1. Introduction
The proliferation of high-dimensional text data on digital platforms has created new opportunities and challenges for predictive modeling and decision making under uncertainty. As online expression becomes a proxy for latent user behavior, structured modeling of unstructured text has gained prominence in computational social science, requiring the integration of dimensionality reduction, probabilistic inference, and latent semantic analysis [
1,
2].
Topic modeling—especially embedding-based algorithms such as Top2Vec (Topical Vectors via Embeddings and Clustering)—offers a robust framework for unsupervised feature extraction by mapping linguistic data into continuous vector spaces and identifying dense clusters via manifold learning and density-based clustering. Compared to generative models like Latent Dirichlet Allocation (LDA), Top2Vec leverages semantic embeddings and hierarchical density estimation, enabling the automatic discovery of coherent themes without pre-specifying the number of components [
3,
4]. While topic models uncover thematic structures, they do not, by themselves, explain downstream behavioral outcomes. To bridge this underexplored area, conditional process modeling—such as moderated mediation analysis—has emerged as a powerful tool in statistical causal inference, enabling the estimation of interaction effects and indirect pathways across hierarchical models. In particular, Hayes’ PROCESS framework formalizes multistage dependencies with bootstrapped confidence intervals, enhancing the interpretability of complex interactions in behavioral data [
5].
Recent advances in text regression have increasingly leveraged sparse modeling techniques, particularly LASSO and its variants, to handle the curse of dimensionality and extract interpretable signals from high-dimensional textual data [
6,
7,
8]. A common strategy involves feeding topic proportions from unsupervised models (e.g., LDA) into supervised pipelines to predict numeric outcomes, as in Bulut’s (2014) Topic machine for ad conversions [
9] or Freo and Luati’s (2024) evaluation of LASSO-type selectors for short-text pricing tasks [
6]. However, such pipelines typically assume linear, unmediated relationships between topic features and outcomes, neglecting both the semantic richness of user-generated expressions and the latent psychological or behavioral mechanisms involved.
To address these limitations, this study advances the field in three substantial ways. First, building on critiques of LDA’s limitations in sparse and affect-rich environments, the paper adopts Top2Vec with contextual embeddings to generate semantically coherent themes tailored to short, fragmented worker discourse. Second, instead of plugging topics directly into regression, we embed them in a moderated mediation process model, consistent with advances in high-dimensional causal inference [
7,
8], capturing how topic-level experiences shape engagement via self-disclosure and are moderated by cognitive complexity and emotional polarity. This structure goes beyond standard LASSO pipelines, aligning with recent calls to bridge sparse modeling with psychological process tracing [
10]. Third, focusing on women platform workers, an under-represented yet policy-relevant population, adds a socially grounded dimension to sparse text regression. Overall, the study synthesizes advances in embedding-based topic modeling [
11], causal sparse learning, and time-aware LASSO optimization [
7], producing a replicable behavioral framework for digital labor research.
At a conceptual level, the integration of semantic topic distributions with moderated mediation frameworks allows for the joint modeling of latent constructs (e.g., self-disclosure) and observable outcomes (e.g., user engagement), where topic probability vectors serve as predictors and psycholinguistic features act as moderators. This modeling strategy provides both explanatory and predictive power, especially when dealing with emotionally loaded and context-dependent textual inputs. Recent studies have begun to combine natural language processing (NLP) and psycholinguistic modeling to investigate outcomes such as marketing virality, mental health detection, and public opinion diffusion [
2,
4,
12,
13]. Research shows that semantic salience and stylistic coherence interact to shape attention allocation and feedback behavior across digital contexts. For instance, studies in message effectiveness and organizational psychology reveal that message content and its presentation style jointly determine audience engagement, confirming that semantic and affective components act as statistically separable but interdependent predictors [
14,
15,
16,
17]. However, few have developed structured models that explicitly integrate semantic content (e.g., topic embeddings) and expressive style (e.g., linguistic indicators) within a moderated mediation framework to predict real-world engagement outcomes with statistical rigor.
In this study, the combined modeling approach is applied to the expressive behaviors of a marginalized labor group: Chinese women delivery riders. Despite representing a growing but under-recognized segment of platform labor, female couriers face systemic constraints, including algorithmic visibility biases, platform design inequities, and limited access to feedback mechanisms [
18,
19]. These constraints not only reduce participation rates but also affect digital visibility and symbolic presence on public forums. Preliminary observations suggest that women’s posts often receive significantly less engagement than those of male riders, indicating a pattern of expressive disparity that may be driven by both content and stylistic cues [
20]. Understanding how these cues influence attention and feedback is therefore central to designing more inclusive digital participation environments.
Drawing on a dataset of 2144 posts from Baidu Tieba, the study explores how women riders express their work-related experiences and how these expressions translate into social feedback, measured via likes, replies, and views. Using Top2Vec for topic extraction and LIWC (Linguistic Inquiry and Word Count)-based psycholinguistic coding [
21], a conditional process model is built that evaluates how work experience themes (
) influence engagement (
) through the mediating role of self-disclosure (
), moderated by cognitive complexity (
) and emotional polarity (
). The paper poses the following research questions:
RQ1: Which types of work experience content are more likely to elicit high levels of self-disclosure?
RQ2: Does the intensity of self-disclosure predict higher engagement (e.g., views, comments, and likes)?
RQ3: Do cognitive and affective linguistic features moderate these expression–engagement pathways?
This paper contributes in three key ways. First, it introduces a scalable framework that embeds semantically meaningful topics into a moderated-mediation model, moving beyond direct LASSO-topic regressions. Second, it reveals that semantic themes and expressive style jointly influence engagement, providing interpretable levers for digital HRM. Third, it offers practical insights for optimizing content delivery, interface communication, and inclusive design in gig-platform ecosystems.
The remainder of this article is organized as follows:
Section 2 outlines the theoretical background and hypothesis development.
Section 3 describes the modeling framework, variable construction, and estimation approach.
Section 4 presents the empirical results.
Section 5 discusses implications.
Section 6 concludes.
2. Theoretical Background and Hypotheses
To understand the mechanisms by which expressive textual features influence community engagement, this study draws upon two complementary theoretical frameworks: Self-Disclosure Theory and Social Exchange Theory. Together, they offer a coherent conceptual structure for modeling how digital content—particularly user-generated narratives—elicits social responses in online labor platforms.
2.1. Self-Disclosure of Women Delivery Riders’ Work Experience
In the platform economy, takeaway riders often work in flexible, task-based, or self-employed roles. However, these jobs are frequently characterized by institutional precarities such as vague platform rules, lack of employment protection, and insufficient managerial support [
22]. In China, an increasing number of women have joined this digital labor force, forming a growing yet marginalized segment of the gig workforce. These women riders not only face algorithmic pressure and customer demands but also a “double dilemma” of labor vulnerability and constrained expressive agency [
23]. Within this context, some women riders have begun to articulate their work experiences, release emotional tension, and seek peer validation on external digital platforms such as Baidu Tieba and WeChat groups. These off-platform disclosures have gradually evolved into informal, yet vital, support and feedback mechanisms [
24].
Self-disclosure, defined as the voluntary communication of personal experiences, emotions, or opinions during social interactions [
25], has become a prevalent expressive strategy among women delivery riders. According to Self-Disclosure Theory, individuals strategically reveal personal information to achieve psychological and social goals, such as seeking support, gaining visibility, or constructing identity [
26,
27]. In digital labor contexts, such disclosures are not merely emotional catharses but also reflect attempts to navigate systemic marginalization. The subject matter of one’s expression—whether it concerns platform injustice, algorithmic control, or customer conflict—plays a crucial role in shaping the intensity and emotional depth of disclosure [
20,
28]. Content that involves risk, unfair treatment, or emotional stress tends to activate stronger motivations for personal narrative sharing [
16].
Women platform workers are especially inclined to adopt expressive styles that emphasize identity, empathy, and emotional transparency. Studies have shown that female workers often employ first-person perspectives, affective language, and detail-oriented storytelling, features that distinguish their narratives as authentic and socially urgent [
23,
29,
30]. These expressions not only facilitate emotional self-regulation but also serve as mechanisms for asserting their visibility and right to be heard. Within the current limitations of on-platform feedback systems, self-disclosure becomes a vital mode of symbolic resistance and community signaling. Therefore, identifying which themes in women riders’ work narratives most strongly evoke self-disclosure is critical for understanding the psycholinguistic foundations of platform labor expression. It also addresses a broader structural challenge: how the platform economy can recognize and respond to the voices of digitally marginalized workers.
Building on Self-Disclosure Theory, the study further argues that topics involving risk, stress, or injustice—such as algorithmic control, regulatory opacity, or customer mistreatment—tend to trigger deeper personal sharing, as individuals seek support, validation, or symbolic recognition [
24,
25]. Psycholinguistic research shows that these high-stakes disclosures are often accompanied by identifiable linguistic features, including first-person pronouns, affective language, and elaborative reasoning (e.g., causal connectives and insight words). These features, commonly captured via LIWC metrics, not only reflect emotional authenticity and cognitive effort but also act as social signals that enhance interpretability and credibility [
31,
32]. In digital settings, such expressions are empirically linked to increased audience responsiveness and social reciprocity, further reinforcing the disclosure–engagement dynamic. Accordingly, this paper proposes hypotheses:
H1: The thematic content of women delivery riders’ work experiences significantly influences the intensity of self-disclosure in online posts.
2.2. Platform Expression: Work Experience, Self-Disclosure, and Community Engagement
In the context of digital labor platforms, self-disclosure functions not only as a means of personal expression but also as a strategic mechanism to elicit social feedback and build interactive relationships [
33]. According to Social Exchange Theory [
34], individuals engage in interactions based on expected rewards and perceived reciprocity, especially when communication carries emotional value or social risk. In online labor communities, expressions that signal vulnerability, effort, or authenticity are often met with increased responsiveness, as they create a sense of shared experience or moral obligation [
35].
Drawing on Social Exchange Theory, the paper models engagement as a form of social reciprocity. Posts that signal emotional vulnerability, cognitive effort, or authenticity are more likely to be interpreted by community members as personally costly or socially valuable contributions [
36,
37,
38]. In return, audiences may respond with reciprocal behaviors—such as likes, supportive comments, or content amplification—as a form of symbolic reward [
39]. This exchange logic implies that engagement is not merely reactive but grounded in perceived expressive investment, making self-disclosure a key mediating mechanism between thematic content and community interaction.
First, the content theme of a post critically shapes its potential to trigger community engagement. Posts addressing topics with high emotional salience—such as performance anxiety, customer conflict, or institutional injustice—are more likely to activate users’ attention and stimulate affective responses [
40,
41]. These emotionally and socially charged themes serve as exchange signals, indicating that the expressers are offering personally costly information, thereby inviting reciprocal engagement from others.
Second, self-disclosure itself acts as an interactional catalyst. Empirical studies have shown that high levels of disclosure—especially those marked by first-person language, affective vocabulary, and detailed personal narratives—enhance the perceived credibility, sincerity, and emotional intensity of the message [
40,
42]. From a social exchange perspective, such disclosures create an imbalance of openness that prompts others to reciprocate through likes, comments, or support. Furthermore, disclosure enhances interpretability by providing contextual and psychological cues that help the audience relate to or empathize with the speaker [
43].
Crucially, the relationship between work experience topics and community engagement may be indirect, mediated by the level of self-disclosure. High-risk or emotionally loaded topics tend to elicit deeper disclosure, which, in turn, increases the likelihood and strength of engagement responses. This content–disclosure–engagement chain embodies a psycholinguistic feedback loop grounded in perceived social value and affective reciprocity [
33,
44]. Among women riders in particular, emotional disclosures are often infused with the desire for recognition, solidarity, and empowerment in the face of labor oppression and gendered marginality [
20].
In sum, both the thematic relevance and the disclosure intensity of labor-related expressions determine whether and how platform communities engage with them. These patterns are especially salient among women delivery riders, whose expressions are often more affectively framed and socially motivated. Based on this rationale, the following hypotheses are proposed:
H2a: Self-disclosure increases the likelihood and intensity of community engagement.
H2b: Self-disclosure mediates the relationship between work experience topics and online community engagement.
2.3. Cognitive Complexity as a Linguistic Moderator
Beyond the semantic content of disclosures, the cognitive complexity of language—defined as the degree of causal reasoning, structural coherence, and analytical elaboration in a post—plays a pivotal role in shaping how expressions are both constructed and socially interpreted [
45]. In psycholinguistic research, cognitively complex narratives are often associated with deeper cognitive effort, epistemic engagement, and uncertainty resolution. These features enhance the perceived credibility, intentionality, and seriousness of the message, making them more persuasive and socially valuable [
32,
46]. From a signaling theory perspective, cognitive complexity functions as a quality signal in digital environments. When platform workers articulate their experiences with greater coherence and elaboration, they reveal not only the factual content of their narratives but also their communicative investment and psychological engagement. Such signals are especially critical in algorithmically mediated labor contexts, where trustworthiness and message salience often rely on linguistic cues rather than formal credentials [
47]. Importantly, cognitive complexity may modulate two distinct stages in the expressive process:
First, it influences the transformation of internal experience into outward disclosure. This extends the logic of the Elaboration Likelihood Model (ELM) beyond its traditional outcome focus. While the ELM primarily addresses how message elaboration affects persuasion and attitude change, our model applies its central tenets upstream, highlighting how individuals with higher cognitive capacity are more likely to engage in effortful expressive construction, particularly when facing complex or emotionally charged work experiences [
48,
49]. In this sense, cognitive elaboration acts as a precondition for self-disclosure, especially in contexts where expression entails social risk or epistemic demand (e.g., algorithmic injustice and institutional ambiguity). This idea aligns with theories of dual-threshold disclosure and social cognition, suggesting that high-barrier content is more likely to be externalized by users who possess sufficient processing capacity.
Second, cognitive complexity enhances the impact of disclosure on social engagement. Posts that exhibit higher levels of structural clarity, analytical depth, and linguistic sophistication are more likely to be perceived as sincere, valuable, and worthy of response. From a social exchange standpoint, such disclosures signal intentionality and reciprocity potential, thereby motivating community members to engage through likes, comments, or peer support [
33,
45]. In digital signaling environments, effortful expression is interpreted as a costly signal, increasing its persuasive weight and interpretive salience.
However, the moderating effect of cognitive complexity is not uniform across all experiential themes. Posts about regulatory barriers or platform mismanagement may benefit from greater elaboration to establish legitimacy and signal reasoned critique. In contrast, emotionally saturated topics—such as harassment, bodily harm, or customer abuse—may rely more on emotional immediacy and authenticity than on analytical sophistication. Excessive complexity in such contexts may even blunt empathic responses or reduce interpretive clarity [
50,
51]. Therefore, we expect the moderating role of cognitive complexity to vary across themes, reflecting the functional demands and emotional stakes of each topic. Based on this reasoning, the paper proposes the following hypotheses:
H3a: Cognitive complexity strengthens the effect of work experience topics on the intensity of self-disclosure.
H3b: Cognitive complexity amplifies the effect of self-disclosure on community engagement.
H3c: The moderating effect of cognitive complexity varies across different work experience topics.
2.4. The Moderating Role of Emotional Polarity
Emotion in digital expression functions not merely as a personal state but as a communicative signal with social consequences. In the context of digitally mediated labor discourse, the emotional polarity of language—particularly the degree of negative affective tone—plays a central role in shaping how self-disclosure is interpreted and responded to by platform communities. According to Social Sharing Theory, individuals are more likely to share experiences that are emotionally intense, especially those involving negative affect such as anger, fear, or frustration [
52,
53]. These emotions serve key social functions: they validate subjective experiences, foster collective understanding, and invite empathic alignment or moral judgment from others. In this way, emotional disclosures act as affective signals that not only convey internal states but also actively mobilize social responses [
54,
55].
For marginalized platform workers—particularly women riders—negative emotional polarity often reflects lived vulnerability and institutional marginality. Expressions of fear, anxiety, injustice, or burnout become both cathartic outlets and calls for recognition in an ecosystem that frequently lacks formal grievance mechanisms. Such disclosures offer communities a chance to align emotionally, share burdens, and signal solidarity, thus driving engagement behaviors like comments, upvotes, and support messages [
33,
56].
However, the amplifying effect of negative emotion is topic contingent. In posts dealing with algorithmic injustice, customer abuse, or labor exploitation, emotionally forceful expression may serve to emphasize urgency, raise moral salience, and elicit stronger social reaction. These topics inherently carry a high emotional load, and negative tone enhances the perceived sincerity, legitimacy, and deservedness of the disclosure. In contrast, for posts centered on routine logistics, technical issues, or mundane observations, excessive negativity may appear misplaced or melodramatic, undermining credibility and discouraging engagement. Thus, the communicative value of emotional polarity is not fixed but is instead dynamically conditioned by the thematic framing of the disclosure. Based on this integration of emotional framing and social sharing dynamics, the research proposes the following:
H4a: Negative emotional polarity enhances the impact of self-disclosure on community engagement.
H4b: The moderating effect of emotional polarity is contingent upon the work experience topics.
2.5. Path Modeling and Structural Assumptions
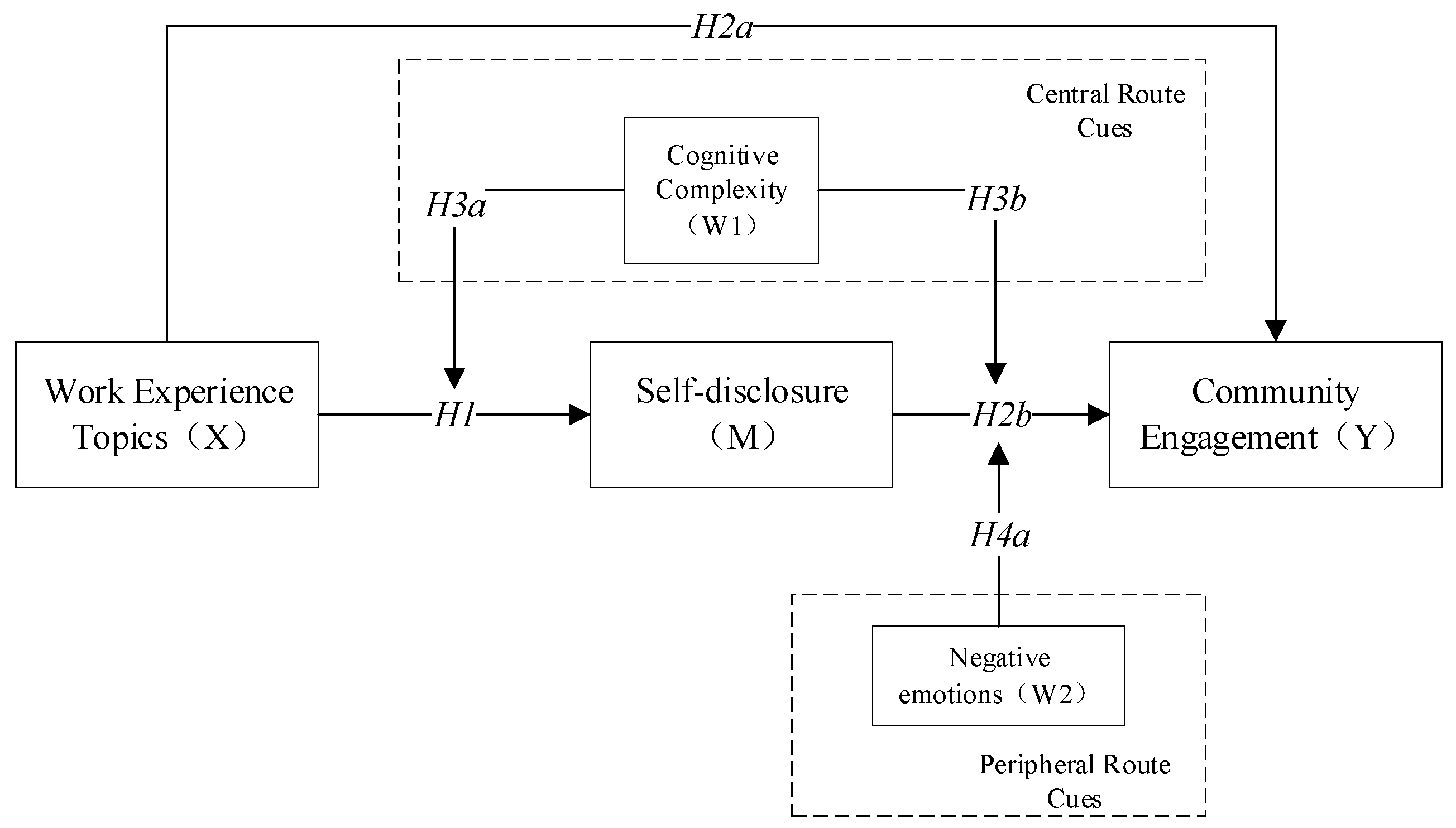
To formalize the hypothesized relationships, this study adopts a two-stage moderated mediation framework that captures how the semantic content and expressive form of user-generated posts influence community engagement. Specifically, the model estimates how work experience topics affect self-disclosure intensity, which, in turn, predicts engagement behaviors.
This sequential pathway is structured as follows:
In Stage 1, topics influence self-disclosure, with this effect moderated by cognitive complexity. This reflects the idea that semantically rich but cognitively elaborate expressions are more likely to prompt intense personal narratives (H1 and H3a).
In Stage 2, self-disclosure drives engagement, and this path is jointly moderated by both cognitive complexity and emotional polarity. These moderators affect how disclosure is interpreted, either as a credible signal of intent or as an affective trigger, consistent with H2b, H3b, and H4a. The model also allows for content-contingent moderation, wherein the effects of complexity and polarity are not uniform but vary depending on the thematic context of the expression (H3c and H4b).
Statistically, these relationships are encoded using the PROCESS macro (Model 4 and Model 58), which estimates both direct effects and conditional indirect effects through bootstrapped confidence intervals. This design enables us to disentangle the explanatory contributions of thematic content, disclosure intensity, and psycholinguistic framing, providing a robust account of expressive behavior in digital labor contexts.
Accordingly,
Figure 1 summarizes the proposed path structure, highlighting both the mediated pathways and the moderating influences that shape the expressive impact of women riders’ narratives.
3. Data and Modeling Methods
This section defines the symbolic variables, outlines the statistical modeling framework, and describes the process by which semantic and psycholinguistic features were extracted and analyzed. The model integrates a topic-based predictor (
), a psycholinguistically derived mediator (
), and a multi-indicator outcome (
), with cognitive complexity (
) and emotional polarity (
) serving as moderators for the two-stage conditional process. The model incorporates topic-based predictors, psycholinguistic mediators, and engagement outcomes, operationalized through a set of symbolic variables defined later in this section.
Figure 1 illustrates the moderated mediation structure, where both the
and
pathways are tested for moderation effects.
3.1. Data Collection and Preprocessing
The data for this study come from Baidu Tieba, China’s mainstream community-based information platform, and related online labor forums. It focuses on the public discussions posted by the delivery riders in their daily work. Baidu Tieba is a social network platform that is characterized by strong openness in content, high topic focus, and stable interaction structure, making it an essential channel for flexible workers such as takeaways and online carriers to share their experiences, vent their emotions, and gain group support [
57]. Compared with other communities with mainly elite users (e.g., Zhihu), posting bars are more characterized by grassroots expression from the perspective of laborers and have a higher user penetration rate, which provides a more representative data field for studying women riders in the Yangtze River Delta region.
The data collection work used a web crawler program written in Python 3.10 to systematically capture all posts and replies containing the keywords, “women riders”, “delivery riders”, “riders”, “platform salary”, “system deduction”, etc., in takeaway rider-related postings from January 2023 to March 2025 and then collect the data from the web crawler program. The collected content is released by users independently and in the form of semi-structured text, including key metadata such as posting time, user ID, content body, view count, comment count, like count, etc. The platform sets a gender field for user accounts, and by combining semantic features, posting language, and geographic location information, the study screened out user text samples that have the identity of “women takeout riders” and focused on postings in communities in the Yangtze River Delta region.
The original sample consists of approximately 2144 main posts and 16,898 replies. Following preprocessing and sample screening, invalid content (such as advertisements, emoji retweets, and missing metadata entries) was eliminated. Additionally, multiple posting behaviors associated with duplicate IDs were merged, and the maximum number of posts per user was limited to three. Consequently, the final valid sample unit comprises 2144 main posts from women riders, along with the corresponding comments and views, which are utilized for the subsequent calculation of the engagement rate index. The associated comments and browsing data are employed for the calculation of participation rate indicators.
In addition, to enhance the scientific control of the sample structure, the study employs a stratified random sampling strategy. This approach balances the sample distribution based on the dimensions of posting time (quarterly) and community activity (high vs. low interaction). This ensures that the obtained samples are representative and diverse in terms of time and information density.
3.2. Variables Definitions
This section presents the mathematical framework used to model the relationship between work-related textual expressions and online community engagement. The proposed model integrates topic probabilities, psycholinguistic indicators, and platform metadata to evaluate how expressive features influence user interaction outcomes. A moderated mediation model is developed and formalized as follows:
Let the dataset consist of
observations, where each post
is associated with the variables in
Table 1:
Although the raw data source consists of unstructured user-generated content (i.e., delivery riders’ forum posts), all variables used in the modeling process were aggregated at the daily level. Each observation in the dataset thus corresponds to a single day, not an individual post. Variables such as topic expression frequencies Topic 1 to Topic 11 (T1–T11), self-disclosure index (SI), cognitive complexity index (CCI), emotional polarity index (EPI), and engagement rate (ER) were transformed into continuous, time-series variables that capture aggregated discourse patterns per day.
This procedure ensured that the final dataset is low dimensional and relatively dense, satisfying the assumptions of OLS-based path analysis. As such, the subsequent PROCESS models applied to this dataset yield interpretable coefficients and valid bootstrapped confidence intervals for mediation and moderation paths [
58].
3.3. Topic Modeling and Psycholinguistic Feature Extraction
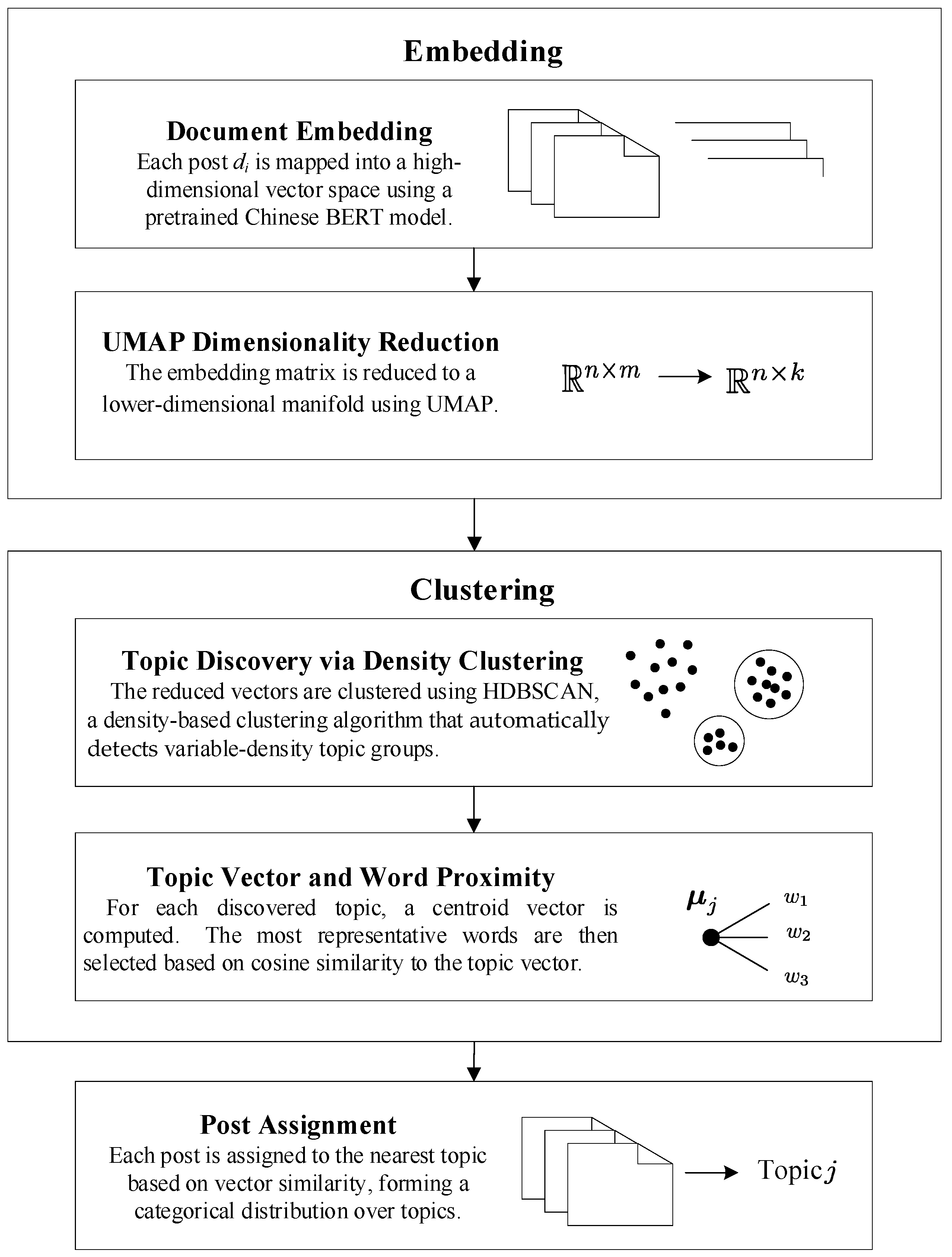
To uncover latent themes in high-dimensional text data, this study employs Top2Vec, an unsupervised topic modeling algorithm that leverages semantic embeddings. Unlike traditional generative models such as LDA, Top2Vec integrates document and word vector spaces to identify dense topic clusters based on contextual meaning rather than word co-occurrence frequency [
4]. Top2Vec offers several advantages that make it especially well suited for analyzing fragmented, affect-laden user-generated content:
No need to pre-specify the number of topics: The model automatically detects the optimal number of topics based on data topology.
Semantic coherence: By capturing contextual meaning through embeddings, Top2Vec improves interpretability, particularly valuable for short and emotionally expressive texts.
The method is computationally efficient and robust when applied to large-scale, high-dimensional corpora [
3,
4].
3.3.1. Algorithmic via Top2Vec Algorithm
Given a corpus , Top2Vec performs the following major steps:
To ensure that embedding and clustering choices were methodologically sound, we benchmarked multiple combinations of topic modeling pipelines. Top2Vec with Chinese BERT embedding and UMAP dimensionality reduction yielded the highest semantic coherence (NPMI = 0.52), substantially outperforming LDA-based alternatives (NPMI = 0.378). Moreover, the Top2Vec with BERT–UMAP–HDBSCAN achieved a Silhouette score of 0.37, indicating more compact and separable topic clusters than PCA- or t-SNE-based reductions (Silhouette < 0.22) (detailed in
Appendix A Table A1). These results justify the adoption of BERT–UMAP–HDBSCAN as a theoretically and empirically grounded pipeline for modeling psycholinguistic structures in multilingual gig-work narratives.
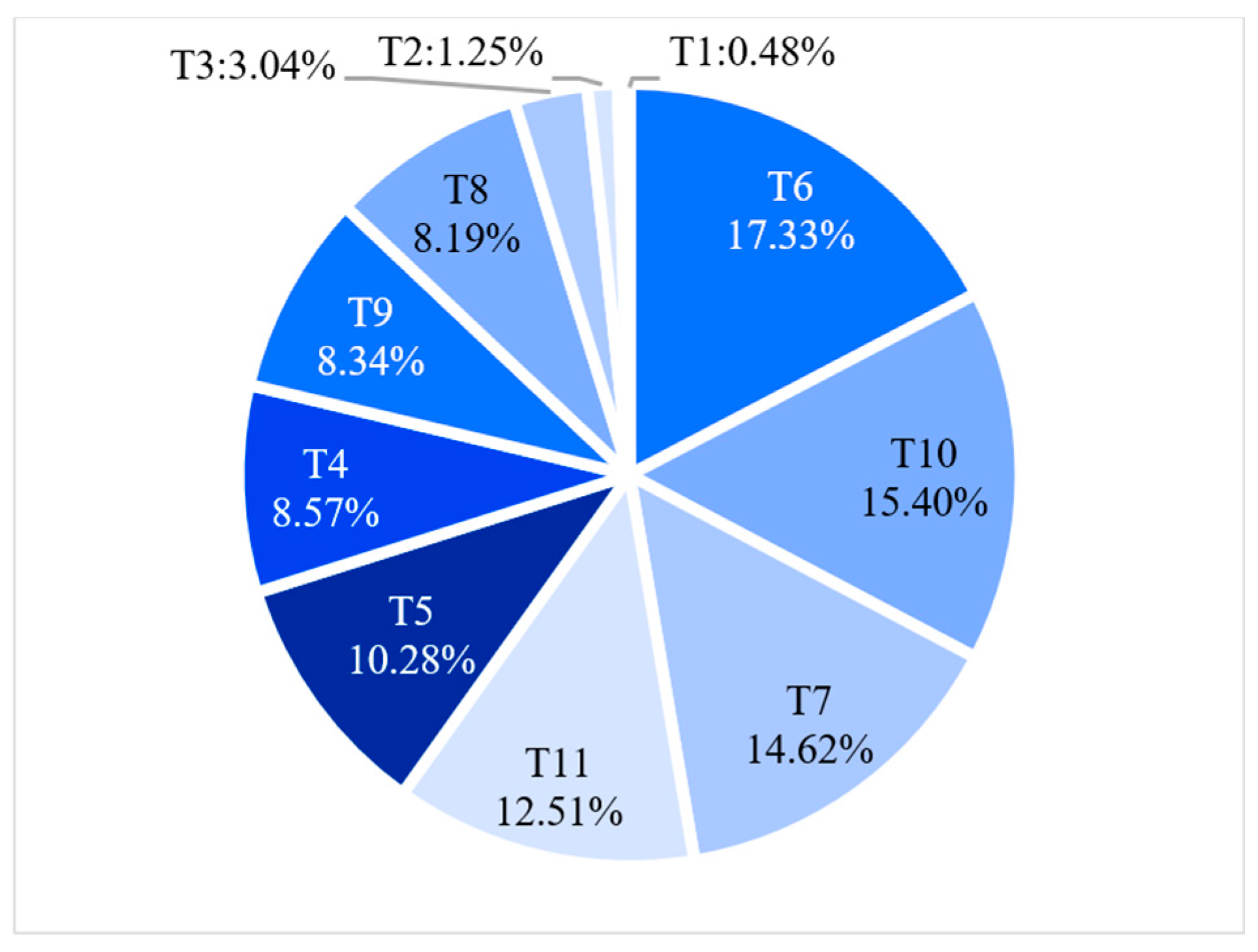
In this study, Top2Vec identifies 11 dominant topics from 2144 women rider posts, each represented by keyword vectors and importance scores (see
Appendix A Table A1). These topics are later used as input variables for statistical modeling (see
Section 4), capturing various dimensions of work experience.
3.3.2. Psycholinguistic Feature Extraction by LIWC
Using the LIWC 2015 dictionary, the paper computes the following:
Self-disclosure intensity (
M) was calculated as the standardized sum of breadth, depth, and length of each post—
—capturing both the richness and extent of personal expression [
33].
Cognitive complexity (
W1) was calculated from LIWC cognitive process categories including the sum of terms related to causation (because), insight (think), tentativeness (perhaps), certainty (definitely), and differentiation (different) [
59].
Emotional polarity (negative) (
W2) was derived from the affective tone of posts using the formula
, centered at 0.5 [
60], where “pos” and “neg” represent the number of positive and negative emotion words.
Engagement rate (
Y), the dependent variable, was computed as (likes + comments)/views for each post. This metric reflects audience interaction normalized by visibility [
61].
All linguistic features are z-standardized before modeling.
Table 2 provides a summary of the main variables used in this study, including their symbol, names, definitions, and measurement methods.
3.4. Moderated Mediation Modeling Framework
The paper defines a two-equation system to capture the mediation and moderation mechanisms, extending Hayes’ conditional process framework (Model 4 and Model 58):
Stage 1 (first-stage moderation):
Stage 2 (second-stage moderation):
In this model, the parameter captures the first-stage moderation effect of cognitive complexity () on the relationship between topical content () and self-disclosure (), while captures the first-stage moderation effect of emotional polarity () on the same path. In the second stage, and represent the moderation effects of cognitive complexity () and emotional polarity () on the impact of self-disclosure () on engagement (), respectively. are residuals. They quantify how the strength of self-disclosure’s impact on engagement varies depending on linguistic style. Equation (4) models how topic content influences self-disclosure; Equation (5) captures the effect of self-disclosure and its interaction with linguistic moderators on engagement outcomes. The interaction terms and represent the moderation effects of cognitive complexity and emotional polarity, respectively. These parameters quantify how both linguistic style and emotional expression moderate the strength and direction of content-to-engagement pathways through self-disclosure. The model structure allows us to assess conditional indirect effects of topical expressions, moderated by both cognitive and emotional linguistic features.
3.5. Indirect Effect Estimation and Bootstrapping
The conditional indirect effect of
on
via
, moderated by
and
, is given by:
The paper followed Hayes’ PROCESS modeling framework, combining Model 4 (simple mediation: ) and Model 58 (moderated mediation with first- and second-stage moderators and ). Specifically, Model 4 was used to test the mediating effect of self-disclosure () between topic content () and engagement (), while Model 58 examined how cognitive complexity () and emotional polarity () moderate the and paths. All continuous variables were mean centered before creating interaction terms to reduce multicollinearity.
This study uses bias-corrected bootstrapping (5000 iterations) within the PROCESS macro, which performs OLS-based regression and generates confidence intervals for both conditional indirect effects and interaction terms, enabling direct interpretation of coefficient direction and magnitude. The following steps were implemented:
Simple slope analysis at −1 SD, mean, and +1 SD levels of and to interpret moderation strength;
Johnson–Neyman technique to locate regions of significance for continuous moderators;
All models include control variables (time and user ID).
4. Empirical Results
To examine how women delivery riders’ work experience expressions influence community engagement, the research estimates a moderated mediation model for each of the eleven identified topics. The original theoretical model included cognitive complexity (
) and emotional polarity (
) as moderators in both stages of the process. However, preliminary analyses revealed that the interaction terms involving
in the first stage (topic × emotional polarity → self-disclosure) were statistically insignificant across all topics (
). Meanwhile, it also indicates that the moderating effect of positive emotional polarity (EPI_N) is statistically insignificant across all tested pathways. Accordingly, the final model specification excludes
from the first-stage moderation path, and negative emotional polarity (EPI_N) was retained as a second-stage moderator to improve parsimony and statistical stability. The revised empirical model includes:
where
: topic probability for observation (extracted via Top2Vec);
: self-disclosure intensity (measured using LIWC);
: engagement rate;
: cognitive complexity index;
: negative emotional polarity index;
: first-stage moderation coefficient ( modulated by );
: second-stage moderation coefficient ( modulated by );
: second-stage moderation coefficient ( modulated by );
, : residuals.
To structure the analysis of how topical expressions influence user engagement via self-disclosure, we draw on the indirect and conditional process model (Model 4 and Model 58) and decompose the indirect effect into four distinct components. These include simple mediation, first-stage moderation, second-stage moderation, and conditional moderated mediation. This decomposition allows us to trace not only whether, but also how and under what conditions, topic-level expression leads to increased engagement. The four effect types are summarized below.
Table 3 presents the empirical results for direct effects, mediated pathways, moderation by psycholinguistic variables, and conditional indirect effects across topics. The formulations allow us to assess both linear and interaction-based paths, aligning with the hypothesis structure developed in
Section 3. All models were implemented using the Hayes PROCESS macro (Model 4 and Model 58) with 5000 bootstrap resamples and 95% bias-corrected confidence intervals. All continuous predictors were mean centered prior to constructing interaction terms to reduce multicollinearity.
4.1. Descriptive Statistics and Variable Correlation Analysis
To evaluate the distributional properties, multicollinearity risk, and inter-relationships among key variables, this study conducted descriptive statistical analysis and nonparametric correlation testing on the final sample of days. All statistical procedures were implemented using SPSS 26.0.
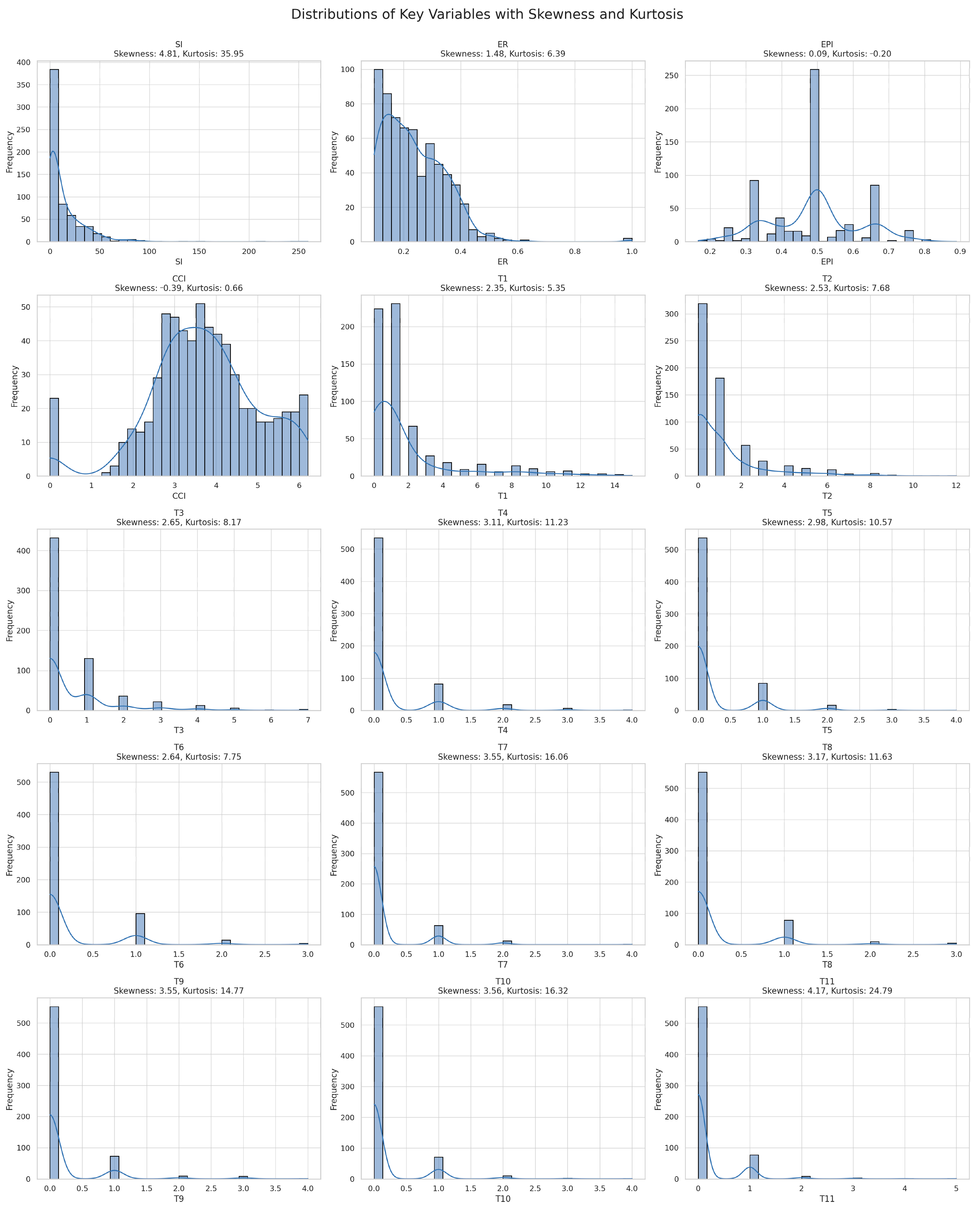
Descriptive Distribution and Variance
As shown in
Figure 3 and
Table 4, the engagement rate (ER) exhibits a positively skewed distribution (skewness = 1.48), with a mean of 0.235 and standard deviation of 0.109, indicating that most posts receive low interaction, with a small number of posts attracting disproportionate attention. This long-tailed pattern is consistent with prior findings on expressive inequality in digital labor [
42]. Although some topic expression variables exhibited right-skewed or zero-inflated distributions, the data were aggregated at the daily level and retained sufficient variance for reliable estimation. Since PROCESS relies on OLS-based path models with bootstrapped confidence intervals, it remains robust to mild sparsity and non-normality in predictors [
53]. Therefore, the use of PROCESS estimation is methodologically valid in this context.
From the
Figure 3 and
Table 4, the self-disclosure index (SI) also demonstrates strong non-normality (skewness = 4.81; kurtosis = 35.95), with values ranging from 0 to 259.23. These extreme values reflect heterogeneity in riders’ expressive behaviors, with some women riders producing much more elaborate and personal posts than others. Topic-related variables (T1–T11), derived from Top2Vec probability distributions, also show sparse activation patterns, where most topics occur infrequently per post. For example, T1 (Service Regulations and Skill Training) has the highest average frequency (mean = 1.798), whereas T7 (Risk Perception and Safe Riding) and T10 (Delivery Process Feedback) have lower means (≤0.2), suggesting unequal salience of lived experiences across themes.
Table 4 reports descriptive statistics and multicollinearity diagnostics (VIFs) for all predictors, including topical variables (T1–T11), psycholinguistic indices (CCI, EPI_N, and EPI_P), and the self-disclosure mediator (SI). As ER serves as the dependent variable, its VIF is not reported.
Table 4 reports descriptive statistics and multicollinearity diagnostics (VIFs) for all predictors, including topical variables (T1–T11), psycholinguistic indices (CCI, EPI_N, and EPI_P), and the self-disclosure mediator (SI). As ER serves as the dependent variable, its VIF is not reported.
Table 4 reports descriptive statistics and multicollinearity diagnostics (VIFs) for all predictors, including topical variables (T1–T11), psycholinguistic indices (CCI, EPI_N, and EPI_P), and the self-disclosure mediator (SI). As ER serves as the dependent variable, its VIF is not reported. All Variance Inflation Factors (VIFs) for predictor variables remain below 3.2, well under the threshold of 5, confirming no serious multicollinearity in subsequent regression analyses.
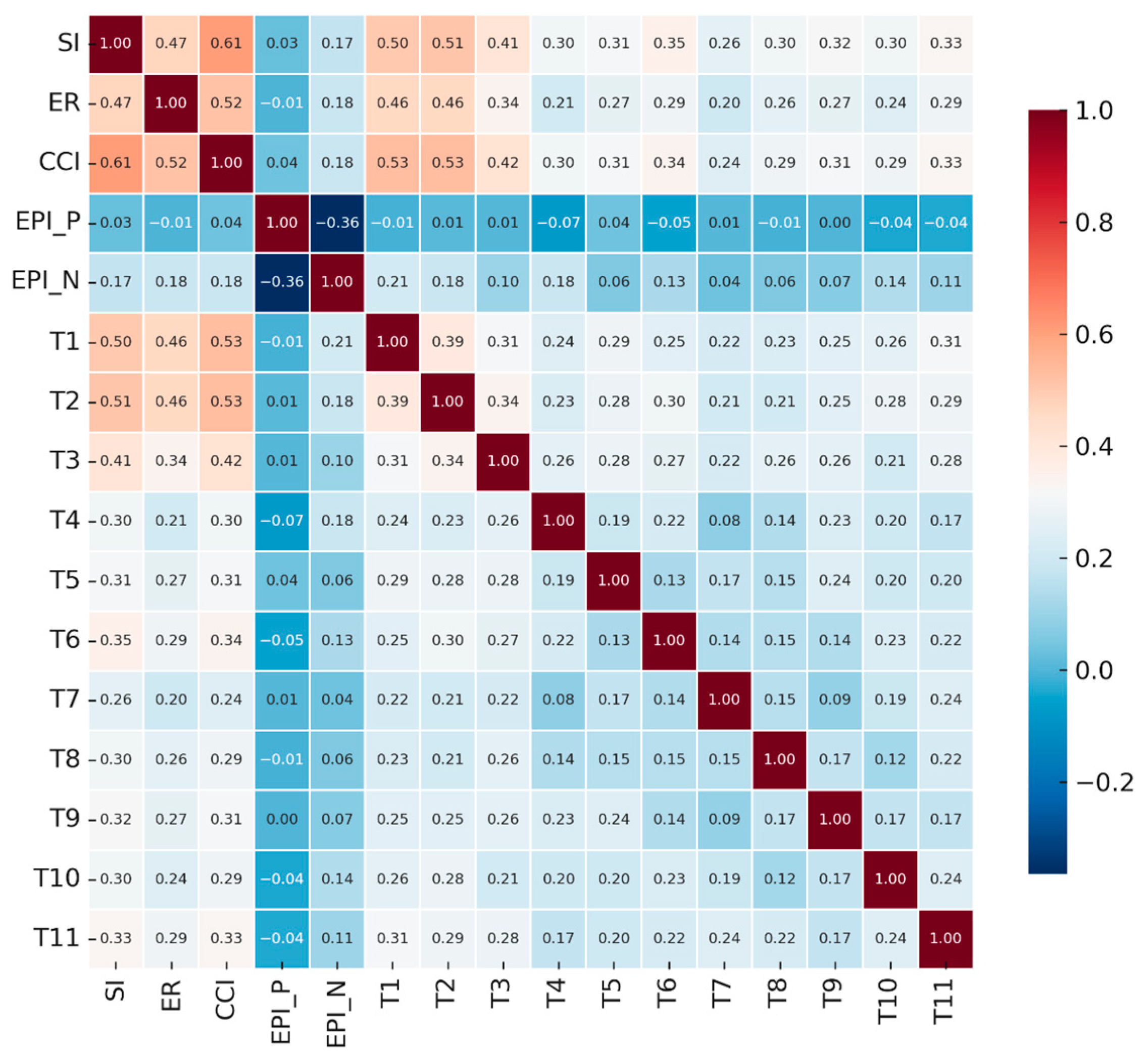
To further assess inter-variable associations,
Figure 4 and
Appendix A Table A3 presents a correlation heatmap based on Kendall’s Tau-b, which is suitable for the non-normal distributions observed in our variables. The results reveal a moderate positive correlation between self-disclosure (SI) and engagement rate (ER)—
,
—supporting the idea that more self-revealing posts attract higher interaction. Cognitive complexity (CCI) is positively associated with both SI (
,
) and ER (
,
), suggesting that analytical language use corresponds to deeper disclosure and broader visibility. Emotional polarity indices exhibit inverse trends: negative polarity (EPI_N) is positively correlated with ER (
,
), whereas positive polarity (EPI_P) exhibits a weak negative correlation with SI (
,
). This implies that emotionally negative content is more expressive and likely to engage others, consistent with predictions from social sharing theory [
53]. Topic variables such as T1 (Service Regulations and Skill Training), T2 (Income Dependency Behavior), and T4 (Technological Control and Labor Burden) correlate significantly with SI and ER, implying that content with institutional or financial stress may trigger greater expressive intensity and thus interaction.
These findings provide preliminary support for the mediation and moderation hypotheses tested in later sections and demonstrate the psycholinguistic regularities embedded in women riders’ digital narratives.
4.2. Mediation Effects Across Topics
To assess the extent to which topical expressions influence engagement through self-disclosure, the study first examines the simple mediation paths (
) across all 11 topics, following the conditional process model introduced earlier (
Table 5,
Table 6 and
Table 7).
Table 5 presents the direct effects of each topic on both self-disclosure intensity (SI) and engagement rate (ER). All paths are statistically significant at the 95% bootstrap confidence level, as evidenced by confidence intervals that exclude zero. This indicates that topic content not only influences users’ willingness to disclose but also directly affects the downstream engagement behavior, supporting Hypothesis H1.
Table 6 further summarizes the indirect effects of each topic on engagement via self-disclosure by PROCESS Model 4. All indirect effects are statistically significant, with bootstrap confidence intervals excluding zero and relatively low standard errors. The magnitude of standardized coefficients (
) in
Table 5 and
Table 6 offers critical insight into the strength and optimization potential of each communication pathway. For instance, Topic 6 (Scenario-Adaptive Behavior) shows a robust mediation structure, with standardized coefficients of 0.4127 (CI [0.0171, 0.0569] without 0) for the T6 → SI path and 0.1414 (CI: [0.0214, 0.0456] without 0) for the SI → ER path. This indicates a strong upstream effect of topic content on self-disclosure, as well as a significant downstream impact of disclosure on engagement. In contrast, topics such as T1 (Service Regulations and Skill Training) and T3 (Order Anomalies and Emergency Response) also show statistically significant effects, but their
values are relatively smaller, reflecting a weaker transmission from experience sharing to audience interaction.
The magnitude of mediation effects varies substantially across topics, revealing that different types of expressive content activate the disclosure-to-engagement pathway to different degrees. As shown in
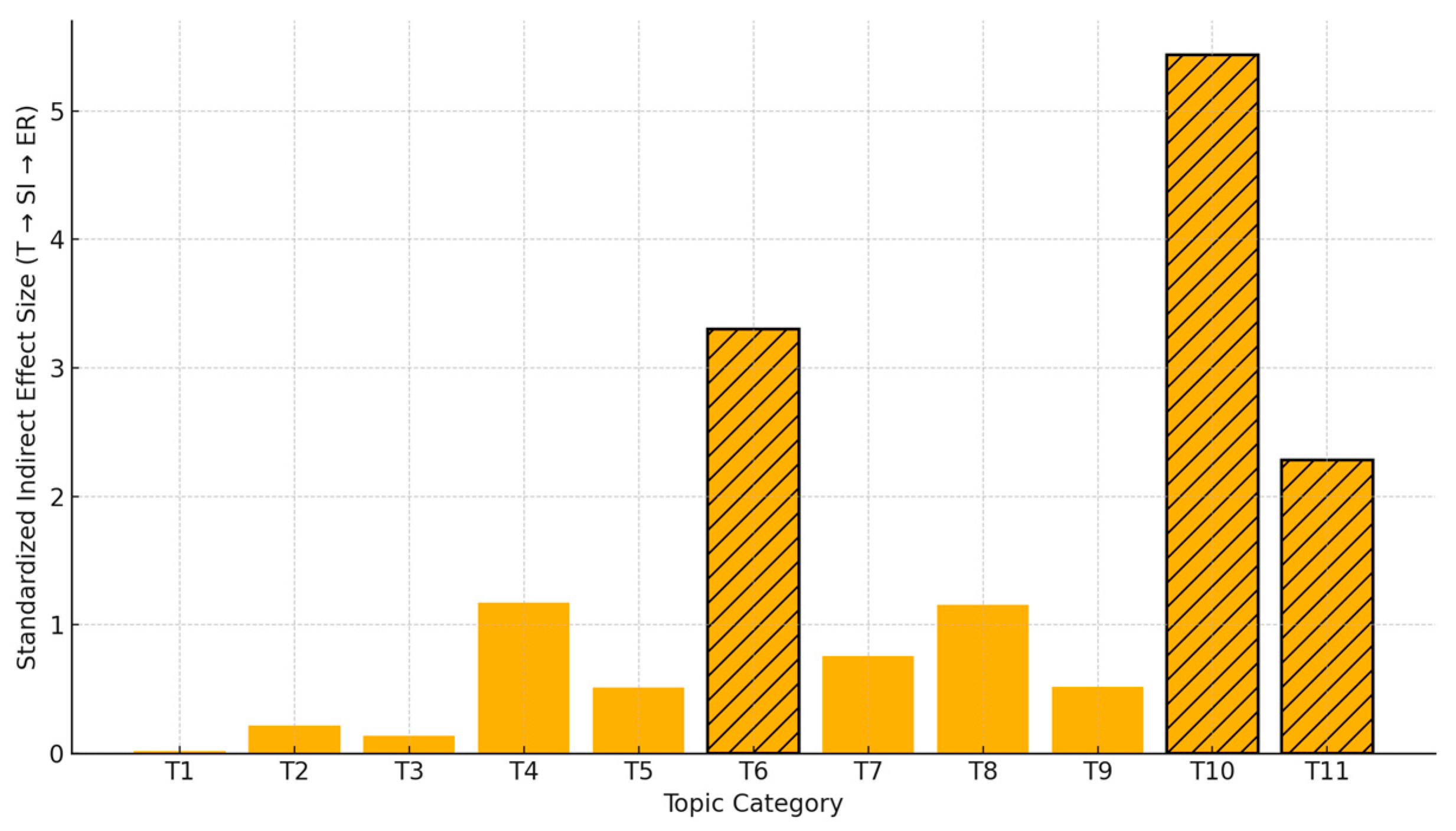
Table 7, Topic 6 (Scenario-Adaptive Behavior) exhibits the strongest mediated effect (0.6119), followed closely by Topic 10 (Delivery Process Feedback) at 0.5436, and Topic 7 (Risk Perception and Safe Riding) at 0.5160. These high values indicate that user narratives involving real-time adaptation, logistical complexity, or feedback loops are particularly effective in eliciting engagement via self-disclosure. Conversely, topics such as T1 (Service Regulations and Skill Training) and T2 (Income Dependency Behavior) show relatively weaker indirect effects (0.0171 and 0.0441, respectively) despite statistically significant direct paths to self-disclosure. This suggests that informational or procedural content—while still influential—may not strongly motivate emotional expression or community response. The contrast between Topic 3 (Order Anomalies and Emergency Response) and Topic 6 (Scenario-Adaptive Behavior) is especially illustrative: while both deal with operational pressure, T6 supports higher engagement due to stronger upstream and downstream path coefficients. These findings support Hypotheses H2a and H2b by confirming that topical variation affects the strength of the expressive–behavioral pathway and highlight the importance of content framing in amplifying user response.
To evaluate the strategic optimization potential of mediated engagement pathways, we computed the relative contribution of each topic’s indirect effect to the overall mediated effect (
Table 7 and
Figure 5). Topics T6 (Scenario-Adaptive Behavior), T10 (Delivery Process Feedback), and T7 (Risk Perception and Safe Riding) emerged as the top contributors, together accounting for 47.35% of the total mediated influence. When expanded to the top five topics, cumulative contribution reached 70.14%, indicating that a small subset of topics drives the majority of expressive-to-engagement transmission. These high-leverage pathways provide a targeted basis for content optimization, recruitment messaging, and algorithmic promotion strategies on digital labor platforms.
4.3. Moderated Mediation Analysis
To investigate how the indirect influence of topic content on user engagement varies under different psychological conditions, we implemented a dual-stage moderated mediation model using PROCESS v4.2 (Model 58). This model incorporates two moderators: cognitive complexity (CCI), which influences both the likelihood of expression and its communicative efficacy, and negative emotional polarity (EPI_N), which modulates the translation of expression into audience response. The conditional indirect effect is defined as Formulas (10) and (11).
4.3.1. Moderating Effects of Cognitive Complexity
Cognitive complexity (CCI) plays a dual role in the expressive pathway. First, it significantly moderates the likelihood that a topic leads to self-disclosure (first-stage moderation). As shown in
Table 8, the interaction term
is significant in multiple topics, most notably T4, T6, T8, and T11. For instance, in Topic 6 (Scenario-Adaptive Behavior), this interaction term is
, with a 95% bootstrap CI of [3.5806, 12.7726] without 0, indicating that users with higher cognitive linguistic expression are substantially more likely to disclose in response to adaptive or situational challenges. Second, CCI also moderates the downstream path from self-disclosure to engagement (
), with small yet robust effects across T4–T11 (e.g.,
CI [0.0002, 0.0009] for T6). This suggests that cognitively structured disclosures are more likely to resonate with the audience and elicit behavioral responses.
As shown in
Appendix A Table A4, the paper highlights (bolding) only those moderation effects that are statistically significant at the 95% level, defined as confidence intervals that do not include zero. The further Johnson–Neyman analysis from
Appendix A Table A4 reveals that this amplification only emerges when CCI surpasses a critical threshold (e.g., CCI > 5.0029, corresponding to 17.08% of the sample above the cut-off), reflecting a selective activation mechanism. These findings jointly support Hypotheses H3a, H3b, and H3c. And they underscore the conditional nature of cognitive effort: it is not universally applied but emerges selectively under semantically demanding themes.
4.3.2. Emotional Polarity as a Secondary Amplifier
Negative emotional polarity (EPI_N), in contrast, functions as a consistent but less potent second-stage moderator. The interaction term
is statistically significant across topics T2–T10, with bootstrap confidence intervals excluding zero and standardized coefficients ranging from 0.0097 (T8) to 0.0131 (T10). For example, in Topic 10 (Delivery Process Feedback), the emotional moderation effect reaches
, CI [0.0053, 0.0201]. Unlike CCI, the Johnson–Neyman region for EPI_N typically spans the entire observed value range, indicating a universal amplification effect: regardless of topic or cognitive framing, emotionally negative disclosures are more likely to elicit engagement (see
Appendix A Table A5). Nevertheless, the absolute magnitude of EPI_N’s effect remains modest, suggesting its role is less about triggering expression than about subtly enhancing resonance.
4.3.3. From Disclosure to Interaction: A Gated Amplification Pathway
While self-disclosure (SI) exhibits statistically significant direct effects on engagement (ER) across all topics (ranging from 0.0009 to 0.0017), with bootstrap confidence intervals excluding zero, its practical impact remains limited in the absence of moderation (see
Table 9). However, once cognitive and emotional moderators are introduced, the indirect pathway becomes substantially amplified, revealing the layered nature of digital expression.
Table 9 summarizes this amplification process by comparing three quantities: the first-stage moderation strength (
), capturing how cognitive complexity (CCI) affects the topic → self-disclosure (
) path; the second-stage moderation strength (
), reflecting how both CCI and emotional polarity (EPI_N) enhance the
linkage; and the direct effect: the unmoderated path from SI to ER, serving as a baseline.
A clear pattern emerges: topics with high values consistently achieve stronger overall expressive impact, even if their baseline coefficient is modest. For Topic 10 (Delivery Process Feedback), for example, its raw disclosure-to-engagement effect is 0.0016 CI [0.0005, 0.0012]—average in scale—but under strong emotional and cognitive moderation (), the effective pathway becomes highly leveraged. Topic 6 (Scenario-Adaptive Behavior) shows an exceptional value of 78.86, indicating that cognitive complexity powerfully amplifies disclosure behavior in this theme. While its value is smaller (0.0419), the compounded effect positions T6 as a highly expressive theme under cognitively demanding conditions. In contrast, Topic 1 (Service Regulations and Skill Training) and Topic 3 (Order Anomalies and Emergency Response) show both low and values (Topic 1: , CI [0.0012, 0.0019]; Topic 3:, CI [0.0013, 0.002]), suggesting that these themes generate weaker audience response even when disclosed. This comparison underscores a “gated amplification” model: governs whether the rider chooses to speak; determines whether the disclosure resonates.
Together, these findings support Hypotheses H4a and H4b. They suggest that expression alone is insufficient: for content to meaningfully engage others, it must pass both a cognitive filter (the cognitive complexity of disclosure) and an emotional amplifier (affective urgency of disclosure). This dual-layered mechanism offers critical insight into how expressive behaviors on digital platforms transition into social attention, and it confirms the theoretical logic behind our moderated mediation model.
4.3.4. Robustness Checks
To assess the stability of our findings, we conducted several robustness checks beyond the bootstrapped confidence intervals reported in all PROCESS estimates. First, we implemented a LASSO-topic baseline using the same Top2Vec-derived topics and control variables to benchmark the explanatory power of our PROCESS framework. The LASSO model selected seven non-zero coefficients at an optimal penalty of and achieved a cross-validated RMSE of 0.7989, MAE of 0.6223, and . While our PROCESS model yielded a slightly higher RMSE (0.8008) and MAE (0.6437), with , it offered additional explanatory insight by uncovering significant mediated effects (e.g.,, , ) and moderated pathways (e.g., , ). These results demonstrate that the PROCESS model maintains comparable predictive performance while capturing psychological mechanisms that are inaccessible to sparse regression. Second, we re-estimated the PROCESS model using alternative engagement metrics (e.g., comment and view volumes), with the results remaining directionally stable. Third, subsample analyses splitting high vs. low self-disclosers (based on median SI) indicated that key indirect effects, particularly those involving T5 and T6, persisted across both groups.
4.4. Effect Strengths and Optimization Potential
To assess the combined influence of topic content, cognitive framing, and emotional tone on behavioral engagement, the study computed the moderated mediation effect for each topic using Formula (12).
As shown in
Table 10 and
Figure 6, the key findings are as follows: Topic 10 (Delivery Process Feedback) demonstrates the highest conditional indirect effect (
), indicating that under cognitively complex and emotionally charged conditions (
,
), this topic exhibits extraordinary amplification from expression to interaction. Despite having no first-stage moderator (
), its strong emotional modulation (
) drives its leading performance. Topic 6 (Scenario-Adaptive Behavior) ranks second (
), driven by high values for both cognitive moderation on expression (
) and strong topic–disclosure linkage (
). This suggests that adaptive behaviors resonate particularly strongly when expressed under cognitive load, such as during complex decision making. Topic 11 (Customer Complaints and Compensation) and Topic 4 (Technological Control and Labor Burden) also show prominent effects (
and
, respectively), both benefiting from dual-stage moderation and emotionally salient content. In contrast, Topics 1 and 3 produce negligible indirect effects (
;
), primarily due to the absence of moderating mechanisms and weaker base path coefficients. These themes—centered on service regulations, skill training, order anomalies, and emergency response—may provoke less psychological investment, limiting their expressive and social utility.
This variation across topics supports the utility of a parametrically moderated mediation model, where cognitive and emotional states not only shape disclosure likelihood but significantly alter the downstream behavioral effect. The quantification of each topic’s pathway strength offers a model-driven basis for prioritizing content categories within behavioral prediction systems.
5. Discussion
5.1. Summary of Core Mechanisms
This study models the behavioral impact of content expression through a two-stage conditional process framework, disentangling how topic-specific disclosures translate into audience engagement under varying cognitive and emotional conditions. The empirical results presented jointly reveal three core mechanisms.
First, topic content exerts a direct and indirect effect on user behavior. As shown in
Table 5 and
Table 6, all eleven themes extracted via Top2Vec significantly influence both self-disclosure intensity and engagement rate, with mediation effects ranging from 0.0039 (T1) to 0.0303 (T6). This confirms that thematic expression—such as scenario adaptation (T6) or Delivery Process Feedback (T10)—acts as a behavioral signal even when not explicitly structured, aligning with prior findings on user-generated semantic cues.
Second, the transition from expression to interaction is not linear but contingent on cognitive and emotional moderators. The analysis in
Section 4.3 demonstrates that cognitive complexity (
) significantly enhances the effect of topic exposure on disclosure (first-stage moderation), while negative emotional polarity (
) strengthens the effect of disclosure on engagement (second-stage moderation). This layered dependency justifies the model’s staged architecture and supports the use of conditional path formulas in behavioral modeling.
Third, the full moderated mediation effect—as computed in
Section 4.4 using both
and
parameters—clarifies which topic pathways are most behaviorally effective under real-world variability. The results show that topics with both high base coefficients and significant modulation terms (e.g., T10 and T6) yield the strongest conditional indirect effects, up to 5.43 times larger than low-modulation topics such as T1.
Cumulatively, these mechanisms highlight that online user behavior is best understood not by linear correlations but through structured cognitive–affective models, where content, cognition, and emotion interact multiplicatively.
5.2. Psycholinguistic Moderators of Behavioral Response
The distinction between the first-stage and second-stage moderation effects provides key insight into how expression becomes actionable engagement. As formalized in Equations (10)–(12), the two-stage model isolates two distinct cognitive–affective pathways as follows: first, the expression pathway: how topic exposure () prompts users to disclose personal experience (), modulated by cognitive complexity (); second, the conversion pathway: how self-disclosure () influences subsequent engagement (), modulated by both and emotional polarity ().
Empirical findings that first-stage moderation plays a dominant role. For example, Topic 6 (Scenario-Adaptive Behavior) and Topic 10 (Delivery Process Feedback) exhibit high values (78.86 and 18.43, respectively), indicating that cognitively complex users are especially sensitive to situational or operational content, which encourages them to share more. This supports the idea that expression is a function of topic resonance × user cognition, rather than topic presence alone.
By contrast, second-stage moderation (
) shows narrower variance across topics, ranging between 0.0039 and 0.2950. While still statistically significant, its behavioral leverage appears more limited. In most cases, the direct effect of self-disclosure on engagement remains within a narrow band (0.0009 to 0.0017), with modest amplification from
(emotional polarity). However, even modest second-stage gains (e.g., T10’s
) can result in high overall indirect effects, as shown in
Table 10.
These results suggest an important asymmetry: while both stages contribute, engagement is primarily driven by whether the user is cognitively activated to speak rather than how affectively intense the speech is. This reinforces the importance of modeling first-stage modulation explicitly, especially in contexts where voice visibility is optional (e.g., digital labor forums). This finding aligns with prior studies linking self-disclosure with engagement in digital communities [
33,
62] but extends them by modeling the conditional structure of disclosure rather than treating it as a static mediator. While previous studies have emphasized the existence of such pathways, our quantification of conditional indirect effects allows for actionable prediction.
5.3. Role of Conditional Moderation in Behavior Prediction
While traditional mediation models can capture the average indirect influence of topic content on engagement via self-disclosure, they are structurally limited in two respects: On the one hand, they assume homogeneity across users in expressive behavior; On the other hand, they overlook how downstream outcomes (e.g., interaction metrics) are shaped by psychological context. By contrast, our conditional process model captures the heterogeneity of mediation effects as a function of cognitive and emotional states.
While traditional mediation models can capture the average indirect influence of topic content on engagement via self-disclosure, they are structurally limited in two key respects:
They assume homogeneity across users in expressive behavior.
They overlook how downstream outcomes (e.g., interaction metrics) are shaped by psychological context.
By contrast, the conditional process model accounts for the heterogeneity of mediation effects as a function of individual-level cognitive and emotional states.
The comparison between unmoderated mediation effects (
) and fully moderated indirect effects (
) illustrates this point. As shown in
Table 10, the baseline indirect effect of Topic 1 is merely 0.0039, yet it increases more than fourfold (to 0.0171) under cognitive and emotional modulation. More strikingly, for Topic 10, the indirect effect rises from 0.0295 to 5.4349 under moderation, an amplification by a factor of 184. These differences are not trivial; they demonstrate how similar content can yield drastically different behavioral outcomes depending on the user’s internal psychological state.
This magnification stems from the structure of the conditional indirect effect (see Equation (12)).
In this equation,
represents cognitive complexity and
emotional polarity. The multiplicative interaction between stages reflects a compounding effect, wherein users with high cognitive complexity experiencing negative affect are more likely to convert self-disclosure into downstream engagement, even when the topic content itself is neutral. This pattern is consistent with psychological theories of signal amplification, which posit that emotionally and cognitively primed individuals perceive even weak stimuli as salient [
47]. Importantly, the findings reveal that relying solely on simple mediation paths—while statistically significant—may obscure conditional variability that is critical for behavioral modeling. Platform interventions based on average effects risk underperforming, especially in psychologically heterogeneous environments. While prior studies have applied process-based models to analyze social influence and self-disclosure on digital platforms [
63,
64], such applications often limit the analysis to simple mediation or moderation paths, without accounting for higher-order interaction effects between psychological states and content features. The use of a dual-stage conditional process model (PROCESS v4.2) expands this tradition by enabling simultaneous estimation of both moderated mediation and conditional indirect effects. This approach allows for a more nuanced understanding of how users’ cognitive complexity and emotional polarity jointly shape the pathway from textual expression to audience engagement, a level of integration rarely implemented in existing behavioral modeling of online discourse. In doing so, we bridge a methodological gap between psycholinguistic modeling and interpretable behavioral prediction in platform contexts. In sum, the conditional mediation structure not only improves model fit but also enhances interpretability by identifying which user–content combinations produce the greatest behavioral return. Such quantified pathway strengths offer a principled basis for behavioral prediction and optimization in digital decision-making contexts.
5.4. Modeling High-Dimensional Discourse for Predictive Decision Making
This study contributes methodologically by embedding high-dimensional textual representations into a psychologically grounded statistical modeling framework for behavior prediction. The proposed pipeline—comprising semantic embedding, dimensionality reduction, and moderated mediation modeling—offers a generalizable and interpretable tool for decision-oriented research in digital contexts.
First, the research enhances topic regression pipelines by integrating semantically coherent topic embeddings derived from Top2Vec into a dual-stage conditional process model. Unlike traditional bag-of-words representations or sparsely selected LASSO features, our method preserves narrative integrity while capturing psychologically meaningful discourse patterns. Specifically, we employ a pre-trained BERT-based Chinese embedding model to extract sentence-level semantics from fragmented, affect-rich user posts. Benchmarking results show a significant improvement in thematic coherence compared to LDA (NPMI = 0.52 vs. 0.378), demonstrating the advantages of transformer-based contextual embeddings in short-form, emotionally charged texts.
This structured integration contrasts with prior approaches using LDA proportions or LASSO-selected terms [
29,
65], which either overlook semantic nuance or ignore theoretical mediation pathways. By embedding Top2Vec-derived constructs into a causal process model, our framework achieves both predictive validity and psychological interpretability, enabling the estimation of both direct and conditional effects, capabilities that are absent in most unsupervised topic pipelines.
Second, to improve topic separation and interpretability, the paper adopts UMAP for embedding dimensionality reduction. Compared with PCA and t-SNE, UMAP better preserves both local and global semantic structures, achieving higher topic coherence (NPMI = 0.52) and tighter cluster compactness (silhouette score = 0.37). These enhancements ensure that the resulting topic features are not only theoretically grounded but also statistically robust in subsequent modeling.
Third, the study applies a dual-stage moderated mediation model (PROCESS v4.2) to trace how topic content influences user engagement through the mediating role of self-disclosure, conditional on users’ cognitive complexity and emotional polarity. This allows us to capture not only average indirect effects but also how psycholinguistic states amplify or suppress behavioral responses. The resulting conditional path coefficients offer actionable insights into when and for whom expressive content becomes behaviorally consequential, providing a principled basis for predictive behavioral modeling and decision optimization.
Fourth, the proposed methodology is inherently modular and extensible. While our empirical application focuses on Chinese-language posts from a food delivery platform, each component—semantic embedding, dimensionality reduction, and process modeling—can be adapted across languages (e.g., LaBSE and XLM-R), domains (e.g., ride-hailing and crowdsourcing), and user communities. This flexibility makes the approach suitable for predictive modeling in high-dimensional, heterogeneous data environments.
Finally, the results show that cognitive and affective pathways linking content to behavior are quantifiable and interpretable. Compared to existing work using LIWC or shallow token features in Chinese [
59], our framework offers deeper interpretive resolution and causal mapping. In summary, this study introduces a replicable, psychologically informed, and semantically enriched modeling pipeline that bridges the gap between discourse abstraction and behavioral prediction. It opens new possibilities for decision-making applications in digital labor and broader computational social science domains.
6. Conclusions and Decision-Making Implications
This study introduces a psychologically informed, statistically grounded framework for modeling how semantically rich textual content influences behavioral engagement in gig economy platforms. By integrating BERT-based Top2Vec embeddings, UMAP dimensionality reduction, and a moderated mediation structure (PROCESS v4.2), we offer a replicable and generalizable pipeline for digital behavior prediction.
The key findings are threefold. First, topic content exerts significant direct and indirect influence on user engagement, with self-disclosure acting as a robust mediator across all topic pathways. Second, cognitive complexity and emotional polarity moderate both stages of the mediation process, yielding highly heterogeneous indirect effects. This interaction structure reveals that identical content may trigger vastly different engagement outcomes depending on users’ psychological profiles. Third, by quantifying indirect pathway strength under different moderator conditions, the model offers granular insights into which communication signals are most likely to elicit meaningful interaction.
From a decision-making perspective, the proposed pipeline enables optimization at multiple levels. Platforms can firstly prioritize content types (e.g., scenario-adaptive narratives or Delivery Process Feedback) with stronger mediated effects; secondly, identify user segments most responsive to specific discursive cues; and thirdly, tailor recommendation systems to align with users’ cognitive and emotional tendencies. Unlike conventional classification or regression approaches that treat features as static predictors, our dual-stage structure incorporates psychological realism, enhancing both predictive accuracy and interpretability.
The generalizability of the method—across domains and user types—further positions it as a versatile tool for real-world applications. Whether used for content targeting in platform labor, discourse analysis in social media, or personalized recommendation in digital platform, this integrated framework bridges the gap between text analytics and behavioral decision making. It contributes not only to methodological rigor but also to actionable insight generation in high-dimensional, user-centered environments.
Future research may extend this framework across cultural or occupational contexts, refine temporal dynamics, or incorporate platform-level metrics such as sharing frequency, sentiment trajectory, or real-time algorithmic feedback to build adaptive prediction models. In addition, while the study focuses on a single Chinese platform, the proposed framework—comprising multilingual embeddings, topic modeling, and regression—is designed to be transferable. Nevertheless, the paper recognizes that linguistic and contextual differences may affect signal salience. Future research should validate the model across alternative domains (e.g., ride-hailing), languages (e.g., English and Spanish), and user types to examine its robustness beyond the studied setting.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}