizing element-specific embedding models.
Apply PCA to reduce the dimensionality of the vectors while maintaining semantic meaning.
3.4. Embedding Filtering
To narrow the search space and enhance the semantic relevance, we employ a two-step filtering process on the embedding space prior to prompt retrieval. This approach ensures efficient selection of candidates in PCA vector embedding, which aligns with the user’s intent.
Category Filtering: Candidates in PCA vector embedding that do not match the category and the sub-category specified in a structured prompt are first removed from the embedding pool. This coarse filter ensures that only contextually relevant prompts remain, refining the initial search pool to conserve computational resources and exclude context-irrelevant data.
Top-k Based Filtering: From the category-filtered candidates, the top-k candidates are selected based on Euclidean similarity within the PCA-reduced vector space of the structured prompt. This step ensures that the most semantically relevant candidates are retained.
This two-stage embedding filtering pipeline effectively balances contextual alignment and computational efficiency, outperforming conventional RAG systems that rely solely on flat similarity rankings.
3.5. Value Filtering
Although the top-k embedding filtering narrows down semantically relevant candidates, redundant or near-duplicate entries may remain. To address this, we introduce value filtering.
This final filtering ensures that the recommendations are relevant and diverse, thereby enhancing practical utility and novelty of the output. As a result, it contributes to reducing the retrieval latency of the overall framework and improving the quality of the clustering. This filtering mechanism, unlike the flat retrieval approach of traditional RAG systems, applies fine-grained semantic constraints, functioning as a powerful tool to support domain-specific decision-making.
3.6. Domain-Specific Decision Support
The proposed framework integrates structured prompting, element-specific embedding, and multi-level filtering to effectively support domain-specific decision-making in large-scale Big Data environments. In diverse domains such as healthcare, finance, and smart manufacturing, prompts are systematically classified into “Category” and “Sub-category,” enabling tailored retrieval of domain-relevant knowledge aligned with user intent and contextual constraints.
For instance, in healthcare applications, sections such as “Speaker: Doctor” and “Required: Symptom Analysis” prioritize domain-specific data like medical records and BioBERT-enhanced embeddings, thereby reducing retrieval ambiguity and facilitating real-time clinical decision support. In finance, the framework leverages specialized models such as BloombergGPT to filter and retrieve market-specific insights, minimizing redundancy and supporting data-driven decision-making under time-sensitive conditions.
Furthermore, the combination of PCA-based dimensionality reduction and semantic constraints in multi-stage filtering effectively excludes irrelevant or excluded elements, producing diverse and high-quality output. The experimental results demonstrate a 32.3% improvement in the silhouette score over traditional RAG, indicating superior clustering quality and semantic cohesion. This structured approach thus enables more precise and adaptive decision-making in complex domain-specific Big Data scenarios.
3.7. Generalizability to Summarization, QA, and Multilingual Tasks
Beyond domain-specific decision support, the proposed structured prompt-based RAG framework exhibits strong potential for generalization across diverse natural language processing tasks, including summarization, question answering (QA), and multilingual scenarios.
Summarization: By systematically structuring input prompts and applying element-specific embedding with multi-level semantic filtering, the framework can extract and compress information into concise contextually coherent summaries. Dimensionality reduction techniques, such as PCA, enhance the efficiency and relevance of retrieved content, supporting robust performance in automatic summarization tasks.
Question Answering (QA): The modular design, which features explicit semantic sections like “Speaker,” “Listener,” and “Instruction,” improves the retrieval and synthesis of relevant responses, even in complex QA scenarios. Category and subcategory classification enables fine-grained control over query scope, boosting factual accuracy, and reducing ambiguity.
Multilingual Extension: With support for domain-specific embedding models and a structured categorization process, the framework is readily extendable to multilingual settings. Integration with multilingual embedding models and conditional filtering protocols ensures that knowledge retrieval and generation remain accurate and context-appropriate across languages, facilitating global application in Big Data environments.
The experimental evidence suggests that the combination of these architectural components enables the framework to be flexibly adapted for various natural language processing tasks beyond decision support—while consistently maintaining precision, diversity, and scalability.
4. Experiments
In this work, we conducted a comprehensive evaluation of our proposed structured prompting and semantic filtering RAG system against a traditional RAG system, focusing on Top-k retrieval diversity. The experimental procedure comprised two phases: (1) Top-k candidate quality evaluation and (2) final output quality assessment by LLM responses. The purpose of the experiments is to demonstrate the limitations of traditional RAG compared to the proposed method, including poor contextual coherence and inadequate adaptation to diverse user prompts with varying structural complexity.
4.1. Experimental Environment and Dataset
The evaluation used lightweight transformer models to generate semantic embeddings, following our structured prompt process. The dataset construction followed our structured-based processing approach, systematically parsing and organizing the prompts into six predefined semantic sections. This structured formatting ensured consistent data representation and improved the reliability of embedding generation, unlike traditional RAG systems that process raw text without semantic segmentation.
4.2. Evaluation Metric
We used two key metrics to evaluate our framework: diversity and clustering quality.
Diversity was assessed by measuring the proportion of unique values within each section. For section
i, the diversity score
is defined as the number of unique values divided by the total number of values in that section. The overall diversity
d is then calculated as the average in all sections:
where
S is the set of sections. This metric addresses redundancy by quantifying how our deduplication mechanism at the embedding level increases the diversity and originality of recommendations compared to traditional RAG systems.
Clustering quality was evaluated using the silhouette score, which quantifies both the cohesion within clusters and the separation between clusters. The silhouette score ranges from to , with higher values indicating more distinct and well-defined clusters. Using this metric, we demonstrated that the structured prompt and semantic filtering RAG framework produces retrieval clusters that are more consistent and clearly separated than those generated by conventional RAG systems.
4.3. Results
Table 2 presents the structured prompt samples utilized for experiments. Three inputs were selected to ensure sufficient semantic diversity in the evaluation.
Table 3 presents the top three retrieved outputs utilizing the proposed method.
Table 4 presents retrieval results by the traditional structured-format RAG system for comparison.
Table 5 presents the LLM-generated responses by the outputs in
Table 3.
Table 6 presents the LLM results based on the traditional structured-format RAG outputs in
Table 4.
Both results achieved a perfect diversity index score of 1.0, indicating non-redundant and varied retrieval. In addition, a silhouette score analysis was conducted to measure the clustering quality of the retrieved documents, utilizing Euclidean distance measurements between embedding vectors. As summarized in
Table 7, the silhouette scores of the two experiments differed, reflecting differences in semantic cohesion. The proposed method yielded higher silhouette scores, suggesting stronger intra-cluster similarity and inter-cluster separation due to holistic semantic representation via normalized vector similarity.
In contrast, the traditional RAG system based on independent retrieval steps often prioritized term frequency or local keyword overlap, thus reducing semantic uniformity within clusters. Furthermore, the final LLM response clusters also exhibited clear differences in quality, as shown in
Table 8.
5. Conclusions
This paper proposed a structured RAG framework, a structured and efficient alternative to traditional RAG systems, that addresses key challenges in prompt diversity, contextual coherence, and response redundancy. The proposed method systematically decomposed each partial prompt into six explicit semantic sections: speaker, listener, instruction, format, required, and excluded, thus preserving user intent and constraints with high fidelity. We independently embedded each component and integrated the resulting embedding vectors using dimensionality reduction techniques, such as PCA, to ensure both semantic distinctiveness and computational efficiency.
Our method introduced a multi-level condition-aware filtering mechanism that initially aligns candidates at the high-level category and subsequently verifies fine-grained constraints. This two-level process enables and accurate retrieval, as well as robust adaptation to diverse and instruction-heavy prompts. Furthermore, we implemented embedding-level deduplication to minimize redundancy and enhance the novelty of generated responses.
The experimental results demonstrated that our structured RAG framework outperforms conventional RAG systems in both clustering quality, as measured by silhouette scores, and information, as indicated by section-wise diversity indices. Our structured RAG framework demonstrated a 32.3% improvement in silhouette scores. Although both systems recorded perfect diversity scores, our structured RAG framework consistently yielded more homogeneous and semantically cohesive clusters, attributable to its structured representation and integrated similarity filtering.
In summary, the proposed RAG framework offers a principled and practical solution to the limitations of traditional RAG pipelines by leveraging structured prompts, multi-level semantic embedding, and conditional retrieval. This approach significantly enhances semantic precision, contextual alignment, and computational efficiency.
Limitations and Future Work
In this paper, we have proposed a structured prompt–based RAG framework for large-scale Big Data analytics and demonstrated its superiority over conventional RAG systems in terms of accuracy, efficiency, and diversity. By decomposing each user query into six distinct semantic elements—Speaker, Listener, Instruction, Format, Required, and Excluded—and applying PCA for dimensionality reduction, our method achieved a 32.3% improvement in the silhouette score while preserving the computational scalability.
However, our study encompasses three principal limitations:
Insufficient Nonlinear Semantic Preservation. PCA, as a linear projection technique, retains only dominant variance components of high-dimensional embeddings, potentially discarding nuanced nonlinear relationships that capture domain-specific semantics.
Absence of Dynamic Self-Improvement. Retrieval ranking and prompt structures are fixed (top-k), precluding reinforcement learning–based fine-tuning (e.g., RLHF) that could adapt the system to evolving user feedback and quality metrics.
Furthermore, beyond the directions previously outlined, we propose the following advances to further enhance the structured prompt–based RAG framework:
Development of Fine-grained Semantic Segmentation and Composition Algorithms: We introduce an adaptive schema that automatically extracts and classifies variable granular semantic elements beyond the six core categories (Speaker, Listener, Instruction, Format, Required, and Excluded) based on domain or task context. The dynamic design of composition rules, either rule-based or learning-based, governs the interaction among the elements of the prompt, thus improving the precision and contextual relevance in prompt interpretation.
Enhancement of Multi-conditional and Hierarchical Filtering: Building upon the existing multi-level filtering pipeline—which sequentially applies category filtering, Top-k selection, and redundancy elimination—we propose integrating additional evaluation criteria such as conditional value filtering and goal-oriented filtering (e.g., reliability, source diversity). We further suggest implementing an adaptive parameter tuning module that dynamically adjusts thresholds and weights at each filtering stage, ensuring robust consistency and accuracy even for complex queries.
By pursuing these avenues, the structured RAG framework can achieve enhanced precision, robustness, and scalability, thereby significantly improving its applicability in real-world industrial environments.


 ,
, 

{kind=link}